
CHAPTER 11 Software Fault Tolerance
Learning objectives of this chapter are to understand:
• The difficulty of tolerating design faults.
• The role of fault tolerance in software dependability.
• The limitations of fault tolerance in achieving software dependability.
• The various techniques available for providing fault tolerance in software.
• The effectiveness of the mechanisms for tolerating software faults.
• The cost of software fault tolerance during development and operation.
11.1 Components Subject to Design Faults
In the past four chapters, we have focused on software fault avoidance and software fault elimination. Now we move on to look at software fault tolerance, and we will be looking at a completely different form of fault tolerance from that which we examined in Chapter 6.
Although our primary interest lies in software dependability, in considering the development of a dependable computing system, identifying all of the system components that might be subject to design faults is important. The real issue is to tolerate design faults, and the techniques developed for software fault tolerance apply to design fault tolerance in other complex logical structures such as processors.
We have mentioned several system components subject to design faults already, but here is the complete list:
System software. All forms of system software upon which we rely are subject to design faults. This includes operating system kernels, file systems, network protocol stacks, compilers, debugging systems, configuration management systems, device drivers, linkers, and loaders.
Application software. Most people think of the software that they write as being the only application software with which they have to be concerned. In doing so, they are forgetting the plethora of libraries that are part of the implementation of high-level languages, the run-time support that the language requires, and the software that is written by others with which their code interacts.
Embedded firmware. Many safety-critical systems use application-specific integrated circuits (ASICs) and field-programmable gate arrays (FPGAs) as part of their implementation. The logic they contain is often referred to as firmware, and such devices are often thought of as “hardware” and thus somehow different. But, in fact, they are just another manifestation of the complex logic that we find in software and so, from the perspective of faults to which they might be subject, they are just as subject to design faults as software. Importantly, they are also subject to degradation faults and so designers have to deal with both. From the perspective of the software engineer, ASICs and FPGAs are best thought of as software.
Processors. In the early days of computing, processor faults were mostly degradation faults. The processors were much less complex than those of today and so were somewhat easier to design. Also, manufacturing techniques were not as good, and so the probability of failure was higher. This situation has reversed in recent years. Processors are much more complex and manufacturing techniques are vastly better. The result is that design defects in processors now tend to dominate. You can probably see this yourself if you ask yourself whether one of the computers you use has ever failed because of processor degradation. Certainly many people have experienced disk and power supply failures, but most people have never experienced a processor degradation fault because such faults are so rare.
Design faults in processors are a different story, and they are now a major area of concern. The most famous design defect (but far from the most serious) is the Intel Pentium FDIV bug in which the original Pentium processor did not compute floating-point division correctly in some obscure cases [152]. In order to seek some protection from processor design faults in the Boeing 777 flight control system, Boeing used three different processors operating in parallel in each channel of the system [155].
Power supplies and wiring. Experience shows that power supplies and power sources tend to suffer from degradation faults at a fairly high rate, but design faults in power supplies are not uncommon. Similarly, design faults in wiring do occur, although the relative simplicity of wiring tends to keep the occurrence of wiring design defects quite low. Obviously, degradation faults in wiring are common and have to be dealt with carefully. Chafing of wiring tends to occur unless routing is done carefully and wiring is restrained from movement. Also, the insulation in wiring tends to degrade over time and so is subject to cracking.
11.2 Issues with Design Fault Tolerance
11.2.1 The Difficulty of Tolerating Design Faults
In general, design faults are much more difficult to tolerate than degradation faults. The reasons for this difficulty are:
Design faults are more difficult to anticipate than degradation faults. We know that things break, i.e., degradation faults will occur, and, in general, we know how they break. Anticipation of the failure of a disk, for example, is fairly easy. All disks will fail eventually. But anticipating the way that things will be designed incorrectly, or, in the case of software, how the software will be written incorrectly, is difficult. From experience, we probably suspect that any piece of software of any significant size will have defects, but we cannot easily anticipate what the faults will be. Fortunately, we can mitigate this problem somewhat by using software techniques that allow us to predict that certain types of fault are absent (see Chapter 8, Chapter 9, and Chapter 10).
The effects of design faults are hard to predict. Since design faults are hard to anticipate, it follows that we cannot predict their effects. A software defect in one program could send corrupt data to multiple other programs. Any of the programs could send corrupt data to peripherals and over network links. How bad the damage is depends upon how quickly the erroneous state can be detected and measures taken to stop the spread of the error. An error that was not detected could continue to spread for an arbitrary time. In some cases, errors have spread to file backups, because they have persisted for protracted periods. We discussed the complexity of erroneous states in Section 3.2. Figure 11.1 is the same as Figure 3.2, and shows a system consisting of several interconnected computers, one of which has an attached disk and printer. The damage to the state from a single fault in Program1 on Computer A ends up affecting the state of three programs on Computer A, one program each on Computers B and C, a disk, and the output from a printer.
A practical example that demonstrates both the difficulty of anticipating design faults and the difficulty of predicting their effects occurred in February 2007. Many of the avionics systems on six Lockheed F22 Raptor fighter aircraft failed as the aircraft crossed the International Date Line [33]. The aircraft were flying from Hawaii to Okinawa, Japan. The aircraft were able to return safely to Hawaii with the assistance of tanker aircraft that had been accompanying them.
The failure semantics that components exhibit are difficult to define. A consequence of the previous point, that the effects of design faults are hard to predict, is the fact that failure semantics for design faults are hard to define. Having well-defined failure semantics is essential if we are to tolerate faults. But how will anything that is subject to design faults appear after a design fault has manifested itself? In particular, how will a piece of software appear after a software fault has caused an error? Software might terminate, but, if it does so, there is no guarantee that the state that is left will be predictable in any way. Also, as we noted in the previous point, making things worse (if that is possible) is that software might continue to execute and keep generating more and more defective state. The creation of defective state could continue for an arbitrary period of time, because there is no guarantee that the offending software will terminate. Having well-defined failure semantics is so important that, even for degradation faults, provision is sometimes made to force the state following a failure to be predictable. Power supplies, for example, employ over-current and over-voltage mechanisms so that the semantics of failure of the power supply or the associated wiring will be that power is withdrawn. Given the difficulty we face with failure semantics for design faults, we have to consider explicit measures to provide predictable failure semantics.
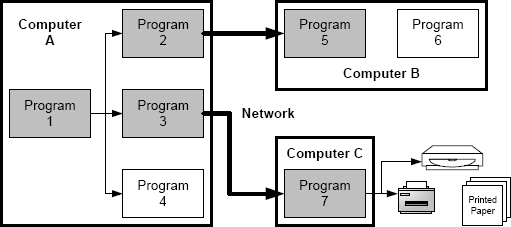
FIGURE 11.1 Possible effect of a single bug on the state of a computer system.
To get a sense of the problem of building fault-tolerant software, think about a piece of software that you have written. Did you know whether the software contained bugs or not? Did you know what the effect of the bugs that at least you suspected would be? Did you know how your software would fail when a bug manifested itself? In particular, did you know whether the software would terminate or keep executing?
Continuing with this challenge, consider the following four questions:
1. Could you modify your software so that it could detect that it was in an erroneous state?
2. Could you modify your software so that it could clean up the operating state and make the state one from which execution could proceed correctly?
3. Could you modify your software so that it could continue execution from the corrected state either with the original functionality or with modified functionality?
4. Could you build the entire software system so that these three activities could be completed automatically?
The point of these four questions is to ask you whether you could make your own software fault tolerant, since these questions are a restatement of the four phases of fault tolerance: error detection, damage assessment, state restoration, and continued service.
11.2.2 Self-Healing Systems
A further question to contemplate is whether you could modify your own software to go beyond fault tolerance into fault repair. Tolerating a fault is difficult and not always successful. A much better situation would be one in which software was written so that when a fault manifested itself, the fault was located and corrected automatically. This is the essence of research on self-healing software systems.
Although self-healing software is a nice idea, building software that can repair faults automatically is probably a long way off. One example of a promising approach is the use of genetic algorithms. In this approach, when an error is detected, the path taken through the software is identified and compared with the paths taken when the software executed test cases for which the software was known to work. Using the collection of paths, the likely location of the fault within the software is identified, and then a series of source-code transformations (mutations in the genetic sense) are applied. Each transformation produces a slightly different program and each of these is executed with both the known good test cases and the failing case. If one of the transformed programs executes all test cases correctly, then there is a chance that the fault has been corrected. For more details on this approach see the work of Weimer et al. [147].
There are examples of systems that can “heal” hardware degradation faults although, inevitably, self-healing in that case consumes components as failed components are replaced by operating spares. The simplest example of this approach is in hybrid redundancy, in which failed components are detected by a voter and replaced with spares that typically are unpowered so as to maximize their “shelf” life (see Section 6.3.4, page 166).
11.2.3 Error Detection
Error detection in fault tolerance for software is essentially the same problem as occurs with testing. How can we tell, reliably, whether or not the software has computed the correct output? When software fails, the symptoms are often complex and include outputs that are “close” to those expected. Software failures can even look like hardware failures. Finally, software failures are often intermittent, i.e., they are due to Heisenbugs (see Section 3.4), and so, even if software fails in a detectable way, the software might well work as desired if we try to re-execute the software as part of an effort to locate the fault.
Software error detection becomes a lot more practical if we merely look for certain types of failure. For example, for software that is operating in real time, failure includes failure to deliver the requisite results by a deadline. Monitoring the software’s output provides an easy way to detect failure to provide output on time. Similarly, some issues with concurrent software can be detected quite easily. A deadlocked system, for example, can be detected by observation of process progress. The fact that error detection is more practical for certain types of failure has led to powerful results in the field of dependability that we look at in Section 11.6.
11.2.4 Forward and Backward Error Recovery
Error recovery is the combination of state restoration and continued service. The basic idea with state restoration is to create a state from which continued service can resume satisfactorily. The way that this is done for degradation faults is to remove the failed component (and frequently much more) from the system in service. If spares are available, they are introduced into the system in service. If no spares are available, the system has to operate without the removed component. This type of state restoration is referred to as forward error recovery, because the state that is produced during state restoration is a new state, not one that existed in the system’s past.
In systems where no spares are available, the system has lost resources with forward error recovery. Since the loss might be substantial (e.g., a complete processor, memory unit, disk system, etc.), the opportunities for continued service are restricted. Continued service almost certainly cannot be the same as the original service, because the overall loss of resources can be considerable.
Error recovery is more flexible and therefore more complex when tolerating software faults than when tolerating degradation faults. The reason for the difference is that, with errors arising from software faults, the possibility exists of returning the system to a state that existed in the past in order to achieve state restoration and provide sophisticated continued service as a result. This technique is called backward error recovery.
When dealing with software, backward error recovery can be very useful. Since we can recreate a state that existed before a fault manifested itself and damaged the state, continued service can be based on a complete and consistent state, and full service could be provided, at least in principle. The notions of forward and backward error are illustrated in Figure 11.2.

FIGURE 11.2 Backward and forward error recovery. Time is shown from left to right. In the case of backward error recovery, the state of the system is restored to a previous state. In forward error recovery, the new state is created by modifying the erroneous state to produce a possible, consistent future state.
If the provision of continued service is able to avoid the fault that damaged the state, then the effect is to reverse time so as to make the system state revert to what it was in the past (hence the name backward error recovery) and “rewrite” history. Provided this is acceptable to the application, then the approach is quite powerful.
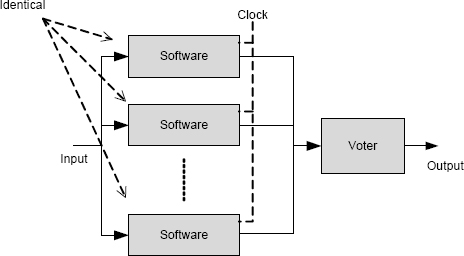
FIGURE 11.3 N-modular system for software in which software is merely replicated. Except for non-determinacy, all copies generate the same output and there is no benefit from the replication.
Backward error recovery is a desirable approach, but it has to be applied carefully. Reversing time means that the entire system state has to be taken back in time, and there has to be certainty that such reversal is complete. Part of a system’s state is its peripherals, including physical objects such as printed paper. Paper cannot be “unprinted”, and so restoring the state of a system cannot include restoring paper to its unprinted condition or any other similar mechanical change.
11.3 Software Replication
Replication worked for degradation faults, so it is tempting to turn to replication again for design faults. A software version of N-modular redundancy for software in which the software is replicated (as we did for hardware when dealing with degradation faults) is shown in Figure 11.3.
This approach seems unlikely to provide any benefit. If the software components are just copies, then surely if one fails, they will all fail. This observation is correct provided two conditions hold:
Each copy receives the same data. Clearly if the copies receive different data, they are likely to act differently. Since we are dealing with copies, supplying them with the same data seems both obvious and essential.
The software is deterministic. If the software is not deterministic, then the different copies might do different things, although the different behaviors are not necessarily useful.
Thus, if these two conditions hold, there is no gain from executing copies of the software in terms of tolerating design faults in the software.
These two conditions are, in fact, rather important, because they need not hold. If they do not hold, then the copies might behave differently, and that might be an advantage to us. Surprisingly, in practice, software designers can force these conditions to be violated quite easily, and violating the conditions can have considerable benefit. The major benefits that ensure occur in dealing with Heisenbugs, which we discuss in Section 11.5.2, and with a general approach to software fault tolerance that is called data diversity, which we discuss in Section 11.5.
11.4 Design Diversity
By definition, design faults are characteristics of design. This observation suggests that, if two or more software systems are built to provide the same functionality but with different designs, they might not all fail on the same input. Exploiting this possibility has led to a technique that is referred to as design diversity.
How might different software systems be built with different designs? The basic idea is to focus on independent development by teams that do not communicate with each other. This isolated development is illustrated in Figure 11.4. Several specific techniques have been proposed:
Different development teams. The idea with different development teams is to have groups of engineers working independently develop two or more versions of a software system. Once the versions are complete, the system is assembled. The different teams must not communicate, because, if they did, they might be influenced in some way to make the same mistakes. Thus, there has to be a way to ensure that the different teams do not discuss their implementations. If a single organization is responsible for more than one implementation, then that organization has to partition its staff, house them in separate sets of offices, ensure that they have no need to communicate for other professional reasons, and provide them with different computers, printers, etc.

FIGURE 11.4 N-modular system in which different teams develop different versions of the software in isolation.
Different software development tools. The use of different development tools is typically used in addition to the use of different development teams. Different tools begins with things like different programming languages (and therefore compilers), and extends to different linkers and loaders, different software development environments, and so on.
Different software design techniques. A special case of using different software development tools is the explicit use of different software design techniques. Comparison of software systems built using functional decomposition with those using object-oriented design reveals apparently considerable differences. Each design technique brings its own software-engineering advantages, and so the choice of technique is usually made using criteria other than dependability.
Different versions over time. Software systems are updated, extended, and enhanced quite often. One way to obtain multiple versions is to use up-to-date and older versions. Provided they supply the same functionality, there is a chance that the defects they contain will be different.
The multiple software systems built with any of these methods could be configured in various ways, much as in hardware architectures. Different software system architectures have been given different names. The two best known architectures are (1) the N-version System introduced by Avizienis and Chen [25] and (2) the recovery block introduced by Randell [114].
11.4.1 N-Version Systems
In an N-version system, the N different versions are executed in parallel, their outputs are collected by a voter, and the voter makes a decision about what value the system’s output should be. The organization of an N-version system is shown in Figure 11.5. An important advantage of an N-version system with N ≥ 3 is that faults are masked. Provided that the voter is able to select the correct output from the set of available outputs, there is no delay or other interruption of service.
A disadvantage of an N-version system is clear from the figure. All of the N versions have to be executed along with the voter, and so considerable hardware resources are needed over and above that needed for a single version.
A clock is needed in an N-version system to synchronize the execution of the different versions and the voter. The versions cannot operate in lockstep, because their execution times will differ. The voter has to be protected against the different execution times of the various versions and against the possibility that versions might fail. If the voter were merely to await the arrival from all the versions and one of them had failed, the voter might wait forever.
Output selection by the voter can use one of several different techniques that have been developed:
• The simplest technique is to choose the value supplied by the majority, if there is a majority.
• Sometimes groups of versions produce the same output, but there is more than one group. In that case, the value returned by the largest group can be used.
• The median value can be used.
• The middle value of the set ordered according to some function can be used.
• The average of all the values can be used.
Designing a voter for a specific system is quite complicated, because outputs can differ in ways that prohibit simple approaches to voting, specifically, numeric differences and algorithmic differences:
Numeric difference. The values supplied by different versions can be correct but differ because of rounding errors or similar numeric issues. Floating-point output values, for example, will not be bit-for-bit the same. The degree of difference that can be expected is system specific and so has to be analyzed for each individual system.
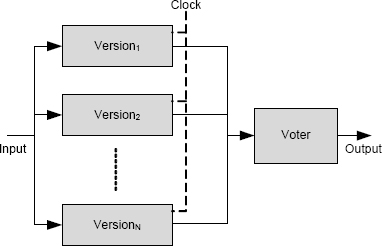
FIGURE 11.5 Operational organization of an N-version system.
The fact that there can be a difference raises a new and important concern. The differences between values returned by different versions must be readily distinguished from erroneous values. Different values that appeared to differ because of rounding error, for example, might actually be different because of a fault. The designer has to answer the question “At what point is the difference in values to be deemed the result of a fault so that erroneous values can be ignored?” This might seem like a problem that is solved easily by setting a limit, but the problem is much more subtle than it appears. Prior to the time at which the value received is deemed to indicate failure, the system will have been operating with the assumption that the value was trustworthy. If the voter used was based on averaging, mid-value selection, or median selection, then the output value could change suddenly as the voter decides that a version has failed and that the version’s output could no longer be trusted. As an example, consider the hypothetical data in Table 11.1. The data in the table is assumed to come from a three-version system (i.e., N = 3) that operates in real time and produces headings (in degrees) for an aircraft. The first row of the table indicates the timeframe for the hypothetical data, and rows two, three, and four are the outputs of the three versions for each frame. In the example, the third version is defective and is drifting slowly away from the correct value that is needed. The voting algorithm being used is the average of the three values, but at timeframe 7, the voter decides that the value from version 3 is sufficiently different from the other two versions that version 3 must be considered failed. At that point, the output becomes just the average of the remaining two versions. As a result, there is a relatively large (six degrees), sudden change in the output value.
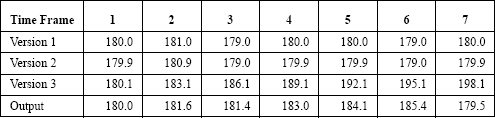
TABLE 11.1. Three-channel system with a failed version (number 3) that drifts.
Algorithmic differences. Another problem with voting is the possibility of two correct outputs being substantially different. Two software versions calculating the roots of a polynomial should compute the same set of values. But if only one value is needed, the versions might select different choices to return. Consider, for example, the computation of a square root. An application might under specify square root, expecting that the positive value would be assumed. If a version returns the negative square root, this value might not be expected, and a simple voter might infer that the associated version had failed. A more elaborate example of the problem of multiple different correct solutions occurs in navigation systems. If two versions compute routes independently, the routes are likely to differ since they will be based on different heuristics. The only way to avoid this is to vote on small increments in the route (perhaps single direction decisions). This approach requires that the versions engage in a vote frequently during the computation using a technique called “cross-check points”. A major disadvantage of introducing cross-check points is that they severely limit the design choices that can be used in the versions. The designs must be able to create the detailed data used in the cross-check points. This limitation is precisely the opposite of what is desired with design diversity, because it limits design choices.
Just as with N-modular redundancy in degradation fault tolerance, a decision about damage assessment has to be made if any of the versions fails to deliver an acceptable value to the voter. Again by analogy with degradation fault tolerance, the usual choice is to assume that the entire version is defective and to omit any values that the version produces in subsequent votes. By doing so, N-version systems are implementing forward error recovery.
Some techniques have been developed to restart failed software versions. The simplest technique is to reset the version and allow it to resume membership in the active set of versions. Resetting a version is problematic if the version maintains state, because the state has to be re-established. The state might have been created over a long period of execution, and this means that special and probably extensive actions need to be taken to re-initialize a failed version.
11.4.2 Recovery Blocks
In a recovery block, the versions, referred to as alternates, are executed in series until one of them, usually the first one, referred to as the primary, is determined to have completed the needed computation successfully. Assessment of the computation of an alternate is by error-detection mechanisms built into the alternate and by a final, external error-detection mechanism called an acceptance test [114]. To the extent possible, the acceptance test is designed to determine whether the output meets the system’s specification. The organization of a recovery block system is shown in Figure 11.6.
The recovery block operates by storing the system’s state, executing one alternate (the primary), and subjecting the primary’s computations to the built-in error-detection mechanisms and the output to the acceptance test. If the built-in mechanisms do not detect an error and the output passes the acceptance test, i.e., meets the specification as defined by the acceptance test, then the output is supplied to the system and the recovery block terminates. If the primary fails, the recovery block restores the system’s state and executes the next alternate. This process continues until the output is determined to be acceptable by the acceptance test or the recovery block runs out of alternates and fails.
The recovery block architecture implements backward error recovery, because the previously stored state is restored whenever an alternate fails. Thus, following state restoration, alternates can assume the complete state, so the alternate can undertake any processing that is deemed appropriate. Specifically, alternates do not have to meet identical specifications provided the acceptance test is properly defined.
Unlike an N-version system, a Recover Block system is not able to mask faults because any faulty alternate is guaranteed to cause a delay as the state is restored and other alternates are executed. Also, since an arbitrary number of alternates might be executed, up to and including the maximum number available, the execution time of a recovery block is unpredictable.
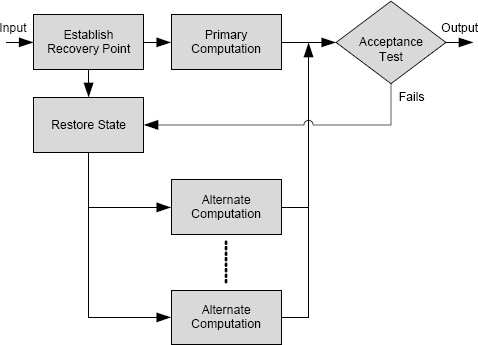
FIGURE 11.6 The recovery block software system architecture.
11.4.3 Conversations and Dialogs
Concurrent Systems
The recovery block framework was designed for sequential programs and has to be enhanced for concurrent programs. In a concurrent program, multiple processes or threads will be operating concurrently and asynchronously. Thus, to provide backward error recovery using recovery blocks, each of the concurrent entities will have to be structured as a recovery block. The issue that arises is the possibility of interacting states because of communication. Parallel processes, for example, are usually written to communicate with each other because the processes are merely building blocks for a larger entity.
The Domino Effect
When processes communicate, the data that passes from one to the other becomes part of the state of the recipient. Thus, in order to effect backward error recovery of the recipient, the sender has to be backed up to a point before the communication took place. To do so requires that the sender actually be backed up to a recovery point that the process established. This recovery point might be well before the point at which the problematic communication took place. The problem gets worse, however, when we realize that between establishing the recovery point and communication with the receiving process, the sending process might have been a recipient itself. Thus, the sender in that communication has to be backed up, and so on and so on. In the end, any number of processes might have to be backed up an arbitrary amount of time to reach a point that is truly a valid earlier state for all of the processes involved. This unconstrained rollback is called the domino effect.
Conversations
To avoid the domino effect, an enhancement to the recovery block structure was devised called a Conversation [114]. A Conversation is a structure covering a group of processes that want to communicate. As each process enters the Conversation, the process establishes a recover point as if the process were entering a recovery block. The most important aspect of a Conversation is that all of the processes that enter must synchronize the evaluations of their acceptance tests. If all acceptance tests pass, then the Conversation is complete and the processes proceed to their subsequent actions. If a process fails its acceptance test, then all of the processes must effect local backward error recovery and reestablish their stored states. Then each process executes an alternate and attempts to reach a point where the process can pass its acceptance test. Recovery and execution of alternates continues until all the processes pass their individual acceptance tests or no more alternates remain.
Dialogs
In related work, Knight and Gregory pointed out that the basic idea of a Conversation is potentially too rigid for many practical situations [53]. All of the processes in a Conversation are expected to eventually pass their individual acceptance tests and this might be impractical. A more effective approach in practice might be to dissolve the Conversation when the processes have to recover and allow the process to undertake an entirely different form of processing. Some processes might need to abandon their interaction with the group and effect some entirely different control path. Others might want to effect some different or reduced form of processing with the group that required an entirely different form of processing, including none. The structure that Knight and Gregory introduced for this flexible form of backward error recovery for communicating sequential processes is called a Dialog [53].
11.4.4 Measuring Design Diversity
Diversity Metrics
No matter what software system architecture is being used, successful fault tolerance using design diversity relies upon the different versions having different designs. How might the difference between designs be measured, or, more formally, how might design diversity be measured? Dealing with this question is a difficult challenge for many reasons. The first problem is to answer the question: “What does it mean for two software systems to have different designs?” In practice, there are no metrics that can measure design diversity in a meaningful way.
Statistical Independence
Even if there were metrics for design diversity and we could be confident that two designs were “different” according to the metric, this would not necessarily mean that the different designs had different faults. If they are to be effective, all of the various design-diverse software architectures rely upon the assumption that versions developed independently will have small probabilities of failing on the same input. Clearly, if versions developed independently fail frequently on the same inputs, then the improvement in dependability that can be expected from the multiple versions is small. As we saw in Section 6.4, large improvements in hardware dependability can be achieved where failures of different components are statistically independent. Unfortunately, statistical independence of faults is known not to be the case for software [80] and probably does not hold for any type of design fault.
If versions that are developed independently do not necessarily fail in a statistically independent way, then how are their failures related and what effect does this have on system dependability? For any given system, there is no known way of predicting the failure rate of the system. Failures for a given system might be statistically independent, might be totally correlated, or anything in between. This range of possibilities means that no specific improvement in dependability can be expected from a design-diverse system, although improvements have been reported in various experiments (e.g., [80]).
For safety-critical systems, the systems most likely to be seeking dependability, the assumption has to be that no improvement in dependability will result from design diversity, because safety-critical systems need high levels of assurance. Indeed, since a design-diverse system is more complex than a single system, a failure rate greater than a single, carefully engineered system is entirely possible.
Modeling Design Diversity
A theoretical model of the failure rate of design-diverse systems was developed by Eckhardt and Lee [41]. This model predicts the failure rate extremely well but can only be used for theoretical studies. The model relies upon the distribution of the probability of failure of a set of versions for each vector of values in the input space. This distribution exists for any given system but cannot be known. If the distribution were known, the points in the input space where coincident failures occur would be known, and so the versions could be repaired.
The Eckhardt and Lee model does enable important “what if questions to be answered about the effect of different distributions. If specific distributions are assumed, the model predicts the failure rate of the resulting design-diverse system. This work has enabled answers to be obtained to questions such as the optimal number of versions. The model shows, for example, that with reasonable assumptions about the correlation distribution, the benefit of an N-version system increases with N up to a specific value and actually decreases thereafter.
11.4.5 Comparison Checking
The availability of several versions when developing a design-diverse system has led many developers to use the N-version structure during system testing. Since the basic structure is intended to provide error detection during execution, obviously the same approach could be used for error detection during testing. Test inputs can be created by any suitable means, the versions executed, and then the outputs compared. The basic structure is shown in Figure 11.7.
The idea of using the N-version structure during testing has been referred to as back-to-back testing, although this term is misleading [145]. The structure does not provide all the elements of testing, just error detection. A more accurate term is comparison checking, and so that is the term used here.
Comparison checking seems like a good idea for two reasons:
• The technique does not require a lot of additional resources because the primary constituents of a comparison-checking system are the software versions that have to be developed anyway.

FIGURE 11.7 System structure for testing using comparison checking.
• The major problem in software testing, i.e., determining whether the output of the software is correct, appears to be solved.
In practice, comparison checking has a subtle problem that makes it far less attractive than it appears. When executing a test case using comparison checking, there are four possible outcomes:
All versions produce correct outputs. The comparator would indicate that the test was successful, and the test process would continue with the next test case.
Some versions produce correct outputs. The comparator would indicate that the test case was unsuccessful and identify the differences between the versions. The developers could then make the necessary corrections to the versions that failed.
All versions produce incorrect but different outputs. The comparator would indicate that the test case was unsuccessful and identify the differences between the versions. Again, the developers could then make the necessary corrections.
All versions produce incorrect but identical outputs. The comparator would indicate that the test was successful, and the test process would continue with the next test case.
The first three outcomes are productive and help developers to improve the software. There will be an unknown but potentially large number of false alarms because of the same set of issues raised with voting in N-version systems. Whether the false alarms become an impediment to development will depend on the rate that they arise for a specific system.
The real issue with comparison checking is the fourth outcome. A set of versions producing identical but incorrect outputs will not signal failure during testing. The defects that are the greatest concern for an operational N-version system or a recovery block, identical failures in all versions, will not be detected during testing. As testing proceeds, the faults that can be detected, i.e., those which cause the versions to have different outputs, will be detected and removed. In the limit, if a set of versions is tested with comparison checking, the versions will converge to compute the same function, including the same erroneous outputs for some inputs. An N-version system constructed from such a set of versions will be no more useful during operation than any of the individual versions.
11.4.6 The Consistent Comparison Problem
The Consistent Comparison Problem (CCP) is a problem that applies only to N-version systems [81]. The problem arises whenever comparisons (if statements, etc.) are used in the logic flow of the software. The problem is:
Without communication, two or more versions in an N-version system cannot ensure that, for any given comparison, the result of the comparison obtained by all the versions will be the same.
Thus, where the versions are making a comparison that relates directly to the application, such as comparing a computed flying altitude in an autopilot against a threshold, the versions might conclude differently about whether the altitude is above or below the threshold.
Unfortunately, there is no algorithmic solution to the problem [81]. In other words, there is no change to the software that can be made which will avoid the problem. Making things worse is that the problem will always occur, even with versions that are individually considered perfect. The rate at which the problem manifests itself is application dependent, and so modeling the effects of the Consistent Comparison Problem in general is problematic.
An example of the problem based on a simple thermostat is illustrated in Figure 11.8. Suppose that a 2-version system is developed to implement a thermostat for a heating furnace. The simple algorithm that is used by the software is to read a temperature sensor periodically to see what the current air temperature is, and then to compare the value read with a set point, the desired temperature. If the air temperature read from the sensor is below the set point, then the software commands the furnace to turn on. The furnace is turned off if the observed temperature is above the set point. This computation is repeated every few seconds.
A complication is that the software is required to implement hysteresis to prevent the furnace from cycling on and off too frequently. The requirements for the system’s hysteresis are to change the furnace state (on to off or vice versa) only if:
• The thermostat has indicated the need for a fixed number of cycles. The number of cycles might be quite high to prevent the effects of transient temperature changes from affecting the furnace state.
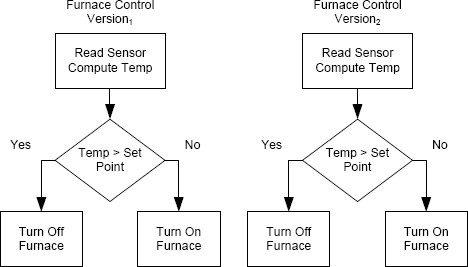
FIGURE 11.8 An example of the Consistent Comparison Problem.
• A specified period of time has passed since the last state change. The specified time period might be several minutes.
The two software versions are intentionally different because the designers are trying to achieve design diversity. Thus, (1) the internal representations of temperature used by the two versions might be different (one might use fixed point and the other floating point, for example); and (2) the algorithm used to transform the sensor reading (which is just bits from an analog-to-digital converter) into engineering units (degrees on an appropriate temperature scale) might be different. The hysteresis algorithms might be different, although this is unlikely because the requirements are quite specific.
Now consider the comparison used to determine whether the furnace should be turned on or off. If the value read from the sensor were close to the set point, the two different versions might well make different decisions, one concluding that the sensor value was below the set point and the other concluding that the sensor value was above the set point. In such a case, the two versions would supply different decisions to their individual implementations of the hysteresis algorithms. In the end, the two versions might supply completely different outputs to the comparator, and the comparator would be forced to conclude that the system had failed.
The idea that springs to mind when faced with this challenge is to suggest that there should be an interval around the set point within which care should be taken. But an interval does not help, because the Consistent Comparison Problem reappears when one asks whether the values to be compared lie within the interval.
Since there is no algorithmic solution to the Consistent Comparison Problem, the only thing to do is for the various versions to communicate. The versions exchange their computed values and compute a consensus value. All of the versions will use this consensus for comparison at any point where comparisons have to be made that derive from the requirements.
Such points of communication are just the cross-check points we saw in Section 11.4.1. This approach is a poor solution to the Consistent Comparison Problem, however, because the result is to restrict the designs of the versions in serious ways. For example, the designs of the versions have to be restricted to ensure that the cross-check points are present and have the proper form. Where several comparisons have to be made in sequence, the comparisons have to be made in the same order in all versions, and, if the exchange that is made at the cross-check points is of data values used in the comparison, then those data values either have to be of the same type or have to be of types for which type switching will not interfere with the comparisons.
The Consistent Comparison Problem occurs in practice, but the frequency with which the problem occurs depends upon the software system designs in the various versions and upon the frequency with which the application supplies values that could make the comparisons inconsistent. For any given system, predicting this frequency of occurrence is problematic.
11.5 Data Diversity
11.5.1 Faults and Data
Design diversity attempts to deal with design faults by having more than one implementation, each with its own design. Each of the different implementations is executed with the same data. What would happen if we executed instances of the same implementation with different data? Recall from Section 11.3 that one of the reasons for avoiding pure software replication was that the replicates would be subject to exactly the same faults if they used exactly the same data and were deterministic.
There is good evidence that software faults are, in many cases, data sensitive [9]. In other words, faults manifest themselves with certain data values yet do not do so with data that is very similar. How this might happen is easy to see when one thinks of the situations in which software fails for special cases. Avoiding the exact data values associated with the special case usually means that the software works.
As an example, consider the tangent of 90°. This particular tangent is undefined, and so if computation of the tangent is included in a program, the programmer must be careful to avoid calling the tangent function with this special value. Failing to check and calling the function will almost certainly lead to failure. Yet a value that is very close will work correctly. The calculator in Microsoft Windows XP indicates (correctly) that 90° is an invalid value, but the calculator is quite happy to calculate the tangent of 89.9999999999° (that is, 89 followed by ten nines). That any application would care if this value were used instead of 90° seems unlikely.
This extreme sensitivity of many software faults to particular data values suggests an approach to dealing with faults that is, in some sense, the opposite of design diversity. The approach is to use multiple instances of a single design but to execute each with different data. Rather obviously, the technique is called data diversity [9].
If data is to be varied in a data-diverse system, where does the variation come from? Implementing data diversity in general seems impossible, because the data is not under the control of the software developer. But in practice, getting different data is not hard.
11.5.2 A Special Case of Data Diversity
Several special cases of the data diversity have been reported, although they were not referred to as data diversity. The best known and most significant of the special cases was developed at Tandem Computers by Jim Gray [51]. The Tandem computer system was developed to provide a platform for applications requiring high availability. Various special facilities were included in the hardware design, the operating system, and in the support offered to application software so as to enable high availability for database applications.
In 1985, Gray was examining failures of Tandem systems reported from the field, and he noticed that some faults in the Tandem system software did not always manifest themselves when the software was executed. In other words, sometimes the software would fail and sometimes not, and this phenomenon occurred even on the same data. Gray coined the phrase Heisenbug to describe this behavior (see Section 3.4).
The observation about Heisenbugs led to the introduction of a form of data diversity in the Tandem system. Since the primary use of the system was database applications, in many circumstances software could be re-executed without harm fairly easily. If software failed while processing a transaction and before the transaction was committed, the transaction could be applied again without harm. When this was done, the processing of the transaction succeeded quite frequently.
Since the transaction that was attempted a second time was the same as the transaction that led to the software failure, why did the software not fail during the second execution? The reason is the inherent non-determinacy in transaction processing that derives from concurrency. Transaction processing involves many steps, some combination of which is executed concurrently. Although the transaction data was the same, the actual sequence of events undertaken by the software was different. By chance, sometimes the fault that led to the failure did not manifest itself during the second execution.

FIGURE 11.9 The N-copy data-diversity software system architecture.
11.5.3 Generalized Data Diversity
The most general form of a data-diverse system was introduced by Ammann and Knight [9]. General data diversity operates by executing identical copies of the software with different data being supplied to each copy. As with design diversity, different system architectures have been developed to implement data diversity. The most important is the N-copy architecture shown in Figure 11.9.
The N-copy system architecture is the data-diverse version of the N-version system architecture from design diversity. An N-copy system operates by having N identical copies of the software executing concurrently. The input data is transformed differently for each of the copies using a technique called data reexpression. The outputs of the copies are transformed so as to recover the expected outputs from the program had it been operating on the original input. The algorithmic means by which the output to be used is obtained from the output that the software produced with reexpressed input is reverse reexpression.
The outputs from the N copies are supplied to a voter. Except for the effects of non-determinacy against which measures have to be taken, copies that executed correctly will have the same outputs. Thus, provided a majority of the copies execute correctly, the voter can select the system output using a simple majority vote.
As an example of data diversity, consider a program designed to sort a file of integers. An N-copy structure can be constructed by operating N copies of the sort program in parallel. A suitable data reexpression algorithm would be to form a permutation of the input values. Each copy of the software is given a different permutation and so operates with different data. However, the copies should all produce the same result, a sorted file, and, in this case, reversing the reexpression is unnecessary. Voting can proceed directly on the output of the copies.
11.5.4 Data Reexpression
Data reexpression is the algorithmic manipulation of data such that:
• The reexpressed data is different from the original data in some way. The difference could be different values, different order of values, different encodings of engineering values, different precision, and so on.
• The software will execute with the different values. The reexpressed data must still be within the expected set of valid inputs for which the software was designed.
• The expected output values can be recovered from the actual outputs generated by the software. Since the data was changed by reexpression, the output might be different from that produced by the original data. This difference will not be a problem as long as there is an algorithmic way to recover the expected outputs.
Data reexpression can be achieved in two different ways: exact reexpression and inexact reexpression. These two terms are defined as follows:
Exact reexpression: An exact reexpression algorithm changes the input data for a program in such a way that the exact output which would have been obtained from the original data can be obtained from the output of the reexpressed data by an algorithmic means.
Inexact reexpression: An inexact reexpression algorithm changes the input data for a program in such a way that the output obtained from the reexpressed data remains acceptable to the application.
Some examples of exact reexpression are:
• Permuting the input data to a sort program. There is no need to reverse the reexpression.
• Adding a constant value to data that comes from a linear scale such as coordinates in a two- or three-dimensional coordinate system. For computations that do not depend on absolute location, the actual coordinates can be translated or rotated. The reverse reexpression that is needed will depend on what the calculation is.
• Reordering the records in a file. Many computations that process large data volumes from files are independent of the order of the records. There is no need to reverse the reexpression.
• Changing the order of the transactions in a transaction-processing system. Large on-line service systems such as reservation systems, many financial systems, and e-commerce web sites complete transactions for a variety of clients, and the order of processing can be varied with no ill effects and with no need for reexpression.
Some examples of inexact reexpression are:
• The time at which sensors are read can be varied between the channels in a real-time system that uses redundant channels. Since the datum read by a sensor is a sample of a real-world physical value that changes over time, sensor readings taken at different times are likely to be slightly different. There is no need to reverse the reexpression.
• Non-integer numeric data values can be changed by small amounts. As with the previous example, a sensor datum is usually represented in digital form with a precision far greater than that which is warranted by the sensor’s accuracy. Thus, small changes to the value are likely to be acceptable to the application. Again, there is no need to reverse the reexpression.
11.5.5 N-Copy Execution and Voting
The execution of the copies in an N-copy system is much simpler than the execution of the versions in an N-version system. The copies are all the same software, and so their execution times are likely to be almost identical, even operating with reexpressed data. An overall synchronization mechanism is still required to make sure that voting takes place only after all the copies have produced a result. Failure of copies is possible, and so the execution system needs to be prepared to manage failed copies by eliminating them from the operating set.
Voting in an N-copy system is also much simpler than with an N-version system. There is no chance of multiple solutions being produced that are correct but different. The data values used in voting will not necessarily be identical, but the values will be very close for most N-copy systems. The range of values that can be produced and for which the voter needs to take account is much simpler to derive because the copies are all the same software.
An important question that developers ask is “How many copies should be used?” Fortunately, there is no major development cost incurred by using more copies rather than less. The copies are exactly that, copies, and so any number can be used. The cost of development of an N-copy system is low, because the only items needed over and above the application itself are:
• The execution framework, including the copy-synchronization facility and the voter.
• The reexpression algorithm.
• The reverse reexpression algorithm.
Usually, these costs are small compared to the development cost of the application itself.
Naturally, there is an operational cost, because the copies all have to be executed. This cost will limit the number of copies, although the advent of multicore processors promises to reduce the impact of this cost. Only a single instance of the software needs to be kept in memory because all of the copies will use the same instructions. Similarly, only one instance of the reexpression and reverse reexpression software need to be available. The system in operation will actually use one process for each actual copy, and the memory needed to add a copy therefore is just the memory needed to support a process.
11.6 Targeted Fault Tolerance
The goal with both design and data diversity is to provide a general approach to fault tolerance that provides protection against a wide variety of software faults. Since neither can do so with a level of assurance that is quantifiable, the value of each for any given system is unknown. For safety-critical applications, this means that choosing to use a general diversity technique is a difficult decision. There might be an improvement in dependability, but for a specific system this cannot be modeled. There is certainly a cost, and that suggests that a better approach might be to use the resources for fault avoidance and fault elimination instead.
An alternative approach is a middle ground in which the application of fault tolerance in software is targeted to specific fault classes. In some systems, certain fault classes lead to errors that are especially serious, and so looking carefully at those fault classes is constructive.
With targeted fault tolerance, the fault classes of interest are identified, and then all the phases of fault tolerance are tailored to those fault classes. The errors associated with the fault classes of interest can usually be determined, and so error detection is much easier. Similarly, once error detection is accomplished, damage assessment, state restoration, and continued service can usually be tailored to the system and the fault classes of interest.
In this section, we examine four different targeted fault tolerance mechanisms. Each of these four techniques is in common use. Keep in mind that each of the techniques is targeting specific fault classes, and so faults outside those targeted classes might manifest themselves during operation with effects that could be serious. If a class of faults that could lead to hazards is missed, then serious failures are possible. As we have noted elsewhere, fault tolerance, including targeted software fault tolerance, should be considered only after fault avoidance and fault elimination have been applied comprehensively.
11.6.1 Safety Kernels
In safety-critical systems, there is a set of hazards that must be avoided. These hazards are usually relatively few in number and relatively easy to define. Statements that define transitions to hazardous states are referred to as safety policies. In discussing the notion of a hazard in Section 3.11 on page 94, we used the following as an example of a hazard:
An elevator shaft with a door open but with no elevator car present.
Avoiding opening a door to the elevator shaft when no car is present is clearly something that we want, and this is an example of a safety policy that needs to be enforced.
An important technology that is most commonly known as a safety kernel is to architect the system so as to check explicitly for system transitions that lead to hazards and stop them. The safety kernel concept as discussed here was proposed originally by Rushby [122], although many other authors have discussed the topic [22, 148, 149].
As an example, consider a controller for a simple microwave oven. The most serious hazard would be to have the microwave generator on when the door was open. The result would be to expose people nearby to high levels of microwave energy. The software in a controller such as this is not especially complicated, but the hazard is very dangerous and so designers want a high level of assurance that the hazard is unlikely to arise. Other software faults might cause problems, such as the timer functioning incorrectly, the display malfunctioning, and so on, but none of these is serious. Dealing with the serious hazard is a candidate for targeted fault tolerance using a safety kernel.
A simple safety-kernel structure in software for this microwave oven controller would consist of:
• A well-protected software component placed between the generator activation logic and the output port that connects to the generator. The role of this software component would be to allow the generator to be turned on only if the door were closed.
• A supplement to the processor’s interrupt handler. The purpose of the supplement would be to intercept the interrupt from the door-opening hardware and turn off the microwave generator if it were on.
The software component needs to have a form like this:

This software would avoid the hazard if there were an attempt to turn on the microwave generator when the door was open for any reason, including faults in the remainder of the software.
This type of protection would not deal with the case where the door was opened while cooking was in progress. Turning off the microwave generator if the door were opened has to be triggered by an interrupt, with the interrupt handler’s first action being to turn off the generator. The code for the interrupt handler might look like this:

There are several important things to note about this example:
• When operating with a structure like this, the software that contained the generator-activation logic could contain any number of faults, but the hazard could not arise provided the simple check was executed (i.e., not circumvented in some way) and this checking software was not damaged by faults elsewhere in the software. With a small software component of this form, we do not need to have high levels of assurance of the remainder of the (possibly complex) software.
• If this simple safety-kernel structure is to provide a high degree of protection, the kernel has to operate as designed no matter what goes wrong with the application software. In other words, there must be no way for the application software to interfere with the safety-kernel software. A simple example of interference would be if the application software went into an infinite loop so that the safety kernel could not execute.
Making sure that there is no interference is complicated in its own way because of the high level of assurance that is required. What is needed is to construct a fault tree for the hazard:
Safety kernel does not prevent system from entering a hazardous state.
The events in the fault tree will include:
– Application software enters infinite loop.
– Safety-kernel software damaged by other software.
– Microwave generator power switched on from another location.
As with any hazard, preparation of the fault tree has to be careful, thorough, and systematic (see Section 4.3). Such fault trees are relatively easy to build; see, for example, the work of Wika [148]. A fault tree for a safety kernel is likely to reveal that modifications such as the addition of an external hardware watchdog timer are needed because that is the only way to be sure that an infinite loop in the software will be stopped.
• A software safety kernel for an application like a microwave oven will have a simple structure much like the example, and so verifying the software fragment is far easier than verifying the software that contained the generator-activation logic. From a practical perspective, this property is useful, because assurance efforts can be focused on the simple structure.
• What happens if this simple safety kernel has to act is not defined. A “fail” indicator could be illuminated for the user, or some other action taken.
In practice, most safety-critical systems are much more complicated than this simple example, and the associated safety kernels are correspondingly more complex. The benefits remain, however. A safety kernel is present to stop the system from transitioning to a hazardous state, and those states are identified during hazard analysis. With a properly designed safety kernel in place, failures of the bulk of the software in the safety-critical system can be tolerated. Finally, the relative simplicity of the safety kernel makes verification a more manageable task.
11.6.2 Application Isolation
Consider the problem of separating different applications in a safety-critical computing system so that they do not interfere with each other. Multiple safety-critical applications often have to be run on a single computer. Being sure that the failure of one does not affect others is important. This topic is an issue in fault tolerance because, in effect, faults in one application are being tolerated so that they do not interfere with other applications.
The requirement here is to guarantee separation of applications or achieve separation with a high degree of assurance. This requirement is brought about by the fact that different applications might fail, but, if they do, they should not affect others. If a failing application causes one or more other applications to fail, then the dependability assessment of those applications will, in all likelihood, not be valid. That makes the system both less dependable and less predictable.
In some systems, this separation is achieved by using one computer for each application. In some sense this is the ideal. Provided the communication system between computers has certain properties, then the separation that is required is present.
If more than one application operates on the same machine, then the ideal of separate computers needs to be effected on the single machine. How could one do this? The approach to follow is to view a separation failure as a hazard and to apply fault-tree analysis. Once a draft fault tree is in place, one can use the fault tree to develop techniques that will reduce the probability of the hazard to a suitably low level. From the fault tree, for example, one can see the effects of an architectural feature such as memory protection and the effects of changing or improving that feature.
Viewing this informally, the types of questions that come up as concerns in separation are:
Architecture: How are processes separated in memory? Could one process read/write the memory of another? How is processor dispatching done? Could one process entering an infinite loop inhibit another process?
Operating System: How does the operating system provide inter-process communication? How does the operating system provide process separation?
Application Development: How are the operating system services provided to applications and can applications abuse the operating system’s interface either accidentally or maliciously? How does an application determine that it is in trouble with excess resource allocation? Could an application deadlock? Does that matter? What could be done to ensure that the application has certain desirable, non-interference properties? Could it be shown that an application could never enter an infinite loop?
Programming Languages: What facilities does the language provide to effect control of memory protection mechanisms, if any? How is concurrency provided? Could a process change its priority and thereby affect another process or application? What can be done in the programming language to support analysis so that we might be sure that there is no interference provided we trust the compiler?
Interference can either be through the processor, memory, or the peripheral devices. Interference through the processor would occur if one application were able to gain control of the processor and fail to relinquish it. Interference through memory would occur is one application were able to write into the memory allocated to another. Finally, interference through a peripheral device would occur if one application could access a peripheral being used by another.
Achieving proper separation without hardware support is impossible. Necessary hardware support includes facilities for timer interrupts and memory protection. Trustworthiness of the operating system is essential also since the operating system is relied upon to provide basic separation services.
To deal with the processor, the existence of a timer interrupt that returns control to the operating system and that cannot be masked by any application no matter what the application does has to be shown. To deal with memory, the hardware protection mechanism has to be shown to stop erroneous writes no matter what an application does. In practice, this can usually be shown quite elegantly using a typical virtual memory mechanism.
Finally, to deal with peripherals, many techniques are possible. Coupling direct memory access with virtual memory provides a fairly simple approach.
The modern implementations of machine virtualization are beginning to have an impact in this area. With systems like VMWare, supporting one virtual machine for each application is possible. The issue of separation then reduces to showing that the virtual machine mechanism works correctly.
11.6.3 Watchdog Timers
In real-time systems, states that systems enter if real-time deadlines are missed tend to be hazards. The system’s designers based their design on a real-time deadline, and so failing to meet that deadline is potentially serious. As an example, consider a simple heart pacemaker that provides pacing stimuli to a patient after calculating whether a stimulus is needed for the current heartbeat. If the software that determines whether a stimulus is needed takes too long to execute, that software will miss its real-time deadline and fail to generate a stimulus if one is needed.
Meeting deadlines in a real-time system is an example of a safety policy. Failing to do so is likely to be hazardous, and the policy needs to be maintained all the time. This policy could be included in a set that was implemented by a safety kernel, but systems frequently deal with the safety policy of meeting deadlines as a special case. The technique used is to implement a watchdog timer.
A watchdog timer is a countdown timer that is set by an application and which raises an interrupt when it expires. The value used to set the timer is beyond the time that the application expects to take to conduct some predefined unit of processing. Normally, when that unit of processing is complete, the timer is reset by the application with a new value. If the application fails to complete the unit of processing before the timer expires, the timer interrupt occurs, allowing some action to be taken to correct what is an unexpected situation.
A typical use of a watchdog timer is to gain control if a real-time deadline is about to be missed. An application is expected to manage time with sufficient care that real-time deadlines are met. By setting a watchdog timer, control can be given to a different piece of software that can take corrective action.
11.6.4 Exceptions
Exceptions are often associated with software fault tolerance, but they are really not intended for that purpose. Some exceptions are raised to indicate an expected and perfectly normal event, such as a printer running out of paper. In such cases, exceptions are being used as asynchronous signals. In other cases, interrupts are defined for custom use in specific programs. Ada, for example, allows programmer defined exceptions and provides a raise statement so that exceptions can be raised explicitly. Using this mechanism, programmers can define their own asynchronous signals. Finally, exceptions are raised because of what most engineers consider to be faults, division by zero and floating point overflow, for example.
The concept of an exception seems as if it ought to be applicable to software fault tolerance. For things like division by zero, the error is detected automatically, and a branch is executed to software that could perform the other three phases of fault tolerance.
Exceptions are not designed as a comprehensive approach to software fault tolerance, and their utility as a fault-tolerance mechanism is limited. The problems with exceptions as a mechanism for software fault tolerance are as follows:
Error detection is incomplete. Detection of things like division by zero and floating-point overflow is all very well, but such events do not cover the space of errors that might arise. In fact, they cover an insignificant fraction of the errors that might arise in a typical large program even if the basic interrupt mechanism is complemented with programmer-defined exceptions.
Damage assessment is difficult. If an exception is raised, all that is known about the system is that the local state associated with the exception is erroneous, e.g., a divisor is zero and should not be. Nothing else is known about the state, and so the software that is executed in the exception handler has to be smart enough to determine what parts of the state are erroneous.
State restoration is difficult. Even if damage assessment were completed satisfactorily, restoring the state is difficult with the semantics of almost all programming languages. The difficulty arises because of the context within which the interrupt handler has to execute. The variables that are in scope are defined by the particular language, and these variables are not the entire set in the program. In languages like Ada, for example, exception handlers are associated with the block in which the exception was raised. Variables not accessible to the block are not accessible to the exception handler. For concurrent programs, the problem is even worse because exception handlers do not necessarily have any access to the concurrent objects.
Continued service is difficult. The semantics of languages dictate what the flow of control has to be when an exception handler completes. The two most common semantics are termination and resumption. In termination semantics, the exception handler and some parts of the associated program are terminated. The parts of a program that are terminated depend on the details of the programming language and the circumstances during execution. In Ada, for example, the block raising the exception is terminated along with the exception handler if there was one. If no handler was provided, the exception is re-raised in the calling program unit, and that unit is terminated if no handler is provided. This process continues until a handler is found or the complete program is terminated. An example of the seriousness of these semantics is evident in the Ariane 5 disaster that was attributed to an unhandled exception [89].
In resumption semantics, the code following the point where the exception was raised is resumed. Doing so assumes that the exception handler was able to deal with whatever caused the exception to be raised in the first place. Gaining a high level of assurance that this is the case is unlikely at best.
11.6.5 Execution Time Checking
An error-detection mechanism can be woven through any piece of software, and the error-detection mechanism can be associated with mechanisms to provide the other phases of fault tolerance. Sophisticated mechanisms have been developed to facilitate the description of erroneous states starting with the simple notion of an assertion and extending through design by contract to comprehensive program specification mechanisms.
An assertion is a predicate (a Boolean expression) that should evaluate to true when the program executes. The expression documents an invariant about the program’s state that follows from the basic design set up by the developers. If the assertion evaluates to false, then some aspect of the state violates the invariant that the developers expected to be true, i.e., an error has been detected.
Some languages, including C, C++, Java, and Eiffel, provide assertion statements as part of their basic syntax. The semantics of the assertion failing vary with the language, but the most common action is to raise an exception.
In a more extensive form, assertion systems allow the documentation of much of the software’s specification within the source code. Eiffel is a good example of this type of language, where the concept is known as design by contract1 [42]. In design by contract, assertions in the form of pre- and post-conditions document the interfaces that software components either assume or provide. These assertions are compiled into the program and evaluated during execution.
A comprehensive system for documenting the specification of a program within the source code is the Anna language defined for Ada ‘83 [91]. Anna text is included in the program as comments and is processed by a precompiler into corresponding Ada statements. When compiled, the result includes execution-time checks of the specification description included in the Anna text.
Anna is much more than an assertion mechanism. The notation includes annotations for all of the Ada ‘83 language elements, allowing, for example, much of the detail of types, variables, expressions, statements, subprograms, and packages to be defined.
Note carefully the difference between the way in which pre- and post-conditions are used in the concepts described here and the way they are used in SPARK Ada. For assertions and all of the concepts associated with them, the determination of compliance with the conditions is checked during execution, and the checks apply to that specific execution only. In SPARK Ada, the conditions are established by static analysis, and so they are shown to hold before execution and for all possible executions.
Execution-time checking is a starting point for a mechanism to provide software fault tolerance. However, as with the other mechanisms in this section, the use of execution-time checking does not provide a comprehensive approach to software fault tolerance upon which we can rely in our efforts to achieve dependability. The problems with execution-time checking are:
Error detection is incomplete. Although valuable, execution-time checking does not provide a comprehensive approach to error detection. Simple assertions, for example, are introduced by programmers in an ad hoc manner for which there is no way to determine coverage. The assertions might catch the error resulting from a fault and they might not. The facilities provided by Eiffel and Anna are far more satisfactory and are potentially comprehensive. Even with these mechanisms, there is no explicit mechanism to check whether the stated pre- and post-conditions are, in fact, the complete conditions upon which a program component relies.
Other phases of fault tolerance are not supported. Execution-time checking is supported in the more advanced cases by language elements, but the semantics of those language elements end typically with either an interrupt being raised or the program terminated. No provision is made for proper damage assessment, state restoration, or continued service.
Key points in this chapter:
♦ Tolerating design faults is more difficult than tolerating degradation faults.
♦ Replication of software provides no protection against software faults.
♦ Design diversity is a general technique for software fault tolerance.
♦ Design diversity has a number of difficulties that limit its applicability and performance.
♦ Data diversity is a general technique for fault tolerance based on the notion of a “Heisenbug” introduced by Jim Gray.
♦ Specialized fault tolerance techniques have been developed that target specific types of design faults.
Exercises
1. Configuration management systems are examples of system software that can be subject to design faults. A configuration management system is not directly involved in the correct creation of a software system as a compiler would be nor in the correct operation of a software system as an operating system would be. Explain how a design defect in a configuration management system could impact the correct operation of a critical computer system.
2. Navigation software is notorious for failing, especially on special cases such as the Equator, the Greenwich meridian, and the International Date Line. A particular ship’s navigation system is based on high-precision latitude and longitude data obtained from GPS. To reach its destination, the ship’s navigation system plots a course along the Earth’s surface from its current location to its destination. Design reexpression and reverse reexpression algorithms that could be used to permit data diversity to be applied to the computations that use the latitude and longitude data.
3. Explain how data diversity might be employed in the navigation software discussed in the previous question.
4. For software faults associated with the troublesome special cases in the navigation software, estimate the reduction in failure rate that is likely to be produced by using data diversity. State carefully any assumptions that you have to make.
5. Suppose you decide to try data diversity on the software used to position the ship’s rudder because you are worried about its dependability. That software takes a specific angle to which the final rudder should be set (a parameter between +60 degrees and -60 degrees) and calculates all the necessary rudder servo settings and actions. Could data diversity be used with this software? If so, how? If not, why not?
6. The failure of the computer system for the hot water tank in Chapter 8, Exercise 5, could be very serious. If the software turns on either heater and leaves the heater on for an extended time, the tank could explode. You decide to modify the software to include a safety kernel to make sure this does not happen. What safety policy would you enforce?
7. For the safety policy that you defined in the previous question, determine what events could allow the hazard “water tank overheats” to arise by building a fault tree for the hazard and assuming that the safety kernel is implemented correctly.
8. Suppose a 3-version programming system is built to compute the dosage in the radiation therapy machine described in Chapter 1, Exercise 13. The computed dose is returned as two floating-point numbers representing required duration and required beam intensity. The system’s voter cannot base its decision on equality of results, because they might not be equal. How could the voter determine the output to be used in a way that preserved the fault-tolerance facilities of the system?
9. Develop a rigorous argument that the use of comparison checking in testing reduces any possible benefit of N-version programming (i.e., reduces the absolute decrease in the probability of failure that N-version programming might provide) with every test in which a difference between the versions arises. Show that in the limit any benefit from N-version programming vanishes.
10. Suppose a 2-version system includes a comparison that is subject to the consistent comparison problem. If the data with which the system effects comparison is randomly distributed between 0 and 1, and if the system computes a new output every millisecond, compute the rate at which the system will fail as a result of inconsistent comparisons if the maximum rounding error to which each version is subject is 0.000001.
11. Is fault tolerance a mechanism that can be used to help implement safety? If so how, and if not, why not?
12. Consider the problem of exploiting Gray’s idea of Heisenbugs in a concurrent system that deadlocks. What would have to be included in the design of such a system to exploit the idea in order to recover from deadlocks?
13. Software rejuvenation [132] is a technique in which software is periodically restarted, e.g., an operating system is rebooted. Empirical evidence indicates that this idea is helpful in preventing failures.
(a) Why does this technique make a difference?
(b) Which attributes of dependability can be affected by this technique and how?
(c) If you were to implement software rejuvenation, how would you determine the times when the restarts should be undertaken?
(d) What are the impacts of this technique on normal operation?
(e) What types of computer system would be most likely to benefit from this technique?
1. Design by contract is a trademark of Interactive Software Engineering, Inc., Goleta, CA.