
In this example, we chose the LeNet5 architecture, which was developed by Yann LeCun, Leon Bottou, Yosuha Bengio, and Patrick Haffner (http://yann.lecun.com/exdb/lenet/). The architecture's details were discussed earlier in the Convolution network architecture section. Here, we'll show you how to implement it with the PyTorch framework.
All the structural parts of the neural networks in the PyTorch framework should be derived from the torch::nn::Module class. The following snippet shows the header file of the LeNet5 class:
#include <torch/torch.h>
class LeNet5Impl : public torch::nn::Module {
public:
LeNet5Impl();
torch::Tensor forward(torch::Tensor x);
private:
torch::nn::Sequential conv_;
torch::nn::Sequential full_;
};
TORCH_MODULE(LeNet5);
Notice that we defined the intermediate implementation class, which is called LeNet5Impl. This is because PyTorch uses a memory management model based on smart pointers, and all the modules should be wrapped in a special type. There is a special class called torch::nn::ModuleHolder, which is a wrapper around std::shared_ptr, but also defines some additional methods for managing modules. So, if we want to follow all PyTorch conventions and use our module (network) with all PyTorch's functions without any problems, our module class definition should be as follows:
class Name : public torch::nn::ModuleHolder<Impl> {}
Impl is the implementation of our module, which is derived from the torch::nn::Module class. There is a special macro that can do this definition for us automatically; it is called TORCH_MODULE. We need to specify the name of our module in order to use it.
The most crucial function in this definition is the forward function. This function, in our case, takes the network's input and passes it through all the network layers until an output value is returned from this function. If we don't implement a whole network but rather some custom layers or some structural parts of a network, this function should assume we take the values from the previous layers or other parts of the network as input. Also, if we are implementing a custom module that isn't from the PyTorch standard modules, we should define the backward function, which should calculate gradients for our custom operations.
The next essential thing in our module definition is the usage of the torch::nn::Sequential class. This class is used to group sequential layers in the network and automate the process of forwarding values between them. We broke our network into two parts, one containing convolutional layers and another containing the final fully-connected layers.
The PyTorch framework contains many functions for creating layers. For example, the torch::nn::Conv2d function created the two-dimensional convolution layer. Another way to create a layer in PyTorch is to use the torch::nn::Functional function to wrap some simple function into the layer, which can then be connected with all the outputs of the previous layer. Notice that activation functions are not part of the neurons in PyTorch and should be connected as a separate layer. The following code snippet shows the definition of our network components:
static std::vector<int64_t> k_size = {2, 2};
static std::vector<int64_t> p_size = {0, 0};
LeNet5Impl::LeNet5Impl() {
conv_ = torch::nn::Sequential(
torch::nn::Conv2d(torch::nn::Conv2dOptions(1, 6, 5)),
torch::nn::Functional(torch::tanh),
torch::nn::Functional(torch::avg_pool2d,
/*kernel_size*/ torch::IntArrayRef(k_size),
/*stride*/ torch::IntArrayRef(k_size),
/*padding*/ torch::IntArrayRef(p_size),
/*ceil_mode*/ false,
/*count_include_pad*/ false),
torch::nn::Conv2d(torch::nn::Conv2dOptions(6, 16, 5)),
torch::nn::Functional(torch::tanh),
torch::nn::Functional(torch::avg_pool2d,
/*kernel_size*/ torch::IntArrayRef(k_size),
/*stride*/ torch::IntArrayRef(k_size),
/*padding*/ torch::IntArrayRef(p_size),
/*ceil_mode*/ false,
/*count_include_pad*/ false),
torch::nn::Conv2d(torch::nn::Conv2dOptions(16, 120, 5)),
torch::nn::Functional(torch::tanh));
register_module("conv", conv_);
full_ = torch::nn::Sequential(
torch::nn::Linear(torch::nn::LinearOptions(120, 84)),
torch::nn::Functional(torch::tanh),
torch::nn::Linear(torch::nn::LinearOptions(84, 10)));
register_module("full", full_);
}
Here, we initialized two torch::nn::Sequential modules. They take a variable number of other modules as arguments for constructors. Notice that for the initialization of the torch::nn::Conv2d module, we have to pass the instance of the torch::nn::Conv2dOptions class, which can be initialized with the number of input channels, the number of output channels, and the kernel size. We used torch::tanh as an activation function; notice that it is wrapped in the torch::nn::Functional class instance. The average pooling function is also wrapped in the torch::nn::Functional class instance because it is not a layer in the PyTorch C++ API; it's a function. Also, the pooling function takes several arguments, so we bound their fixed values. When a function in PyTorch requires the values of the dimensions, it assumes that we provide an instance of the torch::IntArrayRef type. An object of this type behaves as a wrapper for an array with dimension values. We should be careful here because such an array should exist at the same time as the wrapper lifetime; notice that torch::nn::Functional stores torch::IntArrayRef objects internally. That is why we defined k_size and p_size as static global variables.
Also, pay attention to the register_module function. It associates the string name with the module and registers it in the internals of the parent module. If the module is registered in such a way, we can use a string-based parameter search later (often used when we need to manually manage weights updates during training) and automatic module serialization.
The torch::nn::Linear module defines the fully connected layer and should be initialized with an instance of the torch::nn::LinearOptions type, which defines the number of inputs and the number of outputs, that is, a count of the layer's neurons. Notice that the last layer returns 10 values, not one label, despite us only having a single target label. This is the standard approach in classification tasks.
The following code shows the forward function's implementation, which performs model inference:
torch::Tensor LeNet5Impl::forward(at::Tensor x) {
auto output = conv_->forward(x);
output = output.view({x.size(0), -1});
output = full_->forward(output);
output = torch::log_softmax(output, -1);
return output;
}
This function is implemented as follows:
- We passed the input tensor (image) to the forward function of the sequential convolutional group.
- Then, we flattened its output with the view tensor method because fully connected layers assume that the input is flat. The view method takes the new dimensions for the tensor and returns a tensor view without exactly copying the data; -1 means that we don't care about the dimension's value and that it can be flattened.
- Then, the flattened output from the convolutional group is passed to the fully connected group.
- Finally, we applied the softmax function to the final output. We're unable to wrap torch::log_softmax in the torch::nn::Functional class instance because of multiple overrides.
The softmax function converts a vector,  , of dimension
, of dimension 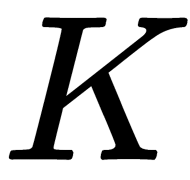 into a vector,
into a vector,  , of the same dimension, where each coordinate,
, of the same dimension, where each coordinate, 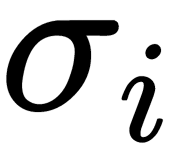 , of the resulting vector is represented by a real number in the range
, of the resulting vector is represented by a real number in the range 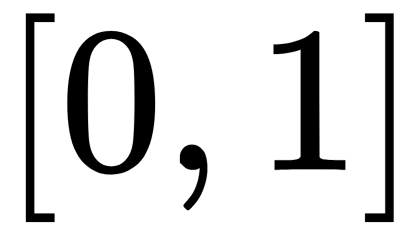 and the sum of the coordinates is 1.
and the sum of the coordinates is 1.
The coordinates are calculated as follows:
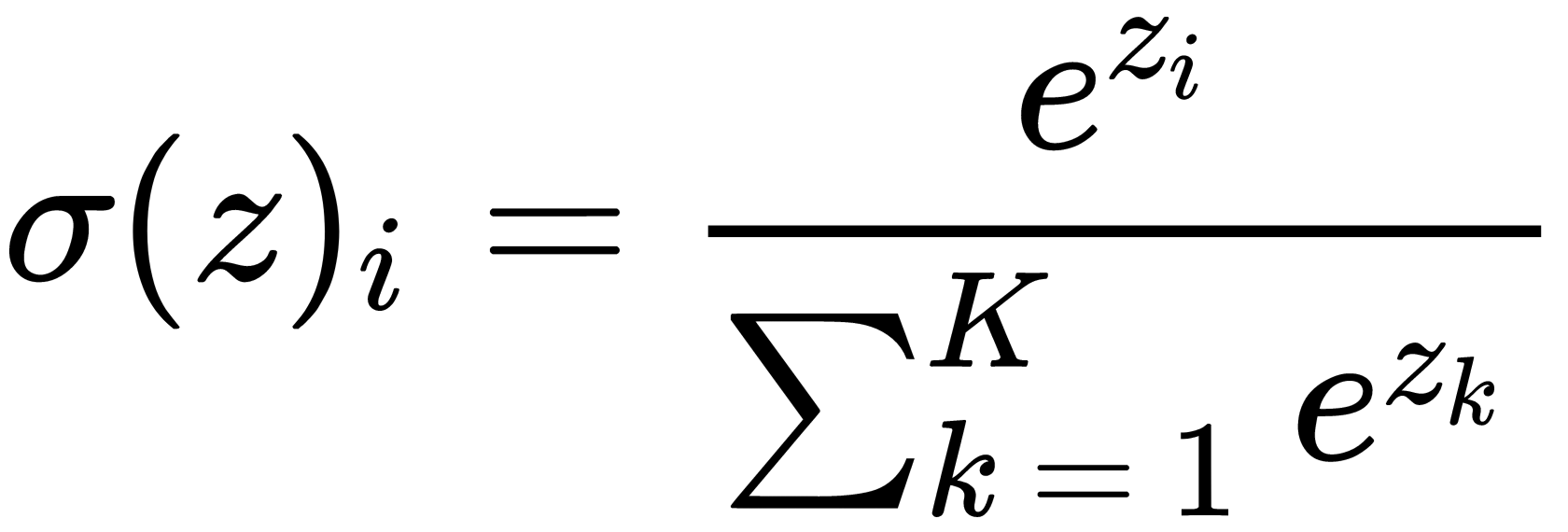
The softmax function is used in machine learning for classification problems when the number of possible classes is more than two (for two classes, a logistic function is used). The coordinates, 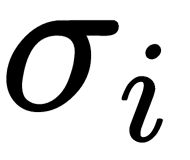 , of the resulting vector can be interpreted as the probabilities that the object belongs to the class,
, of the resulting vector can be interpreted as the probabilities that the object belongs to the class, 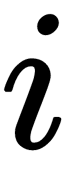 . We chose this function because its results can be directly used for the cross-entropy loss function, which measures the difference between two probability distributions. The target distribution can be directly calculated from the target label value – we create the 10 value's vector of zeros and put one in the place indexed by the label value. Now, we have all the required components to train the neural network.
. We chose this function because its results can be directly used for the cross-entropy loss function, which measures the difference between two probability distributions. The target distribution can be directly calculated from the target label value – we create the 10 value's vector of zeros and put one in the place indexed by the label value. Now, we have all the required components to train the neural network.