
Chapter 10. Message flow
Now that you have established a hierarchy of encapsulated modules that represent an application, you need to orchestrate them and realize the solution. The key point developed throughout the previous chapters is that modules communicate only asynchronously by passing messages. They do not directly share mutable state. You have seen many advantages of this approach along the way, enabling scalability and resilience, especially in concert with location transparency. The alternative, shared-state concurrency, is hard to get right.
There is one further advantage: basing a distributed design exclusively on messages allows you to model and visualize the business processes within your application as message flows. This helps avoid limitations to scalability or resilience early in the planning process.
10.1. Pushing data forward
The fastest way for a message to travel from Alice via Bob to Charlie is if every station along the path sends the message onward as soon as the station receives it. The only delays in this process are due to the transmission of the message between the stations and the processing of the message within each station.
As obvious as this statement is, it is instructive to consider the overhead added by other schemes. Alice could, for example, place the message in shared storage and tell Bob about it. Bob would then retrieve the message from storage, possibly writing it back with some added information, and then tell Charlie about it, who would also look at the shared storage. In addition to the two message sends, you would have to perform three or four interactions with a shared storage facility. Sharing mutable data between distributed entities is not the path to happiness.
Alice also might be concerned about whether Bob currently has time to deal with the message, and might ask him for permission to send it. Bob would reply when ready, Alice would send the message, and then the same procedure would be repeated between Bob and Charlie. Each of the two initial message sends would be accompanied by two more messages that conveyed readiness: first, that of the sender to send more; and then, that of the recipient to receive it.
Patterns like these are well established for purposes of persistence (such as durable message queues) or flow control (as we will discuss in depth in chapter 16), and they have their uses; but when it comes to designing the flow of messages through a Reactive application, it is important to keep the paths short and the messages flowing in one direction as much as possible, always toward the logical destination of the data. You will frequently need to communicate successful reception back to the sender, but that data stream can be kept lean by employing batching to send cumulative acknowledgments.
The previous examples were simplistic, but the same principle applies more broadly. Coming back to the Gmail implementation, incoming emails that are sent to the system’s users need to be transmitted from the SMTP module of the mail part of the application into the per-user storage. On their way, they need to pass through the module that applies user-defined filters to sort each email into the folder it belongs to.
As soon as emails are in per-user storage, they are visible to the user in folder listings and so on; but in order to support a search function across the entire dataset owned by a user, there needs to be an index that is kept up to date at all times. This index could periodically sync up with the current state of the mailbox storage and incorporate new emails, but that would be as inefficient as Bob periodically asking Alice whether there has been a new message since the last one. Keeping the data flowing forward means, in this case, that a copy of the email will be sent to the indexing service after the email has been classified by the filter module, which updates the index in real time. The full process is illustrated in figure 10.1.
Figure 10.1. Data flows forward from the source (the SMTP server module) toward the destination, feeding to the indexing service in parallel to storing the raw data.
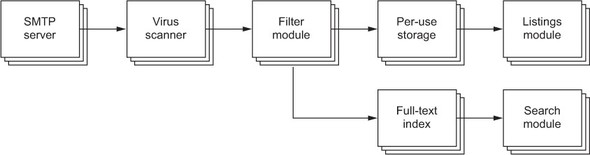
In this fashion, the number of messages that are exchanged is kept to a minimum, and data are treated while they are “hot,” which signifies both their relevance to the user as well as their being in active memory in the computers involved. The alternative of polling every few minutes would be to ask the storage service for an overview of its data and thereby force it to keep the data in memory or read the data back in after a resource shortage or outage.
10.2. Modeling the processes of your domain
Programming with messages exchanged between autonomous modules also lends itself well to the use of ubiquitous language as practiced in domain-driven design. Customers of the software development process, who can be users or product owners, will be most comfortable describing what they want in terms that they understand. This can be exploited for mutual benefit by turning the common language of the problem domain into modules and messages of the application architecture, giving concrete and rigorous definitions. The resulting model will be comprehensible for customers and developers alike, and it will serve as a fixed point for communicating about the emerging product during the development process.
We hinted at the reason behind this utility in section 2.6.2: anthropomorphic metaphors help humans visualize and choreograph processes. It is an act we enjoy, and this creates a fertile ground for finding ways of moving abstract business requirements into the realm of intuitive treatment. This is the reason we talk about Alice, Bob, and Charlie instead of nodes A, B, and C; in the latter case, we would struggle to try to keep our reasoning technical, whereas in the former case we can freely apply the wealth of social experience we have accumulated. It is not surprising that we find good analogies for distributed computing in our society: we are the prototypical distributed system!
Intuition is widely applicable in this process: when two facts need to be combined to perform a certain task, then you know there must be one person who knows both and combines them. This corresponds to the delimited consistency rule. Hierarchical treatment of failure is based on how our society works, and message passing expresses exactly how we communicate. You should use these helpers wherever you can.
10.3. Identifying resilience limitations
When laying out message flows within an application according to the business processes you want to model, you will see explicitly who needs to communicate with whom, or which module will need to exchange messages with what other module. You have also created the hierarchical decomposition of the overall problem and thus obtained the supervision hierarchy, and this will tell you which message flows are more or less likely to be interrupted by failure.
When sending to a module that is far down in the hierarchy and performing work that is intrinsically risky, such as using an external resource, you must foresee communication procedures for reestablishing the message flow after the supervisor has restarted the module. As shown in figure 10.2, in some cases it can be better to send messages via the supervisor from the start so the clients that are the senders of the messages need not reacquire a reference to the freshly started target module so often. They still will need to have recovery procedures in place to implement proper compartmentalization and isolation, but invoking those less frequently will further reduce the effect of a failure.
Figure 10.2. Messages may be sent directly to an actor or to a supervisor acting as a router if the actor itself performs risky operations such as I/O.

Messages may be sent directly to an actor or to a supervisor acting as a router if the actor itself performs risky operations such as I/O.
For this reason, you will see some message flows that are directed from a module to its descendant; but in most cases the supervisor is only involved as a proxy, and the real client is not part of the same supervision subtree. In general, most message flows are horizontal, and supervision is performed on the vertical axis, coming back to the notion that usually the user and the owner of a service are not the same.
10.4. Estimating rates and deployment scale
Focusing on message flows and sketching them out across the application layout allows you to make some educated guesses or apply input rates from previous experience or measurement. As messages flow through the system and are copied, merged, split up, and disseminated, you can trace the associated rate information to obtain an impression of the load the application modules will experience.
When the first prototypes of the most critical modules are ready for testing, you can begin evaluating their performance and use Little’s formula to estimate the necessary deployment size, as detailed in section 2.1.2. You can validate your assumption as to which modules need to be scaled out for performance reasons and where you can consolidate pieces that were split up erroneously.
The ability to perform these predictions and assessments stems from the fact that you have defined messages as concrete units of work that can be counted, buffered, spread out, and so on. You benefit from being explicit about message passing in the design. If you were to hide the distributed nature of the program behind synchronous RPC, this planning tool would be lost, and you would be more concerned about trying to anticipate the size of the thread pools needed in your processes. That is more difficult to do because it requires understanding both the domain and the characteristics of the system where the application will be deployed, which may vary over the life of the system and across the different development, test, and production systems.
10.5. Planning for flow control
Closely related to the estimation process is that you need to foresee bulkheads between different parts of your application. When input message rates exceed the limits you planned for, or when the dynamic scaling of the application is not fast enough to cope with a sudden spike in traffic, you must have measures in place to contain the overflow and protect the other parts of the system.
With a clear picture of how increased message rates are propagated within the application, you can determine at which points requests will be rejected (presumably close to the entrance of the application) and where you need to store messages on disk so that they are processed after the spike has passed or more capacity has been provisioned. These mechanisms will need to be activated at runtime when their time comes, and this process should be fully automatic. Human responses are typically too slow, especially on Sunday morning at 3:00 a.m. You need to propagate the congestion information upstream to enable the sender of a message stream to act on it and refrain from overwhelming the recipient. Patterns for implementing this are discussed in chapter 15; of particular interest are Reactive Streams (www.reactive-streams.org) as a generic mechanism for mediating back pressure in a distributed setting.
10.6. Summary
In this and the previous chapters in part 2 of the book, we have discussed the driving principles behind a Reactive application design. The central concept is to decompose the overall business problem in a hierarchical fashion according to divide et regna into fully encapsulated modules that communicate only by asynchronous, nonblocking, location-transparent message passing. The modularization process is guided and validated by the following rules:
- A modules does one job and does it well.
- The responsibility of a module is bounded by the responsibility of its parent.
- Module boundaries define the possible granularity of horizontal scaling by replication.
- Modules encapsulate failure, and their hierarchy defines supervision.
- The lifecycle of a module is bounded by that of its parent.
- Module boundaries coincide with transaction boundaries.
We illuminated different paradigms ranging from logic programming to shared-state concurrency and concluded that you should prefer a functional, declarative style within these modules and consider the cost of distribution and concurrency when choosing the granularity of your modules. You saw the advantages of explicitly modeling message flows within the system for the purposes of keeping communication paths and latencies short, modeling business processes using ubiquitous language, estimating rates and identifying resilience limitations, and planning how to perform flow control.