
![]()
Big Data Application Architecture
Enterprises and their customers have become very diverse and complex with the digitalization of business. Managing the information captured from these customers and markets to gain a competitive advantage has become a very expensive proposition when using the traditional data analytics methods, which are based on structured relational databases. This dilemma applies not only to businesses, but to research organizations, governments, and educational institutions that need less expensive computing and storage power to analyze complex scenarios and models involving images, video, and other data, as well as textual data.
There are also new sources of data generated external to the enterprise that CXOs want their data scientists to analyze to find that proverbial “needle in a haystack.” New information sources include social media data, click-stream data from web sites, mobile devices, sensors, and other machine-generated data. All these disparate sources of data need to be managed in a consolidated and integrated manner for organizations to get valuable inferences and insights. The data management, storage, and analysis methods have to change to manage this big data and bring value to organizations.
Architecting the Right Big Data Solution
Solution
Prior to jumping on the big data bandwagon you should ensure that all essential architecture components required to analyze all aspects of the big data set are in place. Without this proper setup, you’ll find it difficult to garner valuable insights and make correct inferences. If any of these components are missing, you will not be able to realize an adequate return on your investment in the architecture.
A big data management architecture should be able to consume myriad data sources in a fast and inexpensive manner. Figure 2-1 outlines the architecture components that should be part of your big data tech stack. You can choose either open source frameworks or packaged licensed products to take full advantage of the functionality of the various components in the stack.
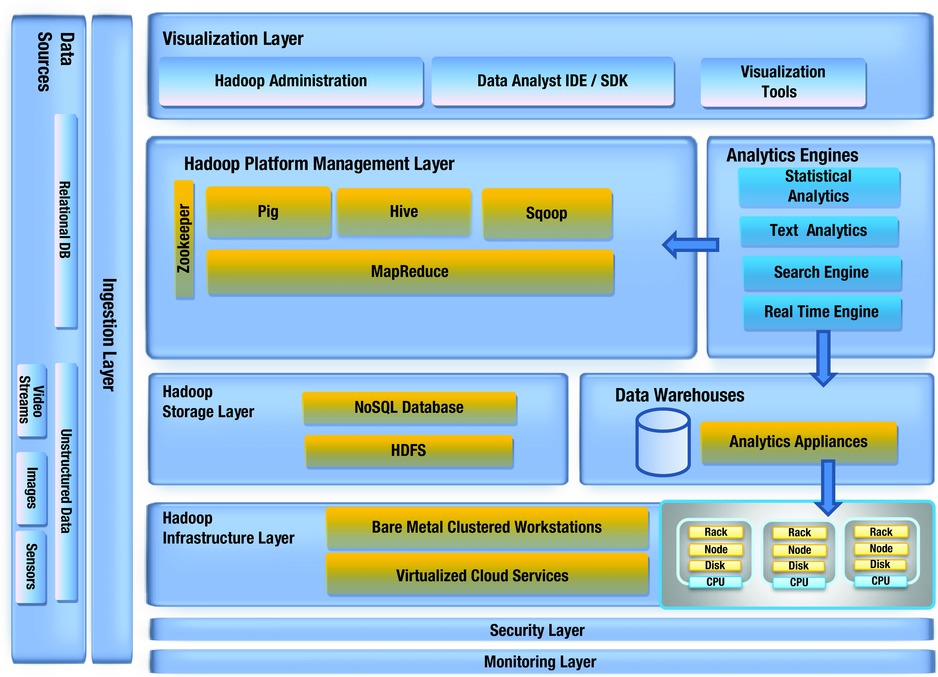
Figure 2-1. The big data architecture
Multiple internal and external data feeds are available to enterprises from various sources. It is very important that before you feed this data into your big data tech stack, you separate the noise from the relevant information. The signal-to-noise ratio is generally 10:90. This wide variety of data, coming in at a high velocity and in huge volumes, has to be seamlessly merged and consolidated later in the big data stack so that the analytics engines as well as the visualization tools can operate on it as one single big data set.
Problem
What are the various types of data sources inside and outside the enterprise that need to be analyzed in a big data solution? Can you illustrate with an industry example?
Solution
The real problem with defining big data begins in the data sources layer, where data sources of different volumes, velocity, and variety vie with each other to be included in the final big data set to be analyzed. These big data sets, also called data lakes, are pools of data that are tagged for inquiry or searched for patterns after they are stored in the Hadoop framework. Figure 2-2 illustrates the various types of data sources.
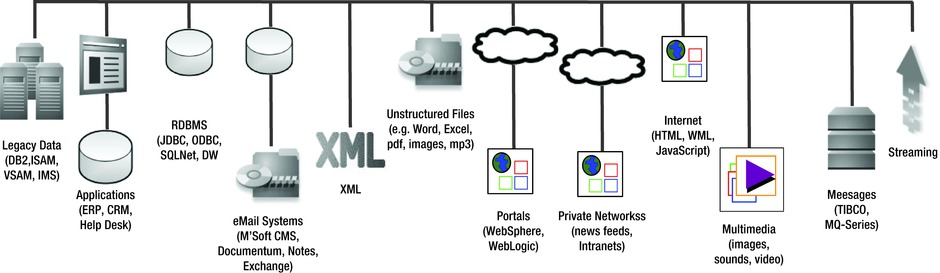
Figure 2-2. The variety of data sources
Traditionally, different industries designed their data-management architecture around the legacy data sources listed in Figure 2-3. The technologies, adapters, databases, and analytics tools were selected to serve these legacy protocols and standards.
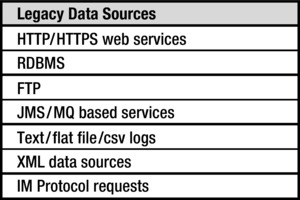
Figure 2-3. Legacy data sources
In the past decade, every industry has seen an explosion in the amount of incoming data due to increases in subscriptions, audio data, mobile data, contentual details, social networking, meter data, weather data, mining data, devices data, and data usages. Some of the “new age” data sources that have seen an increase in volume, velocity, or variety are illustrated in Figure 2-4.
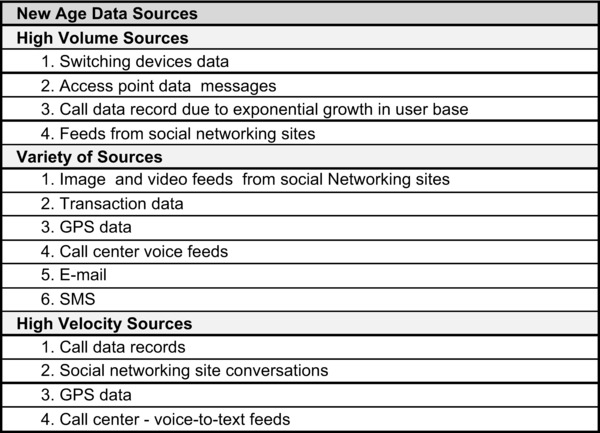
Figure 2-4. New age data sources—telecom industry
All the data sources shown in Figure 2-4 have to be funneled into the enterprise after proper validation and cleansing. It is the job of the ingestion layer (described in the next section) to provide the functionality to be rapidly scalable for the huge inflow of data.
The ingestion layer (Figure 2-5) is the new data sentinel of the enterprise. It is the responsibility of this layer to separate the noise from the relevant information. The ingestion layer should be able to handle the huge volume, high velocity, or variety of the data. It should have the capability to validate, cleanse, transform, reduce, and integrate the data into the big data tech stack for further processing. This is the new edgeware that needs to be scalable, resilient, responsive, and regulatory in the big data architecture. If the detailed architecture of this layer is not properly planned, the entire tech stack will be brittle and unstable as you introduce more and more capabilities onto your big data analytics framework.
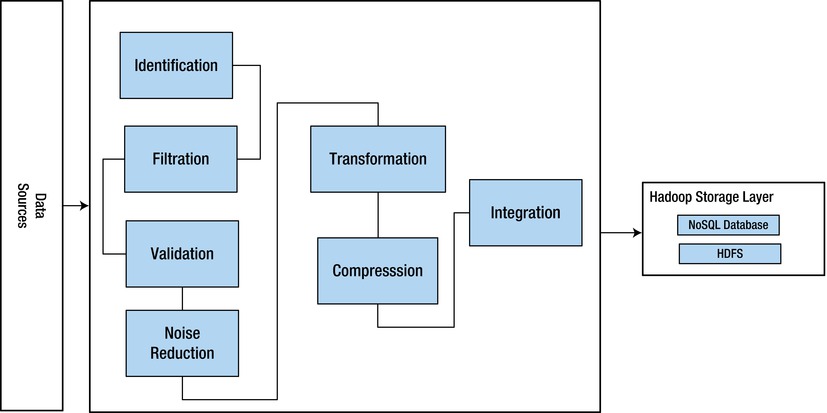
Figure 2-5. Data ingestion layer
Problem
What are the essential architecture components of the ingestion layer?
Solution
The ingestion layer loads the final relevant information, sans the noise, to the distributed Hadoop storage layer based on multiple commodity servers. It should have the capability to validate, cleanse, transform, reduce, and integrate the data into the big data tech stack for further processing.
The building blocks of the ingestion layer should include components for the following:
- Identification of the various known data formats or assignment of default formats to unstructured data.
- Filtration of inbound information relevant to the enterprise, based on the Enterprise MDM repository.
- Validation and analysis of data continuously against new MDM metadata.
- Noise Reduction involves cleansing data by removing the noise and minimizing distrurbances.
- Transformation can involve splitting, converging, denormalizing or summarizing data.
- Compression involves reducing the size of the data but not losing the relevance of the data in the process. It should not affect the analysis results after compression.
- Integration involves integrating the final massaged data set into the Hadoop storage layer— that is, Hadoop distributed file system (HDFS) and NoSQL databases.
There are multiple ingestion patterns (data source-to-ingestion layer communication) that can be implemented based on the performance, scalability, and availability requirements. Ingestion patterns are described in more detail in Chapter 3.
Distributed (Hadoop) Storage Layer
Using massively distributed storage and processing is a fundamental change in the way an enterprise handles big data. A distributed storage system promises fault-tolerance, and parallelization enables high-speed distributed processing algorithms to execute over large-scale data. The Hadoop distributed file system (HDFS) is the cornerstone of the big data storage layer.
Hadoop is an open source framework that allows us to store huge volumes of data in a distributed fashion across low cost machines. It provides de-coupling between the distributed computing software engineering and the actual application logic that you want to execute. Hadoop enables you to interact with a logical cluster of processing and storage nodes instead of interacting with the bare-metal operating system (OS) and CPU. Two major components of Hadoop exist: a massively scalable distributed file system (HDFS) that can support petabytes of data and a massively scalable map reduce engine that computes results in batch.
HDFS is a file system designed to store a very large volume of information (terabytes or petabytes) across a large number of machines in a cluster. It stores data reliably, runs on commodity hardware, uses blocks to store a file or parts of a file, and supports a write-once-read-many model of data access.
HDFS requires complex file read/write programs to be written by skilled developers. It is not accessible as a logical data structure for easy data manipulation. To facilitate that, you need to use new distributed, nonrelational data stores that are prevalent in the big data world, including key-value pair, document, graph, columnar, and geospatial databases. Collectively, these are referred to as NoSQL, or not only SQL, databases (Figure 2-6).

Figure 2-6. NoSQL databases
Problem
What are the different types of NoSQL databases, and what business problems are they suitable for?
Solution
Different NoSQL solutions are well suited for different business applications. Distributed NoSQL data-store solutions must relax guarantees around consistency, availability, and partition tolerance (the CAP Theorem), resulting in systems optimized for different combinations of these properties. The combination of relational and NoSQL databases ensures the right data is available when you need it. You also need data architectures that support complex unstructured content. Both relational databases and nonrelational databases have to be included in the approach to solve your big data problems.
Different NoSQL databases are well suited for different business applications as shown in Figure 2-7.
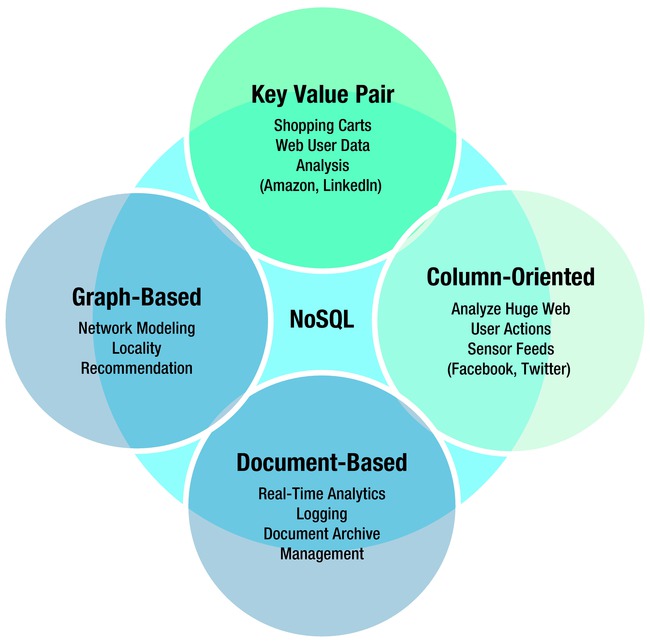
Figure 2-7. NoSQL database typical business scenarios
The storage layer is usually loaded with data using a batch process. The integration component of the ingestion layer invokes various mechanisms—like Sqoop, MapReduce jobs, ETL jobs, and others—to upload data to the distributed Hadoop storage layer (DHSL). The storage layer provides storage patterns (communication from ingestion layer to storage layer) that can be implemented based on the performance, scalability, and availability requirements. Storage patterns are described in more detail in Chapter 4.
The layer supporting the strorage layer—that is, the physical infrastructure—is fundamental to the operation and scalability of big data architecture. In fact, the availability of a robust and inexpensive physical infrastructure has triggered the emergence of big data as such an important trend. To support unanticipated or unpredictable volume, velocity, or variety of data, a physical infrastructure for big data has to be different than that for traditional data.
The Hadoop physical infrastructure layer (HPIL) is based on a distributed computing model. This means that data can be physically stored in many different locations and linked together through networks and a distributed file system. It is a “share-nothing” architecture, where the data and the functions required to manipulate it reside together on a single node. Like in the traditional client server model, the data no longer needs to be transferred to a monolithic server where the SQL functions are applied to crunch it. Redundancy is built into this infrastructure because you are dealing with so much data from so many different sources.
Problem
What are the main components of a Hadoop infrastructure?
Solution
Traditional enterprise applications are built based on vertically scaling hardware and software. Traditional enterprise architectures are designed to provide strong transactional guarantees, but they trade away scalability and are expensive. Vertical-scaling enterprise architectures are too expensive to economically support dense computations over large scale data. Auto-provisioned, virtualized data center resources enable horizontal scaling of data platforms at significantly reduced prices. Hadoop and HDFS can manage the infrastructure layer in a virtualized cloud environment (on-premises as well as in a public cloud) or a distributed grid of commodity servers over a fast gigabit network.
A simple big data hardware configuration using commodity servers is illustrated in Figure 2-8.
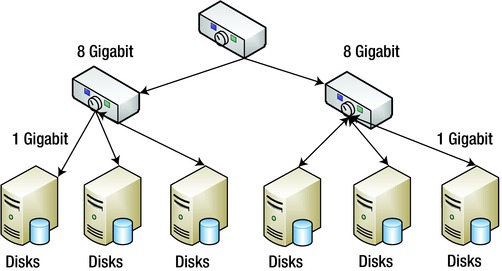
Figure 2-8. Typical big data hardware topology
The configuration pictured includes the following components: N commodity servers (8-core, 24 GBs RAM, 4 to 12 TBs, gig-E); 2-level network, 20 to 40 nodes per rack.
Hadoop Platform Management Layer
This is the layer that provides the tools and query languages to access the NoSQL databases using the HDFS storage file system sitting on top of the Hadoop physical infrastructure layer.
With the evolution of computing technology, it is now possible to manage immense volumes of data that previously could have been handled only by supercomputers at great expense. Prices of systems (CPU, RAM, and DISK) have dropped. As a result, new techniques for distributed computing have become mainstream.
Problem
What is the recommended data-access pattern for the Hadoop platform components to access the data in the Hadoop physical infrastructure layer?
Solution
Figure 2-9 shows how the platform layer of the big data tech stack communicates with the layers below it.
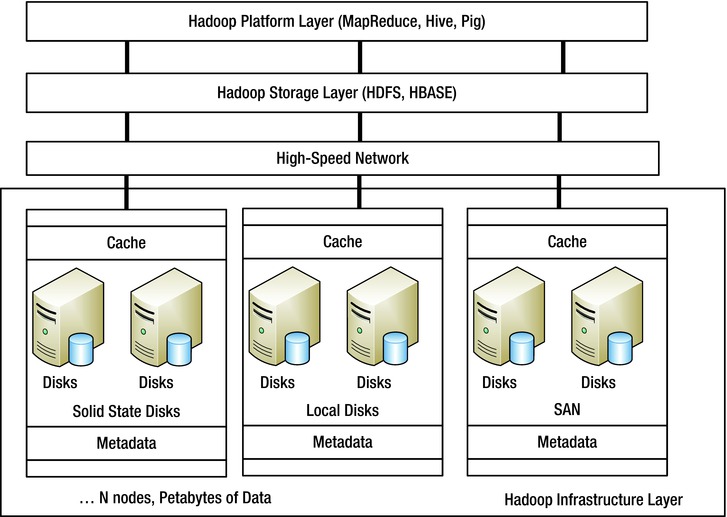
Figure 2-9. Big data platform architecture
Hadoop and MapReduce are the new technologies that allow enterprises to store, access, and analyze huge amounts of data in near real-time so that they can monetize the benefits of owning huge amounts of data. These technologies address one of the most fundamental problems—the capability to process massive amounts of data efficiently, cost-effectively, and in a timely fashion.
The Hadoop platform management layer accesses data, runs queries, and manages the lower layers using scripting languages like Pig and Hive. Various data-access patterns (communication from the platform layer to the storage layer) suitable for different application scenarios are implemented based on the performance, scalability, and availability requirements. Data-access patterns are described in more detail in Chapter 5.
Problem
What are the key building blocks of the Hadoop platform management layer?
Solution
MapReduce was adopted by Google for efficiently executing a set of functions against a large amount of data in batch mode. The map component distributes the problem or tasks across a large number of systems and handles the placement of the tasks in a way that distributes the load and manages recovery from failures. After the distributed computation is completed, another function called reduce combines all the elements back together to provide a result. An example of MapReduce usage is to determine the number of times big data has been used on all pages of this book. MapReduce simplifies the creation of processes that analyze large amounts of unstructured and structured data in parallel. Underlying hardware failures are handled transparently for user applications, providing a reliable and fault-tolerant capability.
Here are the key facts associated with the scenario in Figure 2-10.
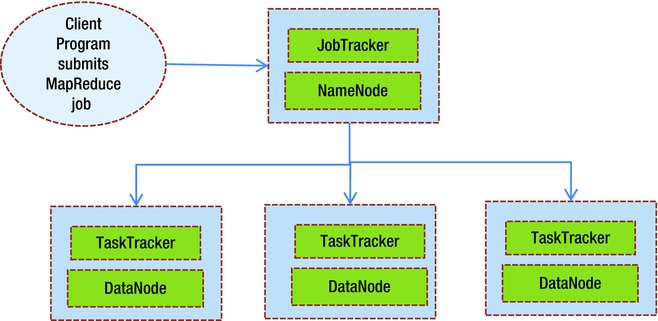
Figure 2-10. MapReduce tasks
- Each Hadoop node is part of an distributed cluster of machines cluster.
- Input data is stored in the HDFS distributed file system, spread across multiple machines and is copied to make the system redundant against failure of any one of the machines.
- The client program submits a batch job to the job tracker.
- The job tracker functions as the master that does the following:
- Splits input data
- Schedules and monitors various map and reduce tasks
- The task tracker processes are slaves that execute map and reduce tasks.
- Hive is a data-warehouse system for Hadoop that provides the capability to aggregate large volumes of data. This SQL-like interface increases the compression of stored data for improved storage-resource utilization without affecting access speed.
- Pig is a scripting language that allows us to manipulate the data in the HDFS in parallel. Its intuitive syntax simplifies the development of MapReduce jobs, providing an alternative programming language to Java. The development cycle for MapReduce jobs can be very long. To combat this, more sophisticated scripting languages have been created for exploring large datasets, such as Pig, and to process large datasets with minimal lines of code. Pig is designed for batch processing of data. It is not well suited to perform queries on only a small portion of the dataset because it is designed to scan the entire dataset.
- HBase is the column-oriented database that provides fast access to big data. The most common file system used with HBase is HDFS. It has no real indexes, supports automatic partitioning, scales linearly and automatically with new nodes. It is Hadoop compliant, fault tolerant, and suitable for batch processing.
- Sqoop is a command-line tool that enables importing individual tables, specific columns, or entire database files straight to the distributed file system or data warehouse (Figure 2-11). Results of analysis within MapReduce can then be exported to a relational database for consumption by other tools. Because many organizations continue to store valuable data in a relational database system, it will be crucial for these new NoSQL systems to integrate with relational database management systems (RDBMS) for effective analysis. Using extraction tools, such as Sqoop, relevant data can be pulled from the relational database and then processed using MapReduce or Hive, combining multiple datasets to get powerful results.
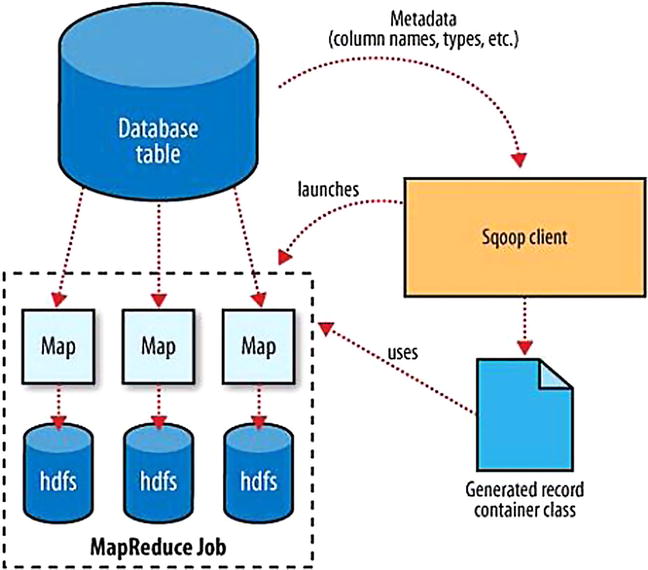
Figure 2-11. Sqoop import process
- ZooKeeper (Figure 2-12) is a coordinator for keeping the various Hadoop instances and nodes in sync and protected from the failure of any of the nodes. Coordination is crucial to handling partial failures in a distributed system. Coordinators, such as Zookeeper, use various tools to safely handle failure, including ordering, notifications, distributed queues, distributed locks, leader election among peers, as well as a repository of common coordination patterns. Reads are satisfied by followers, while writes are committed by the leader.
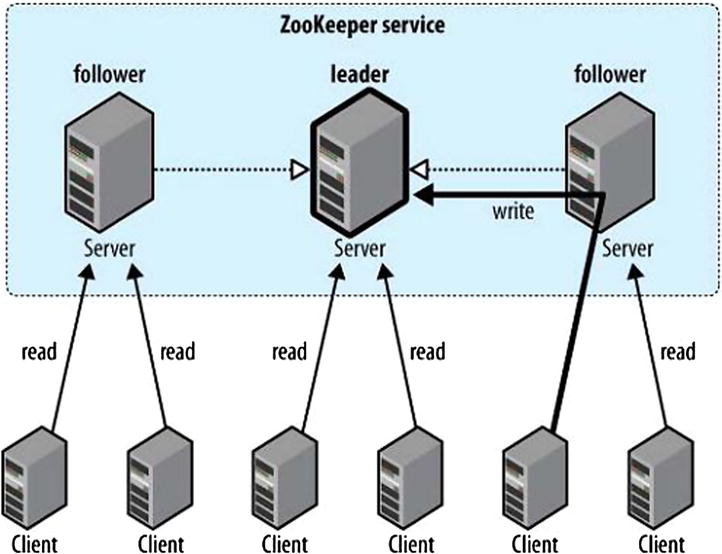
Figure 2-12. Zookeeper topology
Zookeeper guarantees the following qualities with regards to data consistency:
- Sequential consistency
- Atomicity
- Durability
- Single system image
- Timeliness
As big data analysis becomes a mainstream functionality for companies, security of that data becomes a prime concern. Customer shopping habits, patient medical histories, utility-bill trends, and demographic findings for genetic diseases—all these and many more types and uses of data need to be protected, both to meet compliance requirements and to protect the individual’s privacy. Proper authorization and authentication methods have to be applied to the analytics. These security requirements have to be part of the big data fabric from the beginning and not an afterthought.
Problem
What are the basic security tenets that a big data architecture should follow?
Solution
An untrusted mapper or named node job tracker can return unwanted results that will generate incorrect reducer aggregate results. With large data sets, such security violations might go unnoticed and cause significant damage to the inferences and computations.
NoSQL injection is still in its infancy and an easy target for hackers. With large clusters utilized randomly for strings and archiving big data sets, it is very easy to lose track of where the data is stored or forget to erase data that’s not required. Such data can fall into the wrong hands and pose a security threat to the enterprise.
Big data projects are inherently subject to security issues because of the distributed architecture, use of a simple programming model, and the open framework of services. However, security has to be implemented in a way that does not harm performance, scalability, or functionality, and it should be relatively simple to manage and maintain.
To implement a security baseline foundation, you should design a big data tech stack so that, at a minimum, it does the following:
- Authenticates nodes using protocols like Kerberos
- Enables file-layer encryption
- Subscribes to a key management service for trusted keys and certificates
- Uses tools like Chef or Puppet for validation during deployment of data sets or when applying patches on virtual nodes
- Logs the communication between nodes, and uses distributed logging mechanisms to trace any anomalies across layers
- Ensures all communication between nodes is secure—for example, by using Secure Sockets Layer (SSL), TLS, and so forth.
Problem
With the distributed Hadoop grid architecture at its core, are there any tools that help to monitor all these moving parts?
Solution
With so many distributed data storage clusters and multiple data source ingestion points, it is important to get a complete picture of the big data tech stack so that the availability SLAs are met with minimum downtime.
Monitoring systems have to be aware of large distributed clusters that are deployed in a federated mode. The monitoring system has to be aware of different operating systems and hardware . . . hence the machines have to communicate to the monitoring tool via high level protocols like XML instead of binary formats that are machine dependent. The system should also provide tools for data storage and visualization. Performance is a key parameter to monitor so that there is very low overhead and high parallelism.
Open source tools like Ganglia and Nagios are widely used for monitoring big data tech stacks.
Co-Existence with Traditional BI
Enterprises need to adopt different approaches to solve different problems using big data; some analysis will use a traditional data warehouse, while other analysis will use both big data as well as traditional business intelligence methods. The analytics can happen on both the data warehouse in the traditional way or on big data stores (using distributed MapReduce processing). Data warehouses will continue to manage RDBMS-based transactional data in a centralized environment. Hadoop-based tools will manage physically distributed unstructured data from various sources.
The mediation happens when data flows between the data warehouse and big data stores (for example, through Hive/Hbase) in either direction, as needed, using tools like Sqoop.
Real-time analysis can leverage low-latency NoSQL stores (for example, Cassandra, Vertica, and others) to analyze data produced by web-facing apps. Open source analytics software like R and Madlib have made this world of complex statistical algorithms easily accessible to developers and data scientists in all spheres of life.
Problem
Are the traditional search engines sufficient to search the huge volume and variety of data for finding the proverbial “needle in a haystack” in a big data environment?
Solution
For huge volumes of data to be analyzed, you need blazing-fast search engines with iterative and cognitive data-discovery mechanisms. The data loaded from various enterprise applications into the big data tech stack has to be indexed and searched for big data analytics processing. Typical searches won’t be done only on database (HBase) rows (key), so using additional fields needs to be considered. Different types of data are generated in various industries, as seen in Figure 2-13.
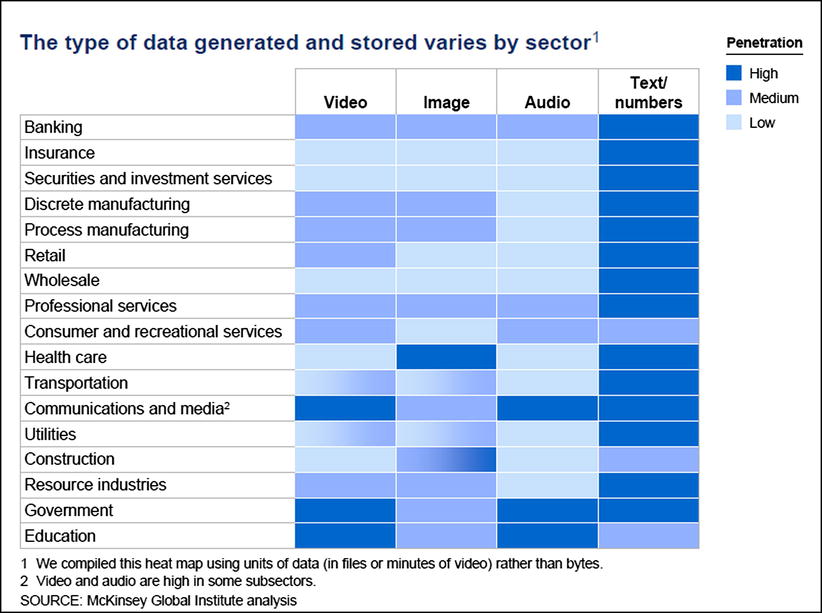
Figure 2-13. Search data types in various industries
Use of open source search engines like Lucene-based Solr give improved search capabilities that could serve as a set of secondary indices. While you’re designing the architecture, you need to give serious consideration to this topic, which might require you to pick vendor-implemented search products (for example, DataStax). Search engine results can be presented in various forms using “new age” visualization tools and methods.
Figure 2-14 shows the conceptual architecture of the search layer and how it interacts with the various layers of a big data tech stack. We will look at distributed search patterns that meet the performance, scalability, and availability requirements of a big data stack in more detail in Chapter 3.
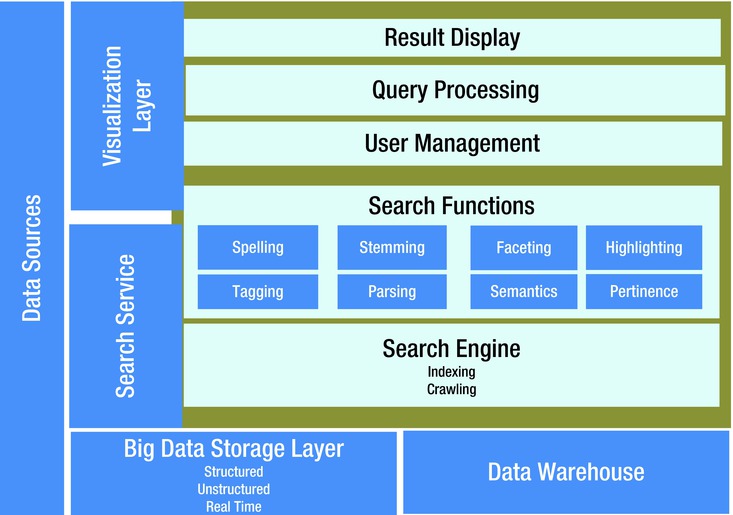
Figure 2-14. Search engine conceptual architecture
Memory has become so inexpensive that pervasive visibility and real-time applications are more commonly used in cases where data changes frequently. It does not always make sense to store state to disk, using memory only to improve performance. The data is so humongous that it makes no sense to analyze it after a few weeks, as the data might be stale or the business advantage might have already been lost.
Problem
How do I analyze my data in real time for agile business intelligence capabilities in a big data environment?
Solution
To take advantage of the insights as early as possible, real-time options (where the most up-to-date data is found in memory, while the data on disk eventually catches up) are achievable using real-time engines and NoSQL data stores. Real-time analysis of web traffic also generates a large amount of data that is available only for a short period of time. This often produces data sets in which the schema is unknown in advance.
Document-based systems can send messages based on the incoming traffic and quickly move on to the next function. It is not necessary to wait for a response, as most of the messages are simple counter increments. The scale and speed of a NoSQL store will allow calculations to be made as the data is available. Two primary in-memory modes are possible for real-time processing:
- Data is deployed between the application and the database to alleviate database load (Figure 2-15).
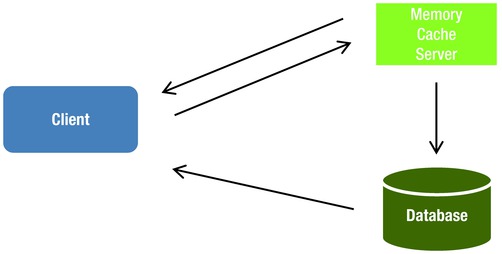
Figure 2-15. In-memory caching
- It’s ideal for caching data to memory that is repeatedly accessed.
- Data is not replicated or persisted across servers.
- It harnesses the aggregate memory of many distributed machines by using a hashing algorithm.
To give you an example, Facebook uses 800 servers to supply over 28 TBs of memory for Memcached—for example, Terracota, EHCache.
- Data is deployed in the application tier as an embeddable database—for example, Derby (Figure 2-16).
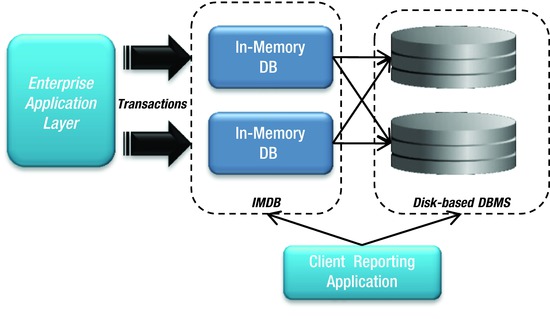
Figure 2-16. In-memory database
- Reading and writing data is as fast as accessing RAM. For example, with a 1.8-GHz processor, a read transaction can take less than 5 microseconds, with an insert transaction taking less than 15 microseconds.
- The database fits entirely in physical memory.
- The data is managed in memory with optimized access algorithms.
- Transaction logs and database checkpoint files are stored to disk.
Problem
Are the traditional analytical tools capable of interpreting and visualizing big data?
Solution
A huge volume of big data can lead to information overload. However, if visualization is incorporated early-on as an integral part of the big data tech stack, it will be useful for data analysts and scientists to gain insights faster and increase their ability to look at different aspects of the data in various visual modes.
Once the big data Hadoop processing aggregated output is scooped into the traditional ODS, data warehouse, and data marts for further analysis along with the transaction data, the visualization layers can work on top of this consolidated aggregated data. Additionally, if real-time insight is required, the real-time engines powered by complex event processing (CEP) engines and event-driven architectures (EDAs) can be utilized. Refer to Figure 2-17 for the interactions between different layers of the big data stack that allow you to harnesses the power of visualization tools.
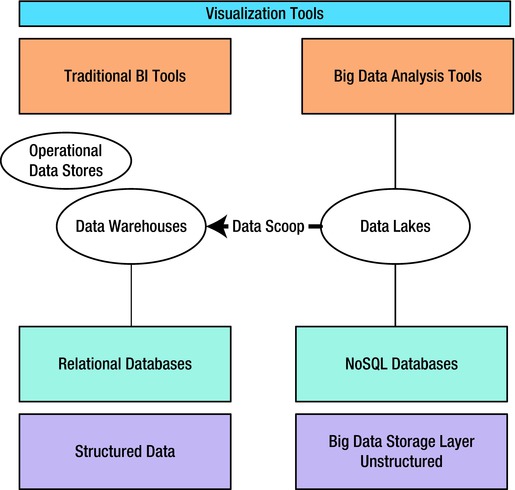
Figure 2-17. Visualization conceptual architecture
The business intelligence layer is now equipped with advanced big data analytics tools, in-database statistical analysis, and advanced visualization tools like Tableau, Clickview, Spotfire, MapR, revolution R, and others. These tools work on top of the traditional components such as reports, dashboards, and queries.
With this architecture, the business users see the traditional transaction data and big data in a consolidated single view. We will look at visualization patterns that provide agile and flexible insights into big data stacks in more detail in Chapter 6.
Big Data Applications
Problem
What is the minimum set of software tools I will need to implement, from end to end, the big data tech stack explained earlier?
Solution
You have a wide choice of tools and products you can use to build your application architecture end to end. We will look at many of them in later chapters as we discuss applying multiple-pattern scenarios to specific business scenarios. Products usually selected by many enterprises to begin their big data journey are shown in Table 2-1. The products listed are predominantly open source based, except for situations where an organization already has an IT investment in products from IBM, Oracle, SAP, EMC, and other companies and would like to leverage the existing licensing agreements to build big data environments at a reasonable price, as well as get continued support from the vendors.
Table 2-1. Big data typical software stack
Purpose |
Products/tools |
|---|---|
Ingestion Layer |
Apache Flume, Storm |
Hadoop Storage |
HDFS |
NoSQL Databases |
Hbase, Cassandra |
Rules Engines |
MapReduce jobs |
NoSQL Data Warehouse |
Hive |
Platform Management Query Tools |
MapReduce, Pig, Hive |
Search Engine |
Solr |
Platform Management Co-ordination Tools |
ZooKeeper, Oozie |
Analytics Engines |
R, Pentaho |
Visualization Tools |
Tableau, Clickview, Spotfire |
Big Data Analytics Appliances |
EMC Greenplum, IBM Netezza, IBM Pure Systems, Oracle Exalytics |
Monitoring |
Ganglia, Nagios |
Data Analyst IDE |
Talend, Pentaho |
Hadoop Administration |
Cloudera, DataStax, Hortonworks, IBM Big Insights |
Public Cloud-Based Virtual Infrastructure |
Amazon AWS & S3, Rackspace |
Problem
How do I transfer and load huge data into public, cloud-based Hadoop virtual clusters?
Solution
As much as enterprises would like to use the public cloud environments for their big data analytics, that desire is limited by the constraints in moving terabytes of data in and out of the cloud. Here are the traditional means of moving large data:
- Physically ship hard disk drives to a cloud provider. The risk is that they might get delayed or damaged in transit.
- The other digital means is to use TCP-based transfer methods such as FTP or HTTP.
Both options are woefully slow and insecure for fulfilling big data needs. To become a viable option for big data management, processing, and distribution, cloud services need a high-speed, non-TCP transport mechanism that addresses the bottlenecks of networks, such as the degradation in transfer speeds that occurs over distance using traditional transfer protocols and the last-mile loss of speed inside the cloud datacenter caused by the HTTP interfaces to the underlying object-based cloud storage.
There are products that offer better file-transfer speeds and larger file-size capabilities, like those offered by Aspera, Signiant, File catalyst, Telestream, and others. These products use a combination of UDP protocol and parallel TCP validation. UDP transfers are less dependable, and they verify by hash or just the file size, after the transfer is done.
Problem
Is Hadoop available only on Unix/Linux-based operating systems? What about Windows?
Solution
Hadoop is about commodity servers. More than 70 percent of the commodity servers in the world are Windows based. Hortonworks data platform (HDP) for Windows, a fully supported, open source Hadoop distribution that runs on Windows Server, was released in May 2013.
HDP for Windows is not the only way that Hadoop is coming to Windows. Microsoft has released its own distribution of Hadoop, which it calls HDInsight. This is available as a service running in an organization’s Windows Azure cloud, or as a product that’s intended to be used as the basis of an on-premises, private-cloud Hadoop installation.
Data analysts will be able to use tools like Microsoft Excel on HDP or HDInsight without the working through the learning curve that comes with implementing new visualization tools like Tableau and Clickview.
Summary
To venture into the big data analytics world, you need a robust architecture that takes care of visualization and real-time and offline analytics and is supported by a strong Hadoop-based platform. This is essential for the success of your program. You have multiple options when looking for products, frameworks, and tools that can be used to implement these logical components of the big data reference architecture. Having a holistic knowledge of these major components ensures there are no gaps in the planning phase of the architecture that get identified when you are halfway through your big data journey.
This chapter serves as the foundation for the rest of the book. Next we’ll delve into the various interaction patterns across the different layers of the big data architecture.