
Chapter 6. Divide and conquer
The previous chapter presumed that programs typically consist of multiple parts that are segregated in some way. Different areas of functionality may be developed by separate teams, modules are accessed via interfaces and packaged such that they can be replaced, and so on. Over the past few decades, much effort has been spent on syntax and semantics for defining modules in programming languages and on libraries and the infrastructure needed to deploy them. The important question is, how do we go about dividing up a problem in order to successfully solve it?
Rewinding the clock more than 2,000 years, we find one of the earliest practitioners of the governance maxim divide et regna: Julius Caesar. The idea is simple: when faced with a number of enemies, create discord and divide them. This will allow you to vanquish them one by one, even though they would easily have defeated you if they had stood united. This strategy was used by the Roman Empire both internally and externally: the key was to purposefully treat different opponents differently, handing out favors and punishment asymmetrically. And this treatment was probably applied recursively, with senators and prefects learning from Caesar’s success.[1]
The authors have no direct evidence for this, but it sounds implausible to propose the opposite.
We do not have the problem of leading a huge empire, nor is fomenting discord one of our methods, but we can still learn from this old Latin saying. We can break a large programming problem down into a manageable handful of subproblems, and then do the same to the subproblems. Thus, we can gradually narrow the scope of what we are working on, drilling progressively deeper into the details of how to implement each particular piece.
6.1. Hierarchical problem decomposition
Imagine that you are building the Gmail application from scratch. You begin with the diffuse intuition that the task is an entangled mess of ad hoc requirements. One way to proceed would be to start from experience or with educated guesses about which technology components will play a role and postulate certain modules based on them: you will need modules for authentication and authorization, for rendering and notifications, and for monitoring and analytics, as well as appropriate storage for all these. You explore and perhaps build proofs of concept, improving your understanding and letting the modules—and their siblings whose necessity you discover—gradually take shape. Bite by bite, you take apart the big task, assigning requirements and features to each module. Many small things end up in utils or misc packages. Ultimately, you end up with hundreds of components that hopefully will work together peacefully to allow users to read their email.
Although possibly not far from the reality of many projects, this approach is not ideal. Breaking down a problem into a lot of smaller problems incurs the overhead of making the individual solutions coexist in the final product. This turns the initial, frighteningly complex problem into an army of smaller problems that may overwhelm you.
6.1.1. Defining the hierarchy
Staying with the example of building Gmail, you might split the responsibilities at the top layer into sign-on, profile, contacts, and mail. Within the contacts module, you must maintain the list of contacts for every user, providing facilities for addition, removal, and editing. You also need query facilities: for example, to support autocompletion while the user is typing recipient addresses in an email (low latency but possibly out of date) and for refined searches (higher latency but fully up to date and complete). The low-latency search function needs to cache an optimized view of the contacts data, which will need to be refreshed from the master list when it changes. The cache and the refreshing service could be separate modules that communicate with one another.
The important difference between this design and the initial one is that you not only break the overall task down into manageable units—you will probably arrive at the same granularity in the end—but also define a hierarchy among the modules. At the bottom of the hierarchy are the nitty-gritty implementation details. Moving up the hierarchy, the components become more and more abstract, approaching the logical high-level functionality that you aim to implement. The relation between a module and its direct descendants is tighter than just a dependency: the low-latency search function, for example, clearly depends on the cache and the refreshing service, but it also provides the scope within which these two modules work—it defines the boundaries of the problem space they solve.
This allows you to focus on a specific problem and solve it well, without trying to generalize prematurely, a practice that is often futile or even destructive. Of course, generalization will eventually happen—most likely at the lower levels of the hierarchy—but it will be a natural process of recognizing that the same (or a very similar) problem has already been solved, and therefore you can reuse the previous solution. Intuitively, you already have experience with this kind of generalization. It is common to reuse low-level libraries, such as collections frameworks. The concept of a list, map, or set is useful across any number of applications. At the next level up, some reuse remains likely. A low-level cache with a refreshing service might be reused in many places. Continuing up the hierarchy, there might be reuse of an interface to an LDAP server to acquire contact information, but it would be more limited. The higher in the hierarchy a module is situated, the more likely it is to be specific to a concrete use case. It is unlikely that the mail module in Gmail will be reused as is in a different application. If you need mail in another context, you are probably better off copying and adapting. Most of the descendant modules will probably be reusable, because they provide more narrowly scoped parts of the solution.
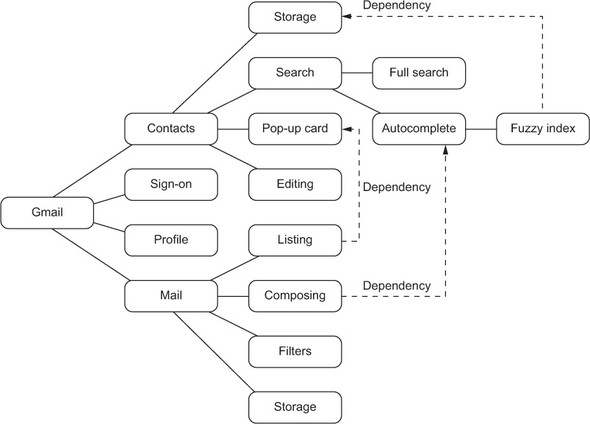
To recapitulate: we can break the task of “building Gmail” into a set of high-level features, such as mail and contacts, defining a module for each one. These modules collaborate to provide the Gmail function, and that is also their only purpose. The contacts module provides a clearly scoped part of the functionality, which is split up across lower-level modules such as autocomplete, which again collaborate to provide the overall contacts function. This hierarchy is depicted in figure 6.1.
Figure 6.1. Partially decomposed module hierarchy of our hypothetical Gmail implementation

6.2. Dependencies vs. descendant modules
In the hierarchical decomposition process, we glossed over one aspect that deserves elaboration: because the mail component in the Gmail example must work with contact information, does its module hierarchy contain that functionality? So far, we have only talked about the piecewise narrowing of problem scope. If that is all you do, parts of the contacts functionality will appear in several places: the module that displays lists of emails will need access to contact details; the module for composing an email will need access to at least the low-latency contact search; and the same goes for the filter-rule editor.
It does not make sense to replicate the same functionality in multiple places. We would like to solve each problem only once, in source code as well as in deployment and operations. Notice that none of the modules we mentioned owns the contacts functionality. It is not a core concern of any of them. Ownership is an important notion when it comes to decomposition. In this case, the question is, who owns which part of the problem space? There should be only one module that is responsible for any given functionality, possibly with multiple concrete implementations; all other modules that need to access that functionality have a dependency on the module that owns it.
We hinted at this distinction earlier when we said that the relationship between a module and its descendants is tighter than just a dependency. Descendant modules cater to a bounded subset of the problem space owned by their parent, each owning its smaller piece in turn. Functionality that lies outside this bound is incorporated by reference, and some other module is responsible for providing it, as illustrated in figure 6.2.
Figure 6.2. Partial module hierarchy showing inter-module dependencies
6.2.1. Avoiding the matrix
The organization of the development team can be at cross-purposes with establishing a good hierarchical decomposition of the software. A common way to organize people is by skill. Put all the front-end JavaScript experts into one group, the server developers in another, and the structured-database developers in a third, have yet another group focus on bulk storage, and so on. Conway’s Law—“Any organization that designs a system will inevitably produce a design whose structure is a copy of the organization’s communication structure”[2]—tells us that the result in the Gmail example would be a front-end module, an application module, and a database module. Within each module, each team would likely define its own submodules for contacts, sign-on, profile, and mail, as shown in figure 6.3.
Paraphrase of Melvin Conway, “How Do Committees Invent?” Datamation (April 1968), www.melconway.com/Home/pdf/committees.pdf.
Figure 6.3. The matrix creates an unwanted extra set of dependencies.

This is not the same as having a contacts module with submodules for the front end, application, and database. The difference is that in the skill-oriented decomposition, there are small, horizontal dependencies between the modules at each level rather than just at the top level of the hierarchy. These dependencies are especially pernicious because they do not usually appear to be a major problem while the first version is being built. Early in the lifecycle of a piece of software, nearly every submodule typically needs to be changed in every release; so whether a given module is deployed as part of the latest whole application release or as part of the latest contacts release makes no difference. Later, horizontal dependencies become problematic. They force a release focused on a single technology, such as upgrading the database version, to affect every module at the same level in the hierarchy. At the same time, every major feature release affects every module along a vertical axis.
6.3. Building your own big corporation
A metaphor that often works well for picturing and speaking about hierarchical problem decomposition is that of a big corporation. At the top, management defines the overall goal and direction (CEO, Chief Architect, and so on). Then there are departments that handle different, very high-level aspects of the goal. Each department is structured into various subgroups of different granularity, until at the bottom we reach the small teams that carry out very specific, narrowly scoped tasks. The ideas behind this structure are similar to the responsibility-oriented problem decomposition described previously: without proper segregation of the responsibilities of the departments, their members would constantly step on each other’s toes while doing their work.
As you work through this hierarchy, think ahead to something that will be considered more in the next chapter: handling failures. If an individual in the hierarchy fails to do their job, the next person up in the hierarchy must handle it. Responsibility flows toward the person in charge, not in lazy circles among coworkers!
If you think now, “Well, that all sounds nice in theory, but my own experience has been that this is exactly how corporations do not work,” the good news is that when applying these techniques to a programming problem, you get to choose the structure and define the relationships between the parts of the hierarchy you create—you get the chance to create your own BigCorp and do it right![3] You get the chance to not repeat the management mistakes of the past. “Matrix management” schemes were popular from the late 1970s to the early 1980s, and they did not work well. The title of an article published in the aftermath of the fad provides some insight: Matrix Management: Not a Structure, a Frame of Mind.[4]
You will probably discover that things are not as easy as you think they should be, which is equally instructive.
Christopher A. Bartlett and Sumantra Ghoshal, “Matrix Management: Not a Structure, a Frame of Mind,” Harvard Business Review (July-August 1990).
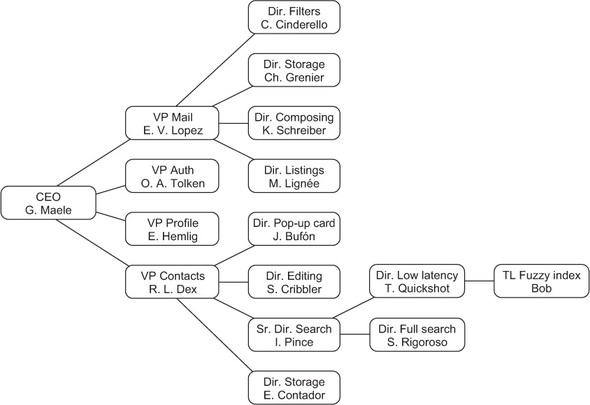
A hierarchical decomposition of responsibilities is shown in figure 6.4, on the example of our venerable Gmail application. Naming the modules according to the role they play within the overall organization of the application helps establish a common vocabulary among the teams and stakeholders involved in development.
Figure 6.4. The BigCorp view of our hypothetical Gmail application (all names are purely fictional, and any similarities to real persons are entirely unintentional).
6.4. Advantages of specification and testing
The process of breaking down a complex task as sketched in the previous sections is iterative, both in the sense of working your way from the root to the leaves of the hierarchy as well as gradually refining your ability to anticipate the decision process. If you find that a component is difficult to specify, meaning its function requires a complex description or is too vague, then you need to step back and possibly retrace your steps to correct a mistake that was made earlier. The guiding principle is that the responsibilities of every module should be clear. A simple measure of that clarity is how concise the complete specification of each module is.
A distinct scope and small rule set also make it easier to verify a module’s implementation: meaningful tests can only be written for properties that are definitive and clearly described. In this sense, the acronym TDD should be taken to mean testability-driven design instead of its usual expansion, test-driven development. Not only should the focus on testing indirectly lead to better design, but problem decomposition according to divide et regna should focus directly on producing modules that are easy to test.
In addition to helping with the design process, recursive division of responsibility helps concentrate communication between different parts of the application into pieces that can be replaced as a whole for the purpose of testing. When testing (parts of) the mail component of the hypothetical Gmail service, the internal structure of the contacts module will not be of interest, so it can be stubbed out as a whole. When testing contacts, you can apply the same technique to its submodules by stubbing out both the low-latency and the refined-search modules. The hierarchical structure enables tests to focus only on specific levels of granularity or abstraction, replacing siblings, descendants, and ancestors in the hierarchy with test stubs.
This is different from hardwiring a special database handle into the application for test, staging, or production mode: the database handle itself is only an implementation detail of whatever module uses the database for storage—for example, call it UserModule. You only need to select a database server from your test bed when testing UserModule; for all other testing, you create an implementation of UserModule that does not use a database at all and contains hardcoded test data instead. This allows everyone who does not develop UserModule itself to write and execute tests on their personal computer without having to install the complete test bed.
6.5. Horizontal and vertical scalability
What have you achieved so far? If you apply what you’ve seen in this chapter, you obtain modules with clearly segregated responsibilities and simple, well-specified interaction protocols. These protocols lend themselves to communication via pure message passing, regardless of whether the collaborating modules are executed within the same (virtual) machine or on different network hosts. The ability to test in isolation is at the same time a testament to the distributability of the components.
The Gmail example encapsulates the low-latency search module in a way that makes it possible to run any number of replicas of it, and so you are free to scale it up or down to handle whatever load users generate. When more instances are needed, they can be deployed to the available computing infrastructure and start populating their special-purpose caches. When ready, they will be called upon to service autocomplete requests from users. This works by having a request router set up as part of the overall low-latency search service. Whenever a new instance comes up, it registers itself with this router. Because all requests are independent of each other, it does not matter which instance performs the job as long as the result is returned within the allotted time.
In this example, depicted in figure 6.5, the size of the deployment directly translates into the end users’ observed latency. Having one instance of the search module running for each user will reduce latency to the minimum possible, given the network’s transfer times and the search algorithm. Reducing the number of instances will eventually lead to congestion, resulting in added latency due to search requests queuing up on the router or on the worker instances. This will in turn reduce the frequency of search requests generated per user (assuming that the client-side code refrains from sending a new request while the old one has not yet answered or timed out).
Figure 6.5. Scalable deployment of the low-latency search service is monitored and scaled up/down by the search supervisor.

Thus, you can choose deployment size so that the search latency is as good as it needs to be, but no better.[5] This is important because running one instance per user is obviously ridiculously wasteful. Reducing the number of instances as much as you can is in your best business interest.
Remember that search latency needs to be formulated in terms of, for example, the 99th percentile, not the average, as explained in chapter 2.
6.6. Summary
By taking inspiration from ancient Roman emperors, we have derived a method of splitting an enormous task into a handful of smaller ones and repeating this process with each subtask until we are left with the components that collaboratively make up our entire application. Focusing on responsibility boundaries allows us to distinguish between who uses a component versus who owns it. We illustrated this procedure with the example of how a big corporation is structured.
On this journey, you have seen that such a hierarchical component structure benefits the specification and hence the testing of components. We also noted that components with segregated responsibilities naturally form units for scaling application deployment vertically as well as horizontally. We will study another benefit of this structure in the next chapter when we talk about failure handling.