
![]()
Parallel Programming
No book on asynchronous programming would be complete without discussing how to improve the performance of your computationally intensive algorithms. Back in March 2005, Herb Sutter, who works for Microsoft, coined the phrase “The free lunch is over,” and he wasn’t referring to the Microsoft canteen. He was referring to the fact that prior to that date, when engineers were faced with the need to make their code run faster, they had two choices. They could profile and optimize the code to squeeze a bit more out of the CPU, or just wait a few months and Intel would produce a new, faster CPU. The latter was known as the “free lunch,” as it didn’t require engineering effort. Around March 2005, the computer industry, faced with the need to keep delivering faster and faster computational units, and the fact that clock speeds couldn’t keep growing at historical rates, made the design decision to add more cores. While more cores offer the possibility of greater throughput, single-threaded applications won’t run any faster on multicore systems, unlike CPUs of the past. Making the code run faster now requires engineering effort. Algorithms have to be rewritten to spread the work across multiple cores; hence “the free lunch is over.”
Traditionally, targeting multicore meant taking readable code and transforming it into a far more complex and hard-to-maintain version utilizing the traditional threading APIs. In an effort to restore the free lunch, there has been a long-term goal of allowing parallelism to be expressed more naturally through the use of constructs like ParallelFor. This was the original goal behind TPL: if parallel programming is to be adopted, it needs to be as easy as conventional programming.
Consider the following piece of code:
int total = SumX() + SumY() + SumZ();
This single line of code currently executes synchronously, computing each individual sum in turn, combining each result as it goes. If the sum methods don’t interfere with each other in any way—in other words they are completely independent of each other—then you could execute them at the same time. Listing 11-1 shows an asynchronous implementation using pre-TPL-like code. This implementation is a far cry from the original synchronous code.
Listing 11-1. Pre-TPL Asynchronous Compute
Func<int> sumX = SumX;
Func<int> sumY = SumY;
Func<int> sumZ = SumZ;
IAsyncResult sumXAsyncResult = sumX.BeginInvoke(null, null);
IAsyncResult sumYAsyncResult = sumY.BeginInvoke(null, null);
IAsyncResult sumZAsyncResult = sumZ.BeginInvoke(null, null);
int total = sumX.EndInvoke(sumXAsyncResult) +
sumY.EndInvoke(sumYAsyncResult) +
sumZ.EndInvoke(sumZAsyncResult);
One of the goals of TPL was to remove this complexity, allowing parallelism to be expressed while keeping the overall structure of the code the same as the synchronous version. For this example it can be achieved just by using the Task API that we have already discussed, as shown in Listing 11-2. In this example, while the code has changed to take advantage of TPL, it has not changed completely—the general structure is retained and arguably has similar levels of readability to that of the synchronous code.
Listing 11-2. TPL-Based Asynchronous Compute
Task<int> sumX = Task.Factory.StartNew<int>(SumX);
Task<int> sumY = Task.Factory.StartNew<int>(SumY);
Task<int> sumZ = Task.Factory.StartNew<int>(SumZ);
int total = sumX.Result + sumY.Result + sumZ.Result;
While this summing algorithm is extremely simple, it does demonstrate that the old-style APIs are not ideal for expressing even this most simple form of parallelism, known as Fork and Join. In this chapter we will examine the features of TPL that enable the parallelization of algorithms while keeping the algorithm as close as possible to its simple synchronous origins—after all, who doesn’t enjoy a free lunch? These features are commonly known as Parallel Framework Extensions (Pfx).
What Is Driving the Need for Parallelism?
Since the start of the computer age we have strived to get solutions to our problems with faster and faster response times. Real-time problems require an answer in a given period of time from when the question is posed, otherwise the answer is useless. Airplane flight control would be one obvious example; another may be voice recognition. A voice recognition system in a car that takes 5 minutes to 100 percent accurately interpret the command is far worse than one that gets it 90 percent right in 2 seconds. Throwing multiple cores at the perfect algorithm will one day result in a 2-second response with 100% accuracy.
Achieving better and better results often requires processing larger and larger datasets. After all, we can produce photorealistic graphics given sufficient rendering time. One day there may be enough parallel computing power inside a games console to do just that. So in all these cases it is not that we can’t solve the problems; we just need to do it faster and with better results, which often requires larger volumes of data.
Coarse- and Fine-Grained Parallelism
There are various ways to distinguish types of parallel programs. One is to describe them as coarse grained or fine grained. Coarse-grained parallelism refers to problems where a single thread handles a request from start to finish, and that parallelism is achieved by the fact that many independent requests are being processed in parallel, thus consuming multiple threads. Examples of coarse-grained parallelism would be a web server or a payroll application. This type of parallelism is relatively easy to implement by mapping each request onto a thread. Each thread then provides a programming model, the same as synchronous programming of old. Coarse-grained parallelism is often found on the server, since servers have plenty of opportunity to handle multiple independent requests. On the client side, things are a little different—there is after all just one user and there are only so many independent things a single user will wish to do at any moment in time.
Consider Microsoft Word. While it is running it is performing multiple tasks:
- UI interaction
- layout
- spell checking
- grammar checking
- autosaving
- printing
We could assign each of these activities its own thread, and if we have six or more cores, maybe the single-user-based task of word processing could utilize all our cores, keeping the application responsive and delivering spelling and grammar suggestions in real time. Six to eight cores on a desktop around the year 2008 would have seemed a powerful machine; the future suggests we will more likely have 200+ cores per desktop. Even if Microsoft reinstated Clippy, it is hard to see how even MS Word could consume that many cores with each core focused on an independent task such as spell checking. To cope with the ever-increasing number of cores on the client, a different approach needs to be considered. One such approach is fine-grained parallelism.
Fine-grained parallelism requires taking each coarse-grained activity and further dividing it into many smaller tasks. Each of these smaller tasks executes in parallel, collaborating with one another where necessary to perform the overall task. It is this form of parallelism that often requires more effort and leads to algorithms becoming extremely complex. The TPL constructs that we will investigate throughout this chapter will attempt to keep the structure of the algorithm intact while supporting fine-grained parallelism.
Task and Data-Based Parallelism
A further way to categorize parallelism is by Task and Data. Task-based parallelism is where an algorithm is broken down into a series of discrete tasks, with each task running a logically different part of the algorithm. Our initial example of calculating a total in Listing 11-2 would be one such example. A car production line would be another example of Task-based parallelism; each stage of the line is performing a different role. Data parallelism, on the other hand, is the same logical code executing in parallel but with a different data set. Weather forecasting algorithms often use such techniques to break down the globe into a series of regions, and each processing element works on its own piece for a given interval.
Is It Worth Trying to Parallelize Everything?
First you have to decide: can something be parallelized? Consider the algorithm to calculate Fibonacci numbers (1, 1, 2, 3, 5, 8, 13, 21, etc.). The next number in the sequence is the sum of the previous two numbers; therefore, in order to calculate the next number you must have already calculated the previous two. This algorithm is inherently sequential, and therefore as much as you may try, it can’t be parallelized. There are many other algorithms or parts of algorithms that have this characteristic. Consider the process of making a cup of tea:
- Fetch the cups
- Fetch the milk
- Put the tea in the pot
- Fill the kettle and switch it on
- Wait for kettle to boil, then pour water into pot
- Wait for tea to brew
- Pour tea into cups, and add milk if required
Clearly we can’t parallelize all these steps, since pouring the water while fetching the milk and cups is clearly not going to work. But we can certainly improve on these steps. The boiling of the kettle is one of the longest parts of the process and has no dependency on anything else, so we should do that first. Assuming that takes longer than fetching the cups and milk and putting tea in the pot, we will have reduced the time taken to brew the cup of tea:
- Fill the kettle and switch it on
- Fetch the cups
- Fetch the milk
- Put tea in pot
- Wait for kettle to boil
- Wait for tea to brew
- Pour tea into cups, and add milk if required
My mother-in-law is a tea-aholic and is always looking for new ways to brew her tea even faster without sacrificing the taste—can we help? We have identified that the boiling the water is one of the most costly parts of the process and we will undoubtedly be blocked in waiting for it to complete. Focusing on parallelizing this part of the process may well yield the best return on effort. Understanding how much of an algorithm can be parallelized is important, since it will dictate what is the maximum potential speedup. This was formalized by Amdahl as follows:
The speedup of a program using multiple processors in parallel computing is limited by the sequential fraction of the program. For example, if 95% of the program can be parallelized, the theoretical maximum speedup using parallel computing would be 20×, no matter how many processors are used.
Source Wikipedia http://en.wikipedia.org/wiki/Amdahl's_law
This is known as Amdahl’s law. Even after considering Amdahl’s law, focusing on boiling the water seems like a good plan. If we were to use two kettles, then we should be able to halve the boil time. In fact, what about having 50 kettles—will that make it even faster? In theory, yes; in practice, possibly not. Imagine the scene: fetching and filling 50 kettles, plugging them in, taking them in turns to fill each one up, switching it on, and, once boiling, fetching each one in turn to pour on the tea. The use of 50 kettles is adding a lot more extra work above and beyond our original single-kettle solution—this is going to consume additional time that may outweigh the benefit of boiling in parallel. Perhaps if we had 50 extra pairs of hands and 50 extra taps it might help, but we would still need to coordinate boiling the water for the tea. The bottom line is that the coordination of running code in parallel has a cost; thus the parallel version of any algorithm is going to require more code to run in order to complete the task. Therefore, when throwing two CPUs at a problem, don’t expect it to become twice as quick.
You now have a good understanding of the need to parallelize and what can and can’t be parallelized. All that is left now is how to parallelize.
Before You Parallelize
One reason for parallelizing an algorithm is to produce a faster result than would be possible if you just used one core. If the parallel version is slower than a single core, other than heating up the room on a cold day this would be regarded as a failure. Unless you have implemented the best single-core implementation of the algorithm first, you will have no idea when you run the code if it is indeed worth that extra energy and complexity. The very nature of parallel programming is that it is asynchronous in nature, and as such every time you run the algorithm there is the possibility for race conditions, affecting the integrity of the overall result. So in the same way that having parallel code that takes longer than a single core is wrong, it is just as wrong to have a faster parallel version that produces wrong results. Therefore, before you parallelize any algorithm, write the best single-threaded version you can first—this will act as a benchmark for your parallel implementations.
Parallel Class
One of the main entry points to implementing parallel functionality using TPL is the System.Threading.Tasks.Parallel class. There are three static methods on this class, with the main focus on loops:
- Parallel.Invoke
- Parallel.For
- Parallel.ForEach
These methods provide a high-level abstraction of the world of parallel programming, allowing algorithms to continue to resemble a familiar synchronous structure. All these methods implement the Fork/Join pattern: when one of these methods is invoked, it will farm out work to multiple TPL tasks and then only complete on the calling thread once all tasks have completed.
A small amount of influence and control is possible with all these methods via a class called ParallelOptions. ParallelOptions allows you to set the following:
- Max number of tasks to be used
- Cancellation token
- Task Scheduler to use
Max number of tasks is useful if you wish to limit the number of tasks that can be used by the framework for a given parallel invocation, and thus most likely influence the number of cores that will be used. With all the Parallel methods, the runtime needs to make a guess at the number of tasks to use for a given parallel invocation. Often this guess is refined if the parallel invocation executes for a reasonable amount of time, as is often the case of parallel loops. If you are aware of the exact hardware you are running on, then in some situations it can be beneficial to set the MaxNumberOfTasks.
CancellationToken allows for external control over early termination of the parallel invocation. Once the supplied cancellation token is signaled, the parallel invocation will not create any more tasks. Once all created tasks have completed, the parallel invocation will return; if it did not successfully complete the parallel invocation due to the effect of cancellation, it will throw an OperationCancelledException.
The Task Scheduler option allows you to define the task scheduler to use for each of the tasks created by the parallel invocation. This allows you to provide your own scheduler and thus influence where and when each task produced by the parallel invocation will run. Otherwise the default scheduler will be used.
Parallel.Invoke
The Invoke method on the parallel class provides the ability to launch multiple blocks of code to run in parallel and, once all are done continue the classic Fork and Join. Listing 11-3 shows a reworked version of our SumX, SumY, and SumZ example. The Invoke method takes an array of the Action delegate (or a variable number of Action delegates, which the compiler turns into an array of Action delegates).
Listing 11-3. Parallel.Invoke
int sumX = 0;
int sumY = 0;
int sumZ = 0;
// Executes SumX, SumY and SumZ in parallel
Parallel.Invoke(
() => sumX = SumX(),
() => sumY = SumY(),
() => sumZ = SumZ()
);
// SumX,SumY and SumZ all complete
int total = sumX + sumY + sumZ;
Is this approach radically different than just explicitly creating the tasks and then combing the results? Probably not, but it does feel a little closer to how the sequential might have originally looked.
One concern regarding Parallel.Invoke is that it only returns when all its supplied actions have completed. If any one of those actions somehow enters an infinite wait, then the Parallel.Invoke will wait forever, something you would wish to avoid. There is no option to pass a timeout to Parallel.Invoke but you could use a CancellationToken instead. A first attempt might look something like the code in Listing 11-4.
Listing 11-4. First Attmept at Canceling a Parallel.Invoke
int sumX = 0;
int sumY = 0;
int sumZ = 0;
CancellationTokenSource cts = new CancellationTokenSource();
cts.CancelAfter(2000);
Parallel.Invoke ( new ParallelOptions() { CancellationToken = cts.Token},
() => sumX = SumX(),
() => sumY = SumY(),
() => sumZ = SumZ()
);
int total = sumX + sumY + sumZ;
This approach will almost certainly not work if one of those methods ends up waiting forever. The only part of the code that is cancellation aware is the Parallel.Invoke method. Once the cancellation has been signaled, it knows not to create any new tasks, but it can’t abort the already spawned tasks. All it can do is wait for the already spawned tasks to complete and, being the patient soul it is, that could be forever. To make this work you need to flow the cancellation token into the various actions and ensure that they are proactive in polling the cancellation token, too, as shown in Listing 11-5.
Listing 11-5. Parallel.Invoke with More Reliable Cancellation
{
Parallel.Invoke(new ParallelOptions() {CancellationToken = cts.Token},
() => sumX = SumX(cts.Token),
() => sumY = SumY(cts.Token),
() => sumZ = SumZ(cts.Token)
);
int total = sumX + sumY + sumZ;
}
catch (OperationCanceledException operationCanceled)
{
Console.WriteLine("Cancelled");
}
If any unhandled exception propagates from any of the actions it is caught and held until all the other actions have completed, and the exception is re-thrown along with any other exceptions from other actions as part of an AggregateException. Since you don’t get access to the underlying Task objects for a given action, there is no way to know which action produced which exception (see Listing 11-6).
Listing 11-6. Parallel.Invoke Error Handling
try
{
Parallel.Invoke( new ParallelOptions() { CancellationToken = cts.Token },
() => { throw new Exception("Boom!"); },
() => sumY = SumY(cts.Token),
() => sumZ = SumZ(cts.Token)
);
int total = sumX + sumY + sumZ;
}
catch (OperationCanceledException operationCanceled)
{
Console.WriteLine("Cancelled");
}
catch (AggregateException errors)
{
foreach (Exception error in errors.Flatten().InnerExceptions)
{
Console.WriteLine(error.Message);
}
}
Parallel.Invoke is therefore a relatively easy way to spawn off multiple parallel actions, wait for them all to complete, and then proceed. But be aware that methods that can wait forever, and have a tendency to one day do just that. By abstracting away the underlying Task API, your code is simpler, but you do lose the ability to easily identify which action failed.
Parallel Loops
As mentioned earlier, when wishing to parallelize an algorithm you should consider Amdahl’s law and decide which parts of the algorithm justify the effort of parallelism. When examining algorithms, we often find that loops typically offer the best opportunity for parallelism, since they can execute a relatively small body of code tens of thousands of times, thus creating a lot of computation—something worth speeding up. Just because a loop has a lot of computation doesn’t necessary mean it is a candidate for parallelizing. A single threaded loop executes in a set order, while a parallel loop works by farming out ranges of the loop to different cores, with each core executing its range in parallel with the other cores. This has the effect of processing the loop out of order. Does that matter? For some algorithms, no, but for others the order does matters. Listing 11-7 is an example of one such loop. This algorithm for producing Fibonacci numbers (as discussed earlier) cannot be parallelized. If the order does matter, the loop is not a candidate for parallelization.
Listing 11-7. Example of Order-Sensitive Loop
long prev = 0;
long prevPrev = 0;
long current = 1;
for (int nFib = 0; nFib < 200; nFib++)
{
Console.WriteLine(current);
prevPrev = prev;
prev = current;
current = prev + prevPrev;
}
If the loop you do wish to parallelize is not order sensitive, then TPL provides two forms of loop parallelization: Parallel.For and Parallel.ForEach, the parallel versions of the C# for and foreach keywords, respectively.
Parallel.For
Listing 11-8 shows a normal C# loop, which when executed prints out all values from 0 to 19 inclusive. If the goal of this loop is to simply output all values from 0 to 19 inclusive and you don’t care about the order, then you can parallelize it.
Listing 11-8. Regular C# Loop
for( int i = 0 ; i < 20 ; i++ )
{
Console.WriteLine(i);
}
To parallelize this loop, remove the use of the C# for statement and replace it with a call to Parallel.For. In this example Parallel.For takes the start and end values for the loop along with an Action<int> delegate representing the body of the loop. The code in Listing 11-9 shows such an implementation; when executed it will display all the values between 0 and 19 inclusive, but each time you run it you may well see varying orders. Even a program as simple as this exposes chaotic behavior, as shown in Figure 11-1.
Listing 11-9. Simple Parallel.For Loop
Parallel.For(0,20,i =>
{
Console.WriteLine(i);
} );
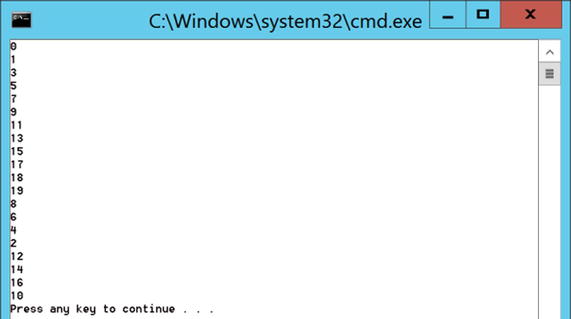
Figure 11-1. One possible outcome of Listing 11-9
The refactored code still resembles the original single-core implementation. The use of lambdas/anonymous methods has allowed you to express the loop body inline, thus resembling the original structure, and hopefully maintaining its readability.
All of the Parallel.XXX methods utilize TPL tasks to execute pieces of work in parallel. One obvious mapping in the case of loops would be to create as many tasks as there are loop iterations, so in the case of Listing 11-9, it would create 20 tasks. If you have at least 20 cores this may well be a good idea, but if you only have 4, not a great idea. The effort required to create a task is not free—it adds additional workload above and beyond the single-core implementation. Therefore it makes sense to create many tasks but to allow many tasks to do many iterations. Listing 11-10 has a modified parallel loop that is printing out the loop index and also the task ID associated with that loop iteration. As you can see from Figure 11-2, many tasks are involved in producing the final result, but not 20.
Listing 11-10. Parallel.For and Associated Tasks
Parallel.For(0, 20, i =>
{
Console.WriteLine("{0} : {1}",Task.CurrentId,i);
});

Figure 11-2. Parallel loop showing task ID and iteration association
The Parallel.For method can’t know the perfect number of tasks to create; it has to guess and keep adjusting its guess based on observed throughput of the loop. The longer and longer a task takes to process each iteration, the more likely it is that creating more tasks to handle a smaller and smaller range of the loop makes sense. This can be illustrated by adding a Thread.SpinWait into each iteration of the loop (to simulate more work). Listing 11-11 has a bit more work per iteration, and Figure 11-3 shows the effect of increased work on the number of tasks created, now that a lot more tasks have been created, allowing for a greater opportunity for parallelism.
Listing 11-11. A Bit More Work per Iteration
Parallel.For(0, 20, i =>
{
Console.WriteLine("{0} : {1}", Task.CurrentId, i);
Thread.SpinWait(100000000);
});
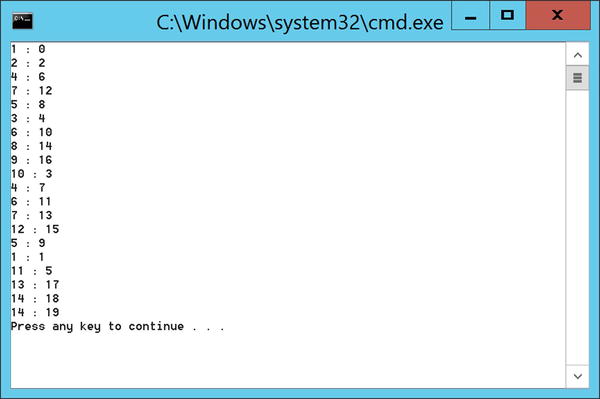
Figure 11-3. The effect of increased work on the number of tasks created
This approach taken by the Parallel class certainly won’t always be optimal but will often provide a respectable speedup (a moderate free lunch). To reach a more optimal solution requires an understanding of the environment the code is running in, whether each iteration of the loop has the same cost, what resources it consumes, and their availability. This level of knowledge is hard to build into a general purpose algorithm. One simple element of tuning you can provide is stating via ParallelOptions and setting MaxDegreeOfParallelis, which will restrict the number of tasks active at any one time, and hence control the level of concurrency. Note that it doesn’t restrict the number of tasks that will be created, but rather limits the number of tasks that will ever be submitted to the scheduler at any moment of time. Throughout this chapter we will look at various ways of refactoring our use of Parallel.XXX to get better performance through our knowledge of the algorithm and the process resources available to us.
Beyond the Trade Show Demos
The code we have looked at so far reassembles the typical trade show demos of Pfx. These examples give you a feeling that parallelization is now really easy and being a threading guru is not essential. Unfortunately the reality of parallelization is somewhat removed from these simple Thread.Sleep or Thread.SpinWait examples, and in this part of the chapter we will look at the more typical issues involved with parallel loops.
For now let us play along with the hope that parallelization is easy. Consider the code in Listing 11-12, which calculates the value of pi (we know, not a typical example for your average workplace, but it is simple enough to highlight a lot of the issues). The algorithm used to calculate pi is a series of summations, and since summing a series in any order produces the same result, this loop does not depend on order and therefore is a candidate for parallelization. Before we start parallelizing this piece of code, we must first benchmark it to obtain the time taken to run on a single core and obtain the expected result. Calling CalculatePi(1000000000) in Listing 11-12 on a single core produce the following result:-
Time Taken: 01.9607748 seconds Result: 3.14159265158926
Listing 11-12. Calculating Pi
// 4 * ( -1.0 / 3.0 + 1.0/5.0 - 1.0/7.0 + 1.0/9.0 - 1.0/11.0 ... )
private static double CalculatePi(int iterations)
{
double pi = 1;
double multiplier = -1;
for (int i = 3; i < iterations; i+=2)
{
pi += 1.0/(double) i*multiplier;
multiplier *= -1;
}
return pi*4.0;
}
An initial first cut at parallelizing Listing 11-12 could be to simply replace the use of a regular for with a Parallel.For. There is, however, one initial obstacle in your way: the Parallel.For loop counter can only be a long or an int and can only be incremented by 1. For this loop you need it to increment by 2, but this is software so you can work around this hiccup. Listing 11-13 represents an initial attempt. On running this code you will receive the following results:
Time Taken: 05.1148 seconds Result: 3.13983501709191
Listing 11-13. First Cut Parallel Pi
private static double ParallelCalculatePi(int iterations)
{
double pi = 1;
double multiplier = -1;
Parallel.For(0, (iterations - 3)/2, loopIndex =>
{
int i = 3 + loopIndex*2;
pi += 1.0/(double) i*multiplier;
multiplier *= -1;
});
return pi * 4.0;
}
This is hardly the result we had hoped for—perhaps the cores weren’t working hard enough—but as you can see from Figure 11-4, the cores were pegged at 100 percent CPU.
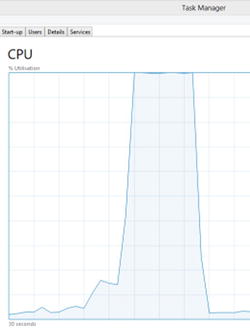
Figure 11-4. CPU utilization when running Parallel.For
Of a greater concern is that you have the wrong result, and multicore sucks. So why the wrong result? Well, Parallel.For isn’t magic. Sure, it is providing an abstraction over the Task API, but fundamentally it is multithreaded programming. In the case of Parallel.For it is executing the body of the loop in parallel by utilizing multiple tasks. The loop body is reading and updating shared variables non-atomically (multiplier and pi), and therefore this is a problem. In the past we have resorted to synchronization primitives in order to update safely; this will further increase the time taken, which is already slower than the single-threaded version.
The use of shared variables is also having an impact on the performance. Each core has its own L1 cache, and in an ideal world, when a method executes it likes to have all its variables already inside that cache. The cache memory is far faster than main memory. If multiple cores are updating the same variable, then clearly they will invalidate one another’s private caches. There is cache coherency logic on the machine to ensure that the other cores get told to eject their cached value, resulting in their having to rebuild the cached entry. Having to rebuild your cache slows things down; by contrast, the single-core version can potentially run 100 percent of the time inside the cache.
CACHE LINES
The CPU caches don’t simply cache discrete values; they cache blocks of memory, typically 256-byte chunks. If any one value inside that 256-byte chunk gets modified, the whole line needs to be rebuilt. Therefore two threads incrementing two different variables could have the same effect on performance as incrementing the same variable—although they won’t suffer from corruption.
To solve this problem we need each task involved in the calculation of pi to just calculate its portion of pi (feeling hungry?), and once it has completed combine it with the other portions of PI to produce the final result. When calculating its portion it does not need to share any variables with any other tasks, thus requiring no synchronization and hopefully not thrashing the cache.
When Parallel.For wishes to use a new task for a portion of the loop, it needs to initialize the local value for the task. To enable this, supply a Func<T> delegate that is responsible for returning the initial value. Note that it’s of type T so your method can return whatever it likes.
Parallel.For then flows this new local value into the loop body in addition to the loop index. During the iteration the task can modify this value, and on completion of an iteration of the loop body, return the value back to Parallel.For. If the Parallel.For wishes to reuse the task for another iteration, the returned value is passed into the task again.
The final part is when a task is no longer required. Parallel.For needs to take its last local value and allow it be combined with local values from other tasks to produce the final result. The combining logic is going to vary, so Parallel.For needs another delegate to provide that functionality. In addition to the initialize delegate, supply an Action<T> with responsibility to receive the last local value for a task and combine it with a global result. Listing 11-14 shows the version of Parallel.For you need to use to make your parallel computation of pi work.
Listing 11-14. Signature of Parallel.For with Per-Task Local State
public static ParallelLoopResult For<TLocal>(int fromInclusive, int toExclusive,
Func< TLocal> localInit,
Func<int,ParallelLoopState, TLocal, TLocal> body,
Action< TLocal> localFinally);
The code in Listing 11-15 has been refactored to use this form of Parallel.For. The loop body now does not use any method-scoped local variables; rather, it is relying purely on variables local to it or ones passed in.
Listing 11-15. Parallel.For Using a Per-Task Value of Pi
private static double ParallelCalculatePi(int iterations)
{
double pi = 1;
Parallel.For(0, (iterations - 3) / 2,
InitialiseLocalPi,
(int loopIndex, ParallelLoopState loopState, double localPi) =>
{
double multiplier = loopIndex%2 == 0 ? -1 : 1;
int i = 3 + loopIndex*2;
localPi+= 1.0/(double) i*multiplier;
return localPi;
},
(double localPi) =>
{
pi += localPi;
});
return pi * 4.0;
}
private static double InitialiseLocalPi()
{ return 0.0;}
Running the code produced the following result:
Time Taken: 01.05 seconds Result: 4.00000021446738
From a time perspective, not bad, but from a results perspective it sucks. In fact, running it a few more times produced the following results:
Time Taken: 01.09 seconds Result: 3.14159265247552
Time Taken: 01.0571 seconds Result: 3.14159266368947
Time Taken: 01.0283 seconds Result: 3.14159265565936
Welcome to the chaotic world of parallel programming. We could just as easily have gotten a good value of pi the first time we ran the code and thus thought our implementation was therefore a good one. Calculating such a well-known value makes it easy to see that producing a value of PI as 4.0 is clearly wrong. When parallelizing algorithms that don’t have such obvious return values it is a lot harder to spot when things go wrong. This is why it is so important to have a simpler single-threaded version of the algorithm to validate results against. The reason for this error is the fact that while the loop body is completely thread safe, the combining logic is not. If multiple tasks complete at the same time, multiple tasks will be executing the line pi += localPi concurrently, and as you know from previous chapters this is not thread safe. To remedy the situation you will need to introduce synchronization; as this is a double you can’t use Interlocked.Add, and thus you will have to use a monitor. Listing 11-16 shows the refactored code.
Listing 11-16. Parallel Pi with Thread-Safe Combiner
private static double ParallelCalculatePi(int iterations)
{
double pi = 1;
object combineLock = new object();
Parallel.For(0, (iterations - 3) / 2,
InitialiseLocalPi,
(int loopIndex, ParallelLoopState loopState, double localPi) =>
{
double multiplier = loopIndex%2 == 0 ? -1 : 1;
int i = 3 + loopIndex*2;
localPi += 1.0/(double) i*multiplier;
return localPi;
},
(double localPi) =>
{
lock (combineLock)
{
pi += localPi;
}
});
return pi * 4.0;
}
Running the code in Listing 11-16 produced the following results over multiple runs.
Time Taken: 01.02 seconds Result: 3.14159265558957
Time Taken: 01.04 seconds Result: 3.1415926555895
Time Taken: 01.07 seconds Result: 3.14159265558942
And so forth.
Note however that the values of pi are all slightly different. While with integer mathematics order doesn’t matter, unfortunately it can make a difference with doubles due to their floating point nature. There are various approaches to get around this but they are beyond the scope of this chapter (see Shewchuk’s algorithm or Sterbenz’s theorem).
Putting the floating issue to one side, you have improved the performance of the pi calculation and produced consistently good approximation values of pi. The speedup isn’t earth-shattering—these numbers were produced on an Intel i7 with four real cores. Expecting a fourfold speedup would be insane, as stated earlier; with the parallel version you need to execute more code to orchestrate the parallelism. Over time more and more cores will appear inside the average machine, thus reducing this effect, with tens of iterations of the loop executing in parallel as opposed to just four in this case. The one big factor affecting performance is the difference in how the loop is being expressed. The synchronous version is using a regular C# for loop, and the parallel version is using a delegate to represent the body of the loop, meaning for each iteration of the loop it has to perform a delegate invocation passing in and returning values. This is far more expensive than just jumping back to the start of the loop. This additional cost is most noticeable when the amount of computation per iteration of the loop is small, as in this case. Therefore to reduce the effect, you need to increase the work undertaken in the loop body. We will explain how this is achieved later in the section titled Nested Loops.
So far you have seen that you can take a for loop and parallelize it if you don’t care about order. Parallel.For requires the loop index to be either an int or a long and can only be incremented by 1. To get the best possible speedup, you need to ensure the loop iterations have no shared state. Parallel.For provides the necessary overloads to allow for this, but the resulting code certainly looks far more complex than our original for loop—not a totally free lunch.
As you can probably guess, Parallel.ForEach provides the parallel equivalent of the C# foreach loop. Parallel.ForEach works by consuming an IEnumerable<T> and farming out elements consumed through the enumerator to multiple tasks, thus processing the elements in parallel. Listing 11-17 shows the equivalent Parallel.ForEach of the initial Parallel.For example in Listing 11-9.
Listing 11-17. Simple Parallel.ForEach
IEnumerable<int> items = Enumerable.Range(0, 20);
Parallel.ForEach(items, i =>
{
Console.WriteLine(i);
});
Parallel.ForEach can therefore be applied to anything that implements IEnumerable (Lists, Arrays, Collections, etc.). One limiting factor with Parallel.For was that you were constrained to int or long and had to increment by 1s. This can be worked around by using an iterator method and Parallel.ForEach instead of Parallel.For as shown in Listing 11-18.
Listing 11-18. Parallel Loop from 1 to 2 in Steps of 0.1
Parallel.ForEach(FromTo(1, 2, 0.1), Console.WriteLine);
. . .
private static IEnumerable<double> FromTo(double start, double end,double step)
{
for (double current = start; current < end; current += step)
{
yield return current;
}
}
Parallel.ForEach has similar overloads to that of Parallel.For, allowing for the use of local loop state and combining logic in the same way they were used for Parallel.For. What makes life harder for Parallel.ForEach compared to Parallel.For is that it potentially won’t know how many items there are to process, since a pure IEnumerable object has no way of yielding how many items there are to consume. Therefore Parallel.ForEach has to start off consuming a few items per task so as to allow many tasks to work on a small data set. As it learns that the IEnumerable stream keeps yielding an initial block size, it asks for larger and larger block sizes. This process is known as partitioning. If Parallel.ForEach could know the size of the IEnumerable stream, it could do a better job of partitioning. Therefore, to give itself the best possible chance internally, it attempts to discover at runtime if the IEnumerable<T> is in fact an array or an IList<T>. Once it knows it is a list or an array, it can use the Count and Length properties respectively to determine the size, and hence do a better job of initial partitioning. Parallel.ForEach therefore works best with arrays or lists.
With a regular loop in C#, you can leave the loop early through the use of a break statement. Since the body of a parallel loop is represented by a delegate, you can’t use the break keyword. To allow this style of behavior for parallel loops, both Parallel.For and Parallel.ForEach provide an overload that allows the loop body delegate to take, in addition to the loop index, a ParallelLoopState object. This loop state object is used to both signal and observe if the loop is to terminate early. Listing 11-19 shows an example of a loop that for each iteration has a 1 in 50 chance of terminating.
Listing 11-19. Early Termination using ParallelLoopState.Break
Random rnd = new Random();
Parallel.For(0, 100, (i, loopState) =>
{
if (rnd.Next(1, 50) == 1)
{
Console.WriteLine("{0} : Breaking on {1}",Task.CurrentId, i);
loopState.Break();
return;
}
Console.WriteLine("{0} : {1}", Task.CurrentId, i);
});
The big difference between break in a regular loop to a parallel loop is that the break can be acted upon immediately and no further iterations will occur. With a parallel loop other iterations could be in progress when a particular iteration requests the break, in which case these iterations can’t be stopped without some cooperation of the iteration. Figure 11-5 shows an example of an early loop termination with break.
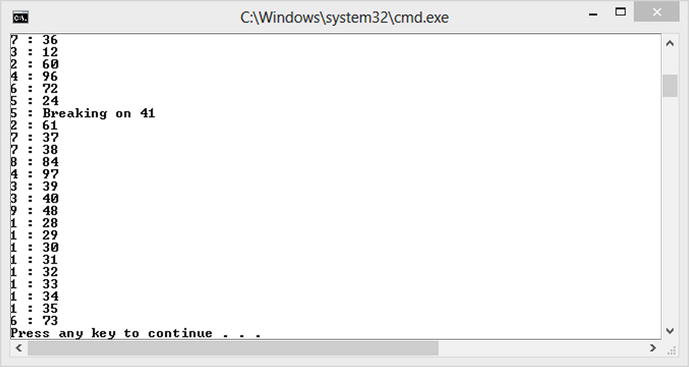
Figure 11-5. Early terminaton of parallel loop using ParallelLoopState.Break()
Although Task 5 has requested termination, Tasks 7, 3, and 1 continue to execute many more iterations. The reason for this is that ParallelLoopState.Break is trying to recreate the semantics of a regular loop break. With a regular loop break, if you break on Iteration 20 you know that all iterations prior to that will have executed. When you issue a ParallelLoopState.Break() the parallel loop ensures that all lower-value iterations will be executed before the loop ends. Studying the output shown in Figure 11-5, we can see that once Task 5 has issued the break apart from Tasks 7, 3, and 1, all other tasks complete their current iteration and end. Tasks 7, 3, and 1 keep running to complete all iterations less than 41. Obviously if iterations have already completed that represent values greater than 41, then there will be no way of rolling back. The behavior is thus not an exact match to the regular break, but it is as close as you can get considering the loop is being executed out of order.
If you do want to terminate the loop as soon as possible and don’t care about guaranteeing that all prior iterations have completed, then ParallelLoopState has another method called Stop. The Stop method attempts to end the loop as soon as possible—once issued, no loop task will start a new iteration. Listing 11-20 shows the same example using Stop instead of a Break. Figure 11-6 shows an example of a run where Stop is issued by Task 9: all remaining tasks finish their current iteration and don’t process any more.
Listing 11-20. Early Loop Termination with ParallelLoopState.Stop()
Random rnd = new Random();
Parallel.For(0, 100, (i, loopState) =>
{
if (rnd.Next(1, 50) == 1)
{
Console.WriteLine("{0} : Stopping on {1}", Task.CurrentId, i);
loopState.Stop();
return;
}
Console.WriteLine("{0} : {1}", Task.CurrentId, i);
});
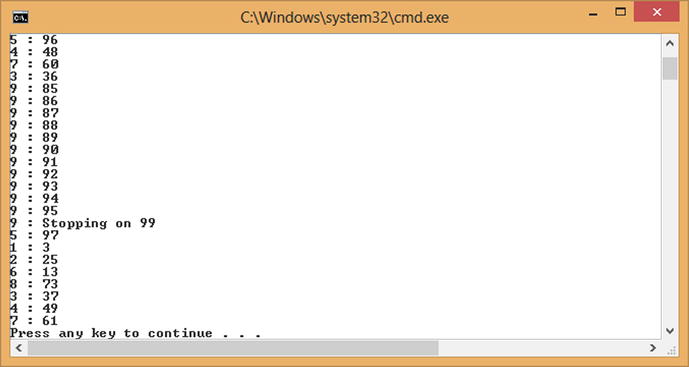
Figure 11-6. Early loop termination using ParallelLoopState.Stop()
In addition to initiating termination of the loop, ParallelLoopState can also be used to determine if another iteration of the loop has initiated termination, or has thrown an unhandled exception. In situations where the loop body takes a considerable amount of time, it may be desirable for the loop body to observe the fact that the loop should end, and assist in shutting down the loop early. Table 11-1 lists the properties available on ParallelLoopState to assist in detection of the need to terminate early.
Table 11-1. Observing Loop State
Property |
Description |
|---|---|
IsExceptional |
Returns true if another iteration has thrown an unhandled exception, preventing the loop from fully completing |
IsStopped |
Returns true if another iteration has requested the loop be stopped as soon as possible |
ShouldExitCurrentIteration |
Returns true if the current iteration is no longer required to complete. In the case of a Stop or Break has been issued by a lower iteration. |
LowestBreakIteration |
Returns a long? representing the iteration in which a Break was issued, null if no Break has been issued. |
Listing 11-21 shows an example of a loop body detecting a stop request and ending the loop body prematurely. Early termination can also be observed outside the loop body by examining the return value from Parallel.For or Parallel.ForEach. The return value is of type ParallelLoopResult and it provides a property called IsCompleted. If the loop did not complete all intended iterations due to a Stop or Break being issued, this will be set to false. Figure 11-7 shows an example run where early termination is being observed.
Listing 11-21. Observing Stop Requests
Random rnd = new Random();
ParallelLoopResult loopResult= Parallel.For(0, 100, (i, loopState) =>
{
if (rnd.Next(1,50) == 1)
{
Console.WriteLine("{0} : Stopping on {1}", Task.CurrentId, i);
loopState.Stop();
return;
}
Thread.Sleep(10);
if ( loopState.IsStopped)
{
Console.WriteLine("{0}:STOPPED",Task.CurrentId);
return;
}
Console.WriteLine("{0} : {1}", Task.CurrentId, i);
});
Console.WriteLine("Loop ran to completion {0}",loopResult.IsCompleted);
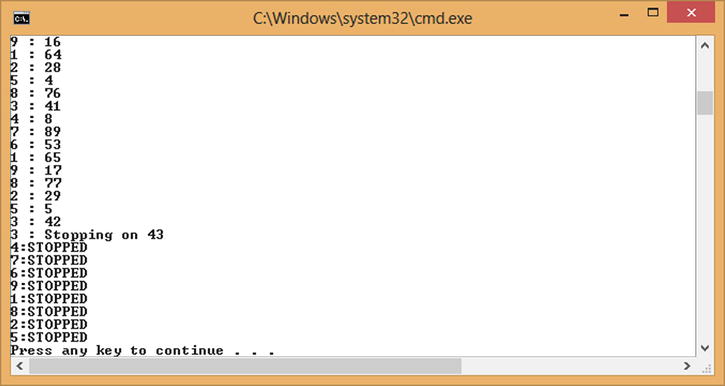
Figure 11-7. Observing Stop requests
If a loop body were to throw an unhandled exception, this would be similar to issuing a Stop request. The exception would be caught by Parallel.For or Parallel.ForEach and then be re-thrown as part of an AggregateException, in order to inform the caller that the loop failed to complete due to exceptions.
Parallel loops are not the same as synchronous loops but, where possible, similar constructs are provided to allow for early termination of a loop. If a loop has completed its said purpose early, use Break and Stop for early graceful termination of the loop. If the loop fails to complete its purpose, then throw an exception, making the caller fully aware that the loop failed to complete its task.
Earlier in Listing 11-16 we parallelized an algorithm to approximate the value of pi. While it was faster than the single-threaded version, the gain wasn’t earth shattering. The reason suggested for the lack of boost was the additional overhead introduced through the use of Parallel.For. The fact that the loop body is now represented by a delegate, and as such each iteration of the loop now involves a delegate invocation this will drastically increase the amount of work for each iteration of the loop. With the amount of work per delegate invocation being so small the effect of parallelization is further lessened. This is a common problem with lots of loops, and as such we often find that one of the better structures to parallelize is not a single loop but nested loops. The code in Listing 11-22 has two loops; each iteration of the outer loop results in 100 iterations of the inner loop. The inner loop could therefore represent a reasonable amount of work. If the outer loop were to be parallelized, leaving the inner loop as the body, this could then represent a reasonable amount of work to compensate for the overhead of delegate invocation.
Listing 11-22. Simple Nested Loop
for (int i = 0; i < 500; i++)
{
for (int j = 0; j < 100; j++)
{
// Do Stuff
}
}
Listing 11-23 shows how to parallelize Listing 11-22.
Listing 11-23. Parallelized nested loop
Parallel.For(0, 500, i =>
{
for (int j = 0; j < 100; j++)
{
// Do Stuff
}
});
“All well and good,” you might say, “but what if my algorithm just has a single loop?” Any single loop can always be turned into an equivalent outer and inner loop as shown in Listing 11-24.
Listing 11-24. Single Loop and Equivalent Nested Loop
for (int i = 0; i < 50000; i++)
{
// Do Stuff
}
for (int i = 0; i < 500; i++)
{
for (int j = 0; j < 100; j++)
{
// Do Stuff
}
}
So the first task is to turn the single loop into two loops. Before we dive into how to produce the parallel version, see Listing 11-25, which shows a refactored nonparallel version of CalculatePI that now uses two loops. The outer loop is a foreach iterating over a stream of Tuple<int,int>. Each Tuple<int,int> represents a range of values for the inner loop to iterate over.
Listing 11-25. CalculatePi Turned into Two Loops
public static double CalculatePi(int iterations)
{
IEnumerable<Tuple<int, int>> ranges = Range(3, iterations, 10000);
double pi = 1;
foreach (var range in ranges)
{
double multiplier = range.Item1 % 2 == 0 ? 1 : -1;
for (int i = range.Item1; i < range.Item2; i+=2)
{
pi += 1.0/(double) i*multiplier;
multiplier *= -1;
}
}
pi *= 4.0;
return pi;
}
private static IEnumerable<Tuple<int, int>> Range(int start, int end, int size)
{
for (int i = start; i < end; i+=size)
{
yield return Tuple.Create(i, Math.Min(i + size,end));
}
}
Now that the algorithm has been refactored into two loops, you can parallelize the outer loop, leaving the inner loop to run synchronously and thus generate sufficient work to justify the overhead of delegate invocation, as shown in Listing 11-26.
Listing 11-26. ParallelCalculatePi with Nested Loops
private static double TwoLoopsParallelCalculatePi(int iterations)
{
IEnumerable<Tuple<int, int>> ranges = Range(3, iterations, 10000);
double pi = 1;
object combineLock = new object();
Parallel.ForEach(ranges.ToList(),
() => 0.0,
(range, loopState, localPi) =>
{
double multiplier = range.Item1%2 == 0 ? 1 : -1;
for (int i = range.Item1; i < range.Item2; i += 2)
{
localPi += 1.0/(double) i*multiplier;
multiplier *= -1;
}
return localPi;
},
localPi =>
{
lock (combineLock)
{
pi += localPi;
}
});
pi *= 4.0;
return pi;
}
As explained earlier, when Parallel.ForEach executes it has to partition the IEnumerable stream, and it does this by combination of guessing and inspecting the actual source type of the stream. It is very hard to write a partitioner that is perfect for every scenario. Rather than Parallel.ForEach consuming an IEnumerable and also creating and using the default partitioner, you can supply it with a partitioner (see Listing 11-27). You can create your own partitioner that has explicit knowledge of how to partition your data source, but we won’t discuss that in this book. TPL ships with some out-of-the-box partitioners that you can take advantage of, made available through Create methods on the System.Collections.Concurrent.Partitioner class.
Listing 11-27. Using Parallel.ForEach Using Partitioner Directly
private static double OptimizedParallelCalculatePiWithPartitioner(int iterations)
{
//IEnumerable<Tuple<int, int>> ranges = Range(3, iterations, 10000);
var ranges = Partitioner.Create(3, iterations, 10000);
double pi = 1;
object combineLock = new object();
Parallel.ForEach(ranges, () => 0.0,
(range, loopState, localPi) =>
{
double multiplier = range.Item1 % 2 == 0 ? 1 : -1;
for (int i = range.Item1; i < range.Item2; i += 2)
{
localPi += 1.0 / (double)i * multiplier;
multiplier *= -1;
}
return localPi;
},
localPi =>
{
lock (combineLock)
{
pi += localPi;
}
});
pi *= 4.0;
return pi;
}
Table 11-2 presents all the times from running the implementations of CalculatePi. The two-loops implementation gets us very close to linear scaling, albeit with some refactoring of the algorithm, so it’s not exactly a free lunch.
Table 11-2. Times for Pi Calculations, Running on an i7 with Four Real Cores and Four Hyper-threaded Cores
Method |
Time Taken (Seconds) |
|---|---|
CalculatePi |
1.89 |
ParallelCalculatePi |
0.88 |
TwoLoopsParallelCalculatePi |
0.5 |
OptimizedParallelCalculatePiWithPartitioner |
0.48 |
PLINQ is the parallel form of LINQ over IEnumerable<T>. PLINQ is not a general parallel framework for all forms of LINQ such as LINQ to Entities. Conventional LINQ is built along the lines of functional programming and typically immutable data. These two characteristics alone make it a great candidate for parallelism as it means multiple tasks can run concurrently, producing and consuming nonshared values. The other key characteristic of LINQ that makes it applicable for parallelism is that LINQ is all about intent, not mechanics. Expecting the compiler to parallelize an arbitrary piece of code is hard. With LINQ we chain together a series of high-level primitives (Where, Select, OrderBy) where each is well understood, and therefore we could have parallel versions of them instead.
![]() Note It is assumed that the reader understands LINQ, and how LINQ utilizes extension methods to provide a declarative mechanism to define queries.
Note It is assumed that the reader understands LINQ, and how LINQ utilizes extension methods to provide a declarative mechanism to define queries.
Listing 11-28 shows a simple LINQ query that produces a list of all the even numbers and prints the length of the list.
Listing 11-28. LINQ Query to Find Even Numbers
using System.Linq;
. . .
IEnumerable<int> numbers = Enumerable.Range(0, 100000000);
var evenNumbers = from number in numbers
where number%2 == 0
select number;
Console.WriteLine(evenNumbers.ToList().Count());
At compile time, the compiler turns the language keywords into extension methods, as per Listing 11-29. It does this by looking for extension methods that extend the source of the query. In this case, since the numbers variable is of type IEnumerable<int>, it selects extension methods that extend IEnumerable<int>, and as such we pick up the single-threaded Where method implementation for LINQ to objects.
Listing 11-29. Extension Method Form of the LINQ Query in Listing 11-28
var evenNumbers = numbers
.Where(number => number%2 == 0);
If numbers were not of type IEnumerable<T>, then the compiler would be looking for another extension method in scope called Where that extends whatever type numbers is. The fact that the compiler is not bound to a specific implementation of Where means that by changing the type of numbers from IEnumerable<T> to a different type, you can bring into scope other implementations of Where—perhaps a parallel version. Listing 11-30 shows how to enable the use of a parallel version of Where. The AsParallel extension method on IEnumerable<T> returns a ParallelQuery<T>; from then on the compiler will have to look for the Where extension method not on IEnumerable<T> but on ParallelQuery<T>. The System.LINQ.ParallelEnumerable class defines all the extension methods for ParallelQuery<T>, so as long as you are using System.Linq you are good to go.
By being able to simply add an AsParallel call to an already easy-to-understand LINQ query and then have it run in parallel makes for a perfect free lunch: code that is not only readable but scales as you add more cores.
Listing 11-30. Parallel Form of LINQ query
IEnumerable<int> numbers = Enumerable.Range(0, 100000000);
var evenNumbers = from number in numbers.AsParallel()
where number%2 == 0
select number;
var evenNumbers2 = numbers.AsParallel()
.Where(number => number%2 == 0);
Moving from Sequential LINQ to PLINQ
Moving from sequential LINQ to Parallel LINQ therefore looks a breeze; however, like all things, there are plenty of issues to consider. In the case of Parallel.For we discussed the issue of having a small loop body, and how the overhead of delegate invocation can drastically inhibit parallelism. The good news for Parallel LINQ is that it is parallelizing LINQ, which already relies on the use of delegates, so you are not adding as much additional overhead. However, if performance is your ultimate goal, then LINQ is not a great starting point—LINQ was never designed for CPU efficiency. Any LINQ statement could be rewritten using a conventional foreach loop and the necessary filtering inside the loop, and it would outperform the LINQ statement. Having said all that, keep in mind that if your LINQ queries comprise I/O, then it is likely that the time spent doing I/O will swamp the time spent doing computing. If you want to use LINQ to keep code simple to maintain but still get the best possible performance out of it, then PLINQ is still a great choice. The fundamental point here is if you care about maximum performance, LINQ and hence PLINQ are unlikely to be your final destination.
PLINQ is also a great choice for less experienced asynchronous programmers, as lots of the thread safety issues are removed by the functional programming style LINQ promotes. Unlike conventional asynchronous programming, you can now feel confident that the code doesn’t have those unexpected race conditions. Perhaps you won’t get the ultimate speedup, but you can have confidence in the speedup you do get.
Last, it’s worth stating that even though you may request the query to run in parallel, if the runtime deems that the query would not benefit from running in parallel, it will revert to running it on a single thread (you can force it to run parallel—more on that later in section Influencing and Configuring the Query).
In the same way that Parallel.ForEach found it harder to partition up the data if it was given a pure IEnumerable<T>, the same is true for PLINQ. PLINQ works best with arrays and IList<T>. Listing 11-31 benchmarks the filtering of just even numbers from a range of numbers. Running this code produce an overall time of 1.09 seconds. The code is then modified as per Table 11-3 and rerun to obtain the time taken to execute that variant.
Listing 11-31. Timed LINQ Query
static void Main(string[] args)
{
IEnumerable<int> numbers =
Enumerable.Range(0, 100000000);
TimeIt(() =>
{
var evenNumbers = from number in numbers
where number%2 == 0
select number;
Console.WriteLine(evenNumbers.Count());
});
}
private static void TimeIt(Action func)
{
Stopwatch timer = Stopwatch.StartNew();
func();
Console.WriteLine("{0}() and took {1}",
func.Method.Name, timer.Elapsed);
}
Table 11-3. Code Modifications and Associated Times Taken to Execute
Original Code |
Replacement Code |
Time Taken (Seconds) |
|---|---|---|
from number in numbers |
from number in numbers.AsParallel() |
1.25 |
Enumerable.Range(0,100000000); |
Enumerable.Range(0,100000000).ToList() |
0.70.22 |
As shown in Table 11-3, for small, simple queries parallelism only works if PLINQ is able to partition efficiently. This very simple example hopefully tells you not to go through your entire code base modifying all LINQ statements to use AsParallel. Remember: Always benchmark code before attempting to optimize. Just because it is easy to throw on an AsParallel doesn’t mean you should.
Does Order Matter?
With conventional LINQ, items are processed in order as they are yielded from the IEnumerable<T> stream. With PLINQ, the processing order and the result order are unknown, just as it was with parallel loops. If you don’t care about order, all is good, but if you do need the results to come out in the same order as the source processing, then you need to tell PLINQ to preserve order. For example, consider a piece of PLINQ processing a CSV file row by row: its job is to take each row in turn, add a row total column, and then output the row to a new file. The order of the output CSV file should match that of the input CSV file. If you were to process this with just AsParallel(), then the output order could be different from that of the input. To preserve its order, call AsOrdered() as per Listing 11-32.
Listing 11-32. Ordered Parallel Query
IEnumerable<string[]> csvRows = GetRows(@"....datastockData.csv").Skip(1);
var rowWithTotalColumn =
from row in csvRows.AsParallel().AsOrdered()
let total = row.Skip(1).Select(c => decimal.Parse(c)).Sum()
select row.Concat(Enumerable.Repeat(total.ToString(), 1)).ToArray();
WriteCsvRows(rowWithTotalColumn, "RowsWithTotal.csv");
Preserving order comes at a cost, since it means the partitioner is more constrained about how it can partition and has to buffer up results before publishing them. Use AsOrdered for algorithms that need to stream data in, process it, and stream it out in the same order. If only part of the query needs to be ordered, then you can revert back to more efficient behavior by using the AsUnOrdered() method.
If all you need to care about is knowing which input index produced a given output, then a more efficient model is simply to flow an index with the data as per Listing 11-33. An example of running the code is shown in Figure 11-8. While the output order does not match that of the input, the output value does now contain a corresponding index of the input that produced the said output.
Listing 11-33. Associating Result with Input Index
IEnumerable<string> values = new List<string>() { "one","two","three","four","five","six"};
var upperCases = values
.Select((value, index) => new {Index = index, Value = value})
.AsParallel()
.Select(valueIndexPair => new {valueIndexPair.Index,Value=valueIndexPair.Value.ToUpper()});
foreach (var upperCase in upperCases)
{
Console.WriteLine("{0}:{1}",upperCase.Index,upperCase.Value);
}
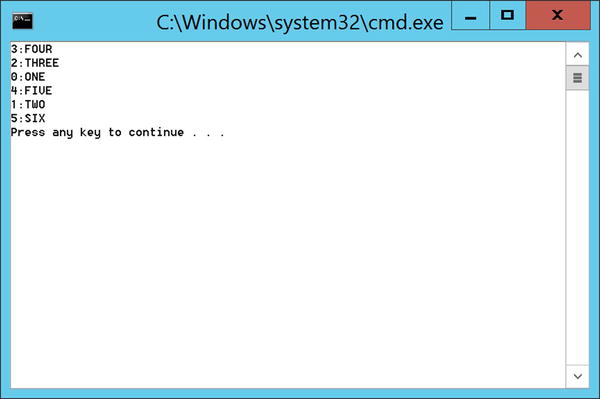
Figure 11-8. Data with index+
Influencing and Configuring the Query
Rather than relying completely on PLINQ default behavior, we can provide various additional bits of configuration to influence how the parallelism takes place. This is achieved through a series of extension methods. Listing 11-34 shows a parallel query that will use two tasks, will always run in parallel, and has been supplied with a cancellation token to allow early cancellation of the query.
Listing 11-34. Configuring the Query
var cts = new System.Threading.CancellationTokenSource();
var upperCases = values
.Select((value, index) => new {Index = index, Value = value})
.AsParallel()
.WithDegreeOfParallelism(2)
.WithExecutionMode(ParallelExecutionMode.ForceParallelism)
.WithCancellation(cts.Token)
.Select(valueIndexPair => new {valueIndexPair.Index,Value=valueIndexPair.Value.ToUpper()});
ForAll
The ForAll method seems an odd addition to PLINQ as it provides virtually identical functionality to that of foreach. The differentiator is that it does allow you to define and consume the parallel query as a single block statement, which can look pretty elegant as shown in Listing 11-35.
Listing 11-35. Define and Consume the Query
new string[] { "http://www.bbc.co.uk",
"http://www.rocksolidknowledge.com",
"http://www.nsa.gov",
"http://www.cia.gov",
}
.AsParallel()
.Select(url => new {url, content = DownloadContent(url)})
.Where(download => download.content.Contains("happy"))
.ForAll(download =>
{
Console.WriteLine("{0} is happy", download.url);
});
Although PLINQ executes a query on multiple threads, if you consume the results in a foreach loop, then the query results must be merged back into one thread and accessed serially by the enumerator. Using ForAll allows the results to be processed in parallel; this therefore extends the parallelization of the processing and as such is encouraged.
The classic Map/Reduce problem is well suited to PLINQ. PLINQ provides some standard aggregation schemes such as Sum, Min, Max, and Average (see Listing 11-36).
Listing 11-36. Parallel Sum
int sum = GenerateNumbers(100000000)
.AsParallel()
.Sum();
For more complex aggregations PLINQ provides its own unique variant of the LINQ Aggregation method to define your own reduce function. The Aggregate method takes four arguments:
- The initial seed value used for each task involved in the aggregation
- A method used to create a localized aggregation. This method initially receives the seed from Step 1, plus the first value to be aggregated by a given task.
- A method used to combine all the localized aggregations
- A method that takes the combined result and provides the final processing before publication of the aggregation
Listing 11-37 shows an example of customized aggregation for calculating the standard deviation of a set of random numbers.
Listing 11-37. Parallel Implementation of Standard Deviation
private static void Main(string[] args)
{
//http://en.wikipedia.org/wiki/Standard_deviation
List<int> values = GenerateNumbers(100000000).ToList();
double average = values.AsParallel().Average();
double std = values
.AsParallel()
.Aggregate(
0.0,
// produces local total
(subTotal, nextNumber) => subTotal += Math.Pow(nextNumber - average, 2),
// sum of all local totals
(total, threadTotal) => total += threadTotal,
// final projection of the combined results
grandTotal => Math.Sqrt(grandTotal / (double)(values.Count - 1))
);
Console.WriteLine(std);
}
private static IEnumerable<int> GenerateNumbers(int quantity)
{
Random rnd = new Random();
for (int i = 0; i < quantity; i++)
{
yield return rnd.Next(1,100);
}
}
Summary
TPL’s parallel extensions provide a relatively high-level form of abstraction to implement parallel algorithms. Parallel.For and Parallel.ForEach have a syntax very close to the regular loop constructs; this helps to maintain the structure of the algorithm but still execute in parallel. What can’t be ignored is the fact that the body of the loop is running over multiple threads, and as such thread safety matters. Solving the thread safety issues through synchronization will often result in poor performance. Ideally you should remove the need to use synchronization by writing loop bodies that have no shared state with other iterations. Refactoring the code to remove the shared state can often introduce extra complexity, making the code far harder to understand than the original single-threaded loop. Further, the size of the loop body may not be of sufficient computational size to justify the effort of parallelism, and again require refactoring through the introduction of nested loops. The final result of all this refactoring is that your code will be a long way from its simple roots. Parallel loops are certainly a huge step forward in enabling multicore programming, but still require the developer to have deep knowledge of multithreaded programming—not the free lunch we had hoped for.
PLINQ offers the best prospect of a free lunch—the declarative and functional nature of LINQ makes it ideal for parallelism. The structure of the LINQ statement varies very little with the introduction of parallelism. Preserving the original structure means we have code that not only performs well, but is also easier to maintain. Ensuring that the PLINQ statement is built purely along functional programming principles means that there is no need to consider thread safety issues, making the code less likely to suffer those sometimes rare but painful race conditions. PLINQ is therefore ideal for less experienced asynchronous programmers. However, remember that LINQ is not designed for performance, so if max performance at all costs is what you desire, then prefer other forms of parallelism.
However you decide to parallelize, remember to benchmark your code before you start. You need to be confident that what you have is faster and produces the correct results.