
In general, optimizers are algorithms that minimize a given function. Remember that training a neural network means simply minimizing the loss function. Chapter 1 looked at the gradient descent optimizer and its variations (mini-batch and stochastic). In this chapter, we look at more advanced and efficient optimizers. We look in particular at Momentum, RMSProp, and Adam. We cover the mathematics behind them and then explain how to implement and use them in Keras.
Available Optimizers in Keras in TensorFlow 2.5
TensorFlow has evolved a lot in the last few years. In the beginning, you could find gradient descent as a class, but it is not available anymore (not directly). Keras offers as of TensorFlow version 2.5 only advanced algorithms. In particular, you will find the following: Adadelta, Adagrad, Adam. Adamax, Ftrl, Nadam, RMSProp, and SGD (gradient descent with momentum). So plain gradient descent is not available anymore out of the box from Keras.
In general, you should determine which optimizers work best for your problem, but if you don’t know where to start, Adam is always a good choice.
Advanced Optimizers
Up to now we have only discussed how gradient descent works. That is not the most efficient optimizer (although it’s the easiest to understand), and there are some modifications to the algorithm that can make it faster and more efficient. This is a very active area of research, and you will find an incredible number of algorithms based on different ideas. This chapter looks at the most instructive and famous ones: Momentum, RMSProp, and Adam.
Additional material that investigates the more exotic optimizers has been written by S. Ruder in a paper called “An overview of gradient descent optimization algorithms” (see https://goo.gl/KgKVgG). The paper is not for beginners and requires a strong mathematical background, but it provides an overview of the more exotic algorithms, including Adagrad, Adadelta, and Nadam. Additionally, it reviews weight-update schemes applicable in distributed environments like Hogwild!, Downpour SGD, and many more. Surely a read worth your time.
To understand the basic idea of momentum (and partially also of RMSProp and Adam), you first need to understand what exponentially weighted averages are. So, let’s start with some mathematics.
Exponentially Weighted Averages
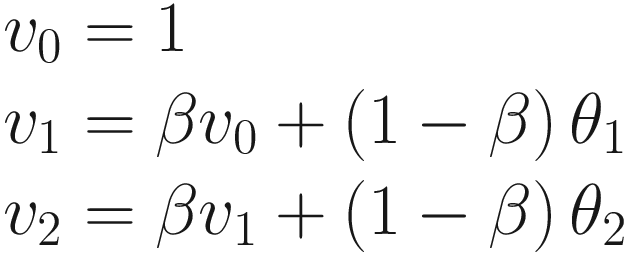
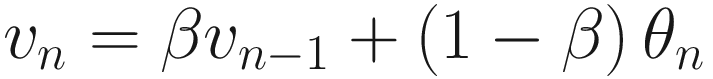
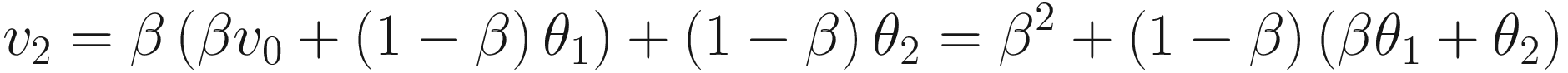
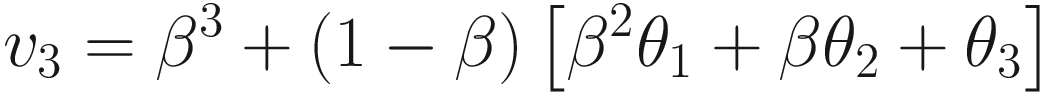
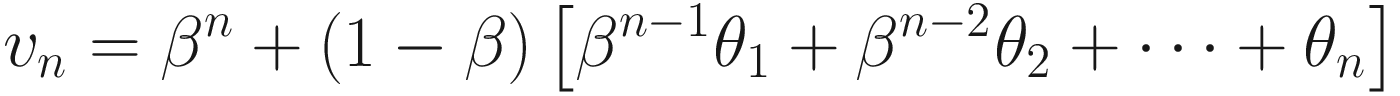
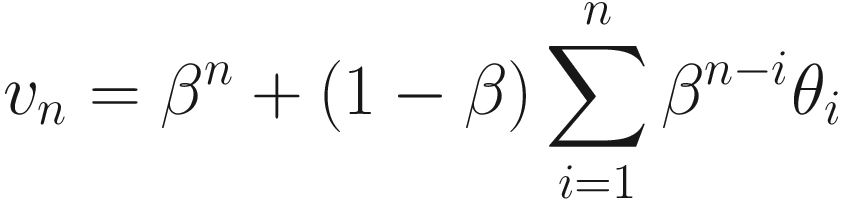
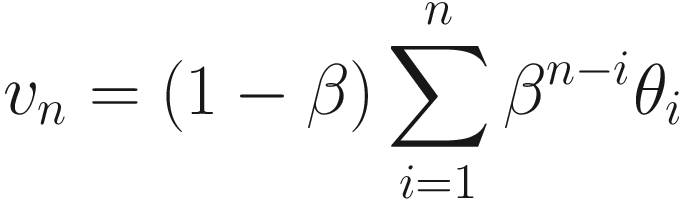
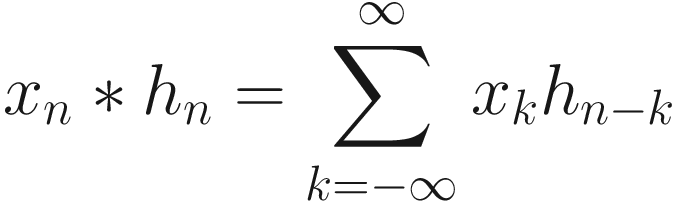
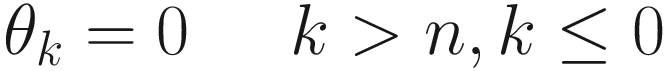
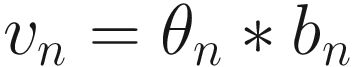
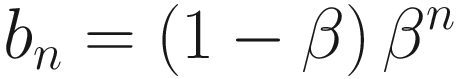

The left side is a plot showing θn (solid line) and bn (dotted line) together. The right side is a plot showing the points that need to be summed to obtain vn for n = 50
Let’s discuss briefly Figure 5-1. The Gaussian curve (θn) will be convoluted with bn to obtain vn. The result can be seen in the right plot. All those terms (1 − β)βn − iθi for i = 1, …, 50 (plotted in the right plot) will be summed to obtain v50. Note that vn is the average of all θn for n = 1, …, 50. Each term is multiplied by a term (bn); that is, 1 for n = 50 and then this decreases rapidly for n decreasing toward 1. Basically, this is a weighted average, with an exponentially decreasing weight. The terms farther from n = 50 are less and less relevant, while the terms close to n = 50 get more weight. This is also a moving average. For each n, all the preceding terms are added and multiplied by a weight (bn).
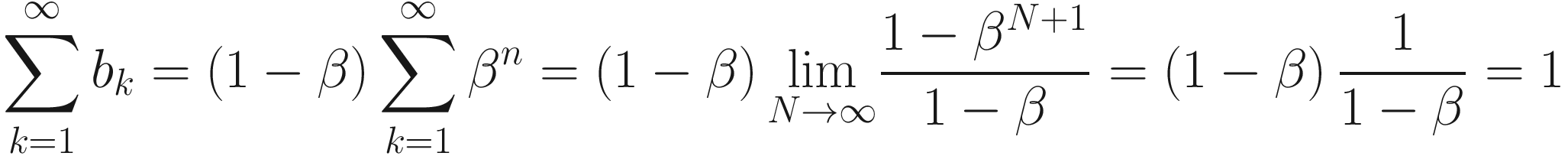
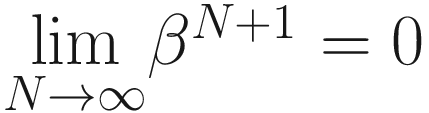 and that for a geometric series we have
and that for a geometric series we have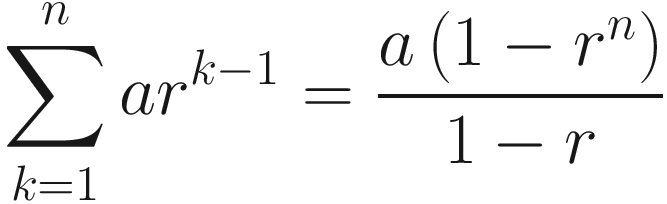
The algorithm we described to calculate vn is nothing else than the convolution of our quantity θi, with a series that has a sum equal to one and has the form (1 − β)βi.
The exponentially weighted average vn of a series of a quantity θn is the convolution vn = θn ∗ bn of our quantity θi with bn = (1 − β)βn, where bn has the property that its sum over the positive values of n is equal to 1. It is the moving average, where each term is multiplied by the weights given by the sequence bn.

The series bn for three values of β: 0.9, 0.8, and 0.3. Note that as β gets smaller, the series is significantly different than zero for an increasingly smaller number of values
This method is at the very core of the Momentum optimizer and more advanced learning algorithms, and you will see in the next sections how it works in practice.
Momentum
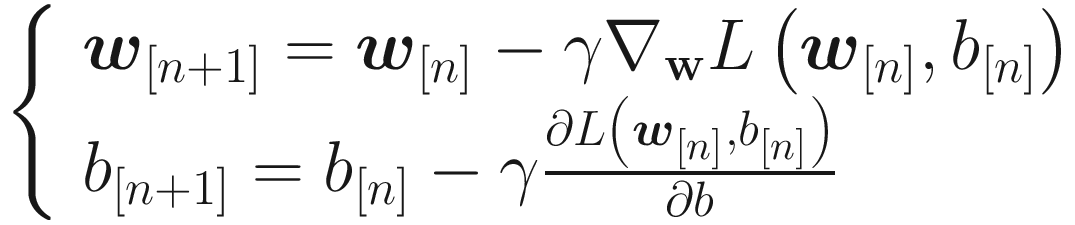
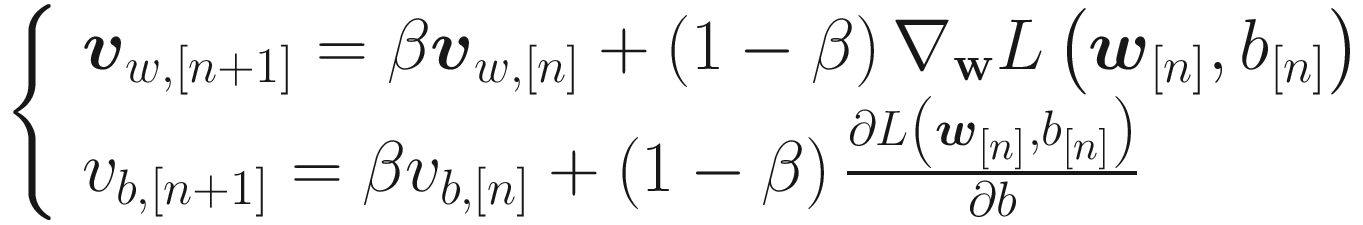
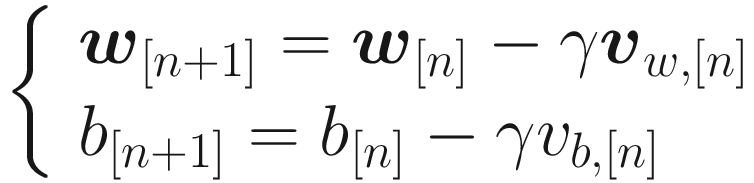
Where vw, [0] = 0 and vb, [0] = 0 are usually chosen. Now that means, instead of using the derivatives of the cost functions with respect to the weights, we update the weights with a moving average of the derivatives. Usually, experience shows that a bias correction could theoretically be neglected.
The Momentum algorithm uses an exponential weighted average of the derivates of the cost function with respect to the weights for the weight updates. This way, in addition to the derivatives at a given iteration being used, the past behavior is also considered. It may happen that the algorithm oscillates around the minimum instead of converging directly. This algorithm can escape from plateaus much more efficiently than standard gradient descent.
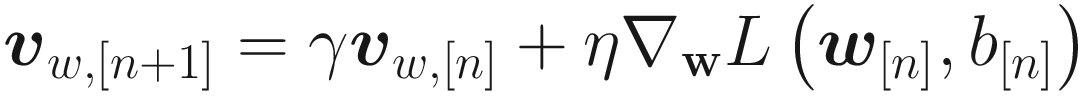
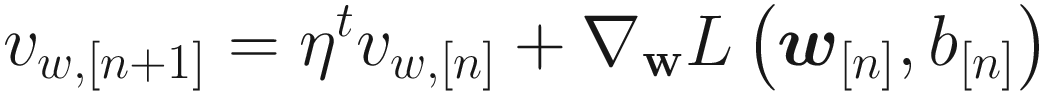
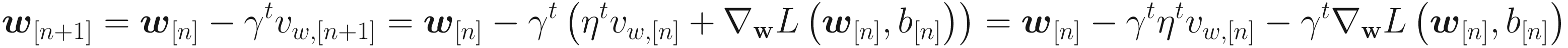
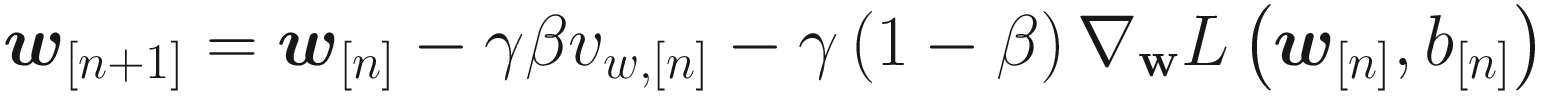
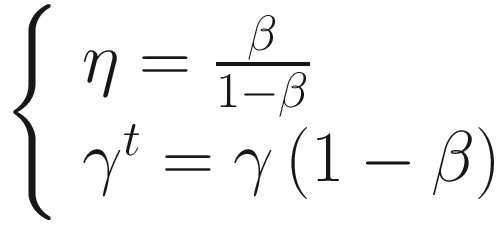
This can be seen by simply comparing the two different equations for the weight updates. Values around η = 0.9 in TensorFlow implementations are used and they typically work well. The momentum almost always converges faster than with plain gradient descent .
Comparing the different parameters in the different optimizers is wrong. When talking about the learning rate, for example, it has a different meaning in the different algorithms. What you should compare is the best convergence speed you can achieve with several optimizers, regardless of the choice of parameters. Comparing the GD for a learning rate of 0.01 with Adam (you will see it later) for the same learning rate does not make much sense. You should compare the optimizers with the parameters to see which gives you the best and fastest convergence.
RMSProp
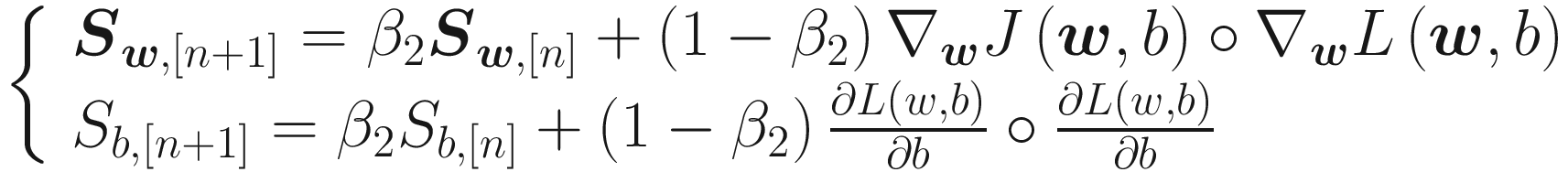
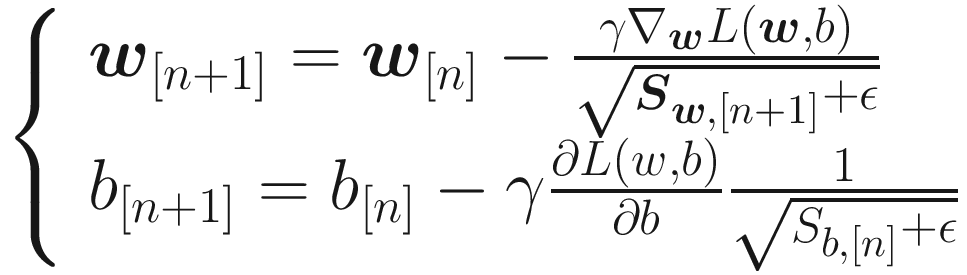
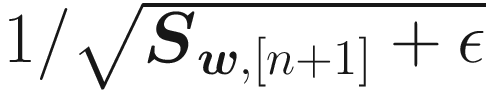 and
and ![$$ 1/sqrt{S_{b,left[n
ight]}+epsilon } $$](https://imgdetail.ebookreading.net/2023/10/9781484280201/9781484280201__9781484280201__files__images__463356_2_En_5_Chapter__463356_2_En_5_Chapter_TeX_IEq3.png) will be smaller and therefore the learning will slow down. The other way around is also true, so if the derivatives are small, the learning will be faster. This algorithm will make the learning faster for the parameters that are slowing it down. In TensorFlow is particular easy to use it simply with this code:
will be smaller and therefore the learning will slow down. The other way around is also true, so if the derivatives are small, the learning will be faster. This algorithm will make the learning faster for the parameters that are slowing it down. In TensorFlow is particular easy to use it simply with this code:Adam
The last algorithm we look at is called Adam (Adaptive Moment estimation) . It combines the ideas of RMSProp and Momentum into one optimizer. Like Momentum, it uses an exponential weighted average of past derivatives and, like RMSProp, it uses the exponentially weighted averages of past squared derivatives.
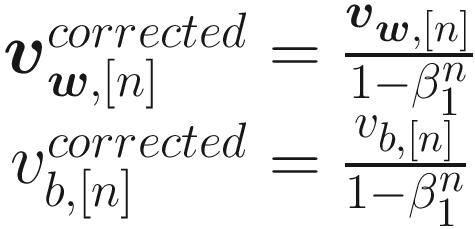
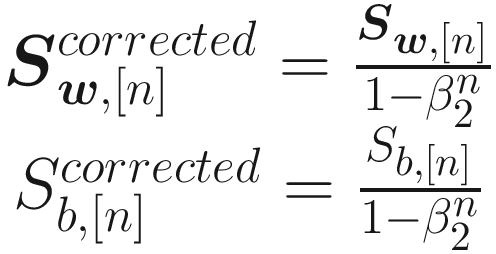
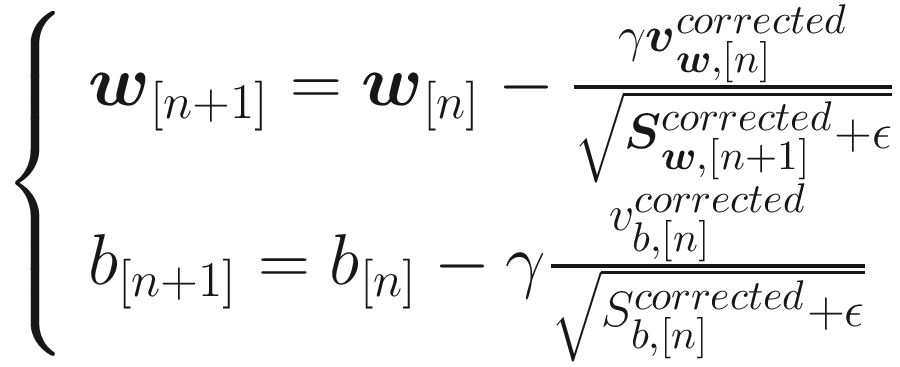
where in this case the typical values for the parameters have been chosen: γ = 0.001, β1 = 0.9, β2 = 0.999, and ϵ = 10−7. Note how, since this algorithm adapts the learning rate to the situation, we can start with a bigger learning rate to speed up the convergence.
Comparison of the Optimizers’ Performance
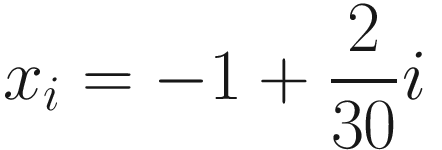
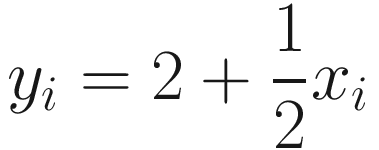
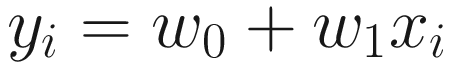

The path that the GD algorithm follows in parameter spaces while minimizing the MSE when starting from (0,0). The number of iterations used for this plot is 200

The path that the GD algorithm, Adam, and RMSProp optimizers follow in parameter spaces while minimizing the MSE when starting from (0,0). The number of iterations used for this plot is 200
![$$ {w}_0^{left[i
ight]} $$](https://imgdetail.ebookreading.net/2023/10/9781484280201/9781484280201__9781484280201__files__images__463356_2_En_5_Chapter__463356_2_En_5_Chapter_TeX_IEq4.png) and
and ![$$ {w}_1^{left[i
ight]} $$](https://imgdetail.ebookreading.net/2023/10/9781484280201/9781484280201__9781484280201__files__images__463356_2_En_5_Chapter__463356_2_En_5_Chapter_TeX_IEq5.png) vs. i, where i indicates the iteration number. In Figure 5-5, you can see how quickly
vs. i, where i indicates the iteration number. In Figure 5-5, you can see how quickly ![$$ {w}_0^{left[i
ight]} $$](https://imgdetail.ebookreading.net/2023/10/9781484280201/9781484280201__9781484280201__files__images__463356_2_En_5_Chapter__463356_2_En_5_Chapter_TeX_IEq6.png) converges to the expected value of 2.0 with the different algorithms. In this case, Adam and GD are on par, while RMSProp seems to be slower.
converges to the expected value of 2.0 with the different algorithms. In this case, Adam and GD are on par, while RMSProp seems to be slower.
The plot of ![$$ {w}_0^{left[i
ight]} $$](https://imgdetail.ebookreading.net/2023/10/9781484280201/9781484280201__9781484280201__files__images__463356_2_En_5_Chapter__463356_2_En_5_Chapter_TeX_IEq7.png) vs. the number of iterations with different optimizers
vs. the number of iterations with different optimizers
![$$ {w}_1^{left[i
ight]} $$](https://imgdetail.ebookreading.net/2023/10/9781484280201/9781484280201__9781484280201__files__images__463356_2_En_5_Chapter__463356_2_En_5_Chapter_TeX_IEq8.png) . Figure 5-6 shows how quickly the different algorithms converge.
. Figure 5-6 shows how quickly the different algorithms converge.
The plot of ![$$ {w}_1^{left[i
ight]} $$](https://imgdetail.ebookreading.net/2023/10/9781484280201/9781484280201__9781484280201__files__images__463356_2_En_5_Chapter__463356_2_En_5_Chapter_TeX_IEq9.png) vs. the number of iterations with different optimizers
vs. the number of iterations with different optimizers

Zoom of Figure 6-5. Plot of ![$$ {w}_1^{left[i
ight]} $$](https://imgdetail.ebookreading.net/2023/10/9781484280201/9781484280201__9781484280201__files__images__463356_2_En_5_Chapter__463356_2_En_5_Chapter_TeX_IEq10.png) vs. the number of iterations with different optimizers
vs. the number of iterations with different optimizers
In Figure 5-7, you can see how, while GD is still converging, Adam is already at the expected value, and RMSProp oscillates around it, since probably it cannot converge completely. This should convince you how efficient Adam is in comparison with other optimizers.
Small Coding Digression
where w0_start = 2.0 and w1_start = 0.5.
where w1_rmsprop_list and w0_rmsprop_list are lists that contain the values of the weights for each iteration. In this way, you can test any other optimizer you are interested in.
Which Optimizer Should You Use?
To make the story short, you should use Adam , as it is generally considered faster and better than the other methods. That does not mean that this is always the case. There are recent research papers that indicate how such optimizers could generalize poorly on new datasets (check out, for example, https://goo.gl/Nzc8bQ). And there are other papers that simply use GD with a dynamical learning rate decay. It mostly depends on your problem. But generally, Adam is a very good starting point.
If you are unsure which optimizer to start with, use Adam. It’s generally considered faster and better than the other methods.

The cost function for the Zalando dataset for a network with four hidden layers, each with 20 neurons. The continous line is plain GD with a learning rate of γ = 0.01, and the dashed line is Adam optimization with γ = 0.1, β1 = 0.9, β2 = 0.999, and ϵ = 10−8
As suggested, when testing complex networks on big datasets, the Adam optimizer is a good place to start. But you should not limit your tests to this optimizer alone. A test of other methods is always worthwhile. Maybe for your problem other approaches will work better!