
While discussing security patterns, we described handling (or, in fact, mishandling) faults as one of the major contributors to the vulnerabilities of SOA, and the inadequately designed Fault/Errors Handling (EH) framework is apparently the main provider of all information to the error/event logs and the "grateful" attacker. We mentioned some simple rules for exception handling inside a single service (Entity or Utility service models) as the sole building block of the entire SOA infrastructure. Implementation of this rule would be enough for an infrastructure that contains only these models of SOAP services or simple REST services without compositions of any complexity. When we have something more complex (such as Task Orchestrated service models) or in fact any external exposure along with associated security risks or (usually) both, something that is a lot more substantial is required. This something in addition to a proper EH's service design will require events logging and log mining/analyzing; it also requires you to add compensation handlers, build compensation policies, bind policies and handlers, and establish manual recovery routines in a worklist as the last line of defense. More often than not, the complexity of the steps we just mentioned is frustratingly high (composition with three sequential invocations can easily span compensation activities with five invocation steps). It is so complex that after several workshops and incomplete prototypes, architects decide to put all of the handling into a work list to come up with a manual resolution with all the associated human-related problems (responsiveness, accuracy, and consistency).
The design of our agnostic composition controller will be incomplete and the whole idea of dynamic composition assembly compromised if we do not demonstrate how to automate error recovery using SOA patterns. Traditional Oracle OFM/SCA realization covers both Rollback and Compensation patterns (where Rollback is part of Atomic Transaction Coordination and Compensation is BPEL/SCA); the automated recovery functionality is usually consolidated in the policy-based Error Hospital OFM facility.
It would be useful to look at the term policy-based and understand what the policy is, how it can be enforced, how many of them there are, and is it really possible to centralize all policies in one center. The role of the Service Repository, whose taxonomy we discussed earlier, has to be observed from one more side.
In this chapter, we are going to discuss standard tools first, explaining what kind of centralizations you have to maintain to achieve Policy Centralization (for recovery, compensation, and composition protection) as well as basic patterns such as Compensative Service Transaction, Service Repository, and Service Instance Routing. However, the main purpose here is to present Automated Recovery Tool (ART), which is capable of automating service recovery and transaction compensation.
Compensation is not exactly proportional to the complexity of your composition. With no rollback option available, returning to a condition that is equivalent to the composition's initial state (before the composition was initiated, or at a certain composition condition where the state of affairs was consistent) is directly related to the duration of the composition. Think of it this way: if you break your wife's favorite cup, a bunch of flowers and another cup would be enough. However, if you forget your wedding anniversary, even a good diamond ring could barely settle this down (although, one positive thing is for certain: you will never forget it again). Talking seriously about services' data consistency, the further we are from the composition's initiation point, the more difficult it will be to remove all relations that occur around the data implanted by service activities. As we mentioned, long running compositions hosted by SCA in general can be presented as a chain of ATCs that are handled by OSB. Actually, this is the shortest description of the agnostic composition controller, which is available in Chapter 3, Building the Core – Enterprise Business Flows, to Chapter 6, Finding the Compromise – the Adapter Framework; it signifies that the centralized exception handling facility should equally cover Rollback and Compensations.
Tip
Regardless of the terminology you have established for your domain, the process of handling errors, exceptions, and system messages, in general, is the same as that of detecting the event, assigning an appropriate action for it, and executing this action in a controlled manner. In the scope of this chapter, the event we understand is not just any event (change of state), but those that are not in the range of our "happy execution plan". A forced event such as Audit is something different, although its data can be stored together with exceptions in the common log.
As we mentioned, a number of corrective actions can be quite substantial, and going further, not all of them can be really corrective. There are some preparations and post-completion steps required; also, the service composition should adhere to certain design rules in order to be more controllable in situations when recovery is needed. We will start with gathering common requirements first and then see which of the Oracle tools can cover them in a generic and reusable way. Our first traditional move is the analysis of a typical SOA landscape.
Firstly, we have to bear in mind that for one single composition, we have six runtime-related SOA frameworks involved from end to end. Therefore, the occurrence of an event requiring extra care must be delivered to the composition controller that is currently involved in coordinating services' collaboration. This delivery process is conditional and depends on the composition phase (initiation, registering participants, requesting participants, invocation, accepting votes, rejecting votes, data assembly/transformation, and final delivery). Thus, an events' origins (the producer that the so-called event produces) and its time of occurrence will define how it should be handled/recorded.
At least four different Oracle products make service interactions possible: OSB, SCA/SOA Suite, ESG, and OER. This is the bare minimum, so the list of products could be much broader. These service engines, buses and orchestrators, as separate products, have their own error-handling facilities. That's quite understandable for separating API gateway error information from the service domain behind it, but it doesn't help with harmonization and unification of exception handling. The master composition controller will get accurate and consistent information about an exception in order to take proper corrective actions. As we could have at least two types of controllers' realizations (demonstrated earlier), handlers' collaboration is not a simple task.
Remember that events can be basic or complex. From the Exception Handler's standpoint, events can be of two types:
- The first type is where there is immediate reaction of an abnormal situation on service, service engine, an element of service infrastructure, or a remote endpoint, provided as an error message (for instance, a SOAP error message for WS-services, or error stack trace for an internal service resource)
- The second type of event talks about the result of statistics gathering and/or patterns' analysis of basic events that is obtained during a certain amount of time (with relation to a certain threshold of time)
By considering all of this together with the previous point, we realize the importance of consolidation of all Error Handlers under one controller; going further, we'll talk about Log Centralization as the source for complex event processing (CEP). Oracle has a number of instruments for data analysis and monitoring; BAM is one of them and is sometimes considered a service transaction monitoring tool. However, some limitations make it unsuitable for runtime composition error handling. BAM is the topic of the next chapter; there, we will talk about it a bit more. Right now, we just need to mention that lack of runtime SOA capabilities makes architects and developers look at log mining and infrastructure monitoring tools such as Nagios (http://www.nagios.org/) closely. In your service infrastructure, you could have your own homemade monitoring/logging tools, and quite often, developers have their own opinions about the usage of log4j and its structure (scattered everywhere). Thus, Log Centralization is one of the primary prerequisites of a successful EH implementation, although, it's not considered a standard SOA pattern (it's just good common sense). By the way, Oracle is putting in some efforts in this direction by presenting different management packs for products' OEMs. Alerts from OEMs can be very useful as an input for EH.
You will also need to consolidate all logs—when we say all, we mean ALL. Data misses from hidden or stray logs, growing uncontrollably, are not only a perfect recipe for service resources' depletion and system crashes, but also a juicy target for attackers—and integration of all Error Handlers are the two main requirements for establishing Policy Centralization. Again, here we are talking about fault policies mostly, setting aside all other policies. This task is harder than the previous type of centralization for several reasons:
- Every tool has its own policy representation and ways of binding it to the event resolution, and different components within SCA have different policies: Mediator, BPL, and HumanTask.
- The WS-Policy specification along with related WS-SecurityPolicy and WS-PolicyAttachment are not related to most internal policies in OFM. They share some common principles, but do not expect them to be compatible or easily transformable. OEG (API Gateway) Policy Studio will not cover all diversities of policies despite its name, and it would be better to not use it for a purpose that is different from security.
Obviously, the complexity of Policy Centralization as a task is proportional to the complexity of underlying individual policies and their alternatives for every Policy Subject within its scope. These terms will be explained shortly (as you will need them for SOA exams), but stating it plainly, centralization of EH policies will be positive only if you anticipate all error scenarios for your compositions and present them in a clear hierarchy. Otherwise, it will be the centralization of false positives, thereby mishandling most of the error situations.
Individual service exception handlers and resource exception handlers could be a good start for building this hierarchy. The process of speculation on possible compositions in which this service might participate in would be the second step, and results of this process should be properly correlated with established Service Layers (also SOA patterns, which are discussed in Chapter 1, SOA Ecosystem – Interconnected Principles, Patterns, and Frameworks), vertically and horizontally. Simply put, this kind of anticipation and countermeasure planning must be commenced right from the service design stage, even before the first line of code is written. Your first WSDL is a good basis for this work. However, what if we cannot anticipate all the possible error situations? Well, manual recovery using SOA Suite Human Workflow is still acceptable for cases that cannot be identified, but the number of these cases must be kept to a minimum. This will ensure that manual recovery operations will be performed in minutes.
For instance, in the article Protecting IDPs from Malformed SAML Requests (Steffo Webber, Oracle), the discussion of OEG policies for securing SAML tokens clearly state that for mitigating SSL flaws, the manual reaction of the vulnerabilities of an SAML token on these threats is acceptable as long as the policy allows you to catch the event and send the alert.
We also have to take into account that any centralization will require storage for policy assertions, and as long as we deal with different policy formats, these assertions have to be expressed in a form that is suitable for the following:
- Transformation and quantification
- Should be understood by humans (ops, rule designers, and business analysts), with possible alterations only by an authorized personnel
Logically, Service Repository would be our first choice with the Service Repository endpoint available.
While talking about storages and logs, we have to make one distinction between Audit and Exceptions. This difference is clear in service components' design where we handle errors in the catch{} block, and Audit any data using log.info() or any other command/library you want. At the OFM tools' level, it's also obvious; for instance, OSB has log activity. The situation is not always clear when we are dealing with orchestration engines where dehydration storage can also be the source of Audit; for custom packages, it can be a common logic. In general, the level of Audit and error reporting is not the same, especially in Identity Management and Perimeter Protection. Also, regarding the Oracle Fusion Audit Framework, you should be aware that applications will not stop operating if the Audit is malfunctioning. Standalone applications can be included into the OFM Audit Framework through the configuration of the jps-config.xml file.
Now, we will consolidate the results of our analysis into common but detailed requirements, which are suitable for extending Oracle's Exception Handling facilities.
Let's get back to Chapter 1, SOA Ecosystem – Interconnected Principles, Patterns, and Frameworks, and look at the figure under the SOA Technology Concept one more time. In the first chapter, we tried to consolidate WS-* specifications in one logical roadmap. Generally speaking, we do not have standards that are specially dedicated to Error Handling, and activities in this area are governed by policies (as we mentioned, not exactly WS-Policies and differently for all vendors); this is due to the importance of the subject we put on the right-hand side of SOA patterns (generic) under the roof of the consolidated Error Hospital (which is Oracle-specific). So, we must have and maintain the following:
- The ultimate importance of the Exception Shielding pattern for SOA security has been explained in the previous chapter. There, we stated that doing shielding and error message sanitation on the gateway is not a good choice because unclean messages will travel across the whole infrastructure until the front door before it is cleansed/blocked. However, what if you do not have a Gateway? Even if you have, think about the processing pressure you put on the secure perimeter, which is already loaded with Message Screening tasks, or the possibility to read an error's theatrical information within your network. Anyway, excessive messaging could unnecessarily stress your network. Therefore, cleansing must be on service at first hand, at least for proper distribution of the workload.
- Another task associated with Exception Shielding is the translation of an error's message/code. Unfortunately, this task cannot be performed on a service; that's the responsibility of the Composition Controller (within Error Handler as well). When the remote application returns a completely valid error message with an error code that is different from your service domain notation, it must be filtered/normalized according to your standards. As a typical composition controller is either an SCA- or OSB-based service, it can be done on these inner layers. Alternatively, it can be done by an adapter in the ABCS Framework using Adapter Factory (which is also OSB-based in our realization). In our design, we have the Lookup functionality, but its main purpose is to extract from the ER transformation descriptor (XQuery function or XSLT) or endpoint's URI. In this case, translation can be performed by transformation, but everything depends on the transformations' complexity. Transformation of an acknowledged message from an external service would be requited anyway, as we should not expect that its format will be the same across different domains; this would be too ideal.
If you decide to handle it in SCA, traditional Domain Value Maps will do the job with the handy
dvm:lookupValuefunction. Later, we will touch upon how it can be done in a traditional way, but you surely remember that DVMs are traditionally stored in OFM MDS, and transformations could be scattered across adapter projects. So, the maintenance of any form of centralization is a question. - After cleansing/normalization, an error's technical information is properly logged. Obvious things such as squeezing the entire stack trace dump into the 2K
VARCHAR2field are solved during the development stage, but the question is a bit broader than the completeness of stored information. According to generic SOA principles, the core requirements for Abstraction and Discoverability (which are not exactly the best of friends) are as follows:- Interpretability of logged data. Data elements that are necessary for making a decision must be easily discoverable and understandable, as many policies will trust their meanings. Just think of this: not all reactions on an event should be immediate; it is desirable to have different handling policies for the same error, and it should depend on the time window and the number of event occurrences in a certain time interval. This means that some abnormal events which happen between business hours (09:00-17:00) should be handled in 5 minutes (retried, passed to compensation, send to human tasklist, or canceled), whereas 02:00-04:00 batch operations' mishaps of the same type must be handled after one hour (the question of why someone could decide to run batch jobs using SOA compositions is not critical for this example; it can be done anyway). Conditions for this kind of discriminant handling with sliding time windows could be really complex, so the data for making decisions must be precise and easily extractable.
- Interpretability also requires proper error classification, and for immediate exceptions, this can be done on an acting service. Even simple segregation of Technical and Functional errors will be helpful for event pattern recognition, but actually, we can do a lot during the initial service design phase. It is our responsibility to identify the framework that will be hosting our service (we will identify the closest neighbours of our service) and types of compositions it will participate in. Thus, for runtime errors, it's quite possible to compose a list of errors and their causes. Right from the start, we can say that most technical errors will be related to utility services, whereas functional types belong to task-orchestrated services. This classification must be stored in the Service Repository, but we should warn you about making it too formal. Example of this registering and classification exercise will be demonstrated further.
- The preceding requirement is the main prerequisite for a low EH footprint. The exception handling system should not consume vital server resources, essential for the business operation environment. The EH component must not only be lightweight, but the physical components should be separated as well to reduce the additional burden on EH. Obviously, the
Retry/Continue/Canceldefault resolutions are properties of OFM service engines (OSB/SCA), and the basic compensation mechanisms are attached to BPEL. However, log consolidation jobs, complex processing of events using patterns, instances of composition controllers, and running EH-related compositions can be moved to the separate environment.
- Next and probably the main EH requirement is the Error Handling automation. In the previous bullet point, we already mentioned the basic resolution operations based on primitive policies, but what we really are looking for is the automation of complex compensations, triggered by irregularities in dynamic compositions. Logically, compensation of such compositions should also be dynamic, which makes this task quite difficult. If service composition error classifications are covered diligently with all the necessary details, dynamic compensation is achievable in various ways: through the standard OFM Error Hospital and/or custom compensation execution plans similar to what we discussed in Chapter 3, Building the Core – Enterprise Business Flows, and Chapter 4, From Traditional Integration to Composition – Enterprise Business Services, which are dedicated to synchronous and asynchronous composition controllers.
- Finally, if dynamic resolution is impossible (too late or too complex), manual resolution is the only option.
Generic Audit requirements in OFM are covered by Audit Framework for any application, included in the Audit policy (yes, another policy), using two-phase event propagation with optional event filtering. Any Audit-enabled application (Java running on WLS or a web app on an HTTP server) can dump Audit data using an Audit API to local storages called bus-stops. In the second phase, an Audit loader agent will upload dumped data to the centralized DB for Log Centralization. In some cases, dispersed bus-stops will suffice, but then you will miss the analytical capabilities that are provided by the Oracle BI Publisher connected to the central DB.
These five major requirements all together present the complete scope of EH that is capable of resolving most SOA errors with reasonably reduced pressure on Ops task forces. Naturally, the complexity of the recovery operations will not disappear only with the realization of what has to be done; to make it happen, quite a considerable amount of work must be done during the service design phase and during the initial exception testing phase in the dev environment.
There must be a strict rule indicating that all draft service versions must be delivered into a JIT environment with a complete set for all possible "rainy day" scenarios. This approach is common for all types of EH resolutions; either you maintain them on a standard Error Hospital using OFM policies or you delegate them to more complex EH composition controllers, linked to the Service Repository with the required EPs. In this case, fulfilling the requirements of service composition error classifications should be the first step, and we will look at it now.
Although service error definition and classification is utterly important for the reasons we just saw, we only have enough room to provide directions for building and maintaining such a list in the Service Repository. This exercise is part of building a Service Profile and a Service-level profile structure (see Chapter 15, SOA Principles of Service Design, Thomas Erl, Prentice Hall). The basis for the exercise is as follows:
- The number of frameworks that will participate in service deployment and interactions.
We mentioned six, but commonly, we should focus on three: EBF, EBS, and ABCS (see the next figure, where the color red indicates errors and orange indicates Audit). For the presence of the ESR framework, we should consider Inventory Endpoint as an abstraction point within EBS.
- Technical layering (vertical) and positioning of the service in core technical layers.
Naturally, we have EBF as only a single layer. Bus and Adapters (not always physically, as some components/patterns are common, such as Adapter Factory) can logically be Northbound and Southbound, so the service operations will also be location-specific.
- The nature of underlying service technical resources.
The resource acquisition error from entity services sharing the same DB should be treated with elevated priority compared to a service with a dedicated configuration file, such as FSO. Continuing on that, it seems to be that Functional type warning from task-orchestration services about gradual performance degradation must be correlated with dehydration DB runtime metrics, and so on.
- Structure of the SOAP fault and other acknowledge and error messages.
The structure of these messages must be associated with logs' structures in order to minimize mappings and transformations on logging APIs and EJBs.
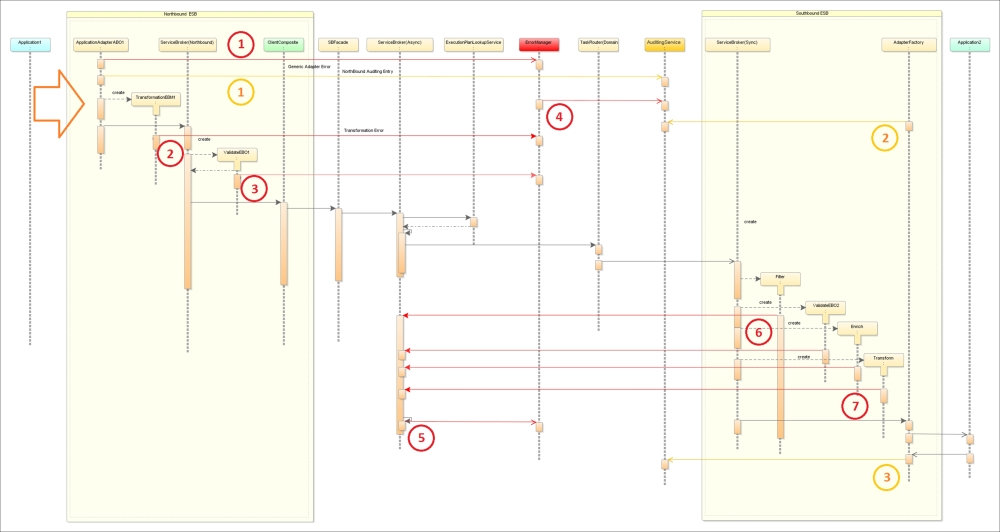
Fault handling sequence diagram in Agnostic Composition Controller
In the preceding sequence diagram, which is the consolidated view of all our SOA layers and frameworks around the agnostic composition controller, starting from the left (northbound), we can identify generic EH rules as follows:
- First, we start with the error in Application Adapter 1 (Active Poller), stating
Service-Legacy wrapper cannot extract data. The reason why an active service adapter cannot connect to the endpoint data source is because DB is offline and Queue is unavailable. Information will be provided to the Error Handler when the common resolution operation "Retry predefined number of times" (configured on ABCS/ OSB, depending on adapter realization), failed last time. Error Manager (ErM) will initiate the process of sending an acknowledgment message to the Legacy Application (if it can accept it, either human or machine readable) and activate data extraction using Dual Protocol again if it's available. Technically, ErM cannot do much about this error on the north side, even if poller is a complex BPEL process that assembles data from various data sources over a prolonged amount of time into a consolidated ABO. This scenario just signifies that the source is not available and business composition cannot be initiated, so the individual legacy adapter will just send a clear message to Audit (the orange line).At the same time, when Adapter-Aggregator is based on an agnostic composition controller, then exception handling should also be agnostic with extraction of resolution action from Service Repository. We should do this with caution, not overloading the SR endpoint with requests that involve trivial responses (OSB can perfectly handle retries with predefined intervals). The advantage of this approach is that you can monitor a controller's state (active or down) more proactively, without the need of having an additional heartbeat and external monitoring (although, it is inevitable for a passive adapter and some other components in the underlying frameworks). Other (additional) reasons could be that the ABCS layer is down, there is a network/firewall issue, file location is detached, the queue is unavailable, load balancer is (mis)configured, and the server (node) is down.
- The next error situation:
data extracted and assembled on the north side, but transformation from ABO1 to EBO failed. The potential reasons for this can be that the XQuery statement is not available, the execution of XQuery returns a business fault, and business data is inconsistent. Here, we cannot blame the application-composition initiator for all these errors; if the transformation descriptor is not available, we might have severe problems with the Enterprise Repository. Recovery options are still limited, but the severity of this problem is very high. If an adapter supports asynchronous communications, the recovery operation will not involve data retransmission from the source. Technically, this error could be related to misconfiguration or erroneous installation, so it can be recognized at earlier stages. - When business data is invalid, we should stop processing immediately and store the inbound message in an Audit log for further investigations. The application source should be informed accordingly.
- What if we get an exception in ErM? In this case, the ErM composition controller will not be able to invoke compensation flows or return names/code of resolution actions to individual components. This problem is quite similar to the situation where the master composition controller fails. (To avoid possible misunderstandings, the main composition controller and the EH composition controller are different instances of the same agnostic composition controller; both of them are based on the SOA pattern and promote Reuse and Composability. In order to reduce the EH footprint, you could decide to physically separate them on different WLS nodes.) Most commonly, this situation is related to the missing/inaccessible routing slip (execution plan). This is a highly critical situation, and a warning will be issued together with a proper Audit.
This is one of the reasons why in your design, you should separate Error Management and Audit. The same is true for errors that occur in Audit, but they are definitely not life threatening and business can continue as usual. Only Error Handler can inform you about the possible causes: invalid Audit message input, JMS queue as an Audit service is unavailable, Audit MDB has malfunctioned, Audit service is down, and Audit DB is down.
Tip
The OFM Audit Framework by default is undisruptive for business processes/applications because of the chain of bus-stops and Audit loaders. The situation could not be so simple in OFM if you decide to include
COMPOSITE_INSTANCE,CUBE_INSTANCE,CI_INDEXES, andDLV_MESSAGEtables into your Audit schema to trace a runtime trail of a message flow, identified by an execution context ID (ECID) outside of the OEM console. Actually, you should do this, as all together these tables can provide you with about 100 status codes regarding the composite instance's state. We do not have space to present them here; you will easily find them in the Oracle documentation. Thus, if your Audit, based on information from these tables, hangs, it's a very bad sign of the health of your SCAs. So, do not build SQL Audit statement killers that could slow down the SCAs' database; on the other hand, missing inconsistent Audit data from these tables indicates the critical situation in SCA. Talking about the status code in general, onlySTATE_CLOSED_COMPLETED (5)should make you happy. Be extra careful aboutSTATE_CLOSED_STALEandSTATE_OPEN_FAULTED. Code 12 (running with faults, recovery required, and suspended) must have the highest priority in your recovery routines. We will talk about SCA Mediator code fromMEDIATOR_INSTANCEa little further. - The next error situation (5 on the previous figure) is similar to the previous error, but occurred on the master controller. Generally speaking, there are two main reasons that are associated with this: either we do not have something to execute or we are unable to invoke something. The first one cannot be handled at runtime, as it's a result of a design-time or deployment mistake. In the controller operation, you do not even have to stop it for fixing this situation. You can disable the failing service first in ESR, then deploy the corrected EP, and enable the service again. Situations where we cannot invoke something or receive an erroneous response from the composition member during runtime are the main reasons why we should have Error Handler with dynamic error resolutions. Exceptions will be handled automatically when: the Service Broker SCA is down; the queue for Async SB is unavailable; BPEL, DB is overloaded or down; threads stuck; called SCA is down; messages cannot be correlated; the message structure invalid; an unknown Correlation ID is provided in the response message.
- Exceptions (parts 6 and 7 in the previous figure) in southbound ESB/ABCS layers, occurred during the execution of EP and/or VETRO pattern operations, will be propagated back to the master controller where they will be handled as mentioned in the previous paragraph. The exception causes are the same as for northbound, but the southbound layer is completely our responsibility; here, we will do everything possible to deliver the service message to the composition member. Basic reties of individual adapters will be handled in OSB locally within the business interval and only then will the error be transmitted back to SB. There are some common reasons for this: the JMS queue is unavailable for async, HTTP Servlet is down, network problems, general OSB technical problems (proxy service not found or disabled), the application server is down, application data source is unavailable, and an error situation on the adapter factory (OSB) together with responses from southbound applications/services will be properly audited (parts 2 and 3 in the previous figure).
In the following table, we will consolidate core exception handlings' properties with regards to a particular framework, a component in a framework, its role, operations performed, possible errors, error causes with relation to the operation, possible resolution actions, and areas where these recovery operations will be performed. Again, we are not going to perform the full mapping operation or present the complete list of values for the operation and possible reasons for an error to occur. This is simply because there is no space for it, and our role is to give you directions and basis for your team exercise. Anyway, your own SOA Framework layering cannot be much different from what is presented in the previous figure. So, after two to three workshops with developers, you will compose the complete spreadsheet, which will be ready to be deployed on ESR and exposed via the Inventory Endpoint for ErM lookup and fire. Regarding error code, you must map the external code to your own coding system and vice-versa if necessary. This mapping will be implemented in DVM or (better) in ESR.
The structure of the spreadsheet with the initial data we mentioned in the preceding table is a balanced scorecard (see the next figure, step 2), which is divided into several tabs for every framework. It contains the logical outcome for a combination: service + performed operation + position in technical infrastructure + process step (this is the service role). The completeness of the spreadsheet will depend on the granularity of the sequence diagrams for all use cases (step 1).
You do not have to use Excel as presented in the following figure. Any tool will do, but in the end, all the details must be stored in ESR (Oracle or custom, step 3) and the runtime part exposed via Service Endpoint for ErM.
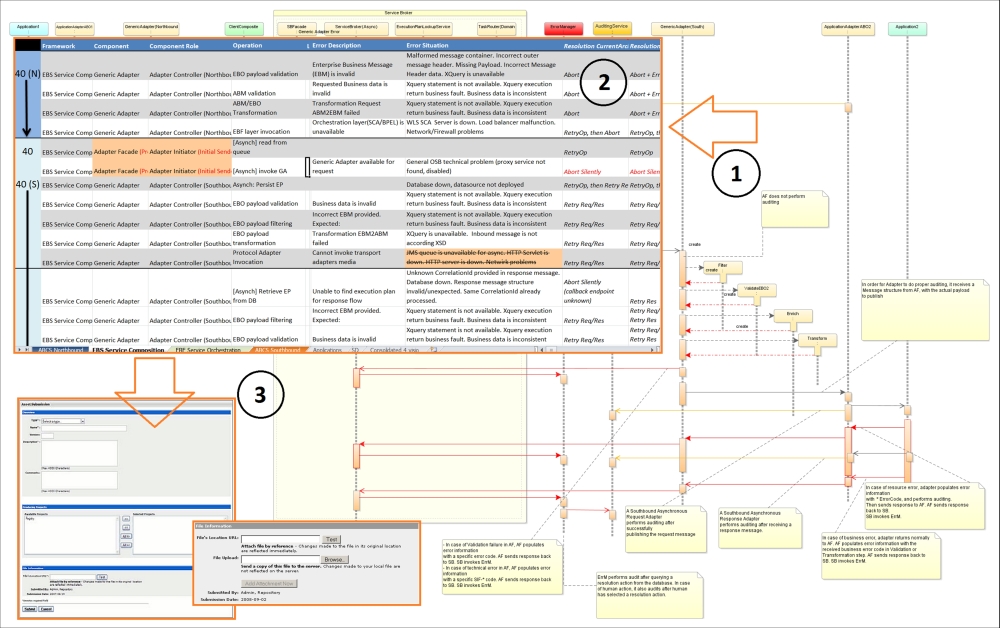
Defining fault resolution actions
In step 3, you will have to enter the results of your analysis into ESR assets (Service Profiles in this case). Optionally, you can upload the source of the entire spreadsheet. Sorry, we do not know how to import Excel into ESR with one click, but if the amount of discovered error-handling data is enormous (please do not overcook it, one step at a time), you can construct insert statements using ER (Chapter 5, Maintaining the Core – the Service Repository, which is dedicated to Enterprise Repository Taxonomy). Custom ER that is based on lightweight taxonomy (covered in the previously mentioned chapter) is much easier, and we used the last figure for building SQL insert statements for data import.
Now, we can see that handling exceptions in complex compositions will be inevitably complex as well. Similar to security, this complexity can be restrained by proper layering and application of SOA patterns as follows:
- Policy Centralization (fault policies first of all) and Metadata Centralization (steps 1, 2, and 3 in the preceding figure)
- Enterprise Repository and Inventory Endpoint
- Logic Centralization (with focus on exception handling)
- Exception Shielding (in assistance to service security)
Now, we are ready to formalize common design rules for taming this complexity.
Common requirements combined with discovered EH handling properties are expressed in the following points. By combining them together, we will strive to deliver fault-handling solutions for the entire SOA infrastructure, where composition controller(s) are the cornerstone. A single component's exception handling (only on BPEL or OSB) is not enough for enterprise-wide implementation, as it will lead to fault misses and mishandling of security threats:
- Rule 1: Error Handling Centralization on SB. EH Centralization will be maintained for agnostic Service Brokers (SBs) that broker service calls between heterogeneous components. Primarily, it must unify the OSB and SCA fault-handling frameworks, allowing error recognition (listening), catching, and propagation of unified policy-based handlers. Two handlers will be maintained for sync and async errors' resolution. This maintenance denotes reuse, as we have already demonstrated two types of Service Brokers that are capable of handling happy and unhappy tasks. Processing centralization will be based on three other Centralizations (Policy, Logic, and Metadata).
- Rule 2: Extend Metadata Centralization on Logs. Centralization must be applied to the metadata (service and fault object/message), policies, and logs. The immediate result of this centralization is the decreasing of fault message Model/Format Transformations between fault frameworks and fault handlers (logging MDBs, for instance). The main goal is to present ESR with all the metadata elements centralized. The MDS is an adequate option for SCA's metadata and policies.
- Rule 3: Contemplate the delegation of primitive recovery actions to service edges. Metadata Centralization after analysis, similar to the one offered previously in the Maintaining Exception Discoverability section, will present the list of common faults and primitive recovery actions (
Retry,Abort, andContinue) that can be immediately delegated to service edges (OSB and ABCS, the first line of EH handling) and provide ways of fault elevation/propagation back to SB (second line). Common faults should include the standard faults defined in the WS-BPEL specification (20 generic faults; see the BPEL 2.0 documentation). Redundancy with your own custom code will be avoided (don't reinvent the wheel, just discover and abstract). - Rule 4: Balance the Policy Centralization on the platform/frameworks. Policy Centralization will be applied to a meaningful extent. This means that by being realistic, we can hardly present some kind of universal policy (as one XML file), suitable for all OFM elements and frameworks. For instance, in SCA, we have fault policy binding for BPEL, Mediator, and SOA composite, and we reference them in
composite.xml. The location of policies can be defined using theoracle.composite.faultPolicyFileproperty and their bindings to the SCA components in theoracle.composite.faultBindingFileproperty. The physical location quite often is MDS (oramds:/apps/faultpolicyfiles/...). In OSB, we have OWSM (including basic security) and WLS 9 (including WS-Policy compliant) policies, and the first one is located in the OWSM policy store. Should we mention the API gateway policy store? So much for centralization. Thus, the rule is to maintain the policy descriptors (in human-readable form) in ESR and clearly define their areas of application. Using this definition one level down, in SCA, we can present clear policy chaining for automated resolutions (policy-id1 -> policy-id2 -> policy-idN), where it's possible. - Rule 5: Minimize log data cleansing by applying the Canonical Expression pattern. Log Centralization (not an SOA pattern) and activities around data collection and cleansing could be a very heavy and complex operation. No, this way, very complex. Why? We will demonstrate it later. For now, consider a separate DB and servers for log assembly/cleansing (depending on the complexity of your logs, of course). The rule of thumb is that the more diligent and accurate you are at the initial design stages (previous figure), the fewer problems you will have at later stages. This rule is so important that we should put it first. Break it (just misspell the stage or resolution code, or name it differently in ESR and your Java/BPEL code) and all further rules will have values that will be close to nothing. The Discoverability SOA principle rules the error-handling process.
- Rule 6: Apply ErM based on Service Roles. Observe service roles when applying rule 4. Complex global policies applied to composition members (SCAs), invoked and handled by the agnostic composition controller (SB) dynamically instead of fixing the error, could make the situation much worse. Simply put, errors in complex dynamic compositions must be handled (at least propagated to) by the same composition controller where all composition members are initially registered. An individual member will have no idea about the complexity of a composition. Thus, Error Hospital and OFM Fault Management Framework, in general, are more suitable for static (defined during design time) compositions (classic BPEL Mediator SCA from Fusion Order Demo). At the same time, standard policies (
fault-binding.xml+ fault-policies.xml => composite.xml) can be good candidates for an agnostic master SB and individual adapter services for the north side. - Rule 7: Maintain strict control on the ErM components footprint on Services and Compositions. As a logical outcome of rule 3, EH decentralization or service decomposition (if we assume Error Handler as a service utility type) will reduce an exception-handling footprint on the service infrastructure. Depending on your hardware specs and daily business workload, you will set thresholds for EH activities such as 5 percent CPU, 10 percent RAM, and 10 percent of total threads (just an example).
- Rule 8: Apply the Redundant Implementation pattern on critical elements of ErM. Redundant implementation of elements of the SOA infrastructure (WLS Nodes and Node manager, and SAN RAC DB) is an absolute must for a resilient HA infrastructure; however, from the EH standpoint, it is also prudent to consider a separate node for ErM SB.
- Rule 9: Provide alternative execution paths for business-critical service compositions. You cannot fix faulty OFM using the same OFM. Automated Recovery Tool (ART), or whatever you call it, must be in the utility service layer with a very shallow technical infrastructure and a maximum of one or two service engines, at least part of it. Just think of this: if an airplane loses its hydraulics, usually it is doomed as it cannot steer. The bitter irony is that there are still plenty of means to keep the plane safe and maneuverable: we could still have the engine's thrust and use it; alternatively, inbound air flows could power a small generator for elevator/rudder servos. Why is it not implemented? Actually it is, but only for some special (mostly military) cases because it's rather expensive. Is it also expensive in SOA? Not at all! We have presented universal XML EPs, and we clearly demonstrated how they can be executed by different engines (BPEL, JEE, XMLDB). So you have it already. Additionally, consider Dual Protocols for helping different engines consume EP and messages (for instance, OraDB can consume an HTTP call more easily than HTTP/SOAP; although, SOAP is not an issue either). Sync/Async pairs are always good, especially with Oracle AQ.
- Rule 10: Avoid SPOF on MetadataStore and provide alternative means to access it. Metadata Centralization, like with any type of centralization, has a natural flaw: SPOF. Its weak point is Inventory Endpoint, which is used by
ExecutionPlanLookupServicein our design (the same is true for any design). In addition Service Grid and Redundant Implementation, consider the dual storage type for your Metadata Storage in ESR. Technically, it's a service data replication (we can assume service metadata elements that are consumed by SB as its sole data) for execution plans. The realization of this design rule is exceedingly simple; in fact, you have it already. As you will remember, initially we implemented EPs as FSO, stored as simple files, and decomposed them as DB elements in Chapter 5, Maintaining the Core – the Service Repository.The
ExecutionPlanLookupServiceis capable to work with both implementations, abstracting physical storage resources. Thus, a simple script or service can easily dump the EP from the database every time some changes occur; how it works was explained in Chapter 6, Finding the Compromise – the Adapter Framework. The same is true for the Oracle ESR implementation, where standard synchronization ESR to the UDDI utility can be extended with an additional functionality for EP FSO. Adhering to this rule will eliminate the risk of ESR runtime unavailability quite gracefully. Unfortunately, it will present a risk when a developer tries to cut some corners and perform alterations directly on FSO, bypassing ESR. Also, this could be the case for an insecure direct object reference vulnerability; see Chapter 7, Gotcha! Implementing Security Layers. Well, there is no perfection in the world. The first issue can be addressed with proper governance (set the watchdogs around your Service Repository). The second is about establishing a Trusted Subsystem pattern and avoiding using SB in adapters at the Service Gateway for external services (which is not always possible). This rule can also be associated with the newly introduced Reference Data Centralization, but we believe that the existing Metadata Centralization pattern is overkill. There is no need to inflate the SOA pattern catalog with obvious things. - Rule 11: Apply EM rules according to service layers. Passive Northbound adapters do not propagate validation errors to EBF. Transformation errors related to missing XSLT should be propagated, but their probability is rather low (usually related to incorrect deployment and fixed in the first hour).
- Rule 12: Propagate the errors according to service layers. VETRO errors from the south will be propagated back to the EBF SB after completing basic recovery operations (if assigned).
- Rule 13: Observe Service Message TTL when applying EH rules. Combined logical outcome of rules 11 and 12 strictly observe service message time-to-live (business validity period, set in MH). If business data is actually set to 30 minutes only and you set the
Retryoption on OSB with three different intervals of 5, 15, and 20 minutes, it will do no good. Again, work diligently on Metadata Centralization (previous figure) and define your business exception policies clearly. Use SOAP/SBDH header elements for propagating business policies to local Error Handlers, together with the State Messaging pattern (Message Tracking Data section in CTU EBM, explained in Chapter 5, Maintaining the Core – the Service Repository). - Rule 14: Maintaining preventive Error Management must be preventive. However, avoid using heartbeat test messages for performing ABCSes (both passive and active, especially for active) health check, either for north or south. This is a valid technique for JIT and Unit tests, but not for production; it could (and most probably will) complicate everything from data cleansing in the production database to opening the door for attackers' message probes. There are plenty of other methods to check the status of your service edges, and JMX should be one of your first choices. Oracle OEM and OEM management packs are shipped with predefined thresholds for main vital parameters. Please use them. It might be funny if it weren't so sad; how many problems could we avoid if the DBA (and Nagios) admin reacted properly on clear
99% of ORABPEL table space is full? - Rule 15: Automated Recovery Solution should be SB-based. Again, Error Management must be preventive. This means that our service edge handlers (with retries, abort and so on), individual service handlers (BPEL Fault Handlers, Compensative Transactions, and Mediator policies), and SB-centralized policy-based handlers are in fact reactive and not truly effective (yet essential). Real prevention comes from the already mentioned Log Centralization, just-in-time analysis of all technical information from the entire technical infrastructure (through JMX, WLST, or Jython), and an immediate response. To come to this realization at this point sounds like telling your 18-year-old kid that there is no Santa. Actually, this realization just spawns another rule in addition to rules 9 and 14; a proactive component that contains ART will be presented effectively, controlling the already mentioned Log Centralization: data log cleansing, on-the-fly analysis, and triggering preventive or recovery actions. Yes, this is actually the event-driven SOA, a combination of Event-Driven Network, Event-Driven Messaging, and Complex Event Processing (CEP); although, for reasons explained in rule 9, we cannot put all our eggs into the "OFM Mediator with BPEL Sensors and Events declared in BPEL's Invoke Operation" basket (those are the main OFM EDN players). Actually, it's not possible technically as we will control the entire OFM's underlying infrastructure; refer to the next figure.
Tip
Every rule paragraph is considerably bigger than one line; however, we have not only manifested the rules, but have also put clear reasons behind each of them for you. These reasons are not only the result of the following SOA design principles and SOA patterns (both clearly indicated), but the quintessence of our own combined experience from various projects. Some say rules are meant to be broken. Go on, break these rules, and see what will happen. The severity of consequences will depend on the complexity of your compositions, from mess in static until disaster in dynamic. The best outcome would be to park every fault for manual resolution, which is far from optimal. Again,these rules are for the implementation of an agnostic Composition Controller. For static task-orchestrated processes the standard OFM Fault Management Framework will suffice and for this type of implementation please follow the rules 3, 4, 11, 12, and 13. We also have to mention that this list can be extended with your own rules, as we could have the design variation on south, around Adapter Factory.
Also, please bear in mind that we will use the rule numbers (from 1 to 15) all the way in this chapter. The number 15 will be some kind of magical number here, because at the end we will see how 15 design rules refer to 15 main Audit event sources.
From top to bottom, one rule is leading to the next, thus summarizing all the preceding 15 rules and SOA patterns (presented in bold) around Preventive Error Managing (rule 15). We can extend the SOA infrastructure diagram from Chapter 7, Gotcha! Implementing Security Layers (related to security, the first figure), with all the layers—the sources of monitoring information, required for proactive management and automated recovery:
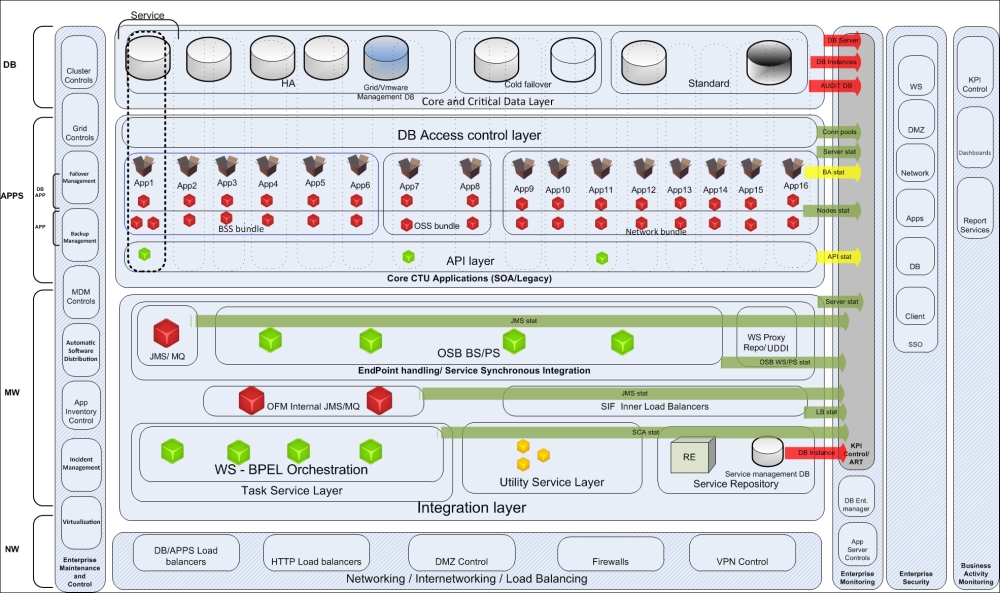
Technical and Functional monitoring flows in a typical SOA infrastructure