
Making IT Better: Managing Changes, Risks, and Quality
In the previous chapter, we have introduced the basics for managing a project. In fact, goals, time, and costs establish the characteristics of the products to build, the work to be performed, its timing, and its costs.
In the scenario, we set in the previous chapter, we followed the process end-to-end, but little space was dedicated to the unpredictability of projects. We discussed uncertainties of estimations and hinted about variations in Section 3.9, where we saw how to evaluate progress in a project.
It is time to start all over! In this chapter, we introduce two main sources of perturbations in the plans we defined in the previous chapter. The first main source of perturbation is a request for changes; the second is project risks. Both are necessary and unavoidable. Fortunately, we also have techniques to control and tame these sources of entropy. They are change control and configuration management, risk management, and quality management.
4.1 Managing Changes
During a project, requests to change the work to be performed or some of the characteristics of the deliverables to produce will originate from internal and external stakeholders, for the most diverse reasons, such as
- Incompleteness or incoherencies in the project requirements or in the description of work, which were not apparent when the project started
- A better comprehension of the system to be developed, which provides an opportunity for a smarter construction of a project deliverable
- A technical opportunity, which could yield a more efficient or a more feature-rich deliverable
- A technical challenge, which makes the construction of the deliverable impossible with the approach chosen when the activity started
- A change in the external environment, including an influent stakeholder changing his/her opinion or a change in the business landscape, such as the launch of a new competing product*
- Noncompliance, if a deliverable does not conform to its specifications.
A request for changes and changes in a project have a cost, provide an opportunity, and constitute a perturbation and a risk.
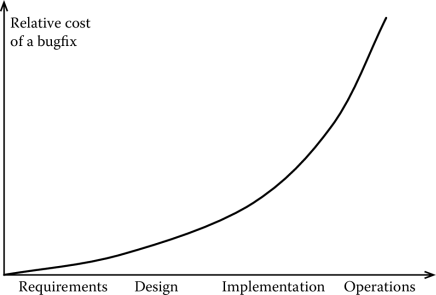
That a request for changes has a cost should be relatively intuitive, although not obvious at first. After all, software is extremely flexible: change a function here, modify something else there, and you are done. This is, however, a simplification. Work is needed to follow up on the change request and ensure that all changes are propagated to the relevant artifacts. As we pointed out in the introduction, the cost of changes in a project, in fact, increases as the project develops. For instance, Figure 4.1 shows the increasing cost of fixing a bug during different phases of software development.
With costs also come opportunities. There are many situations in which a change to the planned course of action gives an opportunity to improve the quality of deliverables at little or no cost or improve other project metrics, such as cost and schedule.
The medium- and long-term effects of changes, however, need to be carefully analyzed and constitute a risk. Introducing a modification in agreed work and taking a new route introduces uncertainties. Under the pressure of project execution, forgetting some initial hypotheses on which a specific choice is based or underestimating the impact of a change can be a significant source of trouble.
Another important consideration is that changing a course of action while the work is not complete requires a lot of discipline and attention to make sure we do not get stuck in the middle of the road, failing to fully implement the new route, and having difficulties going back to the initial situation.
For the reasons mentioned above, it is a good idea to have a controlled process to manage changes. This should be done in the early phases of a project, by adopting or defining a standard to manage changes that are agreed on by all stakeholders.
The process should achieve the following goals:
- Ensuring that all stakeholders agree on the fact that a request for change has occurred. This is to avoid what is called scope creeps, namely, a steady flow of small changes that causes a project to drift out of control. A typical example is a flow of clarifications on the work statement occurring directly between the developers and the customer, which slowly changes the initial formulation of the work to be performed.
- Ensuring that changes are beneficial and agreed on by all stakeholders. Different stakeholders might have contrasting views on the system. If changes are incorporated as soon as they are elicited from one stakeholder, they might disagree with the vision of other stakeholders. We might thus end up building a system that is different from the one some stakeholders expected. This can potentially lead to significant rework, adding and removing features.
- Protecting the coherency of a project and of its outputs. Projects produce many deliverables whose content is interrelated. Every time we introduce a change, we need to ensure that changes propagate to all relevant artifacts. If this is not done, the quality of artifacts will degrade over time causing failures or making a system more difficult to maintain.
Many processes have been proposed to manage changes. They all share four characteristics.
The first is that they formally record and document that a request for a change has occurred. This requires one to document requests, possibly with additional information, such as the originator and motivation. Note that the documentation of request for changes simplifies project acceptance. In fact, even if there is complete agreement between the client and the project team, it might as well be that the reference people change during the project and that the person (or people) in charge of accepting project outputs are different from the ones with whom the changes to the project scope have been agreed with. If such changes are not documented, the situation might be difficult to handle.
The second is that they define how to decide whether a request for a change will be accepted or not. The decision process typically includes an evaluation of the request (e.g., importance and relevance), an evaluation of the ways in which the request can be incorporated, an evaluation of the impact of the request (namely, what has to be changed to accommodate the change), and the approval or rejection process (namely, who decides).
The third is that they all record the life cycle of change requests, so that it can be established whether a change request has been approved and, if so, when it has taken place. The process also ensures that there is accountability for the decisions that are taken in a project.
Finally, all processes specify who has to be involved or informed about the change. This is to ensure that everyone is informed about the current status of a system. When information does not flow as expected, in fact, difficult situations might occur. A very nice example comes again from Cox and Murray (2004). In an early launch of one vector of the Mercury program, a vector failed to lift off from the launchpad. A series of subsequent events, such as the automatic deployment of Mercury’s parachute (which could work as a sail and cause the vector to crashland) and the fact that the vector was fueled and in an unknown status contributed to raising various concerns, till the situation was recovered with no incident. The cause of the failure was traced back to a small change to one of the prongs of one plug connecting the missile to the umbilical tower. One technician had removed a quarter of an inch from one of the prongs of a plug, to ensure that it would fit more easily into the plug; he did not tell anyone. During the launch, however, the shortened prong detached a bit earlier than the longer one, determining a nonnominal situation and causing the onboard computer to decide that it was safer to shut off the engine.
In the following two subsections, we look at two different approaches to change management in software development projects.
*Notice that important and influential stakeholders, similar to politicians, never change their opinion: it is our perception of their thoughts that changes.
4.1.1 Managing Changes in the Traditional Approach
Figure 4.2 shows an example of change management process. It is a simplified version of the one defined (NASA, 2007).
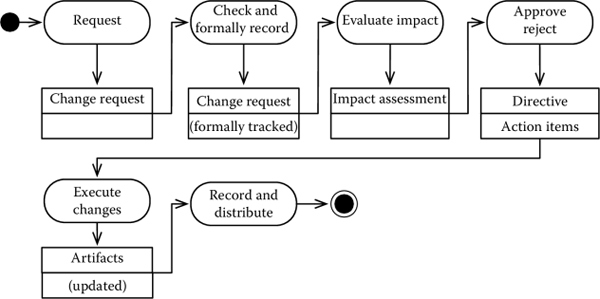
The first step is the creation of a request for a change. Requests are filed by the stakeholders (including the project team) when the need arises. Special templates can be used to file requests, to ensure that a minimal set of information is entered.
Change requests are then assigned a priority and organized as
- Nonconformance reports, in case a released item is not compliant with some of its specifications. They can be further classified according to their severity, for instance, by using a three-level classification (critical, major, minor).
- Concessions, in case an item is compliant with its specifications, but a change of the specification offers an opportunity to meet some needs better.
- Waivers, in case an item is intentionally released without meeting its specifications (because, for instance, the specifications were wrong or irrelevant).
The possible impacts of the change request are then analyzed and the information used to decide whether the change has to be considered further or not. The actual decision procedure varies. In many cases, it is based on a consensus by the members of a control board, which authorizes or rejects a change. In formal environments, an aspect to consider for the operations of the control board is the management of conflicts and situations in which a consensus cannot be reached. A simple solution is based on majority voting. Other solutions include more articulated processes, in which the motivations for a choice are further refined and discussed till an agreement is reached.
Once the decision is taken, a formal record of the decision is kept and the appropriate actions taken. These include doing the technical work to incorporate the changes, properly supervising activities to ensure that all changes take place, and informing all stakeholders. Failing to inform the relevant stakeholders might cause significant trouble, since unaware stakeholders might do work based on obsolete information, compromising the integrity of the system.
As mentioned earlier, other processes have been defined and used. See, for instance, Northwestern University Information Technology (2011) and Fermi National Accelerator Lab (2010).
Change requests are very common in software development. Issue and bug tracking systems are used to keep a record of the change requests and to support the change management process. See Section 6.4 of the Bugzilla Development Team (2006) for a change management process related to software products.
4.1.2 Managing Changes in the Agile Methods
The change management process in agile methodologies is a simplified version of the process described in the previous section.
It is a three-step process composed of the following steps:
- Solicit potential change requests from any project stakeholder, including the project team, clients, and sponsors. If the request originates from the project sponsor or customer, also elicit the potential payoff (how much the change is important for the customer).
- Document the change request, using the most appropriate mean, given the project size and level of formality. Anything from an email to a signed scope request change document can do. Assign the change the status “open” and put it in the product backlog, together with the other feature requests that are planned for the system.
- When the sprint ends, the change request is treated like any other system feature in the backlog.
4.1.3 Configuration Management
Software systems are composed of many different items and artifacts: documents describing requirements and architectures, test plans, test outputs, source code files, manuals, and support scripts (for instance, for managing packaging and deployment), to mention the main ones. These artifacts are the building blocks that need to be assembled together to build an application. Unfortunately, they are also extremely simple to change. These two facts pose two challenges.
The first challenge is that changes to an element of a software system typically impact various other artifacts of the system. Consider, for instance, a modification to a requirement performed after the release of a system, that is, when the source code and other project artifacts are already available. The change to the requirement might cause a modification to the architecture and it will most likely require some portions of the source code to be changed, namely, those that implement the requirement that has changed. This is not all, however: test plans might need to be updated, so that the new test cases test the new version of the requirement (rather than the old version); the user manual might also need to be updated. If the change has a major impact, other system artifacts such as conversion and installation scripts might also need a revision.
The second challenge is that applications live in different configurations and states. For instance, we could have a base version and a pro version, sharing various artifacts or releasing different versions of our product over time. As our system evolves, we will have different versions in use. Our development and support plans will thus have to take into account all the different versions in use.
For instance, as of May 1, 2013, at least four versions of Internet Explorer are in use. The newest and the oldest version, namely, IE10 and IE6, have roughly 6% of the total users, while IE9 and IE8 have, respectively, 18% and 23% of the market share. Other browsers account for the remaining 53% (NetMarketShare, 2013). When Microsoft releases a fix of a critical security bug, it has to do so for all the different versions currently in use.
This is where change and configuration management (CM) come into play. CM is, in fact, a set of activities running in parallel with the development process, whose goal is to establish and maintain the system’s coherency over time. According to NASA (2007), “The impact of not doing CM may result in a project being plagued by confusion, inaccuracies, low productivity, and unmanageable configuration data.” CM clearly interacts with the change management workflow, ensuring that approved changes are dealt with. To support CM activities, versioning systems are used often.
In the rest of this section, we will look at these activities in more detail, starting from some considerations about evolutionary models for software.
4.1.3.1 Configuration Management Goals and Practices
According to the ESA Board for Software (1995), a CM process needs to achieve eight different goals, which are meant to ensure that we have control over our system, its evolution, and that we can properly manage changes that have been approved.
The first four goals focus on ensuring that we can identify the components of our system, that we can build a system from a consistent set of components, that the software components are available and accessible, and that the software never gets lost. These four requirements are not as trivial as they sound. Let us look at some scenarios in which the requirements are not met.
Consider, for instance, a case in which a software system uses a database to store data. The database needs to be populated with an initial set of data that is essential for the system to run. The team uses a setup script to perform this task. As the system evolves, however, most of the development work focuses on other areas. The script is not needed anymore and the team forgets about it. Various releases later, a new fresh installation of the system is required. However, the setup script is not available anymore and needs to be rewritten.
Another very common situation occurs when a system depends upon external libraries and components. If we do not keep them under control, we fail to satisfy the second requirement, namely, that the system is built from a consistent set of components. Think of a situation, for instance, in which we fail to realize that a developer has introduced some incompatible changes to a library that we use to build our system and we do not pay much attention about what version of the library we use.
Finally, ensuring that the software components and the software itself are always available and accessible is sometimes difficult to achieve. Some readers might recognize a situation occurring during software development, in which certain artifacts might reside only on the computer of a developer. Equal attention has to be taken after a system release. Think of a case in which the sources of a system developed years before have to be retrieved to fix a bug. Good data archival procedures and keeping the storage media functional can make the difference.
The points mentioned above are taken care of by a configuration identification activity, which has the goal of defining what artifacts constitute a system. Its outputs include
- The list of items that constitute a product. In the case of software development, the items that typically need to be put under configuration control include the source code, support documents (e.g., requirements and architecture documents), support scripts (e.g., testing and data migration scripts), and manuals. In case of software that requires special components or compilers to be built, it is also a good practice to include the tools necessary to build the software.
- The characteristics of the items, including the relationships among these items, performance, interfaces, and other attributes.
- An appropriate identification and numbering scheme, to uniquely identify an item. The numbering scheme and the list of items are used to define a product baseline, where the baseline is a set of configuration items, that has been formally approved and that can be used as a basis for further development.
The second set of goals of ESA Board for Software (1995) deals with changes. In particular, it states that in a good CM process, every change to the software is approved and documented, changes do not get lost, it is always possible to go back to a previous version, and a history of changes is kept, so that it is always possible to discover who did what and when.
To satisfy this second set of requirements, we need to establish proper procedures for configuration status accounting. In fact, they define how to formally record the item characteristics, history of changes, status of proposed changes, and baseline records, where a baseline record lists, for each baseline, the corresponding version of each configuration item composing the product identified by the baseline. (Baseline records are automatically stored by version control systems.) Configuration status accounting is the responsibility of a designated member of the project team. For software projects, the configuration status accountant is also called the software librarian.
An important operation to keep track of is the release process. Release occurs when a product is released externally to the project. For software systems, the operation occurs when a system is put in production or made available to the public. The artifacts typically associated with a release are the product itself and release notes, that is, a document that lists the most notable (or all the) changes that occurred since the previous release. See Section 2.5 for more details about the release process.
4.1.3.2 Versioning Systems and Software Evolution Models
A versioning system is a tool to support part of the CM process. To present how they work, we start from the discussion about the different versions of Internet Explorer and look at the way in which software evolves. Software, in fact, evolves according to a linear or a branching model.
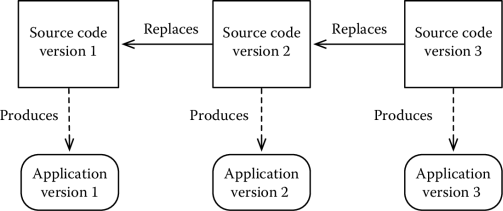
When we have only a single running version of our application, a system can evolve linearly. Each new version of the artifacts to build an application replaces the previous ones. We can maintain copies of the older version of the artifacts—and this is usually a very good practice—or simply forget about them: the only important version is the last one.* This is shown in Figure 4.3. The linear development model works for many different types of applications, including all those web applications offered whose owners retain the code (think, e.g., Google Documents); another example are one-offs.
Things become more complex if our system lives in different configurations (e.g., a base version and a pro version; a version for Linux and one for Mac) or different versions of the same application (like in the case of the Internet Explorer, above). In this situation, we need to keep track of all versions in use and support the parallel evolution of the different versions of our system.
This changes the evolution model from a linear model to a branching model, in which the relationships between different versions of a system can be represented by a tree or, as we will see shortly, a graph. This is shown in Figure 4.4, where the evolution of a system takes into account the fact that each release can evolve independently. Each different version of our system lives in a branch of our tree of configurations.
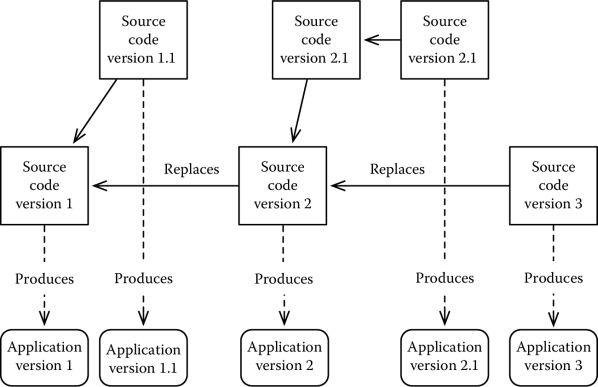
When using a branching model, new versions of a system generate new branches. In some cases, it is possible or necessary to merge branches, that is, build a new system that includes all the features of two different versions of our software. Various tools automatically manage branch merging, if the branches being merged have a common ancestor. This is shown in Figure 4.5.
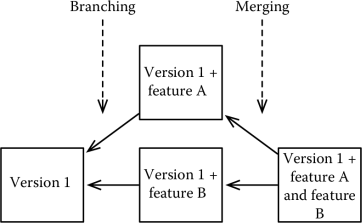
A versioning system is a tool that allows one to manage software evolution both in the linear and the branching models. Versioning systems are typically based on two concepts: a repository, where all the versions of a system reside, and a working copy, which is the copy currently used for development. Commands allow one to commit (i.e., store) artifacts in the repository and retrieve branch, and merge old versions. Versioning systems can be distributed, if there are many repositories that can be branched and merged, or centralized, if there is only one repository. Distributed versioning systems are very popular in open source development.
In modern software development practices, versioning and branching are used extensively: in some development models, a branch is created for every new feature being developed. Merging commands then allow one to put together the different functions being developed in parallel. This development model allows one to separate concerns, since each branch focuses on one set of changes to the code.
A standard way to identify a specific version of a system is to use a numbering system. A popular approach uses three numbers, N.M.P, where P is incremented every time we make a small change to the system, M is changed if we modify a more significant part of the system, and N is changed when the system undergoes major modifications. The version number can be labeled by strings identifying special system states. For instance, “alpha” and “beta” can be used to denote early releases of a system, and “RCX” (where “X” is a number) to denote a “release candidate,” that is, software nearly ready for a public release. Werner (2013) provides clear and simple conventions for version numbering.
*Things are slightly more complex. Sometimes, it is necessary to retrace our steps and restore an old version. This happens, for instance, if we introduce a critical bug. A simple solution is to revert and start all over again.
4.2 Risk Management
Various definitions of risk exist, according to the domain and the standard adopted. Similar to many other definitions given in this book, we use that of Project Management Institute (2004), where a risk is defined as “an uncertain event or condition that, if it occurs, has a positive or a negative effect on a project objective. A risk has a cause and, if it occurs, a consequence.”
Thus, a risk in project management might either have a positive or a negative effect. We speak of menaces to identify risks that might negatively affect a project and opportunities to identify those risks that might positively affect a project.
Many of us are bad at perceiving risks and uncertainty. Unexpected events exert pressure and cause stress and, under stress, we distort reality and take the wrong decisions—the phenomenon is known to psychologists under the term of cognitive distortion; see, for instance, Forensic Psychology Practice Ltd. (1999).
Defining a project that considers risks from the early phases of a project and manages them throughout the project life cycle is therefore a very good idea. There are, in fact, two good uses. First, it gives the project manager and the other stakeholders more tools to understand whether a project is worth undertaking and what factors have to be taken into account and monitored. Second, it gives the project manager the possibility of defining a strategy to manage risks when there is neither the pressure nor the stress coming from a project in full swing.
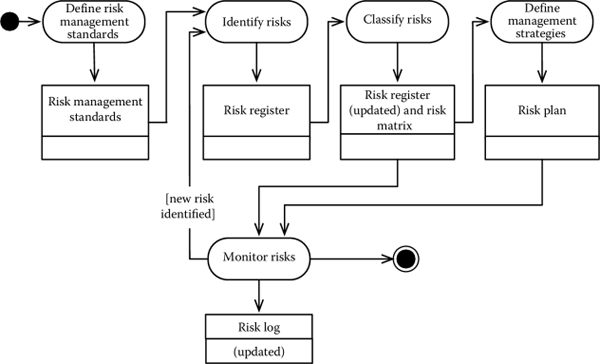
With little variations, the process generally agreed for managing risks is shown in Figure 4.6 and is composed of the following five steps:
- Define standards for managing risks. During this phase, the project manager defines the process according to which risks will be identified along with the procedures for managing risks where they occur.
- Identify risks. During this phase, the project risks are identified.
- Classify risks. During this phase, the project risks are classified by assigning a probability and an impact. This is the basis for understanding the most important risks to track in the project. Different techniques exist to classify risks, some of them qualitative and others based on a quantitative approach.
- Define a management strategy. Given the classification of risks in the previous step, a management strategy is defined for each risk or, better, for classes of risks. This allows the project manager and the stakeholders to agree on the policies to apply should a risk occur.
- Monitor risks. During project execution, the risks are monitored and the appropriate strategies applied should a risk occur.
In the rest of this section, we look at the main techniques and methodologies to implement the different steps.
4.2.1 Define Standards
The first step in this process is the definition of the standards that will be applied during the other phases. The main output of this activity is the definition of a risk management plan, which identifies what are the procedures to monitor and update risks and who is in charge of what operations.
As we will see in the next sections, the management of a risk involves the activation of a contingency plan, defined to properly deal with the risk. The risk management plan defines who is responsible for raising a warning and who is to be warned; who is responsible for approving the activation of the contingency plan; and what are the formal steps to record the activation of the plan.
Note that projects differ greatly in the level of formality and, consequently, on the procedure to activate the contingency plans. For small teams and small projects (or low-risk projects), the procedure might be as simple as a democratic decision. Similar considerations apply to the contingency plans, which could be additional actions that are taken in parallel to the main plan or, in more complex situation, alternative paths of actions that replace the nominal plan.
Another aspect that is often considered by the risk management plan involves the procedures to revise risks and contingency plans. These include both the frequency with which the process will be conducted and, similar to the previous step, the roles and responsibilities.
A good example of a risk management plan can be found in Jones (1998).
4.2.2 Identify Risks
The goal of this activity is to identify all the risks pertaining to a specific project. One of the criticalities related to this activity is to come out with a list that is specific and complete where by complete we mean that all the project risks have been identified, and by specific we mean that the risks apply to the project at hand (rather than applying to any project in general).
Risk identification can be organized in two steps. A collection step allows the project manager to collect all the potential risks of a project. The most common ways of collecting risks include meetings, which can be structured in different ways (see Section 5.3.3.1), analysis of project documents, and the use of checklists, which list common risks for a category of projects.
An analysis steps is then performed to structure the information gathered at the previous point and identify, among all potential critical items, the risks that have to be monitored. The main goal is to avoid common mistakes, such as misinterpreting effects as causes. For instance, the loss of 10,000 euros for a late delivery in a project could be wrongly evaluated as a cause, rather than as the effect of another more fundamental project event, such as poor team performance, which is the actual menace to monitor. There are several analysis techniques and Project Management Institute (2004) provides a rather complete reference on the matter. Here we mention root cause analysis, which progressively identifies the elementary events contributing to a potential risk.
The output of this activity is a risk register, namely, a list of the risks that are applicable to the project at hand. The risk register comes in the form of a table, with one risk per row, and in which the risks are at least annotated with
- A description, which describes and qualifies the risk
- A risk category, to classify the risk as an opportunity or a menace
- A time frame, which corresponds to the period in which the risk can occur
- A root cause, which identifies the root cause of a risk.
Other information, such as probability and impact, is attached to the risk as the analysis progresses (see the next sections).
4.2.3 Some Common Risks in Software Development
Many software development projects have similar features. Starting from general considerations about the risks most often occurring in software development projects can thus be used as an inspiration to determine what are the actual risks that apply to the project we have at hand.
Barry Boehm developed the first and probably most famous list of risks for software systems (Boehm, 1988). His analysis includes the following main reasons why projects fail:
- Personnel shortfalls, due, for instance, to difficulty in getting personnel with adequate skills and maturity.
- Unrealistic schedules and budgets, due to the difficulties we have discussed in the previous chapter.
- Developing the wrong software functions and developing the wrong user interface, due to the difficulties related to understanding correctly the requirements.
- Gold-plating, namely, developing nonimportant functions. This risk originates both from the client, who might ask for features that are not really needed, and from the team, which might engage in lower priority activities that are more fun to develop.
- Continuing stream of requirement changes, as we have discussed in Section 4.1 with the scope creep.
- Shortfalls in externally performed tasks, that is, the quality of the work of subcontractors is lower than that expected and required.
- Performance shortfalls and straining computer science capabilities, when the technical difficulty of the system to be built is considerable.
Various other lists are available on the Internet. Many highlight risks very similar to those identified by Boehm. However, it is also worth mentioning the lack of involvement of stakeholders, the inadequate management of changes, and the lack of an adequate project management methodology. See, for example, Wallace and Keil (2004), Schmidt et al. (2001), and Arnuphaptrairong (2011) for a survey on the matter.
Sommerville (2007) provides a different and higher-level starting point. Risks, in fact, are organized in three main areas: project-related risks, which include all risks related to the development process of a software system, such as schedule and costs; product-related risks, which include all risks inherent in the solution being developed, such as performance and quality; and business-related risks, which include all risks related to the environment in which a project develops, such as the marketability of a solution. Risk identification can thus proceed by analyzing what risks we could have in each area.
4.2.4 Classify Risks
Once we have identified the risks of our project, the next step is to understand what risks are worth monitoring. Risks are usually classified along two dimensions:
- The probability that the risk will occur
- The impact that the risk will have
The combination of probability and impact determines if a risk is worth further attention or not. There are two main approaches to determining probability and impact: qualitative and quantitative.
In the qualitative approach, the project manager (or the person/team responsible for evaluating the risk) gives a rough evaluation of the probability and impact of each risk. The evaluation is given in terms of values chosen out of a predefined scale. A very common classification is given in Table 4.1, where both probability and impact are classified with one out of five values. Different representations can be adopted, such as, for example, text, integers, or real numbers. Their meaning, however, is the same: it is a qualitative measure of the perceived likelihood and impact of a risk.
Common Probability and Impact Ranges
Probability |
Impact |
||||
|---|---|---|---|---|---|
As Text |
As a Real Number |
As an Integer |
As Text |
As a Real Number |
As an Integer |
Very low |
0.2 |
1 |
Negligible |
0.2 |
1 |
Low |
0.4 |
2 |
Small |
0.4 |
2 |
Normal |
0.6 |
3 |
Significant |
0.6 |
3 |
High |
0.8 |
4 |
Severe |
0.8 |
4 |
Very high |
1 |
5 |
Catastrophic |
1 |
5 |
Remark
A mistake that is often made is to believe that representing impact and probability with numbers makes the method quantitative. That is, using 4, rather than severe, moves the assessment from qualitative to quantitative.
Different from what we are doing in this section, however, quantitative methods provide a (mathematically) precise way of determining probability and impact, something that we do not do with the methods we described above.
Probability and impact define the relevance of a risk for a project. Such relevance can be highlighted in two different ways.
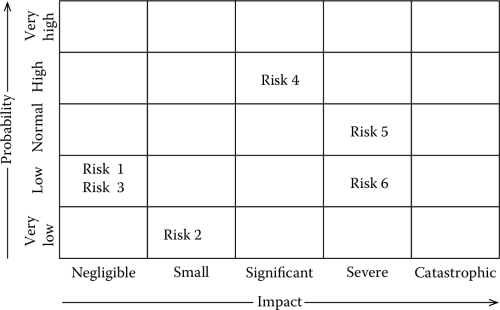
In the first approach, the risks can be shown on a two-dimensional space, in which one axis represents the probability and the other axis represents the impact. Given the fact that we are dealing with finite values, we can present the risks using a risk matrix, in which rows represent the probability and columns the impact.
This is shown in Figure 4.7, where we show six different risks with a different probability and impact. “Risk 1” and “Risk 3,” for instance, have low probability and very low impact.
In the second approach, the risks are assigned a weight, computed as a function of the probability and impact. The main requirement of the function is that it is monotonic with respect to both probability and impact (e.g., it gives higher values when probability or impact increase). A very simple function to compute the weight is
Different from what happens with the risk matrix, probability and impact contribute equally to determining a risk’s weight. That is, a risk with probability 3 and impact 5 has the same weight and importance of a risk with probability 5 and impact 3. Whether this is true for the risks of a project is a decision for the project manager to make. The advantage, however, is that it is faster and simpler to manage.
This is shown, for instance, in Table 4.2, where we list the same risks of Figure 4.7. Notice how “Risk 4” and “Risk 5” have the same weight, in spite of belonging to two different cells in the risk matrix of Figure 4.7.
Classification of Menaces Using a Risk Register
Risk Description |
Probability |
Impact |
Weight |
|---|---|---|---|
Risk 1 |
2 |
1 |
2 |
Risk 2 |
1 |
2 |
2 |
Risk 3 |
2 |
1 |
2 |
Risk 4 |
4 |
3 |
12 |
Risk 5 |
3 |
4 |
12 |
Risk 6 |
2 |
3 |
6 |
4.2.5 Risk Management Strategies
The strategies to deal with menaces aim at reducing probability or impact. More formally, we talk of
- Avoidance, if the project plan or other project conditions are changed in such a way that the risk will not occur. This is thus the most cautious approach, but often it is impossible to use for all risks.
- Mitigation, if the project plan or other project conditions are changed in such away that the probability or the impact of the risk is reduced. Notice that avoidance is a special case of mitigation in which the probability of occurrence is set to zero.
- Transferral, if the risk is transferred onto another party, who is willing to deal with the menace if it occurs. An example of transferral is preparing an insurance. It can be thought of as a way to reduce the impact of a menace to zero, at the cost required for the transferral.
In the case of opportunities, the approach is similar and we talk of
- Exploitation, if the project plan or other project conditions are changed in such a way that the risk will certainly occur.
- Enhancement, if the probability or the impact of the risk is increased.
- Sharing, if the risk is shared with other stakeholders so as to increase the probability (or the impact) if it occurs.
Finally, a strategy that works with both menaces and opportunities is to accept, namely, just deal with the problem (or favorable chance) if it occurs.
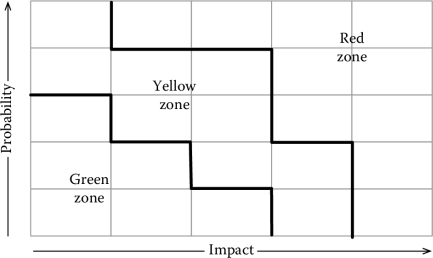
From the discussion in the previous section, it should be clear that not all strategies apply equally well to all risks. For instance, accepting a high probability and high impact menace is calling for trouble. A widely used approach, therefore, is that of organizing risks in three different areas, according to their weight. This is shown in Figure 4.8, where we have organized the risk matrix in three zones. A green zone includes all those risks that are considered acceptable, a yellow zone includes all those risks that require special treatment and special monitoring, and the red zone includes risks that are not acceptable. Projects with risks in the red zone will not be started. Note that the actual boundaries are arbitrary and depend on the inclination to risk of the performing organization.
We can now define how to deal with different classes of menaces. In particular
- Menaces in the green area are simply accepted. Some variability and uncertainty is inherent in any project and the burden of defining a management strategy to deal with the risk could not be worth the time it takes to deal with the risk if it occurs.
- Menaces in the red area need to be removed from the red zone. We need to apply one of the three strategies we have introduced above, namely, avoidance, transferral, or mitigation. Independent of the strategy adopted, the output of the activity is moving the risk to the yellow zone, to the green zone, or to remove it altogether from the table.
- Risks in the yellow area need to be dealt with. Here we need to reason case by case to find an appropriate strategy for each risk. Avoidance, mitigation, and transferral are all viable options. Acceptance might also be a proper strategy, as long as it is not a passive acceptance, but, rather, adequate measures are foreseen if the risk occurs.
A similar discussion can be made for opportunities; we leave it to the reader.
Defining a strategy, however, is not enough, since we also need to ensure that risk occurrences are properly recognized and dealt with. Together with the strategy chosen for a given risk, it is a good practice to define the person responsible for monitoring the risk. This is the person who has the ultimate responsibility of notifying the project manager that a given risk has occurred. Risk recognition could happen through indicators that could, for instance, measure certain aspects of the project.
4.2.6 Budgeting for Risks
Projects should allocate a specific budget to deal with risks and to effectively implement the contingency plans. The budget for risks is added on top of a project budget; when this is not done, costs associated with risks reduce the profit.
There are three approaches to define a budget to deal with risks, which greatly differ depending on the level of complexity and accuracy they provide. These can be chosen according to the information available and according to the other project constraints.
The simplest approach is the allocation of a lump sum, which is computed as a percentage of the project budget. The percentage is calculated according to historical data and, in some cases, it can be up to 30% of a project’s budget.
A slightly more complex approach is illustrated in Figure 4.9, where the budget is allocated according to the probability and impact of a project’s menaces. In particular, if each risk can be assigned a monetary value (for instance, the costs of additional resources to deal with the risk), the following strategies can be identified:
- High-probability and low-impact risks require the whole amount of the risk to be budgeted, since the risk is more likely to occur than not and not having enough money would result in not being able to properly manage the risk.
- Low-probability and low-impact risks: If our project has several risks in this area, the expected monetary value can be used. The expected monetary value of a set of risks is defined as the sum of the impact of each risk multiplied by the probability of occurrence. See below for an example.
- Low-probability and high-impact risks have to be dealt with by special agreements, like, for instance, an insurance or other special funds. Adding them to a project budget, in fact, would not make sense.
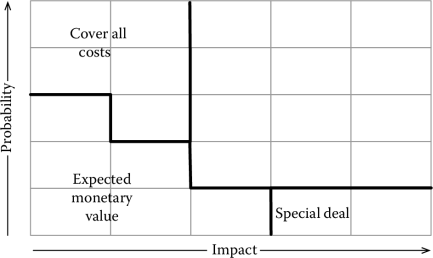
See also Northumbria University (2004) for a more thorough discussion on the matter.
Suppose we have a project with five risks in the green zone, for which we have managed to quantify probability and impact as described in Table 4.3.
An Example of Risks in the Green Zone
Risk
Probability
Impact
R1
0.10
€500.00
R2
0.10
€1000.00
R3
0.20
€400.00
R4
0.15
€1000.00
R5
0.10
€200.00
The expected monetary value of the risks is computed as follows:
Substituting the data in Table 4.3, we get
which is the amount we can allocate to manage risks in the green area. Note that the amount allows us to cover R3 and R5 and most of the costs of R1. If R1, R2, or R3 will occur in the project, we will need to find the money from another source.
A more cautious approach in the example we have made could allocate €1000, enough to cover R2 or R4 and any other risk. However, given the probabilities, all the risks in the table are far more likely not to occur than to occur and the money reserved for these risks is more likely not to be used than to be used. Thus, like in many similar situations, the techniques provide a good reference framework, but the project manager always has the responsibility of understanding situation and context and take the appropriate choice based on all these information.
4.2.7 Risk Monitoring and Control
During project execution, the risk management machinery we have set-up in the previous sections is put into practice. The process is composed of three main activities: reviewing, sharing, and applying contingency plans.
4.2.7.1 Review and Share
With the frequency required, the risk registered is assessed and the risk status is reviewed and updated. For instance, risks can be assigned a status, such as “occurred,” “closed,” “active,” “inactive,” to indicate, respectively, that a risk has occurred (and we are currently dealing with), a risk has been dealt with, a risk is active (and it could occur), and a risk is inactive (and cannot occur anymore). The status is typically shared with the project stakeholders. One way of doing this is, for instance, defining different alert levels (“green,” “amber,” “red”), which encode the level of criticality of the project at a given time in space.
4.2.7.2 Apply Contingency Plans
The procedures for activating the contingency plans and related actions are then started for all those risks that occurred. According to the project size, risk, and formality, the procedures could be very easy and agile or require formal approvals from management. The appropriate resources (including budgetary resources) are then released and allocated to deal with the risk.
An important remark is that the contingency plans should be applied as defined during the risk planning phase. Any run-time change, in fact, poses various criticalities, such as taking the wrong decision under pressure and not activating the proper communication channels to ensure that all the relevant stakeholders are warned.
4.2.7.3 Revise and Iterate
It is important to observe that the project stakeholders might become aware of new risks as the project progresses.
During project monitoring and control, therefore, on top of managing the existing risks, the overall process has to be repeated for each new menace and opportunities identified as the project progresses.
4.3 Quality Management
Intangible as it is, software can fail in many spectacular ways, causing inconveniences significant economic damages, and, in some cases, the loss of human lives. Garfinkel, for instance, in Garfinkel (2005), presents his top ten list of the worst software bugs in history. Among them there is the Ariane 5 software failure, which caused the loss of the rocket and its payload, valued at 500 USD millions.*
Compliance with requirements in software development is often considered a synonym of software testing. Software testing, however, covers only some aspects that determine the overall quality of a software project and its products. For this reason, a sound software quality assurance (SQA) process should be part of any software development project. Thus, SQA process is the planned and systematic set of activities that ensures the conformance of software life cycle processes and products to requirements, standards, and procedures (NASA, 2004).
Following Project Management Institute (2004), a good SQA process is composed of three steps:
- Quality planning, which identifies the relevant standard and practices and the way to implement them
- Quality assurance, which focuses on ensuring that the project applies and follows the quality standards identified at the previous step
- Quality control, which ensures that the products respect the quality standards identified during the planning phase.
Quality control for software can be particularly complex.
Indeed, various nonfunctional characteristics might be part of a software’s specification, and their quality assessment might be particularly tricky. For instance, Rosenberg (2002) mentions nine different nonfunctional characteristics of a software system that might be difficult to assess. Three of them, efficiency, integrity, and usability, refer to product characteristics related to the use of a system. Four others, namely, flexibility (can I change it?), maintainability, portability (will I be able to use it on another machine?), and reusability (think of the Ariane example above) highlight qualities related to how easy it is to change and adapt the system to new environments. The remaining two, namely, testability and reliability, highlight features that are important for safety-critical applications.
Another important aspect is that the input and number of different behaviors of a software system is huge and always outside the range of exhaustive testing (including automated exhaustive testing): defining which test cases and what techniques are necessary and sufficient to get reasonable confidence in a system is difficult.
The third motivation involves safety-critical applications, a domain in which quality control is particularly important and software is required to be fail-safe or fail-operational. Specifically, in case of malfunctions, the software has to maintain the functions or degrade gracefully, without compromising any other component or the general system safety.
*To be more precise, the failure is due to a combination of a software glitch and a management error, which led ESA to reuse the Ariane 4 software for the new Ariane 5 rocket. Unfortunately, the software did not correctly handle the higher input values provided by the more powerful Ariane 5.
4.3.1 Quality Planning
A good quality management plan ensures that the goals of quality management are met in a project.
Goals defined in the scope document and any constraint related to regulations and standards that have to be met are the starting point of a quality plan. All the information thus collected defines the quality assurance and control requirements of a (software development) project. For instance, a project might require software to be developed according to DO-178B, a standard that regulates the development of safety-critical software. A good project needs to find the right balance between quality, costs, and time. Thus requirements have to be analyzed to understand their impact and their importance. To this purpose, for instance, NASA (2009) identifies eight different classes of software systems with different criticality and therefore different quality assurance requirements.
The requirements defined at the previous step allow the project manager or the quality team appointed to ensure that the quality goals are met to define the quality assurance and control activities that will be performed in the project. An important aspect is to ensure that sufficient time is allocated to these activities.
For software systems, quality assurance activities include inspections, reviews, walkthroughs, testing, and formal verification. Together with the activities, it is always a good practice to define the actors and responsibilities. See the rest of this section for more details about the activities that are most commonly used. In certain cases, quality assurance activities can be conducted by the project team (V&V); in other cases, they might require an independent validation (IV&V).
Quality controlf is equally important, since it helps measure the progress we are achieving and whether we are meeting the goals we set. The simplest way to perform quality control is through a quality measuring program, which quantitatively monitors progress and infers information about the effects of quality assurance and control on improving quality. Thus, the quality plan should specify what metrics are collected, with what means, and with what frequency.
Table 4.4, inspired from the NASA Software Assurance Guidebook, recaps the main project deliverables that should be verified with SQA activities, together with some minimum quality criteria.
SQA Activities
Phase |
Deliverable |
Coal |
|---|---|---|
Software concept and initiation phase |
Management plan |
Ensure that processes, procedures, and standards identified in the plan are appropriate, clear, specific, and auditable. Ensure that there is a QA section. |
Software requirements phase |
Software requirements |
SQA assures that software requirements are complete, testable, and properly expressed as functional, performance, and interface requirements. |
Software preliminary design phase |
Architectural (preliminary) design |
Assuring adherence to approved design standards in the management plan. Assuring that all software requirements are allocated to software components. Assuring that a testing verification matrix exists and is kept up to date. Assuring that the interface control documents are in agreement with the standard in form and content. Reviewing preliminary design review documentation and assuring that all the action items are resolved. Assuring that the approved design is placed under configuration management. |
Software detailed design phase |
Architectural (detailed) design |
Assuring that the approved design standards are followed. Assuring that the allocated modules are included in the detailed design. Assuring that the results of design inspections are included in the design. Reviewing critical design review documentation and assuring that all the action items are resolved. |
Software implementation phase |
Implementation |
Results of coding and design activities including the schedule contained in the software development plan. Status of all deliverable items. Configuration management activities and the software development library. Nonconformance reporting and corrective action system. |
Software integration and test phase |
System |
Assuring readiness for testing of all deliverable items. Assuring that all the tests are run according to test and procedures and that any nonconformances are reported and resolved. Assuring that the test reports are complete and correct. Certifying that testing is complete and software and documentation are ready for delivery. Participating in the test readiness review and assuring that all action items are completed. |
Software acceptance and delivery phase |
System |
Assuring the performance of a final configuration audit to demonstrate that all deliverable items are ready for delivery. |
4.3.2 Quality Assurance
The main tools to perform quality assurance are quality audits, that is, independent reviews to determine whether project activities are being performed in compliance with the standards set in the quality plan. Quality audits are conducted analyzing the documentation, by conducting interviews, and by conducting audit and review meetings, which are described in Section 5.3.3.2.3. The output of a quality audit is a report that describes the main findings and, if specific issues have been found, indicates the need for corrective actions.
More information about how to conduct a review can be found in NASA (1990). Some of the warning signs of troublesome projects, according to NASA (1990), include frequent changes in milestones, unexplained fluctuations in personnel, continued delays in software delivery, unreasonable number of nonconformance reports, or change requests.
4.3.3 Quality Control
Techniques for quality control can be organized in three main classes: inspections, analyses, and tests.
Inspections include all those activities to analyze a particular project product and verify whether the product has the required characteristics or not. Checklists are often used to proceed systematically in the review process. For a requirement document, an inspection checklist might prescribe to verify various syntactic and semantic qualities of the requirements. For instance, it could require to verify that each requirement has a unique identifier and a priority, as well as being easily comprehensible and testable.
For source code, walkthroughs—peer reviews performed by analyzing the source code—are a common type of inspection. Some automation can also be achieved using static checkers, which allow one to verify the compliance of source code with predefined (or custom) coding conventions, such as, for instance, the fact that the assignments are not used as test conditions in conditionals.
Analyses include all those activities that are meant to probe and demonstrate that a system has the required quality characteristics. Analyses include, for instance, analysis of control flow, formal verification of the properties of a system, and simulation. See Bozzano and Villafiorita (2010) for more details.
Testing includes all those activities that are meant to verify the behavior of a system under specific conditions. See Section 2.4 for more details.
Figure 4.4, inspired from the NASA Software Assurance Guidebook, recaps the main SQA activities and outputs to verify in a software development project.
4.3.4 Establishing a Metrics Program
Establishing a measurement program allows one to collect quantitative data, which can be used to understand how well a specific quality assurance and control program is working.
Many different measures can be taken and tools exist to automate the collection process. Metrics can be collected about various aspects of a project. In particular, we can collect process metrics, which are meant to measure different significant events in our project, and product metrics, which are meant to measure different characteristics of our system. For software systems, the product metrics can be further organized in size metrics, which are meant to measure the size of a system, and complexity metrics, which are meant to measure the complexity of a system.
An important aspect of a metrics collection program is that often trends are as important as the absolute values. That is, for each measurement we decide to take, we get a lot more information from analyzing its evolution over time, rather than by looking at a specific value at a point in time. To make things a bit more concrete, it is more useful to understand whether the number of bugs is increasing or decreasing over time, rather than to say that our system has, let us say, 42 bugs.
A sound metrics collection program establishes, where possible, automated means for the computation of metrics. For software systems and software-related metrics, this can usually be achieved using source code repositories and specific applications. See Chapter 9 for more details.
4.3.4.1 Size Metrics
Size metrics are meant to measure the size of a system. As we have seen in Section 3.4.5, there are two different approaches to measuring a systems size: size-oriented metrics count the physical lines composing a software system, while function-oriented metrics provide an indication about the size of a system using an abstract measurement of the system’s functions.
Size metrics are commonly used for quality assessment. Simple measures that are taken include source lines of code, delivered source lines of code (defined in Boehm (1981) as the lines of code delivered to the client—i.e., excluding tests, conversion procedures, etc.), blank lines, and comment lines, that is the number of lines in the source code that are comments. The number of classes and the weighted methods per class are two other metrics commonly collected when using object-oriented languages.
4.3.4.2 Complexity Metrics
Complexity metrics are meant to measure the complexity of a system and how difficult it might be to test and maintain a system.
Some metrics, like cyclomatic complexity, are meant to measure the complexity of algorithms (e.g., how many tests and loops there are). They provide an indication of the possibly different states a system can be in and, consequently, of the difficulty of testing and grasping all the possible behaviors.
Other metrics, such as coupling between objects, depth of inheritance, fan-in and fan-out, are meant to measure how coupled different components of a system are; these metrics provide an indication of the difficulties people might encounter in maintaining a system.
Complexity metrics are direct indicators of the quality of a system, since they provide information about various nonfunctional characteristics (such as maintainability) and about a systems testability.
4.3.4.3 Quality Metrics
Various indicators can be derived from the previous metrics and other information in order to get an idea of the quality of a system. They include
- The ratio between lines of comments and lines of codes. This is an indication of the maintainability of a system, on the hypothesis that the comments in the code will help other developers get a better understanding of what a specific portion of a system does.
- Cumulative number of open issues. This is the total number of problems that have been signaled and that have not yet been solved. This allows one to measure whether our process is “converging”. If the number of open issues continues to increase (in spite of our effort of closing them), for instance, this could be a sign that our system is doomed to remain plagued by bugs.
- Error density. This is the number of errors found per source line of code. The error density is computed by counting the ratio between the number of errors found during testing and the system size, possibly organized by error severity. Looking at the trend of error density—whether it is increasing, remaining stable or decreasing—can help one understand whether the development process has some systematic faults.
4.4 Questions and Topics for Discussion
- What are the advantages of a change management process? And those of a quality management program?
- What are the differences between change management and configuration management?
- Perform a risk assessment analysis on the Theater 3001 project.
- What metrics could we use to highlight a scope creep?
- Discuss the merits and difficulties of setting up a metrics program.
References
Arnuphaptrairong, T., 2011. Top ten lists of software project risks: Evidence from the literature survey. In Proceedings of IMECS 2011, pp. 732–737, Hong Kong, March 2011. Newswood Limited. Last retrieved November 2, 2013.
Boehm, B. W., 1981. Software Engineering Economics. Prentice Hall, Englewood Cliffs, NJ.
Boehm, B. W., 1988. A spiral model of software development and enhancement. IEEE Computer 21(5), 61–72.
Bozzano, M. and A. Villafiorita, 2010. Design and Safety Assessment of Critical Systems. CRC Press (Taylor and Francis), an Auerbach Book, Boston, MA.
Bugzilla Development Team, 2006, October. The Bugzilla Guide—2.18.6 Release. Bugzilla. Available at http://www.bugzilla.org/docs/2.18/html/lifecycle.html. Last retrieved April 3, 2013.
Cox, C. B. and C. Murray, 2004, September. Apollo. South Mountain Books, Burkittsville, MD.
ESA Board for Software, 1995, May. Guide to software configuration management. Technical Report PSS-05-09, Issue 1, Revision 1, ESA.
Fermi National Accelerator Lab, 2010, December. Change management process and procedures. Technical report, Fermilab. Available at http://cd-docdb.fnal.gov/cgi-bin/RetrieveFile?docid=3530;filename=ChangApril 3, 2013.
Forensic Psychology Practice Ltd., 1999. Cognitive distortion—A practitioner’s portfolio. Available at http://www.forensicpsychology.co.uk/wp-content/uploads/2011/10/WebCD.pdf. Last retrieved August 30, 2012.
Garfinkel, S., 2005, August. History’s worst software bugs. Available at http://www.wired.com/software/coolapps/news/2005/11/69355. Last retrieved November 15, 2013.
Jones, D., 1998. Project zeus—Risk management plan. Available at http://sce.uhcl.edu/helm/ZEUS/rmpzeus.pdf. Last retrieved June 21, 2013.
NASA, 1990, November. Software quality assurance audits guidebook. Guidebook NASA-GB-A301, NASA. Available at http://www.hq.nasa.gov/office/codeq/doctree/nasa_gb_a301.pdf. Last retrieved June 8, 2013.
NASA, 2004. Software assurance standard. NASA Technical Standard NASA-STD-8739.8 w/Change 1, NASA.
NASA, 2007, December. Systems engineering handbook. Technical Report NASA/SP-2007-6105 Rev1, NASA.
NASA, 2009. Nasa software engineering requirements. NASA Procedural Requirements NPR 7150.2A, NASA. Available at http://nodis3.gsfc.nasa.gov/. Last retrieved June 1, 2013.
NetMarketShare, 2013. Desktop browser version market share. Available at http://www.netmarketshare.com/browser-market-share.aspx?qprid=2&qpcustomd=0. Last retrieved May 1, 2013.
Northumbria University, 2004, November. Risk management. Available at http://www.jiscinfonet.ac.uk/infokits/risk-management/. Last retrieved June 22, 2013.
Northwestern University Information Technology, 2011, June. Change management process. Technical report, Northwestern University Information Technology. Available at http://wiki.it.northwestern.edu/wiki/images/1/1b/Change_Management_Process.pdf. Last retrieved April 3, 2013.
Project Management Institute, 2004. A Guide to the Project Management Body of Knowledge (PMBOK Guides) (4th ed.). Project Management Institute, Newtown Square, Pennsylvania 19073-3299, USA.
Rosenberg, L. H., 2002. Software quality assurance. Available at http://sstc-online.org/2002/SpkrPDFS/MonTracs/p460.pdf. Last retrieved June 8, 2013.
Schmidt, R., M. K. Kalle Lyytinen, and P. Cule, 2001. Identifying software project risks: An international Delphi study. Journal of Management Information Systems 17 (4), 5–36.
Sommerville, I., 2007. Software Engineering (8th ed.). Addison-Wesley, Redwood City, CA.
Wallace, L. and M. Keil, 2004, April. Software project risks and their effect on outcomes. Communnication of the ACM 47(4), 68–73.
Werner, T. P., 2013. Semantic Versioning. Available at http://semver.org/, 2013. Last retrieved May 1, 2013.