
Chapter 9: Designing Cloud-Native Architectures
Nowadays, the microservices architectural model is mainstream. At the time of writing, we are likely in the Trough of Disillusionment. This widespread terminology comes from the Gartner Hype Cycle model and is a way of identifying phases in the adoption of technology, starting from bleeding edge and immaturity and basically going through to commodity.
This means, in my opinion, that even if we are starting to recognize some disadvantages, microservices are here to stay. However, in this chapter, I would like to broaden the point of view and look at the so-called cloud-native architectures. Don't get confused by the term cloud, as these kinds of architectures don't necessarily require a public cloud to run (even if one cloud, or better, many clouds, is the natural environment for this kind of application).
A cloud-native architecture is a way to build resistant, scalable infrastructure able to manage traffic peaks with little to no impact and to quickly evolve and add new features by following an Agile model such as DevOps. However, a cloud-native architecture is inherently complex, as it requires heavy decentralization, which is not a matter that can be treated lightly. In this chapter, we will see some concepts regarding the design and implementation of cloud-native architectures.
In this chapter, you will learn about the following topics:
- Why create cloud-native applications?
- Learning about types of cloud service models
- Defining twelve-factor applications
- Well-known issues in the cloud-native world
- Adopting microservices and evolving existing applications
- Going beyond microservices
- Refactoring apps as microservices and serverless
That's a lot of interesting stuff, and we will see that many of these concepts can help improve the quality of the applications and services you build, even if you are in a more traditional, less cloud-oriented setup. I am sure that everybody reading this chapter already has an idea, maybe a detailed idea, of what a cloud-native application is. However, after reading this chapter, this idea will become more and more structured and complete.
So, to start the chapter, we are going to better elaborate on what a cloud-native application is, what the benefits are, and some tools and principles that will help us in building one (and achieving such benefits).
Why create cloud-native applications?
Undoubtedly, when defining cloud-native, there are a number of different nuances and perspectives that tackle the issue from different perspectives and with different levels of detail, ranging from technical implications to organizational and business impacts.
However, in my opinion, a cloud-native application (or architecture, if you want to think in broader terms) must be designed to essentially achieve three main goals (somewhat interrelated):
- Scalability is, of course, immediately related to being able to absorb a higher load (usually because of more users coming to our service) with no disruption and that's a fundamental aspect. However, scalability also means, in broader terms, that the application must be able to downscale (hence, reducing costs) when less traffic is expected, and this may imply the ability to run with minimal or no changes in code on top of different environments (such as on-premises and the public cloud, which may be provided by different vendors).
- Modularity is about the application being organized in self-contained, modular components, which must be able to interoperate with each other and be replaced by other components wherever needed. This has huge impacts on the other two points (scalability and resiliency). A modular application is likely to be scalable (as you can increase the number of instances of a certain module that is suffering from a load) and can be easily set up on different infrastructures. Also, it may be using the different backing services provided by each infrastructure (such as a specific database or filesystem), thereby increasing both scalability and resiliency.
- Resiliency, as we just mentioned, can be defined as being able to cope with unpredicted events. Such events include application crashes, bugs in the code, external (or backing) services misbehaving, or infrastructure/hardware failures. A cloud-native application must be designed in a way that avoids or minimizes the impact of such issues on the user experience. There are a number of ways to address those scenarios and we will see some in this section. Resiliency includes being able to cope with unforeseen traffic spikes, hence it is related to scalability. Also, as has been said, resiliency can also be improved by structuring the overall application in modular subsystems, optionally running in multiple infrastructures (minimizing single-point-of-failure problems).
As a cloud-native architect, it is very important to see the business benefits provided by such (preceding) characteristics. Here are the most obvious ones, for each point:
- Scalability implies that a system can behave better under stress (possibly with no impacts), but also has predictable costs, meaning a higher cost when more traffic comes and a lower one when it's not needed. In other words, the cost model scales together with the requests coming into the system. Eventually, a scalable application will cost less than a non-scalable one.
- Modularity will positively impact system maintainability, meaning reduced costs as regards changes and the evolution of the system. Moreover, a properly modularized system will facilitate the development process, reducing the time needed for releasing fixes and new features in production, and likely reducing the time to market. Last but not least, a modular system is easier to test.
- Resiliency means a higher level of availability and performance of the service, which in turn means happier customers, a better product, and overall, a better quality of the user experience.
While cloud-native is a broad term, implying a big number of technical characteristics, benefits, and technological impacts, I think that the points that we have just seen nicely summarize the core principles behind the cloud-native concept.
Now, it's hard to give a perfect recipe to achieve each of those goals (and benefits). However, in this chapter, we are going to link each point with some suggestions on how to achieve it:
- PaaS is an infrastructural paradigm providing support services, among other benefits, for building scalable infrastructures.
- The twelve-factor apps are a set of principles that assist in building modular applications.
- Cloud-native patterns are a well-known methodology (also implemented in the MicroProfile specification) for building resilient applications.
In the next section, we are going to define what PaaS is and how our application is going to benefit from it.
Learning about types of cloud service models
Nowadays, it is common to refer to modern, cloud-native architectures by means of a number of different terms and acronyms. The as a service phrase is commonly used, meaning that every resource should be created and disposed of on-demand, automatically. Everything as a service is a wider term for this kind of approach. Indeed, with cloud computing and microservices, applications can use the resources of a swarm (or a cloud, if you want) of smaller components cooperating in a network.
However, such architectures are hard to design and maintain because, in the real world, the network is basically considered unreliable or at least has non-predictable performances. Even if the network behaves correctly, you will still end up with a lot of moving parts to develop and manage in order to provide core features, such as deploying and scaling. A common tool for addressing those issues is PaaS.
PaaS is an inflated term, or, better yet, every as a service term is overused, and sometimes there is no exact agreement and definition of the meaning and the boundaries between each as a service set of tools. This is my personal view regarding a small set of as a service layers (that can be regarded as common sense, and indeed is widely adopted):
- Infrastructure as a Service (IaaS) refers to a layer providing on-demand computational resources needed to run workloads. This implies Virtual Machines (VMs) (or physical servers) can network to make them communicate and store persistent data. It does not include anything above the OS; once you get your machines, you will have to install everything needed by your applications (such as a Java Virtual Machine (JVM), application servers, and dependencies).
- Platform as a Service (PaaS) is used for a layer that abstracts most of the infrastructure details and provides services that are useful for the application to be built and run. So, in PaaS, you can specify the runtimes (VM, dependencies, and servers) needed by your application and the platform will provide it for you to use.
PaaS could also abstract other concepts for you, such as storage (by providing object storage, or other storage services for you to use), security, serverless, and build facilities (such as CI/CD). Last but not least, PaaS provides tools for supporting the upscale and downscale of the hosted applications. Most PaaS platforms provide their own CLIs, web user interfaces, and REST web services to provision, configure, and access each subsystem. PaaS, in other words, is a platform aiming to simplify the usage of an infrastructural layer to devs and ops. One common way of implementing PaaS is based on containers as a way to provision and present a runtime service to developers.
- Software as a Service (SaaS) is one layer up from PaaS. It is mostly targeted at final users more than developers and implies that the platform provides, on-demand, applications ready to use, completely abstracting the underlying infrastructure and implementation (usually behind an API). However, while the applications can be complex software suites, ready for users to access (such as office suites or webmail), they can also be specific services (such as security, image recognition, or reporting services) that can be used and embedded by developers into more complex applications (usually via API calls).
The following diagram shows you a comparison of IaaS, PaaS, and SaaS:

Figure 9.1 – IaaS versus PaaS versus SaaS
Now, we have a definition of boundaries between some as a service layers. We should get back to our initial thoughts, how is PaaS a good way to support a heavily distributed, cloud-native architecture such as "the network is the computer"?
PaaS simplifies the access to the underlying computing resources by providing a uniform packaging and delivering model (usually, by using containers). It orchestrates such components by deploying them, scaling them (both up and down), and trying to maintain a service level wherever possible (such as restarting a faulty component). It gives a set of administration tools, regardless of the technology used inside each component. Those tools address features such as log collection, metrics and observabilities, and configuration management. Nowadays, the most widely used tool for orchestration is Kubernetes.
Introducing containers and Kubernetes
Container technology has a longstanding history. It became popular around 2013 with the Docker implementation, but initial concepts have their roots in the Linux distributions well before then (such as Linux Containers (LXC), launched around 2008). Even there, concepts were already looking very similar to the modern containers that can be found in older systems and implementations (Solaris zones are often mentioned in this regard).
We could fill a whole book just talking about containers and Kubernetes, but for the sake of simplicity and space, we will just touch on the most important concepts useful for our overview on defining and implementing cloud-native architectures, which is the main goal of this book. First things first, let's start with what a container is, simplified and explained to people with a development background.
Defining containers and why they are important
In a single sentence, a container is a way to use a set of technologies in order to fool an application into thinking it has a full machine at its disposal.
To explain this a bit better, containers wrap a set of concepts and features, usually based on Linux technology (such as runc and cgroups), which are used to isolate and limit a process to make it play nicely with other processes sharing the same computational power (physical hardware or VMs).
To achieve those goals, the container technology has to deal with the assignment and management of computing resources, such as networking (ports, IP addresses, and more), CPU, filesystems, and storage. The supporting technology can create fake resources, mapping them to the real ones offered by the underlying resources. This means that a container may think to expose a service on port 80, but in reality, such a service is bound to a different port on the host system, or it can think to access the root filesystem, but in reality, is confined to a well-defined folder.
In this way, it's the container technology that administers and partitions the resources and avoids conflicts between different applications running and competing for the same objects (such as network ports). But that's just one part of the story: to achieve this goal, our application must be packaged in a standard way, which is commonly a file specifying all the components and resources needed by our application to run.
Once we create our container (starting from such a descriptor), the result is an immutable container image (which is a binary runtime that can also be signed for integrity and security purposes). A container runtime can then take our container image and execute it. This allows container applications to do the following:
- Maximize portability: Our app will run where a compatible runtime is executed, regardless of the underlying OS version, or irrespective of whether the resources are provided by a physical server, a VM, or a cloud instance.
- Reduce moving parts: Anything tested in a development environment will look very similar to what will be in production.
- Isolate configurations from executable code: The configurations will need to be external and injected into our immutable runtime image.
- Describe all the components: You should nicely describe all the components of our application, for both documentation purposes and inspection (so you can easily understand, for example, the patch level of all of your Java machines).
- Unify packaging, deployment, and management: Once you have defined your container technology, you can package your applications and they will be managed (started, stopped, scaled, and more) all in the same way regardless of the internal language and technologies used.
- Reduce the footprint: While you could achieve most of the advantages with a VM, a container is typically way lighter (because it will carry only what's needed by the specific application, and not a full-fledged OS). For such a reason, you can run more applications using the same number of resources.
Those are more or less the reasons why container technology became so popular. While some of those are specific to infrastructural aspects, the advantages for developers are evident: think how this will simplify, as an example, the creation of a complete test or dev environment in which every component is containerized and running on the correct version (maybe a production one because you are troubleshooting or testing a fix).
So far so good: containers work well and are a nice tool for building modern applications. What's the warning here? The point is, if you are in a local environment (or a small testing infrastructure), you can think of managing all the containers manually (or using some scripts), such as provisioning it on a few servers and assigning the configurations required. But what will happen when you start working with containers at scale? You will need to worry about running, scaling, securing, moving, connecting, and much more, for hundreds or thousands of containers. This is something that for sure is not possible to do manually. You will need an orchestrator, which does exactly that. The standard orchestrator for containers today is Kubernetes.
Orchestrating containers with Kubernetes
Kubernetes (occasionally shortened to K8s) is, at the time of writing, the core of many PaaS implementations. As will become clear at the end of this section, Kubernetes offers critical supporting services to container-based applications. It originated from work by Google (originally known as Borg) aimed at orchestrating containers providing most of the production services of the company. The Kubernetes operating model is sometimes referred to as declarative. This means that Kubernetes administrators define the target status of the system (such as I want two instances of this specific application running) and Kubernetes will take care of it (as an example, creating a new instance if one has failed).
Following its initial inception at Google, Kubernetes was then released as an open source project and is currently being actively developed by a heterogeneous community of developers, both enterprise sponsored and independent, under the Cloud Native Computing Foundation umbrella.
Kubernetes basic objects
Kubernetes provides a set of objects, used to define and administer how the applications run on top of it. Here is a list of these objects:
- A Pod is the most basic unit in a Kubernetes cluster, including at least one container (more than one container is allowed for some specific use cases). Each Pod has an assigned set of resources (such as CPU and memory) and can be imagined as a Container plus some metadata (including network resources, application configurations, and storage definitions). Here is a diagram for illustration:
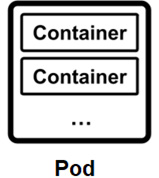
Figure 9.2 – A Pod
- Namespaces are how Kubernetes organizes all the other resources and avoids overlaps. In that sense, they can be intended as projects. Of course, it's possible to restrict access for users to specific namespaces. Commonly, namespaces are used to group containers belonging to the same application and to define different environments (such as dev, test, and prod) in the same Kubernetes cluster.
- Services are network load balancers and DNS servers provided by the Kubernetes cluster. Behind a Service, there are a number of Pods answering incoming requests. In this way, each Pod can access functions exposed from other Pods, thereby circumventing accessing such Pods directly via their internal IP (which is considered a bad and unreliable way). Services are, by default, internal, but they could be exposed and accessed from outside the Kubernetes cluster (by using other Kubernetes objects and configurations that aren't covered here). The following diagram illustrates the structure of a Service:

Figure 9.3 – A Service
- Volumes are a means for Kubernetes to define access to persistent storage to be provided to the Pods. Containers do indeed use, by default, ephemeral storage. If you want a container to have a different kind of storage assigned, you have to deal with volumes. The storage (like many other aspects) is managed by Kubernetes in a pluggable way, meaning that behind a volume definition, many implementations can be attached (such as different storage resources provided by cloud services providers or hardware vendors).
- ConfigMaps and Secrets are the standard way, in Kubernetes, of providing configurations to Pods. They are basically used to inject application properties (such as database URLs and user credentials) without needing an application rebuild. Secrets are essentially the same idea but are supposed to be used for confidential information (such as passwords).
By default, Secrets are strings encoded in Base64 (and so are not really secure), but they can be encrypted in various ways. ConfigMaps and Secrets can be consumed by the application as environment variables or property files.
- ReplicaSet, StatefulSet, and DaemonSet are objects that define the way each Pod should be run. ReplicaSet defines the number of instances (replicas)of the Pods to be running at any given time. StatefulSet is a way to define the ordering in which a given set of Pods should be started or the fact that a Pod should have only one instance running at a time. For this reason, they are useful for running stateful applications (such as databases) that often have these kinds of requirements.
DaemonSet, instead, is used to ensure that a given Pod has an instance running in each server of the Kubernetes cluster (more on this in the next section). DaemonSet is useful for some particular use cases, such as monitoring agents or other infrastructural support services.
- The Deployment is a concept related to ReplicaSet and Pods. A Deployment is a way to deploy ReplicaSets and Pods by defining the intermediate steps and strategy to perform Deployments, such as rolling releases and rollbacks. Deployments are useful for automating the release process and reducing the risk of human error during such processes.
- Labels are the means that Kubernetes uses to identify and select basically every object. In Kubernetes, indeed, it is possible to tag everything with a label and use that as a way to query the cluster for objects identified by it. This is used by both administrators (such as to group and organize applications) and the system itself (as a way to link objects to other objects). As an example, Pods that are load-balanced to respond to a specific service are identified using labels.
Now that we have had a glimpse into Kubernetes' basic concepts (and a glossary), let's have a look at the Kubernetes architecture.
The Kubernetes architecture
Kubernetes is practically a set of Linux machines, with different services installed, that play different roles in the cluster. It may include some Windows servers, specifically for the purpose of running Windows workloads (such as .NET applications).
There are two basic server roles for Kubernetes:
- Masters are the nodes that coordinate with the entire cluster and provide the administration features, such as managing applications and configurations.
- Workers are the nodes running the entire applications.
Let's see a bit about what's in each server role. We'll start with the master node components.
Master nodes, as said, carry out the role of coordinating workloads across the whole cluster. To do so, these are the services that a master node commonly runs:
- etcd server: One of the most important components running on a master is the etcd server. etcd is a stateful component, more specifically, a key-value database. Kubernetes uses it to store the configuration of the cluster (such as the definition of Pods, Services, and Deployments), basically representing the desired state of the entire cluster (remember that Kubernetes works in a declarative way). etcd is particularly suited to such needs because it has quite good performance and works well in a distributed setup (optionally switching to a read-only state if something bad happens to it, thereby allowing limited operativity even under extreme conditions, such as a server crash or a network split).
- API server: To interact with etcd, Kubernetes provides an API server. Most of the actions that happen in Kubernetes (such as administration, configuration checks, and the reporting of state) are done through calls to the API server. Such calls are basically JSON via HTTP.
- Scheduler: This is the component that handles selecting the right worker to execute a Pod. To do so, it can handle the basic requirements (such as the first worker with enough resources or lower loads) or advanced, custom-configured policies (such as anti-affinity and data locality).
- Controller manager: This is a set of processes implementing the Kubernetes logic that we have described so far, meaning that it continuously checks the status of the cluster against the desired status (defined in etcd) and operates the requisite changes if needed. So, for example, if a Pod is running fewer instances than what is configured, the Controller manager creates the missing instances, as shown here:

Figure 9.4 – Master and worker nodes
This set of components, running into master nodes, is commonly referred to as the control plane. In production environments, it's suggested to run the master nodes in a high-availability setup, usually in three copies (on the basis of the etcd requirements for high availability).
As is common in a master/slave setup, the master nodes are considered to be precious resources configured in a high-availability setup. Everything that is reasonably possible should be done to keep the master nodes running and healthy, as there can be unforeseen effects on the Kubernetes cluster in case of a failure (especially if all the master instances fail at the same time).
The other component in a Kubernetes cluster is the worker nodes: worker node components.
The worker nodes are the servers on a Kubernetes cluster that actually run the applications (in the form of Pods). Unlike masters, workers are a disposable resource. With some exceptions, it is considered safe to change the number of worker nodes (by adding or removing them) in a running Kubernetes cluster. Indeed, that's a very common use case: it is one of the duties of the master nodes to ensure that all the proper steps (such as recreating Pods and rebalancing the workload) are implemented following such changes.
Of course, if the changes to the cluster are planned, it is likely to have less impact on the application (because, as an example, Kubernetes can evacuate Pods from the impacted nodes before removing it from the cluster), while if something unplanned, such as a crash, happens, this may imply some service disruptions. Nevertheless, Kubernetes is more or less designed to handle this kind of situation. Master nodes run the following components:
- Container runtime: This is a core component of a worker node. It's the software layer responsible for running the containers included in each Pod. Kubernetes supports, as container runtimes, any implementation of the Container Runtime Interface (CRI) standard. Widespread implementations, at the time of writing, include containerd, Docker, and CRI-O.
- kubelet: This is an agent running on each worker. Kubelet registers itself with the Kubernetes API server and communicates with it in order to check that the desired state of Pods scheduled to run in the node is up and running. Moreover, kubelet reports the health status of the node to the master (hence, it is used to identify a faulty node).
- kube-proxy: This is a network component running on the worker node. Its duty is to connect applications running on the worker node to the outside world, and vice versa.
Now that we have a clear understanding of the Kubernetes objects, server roles, and related components, it's time to understand why Kubernetes is an excellent engine for PaaS, and what is lacking to define it as PaaS per se.
Kubernetes as PaaS
If the majority of your experience is in the dev area, you may feel a bit lost after going through all those Kubernetes concepts. Even if everything is clear for you (or you already have a background in the infrastructural area), you'll probably agree that Kubernetes, while being an amazing tool, is not the easiest approach for a developer.
Indeed, most of the interactions between a developer and a Kubernetes cluster may involve working with .yaml files (this format is used to describe the API objects that we have seen) and the command line (usually using kubectl, the official CLI tool for Kubernetes) and understanding advanced container-based mechanisms (as persistent volumes, networking, security policies, and more).
Those aren't necessarily the most natural skills for a developer. For such reasons (and similar reasons on the infrastructure side), Kubernetes is commonly not regarded as a PaaS per se; it is more like being a core part of one (an engine). Kubernetes is sometimes referred to as Container as a Service (CaaS), being essentially an infrastructure layer that orchestrates containers as the core feature.
One common metaphor used in this regard is with the Linux OS. Linux is made by a low-level, very complex, and very powerful layer, which is the kernel. The kernel is vital for everything in the Linux OS, including managing processes, resources, and peripherals. But no Linux users exclusively use the kernel; they will use the Linux distributions (such as Fedora, Ubuntu, or RHEL), which top up the kernel with all the high-level features (such as tools, utilities, and interfaces) that make it usable to final users.
To use it productively, Kubernetes (commonly referred to in this context as vanilla Kubernetes) is usually complemented with other tools, plugins, and software, covering and extending some areas. The most common are as follows:
- Runtime: This is related to the execution of containers (and probably the closer, more instrumental extensions that Kubernetes needs to rely on to work properly and implement a PaaS model). Indeed, strictly speaking, Kubernetes doesn't even offer a container runtime; but, as seen in the previous section, it provides a standard (the CRI) that can be implemented by different runtimes (we mentioned containerd, Docker, and CRI-O). In the area of runtimes, network and storage are also worth mentioning as stacks are used to provide connectivity and persistence to the containers. As in the container runtime, in both network and storage runtimes, there is a set of standards and a glossary (the aforementioned services, or volumes) that is then implemented by the technology of choice.
- Provisioning: This includes aspects such as automation, infrastructure as code (commonly used tools here include Ansible and Terraform), and container registries in order to store and manage the container images (notable implementations include Harbor and Quay).
- Security: This spans many different aspects of security, from policy definition and enforcement (one common tool in this area is Open Policy Agent), runtime security and threat detection (a technology used here is Falco), and image scanning (Clair is one of the implementations available) to vault and secret encryption and management (one product covering this aspect is HashiCorp Vault).
- Observability: This is another important area to make Kubernetes a PaaS solution that can be operated easily in production. One de facto standard here is Prometheus, which is a time series database widely used to collect metrics from the different components running on Kubernetes (including core components of the platform itself). Another key aspect is log collection, to centralize the logs produced.
Fluentd is a common choice in this area. Another key point (that we already introduced in Chapter 7, Exploring Middleware and Frameworks, in the sections on micro profiling) is tracing, as in the capability of correlating calls to different systems and identifying the execution of a request when such a request is handled by many different subsystems. Common tools used for this include Jaeger and OpenTracing. Last but not least, most of the telemetry collected in each of those aspects is commonly represented as dashboards and graphics. A common choice for doing that is with Grafana.
- Endpoint management: This is a topic related to networking, but at a higher level. It involves the definition, inventory, discovery, and management of application endpoints (that is, an API or similar network endpoints). This area is commonly addressed with a service mesh. It offloads communication between the containers by using a network proxy (using the so-called sidecar pattern) so that such a proxy can be used for tracing, securing, and managing all the calls entering and exiting the container. Common implementations of a service mesh are Istio and Linkerd. Another core area of endpoint management is so-called API management, which is similar conceptually (and technically) to a service mesh but is more targeted at calls coming from outside the Kubernetes cluster (while the service mesh mostly addresses Pod-to-Pod communication). Commonly used API managers include 3scale and Kong.
- Application management: Last but not least, this is an area related to how applications are packaged and installed in Kubernetes (in the form of container images). Two core topics are application definition (where two common implementations are Helm and the Operator Framework) and CI/CD (which can be implemented, among others, using Tekton and/or Jenkins).
All the aforementioned technologies (and many more) are mentioned and cataloged (using a similar glossary) in the CNCF landscape (visit https://landscape.cncf.io). CNCF is the Cloud Native Computing Foundation, which is an organization related to the Linux Foundation, aiming to define a set of vendor-neutral standards for cloud-native development. The landscape is their assessment of technologies that can be used for such goals including and revolving around Kubernetes (which is one of the core software parts of it).
So, I think it is now clear that Kubernetes and containers are core components of PaaS, which is key for cloud-native development. Nevertheless, such components mostly address runtime and orchestration needs, but many more things are needed to implement a fully functional PaaS model to support our applications.
Looking at things the other way around, you can wonder what the best practices are that each application (or component or microservice) should implement in order to fit nicely in PaaS and behave in the best possible way in a cloud-native, distributed setup. While it's impossible to create a magical checklist that makes every application a cloud-native application, there is a well-known set of criteria that can be considered a good starting point. Applications that adhere to this list are called twelve-factor applications.
Defining twelve-factor applications
The twelve-factor applications are a collection of good practices suggested for cloud-native applications. Applications that adhere to such a list of practices will most likely benefit from being deployed on cloud infrastructures, face web-scale traffic peaks, and resiliently recover from failures. Basically, twelve-factor applications are the closest thing to a proper definition of microservices. PaaS is very well suited for hosting twelve-factor apps. In this section, we are going to have a look at this list of factors:
- Codebase: This principle simply states that all the source code related to an app (including scripts, configurations, and every asset needed) should be versioned in a single repo (such as a Git source code repository). This implies that different apps should not share the same repo (which is a nice way to reduce coupling between different apps, at the cost of duplication).
Such a repo is then the source for creating Deployments, which run instances of the application, compiled (where relevant) by a CI/CD toolchain and launched in a number of different environments (such as production, test, and dev). A Deployment can be based on different versions of the same repo (as an example, a dev environment could run experimental versions, containing changes not yet tested and deployed in production, but still part of the same repo).
- Dependencies: A twelve-factor app must explicitly declare all the dependencies that are needed at runtime and must isolate them. This means avoiding depending on implicit and system-wide dependencies. This used to be a problem with traditional applications, as with Java applications running on an application server, or in general with applications expecting some dependencies provided by the system.
Conversely, twelve-factor apps specifically declare and isolate the applications needed. In this way, the application behavior is more repeatable, and a dev (or test) environment is easier to set up. Of course, this comes at the cost of consuming more resources (disk space and memory, mostly). This requirement is one of the reasons for containers being so popular for creating twelve-factor apps, as containers, by default, declare and carry all the necessary dependencies for each application.
- Config: Simply put, this factor is about strictly separating the configurations from the application code. Configurations are intended to be the values that naturally change in each environment (such as credentials for accessing the database or endpoints pointing to external services). In twelve-factor apps, the configurations are supposed to be stored in environment variables. It is common to relax this requirement and store a little configuration in other places (separated from code), such as config files.
Another point is that the twelve-factor apps approach suggests avoiding grouping configurations (such as grouping a set of config values for prod, or one for test) because this approach does not scale well. The advice is to individually manage each configuration property, associating it with the related Deployment. While there are some good rationalizations beyond this concept, it's also not uncommon to relax at this point and have a grouping of configurations following the naming of the environment.
- Backing services: A twelve-factor app must consider each backing service that is needed (such as databases, APIs, queues, and other services that our app depends on) as attached resources. This means that each backing service should be identified by a set of configurations (something such as the URL, username, and password) and it should be possible to replace it without any change to the application code (maybe requiring a restart or refresh).
By adhering to such factors, our app will be loosely coupled to an external service, hence scaling better and being more portable (such as from on-premises to the cloud, and vice versa). Moreover, the testing phase will benefit from this approach because we can easily swap each service with a mock, where needed.
Last but not least, the resiliency of the app will increase because we could, as an example, swap a faulty service with an alternative one in production with little to no outage. In this context, it's also worth noticing that in the purest microservices theory, each microservice should have its own database, and no other microservice should access that database directly (but to obtain the data, it should be mediated by the microservice itself).
- Build, release, and run: The twelve factor approach enforces strict separation for the build, release, and run phases. Build includes the conversion of source code into something executable (usually as the result of a compile process) and the release phase associates the executable item with the configuration needed (considering the target environment).
Finally, the run phase is about executing such a release in the chosen environment. An important point here is that the whole process is supposed to be stateless and repeatable (such as using a CI/CD pipeline), starting from the code repo and configurations. Another crucial point is that each release must be associated with a unique identifier, to map and track exactly where the code and config ended up in each runtime. The advantages of this approach are a reduction in moving parts, support for troubleshooting, and the simplification of rollbacks in case of unexpected behaviors.
- Processes: An app compliant with the twelve factors is executed as one or more processes. Each process is considered to be stateless and shares nothing. The state must be stored in ad hoc backing services (such as databases). Each storage that is local to the process (being disk or memory) must be considered an unreliable cache.
It can be used, but the app must not depend on it (and must be capable of recovering in case something goes wrong). An important consequence of the stateless process model is that sticky sessions must be avoided. A sticky session is when consequent requests must be handled by the same instance in order to function properly. Sticky sessions violate the idea of being stateless and limit the horizontal scalability of applications, and hence should be avoided. Once again, the state must be offloaded to relevant backing services.
- Port binding: Each twelve-factor app must directly bind to a network port and listen to requests on such a port. In this way, each app can become a backing service for other twelve-factor apps. A common consideration around this factor is that usually, applications rely on external servers (such as PHP or a Java application server) to expose their services, whereas twelve-factor apps embed the dependencies needed to directly expose such services.
That's basically what we saw with JEE to cloud-native in the previous chapter; Quarkus, as an example, has a dependency to undertow to directly bind on a port and listen for HTTP requests. It is common to then have infrastructural components routing requests from the external world to the chosen port, wherever is needed.
- Concurrency: The twelve-factor app model suggests implementing a horizontal scalability model. In such a model, concurrency is handled by spinning new instances of the affected components. The smallest scalability unit, suggested to be scaled following the traffic profiles, is the process. Twelve-factor apps should rely on underlying infrastructure to manage the process's life cycle.
This infrastructure can be the OS process manager (such as systemd in a modern Linux system) or other similar systems in a distributed environment (such as PaaS). Processes are suggested to span different servers (such as VMs or physical machines) if those are available, in order to use resources correctly. Take into account the fact that such a concurrency model does not replace other internal concurrency models provided by the specific technology used (such as threads managed by each JVM application) but is considered a kind of extension of it.
- Disposability: Applications adhering to the twelve-factor app should be disposable. This implies that apps should be fast to start up (ideally, a few seconds between the process being launched and the requests being correctly handled) and to shut down. Also, the shutdown should be handled gracefully, meaning that all the external resources (such as database connections or open files) must be safely deallocated, and every inflight request should be managed before the application is stopped.
This fast to start up/safe to shut down mantra will allow for horizontal scalability with more instances being created to face traffic peaks and the ones being destroyed to save resources when no more are needed. Another suggestion is to create applications to be tolerant to hard shutdown (as in the case of a hardware failure or a forced shutdown, such as a process kill). To achieve this, the application should have special procedures in place to handle incoherent states (think about an external resource improperly closed or requests partially handled and potentially corrupted).
- Dev/prod parity: A twelve-factor app must reduce the differences between production and non-production environments as much as possible. This includes differences in software versions (meaning that a development version must be released in production as soon as possible by following the release early, release often mantra).
But the mantra also referred to when different teams are working on it (devs and ops should cooperate in both production and non-production environments, avoiding the handover following the production release and implementing a DevOps model). Finally, there is the technology included in each environment (the backing services should be as close as possible, trying to avoid, as an example, different types of databases in dev versus production environments).
This approach will provide multiple benefits. First of all, in the case of a production issue, it will be easier to troubleshoot and test fixes in all the environments, due to those environments being as close as possible to the production one. Another positive effect is that it will be harder for a bug to find its way into production because the test environments will look like the production ones. Last but not least, having similar environments will reduce the hassle of having to manage multiple variants of stacks and versions.
- Logs: This factor points to the separation of log generation and log storage. A twelve-factor app simply considers logs as an event stream, continuously generated (usually in a textual format) and sent to a stream (commonly the standard output). The app shouldn't care about persisting logs with all the associated considerations (such as log rotation or forwarding to different locations).
Instead, the hosting platform should provide services capable of retrieving such events and handling them, usually on a multitier persistence (such as writing recent logs to files and sending the older entries to indexed systems to support aggregation and searches). In this way, the logs can be used for various purposes, including monitoring and business intelligence on platform performance.
- Admin processes: Many applications provide supporting tools to implement administration processes, such as performing backups, fixing malformed entries, or other maintenance activities. The twelve-factor apps are no exception to this. However, it is recommended to implement such admin processes in an environment as close as possible to the rest of the application.
Wherever possible, the code (or scripts) providing those features should be executed by the same runtime (such as a JVM) and using the same dependencies (the database driver). Moreover, such code must be checked out in the same code repo and must follow the same versioning schema as the application's main code. One approach to achieving this outcome is to provide an interactive shell (properly secured) as part of the application itself and run the administrative code against such a shell, which is then approved to use the same facilities (connection to the database and access to sessions) as the rest of the application.
Probably, while reading this list, many of you were thinking about how those twelve factors can be implemented, especially with the tools that we have seen so far (such as Kubernetes). Let's try to explore those relationships.
Twelve-factor apps and the supporting technology
Let's review the list of the twelve factors and which technologies covered so far can help us to implement applications adhering to such factors:
- Codebase: This is less related to the runtime technology and more to the tooling. As mentioned before, nowadays, the versioning tool widely used is Git, basically being the standard (and for good reason). The containers and Kubernetes, however, are well suited for supporting this approach, providing constructs such as containers, Deployments, and namespaces, which are very useful for implementing multiple deploys from the same codebase.
- Dependencies: This factor is, of course, dependent on the programming language and framework of choice. However, modern container architectures solve the dependency issue in different stages. There is usually one dependency management solution and declaration at a language level (such as Maven for Java projects and npm for JavaScript), useful for building and running the application prior to containerization (as in the dev environment, on a local developer machine).
Then, when containers come into play, their filesystem layering technology can further separate and declare the dependencies from the application (which constitutes the very top layer of a container). Moreover, the application technology is basically able to formalize every dependency of the application, including the runtime (such as JVM) and the OS version and utilities (which is an inherent capability of the container technology).
- Config: This factor has plenty of ways of being implemented easily. I personally very much like the way Kubernetes manages it, defining ConfigMap objects and making them available to the application as environment variables or configuration files. That makes it pretty easy to integrate into almost every programming language and framework, and makes the configuration easy to be versioned and organized per environment. This is also a nice way to standardize configuration management regardless of the technology used.
- Backing services: This factor can be mapped one to one to the Kubernetes Services object. A cloud-native application can easily query the Kubernetes API to retrieve the service it needs, by name or by using a selector. However, it's worth noticing that Kubernetes does not allow a Pod to explicitly declare the dependencies to other Services, likely because it delegates the handling of corner cases (such as a service missing or crashing, or the need for reconnection) to each application. There are, however, multiple ways (such as using Helm charts or operators) in which to set up multiple Pods together, including the Services to talk to each other.
- Build, release, and run: This is pretty straightforward in containers and the Kubernetes world. A build can be intended as the container image build (and the application is, from there, regarded as immutable). The release can be defined with the creation of the build and other objects (including config) needed to import the containerized application into Kubernetes. Last but not least, Kubernetes handles (using the container runtime of choice) the running of the application.
- Processes: This factor is also quite well represented in Kubernetes. Indeed, each container is, by default, confined in its own runtime, while sharing nothing between each other. We know that containers are stateless too. A common strategy for handling the state is by using external resources, such as connections to databases, services, or persistent volumes. It's worth observing that Kubernetes, by using DaemonSets and similar constructs, allows exceptions to this behavior.
- Port binding: Even in this case, Kubernetes and containers allow all the requisite infrastructure to implement apps adhering to the port binding factor. Indeed, with Kubernetes, you can declare the port that your node will listen to (and Kubernetes will manage conflicts that could potentially arise between Pods asking for the same port). With Services, you can add additional capabilities to it, such as port forwarding and load balancing.
- Concurrency: This is inherent to the Kubernetes containers model. You can easily define the number of instances each Pod should run at any point in time. The infrastructure guarantees that all the required resources are allocated for each Pod.
- Disposability: In Kubernetes, the Pod life cycle is managed to allow each application to shut down gracefully. Indeed, Kubernetes can shut down each Pod and prevent new network traffic from being routed to that specific Pod, hence providing the basics for zero downtime and zero data loss. Then, Kubernetes can be configured to run a pre-stop hook, to allow a custom action to be done before the shutdown.
Following that, Kubernetes sends a SIGTERM signal (which is a standard Linux termination signal) to communicate with the application with the intention of stopping it. The application is considered to be responsible for trapping and managing such a signal (disposing of resources and shutting down) if it's still up and running. Finally, after a timeout, if the application has not yet stopped, Kubernetes forcefully terminates it by using a SIGKILL signal (which is a more drastic signal than SIGTERM, meaning that it cannot be ignored by the application that will be terminated). Something similar can be said for the startup: Kubernetes can be configured to do some actions in case the start of a Pod goes wrong (as an example, taking too long).
To do this, each application can be instrumented with probes, to detect exactly when an application is running and is ready to take new traffic. So, even in this case, the infrastructure provides all the necessary pieces to create an application compliant with this specific factor.
- Dev/prod parity: Similar to the other factors in this list, this is more about the processes and disciplines practiced in your particular development life cycle, meaning that no tool can ensure adherence to this factor if there is no willingness to do so. However, with Kubernetes natively being a declarative environment, it's pretty easy to define different environments (normally mapping to namespaces) that implement each development stage needed (such as dev and prod) and make such environments are as similar as possible (with frequent deploys, implementing checks if the versions and configuration differ too much, and using the same kind of backing services).
- Logs: These play a big part in Kubernetes architecture as there are many alternatives to manage them. The most important lesson, however, is that a big and complex infrastructure based on Kubernetes is mandated to use some log collection strategy (usually based on dealing with logs as an event stream). Common implementations of such an approach include using Fluentd as a log collector or streaming log lines into a compatible event broker (such as Kafka).
- Admin processes: This is perhaps a bit less directly mapped to Kubernetes and container concepts and more related to the specific language, framework, and development approaches that are used. However, Kubernetes allows containers to be accessed using a shell, so this way it can be used if the Pod provides the necessary administrative shell tools. Another approach can be to run specific Pods that can use the same technologies as our applications, just for the time needed to perform administrative processes.
As I've said many other times, there is no magic recipe for an application to be cloud-native (or microservices-compliant, or simply performant and well written). However, the twelve factors provide an interesting point of view and give some food for thought. Some of the factors are achievable by using features provided by the hosting platform or other dependencies (think about config or logs), while others are more related to the application architecture (backing services and disposability) or development model (codebase and dev/prod parity).
Following (and extending, where needed) this set of practices will surely be beneficial for the application's performance, resiliency, and cloud readiness. To go further in our analysis, let's look at some of the reasoning behind well-known patterns for cloud-native development and what supporting technologies we can use to implement them.
Well-known issues in the cloud-native world
Monolithic applications, while having many downsides (especially in the area of Deployment frequency and scalability), often simplify and avoid certain issues. Conversely, developing an application as cloud-native (hence, a distributed set of smaller applications) implies some intrinsic questions to face. In this section, we are going to see some of those issues. Let's start with fault tolerance.
Fault tolerance
Fault tolerance is an umbrella term for a number of aspects related to resiliency. The concept basically boils down to protecting the service from the unavailability (or minor failures) of its components. In other words, if you have chained services (which is very common, maybe between microservices composing your application or when calling external services), you may want to protect the overall application (and user experience), making it resilient to the malfunction of some such services.
By architecting your application in this way, you can avoid overstressing downstream components that are already misbehaving (such as giving exceptions or taking too long) and/or implementing a graceful degradation of the application's behavior. Fault tolerance can be obtained in various ways.
To keep this section practical and interesting, I am going to provide an introduction to each pattern and discuss how this can be implemented in Java. As a reference architecture, we are keeping the MicroProfile (as per what we saw in Chapter 7, Exploring Middleware and Frameworks), so we can have a vendor-independent implementation.
Circuit breaker
The most famous fault-tolerance technique is the circuit breaker. It became famous thanks to a very widespread implementation, which is Netflix Hystrix (now no longer actively developed). Resilience4j is widely accepted and commonly maintained as an alternative.
The circuit breaker pattern implies that you have a configurable threshold when calling another service. If such a call fails, according to the threshold, the circuit breaker will open, blocking further calls for a configurable amount of time. This is similar to a circuit breaker in an electrical plant, which will open in case of issues, preventing further damages.
This will allow the next calls to fail fast and avoid further calling to the downstream service (which may likely be already overloaded). The downstream system then has some time to recover (perhaps by manual intervention, with an automatic restart, or autoscaling). Here is an example where a circuit breaker is not implemented:

Figure 9.5 – Without a circuit breaker
As we can see in the preceding diagram, without a circuit breaker, calls to a failed service (due to a crash or similar outages) keep going in timeout. This, in a chain of calls, can cause the whole application to fail. In the following example, we'll implement a circuit breaker:

Figure 9.6 – With a circuit breaker
Conversely, in an implementation using a circuit breaker, in the case of a service failing, the circuit breaker will immediately identify the outage and provide the responses to the service calling (Service A, in our case). The response sent can simply be an error code (such as HTTP 500) or something more complex, such as a default static response or a redirection to an alternative service.
In a MicroProfile, you can configure a circuit breaker as follows:
@CircuitBreaker(requestVolumeThreshold = 4, failureRatio =
0.5, delay = 10000)
public MyPojo getMyPojo(String id){...
The annotation is configured in a way that, if you have a failure ratio of 50% over four requests (so two failures in four calls), the circuit breaker will stay open for 10 seconds, failing immediately on calls in such a time window (without directly calling the downstream instance). However, after 10 seconds, the next call will be attempted to the target system. If the call succeeds, CircuitBreaker will be back to closed, hence working as before. It's worth noticing that the circuit breaker pattern (as well as other patterns in this section) can be implemented at a service mesh level (especially, in a Kubernetes context). As we saw a couple of sections ago, the service mesh works at a network level in Pod-to-Pod communication and can then be configured to behave as a circuit breaker (and more).
Fallback
The fallback technique is a good way to implement a plan B against external services not working. This will allow for a graceful fallback if the service fails, such as a default value or calling an alternative service.
To implement this in a MicroProfile, you can simply use the following annotation:
@Fallback(fallbackMethod = "myfallbackmethod")
public MyPojo getMyPojo(String id){...
In this way, if you get an exception in your getMyPojo method, myfallbackmethod will be called. Such methods must, of course, have a compatible return value. The fallback method, as said, may be an alternative implementation for such default values or different external services.
Retries
Another powerful way to deal with non-working services is to retry. This may work well if the downstream service has intermittent failures, but it will answer correctly or fail in a reasonable amount of time.
In this scenario, you can decide that it's good enough to retry the call in the event of a failure. In a MicroProfile, you can do that using the following annotation:
@Retry(maxRetries = 3, delay = 2000)
public MyPojo getMyPojo(String id){...
As you can see, the maximum number of retries and the delay between each retry are configurable with the annotation. Of course, this kind of approach may lead to a high response time if the downstream system does not fail fast.
Timeout
Last but not least, the timeout technique will precisely address the problem that we have just seen. Needless to say, a timeout is about timeboxing a call, imposing a maximum amount of time for it to be completed before an exception is raised.
In a MicroProfile, you can simply annotate a method and be sure that the service call will succeed or fail within a configured amount of time:
@Timeout(300)
public MyPojo getMyPojo(String id){...
In such a configuration, the desired service will have to complete the execution within 300 ms or will fail with a timeout exception. In this way, you can have a predictable amount of time in your chain of services, even if your external service takes too much time to answer.
All the techniques discussed in this section aim to enhance the resiliency of cloud-native applications and address one very well-known problem of microservices (and, more generally, distributed applications), which is failure cascading. Another common issue in the cloud-native world concerns transactionality.
Transactionality
When working on a classical monolithic Java application, transactions are kind of a resolved issue. You can appropriately mark your code and the container you are running in (be it an application server or other frameworks) to take care of it. This means that all the things that you can expect from a transactional Atomicity, Consistency, Isolation, Durability (ACID)-compliant system are provided, such as rollbacks in the case of failures and recovery.
In a distributed system, this works differently. Since the components participating in a transaction are living in different processes (that may be different containers, optionally running on different servers), traditional transactionality is not a viable option. One intuitive explanation for this is related to the network connection between each participant in the transaction.
If one system asks another to complete an action (such as persisting a record), no answer might be returned. What should the client do then? It should assume that the action has been successful and the answer is not coming for external reasons (such as a network split), or it should assume that the action has failed and optionally retry. Of course, there is no easy way to face these kinds of events. The following are a couple of ideas for dealing with data integrity that can be adopted.
Idempotent actions
One way to solve some issues due to distributed transactionality is idempotency. A service is considered idempotent if it can be safely called more than once with the same data as input, and the result will still be a correct execution. This is something naturally obtained in certain kinds of operations (such as read operations or changes to specific information, such as the address or other data of a user profile), while it must be implemented in some other situations (such as money balance transactions, where a double charge for the same payment transaction is, of course, not allowed).
The most common way to correctly handle idempotency relies on a specific key associated with each call, which is usually obtained from the payload itself (as an example, calculating a hash over all the data passed). Such a key is then stored in a repository (this can be a database, filesystem, or in-memory cache). A following call to the same service with the same payload will create a clash on such a key (meaning that the key already exists in the repository) and will then be handled as a no-operation.
So, in a system implemented in this way, it's safe to call a service more than once (as an example, in case we got no response from the first attempt). In the event that the first call was successful and we received no answer for external reasons (such as a network drop), the second call will be harmless. It's common practice to define an expiration for such entries, both for performance reasons (avoiding growing the repository too much, since it will be accessed at basically every call) and for correctly supporting the use case of your specific domain (for instance, it may be that a second identical call is allowed and legitimate after a specific timeout is reached).
The Saga pattern
The Saga pattern is a way to deal with the problem of transactions in a distributed environment more fully. To implement the Saga pattern, each of the systems involved should expose the opposite of each business operation that includes updating the data. In the payments example, a charge operation (implying a write on a data source, such as a database) should have a twin undo operation that implements a top-up of the same amount of money (and likely provides some more descriptions, such as the reason for such a cancellation).
Such a complementary operation is called compensation, and the goal is to undo the operation in the event of a failure somewhere else. Once you have a list of services that must be called to implement a complex operation and the compensation for each of them, the idea is to call each service sequentially. If one of the services fails, all the previous services are notified, and the undo operation is called on them to put the whole system in a state of consistency. An alternative way to implement this is to call the first service, which will be in charge of sending a message to the second service, and so on. If one of the services fails, the messages are sent back to trigger the requisite compensation operations. There are two warnings regarding this approach:
- The signaling of the operation outcome after each write operation (which will trigger the compensations in case of a failure) must be reliable. So, the case in which a failure happens somewhere and the compensations are not called must be avoided as far as possible.
- The whole system must be considered as eventually consistent. This means that there are some specific timeframes (likely to be very short) in which your system is not in a consistent state (because the downstream systems are yet to be called, or a failure just happened and the compensations are not yet executed).
An elegant way to implement this pattern is based on the concept of change data capture. Change data capture is a pattern used for listening to changes on a data source (such as a database). There are many different technologies to do that, including the polling of the data source or listening for some specific events in the database transaction logs. By using change data capture, you can be notified when a write happens in the data source, which data is involved, and whether the write has been successful. From such events, you can trigger a message or a call for the other systems involved, continuing your distributed transaction or rolling back by executing the compensation methods.
The Saga pattern, in a way, makes us think about the importance of the flow of calls in a microservices application. As seen in this section (and also in the Why create cloud-native applications? section regarding resiliency), the order (and the way) in which we call the services needed to compose our functionality can change the transactionality, resiliency, and efficiency (think about parallel versus serial, as discussed in Chapter 6, Exploring Essential Java Architectural Patterns, under the Implementing for large-scale adoption section). In the next section, we are going to elaborate a bit more on this point.
Orchestration
The Saga pattern highlights the sequence (and operations) in which every component must be called in order to implement eventual consistency. This is a topic that we have somewhat taken for granted.
We have talked about the microservice characteristics and ways of modeling our architectures in order to be flexible and define small and meaningful sets of operations. But what's the best way to compose and order the calls to those operations, so as to create the higher-level operations implementing our use case? As usual, there is no easy answer to this question. The first point to make concerns the distinction between orchestration and another technique often considered an alternative to it, which is choreography. There is a lot of debate ongoing about the differences between orchestration and choreography. I don't have the confidence to speak definitively on this subject, but here is my take on it:
- Orchestration, as in an orchestra, implies the presence of a conductor. Each microservice, like a musician, can use many services (many sounds, if we stay within the metaphor), but it looks for hints from the conductor to make something that, in cooperation with the other microservices, simply works.
- Choreography, as in a dance, is studied beforehand and requires each service (dancer) to reply to an external event (other dancers doing something, music playing, and so on). In this case, we see some similarities with what we saw in the Event-driven and reactive section of Chapter 6, Exploring Essential Java Architectural Patterns).
In this section, we are going to focus on orchestration.
Orchestrating in the backend or the frontend
A first, simple approach to orchestration implies a frontend aggregation level (this may be on the client side or server side). This essentially means having user experience (as in the flow of different pages, views, or whatever the client technology provides) dictate how the microservice functions are called.
The benefit of this approach is that it's easy and doesn't need extra layers, or other technology in your architecture, to be implemented.
The downsides, in my opinion, are more than one. First of all, you are tightly coupling the behavior of the application with the technical implementation of the frontend. If you need to change the flow (or any specific implementation to a service), you are most likely required to make changes in the frontend.
Moreover, if you need to have more than one frontend implementation (which is very common, as we could have a web frontend and a couple of mobile applications), the logic will become sprawled in all of those frontends and a change must be propagated everywhere, thereby increasing the possibility of making mistakes. Last but not least, directly exposing your services to the frontend may imply having a mismatch of granularity between the amount of data microservices offer with the amount of data the frontend will need. So, choices you may need to make in the frontend (as pagination) will need to slip into the backend microservices implementation. This is not the best solution, as every component will have unclear responsibilities.
The obvious alternative is moving the orchestration to the backend. This means having a component between the microservices implementing the backend and the technologies implementing the frontend, which has the role of aggregating the services and providing the right granularity and sequence of calls required by the frontend.
Now the fun begins: How should this component be implemented?
One common alternative to aggregating at the frontend level is to pick an API gateway to do the trick. API gateways are pieces of software, loosely belonging to the category of integration middlewares, that sit as a man in the middle between the backend and frontend, and proxy the API calls between the two. An API gateway is an infrastructural component that is commonly equipped with additional features, such as authentication, authorization, and monetization.
The downside is that API gateways are usually not really tools designed to handle aggregation logic and sequences of calls. So sometimes, they are not capable of handling complex orchestration capabilities, but simply aggregate more calls into one and perform basic format translation (such as SOAP to REST).
A third option is to use a custom aggregator. This means delegating one (or more than one) microservices to act as an orchestrator. This solution provides the maximum level of flexibility with the downside of centralizing a lot of functionalities into a single architectural component. So, you have to be careful to avoid scalability issues (so it must be appropriately scalable) or the solution becoming a single point of failure (so it must be appropriately highly available and resilient). A custom aggregator implies a certain amount of custom code in order to define the sequence of calls and the integration logic (such as formal translation). There are a couple of components and techniques that we have discussed so far that can be embedded and used in this kind of component:
- A business workflow (as seen in Chapter 8, Designing Application Integration and Business Automation) can be an idea for describing the sequence of steps orchestrating the calls. The immediate advantage is having a graphical, standard, and business-understandable representation of what a higher-level service is made of. However, this is not a very common practice, because the current technology of business workflow engines is designed for a different goal (being a stateful point to persist process instances).
So, it may have a performance impact and be cumbersome to implement (as BPMN is a business notation, while this component is inherently technological). So, if this is your choice, it is worthwhile considering a lightweight, non-persistent workflow engine.
- Integration patterns are to be considered with a view of implementing complex aggregation (such as protocol translation) and composition logic (such as sequencing or parallelizing calls). Even in this case, to keep the component scalable and less impactful from a performance standpoint, it is worthwhile considering lightweight integration platforms and runtimes.
- The fault-tolerance techniques that we saw a couple of sections ago are a good fit in this component. They will allow our composite call to be resilient in case of the unavailability of one of the composing services and to fail fast if one of them is misbehaving or simply answering slowly. Whatever your choice for the aggregation component, you should consider implementing fault tolerance using the patterns seen.
Last but not least, a consideration to be made about orchestration is whether and how to implement the backend for frontend pattern (as briefly seen in Chapter 4, Best Practices for Design and Development). To put it simply, different frontends (or better, different clients) may need different formats and granularity for the higher-level API. A web UI requires a different amount of data (and of different formats) than a mobile application, and so on. One way to implement this is to create a different instance of the aggregation component for each of the frontends. In this way, you can slightly change the frontend calls (and the user experience) without impacting the microservices implementation in the backend.
However, as with the frontend aggregation strategy, a downside is that the business logic becomes sprawled across all the implementations (even if, in this case, you at least have a weaker coupling between the frontend and the orchestration component). In some use cases, this may lead to inconsistency in the user experience, especially if you want to implement omnichannel behavior, as in, you can start an operation in one of the frontends (or channels) and continue with it in another one. So, if you plan to have multiple aggregation components (by means of the backend for frontend pattern), you will likely need to have a consistency point somewhere else (such as a database persisting the state or a workflow engine keeping track of the current and previous instances of each call).
This section concludes our overview of microservices patterns. In the next section, we are going to consider when and how it may make sense to adopt microservices and cloud-native patterns or evolve existing applications toward such paradigms.
Adopting microservices and evolving existing applications
So, we had an overview of the benefits of microservices applications and some of their particular characteristics. I think it is now relevant to better consider why you should (or should not) adopt this architectural style. This kind of consideration can be useful both for the creation of new applications from scratch (in what is called green-field development) and modernization (termed brown-field applications). Regarding the latter aspect, we will discuss some of the suggested approaches for modernizing existing applications in the upcoming sections.
But back to our main topic for this section: why should you adopt the microservices-based approach?
The first and most important reason for creating microservices is the release frequency. Indeed, the most famous and successful production experiences of microservices applications are related to services heavily benefitting from being released often.
This is because a lot of features are constantly released and experimented with in production. Remembering what we discussed in relation to the Agile methodologies, doing so allows us to test what works (what the customers like), provide new functionalities often (to stay relevant to the market), and quickly fix issues (which will inevitably slip into production because of the more frequent releases).
This means that the first question to ask is: Will your application benefit from frequent releases? We are talking about once a week or more. Some well-known internet applications (such as e-commerce and streaming services) even push many releases in production every day.
So, if the service you are building will not benefit from releasing this often – or worse, if it's mandated to release according to specific timeframes – you may not need to fully adhere to the microservices philosophy. Instead, it could turn out to be just a waste of time and money, as of course, the application will be much more complicated than a simple monolithic or n-tier application.
Another consideration is scalability. As stated before, many successful production implementations of microservices architectures are related to streaming services or e-commerce applications. Well, that's not incidental. Other than requiring constant experimentation and the release of new features (hence, release frequency), such services need to scale very well. This means being able to handle many concurrent users and absorbing peaks in demand (think about Black Friday in an e-commerce context, or the streaming of live sporting events). That's supposed to be done in a cost-effective way, meaning that the resource usage must be minimized and allocated only when it is really needed.
So, I think you get the idea: microservices architectures are supposed to be applied to projects that need to handle thousands of concurrent requests and that need to absorb peaks of 10 times the average load. If you only need to manage much less traffic, once again microservices could be overkill.
A less obvious point to consider is data integrity. As we mentioned a few sections ago, when talking about the Saga pattern, a microservices application is a heavily distributed system. This implies that transactions are hard or maybe impossible to implement. As we have seen, there are workarounds to mitigate the problem, but in general, everybody (especially business and product managers) should be aware of this difficulty.
It should be thoroughly explained that there will be features that may not be updated in real time, providing stale or inaccurate data (and maybe some missing data too). The system as a whole may have some (supposedly short) timeframes in which it's not consistent. Note that it is a good idea to contextualize and describe which features and scenarios may present these kinds of behaviors to avoid bad surprises when testing.
At the same time, on the technical design side, we should ensure we integrate all possible mechanisms to keep these kinds of misalignments to a minimum, including putting in place all the safety nets required and implementing any reconciliation procedure that may be needed, in order to provide a satisfactory experience to our users.
Once again, if this is not a compromise that everybody in the project team is willing to make, maybe microservices should be avoided (or used for just a subset of the use cases).
As we have already seen in Chapter 5, Exploring the Most Common Development Models, a prerequisite for microservices and cloud-native architectures is to be able to operate as a DevOps team. That's not a minor change, especially in big organizations. But the implications are obvious: since each microservice has to be treated as a product with its own release schedule, and should be as independent as possible, then each team working on each microservice should be self-sufficient, breaking down silos and maximizing collaboration between different roles. Hence, DevOps is basically the only organizational model known to work well in supporting a microservices-oriented project. Once again, this is a factor to consider: if it's hard, expensive, or impossible to adopt this kind of model, then microservices may not be worth it.
An almost direct consequence of this model is that each team should have a supporting technology infrastructure that is able to provide the right features for microservices. This implies having an automated release process, following the CI/CD best practices (we will see more about this in Chapter 13, Exploring the Software Life Cycle). And that's not all: the environments for each project should also be easy to provision on-demand, and possibly in a self-service fashion. Kubernetes, which we looked at a couple of sections ago, is a perfect fit for this.
It is not the only option, however, and in general, cloud providers offer great support to accelerate the delivery of environments (both containers and VMs) by freeing the operations teams from many responsibilities, including hardware provisioning and maintaining the uptime of some underlying systems.
In other words, it will be very hard (or even impossible) to implement microservices if we rely on complex manual release processes, or if the infrastructure we are working on is slow and painful to extend and doesn't provide features for the self-service of new environments.
One big advantage of the microservices architecture is the extensibility and replaceability of each component. This means that each microservice is related to the rest of the architecture via a well-defined API and can be implemented with the technology best suited for it (in terms of the language, frameworks, and other technical choices). Better yet, each component may be evolved, enhanced, or replaced by something else (a different component, an external service, or a SaaS application, among others). So, of course, as you can imagine, this has an impact in terms of integration testing (more on that in Chapter 13, Exploring the Software Life Cycle), so you should really consider the balance between the advantages provided and the impact created and resources needed.
So, as a summary for this section, microservices provide a lot of interesting benefits and are a really cool architectural model, worth exploring for sure.
On the other hand, before you decide to implement a new application following this architectural model, or restructuring an existing one to adhere to it, you should consider whether the advantages will really outweigh the costs and disadvantages by looking at your specific use case and whether you will actually use these advantages.
If the answer is no, or partially no, you can still take some of the techniques and best practices for microservices and adopt them in your architecture.
I think that's definitely a very good practice: maybe part of your application requires strong consistency and transactionality, while other parts have less strict requirements and can benefit from a more flexible model.
Or maybe your project has well-defined release windows (for external constraints), but will still benefit from fully automated releases, decreasing the risk and effort involved, even if they are not scheduled to happen many times a day.
So, your best bet is to not be too dogmatic and use a mix-and-match approach: in this way, the architecture you are designing will be better suited to your needs. Just don't adopt microservices out of FOMO. It will just be hard and painful, and the possibility of success will be very low.
With that said, the discussion around new developmental and architectural methodologies never stops, and there are, of course, some ideas on what's coming next after microservices.
Going beyond microservices
Like everything in the technology world, microservices got to an inflection point (the Trough of Disillusionment, as we called it at the beginning of this chapter). The reasoning behind this point is whether the effort needed to implement a microservices architecture is worth it. The benefit of well-designed microservices architectures, beyond being highly scalable and resilient, is to be very quick in deploying new releases in production (and so experiment with a lot of new features in the real world, as suggested by the adoption of Agile methodology). But this comes at the cost of having to develop (and maintain) infrastructures that are way more complex (and expensive) than monolithic ones. So, if releasing often is not a primary need of your particular business, you may think that a full microservices architecture constitutes overkill.
Miniservices
For this reason, many organizations started adopting a compromise approach, sometimes referred to as miniservices. A miniservice is something in the middle between a microservice and a monolith (in this semantic space, it is regarded as a macroservice). There is not a lot of literature relating to miniservices, mostly because, it being a compromise solution, each development team may decide to make trade-offs based on what it needs. However, there are a number of common features:
- Miniservices may break the dogma of one microservice and one database and so two miniservices can share the same database if needed. However, bear in mind that this will mean tighter coupling between the miniservices, so it needs to be evaluated carefully on a case-by-case basis.
- Miniservices may offer APIs of a higher level, thereby requiring less aggregation and orchestration. Microservices are supposed to provide specific APIs related to the particular domain model (and database) that a particular microservice belongs to. Conversely, a miniservice can directly provide higher-level APIs operating on different domain models (as if a miniservice is basically a composition of more than one microservice).
- Miniservices may share the deployment infrastructure, meaning that the deployment of a miniservice may imply the deployment of other miniservices, or at least have an impact on it, while with microservices, each one is supposed to be independent of the others and resilient to the lack of them.
So, at the end of the day, miniservices are a customized architectural solution, relaxing on some microservices requirements in order to focus on business value, thereby minimizing the technological impact of a full microservices implementation.
Serverless and Function as a Service
As the last point, we cannot conclude this chapter without talking about serverless. At some point in time, many architects started seeing serverless as the natural evolution of the microservices pattern. Serverless is a term implying a focus on the application code with very little to no concern regarding the underlying infrastructure. That's what the less part in serverless is about: not that there are no servers (of course), but that you don't have to worry about them.
Looking from this point of view, serverless is truly an evolution of the microservices pattern (and PaaS too). While serverless is a pattern, a common implementation of it takes the container as the smallest computing unit, meaning that if you create a containerized application and deploy it to a serverless platform, the platform itself will take care of scaling, routing, security, and so on, thereby absolving the developer of responsibility for it.
A further evolution of the serverless platform is referred to as Function as a Service (FaaS). In serverless, in theory, the platform can manage (almost) every technology stack, provided that it can be packaged as a container, while with FaaS, the developer must comply with a well-defined set of languages and technologies (usually Java, Python, JavaScript, and a few others). The advantage that balances such a lack of freedom is that the dev does not need to care about the layers underlying the application code, which is really just writing the code, and the platform does everything else.
One last core characteristic, common to both serverless and FaaS, is the scale to zero. To fully optimize platform usage, the technology implementing serverless and FaaS can shut the application down completely if there are no incoming requests and quickly spin up an instance when a request comes. For this reason, those two approaches are particularly suitable for being deployed on a cloud provider, where you will end up paying just for what you need. Conversely, for implementing the scale to zero, the kind of applications (both the framework and the use case) must be appropriate. Hence, applications requiring a warmup or requiring too long to start are not a good choice.
Also, the management of state in a serverless application is not really an easy problem to solve (usually, as in microservices, the state is simply offloaded to external services). Moreover, while the platforms providing serverless and FaaS capabilities are evolving day after day, it is usually harder to troubleshoot problems and debug faulty behaviors.
Last but not least, there are no real standards (yet) in this particular niche, hence the risk of lock-in is high (meaning that implementations made to run on a specific cloud stack will be lost if we want to change the underlying technology). Considering all the pros and cons of serverless and FaaS, these approaches are rarely used for implementing a full and complex application. They are, instead, a good fit for some specific use cases, including batch computations (such as file format conversions and more) or for providing glue code connecting different, more complex functions (such as the ones implemented in other microservices).
In the next section, we are going to discuss a very hot topic on a strategy for evolving existing applications toward cloud-native microservices and other newer approaches such as serverless.
Refactoring apps as microservices and serverless
As we discussed a couple of sections earlier, software projects are commonly categorized as either green- or brown-field.
Green-field projects are those that start from scratch and have very few constraints on the architectural model that could be implemented.
This scenario is common in start-up environments, for example, where a brand-new product is built and there is no legacy to deal with.
The situation is, of course, ideal for an architect, but is not so common in all honesty (or at least, it hasn't been so common in my experience so far).
The alternative scenario, brown-field projects, is where the project we are implementing involves dealing with a lot of legacy and constraints. Here, the target architecture cannot be designed from scratch, and a lot of choices need to be made, such as what we want to keep, what we want to ditch, and what we want to adapt. That's what we are going to discuss in this section.
The five Rs of application modernization
Brown-field projects are basically application modernization projects. The existing landscape is analyzed, and then some decisions are made to either develop a new application, implement a few new features, or simply enhance what's currently implemented, making it more performant, cheaper, and easier to operate.
The analysis of what's existing is often an almost manual process. There are some tools available for scanning the existing source code or artifacts, or even to dynamically understand how applications behave in production. But often, most of the analysis is done by architects, starting from the data collected with the aforementioned tools, using existing architectural diagrams, interviewing teams, and so on.
Then, once we have a clear idea about what is running and how it is implemented, choices have to be made component by component.
There is a commonly used methodology for this that defines five possible outcomes (the five Rs). It was originally defined by Gartner, but most consultancy practices and cloud providers (such as Microsoft and AWS) provide similar techniques, with very minor differences.
The five Rs define what to do with each architectural component. Once you have a clear idea about how a brown-field component is implemented and what it does, you can apply one of the following strategies:
- Rehost: This means simply redeploying the application on more modern infrastructure, which could be different hardware, a virtualized environment, or using a cloud provider (in an IaaS configuration). In this scenario, no changes are made to the application architecture or code. Minor changes to packaging and configuration may be necessary but are kept to a minimum. This scenario is also described as lift-and-shift migration and is a way to get advantages quickly (such as cheaper infrastructure) while reducing risks and transformation costs. However, of course, the advantages provided are minimal, as the code will still be old and not very adherent to modern architectural practices.
- Refactor: This is very similar to the previous approach. There are no changes to architecture or software code. The target infrastructure, however, is supposed to be a PaaS environment, possibly provided by a cloud provider. In this way, advantages such as autoscaling or self-healing can be provided by the platform itself while requiring only limited effort for adoption. CI/CD and release automation are commonly adopted here. However, once again, the code will still be unchanged from the original, so it may be hard to maintain and evolve.
- Revise: This is a slightly different approach. The application will be ported to a more modern infrastructure (PaaS or cloud), as with the Rehost and Refactor strategies. However, small changes to the code will be implemented. While the majority of the code will stay the same, crucial features, such as session handling, persistence, and interfaces, will be changed or extended to derive some benefits from the more modern underlying infrastructure available. The final product will not benefit from everything the new infrastructure has to offer but will have some benefits. Plus, the development and testing efforts will be limited. The target architecture, however, will not be microservices or cloud-native, rather just a slightly enhanced monolith (or n tier).
- Rebuild: Here, the development and testing effort is way higher. Basically, the application is not ported but instead is rewritten from scratch in order to use new frameworks and a new architecture (likely microservices or microservices plus something additional). The rebuilt architecture is targeted for hosting on a cloud or PaaS. Very limited parts of the application may be reused, such as pieces of code (business logic) or data (existing databases), but more generally, it can be seen as a complete green-field refactoring, in which the same requirements are rebuilt from scratch. Of course, the effort, cost, and risk tend to be high, but the benefits (if the project succeeds) are considered worthwhile.
- Replace: In this, the existing application is completely discarded. It may be simply retired because it's not needed anymore (note that in some methodologies, Retire is a sixth R, with its own dedicated strategy). Or it may be replaced with a different solution, such as SaaS or an existing off-the-shelf product. Here, the implementation cost (and the general impact) may be high, but the running cost is considered to be lower (or zero, if the application is completely retired), as less maintenance will be required. The new software is intended to perform better and offer enhanced features.
In the following table, we can see a summary of the characteristics of each of the approaches:
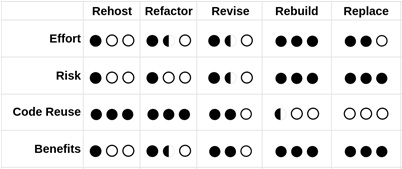
Table 9.1 – The characteristics of the five Rs
As you can see in the preceding table, getting the most benefits means a trade-off of taking on the most effort and risk.
In the following table, some considerations of the benefits of each of these approaches can be seen:

Table 9.2 – The benefits of the five Rs
Once again, most of the benefits come with the last two or three approaches.
However, it's worth noticing that the last two (Rebuild and Replace) fit into a much bigger discussion, often considered in the world of software development: that of build versus buy. Indeed, Rebuild is related to the build approach: you design the architecture and develop the software tailored to your own needs. It may be harder to manage this, but it guarantees maximum control. Most of this book, after all, is related to this approach.
Buy (which is related to Replace), on the other hand, follows another logic: after a software selection phase, you find an off-the-shelf product (be it on-premises or SaaS) and use it instead of your old application. In general, it's easier, as it requires limited to no customization. Very often, maintenance will also be very limited, as you will have a partner or software provider taking care of it. Conversely, the new software will give you less control and some of your requirements and use cases may need to be adapted to it.
As said, an alternative to buy in the Replace strategy is simply to ditch the software altogether. This may be because of changing requirements, or simply because the features are provided elsewhere.
The five Rs approach is to be considered in a wider picture of application modernization and is often targeted at big chunks of an enterprise architecture, targeting tens or hundreds of applications.
I would like to relate this approach to something more targeted to a single application, which is the strangler pattern. The two approaches (five Rs and strangler) are orthogonal and can also be used together, by using the strangler pattern as part of revising (Revise) or rebuilding (Rebuild) an application. Let's look into this in more detail.
The strangler pattern
As outlined in the previous section, the five Rs model is a programmatic approach to identify what to do with each application in an enterprise portfolio, with changes ranging from slightly adapting the existing application to a complete refactoring or replacement.
The strangler pattern tackles the same issue but from another perspective. Once an application to be modernized has been identified, it gives specific strategies to do so, targeting a path ranging from small improvements to a progressive coexistence between old and new, up to the complete replacement of the old technologies.
This approach was originally mentioned by Martin Fowler in a famous paper and relates to the strangler fig, which is a type of tree that progressively encloses (and sometimes completely replaces) an existing tree.
The metaphor here is easy to understand: new application architectures (such as microservices) start growing alongside existing ones, progressively strangling, and ultimately replacing, them. In order to this, it's essential to have control of the ingress points of our users into our application (old and new) and use them as a routing layer. Better yet, there should be an ingress point capable of controlling each specific feature. This is easy if every feature is accessed via an API call (SOAP or REST), as the routing layer can then simply be a network appliance with routing capabilities (a load balancer) that decides where to direct each call and each user. If you are lucky enough, the existing API calls are already mediated by an API manager, which can be used for the same purposes.
In most real applications, however, this can be hard to find, and most likely some of the calls are internal to the platform (so it is not easy to position a network load balancer in the middle). It can also happen that such calls are done directly in the code (via method calls) or using protocols that are not easily redirected over the network (such as Java RMI).
In such cases, a small intervention will be needed by writing a piece of code that adapts such calls from the existing infrastructure to standard over-the-network APIs (such as REST or SOAP), on both the client and server sides.
An alternative technique is to implement the routing functionality in the client layers. A common way to do so is to use feature flags, which have hidden settings and are changeable on the fly by the application administrators who set the feature that must be called by every piece of the UI or the client application.
However, while this approach can be more fine-grained than redirecting at the network level, it may end up being more complex and invasive as it also changes the frontend or client side of the application.
Once you have a mechanism to split and redirect each call, the strangler pattern can finally start to happen. The first step is to identify the first feature – one as isolated and self-contained as possible – to be reimplemented with a new stack and architecture.
The best option is to start with simple but not trivial functionality, in order to keep the difficulty low but still allow you to test the new tools and framework on something meaningful. In order to exactly identify the boundary of each feature, we can refer to the concept of bounded context in DDD, as we saw in Chapter 4, Best Practices for Design and Development.
In order to finance the project, it's a common practice to piggyback the modernization activities together with the implementation of new features, so it is possible that the new piece we are developing is not completely isofunctional with the old one, but contains some additional new functionalities.
Once such a piece of software is ready, we start testing it by sending some traffic toward it. To do so, we can use whatever routing layer is available, be it a network load balancer or a piece of custom code, as we have seen before. For such a goal, advanced routing techniques, such as canary or A/B testing, can be used (more on this in Chapter 13, Exploring the Software Life Cycle).
If something goes wrong, a rollback will always be possible, as the old functionalities will still be present in the existing implementation. If the rollout is successful and the new part of the application works properly, it's time to extend and iterate the application.
More features and pieces of the application are implemented in the new way, and deprecated from the old implementation in an approach that can be parallelized but needs to be strictly governed, in order to easily understand and document which functionality is implemented where and potentially switch back in case of any issue.
Eventually, all the features of the platform will now be implemented in the new stack, which will most likely be based on microservices or something similar.
After a grace period, the old implementation can be discarded and our modernization project will finally be completed, delivering the maximum benefit it has to offer (even more so as we no longer need to keep running and maintaining the old part).

Figure 9.7 – The strangler pattern approach
The preceding diagram that you see is simplified for the sake of space. There will be more than one phase between the start (where all the features are running in the legacy implementation) and the end (where all the features have been reimplemented as microservices, or in any other modern way).
In each intermediate phase (not fully represented in the diagram, but indicated by the dotted lines), the legacy implementation starts receiving less traffic (as less of its features are used), while the new implementation grows in the number of functionalities implemented. Moreover, the new implementation is represented as a whole block, but it will most likely be made up of many smaller implementations (microservices), growing around and progressively strangling and replacing the older application.
Note that the strangler pattern as explained here is a simplification and doesn't take into account the many complexities of modernizing an application. Let's see some of these complexities in the next section.
Important points for application modernization
Whether the modernization is done with the strangler pattern (as seen just now) or a more end-to-end approach covering the whole portfolio (as with the five Rs approach, seen earlier), the approach to modernize an existing application must take care of many, often underestimated, complexities. The following gives some suggestions for dealing with each of them:
- Testing suit: This is maybe the most important of them all. While we will see more about testing in Chapter 13, Exploring the Software Life Cycle, it's easy to understand how a complete testing suite offers the proof needed to ensure that our modernization project is going well and ultimately is complete. In order to ensure that the new implementation is working at least as well as the old one, it's crucial that everything is covered by test suites, possibly automated. If you lack test coverage on the existing implementation, you may have a general feeling that everything is working, but you will likely have some bad surprises on production release. So, if the test coverage on the whole platform is low, it's better to invest in this first before any refactoring project.
- Data consistency: While it wasn't underlined in the techniques we have seen, refactoring often impacts the existing data layer by adding new data technologies (such as NoSQL stores) and/or changing the data structure of existing data setups (such as altering database schemas). Hence, it is very important to have a strategy around data too. It is likely that, if we migrated one bounded context at a time, the new implementation would have a dedicated and self-consistent data store.
However, to do so, we will need to have existing data migrated (by using a data integration technique, as we saw in Chapter 8, Designing Application Integration and Business Automation). When the new release is ready, it will likely have to exchange data with the older applications. To do so, you can provide an API, completely moving the integration from the data layer to the application layer (this is the best approach), or move the data itself using, as an example, the change data capture pattern. As discussed earlier, however, you must be careful of any unwanted data inconsistency in the platform as a whole.
- Session handling: This is another very important point, as for a certain amount of time, the implementation will remain on both the old and new applications and users will share their sessions between both. This includes all the required session data and security information as well (such as if the user is logged in). To handle such sessions, the best approach is to externalize the session handling (such as into an external in-memory database) and make both the old and new applications refer to it when it comes to storing and retrieving session information. An alternative is to keep two separate session-handling systems up to date (manually), but as you can imagine, it's more cumbersome to implement and maintain them.
- Troubleshooting: This has a big impact. For a certain amount of time, the features are implemented using many different systems, across old and new technologies. So, in case of any issue, it will be definitively harder to understand what has gone wrong where. There is not much we could do to mitigate the impact of an issue here. My suggestion is to maintain up-to-date documentation and governance of the project, in order to make clear to everybody where each feature is implemented at any point in time. A further step is to provide a unique identifier to each call, to understand the path of each call, and correlate the execution on every subsystem that has been affected. Last but not least, you should invest in technical training for all staff members to help them master the newly implemented system, which brings us to the next point.
- Training: Other than for the technical staff, to help them support and develop the new technologies of choice, training may be useful for everybody involved in the project, sometimes including the end users. Indeed, while the goal is to keep the system isofunctional and improve the existing one, it is still likely that there will be some impact on the end users. It may be that the UI is changed and modernized, the APIs will evolve somehow, or we move from a fat client for desktop to a web and mobile application. Don't forget that most of these suggestions are also applicable to the five Rs methodology, so you may end up completely replacing one piece of the application with something different (such as an off-the-shelf product), which leads us to the final point.
- Handling endpoints: As in the previous point, it would be great if we could keep the API as similar as possible to minimize the impact on the final customers and the external systems. However, this is rarely possible. In most real-world projects, the API signature will slightly (or heavily) change, along with the UIs. Hence, it's important to have a communication plan to inform everybody involved about the rollout schedule of the new project, taking into account that this may mean changing something such as remote clients; hence, the end users and external systems must be ready to implement such changes, which may be impactful and expensive. To mitigate the impact, you could also consider keeping the older version available for a short period.
As you have seen, modernizing an application with a microservice or cloud-native architecture is definitely not easy, and many options are available.
However, in my personal experience, it may be really worth it due to the return on investment and the reduction of legacy code and technical debt, ultimately creating a target architecture that is easier and cheaper to operate and provides a better service to our end users. This section completes our chapter on cloud-native architectures.
Summary
In this chapter, we have seen the main concepts pertaining to cloud-native architectures. Starting with the goals and benefits, we have seen the concept of PaaS and Kubernetes, which is currently a widely used engine for PaaS solutions. An interesting excursus involved the twelve-factor applications, and we also discussed how some of those concepts more or less map to Kubernetes concepts.
We then moved on to the well-known issues in cloud-native applications, including fault tolerance, transactionality, and orchestration. Lastly, we touched on the further evolution of microservices architectures, that is, miniservices and serverless.
With these concepts in mind, you should be able to understand the advantages of a cloud-native application and apply the basic concepts in order to design and implement cloud-native architectures.
Then, we moved on to look at a couple of methodologies for application modernization, and when and why these kinds of projects are worth undertaking.
In the next chapter, we will start discussing user interactions. This means exploring the standard technologies for web frontends in Java (such as Jakarta Server Pages and Jakarta Server Faces) and newer approaches, such as client-side web applications (using the React framework in our case).
Further reading
- The JBoss community, Undertow (https://undertow.io/)
- Martin Fowler, Patterns of Enterprise Application Architecture (https://martinfowler.com)
- Netflix OSS, Hystrix (https://github.com/Netflix/Hystrix)
- Eclipse MicroProfile, Microprofile Fault Tolerance (https://github.com/eclipse/microprofile-fault-tolerance)
- Chris Richardson, Microservices Architecture (https://microservices.io)
- Richard Watson, Five Ways to Migrate Applications to the Cloud (https://www.pressebox.com/pressrelease/gartner-uk-ltd/Gartner-Identifies-Five-Ways-to-Migrate-Applications-to-the-Cloud/boxid/424552)
- Martin Fowler, StranglerFigApplication (https://martinfowler.com/bliki/StranglerFigApplication.html)
- Paul Hammant, Strangler Applications (https://paulhammant.com/2013/07/14/legacy-application-strangulation-case-studies)