
A decision tree is a supervised machine learning algorithm, based on how a human solves the task of forecasting or classification. Generally, this is a k-dimensional tree with decision rules at the nodes and a prediction of the objective function at the leaf nodes. The decision rule is a function that allows you to determine which of the child nodes should be used as a parent for the considered object. There can be different types of objects in the decision tree leaf—namely, the class label assigned to the object (in the classification tasks), the probability of the class (in the classification tasks), and the value of the objective function (in the regression task).
In practice, binary decision trees are used more often than trees with an arbitrary number of child nodes.
The algorithm for constructing a decision tree in its general form is formed as follows:
- Firstly, check the criterion for stopping the algorithm. If this criterion is executed, select the prediction issued for the node. Otherwise, we have to split the training set into several non-intersecting smaller sets.
- In the general case, a
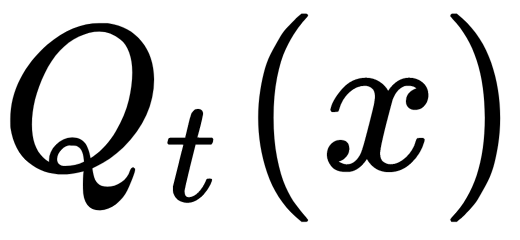 decision rule is defined at the t node, which takes into account a certain range of values. This range is divided into Rt disjoint sets of objects:
decision rule is defined at the t node, which takes into account a certain range of values. This range is divided into Rt disjoint sets of objects:  , where Rt is the number of descendants of the node, and each
, where Rt is the number of descendants of the node, and each 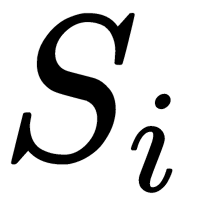 is a set of objects that fall into the
is a set of objects that fall into the 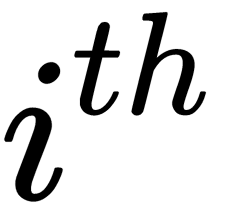 descendant.
descendant. - Divide the set in the node according to the selected rule, and repeat the algorithm recursively for each node.
Most often, the 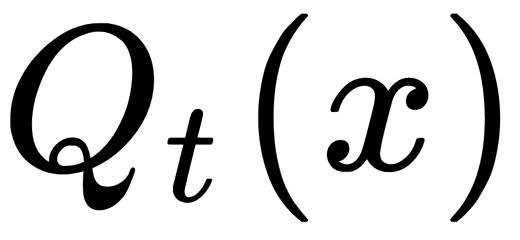 decision rule is simply is the feature—that is,
decision rule is simply is the feature—that is,  . For partitioning, we can use the following rules:
. For partitioning, we can use the following rules:
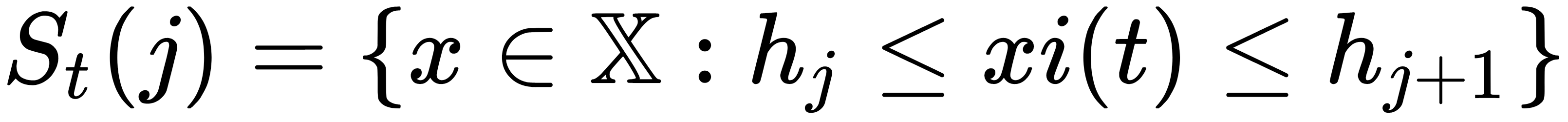 for chosen boundary values
for chosen boundary values 
-
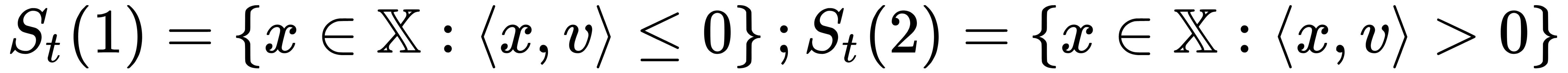 , where
, where  is a vector's scalar product. In fact, it is a corner value check
is a vector's scalar product. In fact, it is a corner value check 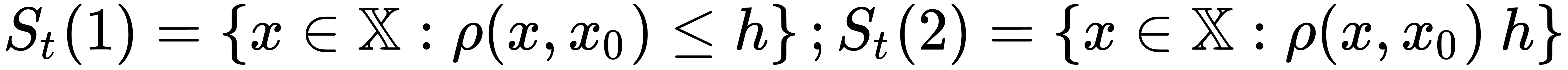 , where the
, where the
distance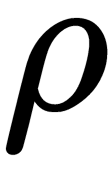 is defined in some metric space (for example,
is defined in some metric space (for example, 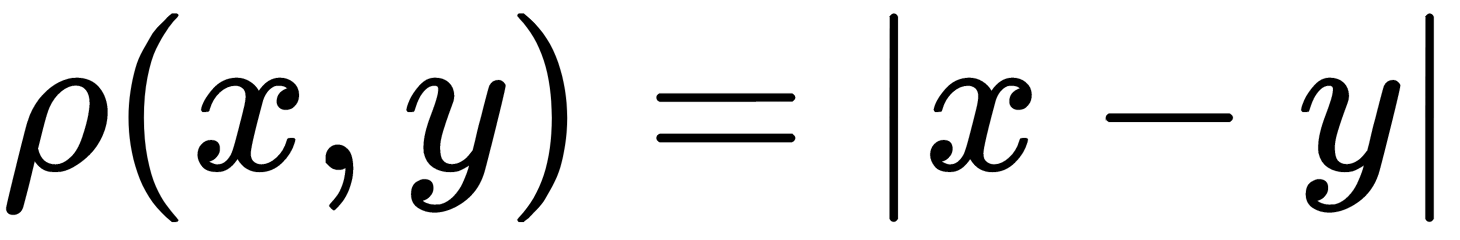 )
) , where
, where 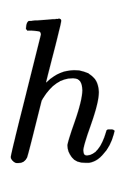 is a predicate
is a predicate
In general, you can use any decision rules, but those that are easiest to interpret are better since they are easier to configure. There is no particular point in taking something more complicated than predicates since you can create a tree with 100% accuracy on the training set, with the help of the predicates.
Usually, a set of decision rules are chosen to build a tree. To find the optimal one among them for each particular node, we need to introduce a criterion for measuring optimality. The 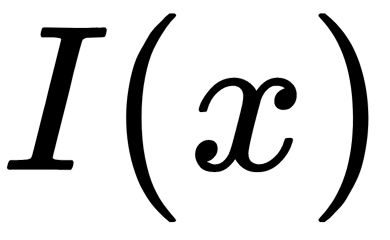 measure is introduced for this, which is used to measure how objects are scattered (regression), or how the classes are mixed (classification) in a specific
measure is introduced for this, which is used to measure how objects are scattered (regression), or how the classes are mixed (classification) in a specific  node. This measure is called the impurity function. It is required for finding a maximum of
node. This measure is called the impurity function. It is required for finding a maximum of 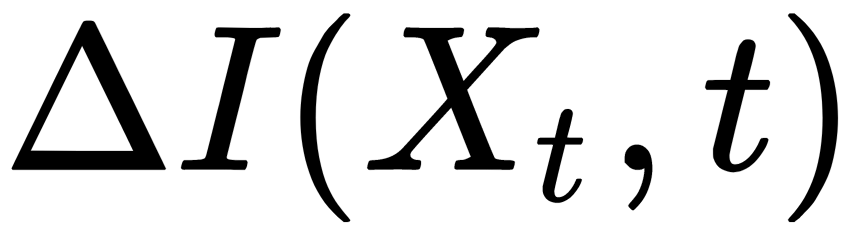 according to all features and parameters from a set of decision rules, in order to select a decision rule. With this choice, we can generate the optimal partition for the set of objects in the current node.
according to all features and parameters from a set of decision rules, in order to select a decision rule. With this choice, we can generate the optimal partition for the set of objects in the current node.
Information gain 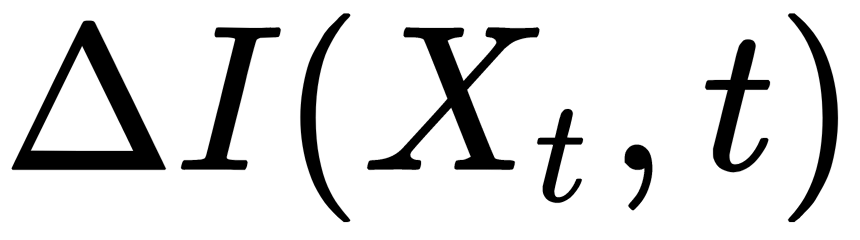 is how much information we can get for the selected split, and is calculated as follows:
is how much information we can get for the selected split, and is calculated as follows:
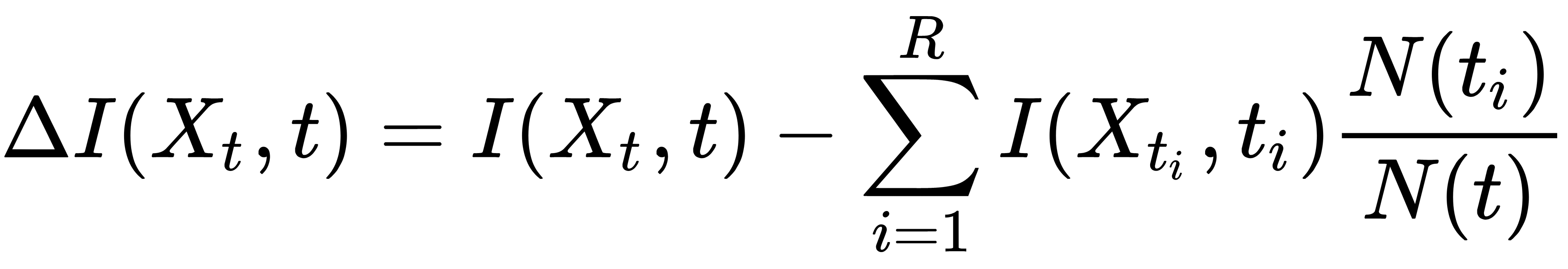
In the preceding equation, the following applies:
- R is the number of sub-nodes the current node is broken into
- t is the current node
 are the descendant nodes that are obtained with the selected partition
are the descendant nodes that are obtained with the selected partition is the number of objects in the training sample that fall into the child i
is the number of objects in the training sample that fall into the child i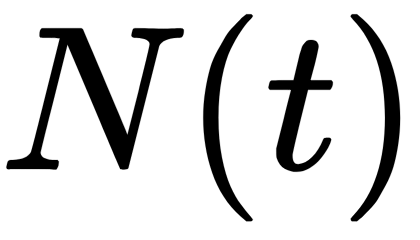 is the number of objects trapped in the current node
is the number of objects trapped in the current node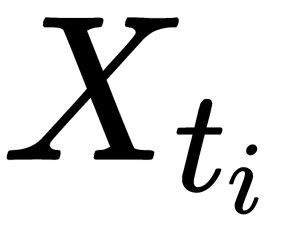 are the objects trapped in the ti th vertex
are the objects trapped in the ti th vertex
We can use the MSE or the mean absolute error (MAE) as the 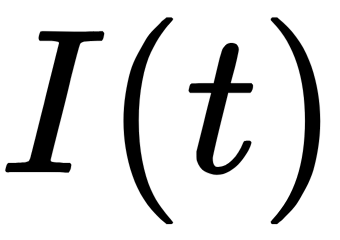 impurity function for regression tasks. For classification tasks, we can use the following functions:
impurity function for regression tasks. For classification tasks, we can use the following functions:
- Gini criterion
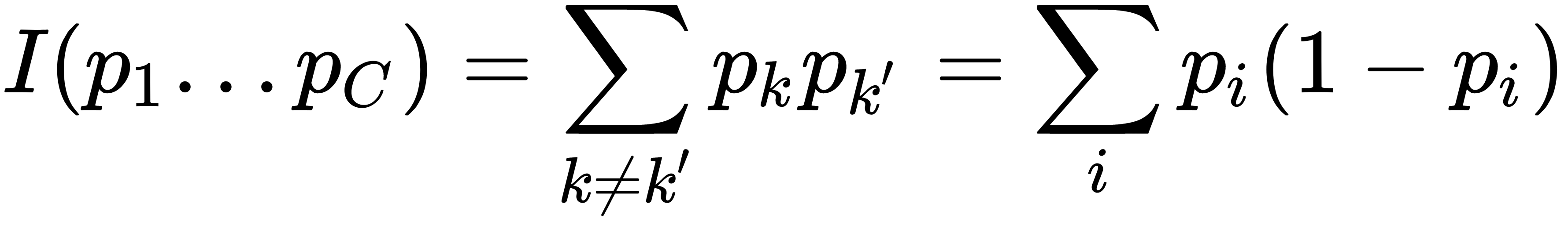 as the probability of misclassification, specifically if we predict classes with probabilities of their occurrence in a given node
as the probability of misclassification, specifically if we predict classes with probabilities of their occurrence in a given node - Entropy
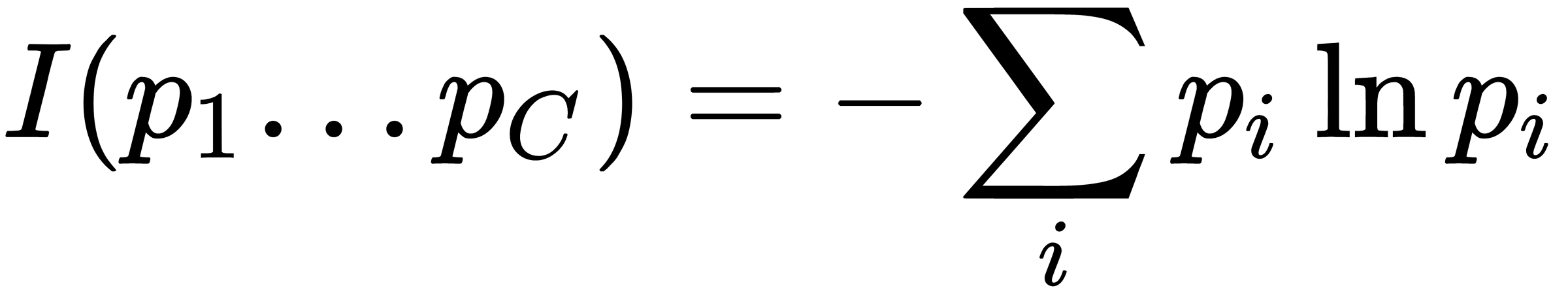 as a measure of the uncertainty of a random variable
as a measure of the uncertainty of a random variable - Classification error
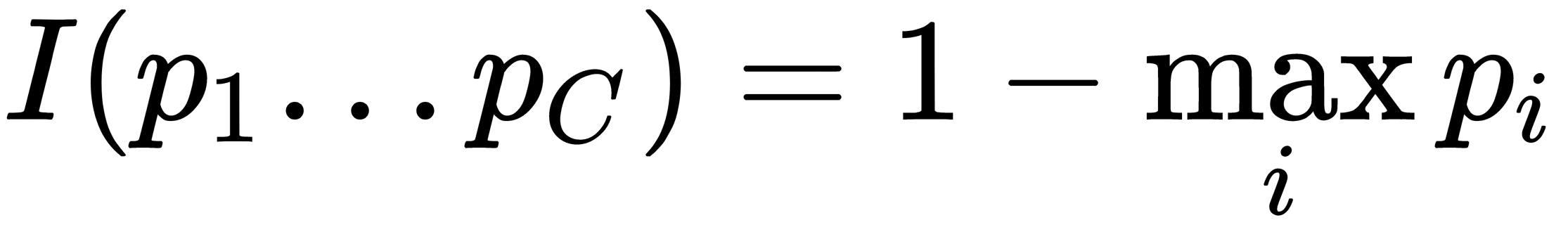 as the error rate in the classification of the most potent class
as the error rate in the classification of the most potent class
In the functions described previously, 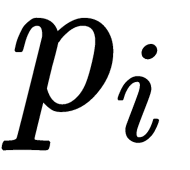 is an a priori probability of encountering an object of class i in a node t—that is, the number of objects in the training sample with labels of class i falling into t divided by the total number of objects in t (
is an a priori probability of encountering an object of class i in a node t—that is, the number of objects in the training sample with labels of class i falling into t divided by the total number of objects in t (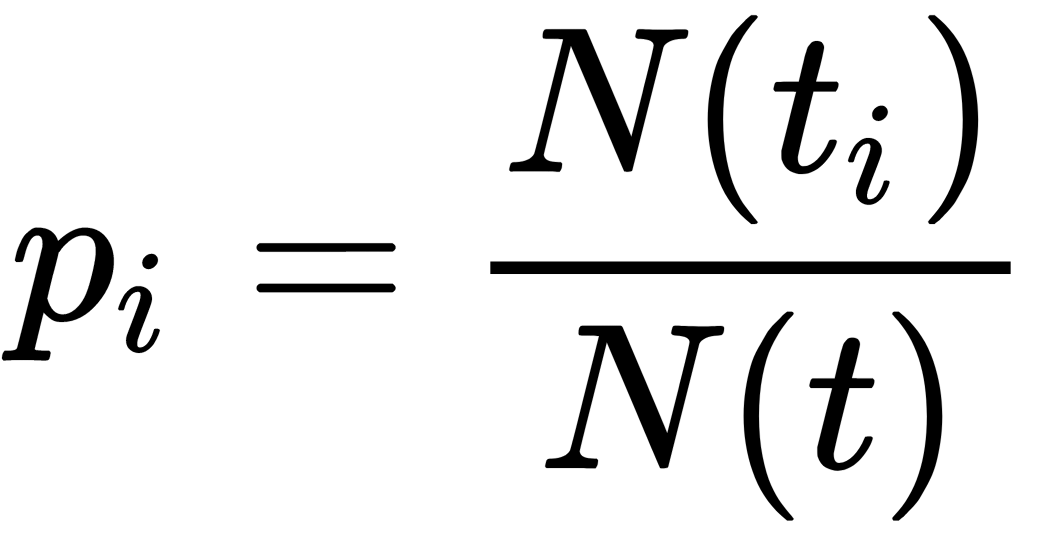 ).
).
The following rules can be applied as stopping criteria for building a decision tree:
- Limiting the maximum depth of the tree
- Limiting the minimum number of objects in the sheet
- Limiting the maximum number of leaves in a tree
- Stopping if all objects at the node belong to the same class
- Requiring that information gain is improved by at least 8 percent during splitting
There is an error-free tree for any training set, which leads to the problem of overfitting. Finding the right stopping criterion to solve this problem is challenging. One solution is pruning—after the whole tree is constructed, we can cut some nodes. Such an operation can be performed using a test or validation set. Pruning can reduce the complexity of the final classifier, and improve predictive accuracy by reducing overfitting.
The pruning algorithm is formed as follows:
- We build a tree for the training set.
- Then, we pass a validation set through the constructed tree, and consider any internal node t and its left and right sub-nodes
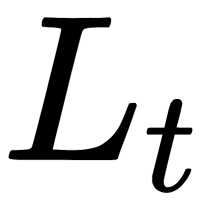 ,
, 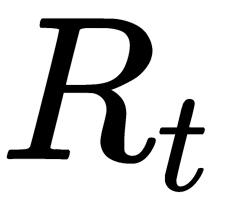 .
. - If no one object from the validation sample has reached t, then we can say that this node (and all its subtrees) is insignificant, and make t the leaf (set the predicate's value for this node equal to the set of the majority class using the training set).
- If objects from the validation set have reached t, then we have to consider the following three values:
- The number of classification errors from a subtree of t
- The number of classification errors from the
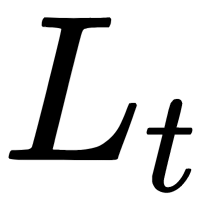 subtree
subtree - The number of classification errors from the
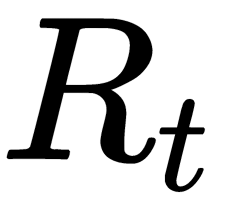 subtree
subtree
If the value for the first case is zero, then we make node t as a leaf node with the corresponding prediction for the class. Otherwise, we choose the minimum of these values. Depending on which of them is minimal, we do the following, respectively:
- If the first is minimal, do nothing
- If the second is minimal, replace the tree from node t with a subtree from node
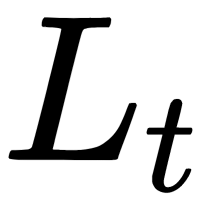
- If the third is minimal, replace the tree from node t with a subtree from node
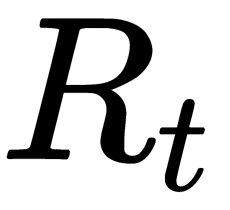
Such a procedure regularizes the algorithm to beat overfitting and increase the ability to generalize. In the case of a k-dimensional tree, different approaches can be used to select the forecast in the leaf. We can take the most common class among the objects of the training that fall in this leaf for classification. Alternatively, we can calculate the average of the objective functions of these objects for regression.
We apply a decision rule to a new object starting from the tree root to predict or classify new data. Thus, it is determined which subtree the object should go into. We recursively repeat this process until we reach some leaf node, and, finally, we return the value of the leaf node we found as the result of classification or regression.