
![]()
Management and BI with HDInsight
Microsoft Azure HDInsight Overview
Under the leadership of new CEO Satya Nadella, Microsoft has become more supportive of collaborating with open source projects. Microsoft listens to customers that are building solutions, which in turn drives sales revenue. Microsoft’s .NET Core server stack is open source, and it supports cross-platform development. Microsoft’s Azure HDInsight is an example of this shift, with direct support of big-data analytics using the open source Apache Hadoop framework. In Microsoft Azure, this integration supports many languages including PHP, Node.js, Java, Python, Hadoop, and others. The change in Microsoft’s support for the open source community has increased the number of open source solutions running on Microsoft Windows by 400%, from 80,000 applications in 2009 spiraling up to 350,000 applications by 2011.
This chapter gives you insight into the meaning of big data and how Azure supports Hadoop (a framework for distributed processing of very large data sets). You also learn how Azure HDInsight directly supports Hadoop. Specifically, you explore the support of Microsoft business intelligence (BI) and analytics for big data using HDInsight in the Azure model of paying only for what you use only when you need it. In addition, HDInsight is a great example of software as a service (SaaS): you can request a 2-node Hadoop cluster or a 100-node Hadoop cluster, and either request is available within 15 to 30 minutes. Azure deploys the cluster and manages it for you with a service-level agreement (SLA), so you don’t have to worry about patching or uptime for the Hadoop service. By the time you reach the end of this chapter, you will have a deeper understanding of how to plan a Azure HDInsight solution to consume and visualize data for an end-to-end solution.
![]() Tip To learn more about the Microsoft shift toward open source projects and the company’s support for open source solutions like Hadoop and MongoDB, as well as to review the open source project directory, go to the Microsoft Openness web site at www.microsoft.com/en-us/openness.
Tip To learn more about the Microsoft shift toward open source projects and the company’s support for open source solutions like Hadoop and MongoDB, as well as to review the open source project directory, go to the Microsoft Openness web site at www.microsoft.com/en-us/openness.
Customers are requesting a supported, mature framework that does not lock businesses or developers into a primary development environment. This is one of the key design criteria of Azure HDInsight. Many companies employ database administrators (DBAs) who design, build, and use traditional database frameworks. Structured frameworks using relational data types for processing rows and columns of data in very large databases with a well-defined database structure are called the database schema. The concept of big data is better defined when the volume of data is too large for traditional relational database containment or when it contains a mixture of structured and unstructured data that doesn’t follow the database schema.
To help you better understand the meaning of big data, we’ll limit our definition to three attributes:
- Velocity: For example, global users posting to Twitter (this social network has tag tracking)
- Variety: Unstructured data (text, numerical, binary, images, and so on)
- Volume: Global server data (structured or unstructured)
Social media companies or products are an example of the complexity of large amounts of unrelated, or big data. Let’s consider two examples of the significance of big data.
The first of two examples of big data is Twitter, which in 2015 will process more than 9,000 tweets per second and over 1 billon tweets in just 5 days. Twitter fits the model of big data by meeting the two-part definition of very large amounts of data and semi-structured or unstructured data, streamed in real time. If you examine the data structure of tweets, they consist of free-form text, including hash tags and shortened web links. A BI solution is needed to disclose patterns of customer satisfaction or dissatisfaction. What business doesn’t need to know if their customers are happy with the company or unhappy with the products or services the company provides?
Consider the visual analysis shown in Figure 15-1. Here Twitter feeds for binge-watching tweets (vertical pegs) are overlaid with snowfall (geographical coverage) on the East Coast. Thus if a snowstorm is forecast, a hardware store may advertise on TV a special price on snow melt to clear driveways. Tracking weather and TV viewing patterns during major events can support sales of products related to those events.
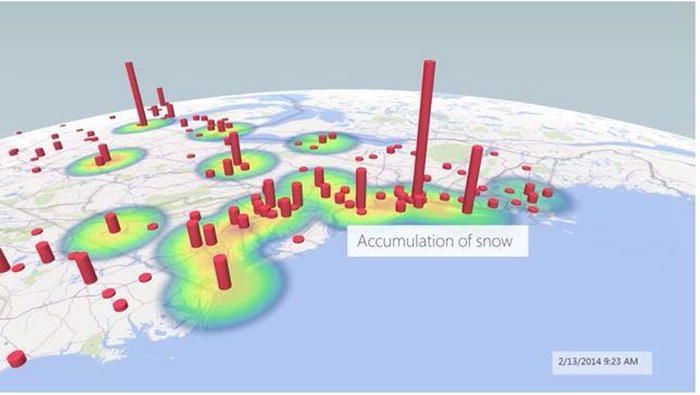
Figure 15-1. Microsoft BI visual analysis of Twitter feeds, illustrating binge-watching of shows during a snow storm
The second example of big data is a web server farm with many servers. A Microsoft BI solution can pull data from web logs on all the servers, scoping traffic in and out of the site server logs, and providing content characteristics including text, time, network addresses, logon identity, and other data to help identify patterns among visitors or consumers.
![]() Tip For examples of big data on Azure, you can view some of the videos in the Azure HDInsight video library at http://azure.microsoft.com/en-us/documentation/videos/index/?services=hdinsight.
Tip For examples of big data on Azure, you can view some of the videos in the Azure HDInsight video library at http://azure.microsoft.com/en-us/documentation/videos/index/?services=hdinsight.
Now that you have a better understanding of big data, what is the role of Hadoop? Knowing this may help you to understand the financial gains available to companies that offer visual BI analytics such as those used in the Twitter example.
Hadoop
Hadoop, as stated earlier in this chapter, is a framework for distributed processing of very large data sets. Many traditional structured databases, like Microsoft SQL Server, can support very large data warehouses and massive data stores. If the data is massive, is streamed extremely fast (as in the Twitter example), and is un-structured—meaning it does not exactly match the criteria of text, binary, or numerical data that can fit into data tables—then some preprocessing must be applied to the incoming data. Normally this is not the best solution for traditional relational database design, so another approach must be used to sort the data for efficiency and speed.
A massive volume of disparate/different data requires a more efficient solution that provides multiple database nodes for processing the data. One node is the name node; you can think of it as the head node (main node) for splitting the workload across multiple nodes using NoSQL database technology. This is the framework for the Hadoop open source distributed processing technology. Figure 15-2 shows how it is architected.
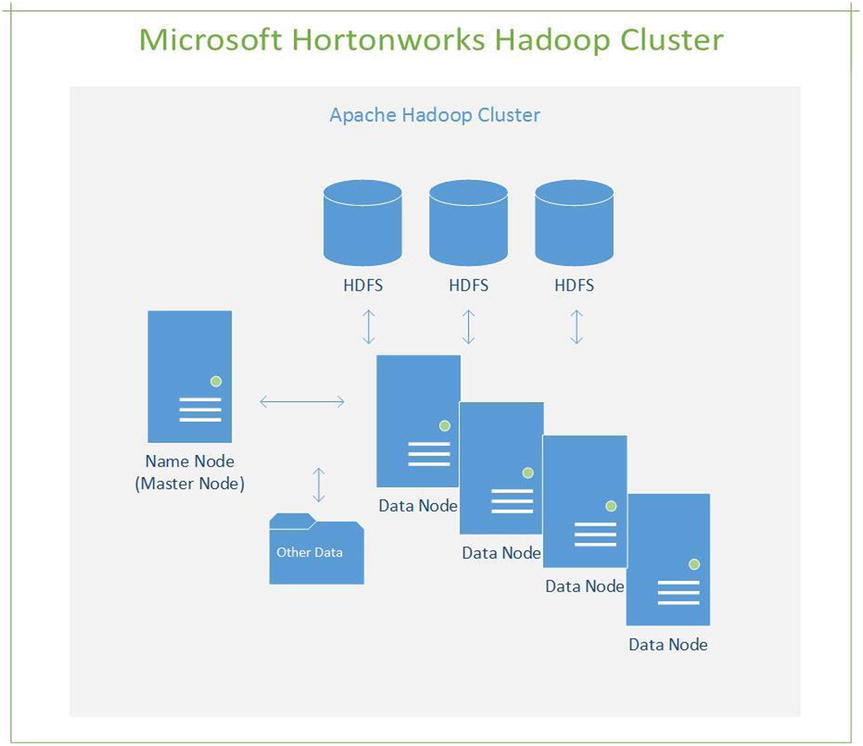
Figure 15-2. Traditional Hadoop cluster showing the main name node and the supporting data nodes as part of the cluster
You may know of additional Hadoop-related open source projects. Table 15-1 lists some open source technologies that work independently and also support Hadoop.
Table 15-1. Open Source Related Projects that Work with Hadoop Frameworks
|
Related Open Projects |
Description |
|---|---|
|
Provides Apache cluster provisioning, management, and monitoring | |
|
Microsoft .NET library for Avro; used in data serialization | |
|
Works with data from the Hadoop Distributed File System (HDFS) source for queries (SQL-like queries) | |
|
Templeton (Butler) service for helping other technologies; provides coordination | |
|
Apache (NoSQL) non-relational database | |
|
Used to coordinate workflows for multiple tasks and to maintain order | |
|
Can work with any data type; used with MapReduce functions | |
|
Apache Storm real-time computation system used to processes big data (like Hadoop) | |
|
Provides integration between data in HDFS tables and data in a traditional relational database | |
|
Coordinates distributed processes |
It is important to know that speed in BI analysis is achieved using a component function of Hadoop called MapReduce (sometimes written as Map/Reduce). MapReduce is a great feature for parallel processing that helps provide the speed and dexterity needed for the Hadoop processes.
To help you understand how the Hadoop architecture supports quick analysis of data faster than structured query databases, let’s look at a simple example of a three-node MapReduce function. In Figure 15-3, the MapReduce workflow illustrates how this component is used in Hadoop.
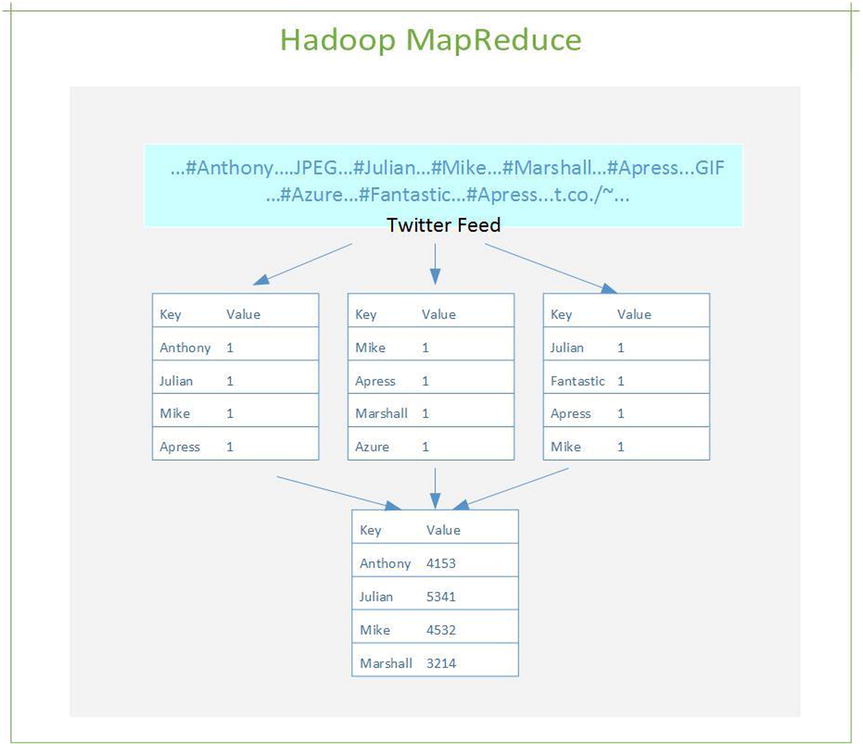
Figure 15-3. MapReduce processing phase illustrating how Hadoop can improve processing speed over structured query databases
How does Hadoop analyze all the data so quickly? The phase using the map reads a portion of the HDFS source data and generates a key value of the data, and it pairs the value by combining the key-value pairs at the reduce phase. If you look at the workflow in Figure 15-3, the different types of text are read from the HDFS source into more than one map node, so the process is very fast. The more nodes that are added to the map portion, the more quickly the analysis is completed. Each node then shares the key-value pair with the reduce node to gain aggregates for each item.
Each key and value is added at each map node and then passed in to the reduce node to provide the total value of each key. The reduce node provides a very specific function to maintain the key with a weighted value or summary.
HDInsight
HDInsight is Microsoft’s managed Hadoop service in the cloud. One of the key advantages of Microsoft Azure is that you pay only for what you use and only when you need it. Let’s take what you have learned about Hadoop and see how Azure HDInsight supports it.
Hortonworks is a vendor that directly supports Hadoop projects. The company worked directly with Microsoft engineers to build a partnership that created a Azure Hadoop solution called HDInsight. Figure 15-4 shows a logical view of HDInsight, which is designed to support the Hortonworks Hadoop architecture. Microsoft and Hortonworks built a 100% open source Hadoop solution on Windows and gave all the code back to the open source community.
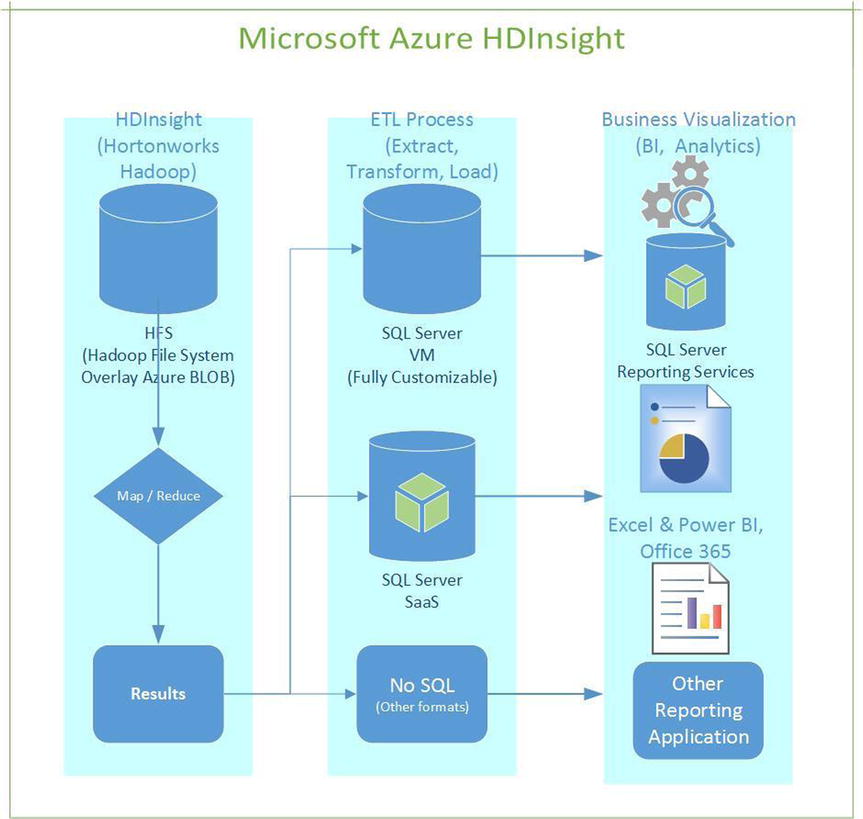
Figure 15-4. Azure HDInsight Hortonworks architecture with support for NoSQL, business analytics, and other reporting applications
In HDInsight, you can see how Hadoop clusters are represented in Azure. Chapter 7 introduced the many ways you can save money by using the Azure Storage service. Because Azure Storage relates to a big-data solution, HDInsight uses Azure blob storage. Specifically, the Azure team supports HDFS by using an HDFS-compliant software layer over Azure blob storage. This HDFS layer provides access to the terabytes and petabytes of Azure storage that some Hadoop applications require.
Many different versions of the Linux and Windows operating systems are available. Table 15-2 describes the versions of open source projects like Amari, HBase, Storm, and others available on these OSs.
Table 15-2. HDInsight Compared on Linux and Windows Platforms
|
Category |
HDInsight on Linux |
HDInsight on Windows |
|---|---|---|
|
Cluster OS |
Ubuntu 12.04 |
Windows Server 2012 R2 |
|
Cluster Type |
Hadoop |
Hadoop, HBase, Storm |
|
Deployment |
Azure Management Portal, cross-platform command line, Azure PowerShell |
Azure Management Portal, cross-platform command line, Azure PowerShell, HDInsight .NET SDK |
|
Cluster UI |
Ambari |
Cluster Dashboard |
|
Remote Access |
Secure Shell (SSH) |
Remote Desktop Protocol (RDP) |
In order for Azure to offer an SLA around HDInsight, a stable platform is configured, tested, and made available as an HDInsight offering. The HDInsight offering’s version number is unique to Azure and not specifically related to a version of Linux, Apache, or Windows.
Table 15-2 shows the versioning control used to identify how the individual components are stacked together and offered as an Azure HDInsight version. It does not correlate with any current HDInsight version offering. The next section walks through the options to build an HDInsight deployment using Azure.
There is one final point to discuss about Hortonworks and the Hortonworks Data Platform (HDP) for Windows. This platform is a fully configurable big data cluster based on Hadoop, and it can be installed on physical on-premises hardware or on Hyper-V hosts with virtual machines on-premises. In addition, the HDP platform can be customized on VMs in Azure. But then it is not a SaaS solution, because it becomes an infrastructure as a service (IaaS) solution that can take on the administration of OS patching and Hadoop updates.
![]() Tip To learn more about the Hortonworks and Microsoft partnership’s support for the Apache Hadoop cluster on Azure, see the Hortonworks and Microsoft partner page at http://hortonworks.com/partner/microsoft/.
Tip To learn more about the Hortonworks and Microsoft partnership’s support for the Apache Hadoop cluster on Azure, see the Hortonworks and Microsoft partner page at http://hortonworks.com/partner/microsoft/.
Deploying HDInsight
In this exercise, you walk through the steps necessary to deploy HDInsight in an Azure subscription. Options available in the deployment of HDInsight (SaaS) depend on the type of Azure subscription (Free Trial, MSDN subscription, or Pay-As-You-Go). The prerequisite for completing this exercise is to have a storage account available in one of the supported regions (West US and so on) to support the HDInsight deployment.
DEPLOYING HDINSIGHT
- From your classic Azure Portal, select the HDInsight workspace, and choose the option to Create an HDInsight Cluster, as shown in Figure 15-5.
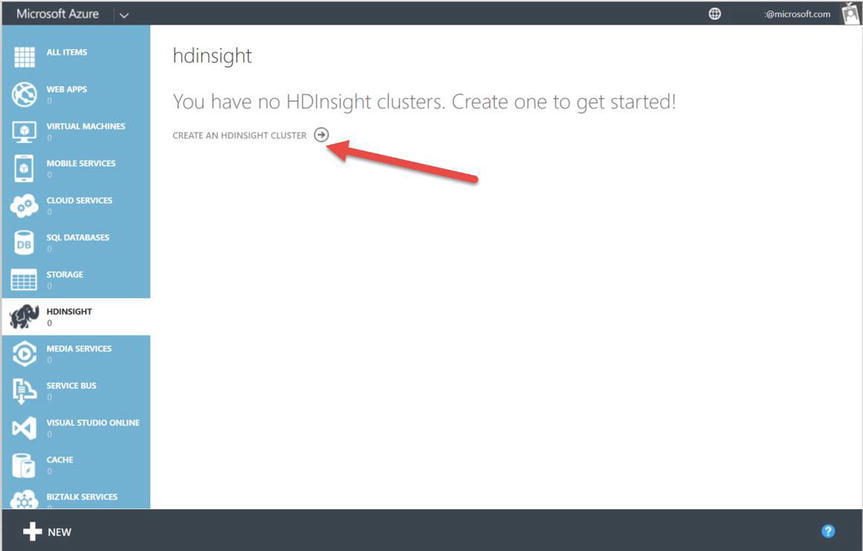
Figure 15-5. Creating an Azure HDInsight cluster
- With this Azure subscription, the Hadoop options are preselected. Notice, however, that in Figure 15-6 the HDInsight options include HBase, Storm, and Custom Create. (Hadoop on Linux is not available for this subscription, but it may be available with your Azure subscription.)
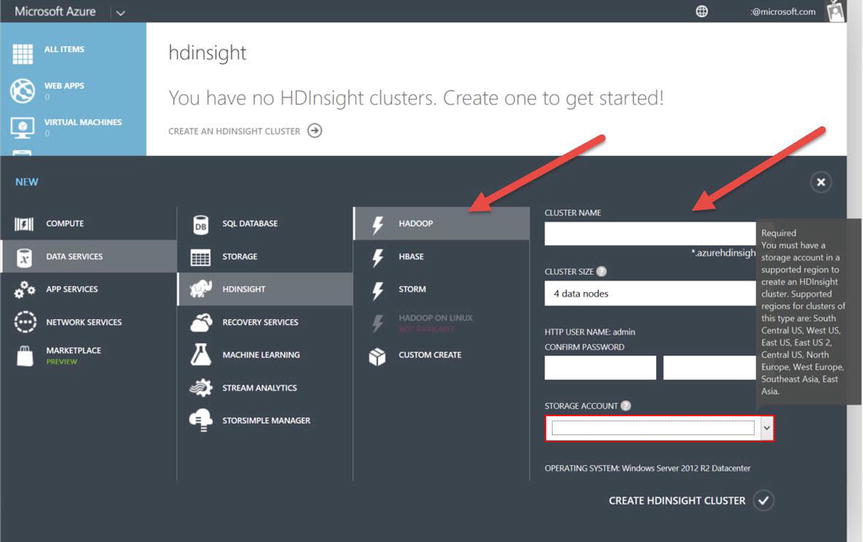
Figure 15-6. Azure HDInsight open source selection
- The cluster name must be unique: use contosohadoop.azurehdinsight.net for this exercise. After you choose the name, you can select the Hadoop cluster size, as shown in Figure 15-7, from 1 node (for testing) up to a 32-node cluster (for production). Also note in Figure 15-7 the HDInsight supported storage account regions identified in the pop-up text window.
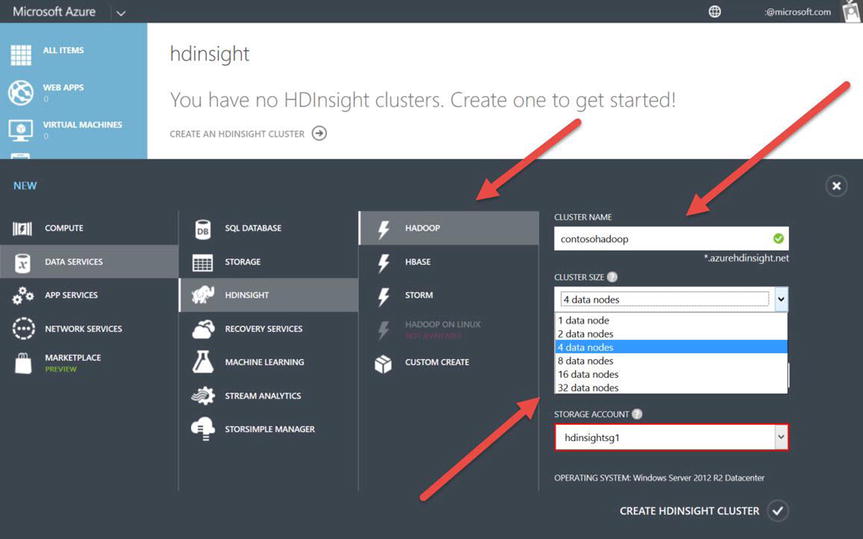
Figure 15-7. Completed Azure HDInsight options
 Tip If your Storage Account entry has a red highlight around it, the storage account was not created in one of the supported Hadoop Azure regions. You cannot create the cluster until you select the correct Azure region for the storage account.
Tip If your Storage Account entry has a red highlight around it, the storage account was not created in one of the supported Hadoop Azure regions. You cannot create the cluster until you select the correct Azure region for the storage account. - If you have created the storage account in one of the supported Azure regions, the new Hadoop SaaS cluster is created and displayed in the HDInsight workspace, as shown in Figure 15-8.
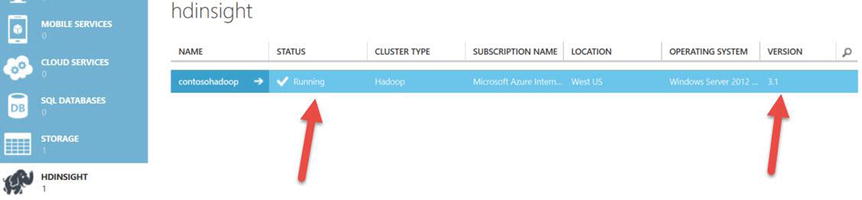
Figure 15-8. Azure HDInsight version 3.1 SaaS cluster running
Tip In Figure 15-8, notice that the HDInsight version is 3.1. This is the Azure Hadoop SaaS version running on Windows Server 2012 R2 with an SLA for uptime. - Select the Get the Tools option shown in Figure 15-9 to install the Azure PowerShell SDK. This is a two-step process; selecting this feature starts the Web Platform Installer, shown in Figure 15-10, to download and install Azure PowerShell.
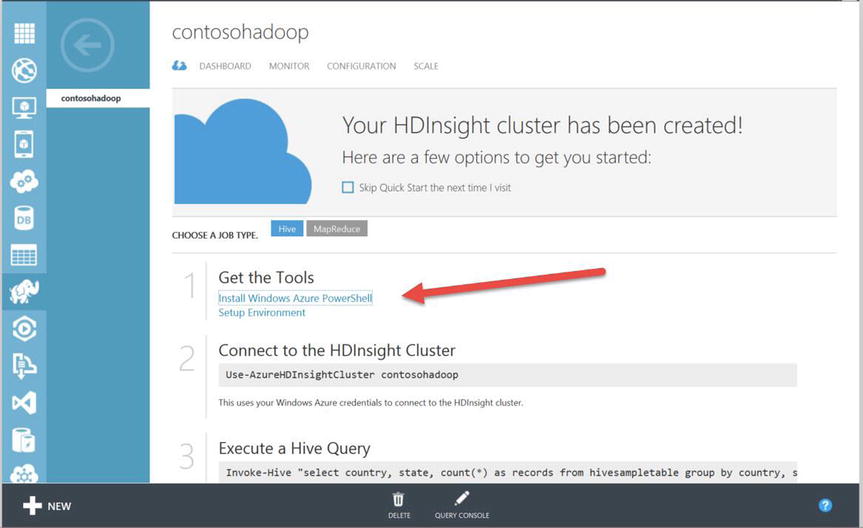
Figure 15-9. Get the Tools option to begin the Azure PowerShell install
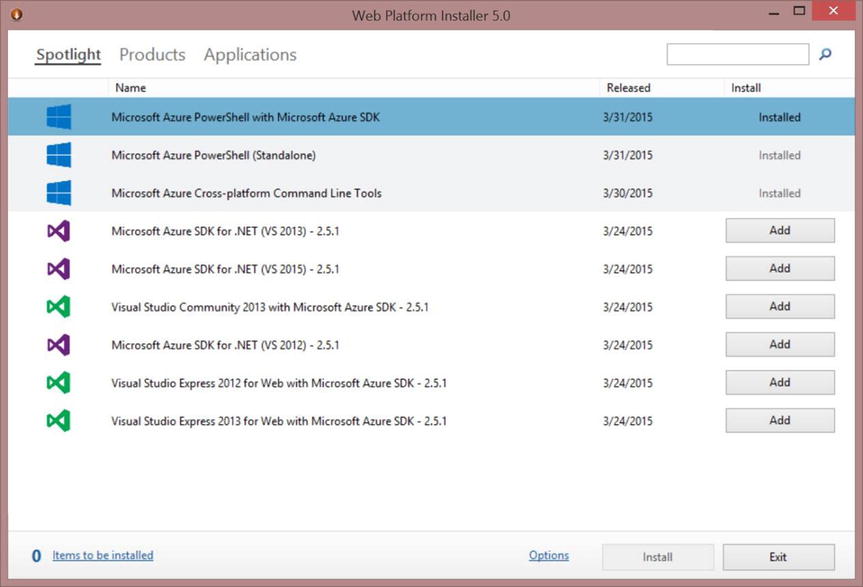
Figure 15-10. Web Platform Installer used to install the Azure PowerShell SDK platform
Defining Azure Business Intelligence
In this section, you learn about the options available to provide both business leaders and senior executives with visual reporting that is meaningful and actionable. Throughout this chapter, you have been introduced to multiple options for processing big data, such as using Pig with Hadoop in HDInsight or Hive, or many of the other projects identified in Table 15-1. Additional options are available for processing big data using traditional development code with Python, C#, C++, and other web-based languages like PHP and JavaScript.
It is also easy to provide BI with universal programs like Microsoft Excel, which provide the functionality needed to use Microsoft Power Query in business reports. The next exercise can be easily completed to produce beautiful reports using Hadoop big-data results.
MICROSOFT EXCEL POWER QUERY
![]() Note To complete this exercise, you must have permissions to install software on your computer.
Note To complete this exercise, you must have permissions to install software on your computer.
- Download Microsoft Power Query for Excel, as shown in Figure 15-11. It is located in the Microsoft Download Center at www.microsoft.com/en-us/download/details.aspx?id=39379.
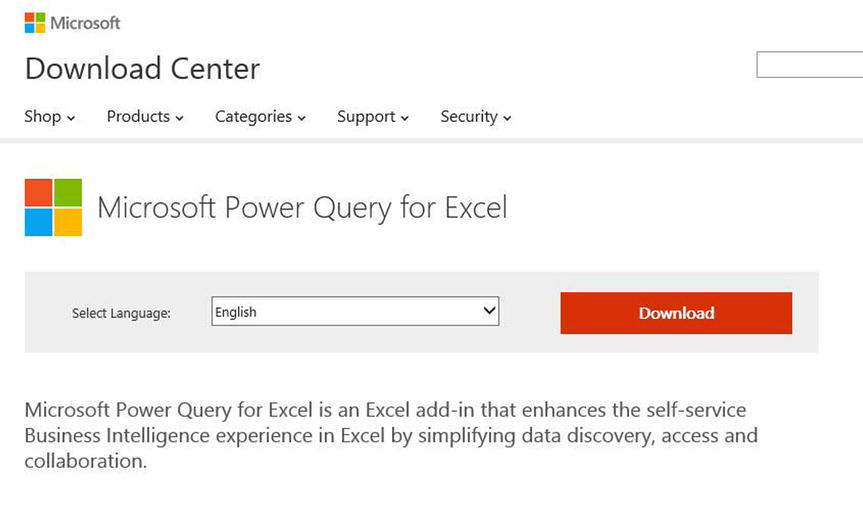
Figure 15-11. Downloading Microsoft Power Query for Excel from the Microsoft Download Center
- Choose the correct version for your Microsoft Office installation: 32-bit or 64-bit. The OS version is not a factor in this decision. To validate what version you are currently running, open Microsoft Word and, in a new or an existing document, choose File
 Account.
Account. - Click the About Word icon. The version is displayed—32-bit or 64-bit—as shown in Figure 15-12. Follow the prompts to install Excel Power Query.
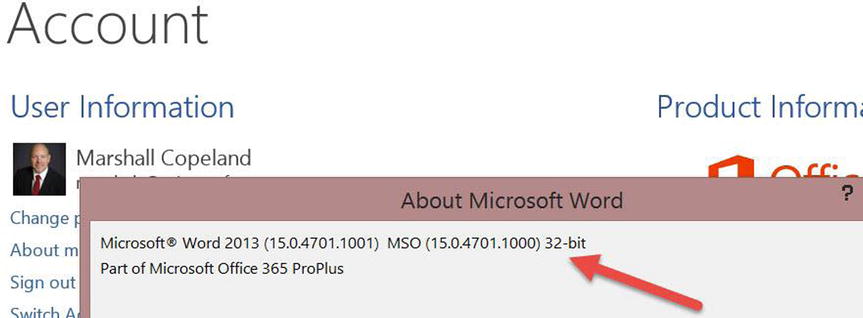
Figure 15-12. Identifying the Office version: 32-bit or 64-bit
- Once Power Query has completed its installation, open Excel, create a new blank workbook, select the Power Query tab, and choose From Other Sources From Hadoop File (HDFS), as shown in Figure 15-13.
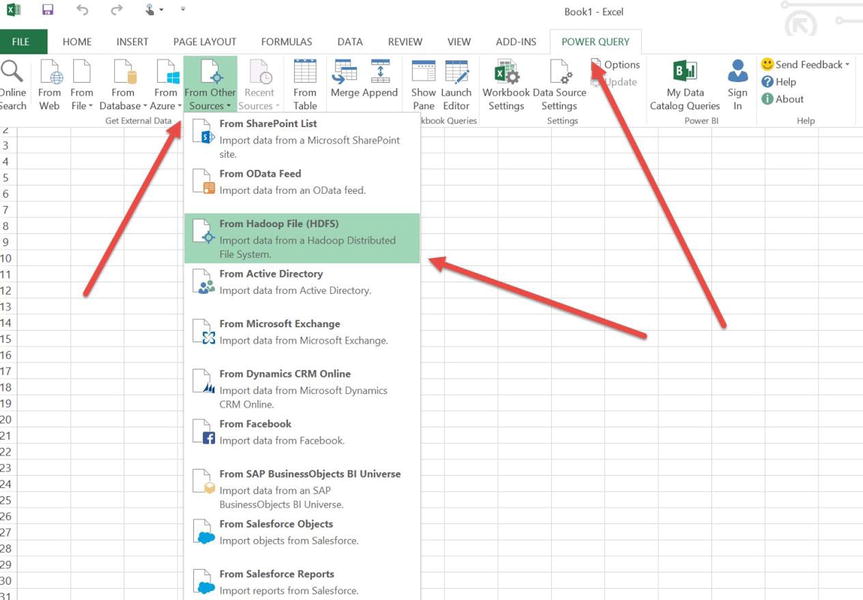
Figure 15-13. Microsoft Excel Power Query add-in
- Enter the name of the Hadoop cluster created in the previous exercise. In the example used for this chapter, the full name is contosohadoop.azurehdinsight.net, as shown in Figure 15-14.
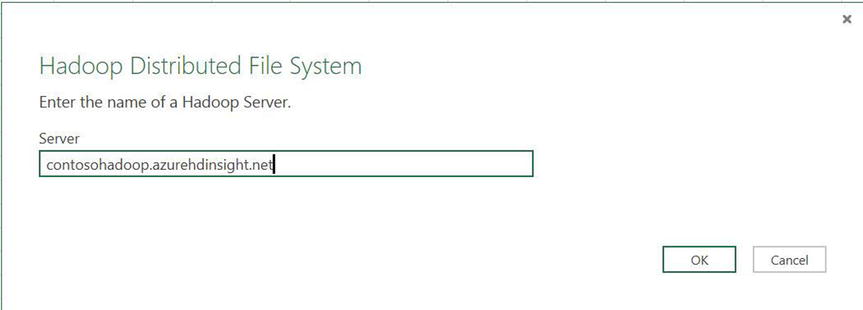
Figure 15-14. Hadoop server name, built using Deploy HDInsight
- Connect to the Hadoop cluster using an anonymous logon or an account, as shown in Figure 15-15.
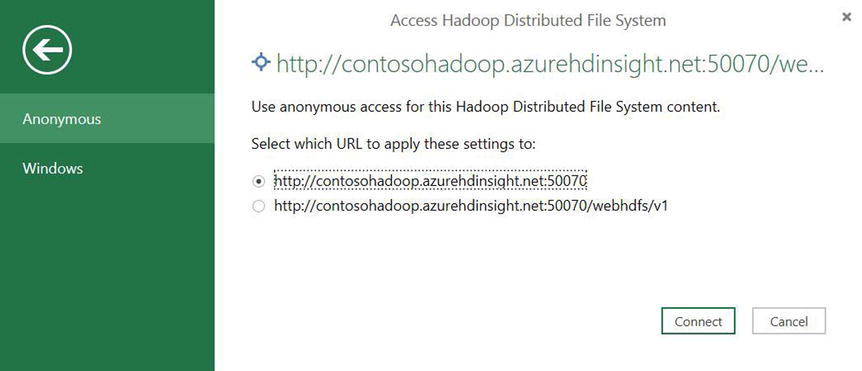
Figure 15-15. Connecting Excel to the Hadoop cluster
- The Excel Query Editor opens, and you can start building Power Query reports from the HDFS data.
You can also connect Microsoft Excel to Hadoop using Microsoft Hive ODBC drivers. Other options are to use Office 365, to import and export data with Sqoop (listed in Table 15-1), and other methods.
![]() Tip You can learn more about Microsoft HDInsight and analytics by exploring the documentation and tutorials at the Azure Hadoop learning guide at http://azure.microsoft.com/en-us/documentation/articles/hdinsight-learn-map.
Tip You can learn more about Microsoft HDInsight and analytics by exploring the documentation and tutorials at the Azure Hadoop learning guide at http://azure.microsoft.com/en-us/documentation/articles/hdinsight-learn-map.
Summary
This chapter introduced you to the world of big data using a Microsoft Azure solution that supports the array of challenges that big data creates. You learned about Hadoop, an Apache open source project, and how Microsoft has partnered with Hortonworks to provide a 100% open source solution. Finally, you stepped though exercises to install HDInsight clusters into your Azure subscription and access the clusters using Microsoft Power Query in Excel.
The next chapter introduces you to configuring Microsoft Intune, which is another Azure solution. Intune supports Apple, Android, and Microsoft Windows phones, tablets, and portable devices. Discussion topics include the technology to support initiatives like bring your own device (BYOD) and how Intune protects corporate data. Additionally, Azure Rights Management Services (RMS) provide extended protection for documents with policy control, enabling end-to-end security of intellectual property mandated by both state and federal laws in order to protect privacy.