
Finally, all principles have now been covered, as well as the tools needed to implement functional and reactive code. By the way, the previous example is already a functional application: component_a, is a pure function, and component_b is a side effect. However, the main code that instantiates and connects both components cannot be a pure function because it uses component_b which is a side effect. If the instantiation of this side effect is moved to a dedicated side effect initialization part of the code then the rest of the code would be completely composed of pure functions. This is the concept of the Cycle.js framework, a JavaScript framework that allows for writing functional and reactive code. These principles have been used by other frameworks since its creation, and they are applicable to Python and RxPY. With just a few changes to Figure 3.2, the architecture of a reactive application with a cycle becomes the following one:
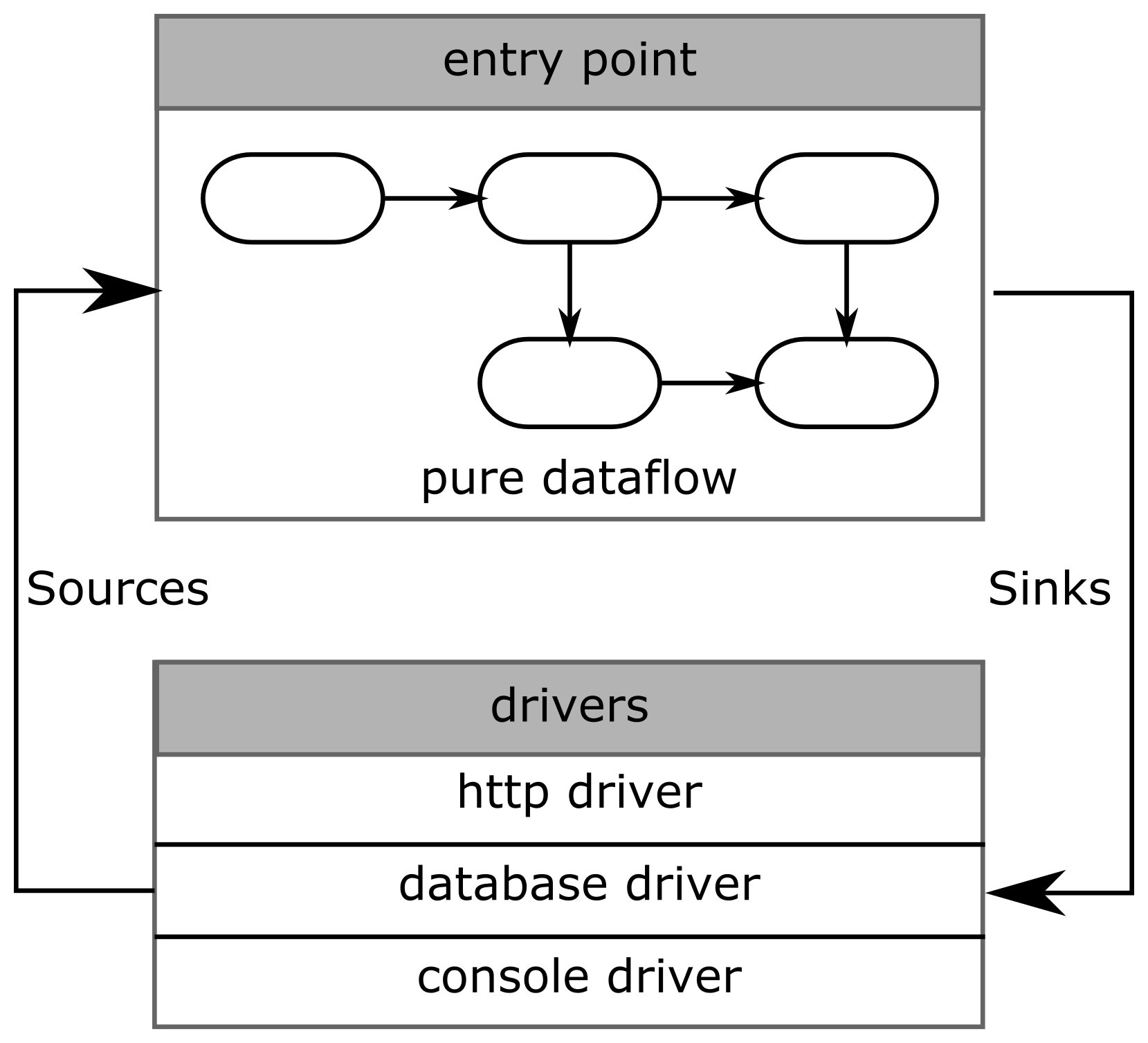
There are three parts in this architecture:
- Application logic: This part is exclusively composed of pure functions.
- Drivers: Drivers are where side effects are implemented. A driver is a function that takes a stream of requests as input and returns a stream of responses.
- Bootstrapping: The bootstrapping of the connection between drivers and the entry point.
The entry point of the application is written as a pure function, where inputs and outputs are observables. A nice consequence of this design is that the entry point is not a special case in the application. It is a component that just happens to be the entry point, and it can be reused as a component in other applications. So an application is composed of several components that share this same prototype, and any of them could be used as an entry point.
Drivers can implement any side effects: network clients and servers, access to a database, printing to the console, retrieving a random value, and so on. Drivers can be split into three categories depending on their communication patterns:
- Some drivers use sink and source observables.
- Some drivers are source drivers. They only produce data.
- Some drivers are sink drivers. They only consume data.
The entry point and the drivers communicate with observables. The communication from the entry point to the drivers is done with sink observables. The communication from the drivers to the entry point is done with source observables. A bootstrap function is in charge of doing the instantiation of the drivers and connecting them to the entry point. This bootstrapping allows you to circularly connect the observables together.