
Chapter 11. Testing reactive applications
Now that we have covered the philosophy, we need to discuss how to verify that the Reactive applications you build are elastic, resilient, and responsive. Testing is covered first because of the importance of proving Reactive capabilities. Just as test-driven design (TDD) allows you to ensure that you are writing logic that meets your requirements from the outset, you must focus on putting into place the infrastructure required to verify elasticity, resilience, and responsiveness.
What we will not cover is how to test your business logic—countless good resources are available on that topic. We will assume that you have picked a methodology and matching tools for verifying the local and synchronous parts of your application and will focus instead on the aspect of distribution that is inherent to Reactive systems.
11.1. How to test
Testing applications is the foremost effort developers can undertake to ensure that code is written to meet all its requirements without defects. Here, a truly Reactive application has several dimensions beyond merely fulfilling the specifications for the logic to be implemented, guided by the principles of responsiveness, elasticity, and resilience. In this book, where patterns are outlined to enable Reactive applications, testing is integral to each pattern described so that you can verify that your application is Reactive. In this chapter, we lay the foundations for this by covering common techniques and principles.
Before delving into patterns of testing, we must define a vocabulary. For anyone who has worked for a mature development organization, testing as a means to reduce risk is ingrained. Consulting firms are also well known for having stringent testing methodologies, in order to reduce the risk of a lawsuit from clients who have expectations about the level of quality for software being delivered. Every test plan is reviewed and approved by each level of the project leadership, from team leads through architects and project management, with the ultimate responsibility residing with the partner or organizational stakeholder to ensure that accountability exists for any improper behavior that may occur. As a result, many levels of functional tests have been identified and codified into standards for successful delivery.
Errors vs. failures
In this chapter—in particular, when we touch on resilience—it will be helpful to recall the distinction between errors and failures, as defined by the glossary[1] of the Reactive Manifesto:
A failure is an unexpected event within a service that prevents it from continuing to function normally. A failure will generally prevent responses to the current, and possibly all following, client requests. This is in contrast with an error, which is an expected and coded-for condition—for example an error discovered during input validation—that will be communicated to the client as part of the normal processing of the message. Failures are unexpected and will require intervention before the system can resume at the same level of operation. This does not mean that failures are always fatal, rather that some capacity of the system will be reduced following a failure. Errors are an expected part of normal operations, are dealt with immediately and the system will continue to operate at the same capacity following an error.
Note
Examples of failures are hardware malfunctions, processes terminating due to fatal resource exhaustion, and program defects that result in corrupted internal state.
11.1.1. Unit tests
Unit tests are the best known of all the kinds of tests: an independent unit of source code, such as a class or function, is tested rigorously to ensure that every line and condition in the logic meets the specification outlined by the design or product owner. Depending on how the code is structured, this can be easy or difficult—monolithic functions or methods inside such a source unit can be difficult to test due to all the varying conditions that can exist in these units.
It is best to structure code into individual, atomic units of work that perform only one action. When this is done, writing unit tests for these units is simple—what are the expected inputs that should successfully result in a value against which assertions can be made, and what are the expected inputs that should not succeed and result in an exception or error?
Because unit tests focus on whether the right response is delivered for a given set of inputs, this level of testing typically does not involve testing for Reactive properties.
11.1.2. Component tests
Component tests are also generally familiar to anyone who writes tests: they test a service’s application programming interface (API). Inputs are passed to each public interface exposed by the API, and, for several variations of correct input data, it is verified that the service returns a valid response.
Error conditions are tested by passing invalid data into each API and checking that the appropriate validation error is returned from the service. Validation errors should be an important design consideration for any public API, in order to convey an explicit error for any input that is deemed invalid for the service to handle appropriately.
Concurrency should also be explored at this level, where a service that should be able to handle multiple requests simultaneously returns the correct value for each client. This can be difficult to test for systems that are synchronous in nature, because concurrency in this case can involve locking schemes; it can be difficult for the person writing the test to create a setup to prove that multiple requests are being handled at the same time.
At this level, you also start testing the responsiveness of a service, to see whether it can reliably keep its service-level agreement (SLA) under nominal conditions. And, for a component that acts as a supervisor for another, you will also encounter aspects of resilience: does the supervisor react correctly to unexpected failures in its subordinates?
11.1.3. String tests
Now we diverge from the ordinary practices of testing, where you need to verify that requests into one service or microservice that depends on other such services or microservices can return the appropriate values. It is important to avoid getting bogged down in the low-level details of functionality that has already been tested at the unit- and component-test levels.
At this level, you also begin to consider failure scenarios in addition to the nominal and error cases: how should a service react to the inability of its dependencies to perform their functions? In addition, it is important to verify that SLAs are kept when dependent services take longer to respond than usual, both when they meet and when they do not meet their respective SLAs.
11.1.4. Integration tests
Typically, systems you build do not exist in a vacuum; prior to this level of testing, dependencies on external components are stubbed out or mocked so that you do not require access to these systems to prove that everything else in the system meets your requirements. But when you reach the level of integration testing, you should ensure that such interactions are proven to work and handle nominal as well as erroneous input as expected.
At this level, you also test for resilience by injecting failures: for example, by shutting off services to see how their communication partners and supervisors react. You also need to verify that SLAs are kept under nominal as well as failure scenarios and under varying degrees of external load.
11.1.5. User-acceptance tests
This final level of testing is not always explicitly executed. Most notable exceptions include situations where the consequences of failing to meet the requirements are severe (for example, space missions, high-volume financial processing, and military applications). The purpose is to prove that the overall implementation meets the project goals set by the client paying for the system to be built. But such testing can be applicable for organizations who treat the product owner as a client and the delivery team as the consulting firm. User-acceptance testing is the level at which the check-writer defines proofs that the system meets their needs, in isolation from those tests implemented by the consulting firm. This provides independent validation that the application, with all its various components and services, fulfills the ultimate goal of the project.
This level of testing may sound unnecessary for projects where an external contractor or firm has been hired to build the implementation, but we argue otherwise. One of the great benefits of test tooling such as behavior-driven development (BDD)[2] is to provide a domain-specific-language (DSL)[3] for testing that even nontechnical team members can read or even implement. Using tools like well-known implementations and variants of Cucumber (https://cucumber.io)—such as Cuke4Duke (https://github.com/cucumber/cuke4duke), Specs2 (http://etorreborre.github.io/specs2), and ScalaTest (www.scalatest.org)—provides business-process leaders on teams with the capability to write and verify tests.
11.1.6. Black-box vs. white-box tests
When testing a component, you must decide whether the test will have access to the component’s internal details. Such details include being able to send commands that are not part of the public interface or to query the internal state that is normally encapsulated and hidden. Testing without access to these is called black-box testing because the component is viewed as a box that hides its inner workings in darkness. The opposite is termed white-box testing because all details are laid bare, like in a laboratory clean room where all internals can be inspected.
A Reactive system is defined by its responses to external stimulus, which means testing for the Reactive properties of your applications or components will primarily be black-box testing, even if you prefer to use white-box testing within the unit tests for the business logic itself. As an example, you might have a minute specification that is very precise about how the incoming data are to be processed, and the algorithm is implemented such that intermediate results can be inspected along the way. The unit tests for this part of the application will be tightly coupled to the implementation itself; and for any change made to the internals, there is a good chance that some test cases will be invalidated.
This piece of code will form the heart of your application, but it is not the only part: data need to be ingested for processing, the algorithm must be executed, and results need to be emitted, and all these aspects require communication and are governed by Reactive principles. You will hence write other tests that verify that the core algorithm is executed when appropriate and with the right inputs and that the output arrives at the desired place after the allotted time in order to keep the SLA for the service you are implementing. All these aspects do not depend on the internal details of the core algorithm; they operate without regard to its inner workings. This has the added benefit that the higher-level tests for responsiveness, elasticity, and resilience will have a higher probability of staying relevant and correct while the core code is being refactored, bugs are fixed, or new features are added.
11.2. Test environment
An important consideration for writing tests is that they must be executed on hardware that is at least somewhat representative of that on which it will ultimately be deployed, particularly for systems where latency and throughput must be validated (to be discussed in section 11.7). This may provide some insight into how well a component or an algorithm may perform, particularly if the task is CPU-intensive, relative to another implementation tested on the same platform.
Many popular benchmarks in the development community are run on laptops: machines with limited resources with respect to number of cores, size of caches and memory, disk subsystems that do not perform data replication, and operating systems that do not match intended production deployments. A laptop is typically constructed with different design goals than a server-class machine, leading to different performance characteristics where some activities may be performed faster and others slower than on the final hardware. Although the laptop may have capabilities that exceed a specific server-class machine (for example, a solid-state drive as opposed to a hard disk for storage) and that make it perform better in certain situations, it likely will not represent the performance to be expected when the application reaches production. Basing decisions on the results of tests executed in such an environment may lead to poor decisions being made about how to improve the performance of an application.
It is an expensive proposition to ask all companies, particularly those with limited financial resources such as startups, to consider mirroring their production environment for testing purposes. But the cost of not doing so can be enormous if an organization makes a poor choice based on meaningless findings derived from a development environment.
Note that deployment in the cloud can make testing more difficult as well. Hypervisors do not necessarily report accurately about the resources they make available in a multitenancy environment, particularly with respect to the number of cores available to applications at any given time. This can make for highly dynamic and unpredictable performance in production. Imagine trying to size thread pools in a very specific way for smaller instances in the cloud where you are not expecting access to more than four virtual CPUs, but there is no guarantee you will receive that at any given moment. If you must verify specific performance via throughput and/or latency, dedicated hardware is a considerably better option.
11.3. Testing asynchronously
The most prominent difficulty that arises when testing Reactive systems is that the pervasive use of asynchronous message passing requires a different way of formulating test cases. Consider testing a translation function that can turn Swedish text into English.
Listing 11.1. Testing a purely synchronous translation function
val input = "Hur mår du?" val output = "How are you?" translate(input) should be(output)
This example uses ScalaTest syntax. The first two lines define the expected input and output strings, and the third line invokes the translation function with the input and asserts that this should result in the expected output. The underlying assumption is that the translate() function computes its value synchronously and that it is done when the function call returns.
A translation service that can be replicated and scaled out will not have the possibility of directly returning the value: it must be able to asynchronously send the input string to the processing resources. This could be modeled by returning a Future[4] for the result string that will eventually hold the desired value:
Recall that a Future is a handle to a value that may be delivered asynchronously at a later time. The code that supplies the value will fulfill the corresponding Promise with it, enabling code that holds a reference to the Future to react to the value using callbacks or transformations. Flip back to chapter 2 to refresh yourself on the details if necessary.
val input = "Hur mår du?" val output = "How are you?" val future = translate(input) // what now?
The only thing you can assert at this point is that the function does indeed return a Future, but probably there will not yet be a value available within it, so you cannot continue with the test procedure.
Another presentation of the translation service might use Actor messaging, which means the request is sent as a one-way message and the reply is expected to be sent as another one-way message at a later point in time. In order to receive this reply, there needs to be a suitable recipient:

TestProbe is an object that contains a message queue to which messages can be sent via the corresponding ActorRef. You use it as the return address in the message to the translation service Actor. Eventually the service will reply, and the message with the expected output string should arrive within the probe; but again, you cannot proceed with the test procedure at this point because you do not know when exactly that will be the case.
11.3.1. Providing blocking message receivers
Note
The methods used to implement the solutions that follow typically are not recommended for regular use because of their thread-blocking nature, but bear with us: even for testing, we will present nicely nonblocking solutions later. Using classical test frameworks can require you to fall back to what is discussed here, and it is educational to consider the progression presented in this section.
One solution to the dilemma is to suspend the test procedure until the translation service has performed its work and then inspect the received value. In case of the Future, you can poll its status in a loop:
while (!future.isCompleted) Thread.sleep(50)
This will check every 50 ms whether the Future has received its value or was completed with an error, not letting the test continue before one or the other occurs. The syntax used is that of scala.concurrent.Future; in other implementations, the name of the status query method could be isDone() (java.util.concurrent.Future), isPending() (JavaScript Q), or inspect() (JavaScript when), to name a few examples. In a real test procedure, the number of loop iterations must be bounded:
var i = 20
while (!future.isCompleted && i > 0) {
i -= 1
Thread.sleep(50)
}
if (i == 0) fail("translation was not received in time")
This will wait only for up to roughly 1 second and fail the test if the Future is not completed within that time window. Otherwise, message loss or a programming error could lead to the Future never receiving a value; then the test procedure would hang and never yield a result.
Most Future implementations include methods that support awaiting a result synchronously. A selection is shown in table 11.1.
Table 11.1. Methods for synchronously awaiting a Future result
|
Synchronous implementation |
|
|---|---|
| Java | future.get(1, TimeUnit.SECONDS); |
| Scala | Await.result(future, 1.second) |
| C++ |
std::chrono::milliseconds span(1000); future.wait_for(span); |
These methods can be used in tests to retain the same test procedure as for the verification of the synchronous translation service.
Listing 11.2. Awaiting the result blocks synchronously on the translation
val input = "Hur mår du?" val output = "How are you?" val result = Await.result(translate(input), 1.second) result should be(output)
With this formulation, you can take an existing test suite for the translation service and mechanically replace all invocations that used to return a strict value so that they synchronously await the value using the returned Future. Because the test procedure is typically executed on its own dedicated thread, this should not interfere with the implementation of the service on its own.
It must be stressed that this technique is likely to fail if applied outside of testing and in production code. The reason is that the caller of the translation service will then no longer be an isolated external test procedure; it will most likely be another service that may use the same asynchronous execution resources. If enough calls are made concurrently in this thread-blocking fashion, then all threads of the underlying pool will be consumed, idly waiting for responses, and the desired computation will not be executed because no thread will be available to pick it up. Timeouts or deadlock will ensue.
Coming back to the test procedures, we still have one open question: how does this work for the case of one-way messaging as in the Actor example? You used a TestProbe as the return address for the reply. Such a probe is equivalent to an Actor without processing capabilities of its own, which provides utilities for synchronously awaiting messages. The test procedure would in this case look like the following.
Listing 11.3. Expecting replies with a TestProbe
val input = "Hur mår du?" val output = "How are you?" val probe = TestProbe() translationService ! Translate(input, probe.ref) probe.expectMsg(1.second, output)
The expectMsg() method will wait up to 1 second for a new message to arrive and, if that happens, compare it to the expected object—the output string, in this case. If nothing or the wrong message is received, then the test procedure will fail with an assertion error.
11.3.2. The crux of choosing timeouts
Most synchronous test procedures verify that a certain sequence of actions results in a given sequence of results: set up the translation service, invoke it, and compare the returned value to the expected one. This means the aspect of time does not play a role in these tests: the test result will not depend on whether running the test is a matter of milliseconds or takes a few hours. The basic assumption is that all processing occurs in the context of the test procedure, literally beneath its frame of control. Therefore, it is enough to react to returned values or thrown exceptions. There will always be a result—infinite loops will be noticed eventually by the human observer.
In an asynchronous system, this assumption no longer holds: it is possible that the execution of the module under test occurs far removed from the test procedure, and replies may not only arrive late, they can also be lost. The latter can be due to programming errors (not sending a reply message, not fulfilling a Promise in some edge case, and so on), or it can be due to failures like message loss on the network or resource exhaustion—if an asynchronous task cannot be enqueued to be run, then its result will never be computed.
For this reason, it is unwise to wait indefinitely for replies during test procedures, because you do not want the entire test run to grind to a halt halfway through just because of one lost message. You need to place an upper bound on waiting times, fail tests that violate it, and move on.
This upper bound should be long enough to allow natural fluctuations in execution times without leading to sporadic test failures; such flakiness would waste resources during development in order to investigate each test failure as to whether it was legitimate or bad luck. Typical sources of bad luck include garbage-collection pauses, network hiccups, and temporary system overload, and all of these can cause a message send that normally takes microseconds to be delayed by up to several seconds.
On the other hand, the upper bound needs to be as low as possible, because it defines the time it takes to give up and move on. You do not want to wait for a verification run to take several hours when one hour would suffice.
Scaling timeouts for different test environments
Choosing the right timeouts is therefore a compromise between worst-case test execution time and false positive error probability. On current notebook computers, it is realistic to expect asynchronous scheduling to occur on the scale of tens of milliseconds. Normally, it happens much faster; but if you are, for example, executing a large test suite with thousands of tests on the JVM, you need to take into account that the garbage collector will occasionally run for a few milliseconds, and you do not want that to lead to test failures because it is expected behavior for a development system.
If you develop a test suite this way and then let it be run on a continuous integration server in the cloud, you will discover that it fails miserably. The server will likely share the underlying hardware with other servers through virtualization, and it may also perform several test runs simultaneously. These and other effects of not having exclusive access to hardware resources lead to greater variations in the execution timing and thereby force you to relax your expectations as to when processing should occur and replies should be received.
Toward this end, many asynchronous testing tools as well as the test suites themselves contain provisions to adapt the given timeouts to different runtime environments. In its simplest form, this means scaling by a constant factor or adding a constant amount to account for the expected variance.
Note
Adapting timeouts to different runtime environments is realized in the ScalaTest framework by mixing in the trait ScaledTimeSpans and overriding the method spanScaleFactor(). Another example is the Akka test suite, which allows the external configuration of a scaling factor that is applied to durations used in TestProbe.expectMsg() and friends (the configuration key is akka.test.timefactor).
Testing service timings
Another issue can arise with testing asynchronous services: due to the inherent freedom of when to reply to a request, we can imagine services that reply only after a certain time has passed or that trigger the periodic execution of some action. All such use cases can be modeled as external services that arrange for messages to be sent at the right times so that other services can depend on them for their scheduling needs.
The difference between testing the timing behavior of a service versus using timeouts for verifying its correctness is illustrated in figure 11.1. If you want to assert that the correct answer is received, you choose a timeout that bounds the maximal waiting time such that normally the test succeeds even if the execution is delayed much longer than would be expected during production use. Testing a service for its timing shifts the aspect of time from a largely ignored bystander role into the center of focus: you now need to put more stringent limits on what to accept as valid behavior, and you may need to establish lower bounds as well.
Figure 11.1. Testing a system for correctness and testing it for its timing properties are significantly different activities.
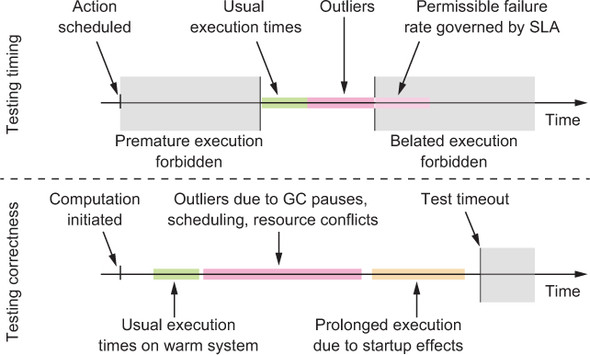
How do you implement a test suite for a scheduler? As an example, the following listing formulates a test case for a scheduler service that is implemented as an Actor, using again a TestProbe as the communication partner that is controlled by the test procedure.
Listing 11.4. Using a TestProbe to receive the response from the scheduler

Here, verification proceeds in two steps. First, you verify that the scheduled message does indeed arrive, using a relaxed time constraint with reasoning similar to that of the timing-agnostic tests discussed in the previous section. Second, you note the time that elapsed between sending the request and receiving the scheduled message and assert that this time interval matches the requested schedule.
The second part is subject to all the timing variations due to external influences earlier, which poses a problem. You cannot evade the issues by relaxing the verification constraints this time, because that would defeat the purpose of the test. This leaves only one way forward: you need to run these timing-sensitive tests in an environment that does not suffer from additional variances. Instead of including them with all the other test suites that you run on the continuous integration servers, you may choose to execute them only on reliable and fast developer machines, which work much better in this regard.
But this is also problematic in that a scheduler that passes these local tests under ideal circumstances may fail to meet its requirements when deployed in production. Therefore, such services need to be tested in an environment that closely matches the intended production environment, in terms of both the hardware platforms used and the kind of processes running simultaneously and their resource configurations. It makes a difference if the timing-sensitive service commands independent resources or shares a thread pool with other computation.
Testing service-level agreements
In chapter 1, we discussed the importance of establishing reliable upper bounds for service response times in order to conclude whether the service is currently working. In other words, each service needs to abide by its SLA in addition to performing the correct function. The test procedures you have seen so far only concentrate on verifying that a given sequence of actions produces the right sequence of results, where in certain cases the result timing may be constrained as well. To verify the SLA, it is necessary to test aspects like the 95th percentile of the request latency: for example, asserting that it must be less than 1 ms. These tests are inherently statistical in nature, necessitating additions to your set of testing tools.
Formulating test cases concerned with latency percentiles for a given request type means you need to perform such requests repeatedly and keep track of the time elapsing between each matching request–response pair. The simplest way to do this is to sequentially perform one request after the other, as shown in the following example, which tests 200 samples and discards the slowest 5%.
Listing 11.5. Determining 95th percentile latency

This test procedure takes note of the response latency for each request in a normal collection, which is sorted in order to extract the 95th percentile (by dropping the highest 5% and then looking at the largest element). This shows that no histogramming package or statistics software is necessary to perform this kind of test, so there is no excuse for skimping on their use. To learn more about the performance characteristics and dynamic behavior of the software you write, though, it is recommended that you visualize the distribution of request latencies; this can be done for regular test runs or in dedicated experiments, and statistics tools will help in this regard.
In the previous listing, requests are fired one by one, so the service will not experience any load during this procedure. The obtained latency values will therefore reflect the performance under ideal conditions; it is likely that under nominal production conditions, the timings will be worse. In order to simulate a higher incoming request rate—corresponding to multiple simultaneous uses of the same service instance—you need to parallelize the test procedure, as shown in figure 11.2. The easiest way to do this is to use Futures.
Figure 11.2. The test procedure initiates multiple calls to the service under test, which may be executed in parallel; aggregates the timings; and verifies that the SLA is met.
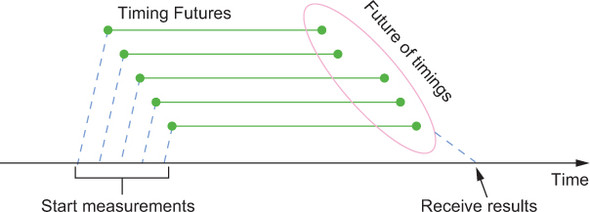
Listing 11.6. Generating the test samples in parallel with the Ask pattern

This time, you use the ? operator to turn the one-way Actor message send into a request–response operation: this method internally creates an ActorRef that is coupled to a Promise and uses the passed-in function to construct the message to be sent. Scala’s function-literal syntax makes this convenient using the underscore shorthand—you can mark the “hole” into which the ActorRef will be placed. The first message sent to this ActorRef will fulfill the Promise, and the corresponding Future is returned from the ? method (pronounced “ask”).
You then transform this Future using the .collect combinator: if it is the expected response, you replace that with the elapsed time. It is essential to remember that Future combinators execute when the Future is completed, in the future. Hence, taking a timestamp in the collect transformation serves as the second look to the watch, whereas the result of the first look was obtained from the test procedure’s context and stored in the start timestamp that you then later reference from the Future transformation.
The for-comprehension returns a sequence of all Futures, which you can turn into a single Future holding a sequence of time measurements by using the Future.sequence() operation. Synchronously awaiting the value for this combined Future lets you then continue in the same fashion as for the sequentially requesting test procedure.
If you execute this parallel test, you will notice that the timings for the service are markedly changed for the worse. This is because you very rapidly fire a burst of requests that pile up in the EchoService’s request queue and then are processed one after the other. On my machine, I had to increase the threshold for the 95th percentile to 100 ms; otherwise, I experienced spurious test failures.
Just as the fully sequential version exercised an unrealistic scenario, the fully parallel one tests a rather special case as well. A more realistic test would be to limit the number of outstanding requests to a given number at all times: for example, keeping 500 in flight. Formulating this with Futures will be tedious and complex;[5] in this case, it is preferable to call on another message-passing component for help. The following example uses an Actor to control the test sequence.
Assuming that the responses can arrive in a different order than the order in which you sent the corresponding requests. This assumption is necessary to make for a service that can be scaled by replication.
Listing 11.7. Using a custom Actor to bound the number of parallel test samples
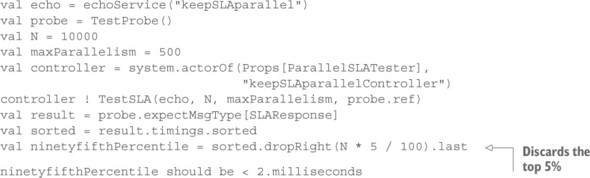
You can find the code for the Actor in the accompanying source code archives. The idea is to send the first maxParallelism requests when starting the test and then send one more for each received response until all requests have been sent. For each request that is sent, a timestamp is stored together with the unique request string; when the corresponding response is received, the current time is used to calculate this request’s response latency. When all responses have been received, a list of all latencies is sent back to the test procedure in an SLAResponse message. From there on, the calculation of the 95th percentile proceeds as usual.
Refining parallel measurements
Looking at the code in the source archive, you will notice listing 11.7 is slightly simplified: instead of directing the responses to the ParallelSLATester, a dedicated Actor is used, which timestamps the responses before sending them on to the ParallelSLATester. The reason is that otherwise the timings might be distorted, because the ParallelSLATester might still be busy sending requests when a response arrives, leading to an artificially prolonged time measurement.
Another interesting aspect is the thread pool configuration. You are welcome to play with the parallelism-max setting to find out when the results are stable across multiple test runs and when they become optimal; for a discussion, see the comments in the source code archives.
11.3.3. Asserting the absence of a message
All verification you have done so far concerned messages that were expected to arrive, but it is equally important to verify that certain messages are not sent. When components interact with protocols that are not purely request–response pairs, this need arises frequently:
- After cancelling a repeating scheduled task
- After unsubscribing from a publish–subscribe topic
- After having received a dataset that was transferred via multiple messages
Depending on whether the messaging infrastructure maintains the ordering for messages traveling from sender to recipient, you can either expect the incoming message stream to cease immediately after having confirmation that the other side will stop, or allow for some additional time during which stragglers may still arrive. The absence of a message can only be asserted by letting a certain amount of time elapse and verifying that indeed nothing is received during this time.
Listing 11.8. Verifying that no additional messages are received

Looking at the expected message timings and summing them up, this procedure should take a bit more than 3 seconds: 1 for the first tick to arrive, some milliseconds for the communication with the scheduler service, and 2 more seconds during which you do nothing. Verifications like this increase the time needed to run the entire test suite, usually even more than most tests that spend their time more actively. It is therefore desirable to reduce occurrences of this pattern as much as possible.
One way to achieve this is to rely on message-ordering guarantees where available. Imagine a service implementing data ingestion and parsing: you send it a request that points it to an accessible location—a file or a web resource—and you get back a series of data records followed by an end-of-file (EOF) marker. Each instance of this service processes requests in a purely sequential fashion, finishing one response series before picking up the next work item. This makes the service easier to write, and scaling it out will be trivial by running multiple instances in parallel; the only externally visible effect is that requests need to contain a correlation ID, because multiple series can be in flight at the same time. The following test procedure demonstrates the interface.
Listing 11.9. Matching responses to requests with a correlation ID

Instead of following this with an expectNoMsg() call to verify that nothing arrives after the EOF message, you might append a second query. During testing, you can ensure that only one instance is active for this service, which means as soon as you receive the elements of the second response series, you can be sure the first one is properly terminated.
11.3.4. Providing synchronous execution engines
The role of timeouts in tests that are not timing-sensitive is only to bound the waiting time for a response that is expected. If you could arrange for the service under test to be executed synchronously instead of asynchronously, then this waiting time would be zero: if the response is not ready when the method returns, then it also will not become available at a later time, because no asynchronous processing facilities are there to enable this.
Such configurability of the execution mechanism is not always available: synchronous execution can be successful only if the computation does not require intrinsic parallelism. It works best for processes that are deterministic, as discussed in chapter 9. If a computation is composed from Futures in a fully nonblocking fashion, then this criterion is satisfied. Depending on the platform that is used, there may be several ways to remove asynchrony during tests. Some implementations, like Scala’s Future, are built on the notion of an ExecutionContext that describes how the execution is realized for all tasks involved in the processing and chaining of Futures. In this case, the only preparation necessary is to allow the service to be configured with an Execution-Context from the outside, either when it is constructed or for each single request. Then the test procedure can pass a context that implements a synchronous event loop. Revisiting the translation service, this might look like the following.
Listing 11.10. Forcing synchronous execution: safe only for nonblocking processes
val input = "Hur mår du?" val output = "How are you?" val ec = SynchronousEventLoop val future = translate(input, ec) future.value.get should be(Success(output))
For implementations that do not allow the execution mechanism to be configured in this fashion, you can achieve the same effect by making the result container configurable. Instead of fixing the return type of the translate method to be a Future, you can abstract over this aspect and allow any composable container to be passed in.[6] Future composition uses methods like map/flatMap/filter (Scala Future), then (Java-Script), and thenAccept (Java CompletionStage). The only source code change needed is to configure the service to use a specific factory for creating Futures so that you can inject one that performs computations synchronously.
In other words, you abstract over the particular kind of monad that is used to sequence and compose the computation, allowing the test procedure to substitute the Future monad for the identity monad. In dynamically typed languages, it is sufficient to create the monad’s unit() and bind() functions, whereas in statically typed languages extra care needs to be taken to express the higher-kinded type signature of the resulting translate() method.
When it comes to other message-based components, chances are not as good that you can find a way to make an asynchronous implementation synchronous during tests. One example is the Akka implementation of the Actor model, which allows the execution of each Actor to be configured by way of selecting a suitable dispatcher. For test purposes, there exists a CallingThreadDispatcher that processes each message directly within the context that uses the tell operator. If all Actors that contribute to the function of a given service are using only this dispatcher, then sending a request will synchronously execute the entire processing chain such that possible replies are already delivered when the tell operator invocation returns. You can use this as follows.
Listing 11.11. Processing messages on the calling thread with CallingThreadDispatcher

The important change is that the Props describing the translation service Actor are configured with a dispatcher setting instead of leaving the decision to the Actor-System. This needs to be done for each Actor that participates in this test case, meaning if the translation service creates more Actors internally, it must be set up to propagate the dispatcher configuration setting to these (and they to their child Actors, and so on; see the source code archives for details). Note that this also requires several other assumptions:
- The translation service cannot use the system’s scheduler, because that would invoke the Actors asynchronously, potentially leading to the output not being transmitted to the probe when you expect it to be.
- The same holds for interactions with remote systems, because those are by nature asynchronous.
- Failures and restarts would in this case also lead to asynchronous behavior, because the translation service’s supervisor is the system guardian that cannot be configured to run on the CallingThreadDispatcher.
- None of the Actors involved are allowed to perform blocking operations that might depend on other Actors running on the CallingThreadDispatcher, because that would lead to deadlocks.
The list of assumptions could be continued with minor ones, but it should be clear that the nature of the Actor model is at odds with synchronous communication: it relies on asynchrony and unbounded concurrency. For simple tests—especially those that verify a single Actor—it can be beneficial to go this route, whereas higher-level integration tests involving the interplay of multiple Actors usually require asynchronous execution.
So far, we have discussed two widely used messaging abstractions, Futures and Actors, and each of them provides the necessary facilities to do synchronous testing if needed. Due to the ubiquity of this form of verification, you will likely continue to see this support in all widespread asynchronous messaging abstractions, although there are already environments that are heavily biased against synchronous waiting—for example, event-based systems like JavaScript—and that will drive the transition toward fully asynchronous testing. We will embark on this spiritual journey in the following sections.
11.3.5. Asynchronous assertions
The first step toward asynchronous testing is the ability to formulate an assertion that will hold at a future point in time. In a sense, you have seen a special case of this already in the form of TestProbe.expectMsg(). This method asserts that within a time interval from now on, a message will be received that has the given characteristics. A generalization of this mechanism is to allow arbitrary assertions to be used. Scala-Test offers this through its eventually construct. Using this, you can rewrite the translation service test case as follows.
Listing 11.12. Moving the timeout parameters to an external configuration
val input = "Hur mår du?"
val output = "How are you?"
val future = translate(input)
eventually {
future.value.get should be(Success(output))
}
This uses an implicitly supplied PatienceConfiguration that describes the time parameters of how frequently and for how long the enclosed verification is attempted before test failure is signaled. With this helper, the test procedure remains fully synchronous, but you obtain more freedom in expressing the conditions under which it will proceed.
11.3.6. Fully asynchronous tests
We have found ways to express test cases for Reactive systems within the framework of traditional synchronous verification procedures, and most systems to date are tested in this fashion. But it feels wrong to apply a different set of tools and principles in the production and verification code bases: there is an impedance mismatch between these two that should be avoidable.
The first step toward fixing this was taken when you devised an Actor to verify the response latency characteristics of EchoService. ParallelSLATester is a fully Reactive component that you developed to test a characteristic of another Reactive component. The only incongruous piece in that test was the synchronous procedure used to start the test and await the result. What you would like to write instead is the following.
Listing 11.13. Handling responses asynchronously to create fully Reactive tests

Here, you initiate the test by sending the TestSLA command to the Actor, using the Ask pattern to get back a Future for the later reply. You then transform that Future to perform the calculation and verification of the latency profile, resulting in a Future that will either be successful or fail, depending on the outcome of the assertion in the next-to-last line. In traditional testing frameworks, this Future will not be inspected, making this approach futile. An asynchronous testing framework, on the other hand, will react to the completion of this Future in order to determine whether the test was successful.
Combining such a test framework with the async/await extension available for .Net languages or Scala makes it straightforward and easily readable to write fully asynchronous test cases. The running example of the translation service would look like this.
Listing 11.14. Using async and await to improve readability of asynchronous tests
async {
val input = "Hur mår du?"
val output = "How are you?"
await(translate(input).withTimeout(5.seconds)) should be(output)
}
This has exactly the same structure as the initial synchronous version in listing 11.1, marking out the asynchronous piece with await() and wrapping the entire case in an async{} block. The advantage over the intermediate version that used the blocking Await.result() construct in listing 11.2 is that the testing framework can execute many such test cases concurrently, reducing the overall time needed for running the entire test suite. This also means you can relax the timing constraints, because a missing reply will not bind as many resources as in the synchronous case. The Future for the next step of the test procedure will not be set in motion; the 5 seconds in this example will also not tick so heavily on the wall clock, because other test cases can make progress while this one is waiting.
As mentioned earlier, JavaScript is an environment that is heavily biased toward asynchronous processing; blocking test procedures as are common in other languages are not feasible in this model. As an example, you can implement the translation service test using Mocha and Chai assertions for Promises.
Listing 11.15. Testing the translation service in JavaScript
describe('Translator', function() {
describe('#translate()', function() {
it('should yield the correct result', function() {
return tr.translate('Hur mår du?')
.should.eventually.equal('How are you?');
})
})
});
The Mocha test runner executes several test cases in parallel, each returning a Promise as in this case. The timeouts after which tests are assumed to be failed if they did not report back can be configured at each level (globally, per test suite, or per test case).
Testing service-level agreements
With test cases being written in an asynchronous fashion, you can revisit the latency percentile verification from another angle. The framework could allow the user to describe the desired response characteristics in addition to the test code and then automatically verify those by running the code multiple times in parallel. Doing so sequentially would be prohibitively expensive in many cases—you would not voluntarily have tested 10,000 iterations of the EchoService in the sequential version in listing 11.5—and, as discussed, it also would not be a realistic measurement. Going back to the SLA test of the echo service in listing 11.7, the test framework would replace the custom ParallelSLATester Actor that was used to communicate with the service under test.
Listing 11.16. Using a request–response factory to generate test traffic
async {
val echo = echoService()
val gauge = new LatencyTestSupport(system)
val latenciesFuture =
gauge.measure(count = 10000, maxParallelism = 500) { i =>
val message = s"test$i"
SingleResult((echo ? (Request(message, _))), Response(message))
}
val latencies = await(latenciesFuture, 20.seconds)
latencies.failureCount should be(0)
latencies.quantile(0.99) should be < 10.milliseconds
}
This is possible because the interaction between the test and the service is of a specific kind: you are performing a load test for a request–response protocol. In this case, you only need a factory for request–response pairs that you can use to generate the traffic as needed, and the shape of the traffic is controlled by the parameters to the measure() method. The asynchronous result of this measurement is an object that contains the actual collections of results and errors that the 10,000 individual tests produced. These data can then easily be analyzed in order to assert that the latency profile fulfills the service-level requirements.
11.3.7. Asserting the absence of asynchronous errors
The last consideration when testing asynchronous components is that not all interactions with them will occur with the test procedure. Imagine a protocol adapter that is mediating between two components that have not been developed together and therefore do not understand the same message formats. In the running example with the translation service, you may at first have a version of the API that is based on text string serialization (version 1).
Listing 11.17. Simple translation API
case class TranslateV1(query: String, replyTo: ActorRef)
The languages to be used for input and output are encoded within the query string, and the reply that is sent to the replyTo address will be just a String. This works for a proof of concept, but later you may want to replace the protocol with a more strictly typed, intuitive version (version 2).
Listing 11.18. Adding stricter types to the translation API
case class TranslateV2(phrase: String,
inputLanguage: String,
outputLanguage: String,
replyTo: ActorRef)
sealed trait TranslationResponseV2
case class TranslationV2(inputPhrase: String,
outputPhrase: String,
inputLanguage: Language,
outputLanguage: Language)
case class TranslationErrorV2(inputPhrase: String,
inputLanguage: Language,
outputLanguage: Language,
errorMessage: String)
This redesign allows more advanced features like automatic detection of the input language to be implemented. Unfortunately, other teams have progressed with implementing a translator using the version 1 protocol already. Let us assume that the decision is made to bridge between this and new clients by adding an adapter that accepts requests made with version 2 of the protocol and serves the replies that are provided by a translation service speaking the version 1 protocol in the background.
For this adapter, you will typically write integration tests, making sure that given a functioning version 1 back end, the adapter correctly implements version 2 of the protocol. To save maintenance effort, you will also write dedicated tests that concentrate on the transformation of requests and replies; this will save time when debugging failures, because you can more easily associate them with either the adapter or the back-end service. A test procedure could look like this.
Listing 11.19. Testing the translation version adapter

Here the test procedure drives both the client side and the back-end side, stubbing each of them out as a TestProbe. The only active component that is executed normally is the protocol adapter. This allows you to not only formulate assertions about how the client-side protocol is implemented, but also control the internal interactions. One such assertion is shown in the last line, where you require the adapter to not make gratuitous requests to the service it is wrapping. Another benefit is that you can inspect the queries that are sent—see both occurrences of the TranslateV1 type—and fail early and with a clear error message if those are incorrect. In an integration test, you would see only overall failures in this case.
This approach works well for such a one-to-one adapter, but it can become tedious or brittle for components that converse more intensely or more diversely with different back ends. There is a middle ground between integration testing and fully controlled interactions: you can stub out the back-end services such that they are still executed autonomously, but in addition to their normal function, they keep the test procedure apprised of unexpected behavior of the component under test. To keep things simple, we will demonstrate this on the translation service adapter again.
Listing 11.20. Mocking error behavior
case object ExpectNominal
case object ExpectError
case class Unexpected(msg: Any)
class MockV1(reporter: ActorRef) extends Actor {
def receive = initial
override def unhandled(msg: Any) = {
reporter ! Unexpected(msg)
}
val initial: Receive = {
case ExpectNominal => context.become(expectingNominal)
case ExpectError => context.become(expectingError)
}
val expectingNominal: Receive = {
case TranslateV1("sv:en:Hur mår du?", replyTo) =>
replyTo ! "How are you?"
context.become(initial)
}
val expectingError: Receive = {
case TranslateV1(other, replyTo) =>
replyTo ! s"error:cannot parse input '$other'"
context.become(initial)
}
}
This mock of the version 1 back end will provide the expected responses during a test, but it will do so only at the appropriate points in time: the test procedure has to explicitly unlock each of the steps by sending either an ExpectNominal or an Expect-Error message. Using this, the test procedure changes to the following.
Listing 11.21. Testing for correct error handling

The test procedure in this case still drives both the client side and the back end, but the latter is more autonomous and allows the test to be written more concisely. The first verification of the absence of asynchronous errors is performed such that it does not introduce additional latency; its purpose is only to aid in debugging test failures in case an asynchronous error from the nominal test step does not subsequently lead to directly visible test failures but instead only bubbles up in the last line of the test.
11.4. Testing nondeterministic systems
The previous section introduced the difficulties that arise from the asynchronous nature of Reactive systems. This had several interesting consequences even though the process that you were testing was fully deterministic: given a certain stimulus, the component will eventually respond with the correct answer—the translation of a given phrase should always yield the same result. In chapter 8, we discussed that in distributed systems, determinism cannot always be achieved: the main reasons are unreliable means of communication and inherent concurrency. Because distribution is integral to Reactive system design, you nevertheless need to be able to test components that exhibit genuine nondeterminism. Such tests are harder to express because the order of execution is not specified as a sequential progression of logic, and for a single test procedure, different outcomes or state transitions are possible and permissible.
11.4.1. The trouble with execution schedules
Anyone who has written tests that are based on a particular event occurring within a specified time has likely seen spurious failures, where a test succeeds most of the time but fails on occasion. What if the execution is correct but the timings are different because of varying insertion orders into queues, or different values being returned based on what was requested in what order?
It is imperative that application developers define all the correct behaviors that can occur based on varying execution schedules. This can be difficult, because it implies that the variance is finite and knowable; and the larger a system is, and with greater numbers of interactions, the more difficult this can be with respect to precision. An example of a tool that supports this kind of functionality is Apache JMeter (http://jmeter.apache.org), where you can use logical controllers to fire requests in varying orders and timings to see whether the responses received match expectations for system behavior. Logical controllers have other useful features as well, including request modification, request repeating, and more. By executing tests with tools such as JMeter, you can root out more logical inconsistencies in your Reactive application than if you always rely on tests being executed in one order and one timing.
11.4.2. Testing distributed components
With distributed systems, which Reactive applications are by definition, some more difficult problems must be considered. Foremost is the idea that a distributed interaction can succeed in one dimension while failing in another. For example, imagine a distributed system where data must be updated across four nodes, but suppose something goes awry on one of the servers and it never responds with a successful update response before a timeout occurs. These are known as partial failures,[7] where latency can increase and throughput can fall because interactions between the many services that make up the application are unable to complete all tasks (see figure 11.3).
Figure 11.3. Illustration of a partial failure occurring when an interaction relies on three services and one interaction cannot be completed successfully
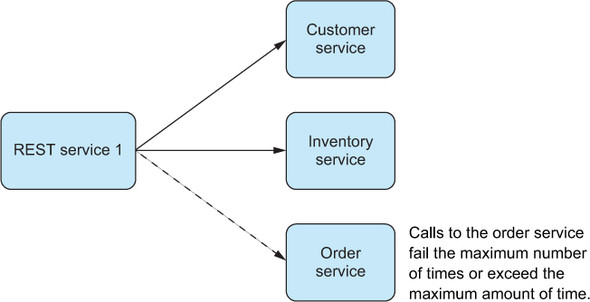
What is particularly tricky about these kinds of failure is that it is unlikely that you can consider all the ways in which a Reactive application may fail partially and derive appropriate behavior for each case. Instead, you should consider what the application should do when something occurs that you did not expect. We discuss this in much more detail in chapter 12.
11.4.3. Mocking Actors
In order to show that a test passes or fails based on external interactions, a popular testing methodology is to mock or stub an external dependency. That means when a class to be tested is constructed, the external services on which it depends are passed into the constructor of the class so they are available at the time they are to be used. But mocking and stubbing a dependence class are two different approaches, each with its own tradeoffs.
Mocks
Mocks are the concept of using an external library or framework to represent a fake instance of a class so that you can make assertions about whether a valid response can be properly handled. For example, imagine a class to be tested that would attempt to persist the data from the class into a database. For unit tests, you would not want to test that interaction to the database, only that the class gives the appropriate result based on whether the attempt to perform that interaction was successful.
To create such tests, many mocking frameworks have sprung up in the past decade that allow you to create a “mock” instance of the class, where calls to the mocking framework instance can be preconfigured to return a specific value for that test. Examples of such frameworks on the Java platform include EasyMock, JMock, Mockito, and ScalaMock. For each test, a mock instance is created and set up with the expected result to a particular interface; and when the call is made, that value is returned and permits you to make assertions that such behavior led to an appropriate result.
Stubs
Many developers consider the idea of using mocking frameworks to be an antipattern, where mocks do not represent an appropriate response mechanism for testing how such interactions take place. These developers instead prefer to use stubs, or test-only implementations of the interface that provide positive or negative responses for each interface based on the kind of response expected. This is considered less brittle at the time refactoring to an interface takes place, because the response from the stubbed method call is better defined.
There is a further consideration with respect to stubs: many developers complain that creating stubs for an interface is painful because it means they have to provide implementations of each public interface even when they are not used for a particular test, because the implementation of the interface specific to the test still requires each method in the interface to have defined behavior, even if that behavior is to do nothing. But developers such as Robert Martin have argued that using mocking frameworks is a “smell test” for APIs that have begun to exceed the single responsibility principle:[8] if the interface is painful to implement as a test stub because so many interfaces have to be implemented, then the class interface is trying to do too much and is exceeding the best practice rules for how each class should be defined with respect to the number of things it can do.
These kinds of arguments are best left to development teams to define, because it is easy to find edge cases that exceed such rules of thumb. As an extreme example, if you have an interface with 100 public interfaces, you will have to provide an implementation of all of them in order to construct a stub for a single test, and this is difficult to do. It is even more difficult to maintain as the API changes during development. If your interfaces are small and represent atomic, granular responsibilities, writing stubs is much simpler and allows for more expressive interpretations of how those dependencies can respond based on certain inputs, particularly when the interactions between the calling class under test and the dependency become more complex.
Reverse Onion testing pattern
A key concept for building effective tests for all applications is to create tests for the entire application from the inside and work outward. This kind of testing is called the Reverse Onion pattern, where the approach is likened to peeling the layers of an onion inversely: putting them back from the center out. This blends directly into the strategy of testing that was discussed in the beginning of the chapter. In taking this approach, the most minute expressions and functions are tested first, moving outward to services in isolation and then to the interactions themselves.
11.4.4. Distributed components
Contextual handlers such as Akka TestKit’s TestProbe are extremely handy for writing Reverse Onion tests. Constructs like these allow you to differentiate between the responses for each request. Each test must have the ability to provide implementations, whether by mocks or stubs, of the Actors/classes on which they depend, so that you can enforce and verify the behavior you expect based on their responses. Once you have built tests with these characteristics, you can effectively test partial failure from the responses you get based on each failed interaction with each of those dependencies for an Actor/class. If you are making a call to three services and you want to test the behavior of the class when two of the three succeed and the third fails, you can do so by stubbing out behavior where the two successful stubs return expected values and the third returns an error (or never returns at all).
11.5. Testing elasticity
For many developers, the concept of testing load or volume is well known. But for Reactive applications, the focus changes from that traditional approach to being able to verify that your application deployment is elastic within the confines of your available infrastructure. Just like everything else in application development, your system needs bounds in time and space, and the space limitation should be the maximum number of nodes you can spin up before you begin applying back pressure. In some cases, you may be running on top of a platform as a service (PaaS) where you “spill over” into public infrastructure like AWS or Rackspace images. But for many companies, that is not an option.
To test and verify elasticity, you first have to know the bounds of throughput per node and the amount of infrastructure you will be deploying to. This should ideally come from the nonfunctional requirements of your application from the outset of the project; but if you have a clear idea of what your existing application’s throughput profile looks like, you can start from there.
Assuming each node can handle 1,000 requests per second, and you have 10 nodes on which you can deploy, you want to test that traffic below a certain threshold only results in the minimum number of servers running that you specify. Tools such as Marathon with Mesos are run through Docker instances that you can query to see whether nodes are up or down, and Marathon has a REST API through which you can make other assertions about the status of the cluster. To provide load to the system, several useful free utilities do the job exceptionally well, such as Bees With Machine Guns (https://github.com/newsapps/beeswithmachineguns) and Gatling (http://gatling.io).
11.6. Testing resilience
Application resilience is a term that needs to be deconstructed. Failure can occur at many levels, and each of them needs to be tested to ensure that an application can be Reactive to virtually anything that can happen. The Reactive Manifesto states that “Resilience is achieved by replication, containment, isolation, and delegation.” This means you need to be able to break down the varying ways that an application can fail, from the micro to the macro level, and test that it can withstand all the things that can go wrong. In every case, a request must be handled and responded to regardless of what happened after it was received.
11.6.1. Application resilience
First are the application concerns, where you must focus on behaviors specific to how the application was coded. These are the areas with which most developers are already familiar and usually involve testing that an exception was received or what the application did as a result of injecting some data or functionality that should fail. In a Reactive application, you should expect that exceptions or failures (as described in section 2.4.3) are not seen by the sender of a message, but communicated through other messages that elevate the failure to being domain events.
This is an important point. Failure has traditionally been regarded as separate from the domain of the application and is typically handled as a tactical issue that must be prevented or communicated outside the realm of the domain for which the application was built. By making failure messages first-class citizens of the application domain, you have the ability to handle failure in a much more strategic fashion. You can create two domains about the application—a domain of success and a domain of failure—and treat each appropriately with staged failure handling.
As an example, imagine an error retrieving valid data from an external source such as a database, where the call to retrieve the data succeeded but the data returned was not valid. This can be handled at one level of the application specific to that request, and either whatever valid data was retrieved is returned to the message sender, or a message connoting that the data was invalid is returned. But if the connection to the external source is lost, that is a broader domain event than the individual request for the data and should be handled by a higher-level component, such as whomever provided the connection that was used in the first place, so that it can begin the process of reestablishing the connection that was lost.
Application resilience comes in two forms: external and internal. External resilience is handled through validation, where data passed into the application is checked to ensure that it meets the requirement of the API; if not, a notification is passed back to the sender (for example, a telephone country code that does not exist in a database of known numbers against which it is checked). Internal resilience includes those errors that occur within the application’s handling of that request once it has been validated.
Execution resilience
As discussed in previous chapters, the most important aspect of execution resilience is supervision of the thread or process where failure can occur. Without it, there is no way for you to discern what happened to a thread or process that failed, and you may not have any way of knowing that a failure occurred at all. Once supervision is in place, you have the capability to handle failure, but you may not necessarily have the ability to test that you are doing the right thing as a result.
To get around this issue, developers sometimes expose internal state for the supervised functionality just so they can effectively test whether that state was unharmed or somehow affected by the supervisor’s management of it. For example, an Actor that is resumed would see no change in its internal state, but an Actor that was restarted would see its internal state return to the initial values it should have after construction. But this has a couple of problems:
- How do you test an Actor that should be stopped based on a specific kind of failure?
- Is it a good idea to expose state that otherwise would not be exposed just for verification purposes? (This would represent a white-box test, by the way.)
To overcome these problems, a couple of patterns can be implemented that give you the ability to determine what failure has occurred or interact with a child Actor that has test-specific supervision implemented. These are patterns that sound similar but have different semantics.
It can be difficult to avoid implementing non-test-specific details in your tests. For example, if a test class attempts to create an Actor directly from the ActorSystem as a child Actor to the user guardian, you will not have control over how the supervision of errors that occur inside that Actor are handled. This may also be different than the expected behavior that is planned for the application and will lead to invalid unit test behavior. Instead, a StepParent can be a test-only supervisor that creates an instance of the Actor to be tested and delivers it back to the test client, which can then interact with the instance in any way it likes. The StepParent merely exists to provide supervision external to the test class so that the test class is not the parent. Assuming you have a basic Actor that you would like to test and that can throw an Exception, it can look as simple as the following.
Listing 11.22. Basic Actor to test
class MyActor extends Actor {
def receive = {
case _ => throw new NullPointerException
}
}
With that basic implementation, you can now create a StepParent strictly for the purpose of testing that will create an instance of that Actor from its own context, thus removing the test class from trying to fulfill that responsibility.
Listing 11.23. Providing a test context for the Actor under test
class StepParent extends Actor {
override val supervisorStrategy = OneForOneStrategy() {
case thr => Restart
}
def receive = {
case p: Props =>
sender ! context.actorOf(p, "child")
}
}
Now you can create a test that uses StepParent to create an Actor to be tested and begin to test whatever behavior you want without having the supervision semantics in the test.
Listing 11.24. Testing the Actor in the context of StepParent
class StepParentSpec extends WordSpec
with Matchers with BeforeAndAfterAll {
implicit val system = ActorSystem()
"An actor that throws an exception" must {
"Be created by a supervisor" in {
val testProbe = TestProbe()
val parent = system.actorOf(Props[StepParent], "stepParent")
parent.tell(Props[MyActor], testProbe.ref)
val child = testProbe.expectMsgType[ActorRef]
... // Test whatever we want in the actor
}
}
override def afterAll(): Unit = {
system.shutdown()
}
}
A FailureParent looks similar, except that it also reports any failures it receives back to the testing class. Assuming that you are going to test the same MyActor, a FailureParent will receive whomever it is supposed to report the failures back to as a constructor argument and, on receipt of a failure, report it to that entity before performing whatever supervision work it intends to do.
Listing 11.25. Reporting failures back to a designated Actor
class FailureParent(failures: ActorRef) extends Actor {
val props = Props[MyFailureParentActor]
val child = context.actorOf(props, "child")
override val supervisorStrategy = OneForOneStrategy() {
case f => failures ! f; Stop
}
def receive = {
case msg => child forward msg
}
}
Now, you can create a test that uses FailureParent to create the Actor to be tested and begin to test whatever behavior you want without having the supervision semantics in the test.
Listing 11.26. Removing supervision from the test
case object TestFailureParentMessage
class FailureParentSpec extends WordSpec
with Matchers with BeforeAndAfterAll {
implicit val system = ActorSystem()
"Using a FailureParent" must {
"Result in failures being collected and returned" in {
val failures = TestProbe()
val failureParent = system.actorOf(
val props = Props(new FailureParent(failures.ref))
val failureParent = system.actorOf(props)
failureParent ! TestFailureParentMessage
failures.expectMsgType[NullPointerException]
}
}
override def afterAll(): Unit = {
system.shutdown()
}
}
API resilience
The previous examples of using StepParent and FailureParent are also a form of API resilience, where the messages being sent between Actors are the API. In this way, you can think of Actors as being atomic examples of microservices. When requests are made of the service via its API, any data passed in must be validated to ensure that it meets the contract of what the service expects. Once proven to be valid, the service can perform the work required to fulfill the request.
When building your own APIs, consider the impact of passing in a mechanism for failure so that you can verify through tests that the behavior of the service is correct. These can be called domain-specific failure injectors.[9] This can be done either by providing a constructor dependency that will simulate or produce the failure, or by passing it as part of the individual request. It may be entirely useful to create a class whose sole purpose is to randomize various kinds of failure so that they are tested at different times or in different execution orders to prove more thoroughly that the failure is appropriately handled. The Akka team has done this with their FailureInjectorTransportAdapter class for internal testing.
11.6.2. Infrastructure resilience
Proving that your application is resilient is a great first step, but it is not enough. Applications depend on the infrastructure on which they run, and they have no control over failures that can take place outside of themselves. Therefore, it is also important that anyone who is serious about implementing a Reactive application also build or use a framework to help them test the application’s ability to cope with infrastructure failures that happen around it.
Some may use the term partition and mean only from the network perspective, but that is not necessarily true. Partitions happen any time a system has increased latency in response to any reason, including stop-the-world garbage collection, database latency, infinite looping, and so on.
Network resilience (LAN and WAN)
One of the most notorious kinds of infrastructure failures is a network partition,[10] where a network is incapable of routing between two or more subnetworks for various reasons. Networks can, and do, fail. Routers can go down just like any other computer, and occasionally paths provided by routing tables that are periodically revised and optimized cannot be resolved. It is best to assume that this will happen to your application and have a protocol for application management in the face of such an event.
Cluster resilience
In the case of a network partition, it is entirely plausible that two or more nodes in a clustered application will not be able to reach each other, and each will assume leadership of a new subcluster that cannot be rejoined or merged. This is called the split-brain problem.[11] The optimistic approach is to allow the two or more subclusters to continue as normal, but if there is any state to be shared between them, this can be difficult to maintain as far as updates that occur in each being resolved to the correct final answer if and when they rejoin. The pessimistic approach is to assume that all is lost, shut down both subclusters, and attempt to restart the application entirely, so that consistency is maintained.
Some cluster-management tools attempt to take a middling approach, where any subcluster with a majority of nodes (greater than 50% of known nodes) will automatically attempt to become the leader of a cluster that stays in operation. Any subcluster with less than 50% of known nodes will then automatically shut down. In theory, this sounds reasonable, but cluster splits can be unreasonable occurrences. It is entirely likely that such a split in the cluster will result in multiple subclusters with less than 50% of known nodes in all of them, and that they will all shut down as a result. The operations teams that manage distributed systems in production have to be always on guard for such events and, again, have a protocol in place for handling them.
Node and machine resilience
Nodes, or instances, are processes running on a machine that represent one instance of an application currently able to perform work. If there is only one node in the entire application, it is not a distributed application and represents a single point of failure(SPOF). If there is more than one node, possibly running on the same physical machine or across several of them, it is a distributed application. If all nodes are running on just one machine, this represents another SPOF, because any failure to the machine will take down the entire application. To make an application provably Reactive, you must be able to test that the removal of any node or machine at runtime does not affect your ability to withstand your application’s expected traffic.
Data-center resilience
Similar to the other infrastructural concepts, deploying an application to a single data center is an SPOF and not a Reactive approach. Instead, deployment to multiple data centers is a requirement to ensure that any major outage in one leaves your application with the capacity to handle all requests in others.
Netflix has created a suite of tools to help it test the robustness of its applications while running in production, called the Simian Army.[a] Netflix has had major outages happen in production and prefers to continue testing its application’s resiliency at the node and machine level even in production. This gives the company tremendous confidence that it can continue to service its customers even in the face of significant failures.
To test node resilience, Netflix uses Chaos Monkey, which randomly disables production instances when executed. Note that this tool is only executed with operations engineers in attendance who closely monitor for any outages that could occur as a result of the outages the tool induces. As a result of success with this tool, Netflix created a legion of other such tools to check for latency, security credential expiration, unused resources, and more.
To check resilience of an entire AWS availability zone, which is an isolation barrier within a deployment region, Netflix uses the Chaos Gorilla. This simulates a failure of an entire availability zone and checks whether the application is able to transition work to instances in other availability zones without downtime. To test data center resilience, Netflix uses the Chaos Kong tool, because the company currently uses multiple AWS regions for the United States alone.
Whether or not you use existing tools, such as those from Netflix, or build your own, it is critical that you test your application’s resilience in the face of myriad infrastructure failures to ensure that your users continue to get the responses they expect. Focus on applying these tools for any application that is critical to the success of your business.
11.7. Testing responsiveness
When testing elasticity and resilience, the focus is primarily on the number of requests your application can handle at any given time and with any given conditions. But responsiveness is mostly about latency, or the time it takes to handle each request. As discussed in previous chapters, one of the biggest mistakes developers make is tracking latency by a metric defined qualitatively, typically by average. But average is a terrible way of tracking latency, because it does not accurately reflect the variance in latency that your application is likely to experience.
Instead, a latency target profile must be created for the application in order for the designers to understand how to assemble the system. For varying throughputs, the expectation must be defined from the outset of what latency is acceptable at specific percentiles. Such a profile might look like the example given in table 11.2.
Table 11.2. Example of expected latency percentiles in relation to external load
|
Request/s |
99% |
99.9% |
99.99% |
99.999% |
|---|---|---|---|---|
| 1,000 | 10 ms | 10 ms | 20 ms | 50 ms |
| 5,000 | 20 ms | 20 ms | 50 ms | 100 ms |
| 20,000 | 50 ms | 50 ms | 100 ms | 250 ms |
What is critical about this profile is that it clearly shows the expectation of how well the application should be able to respond to increased load without failing. You need to create tests that will verify that the response time is mapped appropriately against each percentile for each level of throughput, and this must be part of the continuous integration process to ensure that commits do not impact latency too negatively. There are free tools, such as HdrHistogram (https://github.com/HdrHistogram/HdrHistogram), which can help with the collection of this data and display it in a meaningful way.
11.8. Summary
Testing to prove the ability to respond to varying loads, events, and failures is a critical component to building a Reactive application. Allow the tests to guide the design by making choices based on the results you see. At this point, you should have a clear understanding of the following:
- Testing must begin at the outset of the project and continue throughout every phase of its lifecycle.
- Testing must be functional and nonfunctional to prove that an application is Reactive.
- You must write tests from the inside of the application outward to cover all interactions and verify correctness.
- Elasticity is tested externally, whereas resilience is tested in both infrastructure and internal components of the application.