
Another ensemble learning algorithm implemented in the Shogun library is the random forest algorithm. We'll use it for the same function approximation task. It is implemented in the CRandomForest class. To instantiate an object of this class, we have to pass two parameters to the constructor: one is the number of trees (also, it equals the number of bags the dataset should be divided to); the second is the number of attributes chosen randomly during the node splitting when the algorithm builds a tree.
The next important configuration option is the rule on how the tree results should be combined into the one final answer. The set_combination_rule method is used to configure it. In the following example, we used an object of the CMajorityVote class, which implements the majority vote scheme.
We also need to configure what type of problem we want to solve with the random forest, and we can do this with the set_machine_problem_type method of the CRandomForest class. Another required configuration is a type of feature we want to use within our problem: the nominal or continuous features. This can be done with the set_feature_types method. For the training, we will use the set_labels and the train methods with appropriate parameters, as well as an object of the CRegressionLabels type, and an object of the CDenseFeatures type. For evaluation, the apply_regression method will be used, as illustrated in the following code block:
void RFClassification(Some<CDenseFeatures<DataType>> features,
Some<CRegressionLabels> labels,
Some<CDenseFeatures<DataType>> test_features,
Some<CRegressionLabels> test_labels) {
int32_t num_rand_feats = 1;
int32_t num_bags = 10;
auto rand_forest =
shogun::some<CRandomForest>(num_rand_feats, num_bags);
auto vote = shogun::some<CMajorityVote>();
rand_forest->set_combination_rule(vote);
// mark feature type as continuous
SGVector<bool> feature_type(1);
feature_type.set_const(false);
rand_forest->set_feature_types(feature_type);
rand_forest->set_labels(labels);
rand_forest->set_machine_problem_type(PT_REGRESSION);
rand_forest->train(features);
// evaluate model on test data
auto new_labels = wrap(rand_forest->apply_regression(test_features));
auto eval_criterium = some<CMeanSquaredError>();
auto accuracy = eval_criterium->evaluate(new_labels, test_labels);
...
}
The following diagram shows the result of applying the random forest algorithm from the Shogun library:
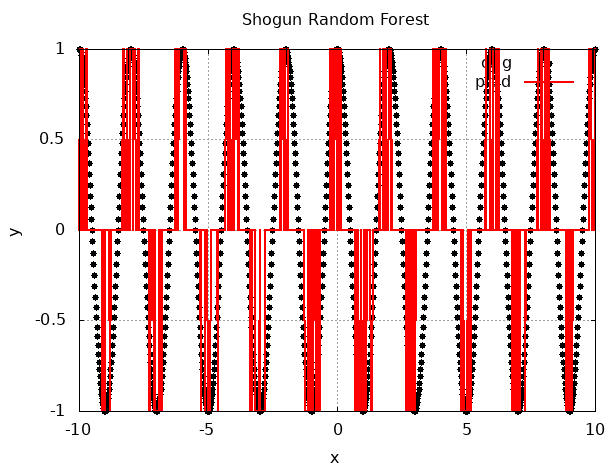
Note that this method is not very applicable to the regression task on this dataset. We can see the gradient boosting used in the previous section produced more interpretable and less error-prone output on this dataset.