
The Basics: Software Development Activities and Their Organization
Software development projects range from the very small to the very large and encompass a wide range of complexity, starting from software developed by a small team in their spare time and ending with projects lasting several years and involving the work of many people.
Similarly, the concept of what it means for a software development project to succeed also varies according to the context. For the small team developing an open source solution, it could be the intellectual challenge of solving a complex problem or the satisfaction of contributing to a community. Time is not critical, nor are costs: having fun in the process probably is.
For people developing safety-critical systems, the challenge is different. They need to ensure that the system will perform as expected in a wide array of operational conditions, including those in which there are malfunctions. Quality and a controlled process are paramount in this context.
Finally, for people developing a web application or another desktop system, the most important aspect could be the the price that can be set for the product or making sure that the product is released before the competition. In this context, time and costs might be the main drivers.
Thus, the activities that are required or beneficial to develop successful software vary from project to project. Some projects might allow a more informal approach, while others are better served by a very structured and controlled process. Going back to the millefoglie example, the goal of this chapter is to present the “pastry,” that is, the activities that are needed to develop software. These are the technical building blocks for constructing software, that is, what we do in the “execute” phase of a software development project. These building blocks will be selected, composed, and organized in different ways, according to the project size and formality, the process adopted, and other management choices in Chapter 4.
2.1 Software Requirements Definition
The first step of any nontrivial software development project is to form an idea about the system that has to be developed.
Software requirements definition includes the methods to identify and describe the features of the system to be built. The main output of this activity is one or more artifacts describing the (software) requirements of a system, namely, the functions it has to implement and the other properties it has to have.
Software requirements are strongly related to the scope document, which defines the goals of a project and which we will see in Chapter 3.
There are two main output formats for these artifacts, textual or diagrammatic.
When the textual format is used, the requirements are written in English, in some cases using a restricted set of language or predefined linguistic patterns. For instance, special words, such as “shall,” might be required to indicate an essential requirement—see, for example, Brader (1997).
Concerning the structure, the requirements are often presented as lists of items, one per requirement. Another very common representation writes requirements in the form of user stories, using the following pattern:
As a [user] I want to do [this] because of [that].
The advantage of this approach is that each requirement clearly identifies the user, the function that has to be performed, and the motivation for the function to be implemented, something that helps identify the priority or importance of a requirement.
The diagrammatic notation describes requirements with a mix of diagrams and textual descriptions. Diagrams depict the interaction between the user and the system and the textual description explains the interaction using a sequence of steps. The most common graphical notation is that of the use case diagrams of UML and the corresponding textual descriptions are called use cases (Booch et al., 1999; Fowler and Scott, 2000).
The requirement engineering discipline includes the activities necessary to define and maintain requirements over time. Simplifying a bit, requirements engineering entails a cyclical refinement process in which the following steps are repeated at increasing levels of detail till a satisfactory level of know-how about a system is achieved.
In more detail, the process is composed of four steps:
- Requirements elicitation
- Requirements structuring
- User experience design
- Requirements validation.
2.1.1 Requirements Elicitation
Requirements elicitation is the activity during which the list of features of a system are elicited from the customer. This activity can be performed with interviews, workshops, or the analysis of existing documents.
2.1.2 Requirements Structuring
Requirements structuring is the phase during which the requirements are annotated to make their management and maintenance simpler.
During the process, requirements are
- Isolated and made identifiable. Each requirement is clearly isolated and distinguished from the others and is also assigned a unique identifier. This allows one to reason and manipulate each requirement more easily. Concerning identification, a commonly used practice is that of assigning each requirement a number or a combination of some characters (describing the type of requirements) and a number.
- Organized and classified. A simple classification distinguishes between functional and nonfunctional requirements. The former are requirements describing what the system has to do. The latter are requirements describing what other properties the system should exhibit (e.g., “the system will have to run on Windows devices”). Functional requirements are usually organized in functional areas. Each functional area groups requirements describing a homogeneous set of functions. For instance, a requirement document might have an “accounting functions” section describing all requirements pertaining to accounting functions. Nonfunctional requirements are often organized in four groups: usability, reliability, performance, and supportability.
- Annotated. Requirements are annotated to simplify their management and to support planning activities, like, for instance, which requirements should be implemented first. It is a good practice to assign each requirement at least two properties, namely, the importance for the customer and the difficulty to develop, for instance, using values from 1 to 5. We will see other types of classifications in Section 3.2.1.
Requirements evolve over time and a sound approach to requirement management also necessitates defining a proper strategy to control the evolution of requirements. We will see some of the issues in Section 4.1. Here, it is sufficient to mention that requirements are often annotated with
- Traceability information, which has the goal of highlighting where a requirement originates from. Traceability shows the relationships among requirements and the relationships among requirements and other artifacts of software development. This allows one to understand the impact of changes. See Gotel and Finkelstein (1994) for a formal definition and more details.
- History log, which records the changes each requirement has undergone. The history log traces how requirements have changed over time.
Figure 2.1 shows an example of a template of an annotated requirement.

2.1.3 User Experience Design
User experience design has the goal of providing a coherent and satisfying experience on the different artifacts that constitute a software system, including its design, interface, interaction, and manuals. It is defined in International Organization for Standardization (2010) as the extent to which a product can be used by specified users to achieve specified goals with effectiveness, efficiency, and satisfaction in a specified context of use.
The typical user experience design activities include
- User-centered analysis, which has the goal of understanding how users will interact with the system. It runs in parallel with the requirements definition and requires the organization of workshops and other activities (e.g., surveys) to profile the users, analyze which tasks they will perform, and define which style guides will be followed in designing the system.
- User-centered design, which has the goal of specifying how users will actually interact with the system. It runs in parallel with the requirements definition and system design (see the next section). The outputs include storyboards describing the interaction, mock-ups, and prototypes. (A mock-up is a full-size model of something that has not yet been built, showing how it will look or operate (Cambridge University Press, 2013).)
2.1.4 Requirements Validation
Requirements validation is the phase during which the requirements are analyzed to find
- Inconsistencies, for example, two requirements require a system to behave in contradictory ways. In a common situation, a requirement document includes two requirements, the first prescribing a general behavior (e.g., “the system should always abort in case of error”) and the other suggesting the opposite one in a specific situation comprised also in the general requirement (e.g., “the system should recover from a sensor-reading error”).
- Incompleteness, when no information is given about a specific situation.
- Duplicates, when one requirement describes a function already described by another requirement.
Different techniques can be used to validate requirements. We mention inspections and formal analyses. Document inspections are based on the work of a team that analyzes the content of documents and highlights any issue. The technique relies on the ability and experience of the team. Formal analyses use mathematical notations (such as first-order logic) to represent requirements and automated tools (such as theorem provers and model checkers) to prove properties about the requirements. Several notations and approaches are available; see, for instance, Clarke et al. (2000), Bozzano and Villafiorita (2010), and Spivey (1989) for more details.
Notice that the goals of this phase overlap with those of quality management. We will see more about verification and validation techniques in Section 4.3.
2.2 Business Modeling
In the 1990s, the university where I teach—a complex organization in which different offices have considerable organizational autonomy—kept personnel records in different databases: one for contracts, another for teaching assignments, another for granting entrance to laboratories, to name some. The database was not connected; any change had to be propagated manually to all databases, causing inconsistencies, omissions, and a lot of extra work to try and keep data in sync.
Enterprise resource systems (ERP) are systems that can automate and simplify the processes of an organization, integrating the data and the procedures of different business units. These systems are usually composed of standardized components, which implement the main procedures of an organization in a particular business sector (e.g., government, logistics, services). Their introduction in an organization typically requires them to act not only on the system, personalizing data, procedures, and functions, but also on the organization, by changing the existing procedures to take full advantage of the system being introduced.
In this kind of project, understanding how work is carried out in an organization is often more relevant than eliciting the requirements of the system to be built, since an important part of the project work will focus on mapping the current procedures and changing them to accommodate those that supported by the ERP.
The activity to understand how an organization is structured and works is called business process modeling or business modeling in short. Those to modify the current procedures go under the name of business process re-engineering.
Business modeling and business re-engineering are usually organized in two main steps. An initial “as is” analysis describes the organization before the introduction of a new system. The “as is” analysis helps one understand the current infrastructure and needs. A complete analysis will include
- A description of the organizational structure, highlighting the chain of responsibility and accountability.
- A description of the business processes, describing how the organization carries out the different procedures.
- A map of the existing IT infrastructure, highlighting hardware, systems, and databases.
- A list of the business entities, highlighting the data produced and processed by the organization.
Following the “is” analysis, a “to be” phase defines how the organization will change with the introduction of the new system. The “to be” analysis produces the same set of information required by the “as is” analysis, but it describes the processes, the systems, and the business data that will be introduced to make operations more efficient.
Let us see in more detail the information produced with the “as is” and the “to be” analyses.
2.2.1 Mapping the Organizational Structure
Mapping the organizational structure has the goal of understanding how an organization is structured.
The information to collect includes the list of the different business units and the lines of responsibility. More detailed analyses also include the roles or the staff employed by each business unit and the functions assigned to each role or person.
The output is a text document or an organizational chart describing the units and their functions. It is used to identify the changes that will have to be implemented in the organization to support the new processes.
2.2.2 Modeling the Business Processes
Modeling the business processes has the goal of documenting how an organization carries out its procedures.
These are typically represented with flow diagrams sketched, for instance, using the business process modeling notation—BPMN (OMG, 2011). Business processes highlight, for each process, which steps need to be performed, by whom, and what outputs are produced and consumed. The specification should model both nominal and exceptional situations. For instance, if the target of the analysis is a paper-based procedure to authorize a trip, a good process description will document what happens when everything flows as expected and how the organization recovers if some error occurs—for example, a paper form is lost in the middle of a procedure.
A difficult aspect of this analysis is capturing not only the formal procedures but also the current practices, namely, how people actually carry out the procedures. The ethnography software engineering field focuses on methods to simplify this activity. See, for instance, Rönkköa (2010) for an introduction on the matter.
The output is a document containing the processes, possibly organized by area or by business unit. It is the basis to specify the new business processes or the requirements of the systems that will have to implement them.
2.2.3 Mapping the Existing IT Infrastructure
Mapping the IT infrastructure has the goal of understanding what IT systems are currently used in an organization, with what purpose, which data they store, and what lines of communications exist, if any.
Various notations can be used; the most formal ones are based on UML and could include component and deployment diagrams. Textual descriptions often complement the diagrams.
The output is a document. It is the basis to plan data migration and data integration activities. The former occurs when an existing system will be dismissed and the data it manages have to be migrated to a new system. The latter occurs when the system will remain in use and will have to communicate with the new system being introduced.
2.2.4 Mapping Business Entities
Mapping the business entities has the goal of documenting which data are processed by an organization, by whom, and with what purpose.
During this activity, analysts typically produce data models and CRUD matrices. The former list the data processed by the business processes. They are presented with class diagrams or textual descriptions.
The latter define the access rights to the data. It is presented as a matrix, whose rows list the data and whose columns list the business units. Each cell contains any combination of the CRUD letters to indicate which unit creates (“C”) specific data, which unit reads (“R”) it, which unit can update (“U”) the data, and which units delete (“D”) the data.
2.3 Design and Implementation
The goals of design (also system design or architectural design in the rest of the book) and implementation are, respectively, to draw the blueprint of the system to be implemented and actually implement it.
2.3.1 System Design
System design defines the structure of the software to build or system architecture. The output of this activity is one or more documents which describe, with diagrams and text, the structure of the system to build, namely: what software components constitute the system, which function each component implements, and how the components are interconnected. The activity is particularly relevant for technical and managerial reasons.
In fact, design allows one to break the complexity of building a system by separating concerns, that is, by allocating functions to components, and by specifying functions in terms of more elementary and simpler to implement components.
The system architecture can also be used as an input to plan development. In fact, given the list and structure of components that have to be developed, there is a natural organization of work that follows the structure of the system. We will see this in more detail in Section 3.3.
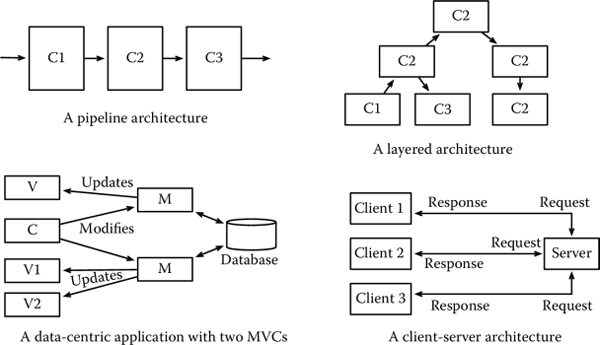
The definition of a system architecture can be based on a pattern or predefined blueprints. Many different architectural blueprints have been proposed in the literature. Among these, some of the most commonly used include:
- Pipe and filter, that is, a paradigm according to which the application is structured as a chain of processing elements. Each element of the pipe takes an input from the previous element, processes it, and passes it onto the next element. In a pipe and filter architecture, once the boundaries among the elements of the pipe are clearly defined, the development of each element can proceed in parallel with that of the others. In this architecture, the input/output specification is a critical piece of information to ensure that all components integrate as expected. See the discussion about integration testing in Section 2.4 for more details.
- Layered/hierarchical, by contrast, is an architectural style in which the different elements of a system are organized hierarchically. Lower levels of the architecture perform simpler functions, while higher levels are responsible for the implementation of more complex functions. Lower layers pass information about the environment or their status to the higher levels, which in turn send commands to the lower levels. An example of layered architecture is that of an embedded system in which we can distinguish two levels. At the lower level, sensors are responsible for reading data from the environment and processing inputs. At the higher level, a controller takes the input of the sensors and decides the action to perform, sending appropriate commands to the actuators. These, in turn, are responsible for interacting with the environment executing the commands of the controller.
- Data-centric is an architecture used when data storage and elaboration are central. Many data-centric architectures rely on a database to store data and are often based on the model view controller (MVC) pattern, according to which, for each data to be processed by the application:
- The model defines how data are to be stored and manipulated.
- The view defines how data are to be presented to the user or other systems interacting with the one we are developing. Multiple views can be associated with a single model or, vice versa, some views can display the data of different models.
- The controller defines the logic of the operations, that is, what sequences of transformations make sense of the data and what actions the users can perform.
Many web applications and many desktop applications use the data-centric architectural style.
- Client-server is an architecture in which the functions of a system are split between a server, which performs the main functions, and various clients, which interact with the server, requesting services.
Figure 2.2 provides a pictorial representation of the different architectural styles we have just presented. Notice how the data-centric architecture is composed of two MVCs.
A popular way of presenting the architecture of a software system is the one proposed in Kruchten (1995), which is based on the UML, and according to which the architecture of a software system is described by “4+1” diagrams.
Four diagrams describe the structure of the system. In particular
- The logical view identifies the main elements and data structures of the system to build. It is best described with class and sequence diagrams.
- The component view provides a programmer-oriented view of the system. It is mainly concerned with the components to be developed and is best described in UML with class and component and package diagrams.
- The process view provides a specification of the behavior of the system: interactions among components and the sequence of actions that are required to implement the user functions. It is best described with sequence and communication diagrams.
- The physical view provides a specification of the physical deployment of a system, that is, on what computer or process each element of the architecture will run. It is best described by a deployment diagram.
The last view is the use case diagram view, which we have briefly described in Section 2.1.
2.3.2 Implementation
The goal of the implementation phase is writing the code implementing the components individuated in the architecture.
Some of the aspects of this activity that are more closely related to project management include
- Collection of productivity and size metrics, which allow one to measure the speed at which code is delivered and the amount of work that has been performed. This is covered in more detail in Section 3.4.5, where we introduce estimation techniques based on software size, and in Section 3.9, where we present monitoring techniques.
- Collection of quality metrics, which allow one to measure the quality of the system to be developed and trends in the development process. This is covered in more detail in Section 4.3.
- The use of coding standards, which are guidelines describing best practices and the preferred styles to write code. Coding standards are adopted to ensure that the work of different programmers is similarly structured. Different standards are available. One which is adopted by the open source community is described in (Free Software Foundation, 2013). See Section 4.3 for more details.
2.4 Verification and Validation
Verification is the set of activities performed on a system to ensure that the system implements the requirements correctly. The definition is taken from SAE (1996) and distinguishes verification from validation, which is instead performed to ensure that the requirements describe the intended system. Thus, validation ensures that we are building the right system, while verification ensures that we built the system right.
Verification and validation are collectively known by the acronym V&V. The main way of performing V&V of software systems is testing. However, also see Sections 2.1.4 and 4.3 for a more complete discussion.
2.4.1 Testing
Testing is one way of performing verification and validation. Other methodologies include simulation, formal validation, and inspections.
Testing activities can be classified according to their scope. In this case, we distinguish between the following:
- Unit testing, when the goal is to verify the behavior of a piece of code, such as a class. Unit testing verifies that the code under investigation behaves as specified by the system architecture. The execution of unit tests can be easily automated, since they can be written as pieces of code. Some development paradigms, in fact, suggest writing unit tests before the code, as a way to encourage testing and to define executable and unambiguous specifications of the expected behavior of a piece of code.
- Integration testing, when the goal of the testing activity is to ensure that the components of a system behave as expected when they are assembled. Integration testing looks for inconsistencies in the way data are exchanged between components. These errors are relatively simple to introduce and their effect can be catastrophic. Consider a situation in which one component returns an array of characters, while the one connected to it expects a string.
- System testing, when the goal of the testing activity is to ensure that the system behaves as expected and correctly implements all the requirements. System testing uses the requirements document as input and defines a set of test cases that verify whether a system implements the requirements. See Section 2.4.2.1 for more details.
- Usability testing, running in parallel with the other testing activities, has the goal of verifying whether the user experience and interaction are intuitive, effective, and satisfying. Usability testing is particularly relevant in designing user interfaces for safety-critical systems to reduce the probability of human errors.
2.4.2 Organizing Testing Activities
While unit tests are written and executed by the developer writing the code being tested, integration and system test are typically performed by an independent team and are organized in the following two steps:
- Test plan definition
- Test execution and reporting.
Many software engineering books also include a test planning activity, which has the goal of identifying the resources, the schedule, and the order in which the tests will be executed. This emphasizes the fact that testing can be organized as a subproject and have its own plans and schedule.
2.4.2.1 Test Plan Definition
Starting from the requirements of a system, the goal of the test plan definition is to write the tests that will be performed on the system.
The output of this activity is a document listing a set of test cases, each of which describes how to perform a test on the system. Test cases are structured natural language descriptions that specify all the information needed to carry out a test, such as the initial state of the system, the inputs to be provided, the steps to be performed, the expected outputs, and the expected final state of the system.
Different test cases need to be defined for each requirement. Each test case, in fact, verifies either a particular condition specified by the requirement or the implementation of the requirement in different operational conditions.
Traceability information, which links a test case to the requirement it tests, helps manage changes and the overall maintenance process.
2.4.2.2 Test Execution and Reporting
Starting from the test plan definition, test execution and reporting is the activity during which the team or automated procedures execute tests and report on the outputs, that is, which tests succeeded and which failed.
Manual test execution is time consuming and demands motivation and commitment from the people performing it. There are various reasons for this.
The first is that it is repetitive: some operations have to be repeated over and over again to put the system in a known state before starting a test. Attention, however, has to remain high to ensure that all glitches are properly recognized and reported.
The second is that testing is the last activity before releasing a system. It requires quite some commitment to work hard at this stage of development to demonstrate that a system does not work and needs one to go back to the design room.
The third is that when an error is found, the process stops till a fix is found. When the fix is ready, it is necessary to start the testing activities all over again, possibly including the definition of new test cases, to verify that the bug has actually been fixed. This is to ensure that there are no regressions, that is, working functions have not been unintentionally broken by the fix. The corresponding workflow is shown in Figure 2.3.
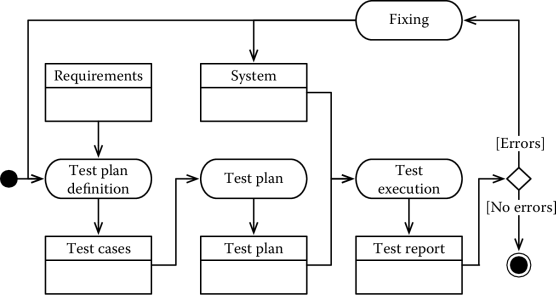
Different strategies have been proposed to write effective test cases. It has to be remarked, however, that testing is rarely complete and it can only demonstrate that a system does not work, rather than proving that a system is correct.
2.5 Deployment
The final step of the development process is releasing and installing a system so that it can be used by the customer and operations start. The transition to operations can be very simple for the project team. Consider, for instance, a case in which a software is handed to the client as a self-installing application in a CD, or made available on a website for customers to download.
In other situations, deployment needs to be carefully planned. This happens when a new software system replaces an obsolete system performing business-or mission-critical functions. In this situation, the goal is to move to the new technology without interrupting the service.
Consider a case in which a system controlling the routing of luggage in an airport needs to be upgraded. The development and installation of the new version of the system has to be organized so that no interruptions occur and no luggage is mismanaged.
A standard practice for projects of this kind makes sure that any change or software evolution does not interfere with production. To achieve this goal, the project team sets up three exact and independent replicas of the same operating environment, as shown in Figure 2.4. In particular, we distinguish between the following:
- A development environment, where the actual development of the software takes place. The development environment is completely isolated from production, and therefore there is no concern of blocking any critical activity. If data are needed to verify the behavior of the software being developed, a replica of the data in production is used. If there are privacy concerns, like in the case of medical or banking systems, the data on which developers operate are fake or an anonymized version of the data in production.
- A testing environment, where the team tests a system that is ready for deployment. The testing environment is isolated from the development and the production environment, so that, on the one hand, no changes made by developers interfere with testing and, on the other, that testing activities can proceed without any risk of interrupting production. Similar to the production environment, testing activities use replicas of the production data or fake versions.
- A production environment, where the system is actually used. Any change to the production environment interferes (positively or negatively) with the operations for which a system is used.
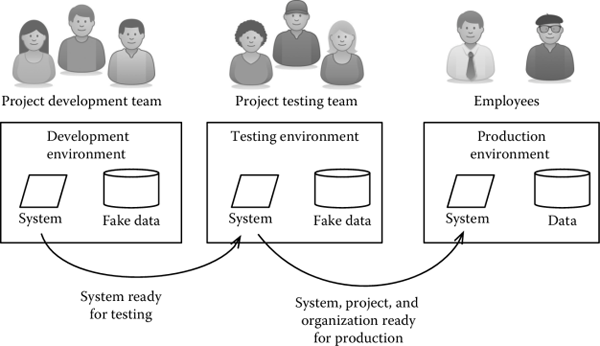
Even if we separate development and testing from production, alas, it is still necessary to ensure a smooth transition of operations when the new system is ready. In general, three factors need to be taken into account when deploying a new system.
They are
- The human factor: are the people ready to use the system?
- The data factor: are all the data that are needed for the system to run available to the new software?
- The hardware factor: are all interfaces ready and functional?
The deployment process thus typically requires to perform an assessment of readiness and evaluation of the gaps, which has the goals of understanding the main criticalities and risks. An analysis of documents and interviews with project stakeholders highlights all the critical issues related to the deployment of the new technology.
This is followed by the selection of a migration strategy, which defines an approach to the introduction of the new system. According to Wysocki (2011), the following approaches are possible:
- Cut-over, when the old system is replaced by the new one.
- Parallel approach, when the old and the new systems operate simultaneously for a period. This allows the new system to be tested and evaluated before the actual switch takes place.
- Piloting, when the system is installed for a limited number of users or for a specific business unit. This approach reduces the burden to users (who do not have to live with two systems), but it maintains the complexity of having two environments—the old and the new systems—both alive.
- Phased approach, when functions are rolled out incrementally.
Notice that, in all the approaches mentioned above, with the exclusion of the cut-over approach, appropriate measures have to be taken to maintain or transfer data from the old system to the new system. For instance, in the piloting approach, adequate procedural or technical interfaces need to be defined, so that the data produced by the business unit operating the new system can be used by the units using the old system.
When the strategy is agreed upon, the final step is the implementation of the release process, which in turn consists of the following steps:
- Deliver training, to ensure that the users acquire the necessary skills to use the new system.
- Perform data migration, which includes updating the data used in the production environment so that it can be used by the new system. This is a delicate step, which requires a thorough testing of the migration scripts and a backup of the existing data structures.
- Install the new system, which puts the new system in production.
- Set up the support infrastructure, namely, set up an infrastructure to support operations. More on this in the next section.
Notice that data migration and the installation of the new system need to be performed contextually. They are typically performed in a period and time where a service can be interrupted and system can be taken off-line to reduce pressure on the team and risks, should something not go as expected.
2.6 Operations and Maintenance
Operations and maintenance include the activities to ensure that a product remains functional after its release.
2.6.1 Supporting and Monitoring Operations
In general, operations are outside the scope of a project. However, many one-off development projects plan a support activity after a system is released to ensure that the project outputs meet the quality goals and the transition to operations is as smooth as possible.
The goals of this activity typically include
- Providing technical support. The support is meant to help users get acquainted with the system and it can be organized as a help-desk collecting tickets from users. Some of these tickets are requests for clarifications on the use of the system. Others will signal malfunctions, glitches, and requests for improvement, triggering maintenance activities. See the next section for more details.
- System monitoring. A set of metrics might be collected on the system after its initial release to monitor performances, issues, and other system features.
2.6.2 Maintenance
Maintenance occurs throughout the lifecycle of a system, before it is retired. It can be framed either as a project or operational work and, as such, it often poses a dilemma to the project manager.
ISO/IEC (2006) identifies four categories of maintenance for software:
- Corrective, if relative to fixing an issue discovered after the release of the system.
- Preventive, if relative to fixing an issue that was discovered but has not occurred (or at least signaled by users).
- Adaptive, if relative to adapting a system to changed external conditions. Adaptive maintenance includes, for instance, activities related to updating a software to work with a new release of an operating system.
- Perfective, if relative to improving some characteristics of a system, like, for instance, performances.
Of these, perfective and corrective maintenance are triggered by suggestions and bug reports sent by users. Suggestions and bug reports are also called issues or tickets.
When maintenance is the last activity of a project, two points have to be considered. The first is how much work has to be allocated, since we do not know in advance how many defects will be signaled. A general strategy is considering the complexity of the system, looking at the outputs of the testing phase, and allocating a percentage of the overall development effort. The second point is distinguishing between tickets that are in the scope of the project (called “nonconformance reports”) and tickets that are outside the scope of a project (called “concessions”). In fact, as users start using the system, they might come out with new ideas and proposals. However, the implementation of these new features is often better framed within the scope of a new project.
When the planned maintenance period ends, tickets might still arrive. In these situations, organizations and managers are faced with the dilemma of whether the activities should be framed in the context of a new project or not. In some cases, in fact, the amount of work required for the fixes does not justify setting up the machinery of a project. The choice, of course, can boomerang if a continuous stream of small change requests keeps coming in or if the fixes turn out to be more complex than initially envisaged. While there is no silver bullet to decide on the matter, one good practice is to have the team always monitor the time they spend on maintenance activities.
Agile methodologies, by contrast, blur the distinction between development and maintenance by organizing the development of a system in iterations. Each iteration includes the development of new planned features and selected tickets identified since the last release. This will be explained in more detail in Chapter 7.
2.6.3 Organizing Support and Maintenance Activities
One important aspect of support and maintenance activities is keeping formal track of the tickets.
This is usually achieved by
- Defining a workflow for tickets, which describes how bug reports are formally tracked and managed. Workflows can be very simple or more articulated, if a formal quality control or configuration management process is in place.
- Automating the collection and management of tickets. This is usually achieved by introducing a bug tracking system. A bug tracking system allows one to maintain a list of tickets and trace their workflow states. Many of these tools also allow one to produce reports and statistics, which can be used by managers to infer information about a systems quality and about the efficacy of testing activities.
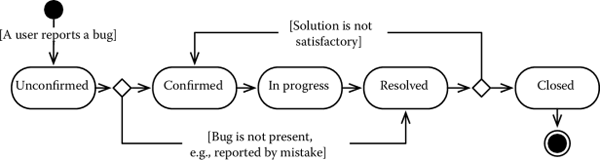
Figure 2.5 shows an example workflow, adapted from the Bugzilla Development Team (2013). A bug starts in the state unconfirmed after it is reported by a user. If the quality assurance team confirms its presence, the bug goes in the state confirmed, where it can be taken in charge by a developer. The state of the bug thus moves to the state in progress. When the developers consider the fix to be adequate, he or she sets the state to resolved. V&V by the quality assurance team, finally, determines whether the solution is satisfactory, in which case the bug is closed. Alas, if V&V determines the fix is not adequate, the bug returns in the state confirmed and another solution has to be found.
2.7 Questions and Topics for Discussion
- We have seen many artifacts and document produced by the software development activities. A documentation plan is a specification of the documents that will be produced in a project. Define a documentation plan for the technical documents of a one-off development project.
- Software development is a progressive refinement and many of the documents defined in the early stages are used to guide the development of subsequent activities. This generates a series of dependencies among the artifacts. For instance, the design document depends on the requirement document, since any change to the requirement document might cause a change to the design document. Highlight the dependencies among the documents produced in a business re-engineering project.
- On which technical documents does the “test plan definition document” depend? (Refer to the previous question for the definition of dependency.)
- Define a template for a test case. Many templates are available on the Internet. Try and see how your template differs from the ones you can find on the Internet.
- Suppose a company is about to switch to a new system for managing the reimbursements of travel expenses. Discuss the merits and risks of the different approaches we have presented, namely, cut-over, parallel approach, piloting, and phased approach for the case at hand.
- On many occasions, the implementation of tickets is a planned activity. Define a workflow for tickets that involves an authorization from the project manager and an acceptance of the fix from the customer.
References
Booch, G., J. Rumbaugh, and I. Jacobson, 1999. The Unified Modeling Language. Addison-Wesley, Boston, MA, USA.
Bozzano, M. and A. Villafiorita, 2010. Design and Safety Assessment of Critical Systems. Boston, MA: CRC Press (Taylor & Francis), an Auerbach Book.
Brader, S., 1997. Key words for use in rfcs to indicate requirement levels. Request for Comments 2119, Network Working Group. Available at http://www.ietf.org/rfc/rfc2119.txt. Last accessed May 1, 2013.
Bugzilla Development Team, 2013, March. The Bugzilla Guide—4.2.5 Release. Bugzilla. http://www.bugzilla.org/docs/4.2/en/html/index.html. Last retrieved November 15, 2013.
Cambridge University Press, 2013. Cambridge Advanced Learner’s Dictionary & Thesaurus. Cambridge University Press, Cambridge, England. Available at http://dictionary.cambridge.org/dictionary. Last retrieved May 1, 2013.
Clarke, E. M., O. Grumberg, and D. A. Peled, 2000. Model Checking. MIT Press, Cambridge, MA, USA.
Fowler, M. and K. Scott, 2000. UML Distilled (2nd Ed.): A Brief Guide to the Standard Object Modeling Language. Boston, MA: Addison-Wesley.
Free Software Foundation, 2013, April. Gnu coding standards. Available at http://www.gnu.org/prep/standards/. Last retrieved May 1, 2013.
Gotel, O. C. and A. C. W. Finkelstein, 1994. An analysis of the requirements traceability problem. In Proceedings of ICRE94, 1st International Conference on Requirements Engineering, Colorado Springs, CO: IEEE CS Press.
International Organization for Standardization, 2010. Ergonomics of human-system interaction. Technical Report 9241-210:2010, ISO.
ISO/IEC, 2006, September. Software engineering—software life cycle processes— maintenance. Technical Report IEEE Std 14764-2006, ISO/IEC.
Kruchten, P., 1995. Architectural blueprints—The “4+1” view model of software architecture. IEEE Software 12(6), 44–50.
OMG, 2011, January. Business process model and notation (bpmn). Technical Report formal/2011-01-03, OMG. Available at http://www.omg.org/spec/BPMN/2.0/. Last retrieved June 10, 2013.
Rönkköa, K., 2010, November. Ethnography. Encyclopedia of Software Engineering.
SAE, 1996. Certification considerations for highly-integrated or complex aircraft systems. Technical Report ARP4754, Society of Automotive Engineers.
Spivey, J. M., 1989. The Z Notation: A Reference Manual. Upper Saddle River, NJ: Prentice-Hall, Inc.
Wysocki, R. K., 2011, October. Effective Project Management: Traditional, Agile, Extreme (6, illustrated ed.). John Wiley & Sons, New York, NY, USA.