
For much of the history of AI research and applications, working with images was particularly difficult. In the early days, machines could barely hold images in their small memories, let alone process them. Computer vision as a subfield of AI and ML made significant strides throughout the 1990s and 2000s with the proliferation of cheap hardware, webcams and new and improved processing-intensive algorithms such as feature detection and optical flow, dimensionality reduction, and 3D reconstruction from stereo images. Through this entire time, extracting good features from images required a bit of cleverness and luck. A face recognition algorithm, for example, could not do its job if the image features provided to the algorithm were insufficiently distinctive. Computer vision techniques for feature extraction included convolutions (such as blurring, dilation, edge detection, and so on); principal component analysis to reduce the dimensions of a set of images; corner, circle, and line detection; and so on. Once features were extracted, a second algorithm would examine these features and learn to recognize different faces, recognize objects, track vehicles, and other use cases. If we look specifically at the use case of classifying images, for example, labeling a photo as "cat," "dog," "boat," and so on, neural networks were often used due to their success at classifying other kinds of data such as audio and text. The input features for the neural network included an image's color distribution, edge direction histograms, and spatial moments (that is, the image's orientation or locations of bright regions). Notably, these features are generated from the image's pixels but do not include the pixels themselves. Running a neural network on a list of pixel color values, without any feature extraction pre-processing, yielded poor results.
The new approach, deep learning (DL), figures out the best features on its own, saving us significant time and saving us from engaging in a lot of guesswork. This chapter will demonstrate how to use DL to recognize logos in photos. We will grab these photos from Twitter, and we'll be looking for soft drinks and beer.
Along the way, we will examine how neural networks and DL work and demonstrate the use of state-of-the-art open source software.
In this chapter, together we will cover and explore:
- How neural networks and DL are used for image processing
- How to use an application of DL for detecting and recognizing brand logos in images
- The
Keraslibrary, part ofTensorFlow, and YOLO for the purpose of image classification
The first thing we must do is to examine the recent and dramatic increase in the adoption of ML, specifically with respect to image processing. In 2016, The Economist wrote a story titled, From not working to neural networking about the yearly ImageNet Large Scale Visual Recognition Challenge (ILSVRC), which started in 2010 and finalized in 2017 (From not working to neural networking, The Economist, June 25, 2016, https://www.economist.com/special-report/2016/06/25/from-not-working-to-neural-networking). This competition challenged researchers to develop techniques for labeling millions of photos of 1,000 everyday objects. Humans would, on average, label these photos correctly about 95% of the time. Image classification algorithms, such as those we alluded to previously, performed at best with 72% accuracy in the first year of the competition. In 2011, the algorithms were improved to achieve 74% accuracy.
In 2012, Krizhevsky, Sutskever, and Hinton from the University of Toronto cleverly combined several existing ideas known as convolutional neural networks (CNN) and max pooling, added rectified linear units (ReLUs) and GPU processing for significant speedups, and built a neural network composed of several "layers." These extra network layers led to the rise of the term "deep learning," resulting in an accuracy jump to 85% (ImageNet classification with deep convolutional neural networks, Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, in Advances in neural information processing systems, pp. 1097-1105, 2012, http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf). In the five following years, this fundamental design has been refined to achieve 97% accuracy, which was beating the human performance. The rise of DL and the rejuvenation of interest in ML began here. Their paper about this new DL approach, titled ImageNet classification with deep convolutional neural networks, has been cited nearly 29,000 times, at a dramatically increasing rate over the years:
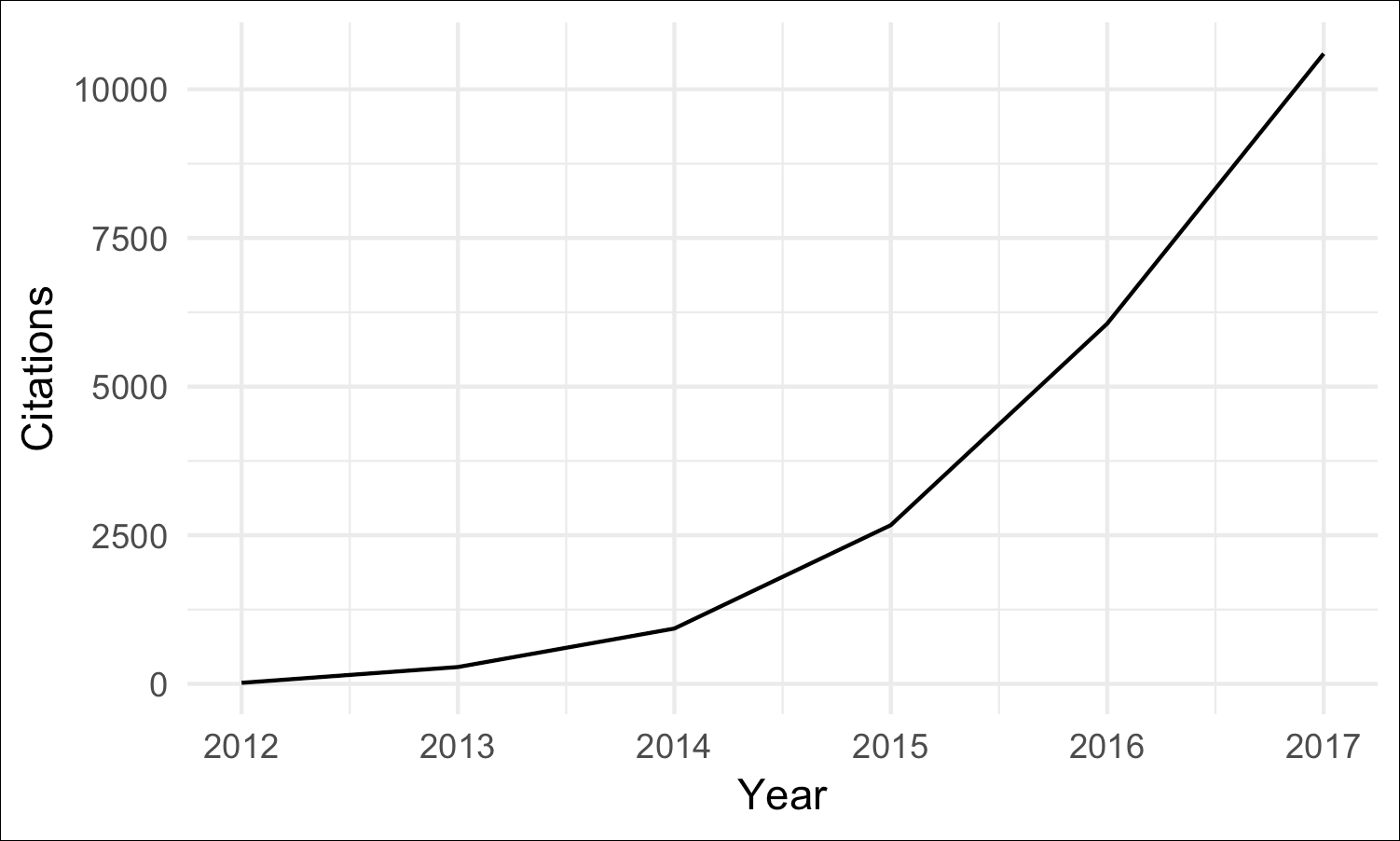
Figure 1: Count of citations per year of the paper, ImageNet classification with deep convolutional neural networks, according to Google Scholar
The key contribution of their work was showing how you could achieve dramatically improved performance while simultaneously completely avoiding the need for feature extraction. The deep neural network does it all: the input is the image without any pre-processing, the output is the predicted classification. Less work, and greater accuracy! Even better, this approach was quickly shown to work well in a number of other domains besides image classification. Today, we use DL for speech recognition, NLP, and so much more.
A recent Nature paper, titled Deep learning (Deep learning, LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton, Nature 521(7553), pp. 436-444, 2015), summarizes its benefits:
Deep learning is making major advances in solving problems that have resisted the best attempts of the artificial intelligence community for many years. It has turned out to be very good at discovering intricate structures in high-dimensional data and is therefore applicable to many domains of science, business, and government. In addition to beating records in image recognition and speech recognition, it has beaten other machine-learning techniques at predicting the activity of potential drug molecules, analyzing particle accelerator data, reconstructing brain circuits, and predicting the effects of mutations in non-coding DNA on gene expression and disease. Perhaps more surprisingly, deep learning has produced extremely promising results for various tasks in natural language understanding, particularly topic classification, sentiment analysis, question answering, and language translation.
We think that deep learning will have many more successes in the near future because it requires very little engineering by hand, so it can easily take advantage of increases in the amount of available computation and data. New learning algorithms and architectures that are currently being developed for deep neural networks will only accelerate this progress.
Deep learning, LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton, Nature 521(7553), pp. 436-444, 2015
The general public's interest in ML and DL can be demonstrated by plotting Google search trends. It's clear that a revolution has been underway since about 2012:
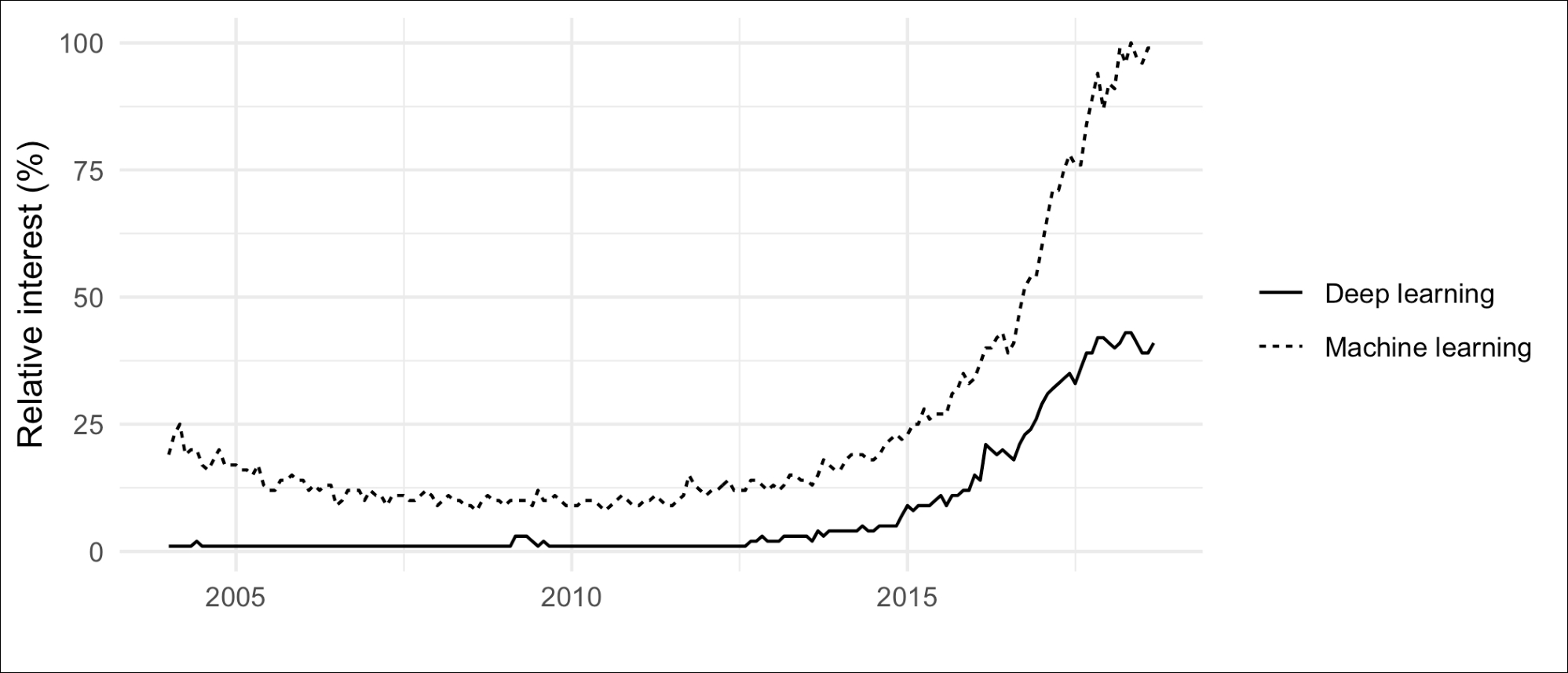
Figure 2: Google search frequency for "deep learning" and "machine learning." The y-axis shows relative interest rather than a raw count, so the largest value raw count will be marked 100%.
This revolution is not just an outcome of that 2012 paper. Rather, it's more of a result of a combination of factors that have caused ML to achieve a staggering series of successes across many domains in just the last few years.
First, large datasets (such as ImageNet's millions of images) have been acquired from the web and other sources. DL and most other ML techniques require lots of example data to achieve good performance. Second, algorithms have been updated to make use of GPUs to fundamentally change the expectations of ML training algorithms. Before GPUs, one could not reasonably train a neural network on millions of images; that would take weeks or months of computing time. With GPUs and new optimized algorithms, the same task can be done in hours. The proliferation of consumer-grade GPUs was initially the result of computer gaming, but their usefulness has now extended into ML and bitcoin mining. In fact, bitcoin mining has been such a popular use of GPUs that the demand dramatically impacted prices of GPUs for a period of time (Bitcoin mining leads to an unexpected GPU gold rush, Lucas Mearian, ComputerWorld, April 2, 2018, https://www.computerworld.com/article/3267744/computer-hardware/bitcoin-mining-leads-to-an-unexpected-gpu-gold-rush.html), in some cases causing prices to double.
Third, the field of ML has developed a culture of sharing of code and techniques. State-of-the-art, industrial-strength libraries such as TensorFlow (https://www.tensorflow.org/), PyTorch (https://pytorch.org/), and scikit-learn (http://scikit-learn.org/stable/) are open source and simple to install.
Researchers and hobbyists often implement algorithms described in newly published papers using these tools, thus allowing software engineers, who may be outside the research field, to quickly make use of the latest developments.
Further evidence of the rapid increase in publications, conference attendance, venture capital funding, college course enrolment, and other metrics that bear witness to the growing interest in ML and DL can be found in AI Index's 2017 annual report (http://www.aiindex.org/2017-report.pdf). For example:
- Published papers in AI have more than tripled from 2005 to 2015
- The number of startup companies developing AI systems in the US in 2017 was fourteen times the number in 2000
TensorFlow, the software we will be using in this chapter, had 20,000 GitHub stars (similar to Facebook likes) in 2016, and this number grew to more than 80,000 by 2017