
Most of the available how-to guides for working with OpenCV in Java require you to have an insane amount of knowledge before getting started. The good news for you is that with what you have learned up to now with this book, you can get started with OpenCV in Java in seconds.
Going Sepia: OpenCV Java Primer
Choosing sepia is all to do with trying to make the image look romantic and idealistic. It’s sort of a soft version of propaganda.
—Martin Paar1
In this section, you will be introduced to some basic OpenCV concepts . You’ll learn how to add the files needed for working with OpenCV in Java, and you’ll work on a few simple OpenCV applications, like smoothing, blurring images, or indeed turning them into sepia images.
A Few Files to Make Things Easier…
Visual Studio Code is clever, but to understand the code related to the OpenCV library, it needs some instructions. Those instructions are included in a project’s metadata file, which specifies what library and what version to include to run the code.
HelloCv.java, which contains the main Java code
AppTest.java, which contains the bare minimum Java test file
pom.xml, which is a project descriptor that Visual Studio Code can use to pull in external Java dependencies
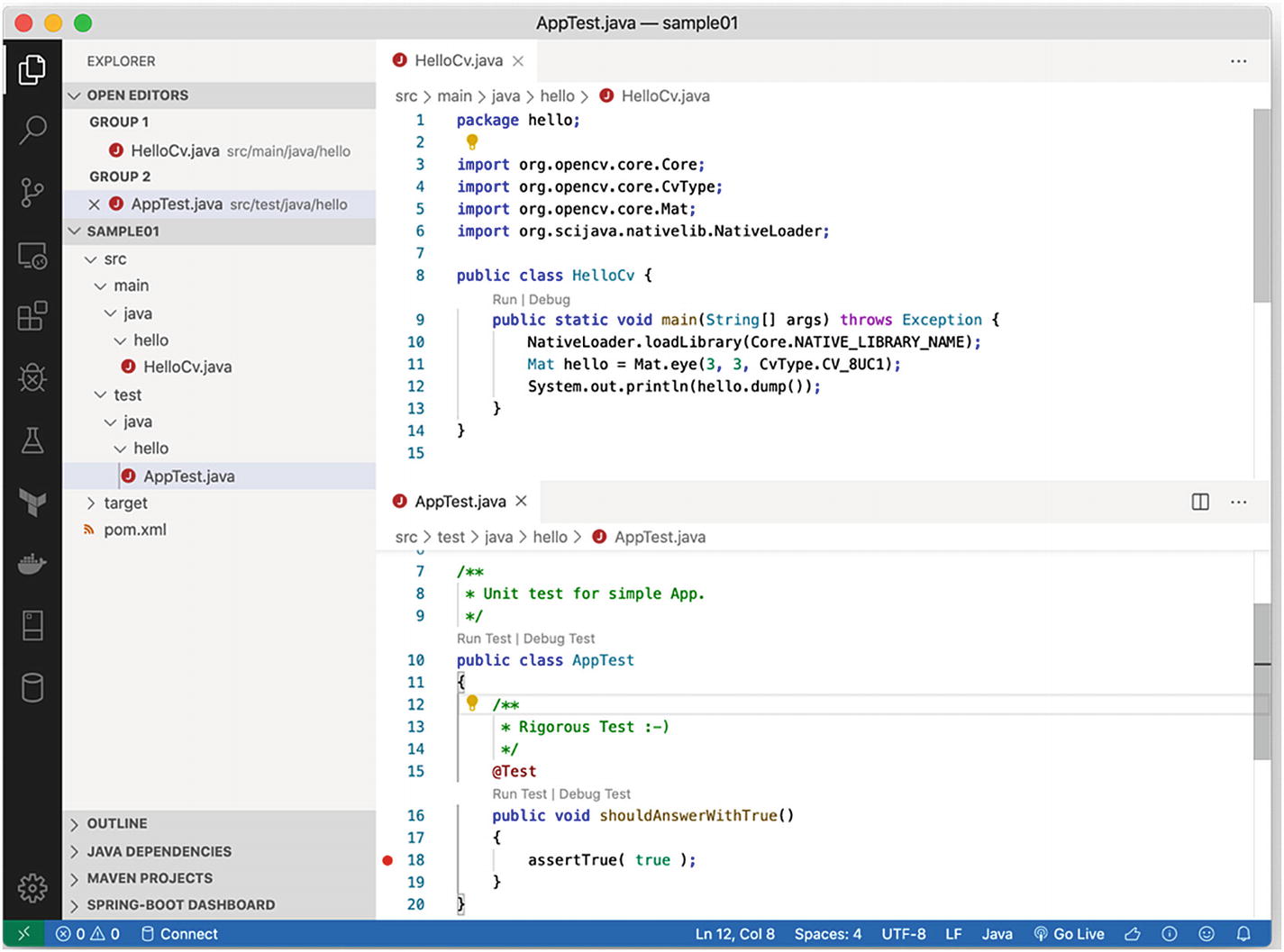
Project layout
Figure 2-1 shows the two Java files, so you can see the content of each; in addition, the project layout has been expanded so all the files are listed on the left.
This view should look familiar to you from the previous chapter, and you can immediately try running the HelloCv.java code using the Run or Debug link at the top of the main function.
First OpenCV Mat
Let’s go through the code line by line to understand what is happening behind the scenes.
This step is required because OpenCV is not a Java library; it is a binary compiled especially for your environment.
You have a library compiled for your machine.
The library is placed somewhere where the Java runtime on your computer can find it.
In this book, we will rely on some packaging magic, where the library is downloaded and loaded automatically for you and where, along the way, the library is placed in a location that NativeLoader handles for you. So, there’s nothing to do here except to add that one-liner to the start of each of your OpenCV programs; it’s best to put it at the top of the main function.
That second line creates a Mat object. A Mat object is, as explained a few seconds ago, a matrix. All image manipulation, all video handling, and all the networking are done using that Mat object. It wouldn’t be too much of a stretch to say that the main thing OpenCV is programmatically doing is proposing a great programming interface to work with optimized matrices, in other words, this Mat object.
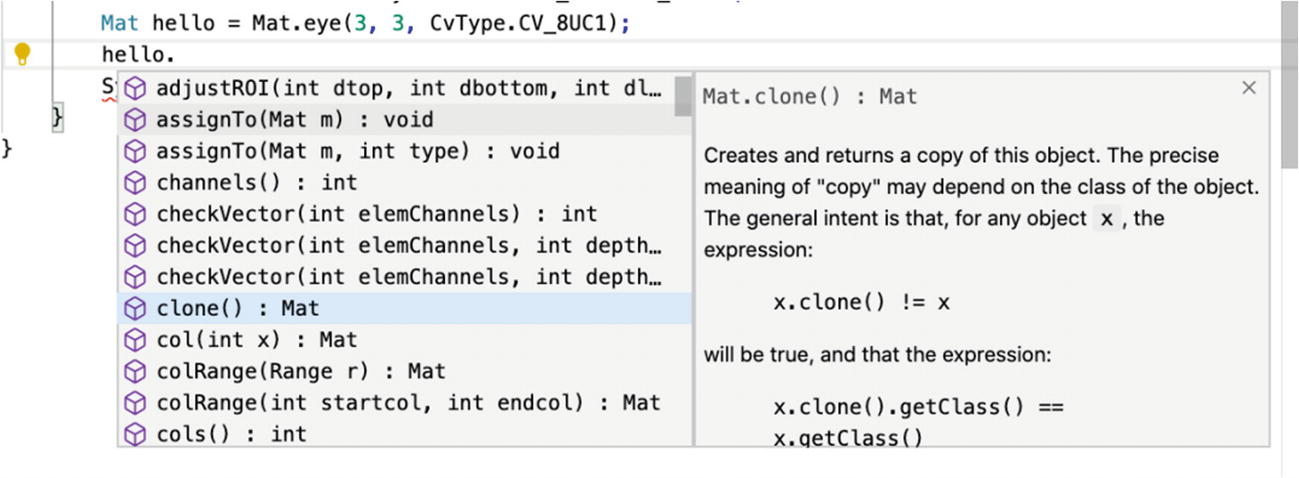
Inline documentation for the OpenCV Mat object
Within the one-liner, you create a 3×3 matrix, and the internal type of each element in the matrix is of type CV_8UC1. You can think of 8U as 8 bits unsigned, and you can think of C1 as channel 1, which basically means one integer per cell of the matrix.
OpenCV Types for OpenCV Mat Object
Name | Type | Bytes | Signed | Range |
|---|---|---|---|---|
CV_8U | Integer | 1 | No | 0 to 255 |
CV_8S | Integer | 1 | Yes | −128 to 127 |
CV_16S | Integer | 2 | Yes | −32768 to 32767 |
CV_16U | Integer | 2 | No | 0 to 65535 |
CV_32S | Integer | 4 | Yes | −2147483648 to 2147483647 |
CV_16F | Float | 2 | Yes | −6.10 × 10-5 to 6.55 × 104 |
CV_32F | Float | 4 | Yes | −1.17 × 10-38 to 3.40 × 1038 |
The number of channels in a Mat is also important because each pixel in an image can be described by a combination of multiple values. For example, in RGB (the most common channel combination in images), there are three integer values between 0 and 256 per pixel. One value is for red, one is for green, and one is for blue.
Some Blue…
Executing the previous code will give you this 50×50 Mat, where each pixel is made of three channels, meaning three values, but note that in OpenCV, RGB values are reversed by design (why, oh, why?), so it is actually BGR. The value for blue comes first in the code.

Sea blue
Operations on Mat objects are usually done using the org.opencv.core.Core class. For example, adding two Mat objects is done using the Core.add function, two input objects, two Mat objects, and a receiver for the result of the addition, which is another Mat.
Adding Two Mat Objects Together
Now, we’ll let you practice a little bit and perform the same operation on a 50×50 Mat and show the result in a window again with HighGui.

OpenCV Primer 2: Loading, Resizing, and Adding Pictures
You’ve seen how to add super small Mat objects together, but let’s see how things work when adding two pictures , specifically, two big Mat objects, together.

Marcel at work
I’ve never seen Marcel at the beach, but I would like to have a shot of him near the ocean.

The beach where Marcel is heading to
Adding these two pictures together properly is going to take just a bit of work the first time, but it will be useful to understand how OpenCV works.
Simple Addition
First Try at Adding Two Mats
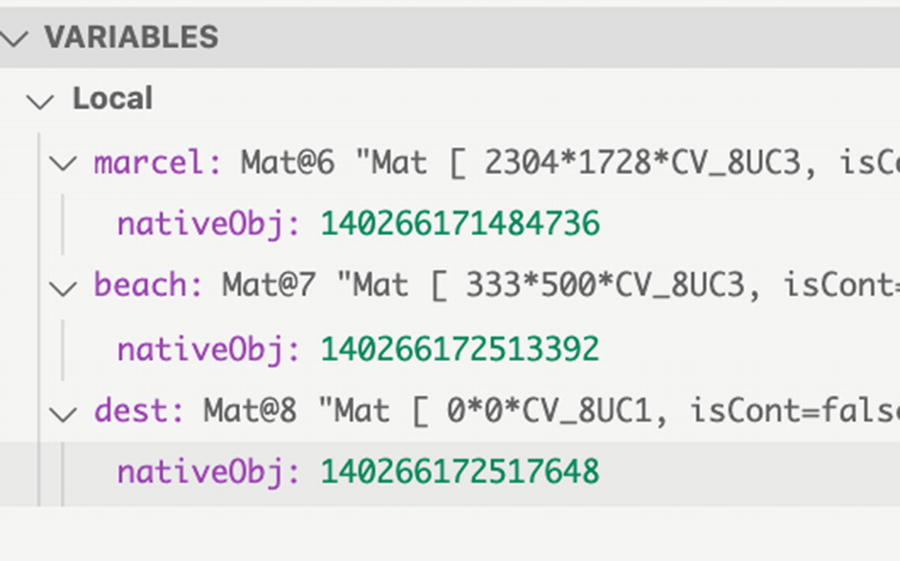
Debugging Mats
Before adding a breakpoint, we can see that the Marcel Mat is indeed 2304×1728, while the beach Mat is smaller at 333×500, so we definitely need to resize the second Mat to match that of Marcel. If we do not perform this resizing step, OpenCV does not know how to compute the result of the add function and gives the error message shown earlier.
Resizing

White, white, very white Marcel at the beach
Hmm. It’s certainly better because the program runs to the end without error, but something is not quite right. The output picture gives an impression of being over-exposed, and looks way too bright. And indeed, if you look, most of the output image pixels have maximum RGB values of 255,255,255, which is the RGB value for white.
We should do an addition in a way that keeps the feeling of each Mat but still not goes over the maximum 255,255,255 value.
Weighted Addition
Preserving meaningful values in Mat objects is certainly something that OpenCV can do. The Core class comes with a weighted version of the add function that is conveniently named addWeighted. What addWeighted does is multiply values of each Mat object, each by a different scaling factor. It’s even possible to adjust the result value with a parameter called gamma.
The input image1
alpha, the factor to apply to image1’s pixel values
The input image2
beta, the factor to apply to image2’s pixel values
gamma, the value to add to the sum
The destination Mat
Marcel Goes to the Beach

addWeighted. Marcel can finally relax at the beach
Back to Sepia
At this stage, you know enough about Mat computation in OpenCV that we can go back to the sepia example presented a few pages earlier.
In the sepia sample, we were creating a kernel, another Mat object, to use with the Core.transform function .
The number of channels of each pixel in the output equals the number of rows of the kernel.
The number of columns in the kernel must be equal to the number of channels of the input, or +1.
The output value of each pixel is a matrix transformation, and the matrix transformation of every element of the array src stores the results in dst, where dst[ I ] = m x src[ I ].
Core.transform Samples
Source | Kernel | Output | Computation |
|---|---|---|---|
[2 3] | [5] | [10 15] | 10 = 2 × 5 15 = 3 × 5 |
[2 3] | [5 1] | [11 16] | 11 = 2 × 5 + 1 16 = 3 × 5 + 1 |
[2 3] | [5 10] | [(10, 20) (15, 30)] | (10 = 2 × 5 20 = 2 × 10) (15 = 3 × 5 30 = 3 × 10) |
[2] | [1 2 3 4] | [(4 10)] | 4 = 2 × 1 + 2 10 = 3 × 2 + 4 |
[2 3] | [1 2 3 4] | [(4 10) (5 13)] | 4 = 2 × 1 + 2 10 = 2 × 3 + 4 5 = 3 × 1 + 2 13 = 3 × 3 + 4 |
[2] | [1 2 3] | [(2 4 6)] | 2 = 2 × 1 4 = 2 × 2 6 = 2 × 3 |
[2] | [1 2 3 4 5 6] | [(4 10 16)] | 4 = 2 × 2 + 1 10 = 2 × 3 + 4 16 = 2 × 5 + 6 |
[(190 119 10)] | [0.5 0.2 0.3] | [122] | 122 = 190 × 0.5 + 119 × 0.2 + 10 × 0.3 |
The OpenCV Core.transform function can be used in many situations and is also at the root of turning a color image into a sepia one.
Let’s see whether Marcel can be turned into sepia. We apply a straightforward transform with a 3×3 kernel, where each value is computed as was just explained.
As, you can see, the values for red are largely pinned down, with each multipliers around 0.1, and green has the most impact on the pixel values for the resulting Mat objects.

Marcel does not know he’s going to turn into sepia soon
Sepia Marcel
As you can see, the BGR output of each pixel is computed from the value of each channel of the same pixel in the input.

Marcel turned into sepia
That was a bit of yellowish sepia. What if we need more red? Go ahead and try it.
Increasing the red means increasing the values of the R channel, which is the third row of the kernel matrix.

Red sepia version of Marcel
You can play around and try a few other values for the kernel so that the sepia turns greener or bluer…and of course try it with your own cat if you have one. But, can you beat the cuteness of Marcel?
Finding Marcel: Detecting Objects Primer
Let’s talk about how to detect objects using Marcel the cat.
Finding Cat Faces in Pictures Using a Classifier
Before processing speeds got faster and neural networks were making the front pages of all the IT magazines and books, OpenCV implemented a way to use classifiers to detect objects within pictures.
Classifiers are trained with only a few pictures, using a method that feeds the classifier with training pictures and the features you want the classifier to detect during the detection phase.
Haar features
Hog features
Local binary pattern (LBP) features
The OpenCV documentation on cascade classifiers (https://docs.opencv.org/4.1.1/db/d28/tutorial_cascade_classifier.html) is full of extended details when you want to get some more background information. For now, the goal here is not to repeat this freely available documentation.
What Is a Feature?
Features are key points extracted from a set of digital pictures used for training, something that can be reused for matching on totally new digital inputs.
For example, an ORB classifier, nicely explained in “Object recognition with ORB and its Implementation on FPGA” (http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.405.9932&rep=rep1&type=pdf) is a very fast binary descriptor based on BRIEF. The other famous feature-based algorithms are Scale Invariant Feature Transform (SIFT) and Speed Up Robust Features (SURF); all these are looking to match features for a set of known images (what we are looking for) on new inputs.
ORB Feature Extraction

Extracting ORB features on Marcel
Cascade classifiers are called that because they internally have a set of different classifiers, each of them getting a deeper, more detailed chance of a match at a cost of speed. So, the first classifier will be very fast and get a positive or a negative, and if positive, it will pass the task on to the next classifier for some more advanced processing, and so on.
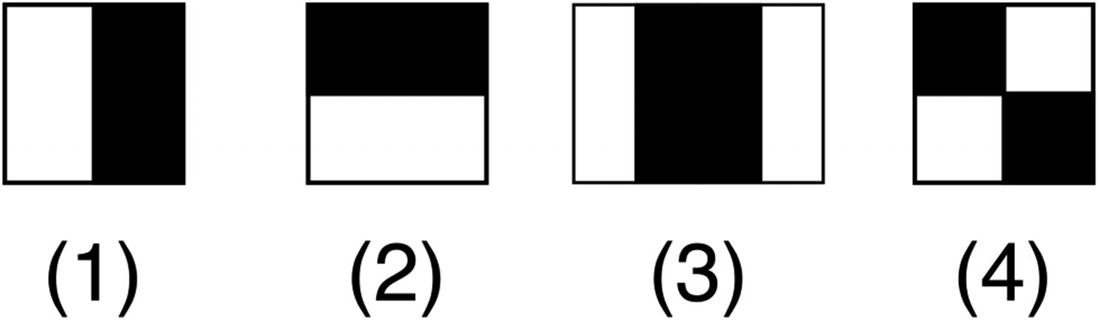
Haar feature types
Since the features are easily computed, the number of images required for training Haar-based object detection is quite low. Most importantly, up until recently, with low CPU speeds on embedded systems, those classifiers had the advantage of being very fast.
Where in the World Is Marcel?
So, enough talking and reading about research papers. In short, a Haar-based cascade classifier is good at finding features of faces, of humans or animals, and can even focus on eyes, noses, and smiles, as well as on features of a full body.
The classifiers can also be used to count the number of moving heads in video streams and find out whether anyone is stealing things from the fridge after bedtime.
- 1.
Load the classifier from an XML definition file containing values describing the features to look for.
- 2.
Access a Mat object called detectMultiScale directly on the input Mat object, and a Mat object called MatOfRect, which is a specific OpenCV object designed to handle lists of rectangles nicely.
- 3.
Once the previous call is finished, MatOfRect is filled with a number of rectangles, each of them describing a zone of the input image, where a positive has been found.
- 4.
Do some artsy drawing on the original picture to highlight what was found by the classifier.
- 5.
Save the output.
Calling a Cascade Classifier on an Image
Too many Marcels…
Filter the rectangles based on their sizes in the loop on rectangles. While this is often used thanks to its simplicity, this adds a chance to focus on false positives.
Pass in extra parameters to detectMultiScale, specifying, among other things, a certain number of required neighbors to get a positive or indeed a minimum size for the returned rectangles.
detectMultiScale Parameters
Parameter | Description |
|---|---|
image | Matrix of the type CV_8U containing an image where objects are detected. |
objects | Vector of rectangles where each rectangle contains the detected object; the rectangles may be partially outside the original image. |
scaleFactor | Parameter specifying how much the image size is reduced at each image scale. |
minNeighbors | Parameter specifying how many neighbors each potential candidate rectangle should have to be retained. |
flags | Not used for a new cascade. |
minSize | Minimum possible object size. Objects smaller than this value are ignored. |
maxSize | Maximum possible object size. Objects larger than this value are ignored if the maxSize == minSize model is evaluated on a single scale. |
scalefactor=2
minNeighbors=3
flags=-1 (ignored)
size=300x300
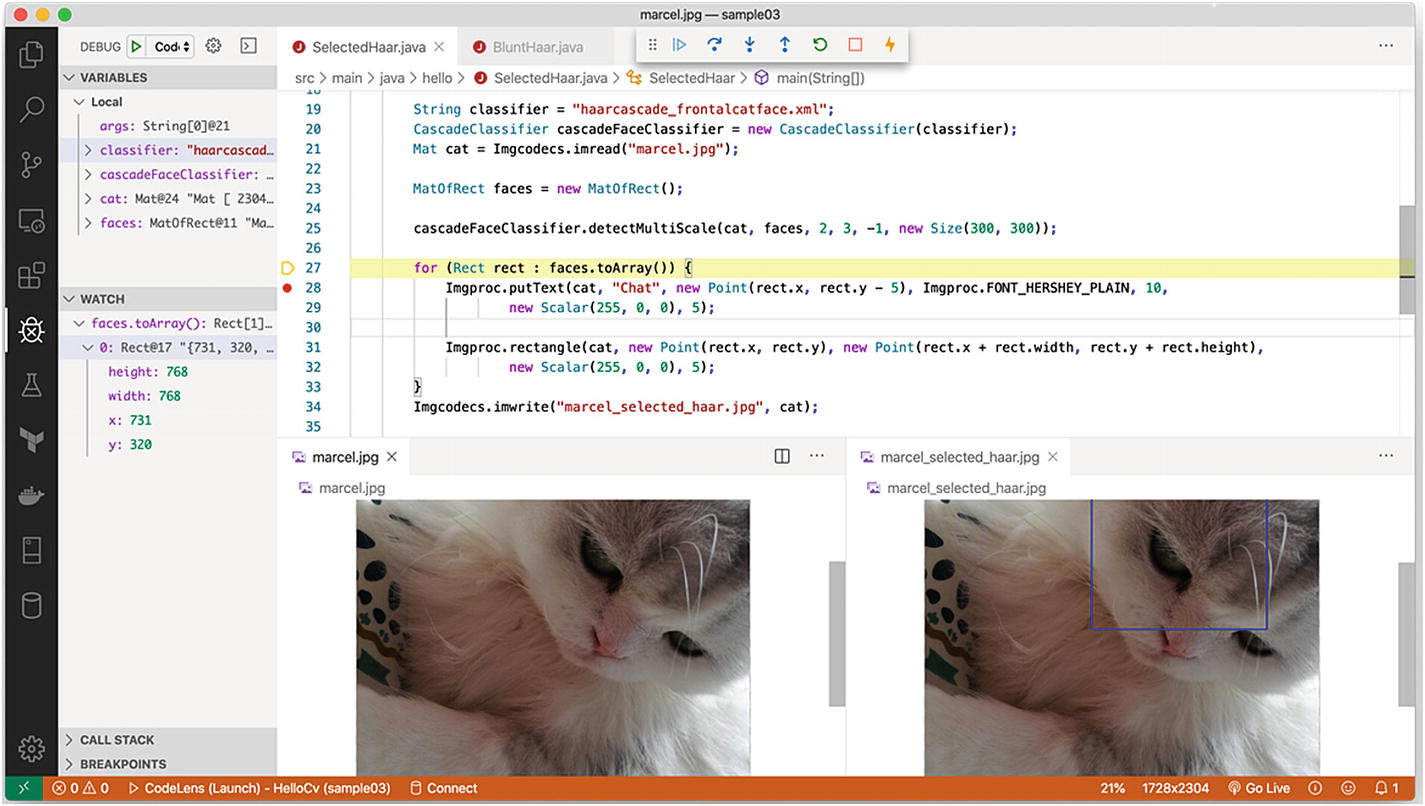
Debugging session while looking for Marcel
The output is already included in the layout, but you will notice the found rectangles are now limited to only one rectangle, and the output gives only one picture (and, yes, there can be only one Marcel).
Finding Cat Faces in Pictures Using the Yolo Neural Network
We have not really seen how to train cascade classifiers to recognize things we want them to recognize (because it’s beyond the scope of this book). The thing is, most classifiers have a tendency to recognize some things better than others, for example, people more than cars, turtles, or signs.
Detection systems based on those classifiers apply the model to an image at multiple locations and scales. High-scoring regions of the image are considered detections.
The neural network Yolo uses a totally different approach. It applies a neural network to the full image. This network divides the image into regions and predicts bounding boxes and probabilities for each region. These bounding boxes are weighted by the predicted probabilities.
Yolo has proven fast in real-time object detection and is going to be our neural network of choice to run in real time on the Raspberry Pi in Chapter 3.
Later, you will see how to train a custom Yolo-based model to recognize new objects that you are looking for, but to bring this chapter to a nice and exciting end, let’s quickly run one of the provided default Yolo networks, trained on the COCO image set, that can detect a large set of 80 objects, cats, bicycle, cars, etc., among other objects.
As for us, let’s see whether Marcel is up to the task of being detected as a cat even through the eyes of a modern neural network.
The final sample introduces a few more OpenCV concepts around deep neural networks and is a great closure for this chapter.
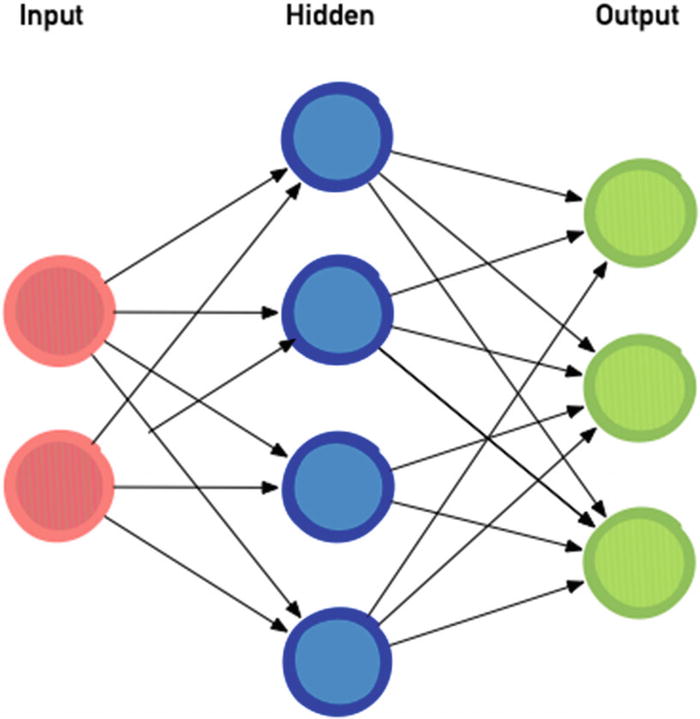
My brain
I actually do hope reality is slightly different and my brain is way more colorful.
What you see in Figure 2-17 at first sight is the configuration of the network. Figure 2-17 shows only one hidden layer in between the input and output layers, but standard deep neural networks have around 60 to 100 hidden layers and of course way more dots for inputs and outputs.
In many cases, the network maps the image, with a hard-coded size specific to that network, from one pixel to one dot. The output is actually slightly more complicated, containing among other things probabilities and names, or at least an index of names in a list.
During the training phase, each of the arrows in the diagram, or each neuron connection in the network, is slowly getting a weight, which is something that impacts the value of the next neuron, which is a circle, in the next hidden or output layer.
When running the code sample, we will need both a config file for the graphic representation of the network, with the number of hidden layers and output layers, and a file for the weights, which includes a number for each connection between the circles.
Let’s move from theory to practice now with some Java coding. We want to give some file as the input to this Yolo-based network and recognize, you guessed it, our favorite cat.
- 1.
Load the network as an OpenCV object using two files. As you have seen, this needs both a weight file and a config file.
- 2.
In the loaded network, find out the unconnected layers, meaning the layers that do not have an output. Those will be output layers themselves. After running the network, we are interested in the values contained in those layers.
- 3.
Convert the image we would like to detect objects from to a blob, something that the network can understand. This is done using the OpenCV function blobFromImage, which has many parameters but is quite easy to grasp.
- 4.
Feed this beautiful blob into the loaded network, and ask OpenCV to run the network using the function forward. We also tell it the nodes we are interested in retrieving values from, which are the output layers we computed before.
- 5.Each output returned by the Yolo model is a set of the following:
Four values for the location (basically four values to describe the rectangle)
Values representing the confidence for each possible object that our network can recognize, in our case, 80
- 6.
We move to a postprocess step where we extract and construct sets of boxes and confidences from the outputs returned by the network.
- 7.
Yolo has a tendency to send many boxes for the same results; we use another OpenCV function, Dnn.NMSBoxes, that removes overlapping by keeping the box with the highest confidence score. This is called nonmaximum suppression (NMS).
- 8.
We display all this on the picture using annotated rectangles and text, as is the case for many object detection samples.
Running Yolo on Images

Yolo based detection confirms Marcel is a cute cat
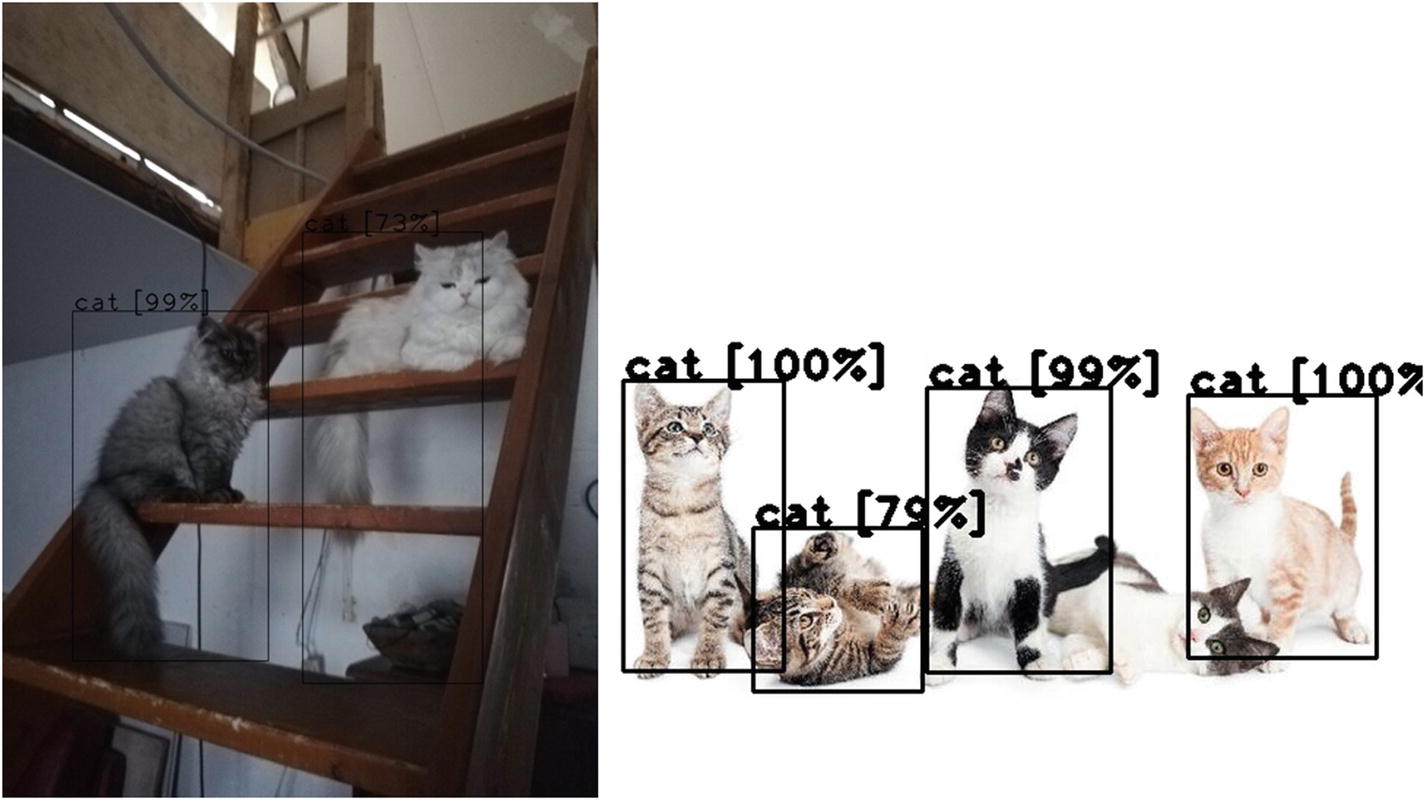
Many cats
An exercise for you at this point is to change the parameters of the Dnn.NMSBoxes function call to see whether you can get the two boxes to show at the same time.
The problem with static images is that it is difficult to get the extra context that we have in real life. This is a shortcoming that goes away when dealing with sets of input images coming from a live video stream.
So, with Chapter 2 wrapped up, you can now do object detection on pictures. Chapter 3 will take it from here and use the Raspberry Pi to teach you about on-device detection.