
Chapter 8. Tuning and Debugging Spark
This chapter describes how to configure a Spark application and gives an overview of how to tune and debug production Spark workloads. Spark is designed so that default settings work “out of the box” in many cases; however, there are still some configurations users might want to modify. This chapter outlines Spark’s configuration mechanisms and highlights some options users might want to tweak. Configuration is also useful for tuning an application’s performance; the second part of this chapter covers the fundamentals necessary for understanding the performance of a Spark application, along with the associated configuration settings and design patterns for writing high performance applications. We also cover information about Spark’s user interface, instrumentation, and logging mechanisms. These are all useful when you are performance tuning or troubleshooting issues.
Configuring Spark with SparkConf
Tuning Spark often simply means changing the Spark application’s runtime
configuration. The primary configuration
mechanism in Spark is the SparkConf class. A SparkConf instance is required when you are
creating a new SparkContext, as shown in Examples 8-1 through 8-3.
Example 8-1. Creating an application using a SparkConf in Python
# Construct a confconf=newSparkConf()conf.set("spark.app.name","My Spark App")conf.set("spark.master","local[4]")conf.set("spark.ui.port","36000")# Override the default port# Create a SparkContext with this configurationsc=SparkContext(conf)
Example 8-2. Creating an application using a SparkConf in Scala
// Construct a confvalconf=newSparkConf()conf.set("spark.app.name","My Spark App")conf.set("spark.master","local[4]")conf.set("spark.ui.port","36000")// Override the default port// Create a SparkContext with this configurationvalsc=newSparkContext(conf)
Example 8-3. Creating an application using a SparkConf in Java
// Construct a confSparkConfconf=newSparkConf();conf.set("spark.app.name","My Spark App");conf.set("spark.master","local[4]");conf.set("spark.ui.port","36000");// Override the default port// Create a SparkContext with this configurationJavaSparkContextsc=JavaSparkContext(conf);
The SparkConf class is quite simple: a SparkConf instance
contains key/value pairs of configuration options the user would like to override.
Every configuration option in Spark is based on a string key and value. To use a
SparkConf object you create one, call set() to add
configuration values, and then supply it to the SparkContext constructor. In addition
to set(), the SparkConf class includes a small number of
utility methods for setting common parameters. In the preceding three examples, you
could also call setAppName() and setMaster() to set the
spark.app.name and the spark.master configurations,
respectively.
In these examples, the SparkConf values are set programmatically in the
application code. In many cases, it is more convenient to populate configurations
dynamically for a given application. Spark allows setting configurations dynamically
through the spark-submit tool. When an application is launched with spark-submit, it injects
configuration values into the environment. These are detected and automatically filled in when a new
SparkConf is constructed. Therefore, user applications can simply
construct an “empty” SparkConf and pass it directly to the SparkContext
constructor if you are using spark-submit.
The spark-submit tool provides built-in flags for the most common Spark
configuration parameters and a generic --conf flag that accepts any Spark
configuration value. These are demonstrated in Example 8-4.
Example 8-4. Setting configuration values at runtime using flags
$bin/spark-submit--class com.example.MyApp--masterlocal[4]--name"My Spark App"--conf spark.ui.port=36000myApp.jar
spark-submit also supports loading configuration values from a file.
This can be useful to set environmental configuration, which may be shared across
multiple users, such as a default master. By
default, spark-submit will look for a file called
conf/spark-defaults.conf in the Spark directory and attempt to read
whitespace-delimited key/value pairs from this file. You can also customize the exact
location of the file using the --properties-file flag to
spark-submit, as you can see in Example 8-5.
Example 8-5. Setting configuration values at runtime using a defaults file
$bin/spark-submit--class com.example.MyApp--properties-file my-config.confmyApp.jar## Contents of my-config.conf ##spark.masterlocal[4]spark.app.name"My Spark App"spark.ui.port 36000
Tip
The SparkConf associated with a given application is immutable once it
is passed to the SparkContext constructor. That means that all configuration
decisions must be made before a SparkContext is instantiated.
In some cases, the same configuration property might be set in multiple places. For instance, a user might call setAppName() directly on a
SparkConf object and also pass the --name flag to
spark-submit. In these cases Spark has a specific precedence order. The
highest priority is given to configurations declared explicitly in the user’s code
using the set() function on a SparkConf object. Next are
flags passed to spark-submit, then values in the properties file, and
finally default values. If you want to know which configurations are in place for a
given application, you can examine a list of active configurations displayed through
the application web UI discussed later in this chapter.
Several common configurations were listed in Table 7-2. Table 8-1 outlines a few additional configuration options that might be of interest. For the full list of configuration options, see the Spark documentation.
| Option(s) | Default | Explanation |
|---|---|---|
|
512m |
Amount of memory to use per executor process, in the same format as JVM memory strings (e.g., 512m, 2g). See “Hardware Provisioning” for more detail on this option. |
|
(none) |
Configurations for bounding the number of cores used by the application. In
YARN mode |
|
|
Setting to |
|
|
An internal timeout used for tracking the liveness of executors. For jobs
that have long garbage collection pauses, tuning this to be 100 seconds (a
value of |
|
(empty) |
These three options allow you to customize the launch behavior of executor
JVMs. The three flags add extra Java options, classpath entries, or path
entries for the JVM library path. These parameters should be specified as
strings (e.g.,
|
|
|
Class to use for serializing objects that will be sent over the network or
need to be cached in serialized form.
The default of Java Serialization works with any serializable Java object but
is quite slow, so we recommend using
|
|
(random) |
Allows setting integer port values to be used by a running Spark
applications. This is useful in clusters where network access is secured. The
possible values of |
|
|
Set to |
|
|
The storage location used for event logging, if enabled. This needs to be in a globally visible filesystem such as HDFS. |
Almost all Spark configurations occur through the SparkConf construct,
but one important option doesn’t. To set the local
storage directories for Spark to use for shuffle data (necessary for standalone and
Mesos modes), you export the SPARK_LOCAL_DIRS environment variable inside of conf/spark-env.sh to a comma-separated list of storage
locations. SPARK_LOCAL_DIRS is described in detail in “Hardware Provisioning”. This is specified
differently from other Spark configurations because its value may be different on
different physical hosts.
Components of Execution: Jobs, Tasks, and Stages
A first step in tuning and debugging Spark is to have a deeper understanding of the system’s internal design. In previous chapters you saw the “logical” representation of RDDs and their partitions. When executing, Spark translates this logical representation into a physical execution plan by merging multiple operations into tasks. Understanding every aspect of Spark’s execution is beyond the scope of this book, but an appreciation for the steps involved along with the relevant terminology can be helpful when tuning and debugging jobs.
To demonstrate Spark’s phases of execution, we’ll walk through an example application and see how user code compiles down to a lower-level execution plan. The application we’ll consider is a simple bit of log analysis in the Spark shell. For input data, we’ll use a text file that consists of log messages of varying degrees of severity, along with some blank lines interspersed (Example 8-6).
Example 8-6. input.txt, the source file for our example
## input.txt ## INFO This is a message with content INFO This is some other content (empty line) INFO Here are more messages WARN This is a warning (empty line) ERROR Something bad happened WARN More details on the bad thing INFO back to normal messages
We want to open this file in the Spark shell and compute how many log messages appear at each level of severity. First let’s create a few RDDs that will help us answer this question, as shown in Example 8-7.
Example 8-7. Processing text data in the Scala Spark shell
// Read input filescala>valinput=sc.textFile("input.txt")// Split into words and remove empty linesscala>valtokenized=input.|map(line=>line.split(" ")).|filter(words=>words.size>0)// Extract the first word from each line (the log level) and do a countscala>valcounts=tokenized.|map(words=>(words(0),1)).|reduceByKey{(a,b)=>a+b}
This sequence of commands results in an RDD, counts, that will contain
the number of log entries at each level of severity. After executing these lines
in the shell, the program has not performed any actions. Instead, it has implicitly
defined a directed acyclic graph (DAG) of RDD objects that will be used later once an
action occurs. Each RDD maintains a pointer to one or more parents along with
metadata about what type of relationship they have. For instance, when you call
val b = a.map() on an RDD, the RDD b keeps a reference to
its parent a. These pointers allow an RDD to be traced to all of its
ancestors.
To display the lineage of an RDD, Spark
provides a toDebugString() method. In Example 8-8, we’ll look at some of the RDDs we created in the
preceding example.
Example 8-8. Visualizing RDDs with toDebugString() in Scala
scala>input.toDebugStringres85:String=(2)input.textMappedRDD[292]attextFileat<console>:13|input.textHadoopRDD[291]attextFileat<console>:13scala>counts.toDebugStringres84:String=(2)ShuffledRDD[296]atreduceByKeyat<console>:17+-(2)MappedRDD[295]atmapat<console>:17|FilteredRDD[294]atfilterat<console>:15|MappedRDD[293]atmapat<console>:15|input.textMappedRDD[292]attextFileat<console>:13|input.textHadoopRDD[291]attextFileat<console>:13
The first visualization shows the input RDD. We created this RDD by
calling sc.textFile(). The lineage gives us some clues as to what
sc.textFile() does since it reveals which RDDs were created in the
textFile() function. We can see that it creates a
HadoopRDD and then performs a map on it to create the returned RDD. The
lineage of counts is more complicated. That RDD has several ancestors,
since there are other operations that were performed on top of the input
RDD, such as additional maps, filtering, and reduction. The lineage of
counts shown here is also displayed graphically on the left side of Figure 8-1.
Before we perform an action, these RDDs simply store metadata that will help us
compute them later. To trigger computation, let’s call an action on the counts RDD and
collect() it to the driver, as shown in Example 8-9.
Example 8-9. Collecting an RDD
scala>counts.collect()res86:Array[(String,Int)]=Array((ERROR,1),(INFO,4),(WARN,2))
Spark’s scheduler creates a physical execution plan to compute the RDDs needed for
performing the action. Here when we call collect() on the RDD, every
partition of the RDD must be materialized and then transferred to the driver
program. Spark’s scheduler starts
at the final RDD being computed (in this case, counts) and works backward
to find what it must compute. It visits that RDD’s parents, its parents’ parents, and
so on, recursively to develop a physical plan necessary to compute all ancestor RDDs.
In the simplest case, the scheduler outputs a computation stage for each RDD
in this graph where the stage has tasks for each partition in that RDD. Those stages are
then executed in reverse order to compute the final required RDD.
In more complex cases, the physical set of stages will not be an exact 1:1
correspondence to the RDD graph. This can occur when the scheduler performs
pipelining, or collapsing of multiple RDDs into a single stage. Pipelining occurs when RDDs can be computed from their parents
without data movement. The lineage output shown in Example 8-8 uses indentation levels to show where RDDs are
going to be pipelined together into physical stages. RDDs that exist at the same level
of indentation as their parents will be pipelined during physical execution. For
instance, when we are computing counts, even though there are a large
number of parent RDDs, there are only two levels of indentation shown. This indicates
that the physical execution will require only two stages. The pipelining in this case
is because there are several filter and map operations in sequence. The right half of
Figure 8-1 shows the two stages
of execution that are required to compute the counts RDD.
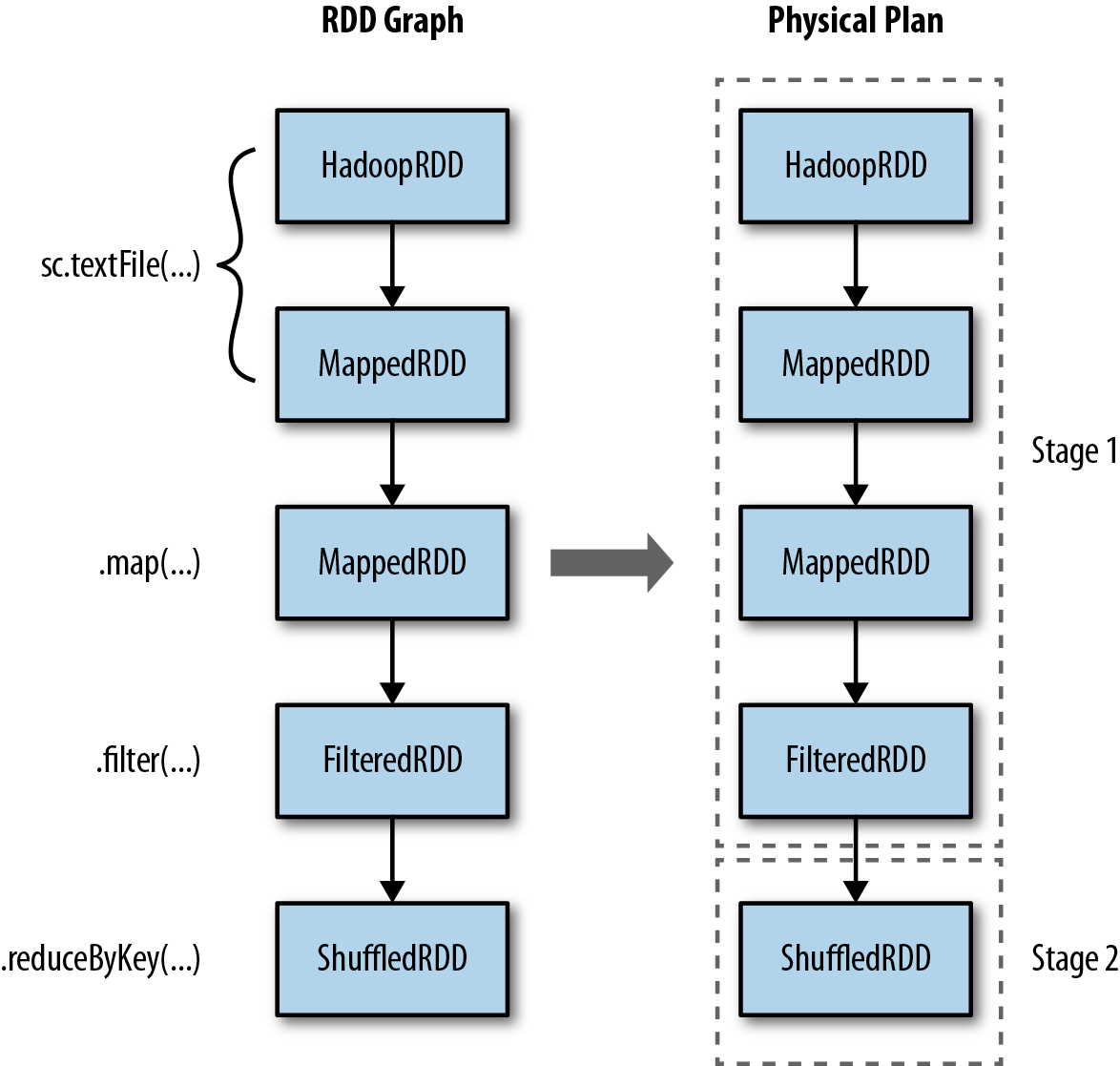
Figure 8-1. RDD transformations pipelined into physical stages
If you visit the application’s web UI, you will see that two stages occur in order to
fulfill the collect() action. The Spark UI can be found at http://localhost:4040 if you are running this example on your own
machine. The UI is discussed in more detail later in this chapter, but you can use it
here to quickly see what stages are executing during this program.
In addition to pipelining, Spark’s internal scheduler may truncate the lineage of the
RDD graph if an existing RDD has already been persisted in cluster memory or on
disk. Spark can
“short-circuit” in this case and just begin computing based on the persisted RDD. A
second case in which this truncation can happen is when an RDD is already materialized
as a side effect of an earlier shuffle, even if it was not explicitly
persist()ed. This is an under-the-hood optimization that takes
advantage of the fact that Spark shuffle outputs are written to disk, and exploits the
fact that many times portions of the RDD graph are recomputed.
To see the effects of caching on physical execution, let’s cache the
counts RDD and see how that truncates the execution graph for future
actions (Example 8-10). If you revisit the
UI, you should see that caching reduces the number of stages required when executing
future computations. Calling collect() a few more times will reveal only
one stage executing to perform the action.
Example 8-10. Computing an already cached RDD
// Cache the RDDscala>counts.cache()// The first subsequent execution will again require 2 stagesscala>counts.collect()res87:Array[(String,Int)]=Array((ERROR,1),(INFO,4),(WARN,2),(##,1),((empty,2))// This execution will only require a single stagescala>counts.collect()res88:Array[(String,Int)]=Array((ERROR,1),(INFO,4),(WARN,2),(##,1),((empty,2))
The set of stages produced for a particular action is termed a job. In each case when we invoke actions such as count(), we are
creating a job composed of one or more stages.
Once the stage graph is defined, tasks are created and dispatched to an internal scheduler, which varies depending on the deployment mode being used. Stages in the physical plan can depend on each other, based on the RDD lineage, so they will be executed in a specific order. For instance, a stage that outputs shuffle data must occur before one that relies on that data being present.
A physical stage will launch tasks that each do the same thing but on specific partitions of data. Each task internally performs the same steps:
-
Fetching its input, either from data storage (if the RDD is an input RDD), an existing RDD (if the stage is based on already cached data), or shuffle outputs.
-
Performing the operation necessary to compute RDD(s) that it represents. For instance, executing
filter()ormap()functions on the input data, or performing grouping or reduction. -
Writing output to a shuffle, to external storage, or back to the driver (if it is the final RDD of an action such as
count()).
Most logging and instrumentation in Spark is expressed in terms of stages, tasks, and shuffles. Understanding how user code compiles down into the bits of physical execution is an advanced concept, but one that will help you immensely in tuning and debugging applications.
To summarize, the following phases occur during Spark execution:
- User code defines a DAG (directed acyclic graph) of RDDs
-
Operations on RDDs create new RDDs that refer back to their parents, thereby creating a graph.
- Actions force translation of the DAG to an execution plan
-
When you call an action on an RDD it must be computed. This requires computing its parent RDDs as well. Spark’s scheduler submits a job to compute all needed RDDs. That job will have one or more stages, which are parallel waves of computation composed of tasks. Each stage will correspond to one or more RDDs in the DAG. A single stage can correspond to multiple RDDs due to pipelining.
- Tasks are scheduled and executed on a cluster
-
Stages are processed in order, with individual tasks launching to compute segments of the RDD. Once the final stage is finished in a job, the action is complete.
In a given Spark application, this entire sequence of steps may occur many times in a continuous fashion as new RDDs are created.
Finding Information
Spark records detailed progress information and performance metrics as applications execute. These are presented to the user in two places: the Spark web UI and the logfiles produced by the driver and executor processes.
Spark Web UI
The first stop for learning about the behavior and performance of a Spark application is Spark’s built-in web UI. This is available on the machine where the driver is running at port 4040 by default. One caveat is that in the case of the YARN cluster mode, where the application driver runs inside the cluster, you should access the UI through the YARN ResourceManager, which proxies requests directly to the driver.
The Spark UI contains several different pages, and the exact format may differ across Spark versions. As of Spark 1.2, the UI is composed of four different sections, which we’ll cover next.
Jobs: Progress and metrics of stages, tasks, and more
The jobs page, shown in Figure 8-2, contains detailed execution information for active and recently completed Spark jobs. One very useful piece of information on this page is the progress of running jobs, stages, and tasks. Within each stage, this page provides several metrics that you can use to better understand physical execution.
Tip
The jobs page was only added in Spark 1.2, so you may not see it in earlier versions of Spark.
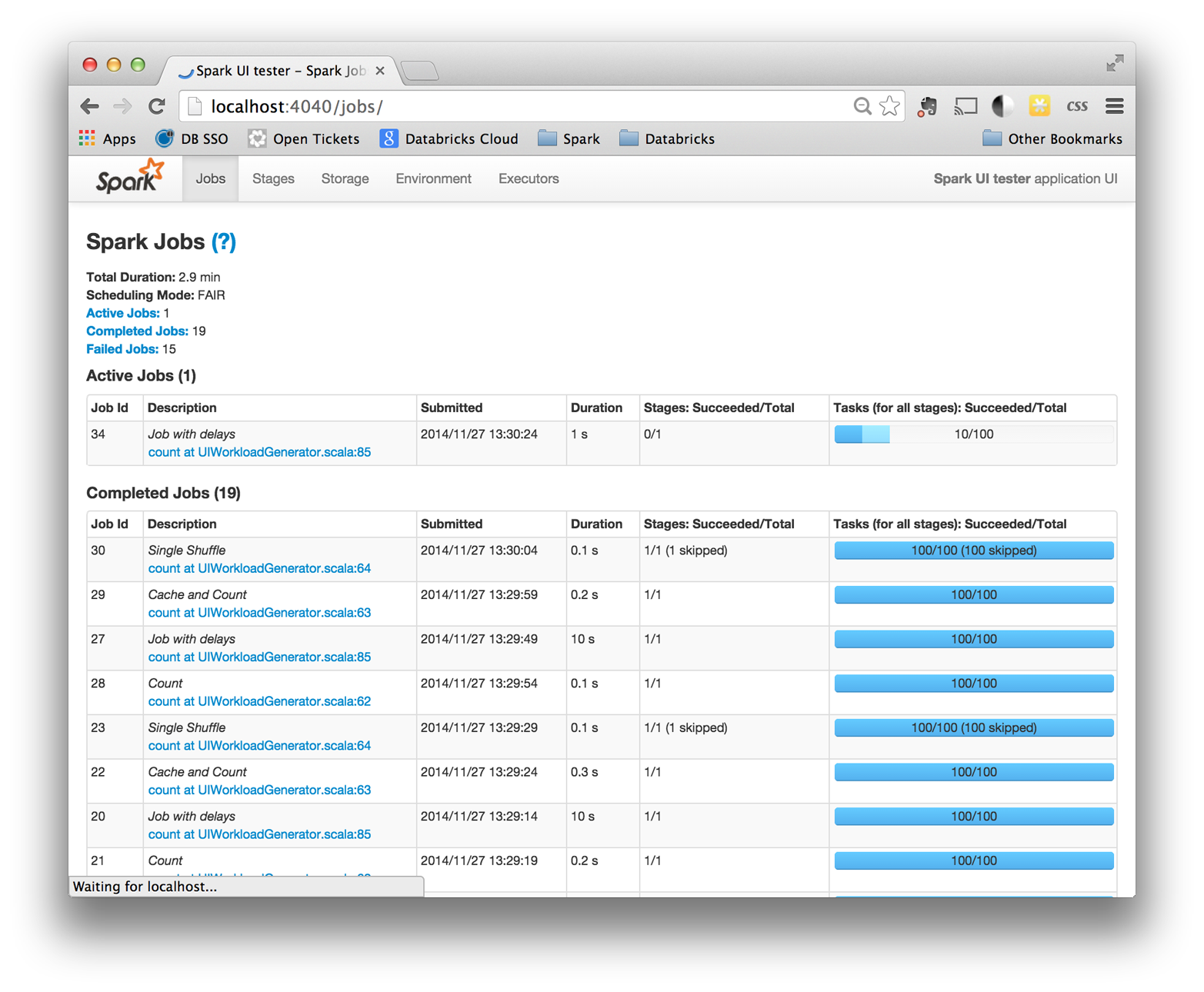
Figure 8-2. The Spark application UI’s jobs index page
A common use for this page is to assess the performance of a job. A good first step is to look through the stages that make up a job and see whether some are particularly slow or vary significantly in response time across multiple runs of the same job. If you have an especially expensive stage, you can click through and better understand what user code the stage is associated with.
Once you’ve narrowed down a stage of interest, the stage page, shown in Figure 8-3, can help isolate performance issues. In data-parallel systems such as Spark, a common source of performance issues is skew, which occurs when a small number of tasks take a very large amount of time compared to others. The stage page can help you identify skew by looking at the distribution of different metrics over all tasks. A good starting point is the runtime of the task; do a few tasks take much more time than others? If this is the case, you can dig deeper and see what is causing the tasks to be slow. Do a small number of tasks read or write much more data than others? Are tasks running on certain nodes very slow? These are useful first steps when you’re debugging a job.
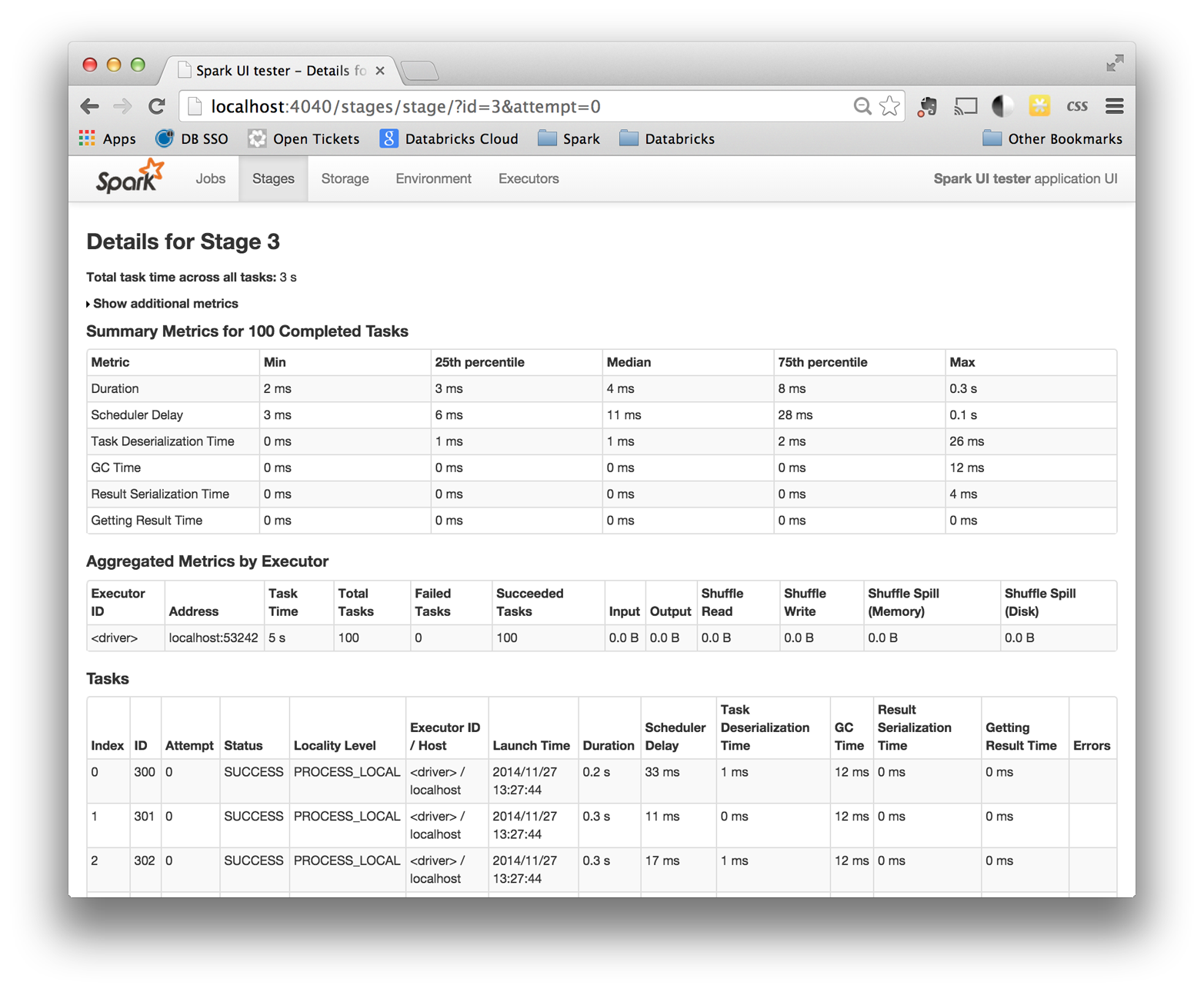
Figure 8-3. The Spark application UI’s stage detail page
In addition to looking at task skew, it can be helpful to identify how much time tasks are spending in each of the phases of the task lifecycle: reading, computing, and writing. If tasks spend very little time reading or writing data, but take a long time overall, it might be the case that the user code itself is expensive (for an example of user code optimizations, see “Working on a Per-Partition Basis”). Some tasks may spend almost all of their time reading data from an external storage system, and will not benefit much from additional optimization in Spark since they are bottlenecked on input read.
Storage: Information for RDDs that are persisted
The storage page contains
information about persisted RDDs. An RDD is persisted if someone called
persist() on the RDD and it was later computed in some
job. In some cases, if many RDDs are cached, older ones will fall out of
memory to make space for newer ones. This page will tell you exactly what
fraction of each RDD is cached and the quantity of data cached in various
storage media (disk, memory, etc.). It can be helpful to scan this page and
understand whether important datasets are fitting into memory or not.
Executors: A list of executors present in the application
This page lists the active executors in the application along with some metrics around the processing and storage on each executor. One valuable use of this page is to confirm that your application has the amount of resources you were expecting. A good first step when debugging issues is to scan this page, since a misconfiguration resulting in fewer executors than expected can, for obvious reasons, affect performance. It can also be useful to look for executors with anomalous behaviors, such as a very large ratio of failed to successful tasks. An executor with a high failure rate could indicate a misconfiguration or failure on the physical host in question. Simply removing that host from the cluster can improve performance.
Another feature in the executors page is the ability to collect a stack trace from executors using the Thread Dump button (this feature was introduced in Spark 1.2). Visualizing the thread call stack of an executor can show exactly what code is executing at an instant in time. If an executor is sampled several times in a short time period with this feature, you can identify “hot spots,” or expensive sections, in user code. This type of informal profiling can often detect inefficiencies in user code.
Environment: Debugging Spark’s configuration
This page enumerates the set of active properties in the environment of your Spark application. The configuration here represents the “ground truth” of your application’s configuration. It can be helpful if you are debugging which configuration flags are enabled, especially if you are using multiple configuration mechanisms. This page will also enumerate JARs and files you’ve added to your application, which can be useful when you’re tracking down issues such as missing dependencies.
Driver and Executor Logs
In certain cases users can learn more information from Spark by inspecting the logs produced directly by the driver program and executors. Logs contain more detailed traces of anomalous events such as internal warnings or detailed exceptions from user code. This data can help when you’re troubleshooting errors or unexpected behavior.
The exact location of Spark’s logfiles depends on the deployment mode:
-
In Spark’s Standalone mode, application logs are directly displayed in the standalone master’s web UI. They are stored by default in the work/ directory of the Spark distribution on each worker.
-
In Mesos, logs are stored in the work/ directory of a Mesos slave, and accessible from the Mesos master UI.
-
In YARN mode, the easiest way to collect logs is to use YARN’s log collection tool (running
yarn logs -applicationId <app ID>) to produce a report containing logs from your application. This will work only after an application has fully finished, since YARN must first aggregate these logs together. For viewing logs of a running application in YARN, you can click through the ResourceManager UI to the Nodes page, then browse to a particular node, and from there, a particular container. YARN will give you the logs associated with output produced by Spark in that container. This process is likely to become less roundabout in a future version of Spark with direct links to the relevant logs.
By default Spark outputs a healthy amount of logging information. It is also
possible to customize the logging behavior to change the logging level or log
output to non-standard locations. Spark’s logging subsystem is based on log4j, a widely used
Java logging library, and uses log4j’s configuration format. An example log4j
configuration file is bundled with Spark at
conf/log4j.properties.template. To customize Spark’s logging, first copy the example to a file
called log4j.properties. You can then modify behavior such as the root
logging level (the threshold level for logging output). By default, it is
INFO. For less log output, it can be set to WARN or
ERROR. Once you’ve tweaked the logging to match your desired level
or format, you can add the log4j.properties file using the
--files flag of spark-submit. If you have trouble
setting the log level in this way, make sure that you are not including any JARs
that themselves contain log4j.properties files with your application.
Log4j works by scanning the classpath for the first properties file it finds, and
will ignore your customization if it finds properties somewhere else first.
Key Performance Considerations
At this point you know a bit about how Spark works internally, how to follow the progress of a running Spark application, and where to go for metrics and log information. This section takes the next step and discusses common performance issues you might encounter in Spark applications along with tips for tuning your application to get the best possible performance. The first three subsections cover code-level changes you can make in order to improve performance, while the last subsection discusses tuning the cluster and environment in which Spark runs.
Level of Parallelism
The logical representation of an RDD is a single collection of objects. During physical execution, as discussed already a few times in this book, an RDD is divided into a set of partitions with each partition containing some subset of the total data. When Spark schedules and runs tasks, it creates a single task for data stored in one partition, and that task will require, by default, a single core in the cluster to execute. Out of the box, Spark will infer what it thinks is a good degree of parallelism for RDDs, and this is sufficient for many use cases. Input RDDs typically choose parallelism based on the underlying storage systems. For example, HDFS input RDDs have one partition for each block of the underlying HDFS file. RDDs that are derived from shuffling other RDDs will have parallelism set based on the size of their parent RDDs.
The degree of parallelism can affect performance in two ways. First, if there is too little parallelism, Spark might leave resources idle. For example, if your application has 1,000 cores allocated to it, and you are running a stage with only 30 tasks, you might be able to increase the level of parallelism to utilize more cores. If there is too much parallelism, small overheads associated with each partition can add up and become significant. A sign of this is that you have tasks that complete almost instantly—in a few milliseconds—or tasks that do not read or write any data.
Spark offers two ways to tune the degree of parallelism for operations. The first
is that, during operations that shuffle data, you can always give a degree of
parallelism for the produced RDD as a parameter. The second is that any existing
RDD can be redistributed to have more or fewer partitions. The
repartition() operator will randomly shuffle an RDD into the
desired number of partitions. If you know you are shrinking the RDD, you can use the
coalesce() operator; this is more efficient than
repartition() since it avoids a shuffle operation. If you think you
have too much or too little parallelism, it can help to redistribute your data
with these operators.
As an example, let’s say we are reading a large amount of data from S3, but then
immediately performing a filter() operation that is likely to exclude
all but a tiny fraction of the dataset. By default the RDD returned by
filter() will have the same size as its parent and might have many
empty or small partitions. In this case you can improve the application’s
performance by coalescing down to a smaller RDD, as shown in Example 8-11.
Example 8-11. Coalescing a large RDD in the PySpark shell
# Wildcard input that may match thousands of files>>>input=sc.textFile("s3n://log-files/2014/*.log")>>>input.getNumPartitions()35154# A filter that excludes almost all data>>>lines=input.filter(lambdaline:line.startswith("2014-10-17"))>>>lines.getNumPartitions()35154# We coalesce the lines RDD before caching>>>lines=lines.coalesce(5).cache()>>>lines.getNumPartitions()4# Subsequent analysis can operate on the coalesced RDD...>>>lines.count()
Serialization Format
When Spark is transferring data over the network or spilling data to disk, it needs to serialize objects into a binary format. This comes into play during shuffle operations, where potentially large amounts of data are transferred. By default Spark will use Java’s built-in serializer. Spark also supports the use of Kryo, a third-party serialization library that improves on Java’s serialization by offering both faster serialization times and a more compact binary representation, but cannot serialize all types of objects “out of the box.” Almost all applications will benefit from shifting to Kryo for serialization.
To use Kryo serialization, you can set the spark.serializer setting
to org.apache.spark.serializer.KryoSerializer. For best performance,
you’ll also want to register classes with Kryo that you plan to serialize, as
shown in Example 8-12. Registering a
class allows Kryo to avoid writing full class names with individual objects, a space savings that can
add up over thousands or millions of serialized records. If you want to force this
type of registration, you can set spark.kryo.registrationRequired to
true, and Kryo will throw errors if it encounters an unregistered
class.
Example 8-12. Using the Kryo serializer and registering classes
valconf=newSparkConf()conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")// Be strict about class registrationconf.set("spark.kryo.registrationRequired","true")conf.registerKryoClasses(Array(classOf[MyClass],classOf[MyOtherClass]))
Whether using Kryo or Java’s serializer, you may encounter a
NotSerializableException if your code refers to a
class that does not extend Java’s Serializable interface. It can be difficult to
track down which class is causing the problem in this case, since many different
classes can be referenced from user code. Many JVMs support a special option to
help debug this situation: "-Dsun.io.serialization.extended
DebugInfo=true". You can enable this option this using the
--driver-java-options and --executor-java-options
flags to spark-submit. Once you’ve found the class in question, the
easiest solution is to simply modify it to implement Serializable. If you cannot
modify the class in question you’ll need to use more advanced workarounds, such as
creating a subclass of the type in question that implements Java’s Externalizable interface or customizing the
serialization behavior using Kryo.
Memory Management
Spark uses memory in different ways, so understanding and tuning Spark’s use of memory can help optimize your application. Inside of each executor, memory is used for a few purposes:
- RDD storage
-
When you call
persist()orcache()on an RDD, its partitions will be stored in memory buffers. Spark will limit the amount of memory used when caching to a certain fraction of the JVM’s overall heap, set byspark.storage.memoryFraction. If this limit is exceeded, older partitions will be dropped from memory. - Shuffle and aggregation buffers
-
When performing shuffle operations, Spark will create intermediate buffers for storing shuffle output data. These buffers are used to store intermediate results of aggregations in addition to buffering data that is going to be directly output as part of the shuffle. Spark will attempt to limit the total amount of memory used in shuffle-related buffers to
spark.shuffle.memoryFraction. - User code
-
Spark executes arbitrary user code, so user functions can themselves require substantial memory. For instance, if a user application allocates large arrays or other objects, these will contend for overall memory usage. User code has access to everything left in the JVM heap after the space for RDD storage and shuffle storage are allocated.
By default Spark will leave 60% of space for RDD storage, 20% for shuffle memory, and the remaining 20% for user programs. In some cases users can tune these options for better performance. If your user code is allocating very large objects, it might make sense to decrease the storage and shuffle regions to avoid running out of memory.
In addition to tweaking memory regions, you can improve certain elements of
Spark’s default caching behavior for
some workloads. Spark’s default cache() operation persists memory
using the MEMORY_ONLY storage level.
This means that if there is not enough space to cache new RDD partitions, old ones
will simply be deleted and, if they are needed again, they will be recomputed. It
is sometimes better to call persist() with the
MEMORY_AND_DISK storage level, which instead
drops RDD partitions to disk and simply reads them back to memory from a local
store if they are needed again. This can be much cheaper than recomputing blocks
and can lead to more predictable performance. This is particularly useful if your
RDD partitions are very expensive to recompute (for instance, if you are reading
data from a database). The full list of possible storage levels is given in Table 3-6.
A second improvement on the default caching policy is to cache serialized objects
instead of raw Java objects, which you can accomplish using the
MEMORY_ONLY_SER or MEMORY_AND_DISK_SER storage
levels. Caching
serialized objects will slightly slow down the cache operation due to the cost of
serializing objects, but it can substantially reduce time spent on garbage
collection in the JVM, since many individual records can be stored as a single
serialized buffer. This is because the cost of garbage collection scales with the
number of objects on the heap, not the number of bytes of data, and this caching
method will take many objects and serialize them into a single giant buffer.
Consider this option if you are caching large amounts of data (e.g., gigabytes) as
objects and/or seeing long garbage collection pauses. Such pauses would be visible
in the application UI under the GC Time column for each task.
Hardware Provisioning
The hardware resources you give to Spark will have a significant effect on the completion time of your application. The main parameters that affect cluster sizing are the amount of memory given to each executor, the number of cores for each executor, the total number of executors, and the number of local disks to use for scratch data.
In all deployment modes, executor memory is set with
spark.executor.memory or the --executor-memory flag to
spark-submit. The options for
number and cores of executors differ depending on deployment mode. In YARN you can set
spark.executor.cores or the --executor-cores flag and
the --num-executors flag to determine the total count. In Mesos and
Standalone mode, Spark will greedily acquire as many cores and executors as are
offered by the scheduler. However, both Mesos and Standalone mode support setting
spark.cores.max to limit the total number of cores
across all executors for an application. Local disks are used for scratch storage
during shuffle operations.
Broadly speaking, Spark applications will benefit from having more memory and cores. Spark’s architecture allows for linear scaling; adding twice the resources will often make your application run twice as fast. An additional consideration when sizing a Spark application is whether you plan to cache intermediate datasets as part of your workload. If you do plan to use caching, the more of your cached data can fit in memory, the better the performance will be. The Spark storage UI will give details about what fraction of your cached data is in memory. One approach is to start by caching a subset of your data on a smaller cluster and extrapolate the total memory you will need to fit larger amounts of the data in memory.
In addition to memory and cores, Spark uses local disk volumes to store
intermediate data required during shuffle operations along with RDD partitions
that are spilled to disk.
Using a larger number of local disks can help accelerate the performance of Spark
applications. In YARN mode,
the configuration for local disks is read directly from YARN, which provides its
own mechanism for specifying scratch storage directories. In Standalone mode, you
can set the SPARK_LOCAL_DIRS environment variable in
spark-env.sh when deploying the Standalone cluster and Spark
applications will inherit this config when they are launched. In Mesos mode, or if
you are running in another mode and want to override the cluster’s default storage
locations, you can set the spark.local.dir option. In all cases you specify the local directories using a single
comma-separated list. It is common to have one local directory for each disk
volume available to Spark. Writes will be evenly striped across all local
directories provided. Larger numbers of disks will provide higher overall
throughput.
One caveat to the “more is better” guideline is when sizing memory for
executors. Using very large heap sizes can cause garbage collection
pauses to hurt the throughput of a Spark job. It can sometimes be beneficial to
request smaller executors (say, 64 GB or less) to mitigate this issue. Mesos and
YARN can, out of the box, support packing multiple, smaller executors onto the
same physical host, so requesting smaller executors doesn’t mean your application
will have fewer overall resources. In Spark’s Standalone mode, you need to launch
multiple workers (determined using SPARK_WORKER_INSTANCES) for a
single application to run more than one executor on a host. This
limitation will likely be removed in a later version of Spark. In addition to
using smaller executors, storing data in serialized form (see “Memory Management”) can also help alleviate
garbage collection.
Conclusion
If you’ve made it through this chapter, you are well poised to tackle a production Spark use case. We covered Spark’s configuration management, instrumentation and metrics in Spark’s UI, and common tuning techniques for production workloads. To dive deeper into tuning Spark, visit the tuning guide in the official documentation.