
The request/response communication pattern involves two peers. This pattern is a bidirectional communication: a client asks for something from a service, and the service answers to this query. The following figure shows how this pattern works:

This communication pattern is probably the most used of all the available patterns. This is probably because it is the pattern used for human communication. Just like publish/subscribe, this pattern can be used on all kinds of communication: intra-process, inter-process, and on network links with Remote Procedure Calls (RPCs):
- Intra-process request/response is the pattern implemented by functions and methods of classes: a requester calls a function to request something, and the function answers this request. In this case, the function is the entity providing the service.
- Inter-process request/response is widely used on operating systems to make different daemons and applications communicate with each other. Usually, it is implemented in the same services as those providing publish/subscribe. However, in this case the communication on the message bus is between two peers, and no other client of the message bus can access these messages.
- Network request/response is available via many different protocols. From veterans such as CORBA, to universal protocols such as HTTP, all consortiums, and virtually all software companies, have implemented their own RPC protocol.
Request/response is quite different from publish/subscribe: the first protocol is bidirectional, while the latter is unidirectional. The first one is pull-based while the second one is push-based. This difference between pull and push communication is the key to understanding why observables can be used as a base tool to implement all communication patterns.
Pull-based communication is driven by the component which receives the information. This component actively requests information whenever it is needed. On the other hand, push-based communication is driven by the component that produces events. The receiver has no control over when this information will be available. So at first, it seems that these two modes are exclusive since some use cases can be implemented only in one or the other way (at least for an efficient implementation):
- Any request that can provide a different information at each request, or a request whose answer depends on the provided input, is inherently pull-based: a producer has no way of providing the correct information at the correct time without a query coming in from the requester.
- An event that can occur at any time, independently from any request, is inherently push-based: a consumer cannot just query the producer to know if something happened. To some extents, this is possible but it means that events must be buffered by the producer until all receivers have consumed them, and the consumers must constantly query the producer. This is usually known as polling, and when it is done in a very basic way, it is quite inefficient.
There are many examples where push-based communication has been implemented on top of a pull-based protocol. One of the most used ones is HTTP long polling, where the consumer sends an HTTP request, and the producer completes this query when an event is available. However, this is usually the beginning of trouble. In this example, if an event occurs between two HTTP requests, then the event is lost. One way to circumvent this issue is to use several HTTP connections so that one is always active, and no event is lost. Bidirectional-streams Over Synchronous HTTP (BOSH), is one protocol using this trick to implement eventing on top of HTTP. Needless to say, such implementations are quite complex.
On the other hand, there are no widely known protocols implementing pull-based communication on top of push-based communication. MQTT 5 may become the first one, with request/response being implemented on top of the publish/subscribe pattern of MQTT. Let's see why implementing a pull communication on top of a push communication, while counterintuitive, is more simple, and probably more efficient than the other way.
The first requirement for pull communication is a bidirectional channel. The previous part showed how to implement this on top of two logically linked unidirectional channels. The second requirement is that one request must lead to one, and only one, answer (either a success with a value, or a failure). This description is a subset of the features provided by an observable. So, a response can be represented as an observable that emits a single item in the case of success, and completes on error in the case of failure. The following figure shows a possible request/response pattern implemented on top of observables:
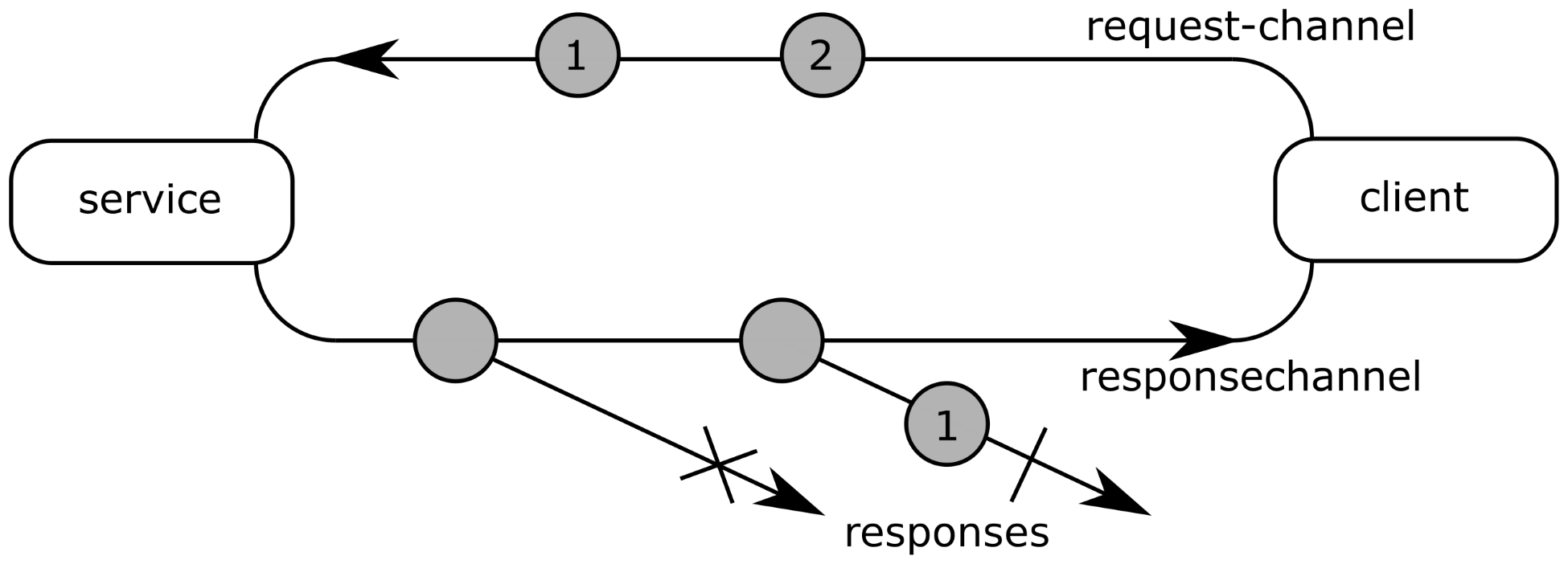
The implementation relies on a bidirectional channel implemented on top of two observables, as explained previously. Each request is encoded as an item emitted on the request-channel observable. The response-channel observable is a higher-order observable, where each item is a response observable. A response observable emits, at most, one item containing the answer, before it completes. In the case of failure, the response observable completes on error without emitting any item. In Figure 12.9, the request 1 succeeds, while request 2 fails.
The problem with such an implementation is that many messages have to be exchanged on the network link: since each response is an observable, a new observable must be created, subscribed, and disposed for each answer. So, instead of the implementation shown in Figure 12.9, a more optimized one is shown in the following figure:
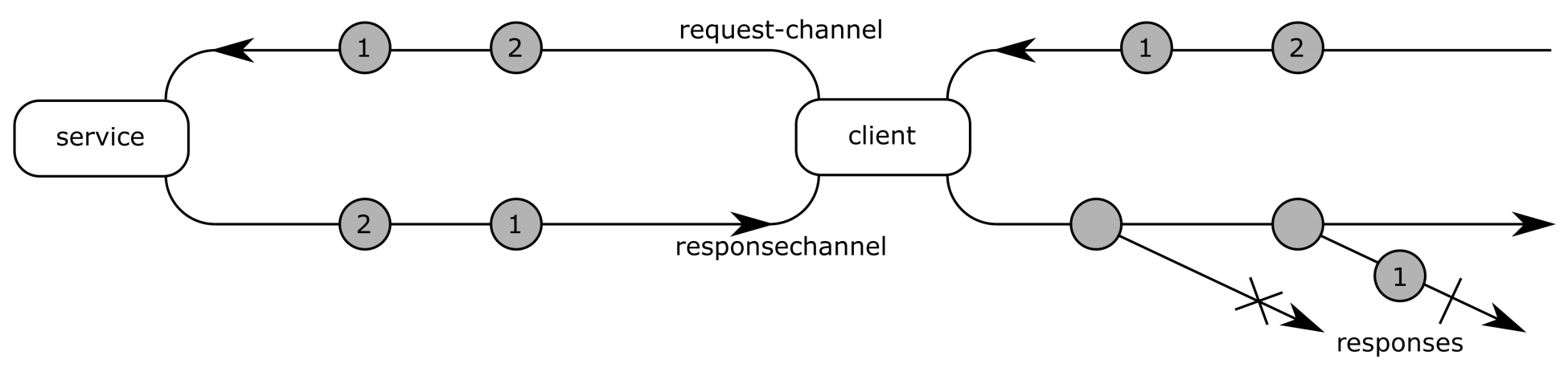
In this implementation, an answer is encoded as a single item on the network link. Then these items are exposed as observables on the client side. This allows us to still use observables as responses, but without any overhead on the network link.
The following figure shows a sequence diagram of one client sending a request to a service:
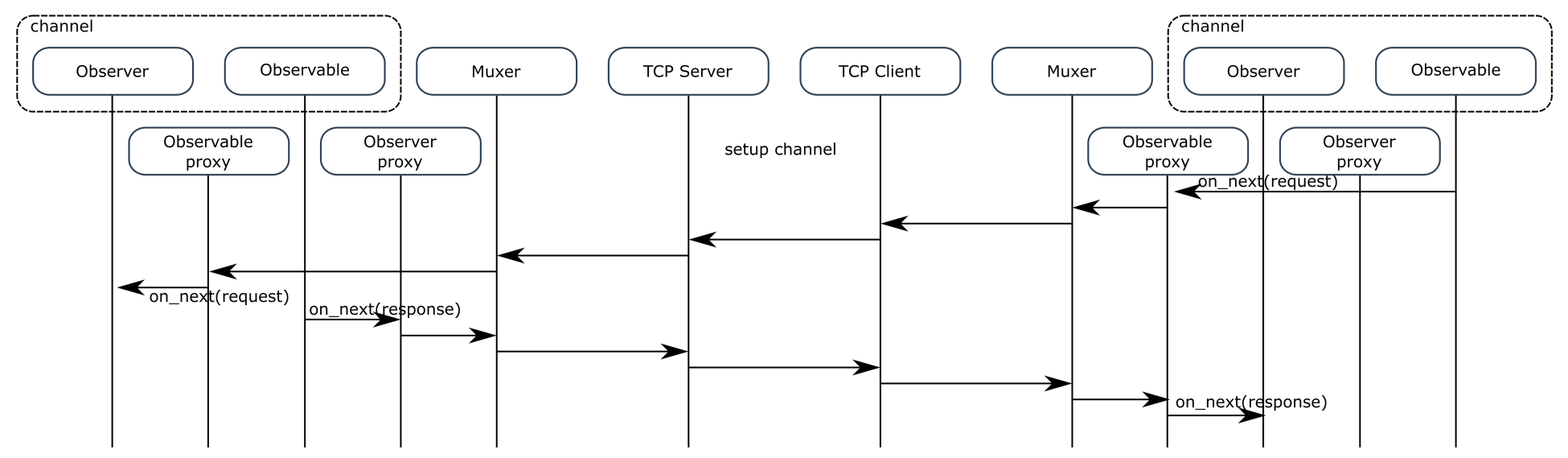
The channel setup part is omitted here because it has already been detailed in Figure 12.7. Once the channel is established, each request is emitted as an on_next message on the network link, and the response is also emitted as an on_next message on the link. The request message must contain a request ID field, sent back in the response, so that the response can be associated to the correct request. Also, in the event of an error, then the error is emitted as an on_next message, not an error message. Otherwise this would close the channel, which is not the expected behavior.