
![]()
TPL Dataflow
Classic concurrent programming simply took synchronous programming and said, “Let us have lots of synchronous execution running at the same time, through the use of threads.” To this end we have used the Task abstraction to describe concurrency; all is good until we introduce mutable shared state. Once mutable shared state is involved, we have to consider synchronization strategies. Adding the correct and most efficient form of synchronization adds complexity to our code. The one glimmer of hope is that we can retain some degree of elegance through the use of concurrent data structures and more complex synchronization primitives; but the fact remains that we still have to care about mutable shared state.
But let us dream of a world where we don’t have to think about synchronization; where we just write the code, and the way we structure it results in no synchronization issues. In this world each object has its own private thread of execution, and only ever manipulates its own internal state. Instead of one single thread executing through many objects by calling object methods, objects send asynchronous messages to each other. If the object is busy processing a previous message, the message is queued. When the object is no longer busy it then processes the next message. Fundamentally, if each object only has one thread of execution, then updating its own internal state is perfectly safe. To alter another object’s state, it needs to send a message, which again will only get acted upon by that object’s private thread. It is this style of programming that TPL Dataflow is looking to promote, not a single lock or semaphore insight.
The Building Blocks
TPL Dataflow comprises a series of blocks (an odd word, we realize, when discussing concurrency). Blocks are essentially a message source, target, or both. In addition to receiving and sending messages, a block represents an element of concurrency for processing the messages it receives. Multiple blocks are linked together to produce networks of blocks. Messages are then posted asynchronously into the network for processing. Each block can perform processing on the message prior to offering a message to another block. So while by default each block only processes one message at a time, if multiple messages are active in different blocks we have concurrency.
Consider the following use case. At periodic times in the day, a report is run against a database and the results from the report uploaded to a web service. The data contained in each database row need to be transformed into a data object ready to be sent to the web service. For network efficiency the web service receives multiple data objects as part of a single request, up to a defined maximum. The following process could be broken down into a series of blocks, where each block is responsible for doing some part of the overall processing. Figure 10-1 shows what that might look like.
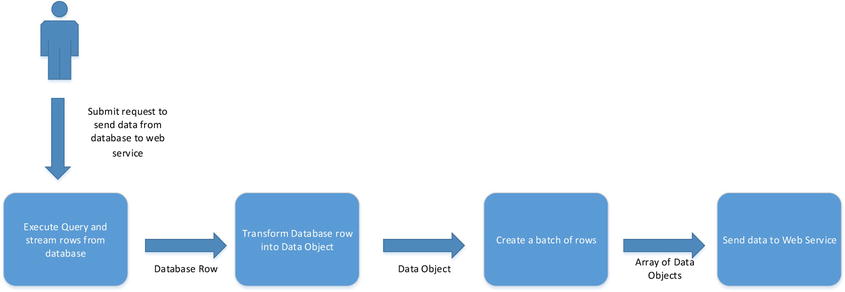
Figure 10-1. Process pipeline
Each block has its own thread of execution, so in the case just described, while one thread is fetching the next row from the database another thread is transforming the previous row. When we have sufficient rows, another thread will send the data to the web server, while the other blocks continue to fetch and transform database rows. This is akin to Henry Ford’s car production line, where each worker was autonomous in performing his specific job. This concurrency works beautifully as long as each block takes the same time to process; otherwise we end up with bottlenecks.
Obviously we can’t always guarantee that each block will take the same time, so blocks have buffers, allowing the previous block to reliably deliver its result and move on to its next piece of processing. Buffers are useful to iron out bursts of activity, but they don’t solve the fundamental problem of a bottleneck. If this were a car production line, we could solve the problem either by breaking down the bottleneck block into smaller blocks or, alternatively, by introducing multiple workers for that particular block with each worker still working autonomously. The equivalent of workers in our domain is threads, so we could introduce the idea of multiple threads inside a given block. Assuming each thread in a given block does not share mutable state with another thread, all will remain good. Figure 10-2 shows how the application could be reconfigured to use multiple threads inside some of the blocks. This new configuration allows three database rows to be processed concurrently and allows two concurrent batches to be delivered to the web server.
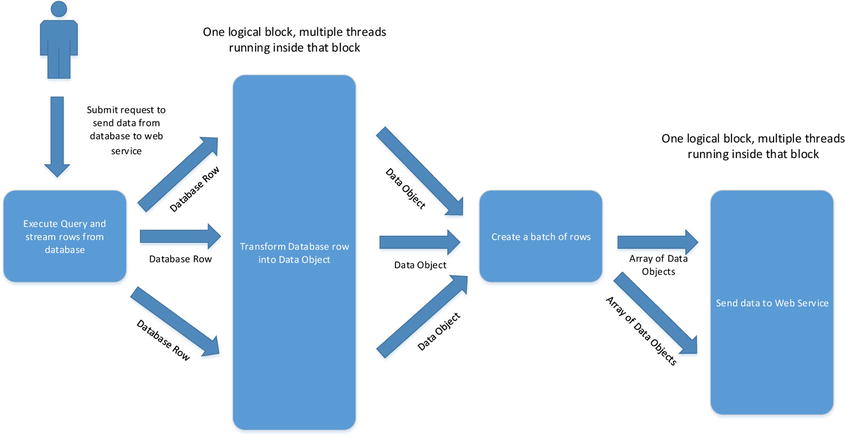
Figure 10-2. Improved pipeline, multiple threads per block
This is essentially what TPL Dataflow is: the ability to describe algorithms using a network of asynchronous message-passing autonomous blocks.
GETTING TPL DATAFLOW
TPL Dataflow, unlike TPL itself, is not distributed as part of the .NET framework. It is available as a package installed via NuGet. See www.nuget.org/packages/Microsoft.Tpl.Dataflow for more details of how to install it. To use TPL Dataflow you will also need to be using at least .NET 4.5.
Producer and Consumer Revisited
I can hear you groaning, so I promise this will be the last time we revisit this pattern. In Chapter 5 you built a producer consumer implementation using BlockingCollection<T>; for that particular implementation you spun up a fixed number of consumer threads. When these threads had no items to process they slept peacefully. As discussed in Chapter 9, having a thread sleeping is often better than having it spinning, but ideally you would like the thread to retire back to the thread pool. Implementing such a scheme is nontrivial using basic TPL; however, TPL Dataflow makes it a breeze. Listing 10-1 shows a very simple Dataflow application that achieves our goal. Here we have a single ActionBlock<int>. ActionBlock<T> can receive input of type T, executing the supplied logic (Action<T>) to act on the value of T. ActionBlocks are leaf nodes in a Dataflow network, and therefore cannot be used as sources to other blocks. One way of supplying values of T to a ActionBlock<T> is to call the Post method on the ActionBlock<T> itself. The Post method will attempt to deliver the value to the ActionBlock<T>; if it is unable to accept it immediately the post will fail and the Post method will return false.
Listing 10-1. Lazy Producer Consumer
using System;
using System.Threading;
using System.Threading.Tasks;
// You will need to get the TPL bits from NuGet, as per start of chapter
using System.Threading.Tasks.Dataflow;
namespace ProducerConsumerDataFlow
{
class Program
{
static void Main(string[] args)
{
var consumerBlock = new ActionBlock<int>(new Action<int>(Consume));
PrintThreadPoolUsage("Main");
for (int i = 0; i < 5; i++)
{
consumerBlock.Post(i);
Thread.Sleep(1000);
PrintThreadPoolUsage("loop");
}
// Tell the block no more items will be coming
consumerBlock.Complete();
// wait for the block to shutdown
consumerBlock.Completion.Wait();
}
private static void Consume(int val)
{
PrintThreadPoolUsage("Consume");
Console.WriteLine("{0}:{1} is thread pool thread {2}",Task.CurrentId,val,
Thread.CurrentThread.IsThreadPoolThread);
}
private static void PrintThreadPoolUsage(string label)
{
int cpu;
int io;
ThreadPool.GetAvailableThreads(out cpu,out io);
Console.WriteLine("{0}:CPU:{1},IO:{2}",label,cpu,io);
}
}
}
Running the code in Listing 10-1 produces the output shown in Figure 10-3. This shows that the items are being consumed on a thread pool thread, and as a consequence there are fewer threads available in the thread pool. When no items are available for consumption, the number of available threads in the thread pool returns to the recorded initial level of 1,023. This therefore shows that while there are no items to consume, you are not simply sleeping on a thread pool thread.
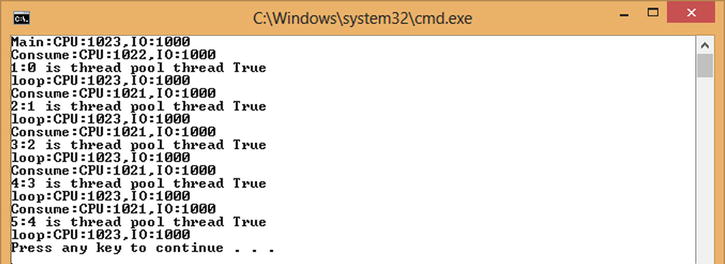
Figure 10-3. Lazy producer consumer
ActionBlock<T>therefore consumes thread resources when it has items to process, but retires the thread when it has no work to do, thus fulfilling our initial requirement.
Let us examine what happens if we supply more work than can be immediately dealt with by the ActionBlock<T>. Listing 10-2 shows an eager producer and a slow consumer.
Listing 10-2. Slow Consumer
class Program
{
static void Main(string[] args)
{
var consumerBlock = new ActionBlock<int>(new Action<int>(SlowConsumer));
for (int i = 0; i < 5; i++)
{
consumerBlock.Post(i);
}
consumerBlock.Complete();
consumerBlock.Completion.Wait();
}
private static void SlowConsumer(int val)
{
Console.WriteLine("{0}: Consuming {1}", Task.CurrentId,val);
Thread.Sleep(1000);
}
The SlowConsume method in Listing 10-2 takes approximately 1 second to process each item. You are posting items at a far greater frequency than that, so you may have therefore expected the Post to fail. While the ActionBlock<T> by default can only process one item at a time, it also has by default an unbounded buffer so it can keep receiving items while processing. This is known as a greedy block (see Figure 10-4).

Figure 10-4. Greedy ActionBlock<int>
By default ActionBlock<T> only has a single thread of execution; this and many other options can be changed by supplying a configured instance of ExecutionDataflowBlockOptions when creating the ActionBlock<T> (see Figure 10-5). The fragment of code in Listing 10-3 creates a block that can process two messages concurrently. Needless to say, if there is only one item to process only one thread will be active.
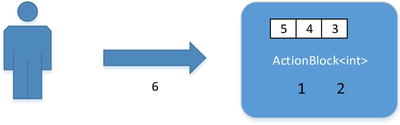
Figure 10-5. ActionBlock<int> with MaxDegreeOfParallelism = 2
Listing 10-3. Two-Thread Action Block
. . .
var blockConfiguration = new ExecutionDataflowBlockOptions()
{
NameFormat="Type:{0},Id:{1}", // Effects ToString() on block (useful for debugging/logging)
MaxDegreeOfParallelism = 2, // Up to two tasks will be used to process items
};
var consumerBlock = new ActionBlock<int>(new Action<int>(SlowConsumer) ,
blockConfiguration);
Console.WriteLine(consumerBlock.ToString());
Modifying Listing 10-2 to use the preceding block configuration would result in the output shown in Figure 10-6. Now you can see two tasks are being used to process the items concurrently (Tasks 2 and 3).
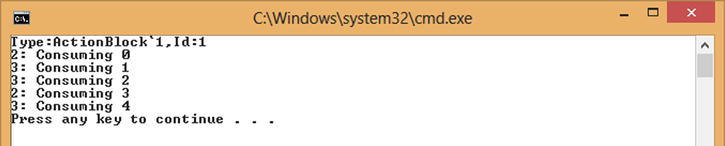
Figure 10-6. Multiple tasks executing inside a block
While the examples so far are very simple, they set you off on a new approach to writing concurrent applications. Rather than having to deal with the mechanics of creating tasks, simply define blocks of code and associated levels of concurrency.
Linking Blocks
Isolated blocks aren’t really that interesting. What is far more interesting is when multiple blocks are connected together to form a network of concurrent activity. An ActionBlock<T> acts as a network edge, there are other block types that can be used to form the start or body of a network. These blocks are linked together to form a network, so that as data are posted into one block and processed, they can then flow into the input of a connected block. Table 10-1 contains details of the block types that come out of the box.
Table 10-1. Types of Dataflow Blocks
Block Type |
Description |
|---|---|
BufferBlock<T> |
Buffers input, useful for load balancing non greedy consumers |
TransformBlock<TInput,TOutput> |
Transforms an input to a different output |
TransformManyBlock<TInput,TOutput> |
Transforms an input into many outputs, similar to LINQ SelectMany |
BatchBlock<T> |
Collects a configured number of input items to create an array of output items. In addition, batch can be trigged programmatically (e.g., every n seconds). |
BroadcastBlock<T> |
Makes the last value posted to the block available for any connected block. Useful for when you just want to know the latest value, and old values are meaningless. |
WriteOnceBlock<T> |
Same as broadcast but only makes available first posted value. |
JoinBlock<T1,T2>JoinBlock<T1,T2,T3> |
Takes input from two or three blocks, only consumes value when there is sufficient inputs. Produces an output of Tuple<T1,T2> or Tuple<T1,T2,T3>. Useful for Fork/Join scenarios |
BatchedJoinBlock<T1,T2>BatchedJoinBlock<T1,T2,T3> |
A batched version of the JoinBlock |
Let us first consider the piece of code in Listing 10-4. The purpose of this code is to turn a color-based image into a grayscale image. The code is expected to initially run on the UI thread; so as to not block the UI thread, it creates a task to run the image processing and, once completed, fires an event on the UI thread to indicate it is done.
Listing 10-4. Asynchronously Converts Images to WPF Grayscale Bitmap Images
public class ImageProcessor
{
public event EventHandler<ProcessedImageEventArgs> ProducedGrayScaleImage = delegate { };
public void ProcessFile(string filename)
{
Task.Run(() =>LoadAndToGrayScale(filename))
.ContinueWith(toGrayTask =>ProducedGrayScaleImage(this,
new ProcessedImageEventArgs(toGrayTask.Result)),
TaskScheduler.FromCurrentSynchronizationContext());
}
private static BitmapSource LoadAndToGrayScale(string path)
{
var img = new BitmapImage(new Uri(path));
return ToGrayScale(img);
}
private static BitmapSource ToGrayScale(BitmapSource bitmapSource)
{
. . .
}
}
Instead of explicitly using tasks, you could refactor to use two dataflow blocks, as per Figure 10-7.

Figure 10-7. Convert image to grayscale using dataflow blocks
Items can be posted to the transform block in the same way as you previously posted work to an action block. Unlike the action block, the transform block has a responsibility not just to consume but to produce. For the transform block to work, you need to supply the transformation logic. This is achieved by supplying a Func<TInput,TOuput> to the block. When data are posted to the block, the supplied function is invoked to produce the output. As with the action block, the transform block will have by default only a single task executing at any one time to perform the transformation logic.
By default ActionBlock<T> tasks will use the default task scheduler, which is not what we want, since this block’s responsibility is to fire the event on the UI thread. To solve this, create the ActionBlock<T> specifying that you want it to use the task scheduler associated with the current synchronization context.
Once both the blocks have been created, you need to link them up. To do this, there is a LinkTo method on the TransformBlock<TInput,TOutput>. This LinkTo method takes as an argument any block that has an input type of TOutput. The LinkTo method is actually defined on the ISourceBlock<TOutput> interface, which is implemented by any block that can be a source (i.e., has an output). In a similar fashion, any block that has input, implements ITargetBlock<T>. The LinkTo method returns an IDisposable object, which when disposed removes the link between the blocks.
Last, modify the ProcessFile method simply to post the requested file to the transform block, and return in the hope that someday an event will fire with the converted image (see Listing 10-5).
Listing 10-5. Dataflow for Converting Image to Grayscale
public class ImageProcessor
{
public event EventHandler<ProcessedImageEventArgs> ProducedGrayScaleImage = delegate { };
private TransformBlock<string, BitmapSource> loadAndToGrayBlock;
private ActionBlock<BitmapSource> publishImageBlock;
public ImageProcessor()
{
loadAndToGrayBlock = new TransformBlock<string, BitmapSource>(
(Func<string, BitmapSource>)LoadAndToGrayScale);
publishImageBlock = new ActionBlock<BitmapSource>((Action<BitmapSource>) PublishImage,
new ExecutionDataflowBlockOptions()
{
TaskScheduler = TaskScheduler.FromCurrentSynchronizationContext()
});
loadAndToGrayBlock.LinkTo(publishImageBlock);
}
public void ProcessFile(string filename)
{
loadAndToGrayBlock.Post(filename);
}
private void PublishImage(BitmapSource img)
{
ProducedGrayScaleImage(this,new ProcessedImageEventArgs(img));
}
private static BitmapSource LoadAndToGrayScale(string path)
{
var img = new BitmapImage(new Uri(path));
return ToGrayScale(img);
}
private static BitmapSource ToGrayScale(BitmapSource bitmapSource)
{
. . .
}
}
Listing 10-5 contains the refactored code that now utilizes blocks to provide concurrency as opposed to using tasks explicitly. Instead of thinking about threads of execution, think about blocks of concurrent execution, stimulated by asynchronous messages.
Transform Many Block
The ImageProcessor class currently allows you to process individual files, but what if you wanted to process an entire directory? Simple enough—just iterate through all the image files from a directory search and post the file, as per Listing 10-6. While this will obviously work, you are in fact missing an opportunity to keep things fast and fluid: rather than performing the directory search on the UI thread, you could encapsulate the directory search functionality inside a new block. The UI thread will then just simply post the directory start point to that block, and return to UI processing.
Listing 10-6. Process Multiple Files
public void ProcessDirectory(string dir)
{
DirectoryInfo directory = new DirectoryInfo(dir);
foreach (FileInfo file in directory.GetFiles("*.jpg"))
{
loadAndToGrayBlock.Post(file.FullName);
}
}
The TransformBlock<TInput,TOuput> block produces as many outputs as it receives inputs. You now need a block that takes a directory path as an input and potentially can produce many image files, thus producing an imbalance of inputs to outputs. You could make the directory block produce, say, a List<string>, but that would batch as opposed to stream. A more scalable approach would be to use a TransformManyBlock<TInput,TOutput>; this block does not simply take a Func<TInput,TOutput> but a Func<TInput,IEnumerable<TOutput>>. The code for the block produces an IEnumerable<TOutput>, potentially offering many results that can then be passed onto a linked block. The Dataflow framework consumes the IEnumerable<TOutput>, making the output as it becomes available to any linked blocks. Figure 10-8 shows the new block topology, allowing directories and files to be processed concurrently.
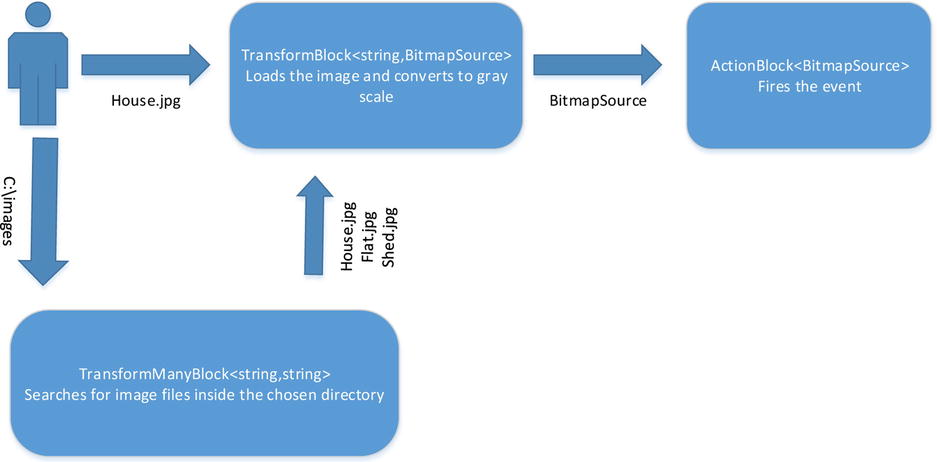
Figure 10-8. Transform many images
To implement this new topology, you need to create an instance of a TransformManyBlock and provide a method on the ImageProcessor class to take a directory and post it to the block (Listing 10-7).
Listing 10-7. TransformMany
public class ImageProcessor
{
public event EventHandler<ProcessedImageEventArgs> ProducedGrayScaleImage = delegate { };
private TransformManyBlock<string, string> imageCollectionBlock;
private TransformBlock<string, BitmapSource> loadAndToGrayBlock;
private ActionBlock<BitmapSource> publishImageBlock;
public ImageProcessor()
{
imageCollectionBlock = new TransformManyBlock<string, string>(
(Func<string, IEnumerable<string>>) FindImagesInDirectory);
loadAndToGrayBlock = new TransformBlock<string, BitmapSource>(
(Func<string, BitmapSource>)LoadAndToGrayScale);
publishImageBlock = new ActionBlock<BitmapSource>((Action<BitmapSource>) PublishImage,
new ExecutionDataflowBlockOptions()
{
TaskScheduler = TaskScheduler.FromCurrentSynchronizationContext()
});
imageCollectionBlock.LinkTo(loadAndToGrayBlock);
loadAndToGrayBlock.LinkTo(publishImageBlock);
}
public void ProcessFile(string filename)
{
loadAndToGrayBlock.Post(filename);
}
public void ProcessDirectory(string dir)
{
imageCollectionBlock.Post(dir);
}
private IEnumerable<string> FindImagesInDirectory(string dir)
{
var directory = new System.IO.DirectoryInfo(dir);
return directory
.GetFiles("*.jpg")
.Select(file => file.FullName);
}
private void PublishImage(BitmapSource img)
{
ProducedGrayScaleImage(this, new ProcessedImageEventArgs(img));
}
private static BitmapSource LoadAndToGrayScale(string path)
{
var img = new BitmapImage(new Uri(path));
return ToGrayScale(img);
}
private static BitmapSource ToGrayScale(BitmapSource bitmapSource)
{
. . .
}
}
Now that you have a working network of blocks, you can start to consider further concurrency. At present you are only using a single task to turn images into grayscale; of all the blocks this is the one that will take the time. The grayscale processing of each image is isolated—you don’t need to care about the order in which the images appear, and therefore it seems logical that you should assign multiple tasks to this block. Listing 10-8 shows the necessary change to the ImageProcessor class to enable concurrent processing of images.
Listing 10-8. Many Tasks Performing Image Conversion
loadAndToGrayBlock = new TransformBlock<string, BitmapSource>(
(Func<string, BitmapSource>)LoadAndToGrayScale,
new ExecutionDataflowBlockOptions()
{
MaxDegreeOfParallelism = 4,
});
While you easily could have written the image processor using tasks, one advantage to using TPL Dataflow is being able to control the number of threads for a given role. In a large application you may very well want to take finer control over how compute resources are being shared across the entire application, and not just have them be shared evenly, as would be the case if everything were throttled exclusively by the thread pool.
RELINQUISHING TASKS
A very strange option on the ExecutionDataflowBlockOptions is the ability to set the maximum number of requests handled by a given task, by setting the MaxMessagesPerTask property. Unlike humans, tasks don’t degrade over time, so why would you do this? If a dataflow block is constantly fed work, the task will never end, and if the thread pool is inclined not to create more threads, there may be a buildup of work waiting to run. Ending the task after it has processed n pieces of work could help short-lived tasks run without having to grow the thread pool.
Preservation of Order
Increasing the concurrency for a given block allows a block to process multiple messages at the same time. If the processing of each message takes the same time, then you might expect the order of the output messages to be in the same order as their corresponding input messages: I1,I2,I3 => O1,O2,O3. If, however, it took a lot longer to process I1 compared to I2,I3, then perhaps O2,O3,O1 would be an expected outcome. TPL Dataflow blocks preserve order; if I1 did take longer to process than I2,I3, then O2,O3 will be not be published until I1 had completed and O1 published. This preservation of order can be advantageous for solving problems concurrently that still require order, something that is often hard to solve with conventional parallel programming techniques.
If order is not a requirement, then don’t increase the degree of parallelism for a given block; instead allow a single source block to link to multiple consumer blocks.
Linking to Multiple Targets
So far we have only considered linking a source block to a single target block. Consider the situation where, based on a given input, data are fetched from a database, and for performance reasons the database is mirrored, allowing data to be fetched from either database. You should therefore consider building a dataflow as described in Figure 10-9. Assuming that if Server A is busy, Server B will be offered the query, then if both blocks are busy the previous block will wait until either becomes available. Just simply linking up multiple targets in this way, unfortunately, will not give you this effect. Most blocks by default have associated with them an unbounded queue that allows them to receive messages even if they are busy. This is known as greedy behavior, and the level of greediness can be controlled by setting the capacity of the queue. To make a block non-greedy, simply set the queue length to 1. Greedy blocks can therefore accept messages even if they are busy processing a previous message. Non-greedy blocks will refuse messages while they are busy processing message(s). If a message is refused by one block, the next linked block will be offered the message. If all blocks refuse the message, the first block to become available to process the message will do so (see Listing 10-9).
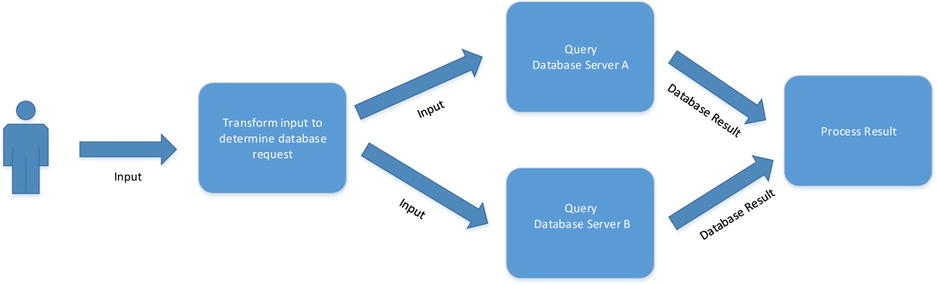
Figure 10-9. Load-balanced mirrored databases
Listing 10-9. Greedy and Non-greedy Blocks
class Program
{
static void Main(string[] args)
{
var greedy = new ExecutionDataflowBlockOptions();
var nonGreedy = new ExecutionDataflowBlockOptions()
{
BoundedCapacity = 1
};
ExecutionDataflowBlockOptions options = greedy;
var firstBlock = new ActionBlock<int>(i => Do(i,1,2), options);
var secondBlock = new ActionBlock<int>(i => Do(i,2,1), options);
var thirdBlock = new ActionBlock<int>(i => Do(i,3,2), options);
var transform = new TransformBlock<int,int>(i=>i*2);
transform.LinkTo(firstBlock);
transform.LinkTo(secondBlock);
transform.LinkTo(thirdBlock);
for (int i = 0; i <= 10; i++)
{
transform.Post(i);
}
Console.ReadLine();
}
private static void Do(int workItem , int nWorker, int busyTimeInSeconds)
{
Console.WriteLine("Worker {0} Busy Processing {1}",nWorker,workItem);
Thread.Sleep(busyTimeInSeconds * 1000 );
Console.WriteLine("Worker {0} Done",nWorker);
}
}
Running the code in Listing 10-9 will show greedy behavior, as shown in Figure 10-10. Here Worker 1 has an unbounded queue, so while it is busy it can still accept requests, which it eventually processes.
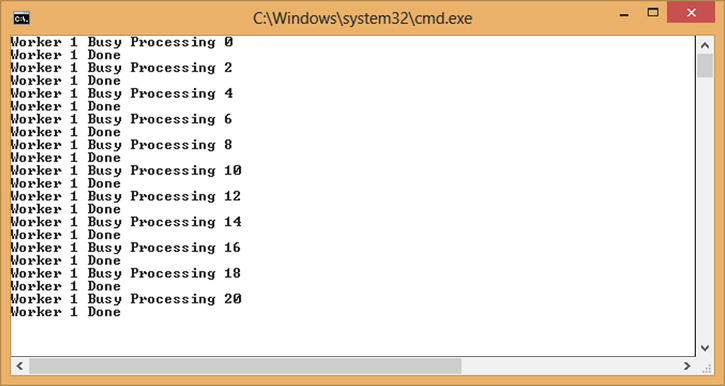
Figure 10-10. Greedy worker
Modifying the code in Listing 10-9 to use the nonGreedy configuration will produce the output shown in Figure 10-11. With a capacity of 1, each worker refuses any more work until it is idle, resulting in messages being acted upon by the first available worker.
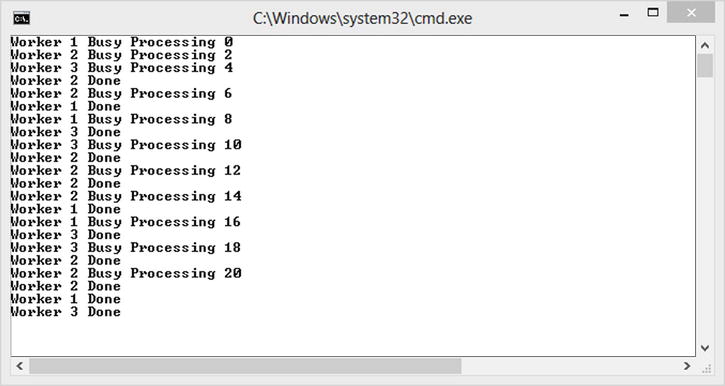
Figure 10-11. Non-greedy blocks
Conditional Linking
All the linking discussed so far has been unconditional; all the output of the source block has flowed to the input of one of the linked target blocks. Dataflow blocks can be linked on a conditional basis, too, allowing data to be filtered. This allows the programming constructs of if/else, switch/case, and recursion to be modeled in a dataflow network.
Consider the following use case. A report needs to be run against an accountancy ledger. In the ledger there will be credit entries and debit entries. The purpose of the code is to generate two CSV files: one to contain credit entries, the other debit. Utilizing TPL Dataflow, one possible topology is shown in Figure 10-12. The last block examines the data and decides which CSV file to write the data to, a simple if/else in this case.
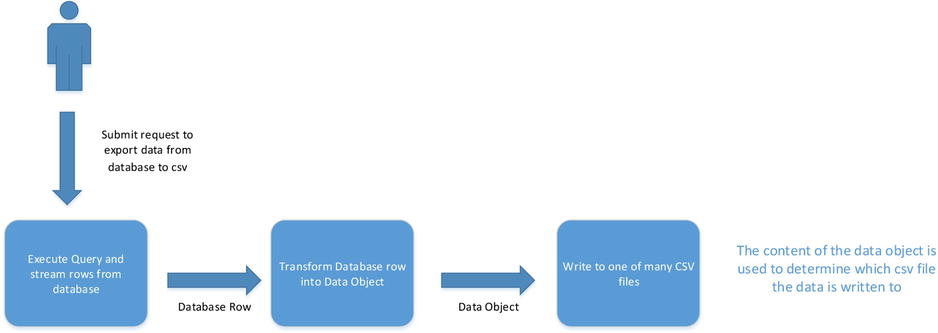
Figure 10-12. Accountancy ledger to CSV files
The topology in Figure 10-12 will undoubtedly work and provide some degree of concurrency, but you could do better. After all, it should be possible to write a debit row at the same time as a credit row, since different resources are being consumed (Credit.csv or Debit.csv). You can’t simply increase the concurrency of the block, since you clearly can’t have multiple credit rows being written at the same time, as this would potentially lead to corruption of the file on disk. What you need to do is create two blocks: one for writing credit rows and the other for writing debit rows. The credit row block should only receive data objects that contain credit information, and the debit row block should receive only data objects that contain debit information. This new topology is shown in Figure 10-13.
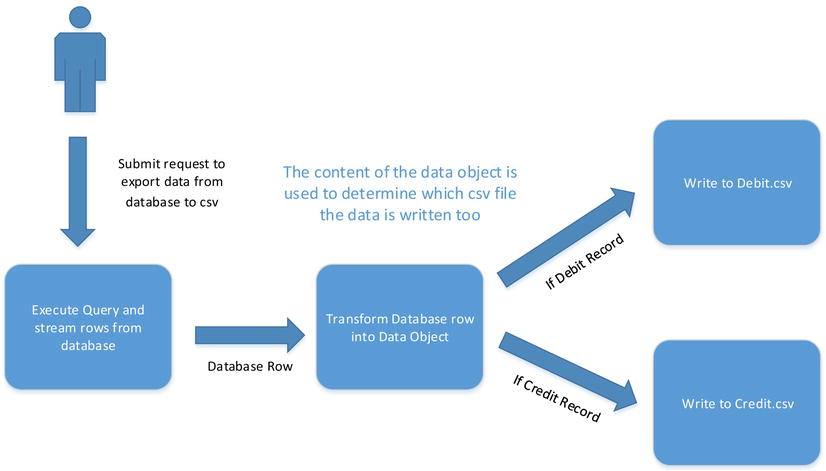
Figure 10-13. Conditional linking
To implement the topology in Figure 10-11, you will make use of a variant of the LinkTo method that takes a Predicate<T>. The predicate is used by the framework to determine if the message should be delivered to the linked block. If the condition fails, the message is offered to the next linked block, until a block accepts the message. If no block accepts the message, then for most source block types this will result in a blockage and potentially an OutOfMemoryException as further messages get buffered up, waiting for the undeliverable message to be delivered. It would therefore be worth considering having a final unconditional link on a block, to catch all messages and prevent a blockage. Listing 10-10 provides a skeleton implementation of Figure 10-13. Having the unknownLedgerEntryBlock means you will have a point in the application where you can gracefully handle unexpected behavior.
Listing 10-10. Skeleton Code for Concurrent CSV Processing
public interface ILedgerEntry
{
bool IsCredit { get; }
bool IsDebit { get; }
};
public class CsvImporter
{
private TransformManyBlock<string, object[]> databaseQueryBlock;
private TransformManyBlock<object[], ILedgerEntry> rowTGoLedgerBlock;
private ActionBlock<ILedgerEntry> debitBlock;
private ActionBlock<ILedgerEntry> creditBlock;
private ActionBlock<ILedgerEntry> unknownLedgerEntryBlock;
public CsvImporter()
{
databaseQueryBlock = new TransformManyBlock<string, object[]>(
(Func<string, IEnumerable<object[]>>) ExecuteQuery);
rowTGoLedgerBlock = new TransformManyBlock<object[], ILedgerEntry>(
(Func<object[], IEnumerable<ILedgerEntry>>) MapDatabaseRowToObject);
debitBlock = new ActionBlock<ILedgerEntry>((Action<ILedgerEntry>) WriteDebitEntry);
creditBlock = new ActionBlock<ILedgerEntry>((Action<ILedgerEntry>) WriteCreditEntry);
unknownLedgerEntryBlock = new ActionBlock<ILedgerEntry>(
(Action<ILedgerEntry>)LogUnknownLedgerEntryType);
databaseQueryBlock.LinkTo(rowTGoLedgerBlock);
rowTGoLedgerBlock.LinkTo(debitBlock, le => le.IsDebit); //if IsDebit
rowTGoLedgerBlock.LinkTo(creditBlock, le => le.IsCredit); // else if IsCredit
rowTGoLedgerBlock.LinkTo(unknownLedgerEntryBlock); // else
}
public void Export(string connectionString)
{
databaseQueryBlock.Post(connectionString);
}
private IEnumerable<object[]> ExecuteQuery(string arg){ yield break; }
private IEnumerable<ILedgerEntry> MapDatabaseRowToObject(object[] arg) { yield break;}
private void WriteDebitEntry(ILedgerEntry debitEntry) { }
private void WriteCreditEntry(ILedgerEntry creditEntry) { }
private void LogUnknownLedgerEntryType(ILedgerEntry obj){}
}
![]() Note We are not stating that all traditional if/else should be turned into dataflow blocks. What we are suggesting is that when the bodies of the if/else blocks are not mutating shared resources, we have an opportunity to introduce greater concurrency.
Note We are not stating that all traditional if/else should be turned into dataflow blocks. What we are suggesting is that when the bodies of the if/else blocks are not mutating shared resources, we have an opportunity to introduce greater concurrency.
Another interesting use of conditional linking is in implementing recursion. It is not unusual to see algorithms that use call stack–based recursion to walk a tree. Listing 10-11 shows an example of classic recursive programming technique to obtain a list of all files under a supplied directory.
Listing 10-11. Call Stack–Based Recursion
private static IEnumerable<string> GetFiles(string path)
{
DirectoryInfo dir = new DirectoryInfo(path);
foreach (FileInfo file in dir.GetFiles())
{
yield return dir.FullName;
}
foreach (DirectoryInfo subDir in dir.GetDirectories())
{
foreach (string file in GetFiles(subDir.FullName))
{
yield return file;
}
}
}
Recursive programming can be expressed with dataflow blocks by conditionally linking blocks back to themselves, as shown in Figure 10-14 and implemented in Listing 10-12.
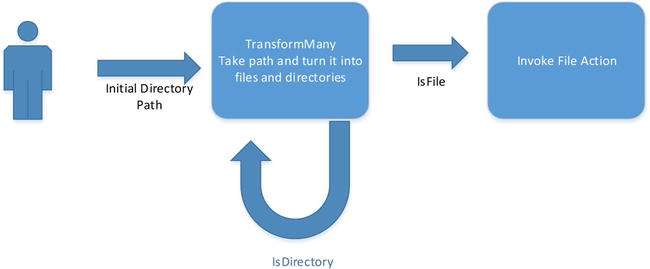
Figure 10-14. Recursive directory walk using TransformMany block
Listing 10-12. Recursion Using Dataflow Blocks
public class DirectoryWalker
{
private ActionBlock<string> fileActionBlock;
private TransformManyBlock<string, string> directoryBrowseBlock;
public DirectoryWalker(Action<string> fileAction)
{
directoryBrowseBlock = new TransformManyBlock<string, string>(
(Func<string, IEnumerable<string>>)(GetFilesInDirectory));
fileActionBlock = new ActionBlock<string>(fileAction);
directoryBrowseBlock.LinkTo(directoryBrowseBlock, Directory.Exists);
directoryBrowseBlock.LinkTo(fileActionBlock);
}
public void Walk(string path)
{
directoryBrowseBlock.Post(path);
}
private IEnumerable<string> GetFilesInDirectory(string path)
{
var dir = new DirectoryInfo(path);
return dir.EnumerateFileSystemInfos().Select(fi => fi.FullName);
}
}
. . .
var walker = new DirectoryWalker(Console.WriteLine);
walker.Walk(@"C: emp");
Console.ReadLine();
Shutting Down Gracefully
Graceful termination of dataflow networks can be just as important as initiating them. It may be important to know when a given dataflow network has processed all the inputs. Running Listing 10-13 will not display numbers 0 to 9, since the main thread will terminate and hence the process before the block’s task will process any items.
Listing 10-13. Early Termination
class Program
{
static void Main(string[] args)
{
var actionBlock = new ActionBlock<int>( (Action<int>)Console.WriteLine );
for (int i = 0; i < 10; i++)
{
actionBlock.Post(i);
}
}
}
To remedy the situation, you need to refactor the code to wait for the action block to complete all posted items. Each block has associated with it a property called Completion of type Task. The status of this task reflects the status of the block. While the block is still processing or waiting for more items, it is in a state of WaitingForActivation. Once it knows there are no more items to process, it will end in a state of RanToCompletion. This means therefore that to wait for a block to complete, you can use Task.Wait or await on the Completion property. Obviously the block isn’t psychic; you need to inform it that no more items will be sent to the block. To signal no more items will be sent, a call is made to the block’s Complete method. Any further posts to the block will now fail; once all the queued-up items on the block have been processed, the Completion task will end in a state of RanToCompletion. Listing 10-14 shows the refactored code now in a form that will post all 10 items and then declare no more items will be coming by calling Complete, and then waiting for the block to process all 10 items by calling Completion.Wait. Running the code will now produce the output shown in Figure 10-15.
Listing 10-14. Graceful Termination
class Program
{
static void Main(string[] args)
{
var actionBlock = new ActionBlock<int>((Action<int>) Console.WriteLine);
for (int i = 0; i < 10; i++)
{
actionBlock.Post(i);
}
Console.WriteLine("Completing..");
actionBlock.Complete();
Console.WriteLine("Waiting..");
actionBlock.Completion.Wait();
Console.WriteLine(actionBlock.Completion.Status);
}
}
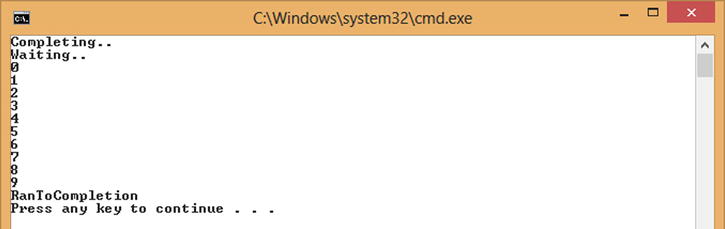
Figure 10-15. Waiting for block to complete
Propagating Completion
As already discussed, dataflow blocks are often not used as islands but as part of a larger network of blocks. Listing 10-15 shows some example code that contains two linked blocks. Ten items are posted to the first block; then the block is told there will be no more, and the main thread then waits for the first block to complete. Once the block is completed, the application terminates. Since the second block takes 0.5 seconds to process each block, the main thread will terminate before the second block completes processing its first item.
Listing 10-15. Premature Completion
class Program
{
static void Main(string[] args)
{
var firstBlock = new TransformBlock<int, int>(i => i*2);
var secondBlock = new ActionBlock<int>( i =>
{
Thread.Sleep(500);
Console.WriteLine(i);
});
firstBlock.LinkTo(secondBlock);
for (int i = 0; i < 10; i++)
{
firstBlock.Post(i);
}
firstBlock.Complete();
firstBlock.Completion.Wait();
}
}
To resolve this premature termination issue, you could add two additional lines after the completion logic for the first block:
secondBlock.Complete();
secondBlock.Completion.Wait();
It is important to ensure that you don’t complete the second block until the first block has completed, since the second block will not accept any further input once it has been told to complete. As you can probably imagine this would get tedious as you increased the number of blocks. An alternative is to allow completion to automatically flow to each of its linked blocks as a block completes. Listing 10-16 shows refactored code that now utilizes completion propagation. Automatic propagation is requested as part of linking one block to another. Once the source block has been marked as complete and it has processed all queued items, it informs the linked block that it is now complete. This now greatly simplifies the logic necessary to determine when all inputs have been fully processed by the dataflow network.
Listing 10-16. Automatic Completion Propagation
class Program
{
static void Main(string[] args)
{
var firstBlock = new TransformBlock<int, int>(i => i*2);
var secondBlock = new ActionBlock<int>( i =>
{
Thread.Sleep(500);
Console.WriteLine(i);
});
firstBlock.LinkTo(secondBlock , new DataflowLinkOptions(){PropagateCompletion = true});
for (int i = 0; i < 10; i++)
{
firstBlock.Post(i);
}
firstBlock.Complete();
secondBlock.Completion.Wait();
}
}
So far we have only considered the happy side of programming, when everything just works. In the real world we have to consider error handling, and in .NET this takes the form of exceptions. Dataflow blocks are fundamentally blocks of code, and as such they can throw exceptions. Consider the code in Listing 10-17. The first two work items should work fine. The third item will cause a divide by zero exception and hence will not produce any output. But what about the fourth item? There are two possibilities: the block swallows the exception and processes the fourth item, or it refuses to process any more items. The actual behavior is the latter; once a block experiences an unhandled exception, it places the block into a faulted state and refuses to process or receive any more messages.
Listing 10-17. Unhandled Divide by Zero Exception
private static void Main(string[] args)
{
var divideBlock = new ActionBlock<Tuple<int, int>>(
(Action<Tuple<int, int>>) (input => Console.WriteLine(input.Item1/input.Item2)));
divideBlock.Post(Tuple.Create(10, 5));
divideBlock.Post(Tuple.Create(20, 4));
divideBlock.Post(Tuple.Create(10, 0));
divideBlock.Post(Tuple.Create(10, 2));
Console.ReadLine();
}
Catching the exception and dealing with it inside the block is obviously one remedy, and makes perfect sense if the exception doesn’t indicate that the overall dataflow network is now effectively broken, as shown in Listing 10-18.
Listing 10-18. Handling Nonfatal Exceptions Inside the Block
private static void Main(string[] args)
{
var divideBlock = new ActionBlock<Tuple<int, int>>((Action<Tuple<int, int>>)
delegate(Tuple<int, int> pair)
{
try
{
Console.WriteLine(pair.Item1/pair.Item2);
}
catch (DivideByZeroException)
{
Console.WriteLine("Dude, can't divide by zero");
}
});
divideBlock.Post(Tuple.Create(10, 5));
divideBlock.Post(Tuple.Create(20, 4));
divideBlock.Post(Tuple.Create(10, 0));
divideBlock.Post(Tuple.Create(10, 2));
Console.ReadLine();
}
In cases where the underlying exception implies that it is not safe or desirable to proceed with any more messages, then the recovery logic is probably best suited outside the dataflow network. The Completion task discussed earlier provides a means for externally observing if a block has received an unhandled exception. If the status of the Completion task is in a state of Faulted, then this indicates the block is in a faulted state and will perform no further processing. Listing 10-19 demonstrates the wiring up of a continuation in the case of the block ending in a faulted state.
Listing 10-19. Externally Handling a Block Exception
private static void Main(string[] args)
{
var divideBlock = new ActionBlock<Tuple<int, int>>(
(Action<Tuple<int, int>>) (input => Console.WriteLine(input.Item1/input.Item2)));
divideBlock.Post(Tuple.Create(10, 5));
divideBlock.Post(Tuple.Create(20, 4));
divideBlock.Post(Tuple.Create(10, 0));
divideBlock.Post(Tuple.Create(10, 2));
divideBlock
.Completion
.ContinueWith(dbt =>
{
Console.WriteLine("Divide block failed Reason:{0}",
dbt.Exception.InnerExceptions.First().Message);
}, TaskContinuationOptions.OnlyOnFaulted);
Console.ReadLine();
}
![]() Note The Exception exposed by the Completion task will be an AggregateException. This allows for the fact that a block may have multiple active tasks (MaxDegreeOfParallelism > 1), all of which may have ended in a faulted state.
Note The Exception exposed by the Completion task will be an AggregateException. This allows for the fact that a block may have multiple active tasks (MaxDegreeOfParallelism > 1), all of which may have ended in a faulted state.
So far we have examined error handling at the individual block level. Externally handling errors at the block level can become tedious. A more convenient approach may be to just handle the final outcome of the dataflow network, in the same way we often put a try/catch around a block of sequential processing. When linking blocks together, the setting of the PropagateCompletion flag as part of the DataflowLinkOptions will not only propagate successful completion but also propagate errors. Listing 10-20 implements a two-block network, where the error originates in the first block but it is the Wait on the second block that receives the error.
Listing 10-20. Propagating Errors
private static void Main(string[] args)
{
var divideBlock = new TransformBlock<Tuple<int, int>, int>(
input => input.Item1 / input.Item2);
var printingBlock = new ActionBlock<int>((Action<int>)Console.WriteLine);
divideBlock.LinkTo(printingBlock, new DataflowLinkOptions() { PropagateCompletion = true });
divideBlock.Post(Tuple.Create(10, 5));
divideBlock.Post(Tuple.Create(20, 4));
divideBlock.Post(Tuple.Create(10, 0));
divideBlock.Post(Tuple.Create(10, 2));
divideBlock.Complete();
try
{
printingBlock.Completion.Wait();
}
catch (AggregateException errors)
{
foreach (Exception error in errors.Flatten().InnerExceptions)
{
Console.WriteLine("Divide block failed Reason:{0}", error.Message);
}
}
}
Error handling is a fundamental part of any application, and dataflow networks are no exception to this rule. When building a dataflow network, consider where to place the error handling.
- If the exception can be handled internally, keeping the dataflow network integrity intact, do so.
- If the exception implies the dataflow network integrity is now compromised, consider handling the exception externally, via a continuation.
- Propagating completion often simplifies exception handling, allowing a single piece of error-handling logic.
Ignoring error handling can easily result in a dataflow network that sits idle, not receiving any new messages—a nightmare to debug.
You have seen that dataflow networks can be asked to complete by stating no further inputs will be supplied to the block. The block will still continue running while it has more queued work to process and has not entered a Faulted state. If you then wait on the block, you can be confident that all requests have been successfully acted upon. Waiting for the network to fully process all outstanding items may not be completely desirable. A quicker form of termination may be required; obviously simply ending the process would be one such technique, potentially leaving external resources in an inconsistent state (e.g., an XML file not closed off correctly). A halfway point between fully completing all requests and ending abruptly is to make use of TPL's CancellationTokenSource and CancellationToken.
When a block is created, it can be supplied with a CancellationToken. This token is observed by the block to determine if the block should cease receiving, acting on, or producing values. Listing 10-21 creates a block and associates a CancellationToken with the block. The block is then posted three items; the processing of each item takes 1 second. If at any time the Enter key is pressed while these items are being processed, the main thread calls cts.Cancel(), thus requesting the block to cancel. If the block has not already completed all the enqueued requests, the block will end in a canceled state.
Listing 10-21. Cancelling a Block
private static void Main(string[] args)
{
CancellationTokenSource cts = new CancellationTokenSource();
var slowAction = new ActionBlock<int>( (Action<int>) (
i =>
{
Console.WriteLine("{0}:Started",i);
Thread.Sleep(1000);
Console.WriteLine("{0}:Done", i);
}),
new ExecutionDataflowBlockOptions() { CancellationToken = cts.Token} );
slowAction.Post(1);
slowAction.Post(2);
slowAction.Post(3);
slowAction.Complete();
slowAction
.Completion
.ContinueWith(sab => Console.WriteLine("Blocked finished in state of {0}",
sab.Status));
Console.ReadLine();
cts.Cancel();
Console.ReadLine();
}
Running the code in Listing 10-21 and pressing Enter while it is processing the second item produces the output shown in Figure 10-16. Once called, the block does not attempt to process Item 3, but it does complete the processing of Item 2. Thus far the cancellation token is only being observed by the block and not the code running inside the block.

Figure 10-16. Cancelling while processing Item 2
The framework can’t just simply decide to abort the code, and so the code inside the block also needs to observe the cancellation token when it is safe to abort. Listing 10-22 shows the necessary changes to the block to make it respond to the cancellation, too.
Listing 10-22. Cancelling Block and Code
var slowAction = new ActionBlock<int>(
(Action<int>) (i =>
{
Console.WriteLine("{0}:Started",i);
cts.Token.WaitHandle.WaitOne(1000);
cts.Token.ThrowIfCancellationRequested();
Console.WriteLine("{0}:Done", i);
}),
new ExecutionDataflowBlockOptions() { CancellationToken = cts.Token} );
When multiple blocks are linked together with the PropagateCompletion property set to true, canceling a block will then mark the linked blocks as complete and in a state of RanToCompletion, potentially starting a completion chain reaction through the remaining linked blocks. To cause a more rapid shutdown, each block must share the cancellation token.
All the blocks we have looked at so far have required some additional code to fulfill the main purpose of the block. These blocks are sometimes referred to as execution blocks. In addition to these blocks, there are some general-purpose glue blocks that help in connecting various execution blocks together.
Execution blocks have the possibility to buffer items internally. Earlier you saw that you can control the size of that buffer to create non-greedy blocks, blocks that would not consume items unless they could process them immediately. You can use this technique to provide a form of load balancing as shown in Figure 10-17, in which the Server A block will only accept requests if it is not busy, and likewise Server B.
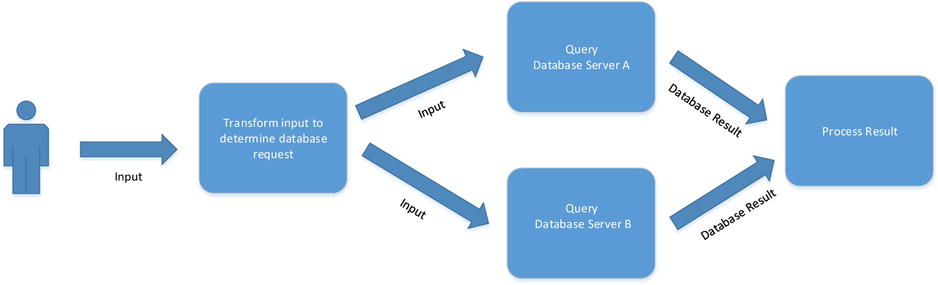
Figure 10-17. Nonbuffered load balancing
The problem with the approach in Figure 10-17 is that if both Server A and Server B are busy, the transform feeding these two blocks becomes blocked and cannot process any more inputs. So ideally you want to buffer any output from the transform block and then have either Server A or Server B process the output when they are free.
Listing 10-23 shows a simplified example using the topology shown in Figure 10-18. Running the code will demonstrate that the transfer block completes all its processing very quickly and that the two load-balanced processor blocks eventually consume everything in the buffer.
Listing 10-23. Buffered Load Balanced
static void Main(string[] args)
{
var nonGreedy = new ExecutionDataflowBlockOptions() {BoundedCapacity = 1};
var flowComplete = new DataflowLinkOptions() {PropagateCompletion = true};
var processorA = new ActionBlock<int>((Action<int>)( i => Processor("A",i)),nonGreedy);
var processorB = new ActionBlock<int>((Action<int>)( i => Processor("B",i)),nonGreedy);
var transform = new TransformBlock<int, int>(i => i*2);
var buffer = new BufferBlock<int>();
buffer.LinkTo(processorA,flowComplete);
buffer.LinkTo(processorB,flowComplete);
transform.LinkTo(buffer);
// transform.LinkTo(processorA);
// transform.LinkTo(processorB);
for (int i = 0; i < 5; i++)
{
transform.Post(i);
}
transform.Complete();
transform.Completion.Wait();
Console.WriteLine("All work buffered ");
Console.ReadLine();
}
private static void Processor( string name , int value)
{
Console.WriteLine("Processor {0}, starting : {1}",name,value);
Thread.Sleep(1000);
Console.WriteLine("Processor {0}, done : {1}",name,value);
}
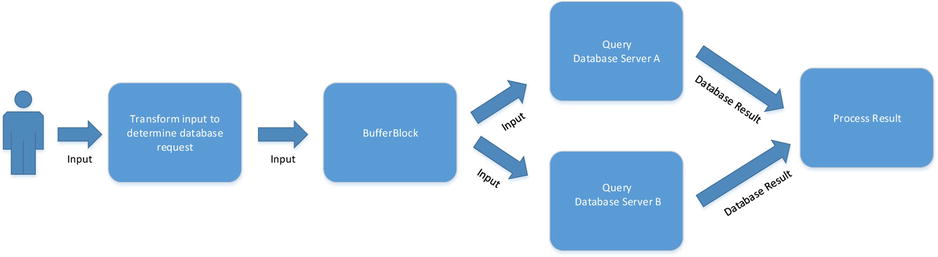
Figure 10-18. Buffered load balancing
Modifying Listing 10-23 by uncommenting the transform.LinkTo(processorA) or transform.LinkTo(processorB) and commenting out transform.LinkTo(buffer) will show the effect of load balancing without the buffer. The effect you will observe is that the transform block takes longer to produce all the items as it is waiting for a consumer before publishing the next value.
Buffer blocks are therefore useful when you need a shared buffer across multiple consumers, and each consumer has its own internal constrained buffer. The internal constrained buffer should be set to the same value as the MaxDegreeOfParallelism property for the block in order to ensure a non-greedy block.
Thus far you have seen that transform blocks for a given input can produce one to many outputs. The consumer of these outputs needs to receive the output before the transform block can produce a new item. There will be times when for efficiency or convenience the consumer would rather not deal with each individual output, but would prefer a batch of outputs. Classic use cases for this may be to upload results to a web service or update a database; a round trip per result is inefficient, and batching them means paying the latency cost once for all the items in the batch. Another possible use case would be a dataflow network producing values that need to be used to update the UI, but marshaling back onto the UI thread per request may cause the UI to become sluggish. Marshaling less frequently and performing many updates may result in a more fluid UI. Listing 10-24 shows an example of using buffer blocks to provide sampling of a dense dataflow. The main thread is producing a new value every 10 milliseconds, the averager action block receives the generated values in batches of 100, and then outputs a sample result by simply averaging all the values. If the batch block was marked as complete, a partial batch is propagated.
Listing 10-24. Sampling by Averaging 100 Items
public static void Main()
{
int batchSize = 100;
var batcher = new BatchBlock<int>(batchSize);
var averager = new ActionBlock<int[]>(values => Console.WriteLine(values.Average()));
batcher.LinkTo(averager);
var rnd = new Random();
while (true)
{
Thread.Sleep(10);
batcher.Post(rnd.Next(1, 100));
}
}
Listing 10-24 demonstrates batching based on quantity; it may be more desirable to batch on a time interval basis (e.g., for UI update). This can be achieved with the BatchBlock, too, by setting the batch size to int.MaxValue and then calling TriggerBatch method at a given time interval (see Listing 10-25).
Listing 10-25. Sampling by Interval
public static void Main()
{
var batcher = new BatchBlock<int>(int.MaxValue);
var averager = new ActionBlock<int[]>(values => Console.WriteLine(values.Average()));
batcher.LinkTo(averager);
var timer = new Timer(_ => batcher.TriggerBatch(),null,
TimeSpan.FromSeconds(1),
TimeSpan.FromSeconds(1));
var rnd = new Random();
while (true)
{
batcher.Post(rnd.Next(1, 100));
}
}
BatchBlocks are useful when processing of individual results is too costly, or there is a need to perform a Many-1 transformation.
Broadcast Block
Broadcast blocks differ from all the other blocks in that they can deliver the same message to multiple targets. This allows the building of networks where many blocks receive the same message, and thus can act on it in parallel. Consider the network in Figure 10-19; here data arrive via some external input and are posted to a BroadcastBlock<T>. The broadcast block can then propagate the input to all the linked blocks. If the block is not busy or it has sufficient buffer (greedy), then the input will be propagated. If the block is busy or has insufficient buffer, the input is not propagated. The two consumers in Figure 10-19 both get to see all the messages. Processing the data inside the Process Data block is very quick compared to writing to disk, and therefore it may be that the disk can’t keep up with the input stream. Buffering could be used, but this could easily result in an out of memory exception if the input rate is relentless. Configuring the write data block to be non-greedy means that it writes as much data as it can, and any items that occur while it is busy it will never see. The process data block, on the other hand, is configured to be greedy, so any slight bumps in processing will still result in it receiving all the input. BroadcastBlock<T> therefore doesn’t guarantee delivery.
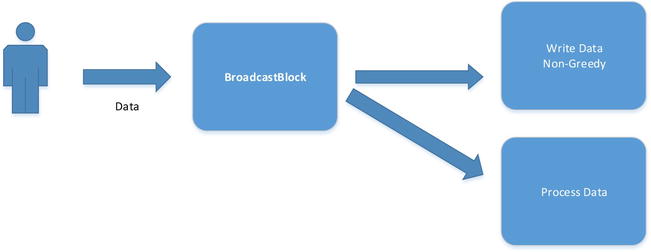
Figure 10-19. Broadcast block with greedy and non-greedy consumers
Listing 10-26 shows a simplified code example of Figure 10-19. The key point of interest is around the constructor of the BroadcastBlock<T>. As stated earlier, BroadcastBlock<T> can propagate the same input to many receivers. It may be important to ensure that each receiver, while getting the same data, receives them as a cloned copy. With each receiver getting their own copy this removes any potential mutable shared state issues. The BroadcastBlock<T> takes a function responsible for cloning the value to propagate; in this case you are simply using an identity function, as with a value type the value is always cloned.
Listing 10-26. Greedy and Non-greedy Broadcast Consumers
private static void Main(string[] args)
{
var nonGreedy = new ExecutionDataflowBlockOptions() {BoundedCapacity = 1};
var greedy = new ExecutionDataflowBlockOptions();
var source = new BroadcastBlock<int>(i => i);
var consumeOne = new ActionBlock<int>((Action<int>) ConsumerOne, nonGreedy);
var consumeTwo = new ActionBlock<int>((Action<int>) ConsumerTwo, greedy);
source.LinkTo(consumeOne);
source.LinkTo(consumeTwo);
for (int j = 0; j < 10; j++)
{
source.Post(j);
Thread.Sleep(50);
}
Console.ReadLine();
}
private static void ConsumerTwo(int obj)
{
Console.WriteLine("Consumer two {0}",obj);
Thread.Sleep(60);
}
private static void ConsumerOne(int obj)
{
Console.WriteLine("Consumer one {0}",obj);
Thread.Sleep(100);
}
Running the code in Listing 10-26 produces the output shown in Figure 10-20. With "Consumer one" taking longer than "Consumer two" to process each request, and configured to be non-greedy, it does not see all requests. "Consumer two" is configured to be greedy and as such will always see all requests. Consider using a BroadcastBlock<T> when many blocks need to act upon a single message, or when live processing is more relevant than historical processing.
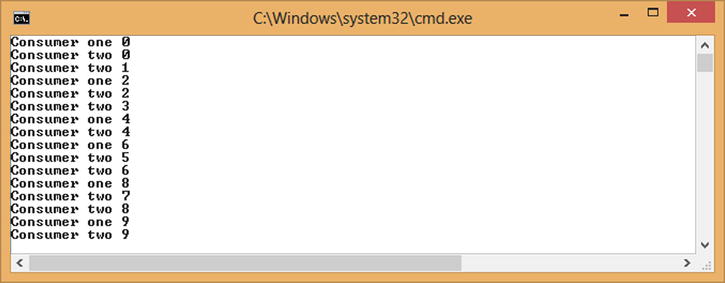
Figure 10-20. Output of greedy and non-greedy broadcast consumers
Joining
In situations where a block requires multiple inputs in order to perform its processing, you can utilize the JoinBlock<T1,T2> or JoinBlock<T1,T2,T3>. Consider the network described in Figure 10-21. Here we have two buffers: one that contains work items, the other network nodes capable of acting on work items. The scheduler’s job is to pair up a work item with an available node. Once it has paired up, it passes the paired value as a Tuple<T1,T2> onto the dispatcher who acts on the pair by sending the work item to the node. Once the dispatcher is aware that the node has completed the work item, the node is placed back into the work buffer. Listing 10-27 shows an implementation of such a scheduler using WCF. The key part to note is that when linking up to a JoinBlock<T1,T2>, you don’t link up directly to the block but to one of its targets. The JoinBlock then outputs a form of tuple depending on the number of blocks it has been asked to join. The implementation of the dispatcher block that actually invokes the work item is invoking the remote node asynchronously, allowing the dispatcher to immediately process any more work item node pairs. Thus there is very little need to increase the level of parallelism at this point.
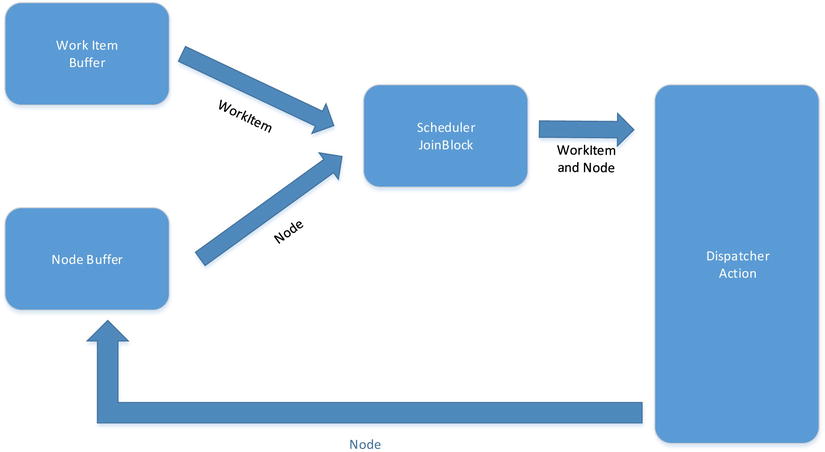
Figure 10-21. Grid scheduler
Listing 10-27. WCF-Based Grid Scheduler
[ServiceContract]
public interface IGridNode<in T>
{
[OperationContract]
Task InvokeAsync(T workItem);
}
public class GridDispatcher<T>
{
private BufferBlock<T> workItems = new BufferBlock<T>();
private BufferBlock<Uri> nodes = new BufferBlock<Uri>();
private JoinBlock<Uri, T> scheduler = new JoinBlock<Uri, T>();
private ActionBlock<Tuple<Uri, T>> dispatcher;
public GridDispatcher(IGridNode<T> localService )
{
dispatcher = new ActionBlock<Tuple<Uri, T>>((Action<Tuple<Uri, T>>) Dispatch);
workItems.LinkTo(scheduler.Target2);
nodes.LinkTo(scheduler.Target1);
scheduler.LinkTo(dispatcher);
}
public void RegisterNode(Uri uri)
{
nodes.Post(uri);
}
public void SubmitWork(T workItem)
{
workItems.Post(workItem);
}
private void Dispatch(Tuple<Uri, T> nodeAndWorkItemPair)
{
var cf = new ChannelFactory<IGridNode<T>>(new NetTcpBinding(),
new EndpointAddress(nodeAndWorkItemPair.Item1));
IGridNode<T> proxy = cf.CreateChannel();
proxy.InvokeAsync(nodeAndWorkItemPair.Item2)
.ContinueWith(t =>
{
((IClientChannel)proxy).Close();
nodes.Post(nodeAndWorkItemPair.Item1);
});
}
}
The code in Listing 10-27 will only send a work item to a node when it is not busy and there are work items to act upon. Let us now modify the network to allow the scheduler node to also act upon work locally. Figure 10-22 shows what this new network looks like; you now have two blocks feeding off the work items buffer. The local dispatcher executes the work item on the local node; this does not need to go via WCF. The local dispatcher can have MaxDegreeOfParallelism configured based on the number of cores you wish to utilize. Simply implementing a new ActionBlock<T> would by default be greedy, so this would not be desirable behavior. The new ActionBlock<T> needs to be configured so that it only concurrently consumes as many work items as it has MaxDegreeOfParallelism. Unfortunately that is not the only change that will be required—the JoinBlock<T1,T2> also has to have its greediness configured. By default the join block will consume each of its sources one by one, and when it has a request from all sources it propagates the tuple. This therefore creates a problem with the network in Figure 10-22, because in the case where there are no nodes available the JoinBlock<T1,T2> will still consume work items, preventing the local dispatcher of consuming when it is available. To prevent this behavior you need to configure the JoinBlock<T1,T2> so that it only consumes items when all the sources have an item available.
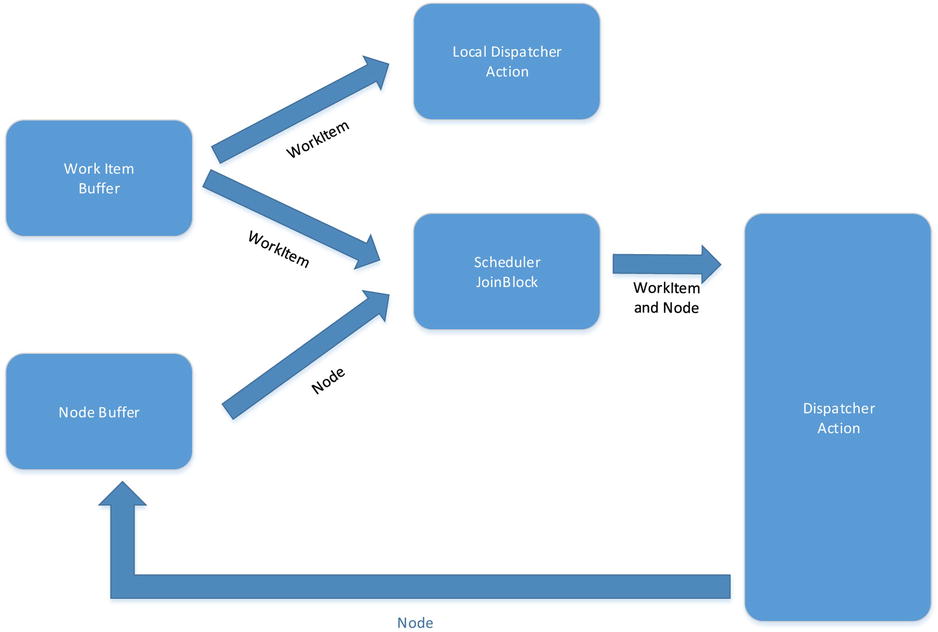
Figure 10-22. Node and local dispatcher
The code in Listing 10-28 contains a partial rework of the GridDispatcher<T> class presented in Listing 10-27, but now with the local dispatcher and the JoinBlock<T,T2> configured to be non-greedy.
Listing 10-28. Node and Local Dispatcher
public class GridDispatcher<T>
{
private BufferBlock<T> workItems = new BufferBlock<T>();
private BufferBlock<Uri> nodes = new BufferBlock<Uri>();
private JoinBlock<Uri, T> scheduler = new JoinBlock<Uri, T>(
new GroupingDataflowBlockOptions() { Greedy = false});
private ActionBlock<Tuple<Uri, T>> dispatcher;
private ActionBlock<T> localDispatcher;
public GridDispatcher(IGridNode<T> localService )
{
localDispatcher = new ActionBlock<T>(wi =>
{
Console.WriteLine("Executing Locally");
return localService.InvokeAsync(wi);
},
new ExecutionDataflowBlockOptions()
{ BoundedCapacity = 2,MaxDegreeOfParallelism = 2});
dispatcher = new ActionBlock<Tuple<Uri, T>>((Action<Tuple<Uri, T>>) Dispatch);
workItems.LinkTo(localDispatcher);
nodes.LinkTo(scheduler.Target1);
workItems.LinkTo(scheduler.Target2);
scheduler.LinkTo(dispatcher);
}
. . .
}
While this solution could have been built with two blocking concurrent queues and some long-running tasks, the dataflow solution is far more elegant, removing the need to concern yourself with having idle threads, or considering which queue to consume first. Consider using join blocks when multiple resources are required in order to perform the next process step. By configuring the blocks to be non-greedy, resources can be efficiently shared by multiple consumers.
ActionBlock, TransformBlock, and TransformManyBlock all require additional code to perform the core function of the block. The code for the block is executed inside one or many tasks, and during its execution the code may very well need to execute long-running operations such as database queries or web service calls. If these interactions take the form of blocking calls it could be considered an abuse of the thread. An example of such an abuse is Listing 10-29. The code attempts to determine which web sites from a set of known web sites contain the word happy on their home page. Multiple web sites can be accessed in parallel, so MaxDegreesOfParallelism is set to 4. The abuse in this code comes in the form of blocking while trying to download the web page content. While the code is blocked waiting for the web server to respond, the thread is sitting idle, when it potentially could have been put to other uses inside the process.
Listing 10-29. Blocking Block
public static void Main()
{
string[] urls = new string[] {
"http://www.bbc.co.uk",
"http://www.cia.gov",
"http://www.theregister.co.uk"
};
var happySites = new List<string>();
var isHappySiteBlock = new TransformBlock<string, Tuple<string, bool>>(
(Func<string, Tuple<string, bool>>) IsHappy,
new ExecutionDataflowBlockOptions() { MaxDegreeOfParallelism = 4 }
);
var addToHappySitesBlock = new ActionBlock<Tuple<string, bool>>(
(Action<Tuple<string, bool>>) (tuple => happySites.Add(tuple.Item1)));
isHappySiteBlock.LinkTo(addToHappySitesBlock,
new DataflowLinkOptions() {PropagateCompletion = true},
tuple => tuple.Item2);
// non happy sites just ignored
isHappySiteBlock.LinkTo(DataflowBlock.NullTarget<Tuple<string, bool>>());
foreach (string url in urls)
{
isHappySiteBlock.Post(url);
}
isHappySiteBlock.Complete();
addToHappySitesBlock.Completion.Wait();
happySites.ForEach(Console.WriteLine);
}
private static Tuple<string,bool> IsHappy(string url)
{
using(var client = new WebClient())
{
// Blocking call, thread idle waiting for response
string content = client.DownloadString(url);
return Tuple.Create(url,content.ToLower().Contains("happy"));
}
}
Ideally you would like the isHappyBlock to execute code up to the point of performing the I/O and then yield, executing again once the I/O has completed. To this end the executing code blocks can accept code that returns a Task or Task<T> in the case of a transform blocks. The code in Listing 10-30 shows a refactored version that now returns a Task<T>, allowing the method thread to be reused.
Listing 10-30. Asynchronous Code Block
var isHappySiteBlock = new TransformBlock<string, Tuple<string, bool>>(
(Func<string, Task<Tuple<string, bool>>>) IsHappyAsync,
new ExecutionDataflowBlockOptions() {MaxDegreeOfParallelism = 4});
. . .
private static Task<Tuple<string, bool>>IsHappyAsync(string url)
{
var client = new WebClient();
// Execute asynchronous IO with a continuation
return client.DownloadStringTaskAsync(url)
.ContinueWith(dt =>
{
string content = dt.Result;
return Tuple.Create(url, content.ToLower().Contains("happy"));
});
}
![]() Note Just as with a synchronous code block, the block does not consider an asynchronous code block to have completed until the task it returns has completed, preserving the behavior of processing only MaxDegreeOfParallelism requests at a time per block.
Note Just as with a synchronous code block, the block does not consider an asynchronous code block to have completed until the task it returns has completed, preserving the behavior of processing only MaxDegreeOfParallelism requests at a time per block.
This gets a load easier in C# 5 with async and await. Listing 10-31 shows the refactored code utilizing async and await.
Listing 10-31. Simplier Asynchronous Code Block Using async and await
private static async Task<Tuple<string, bool>>IsHappyAsync(string url)
{
using (var client = new WebClient())
{
string content = awaitclient.DownloadStringTaskAsync(url);
return Tuple.Create(url, content.ToLower().Contains("happy"));
}
}
Asynchronous code blocks allow dataflow execution blocks to utilize threads efficiently using the simple programming model of async and await.
Summary
Dataflow blocks present an alternative approach to classical multithreaded programming. In lots of ways the structure of the code is closer to the real world, where component parts of an overall system are generally autonomous. The fact that each piece of autonomous execution can maintain its own state greatly simplifies the complexity of thread safety, keeping the code simple and elegant. The declarative nature of how the networks are put together further enhances the ability to visualize and maintain the code. Chapter 15 will utilize a debugger visualizer to visualize the topology and state of a live dataflow network. Also, in Chapter 14 we will introduce the Reactive Framework, which makes it a breeze to turn the output of a TPL Dataflow network into an observable event stream.