
Chapter 9. Spark SQL
This chapter introduces Spark SQL, Spark’s interface for working with structured and semistructured data. Structured data is any data that has a schema—that is, a known set of fields for each record. When you have this type of data, Spark SQL makes it both easier and more efficient to load and query. In particular, Spark SQL provides three main capabilities (illustrated in Figure 9-1):
-
It can load data from a variety of structured sources (e.g., JSON, Hive, and Parquet).
-
It lets you query the data using SQL, both inside a Spark program and from external tools that connect to Spark SQL through standard database connectors (JDBC/ODBC), such as business intelligence tools like Tableau.
-
When used within a Spark program, Spark SQL provides rich integration between SQL and regular Python/Java/Scala code, including the ability to join RDDs and SQL tables, expose custom functions in SQL, and more. Many jobs are easier to write using this combination.
To implement these capabilities, Spark SQL provides a special type of RDD called SchemaRDD. A SchemaRDD is an RDD of Row objects, each representing a record. A SchemaRDD also knows the schema (i.e., data fields) of its rows. While SchemaRDDs look like regular RDDs, internally they store data in a more efficient manner, taking advantage of their schema. In addition, they provide new operations not available on RDDs, such as the ability to run SQL queries. SchemaRDDs can be created from external data sources, from the results of queries, or from regular RDDs.
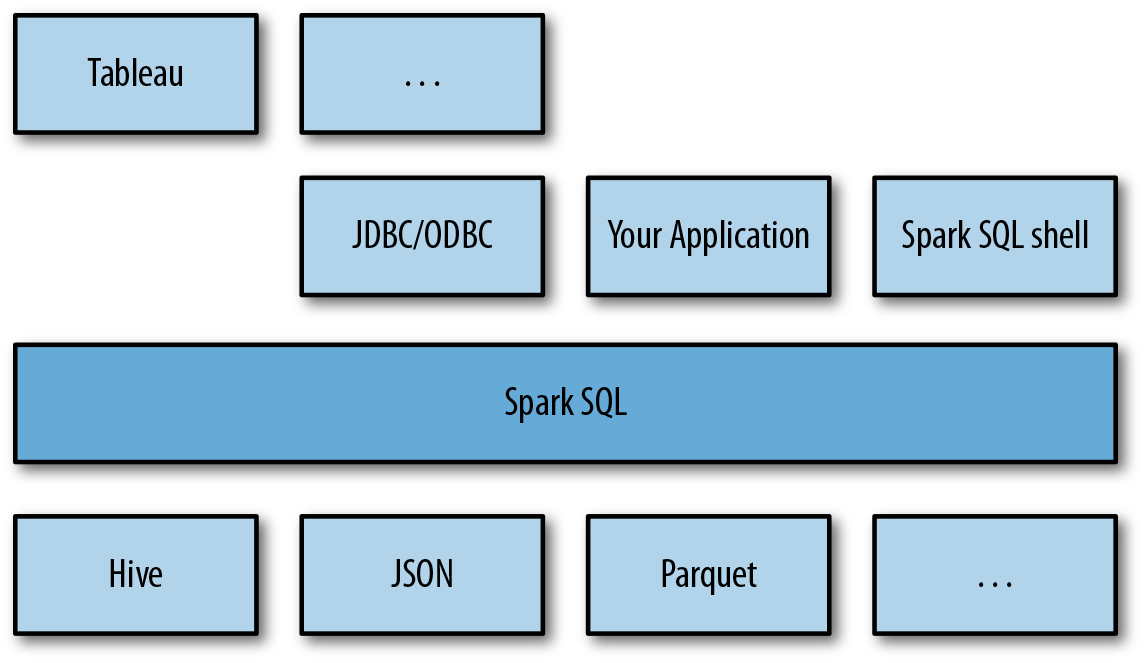
Figure 9-1. Spark SQL usage
In this chapter, we’ll start by showing how to use SchemaRDDs inside regular Spark programs, to load and query structured data. We’ll then describe the Spark SQL JDBC server, which lets you run Spark SQL on a shared server and connect either SQL shells or visualization tools like Tableau to it. Finally, we’ll discuss some advanced features. Spark SQL is a newer component of Spark and it will evolve substantially in Spark 1.3 and future versions, so consult the most recent documentation for the latest information on Spark SQL and SchemaRDDs.
As we move through this chapter, we’ll use Spark SQL to explore a JSON file with tweets. If you don’t have any tweets on hand, you can use the Databricks reference application to download some, or you can use files/testweet.json in the book’s Git repo.
Linking with Spark SQL
As with the other Spark libraries, including Spark SQL in our application requires some additional dependencies. This allows Spark Core to be built without depending on a large number of additional packages.
Spark SQL can be built with or without Apache Hive, the Hadoop SQL engine.
Spark SQL with Hive support allows us to access Hive tables, UDFs (user-defined functions), SerDes (serialization and deserialization formats), and the Hive query language (HiveQL). Hive query language (HQL)
It is important to note that including the Hive libraries does not require an existing Hive installation.
In general, it is best to build Spark SQL with Hive support to access these features.
If you download Spark in binary form, it should already be built with Hive support.
If you are building Spark from source, you should run sbt/sbt -Phive assembly.
If you have dependency conflicts with Hive that you cannot solve through exclusions or shading, you can also build and link to Spark SQL without Hive. In that case you link to a separate Maven artifact.
In Java and Scala, the Maven coordinates to link to Spark SQL with Hive are shown in Example 9-1.
Example 9-1. Maven coordinates for Spark SQL with Hive support
groupId = org.apache.spark artifactId = spark-hive_2.10 version = 1.2.0
If you can’t include the Hive dependencies, use the artifact ID spark-sql_2.10 instead of spark-hive_2.10.
As with the other Spark libraries, in Python no changes to your build are required.
When programming against Spark SQL we have two entry points depending on whether we need Hive support.
The recommended entry point is the HiveContext to provide access to HiveQL and other Hive-dependent functionality.
The more basic SQLContext provides a subset of the Spark SQL support that does not depend on Hive.
The separation exists for users who might have conflicts with including all of the Hive dependencies.
Using a HiveContext does not require an existing Hive setup.
HiveQL is the recommended query language for working with Spark SQL. Many resources have been written on HiveQL, including Programming Hive and the online Hive Language Manual. In Spark 1.0 and 1.1, Spark SQL is based on Hive 0.12, whereas in Spark 1.2 it also supports Hive 0.13. If you already know standard SQL, using HiveQL should feel very similar.
Tip
Spark SQL is a newer and fast moving component of Spark. The set of compatible Hive versions may change in the future, so consult the most recent documentation for more details.
Finally, to connect Spark SQL to an existing Hive installation, you must copy your hive-site.xml file to Spark’s configuration directory ($SPARK_HOME/conf). If you don’t have an existing Hive installation, Spark SQL will still run.
Note that if you don’t have an existing Hive installation, Spark SQL will create its own Hive metastore (metadata DB) in your program’s work directory, called metastore_db. In addition, if you attempt to create tables using HiveQL’s CREATE TABLE statement (not CREATE EXTERNAL TABLE), they will be placed in the /user/hive/warehouse directory on your default filesystem (either your local filesystem, or HDFS if you have a hdfs-site.xml on your classpath).
Using Spark SQL in Applications
The most powerful way to use Spark SQL is inside a Spark application. This gives us the power to easily load data and query it with SQL while simultaneously combining it with “regular” program code in Python, Java, or Scala.
To use Spark SQL this way, we construct a HiveContext (or SQLContext for those wanting
a stripped-down version) based on our SparkContext. This context provides additional functions for querying and interacting with Spark SQL data. Using the HiveContext, we can build SchemaRDDs, which represent our structure data, and operate on them with SQL or with normal RDD operations like map().
Initializing Spark SQL
To get started with Spark SQL we need to add a few imports to our programs, as shown in Example 9-2.
Example 9-2. Scala SQL imports
// Import Spark SQLimportorg.apache.spark.sql.hive.HiveContext// Or if you can't have the hive dependenciesimportorg.apache.spark.sql.SQLContext
Scala users should note that we don’t import HiveContext._, like we do with the SparkContext, to get access to implicits.
These implicits are used to convert RDDs with the required type information into Spark SQL’s specialized RDDs for querying.
Instead, once we have constructed an instance of the HiveContext we can then import the implicits by adding the code shown in Example 9-3. The imports for Java and Python are shown in Examples 9-4 and 9-5, respectively.
Example 9-3. Scala SQL implicits
// Create a Spark SQL HiveContextvalhiveCtx=...// Import the implicit conversionsimporthiveCtx._
Example 9-4. Java SQL imports
// Import Spark SQLimportorg.apache.spark.sql.hive.HiveContext;// Or if you can't have the hive dependenciesimportorg.apache.spark.sql.SQLContext;// Import the JavaSchemaRDDimportorg.apache.spark.sql.SchemaRDD;importorg.apache.spark.sql.Row;
Example 9-5. Python SQL imports
# Import Spark SQLfrompyspark.sqlimportHiveContext,Row# Or if you can't include the hive requirementsfrompyspark.sqlimportSQLContext,Row
Once we’ve added our imports, we need to create a HiveContext, or a SQLContext if we cannot bring in the Hive dependencies (see Examples 9-6 through 9-8). Both of these classes take a SparkContext to run on.
Example 9-6. Constructing a SQL context in Scala
valsc=newSparkContext(...)valhiveCtx=newHiveContext(sc)
Example 9-7. Constructing a SQL context in Java
JavaSparkContextctx=newJavaSparkContext(...);SQLContextsqlCtx=newHiveContext(ctx);
Example 9-8. Constructing a SQL context in Python
hiveCtx=HiveContext(sc)
Now that we have a HiveContext or SQLContext, we are ready to load our data and query it.
Basic Query Example
To make a query against a table, we call the sql() method on the HiveContext or SQLContext.
The first thing we need to do is tell Spark SQL about some data to query.
In this case we will load some Twitter data from JSON, and give it a name by registering it
as a “temporary table” so we can query it with SQL.
(We will go over more details on loading in “Loading and Saving Data”.)
Then we can select the top tweets by retweetCount. See Examples 9-9 through 9-11.
Example 9-9. Loading and quering tweets in Scala
valinput=hiveCtx.jsonFile(inputFile)// Register the input schema RDDinput.registerTempTable("tweets")// Select tweets based on the retweetCountvaltopTweets=hiveCtx.sql("SELECT text, retweetCount FROMtweets ORDER BY retweetCount LIMIT 10")
Example 9-10. Loading and quering tweets in Java
SchemaRDDinput=hiveCtx.jsonFile(inputFile);// Register the input schema RDDinput.registerTempTable("tweets");// Select tweets based on the retweetCountSchemaRDDtopTweets=hiveCtx.sql("SELECT text, retweetCount FROMtweets ORDER BY retweetCount LIMIT 10");
Example 9-11. Loading and quering tweets in Python
input=hiveCtx.jsonFile(inputFile)# Register the input schema RDDinput.registerTempTable("tweets")# Select tweets based on the retweetCounttopTweets=hiveCtx.sql("""SELECT text, retweetCount FROMtweets ORDER BY retweetCount LIMIT 10""")
SchemaRDDs
Both loading data and executing queries return SchemaRDDs.
SchemaRDDs are similar to tables in a traditional database.
Under the hood, a SchemaRDD is an RDD composed of Row objects with additional schema information of the types in each column.
Row objects are just wrappers around arrays of basic types (e.g., integers and strings), and we’ll cover them in more detail in the next section.
One important note: in future versions of Spark, the name SchemaRDD may be changed to DataFrame. This renaming was still under discussion as this book went to print.
SchemaRDDs are also regular RDDs, so you can operate on them using existing RDD transformations like map() and filter(). However, they provide several additional capabilities.
Most importantly, you can register any SchemaRDD as a temporary table to query it via HiveContext.sql or SQLContext.sql. You do so using the SchemaRDD’s registerTempTable() method, as in Examples 9-9 through 9-11.
Tip
Temp tables are local to the HiveContext or SQLContext being used, and go away when your application exits.
SchemaRDDs can store several basic types, as well as structures and arrays of these types. They use the HiveQL syntax for type definitions. Table 9-1 shows the supported types.
| Spark SQL/HiveQL type | Scala type | Java type | Python |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The last type, structures, is simply represented as other Rows in Spark SQL. All of these types can also be nested within each other; for example, you can have arrays of structs, or maps that contain structs.
Working with Row objects
Row objects represent records inside SchemaRDDs, and are simply fixed-length arrays of fields.
In Scala/Java, Row objects have a number of getter functions to obtain the value of each field given its index.
The standard getter, get (or apply in Scala), takes a column number and returns an Object type (or Any in Scala)
that we are responsible for casting to the correct type.
For Boolean, Byte, Double, Float, Int, Long, Short, and String, there is a getType() method, which returns that type. For example, getString(0) would return field 0 as a string, as you can see in Examples 9-12 and 9-13.
Example 9-12. Accessing the text column (also first column) in the topTweets SchemaRDD in Scala
valtopTweetText=topTweets.map(row=>row.getString(0))
Example 9-13. Accessing the text column (also first column) in the topTweets SchemaRDD in Java
JavaRDD<String>topTweetText=topTweets.toJavaRDD().map(newFunction<Row,String>(){publicStringcall(Rowrow){returnrow.getString(0);}});
In Python, Row objects are a bit different since we don’t have explicit typing. We just access the ith element using row[i]. In addition, Python Rows support named access to their fields, of the form row.column_name, as you can see in Example 9-14. If you are uncertain of what the column names are, we illustrate printing the schema in “JSON”.
Example 9-14. Accessing the text column in the topTweets SchemaRDD in Python
topTweetText=topTweets.map(lambdarow:row.text)
Caching
Caching in Spark SQL works a bit differently.
Since we know the types of each column, Spark is able to more
efficiently store the data. To make sure that we cache using the memory efficient representation, rather than the full objects,
we should use the special hiveCtx.cacheTable("tableName") method.
When caching a table Spark SQL represents the data in an in-memory columnar format.
This cached table will remain in memory only for
the life of our driver program, so if it exits we will need to recache our data. As with RDDs, we cache tables when we
expect to run multiple tasks or queries against the same data.
You can also cache tables using HiveQL/SQL statements. To cache or uncache a table simply run CACHE TABLE tableName or UNCACHE TABLE tableName. This is most commonly used with command-line clients to the JDBC server.
Cached SchemaRDDs show up in the Spark application UI much like other RDDs, as shown in Figure 9-2.
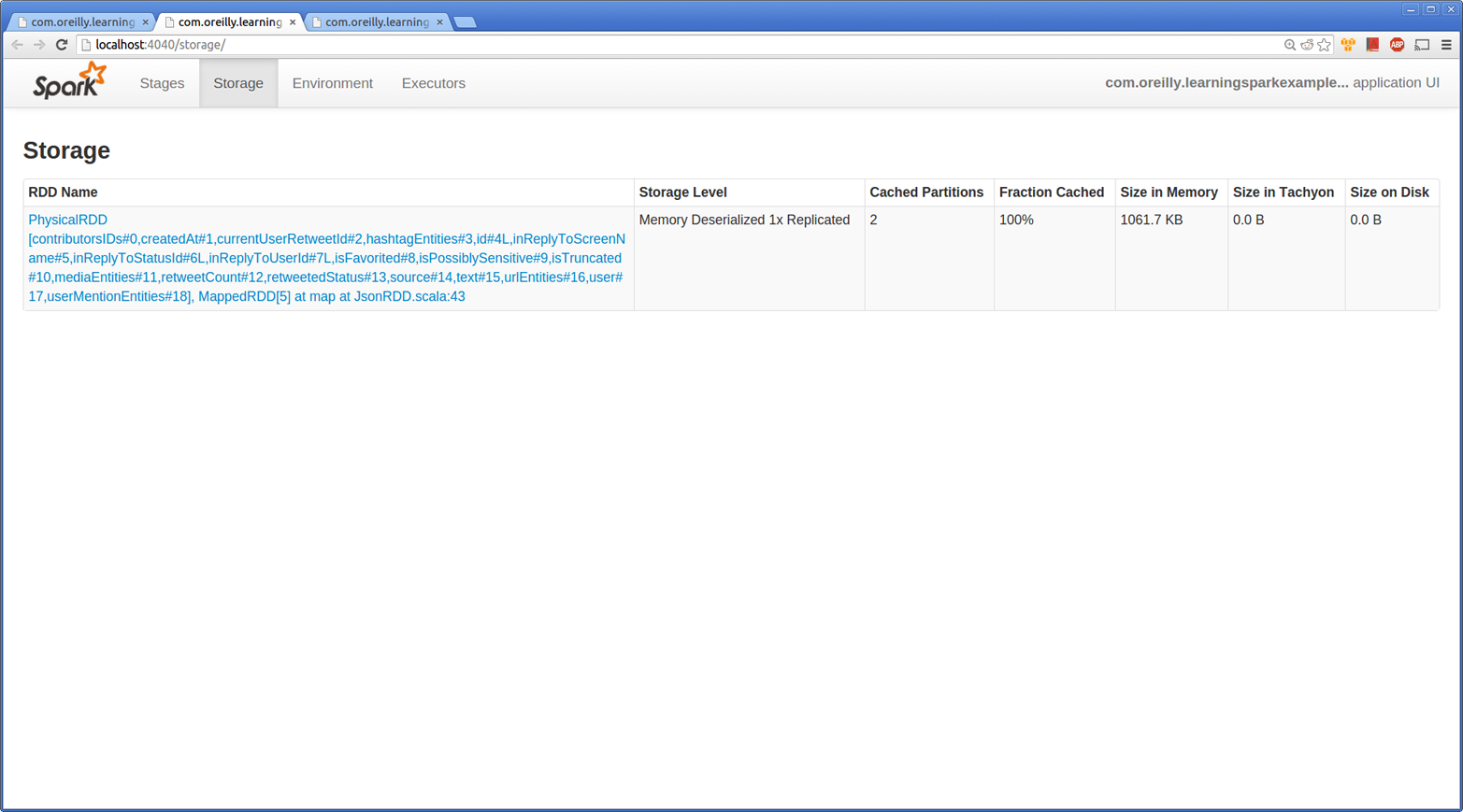
Figure 9-2. Spark SQL UI of SchemaRDD
We discuss more about how Spark SQL caching performance works in “Spark SQL Performance”.
Loading and Saving Data
Spark SQL supports a number of structured data sources out of the box, letting you get Row objects from them without any complicated loading process. These sources include Hive tables, JSON, and Parquet files. In addition, if you query these sources using SQL and select only a subset of the fields, Spark SQL can smartly scan only the subset of the data for those fields, instead of scanning all the data like a naive SparkContext.hadoopFile might.
Apart from these data sources, you can also convert regular RDDs in your program to SchemaRDDs by assigning them a schema. This makes it easy to write SQL queries even when your underlying data is Python or Java objects. Often, SQL queries are more concise when you’re computing many quantities at once (e.g., if you wanted to compute the average age, max age, and count of distinct user IDs in one pass). In addition, you can easily join these RDDs with SchemaRDDs from any other Spark SQL data source. In this section, we’ll cover the external sources as well as this way of using RDDs.
Apache Hive
When loading data from Hive, Spark SQL supports any Hive-supported storage formats (SerDes), including text files, RCFiles, ORC, Parquet, Avro, and Protocol Buffers.
To connect Spark SQL to an existing Hive installation, you need to provide a Hive configuration. You do so by copying your hive-site.xml file to Spark’s ./conf/ directory. If you just want to explore, a local Hive metastore will be used if no hive-site.xml is set, and we can easily load data into a Hive table to query later on.
Examples 9-15 through 9-17 illustrate querying a Hive table. Our example Hive table has two columns, key (which is an integer) and value (which is a string). We show how to create such a table later in this chapter.
Example 9-15. Hive load in Python
frompyspark.sqlimportHiveContexthiveCtx=HiveContext(sc)rows=hiveCtx.sql("SELECT key, value FROM mytable")keys=rows.map(lambdarow:row[0])
Example 9-16. Hive load in Scala
importorg.apache.spark.sql.hive.HiveContextvalhiveCtx=newHiveContext(sc)valrows=hiveCtx.sql("SELECT key, value FROM mytable")valkeys=rows.map(row=>row.getInt(0))
Example 9-17. Hive load in Java
importorg.apache.spark.sql.hive.HiveContext;importorg.apache.spark.sql.Row;importorg.apache.spark.sql.SchemaRDD;HiveContexthiveCtx=newHiveContext(sc);SchemaRDDrows=hiveCtx.sql("SELECT key, value FROM mytable");JavaRDD<Integer>keys=rdd.toJavaRDD().map(newFunction<Row,Integer>(){publicIntegercall(Rowrow){returnrow.getInt(0);}});
Parquet
Parquet is a popular column-oriented storage format that can store records with nested fields efficiently. It is often used with tools in the Hadoop ecosystem, and it supports all of the data types in Spark SQL. Spark SQL provides methods for reading data directly to and from Parquet files.
First, to load data, you can use HiveContext.parquetFile or SQLContext.parquetFile, as shown in Example 9-18.
Example 9-18. Parquet load in Python
# Load some data in from a Parquet file with field's name and favouriteAnimalrows=hiveCtx.parquetFile(parquetFile)names=rows.map(lambdarow:row.name)"Everyone"names.collect()
You can also register a Parquet file as a Spark SQL temp table and write queries against it. Example 9-19 continues from Example 9-18 where we loaded the data.
Example 9-19. Parquet query in Python
# Find the panda loverstbl=rows.registerTempTable("people")pandaFriends=hiveCtx.sql("SELECT name FROM people WHERE favouriteAnimal ="panda"")"Panda friends"pandaFriends.map(lambdarow:row.name).collect()
Finally, you can save the contents of a SchemaRDD to Parquet with saveAsParquetFile(), as shown in Example 9-20.
Example 9-20. Parquet file save in Python
pandaFriends.saveAsParquetFile("hdfs://...")
JSON
If you have a JSON file with records fitting the same schema, Spark SQL can infer the schema by scanning the file and let you access fields by name (Example 9-21). If you have ever found yourself staring at a huge directory of JSON records, Spark SQL’s schema inference is a very effective way to start working with the data without writing any special loading code.
To load our JSON data, all we need to do is call the jsonFile() function on our hiveCtx, as shown in Examples 9-22 through 9-24.
If you are curious about what the inferred schema for your data is, you can call printSchema on the
resulting SchemaRDD (Example 9-25).
Example 9-21. Input records
{"name":"Holden"}{"name":"Sparky The Bear","lovesPandas":true,"knows":{"friends":["holden"]}}
Example 9-22. Loading JSON with Spark SQL in Python
input=hiveCtx.jsonFile(inputFile)
Example 9-23. Loading JSON with Spark SQL in Scala
valinput=hiveCtx.jsonFile(inputFile)
Example 9-24. Loading JSON with Spark SQL in Java
SchemaRDDinput=hiveCtx.jsonFile(jsonFile);
Example 9-25. Resulting schema from printSchema()
root |-- knows: struct (nullable = true) | |-- friends: array (nullable = true) | | |-- element: string (containsNull = false) |-- lovesPandas: boolean (nullable = true) |-- name: string (nullable = true)
You can also look at the schema generated for some tweets, as in Example 9-26.
Example 9-26. Partial schema of tweets
root |-- contributorsIDs: array (nullable = true) | |-- element: string (containsNull = false) |-- createdAt: string (nullable = true) |-- currentUserRetweetId: integer (nullable = true) |-- hashtagEntities: array (nullable = true) | |-- element: struct (containsNull = false) | | |-- end: integer (nullable = true) | | |-- start: integer (nullable = true) | | |-- text: string (nullable = true) |-- id: long (nullable = true) |-- inReplyToScreenName: string (nullable = true) |-- inReplyToStatusId: long (nullable = true) |-- inReplyToUserId: long (nullable = true) |-- isFavorited: boolean (nullable = true) |-- isPossiblySensitive: boolean (nullable = true) |-- isTruncated: boolean (nullable = true) |-- mediaEntities: array (nullable = true) | |-- element: struct (containsNull = false) | | |-- displayURL: string (nullable = true) | | |-- end: integer (nullable = true) | | |-- expandedURL: string (nullable = true) | | |-- id: long (nullable = true) | | |-- mediaURL: string (nullable = true) | | |-- mediaURLHttps: string (nullable = true) | | |-- sizes: struct (nullable = true) | | | |-- 0: struct (nullable = true) | | | | |-- height: integer (nullable = true) | | | | |-- resize: integer (nullable = true) | | | | |-- width: integer (nullable = true) | | | |-- 1: struct (nullable = true) | | | | |-- height: integer (nullable = true) | | | | |-- resize: integer (nullable = true) | | | | |-- width: integer (nullable = true) | | | |-- 2: struct (nullable = true) | | | | |-- height: integer (nullable = true) | | | | |-- resize: integer (nullable = true) | | | | |-- width: integer (nullable = true) | | | |-- 3: struct (nullable = true) | | | | |-- height: integer (nullable = true) | | | | |-- resize: integer (nullable = true) | | | | |-- width: integer (nullable = true) | | |-- start: integer (nullable = true) | | |-- type: string (nullable = true) | | |-- url: string (nullable = true) |-- retweetCount: integer (nullable = true) ...
As you look at these schemas, a natural question is how to access nested fields and array fields.
Both in Python and when we register a table, we can access nested elements by using the . for each level of nesting (e.g., toplevel.nextlevel).
You can access array elements in SQL by specifying the index with [element], as shown in Example 9-27.
Example 9-27. SQL query nested and array elements
selecthashtagEntities[0].textfromtweetsLIMIT1;
From RDDs
In addition to loading data, we can also create a SchemaRDD from an RDD. In Scala, RDDs with case classes are implicitly converted into SchemaRDDs.
For Python we create an RDD of Row objects and then call inferSchema(), as shown in Example 9-28.
Example 9-28. Creating a SchemaRDD using Row and named tuple in Python
happyPeopleRDD=sc.parallelize([Row(name="holden",favouriteBeverage="coffee")])happyPeopleSchemaRDD=hiveCtx.inferSchema(happyPeopleRDD)happyPeopleSchemaRDD.registerTempTable("happy_people")
With Scala, our old friend implicit conversions handles the inference of the schema for us (Example 9-29).
Example 9-29. Creating a SchemaRDD from case class in Scala
caseclassHappyPerson(handle:String,favouriteBeverage:String)...// Create a person and turn it into a Schema RDDvalhappyPeopleRDD=sc.parallelize(List(HappyPerson("holden","coffee")))// Note: there is an implicit conversion// that is equivalent to sqlCtx.createSchemaRDD(happyPeopleRDD)happyPeopleRDD.registerTempTable("happy_people")
With Java, we can turn an RDD consisting of a serializable class with public getters and setters into a schema RDD by calling applySchema(), as Example 9-30 shows.
Example 9-30. Creating a SchemaRDD from a JavaBean in Java
classHappyPersonimplementsSerializable{privateStringname;privateStringfavouriteBeverage;publicHappyPerson(){}publicHappyPerson(Stringn,Stringb){name=n;favouriteBeverage=b;}publicStringgetName(){returnname;}publicvoidsetName(Stringn){name=n;}publicStringgetFavouriteBeverage(){returnfavouriteBeverage;}publicvoidsetFavouriteBeverage(Stringb){favouriteBeverage=b;}};...ArrayList<HappyPerson>peopleList=newArrayList<HappyPerson>();peopleList.add(newHappyPerson("holden","coffee"));JavaRDD<HappyPerson>happyPeopleRDD=sc.parallelize(peopleList);SchemaRDDhappyPeopleSchemaRDD=hiveCtx.applySchema(happyPeopleRDD,HappyPerson.class);happyPeopleSchemaRDD.registerTempTable("happy_people");
JDBC/ODBC Server
Spark SQL also provides JDBC connectivity, which is useful for connecting business intelligence (BI) tools to a Spark cluster and for sharing a cluster across multiple users. The JDBC server runs as a standalone Spark driver program that can be shared by multiple clients. Any client can cache tables in memory, query them, and so on, and the cluster resources and cached data will be shared among all of them.
Spark SQL’s JDBC server corresponds to the HiveServer2 in Hive. It is also known as the “Thrift server” since it uses the Thrift communication protocol. Note that the JDBC server requires Spark be built with Hive support.
The server can be launched with sbin/start-thriftserver.sh in your Spark directory (Example 9-31).
This script takes many of the same options as spark-submit.
By default it listens on localhost:10000, but we can change these with either environment variables
(HIVE_SERVER2_THRIFT_PORT and HIVE_SERVER2_THRIFT_BIND_HOST), or with Hive
configuration properties (hive.server2.thrift.port and hive.server2.thrift.bind.host). You can also specify Hive properties on the command line with --hiveconf property=value.
Example 9-31. Launching the JDBC server
./sbin/start-thriftserver.sh --master sparkMaster
Spark also ships with the Beeline client program we can use to connect to our JDBC server, as shown in Example 9-32 and Figure 9-3. This is a simple SQL shell that lets us run commands on the server.
Example 9-32. Connecting to the JDBC server with Beeline
holden@hmbp2:~/repos/spark$./bin/beeline -u jdbc:hive2://localhost:10000 Spark assembly has been built with Hive, including Datanucleus jars on classpath scancompletein 1ms Connecting to jdbc:hive2://localhost:10000 Connected to: Spark SQL(version 1.2.0-SNAPSHOT)Driver: spark-assembly(version 1.2.0-SNAPSHOT)Transaction isolation: TRANSACTION_REPEATABLE_READ Beeline version 1.2.0-SNAPSHOT by Apache Hive 0: jdbc:hive2://localhost:10000> show tables;+---------+|result|+---------+|pokes|+---------+1row selected(1.182 seconds)0: jdbc:hive2://localhost:10000>
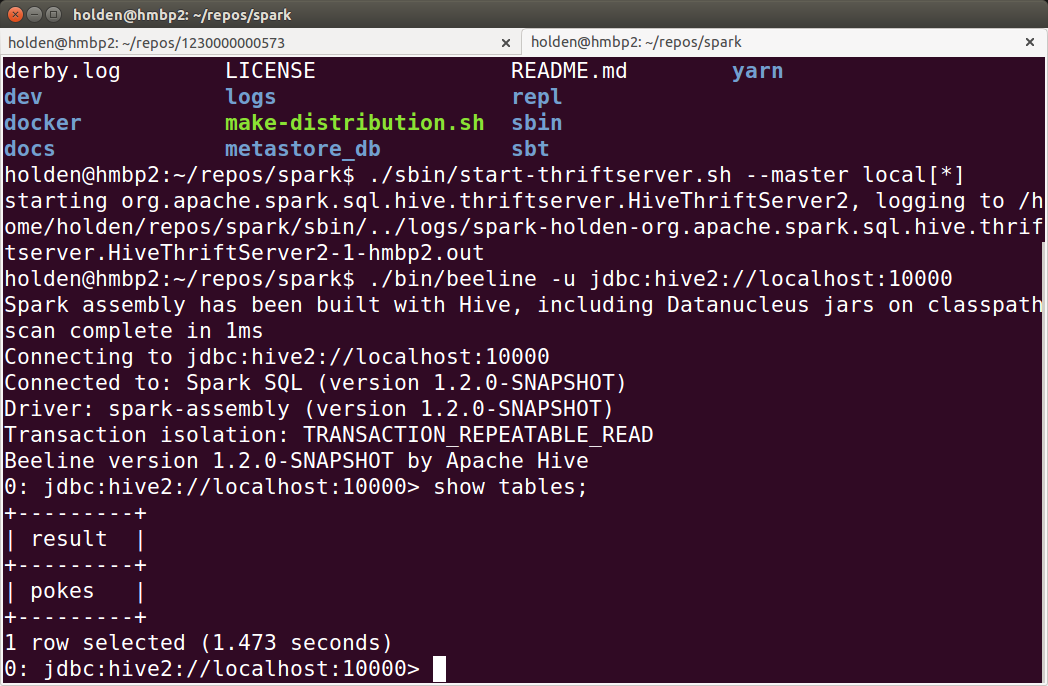
Figure 9-3. Launching the JDBC server and connecting a Beeline client
Tip
When we start the JDBC server, it goes into the background and directs all of its output to a logfile. If you encounter issues with queries you run against the JDBC server, check out the logs for more complete error messages.
Many external tools can also connect to Spark SQL via its ODBC driver. The Spark SQL ODBC driver is produced by Simba and can be downloaded from various Spark vendors (e.g., Databricks Cloud, Datastax, and MapR). It is commonly used by business intelligence (BI) tools such as Microstrategy or Tableau; check with your tool about how it can connect to Spark SQL. In addition, most BI tools that have connectors to Hive can also connect to Spark SQL using their existing Hive connector, because it uses the same query language and server.
Working with Beeline
Within the Beeline client, you can use standard HiveQL commands to create, list, and query tables. You can find the full details of HiveQL in the Hive Language Manual, but here, we show a few common operations.
First, to create a table from local data, we can use the CREATE TABLE command, followed by LOAD DATA. Hive easily supports loading text files with a fixed delimiter such as CSVs, as well as other files, as shown in Example 9-33.
Example 9-33. Load table
>CREATETABLEIFNOTEXISTSmytable(keyINT,valueSTRING)ROWFORMATDELIMITEDFIELDSTERMINATEDBY',';>LOADDATALOCALINPATH'learning-spark-examples/files/int_string.csv'INTOTABLEmytable;
To list tables, you can use the SHOW TABLES statement (Example 9-34). You can also describe each table’s schema with DESCRIBE tableName.
Example 9-34. Show tables
>SHOWTABLES;mytableTimetaken:0.052seconds
If you’d like to cache tables, use CACHE TABLE tableName. You can later uncache tables with UNCACHE TABLE tableName. Note that the cached tables are shared across all clients of this JDBC server, as explained earlier.
Finally, Beeline makes it easy to view query plans.
You can run EXPLAIN on a given query to see what the execution plan will be, as shown in Example 9-35.
Example 9-35. Spark SQL shell EXPLAIN
spark-sql>EXPLAINSELECT*FROMmytablewherekey=1;==PhysicalPlan==Filter(key#16=1)HiveTableScan[key#16,value#17],(MetastoreRelationdefault,mytable,None),NoneTimetaken:0.551seconds
In this specific query plan, Spark SQL is applying a filter on top of a HiveTableScan.
From here you can also write SQL to query the data. The Beeline shell is great for quick data exploration on cached tables shared by multiple users.
Long-Lived Tables and Queries
One of the advantages of using Spark SQL’s JDBC server is we can share cached tables between multiple programs. This
is possible since the JDBC Thrift server is a single driver program. To do this, you only need to register the table and then run the CACHE command on it, as shown in the previous section.
Standalone Spark SQL Shell
Apart from its JDBC server, Spark SQL also supports a simple shell you can use as a single process, available through ./bin/spark-sql. This shell connects to the Hive metastore you have set in conf/hive-site.xml, if one exists, or creates one locally. It is most useful for local development; in a shared cluster, you should instead use the JDBC server and have users connect with beeline.
User-Defined Functions
User-defined functions, or UDFs, allow you to register custom functions in Python, Java, and Scala to call within SQL. They are a very popular way to expose advanced functionality to SQL users in an organization, so that these users can call into it without writing code. Spark SQL makes it especially easy to write UDFs. It supports both its own UDF interface and existing Apache Hive UDFs.
Spark SQL UDFs
Spark SQL offers a built-in method to easily register UDFs by passing in a function in your programming language. In Scala and Python, we can use the native function and lambda syntax of the language, and in Java we need only extend the appropriate UDF class. Our UDFs can work on a variety of types, and we can return a different type than the one we are called with.
In Python and Java we also need to specify the return type using one of the SchemaRDD types,
listed in Table 9-1. In Java these types are found in org.apache.spark.sql.api.java.DataType and
in Python we import the DataType.
In Examples 9-36 and 9-37, a very simple UDF computes the string length, which we can use to find out the length of the tweets we’re using.
Example 9-36. Python string length UDF
# Make a UDF to tell us how long some text ishiveCtx.registerFunction("strLenPython",lambdax:len(x),IntegerType())lengthSchemaRDD=hiveCtx.sql("SELECT strLenPython('text') FROM tweets LIMIT 10")
Example 9-37. Scala string length UDF
registerFunction("strLenScala",(_:String).length)valtweetLength=hiveCtx.sql("SELECT strLenScala('tweet') FROM tweets LIMIT 10")
There are some additional imports for Java to define UDFs. As with the functions
we defined for RDDs we extend a special class. Depending on the number of parameters
we extend UDF[N], as shown in Examples 9-38 and 9-39.
Example 9-38. Java UDF imports
// Import UDF function class and DataTypes// Note: these import paths may change in a future releaseimportorg.apache.spark.sql.api.java.UDF1;importorg.apache.spark.sql.types.DataTypes;
Example 9-39. Java string length UDF
hiveCtx.udf().register("stringLengthJava",newUDF1<String,Integer>(){@OverridepublicIntegercall(Stringstr)throwsException{returnstr.length();}},DataTypes.IntegerType);SchemaRDDtweetLength=hiveCtx.sql("SELECT stringLengthJava('text') FROM tweets LIMIT 10");List<Row>lengths=tweetLength.collect();for(Rowrow:result){System.out.println(row.get(0));}
Hive UDFs
Spark SQL can also use existing Hive UDFs.
The standard Hive UDFs are already automatically included.
If you have a custom UDF, it is important to make sure that the JARs for your UDF are included with your
application. If we run the JDBC server, note that we can add this with the --jars command-line flag.
Developing Hive UDFs is beyond the scope of this book, so we will instead introduce how to use existing Hive UDFs.
Using a Hive UDF requires that we use the HiveContext instead of a regular SQLContext.
To make a Hive UDF available, simply call hiveCtx.sql("CREATE TEMPORARY FUNCTION name AS class.function").
Spark SQL Performance
As alluded to in the introduction, Spark SQL’s higher-level query language and additional type information allows Spark SQL to be more efficient.
Spark SQL is for more than just users who are familiar with SQL. Spark SQL makes it very easy to perform conditional aggregate operations, like counting the sum of multiple columns (as shown in Example 9-40), without having to construct special objects as we discussed in Chapter 6.
Example 9-40. Spark SQL multiple sums
SELECTSUM(user.favouritesCount),SUM(retweetCount),user.idFROMtweetsGROUPBYuser.id
Spark SQL is able to use the knowledge of types to more efficiently represent our data. When caching data, Spark SQL uses an in-memory columnar storage. This not only takes up less space when cached, but if our subsequent queries depend only on subsets of the data, Spark SQL minimizes the data read.
Predicate push-down allows Spark SQL to move some parts of our query “down” to the engine we are querying. If we wanted to read only certain records in Spark, the standard way to handle this would be to read in the entire dataset and then execute a filter on it. However, in Spark SQL, if the underlying data store supports retrieving only subsets of the key range, or another restriction, Spark SQL is able to push the restrictions in our query down to the data store, resulting in potentially much less data being read.
Performance Tuning Options
There are a number of different performance tuning options with Spark SQL; they’re listed in Table 9-2.
| Option | Default | Usage |
|---|---|---|
|
|
When |
|
|
Compress the in-memory columnar storage automatically. |
|
|
The batch size for columnar caching. Larger values may cause out-of-memory problems |
|
|
Which compression codec to use. Possible options include |
Using the JDBC connector, and the Beeline shell, we can set these performance options, and other options, with the set command, as shown in Example 9-41.
Example 9-41. Beeline command for enabling codegen
beeline>setspark.sql.codegen=true;SETspark.sql.codegen=truespark.sql.codegen=trueTimetaken:1.196seconds
In a traditional Spark SQL application we can set these Spark properties on our Spark configuration instead, as shown in Example 9-42.
Example 9-42. Scala code for enabling codegen
conf.set("spark.sql.codegen","true")
A few options warrant special attention. First is spark.sql.codegen, which causes Spark SQL to compile each query to Java bytecode before running it. Codegen can make long queries or frequently repeated queries substantially faster, because it generates specialized code to run them. However, in a setting with very short (1–2 seconds) ad hoc queries, it may add overhead as it has to run a compiler for each query.13 Codegen is also still experimental, but we recommend trying it for any workload with large queries, or with the same query repeated over and over.
The second option you may need to tune is spark.sql.inMemoryColumnarStorage.batchSize. When caching SchemaRDDs, Spark SQL groups together the records in the RDD in batches of the size given by this option (default: 1000), and compresses each batch. Very small batch sizes lead to low compression, but on the other hand, very large sizes can also be problematic, as each batch might be too large to build up in memory. If the rows in your tables are large (i.e., contain hundreds of fields or contain string fields that can be very long, such as web pages), you may need to lower the batch size to avoid out-of-memory errors. If not, the default batch size is likely fine, as there are diminishing returns for extra compression when you go beyond 1,000 records.
Conclusion
With Spark SQL, we have seen how to use Spark with structured and semistructured data. In addition to the queries explored here, it’s important to remember that our previous tools from Chapter 3 through Chapter 6 can be used on the SchemaRDDs Spark SQL provides. In many pipelines, it is convenient to combine SQL (for its conciseness) with code written in other programming languages (for their ability to express more complex logic). When you use Spark SQL to do this, you also gain some optimizations from the engine’s ability to leverage schemas.
13 Note that the first few runs of codegen will be especially slow as it needs to initialize its compiler, so you should run four to five queries before measuring its overhead.