In this chapter, the process of doing machine learning inside Power BI Query Editor by writing R code will be explained. The main aim here is to provide some examples of how we can use R codes for predictive analysis (classification and regression). The concepts and codes related to some of the algorithms will be provided. In addition, the process of automating predictions via parameters inside Power BI Query Editor also will be discussed.
Neural Networks
What we expect from a computer is that we provide some inputs and then receive outputs that match our needs. Scientists try to mimic the human brain by creating an intelligence machine—a machine that does the same reasoning as humans.
The most important element of the human brain is neurons. Human brains consist of 75 million neurons. Each neuron is connected to others via synapses. So what we have in a neural network are some nodes that are connected to one another. In the human body, if a neuron is triggered by some external element, it will pass the message from the receiver node to other nodes, via synapsis. (Figure 7-1).
Figure 7-1
Neural system
Neural networks mimic the same concepts as the human brain. One node gets some input from the environment, and the neural network model creates outputs that produce the result just as a computer system would (Figure 7-2).
Figure 7-2
Computer system architecture
In a neural network there is a
Set of inputs nodes
Set of output nodes
Some processing in the middle, to achieve a good result
A flow of information
A connection between nodes
Some of the connections are more important than others, meaning that they have a greater impact on the results than others. In neural networks, we refer to this importance as the connections’ weights.
Another analogy that better expresses the goal of a neural network is the descent after climbing a mountain. When we reach the summit and the weather is foggy, we are only able to see one meter ahead. We must decide which direction to choose with only one meter of visibility. We take a first step based on the location, again deciding which direction to follow and taking other steps. So, with each step we are evaluating the course and choosing the best way to come down from the mountain (Figure 7-3).
Figure 7-3
Neural network comparison with mountain climbing
Each decision can be viewed as a node that leads us to a better and faster resolution. In a neural network, there are some hidden nodes that perform the main task. They find the best value for the output while using a function called an activation function.
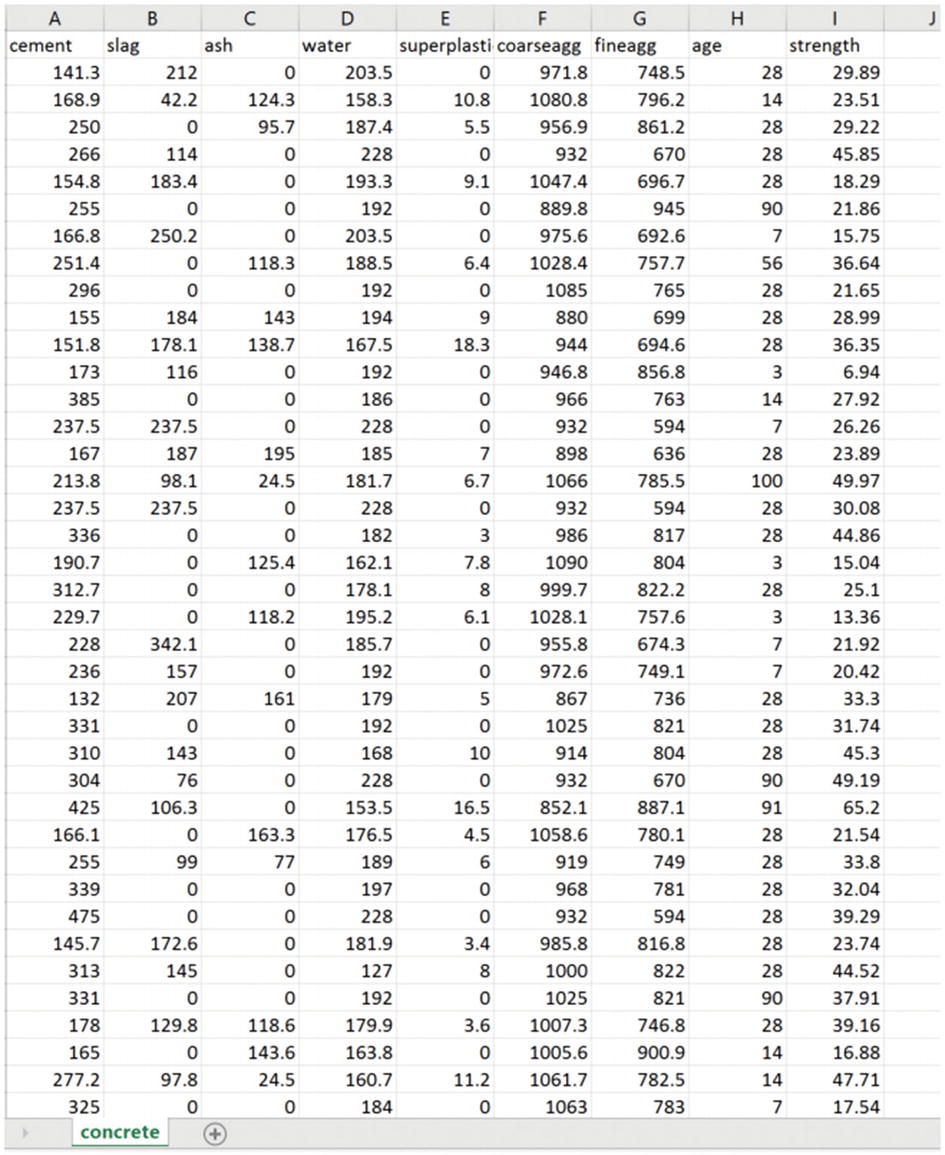
In this section, I am going to refer to an example from Machine Learning with R [1]. The example is about predicting the strength of concrete. The concrete has been used in many different structures, such as a bridge, apartment, roadways, and so on. For safety, the strength of the concrete is critical. The concrete’s strength depends on the material used to create it, such as cement, slag, ash, water, and so forth. We have a data set of the ingredients of the concrete (Figure 7-4). You can download it from “Machine Learning with R datasets” [2].
Figure 7-4
Concrete data set
A neural network can be used for predicting a value or class, or it can be used for predicting multiple things. In our example, we are going to predict a value, that is, the strength of concrete. First, we load the data in Power BI, and in Query Editor, we write some R codes. Then we must make some data transformations (Figure 7-5).
Figure 7-5
Pivot using Python codes
As you can see in Figure 7-5, in the sections labeled 2, 3, and 4 (circled in red), data is not on the same scale. We must impose some data normalization before applying any machine learning. The process of data normalization is explained in Chapter 6. The same code is used to normalize the data here.
After data cleaning and data transformation, we must separate in the data set some parts for training and some for testing. This process helps the model to learn from data and to mimic the data behavior. Therefore, we must devote more than 70% of the data for training and the rest for testing. To avoid bias, we must shuffle the data. A sample function in R has been used to create random row numbers for the data set. In addition, 80% of the data has been put in the training data set and the rest reserved for testing.
nrows<-nrow(dataset)
sampledata<-sample(nrows,0.8∗nrows)
concrete_train <- concrete_norm[sampledata,]
concrete_test <- concrete_norm[-sampledata,]
There are many packages and algorithms for using neural network algorithms in R. One such package is neuralnet. This package contains a function for a neural network algorithm. To use this package, we must install it in RStudio, using install.packages() first. After installing the package, we only have to refer to the vis package library command.
library("neuralnet")
The next step is to create a training model using the training data set and identifying which column we are going to predict.
And we must create an output data set to show to the user.
output<-dataset[-sampledata,]
output$Pred<-predicted_strength∗100
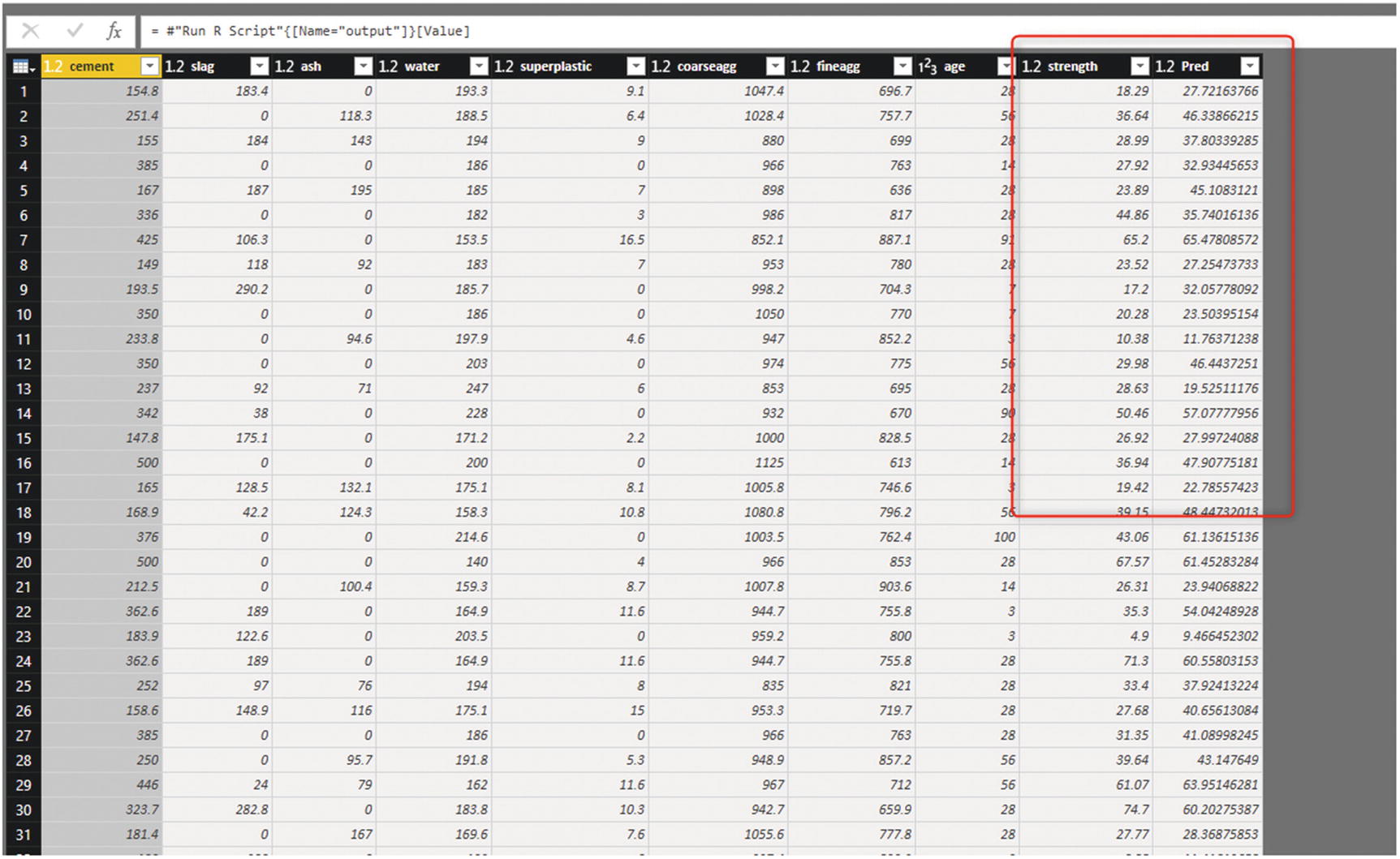
The result will be stored in an output variable that is in a data frame structure. Another important consideration is that Power Query only recognizes the data. Frame format. So, other data structures, such as vectors, lists, and matrices cannot be shown in the Power Query editor (Figure 7-6).
Figure 7-6
Prediction result
It is possible to see the neural network structure in the visualization area, to see the hidden node, layer, and so forth. Therefore, we must duplicate the data set for concrete in Power BI Report, using the R custom visual, as shown in Figure 7-7. Next, we must write the same codes for neural network prediction and add another line for plotting the model. Run the code, and you will see the neural network structure that has just appeared on the layer, and the error is 3.001.
We can mitigate the error by changing the number of hidden nodes and layers.
Decision Trees
A decision tree is a common approach for doing machine learning. This tool can be used for prediction, descriptive analysis, and feature selection. A decision tree follows the way that we reach decisions. Imagine a job seeker who wants to decide among a number of different jobs. He or she has established some criteria for his/her selection, such as the following: What are the responsibilities? What is the annual salary or hourly rate? Finally, how many times a year is travel required? We can simulate the job seeker’s decision-making process, as shown in Figure 7-8. The root of the tree is the main decision point, that is, saying yes or no to the job. Then the most important criterion is whether the job title matches the searcher’s expertise. The second most important criterion is salary. Finally, if there is no leaf, the third criterion is to check the number of required travel days per year. The decision tree uses information gain theory to identify what is the main criteria are for tree branching. Details on how this works are available at http://radacad.com/decision-tree-conceps-part-1 [3].
Figure 7-8
Decision tree for job-seeking
There are different ways of using decision trees in Power BI. One approach involves Power BI custom visualization.
To access this, you first must sign in to a Power BI account (Figure 7-9).
Figure 7-9
Power BI account
We must retrieve the visual from the Visualization panel by clicking the three dots and then choosing the Import from store option (Figure 7-10).
Figure 7-10
Importing a Visual from the store
On the Power BI custom visual page, there are different categories of visuals, including Filters, KPIs, Maps, Advanced Analytics, and more (Figure 7-11).
Figure 7-11
Power BI custom visuals
You need only click the Advanced Analytics option and then select Decision Tree Chart (Figure 7-12). Click the Add button to add the chart to Power BI visualization.
Figure 7-12
Decision tree custom visual in the Power BI store
Note
When you add this chart for the first time, you must be sure that you already have RStudio or any R version on your machine. Power BI will start to install some of the required packages, such as rpart into your local R version. Just allow Power BI install all the packages. In the next step, a new custom visual will appear in the Power BI Visualizations panel (Figure 7-13).
Figure 7-13
Decision tree custom visual in the Visualizations panel
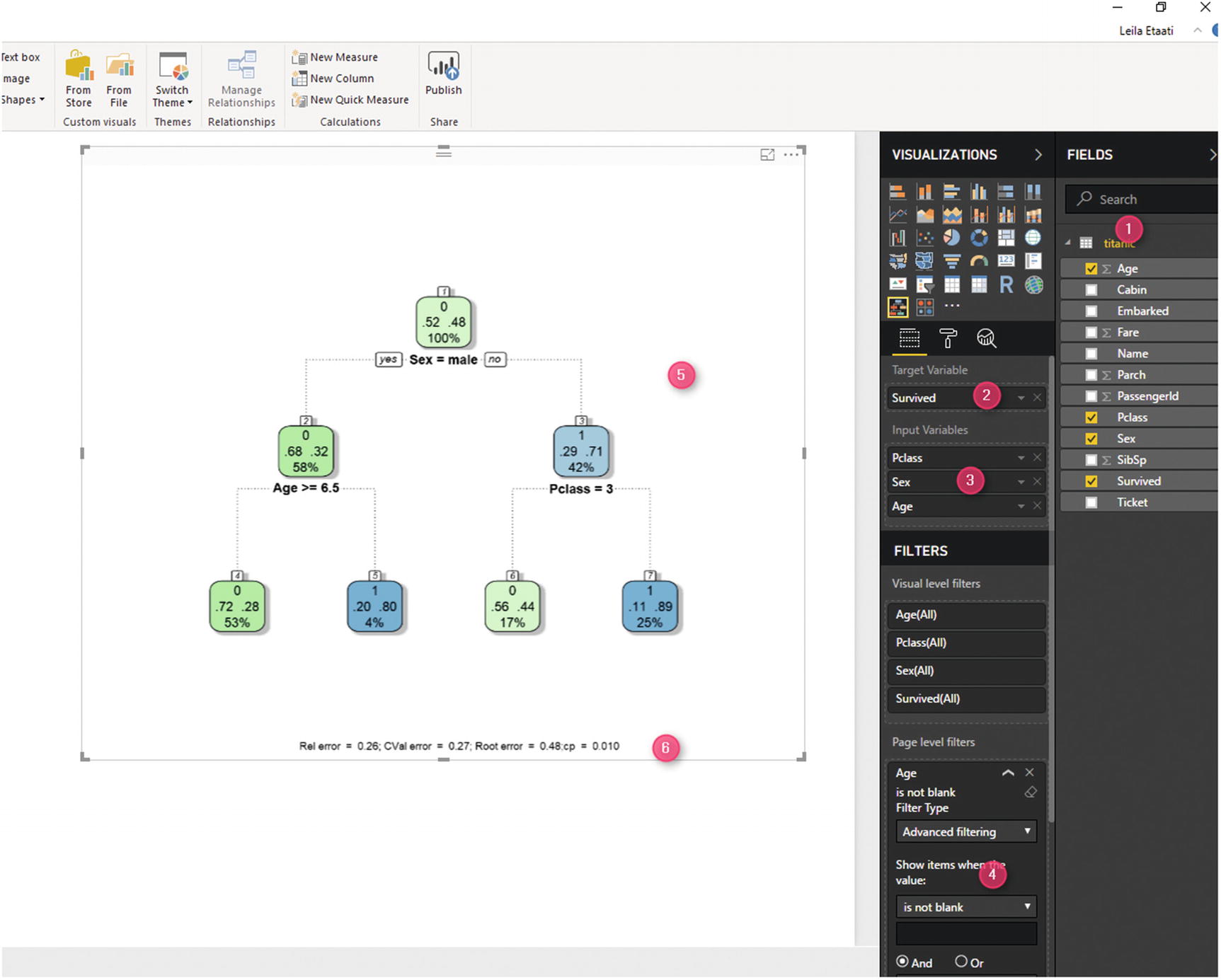
To test the custom visual, we must import some data into Power BI Desktop for predictive analysis. The data is a free data set about the Titanic disaster [4]. We must choose the fields for decision making. The main aim (target) is to predict whether people survived. To do that, first we have to choose a couple of columns that may affect passenger survival, such as age, gender, and passenger class. Next, put the Survived column as the target variable, in the related data field (Figure 7-14).
Figure 7-14
Power Query filter value
The next step is to remove the missing values (“blank”) from the age column. Finally, the related decision tree chart appears in Power BI Report (Figure 7-14).
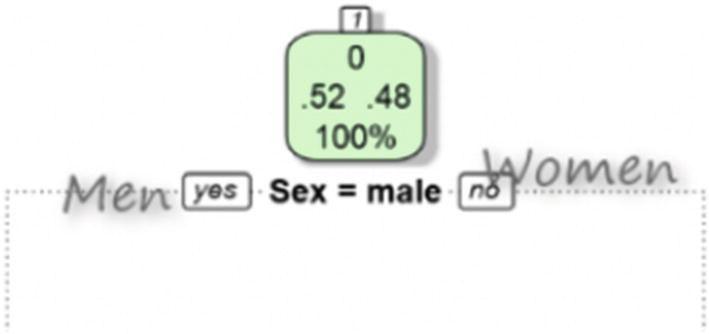
At the root of tree, there are four numbered tags. 0 stands for passengers who could not have survived. Also, these people are identified by a green tag. The “100%” means that all data is at the root. The “0.52” and “0.48” indicate that about 0.52 are men and 0.48 are women. In other words, the first attribute that the decision tree decided to analyze (based on entropy theory) is the gender of the passengers (Figure 7-15).
Figure 7-15
The root node in the decision tree
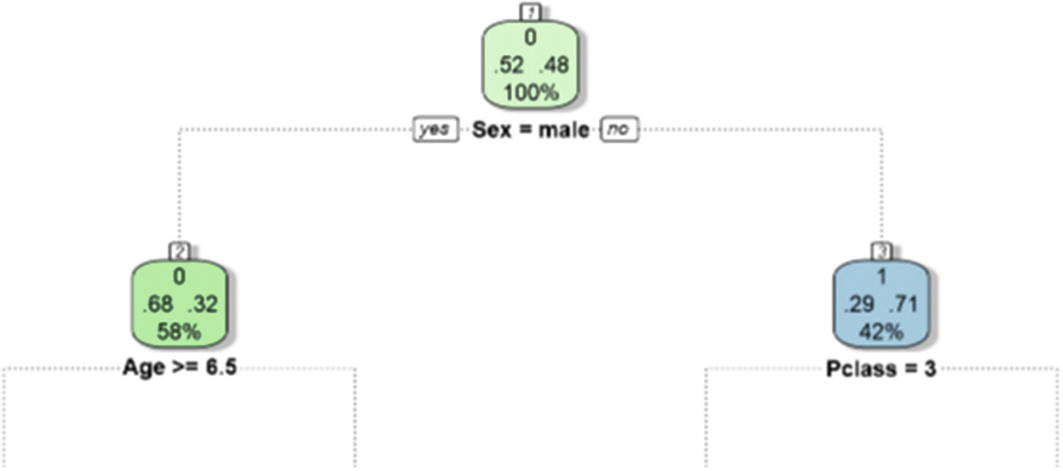
For the next level, on the left, the tag is in green, and it already branches to represent the male passengers. Based on that branch, we can summarize that most of the male passengers did not survive (0). However, as you can see in Figure 7-16, for women (the branch at the right side), the attribute that is going to be analyzed is passenger class.
Figure 7-16
The second Level of Tree Analysis
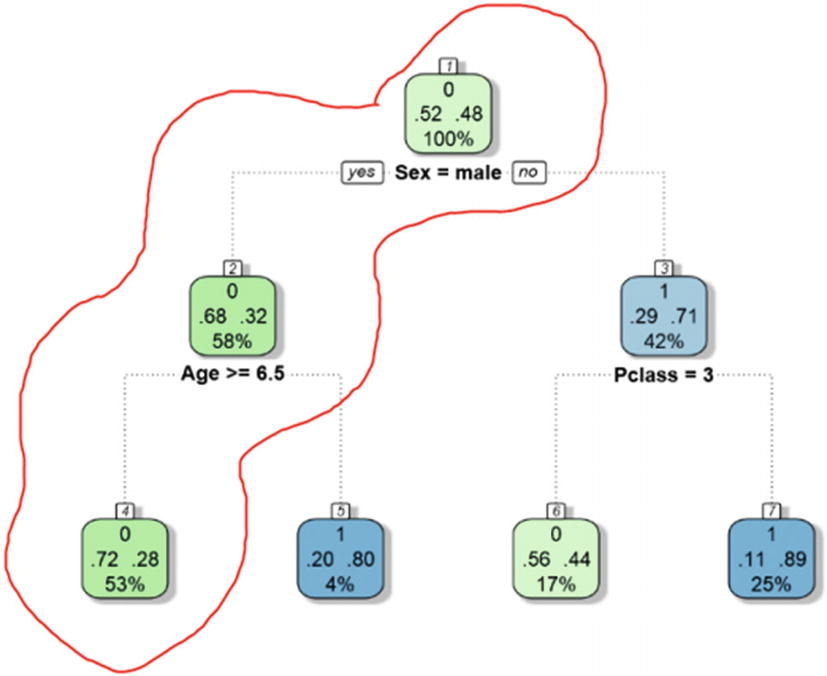
For men (root) older than seven years of age (second node), there is a 58% possibility that they will not survive (green tag and 0) (Figure 7-17).
Figure 7-17
The decision tree analysis for men
Men (root) older than seven years old (second node) will not survive (green tag and 0), with the possibility of 53%. Also, males younger than seven will survive.
A decision tree inside Power Query can be used to do machine learning and show the result in Power BI Report (the same process that has been explained in the “Neural Networks” section).
In the next section, I am going to write R code for a decision tree inside Power Query and show how it is possible to pass parameters to it.
Automated Machine Learning Inside Power Query
In the previous section, I explained how decision trees can be used for prediction analysis. Now we are going to use it inside Power Query, for predictions without a specific chart.
First, we must click the Power Query Editor at the top of the page, to navigate to the Power Query environment. In Power Query, you must first download the data set for the Titanic from www.kaggle.com/c/titanic [4]. Then, click New Source, select the Text/CSV option to import the data set, and click OK (Figure 7-18).
Figure 7-18
Importing the Titanic data set into Power Query
After importing the data set into Power Query, we must navigate to the Transform tab, then to Run R scripts. In the R editor, we will be able to write R codes. The first line of the code refers to a library named rpart. The rpart package first must be installed in your RStudio. Before installation, first make sure that you do not have it, by using the following command:
Library("rpart")
Otherwise, in RStudio, use the following code, to see what library is already installed on your machine.
packagematrix <- installed.packages();
NameOnly <- packagematrix[,1];
OutputDataSet <- as.data.frame(NameOnly);
OutputDataSet
First, we must ensure that rpart has been installed on our machine. Then we write the following code in the R editor (just as what we did earlier in this chapter for neural networks). We must now refer to the rpart library and divide the data either for training or testing.
library(rpart)
numrows<-nrow(dataset)
sampledata<-sample(numrows,0.8∗numrows)
train<-dataset[sampledata,]
test<-dataset[-sampledata,]
Creating model is the next step. This pertains to the attributes we want to predict and create a model for, based on the training data set. In addition, we must have a formula for Survived ~. This indicates that we want to predict the survive column according to age, sex, and passenger class. The predict function will be used to predict the survival of the prediction analysis.
So, the result of the prediction will be shown in Power Query, with the name rpartresult. The result will consist of two different additional columns. “X0” stands for the probability of passengers not surviving, and “x1” is the probability of passengers surviving. Now imagine that we want to use the rpart algorithm for classifying another data set, such as the cancer-related data discussed in Chapter 6. It is possible to parameterize the R code for passing the desired data set, prediction column, and so forth, to the R codes. To do this, we must duplicate the data set (Figure 7-19).
Figure 7-19
Duplicating the Titanic data set
Now just right-click the new data set, to create a function out of it. There is a need to create a function from the new duplicated data set (Figure 7-20).
Figure 7-20
Creating a function in Power Query
After creating a function, we must customize it, by passing parameters. To do this, we must navigate to Advanced Editor (Figure 7-21).
Figure 7-21
Advanced Editor in Power Query
In Advanced Editor, it is possible to see the steps previously applied to the Titanic data set in M language. As you can see in Figure 7-22, the source of the data set has been identified from my local machine.
Figure 7-22
Advanced Editor for writing in M language
The first three lines should be substituted with the followning one:
(#"Source Table" as table) as table=>
let
Source = #"Source Table",
In the first line, we define a variable named Source Table, and in the third line, we assign it to the Source variable. In the next step, we will remove some of the lines starting with Promoted Headers and Changed Type. These lines are solely for the specific data set (titanic) transformation. Now we have the following lines, for which we must still make some transformation:
(#"Source Table" as table) as table=>
let
Source = #"Source Table",
#"Run R Script" = R.Execute("# 'dataset' holds the input data for this script#(lf)library(rpart) #(lf)numrows<-nrow(dataset)#(lf)sampledata<-sample(numrows,0.8∗numrows)#(lf)train<-dataset[sampledata,]#(lf)test<-dataset[-sampledata,]#(lf)DT<-rpart(Survived~ Age+Pclass+Sex,data=train,method=""class"")#(lf)prediction<-predict (DT,test)#(lf)rpartresult<-data.frame(prediction,test)",[dataset=#"Changed Type"]),
rpartresult = #"Run R Script"{[Name="rpartresult"]}[Value]
in
rpartresult
in
Source
As you can see in preceding code, we have a header line #"Run R Script" = that contains a function R.Execute. This function contains all the R codes that we wrote. In M language, the output of one function will be passed to the next one. The previous function is for changing type Changed Type, which we already deleted. Now we must change the code in Run R Script, as follows:
#"Run R Script" = R.Execute("# 'dataset' holds the input data for this script#(lf)library(rpart) #(lf)numrows<-nrow(dataset)#(lf)sampledata<-sample(numrows,0.8∗numrows)#(lf)train<-dataset[sampledata,]#(lf)test<-dataset[-sampledata,]#(lf)DT<-rpart(Survived~ Age+Pclass+Sex,data=train,method=""class"")#(lf)prediction<-predict (DT,test)#(lf)rpartresult<-data.frame(prediction,test)",[dataset=#"Changed Type"]),
The Changed Type should be substituted with Source, as shown in the following code:
let
Source = #"Source Table",
#"Run R Script" = R.Execute("# 'dataset' holds the input data for this script#(lf)library(rpart) #(lf)numrows<-nrow(dataset)#(lf)sampledata<-sample(numrows,0.8∗numrows)#(lf)train<-dataset[sampledata,]#(lf)test<-dataset[-sampledata,]#(lf)DT<-rpart(Survived~ Age+Pclass+Sex,data=train,method=""class"")#(lf)prediction<-predict (DT,test)#(lf)rpartresult<-data.frame(prediction,test)",[dataset=Source]),
rpartresult = #"Run R Script"{[Name="rpartresult"]}[Value]
in
rpartresult
in
Source
We still must make some additional changes. These are to be applied to the Name column that we want to predict. Currently, it is “Survived~ Age+Pclass+Sex,” but we want to substitute the Survived column with a parameter that the user provided. Also, rather than another column for input, we want to consider all the columns. As a result, we must change the code, as follows:
(#"Source Table" as table, #"Prediction Column"as text) as table=>
let
Source = #"Source Table",
#"Run R Script" = R.Execute("# 'dataset' holds the input data for this script#(lf)library(rpart) #(lf)numrows<-nrow(dataset)#(lf)sampledata<-sample(numrows,0.8∗numrows)#(lf)train<-dataset[sampledata,]#(lf)test<-dataset[-sampledata,]#(lf)DT<-rpart( "&#"Prediction Column"&"~ .,data=train,method=""class"")#(lf)prediction<-predict (DT,test)#(lf)rpartresult<-data.frame(prediction,test)",[dataset=Source]),
rpartresult = #"Run R Script"{[Name="rpartresult"]}[Value]
in
rpartresult
in
Source
We must refine the code a bit, by removing the last line in Source. So, the final code will be
(#"Source Table" as table,#"Prediction Column"as text) as table=>
let
Source = #"Source Table",
#"Run R Script" = R.Execute("# 'dataset' holds the input data for this script#(lf)library(rpart) #(lf)numrows<-nrow(dataset)#(lf)sampledata<-sample(numrows,0.8∗numrows)#(lf)train<-dataset[sampledata,]#(lf)test<-dataset[-sampledata,]#(lf)DT<-rpart( "&#"Prediction Column"&"~ .,data=train,method=""class"")#(lf)prediction<-predict (DT,test)#(lf)rpartresult<-data.frame(prediction,test)",[dataset=Source]),
rpartresult = #"Run R Script"{[Name="rpartresult"]}[Value]
in
rpartresult
After running the code, we will have a function with an input variable (Figure 7-23).
Figure 7-23
Creating a function for classification with two inputs
To test the function, we must create a data set to pass to the function. Import the new Titanic data set, then Ctrl+Click the four main columns: Survived, Pclass, Age, and Sex. Next, right-click and select the Remove Columns option (Figure 7-24).
Figure 7-24
Selecting the columns
Finally, there is a data set with four columns now ready to pass to the function. In the function, for the first parameter, we must choose the Titanic data set, and for the second, the Prediction Column named Survived (Figure 7-25).
Figure 7-25
Invoking the function
Next, we may get a message for Edit Permission that is about providing permission to run external scripts on the query (Figure 7-26).
Figure 7-26
Permission request
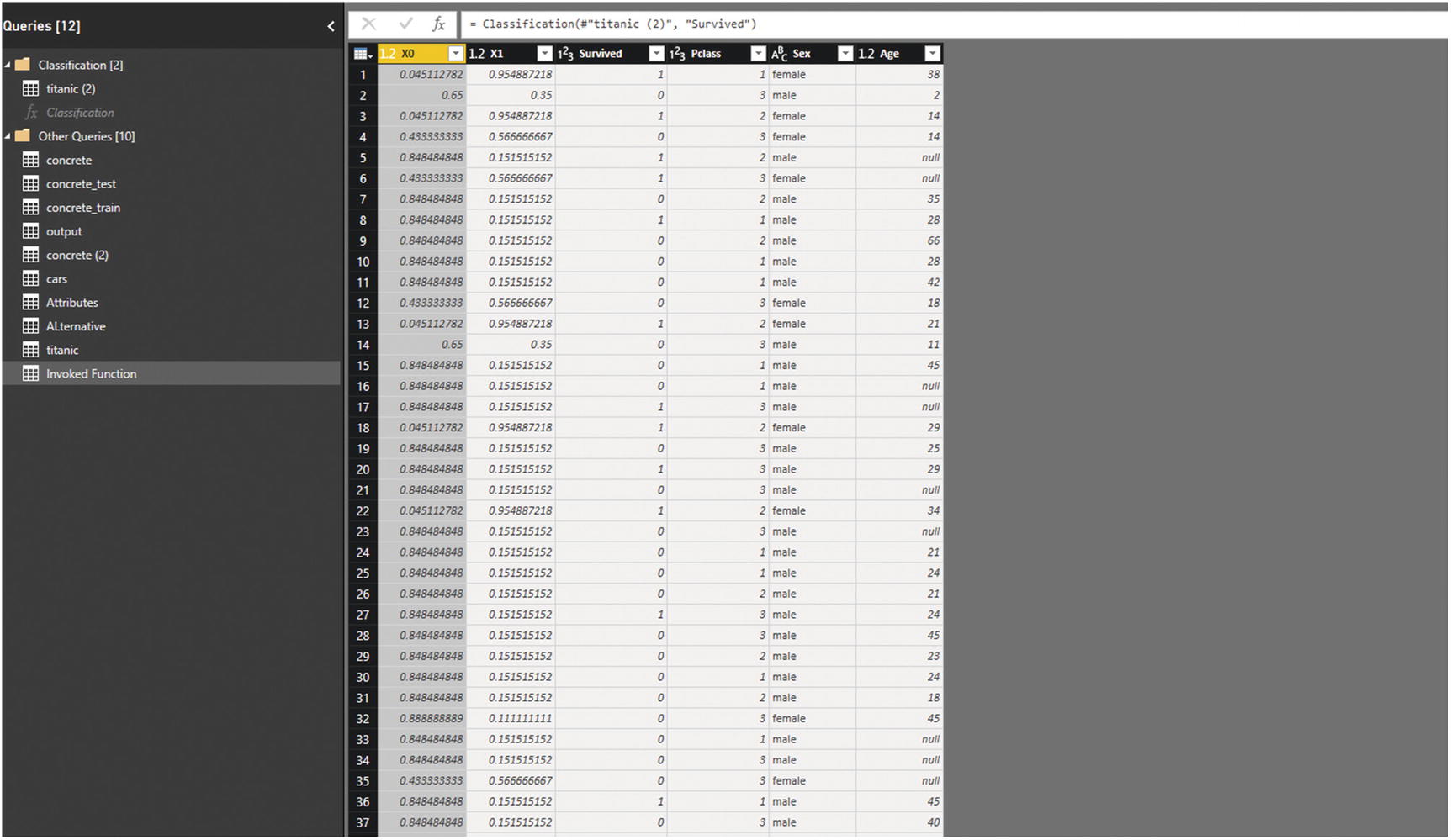
After accepting the permission, we can now see the result, as shown in Figure 7-27.
Figure 7-27
Function result for Titanic data set
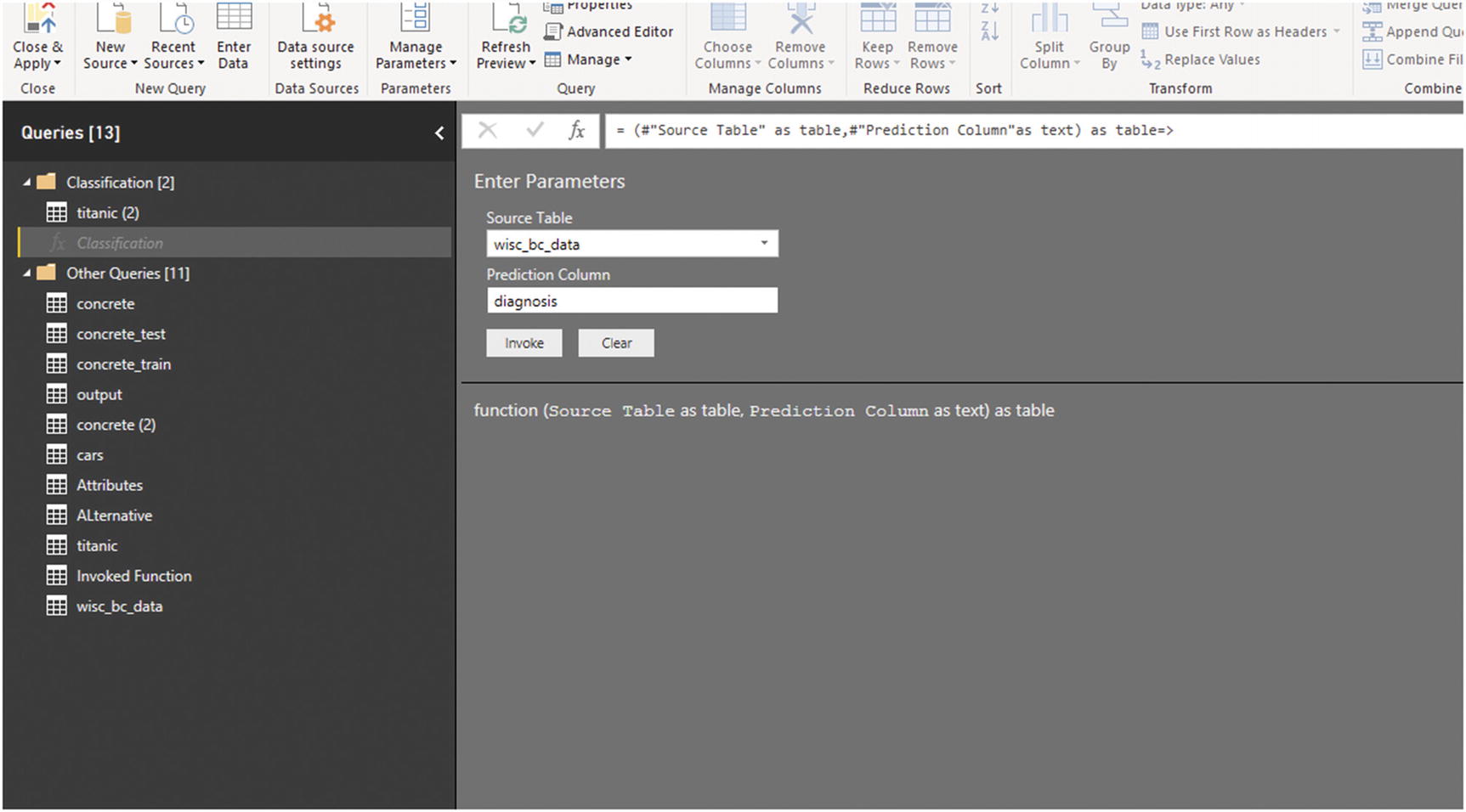
To test the function, I imported another data set [5] that was introduced in Chapter 6. It is a data set related to breast cancer patients. I want to predict patient diagnosis: will a patient’s cancer become malignant “M” or benign “B.” We follow the same process as before for this new data set. First, we import it, then we pass the name and column of the data set to the function (Figure 7-28).
Figure 7-28
Call classification function for the cancer data set
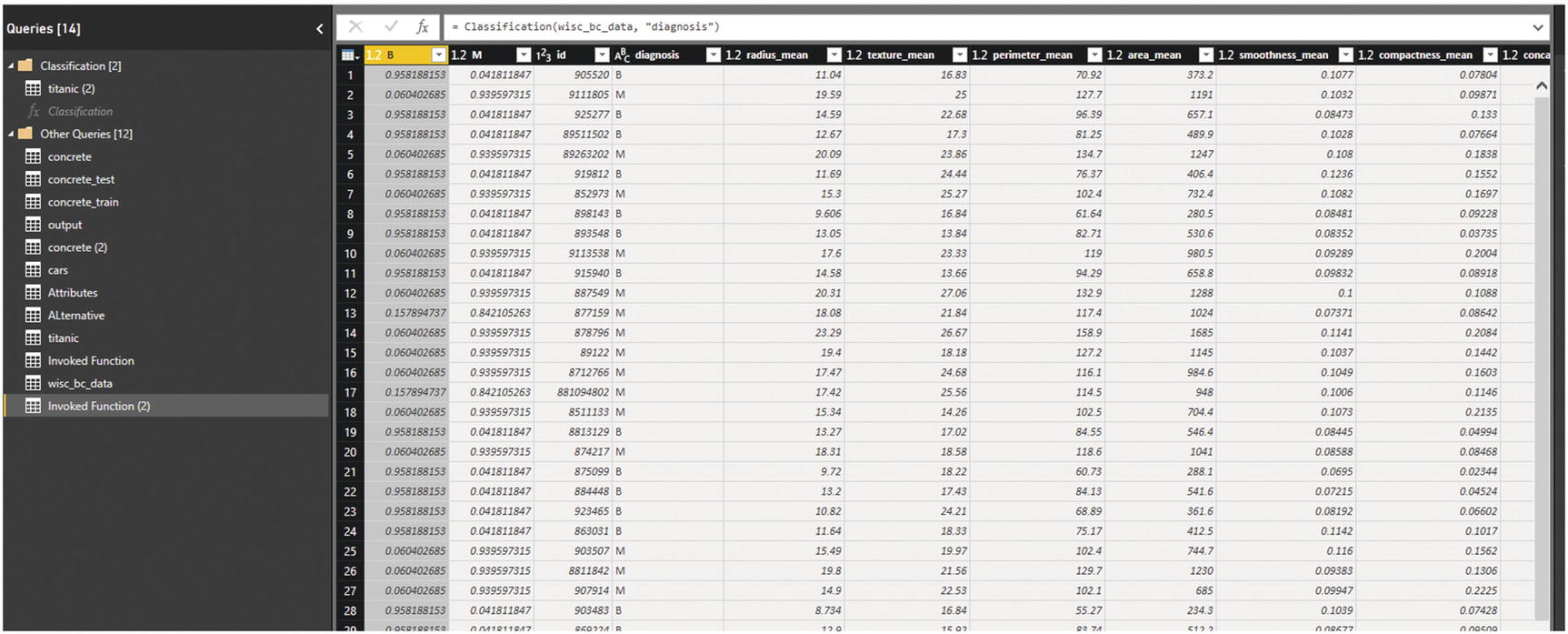
After invoking the function, the prediction result appears as a new query (Figure 7-29).
Figure 7-29
Prediction result for cancer diagnosis data set
Summary
The main aim of this chapter was to show how we can perform machine learning inside the Power Query Editor using R codes. Two different algorithms were introduced: neural networks and decision trees. I discussed how you can set parameters for making machine learning much more flexible. In the next chapter, I will discuss descriptive analysis using Power BI.
References
[1]
Lantz, Brett. Machine Learning with R. Birmingham, UK: Packt Publishing, 2015.