
In this chapter, an overview of how to use HDInsight for the purpose of machine learning will be presented. HDInsight is based on Apache Spark and used for in-memory cluster processing. Processing data in-memory is much faster than disk-based computing. Spark also supports the Scala language, which supports distributed data sets. Creating a cluster in Spark is very fast, and it is able to use Jupyter Notebook, which makes data processing and visualization easier. Spark clusters can also be integrated with Azure Event Hub and Kafka. Moreover, it is possible to set up Azure Machine Learning (ML) services to run distributed R computations. In the next section, the process of setting up Spark in HDInsight will be discussed.
HDInsight Overview
HDInsight is an open source analytics and cloud-based service. Integration with Azure HDInsight is easy, fast, and cost-effective for processing massive amounts of data. There are many different use-case scenarios for HDInsight, such as ETL (extract, transform, and load), data warehousing, machine learning, Internet of things (IoT), and so forth.
The main benefit of using HDInsight for machine learning is access to a memory-based processing framework. HDInsight helps developers to process and analyze big data and develop solutions, using some great and open source frameworks, such as Hadoop, Spark, Hive, LLAP, Kafka, Storm, and Microsoft Machine Learning Server [1].
Setting Up Clusters in HDInsight
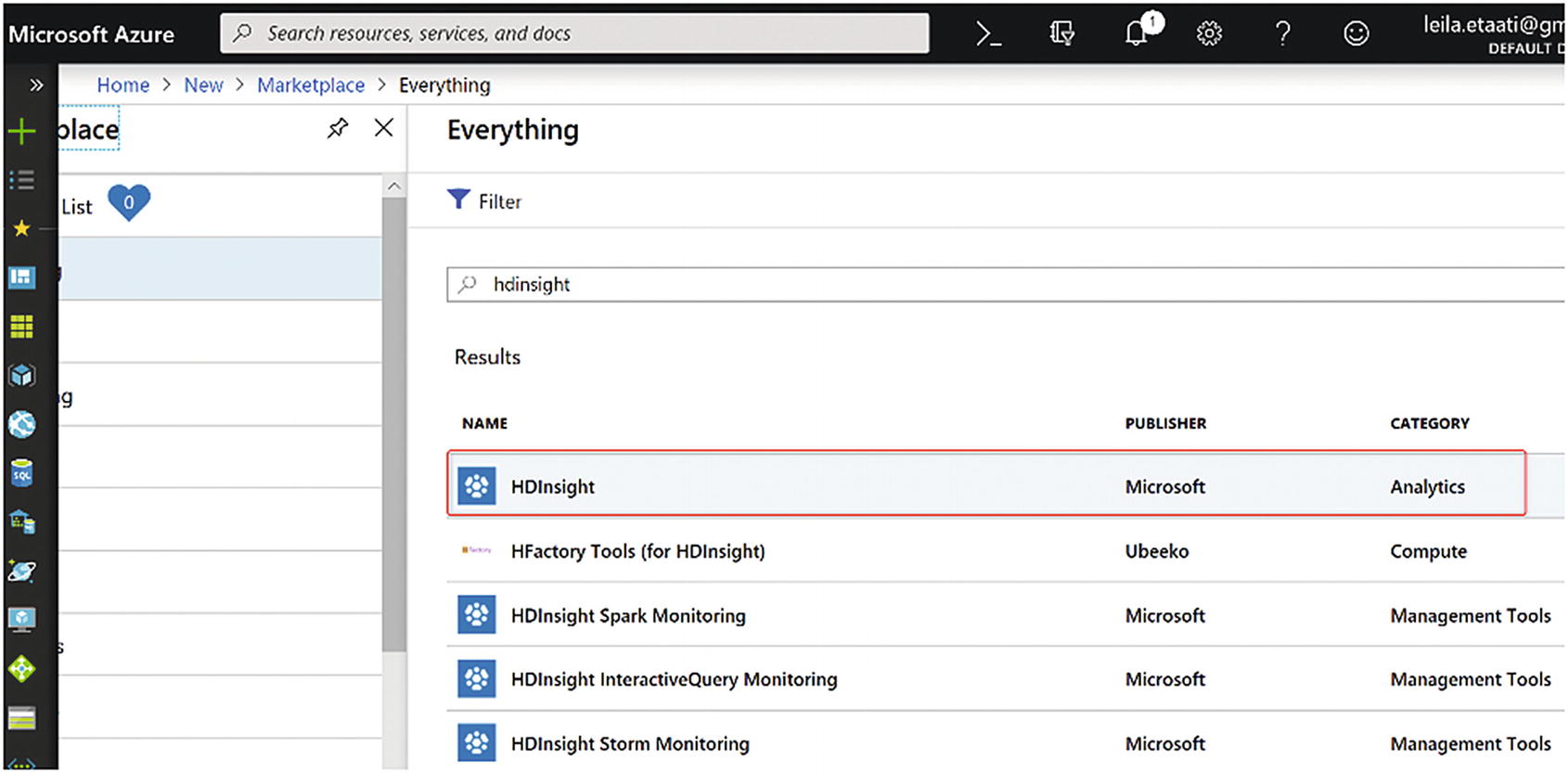
Setting up HDInsight in Azure
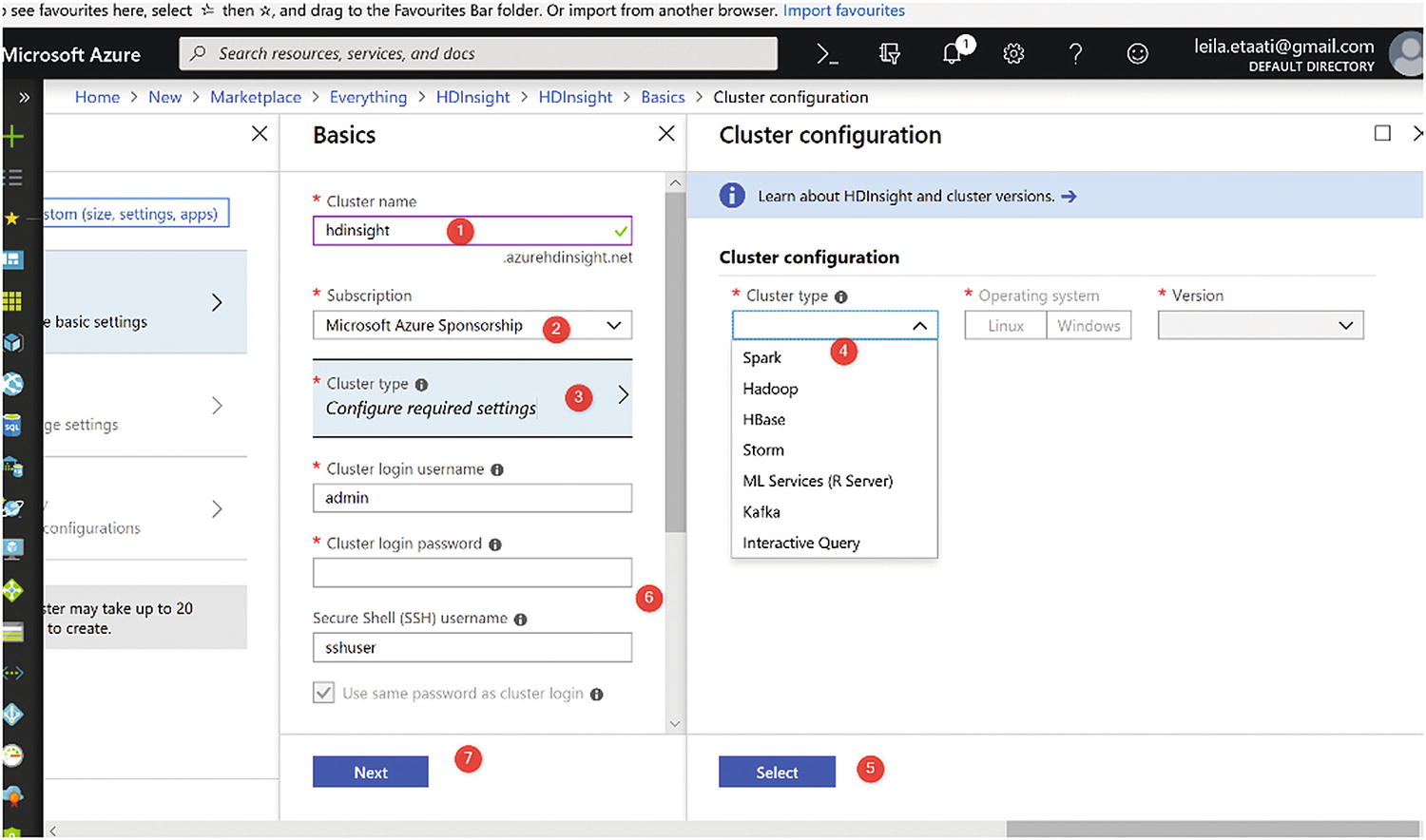
Creating HDInsight in Azure
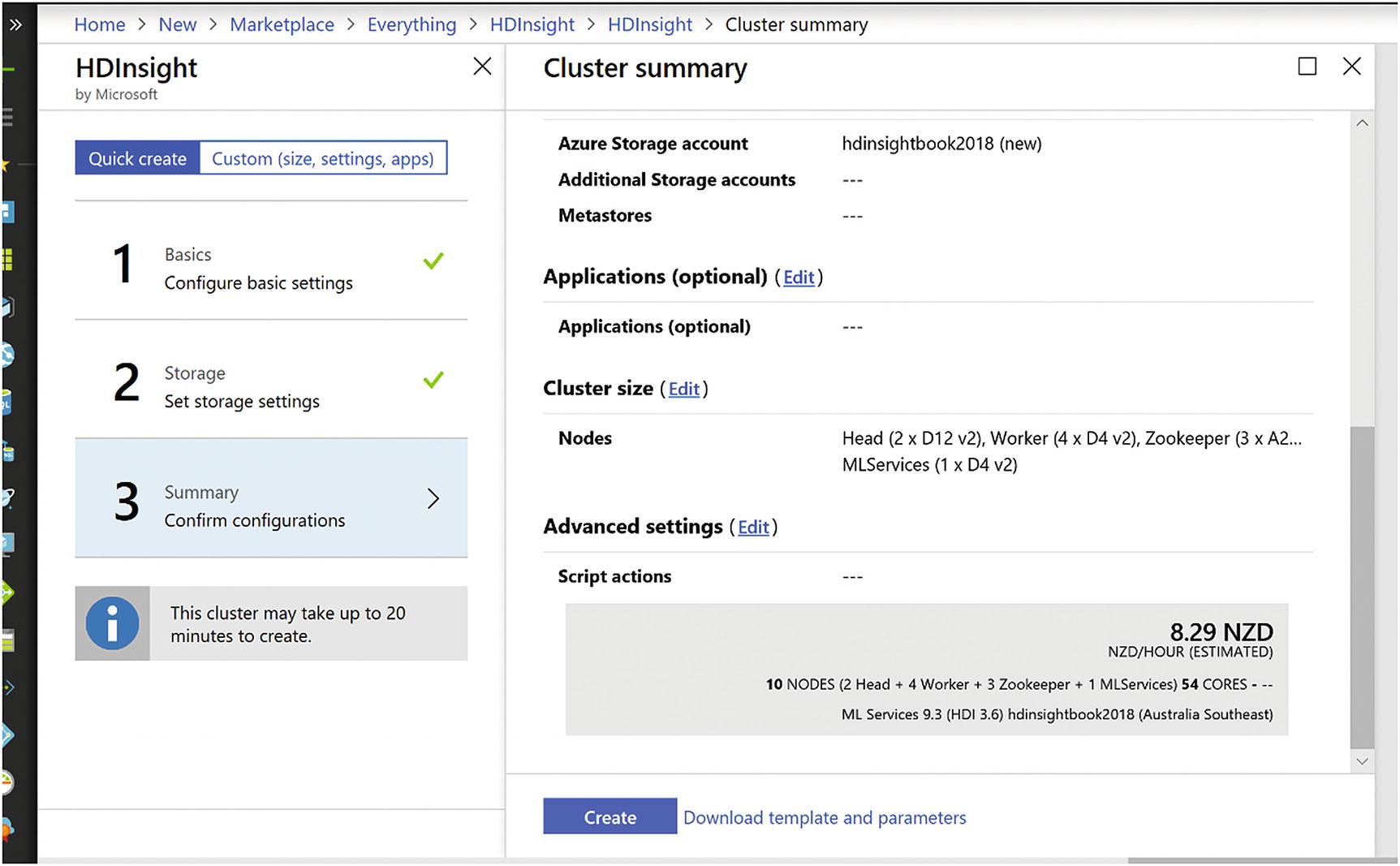
Setting up HDInsight
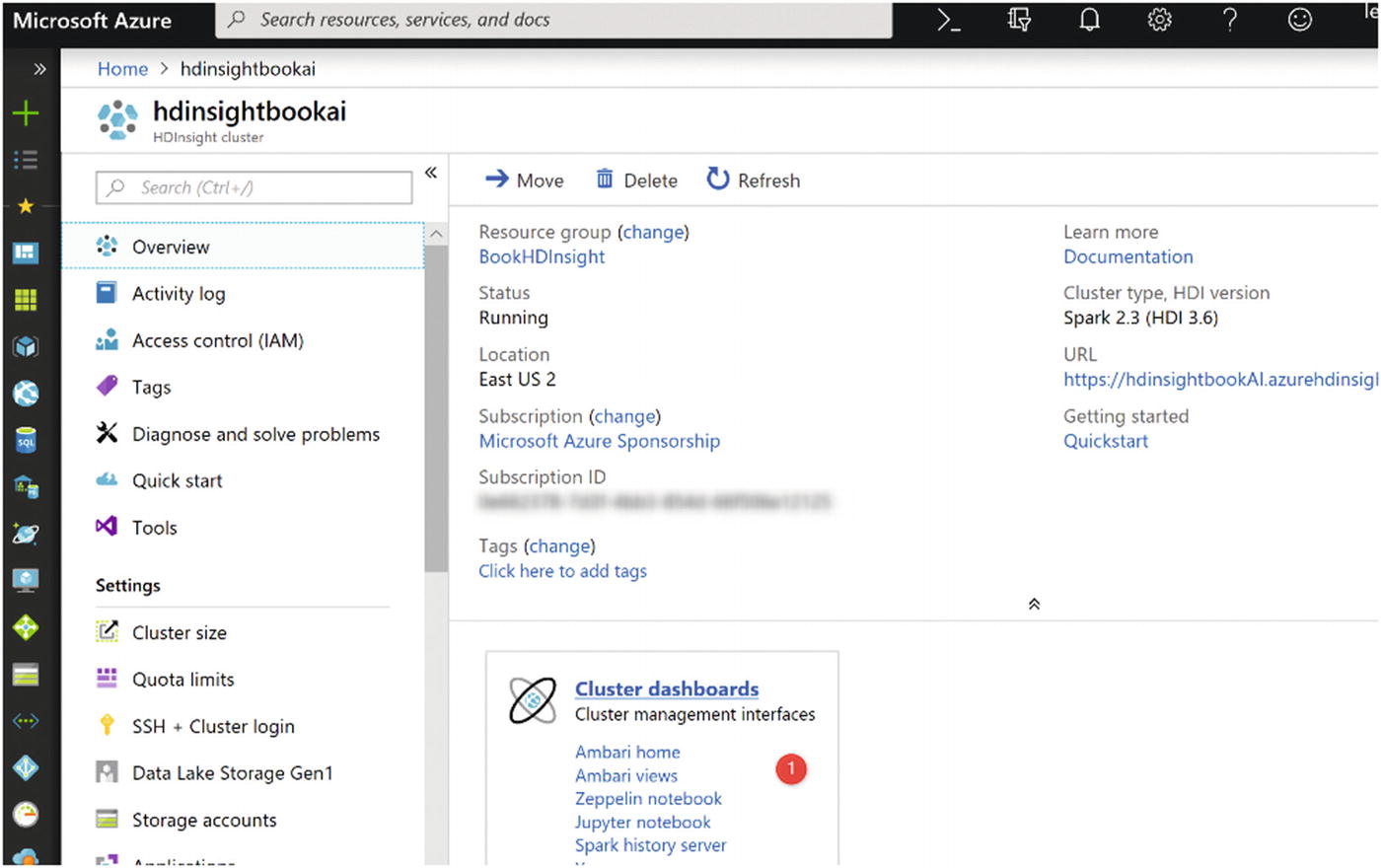
HDInsight environment
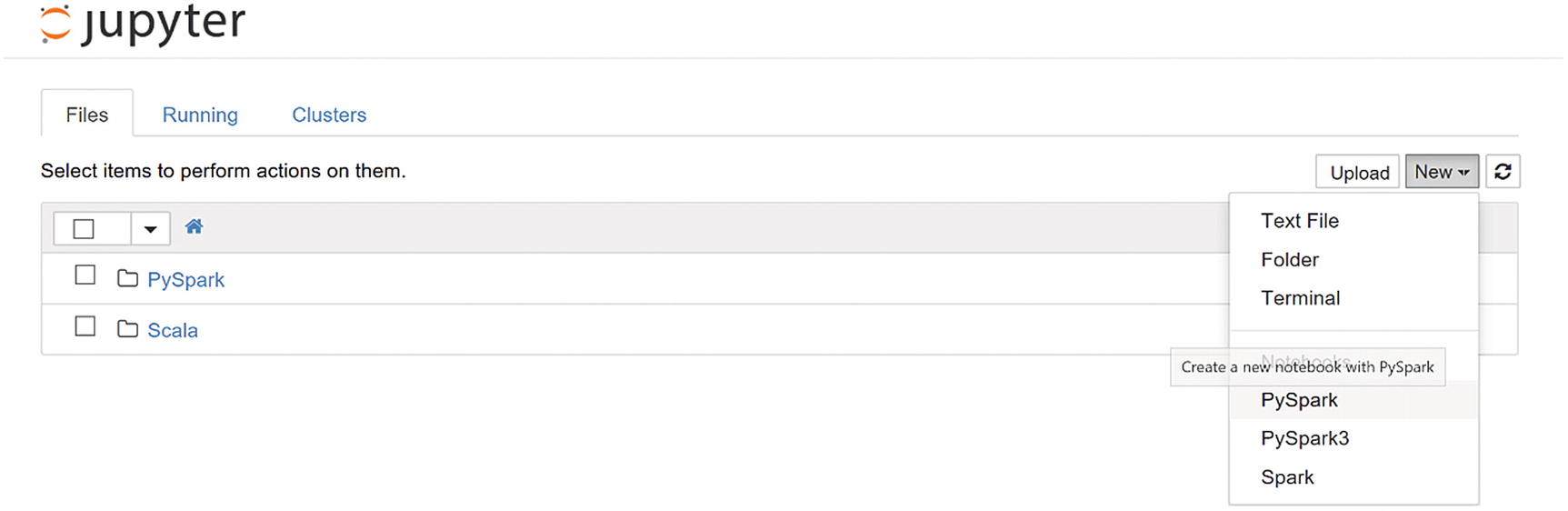
Jupyter Notebook environment
As you can see in Figure 15-5, there are environment options, such as PySpark, PySpark3, and Spark. You can write the Python code in all of them.
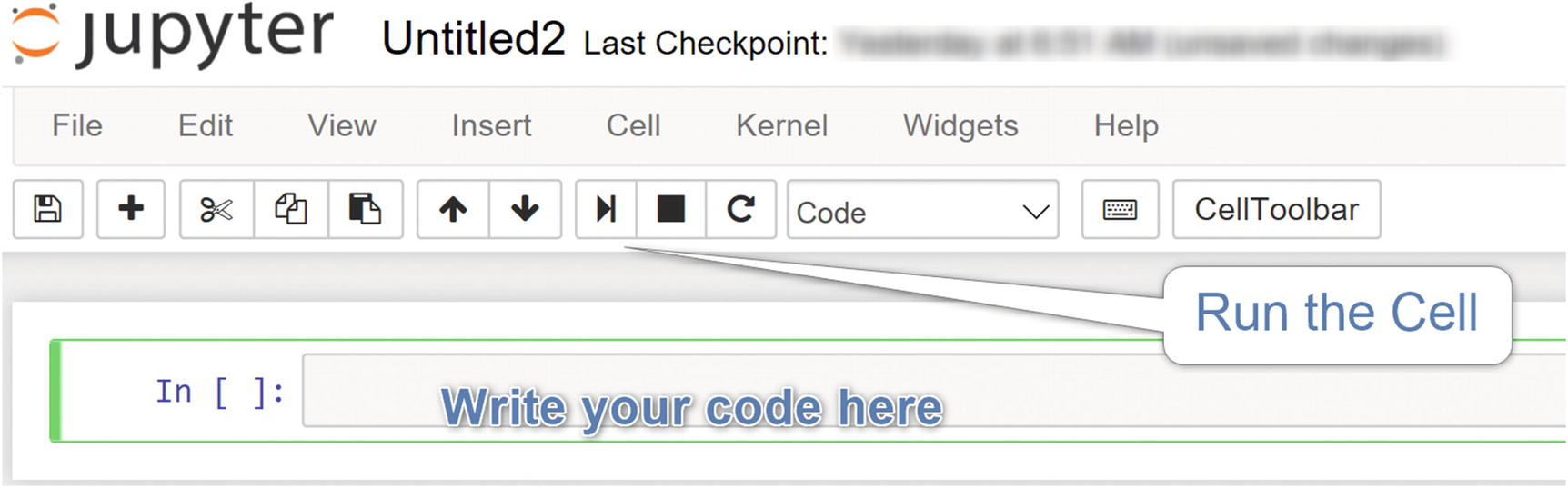
Jupyter Notebook environment
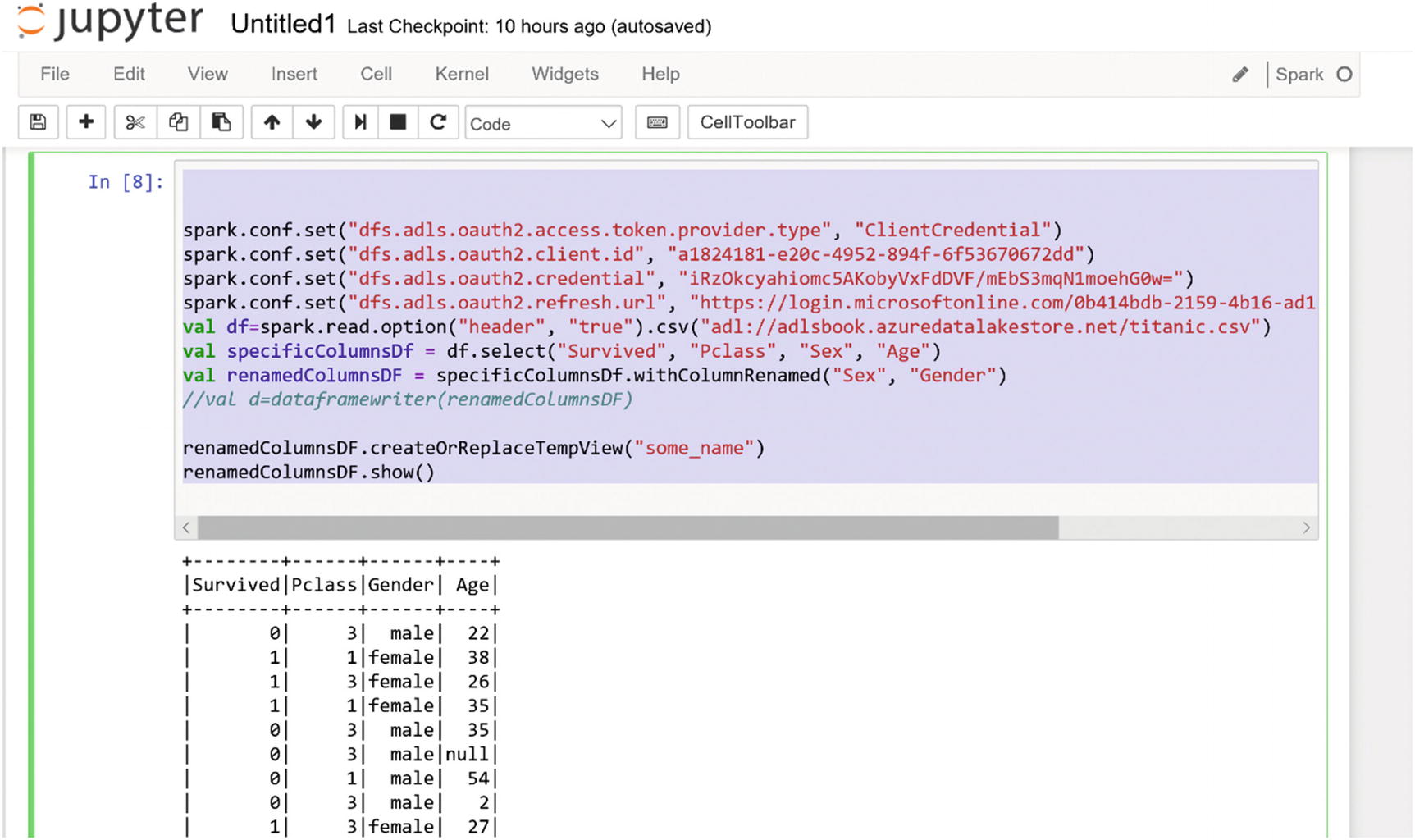
Getting the data from Azure Data Lake Store Gen1
It is also possible to perform machine learning in Jupyter Notebook with Spark. For an example, follow the tutorial available at https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-ipython-notebook-machine-learning .
Summary
This chapter presented an overview of HDInsight and how to set it up. How to use HDInsight for different purposes was explained briefly, as well as how to set up HDInsight inside the Azure environment and how to access Jupyter Notebook for the purpose of writing codes in a PySpark, Spark, or PySpark3 environment. An example of how to connect to Azure Data Lake Store Gen1 to fetch the data was shown.
Reference
- [1]
Microsoft Azure, “Azure HDInsight Documentation,” https://docs.microsoft.com/en-us/azure/hdinsight/ , 2019.