
Once the web pages are collected from the Web, there are natural language processing algorithms that are able to extract relevant information for different commercial purposes apart from building a web search engine. We will discuss here algorithms that are able to extract the main topics on the collection of documents (latent Dirichlet analysis) and to extract the sentiment or opinion of each web page (opinion mining techniques).
Latent Dirichlet allocation (LDA) is a natural language processing algorithm that belongs to the generative model category. The technique is based on the observations of some variables that can be explained by other underlined unobserved variables, which are the reasons the observed data is similar or different.
For example, consider text documents in which words are the observations. Each document can be the result of a mixture of topics (unobserved variables) and each word refers to a specific topic.
For instance, consider the two following documents describing two companies:
- doc1: Changing how people search for fashion items and, share and buy fashion via visual recognition, TRUELIFE is going to become the best approach to search the ultimate trends …
- doc2: Cinema4you enabling any venue to be a cinema is a new digital filmed media distribution company currently in the testing phase. It applies technologies used in Video on Demand and broadcasting to ...
LDA is a way of automatically discovering latent topics that these documents contain. For example, given these documents and asked for two topics, LDA might return the following words associated with each topic:
- topic 1: people Video fashion media…
- topic 2: Cinema technologies recognition broadcasting…
Therefore, the second topic can be labeled as technology while the first as business.
Documents are then represented as mixtures of topics that spit out words with certain probabilities:
- doc1: topic 1 42%,topic 2 64%
- doc2: topic 1 21%, topic 2 79%
This representation of the documents can be useful in various applications such as clustering of pages in different groups, or to extract the main common subjects of a collection of pages. The mathematical model behind this algorithm is explained in the next paragraph.
Documents are represented as random mixtures over latent topics, where each topic is characterized by a distribution over words. LDA assumes the following process for a corpus consisting of M documents, d=(d1, …, dM), with each i containing Ni words. If V is the length of the vocabulary, a word of document i is represented by a vector wi of length V, where only an element wiv=1 and the others are 0:
The number of latent dimensions (topics) is K, and for each document, ![]() is the vector of topics associated with each word wi, where zi is a vector of 0's of length K except for the element j, zij=1, that represents the topic wi has been drawn from.
is the vector of topics associated with each word wi, where zi is a vector of 0's of length K except for the element j, zij=1, that represents the topic wi has been drawn from.
b indicates the K ´V matrix, where bij represents the probability that each word j in the vocabulary is drawn from topic i: ![]() .
.
So, each row i of b is the word's distribution of topic i, while each column j is the topic's distribution of word j. Using these definitions, the process is described as follows:
- From a chosen distribution (usually Poisson), draw the length of each document Ni.
-
For each document di, draw the topic distribution qi, as a Dirichlet distribution Dir(a), where
 and a is a parameter vector of length K such that
and a is a parameter vector of length K such that  .
.
-
For each document di, for each word n, draw a topic from the multinomial
 .
.
-
For each document di, for each word n, and for each topic zn, draw a word wn from a multinomial given by the row zn of b,
 .
.
The objective of the algorithm is to maximize the posterior probability for each document:

Applying the conditional probability definition, the numerator becomes the following:
So, the probability that the document i is given by topic vector z and word probability matrix b can be expressed as a multiplication of the single word probabilities:
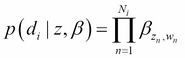
Considering that zn is a vector with only one component j different from 0, zjn=1, then ![]() . Substituting these expressions on (2):
. Substituting these expressions on (2):

The denominator of (1) is obtained simply by integration over qi and summation over z. The final values of the topic distribution qi and the words per topic distribution (rows of b) are obtained by calculating this probability by approximated inference techniques; those are beyond the scope of this book.
The parameter a is called the concentration parameter, and it indicates how much the distribution is spread over the possible values. A concentration parameter of 1 (or k, the dimension of the Dirichlet distribution, by the definition used in topic modeling literature) results in all sets of probabilities being equally probable. Meanwhile, in the limit as the concentration parameter tends towards zero, only distributions with nearly the entire mass concentrated on one of their components are likely (the words are less shared among different topics and they concentrate on a few topics).
As an example, a 100,000-dimension categorical distribution has a vocabulary of 100,000 words even though a topic may be represented by a couple of hundred words. As a consequence, typical values for the concentration parameter are between 0.01 and 0.001, or lower if the vocabulary's size is millions of words or higher.
According to L. Li and Y. Zhang's paper An empirical study of text classification using Latent Dirichlet Allocation, LDA can be used as an effective dimension reduction method for text modeling. However, even though the method has performed well in various applications, there are certain issues to consider. The initialization of the model is random, which means it can lead to different results in each run. Also, the choice of concentration parameters is important, but there is no standard method to choose them.
Consider again the movie reviews' web pages, textreviews, already preprocessed in the Movie review query example section, and LDA is applied to test whether it is possible to gather reviews on different topics. As usual, the following code is available in postprocessing.ipynb at https://github.com/ai2010/machine_learning_for_the_web/tree/master/chapter_4/:

As usual we have transformed each document in tokens (a different tokenizer has been used) and the stop words have been removed. To achieve better results, we filter out the most frequent words (such as movie and film) that do not add any information to the pages. We ignore all the words with more than 1,000 occurrences or observed less than three times:

Now we can train the LDA model with 10 topics (passes is the number of training passes through the corpus):

The code returns the following 10 most probable words associated with each topic:

Although not all the topics have an easy interpretation, we can definitely see that topic 2 is associated with the words disney, mulan (a Disney movie), love, and life is a topic about animation movies, topic 6 is associated with the words action, alien, bad, and planet is related to fantasy sci-fi movies. In fact, we can query all the movies with most probable topic equal to 6 like this:

This will return:
Rock Star (2001) Star Wars: Episode I - The Phantom Menace (1999) Zoolander (2001) Star Wars: Episode I - The Phantom Menace (1999) Matrix, The (1999) Volcano (1997) Return of the Jedi (1983) Daylight (1996) Blues Brothers 2000 (1998) Alien³ (1992) Fallen (1998) Planet of the Apes (2001)
Most of these titles are clearly sci-fi and fantasy movies, so the LDA algorithm clusters them correctly.
Note that with the documents' representations in the topic space (lda_lfq[corpus]), it would be possible to apply a cluster algorithm (see Chapter 2, Machine Learning Techniques – Unsupervised Learning) but this is left to the reader as an exercise. Note also that each time the LDA algorithm is run, it may lead to different results due to the random initialization of the model (that is, it's normal if your results are different from what it is shown in this paragraph).
Opinion mining or sentiment analysis is the field of study of text to extract the opinion of the writer, which can usually be positive or negative (or neutral). This analysis is particularly useful especially in marketing to find the public opinion on products or services. The standard approach is to consider the sentiment (or polarity), negative or positive, as the target of a classification problem. A dataset of documents will have as many features as the number of different words contained in the vocabulary, and classification algorithms such as SVM and Naive Bayes are typically used. As an example, we consider the 2,000 movie reviews already used for testing LDA and information retrieval models that are already labeled (positive or negative). All of the code discussed in this paragraph is available on the postprocessing.ipynb IPython notebook at https://github.com/ai2010/machine_learning_for_the_web/tree/master/chapter_4/. As before, we import the data and preprocess:

The data is then split into a training set (80%) and a test set (20%) in a way the nltk library can process (a list of tuples each or those with a dictionary containing the document words and the label):

Now we can train and test a NaiveBayesClassifier (multinomial) using the nltk library and check the error:

The code returns an error of 28.25%, but it is possible to improve the result by computing the best bigrams in each document. A bigram is defined as a pair of consecutive words, and the X2 test is used to find bigrams that do not occur by chance but with a larger frequency. These particular bigrams contain relevant information for the text and are called collocations in natural language processing terminology. For example, given a bigram of two words, w1 and w2, in our corpus with a total number of N possible bigrams, under the null hypothesis that w1 and w2 occur independently to each other, we can fill a two-dimensional matrix O by collecting the occurrences of the bigram (w1, w2) and the rest of the possible bigrams, such as these:
|
w1 |
Not w1 | |
|---|---|---|
|
w2 |
10 |
901 |
|
Not w2 |
345 |
1,111,111 |
The X2 measure is then given by  , where Oij is the number of occurrences of the bigram given by the words (i, j) (so that O00=10 and so on) and Eij is the expected frequency of the bigram (i, j) (for example,
, where Oij is the number of occurrences of the bigram given by the words (i, j) (so that O00=10 and so on) and Eij is the expected frequency of the bigram (i, j) (for example,  ). Intuitively, X2 is higher the more the observed frequency Oij differs from the expected mean Eij, so the null hypothesis is likely to be rejected. The bigram is a good collocation and it contains more information than a bigram that follows the expected means. It can be shown that the X2 can be calculated as the f test (also called mean square contingency coefficient) multiplied by the total number of bigram occurrences N, as follows:
). Intuitively, X2 is higher the more the observed frequency Oij differs from the expected mean Eij, so the null hypothesis is likely to be rejected. The bigram is a good collocation and it contains more information than a bigram that follows the expected means. It can be shown that the X2 can be calculated as the f test (also called mean square contingency coefficient) multiplied by the total number of bigram occurrences N, as follows:

More information about the collocations and the X2 methods can be found in Foundations of Statistical Natural Language Processing by C. D. Manning and H. Schuetze (1999). Note also that the X2, as the information gain measure (not discussed here), can be thought of as a feature selection method as defined in Chapter 3, Supervised Machine Learning. Using the nltk library, we can use the X2 measure to select the 500 best bigrams per document and then train a Naive Bayes classifier again, as follows:

This time the error rate is 20%, which is lower than in the normal method. The X2 test can also be used to extract the most informative words from the whole corpus. We can measure how much the single word frequency differs from the frequency of the positive (or negative) documents to score its importance (for example, if the word great has a high X2 value on positive reviews but low on negative reviews, it means that the word gives information that the review is positive). The 10,000 most significant words of the corpus can be extracted by calculating for each of them, the the overall frequency on the entire corpus and the frequencies over the positive and negative subsets:

Now we can simply train a Naive Bayes classifier again using only the words in the bestwords set for each document:

The error rate is 12.75%, which is remarkably low considering the relatively small dataset. Note that to have a more reliable result, a cross-validation method (see Chapter 3, Supervised Machine Learning) should be applied, but this is given to the reader as an exercise. Also note that the Doc2Vec vectors (compute in the Movie review query example section) can be used to train a classifier. Assuming that the Doc2Vec vectors have already been trained and stored in the model_d2v.doc2vec object, as usual we split the data into a training dataset (80%) and a test set (20%):

Then we can train an SVM classifier (radial basis function kernel (RBF) kernel) or a logistic regression model:

Logistic regression and SVM give very low accuracies, of 0.5172 and 0.5225 respectively. This is mostly due to the small size of the training dataset, which does not allow us to train algorithms that have a large number of parameters to train, such as neuron networks.