
Chapter 7. Running on a Cluster
Introduction
Up to now, we’ve focused on learning Spark by using the Spark shell and examples that run in Spark’s local mode. One benefit of writing applications on Spark is the ability to scale computation by adding more machines and running in cluster mode. The good news is that writing applications for parallel cluster execution uses the same API you’ve already learned in this book. The examples and applications you’ve written so far will run on a cluster “out of the box.” This is one of the benefits of Spark’s higher level API: users can rapidly prototype applications on smaller datasets locally, then run unmodified code on even very large clusters.
This chapter first explains the runtime architecture of a distributed Spark application, then discusses options for running Spark in distributed clusters. Spark can run on a wide variety of cluster managers (Hadoop YARN, Apache Mesos, and Spark’s own built-in Standalone cluster manager) in both on-premise and cloud deployments. We’ll discuss the trade-offs and configurations required for running in each case. Along the way we’ll also cover the “nuts and bolts” of scheduling, deploying, and configuring a Spark application. After reading this chapter you’ll have everything you need to run a distributed Spark program. The following chapter will cover tuning and debugging applications.
Spark Runtime Architecture
Before we dive into the specifics of running Spark on a cluster, it’s helpful to understand the architecture of Spark in distributed mode (illustrated in Figure 7-1).
In distributed mode, Spark uses a master/slave architecture with one central coordinator and many distributed workers. The central coordinator is called the driver. The driver communicates with a potentially large number of distributed workers called executors. The driver runs in its own Java process and each executor is a separate Java process. A driver and its executors are together termed a Spark application.
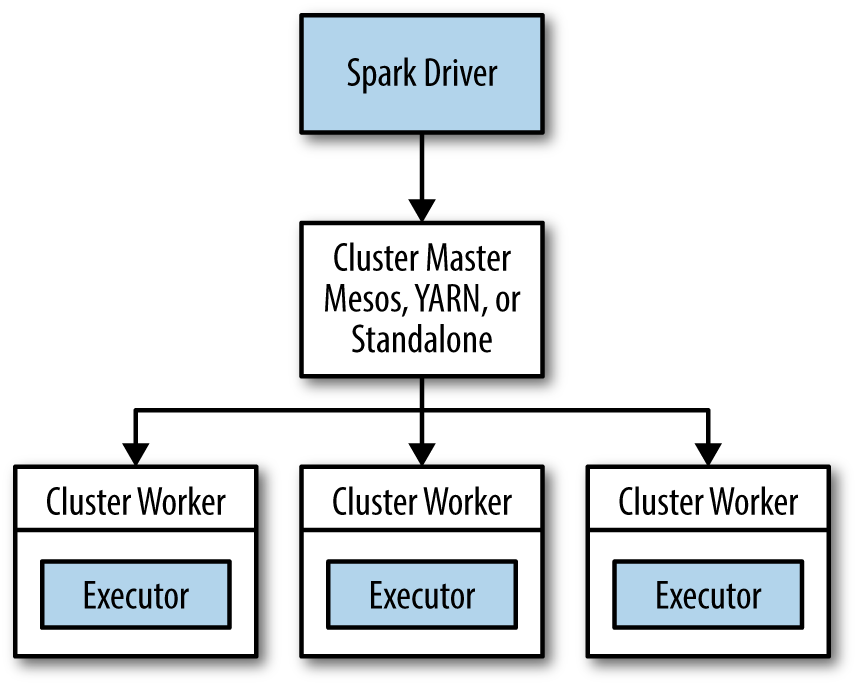
Figure 7-1. The components of a distributed Spark application
A Spark application is launched on a set of machines using an external service called a cluster manager. As noted, Spark is packaged with a built-in cluster manager called the Standalone cluster manager. Spark also works with Hadoop YARN and Apache Mesos, two popular open source cluster managers.
The Driver
The driver is the process where the main() method of your program runs. It is the
process running the user code that creates a SparkContext, creates RDDs, and performs
transformations and actions. When you launch a Spark shell, you’ve created a driver program
(if you remember, the Spark shell comes preloaded with a SparkContext called sc).
Once the driver terminates, the application is finished.
When the driver runs, it performs two duties:
- Converting a user program into tasks
-
The Spark driver is responsible for converting a user program into units of physical execution called tasks. At a high level, all Spark programs follow the same structure: they create RDDs from some input, derive new RDDs from those using transformations, and perform actions to collect or save data. A Spark program implicitly creates a logical directed acyclic graph (DAG) of operations. When the driver runs, it converts this logical graph into a physical execution plan.
Spark performs several optimizations, such as “pipelining” map transformations together to merge them, and converts the execution graph into a set of stages. Each stage, in turn, consists of multiple tasks. The tasks are bundled up and prepared to be sent to the cluster. Tasks are the smallest unit of work in Spark; a typical user program can launch hundreds or thousands of individual tasks.
- Scheduling tasks on executors
-
Given a physical execution plan, a Spark driver must coordinate the scheduling of individual tasks on executors. When executors are started they register themselves with the driver, so it has a complete view of the application’s executors at all times. Each executor represents a process capable of running tasks and storing RDD data.
The Spark driver will look at the current set of executors and try to schedule each task in an appropriate location, based on data placement. When tasks execute, they may have a side effect of storing cached data. The driver also tracks the location of cached data and uses it to schedule future tasks that access that data.
The driver exposes information about the running Spark application through a web interface, which by default is available at port 4040. For instance, in local mode, this UI is available at http://localhost:4040. We’ll cover Spark’s web UI and its scheduling mechanisms in more detail in Chapter 8.
Executors
Spark executors are worker processes responsible for running the individual tasks in a given Spark job. Executors are launched once at the beginning of a Spark application and typically run for the entire lifetime of an application, though Spark applications can continue if executors fail. Executors have two roles. First, they run the tasks that make up the application and return results to the driver. Second, they provide in-memory storage for RDDs that are cached by user programs, through a service called the Block Manager that lives within each executor. Because RDDs are cached directly inside of executors, tasks can run alongside the cached data.
Cluster Manager
So far we’ve discussed drivers and executors in somewhat abstract terms. But how do drivers and executor processes initially get launched? Spark depends on a cluster manager to launch executors and, in certain cases, to launch the driver. The cluster manager is a pluggable component in Spark. This allows Spark to run on top of different external managers, such as YARN and Mesos, as well as its built-in Standalone cluster manager.
Tip
Spark’s documentation consistently uses the terms driver and executor when describing the processes that execute each Spark application. The terms master and worker are used to describe the centralized and distributed portions of the cluster manager. It’s easy to confuse these terms, so pay close attention. For instance, Hadoop YARN runs a master daemon (called the Resource Manager) and several worker daemons called Node Managers. Spark can run both drivers and executors on the YARN worker nodes.
Launching a Program
No matter which cluster manager you use, Spark provides a single script you can use to submit
your program to it called spark-submit. Through various options, spark-submit can connect
to different cluster managers and control how many resources your application gets.
For some cluster managers, spark-submit can run the driver within the cluster (e.g., on a YARN
worker node), while for others, it can run it only on your local machine.
We’ll cover spark-submit in more detail in the next section.
Summary
To summarize the concepts in this section, let’s walk through the exact steps that occur when you run a Spark application on a cluster:
-
The user submits an application using
spark-submit. -
spark-submitlaunches the driver program and invokes themain()method specified by the user. -
The driver program contacts the cluster manager to ask for resources to launch executors.
-
The cluster manager launches executors on behalf of the driver program.
-
The driver process runs through the user application. Based on the RDD actions and transformations in the program, the driver sends work to executors in the form of tasks.
-
Tasks are run on executor processes to compute and save results.
-
If the driver’s
main()method exits or it callsSparkContext.stop(), it will terminate the executors and release resources from the cluster manager.
Deploying Applications with spark-submit
As you’ve learned, Spark provides a single tool for submitting jobs across all cluster managers, called
spark-submit. In Chapter 2 you saw a simple example of submitting a Python
program with spark-submit, repeated here in Example 7-1.
Example 7-1. Submitting a Python application
bin/spark-submit my_script.py
When spark-submit is called with nothing but the name of a script or JAR, it simply runs the
supplied Spark program locally. Let’s say we wanted to submit this program to a Spark Standalone
cluster. We can provide extra flags with the address of a Standalone cluster and a specific
size of each executor process we’d like to launch, as shown in Example 7-2.
Example 7-2. Submitting an application with extra arguments
bin/spark-submit --master spark://host:7077 --executor-memory 10g my_script.py
The --master flag specifies a cluster URL to connect to; in this case, the spark:// URL
means a cluster using Spark’s Standalone mode (see Table 7-1). We will discuss other URL types later.
| Value | Explanation |
|---|---|
|
Connect to a Spark Standalone cluster at the specified port. By default Spark Standalone masters use port 7077. |
|
Connect to a Mesos cluster master at the specified port. By default Mesos masters listen on port 5050. |
|
Connect to a YARN cluster. When running on YARN you’ll need to set the
|
|
Run in local mode with a single core. |
|
Run in local mode with |
|
Run in local mode and use as many cores as the machine has. |
Apart from a cluster URL,
spark-submit provides a variety of options that let you control specific details about a
particular run of your application. These options fall roughly into two categories. The first is
scheduling information, such as the amount of resources you’d like to request for your job
(as shown in Example 7-2). The second is information about the runtime dependencies of your
application, such as libraries or files you want to deploy to all worker machines.
The general format for spark-submit is shown in Example 7-3.
Example 7-3. General format for spark-submit
bin/spark-submit[options]<app jar|python file>[app options]
[options] are a list of flags for spark-submit. You can enumerate all possible flags by
running spark-submit --help. A list of common flags is enumerated in
Table 7-2.
<app jar | python file> refers to the JAR or Python script containing the entry point into your
application.
[app options] are options that will be passed onto your application. If the main() method of your
program parses its calling arguments, it will see only [app options] and not the flags specific
to spark-submit.
| Flag | Explanation |
|---|---|
|
Indicates the cluster manager to connect to. The options for this flag are described in Table 7-1. |
|
Whether to launch the driver program locally (“client”) or on one of the worker
machines inside the cluster (“cluster”). In client mode |
|
The “main” class of your application if you’re running a Java or Scala program. |
|
A human-readable name for your application. This will be displayed in Spark’s web UI. |
|
A list of JAR files to upload and place on the classpath of your application. If your application depends on a small number of third-party JARs, you can add them here. |
|
A list of files to be placed in the working directory of your application. This can be used for data files that you want to distribute to each node. |
|
A list of files to be added to the PYTHONPATH of your application. This can contain .py, .egg, or .zip files. |
|
The amount of memory to use for executors, in bytes. Suffixes can be used to specify larger quantities such as “512m” (512 megabytes) or “15g” (15 gigabytes). |
|
The amount of memory to use for the driver process, in bytes. Suffixes can be used to specify larger quantities such as “512m” (512 megabytes) or “15g” (15 gigabytes). |
spark-submit also allows setting arbitrary SparkConf configuration options using either the
--conf prop=value flag or providing a properties file through --properties-file that contains
key/value pairs. Chapter 8 will discuss Spark’s configuration system.
Example 7-4 shows a few longer-form invocations of spark-submit using various options.
Example 7-4. Using spark-submit with various options
# Submitting a Java application to Standalone cluster mode$./bin/spark-submit--master spark://hostname:7077--deploy-mode cluster--class com.databricks.examples.SparkExample--name"Example Program"--jars dep1.jar,dep2.jar,dep3.jar--total-executor-cores300--executor-memory 10gmyApp.jar"options""to your application""go here"# Submitting a Python application in YARN client mode$exportHADOP_CONF_DIR=/opt/hadoop/conf$./bin/spark-submit--master yarn--py-files somelib-1.2.egg,otherlib-4.4.zip,other-file.py--deploy-mode client--name"Example Program"--queue exampleQueue--num-executors40--executor-memory 10gmy_script.py"options""to your application""go here"
Packaging Your Code and Dependencies
Throughout most of this book we’ve provided example programs that are self-contained and had no
library dependencies outside of Spark. More often, user programs depend on third-party
libraries. If your program imports any libraries that are not in the org.apache.spark package or
part of the language library, you need to ensure that all your dependencies are present
at the runtime of your Spark application.
For Python users, there are a few ways to install third-party libraries. Since PySpark uses the
existing Python installation on worker machines, you can install dependency libraries directly on
the cluster machines using standard Python package managers (such as pip or easy_install), or
via a manual installation into the site-packages/ directory of your Python installation.
Alternatively, you can submit individual libraries using the --py-files argument to
spark-submit and they will be added to the Python interpreter’s path. Adding libraries manually
is more convenient if you do not have access to install packages on the cluster, but do keep in
mind potential conflicts with existing packages already installed on the machines.
What About Spark Itself?
When you are bundling an application, you should never include Spark itself in the list of
submitted dependencies. spark-submit automatically ensures that Spark is present in the path
of your program.
For Java and Scala users, it is also possible to submit individual JAR files using the --jars
flag to spark-submit. This can work well if you have a very simple dependency on one or two
libraries and they themselves don’t have any other dependencies. It is more common, however, for
users to have Java or Scala projects that depend on several libraries. When you submit
an application to Spark, it must ship with its entire transitive dependency graph to the
cluster. This includes not only the libraries you directly depend on, but also their dependencies,
their dependencies’ dependencies, and so on. Manually tracking and submitting this set of JAR files
would be extremely cumbersome. Instead, it’s common practice to rely on a build tool
to produce a single large JAR containing the entire transitive dependency graph of an application.
This is often called an uber JAR or an assembly JAR, and most Java or Scala build tools can
produce this type of artifact.
The most popular build tools for Java and Scala are Maven and sbt (Scala build tool). Either tool can be used with either language, but Maven is more often used for Java projects and sbt for Scala projects. Here, we’ll give examples of Spark application builds using both tools. You can use these as templates for your own Spark projects.
A Java Spark Application Built with Maven
Let’s look at an example Java project with multiple dependencies that produces an uber JAR. Example 7-5 provides a Maven pom.xml file containing a build definition. This example doesn’t show the actual Java code or project directory structure, but Maven expects user code to be in a src/main/java directory relative to the project root (the root should contain the pom.xml file).
Example 7-5. pom.xml file for a Spark application built with Maven
<project><modelVersion>4.0.0</modelVersion><!-- Information about your project --><groupId>com.databricks</groupId><artifactId>example-build</artifactId><name>Simple Project</name><packaging>jar</packaging><version>1.0</version><dependencies><!-- Spark dependency --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.10</artifactId><version>1.2.0</version><scope>provided</scope></dependency><!-- Third-party library --><dependency><groupId>net.sf.jopt-simple</groupId><artifactId>jopt-simple</artifactId><version>4.3</version></dependency><!-- Third-party library --><dependency><groupId>joda-time</groupId><artifactId>joda-time</artifactId><version>2.0</version></dependency></dependencies><build><plugins><!-- Maven shade plug-in that creates uber JARs --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>2.3</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals></execution></executions></plugin></plugins></build></project>
This project declares two transitive dependencies: jopt-simple, a Java library to perform option
parsing, and joda-time, a library with utilities for time and date conversion. It also depends on
Spark, but Spark is marked as provided to ensure that Spark is never packaged with the application
artifacts. The build includes the maven-shade-plugin to create an uber JAR containing all of its
dependencies. You enable this by asking Maven to execute the shade goal of the plug-in every time
a package phase occurs. With this build configuration, an uber JAR is created automatically
when mvn package is run (see Example 7-6).
Example 7-6. Packaging a Spark application built with Maven
$mvn package# In the target directory, we'll see an uber JAR and the original package JAR$ls target/ example-build-1.0.jar original-example-build-1.0.jar# Listing the uber JAR will reveal classes from dependency libraries$jar tf target/example-build-1.0.jar ... joptsimple/HelpFormatter.class ... org/joda/time/tz/UTCProvider.class ...# An uber JAR can be passed directly to spark-submit$/path/to/spark/bin/spark-submit --masterlocal... target/example-build-1.0.jar
A Scala Spark Application Built with sbt
sbt is a newer build tool most often used for Scala projects. sbt assumes a similar project
layout to Maven. At the root of your project you create a build file called build.sbt
and your source code is expected to live in src/main/scala. sbt build files are written
in a configuration language where you assign values to specific keys in order to define
the build for your project. For instance, there is a key called name, which contains the
project name, and a key called libraryDependencies, which contains a list of dependencies
of your project. Example 7-7 gives a full sbt build file for a simple
application that depends on Spark along with a few other third-party libraries. This build
file works with sbt 0.13. Since sbt evolves quickly, you may want to read its most recent
documentation for any formatting changes in the build file format.
Example 7-7. build.sbt file for a Spark application built with sbt 0.13
importAssemblyKeys._name:="Simple Project"version:="1.0"organization:="com.databricks"scalaVersion:="2.10.3"libraryDependencies++=Seq(// Spark dependency"org.apache.spark"%"spark-core_2.10"%"1.2.0"%"provided",// Third-party libraries"net.sf.jopt-simple"%"jopt-simple"%"4.3","joda-time"%"joda-time"%"2.0")// This statement includes the assembly plug-in capabilitiesassemblySettings// Configure JAR used with the assembly plug-injarNameinassembly:="my-project-assembly.jar"// A special option to exclude Scala itself form our assembly JAR, since Spark// already bundles Scala.assemblyOptioninassembly:=(assemblyOptioninassembly).value.copy(includeScala=false)
The first line in this build file imports some functionality from an sbt build plug-in
that supports creating project assembly JARs. To enable this plug-in
we have to also include a small file in a project/ directory that
lists the dependency on the plug-in. Simply create a file called project/assembly.sbt
and add the following to it: addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.11.2").
The exact version of sbt-assembly you use might differ if you build with a newer version of
sbt. Example 7-8 works with sbt 0.13.
Example 7-8. Adding the assembly plug-in to an sbt project build
# Display contents of project/assembly.sbt$cat project/assembly.sbt addSbtPlugin("com.eed3si9n"%"sbt-assembly"%"0.11.2")
Now that we have a well-defined build, we can create a fully assembled Spark application JAR (Example 7-9).
Example 7-9. Packaging a Spark application built with sbt
$sbt assembly# In the target directory, we'll see an assembly JAR$ls target/scala-2.10/ my-project-assembly.jar# Listing the assembly JAR will reveal classes from dependency libraries$jar tf target/scala-2.10/my-project-assembly.jar ... joptsimple/HelpFormatter.class ... org/joda/time/tz/UTCProvider.class ...# An assembly JAR can be passed directly to spark-submit$/path/to/spark/bin/spark-submit --masterlocal... target/scala-2.10/my-project-assembly.jar
Dependency Conflicts
One occasionally disruptive issue
is dealing with dependency conflicts in cases where a user application and Spark itself both
depend on the same library. This comes up relatively rarely, but when it does, it can be vexing
for users. Typically, this will manifest itself when a
NoSuchMethodError, a ClassNotFoundException, or some other JVM exception related to
class loading is thrown during the execution of a Spark job. There are two solutions to this problem.
The first is to modify your application to depend on the same version of the third-party library
that Spark does. The second is to modify the packaging of your application using a procedure that
is often called “shading.” The Maven build tool supports shading through advanced configuration
of the plug-in shown in Example 7-5 (in fact, the shading capability is why the plug-in
is named maven-shade-plugin). Shading allows you to make a second copy of the conflicting
package under a different namespace and rewrites your application’s code to use the
renamed version. This somewhat brute-force technique is quite effective at resolving runtime
dependency conflicts. For specific instructions on how to shade dependencies, see the
documentation for your build tool.
Scheduling Within and Between Spark Applications
The example we just walked through involves a single user submitting a job to a cluster. In reality, many clusters are shared between multiple users. Shared environments have the challenge of scheduling: what happens if two users both launch Spark applications that each want to use the entire cluster’s worth of resources? Scheduling policies help ensure that resources are not overwhelmed and allow for prioritization of workloads.
For scheduling in multitenant clusters, Spark primarily relies on the cluster manager to share resources between Spark applications. When a Spark application asks for executors from the cluster manager, it may receive more or fewer executors depending on availability and contention in the cluster. Many cluster managers offer the ability to define queues with different priorities or capacity limits, and Spark will then submit jobs to such queues. See the documentation of your specific cluster manager for more details.
One special case of Spark applications are those that are long lived, meaning that they are never intended to terminate. An example of a long-lived Spark application is the JDBC server bundled with Spark SQL. When the JDBC server launches it acquires a set of executors from the cluster manager, then acts as a permanent gateway for SQL queries submitted by users. Since this single application is scheduling work for multiple users, it needs a finer-grained mechanism to enforce sharing policies. Spark provides such a mechanism through configurable intra-application scheduling policies. Spark’s internal Fair Scheduler lets long-lived applications define queues for prioritizing scheduling of tasks. A detailed review of these is beyond the scope of this book; the official documentation on the Fair Scheduler provides a good reference.
Cluster Managers
Spark can run over a variety of cluster managers to access the machines in a cluster. If you only want to run Spark by itself on a set of machines, the built-in Standalone mode is the easiest way to deploy it. However, if you have a cluster that you’d like to share with other distributed applications (e.g., both Spark jobs and Hadoop MapReduce jobs), Spark can also run over two popular cluster managers: Hadoop YARN and Apache Mesos. Finally, for deploying on Amazon EC2, Spark comes with built-in scripts that launch a Standalone cluster and various supporting services. In this section, we’ll cover how to run Spark in each of these environments.
Standalone Cluster Manager
Spark’s Standalone manager offers a simple way to run applications on a cluster. It consists of a master and multiple workers, each with a configured amount of memory and CPU cores. When you submit an application, you can choose how much memory its executors will use, as well as the total number of cores across all executors.
Launching the Standalone cluster manager
You can start the Standalone cluster manager either by starting a master and workers by hand, or by using launch scripts in Spark’s sbin directory. The launch scripts are the simplest option to use, but require SSH access between your machines and are currently (as of Spark 1.1) available only on Mac OS X and Linux. We will cover these first, then show how to launch a cluster manually on other platforms.
To use the cluster launch scripts, follow these steps:
-
Copy a compiled version of Spark to the same location on all your machines—for example, /home/yourname/spark.
-
Set up password-less SSH access from your master machine to the others. This requires having the same user account on all the machines, creating a private SSH key for it on the master via
ssh-keygen, and adding this key to the .ssh/authorized_keys file of all the workers. If you have not set this up before, you can follow these commands:# On master: run ssh-keygen accepting default options$ssh-keygen -t dsa Enter file in which to save the key(/home/you/.ssh/id_dsa):[ENTER]Enter passphrase(emptyforno passphrase):[EMPTY]Enter same passphrase again:[EMPTY]# On workers:# copy ~/.ssh/id_dsa.pub from your master to the worker, then use:$cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys$chmod644~/.ssh/authorized_keys -
Edit the conf/slaves file on your master and fill in the workers’ hostnames.
-
To start the cluster, run
sbin/start-all.shon your master (it is important to run it there rather than on a worker). If everything started, you should get no prompts for a password, and the cluster manager’s web UI should appear at http://masternode:8080 and show all your workers. -
To stop the cluster, run
bin/stop-all.shon your master node.
If you are not on a UNIX system or would like to launch the cluster manually, you can also start the master and workers by hand, using the spark-class script in Spark’s bin/ directory. On your master, type:
bin/spark-class org.apache.spark.deploy.master.Master
Then on workers:
bin/spark-class org.apache.spark.deploy.worker.Worker spark://masternode:7077
(where masternode is the hostname of your master). On Windows, use instead of /.
By default, the cluster manager will automatically allocate the amount of CPUs and memory on each worker and pick a suitable default to use for Spark. More details on configuring the Standalone cluster manager are available in Spark’s official documentation.
Submitting applications
To submit an application to the Standalone cluster manager, pass spark://masternode:7077 as the master argument to
spark-submit. For example:
spark-submit --master spark://masternode:7077 yourapp
This cluster URL is also shown in the Standalone cluster manager’s web UI, at http://masternode:8080. Note that the hostname and port used during submission must exactly match the URL present in the UI. This can trip up users who try to encode an IP address, for instance, instead of a hostname. Even if the IP address is associated with the same host, submission will fail if the naming doesn’t match exactly. Some administrators might configure Spark to use a different port than 7077. To ensure consistency of host and port components, one safe bet is to just copy and paste the URL directly from the UI of the master node.
You can also launch spark-shell or pyspark against the cluster in the same way, by passing the --master parameter:
spark-shell --master spark://masternode:7077 pyspark --master spark://masternode:7077
To check that your application or shell is running, look at the cluster manager’s web UI http://masternode:8080 and make sure that (1) your application is connected (i.e., it appears under Running Applications) and (2) it is listed as having more than 0 cores and memory.
Tip
A common pitfall that might prevent your application from running is requesting more memory for executors (with the --executor-memory flag to spark-submit) than is available in the cluster. In this case, the Standalone cluster manager will never allocate executors for the application. Make sure that the value your application is requesting can be satisfied by the cluster.
Finally, the Standalone cluster manager supports two deploy modes for where the driver program of your application runs. In client mode (the default), the driver runs on the machine where you executed spark-submit, as part of the spark-submit command. This means that you can directly see the output of your driver program, or send input to it (e.g., for an interactive shell), but it requires the machine from which your application was submitted to have fast connectivity to the workers and to stay available for the duration of your application. In contrast, in cluster mode, the driver is launched within the Standalone cluster, as another process on one of the worker nodes, and then it connects back to request executors. In this mode spark-submit is “fire-and-forget” in that you can close your laptop while the application is running. You will still be able to access logs for the application through the cluster manager’s web UI. You can switch to cluster mode by passing --deploy-mode cluster to spark-submit.
Configuring resource usage
When sharing a Spark cluster among multiple applications, you will need to decide how to allocate resources between the executors. The Standalone cluster manager has a basic scheduling policy that allows capping the usage of each application so that multiple ones may run concurrently. Apache Mesos supports more dynamic sharing while an application is running, while YARN has a concept of queues that allows you to cap usage for various sets of applications.
In the Standalone cluster manager, resource allocation is controlled by two settings:
- Executor memory
-
You can configure this using the
--executor-memoryargument tospark-submit. Each application will have at most one executor on each worker, so this setting controls how much of that worker’s memory the application will claim. By default, this setting is 1 GB—you will likely want to increase it on most servers. - The maximum number of total cores
-
This is the total number of cores used across all executors for an application. By default, this is unlimited; that is, the application will launch executors on every available node in the cluster. For a multiuser workload, you should instead ask users to cap their usage. You can set this value through the
--total-executor-coresargument tospark-submit, or by configuringspark.cores.maxin your Spark configuration file.
To verify the settings, you can always see the current resource allocation in the Standalone cluster manager’s web UI, http://masternode:8080.
Finally, the Standalone cluster manager works by spreading out each application across the maximum number of executors by default. For example, suppose that you have a 20-node cluster with 4-core machines, and you submit an application with --executor-memory 1G and --total-executor-cores 8. Then Spark will launch eight executors, each with 1 GB of RAM, on different machines. Spark does this by default to give applications a chance to achieve data locality for distributed filesystems running on the same machines (e.g., HDFS), because these systems typically have data spread out across all nodes. If you prefer, you can instead ask Spark to consolidate executors on as few nodes as possible, by setting the config property spark.deploy.spreadOut to false in conf/spark-defaults.conf. In this case, the preceding application would get only two executors, each with 1 GB RAM and four cores. This setting affects all applications on the Standalone cluster and must be configured before you launch the Standalone cluster manager.
High availability
When running in production settings, you will want your Standalone cluster to be available to accept applications even if individual nodes in your cluster go down. Out of the box, the Standalone mode will gracefully support the failure of worker nodes. If you also want the master of the cluster to be highly available, Spark supports using Apache ZooKeeper (a distributed coordination system) to keep multiple standby masters and switch to a new one when any of them fails. Configuring a Standalone cluster with ZooKeeper is outside the scope of the book, but is described in the official Spark documentation.
Hadoop YARN
YARN is a cluster manager introduced in Hadoop 2.0 that allows diverse data processing frameworks to run on a shared resource pool, and is typically installed on the same nodes as the Hadoop filesystem (HDFS). Running Spark on YARN in these environments is useful because it lets Spark access HDFS data quickly, on the same nodes where the data is stored.
Using YARN in Spark is straightforward: you set an environment variable that points to your Hadoop configuration directory, then submit jobs to a special master URL with spark-submit.
The first step is to figure out your Hadoop configuration directory, and set it as the environment variable HADOOP_CONF_DIR. This is the directory that contains yarn-site.xml and other config files; typically, it is HADOOP_HOME/conf if you installed Hadoop in HADOOP_HOME, or a system path like /etc/hadoop/conf. Then, submit your application as follows:
exportHADOOP_CONF_DIR="..."spark-submit --master yarn yourapp
As with the Standalone cluster manager, there are two modes to connect your application to the cluster: client mode, where the driver program for your application runs on the machine that you submitted the application from (e.g., your laptop), and cluster mode, where the driver also runs inside a YARN container. You can set the mode to use via the --deploy-mode argument to spark-submit.
Spark’s interactive shell and pyspark both work on YARN as well; simply set HADOOP_CONF_DIR and pass --master yarn to these applications. Note that these will run only in client mode since they need to obtain input from the user.
Configuring resource usage
When running on YARN, Spark applications use a fixed number of executors, which you can set via the --num-executors flag to spark-submit, spark-shell, and so on. By default, this is only two, so you will likely need to increase it. You can also set the memory used by each executor via --executor-memory and the number of cores it claims from YARN via --executor-cores. On a given set of hardware resources, Spark will usually run better with a smaller number of larger executors (with multiple cores and more memory), since it can optimize communication within each executor. Note, however, that some clusters have a limit on the maximum size of an executor (8 GB by default), and will not let you launch larger ones.
Some YARN clusters are configured to schedule applications into multiple “queues” for resource management purposes. Use the --queue option to select your queue name.
Finally, further information on configuration options for YARN is available in the official Spark documentation.
Apache Mesos
Apache Mesos is a general-purpose cluster manager that can run both analytics workloads and long-running services (e.g., web applications or key/value stores) on a cluster. To use Spark on Mesos, pass a mesos:// URI to spark-submit:
spark-submit --master mesos://masternode:5050 yourapp
You can also configure Mesos clusters to use ZooKeeper to elect a master when running in multimaster node. In this case, use a mesos://zk:// URI pointing to a list of ZooKeeper nodes. For example, if you have three ZooKeeper nodes (node1, node2, and node3) on which ZooKeeper is running on port 2181, use the following URI:
mesos://zk://node1:2181/mesos,node2:2181/mesos,node3:2181/mesos
Mesos scheduling modes
Unlike the other cluster managers, Mesos offers two modes to share resources between executors on the same cluster. In “fine-grained” mode, which is the default, executors scale up and down the number of CPUs they claim from Mesos as they execute tasks, and so a machine running multiple executors can dynamically share CPU resources between them. In “coarse-grained” mode, Spark allocates a fixed number of CPUs to each executor in advance and never releases them until the application ends, even if the executor is not currently running tasks. You can enable coarse-grained mode by passing --conf spark.mesos.coarse=true to spark-submit.
The fine-grained Mesos mode is attractive when multiple users share a cluster to run interactive workloads such as shells, because applications will scale down their number of cores when they’re not doing work and still allow other users’ programs to use the cluster. The downside, however, is that scheduling tasks through fine-grained mode adds more latency (so very low-latency applications like Spark Streaming may suffer), and that applications may need to wait some amount of time for CPU cores to become free to “ramp up” again when the user types a new command. Note, however, that you can use a mix of scheduling modes in the same Mesos cluster (i.e., some of your Spark applications might have spark.mesos.coarse set to true and some might not).
Client and cluster mode
As of Spark 1.2, Spark on Mesos supports running applications only in the “client” deploy mode—that is, with the driver running on the machine that submitted the application. If you would like to run your driver in the Mesos cluster as well, frameworks like Aurora and Chronos allow you to submit arbitrary scripts to run on Mesos and monitor them. You can use one of these to launch the driver for your application.
Configuring resource usage
You can control resource usage on Mesos through two parameters to spark-submit: --executor-memory, to set the memory for each executor, and --total-executor-cores, to set the maximum number of CPU cores for the application to claim (across all executors). By default, Spark will launch each executor with as many cores as possible, consolidating the application to the smallest number of executors that give it the desired number of cores. If you do not set --total-executor-cores, it will try to use all available cores in the cluster.
Amazon EC2
Spark comes with a built-in script to launch clusters on Amazon EC2. This script launches a set of nodes and then installs the Standalone cluster manager on them, so once the cluster is up, you can use it according to the Standalone mode instructions in the previous section. In addition, the EC2 script sets up supporting services such as HDFS, Tachyon, and Ganglia to monitor your cluster.
The Spark EC2 script is called spark-ec2, and is located in the ec2 folder of your Spark installation. It requires Python 2.6 or higher. You can download Spark and run the EC2 script without compiling Spark beforehand.
The EC2 script can manage multiple named clusters, identifying them using EC2 security groups. For each cluster, the script will create a security group called clustername-master for the master node, and clustername-slaves for the workers.
Launching a cluster
To launch a cluster, you should first create an Amazon Web Services (AWS) account and obtain an access key ID and secret access key. Then export these as environment variables:
exportAWS_ACCESS_KEY_ID="..."exportAWS_SECRET_ACCESS_KEY="..."
In addition, create an EC2 SSH key pair and download its private key file (usually called keypair.pem) so that you can SSH into the machines.
Next, run the launch command of the spark-ec2 script, giving it your key pair name, private key file, and a name for the cluster. By default, this will launch a cluster with one master and one slave, using m1.xlarge EC2 instances:
cd /path/to/spark/ec2
./spark-ec2 -k mykeypair -i mykeypair.pem launch myclusterYou can also configure the instance types, number of slaves, EC2 region, and other factors using options to spark-ec2. For example:
# Launch a cluster with 5 slaves of type m3.xlarge./spark-ec2 -k mykeypair -i mykeypair.pem -s5-t m3.xlarge launch mycluster
For a full list of options, run spark-ec2 --help. Some of the most common ones are listed in Table 7-3.
| Option | Meaning |
|---|---|
|
Name of key pair to use |
|
Private key file (ending in .pem) |
|
Number of slave nodes |
|
Amazon instance type to use |
|
Amazon region to use (e.g., |
|
Availability zone (e.g., |
|
Use spot instances at the given spot price (in US dollars) |
Once you launch the script, it usually takes about five minutes to launch the machines, log in to them, and set up Spark.
Logging in to a cluster
You can log in to a cluster by SSHing into its master node with the .pem file for your keypair. For convenience, spark-ec2 provides a login command for this purpose:
./spark-ec2 -k mykeypair -i mykeypair.pem login mycluster
Alternatively, you can find the master’s hostname by running:
./spark-ec2 get-master mycluster
Then SSH into it yourself using ssh -i keypair.pem root@masternode.
Once you are in the cluster, you can use the Spark installation in /root/spark to run programs. This is a Standalone
cluster installation, with the master URL spark://masternode:7077. If you launch an application with spark-submit,
it will come correctly configured to submit your application to this cluster automatically.
You can view the cluster’s web UI at http://masternode:8080.
Note that only programs launched from the cluster will be able to submit jobs to it with spark-submit; the firewall
rules will prevent external hosts from submitting them for security reasons. To run a prepackaged application on the
cluster, first copy it over using SCP:
scp -i mykeypair.pem app.jar root@masternode:~
Destroying a cluster
To destroy a cluster launched by spark-ec2, run:
./spark-ec2 destroy mycluster
This will terminate all the instances associated with the cluster (i.e., all instances in its two security groups, mycluster-master and mycluster-slaves).
Pausing and restarting clusters
In addition to outright terminating clusters, spark-ec2 lets you stop the Amazon instances running your cluster and then start them again later. Stopping instances shuts them down and makes them lose all data on the “ephemeral” disks, which are configured with an installation of HDFS for spark-ec2 (see “Storage on the cluster”). However, the stopped instances retain all data in their root directory (e.g., any files you uploaded there), so you’ll be able to quickly return to work.
To stop a cluster, use:
./spark-ec2 stop mycluster
Then, later, to start it up again:
./spark-ec2 -k mykeypair -i mykeypair.pem start mycluster
Tip
While the Spark EC2 script does not provide commands to resize clusters, you can resize them by adding or removing
machines to the mycluster-slaves security group. To add machines, first stop the cluster, then use the AWS management
console to right-click one of the slave nodes and select “Launch more like this.” This will create more instances in the
same security group. Then use spark-ec2 start to start your cluster. To remove machines, simply terminate them from
the AWS console (though beware that this destroys data on the cluster’s HDFS installations).
Storage on the cluster
Spark EC2 clusters come configured with two installations of the Hadoop filesystem that you can use for scratch space. This can be handy to save datasets in a medium that’s faster to access than Amazon S3. The two installations are:
-
An “ephemeral” HDFS installation using the ephemeral drives on the nodes. Most Amazon instance types come with a substantial amount of local space attached on “ephemeral” drives that go away if you stop the instance. This installation of HDFS uses this space, giving you a significant amount of scratch space, but it loses all data when you stop and restart the EC2 cluster. It is installed in the /root/ephemeral-hdfs directory on the nodes, where you can use the
bin/hdfscommand to access and list files. You can also view the web UI and HDFS URL for it at http://masternode:50070. -
A “persistent” HDFS installation on the root volumes of the nodes. This instance persists data even through cluster restarts, but is generally smaller and slower to access than the ephemeral one. It is good for medium-sized datasets that you do not wish to download multiple times. It is installed in /root/persistent-hdfs, and you can view the web UI and HDFS URL for it at http://masternode:60070.
Apart from these, you will most likely be accessing data from Amazon S3, which you can do using the s3n:// URI scheme in Spark. Refer to “Amazon S3” for details.
Which Cluster Manager to Use?
The cluster managers supported in Spark offer a variety of options for deploying applications. If you are starting a new deployment and looking to choose a cluster manager, we recommend the following guidelines:
-
Start with a Standalone cluster if this is a new deployment. Standalone mode is the easiest to set up and will provide almost all the same features as the other cluster managers if you are running only Spark.
-
If you would like to run Spark alongside other applications, or to use richer resource scheduling capabilities (e.g., queues), both YARN and Mesos provide these features. Of these, YARN will likely be preinstalled in many Hadoop distributions.
-
One advantage of Mesos over both YARN and Standalone mode is its fine-grained sharing option, which lets interactive applications such as the Spark shell scale down their CPU allocation between commands. This makes it attractive in environments where multiple users are running interactive shells.
-
In all cases, it is best to run Spark on the same nodes as HDFS for fast access to storage. You can install Mesos or the Standalone cluster manager on the same nodes manually, or most Hadoop distributions already install YARN and HDFS together.
Finally, keep in mind that cluster management is a fast-moving space—by the time this book comes out, there might be more features available for Spark under the current cluster managers, as well as new cluster managers. The methods of submitting applications described here will not change, but you can check the official documentation for your Spark release to see the latest options.
Conclusion
This chapter described the runtime architecture of a Spark application, composed of a driver process and a distributed set of executor processes. We then covered how to build, package, and submit Spark applications. Finally, we outlined the common deployment environments for Spark, including its built-in cluster manager, running Spark with YARN or Mesos, and running Spark on Amazon’s EC2 cloud. In the next chapter we’ll dive into more advanced operational concerns, with a focus on tuning and debugging production Spark applications.