
An integral part of data science is executing efficient computations on large datasets. Such computations are driven by computer programs, and as problems increase in size and complexity, the accompanying software solutions tend to become larger and more intricate, too. Such software is built by organizations structured around teams. Data science is also a team effort, so effective communication and collaboration is extremely important in both software engineering and data science. Software developed by one team must be comprehensible to other teams to foster use, reuse, and evolution. This is where software maintainability, as a pertinent quality attribute, kicks in. This chapter presents important lessons from the realm of software engineering in the context of data science. The aim is to educate data science practitioners how to craft evolvable programs and increase productivity.
This chapter illustrates what it means to properly fix existing code, how to craft proper application programming interfaces (APIs), why being explicit helps to avoid dangerous defects in production, etc. The material revolves around code excerpts with short, theoretical explanations. The focus is on pragmatic approaches to achieve high quality and reduce wasted time on correcting bugs. This will be an opportunity for data product developers of all skill levels to see rules in action, while managers will get crucial insights into why investing in quality up front is the right way to go. You will learn how and why principles of software engineering in the context of The Zen of Python materialize in practice.
After all, the critical programming concerns of software engineering and artificial intelligence tend to coalesce as the systems under investigation become larger.
—Alan J. Perlis, Foreword to Structure and Interpretation of Computer Programs, Second Edition (MIT Press, 1996)
Usually, data science is described as a discipline embracing mathematical skills, computer science skills, and domain expertise. What is lacking here is the notion of engineering and economics (science of choices). Software engineering aspects are important to create maintainable, scalable, and dependable solutions. ISO/IEC/IEEE Systems and Software Engineering Vocabulary (SEVOCAB; see https://pascal.computer.org ) defines software engineering as “the application of a systematic, disciplined, quantifiable approach to the development, operation, and maintenance of software; that is, the application of engineering to software.” This chapter tries to cover the gap and explain the role of engineering and economics in data science.
Changes programming languages, required to address the challenges of large-scale software development, are imminent; shifts in Python are already underway. In this respect, Python will share the destiny of many other enterprise-level languages (it is instructive to evoke Java’s evolution over the last two decades). This chapter mentions some crucial quality assurance tools that augment Python’s expressiveness to be a better fit for enterprise software systems.
At any rate, there is no point in recounting known facts or solely musing about theory. Therefore, the content of this chapter is rather atypical and centers on hidden but crucial aspects of the software industry.
Characteristics of a Large-Scale Software System
The biggest difference between a large-scale software system and a small-scale one revolves around the software’s life cycle model . It refers to all the phases of a software product, from initial development, through exploitation, maintenance, evolution, and retirement. To make the discussion simple, our notion of large-scale is a software system that cannot be implemented by a small team; is part of a complex, socio-technical, software-intensive system; and whose retirement would have a huge business impact. Software maintenance and evolution is usually the longest phase in a large-scale software system’s life cycle; for some safety-critical software systems, it may span a couple of decades. This means that most activities will happen after the deployment of the first production version.
It is instructive to use a tournament chess game as an analogy to the software life cycle model. As with software, such a chess game is preceded by an initial preparation and planning phase (e.g., analyze your opponent’s style of play and opening repertoire, recall past experience with the opponent, compare your current standings, decide whether you want to aggressively push for a win, etc.). You cannot approach the game as amateurs do by simply making moves based on the current position of the chess pieces. During the game you balance resources (material, time, position, etc.), apply theory, use experience, and progress through stages (opening, middle game, and end game). The stages of a chess game are mapped to the phases of the software life cycle model in Figure 3-1.
To keep the cycle rolling, a holistic approach to software engineering is required. You must evaluate a broad spectrum of possibilities to properly judge the potential vectors of changes. These dictate where your software must be flexible in order to accommodate future additions and improvements. In each round, you must also address waves of change requests; this is similar to chess, where you must constantly monitor what your opponent is doing and alter your strategy accordingly. Finally, as in chess, if you mess up the requirements or devise a wrong architecture, then it is very difficult to make corrections later. In chess, a bad opening would turn your game into a struggle for a draw.
While in chess everything ends in the last stage, this is completely different in the development of a large-scale software system. The cycles are chained and encompass developments of new features. There is even a view that software maintenance and evolution is a continuation of the development phase, and in this respect, we talk about perpetual evolution (successful improvements and extensions of a product). In some sense, developing a small software product is like a single chess game, while developing a large-scale software system is akin to a very long tournament.
Corrective maintenance (correction): Related to fixing failures (observable problems causing some harm in production) that are usually reported by a customer.
- Adaptive maintenance (enhancement): Pertains to modifications due to changes in the environment (e.g., business process, external regulatory law, platform, technology, etc.). The goal is to proactively keep the software usable.
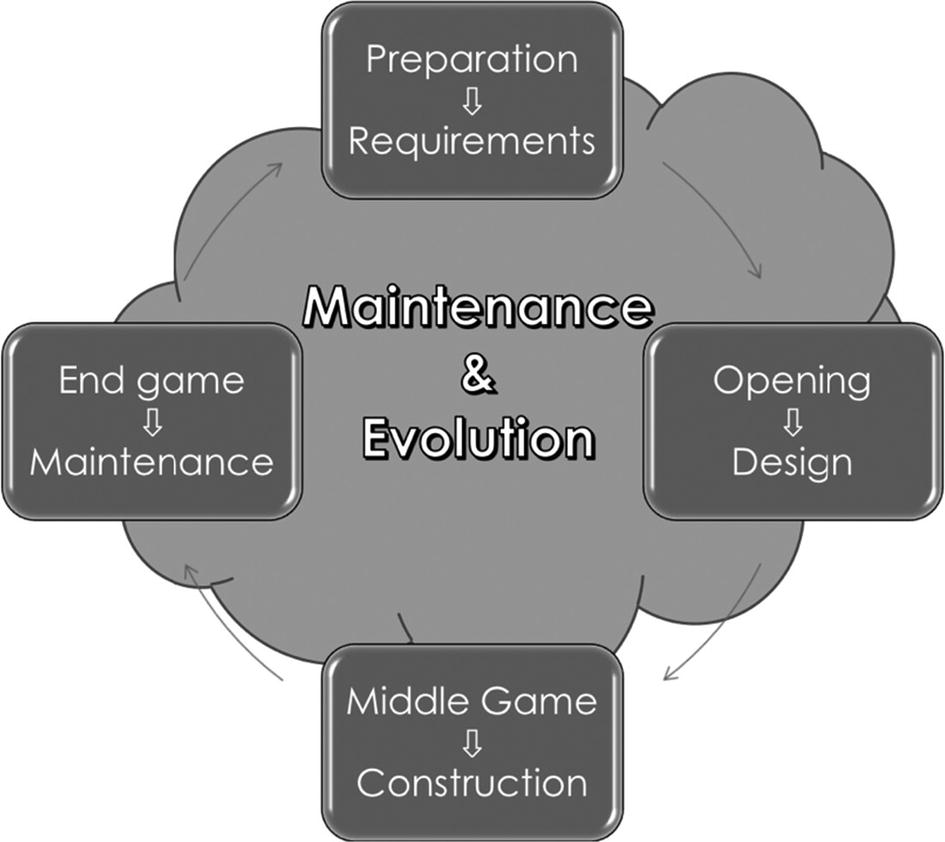 Figure 3-1
Figure 3-1Mapping of chess stages to software’s life cycle model
Preventive maintenance (correction): Related to fixing faults before they transform into a failure. Suppose that your code has a function accepting a numeric argument that is used as a divisor. Without checking against zero, it may generate an exception. However, if that argument will never receive a value of zero, then this potential fault cannot become a failure (operational fault). This requires a thorough understanding of how a customer will use a product, as some faults may never turn into failures under some circumstances.
Perfective maintenance (enhancement): Deals with all sorts of proactive changes to boost the quality of the software (including maintainability). This activity is essential to combat the detrimental effects of continuous changes to a code base during maintenance and evolution. As new features are added, complexity increases, and the existing code structure deteriorates. This is nicely documented in Lehman’s laws of software evolution .
S type system: Has a finite enumerable problem space with a fixed environment. Once the initial requirements are specified, nothing will change in the future (here, we don’t count potential user interface enhancement as impactful changes). For example, the popular Tic-Tac-Toe game is an S type system.
P type system: Has a complex problem space with a fixed environment. Various heuristics are applied to search the problem space. An improvement to the abstract model does induce a considerable change in the system. For example, popular board games like chess and Go are P type systems.
E type system: The most complex system type due to a highly dynamic environment. It is impossible to predict with 100% accuracy how the environment will fluctuate in the future. Unfortunately, nobody can assure that a new law will not disturb the original architecture of the system. A perfect recent example of this is enactment of the EU’s General Data Protection Regulation (GDPR; see https://gdpr-info.eu ), compliance with which required many organizations to make considerable investments in software system updates. All in all, large-scale data science products belong to this category.
The initial development of a new product
Enhancement maintenance-type activities
Correction maintenance-type activities
Customer support
Evidently, the ratio is 3:1 between maintenance and initial development. Consequently, we should beware of being fast at the expense of quality. Many immature companies nurture a false belief that tooling is the silver bullet. They will both speed things up and compensate for human deficiencies (lack of knowledge and experience, inattentiveness, etc.). As you will later see, the only solution is to invest in people before anything else.
Software Engineering Knowledge Areas
Software Requirements
Software Design
Software Construction
Software Testing
Software Maintenance
Software Configuration Management
Software Engineering Management
Software Engineering Process
Software Engineering Models and Methods
Software Quality
Software Engineering Professional Practice
Software Engineering Economics
Computing Foundations
Mathematical Foundations
Engineering Foundations
Computer Engineering
Computer Science
General Management
Mathematics
Project Management
Quality Management
Systems Engineering
Computer science and mathematics are obvious foundations, but people have difficulties grasping systems engineering (read the sidebar “Success or Not?”). The latter is a much broader discipline that gives meaning to software products by putting them into a socio-technical context.
Success or Not?
I am pretty sure that you’ve received many auto-generated birthday greeting e-mail messages up so far. Suppose that the software generating these is impeccable. It searches the user database each day and filters out all users who were born on that date. It then produces messages using a common template and sends them out. Are you happy when you receive such a message? Personally, I think they are extremely annoying. You likely are glad to get a message from your spouse, kid, relative, friend, or colleague, but probably not from a machine programmed to mechanically deliver greetings.
From the viewpoint of software engineering, the company may say that this software is a total success. Nonetheless, if no one wants to receive auto-generated greetings, it is a complete failure from the standpoint of systems engineering. The software is useless despite working perfectly.
Rules, Principles, Conventions, and Standards

The set of rules that you get after executing import this in a Python console
As you can see, according to The Zen of Python, it is crucial to eschew the temptation of treating rules and principles as dogmas. This is superbly illustrated by contrasting the first and ninth rules (which I have connected with a curved arrow). So, even The Zen of Python warns us about this problem. My commentary inside the box on the left provides an example of why vehemently trying to satisfy a rule could cause problems. On the other hand, there is an important meta-rule (the eighth rule, shown with a border) to remind us that it is equally wrong to blatantly ignore rules. You must know what you’re doing before departing from any sort of edict. “Readability counts” has a central location, with good reason. Software engineers spend most of their time during maintenance and evolution on understanding code.
This chapter implicitly follows the rules listed in Figure 3-2; the exposition of topics relies on simple examples (the Zen mentions implementation details instead of narrative). An absence of such examples could indicate a vague topic, an inept lecturer, or both. The illustrations that follow are indeed as simple as possible to keep your focus on the core subject. There is a key Agile principle (see https://agilemanifesto.org/principles ) about simplicity that states “Simplicity--the art of maximizing the amount of work not done--is essential.” Ironically, this is the most misapplied tenet. The work required to realize what should be expelled is everything but simple.
- Pylint ( https://www.pylint.org ) offers features such as:
Code style checking (visit https://www.python.org/dev/peps/pep-0008 )
Reverse engineering support (integrated with Pyreverse to produce UML diagrams from code)
Refactoring help (such as detection of duplicated code)
IDE integration (for example, it is an integral part of Spyder)
Error detection (customizable checkers)
Codacy ( https://www.codacy.com ) provides automated code reviews.
CodeFactor ( https://www.codefactor.io ) also provides automated code reviews.
- Radon ( https://pypi.org/project/radon ) offers features such as:
McCabe’s cyclomatic complexity (explained a bit later in the chapter)
Raw metrics, including source lines of code (SLOC), comment lines, blank lines, etc.
Halstead metrics
Maintainability index
Mypy ( https://mypy-lang.org ) is an experimental, optional static type checker for Python. Statically typed languages are known to have advantages over dynamically typed ones for large code bases. The ability of a compiler to detect type-related omissions early is often a lifesaver. So, it isn’t surprising to see this tool on the plate.
The preceding tools calculate quantitative proxies for qualitative aspects of a code base. Consequently, they can only report and act upon efficiently measurable indicators. Often, the most important traits of a software development endeavor are hard or impossible to measure. People-related elements belong to this class. The next section explains this phenomenon in more detail.
Context Awareness and Communicative Abilities
Context and knowledge oblivious
The recipient will blindly follow instructions without seeking out help for further clarification. This type of person will guess instead of basing his decision on facts. Moreover, due to lack of knowledge, he will make up ad hoc rules/principles, as he judges appropriate. You may try excessive micromanagement, which is equally troublesome for both parties. This behavior is depicted in Figure 3-3.
Knowledgeable
This class is very similar to the previous one, the only difference being that this type of person has proper knowledge and thus will stick to major rules and principles of the discipline. This behavior is depicted in Figure 3-4.
Context aware and knowledgeable
This type of person seeks to maintain a constant feedback loop by proactively asking questions, as needed. This behavior is depicted in Figure 3-5.
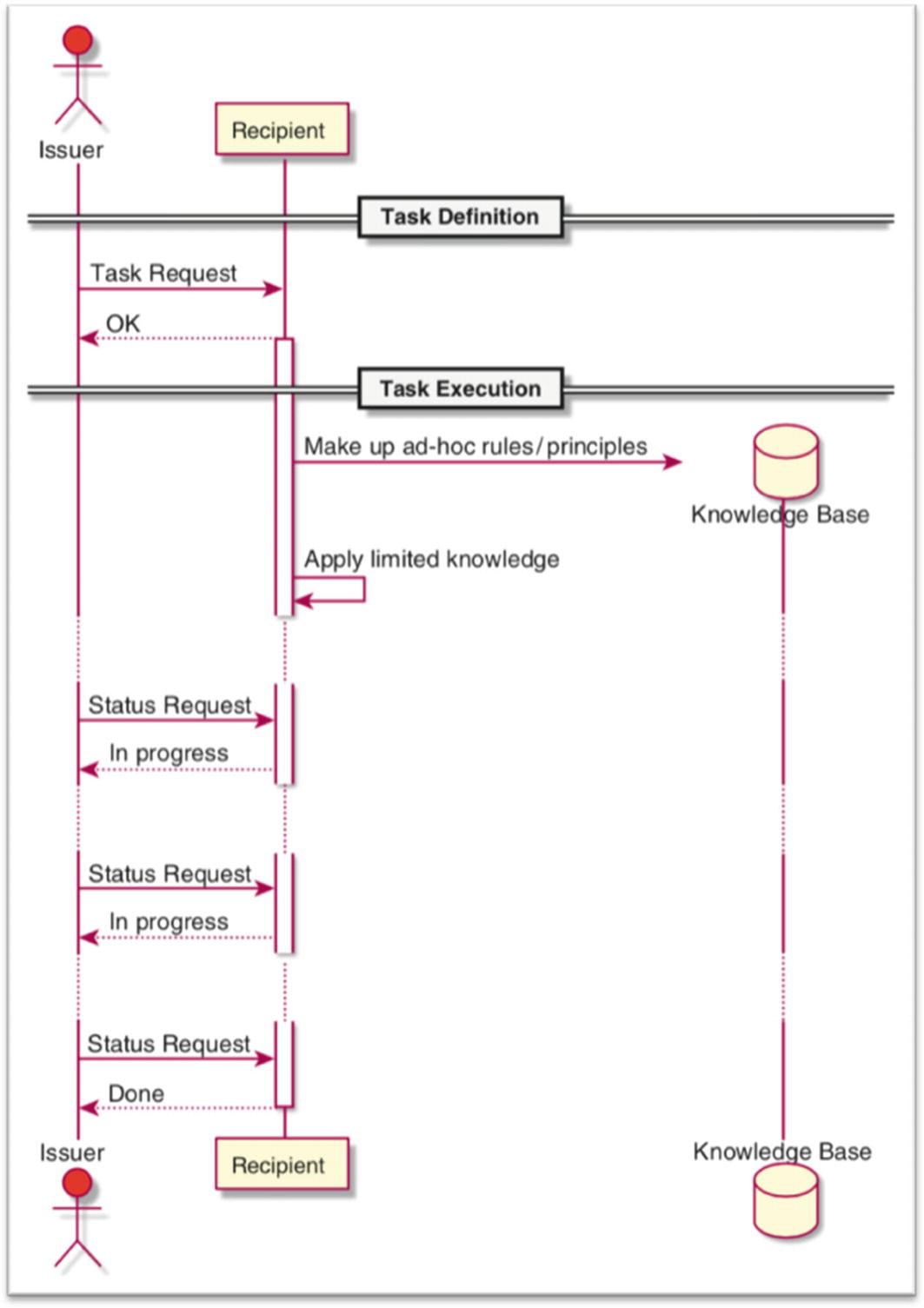
The final “Done” message doesn’t imply that the business goals are met (adapted with permission from reference [2]). The quality of the result is also questionable.
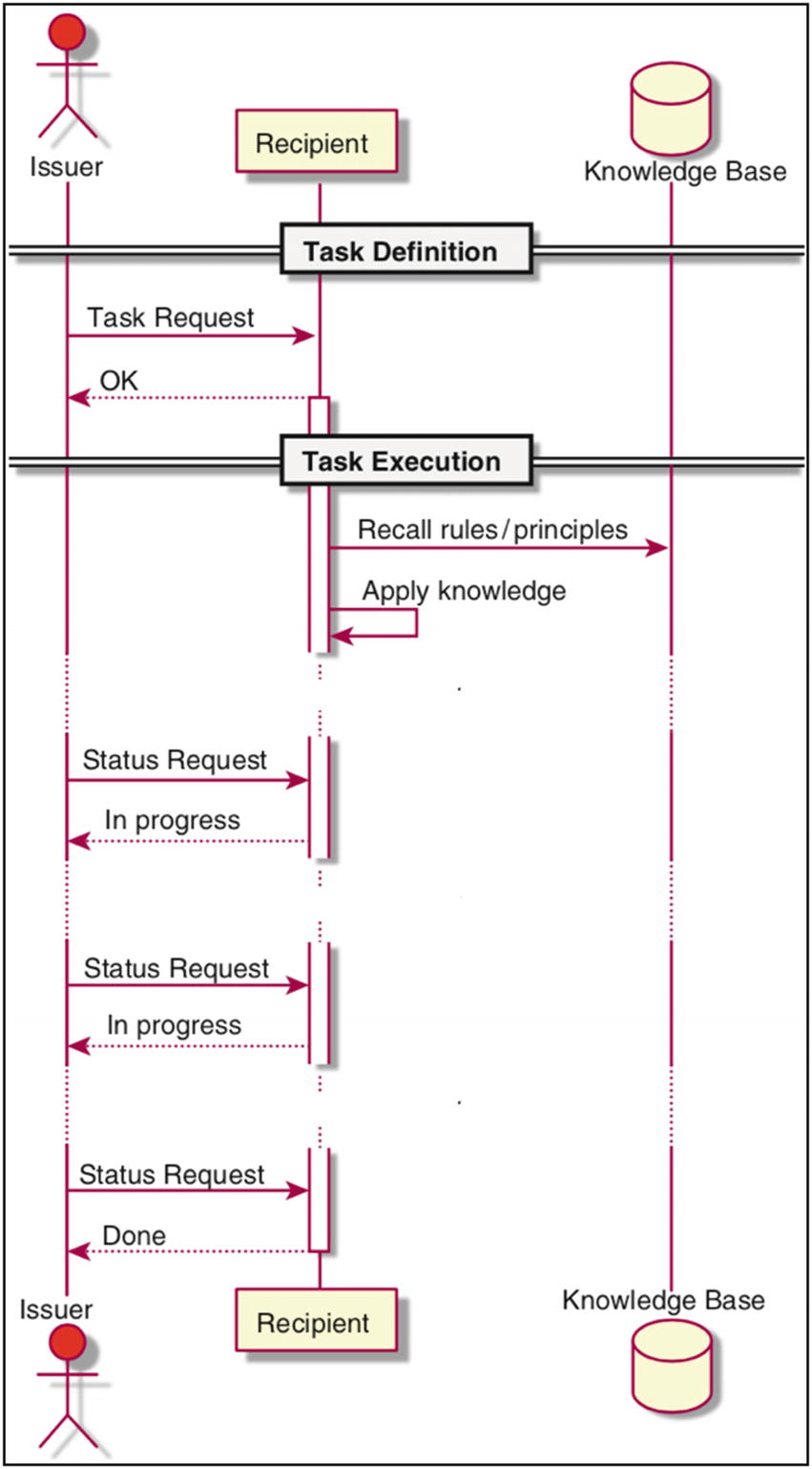
The final “Done” message doesn’t imply that the business goals are met (adapted with permission from [2]). The quality of the result may be proper.
Software engineers must be conscious of the language of business and talk to management in terms of money flows. Otherwise, there is a danger of destroying the precious feedback loop between development and management, resulting in two isolated factions (something that frequently happens in organizations). Such separation has detrimental consequences on success of the business.
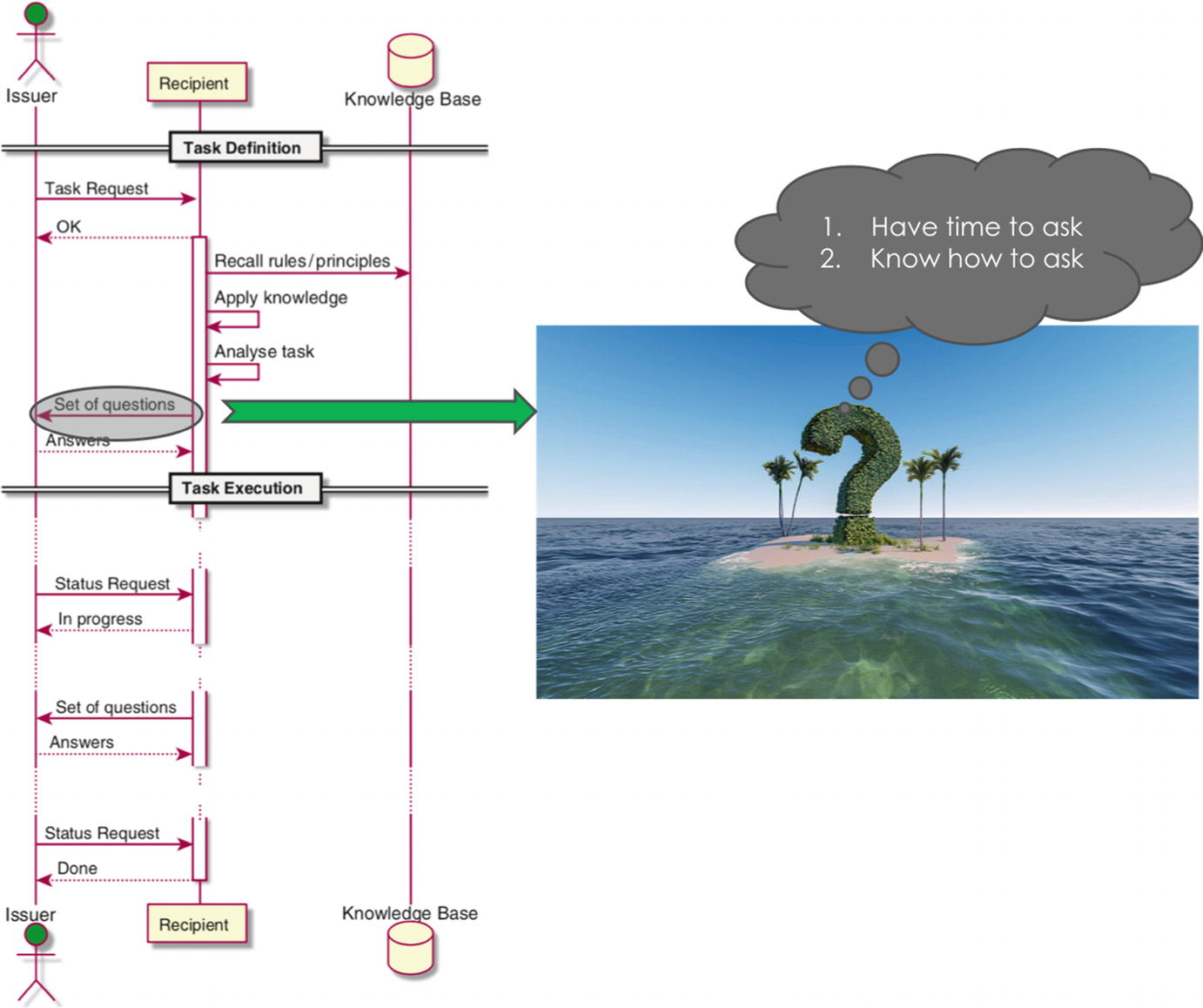
This person tries to solve the right problem with high quality (adapted with permission from [2])
Reducing Cyclomatic Complexity
Cyclomatic complexity is a measure that increases with the number of alternative execution flows of a program. For example, every conditional statement bumps the score. A less complex code will have a lower cyclomatic number. Suppose that management has decided to reduce the cyclomatic complexity of a code base by allowing developers to look for opportunities to simplify the current code.
Function to Sort an Input Array into Ascending Order
After executing sort([-2, -4, 100, 3, 4.1]) the function returns [100, 4.1, 3, -2, -4]. Sure, it will also alter the input array, as it sorts in place.
Version of Sort Function with a Lower Cyclomatic Complexity
All in all, besides reducing the cyclomatic complexity, the global evaluation score went up from 1.67 to an astonishingly high 5! What has happened? Has Pylint failed? Obviously, the end result is far from what was expected by management. The code doesn’t even function properly anymore.
Caution
When basic mathematical logic fails, then nothing else matters. In this case, the developer believed that implication is equivalent to its converse. This is false; that is, φ ⇒ ψ⇎ ψ ⇒ φ! A lower cyclomatic complexity doesn’t imply a less complex code. The corollary is that tools alone are not enough! People should drive the tools, and not vice versa.
Cone of Uncertainty and Having Time to Ask
The Cone of Uncertainty represents a graphical model about best-case reduction of estimation error during the lifetime of a project (see Exercise 3-1 and visit https://www.construx.com/software-thought-leadership/books/the-cone-of-uncertainty ). The Cone of Uncertainty tells us that in a well-managed project, we may expect to have less variability in project scope (size, cost, or features) as the project progresses toward its end. Less variability implies higher predictability and accuracy of estimates. At the very beginning of a project, the variability is huge (in the range of [0.25×, 4×]). Anything <1× signifies underestimation, while >1× signifies overestimation. Obviously, 1× represents total predictability. The Cone of Uncertainty is biased toward the lower bound; in other words, there is a higher tendency to underestimate.
Initial concept
Approved product definition
Marketing requirements complete
Detailed technical requirements complete and user interface design complete (expected variability is around [0.8×, 1.25×])
Detailed design complete
Both project leaders and software engineers must differentiate between estimation and commitment. The latter is only allowed when the cone is sufficiently narrow (when the variability is in the range of [0.8×, 1.25×]). Making commitments earlier just depletes your time to focus on quality, as unrealistic expectations cause stress and hasty work. Moreover, all participants in the project must work hard to keep the cone narrowing. Otherwise, it will look more like a cloud, with equally high variability throughout the project. The cone doesn’t narrow by itself over time.
Danger zone: Variability in the range [1.25×, 4×] with linear penalty (per Parkinson’s law, which states that people will always fill in their time slots with some work):
overestimation➟undercommittment➟low pressure➟moderate quality
Danger zone: Variability in the range [0.25×, 0.8×] with exponential penalty:
underestimation➟overcommittment➟extreme pressure➟low quality
Allowed zone: Variability in the range [0.8×, 1.25×] without penalty:
good estimation➟good committment➟optimal pressure➟high quality
The Cone of Uncertainty and the heuristics around estimation and commitment are as important to data science projects as they are to any other software projects. Both are financed by stakeholders who make decisions based upon project plans.
Fixing a Bug and Knowing How to Ask
- 1.
An issue is discovered and reported in a bug tracking system.
- 2.
Work is estimated.
- 3.
The issue is assigned and prioritized.
- 4.
Proper unit tests are written.
- 5.
The bug is fixed, and all tests are passing.
- 6.
The status is set and a hot fix is deployed.
Code with a Defect As Reported by Customer
Unit Test for the Function from Listing 3-3
“Correct” Version of the Code
All tests are passing now, so the developer had announced that the job is finished. At least, this is definitely the case from the viewpoint of tools and an established process in our fictional company. What do you think? The solution uses two ugly temporary variables and is a superb example of a simple but needlessly complicated code (look up the rule about this in The Zen of Python). In companies where only quantity matters (such as the number of fixes per some time period), this is the kind of maintenance work that happens. Over time the code base drifts into a territory of confusion, unreadability, and fragility.
A Better Fix
An Improved Fix That Tries to Clean Up the Mess in the Original Code
Observe that the code is literally following the formula from the embedded documentation. Sure, it also fixes the original bug. The developer has determined to step back and prevent being mentally locked into the current solution. The following quote from Albert Einstein buttresses this mindset: “No problem can be solved from the same level of consciousness that created it.”
Nonetheless, there is a problem! The extra time equates to an outlay of money by the company, so management will want to know the reason behind such unexpected expenditure. This is where developers get trapped and demolish future opportunities for similar enhancements.
Scenario 1: The Developer Doesn’t Speak the Language of Business
I have eliminated two temporary variables.
The code is now beautiful and fully aligned with the embedded documentation.
It is faster.
It uses less memory.
It has fewer SLOC.
I have improved the global evaluation score from 4.44 up to 5.
Honestly, none of these are decipherable to managers; they hear them as technical mumbo-jumbo. Their reaction is typically along the lines of “The money was spent on NOTHING! Nobody approved you to work on this!”
Scenario 2: The Developer Does Speak the Language of Business
I have spent T1 time to understand the original code.
I have spent an additional T2 time to refactor it to improve maintainability; no new risks were added.
This code is central to the core functioning of our system.
Other developers will only need to spend T3 time to understand it, where T3 is 20% of T1.
The
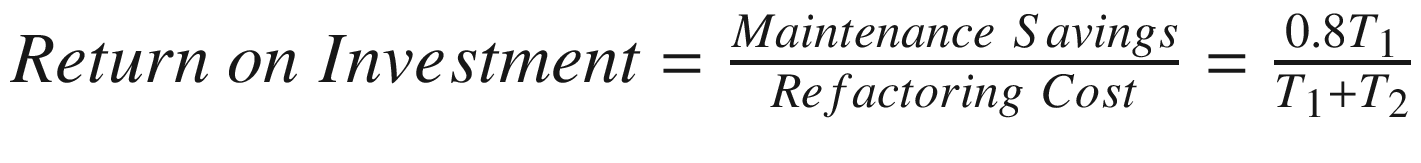 .
.
This developer is absolutely aware of her role in the company and knows how the software that she has modified contributes to the business. She most likely carefully listens to what the CEO is talking about during quarterly company meetings to better align her work with the company’s mission and strategic objectives. Furthermore, she understands that management wants to hear about risks, which ordinary developers typically don’t realize, to their own detriment (they usually have poor skills in risk management).
The reaction of management in this scenario likely would be completely dissimilar to the previous case, with full approval given to the developer. This is how developers can get support for further improvements.
A More Advanced Fix
A Fast, Vectorized Version
Clearly, this variant is slightly more convoluted than the previous one. This shouldn’t surprise you, as it is a known fact that performance optimization hinders maintainability. In data science projects, some performance-related decisions are considered as a norm, like using the NumPy framework from the very beginning.
Scenario 1: The Developer Doesn’t Speak the Language of Business
I have solved the problem with NumPy, which nowadays is used by everybody.
I have eliminated the for loop and reduced SLOC.
The code is much faster now due to vectorized operations.
This function will serve as an example of NumPy for other developers.
Again, management will hear this as purely technical rhetoric. The concomitant reaction of management would likely be negative, such as “So, this madness won’t stop here? Nobody is allowed to be NumPying around without authorization!”
Scenario 2: The Developer Does Speak the Language of Business
After T time, I’ve improved the performance of a critical part of our product, based upon profiling. This has created a performance budget that didn’t exist previously.
The function’s higher speed increases throughput in processing client requests. This reduces the risk of losing clients in peak periods and may positively impact the conversion rate.
- NumPy (a new framework) was introduced with minimal risks:
It is a popular open-source Python framework with a huge and vibrant community.
It is well maintained and documented.
I am an experienced user of this framework. No immediate extra costs (training time, consultants, etc.) are required.
This developer is acquainted with the architecture, so he knows where and why to improve the performance budget. Moreover, he takes care to explain how risks are mitigated with an introduction of a new framework. Developers quite often recklessly import packages just because they have seen neat stuff in them. If this trend is left without control in a company, then all sorts of problems may arise (not to mention pesky security issues). All in all, the preceding arguments again are likely to receive a green light from management.
Handling Legacy Code
A software system may transform into legacy code for many reasons: it uses an outdated technology; it is utterly non-evolvable due to its deteriorated quality; it is pushed out by novel business solutions; and so forth. Nevertheless, sometimes you will need to handle such code. The biggest conundrum is to reverse engineer it in an attempt to recover the necessary information to grasp its design and implementation. Don’t forget that legacy code is sparsely covered by automated tests and isn’t properly documented. All that you have is the bare source code. This section emphasizes the importance of documentation (test cases are a type of documentation) to avoid developing code that is essentially legacy code after its first release. The next chapter is devoted to JupyterLab, which is all about this matter.
Understanding Bug-Free Code
Our First Bug-Free Legacy Code Example
We have fully recovered the behavior.2 Is behavior all that matters? The original version doesn’t rely on the math package and works solely with integers. Is this fact important? Well, these may be very important details. What if the code must be portable and capable of running on constrained devices that don’t support floating point arithmetic? We need more information.
Understanding Faulty Code
Mysterious Code That Also Contains a Bug That We Need to Uncover
Our Attempt to Come Up with a Bug-Free Version by Swapping the Bold Lines in Listing 3-9
- 1.
The output is the nearest existing number k, such that the quantity of numbers less than k is closest to the quantity of numbers greater or equal to k.
- 2.
The output is the nearest existing number k, such that the quantity of numbers less than or equal to k is closest to the quantity of numbers greater than k.
With faulty code we were not even able to fully recover the behavior.
The Importance of APIs
Protects clients from internal system changes
Protects the system against careless usage
Allows management of technical debt
Prevents entropy from flowing from one side to the other
An API must efficiently communicate the intended usage and behavior of some piece of a system. Furthermore, it should enable a client to gradually comprehend the target system, as needed. An API that forces you to understand everything before being able to interact with a system is a failure. Equally bad is to be forced to look into the source code to understand what a function or class performs. Structuring an API should revolve around the entropy model regarding the matching system.
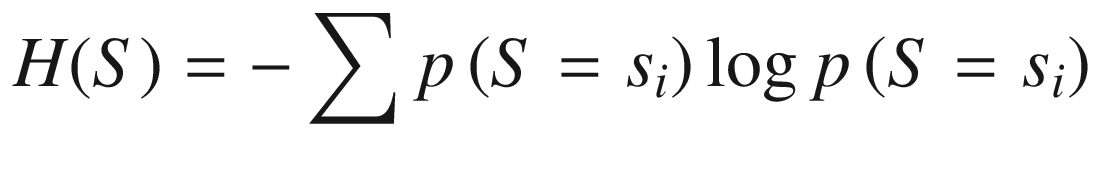
where si is an assumed state of the system.
The API is a set of artifacts (usually abstractions); in other words, API = {a1, a2,…, am}. Knowing some element of an API should generate an information gain formulated as
IG(S, API) = H(S) – H(S|API)(2)
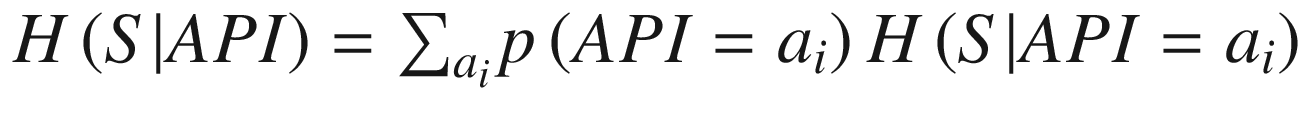 (3)
(3)
A good API should order its elements according to the law of diminishing returns . This entails knowing that, for example, a package name should have a higher impact on your information gain (according to (2) and (3)) than stumbling across an internal method parameter of a deeply hidden class. Also, after seeing some function’s name and establishing a sound understanding about its behavior, none of its parameters should oblige you to reevaluate your original conception. The next subsection will illuminate this issue.
There will always be emergent properties and empirically observable behaviors of a system not specified in an API. Such “holes” may be occluded via consumer-driven contracts (CDCs) . These are augmentations of the API that are created by clients (they may be shaped as a set of test cases). Once those are attached to an API, then the cumulative information gain due to CDCs is defined as
IG(S, CDC) = IG(S, API U CDC)(4)
All this semiformal reasoning entails that you must carefully name your abstractions. The names must not contradict the abstractions themselves. The next section gives a concrete example.
Fervent Flexibility Hurts Your API
Listing of fibonacci1.py to Produce the First n Fibonacci Numbers
If you execute fibonacci(10), then you will get [1, 1, 2, 3, 5, 8, 13, 21, 34, 55]. The bold parts of Listing 3-11 constitute the contract for the abstraction called Fibonacci sequence. The name of the function tells us what we should expect as a return value given an input n. All seems consistent for now.
Listing of fibonacci2.py to Produce the First n Fibonacci-like Numbers
If you execute fibonacci(10), then you will still get [1, 1, 2, 3, 5, 8, 13, 21, 34, 55], so compatibility is preserved. However, if you run fibonacci(10, 5, 12), then you will receive [12, 17, 29, 46, 75, 121, 196, 317, 513, 830]. This sequence is correctly constructed by the code but is pointless. It has nothing to do with the Fibonacci sequence.3 The function’s name fibonacci is inconsistent with its behavior. Furthermore, you must reassess your impression about the function after seeing those strange parameters f0 and f1.
This problem is also abundant in popular frameworks. For example, here is the signature of the function from NumPy to allegedly produce a histogram: histogram(a, bins=10, range=None, normed=None, weights=None, density=None). If they aren’t set to True, then the output is simply not a histogram (the normed parameter is deprecated, so only density matters).
Listing of sequencer.py to Produce Various Sequences
Now, any client may use fibonacci directly , or devise their own sequence with this new utility function. Even a more correct design would distribute these functions into separate modules. They are not at the same abstraction level. Grouping familiar abstractions in the same layer is the tenet of stratified or layered design. APIs should follow this strategy.
The Socio-* Pieces of Software Production
Those trained and experienced in software development are often not trained in the kinds of socio-economic organizational skills needed for running large-scale software development. The socio-technical and socio-economic requirements for software production work remain understudied and elusive. 4
This conundrum is tightly associated with data science. Data science is a team sport, relies on software solutions, and executes in a broader sociological context (this is also the primary focus of systems engineering). Consequently, the following example equally applies both to systems and software engineering and to data science. The objective is to debunk the myth that being purely data-driven is both a necessary and sufficient condition for success.
There are two-primary socio-* parts of software: socio-economic and socio-technical. These have to be in balance. The socio-economic component ensures healthy business, while the socio-technical aspect keeps people happy. The crucial problem with data-driven approaches is that they are good for things that can be measured (preferably with tool support) but are not good for the many equally important characteristics that are hard to quantify.
Funny Elevator Case Study
The First Unoptimized Variant of Our Function
Minimum performance: Below this threshold, the product is not acceptable. In our case, this value is 5 seconds for all test cases (i.e., the worst-case running time).
Target performance: This is what you are aiming for. In our case, 1 second.
Maximum performance: Above this threshold, there is economic motivation to spend resources for further improvement. In our case, 0.1 second.
Without this range, testers may reject your work just because execution time is negligibly below the target. Most of the time, the product is performing quite well even without exactly hitting the target. Of course, you must establish the baseline (our initial code) and track progress over time.
First Optimization Attempt
 . We just need to account for the nightly plunges. Listing 3-15 shows the faster version of our code.
. We just need to account for the nightly plunges. Listing 3-15 shows the faster version of our code.The Next Variant of Our Software
This is a remarkable improvement compared to the original version. After all, the first four test cases are within acceptable limits. Data (running times) should reassure us that we are on the right track. Observe that the code is a bit more complex, which is a natural consequence of performance optimization.
Note
We are now moving in the realm of socio-economic aspects, since we are trying to optimize a business-critical part of the code base. We measure improvements and let data drive us toward better variants. This is a typical route in mature software companies. You should avoid the temptation to make changes based on guessing about problems.
Second Optimization Attempt
The Very Fast Variant of Our Code
All running times are way below our imaginary 0.1 second. Should anyone question this achievement? Solely from the socio-economic viewpoint, this version is perfect. It is a business enabler, since all use cases are working within acceptable performance limits. What about the socio-technical aspect? This is exactly what many organizations miss due to blindly being data-driven. This version is an abomination from the socio-technical perspective. It is simply awful!
Teammate- and Business-Friendly Variant
Overall Best Version of Our Code with O(1) Running Time
Is it possible to land here after publishing the previous incomprehensible variant? Well, this is a tough question. You will need to convince management that something that enabled the business to roll now must be rewritten. Your only chance is to apply software economics and justify your intention by expressing how much the business will save through such maintainable software. It will be very hard to explain in monetary terms the beautiful code’s positive impact on team morale and happiness. For this you must be a lucky person who is surrounded by unselfish management.
Exercise 3-1. Draw The Cone of Uncertainty
Look up the Cone of Uncertainty at https://www.construx.com/books/the-cone-of-uncertainty and try to reproduce it using the matplotlib framework (which is introduced in Chapter 6). The outcome of such a visualization would be a conceptual diagram. It doesn’t contain actual values, but rather artificial ones just to showcase the phenomenon.
Hint: You may want to read the excellent tutorial for matplotlib at https://realpython.com/python-matplotlib-guide , which contains examples of conceptual graphs.
Summary
This chapter has tried to illuminate the importance of being context aware and knowing the sociological aspects of software production. Both are indispensable attributes in large-scale software development and data science. They cannot be treated separately once you recognize that computing is at the heart of scaling toward Big Data problems. Most topics discussed in this chapter are barely touched upon in classical courses, and thus practitioners typically learn them the hard way.
Python is the most popular language of data science thanks to its powerful frameworks, like those found in the SciPy ecosystem. Acquaintance with reuse-based software engineering is essential to properly apply those frameworks. Part of this effort revolves around topics touched upon in this chapter (APIs, readable code bases, adequate documentation, judicious use of abstractions, usage of tools, etc.).
As a data scientist, you will surely work under pressure with strict deadlines. This is the main difference between working as a professional in a software company and volunteering on open-source projects. This chapter’s goal was to prepare you for working in large enterprises.
References
- 1.
Liam Tung, “Developers, Despair: Half Your Time Is Wasted on Bad Code,” https://www.zdnet.com/article/developers-despair-half-your-time-is-wasted-on-bad-code , Sept. 11, 2018.
- 2.
Ervin Varga, Unraveling Software Maintenance and Evolution: Thinking Outside the Box, Springer, 2017.
- 3.
Pierre Bourque and Richard E. (Dick) Fairley (Editors), Guide to the Software Engineering Body of Knowledge (SWEBOK): Version 3.0, IEEE Computer Society, 2014.
- 4.
Ervin Varga, Creating Maintainable APIs: A Practical, Case-Study Approach, Apress, 2016.
- 5.
Ervin Varga, “Do APIs Matter?,” https://www.apress.com/gp/blog/all-blog-posts/do-apis-matter/11524110 , Dec. 10, 2016.