
Chapter 1, An Introduction to Reactive Programming, discussed in detail the principles of event-driven programming and reactive programming. As explained in the previous chapter, event-driven programming can be implemented in many ways: with different programming paradigms such as imperative or object-oriented, but also with different concurrency mechanisms. Asynchronous programming is one way to manage concurrency.
Concurrency is several tasks competing for the same resource at the same time. The definition of "at the same time" can be different depending on the resource being used. There are two main resources that a task may require: a Central Processing Unit (CPU) and I/O. In most cases, a task is either CPU bound or I/O bound; that is, either a task makes a lot of computations and is constrained by the available CPU resources, or a task takes a lot of I/O actions and is constrained by the available I/O resources. Depending on the type of task, different concurrency mechanisms can be used in Python: processes, threads, and async. The following table shows them and in what case they are the most adapted:
| Process | Thread | Async | |
| CPU bound | Yes | Yes, with restrictions | No |
| I/O bound | Very limited | Limited | Yes |
Processes and threads are well suited to handle concurrency on CPU-bound tasks because they allow several tasks to run at the same time on the different execution units of the CPU. This is the easiest way to use all the cores of a CPU instead of using only one, which is the default situation when writing a Python program. With processes, several instances of the Python interpreter run at the same time, and so each one can use one core of the CPU. When using threads, several cores of the CPU are used within the same process. The advantage (or drawback depending on the point of view) of threads over processes is that they share the same memory space. So threads can share memory more efficiently than processes. The latter need to copy data when communicating together. (It is possible to share memory between processes, but via APIs specific to each operating system.)
From the point of view of the operating system, processes and threads allow the same performance if the tasks are CPU-bound. Each task can run independently of each other. However, this is not the case in Python. The implementation of the CPython interpreter, which is the most used one, relies on a global lock, also known as the Global Interpreter Lock (GIL). The GIL is a lock which prevents several executions of Python code occurring at the same time. This means that multithreading in Python is very limited because two threads will never run concurrently even when several cores are available on the CPU. This is why multithreading should be avoided in most cases when using Python because it does not allow you to fully benefit from multiple cores.
Processes can be used to manage I/O concurrency. But since each single-threaded process can execute only on one task at a time, it means that when a task is waiting for an I/O operation to complete, it blocks the whole process and no other task can run during that time. The following figure shows an example of what happens in such a case:
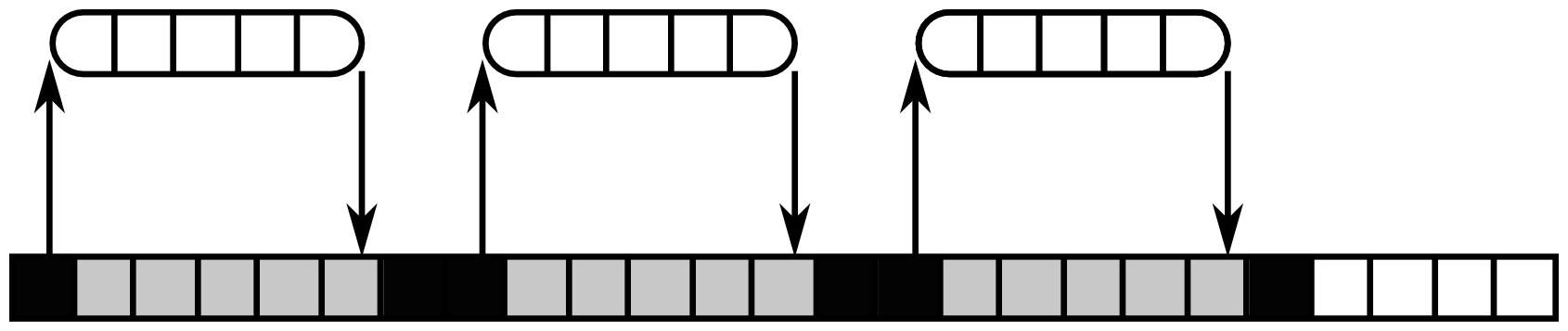
The task has three I/O operations to execute. Each I/O operation takes five cycles to complete. When an I/O operation completes, the task needs one cycle to handle its result. In this case, the CPU is active for six cycles (the black blocks) and blocked during 15 cycles. During these 15 cycles, no other code can run on the process. With such a design, I/O concurrency can be implemented by executing many processes. But this is not scalable because it will consume a lot of memory, and orchestrating all these processes can be difficult and inefficient.
Threads are a better way to handle I/O concurrency because they allow you to execute several operations at the same time in the same process. Compared to a single threaded process, this allows the main thread of the process to always be available when I/O operations are ongoing. This is shown in the following diagram:
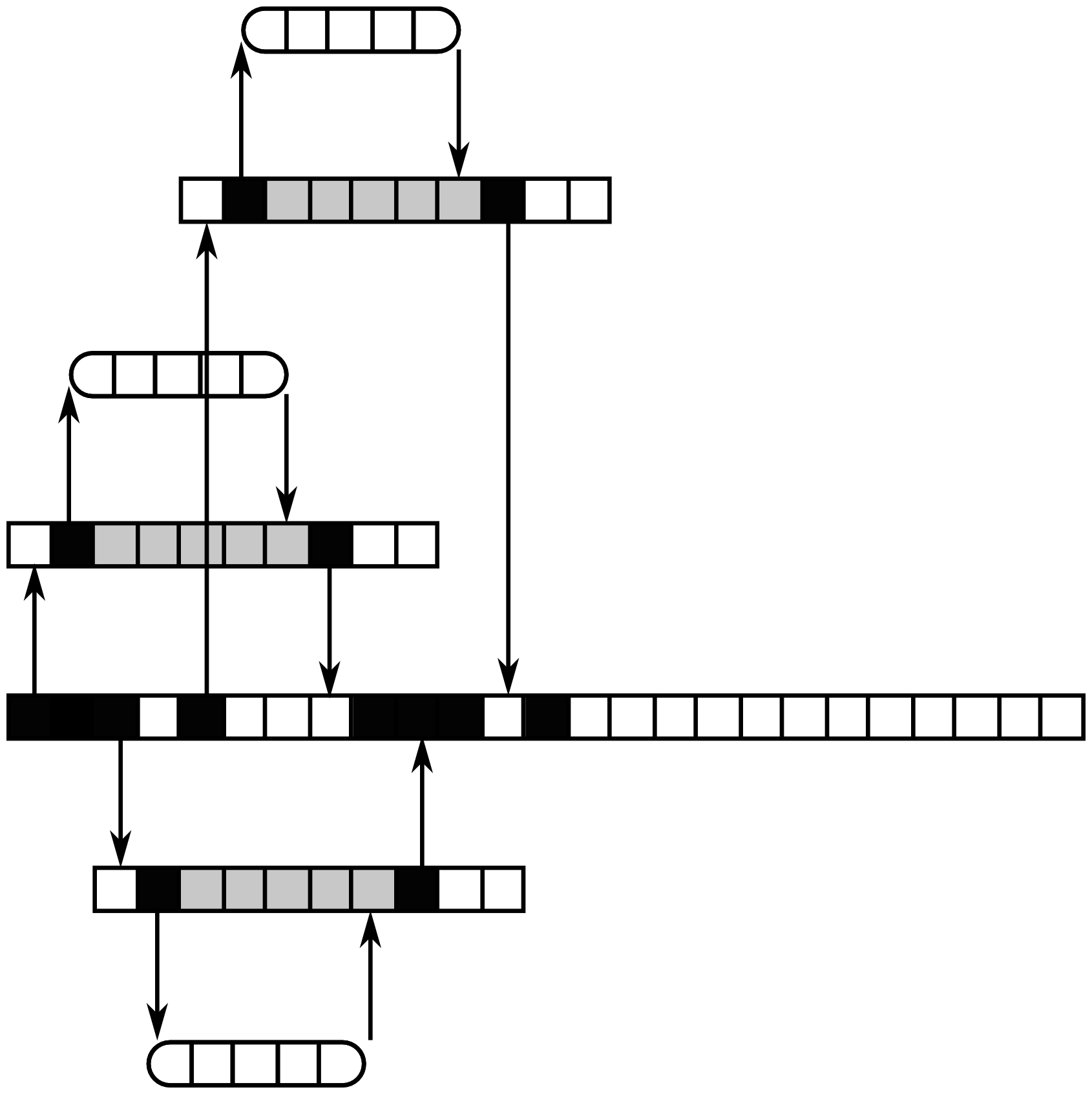
There are four execution units here: the main thread of the process (the longest in the figure) and three other threads. Just as before, three I/O operations must be executed. In this case, one thread is used for the execution of each operation. As we can see, the main thread is never blocked, and so it can execute other tasks when I/O operations are ongoing. The other benefit is that the I/O operations can now execute concurrently. On the CPU cycle eight in Figure 2.2, the three I/O operations are ongoing. Each thread is still blocked when it executes its I/O operation, but it does not block the whole program.
Multiprocess and multithreaded designs are used in a lot of widely used projects that rely on I/O bound tasks. However, this design quickly hits limits in intensive use cases. These limits can be overcome by using more powerful systems (more CPU cores/more memory) but it has a cost. This is where asynchronous programming has a big advantage. Asynchronous programming allows you to handle I/O concurrency much more efficiently than other solutions.
The principle of asynchronous programming is that instead of waiting for blocking I/O operations on several execution units, a single execution unit multiplexes non-blocking I/O operations. The following figure shows this:
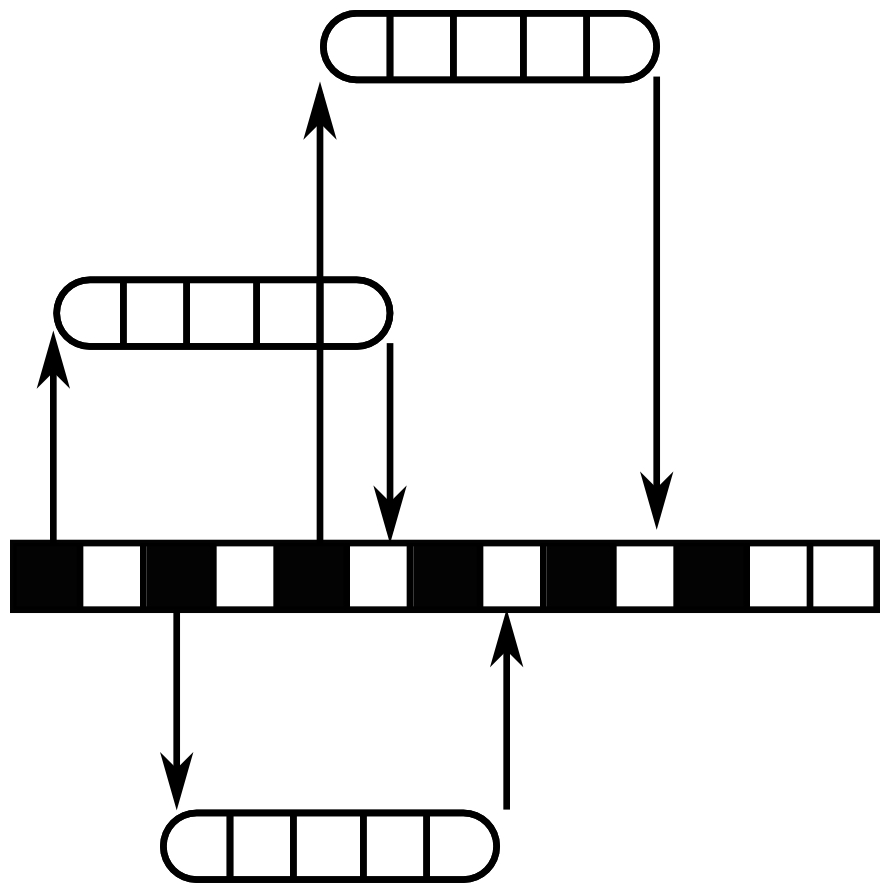
Notice how the figure is much simpler than the multithreaded design and much shorter (in terms of cycles being used) than the multiprocess one. This is a visual way to show that, system wise, asynchronous design is simpler than multithreading and more efficient than blocking I/O operations. In this case, once the first I/O operation is started then the execution unit is not blocked, so it can start the second and third I/O operations even though the previous one(s) is/are still ongoing. Once an operation has completed, the main thread is notified and can handle the result. So, the execution of the three I/O operations has been multiplexed on a single execution unit, and during their whole execution the CPU was never blocked.
Systems that are I/O bound such as network systems (proxies, servers, message brokers, and so on) are usually more efficient when they are programmed in an asynchronous way than with blocking calls. Since asynchronous programming requires fewer system resources to execute the same actions than blocking programming, it scales better and limits costs at the end. However, many programmers choose to start with multithreaded designs for I/O-bound tasks. As explained in Chapter 1, An Introduction to Reactive Programming, the main reason for this is that in a lot of cases, multithreaded seems easier at the beginning, especially when the programming language has no facility to deal with asynchronous programming. However, when all the tools are available to develop code asynchronously, then going asynchronous for I/O-bound tasks is probably a better choice in the long-term because real-time bugs in multithreaded code can be really hard to reproduce and fix, while asynchronous code is predictive and so easier to test.