
Chapter 6: Exploring Essential Java Architectural Patterns
In the last chapter, you had an overview of the most common development models, from the older (but still used) Waterfall model to the widely used and appreciated DevOps and Agile.
In this chapter, you will have a look at some very common architectural patterns. These architectural definitions are often considered basic building blocks that are useful to know about in order to solve common architectural problems.
You will learn about the following topics in this chapter:
- Encapsulation and hexagonal architectures
- Learning about multi-tier architectures
- Exploring Model View Controller
- Diving into event-driven and reactive approaches
- Designing for large-scale adoption
- Case studies and examples
After reading this chapter, you'll know about some useful tools that can be used to translate requirements into well-designed software components that are easy to develop and maintain. All the patterns described in this chapter are, of course, orthogonal to the development models that we have seen in the previous chapters; in other words, you can use all of them regardless of the model used.
Let's start with one of the most natural architectural considerations: encapsulation and hexagonal architectures.
Encapsulation and hexagonal architectures
Encapsulation is a concept taken for granted by programmers who are used to working with object-oriented programming and, indeed, it is quite a basic idea. When talking about encapsulation, your mind goes to the getters and setters methods. To put it simply, you can hide fields in your class, and control how the other objects interact with them. This is a basic way to protect the status of your object (internal data) from the outside world. In this way, you decouple the state from the behavior, and you are free to switch the data type, validate the input, change formats, and so on. In short, it's easy to understand the advantages of this approach.
However, encapsulation is a concept that goes beyond simple getters and setters. I personally find some echoes of this concept in other modern approaches, such as APIs and microservices (more on this in Chapter 9, Designing Cloud-Native Architectures). In my opinion, encapsulation (also known as information hiding) is all about modularization, in that it's about having objects talk to each other by using defined contracts.
If those contracts (in this case, normal method signatures) are stable and generic enough, objects can change their internal implementation or can be swapped with other objects without breaking the overall functionality. That is, of course, a concept that fits nicely with interfaces. An interface can be seen as a super contract (a set of methods) and a way to easily identify compatible objects.
In my personal view, the concept of encapsulation is extended with the idea of hexagonal architectures. Hexagonal architectures, theorized by Alistair Cockburn in 2005, visualize an application component as a hexagon. The following diagram illustrates this:
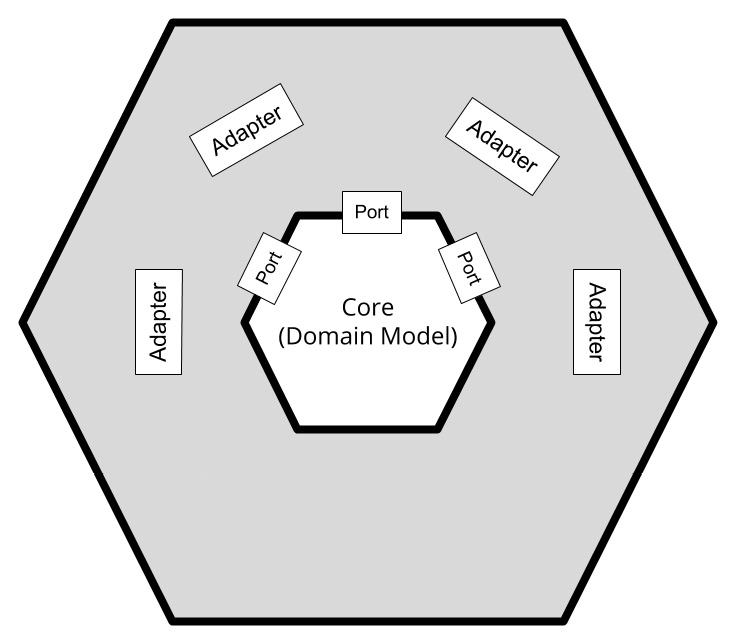
Figure 6.1 – Hexagonal architecture schema
As you can see in the preceding diagram, the business logic stays at the core of this representation:
- Core: The core can be intended to be the domain model, as seen in Chapter 4, Best Practices for Design and Development. It's the real distinctive part of your application component – the one solving the business problem.
- Port: Around the core, the ports are represented. The domain model uses the ports as a way to communicate with other application components, being other modules or systems (such as databases and other infrastructures). The ports are usually mapped to use cases of the module itself (such as sending payments). However, more technical interpretations of ports are not unusual (such as persisting to a database).
- Adapter: The layer outside the ports represents the adapters. The Adapter is a well-known pattern in which a piece of software acts as an interpreter between two different sides. In this case, it translates from the domain model to the outside world, and vice versa, according to what is defined in each port. While the diagram is in the shape of a hexagon, that's not indicative of being limited to six ports or adapters. That's just a graphical representation, probably related to the idea of representing the ports as discrete elements (which is hard to do if you represent the layers as concentric circles). The hexagonal architecture is also known as Ports and Adapters.
Important Note:
There is another architectural model implementing encapsulation that is often compared to hexagonal architectures: Onion architectures. Whether the hexagonal architecture defines the roles mentioned earlier, such as core, ports, and adapters, the Onion architecture focuses the modeling on the concept of layers. There is an inner core (the Domain layer) and then a number of layers around it, usually including a repository (to access the data of the Domain layer), services (to implement business logic and other interactions), and a presentation layer (for interacting with the end user or other systems). Each layer is supposed to communicate only with the layer above itself.
Hexagonal architectures and Domain Driven Design
Encapsulation is a cross-cutting concern, applicable to many aspects of a software architecture, and hexagonal architectures are a way to implement this concept. As we have seen, encapsulation has many touchpoints with the concept of Domain-Driven Design (DDD). The core, as mentioned, can be seen as the domain model in DDD. The Adapter pattern is also very similar to the concept of the Infrastructure layer, which in DDD is the layer mapping the domain model with the underlying technology (and abstracting such technology details).
It's then worth noticing that DDD is a way more complete approach, as seen in Chapter 4, Best Practices for Design and Development, tackling things such as defining a language for creating domain model concepts and implementing some peculiar use cases (such as where to store data, where to store implementations, how to make different models talk to each other). Conversely, hexagonal architectures are a more practical, immediate approach that may directly address a concern (such as implementing encapsulation in a structured way), but do not touch other aspects (such as how to define the objects in the core).
Encapsulation and microservices
While we are going to talk about microservices in Chapter 9, Designing Cloud-Native Architectures, I'm sure you are familiar with, or at least have heard about, the concept of microservices. In this section, it's relevant to mention that the topic of encapsulation is one of the core reasonings behind microservices. Indeed, a microservice is considered to be a disposable piece of software, easy to scale and to interoperate with other similar components through a well-defined API.
Moreover, each microservice composing an application is (in theory) a product, with a dedicated team behind it and using a set of technologies (including the programming language itself) different from the other microservices around it. For all those reasons, encapsulation is the basis of the microservices applications, and the concepts behind it (as the ones that we have seen in the context of hexagonal architectures) are intrinsic in microservices.
So, as you now know, the concept of modularization is in some way orthogonal to software entities. This need to define clear responsibilities and specific contracts is a common way to address complexity, and it has a lot of advantages, such as testability, scaling, extensibility, and more. Another common way to define roles in a software system is the multi-tier architecture.
Learning about multi-tier architectures
Multi-tier architectures, also known as n-tier architectures, are a way to categorize software architectures based on the number and kind of tiers (or layers) encompassing the components of such a system. A tier is a logical grouping of the software components, and it's usually also reflected in the physical deployment of the components. One way of designing applications is to define the number of tiers composing them and how they communicate with each other. Then, you can define which component belongs to which tier. The most common types of multi-tier applications are defined in the following list:
- The simplest (and most useless) examples are single-tier applications, where every component falls into the same layer. So, you have what is called a monolithic application.
- Things get slightly more interesting in the next iteration, that is, two-tier applications. These are commonly implemented as client-server systems. You will have a layer including the components provided to end users, usually through some kind of graphical or textual user interfaces, and a layer including the backend systems, which normally implement the business rules and the transactional functionalities.
- Three-tier applications are a very common architectural setup. In this kind of design, you have a presentation layer taking care of interaction with end users. We also have a business logic layer implementing the business logic and exposing APIs consumable by the presentation layer, and a data layer, which is responsible for storing data in a persistent way (such as in a database or on a disk).
- More than three layers can be contemplated, but that is less conventional, meaning that the naming and roles may vary. Usually, the additional tiers are specializations of the business logic tier, which was seen in the previous point. An example of a four-tier application was detailed in Chapter 4, Best Practices for Design and Development, when talking about the layered architecture of DDD.
The following diagram illustrates the various types of multi-tier architectures:
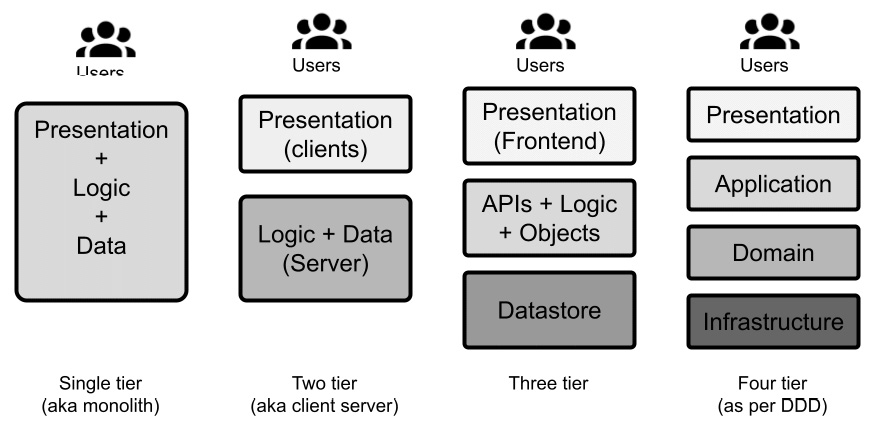
Figure 6.2 – Multi-tier architectures
The advantages of a multi-tier approach are similar to those that you can achieve with the modularization of your application components (more on this in Chapter 9, Designing Cloud-Native Architectures). Some of the advantages are as follows:
- The most relevant advantage is probably scalability. This kind of architecture allows each layer to scale independently from each other. So, if you have more load on the business (or frontend, or database) layer, you can scale it (vertically, by adding more computational resources, or horizontally, by adding more instances of the same component) without having a huge impact on the other components. And that is also linked to increased stability overall: an issue on one of the layers is not so likely to influence the other layers.
- Another positive impact is improved testability. Since you are forced to define clearly how the layers communicate with each other (such as by defining some APIs), it becomes easier to test each layer individually by using the same communication channel.
- Modularity is also an interesting aspect. Having layers talking to each other will enforce a well-defined API to decouple each other. For this reason, it is possible (and is very common) to have different actors on the same layer, interacting with the other layer. The most widespread example here is related to the frontend. Many applications have different versions of the frontend (such as a web GUI and a mobile app) interacting with the same underlying layer.
- Last but not least, by layering your application, you will end up having more parallelization in the development process. Sub teams can work on a layer without interfering with each other. The layers, in most cases, can be released individually, reducing the risks associated with a big bang release.
There are, of course, drawbacks to the multi-tier approach, and they are similar to the ones you can observe when adopting other modular approaches, such as microservices. The main disadvantage is to do with tracing.
It may become hard to understand the end-to-end path of each transaction, especially (as is common) if one call in a layer is mapped to many calls in other layers. To mitigate this, you will have to adopt specific monitoring to trace the path of each call; this is usually done by injecting unique IDs to correlate the calls to each other to help when troubleshooting is needed (such as when you want to spot where the transactions slow down) and in general to give better visibility into system behavior. We will study this approach (often referred to as tracing or observability) in more detail in Chapter 9, Designing Cloud-Native Architectures.
In the next section, we will have a look at a widespread pattern: Model View Controller.
Exploring Model View Controller
At first glance, Model View Controller (MVC) may show some similarities with the classical three-tier architecture. You have the classification of your logical objects into three kinds and a clear separation between presentation and data layers. However, MVC and the three-tier architecture are two different concepts that often coexist.
The three-tier architecture is an architectural style where the elements (presentation, business, and data) are split into different deployable artifacts (possibly even using different languages and technologies). These elements are often executed on different servers in order to achieve the already discussed goals of scalability, testability, and so on.
On the other hand, MVC is not an architectural style, but a design pattern. For this reason, it does not suggest any particular deployment model regarding its components, and indeed, very often the Model, View, and Controller coexist in the same application layer.
Taking apart the philosophical similarity and differences, from a practical point of view, MVC is a common pattern for designing and implementing the presentation layer in a multi-tier architecture.
In MVC, the three essential components are listed as follows:
- Model: This component takes care of abstracting access to the data used by the application. There is no logic to the data presented here.
- View: This component takes care of the interaction with the users (or other external systems), including the visual representation of data (if expected).
- Controller: This component receives the commands (often mediated by the view) from the users (or other external systems) and updates the other two components accordingly. The Controller is commonly seen as a facilitator (or glue) between the Model and View components.
The following diagram shows you the essential components of MVC:

Figure 6.3 – MVC components
Another difference between MVC and the three-tier architecture is clear from the interaction of the three components described previously: in a three-tier architecture, the interaction is usually linear; that is, the presentation layer does not interact directly with the data layer. MVC classifies the kind and goal of each interaction but also allows all three components to interact with each other, forming a triangular model.
MVC is commonly implemented by a framework or middleware and is used by the developer, specific interfaces, hooks, conventions, and more.
In the real world, this pattern is commonly implemented either at the server side or the client side.
Server-side MVC
The Java Enterprise Edition (JEE) implementation is a widely used example (even if not really a modern one) of an MVC server-side implementation. In this section, we are going to mention some classical Java implementations of web technologies (such as JSPs and servlets) that are going to be detailed further in Chapter 10, Implementing User Interaction.
In terms of relevance to this chapter, it's worthwhile knowing that in the JEE world, the MVC model is implemented using Java beans, the view is in the form of JSP files, and the controller takes the form of servlets, as shown in the following diagram:
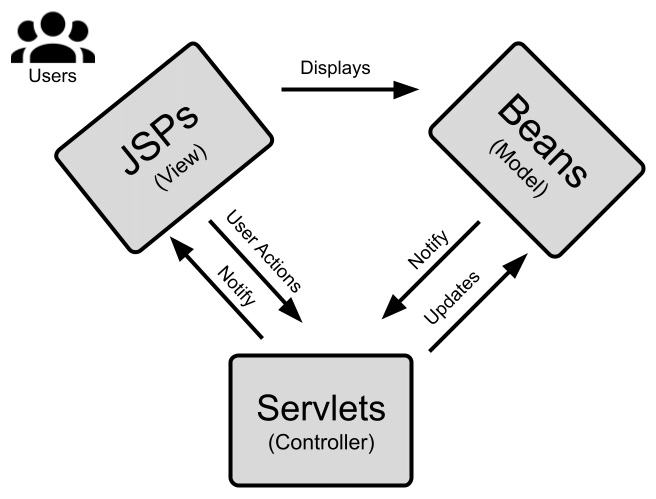
Figure 6.4 – MVC with JEE
As you can see, in this way, the end user interacts with the web pages generated by the JSPs (the View), which are bound to the Java Beans (the Model) keeping the values displayed and collected. The overall flow is guaranteed by the Servlets (the Controller), which take care of things such as the binding of the Model and View, session handling, page routing, and other aspects that glue the application together. Other widespread Java MVC frameworks, such as Spring MVC, adopt a similar approach.
Client-side MVC
MVC can also be completely implemented on the client side, which usually means that all three roles are played by a web browser. The de facto standard language for client-side MVC is JavaScript.
Client-side MVC is almost identical to single-page applications. We will see more about single-page applications in Chapter 10, Implementing User Interaction, but basically, the idea is to minimize page changes and full-page reloads in order to provide a near-native experience to users while keeping the advantages of a web application (such as simplified distribution and centralized management).
The single-page applications approach is not so different from server-side MVC. This technology commonly uses a templating language for views (similar to what we have seen with JSPs on the server side), a model implementation for keeping data and storing it in local browser storage or remotely calling the remaining APIs exposed from the backend, and controllers for navigation, session handling, and more support code.
In this section, you learned about MVC and related patterns, which are considered a classical implementation for applications and have been useful for nicely setting up all the components and interactions, separating the user interface from the implementation.
In the next section, we will have a look at the event-driven and reactive approaches.
Diving into event-driven and reactive approaches
Event-driven architecture isn't a new concept. My first experiences with it were related to GUI development (with Java Swing) a long time ago. But, of course, the concept is older than that. And the reason is that events, meaning things that happen, are a pretty natural phenomenon in the real world.
There is also a technological reason for the event-driven approach. This way of programming is deeply related to (or in other words, is most advantageous when used together with) asynchronous and non-blocking approaches, and these paradigms are inherently efficient in terms of the use of resources.
Here is a diagram representing the event-driven approach:
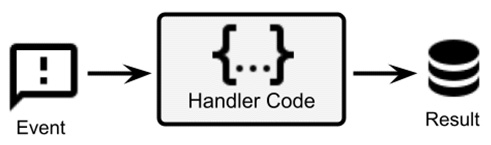
Figure 6.5 – Event-driven approach
As shown in the previous diagram, the whole concept of the event-driven approach is to have our application architecture react to external events. When it comes to GUIs, such events are mostly user inputs (such as clicking a button, entering data in text fields, and so on), but events can be many other things, such as changes in the price of a stock option, a payment transaction coming in, data being collected from sensors, and so on.
Another pattern worth mentioning is the actor model pattern, which is another way to use messaging to maximize the concurrency and throughput of a software system.
I like to think that reactive programming is an evolution of all this. Actually, it is probably an evolution of many different techniques.
It is a bit harder to define reactive, probably because this approach is still relatively new and less widespread. Reactive has its roots in functional programming, and it's a complete paradigm shift from the way you think about and write your code right now. While it's out of the scope of this book to introduce functional programming, we will try to understand some principles of reactive programming with the usual goal of giving you some more tools you can use in your day-to-day architect life and that you can develop further elsewhere if you find them useful for solving your current issues.
But first, let's start with a cornerstone concept: events.
Defining events, commands, and messages
From a technological point of view, an event can be defined as something that changes the status of something. In an event-driven architecture, such a change is then propagated (notified) as a message that can be picked up by components interested in that kind of event.
For this reason, the terms event-driven and message-driven are commonly used interchangeably (even if the meaning may be slightly different).
So, an event can be seen as a more abstract concept to do with new information, while a message can be seen as how this information is propagated throughout our system. Another core concept is the command. Roughly speaking, a command is the expression of an action, while an event is an expression of something happening (such as a change in the status of something).
So, an event reflects a change in data (and somebody downstream may need to be notified of the change and need to do something accordingly), while a command explicitly asks for a specific action to be done by somebody downstream.
Again, generally speaking, an event may have a broader audience (many consumers might be interested in it), while a command is usually targeted at a specific system. Both types of messages are a nice way to implement loose coupling, meaning it's possible to switch at any moment between producer and consumer implementations, given that the contract (the message format) is respected. It could be even done live with zero impact on system uptime. That's why the usage of messaging techniques is so important in application design.
Since these concepts are so important and there are many different variations on brokers, messages, and how they are propagated and managed, we will look at more on messaging in Chapter 8, Designing Application Integration and Business Automation. Now, let's talk about the event-driven approach in detail.
Introducing the event-driven pattern and event-driven architecture
The event-driven pattern is a pattern and architectural style focused on reacting to things happening around (or inside of) our application, where notifications of actions to be taken appear in the form of events.
In its simplest form, expressed in imperative languages (as is widespread in embedded systems), event-driven architecture is managed via infinite loops in code that continuously poll against event sources (queues), and actions are performed when messages are received.
However, event-driven architecture is orthogonal to the programming style, meaning that it can be adopted both in imperative models and other models, such as object-oriented programming.
With regard to Object-Oriented Programming (OOP), there are plenty of Java-based examples when it comes to user interface development, with a widely known one being the Swing framework. Here you have objects (such as buttons, windows, and other controls) that provide handlers for user events. You can register one or more handlers (consumers) with those events, which are then executed.
From the point of view of the application flow, you are not defining the order in which the methods are executing. You are just defining the possibilities, which are then executed and composed according to the user inputs.
But if you abstract a bit, many other aspects of Java programming are event-driven. Servlets inherently react to events (such as an incoming HTTP request), and even error handling, with try-catch, defines the ways to react if an unplanned event occurs. In those examples, however, the events are handled internally by the framework, and you don't have a centralized middleware operating them (such as a messaging broker or queue manager). Events are simply a way to define the behavior of an application.
Event-driven architecture can be extended as an architectural style. Simply put, an event-driven architecture prescribes that all interactions between the components of your software system are done via events (or commands). Such events, in this case, are mediated by a central messaging system (a broker, or bus).
In this way, you can extend the advantages of the event-driven pattern, such as loose coupling, better scalability, and a more natural way to represent the use case, beyond a single software component. Moreover, you will achieve the advantage of greater visibility (as you can inspect the content and number of messages exchanged between the pieces of your architecture). You will also have better manageability and uptime (because you can start, stop, and change every component without directly impacting the others, as a consequence of loose coupling).
Challenges of the event-driven approach
So far, we have seen the advantages of the event-driven approach. In my personal opinion, they greatly outweigh the challenges that it poses, so I strongly recommend using this kind of architecture wherever possible. As always, take into account that the techniques and advice provided in this book are seldom entirely prescriptive, so in the real world I bet you will use some bits of the event-driven pattern even if you are using other patterns and techniques as your main choice.
However, for the sake of completeness, I think it is worth mentioning the challenges I have faced while building event-driven architectures in the past:
- Message content: It's always challenging to define what should be inside a message. In theory, you should keep the message as simple and as light as possible to avoid hogging the messaging channels and achieve better performance. So, you usually have only a message type and references to data stored elsewhere.
However, this means that downstream systems may not have all the data needed for the computation in the message, and so they would complete the data from external systems (typically, a database). Moreover, most of the messaging frameworks and APIs (such as JMS) allow you to complete your message with metadata, such as headers and attachments. I've seen endless discussions about what should go into a message and what the metadata is. Of course, I don't have an answer here. My advice, as always, is to keep it as simple as possible.
- Message format: Related to the previous point, the message format is also very relevant. Hence, after you establish what information type should be contained in each message, the next step is to decide the shape this information should have. You will have to define a message schema, and this should be understandable by each actor. Also, message validation could be needed (to understand whether each message is a formally valid one), and a schema repository could be useful, in order to have a centralized infrastructure that each actor can access to extract metadata about how each message should be formatted.
- Transactional behavior: The write or read of a message, in abstract, constitutes access to external storage (not so different from accessing a database). For this reason, if you are building a traditional enterprise application, when you are using messaging, you will need to extend your transactional behavior.
It's a very common situation that if your consumer needs to update the database as a consequence of receiving a message, you will have a transaction encompassing the read of the message and the write to the database. If the write fails, you will roll back the read of the message. In the Java world, you will implement this with a two-phase commit. While it's a well-known problem and many frameworks offer some facilities to do this, it's still not a simple solution; it can be hard to troubleshoot (and recover from) and can have a non-negligible performance hit.
- Tracing: If the system starts dispatching many messages between many systems, including intermediate steps such as message transformations and filtering, it may become difficult to reconstruct a user transaction end to end. This could lead to a lack of visibility (from a logical/use case point of view) and make troubleshooting harder. However, you can easily solve this aspect with the propagation of transaction identifiers in messages and appropriate logging.
- Security: You will need to apply security practices at many points. In particular, you may want to authenticate the connections to the messaging system (both for producing and consuming messages), define access control for authorization (you can read and write only to authorized destinations), and even sign messages to ensure the identity of the sender. This is not a big deal, honestly, but is one more thing to take into account.
As you can see, the challenges are not impossible to face, and the advantages will probably outweigh them for you. Also, as we will see in Chapter 9, Designing Cloud-Native Architectures, many of these challenges are not exclusive to event-driven architecture, as they are also common in distributed architectures such as microservices.
Event-driven and domain model
We have already discussed many times the importance of correctly modeling a business domain, and how this domain is very specific to the application boundaries. Indeed, in Chapter 4, Best Practices for Design and Development, we introduced the idea of bounded context. Event-driven architectures are dealing almost every time with the exchange of information between different bounded contexts.
As already discussed, there are a number of techniques for dealing with such kinds of interactions between different bounded contexts, including the shared kernel, customer suppliers, conformity, and anti-corruption layer. As already mentioned, unfortunately, a perfect approach does not exist for ensuring that different bounded contexts can share meaningful information but stay correctly decoupled.
My personal experience is that the often-used approach here is the shared kernel. In other words, a new object is defined and used as an event format. Such an object contains the minimum amount of information needed for the different bounded contexts to communicate. This does not necessarily mean that the communication will work in every case and no side effects will occur, but it's a solution good enough in most cases.
In the next section, we are going to touch on a common implementation of the event-driven pattern, known as the actor model.
Building on the event-driven architecture – the actor model
The actor model is a stricter implementation of the event-driven pattern. In the actor model, the actor is the most elementary unit of computation, encapsulating the state and behavior. An actor can communicate with other actors only through messages.
An actor can create other actors. Each actor encapsulates its internal status (no actor can directly manipulate the status of another actor). This is usually a nice and elegant way to take advantage of multithreading and parallel processing, thereby maintaining integrity and avoiding explicit locks and synchronizations.
In my personal experience, the actor model is a bit too prescriptive when it comes to describing bigger use cases. Moreover, some requirements, such as session handling and access to relational databases, are not an immediate match with the actor model's logic (though they are still implementable within it). You will probably end up implementing some components (maybe core ones) with the actor model while having others that use a less rigorous approach, for the sake of simplicity. The most famous actor model implementation with Java is probably Akka, with some other frameworks, such as Vert.x, taking some principles from it.
So far, we have elaborated on generic messaging with both the event-driven approach and the actor model.
It is now important, for the purpose of this chapter, to introduce the concept of streaming.
Introducing streaming
Streaming has grown more popular with the rise of Apache Kafka even if other popular alternatives, such as Apache Pulsar, are available. Streaming shares some similarities with messaging (there are still producers, consumers, and messages flowing, after all), but it also has some slight differences.
From a purely technical point of view, streaming has one important difference compared with messaging. In a streaming system, messages persist for a certain amount of time (or, if you want, a specified number of messages can be maintained), regardless of whether they have been consumed or not.
This creates a kind of sliding window, meaning that consumers of a streaming system can rewind messages, following the flow from a previous point to the current point. This means that some of the information is moved from the messaging system (the broker, or bus) to the consumers (which have to maintain a cursor to keep track of the messages read and can move back in time).
This behavior also enables some advanced use cases. Since consumers can see a consolidated list of messages (the stream, if you like), complex logic can be applied to such messages. Different messages can be combined for computation purposes, different streams can be merged, and advanced filtering logic can be implemented. Moreover, the offloading of part of the logic from the server to the consumers is one factor that enables the management of high volumes of messages with low latencies, allowing for near real-time scenarios.
Given those technical differences, streaming also offers some conceptual differences that lead to use cases that are ideal for modeling with this kind of technology.
With streams, the events (which are then propagated as messages) are seen as a whole information flow as they usually have a constant rate. And moreover, a single event is normally less important than the sequence of events. Last but not least, the ability to rewind the event stream leads to better consistency in distributed environments.
Imagine adding more instances of your application (scaling). Each instance can reconstruct the status of the data by looking at the sequence of messages collected until that moment, in an approach commonly defined as Event Sourcing. This is also a commonly used pattern to improve resiliency and return to normal operations following a malfunction or disaster event. This characteristic is one of the reasons for the rising popularity of streaming systems in microservice architectures.
Touching on reactive programming
I like to think of reactive programming as event-driven architecture being applied to data streaming. However, I'm aware that that's an oversimplification, as reactive programming is a complex concept, both from a theoretical and technological point of view.
To fully embrace the benefits of reactive programming, you have to both master the tools for implementing it (such as RxJava, Vert.x, or even BaconJS) and switch your reasoning to the reactive point of view. We can do this by modeling all our data as streams (including changes in variables content) and writing our code on the basis of a declarative approach.
Reactive programming considers data streams as the primary construct. This makes the programming style an elegant and efficient way to write asynchronous code, by observing streams and reacting to signals. I understand that this is not easy at all to grasp at first glance.
It's also worth noting that the term reactive is also used in the context of reactive systems, as per the Reactive Manifesto, produced in 2014 by the community to implement responsive and distributed systems. The Reactive Manifesto focuses on building systems that are as follows:
- Responsive: This means replying with minimal and predictable delays to inputs (in order to maximize the user experience).
- Resilient: This means that a failure in one of the components is handled gracefully and impacts the whole system's availability and responsiveness as little as possible.
- Elastic: This means that the system can adapt to variable workloads, keeping constant response times.
- Message-driven: This means that systems that adhere to the manifesto use a message-driven communication model (hence achieving the same goals as described in the Introducing the event-driven pattern and event-driven architecture section).
While some of the goals and techniques of the Reactive Manifesto resonate with the concepts we have explored so far, reactive systems and reactive programming are different things.
The Reactive Manifesto does not prescribe any particular approach to achieve the preceding four goals, while reactive programming does not guarantee, per se, all the benefits pursued by the Reactive Manifesto.
A bit confusing, I know. So, now that we've understood the differences between a reactive system (as per the Reactive Manifesto) and reactive programming, let's shift our focus back to reactive programming.
As we have said, the concept of data streaming is central to reactive programming. Another fundamental ingredient is the declarative approach (something similar to functional programming). In this approach, you express what you want to achieve instead of focusing on all the steps needed to get there. You declare the final result (leveraging standard constructs such as filter, map, and join) and attach it to a stream of data to which it will be applied.
The final result will be compact and elegant, even if it may not be immediate in terms of readability. One last concept that is crucial in reactive programming is backpressure. This is basically a mechanism for standardizing communication between producers and consumers in a reactive programming model in order to regulate flow control.
This means that if a consumer can't keep up with the pace of messages received from the producer (typically because of a lack of resources), it can send a notification about the problem upstream so that it can be managed by the producer or any other intermediate entity in the stream chain (in reactive programming, an event stream can be manipulated by intermediate functions). In theory, backpressure can bubble up to the first producer, which can also be a human user in the case of interactive systems.
When a producer is notified of backpressure, it can manage the issue in different ways. The most simple is to slow down the speed and just send less data, if possible. A more elaborate technique is to buffer the data, waiting for the consumer to get up to speed (for example, by scaling its resources). A more destructive approach (but one that is effective nevertheless) is to drop some messages. However, this may not be the best solution in every case.
With that, we have finished our quick look at reactive programming. I understand that some concepts have been merely mentioned, and things such as the functional and declarative approaches may require at least a whole chapter on their own. However, a full deep dive into the topic is beyond the scope of this book. I hope I gave you some hints to orient yourself toward the best architectural approach when it comes to message- and event-centric use cases.
In this section, you learned about the basic concepts and terms to do with reactive and event-driven programming, which, if well understood and implemented, can be used to create high-performance applications.
In the next section, we will start discussing how to optimize our architecture for performance and scalability purposes.
Designing for large-scale adoption
So far, in this chapter, we have discussed some widespread patterns and architectural styles that are well used in the world of enterprise Java applications.
One common idea around the techniques that we have discussed is to organize the code and the software components not only for better readability, but also for performance and scalability.
As you can see (and will continue to see) in this book, in current web-scale applications, it is crucial to think ahead in terms of planning to absorb traffic spikes, minimize resource usage, and ultimately have good performance. Let's have a quick look at what this all means in our context.
Defining performance goals
Performance is a very broad term. It can mean many different things, and often you will want to achieve all performance goals at once, which is of course not realistic.
In my personal experience, there are some main performance indicators to look after, as they usually have a direct impact on the business outcome:
- Throughput: This is measured as the number of transactions that can be managed per time unit (usually in seconds). The tricky part here is to define exactly what a transaction is in each particular context, as probably your system will manage different transaction types (with different resources being needed for each kind of transaction). Business people understand this metric instantaneously, knowing that having a higher throughput means that you will spend less on hardware (or cloud) resources.
- Response time: This term means many different things. It usually refers to the time it takes to load your web pages or the time it takes to complete a transaction. This has to do with customer satisfaction (the quicker, the better). You may also have a contractual Service Level Agreement (SLA); for example, your system must complete a transaction in no more than x milliseconds. Also, you may want to focus on an average time or set a maximum time threshold.
- Elapsed time: This basically means the amount of time needed to complete a defined chunk of work. This is common for batch computations (such as in big data or other calculations). This is kind of a mix of the previous two metrics. If you are able to do more work in parallel, you will spend less on your infrastructure. You may have a fixed deadline that you have to honor (such as finishing all your computations before a branch opens to the public).
Performance tuning is definitely a broad topic, and there is no magic formula to easily achieve the best performance. You will need to get real-world experience by experimenting with different configurations and get a lot of production traffic, as each case is different. However, here are some general considerations for each performance goal that we have seen:
- To enhance throughput, your best bet is to parallelize. This basically means leveraging threading where possible. It's unbelievable how often we tend to chain our calls in a sequential way. Unless it is strictly necessary (because of data), we should parallelize as much as we can and then merge the results.
This entails, basically, splitting each call wherever possible (by delegating it to another thread), waiting for all the subcalls to complete in order to join the results in the main thread, and returning the main thread to the caller. This is particularly relevant where the subcalls involve calling to external systems (such as via web services). When parallelizing, the total elapsed time to answer will be equal to the longest subcall, instead of being the sum of the time of each subcall.
In the next diagram, you can see how parallelizing calls can help in reducing the total elapsed time needed to complete the execution of an application feature:
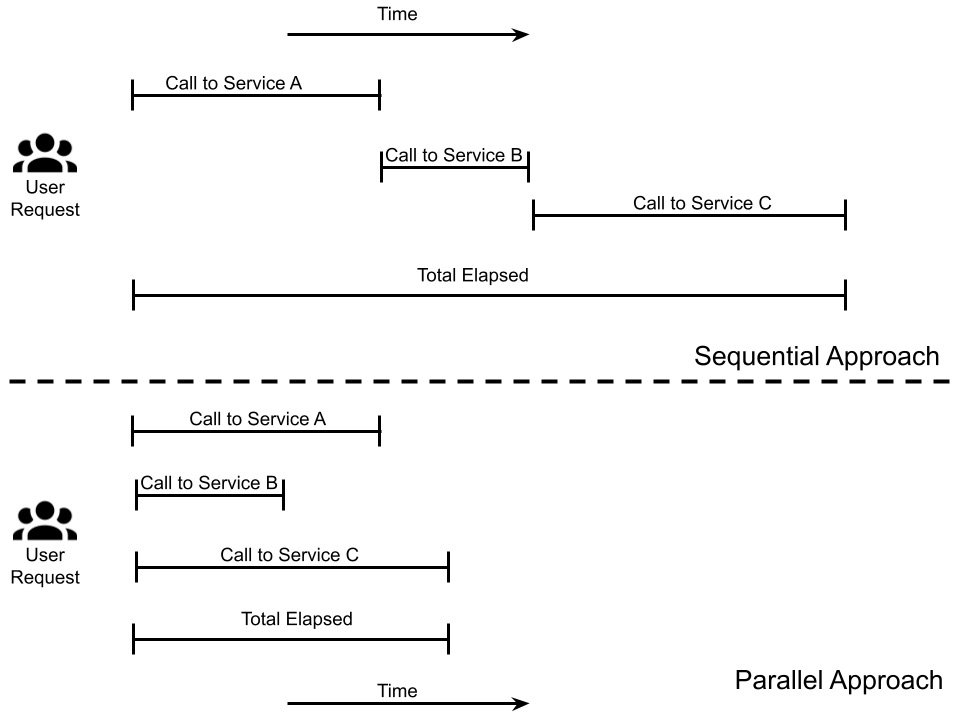
Figure 6.6 – Sequential versus parallel approach
- There should be a physical separation of our service based on the load and the performance expectations (something greatly facilitated by containers and microservices architecture). Instead of mixing all your APIs, you may want to dedicate more resources to the more critical ones (perhaps even dynamically, following the variation of traffic) by isolating them from the other services.
- For better response times, async is the way to go. After reviewing the previous sections for advice, I suggest working with your business and functional analysts and fighting to have everything be as asynchronous as possible from a use case perspective.
It is very uncommon to have really strict requirements in terms of checking everything on every backend system before giving feedback to your users. Your best bet is to do a quick validation and reply with an acknowledgment to the customer. You will, of course, need an asynchronous channel (such as an email, a notification, or a webhook) to notify regarding progression of the transaction. There are countless examples in real life; for example, when you buy something online, often, your card funds won't even be checked in the first interaction. You are then notified by email that the payment has been completed (or has failed). Then, the package is shipped, and so on. Moreover, optimizing access to data is crucial; caching, pre-calculating, and de-duplicating are all viable strategies.
- When optimizing for elapsed time, you may want to follow the advice previously given: parallelizing and optimizing access to data is key. Also, here, you may want to rely on specialized infrastructure, such as scaling to have a lot of hardware (maybe in the cloud) and powering it off when it is not needed, or using infrastructures optimized for input/output. But the best advice is to work on the use case to maximize the amount of parallelizable work, possibly duplicating part of the information.
We will learn more about performance in Chapter 12, Cross-Cutting Concerns. Let's now review some key concepts linked to scalability.
Stateless
Stateless is a very recurrent concept (we will see it again in Chapter 9, Designing Cloud-Native Architectures). It is difficult to define with simple words, however.
Let's take the example of an ATM versus a workstation.
Your workstation is something that is usually difficult to replace. Yes, you have backups and you probably store some of your data online (in your email inbox, on the intranet, or on shared online drives). But still, when you have to change your laptop for a new one, you lose some time ensuring that you have copied any local data. Then, you have to export and reimport your settings, and so on. In other words, your laptop is very much stateful. It has a lot of local data that you don't want to lose.
Now, let's think about an ATM. Before you insert your card, it is a perfectly empty machine. It then loads your data, allows cash withdrawal (or whatever you need), and then it goes back to the previous (empty) state, ready for the next client to serve. It is stateless from this point of view. It is also engineered to minimize the impact if something happens while you are using it. It's usually enough to end your current session and restart from scratch.
But back to our software architecture: how do we design an architecture to be stateless?
The most common ways are as follows:
- Push the state to clients: This can mean having a cookie in the customer browser or having your APIs carry a token (such as a JWT). Every time you get a request, you may get to choose the best instance for your software (be it a container, a new JVM instance, or simply a thread) to handle it – which will it be: the closest to the customer, the closest to the data, or simply the one with the least amount of load at that moment?
- Push the state to an external system: You can offload the state to a dedicated system, such as a distributed cache. Your API (and business logic) only need to identify the user. All the session data is then loaded from a dedicated system. Any new instance can simply ask for the session data. Of course, your problem is then how to scale and maximize the uptime of such a caching system.
Whatever your approach is, think always about the phoenix; that is, you should be able to reconstruct the data from the ashes (and quickly). In this way, you can maximize scaling, and as a positive side effect, you will boost availability and disaster recovery capabilities. As highlighted in the Introducing streaming section, events (and the event sourcing technique) are a good way to implement similar approaches. Indeed, provided that you have persisted all the changes in your data into a streaming system, such changes could be replayed in case of a disaster, and you can reconstruct the data from scratch.
Beware of the concept of stickiness (pointing your clients to the same instance whenever possible). It's a quick win at the beginning, but it may lead you to unbalanced infrastructure and a lack of scalability. The next foundational aspect of performance is data.
Data
Data is very often a crucial aspect of performance management. Slow access times to the data you need will frustrate all other optimizations in terms of parallelizing or keeping interactions asynchronous. Of course, each type of data has different optimization paths: indexing for relational databases, proximity for in-memory caching, and low-level tuning for filesystems.
However, here are my considerations as regards the low-hanging fruit when optimizing access to data:
- Sharding: This is a foundational concept. If you can split your data into smaller chunks (such as by segmenting your users by geographical areas, sorting using alphabetical order, or using any other criteria compliant with your data model), you can dedicate a subset of the system (such as a database schema or a file) to each data shard.
This will boost your resource usage by minimizing the interference between different data segments. A common strategy to properly cluster data in shards is hashing. If you can define a proper hashing function, you will have a quick and reliable way to identify where your data is located by mapping the result of the hashing operation to a specific system (containing the realm that is needed). If you still need to access data across different shards (such as for performing computations or for different representations of data), you may consider a different sharding strategy or even duplicating your data (but this path is always complex and risky, so be careful with that).
- Consistency point: This is another concept to take care of. It may seem like a lower-level detail, but it's worthwhile exploring. To put it simply: how often do you need your data to persist? Persistence particularly common in long transactions (such as ones involving a lot of submethods). Maybe you just don't need to persist your data every time; you can keep it in the memory and batch all the persistence operations (this often includes writing to files or other intensive steps) together.
For sure, if the system crashes, you might lose your data (and whether to take this risk is up to you), but are you sure that incongruent data (which is what you'd have after saving only a part of the operations) is better than no data at all? Moreover, maybe you can afford a crash because your data has persisted elsewhere and can be recovered (think about streaming, which we learned about previously). Last but not least, is it okay if your use case requires persistence at every step? Just be aware of that. Very often, we simply don't care about this aspect, and we pay a penalty without even knowing it.
- Caching: This is the most common technique. Memory is cheap, after all, and almost always has better access times than disk storage. So, you may just want to have a caching layer in front of your persistent storage (database, filesystem, or whatever). Of course, you will end up dealing with stale data and the propagation of changes, but it's still a simple and powerful concept, so it's worth a try.
Caching may be implemented in different ways. Common implementations include caching data in the working memory of each microservice (in other words, in the heap, in the case of Java applications), or relying on external caching systems (such as client-server, centralized caching systems such as Infinispan or Redis). Another implementation makes use of external tools (such as Nginx or Varnish) sitting in front of the API of each microservice and caching everything at that level.
We will see more about data in Chapter 11, Dealing with Data, but for now, let me give you a spoiler about my favorite takeaway here: you must have multiple ways of storing and retrieving data and using it according to the constraints of your use case. Your mobile application has a very different data access pattern from a batch computation system. Now, let's go to the next section and have a quick overview of scaling techniques.
Scaling
Scaling has been the main mantra so far for reaching performance goals and is one of the key reasons why you would want to architect your software in a certain way (such as in a multi-tier or async fashion). And honestly, I'm almost certain that you already know what scaling is and why it matters. However, let's quickly review the main things to consider when we talk about scaling:
- Vertical scaling is, somewhat, the most traditional way of scaling. To achieve better performance, you need to add more resources to your infrastructure. While it is still common and advisable in some scenarios (such as when trying to squeeze more performance from databases, caches, or other stateful systems), it is seldom a long-term solution.
You will hit a blocking limit sooner or later. Moreover, vertical scaling is not very dynamic, as you may need to purchase new hardware or resize your virtual machine, and maybe downtime will be needed to make effective changes. It is not something you can do in a few seconds to absorb a traffic spike.
- Horizontal scaling is way more popular nowadays as it copes well with cloud and PaaS architectures. It is also the basis of stateless, sharding, and the other concepts discussed previously. You can simply create another instance of a component, and that's it. In this sense, the slimmer, the better. If your service is very small and efficient and takes a very short time to start (microservices, anyone?), it will nicely absorb traffic spikes.
You can take this concept to the extreme and shut down everything (thereby saving money) when you have no traffic. As we will see in Chapter 9, Designing Cloud-Native Architectures, scaling to zero (so that no instance is running if there are no requests to work with) is the concept behind serverless.
- We are naturally led to think about scaling in a reactive way. You can get more traffic and react by scaling your components. The key here is identifying which metric to look after. It is usually the number of requests, but memory and CPU consumption are the other key metrics to look after. The advantage of this approach is that you will consume the resources needed for scaling just in time, hence you will mostly use it in an efficient way. The disadvantage is that you may end up suffering a bit if traffic increases suddenly, especially if the new instances take some time to get up and running.
- The opposite of reactive scaling is, of course, proactive scaling. You may know in advance that a traffic spike is expected, such as in the case of Black Friday or during the tax payment season. If you manage to automate your infrastructure in the right way, you can schedule the proper growth of the infrastructure in advance. This may be even more important if scaling takes some time, as in vertical scaling. The obvious advantage of this approach is that you will be ready in no time in case of a traffic increase, as all the instances needed are already up and running. The disadvantage is that you may end up wasting resources, especially if you overestimate the expected traffic.
With this section, we achieved the goals of this chapter. There was quite a lot of interesting content. We started with hexagonal architectures (an interesting example of encapsulation), before moving on to multi-tier architectures (a very common way to organize application components). Then, you learned about MVC (a widely used pattern for user interfaces), event-driven (an alternative way to design highly performant applications), and finally, we looked at some common-sense suggestions about building highly scalable and performant application architectures.
It is not possible to get into all the details of all the topics discussed in this chapter. However, I hope to have given you the foundation you need to start experimenting and learning more about the topics that are relevant to you.
And now, let's have a look at some practical examples.
Case studies and examples
As with other chapters in this book, let's end this chapter with some practical considerations about how to apply the concepts we've looked at to our recurrent example involving a mobile payment solution. Let's start with encapsulation.
Encapsulating with a hexagonal architecture
A common way to map hexagonal concepts in Java is to encompass the following concept representations:
- The core maps into the domain model. So, here you have the usual entities (Payment, in our example), services (PaymentService, in this case), value objects, and so on. Basically, all the elements in the core are Plain Old Java Objects (POJOs) and some business logic implementations.
- Here, the ports are the interfaces. They are somewhere in the middle, between a logical concept in the domain realm (enquire, notify, and store, in our example) and the respective technical concepts. This will promote the decoupling of the business logic (in the core) and the specific technology (which may change and evolve).
- The adapters are implementations of such interfaces. So, an enquire interface will be implemented by SoapAdapter, RestAdapter, and GraphQLAdapter, in this particular case.
- Outside of the hexagon, the external actors (such as the mobile app, databases, queues, or even external applications) interact with our application domain via the adapters provided.
The following diagram illustrates the preceding points:

Figure 6.7 – Hexagonal architecture example
Here are some key considerations:
- The cardinality is completely arbitrary. You are not limited to six ports or adapters. Each port can map to one or more adapters. Each external system can be bound to one or more adapters. Each adapter can be consumed by more than one external system (they are not exclusive unless you want them to be).
This logical grouping can be seen at the level that you want. This could be an application, meaning that everything inside the hexagon is deployed on a single artifact – an Enterprise Application Archive (EAR) or a Java Application Archive (JAR) – in a machine, or it could be a collection of different artifacts and machines (as in a microservices setup). In this case, most probably you will decouple your interfaces with REST or something similar, to avoid sharing dependencies across your modules.
- The advantage in terms of test coverage is obvious. You can switch each adapter into a mock system, to test in environments that don't have the complete infrastructure. So, you can test your notifications without the need for a queue, or test persistence without the need for a database. This, of course, will not replace end-to-end testing, in which you have to broaden your test and attach it to real adapters (such as in automating tests that call REST or SOAP APIs) or even external systems (such as in testing the mobile app or the web app itself).
As usual, I think that considering hexagonal modeling as a tool can be useful when implementing software architecture. Let's now have a quick look at multi-tier architecture.
Componentizing with multi-tier architecture
Multi-tier architecture gives us occasion to think about componentization and, ultimately, the evolution of software architectures. If we think about our mobile payment application, a three-tier approach may be considered a good fit. And honestly, it is. Historically, you probably wouldn't have had many other options than a pure, centralized, client-server application. Even with a modern perspective, starting with a less complex approach, such as the three-tier one, it can be a good choice for two reasons:
- It can be considered a prototypization phase, with the goal of building a Minimum Viable Product (MVP). You will have something to showcase and test soon, which means you can check whether you have correctly understood the requirements or whether users like (and use) your product. Moreover, if you designed your application correctly (using well-designed APIs), maybe you can evolve your backend (toward multi-tier or microservices) with minimal impact on the clients.
- It can be a good benchmark for your domain definition. As per the famous Martin Fowler article (Monolith First), you may want to start with a simpler, all-in-one architecture in order to understand the boundaries of your business logic, and then correctly decomponentize it in the following phase (maybe going toward a cloud-native approach).
In the next diagram, you can see a simple representation of an application's evolution from three-tier to microservices:

Figure 6.8 – Tier segmentation evolution
As you can see in the previous diagram, each component change has a role and name. There are some key considerations to make about this kind of evolution:
- We will see more about microservices in Chapter 9, Designing Cloud-Native Architectures. For now, consider the fact that this example will only represent architectural evolution over time and how your tier segmentation can evolve. Microservices is probably not similar to multi-tier architecture, as some concepts (such as responsibilities in terms of data representation in views) are orthogonal to it (in other words, you can still have concepts from three-tier on top of microservices).
- We are starting with three tiers because it is simply an antipattern to have business logic mixed together with your data in terms of being deployed to the database (with stored procedures and such). However, in my opinion, having an external database does not constitute a data layer per se. So, in this example, the three-tier architecture can also be seen as a two-tier/client-server architecture, with the external database simply being a technological detail.
- In the real world, there is no defined boundary between one architectural view (such as three-tier) and another alternative (such as microservices). It's not as if one day you will transition from client-server (or three-tier) to microservices. You will probably start adding more layers, and then reorganize some capabilities into a complete microservice from the ground up and offload some capabilities to it.
In general, it is possible to have a few differing architectural choices coexisting in the same application, perhaps just for a defined (limited) time, leading to a transition to a completely different architecture. In other words, your three-tier architecture can start with some modularized microservices alongside tiers (making it a hybrid architecture, bringing different styles together), and then the tiered part can be progressively reduced and the microservices part increased, before a final and complete move to a microservices implementation.
Once again, this is designed to give you some food for thought as to how to use some key concepts seen in this chapter in the real world. It's important to understand that it's rare (and maybe wrong) to completely and religiously embrace just one model, for instance, starting with a pure three-tier model and staying with it even if the external conditions change (if you start using a cloud-like environment, for example).
Planning for performance and scalability
As seen in the previous sections, performance is a broad term. In our example, it is likely that we will want to optimize for both throughput and response time. It is, of course, a target that is not easy to reach, but it is a common request in this kind of project:
- Throughput means a more sustainable business, with a lower cost for each transaction (considering hardware, power, software licenses, and so on).
- Response time means having a happier customer base and, ultimately, the success of the project. Being an online product, it is expected today that access to this kind of service (whether it is for making a payment or accessing a list of transactions) happens with zero delay; every hiccup could lead a customer to switch to alternative platforms.
Also, you may want to have a hard limit. It is common to have a timeout, meaning that if your payment takes more than 10 seconds, it is considered to have failed and is forcefully dropped. That's for limiting customer dissatisfaction and avoiding the overloading of the infrastructure.
But how do you design your software architecture to meet such objectives? As usual, there is no magic recipe for this. Performance tuning is a continuous process in which you have to monitor every single component for performance and load, experiment to find the most efficient solution, and then switch to the next bottleneck. However, there are a number of considerations that can be made upfront:
- First of all, there is transactional behavior. We will see in Chapter 9, Designing Cloud-Native Architectures, how heavily decentralized architectures, such as microservices, do not cope well with long and distributed transactions. Even if you are not yet in such a situation and you are starting with a simpler, three-tier architecture, having long transaction boundaries will cause serialization in your code, penalizing your performance.
To avoid this, you have to restrict the transaction as much as possible and handle consistency in different ways wherever possible. You may want to have your transaction encompass the payment request and the check of monetary funds (as in the classic examples about transactions), but you can take most of the other operations elsewhere. So, notifications and updates of non-critical systems (such as CRMs or data sources only used for inquiries) can be done outside of the transactions and retried in the case of failures.
- As a follow-up from the previous point, it should be taken into account that you don't have to penalize the most common cases to avoid very remote cases unless they have dramatic consequences. So, it is okay to check funds before making the payments in a strict way (as in the same transaction), because a malfunction there can cause bad advertising and a loss of trust in your platform, with potentially devastating consequences.
But you can probably afford to have a notification lost or sent twice from time to time if this means that 99% of the other transaction are performing better. And the rules can also be adapted to your specific context. Maybe the business can accept skipping some online checks (such as anti-fraud checks) in payment transactions of small amounts. The damage of some fraudulent transactions slipping through (or only being identified after the fact) may be lower than the benefit in terms of performance for the vast majority of licit traffic.
- In terms of asynchronous behavior, as has been seen, it is expected that you only do synchronously what's essential to do synchronously. So, apart from the obvious things such as notifications, every other step should be made asynchronous if possible – for example, updating downstream systems.
So, in our use case, if we have a transactional database (or a legacy system) storing the user position that is used to authorize payments, it should be checked and updated synchronously to keep consistency. But if we have other systems, such as a CRM that stores the customer position, perhaps it's okay to place an update request in a queue and update that system after a few seconds, when the message is consumed and acted upon.
- Last but not least, in terms of scaling, the more your component will be stateless, the better. So, if we have each step of the payment process carrying over all the data needed (such as the customer identifier and transaction identifier), maybe we can minimize the lookups and checks on the external systems.
In the case of more load, we can (in advance, if it is planned, or reactively if it is an unexpected peak) create more instances of our components. Then, they will be immediately able to take over for the incoming requests, even if they originated from existing instances.
So, if you imagine a payment transaction being completed in more than one step (as in first checking for the existence of the recipient, then making a payment request, then sending a confirmation), then it may be possible that each of those steps is worked on by different instances of the same component. Think about what would happen if you had to manage all those steps on the same instance that started the process because the component stored the data in an internal session. In cases of high traffic, new instances would not be able to help with the existing transactions, which would have to be completed where they originated. And the failure of one instance would likely create issues for users.
This completes the content of this chapter. Let's quickly recap the key concepts that you have seen.
Summary
In this chapter, you have seen a lot of the cornerstone concepts when it comes to architectural patterns and best practices in Java. In particular, you started with the concept of encapsulation; one practical way to achieve it is the hexagonal architecture. You then moved to multi-tier architectures, which is a core concept in Java and JEE (especially the three-tier architecture, which is commonly implemented with beans, servlets, and JSPs).
There was a quick look at MVC, which is more a design pattern than an architectural guideline but is crucial to highlight some concepts such as the importance of separating presentation from business logic. You then covered the asynchronous and event-driven architecture concepts, which apply to a huge portion of different approaches that are popular right now in the world of Java. These concepts are known for their positive impacts on performance and scalability, which were also the final topics of this chapter.
While being covered further in other chapters, such as Chapter 9, Designing Cloud-Native Architectures, and Chapter 12, Cross-Cutting Concerns, here you have seen some general considerations about architecture that will link some of the concepts that you've seen so far, such as tiering and asynchronous interactions, to specific performance goals.
In the next chapter, we will look in more detail at what middleware is and how it's evolving.
Further reading
- Hexagonal architecture, by Alistair Cockburn (https://alistair.cockburn.us/hexagonal-architecture/)
- Java Performance: The Definitive Guide: Getting the Most Out of Your Code, by Scott Oaks, published by O'Reilly Media (2014)
- Kafka Streams in Action, by William P. Bejeck Jr., published by Manning
- Scalability Rules 50 Principles for Scaling Web Sites, by Martin L. Abbott and Michael T. Fisher, published by Pearson Education (2011)
- Monolith First, by Martin Fowler (https://www.martinfowler.com/bliki/MonolithFirst.html)