
![]()
Performance and Optimization of Solutions
Building Scribe integration and migration solutions with an eye on performance requires that you utilize certain patterns and approaches that aren’t obvious when first developing with the platform. When processing large numbers of records, or records that require large numbers of transformations in order to complete the mapping, you must work toward optimized solutions. This chapter outlines how to introduce multithreading into your solutions through the use of MSMQ (Microsoft Message Queuing), how to work with local IDs, and several other topics that will ensure you are building solutions that are fully optimized and built for performance.
![]() Note The number of records you are processing will drive your development. If your DTS (Data Translation Specification) package is dealing with a small set of data, then you can afford to write DTS solutions that are not optimized. You can take shortcuts with your coding and still have a viable solution. However, when you are dealing with huge record sets (thousands or tens of thousands of records), you need to architect your solution based on this, and apply the patterns outlined in this section to your implementation approach.
Note The number of records you are processing will drive your development. If your DTS (Data Translation Specification) package is dealing with a small set of data, then you can afford to write DTS solutions that are not optimized. You can take shortcuts with your coding and still have a viable solution. However, when you are dealing with huge record sets (thousands or tens of thousands of records), you need to architect your solution based on this, and apply the patterns outlined in this section to your implementation approach.
Scribe has multithreading functionality. However, in order to utilize this functionality, you must build a distributed solution that has at least two DTS files, which communicate with one another using MSMQ. Building this pattern takes a little more time than a standard single DTS solution, but it will increase your processing horsepower substantially. When processing large volumes of data, it can mean the difference between hours of processing and weeks of processing time.
When you create a single DTS package, and run it in either the Workbench or the Scribe Console, it is single threaded. It picks up a single row of data from the source connection, maps it and processes it, runs it through whatever steps have been configured, and delivers it to the target. If it runs into an error, the error is logged. Once complete, it loops to the next record in the source and performs that same logic. Figure 7-1 illustrates this flow.
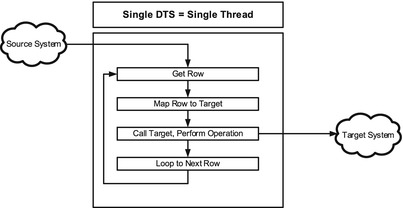
Figure 7-1. A standard single-threaded DTS package
Even DTS packages that incorporate the bulk mode functionality found on some adapters operate in single-threaded capacity. The bulk mode setting, found on the Operation tab of the Configure Steps window within the Workbench (see Chapter 4 for more details) allows for batching many individual rows together into the same transaction on the target. It will potentially reduce the number of operations that the DTS package has to perform, but it still happens sequentially. A batch of 100 records will be processed before the next batch of 100 records can be processed. Figure 7-2 illustrates the single-threaded DTS with batching.
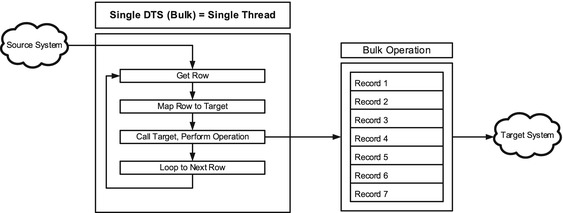
Figure 7-2. A standard single-threaded DTS package
Only when two or more DTS packages, using MSMQ, are built and deployed to the Scribe Console can multithreading take place. The pattern shown in Figure 7-3 illustrates a fully configured multithreaded Scribe DTS solution. The first DTS package is single threaded, pulling the data from the source and writing it to the target MSMQ. The second DTS picks up a record from the queue and pushes it to the target. By using the MSMQ, Scribe can spin up multiple instances of the second DTS package, which means that multiple messages from the queue will be processed in parallel.
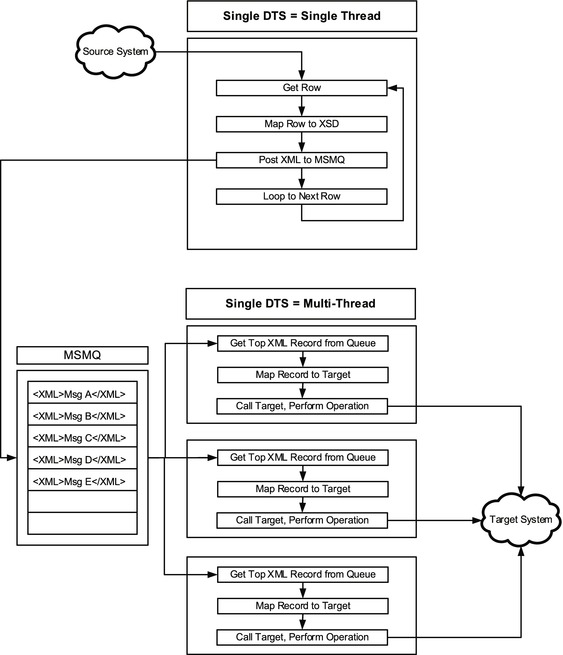
Figure 7-3. Processing DTS files in parallel using MSMQ
The steps to take in order to create a multithreaded solution are as follows:
- Create a DTS package that reads from your source (for example, a SQL table) and maps it to an XML target. See Chapter 6 for more details on using an XDR/schema and XML as a target connection. This XML target should be output to the MSMQ on the Scribe server.
- Create a second DTS package that uses an XML source and reads from it from the same MSMQ that is being written to in the previous step. The target should be pointed to a valid target connection (such as SQL or Dynamics CRM).
- Open the Scribe Console and deploy both of the DTS packages (see Chapter 5 for details about deploying and configuring DTS files in the console). Make sure that the filter set on the second DTS, which tells it what XML records to pull from the queue, matches the XDR/schema type published to the queue by the first DTS (see Chapter 6 for details on working with the queue, XDRs, and filters).
![]() Note Make sure that the Scribe Console is configured to utilize all the processors available to it. In order to do so, right-click the Integration Server folder. Select Properties. The window you see in Figure 7-4 will be shown. You will see that there are a large number of “Procs Assigned” to the DEFAULT processor group. Make sure that you are utilizing all the available processors, and that the maximum processors are assigned to the DEFAULT group. There is no “correct” configuration here; you will have to experiment to see what settings give your solutions the best response times.
Note Make sure that the Scribe Console is configured to utilize all the processors available to it. In order to do so, right-click the Integration Server folder. Select Properties. The window you see in Figure 7-4 will be shown. You will see that there are a large number of “Procs Assigned” to the DEFAULT processor group. Make sure that you are utilizing all the available processors, and that the maximum processors are assigned to the DEFAULT group. There is no “correct” configuration here; you will have to experiment to see what settings give your solutions the best response times.
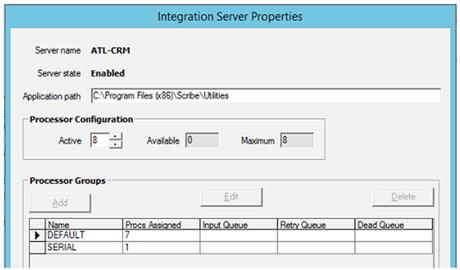
Figure 7-4. Configuring processors in the Scribe Console
Chapter 4 detailed how to incorporate premapping of data into your solution. Premapping not only simplifies your solutions but also increases performance. An additional concept related to premapping is the idea of localizing your lookups and adding these lookup values to your initial data set (the premapped data). A local lookup refers to downloading all of your target lookup IDs so that they reside on your local network. By doing this, the DTS packages no longer have to query IDs from the target connection as a separate transaction for each individual row.
To illustrate the use of a local lookup, and to see how it improves performance, take the following scenario as an example: you are loading contact records from SQL Server into Dynamics CRM. The source record set consists of 100,000 contacts. Each contact has an account that it is related to. In addition, it also has a state and county. All three of these fields are unique identifiers that relate the contact to existing records in the target.
You can take two approaches. The first uses DBLOOKUPs (or similar) to get the ID of each related record. This method is self-contained within the DTS package. The second uses the local lookup approach, and it loads the related record IDs as part of the initial source data set for the DTS. Both of these approaches are outlined in this section, so that you can see the difference in performance and structure for each.
Figure 7-5 illustrates the first approach, which uses DBLOOKUPs. In this scenario, the DTS package uses a variable for each of the three lookups using the DBLOOKUP method. This means that a minimum of four individual operations will be made against the target for each row: the account lookup, the state lookup, the county lookup, and the actual insert/update of the record. For 100,000 records, a minimum of 400,000 operations will take place against the target.
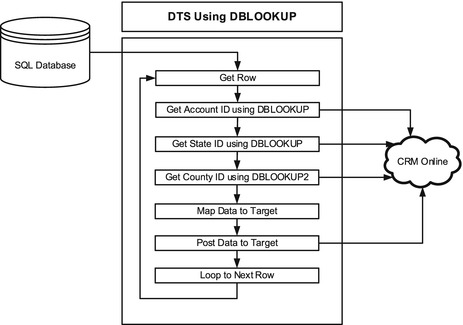
Figure 7-5. Using DBLOOKUPs
It is worth noting that one of the DBLOOKUP functions is dependent on the outcome of a previous lookup. The CountyID requires that the StateID is first returned. The StateID is then passed in as a second lookup parameter using the DBLOOKUP2 function. There is additional weight added to the solution due to this additional reference and parameter for DBLOOKUP2. Listing 7-1 shows the three functions.
DBLOOKUPs are valuable and easy to implement, but they are not the most efficient solution. In a DTS implementation where a large number of records are being processed, DBLOOKUPs will require too much time and processing power. The alternative is the local lookup, illustrated in Figure 7-6.
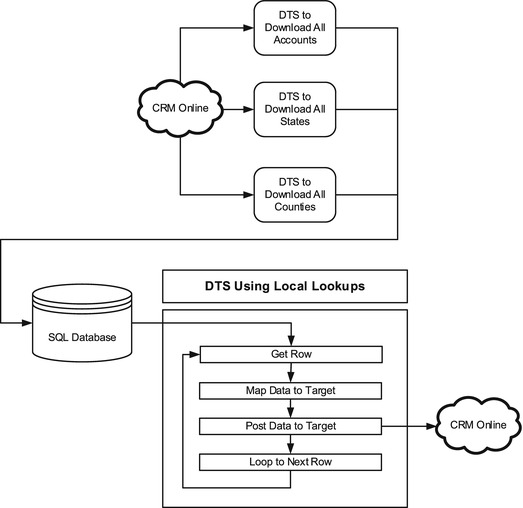
Figure 7-6. Using local lookups
The local lookup pattern consists of creating one DTS package for each of the entities that needs to be referenced. In the current example, three DTS packages would be created. Each DTS would connect to CRM Online and pull all of the records for the specific entity it is dealing with (account, new_state, and new_county) and download the IDs to a local SQL Server table (this could be on the SCRIBEINTERNAL database, or elsewhere).
Figure 7-7 shows an example of the account DTS. It uses the account entity in the CRM Online instance as the source and pulls down all the records. It uses the SQL table stored in the SCRIBEINTERNAL database shown in Listing 7-2 to store the account id and the account number. You will need to do the same for each of the entities for which you will be doing a local lookup (state and county tables scripts are also in Listing 7-2).
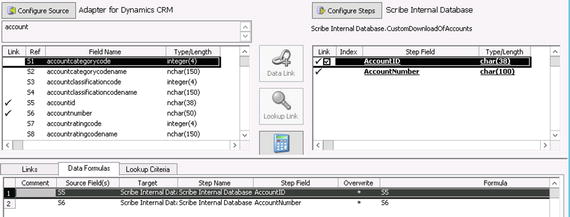
Figure 7-7. Simple DTS to pull all accounts down to a local SQL table
![]() Note You will want to download your IDs to a table that is easy to reference from the SQL you are using in your DTS source connection. This SQL will premap the IDs (see Chapter 4 for more detail on premapping).
Note You will want to download your IDs to a table that is easy to reference from the SQL you are using in your DTS source connection. This SQL will premap the IDs (see Chapter 4 for more detail on premapping).
The account number is used as the local lookup value in the source connection of the main DTS package that loads data into CRM, as shown in Listing 7-3 (the full source configuration is shown in Figure 7-8). This SQL does the lookup and mapping of the IDs during the querying of the data so that no logic is needed in the DTS. The IDs come through ready to be loaded directly into CRM. Based on the query in Listing 7-3, the DTS package will get all of fields from the Warranty table plus the three additional premapped IDs for account (AccountIDFinal), state (StateIDFinal), and county (CountyIDFinal).
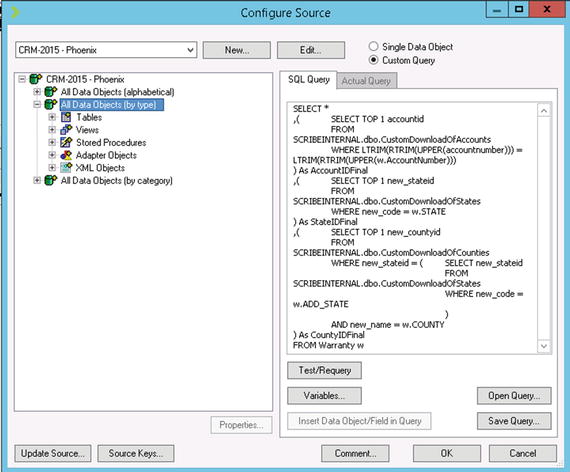
Figure 7-8. The source SQL in the main DTS file, with premapped IDs
The performance gains of using local lookups can be significant. When dealing with large record sets, many hours can be shaved off the runtimes. You will need to incorporate some coordination into your solutions to ensure that you have downloaded the latest data from your target prior to doing the local lookup, but this is a price worth paying given the performance improvements you will get.
Considerations with Adapter Operations
There are a number of operations available on Scribe Adapters which can be set within the Operation tabs of the Configure Steps window in the Workbench. The operations available are dependent on the adapter. For example, the XML adapter only allows for “Insert,” whereas the CRM adapter has many (see Figure 7-9 for full list). When you are working with these operations, you must take into consideration the number of records you are dealing with and the types of connections the adapter must make.
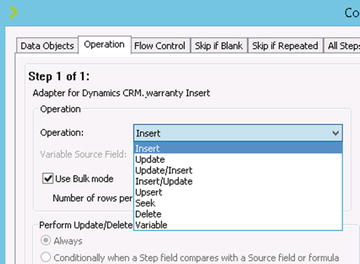
Figure 7-9. Operations available for Dynamics CRM Adapter
Update/Insert Operation vs. Update and Insert Operations
To understand how these operations can impact your DTS performance, take the case shown in Figure 7-10 as an example. You have source data that needs to be either inserted or updated in the target entity. Logically, you choose either the Update/Insert or Insert/Update operation. These ensure that if the record exists in the target, it gets updated, and if it does not exist, it gets created. However, this is not a single operation. The adapter must work through up to two operations for each record.
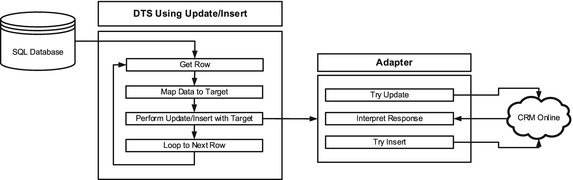
Figure 7-10. Update/Insert has multiple communications with target
In the case of the Update/Insert operation, the adapter must first see if the record exists or perform an update and catch the error if it doesn’t exist (this depends on the way the individual adapter has been coded, and how the target system’s API works). If either of these indicate that the record doesn’t exist, then the insert operation will occur. The overhead here is high, and while it isn’t a big deal when dealing with small record sets, it becomes unwieldy with large ones.
In order to deal with this, you have one solid option to improve performance, and that is to split your DTS into two individual DTS packages. The first DTS handles inserts, while the second handles updates. Your source data is filtered in each DTS to only get those records that already exist for the update DTS, and only those that do not yet exist in the insert DTS. Figure 7-11 illustrates this approach.
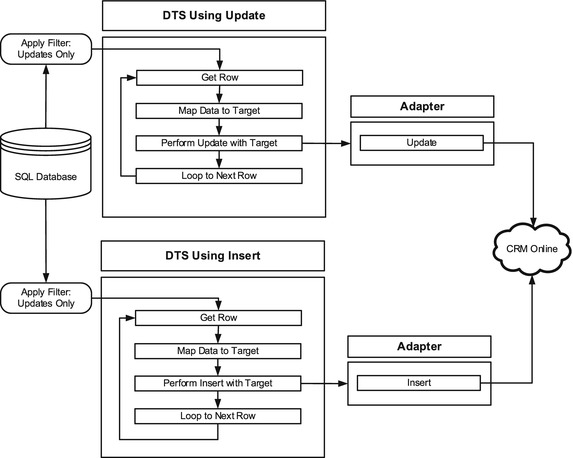
Figure 7-11. Individual insert or update, single communication with target
![]() Note For online-based targets (like CRM Online), you can determine if a record exists by doing a pre-download of all the entity records, similar to the approach taken in the downloading of lookups, noted elsewhere in this book. For on premise targets, it is likely even simpler—you can query their databases directly on your network as part of your source data/premapping, and deal with the data before it ever gets into your DTS.
Note For online-based targets (like CRM Online), you can determine if a record exists by doing a pre-download of all the entity records, similar to the approach taken in the downloading of lookups, noted elsewhere in this book. For on premise targets, it is likely even simpler—you can query their databases directly on your network as part of your source data/premapping, and deal with the data before it ever gets into your DTS.
![]() Note By splitting your DTS packages into two separate packages, one for inserts and one for updates, you decrease the total amount of communication you have with your target system (depending on the adapter used). For example, using the split model, if you have 100K records in your source, and 75K of them are updates and 25K of them are inserts, your total number of records processed is 100K. In contrast, using the single DTS with an update/insert operation, you will have at least 125K hits against your target, as each update/insert must first do the update, and, if that fails, then do the insert.
Note By splitting your DTS packages into two separate packages, one for inserts and one for updates, you decrease the total amount of communication you have with your target system (depending on the adapter used). For example, using the split model, if you have 100K records in your source, and 75K of them are updates and 25K of them are inserts, your total number of records processed is 100K. In contrast, using the single DTS with an update/insert operation, you will have at least 125K hits against your target, as each update/insert must first do the update, and, if that fails, then do the insert.
In some cases, you may not need to split your DTS package—you can simply do away with the updating of data. You can clear your target data out prior to running your DTS package, and program your DTS package to simply handle inserts. There is nothing faster than a DTS package with an adapter that allows for bulk inserts.
Using Dynamics CRM again to illustrate this concept, imagine that you have loaded 100,000 contact records as part of an initial migration of data. Now, two weeks later, you want to run that load again in order to get the latest data. By default, you would use the Update/Insert operation (or similar) to update the data in CRM if it is present, and insert it if it isn’t. Or, you could go into CRM, initiate a bulk delete command (see Figure 7-12) against the contact records, wait for that bulk deletion operation to complete, and then run your Insert-only DTS package.
Figure 7-12. Bulk deletion of contact records in Dynamics CRM
You will reduce your runtime drastically by using an Insert rather than a combination operation like Update/Insert. This approach is most useful within a development or test setting, where you may have to load/reload data multiple times while developing migration scripts and processes. A production environment likely would not be a good place to do mass deletes, as you may lose data (and auditing/tracing) that has been updated by users within your target system.
Limiting the Number of Records to Process
You can improve performance of some DTS solutions by limiting the number of records that are processed in any given run. For example, if you have one million records in your source table, and you have a DTS file that is pushing those into MSMQ where another DTS file can pick the messages up and process them on multiple threads, you may want to limit the total number of records processed in the source DTS. You will find that publishing hundreds of thousands of records to MSMQ may bog down your system, or even result in out-of-memory errors. This all depends on your server environment and message size, but regardless, large numbers of messages can be processed more quickly when dealing with smaller batches of data.
Limiting the number of rows can be done in several ways. The first is simply adding a WHERE clause to your source connection in your DTS (assuming you are using SQL). This clause would grab only the first 50,000 records, or records 50,001 through 100,000. You could base this on the ID, and each time you run the process manually, you could update this WHERE clause.
Another way to do it would be to use a temporary table to store the ID of the last message processed. Then, you could include this in your source query, and update it at the end of the DTS process. The DTS could then be scheduled in the Console to run every hour. When it kicks off it would read the first 50,000 records (as an example), and when complete, it would update the configuration table indicating that the last record processed was ID of 50,000. In an hour, when the process kicks off again, the source result set would take into account the value in this configuration table and pull results starting at 50,001.
Conclusion
The optimization of your Scribe processes requires that you consider the number of records you are going to be processing, the types of data transformations you will be performing in your mapping, the options you have in writing data via the adapter that you will be using, and what technologies aside from Scribe you have at your disposal. Architecting a well-performing DTS solution sometimes requires several tries using different techniques and monitoring their performance in order to get something that will meet your needs. Once you understand the various patterns, however, and have worked through a number of implementations, you will be able to design well-performing, optimized DTS solutions. As the next chapter outlines, it is possible to build well-performing, multithreaded Scribe solutions.