
With spring giving way to the full heat of summer, Ben is feeling his oats. He’s made several big bets – such as promising Tabrez that he can deliver releases to production in half the time they were formerly, in only 38 days! What gives him confidence that he can deliver on this promise?
Perhaps, knowing how bad things were when they started, he’s now more comfortable with their capacity to absorb change. Barely under a year ago, they were stuck in the mud. Technical debt was piling up unseen, and his business partners were outraged at their slow time to deliver on promised features. QA was lagging hopelessly behind, catching few serious errors but introducing weeks of delays and high support costs. Releases commonly ran red and required multiple manual handoffs. Rarely were requests prioritized or evaluated from an objective point of view; the concept of Minimum Viable Products and the ability to turn off an unsuccessful feature was completely unknown.
Now though, Ben is feeling like he finally has a place to stand. It began with more of a focus on the work the team itself was producing, instilling quality early on. This meant a team definition of done, enforced with common, well-structured peer reviews run along the friendly but effective lines of a “family dinner.” Blame-free postmortems in partnership with Operations led to more emphasis on setting up runbooks and automation to find and fix root problems. Also, helping cut down on their firefighting time was setting aside capacity to work on big-picture delivery pipeline improvements and requiring a healthy level of live site support by the devs.
Breaking their teams down into smaller “SWAT” teams tasked with supporting a single value stream end to end promises to cut down on some of the significant delay wastes they’re suffering and possibly paves the way for microservices and a cleaner services-based architectural model.
Perhaps, best of all, what was a murky “fog of war” is now looking a little clearer. They are starting to have better displays of the global delivery flow and limiting factors, thanks to some careful analysis following several rounds of value stream mapping exercises. There’s more work to be done here however until they are truly seeing things from the eyes of the business. And monitoring is still far from being an essential part of any new service or app, which means their available data stores still have significant blind spots.
Can they move closer to a true Continuous Delivery model? Will the shift in focus from velocity and delivery rates to recovery time pay off in the availability-centric metrics that Ben’s partners care about? And what happens when the wheels really fall off the bus, and there’s a significant, long-term outage?
By the Numbers (Metrics and Monitoring)
“Well, there’s your answer, right there. See that? You got the email; I can see the alert right there. Maybe check your spam filter or your inbox rules.”
I lean forward, frustration tightening the muscles along my shoulders. “Yeah, we got that alert, along with several thousand others that look just like it. I’m so tired of all this CYA bullcrap, Kevin.”
I’m pissed off, and with good reason. I just got out of a severe ass-chewing session with Tabrez, who’s asking me why we were the last ones to know that the Footwear app was down. People were locked out all weekend; it was a mess, and we look like idiots. This is just after promising Tabrez and my boss that end-to-end support and smaller, cross-functional teams would fix these kinds of drops. And once again, I’m getting this pass-the-buck attitude by Operations, refusing to take any responsibility for the messes they create.
Enough, I tell myself, is enough. “You keep telling me that things are going to get better. This isn’t better, Kevin.” I jab my finger into Kevin’s chest, twice. My voice is taking on a hard edge. “It’s a total lack of accountability, and it’s completely unacceptable to me. Understand?”
Kevin looks at me wide-eyed like an owl, but remains silent; the entire room is frozen. Almost immediately, I feel a wash of regret, but it’s too late to turn back now. I’m about to drive home a few more points when I feel a hand gripping my wrist, hard. “Ben, can I talk to you outside for a few minutes? … Excuse us folks.”
Out in the hallway, Alex looks around, then impales me with an icy stare. “What… are… you doing here, Ben?”
I make a few noises about how I’m accountable for how the app performs and that my feet that are getting put to the fire. My heart isn’t really in it though. I’m in an untenable position; it really isn’t like me to lose control as I just did. I finish by stammering weakly, “It’s past time for me to stop taking the heat for guys like Kevin…”
“Guys like Kevin are part of the team, Ben. And I’m the team lead for this group. Now you set out the rules for this SWAT team, beginning with honesty and transparency. And you are the one that keeps saying that we’re adults, that you trust us to have the right motives and a strong internal work ethic. And we started out this meeting with the slide on having a blameless postmortem – that was something YOU pushed for. Now, how do you think this is going to go over if you come down on Kevin like a bag of hammers when we have a problem?”
I mull this over, my jaw working a little. “All right. Fair enough, I’ll back off. Alex, you are the team lead, and I trust you implicitly. But this could not have happened at a worse time. Tabrez and I want to see some accountability here; people need to step up to the plate and take ownership of the problem.”
Alex still has a stern look, but he puts a hand on my shoulder. “Ben, you’re my direct and you know I follow your lead. You’ve never had to worry about me going behind your back. But now that you’ve set the template for the team – I want you to take a step back here and watch how the team chooses to resolve this problem. And I bet you coffee tomorrow that the problem is not named Kevin. OK?”
“Deal.” We reenter the conference room; Alex continues. “All right, now where were we… oh yeah, let’s talk about monitoring and alerts. Do we have the response team people here in the room?”
For this week, it was Ryan that was on point for live site support. He confirms what I’d been saying earlier; “Yeah, there was that alert, in an email on Saturday night. It went out to every dev on the team, and Ops got it as well. The problem was, it wasn’t acted on – it was buried in a snowdrift of other email alerts. It had about nine exclamation points in the subject line and was flagged Important, but that was also true of about three hundred other emails over that time period. There just isn’t a way I can see, going back in time, where any support engineer could have known something was seriously wrong.”
Kevin sighs in frustration. “So, Microsoft in their infinite wisdom chose to roll out a security patch that forced a restart on Saturday about 3 pm. When that happened, for whatever reason IIS didn’t restart, which meant the Footwear authentication service abended. From our perspective in Ops, this was just a short downtime, and all the server metrics looked great across the board. CPU, memory, disk health – all looked green. Why IIS didn’t restart, as it should have, is still a mystery I’m trying to resolve. So far I can’t simulate that when I run manual restarts on staging.”
Padma says, “This looks like a masking problem to me. Yes, it’s terrible that the service was down, and we need to look into why it didn’t restart. But fixing this one problem doesn’t guarantee something else just a little different won’t reoccur. So the problem we should be drilling in on and focusing our efforts is our monitoring. Right now, it’s too noisy to be effective. People are oversaturated with old-school email alerts and are tuning it out.”
Vigorous head nods can be seen around the room; Alex says with a smile, “Yeah, I can see that’s the consensus feeling here. This isn’t the first time we’ve pointed out a need to reset with our alerts and monitoring. Kevin, you’re our resident SME on that subject, what’s your thoughts?”
Kevin, after hemming and hawing a little, finally allows that – at ten years old and counting – their homegrown monitoring system is starting to show some signs of age. “When we first wrote this, none of the SaaS stuff we see out there was in existence, and I think we all looked at email or pages as being the best way to raise alarms. I think it’d be very dangerous to turn it off though.”
“No, no one is saying that – we need to know what’s going on.” George, who’s been silent most of this time, is now drumming his fingers on the table, deep in thought. “It’s becoming clearer that this is a bigger problem than just this one isolated incident. Tuesday we’re meeting with our frontline peeps to go over the issues for the week. I think that’d be a great time to talk about a reset on our alerts. If they’re truly as noisy and ineffective as the group seems to think – maybe we look into tuning these alerts so they only happen with the truly high priority conditions. I’d be willing to bet our support people would love it too if we could log more diagnostic information and embed as much of that as possible in that very first triggered email.”
“Does everybody realize what we’re asking for here?” Harry looked around the room, in full Grumpy Oatmeal Guy mode. His bushy white mustache quivers in indignation. “Are we seriously thinking about shotgunning logging statements throughout our apps and services? That’s crazy talk. Monitoring agents will kill our latency numbers; people will be more upset about our performance, not less. And it gives us yet another set of systems to worry about when it comes to keeping our configurations consistent and up to date.”
Alex says, “I’m not worried about some supposed massive overhead from monitoring agents; this is not the nineties, our systems are much more powerful and the agents are much more lightweight.”
Harry’s on the top of his game. “This is a lot of work we’re talking about, and I don’t think anyone is thinking enough about costs, you just want to plunge ahead and think this will work out of the box. I mean, Etsy says to measure anything and everything – which is great if you’re a storage vendor! That data that we’re talking about collecting and monitoring, we don’t have anything set up yet to handle it. It’ll take us weeks, months to get logging set up across all our systems, especially our legacy stuff. This is difficult and EXPENSIVE, guys. The business won’t stand for it.”
George counters, “Fair enough. Maybe we need to think a little more about what we can cover without having to run out and buy anything. How does this sound – on Tuesday, we go over with the response team the last ten issues that have cropped up, and which could have been detected with better monitoring or logging. Then we go back and add that to our existing engine, and keep repeating that question every week. In a few months, we should have MOST of the common scenarios covered, without having to kick off a massive rewrite like you seem to be worried about.”
This doesn’t fly so well; most people in the room are wanting a new framework that’s more extensible and powerful. As you’d expect with a gaggle of engineers, we go right to tooling and software options. Ryan likes Pingdom; Padma favors the ELK stack, and others are weighing in for Raygun. For a few minutes, we bat this around, but in the end George’s suggestion – which happens to be lowest cost – carries the day. We agree that if the support teams find serious gaps that our homespun logging and aggregation system can’t handle, we’ll begin investigating some of the newer SAAS-based monitoring options as a replacement.
Ryan says, “I’d like to see our scoreboard change a little. We need to have metrics that actually matter showing on those damn screens in the team meeting room. I’m just going to say it – we don’t need to have server metrics staring us in the face every time I look at the application health. Let’s take this outage as an example – what we should be measuring is our page response time and success/fail rates on user logins. This is a global app and if we know a page is suddenly taking 10 seconds to load, where yesterday it was taking half a second, we know there’s a problem.”
I’ve cooled off a while ago, and Ryan’s thought makes me grin; it’s something Tabrez and I have spent a lot of time on lately. I send him a text: Hey, get over here, this is interesting.
Harry is really starting to get some traction with a particularly epic rant on a favorite topic, On The Cluelessness Of Managers. “Well, that’s the problem with WonderTek, isn’t it? A lack of focus? I mean, they tell us they want us to drive things through to completion, and the next day we get handed down nine different numbers as some kind of half-assed quota to meet. It’s ridiculous!”, he harrumphs. “Better not to give us anything at all. I swear to God, this company has a severe case of ADD. Every new manager we get seems to have the attention span of a meth-addicted hamster…”
Harry’s air of wounded outrage finally breaks me, and I start to laugh, just as Tabrez slips into the room and takes a seat. “Ha!! Well, call me guilty on that, I guess. Harry, you’ve got a point, but with all due respect I get a few hundred more emails a day than you do, which might explain some of that distraction. Anyway, we’re not trying to create world peace here, we just want to talk specifics about our monitoring and alerts. Does everyone agree with Ryan? Do we need to change our displays so they’re showing our user’s actual experience across every region?”
The group kicks around some more ideas. Padma is advocating for us to make reliability and availability our lingua franca. “After all,” she says sharply, “if an application isn’t available, anything else doesn’t matter. The question we should always be asking is, how are we going to improve our availability? Right now our standards are impossibly high. We have a SLA but it’s totally unrealistic; a single five-minute outage would put us over the edge. We need to rethink how we measure and enforce reliability – even if that means capping our releases, the same way Google does, if we’re out of our budget on availability. Right now it’s just a paper tiger.”
Tabrez finally speaks up. “I agree with you, Padma, and maybe showing our current SLA is a good thing. And I agree that our current SLA standards need to be rethought; I’d settle for 99% availability at this point.”
“Padma has a point when she says that our expectations are too high,” George replies. “We keep getting mixed signals from you, Tabrez – you say you want velocity, and we have a pile of features you’ve put on our plate. Which is great – but then you are also asking for 99% availability. The only way we can meet that is to freeze all changes – to the environments, network, or the app itself. You don’t want us grinding to a halt, but you don’t want any downtime. We can’t do both.”
Surprisingly, Tabrez yields on this point, allowing that perhaps we need to rethink our availability SLA’s during beta periods. But he presses for a more valuable dashboard in business terms: “If we want this dashboard to answer the key question of the application’s health, then I think displaying a chart showing successful vs failed logins every day over the previous 30 days is a great place to start. And I’d love to see a global map, where if the average page response takes longer than 5 seconds, it turns the region yellow or red.”
Alex brings up the concern from earlier that the team is being given too cluttered a dashboard to monitor and that the metrics we’re tracking are constantly being swapped out.
Tabrez laughs. “Well, yeah, I’d have to agree. So let’s simplify. I’d say, yes show the current SLA as a reference point, say top right. But I’d also like to see our bug trends as we’ve done in the past. Maybe transaction rate as well. For our customers… what matters also is our communication when things go haywire. That means we need to get them talking to a human being in 15 minutes or less – and hopefully their problem resolved in that time. I keep bringing this up but – that’s why we’re tracking our long-running tickets, those longer than 15 minutes. If we’ve guessed right with this new, more direct support model, I’m hopeful we can cut these in half over the next few months.”
Alex says, “Well, I see we’re almost out of time, but this has got me thinking. I’ll say this – while I want to see some of the user-centric numbers that Tabrez is talking about on some displays, I do think we’re not breaking rules by having some developer-centric screens. Our SLA itself, that’s important but we need to keep in mind that’s the effect, not the cause. Some block-and-tackle work in knocking down our most frequent errors and bugs is where we’ll actually see results. I’ll be a fly on the wall with tomorrow’s talk with the critsit response team. But we should be careful not to focus on mean time between failures – that’ll just make us conservative, as Tabrez has said, and I know we’re going to have more outages.”
It looks like I’m going to have to buy Alex coffee tomorrow, but I’m OK with that. I chip in, “For my part, I’m hearing that it’s frustrating to constantly have the goalposts get moved. This outage – as embarrassing as it was – just shows us how vital it is to minimize the impact of any outage. That question we need to keep asking hits the nail on the head: ‘How long does it take us to detect and restore service?’ So – despite Harry here calling me a methhead rodent” – some laughter ripples through the room – “I’m not changing direction. We’re staying focused on the one number we agreed weeks ago as a delivery team, and that’s MTTR.”
Ryan can’t leave well enough alone and says, “So are we going to stick with Kevin’s bubblegum-and-popsicle-stick monitoring system, or are we going to get Raygun set up as I’ve been pushing for the past two years?”
Before I can speak, I feel that grip on my wrist again; Alex replies crisply, “Let’s not skip ahead to a solution until we’ve defined the problem better. There’s all kinds of great vendors out there, and it looks like everyone here has their favorite. If there’s truly a gap that’s causing a blind spot, we’ll identify it and buy a better tool, I promise.”
George stands up. “One last thought – was the problem here that the tool we currently have is hopelessly inadequate? Or is it that we’ve spent the last decade thinking that setting up monitoring and alerts is someone else’s job?”
He looks around the room. “I don’t know what the solution is going to look like here, but I do know the problem we experienced over the weekend was just a symptom. For that symptom not to be repeated, we need to make sure that monitoring is seen as everyone’s job. So if Tabrez says availability and long-running tickets are a problem for the customer, that means our dashboards need to show this. If it’s not visible, we can’t improve it. And we’ll make this a part of our weekly review – seeing how useful our alert thresholds are, whether we can improve in the data we’re storing, and how easy we’re making it for the coders to implement this as a reusable framework. Does that sound like a good action plan?”
As the meeting breaks up, a beaming Tabrez gives me two jarring pats on the shoulder on the way out of the room. “Hey, this is the first time I’ve seen any kind of customer focus from you guys. And it seems like you’re asking the right questions. Keep it up!”
I find myself whistling all the way back to my office. Alex had been right; in the end, the team had stayed on course and was finding solutions to their own problems. Things were starting to really click!
Letting Our Freak Flag Fly (Feature Flags, Continuous Delivery)
This morning, I thought I’d shake it up a little bit and invite Alex in on my daily trek over to Footwear. They had an upcoming launch of a new shoe line set for mid-September, and Alex had some interesting new ideas on how we could better coordinate on the release. After Alex had explained his thinking, I could hear the devious MBA side of me starting to cackle with glee. This was the juiciest opportunity to build a better relationship that I’ve seen in months.
“So, you’re saying you want us in the driver’s seat for this upcoming release? And you want to kick it off next week?” Tabrez gives us a heavy are you serious? look and sighs. “Look, we’ve come a long way, and I trust you guys. But I kind of feel like you’re asking me to stand on a red X right now. And from what you showed me last week, what we have just isn’t ready for prime time.”
I laugh; in Tabrez’s place, I would have reacted exactly the same way. “Hey, I totally get where you are coming from. Relax, we’re not asking you to do anything groundbreaking or risky. In fact, I think you’ll find that Alex’s suggestion here is going to make our lives a lot easier.”
Tabrez’s eyebrows are still arched, but he allows us to continue. Alex pulls up a new release dashboard he’s been working on for the past week. “So, we’ve been talking about our release patterns, and it’s clear we still have a lot of work to do. For example, right now we’re checking in our work many times a day – but we’re still releasing once every three weeks or so. That’s just not a quick enough feedback cycle for us to catch problems early enough.”
Tabrez interrupted, “I thought that was why we invested as much time as we have into bumping up our unit test coverage. You told me that was the big pain point and it’d help us get earlier detection on bugs.”
“Yes, you’re right, and you know from our retrospectives and our scorecards – our revised testing harness is catching more bugs early on, at check-in. But this is just like with your factory manufacturing floor – once we knock down one constraining point, there will be another constraint we’ll have to focus on. Right now, it looks like that’s centered around the way we are rolling out our releases. Right now, they’re too big to fail, and that’s costing us.”
Tabrez nods his head slowly. “Yeah, I think I understand that. I’m thinking back now to two months ago, when Tina on my team asked you to roll back that user forum feature that was flatlining. It took about two weeks to pull out that code as I remember. But you still haven’t answered my question; how does this new project dashboard make my life easier?”
I decided to break in. “That’s a great example. In fact, it was that same messy rollback that got us thinking about feature flags and a more gradual way of rolling out changes behind the scenes. Going back in time, what if we could have made that feature exposed only to your Footwear people for their acceptance testing? Or maybe exposed it just to a set of beta users that you trust?”
Tabrez smiled. “Of course, that would have been terrific. But for this particular launch – this is very sensitive information, Ben, and we can’t risk our competitors getting ahold of it. It’s much safer for us to lock down this functionality until we can turn it on as part of a coordinating marketing launch. With this new line of shoes – I can’t go into details on what makes it special, but if it takes off like I think it will, it could mean hundreds of millions of dollars. We’re talking about three years of global effort here at stake – it’s an amazing innovation.”
I try a different tack. “Totally understood, and you’re right. Up to now, you’ve handed work off to us and we come back weeks or months later – and there’s this messy back and forth on coordinating the release. There’s an opportunity here to kill two birds with one stone – with feature flags or toggling, my team can introduce changes sooner for your Footwear people to review – which will make our release cycle tighter and give us the feedback we need. And we think once your Footwear team experiments with this dashboard, you’ll get addicted – it’ll be so much easier for you to gate and control who sees what with these high-profile launches. With this much at stake – wouldn’t you feel better if Footwear was at the wheel?”
Alex presses the advantage a little. “As you can see from this dashboard, it’s really easy for us to show every flag we’re using with the app in one list. We can turn them on or off with a single click; but we’re only allowing you and a few people you delegate to have that kind of control. We can set up tags so our sysops people can filter out their environmental config changes as a toggle, and have a flag so we can put the site in maintenance mode during our database refreshes. You can see here – we’ve already got snippets set up in the code so the new shoe line launch pages can be viewed by Footwear, and only Footwear, with a single click.” He catches Tabrez’s look and hastily adds, “These are blank pages so far with nothing sensitive or proprietary until you give the OK, Tabrez. But our thinking is, it’ll be much safer for you to be at the helm of this launch than us. You know which users should be granted access, and what level of access they should have.”
Tabrez had pulled Alex’s laptop away and was messing around with the dashboard as he was talking. He looks up and gives me that half-smile that I’ve learned was a good sign; maybe this will work. “It looks like we’ve even got an audit trail here, so we can track who’s changing things. Hmmm… you know for a few months now I’ve been wondering how we can do a pre-launch and demo for a few of our top retailers, three weeks ahead of the general release. This could be what I’ve been looking for.”
His eyes keep going back to the slick dashboard and the list of toggled release features. “Hmmm. I’m willing to give this a try, but if you’re asking us to share the responsibility around the release – and that’s exactly what you’re trying to do, Ben – you need to step up to the plate. Give us training and a clear set of documentation. I’ll have my team play around with this for a week, and they’ll give me a yes/no call on going forward with this. If it looks like it’s just more of a headache or a distraction from our actual design and planning work, I’ll drop this thing like the world’s hottest potato.”
I smile. “OK, so we’ve got a plan then.” I’m quietly confident that we won’t be scaling this back in a week. Tabrez is going to find this very impactful in terms of better coordination on upcoming releases and having complete control over when and who sees his new features. Once we get him and his team in charge of selectively turning on new features to beta groups, he won’t want to turn us back.
Alex looks a little depressed on the way back across the street, though. I pat him on the shoulder. “Look, that was the best reaction we could have hoped for. Tabrez has been around the block a few times, and he’s not going to be dancing with happiness about any proposed solution from us that looks like more work for his people. He didn’t say no, Alex. In fact, I think he’s going to say yes – just because it gets him the beta program he wants.”
Alex replied, “You know as well as I do, this is something we need if we’re going to get out of this ‘push and pray’ cycle. We shouldn’t let Tabrez be the decider on something that matters this much to the team. I can’t believe I have to go back to them and announce that we’re waiting on a yes decision on a bunch of shoe designers.”
I stop in the pathway. “Alex, two things. First off, Tabrez very much is our boss. He has every right to tell us what to do, because the shoes his team produces and markets pay our salaries. If we say we want to partner better with them, we need to act like it and get their input instead of just pushing things on them.
“Second, I think you misunderstood the whole point of that conversation. We already know these massive tsunami releases aren’t working for us. Tabrez is making the call on how much control he wants his team to have over the release pace, but I never said we would be rolling back any of the things we’ve been talking about as a team – feature flags, canary releases or blue/green deployments. It’s clear to me we need all of those things, and it’s a core competency that we own, the way we handle our business. I’m not asking for permission on how we do our work, OK?”
Alex looks relieved, and we head into the café to grab some sandwiches. We talk a little more shop about the upcoming feature launch, then get caught up a little with our home life. As we chat, I can’t stop smiling. I feel very confident that Tabrez and his team would find the fine-tuned control and segmentation capabilities around feature flags and controlling releases addicting.
This would solve so many problems for us in coordinating releases, getting better feedback, and help in breaking down more barriers. Being able to decouple our deployments from feature releases was going to be a huge step forward.
Backlash (Disaster Recovery and Gamedays)
As I’ve come to expect, 3 days after the outage I get a single agenda-less meeting invite from Emily. Normally, I might have ignored it, but in this case, she’s invited both Douglas and Tabrez; all managers, not a single technical person in the room. It’s time for another discussion around better discipline with our releases, was all she’d say when I asked her the purpose of the meeting.
So, I was going in blind and unprepared, a nice little sacrificial lamb – and given some recent problems we’ve had, it didn’t take a Rhodes scholar to guess her real aim.
Worst of all, it looks like I’m walking into an ambush on ground she’s prepared well in advance. Emily had evidently met with Douglas privately earlier. They were already in the conference room, chatting and smiling, as Tabrez and I walk in. Emily gives me her very best Cheshire cat grin; I could almost see feathers poking out of the corner of her mouth. I smile back evenly with as much false warmth as I can manage.
Emily and I have come a long way, but we don’t see eye to eye on everything; she can be a dangerous opponent. I remind myself, don’t show weakness, let her make the first move.
Emily wastes no time chatting about the weather and just launches right in, confident of success. “As I was just explaining to Douglas – we really need to rein in some of the bad traits we’ve been seeing with this Footwear application. It’s a disaster and the support costs to my team have been skyrocketing. You can’t believe how angry your customers have been on the phone – honestly, it just seems so sloppy.”
She taps a set of papers on the table and smiles again. “With Sysops, we’re in a better position and more experienced to provide availability support. I really regret your not involving us earlier, it could have brought the site up hours earlier. And the SWAT teams you instituted don’t seem to be working out very well in practice. When I went to your engineering team, they seemed completely at a loss as to what to do. There wasn’t a runbook or a plan – people were running around like chickens. It took me several hours to regain control.”
I resist the urge to snort. Alex had come to me later in a rage. “You should have seen it, Ben – she was like Christ coming to cleanse the temple. You would have thought she was riding in a chariot pulled by four white horses. And she immediately starts running from engineer to engineer, bellowing out about needing a status, and what the ETA was.” Alex said that by the time he was able to gently ease her out of the room to allow the team time to work the problem, Alice had cost them about an hour.
That was a card I could play, but for now it stayed in my hand. “That’s a little different than how I heard it, but don’t let me stop you. Let’s say our response wasn’t perfect – which I certainly agree with. And I know you have the best interests of WonderTek at heart.” I gave her my best guileless smile, trying to get a glimpse of her endgame. “What’s your proposed solution?”
Emily turned to Douglas with an upraised eyebrow in mock surprise. “Really? I would have thought this would have been more familiar to you by now but – if you want me to repeat myself, here goes. As I was telling Douglas, we’ve seen great results so far with that Change Authorization Board. In fact, we have 70% of the company’s assets now being released under this process. It’s past time that Footwear gets folded into this company-wide mandate.” She goes on for a few more minutes, and I found myself dozing off a bit as she was describing the new authorization forms we’d need to complete, and the approval chain before any production release – “minor or major, we can’t have any deviances!” – and of course her personal favorite, the Zero Defect Meetings.
In the end, she was right – this was a familiar argument, and by now I found it tediously repetitive. I’d been able to fend this off in the past with a sincere effort to collaborate, though admittedly I’d missed a few of the release planning sessions.
What made this uncertain was the Douglas factor; I have no idea which way he’ll swing. He values teamwork, I tell myself, nodding brightly as she wraps up her speech with a glorious vision of how effortless and problem-free our lives will become under this new program. Speak and think in terms of the team and the best interests of the whole.
Douglas is watching me carefully but so far has not given me any signs; the man had the perfect poker face. I’ve seen pictures of Half Dome that looked more expressive. “So, Ben, I’m curious about your position on this. We’ve talked several times about folding in a more rigorous change control process. In light of… recent events… do you think it’s time that we put that back on the table?”
I remember the tap dance act that Richard Gere did in the movie Chicago and decide to use one of Emily’s favorite tactics: the endless monologue. “Absolutely, it should be. I think all options should be on the table – if we can prove they add value and are solving the problem. Emily, if I understand your position right here, it seems like you are advocating for a better change control process, correct? Meaning a weekly change approval process and zero defect meetings, perhaps a change window for a gated release in the evening hours. Did I get that about right?”
Emily’s smile takes on a hint of exasperation; she’s wondering about my next move, too. “Yessss, Ben, exactly the same process that the rest of us have been following for the past three months. You know this. I shouldn’t have to go into all the benefits this offers again in terms of compliance, security, better governance. I’m frankly a little shocked it’s taken your team this long to come to the table.”
Last week, I caught a glimpse of the poor saps dragging themselves out of Emily’s vaunted Zero Defect Meeting and suppressed a shudder. Ukrainian serfs dragging around wheelbarrows of potatoes looked happier and more fulfilled. Time to get back to the tap dance. “Ok, so we did have an outage a few days ago – one that took us the better part of six hours to resolve. And it’s even worse than you’ve described.”
I ask if they’ve taken a look at the postmortem; as I suspected, neither Douglas nor Emily had taken the time. I call in Alex, Rajesh, and Rob, who had been handling live site support that week. They took the team through the findings, including the timeline of what had happened and the root causes that the group had identified so far.
As I’d admitted, it didn’t look pretty. We had checked in a change to our shopping cart processing routines, one that was fairly minor in scope in handling payment processing. Unfortunately, we’d missed some dependencies where this same module was used elsewhere by the WonderTek apparel team. The modification immediately froze all transactions across WonderTek’s eCommerce sites; in-process orders began timing out, and carts were stuck in an in-process state. Worse, our end-to-end testing had not anticipated this specific scenario, and our peer review had missed the hidden dependency.
Once the problem had been detected – which according to the timeline had taken nearly 90 minutes – the team had immediately flipped back the feature flag covering the change. But our old enemy the data model once again proved to be a sticking point; the changes to the backend entities could not be rolled back, and shopping carts were still in a halted state. It took a full recovery of the database from the most recent backup to bring the backend to a stable, operable state that was consistent with the UI and service layer. Several hours’ worth of transactions had been lost or compromised, which translated to nearly $200K in lost revenue.
Tabrez chips in once Ryan and Alex were finished with their recap. “Even worse for us was the gap in communication. It took us far too long to realize something was wrong, and to track down and isolate the issue and roll it back. In the meantime, we didn’t have a good communications chain with our customers, who were left nearly completely in the dark for almost half a day. I’ve been fielding angry calls for the past several days on this, and it’s been all over the news. We’ve been able to soothe some hurt feelings, but there’s no question that our rep has taken yet another hit from this.”
Time for another round of tap dancing. “OK, so now we’ve got a much clearer idea of the problem. I’m still a little unclear though – you say the rollbacks weren’t clean because of the data layer component. Does that mean that we should consider feature flags and continual delivery ineffective for us?”
Alex smiles. “Well, we’re still trying to determine why this didn’t come up with our beta customers. But I would say there’s not just one single root cause here. We’ve identified six action items, which you’ll see in the report.” He passed around a written copy of the postmortem and explained some of the areas that were exposed as weak points. “We know our time to detect was laughably slow here – 90 minutes. Ideally, we’d have eyes on the order processing rate; that’s our lifeblood, but it’s not a part of our current dashboard, and it needs to be. We would have seen this almost immediately if we’d had that showing, and it will also help keep our team better focused on the business impacts of the features we’re working on. Also, we feel that entity changes in the future should always be additive, never destructive – in other words, we can add columns but never change or remove them in a table. That should help with making rollbacks less painful. We’ve added all of these as items to our upcoming sprint as tasks.”
I flip Emily an olive branch. “Another concern I have is that broken communication chain. Let’s start with internally. For example, Emily came in and started cracking the whip to see what our current state is. But ideally, we wouldn’t have needed that. We had some team members in the room, and others were calling in to a conference call that we’d set up. But as a manager I can’t tell what the status is from a conference call, and we can’t use an audio call to come up with a timeline and order of events easily. Do you have any thoughts about how we can knock down that issue?”
“Yes, since we’re distributed at times, it’d be a good idea for us to have a virtual chat room, open and available for any high severity problem,” Rob answers. “That’s in the report and we’re looking into some different lightweight chat solutions now.”
I feel badly for Rob; as the primary live site engineer that week, he’d taken the brunt of the impact. He looks hollow eyed and haggard, completely spent. “I also like some of the concepts behind a self-healing, unbreakable pipeline. There’s no reason why we can’t have our software notice a dramatic shift in a KPI like order processing and trigger either an alarm or automatically roll back to a previous version. Investigating that as a potential solution is tops on my list for next sprint.” His laugh has just a slight bitter edge. “I can tell you honestly, I hope it’s a long time before we have another release like this one. Once we refactor our testing, I doubt this exact same issue is going to crop up again – so we need to make sure anything we come up as a fix is looking ahead, not backwards.”
Tabrez says, “That covers our internal communications lag, but it doesn’t address our customer relations issue. I’m working on some ideas now where we can provide better notification during an outage.” Tabrez told me that one of his new business KPIs was MTTN – Mean Time to Notify. I laughed, but it turned out he was serious. What hurt us wasn’t so much the downtime, but the long lag between our services being back up and customers finding out we were back open for business.
Emily says in a flat tone, “Gentlemen, we’re really getting away from the point here. This change would never have made it out the door with the company’s CAB review process in place. We’re just buying time until the next high-visibility outage.”
I’m tempted to call out her counterfactual reasoning; instead, I spread my hands out in surrender. “Emily, if I thought a weekly CAB meeting would help solve this problem, I’d jump on it with both feet. But it sounds to me like all a weekly off-hours change window would do is hold up our releases so they’re larger in size – meaning there’s a greater chance that things would break. We want to be releasing more often, not less. So far, our customer has been happy with our release pace and the greater safety controls we’ve put in place by gradually toggling new features in release rings.”
I turn to Tabrez for backup, who responds with a strong affirmative nod – our partnership is still going strong. “The problem here wasn’t that we didn’t have governance or a strong, well thought out release process. I mean, we were able to identify a fix and come back to a stable state using artifacts only in our version control and our standard release process; that proves it’s viable. What we’ve identified is some gaps in our testing and in the way we make changes to our data layer, along with some changes we need to make to monitoring and log aggregation. But we can’t say that these controls weren’t in place, or that they’re insecure, not auditable, or unrepeatable.”
“I would be angry if they were either minimizing this problem or trying to point blame elsewhere. But we’ve asked them to take on a greater share of production support and solve their own problems; to me, this is a good example of that. We’re not perfect, but we aren’t making the same mistakes twice.” I look now at Douglas, our judge and jury. “If we’re thinking in terms of the team… If we’re putting their best interests and those of the business first, then we should probably take their recommendations into account. There’s several items here in their action list that I will make sure gets followed through on – in particular, I’d like to see us put our availability more to the test. We need to have a monthly DR exercise, where we’re whacking environments or deliberately redlining a release and seeing if our rollbacks are working as they should. The team calls this a Gameday, and I’d like Emily’s help in coming up with a few realistic scenarios for next month.”
Finally, the hint of a smile on that granite face. “Hmmmm… well, Tabrez, what do you think? We had this outage, and it impacted your team most of all – do you have confidence we’re on target with our solutions?”
Tabrez says, “I’d say there’s still work to be done when it comes to communication. We needed better visibility during the event of what’s going on, and a better coordinated response post-event. That’s for Ben and I to take on and resolve. But yes, I’m actually pleased with the items I see here in this plan.”
All the work I’ve put into my relationship with Tabrez is paying off now; Emily is facing a phalanx. She rocks back in her chair in disbelief as she sees her chances slip away. “Douglas, I thought we were on the same page here. Are you going to allow things to drift like this – ”
Douglas turns to her, and now she’s getting the full weight of his stare. “Emily, we are not drifting. I wanted a solution that the team could back, and it seems like Ben has a workable one ready. That’s very different from what you were describing to me earlier.” He stands up and says to me – “Ben, give me a report in a month and tell me how these action items are progressing. And Tabrez, you know I’d value your feedback as well.”
Emily grabs me by the arm, just as I’m leaving the room, still trying to salvage a victory. “Ben, I don’t understand why you’re digging in like this. You know that until we have better controls over releases, you’ll never have a stable app, and it’s embarrassing the company.”
Once again, I find myself admiring her unsinkable determination – time to show a little iron of my own. “Emily, I don’t agree with you that we lack controls, but we do lack manual controls. You and I are on a good road now, and we’re cooperating better when it comes to standing up infrastructure and coordinating releases. So let’s not fight now. If you could prove to me that this rigid approval process will prevent issues, I’d buy in – tomorrow. But I trust my eyes, and the numbers show that our stability and resilience are rising.”
She’s still angry, and for a few days we grump at each other in the hallways and avoid eye contact. But give her credit; Emily is a good manager, and she’s all about protecting her team. Better DR doesn’t take much salesmanship, and soon enough it becomes her baby. She and Kevin start putting together some fascinating Gameday disaster recovery scenarios, which are first attempted – with great hesitation – on some staging environments.
Months later, when we finally get the nerve to go live ammo and start knocking out some production environments during the day, her team handles coordination and recovery from the aftermath brilliantly. We bring beer and pizza by for her entire team and give them a standing ovation. We’ve crossed a major milestone, and she’s glowing with pride.
I’m glad I sunk the time I did into trying to understand Emily’s position; I’m also glad that we kicked back on a new manual gate. It’s almost certain that this would have slowed down our release rate. Worse, it was kicking us off in the opposite direction from where we wanted the team to go; it was fear motivated, not trust motivated. And I had that bet with Tabrez to think about.
I have to hand it to the guy – when we blow our 38-day release cycle goal a few months after this and get our releases out on a weekly cadence, Tabrez takes us all out to celebrate – on his dime. Indian food, at one of Padma’s favorite places – the heat of the spices was almost enough to make me call in sick the next day. I know we’ve still got a ways to go in improving our release turnaround time, but for now – I’m satisfied.
Behind the Story
Dashboarding and monitoring should have been far more prominent in the team’s journey; in this chapter, they finally begin to pay more attention to the numbers that matter most to their business partners, which reflect global value. Why is this important? And how do feature flags help enable a more continuous flow of value without increasing risk?
We have yet to see any major DevOps transformation that didn’t hit some major roadblocks, usually cultural. In this chapter, Emily’s drive to instill better governance through a manual approval process is in direct conflict with the team’s mandate to control and optimize their flow rate. What’s the best way to handle the massive cultural shifts required for any comprehensive DevOps movement?
Metrics and Monitoring
Engineering is done with numbers. Analysis without numbers is only an opinion.
—Akin’s 1st Law of Spacecraft Design
One accurate measurement is worth a thousand expert opinions.
—Grace Hopper
The lateral line, a kind of fish-length marshaling yard conveying vibrations from a receptive network of neuromasts to central data analysis quartered in the head, constantly monitors water for changes in pressure, telling fish not only where they are but also what’s around them and what it’s doing. A fish blinded by sadistic scientists with too much time on their hands can still find its prey through the lateral line. But leave the eyes alone and block off the lateral line, and the fish starves. 1
For fish, weightlifters, and DevOps devotees, the statement holds true; if you can’t measure it, you can’t improve it.
Most people would not argue with this statement; yet coming up with the right numbers to track or even having a common measurement of what success looks like is a real struggle for many organizations. In the section “By The Numbers,” Ben’s team is just starting to come to grips with this problem. It’s in the nick of time; with hindsight, the team will come to realize that waiting so long to address transparency was their single biggest mistake.
What are some keys to keeping the lateral line feeding the information you need to survive and thrive in a hostile and complex operating environment?
Pervasive Information Radiators
Let’s take the topic of pervasive information radiators as an example. We’ve already mentioned that Toyota made pervasive information displays a cornerstone of their Lean manufacturing process. Quality and the current build process state were constantly updated and available at a glance from any point on the factory floor.
When it comes to using displays to create a common awareness of flow, software appears to be lagging badly behind manufacturing. In most enterprises we’ve engaged with, monitors are either missing or only displaying part of the problem. Every team gathering area and war room should have at least one and preferably many displays.
Gathering metrics is too important to be optional or last in priority. We would never get in a car that didn’t have a speedometer and gas gauge front and center. Constant real-time monitoring and dashboarding is a critical part of safe operations for any vehicle. The same is true with the services and products we deploy; none are “fire and forget” missiles. If it’s running in production – it must be monitored.
It’s not an overstatement to say instrumentation is one of the most valuable, impactful components of any application we build. Without it, we won’t know what aspects of the app are in use – meaning our backlog will be prioritized based on best guesses. And that “thin blue line” of initial support will have no information on hand to triage and knock down common problems; second and third-tier responders will waste hours trying to reconstruct performance or operating issues because of blind spots in activity logs and a low signal-to-noise ratio.
And yet it’s often the first thing that’s thrown out when budgets are tight. Here’s where an effective project manager or team lead earns her pay; stand your ground and don’t allow short-sighted project time crunches or cost constraints to sabotage a crucial part of your architecture.
A clean dashboard showing valuable numbers is a first-class citizen of the project – the veins of your app’s circulatory system. Your code reviews and design reviews should drill in on how monitoring will be set up and what alert thresholds are appropriate.
We do track one metric that is very telling – the number of defects a team has. We call this the bug cap. You just take the number of engineers and multiply it by 4 – so if your team has 10 engineers, your bug cap is 40. We operate under a simple rule – if your bug count is above this bug cap, then in the next sprint you need to slow down and pay down that debt. This helps us fight the tendency to let technical debt pile up and be a boat anchor you’re dragging everywhere and having to fight against. With continuous delivery, you just can’t let that debt creep up on you like that. We have no dedicated time to work on debt – but we do monitor the bug cap and let each team manage it as they see best.
I check this number all the time, and if we see that number go above the limit we have a discussion and find out if there’s a valid reason for that debt pileup and what the plan is to remedy. Here we don’t allow any team to accrue a significant debt but we pay it off like you would a credit card – instead of making the minimum payment though we’re paying off the majority of the balance, every pay period. It’s often not realistic to say “Zero bugs” – some defects may just not be that urgent or shouldn’t come ahead of a hot new feature work in priority. This allows us to keep technical debt to reasonable number and still focus on delivering new capabilities.
We have an engineering scorecard that’s visible to everyone but we’re very careful about what we put on that. Our measurements are very carefully chosen and we don’t give teams 20 things to work on – that’s overwhelming. With every metric that you start to measure, you’re going to get a behavior – and maybe some bad ones you weren’t expecting. We see a lot of companies trying to track and improve everything, which seems to be overburdening teams – no one wants to see a scorecard with 20 red buttons on it! 2
This isn’t saying that the scoreboard and dashboard displays for the Azure DevOps team are simplistic. There’s thumbnail charts showing pipeline velocity (time to build, deploy, test, and failed/flaky automation), live site health (time to communicate, mitigate, incident prevention items, SLA per customer), and those powerful business-facing metrics – engagement, satisfaction, and feature usage. It tells an engaging and comprehensive story, and even better – it’s actually used, serving as a touchstone as their small-sized delivery teams align around that centrally set mission and purpose.
But to us the better story is what you don’t see – what the Azure DevOps management team chooses NOT to watch. They don’t track story point velocity. Team burndowns are nowhere to be found on any scoreboards, or the number of bugs found. They don’t show team capacity, or the lines of code (uggh!) delivered, or even original vs. current estimates. If a KPI like the preceding doesn’t matter to the end user, and it doesn’t drive the right kind of behavior, it should be dropped – pronto!
It’s Not As Hard As You Think
One common fear we hear often is that it’s somehow difficult and time-consuming to get monitoring set up. Actually, setting up monitoring is almost frighteningly easy. (Setting up the right kind of monitoring is where the pain comes in. We’ll get into that later!)
As with all things, starting simple is the key: what about timing how long database queries take? Or how long some external vendor API takes to respond? Or how many logins happen throughout the day?
Like we said earlier – the single biggest mistake Ben makes in this book is waiting so long to get to monitoring. It honestly should have been first and would have saved the team some time-wasting cul-de-sacs. The most formidable enemy in any transformation on the scale that DevOps demands is inertia. And the most powerful weapon you have to wield against falling back into old habits is the careful and consistent use of numbers to tell a story.
Once you start instrumenting your app, it becomes addictive. App metrics are so useful for a variety of things, you’ll wonder why you didn’t get started sooner. Your business partners, who usually were completely in the dark before, will welcome more detail around issues and changes shown in your information radiators. And it’s a key part of completing the feedback cycle between your development and Ops teams.
There’s a variety of great tools out there; it’s almost impossible to pick a bad one. Do what our friend JD Trask of Raygun recommends – take a Friday afternoon, and just get it done.
Monitoring Is for Everyone
Similar to security, if left as a late-breaking audit step monitoring can gain a rep as just another painful gate to hurdle.
Monitoring is a skill, not a job title. It’s far too important to be relegated to one “monitoring expert” to handle; everyone on your team should know and be familiar with setting up instrumentation.
The successful companies we interviewed all made monitoring a first-class concern – and they made it a breeze to wire in. Engineers will always find the shortest distance between two points. Most of the winning strategies we’ve seen made it easier to do the right thing, providing a clear, constantly improving library with usage guidelines and an ongoing training program. Many were flexible and collaborative, allowing extendability or completely different approaches – as long as it provided a similar level of coverage.
We talked about flow – another key piece is getting feedback. Most companies simply don’t think to implement things to see that they’re getting consistent, frequent feedback from customers. In your customer facing apps, do they have a way of providing feedback – a smiley face, or a direct way to call on a new feature? I don’t see orgs doing enough around the feedback loop; if they do have a feedback loop its manual, with long delays and full of waste and misinterpretation. 3
Monitoring is too important to leave to end of project, that’s our finish line. So we identify what the KPI’s are to begin with. Right now it revolves around three areas – performance (latency of requests), security (breach attempts), and application logs (errors returned, availability and uptime).
…Sometimes of course we have customers that want to go cheap on monitoring. So, quite often, we’ll just go to app level errors; but that’s our bare minimum. We always log, sometimes we don’t monitor. We had this crop up this morning with a customer – after a year or more, we went live, but all we had was that minimal logging. Guess what, that didn’t help us much when the server went down!
Going bare-bones on monitoring is something customers typically regret, because of surprises like that. Real user monitoring, like you can get with any cloud provider, is another thing that’s incredibly valuable checking for things like latency across every region. 4
What Numbers Matter?
The WonderTek team could have chosen any one of a number of KPI’s. If the issue was testing and a lack of quality around release gates, automated test coverage could have been shown. If defects and bugs continued to skyrocket, defect counts, the amount of unplanned work, or build failures could be highlighted. If development velocity was waning, velocity in function points could have been shown, sprint by sprint. If infrastructure is creaky and environment changes are hurting service availability, the number of unique environments in production or server/sysadmin ratios could be shown. Or – Alex’s white whale – if developers are sullen and mutinous over excessive build times disrupting their work flow, daily average build times could have been monitored carefully. If the problem was failed or incomplete transactions, failed orders could be displayed. Google for its service layer focuses on what it calls the four “golden signals” – latency, traffic, errors, and saturation.5
The best metrics we’ve seen aren’t generic but are very specific answers to a very unique problem the company has identified. For example, a little more drilling into the issue of configuration drift by Emily’s team could have shown a large number of unique, snowflake servers that were brittle and irreplaceable, “pets.” Showing the number of unique configurations in production as a trend over time could help spur visibility. Tracking the number of times a VM had to be logged onto directly in remediation vs. remote diagnosis could point the team toward the need for better configuration management and more complete log aggregation. Showing the number of sysadmins per server can expose lack of automation around standing up and servicing IAAS environments. For Ben’s team, showing the amount of unplanned work each sprint will indicate if the improvements they’ve planned around live site support are helping reduce the burden of firefighting on feature development.6
The team started out with a complex dashboard and a slew of numbers to watch; over time, they’ve winnowed this down to one key aspect that seems to matter most to the business – MTTR, or recovery time. That doesn’t mean that they’re not watching other numbers, too. The displays for an Operations person may not show the exact same set of metrics that a developer’s screen would. But, MTTR is emerging for WonderTek as the single number that should matter most to everyone in their delivery chain.
I think telemetry is the first thing. If you don’t get the telemetry right, everything, all bets are off. I’m sorry. If you cannot measure it and you can’t see what’s actually happening in your system… we rely on that first and foremost. You’ve got to make sure that you’re hitting that reliability number for your customer… From there, I think it depends on the product. 7
Resilience was the right choice for the team given their current state and operating conditions, but that may not be the case months down the road. You’ll find the KPIs that matter most to your enterprise might shift over time, and it’s easy to be glib and understate how challenging and difficult it is to articulate and then capture that powerful business-facing metric.
We commonly see lead times ignored in value stream maps and KPI charts, for example, because it’s difficult to measure and has such a high degree of variation. But two of our biggest heroes, Mary and Tom Poppendieck, have pointed out the lessons from manufacturing in identifying lead time as a key metric, going so far as to say that it identifies more about the delivery process health than any other metric. Asking, “How long would it take your org to deploy a change that involves a single line of code?” pinpoints issues with tooling and process that are hurting delivery times; asking “Can this be done on a repeatable, reliable basis?” brings to light gaps in areas like automated testing that are impacting quality.8
We focus on two things – lead time (or cycle time in the industry) and production impact. We want to know the impact in terms of lost opportunity – when the fab slows down or stops because of a change or problem. That resonates very well with management, it’s something everyone can understand.
But I tell people to be careful about metrics. It’s easy to fall in love with a metric and push it to the point of absurdity! I’ve don’t this several times. We’ve dabbled in tracking defects, bug counts, code coverage, volume of unit testing, number of regression tests – and all of them have a dark side or poor behavior that is encouraged. Just for example, let’s say we are tracking and displaying volume of regression tests. Suddenly, rather than creating a single test that makes sense, you start to see tests getting chopped up into dozens of tests with one step in them so the team can hit a volume metric. With bug counts – developers can classify them as misunderstood requirement rather than admitting something was an actual bug. When we went after code coverage, one developer wrote a unit test that would bring the entire module of code under test and ran that as one gigantic block to hit their numbers.
We’ve decided to keep it simple – we’re only going to track these 2 things – cycle time and production impact – and the teams can talk individually in their retrospectives about how good or bad their quality really is. The team level is also where we can make the most impact on quality.
I’ve learned a lot about metrics over the years from Bob Lewis’ IS Survivor columns. Chief among those lessons is to be very, very careful about the conversation you have with every metric. You should determine what success looks like, and then generate a metric that gives you a view of how your team is working. All subsequent conversations should be around ‘if we’re being successful’ and not ‘are we achieving the metric.’ The worst thing that can happen is that I got what I measured. 9
Keep It Customer Facing
It bears repeating: it’ll be harder than you think to come up with the right numbers. More than likely, your initial few tries will be off target and your KPI choices will need to be tweaked significantly.
The Azure DevOps management team, for example, struggled to come up with numbers and metrics that accurately reflect customer satisfaction; see the interview with Sam Guckenheimer in the Appendix for more on this. They would tell you that the payoffs are well worth it. Most companies are still aligned around localized incentives and rewards that pit groups against each other or are otherwise disconnected from the actual success of the work in the eyes of customers. Changing incentives and management attention to global KPIs revolving around customer satisfaction, retention, and adoption elevates creates a startling change; no longer are we fighting against the current.
…It frustrates me that people focus on number of deployments a day as a success metric. ‘If you’re deploying 10 million times a day, you’re doing DevOps!’ No. That doesn’t matter to your customers at all. They want value.
So, does your site work? Are you delivering the features they want? Don’t get caught up in the wrong metrics. Things like test code coverage, build deploy numbers, even build failures – they don’t mean anything compared to customer satisfaction. Find out how to measure that – everything else is just signals, useful information but not the real definition of success. 10
It’s quite shocking how little empathy there is by most software engineers for their actual end users. You would think the stereotypical heads-down programmer would be a dinosaur, last of a dying breed, but it’s still a very entrenched mindset.
I sometimes joke that for most software engineers, you can measure their entire world as being the distance from the back of their head to the front of their monitor! There’s a lack of awareness and even care about things like software breaking for your users, or a slow loading site. No, what we care about is – how beautiful is this code that I’ve written, look how cool this algorithm is that I wrote.
We sometimes forget that it all comes down to human beings. If you don’t think about that first and foremost, you’re really starting off on the wrong leg.
One of the things I like about Amazon is the mechanisms they have to put their people closer to the customer experience. We try to drive that at Raygun too. We often have to drag developers to events where we have a booth. Once they’re there, the most amazing thing happens – we have a handful of customers come by and they start sharing about how amazing they think the product is. You start to see them puff out their chests a little – life is good! And the customers start sharing a few things they’d like to see – and you see the engineers start nodding their heads and thinking a little. We find those engineers come back with a completely different way of solving problems, where they’re thinking holistically about the product, about the long-term impact of the changes they’re making. Unfortunately, the default behavior is still to avoid that kind of engagement, it’s still out of our comfort zone. 11
A Single View of Success
What’s it worth to have that single view of success? For Alaska Air, keeping their eyes on takeoff time and shaving a few minutes per flight save them enough to buy a few more Boeing 737’s for their fleet every year. For Amazon, keeping order rates front and center in displays at every level keeps their distribution centers humming and spurs creative new ideas.
The only thing worse than misusing metrics as a stick instead of a carrot, it seems, is not gathering any at all and hoping for the best. One person we interviewed told us that any data gathered has to focus on the question, “Is what I’m doing getting us closer to a desirable customer outcome?” Process improvements, project objectives all should take a back seat to that customer focus. Yet, in some organizations, he saw an almost allergic response to metrics – “we know this is the right thing to do, we’re not going to measure anything – just tell stories and hope things will get better.” Incredulously, he asked: “In that case, how do you know things are actually improving?”
It can’t be overstated the power that a single highly visible number can have. In one previous company, we knew that our automated testing was lagging months behind new feature development, but there we were in the middle of a death march to make our promised delivery dates. There simply was no appetite for sparing any work toward improving quality as the team was falling behind.
The solution was simple: visibility. We put the automated test coverage on the top right of every retrospective in a big 2-inch square box, in bright purple. Suddenly, executives and sponsors were dropping by worriedly several times a day, concerned about the lack of test coverage and asking what could be done. Now our project could get the resources and attention needed to raise our test levels up to an acceptable state.
Metrics are a two-edged sword, however. Several that we talked to mentioned the dangerous allure of trying to track too much, or tracking the wrong thing. Try to expose everything as an improvement target, and the effort will stall out due to lack of focus.
The area that causes the most inertia is a lack of right measurements for practitioners and teams. People will not change their behaviors, unless the way they are being measured matches the new, desired behaviors. Furthermore, to deliver true collaboration and a sense of a single team working toward a singular set of goals across silos, these measurements of success should be the same among all practitioners. Dev, test, and Ops need to have common or at least similar metrics that their success is measured on. Everyone – and I mean everyone – has to be made responsible for deploying to production. 12
What’s the solution to what Puppet has called the “land and expand” issue – where people are overwhelmed by a maelstrom of issues and choices and don’t know where to start? We’re betting that out of the seemingly endless cloud of problems facing you, there’s one workstream in particular that is a recurring pain point. And with that app or service, there’s likely one thing that in particular sticks out as being a pervasive, time-sucking mess. Perhaps, it’s latency in your app; perhaps, it’s dropped orders, security, availability, or hassles with deployments. Whatever that one single pain point is, and assuming it’s low-hanging fruit, build your monitoring around that.
I love monitoring and I hate how often it gets put last or gets swept under the table. If you think about it, it’s just testing but it’s done in production. So just like with testing – don’t think plain vanilla metrics – but think about what you need to do to make sure the application is running correctly from the user’s perspective. Then implement some way of watching that in your monitoring. 13
Alcoa and the Keystone Habit
Enterprises that struggle with dashboarding tend to clutter up their displays with nonessential or generic data. That kind of complexity dilutes the impact of information radiators and doesn’t force behavioral changes; any message is lost in the noise. In contrast, Microsoft in their dashboarding has a variety of KPIs exposed, but typically one in particular dominates the screen. Most of the successful companies we’ve seen choose to focus on one particular KPI at a time as a primary theme.
As an example, let’s take a close look at the how the aluminum manufacturer Alcoa was transformed in the late 1980s. The company was in trouble, and a new CEO, Paul O’Neill, was brought in to right the ship. He found a deep chasm between management and the union workers. To bridge the gap, he made safety the problem – the single mission for the entire company. He stood before investors and announced:
“Every year, numerous Alcoa workers are injured so badly that they miss a day of work. Our safety record is better than the general American workforce, especially considering that our employees work with metals that are 1500 degrees and machines that can rip a man’s arm off. But it’s not good enough. I intend to make Alcoa the safest company in America. I intend to go for zero injuries.”
The Wall Street audience was expecting the usual comforting talk about revenue growth, profit, and inventory levels, and was completely stunned. When asked about inventory levels, O’Neill responded, “I’m not certain you heard me. If you want to understand how Alcoa is doing, you need to look at our workplace safety figures.”
This message caused a minor stampede with the shareholders at the meeting. As weeks and months went by and O’Neill’s attention didn’t shift off of safety, it looked like O’Neill was completely disconnected from the realities of running an enterprise as complex and threatened as Alcoa.
Yet, the continued emphasis on safety made an impact. Over O’Neill’s tenure, Alcoa dropped from 1.86 lost work days to injury per 100 workers to 0.2. By 2012, the rate had fallen to 0.125. Surprisingly, that impact extended beyond worker health. One year after O’Neill’s speech, the company’s profits hit a record high.
Focusing on that one critical metric, or what Charles Duhigg in The Power of Habit referred to as a “keystone habit,” created a change that rippled through the whole culture. With Alcoa, O’Neill’s focus on worker safety led to an examination of an inefficient manufacturing process – one that made for suboptimal aluminum and danger for workers.
I knew I had to transform Alcoa. But you can’t order people to change. So I decided I was going to start by focusing on one thing. If I could start disrupting the habits around one thing, it would spread throughout the entire company. 14
O’Neill’s single-minded focus on worker safety initially looked like a terrible decision. But his success at Alcoa shows the transformative power of clarity around one carefully chosen number.
What’s Happening with Your Error Logs?
…I think we’re still way behind the times when it comes to having true empathy with our end users. It’s surprising how entrenched that mindset of monitoring being an afterthought or a bolt-on can be. Sometimes we’ll meet with customers and they’ll say that they just aren’t using any kind of monitoring, that it’s not useful for them. And we show them that they’re having almost 200,000 errors a day – impacting 25,000 users each day with a bad experience.
It’s always a much, much larger number than they were expecting – by a factor of 10 sometimes. Yet somehow, they’ve decided that this isn’t something they should care about. A lot of these companies have great ideas that their customers love – but because the app crashes nonstop, or is flaky, it strangles them. You almost get the thinking that a lot of people would really rather not know how many problems there really are with what they’re building.
…This isn’t rocket science, and it isn’t hard. Reducing technical debt and improving speed is just a matter of listening to what your own application is telling you. By nibbling away on the stuff that impacts your customers the most, you end up with a hyper reliable system and a fantastic experience, the kind that can change the entire game. One company we worked with started to just take the top bug or two off their list every sprint and it was dramatic – in 8 weeks, they reduced the number of impacted customers by 96%!
…Real user monitoring, APM, error and crash reporting – this stuff isn’t rocket science. But think about how powerful a motivator those kinds of gains are for behavioral change in your company. Data like that is the golden ticket you need to get support from the very top levels of your company. 15
It’s easy to get overwhelmed when we’re talking about wading through error logs with six-figure error counts. But we love the pragmatic approach John-Daniel explained in great detail in his interview with us, of grouping and prioritizing these problems in terms of customer impact – not the number of occurrences! – and dropping the top two or three onto the work queue for the next sprint. Talk about a game changer in terms of actionable customer feedback!
Beware of Misusing Metrics
A successful measure of performance should have two key characteristics. First, it should focus on a global outcome to ensure teams aren’t pitted against each other. The classic example is rewarding developers for throughput and operations for stability: this is a key contributor to the “wall of confusion” in which development throws poor quality code over the wall to operations, and operations puts in place painful change management processes as a way to inhibit change. Second, our measure should focus on outcomes not output: it shouldn’t reward people for putting in large amounts of busywork that doesn’t actually help achieve organizational goals. 16
Metrics are often misused by pathological or bureaucratic cultures as a form of control; it’s clumsy and in the end counterproductive. In fulfillment of Deming’s warning that “wherever there is fear, you get the wrong figures,” valuable information begins being spun or filtered. Once people start being punished for missing target metrics, data is inevitably manipulated so targets are met and blame is shifted. Typically, the numbers selected by these orgs reflect the goals and values of a single functional silo and are rarely updated or changed.
Generative, forward-thinking organizations don’t measure results by KPIs – we heard from several high-level executives that they use these numbers as a starting point for conversations to better understand the current state and make improvements vs. blind punishment. (One went so far as to say to us, “We love it when teams report red – that means they’re being aggressive, and honest!”) They’re never used as a hammer – only as a frame for a conversation about current state and blockers.
So, be careful about what you choose to show on your dashboards; it may have long-lasting unintended consequences. When Dave was first experimenting with Agile as a team lead, he started carping on burndown charts. Surprise – suddenly the team’s burndown charts became beautiful, flawless, 45-degree angle lies!
The Hawthorne Effect (also known as the Observer Effect) tells us that what we choose to measure has an enormous influence. Organizations that choose to focus on lines of code delivered as a measure of velocity will suddenly see those numbers jump as developers churn out lots of short lines of sloppy code to “make their numbers.” If the focus is ticket elapsed time to resolution, testers will log easily fixed bugs and close them out in droves, requiring multiple tickets to be opened for the same problem.
These are both examples of “vanity metrics” – numbers that are easy to measure and gather – but solve essentially local problems and encourage fudging. If a number we’re tracking changes and there is nothing we can do in response, it’s a vanity metric. Before setting up any KPI, it’s important to check and ask: “What will we do differently based on changes to this metric?”17
For example, let’s take the popular metric of server response times. This is a very easy number to collect, but does it really show the actual user experience – say of a customer trying to log on from a remote location in Indonesia, on a 7-year-old phone, connecting via a 3G network? Operations teams in particular lean strongly toward OS metrics like CPU, memory, network, disk, etc. Yet, these metrics by themselves don’t answer the key question – “is the app working? What’s our customer experience like?” Of course, these numbers have value, especially in diagnostics, and we want to store them – but they shouldn’t be key drivers out of context for any decisions, and we need to be careful about the alarms triggered from these events as they may just add noise.
If you can define the outcome you really want, give examples of it, and identify how those consequences are observable, then you can design measurements that will measure the outcomes that matter. The problem is that, if anything, managers were simply measuring what seemed simplest to measure. 18
It’s easy to see why complicated or ultimately meaningless displays are often the default behavior. SAAS software vendors make selecting from specific canned, generic scenarios very easy. (Which, by the way, we’re fine with – as a starting point!) The alternative of drilling into what success means exactly and what numbers should define risk – let alone how to gather this in an actionable way – involves an incredible amount of work over long periods of time. Yet, despite this hassle and expense, uniformly the experts we spoke to considered useful monitoring to be not just worth it but vital – the single underlying foundation of every improvement made.
Don’t Forget About the Pipeline Itself
Before we leave this topic, we should discuss the one part of your software you might be tempted to overlook – the build process itself. It’s tempting to think of this as being ultimately not as high a priority to watch as our application facing KPIs. However, if your current release process can’t tell you when deployments started, when they ended, who deployed it and which build was triggered – and if it can’t send out alarms or fail builds where SLAs are at risk and regressions are likely – this is a threat to the jugular vein of the enterprise, and addressing this should be first and foremost. Keeping the build pipeline green and humming should be every delivery team’s top priority, far more important than delivering new features.
Adrian Cockroft has mentioned that one of his favorite metrics is how many meetings and work tickets are required to perform a release. Publishing this widely exposes pain and helps to reduce the effort required to deliver work.19
Buy or Build?
Should you buy a solution or build your own? There’s successful examples we could to point to from both camps; Etsy loves the flexibility its custom solutions (including StatsD) provide; Google enthusiastically promotes Borgmon or Prometheus. Other companies such as Target, AirBnb, Pinterest, and Yelp rave about the power and ease of implementation that comes with SAAS-based solutions like New Relic.
We’ll bow out of this argument, but not without making this observation; as with all other strategic decisions around COTS products, beware the hidden opportunity costs. It’s frighteningly common to underestimate the amount of work it takes to build a truly robust and flexible enterprise-ready monitoring system. Let’s say you make the decision to build out a custom solution from scratch, which ends up requiring almost six people at $200K apiece to develop and support. Was that $1.2M annual operating cost worth it, vs. paying $150K a year for a SaaS package? And how valuable would those six people have been elsewhere on the delivery teams – creating something that could actually give your company a competitive advantage? It does seem to us that, as SaaS solutions become more powerful, robust, and adaptable, most companies should put more thought into this analysis before attempting to build their own custom monitoring solution.
Another short-circuit to the learning process some companies fall into is with analytics. I’m still seeing a lot of people rolling their own analytics. That’s ridiculous – they really need to be using a vendor! I don’t care who you use, dammit, just use pick one. Trust with one vendor is a key aspect of Deming’s teachings. You really can’t put enough stress on how important it is to get feedback, more often, more accurately to the people that need it. In Lean Manufacturing this isn’t as big of a deal – you can’t change a car platform every month – but in software you can and should be adjusting and changing almost by the day. 20
Too many security organizations put tools before operations. They think “we need to buy a log management system” or “I will assign one analyst to antivirus duty, one to data leakage protection duty.” And so on. A tool-driven team will not be effective as a mission-driven team. When the mission is defined by running software, analysts become captive to the features and limitations of their tools. Analysts who think in terms of what they need in order to accomplish their mission will seek tools to meet those needs, and keep looking if their requirements aren’t met. Sometimes they even decide to build their own tools. 21
Anything worth solving takes a bit of effort, and monitoring a complex system is certainly no exception. Relatedly, there is no such thing as the single-pane-of-glass tool that will suddenly provide you with perfect visibility into your network, servers, and applications, all with little to no tuning or investment of staff. Many monitoring software vendors sell this idea, but it’s a myth. Monitoring isn’t just a single, cut-and-dry problem – it’s actually a huge problem set... If you are running a large infrastructure (like I suspect many of you are), then paying attention only to your servers won’t get you very far: you’ll need to monitor the network infrastructure and the applications too. Hoping to find a single tool that will do all of that for you is simply delusional.
My advice is to choose tools wisely and consciously, but don’t be afraid of adding new tools simply because it’s yet another tool. It’s a good thing that your network engineers are using tools specialized for their purpose. It’s a good thing that your software engineers are using APM tools to dive deep into their code. In essence, it’s desirable that your teams are using tools that solve their problems, instead of being forced into tools that are a poor fit for their needs in the name of “consolidating tools.” If everyone is forced to use the same tools, it’s unlikely that you’re going to have a great outcome, simply due to a poor fit. On the other hand, where you should be rightfully worried is when you have many tools that have an inability to work together. If your systems team can’t correlate latency on the network with poor application responsiveness, you should reevaluate your solutions. 22
Be Thoughtful About Alerting
Practical Monitoring also pointed out that many misunderstand the purpose of monitoring, perhaps because of older tools like Nagios, and think its primary purpose is to generate alerts when things go haywire. But monitoring’s purpose goes well beyond that of being an annoying squawkbox. Instead, monitoring is for asking questions. Alerts are just one possible outcome. Perhaps, immediate action is needed; maybe, a PagerDuty or SMS alert needs to be sent. Or the logs generated could be sent to an internal chatroom or custom website app. Or the information should just be stored, quietly, for when it’s needed later.
Noisy alerts suck. Noisy alerts cause people to stop trusting the monitoring system, which leads people to ignoring it entirely. How many times have you looked at an alert and thought, “I’ve seen that alert before. It’ll clear itself up in a few minutes, so I don’t need to do anything”? The middle ground between high-signal monitoring and low-signal monitoring is treacherous. This is the area where you’re getting lots of alerts, some actionable and some not, but it’s not to the point that you don’t trust the monitoring. Over time, this leads to alert fatigue.
Alert fatigue occurs when you are so exposed to alerts that you become desensitized to them. Alerts should (and do!) cause a small adrenaline rush. You think to yourself, “Oh crap! A problem!” Having such a response 10 times a week, for months on end, results in long-term alert fatigue and staff burnout. The human response time slows down, alerts may start getting ignored, sleep is impacted – sound familiar yet? The solution to alert fatigue is simple on its face: fewer alerts. In practice, this isn’t so easy. There are a number of ways to reduce the amount of alerts you’re getting: Go back to the first tip: do all your alerts require someone to act? Look at a month’s worth of history for your alerts. What are they? What were the actions? What was the impact of each one? Are there alerts that can simply be deleted? What about modifying the thresholds? Could you redesign the underlying check to be more accurate? What automation can you build to make the alert obsolete entirely? 23
The scene in the section “By the Numbers” comes from a real experience we endured, and it’s a classic example of the siloed thinking that DevOps is meant to target. One Monday morning, not so very long ago, we came in to find our customers screaming that our service had been unresponsive for most of the weekend. After some diagnosis, we determined that a weekend patch of the server OS had shut down IIS, and the service hadn’t restarted. “Well, yeah,” said our IT partner who had run the patch and then walked away. “Didn’t you get the alert?” And there, of course, sitting patiently in our inbox was that alert – buried with several hundred other alerts that looked exactly the same that had been generated that day.
This was patently a dangerous and unreliable monitoring system; normal operations were generating a flurry of ass-covering alerts, which in turn both overwhelmed and desensitized support teams and masked actual customer problems.
We’re with Mike – noisy alerts suck. The alerting system we just described was a Chihuahuua – yippy and highstrung. When it comes to alerts, we want big dogs – German Shepherds, Dobermans. When a big dog barks, you know there’s a real problem, and it raises an actionable alert. Kill noisy or ineffective alerts with a weekly review by the on-call team; go through the weekly alerts generated with a mission to either turn off as many alerts as possible, or improve the quality of the signals being generated.
Feature Flags, Continuous Delivery
A phased approach to continuous delivery is not only preferable, it’s infinitely more manageable.
—Maurice Kherlakian
The most powerful tool we have as developers is automation.
—Scott Hanselman
Automating chaos just gives faster chaos.
—Mark Fewster
On the surface the section “Letting Our Freak Flag Fly” is discussing feature flags, but really it’s about the team making it that last mile – where value is being deployed continuously.
We didn’t want to cover feature flags at all when we first started this book; it became increasingly obvious that it couldn’t be avoided. There’s just too many companies out there that have found feature flags to be invaluable when it comes to making their releases safer and faster – a catalyst for true continuous delivery.
The end goal though is always the same. Your target, your goal is to get as close as you can to Continuous Integration / Continuous Delivery. Aiming for continuous delivery is the most productive single thing an enterprise can do, pure and simple. There’s tools around this – obviously working for Puppet I have my personal bias as to what’s best. But pick one, after some thought – and play with it. Start growing out your testing skills, so you can trust your release gates. 24
Continuous Means More Often Than You Think
Can we just say this – it’s very common for thought leaders and architects to hit the lecture circuit boasting about their company’s high-performing CI/CD pipelines and best-of-breed DevOps culture – while there’s some very ugly things happening behind the curtains to get things to actually work.
We talked to many developers who claim vigorously – yes, of course we do continuous delivery! But it turns out that while they may be checking in code perhaps many times a day, that’s not when releases actually happen to production. Usually, these are gated in some way for reviews or approvals, or there’s some kind of lengthy handoff process – and is bundled into a larger release including hundreds of other changes as a scheduled build over a weekend, or at night. This simply is not continuous delivery.
We’re in this position where people feel they ought to be doing continuous delivery, but are people actually doing it? In my experience no. I think that it’s very patchy. I have a friend Mike Roberts who I used to work with when I was at ThoughtWorks, and he says “Continuous is much more often than you think.” And I think that applies very much to this.
I have a test for continuous delivery, which is, ‘Could I, at any point in time, press a button, and take what’s in version control and ship it, with a Mojito in my hand?’ That’s my continuous delivery Mojito test. A lot of people don’t pass that. A lot of people are still doing releases evenings and weekends. And while they might have automated it, and while they might be doing it more often than they used to, this idea that at any time in the day I can press a button and push to prod whatever’s in trunk right now, I don’t think there are actually that many places that could put their hands on their heart and say they’re doing that. 25
That frustration is echoed in Jez’s earlier book: “We can honestly say we haven’t found a build or deployment process that couldn’t be automated with sufficient work and ingenuity…It’s hard to argue with the value of automated releases – but it’s amazing how few production systems we’ve encountered are fully automated.”26
What Stops Us
If a fully automated and continuous release cycle is so desirable and wonderful, why aren’t we seeing it more often? Why isn’t this every DevOps implementation moving toward CD as a technical goal?
No surprise, the culprit is usually fear. There’s such a high element of risk associated with changing any truly complex system as we have with software. Software releases can become a dragon with a long and destructive tail; we’ve all been in big-push war room releases and have scar tissue to show from the bloody aftermath. Worst of all is the icy stabbing shivers down our spine when something inevitably doesn’t work as we expected: Can we roll this back? What happens if we’ve hosed the entire app and we can’t salvage our data? Is this going to kill our entire update and push this thing out another year? What am I going to tell my boss, what are our customers going to say?
This fear is both understandable and sometimes a little dated. Software and the way we can deliver it is more malleable than it used to be. Fifteen years ago, when software was developed and deployed in multiyear releases as shrink-wrapped CDs, we had some real obstacles to being able to deploy software safely and at velocity. With long testing and integration cycles, every release was “push and pray,” a massive effort to get to launch – and weeks or months of death marches to provide postrelease support and hotfixes. The penalty for failure was high – rolling back features involved an update or patch, which of course carried its own risks and embarrassment. Releases were either on or off – if bugs were serious enough, the team would have to kill the new feature for the entire userbase until the next gigantic launch milestone.
Dave remembers very vividly being asked to pull out part of a new application as it was deemed not yet ready for prime time. Of course, three months in, that was a little like saying hey, great coffee, but I really didn’t want half-and-half in that. Can you take that out? And the answer of course is – yes, but it’ll take some work. Weeks of work, as it turned out.
Controlling the Blast Radius
Thankfully, since then both our tooling and the way that software is being delivered has closed the gap. We’re getting better at hiding new functionality until it’s ready; we use components or microservices to decouple parts of the application that change faster; and simpler but more powerful branching strategies allow us to roll out new features much more smoothly from mainline. We can control the blast radius of any new release by using deployment rings, allowing us to see how our software is actually holding up under production load by gradually releasing it outward, starting with internal or beta customers – a canary release. And failover can become a configuration toggle; we can use load balancing and deployment slots to shift some users to a newer (green) version while keeping the older (blue) version live; monitoring allows us to quickly turn off traffic to the green environment until serious problems are debugged and resolved.
Flickr is somewhat unique in that it uses a code repository with no branches; everything is checked into head, and head is pushed to production several times a day. This works well for bug fixes that we want to go out immediately, but presents a problem when we’re working on a new feature that takes several months to complete. …Feature flags and flippers mean we don’t have to do merges, and that all code (no matter how far it is from being released) is integrated as soon as it is committed. Deploys become smaller and more frequent; this leads to bugs that are easier to fix, since we can catch them earlier and the amount of changed code is minimized.
…This style of development isn’t all rainbows and sunshine. We have to restrict it to the development team because occasionally things go horribly wrong; it’s easy to imagine code that’s in development going awry and corrupting all your data. Also, after launching a feature, we have to go back in the code base and remove the old version (maintaining separate versions of all features on Flickr would be a nightmare). But overall, we find it helps us develop new features faster and with fewer bugs. 27
Flickr’s implementation of feature flags worked such wonders that John Allspaw once commented that it “increases everyone’s confidence to the point of apathy, as far as fear of load-related issues are concerned. I have no idea how many code deploys were made to production on any given day in the past 5 years… because for the most part I don’t care, because those changes made in production have such a low chance of causing issues.”28
Feature flagging is not a new concept; developers have been wrapping sections of code with targeted if/else statements for decades to control releases. It was stunningly easy to implement; the problem was administration and governance as part of a life cycle. Managing these flags, handling access permissions, and controlling their lifetime were a logistical challenge. That’s all changed in the past decade; a variety of great open source and SaaS software exists that allows us easy visibility and administration of flags.
Decoupling releases from feature deployments can change everything. Now, we have a pragmatic, controlled way to get to continuous deployment and delivery without causing people to think that they’re on a runaway train. Rollbacks and hotfixes are less stressful, involving a ramp down or feature toggle “kill switch.” Every phase of planning, writing, testing, launching, and collecting user feedback is more controllable, giving us confidence that we are in charge of the entire release cycle, and how and what our customers are able to see.
Feature flags tie in very well with all the nifty little release gimmicks we discussed earlier – deployment rings, A/B or blue/green releases, automated rollbacks, and self-healing release pipelines. We can roll out our changes to a small group of people and slowly raise the exposure level to 100% as we grow more confident that things aren’t breaking. We can form a beta or preview user group for our experiments, quickly and easily; allow early access for power users; or set up a premium plan. In short, the collection of launch techniques revolving around feature flags allows us to learn and experiment.
Feature flags allow us to do more work against mainline or trunk, eliminating the problems caused by long-lived feature branches. By using blue/green releases, we can see how a new feature is being received – and if it’s hitting our KPI targets better than the older system. Testing in production is now a possibility, reducing our reliance on building expensive staging environments that imperfectly and expensively attempt to simulate production conditions. And it’s been used successfully with that most powerful form of version control – helping IT teams make structural changes or updates to infrastructure and assisting with validation and rollbacks of configuration and environment changes.29
Using feature toggles changes the way we view change management. We’ve always viewed delivery as the release of something. Now we can say, the deployment and the release are two different activities. Just because I deploy something doesn’t mean it has to be turned on. We used to view releases as a change, which means we needed to manage them as a risk. Feature toggles flips the switch on this where we say, deployments can happen early and often and releases can happen at a different cadence that we can control, safely. What a game-changer that is! 30
Controlling the Life Cycle
We’re enthusiastic about feature flags and everything they can enable in terms of positive behaviors and capabilities around releases. But, we admit they’re not a panacea. If left untended or implemented without thinking about controlling their life cycle, feature flags can clutter up your codebase and become a tangled, unmanageable mess of technical debt. It doesn’t eliminate the need to think about domain-driven design, components, or microservices.
When used as a kill switch, they can be vulnerable to cascading or dependency failures; it doesn’t eliminate the need for planning and practicing DR; regular and realistic gameday practices may be a more effective practice in terms of reducing fear and improving MTTR. They won’t provide much insulation when it comes to overcoming sloppy code or ineffective testing. They make a terrible crutch in trying to compensate for a lack of automation. Just as an example, the famous Knight Capital debacle in August 2012, which bankrupted the company after an out of control release ate up nearly $400M in bad trades, was a high-visibility disaster triggered by an engineering team that used feature flags.31
So, treat flags or toggles like anything else, a useful tool but one that requires some thought in its application. Remember that their intended purpose is to be short-lived, transient. Many development teams do a kind of three-step dance – rolling out a release at the end of a sprint with any new functionality turned off; then the following sprint turning on the functionality; and the sprint after, removing the tags or markup created.
Much like with monitoring, you may find maintenance and administration of this to be worth investing in with a COTS or SaaS product, vs. trying to spin up a homegrown solution – especially where a slick user-friendly dashboard is needed in partnering with a business stakeholder.
Regardless of your choice of management tools or implementation style, we predict you’ll find feature flags to be one very nifty little trick that can move you closer to a safer, more controlled release pattern.
Disaster Recovery and Gamedays
I confess plainly not to control events but to being controlled by them.
—Abraham Lincoln
Simple, clear purpose and principles give rise to complex and intelligent behavior. Complex rules and regulations give rise to simple and stupid behavior.
—Dee Hock
Bad managers believe in the illusion of control – there’s lots of meetings, trying to break a complex system down into simple disconnected parts. Good managers on the other hand have a shared consciousness but decentralized control.
—Damon Edwards32
We had a friend get into a very serious car accident not too long ago in New York; thankfully, she emerged from the wreckage with no life-threatening injuries. But long after the physical trauma was over, her body continued to “overclench” as her body’s nervous system tightened up and sent false alarm signals in a protective instinct. This led to over a year of painful and intensive physical therapy, as she fought to relax the stressed muscles and nerves in her neck and shoulders.
In the wake of a disaster, the human biological response is often to overcorrect. If you’ve ever broken a bone, you know the feeling; long after the cast is off and everything is back to 100% health, we treat it gingerly, carefully, like the bone is made of balsa wood. Both organizations and people carry a strong and long-lasting memory of traumatic events, and it’s hard to shake it off and get over the mental aftereffects of a catastrophic failure.
Counterfactual Arguments Around Failure
In Backlash, Emily is championing what appears to be a powerful argument for better change controls and release management. And yet – for WonderTek to continue on in its upward trajectory, the solutions she is fighting for represents a kind of overclenching. Thankfully, Ben and Tabrez had some strong arguments ready that focus less on instituting artificial gates and reducing failure rates, and more on increasing recovery times.
- 1.
Blame change control. “Hey, better change management practices could have prevented this!”
- 2.
Blame testing – “If we had better QA, we could have caught this before it hit production!”
It’s hard to argue with either of these seemingly logical stances – especially early on in the recovery cycle. But as Gene Kim has noted, “in environments with low-trust, command and control cultures, the outcomes of their change control and testing countermeasures end up hurting more than they help. Builds become bigger, less frequent and more risky.”34
Huh? If the goal is more safety and reliability, why are these countermeasures so ineffective?
The Vicious Cycle of MTBF-Centric Thinking
Let’s say Emily wins this round, and immediately management begins imposing long and mandatory weekly change control every week to approve releases and go over defects from the previous week. We all know how hard it is to kill a committee, and their mandates and scope always seem to grow over time. Soon enough, we’ll begin seeing perhaps dozens of attendees being hauled in front of a kind of inquisitorial Star Chamber. The reviewers are usually managers or director level executives, far removed from the actual process of writing and deploying code; they’ll have little ability to prevent errors from happening. But they do have the power to hold up releases pending their seal of approval and punish the guilty in front of their peers. Worse, this is a hard stop; there’s a physical limit to how many CAB meetings that can be held, and releases can’t be sped up past this gate.
A manual approval process for any change leads to increased batch sizes and deployment lead times – which leads, inevitably, to larger, more risky deployments that are much harder to troubleshoot when things go wrong. As the feedback loop is so stretched out at this point, developers have a much more difficult time detecting when errors are being introduced; they learn to “play it safe” and minimize any changes in this new climate of blame and distrust. Under great pressure, the QA team begins to clamp down and add more manual, time-consuming exploratory, and end-to-end tests as a part of a longer gated release process.
Change windows get tighter, forcing work at a fevered pitch – and often moving releases to a “safer” window late at night, when human systems are at their lowest point biologically, when mistakes can slip by us. (Often, we’ve noted that one of the biggest signs of dysfunction with a release process is when they are scheduled – nighttime or weekends vs. a middle-of-the-day release speaks volumes about how the organization views safety and velocity.)
In short, it’s a reactionary, 180-degree backlash to the kind of trust-based, automation-enabled flow at the heart of the DevOps movement. Delays are introduced at every point of our release process:
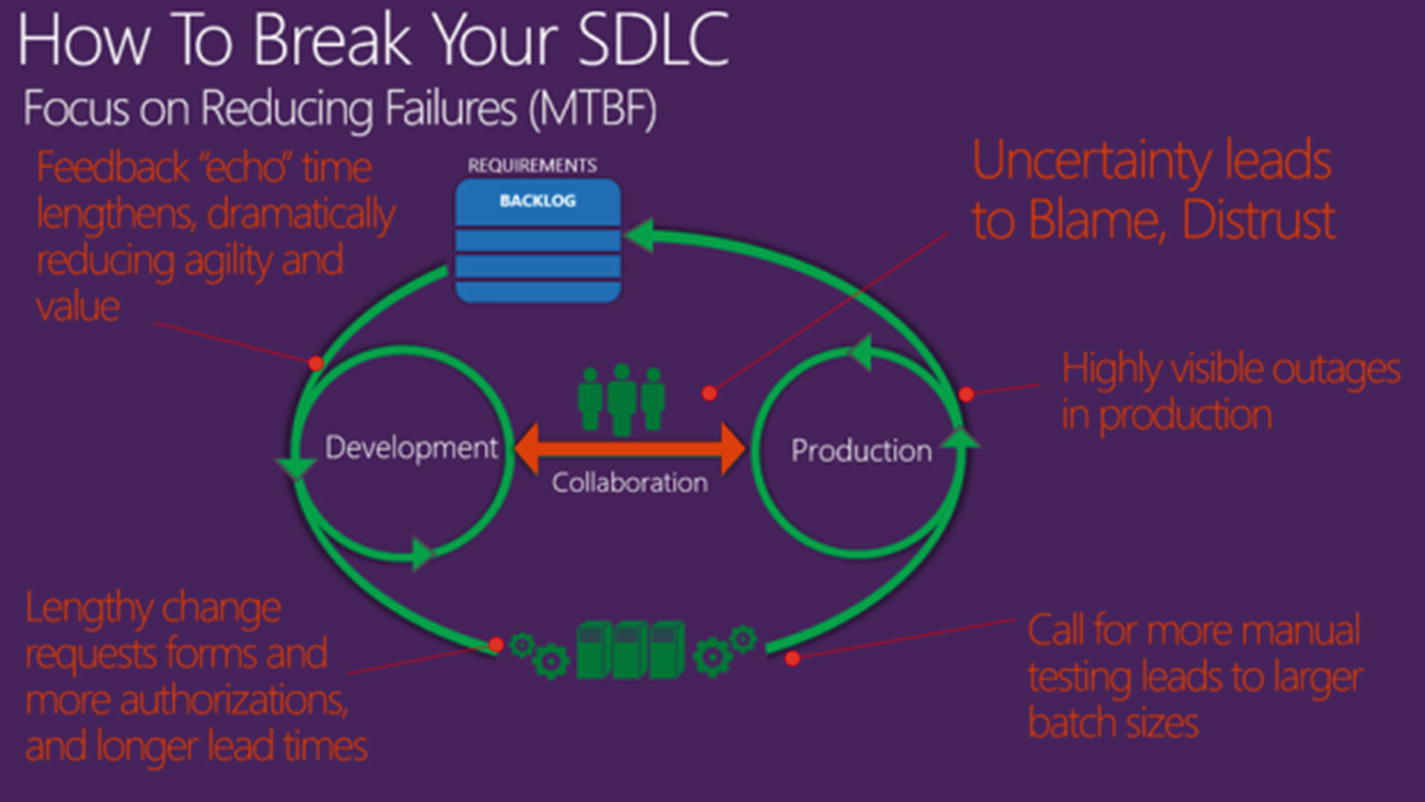
The main issue causing this vicious cycle is that the executive layer is focusing on reducing MTBF, or the mean time between failures, and is trying to bring the number of defects to zero – a practical impossibility. Management’s drive for improved “transparency” and “accountability” is setting the team up for failure due to unreasonable expectations – and setting the conditions for higher-risk releases with a larger blast radius.
This is well backed up by evidence; a key finding of several studies is that high-performing orgs relied more on peer review and less on an external, gated approval of changes. The more organizations rely on change approval, the worse their IT performance in both stability (MTTR and change fail rate) and throughput (deployment lead times and frequency).35
Recovery and Detection Time Is a Better Choice
That’s not the way that we see successful DevOps companies operate. Instead of a drive to reduce their failure counts, these organizations are learning centric and recognize that failure is inevitable – that outages will happen, despite every precaution. Instead, they try to treat each failure as an opportunity – what test was missing that could have caught this, what gap in our processes can address this next time?
Especially, they focus on improving their reaction time – improving their time to recovery, MTTR (Mean Time to Recover) , which often begins with better detection mechanisms and dropping the time to detect a problem (MTTD). Testing and infrastructure as code – that famous passage about wanting “cattle not pets,” that is, blowing away and recreating environments at whim – form the heart of a more adaptive, flexible response strategy.
Use of version control for all production artifacts – This includes everything you’d need to roll out an application – including every artifact needed for infrastructure and networking config. When an error is identified in production, this means you can quickly either redeploy the last good state or fix the problem and roll forward, reducing our time to recover.
Monitoring system and application health – Logging and monitoring systems make it easy to detect failures and identify the events that contributed to them. Proactive monitoring of system health based on threshold and rate-of-change warnings enables us to preemptively detect and mitigate problems.36
A Change to a Virtuous Cycle
There’s many areas we could focus on in describing a better, virtuous cycle in improving reliability, as follows:

The virtuous cycle earlier is based on instilling quality as early as possible in our development cycle – just as Toyota focused less on late-inspection and audits of cars rolling off the assembly line, and more on identifying and resolving the source of defects very early on in the process. It begins with the realization that smaller is better – that we want our releases coming early and often and sized very small so we’ll be able to make cleaner rollbacks if needed. So, there’s a careful focus on making sure our alarm systems and telemetry is in place and is detecting problems as they should – and false positives and unnecessary alerts are being weeded out on an ongoing basis.
We have better, more effective peer reviews in place to catch problems early – and we don’t allow untested code or flaky tests to make it out the door. Even our infrastructure and systems configuration are kept in version control – no one is logging onto VMs and making manual, unauditable, unrepeatable changes. And perhaps in our release strategy, we are using feature flags or canary releases to carefully gauge the impacts of our changes and roll them back with a single config change if there are problems.
It’s important to make clear that we are not proposing to take away the safety that a lengthy manual review cycle appears to offer. Instead, we’re replacing these controls with something more data driven. If we can demonstrate a low MTTR and a high success rate with our build pipeline, that’s the best argument possible that we possess an auditable, effective control environment that accomplishes the desired goal.
It may seem like allowing pushbutton releases straight to production in this way is a dangerous amount of control to give to the program teams. But remember we still have our postmortem process – which may be blameless but are wickedly effective in tracking down and eliminating root causes. By forcing the devs to carry a portion of the production support burden, and by making their technical debt visible with public scorecards and dashboarding, there’s a strong internal motivation to keep services reliable and available. And this is the best way of allowing teams to be self-policing; the people running the deployments know the code, are familiar with its operation and failure points and interdependencies, and will be in the best possible position to handle rollbacks and recovery.
Practicing for Armageddon – Gamedays
Backlash also discusses the vital role of Gamedays, which we wish we could have spent more time on. Netflix was one of our first leaders in this area, with the notion of whacking production artifacts at whim and en masse with products like Chaos Monkey and Simian Army.
At Amazon, they sometimes power off a facility with no notice and then let the systems fail naturally and allow people to follow their processes. This helps expose latent defects and new points of failure that were unexpected – such as people not knowing how to access a conference bridge call.
Google similarly practices gamedays that simulate earthquake, DCs suffering complete loss of power, and even aliens attacking cities. For more on this, there’s more about Gamedays in Chapter 5 on production support and in the Appendix with our interviews with Seth Vargo, Betsy Byer, and Stephen Thorne of Google.
Most of my clients aren’t brave enough to run something like Simian Army or Chaos Monkey on live production systems! But we do gamedays, and we love them. Here’s how that works:
I don’t let the team know what the problem is going to be, but one week before launch – on our sandbox environments, we do something truly evil to test our readiness. And we check how things went – did alerts get fired correctly by our monitoring tools? Was the event logged properly? How did the escalation process work, and did the right people get the information they needed fast enough to respond? Did they have the access they needed to make the changes? Were we able to use our standard release process to get a fix out to production? Did we have the right amount of redundancy on the team? Was the runbook comprehensive enough, and were the responders able to use our knowledgebase to track down similar problems in the past to come up with a remedy?
The whole team loves this, believe it or not. We learn so much when things go bump in the night. Maybe we find a problem with auto healing, or there’s an opportunity to change the design so the environments are more loosely coupled. Maybe we need to clear up our logging, or tune our escalation process, or spread some more knowledge about our release pipeline. There’s always something, and it usually takes us at least a week to fold in these lessons learned into the product before we do a hard launch. Gamedays are huge for us – so much so, we make sure it’s a part of our statement of work with the customer.
For one recent product, we did three Gamedays on sandbox and we felt pretty dialed in. So, one week before go-live, we injected a regional issue on production – which forced the team to duplicate the entire environment into a completely separate region using cold backups. Our SLA was 2 hours; the whole team was able to duplicate the entire production set from Oregon to Virginia datacenters in less than 45 minutes! It was such a great team win, you should have seen the celebration. 37
The Price of Failure
We put this section in the book as a reminder – as if we needed one – that people are not angels. Any DevOps implementation that pretends that people have inherently “good” motives or ignores the human factor in making large course corrections is likely doomed from the start.
Emily’s drive for more control makes perfect logical sense from an Operations point of view; instituting better “process” and a public review and approval gate will lead directly to better stability, in her view. This is classic red-tie MBA/Six Sigma thinking, and it’s in the DNA of most executives for the past 70 years: identifying the constraint or problem and instilling better process to reduce defects and variance.
Emily is just doing what she’s always done – making some political hay out of a highly visible misstep by a peer, widening her power base. You could call it mean-spirited, selfish, short-sighted, or Darwinian – or simply the way successful managers get ahead in most of the organizations we’ve known. Angelic it ain’t – but it is how things work. This is an old game, and it’s an integral part of life in the corporate world – an undertow that needs to be taken into account in any push for change.
Executives and managers instinctively understand the political costs of mistakes from a survival perspective. We wish that more DevOps disciples and engineers took this into account in their thinking. Be pragmatic and conservative: take care in choosing what bets are worth making in your transformation, how much risk you can afford to take. Ben’s efforts to have the business be his protector and limiting impact by making any changes revolve around numbers and experimentation – vs. a contest of wills between entrenched groups – are good survival strategies. Numbers, as we’ve already discussed, make excellent insulation.
The arguments Emily is making appear to be both sensible and safety oriented. But the immediate effect would be a flow-killing dam that will actually increase risk and instability. Involving Ben’s business partner Footwear in making the big-picture decisions around risk and a viable release strategy pay off, as Tabrez has gained a better comfort level with a faster release cycle and more reliance on automated testing and rollbacks. (Having the stakeholder involved in risk discussions and setting error budgets is a fundamental part of the growing SRE movement.)
The key is to make sure you are prioritizing improvements that will do the most to improve the flow. So, start with the bottleneck and fix it, then identify and fix the next bottleneck. This is the key to improving flow. If your test cycle is taking six weeks to run and your management approval takes a day, it does not make any sense to take on the political battle of convincing your organization that DevOps means it needs to let developers push code into production. If, on the other hand, testing takes hours, your trunk is always at production levels of quality, and your management approval takes days, then it makes sense to address the approval barriers that are slowing down the flow of code. 38
If you’re at an organization where CAB reviews or “zero defect” meetings are institutionalized, make visible the high cost of delayed feedback and the fallout from big-delta “tsunami releases.” Challenge the value of any unnecessary artifacts or gates that are building up pressure. Go through the last few hundred approvals and ask – how many were rejected, and why? Are we adding value or introducing delays? Keep complaining, loudly – show in your value stream maps the waste caused by these artificial gates, and don’t rest until they’re removed.