
Chapter 10: DDD – The Domain Layer
The previous chapter was an overall view of Domain-Driven Design (DDD), where you learned about the fundamental layers, building blocks, and principles of DDD. You also gained an understanding of the structure of the ABP solution and its relation to DDD.
This chapter completely focuses on the implementation details of the domain layer with a lot of code examples and best practice suggestions. Here are the topics we will cover in this chapter:
- Exploring the example domain
- Designing aggregates and entities
- Implementing domain services
- Implementing repositories
- Building specifications
- Publishing domain events
Technical requirements
You can clone or download the source code of the EventHub project from GitHub: https://github.com/volosoft/eventhub.
If you want to run the solution in your local development environment, you need to have an IDE/editor (such as Visual Studio) to build and run ASP.NET Core solutions. Also, if you want to create ABP solutions, you need to have the ABP CLI installed, as explained in Chapter 2, Getting Started with ABP Framework.
Exploring the example domain
The examples in this chapter and the next chapter will mostly be based on the EventHub solution. So, it is essential to understand the domain first. Chapter 4, Understanding the Reference Solution, has already explained the solution. You can check it if you want to refamiliarize yourself with the application and the solution structure. Here, we will explore the technical details and the domain objects.
The following list introduces and explains the main concepts of the domain:
- Event is the root object that represents an online or in-person event. An event has a title, description, start time, end time, registration capacity (optional), and a language (optional) as the main properties.
- An event is created (organized) by an Organization. Any User in the application can create an organization and organize events within that organization.
- An event can have zero or more Tracks with a track name (typically a simple label such as 1, 2, 3 or A, B, C). A track is a sequence of sessions. An event with multiple tracks makes it possible to organize parallel sessions.
- A track contains one or more Sessions. A session is a part of the event where attendees typically listen to a speaker for a certain length of time.
- Finally, a session can have zero or more Speakers. A speaker is a person who talks in the session and makes a presentation. Generally, every session will have a speaker. But sometimes, there can be multiple speakers, or there can be no speaker associated with the session. Figure 10.1 (in the next section) shows the relation of an event to its tracks, sessions, and speakers.
- Any user in the application can Register for an event. Registered users are notified before the event starts or if the event time changes.
You've learned about the fundamental objects in the EventHub application. The next section explains the first building block of DDD: aggregates.
Designing aggregates and entities
It is very important to design your entities and aggregate boundaries since the rest of the solution components will be based on that design. In this section, we will first understand what an aggregate is. Then we will see some key principles of an aggregate design. Finally, I will introduce some explicit rules and code examples to understand how we should implement aggregates.
What is an aggregate root?
An aggregate is a cluster of objects bound together by an aggregate root object. The aggregate root object is responsible for implementing the business rules and constraints related to the aggregate, keeping the aggregate objects in a valid state and preserving the data integrity. The aggregate root and the related objects have methods to achieve that responsibility.
The Event aggregate shown in the following figure is a good example of aggregates:
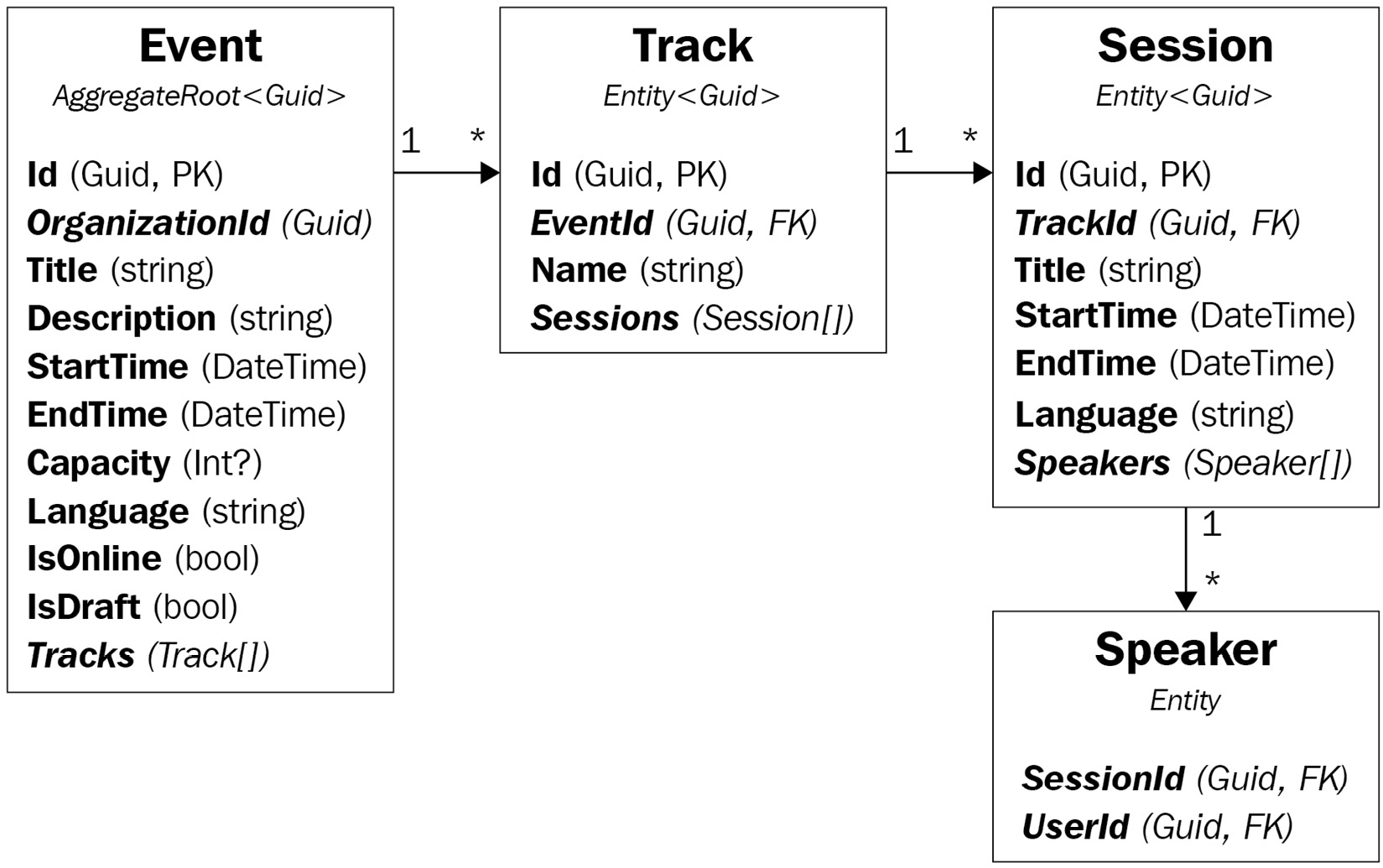
Figure 10.1 – The Event aggregate
The examples in this chapter will mostly be based on the Event aggregate since it represents the essential concept of the EventHub solution. So, we should understand its design:
- The Event object is the aggregate root here, with a GUID primary key. It has a collection of Track objects (an event can have zero or more tracks).
- A Track is an entity with a GUID primary key and contains a list of Session objects (a track should have one or more sessions).
- A Session is also an entity with a GUID primary key and contains a list of Speaker objects (a session can have zero or more speakers).
- A Speaker is an entity with a composite primary key that consists of SessionId and UserId.
Event is a relatively complex aggregate. Most of the aggregates in an application will consist of a single entity, the aggregate root entity.
The aggregate root is also an entity with a special role in the aggregate: it is the root entity of the aggregate and is responsible for sub-collections. I will refer to the term Entity for both aggregate root and sub-collection entities. So, the entity rules are valid for both object types, unless I specifically refer to one of them.
In the next sections, I will introduce two fundamental properties of an aggregate, a single unit and a serialized object.
A single unit
An aggregate is retrieved (from the database) and stored (in the database) as a single unit, including all the properties and sub-collection entities. For example, if you want to add a new Session to an Event, you should do the following:
- Read the related Event object from the database with all the Track, Session, and Speaker objects.
- Use a method of the Event class to add the new Session object to a Track of the Event.
- Save the Event aggregate to the database together with the new changes.
This might seem inefficient to developers who are used to working with relational databases and ORMs such as EF Core. However, it is necessary because that's how we keep the aggregate objects consistent and valid by implementing the business rules.
Here is a simplified example application service method implementing that process:
public class EventAppService
: EventHubAppService, IEventAppService
{
//...
public async Task AddSessionAsync(Guid eventId,
AddSessionDto input)
{
var @event =
await _eventRepository.GetAsync(eventId);
@event.AddSession(input.TrackId, input.Title,
input.StartTime, input.EndTime);
await _eventRepository.UpdateAsync(@event);
}
}
For this example, the event.AddSession method internally checks whether the new session's start time and end time conflict with another session on the same track. Also, the time range of the session should not overflow the event time range. We may have other business rules, too. We may want to limit the number of sessions in an event or check whether the session's speaker has another talk in the same time range.
Remember that DDD is for state changes. If you need a mass query or to prepare a report, you can optimize your database query as much as possible. However, for any change on an aggregate, we need all the objects on that aggregate to apply the business rules related to that change. If you are worried about the performance, see the Keep aggregates small section.
At the end of the method, we've updated the Event entity using the repository's UpdateAsync method. If you are working with EF Core, you do not need to explicitly call the UpdateAsync method, thanks to EF Core's change tracking system. The changes will be saved since ABP's Unit of Work system calls the DbContext.SaveChangesAsync() method for you. However, for example, the MongoDB .NET Driver has no change tracking system, and you should explicitly call the UpdateAsync method to the Event object if you're using MongoDB.
About the IRepository.GetAsync Method
The GetAsync method of the repository (used in the preceding example code block) retrieves the Event object as an aggregate (with all sub-collections) as a single unit. It works out of the box for MongoDB, but you need to configure your aggregate for EF Core to enable that behavior. See the The Aggregate pattern section in Chapter 6, Working with the Data Access Infrastructure, to remember how to configure it.
Retrieving and saving an aggregate as a single unit brings us the opportunity to make multiple changes to the objects of a single aggregate and save all of them together with a single database operation. This way, all the changes in that aggregate become atomic by nature without needing an explicit database transaction.
The Unit of Work System
If you need to change multiple aggregates (of the same or different types), you still need a database transaction. In this case, ABP's Unit of Work system (explained in Chapter 6, Working with the Data Access Infrastructure) automatically handles database transactions by convention.
A serializable object
An aggregate should be serializable and transferrable on the wire as a single unit, including all of its properties and sub-collections. That means you are able to convert it to a byte array or an XML or JSON value, then deserialize (re-construct) it from the serialized value.
EF Core does not serialize your entities, but a document database, such as MongoDB, may serialize your aggregate to a BSON/JSON value to store in the data source.
This principle is not a design requirement for an aggregate, but it is a good guide while determining the aggregate boundary. For example, you cannot have properties referencing entities of other aggregates. Otherwise, the referenced object is also serialized as a part of your aggregate.
Let's look at some more principles. The first rule, introduced in the next section, is the key practice to make an aggregate serializable.
Referencing other aggregates by their ID
The first rule says that an aggregate (including the aggregate root and other classes) should not have navigation properties to other aggregates but can store their ID values when necessary.
This rule makes the aggregate a self-contained, serializable unit. It also helps to not leak the business logic of an aggregate into another aggregate, by hiding aggregate details from other aggregates.
See the following example code block:
public class Event : FullAuditedAggregateRoot<Guid>
{
public Organization Organization { get; private set; }
public string Title { get; private set; }
...
}
The Event class has a navigation property to the Organization aggregate, which is prohibited by this rule. If we serialize an Event object to a JSON value, the related Organization object is also serialized.
In a proper implementation, the Event class can have an OrganizationId property for the related Organization:
public class Event : FullAuditedAggregateRoot<Guid>
{
public Guid OrganizationId { get; private set; }
public string Title { get; private set; }
...
}
Once we have an Event object and need to access the related organization details, we should query the Organization object from the database using OrganizationId (or perform a JOIN query to load them together at the beginning).
If you are using a document database, such as MongoDB, this rule will seem natural to you. Because if you add a navigation property to the Organization aggregate, then the related Organization object is serialized and saved in the collection of Event objects in the database, which duplicates the organization data and copies it into all events. However, with relational databases, ORMs such as EF Core allow you to use such navigation properties and handle the relation without any problem. I still suggest implementing this rule since it keeps your aggregates simpler and reduces the complexity of loading related data. If you don't want to apply this rule, you can refer to the Database provider independence section of Chapter 9, Understanding Domain-Driven Design.
The next section expresses a best practice: keep your aggregates small!
Keep aggregates small
Once we load and save an aggregate as a single unit, we may have performance and memory usage problems if the aggregate is too big. Keeping an aggregate simple and small is an essential principle, not just for performance but also to reduce the complexity.
The main aspect that makes an aggregate big is the potential number of sub-collection entities. If a sub-collection of an aggregate root contains hundreds of items, that's a sign of a bad design. In a good aggregate design, the items in a sub-collection should not exceed a few dozen and should remain below 100–150 in edge cases.
See the Event aggregate in the following code block:
public class Event : FullAuditedAggregateRoot<Guid>
{
...
public ICollection<Track> Tracks { get; set; }
public ICollection<EventRegistration> Registrations {
get; set; }
}
public class EventRegistration : Entity
{
public Guid EventId { get; set; }
public Guid UserId { get; set; }
}
There are two sub-collections of the Event aggregate in this example: Tracks and Registrations.
The Tracks sub-collection is a collection of parallel tracks in the event. It typically contains a few items, so there's no problem with loading the tracks while loading an Event entity.
The Registrations sub-collection is a collection of the registration records for the event. Thousands of people can register for a single event, which will be a significant performance problem if we load all registered people whenever loading an event. Also, most of the time, we don't need all registered users while manipulating an Event object. So, it would be better not to include the collection of registered people in the Event aggregate. In this example, the EventRegistration class is a sub-collection entity. For a better design, we should make it a separate aggregate root class.
There are three main considerations while determining the boundaries of an aggregate:
- The objects related and used together
- Data integrity, validity, and consistency
- The load and save performance of the aggregate (as a technical consideration)
In real life, most aggregate roots won't have any sub-collections. When you think to add a sub-collection to an aggregate, think about the object size as a technical factor.
Concurrency Control
Another problem with big aggregate objects is that they increase the probability of the concurrent update problem since big objects are more likely to be changed by multiple users simultaneously. ABP Framework provides a standard model for concurrency control. Please refer to the documentation: https://docs.abp.io/en/abp/latest/Concurrency-Check.
In the next section, we will discuss single and composite primary keys for entities.
Determining the primary keys for entities
Entities are determined by their ID (a unique identifier or the primary key (PK)) rather than by other properties. ABP Framework allows you to choose any type of PK that your database provider supports. However, it uses the Guid type for the entities of the pre-built modules. It also assumes that the user ID and tenant ID types are Guid. We discussed this topic in the The GUID PK section of Chapter 6, Working with the Data Access Infrastructure.
ABP also allows you to use composite primary keys for your entities. A composite primary key consists of two or more properties (of an entity) that become a unique value together.
As a best practice, use a single primary key (a Guid value, an incremental integer value, or whatever you want) for the aggregate root. You can use a single or composite primary for sub-collection entities.
Composite Keys in Non-Relational Databases
Composite primary keys for sub-collection entities are generally used in relational databases because sub-collections have their own tables in a relational database. However, in a document database (such as MongoDB), you don't define primary keys for sub-collection entities since they don't have their own database collections. Instead, they are stored as a part of the aggregate root.
In the EventHub project, Event is an aggregate root with a Guid primary key. Track, Session, and Speaker are sub-collection entities as a part of the Event aggregate. Track and Session entities have Guid primary keys, but the Speaker entity has a composite primary key.
The Speaker entity class is shown in the following code block:
public class Speaker : Entity
{
public Guid SessionId { get; private set; }
public Guid UserId { get; private set; }
public Speaker(Guid sessionId, Guid userId)
{
SessionId = sessionId;
UserId = userId;
}
public override object[] GetKeys()
{
return new object[] {SessionId, UserId};
}
}
SessionId and UserId compose the unique identifier for the Speaker entity. The Speaker class is derived from the Entity class (without a generic argument). When you derive from the non-generic Entity class, ABP Framework forces you to define the GetKeys method to obtain the components of the composite key. If you want to use composite keys, refer to the documentation of your database provider (such as EF Core) to learn how to configure them.
Beginning with the next section, we will look at the implementation details of aggregates and entities.
Implementing entity constructors
A constructor method is used to create an object. The compiler creates a default parameterless constructor when we don't explicitly add a constructor to the class. Defining a constructor is a good way to ensure an object is properly created.
An entity's constructor is responsible for creating a valid entity. It should get the required values as the constructor parameters to force us to supply these values during object creation so the new object is useful just after creation. It should check (validate) these parameters and set the properties of the entity. It should also initialize sub-collections and perform additional initialization logic if necessary.
The following code block shows an entity (an aggregate root entity) from the EventHub project:
public class Country : BasicAggregateRoot<Guid>
{
public string Name { get; private set; }
private Country() { } // parameterless constructor
public Country(Guid id, string name)
//primary constructor
: base(id)
{
Name = Check.NotNullOrWhiteSpace(
name, nameof(name),
CountryConsts.MaxNameLength);
}
}
Country is a very simple entity that has a single property: Name. The Name property is required, so the Country primary constructor (the actual constructor that is intended to be used by the application developers) forces the developer to set a valid value to that property by defining a name parameter and checking whether it is empty or exceeds a maximum length constraint. Check is a static class of ABP Framework with various methods used to validate method parameters and throw an ArgumentException error for invalid parameters.
The Name property has a private setter, so there is no way to change this value after the object creation. We can assume that countries don't change their names, for this example.
The Country class's primary constructor takes another parameter, Guid id. We don't use Guid.NewGuid() in the constructor since we want to use the IGuidGenerator service of ABP Framework, which generates sequential GUID values (see The GUID PK section of Chapter 6, Working with the Data Access Infrastructure). We directly pass the id value to the base class (BasicAggregateRoot<Guid> in this example) constructor, which internally sets the Id property of the entity.
The Need for Parameterless Constructors
The Country class also defines a private, parameterless constructor. This constructor is just for ORMs, so they can construct an object while reading from the database. Application developers do not use it.
Let's see a more complex example, showing the primary constructor of the Event entity:
internal Event(
Guid id,
Guid organizationId,
string urlCode,
string title,
DateTime startTime,
DateTime endTime,
string description)
: base(id)
{
OrganizationId = organizationId;
UrlCode = Check.NotNullOrWhiteSpace(urlCode, urlCode,
EventConsts.UrlCodeLength,
EventConsts.UrlCodeLength);
SetTitle(title);
SetDescription(description);
SetTimeInternal(startTime, endTime);
Tracks = new Collection<Track>();
}
The Event class's constructor takes the minimal required properties as the parameters, and checks and sets them to the properties. All these properties have private setters (see the source code) and are set via the constructor or some methods of the Event class. The constructor uses these methods to set the Title, Description, StartTime, and EndTime properties.
Let's see the SetTitle method's implementation:
public Event SetTitle(string title)
{
Title = Check.NotNullOrWhiteSpace(title, nameof(title),
EventConsts.MaxTitleLength,
EventConsts.MinTitleLength);
Url = EventUrlHelper.ConvertTitleToUrlPart(Title) + "-"
+ UrlCode;
return this;
}
The SetTitle method assigns the given title value to the Title property by checking the constraints. It then sets the Url property, a calculated value based on the Title property, and the UrlCode property. This method is public, to use later when we need to change the Event entity's Title property.
UrlCode is an eight-character random unique value that is sent to the constructor and never changes. Let's see another method that the constructor calls:
private Event SetTimeInternal(DateTime startTime,
DateTime endTime)
{
if (startTime > endTime)
{
throw new BusinessException(EventHubErrorCodes
.EventEndTimeCantBeEarlierThanStartTime);
}
StartTime = startTime;
EndTime = endTime;
return this;
}
Here, we have a business rule: the StartTime value cannot be later than the EndTime value.
The EventHub constructor is internal to prevent creating Event objects out of the domain layer. The application layer should always use the EventManager domain service to create a new Event entity. In the next section, we will see why we've designed it like that.
Using services to create aggregates
The best way to create and initialize a new entity is using its public constructor because it is the simplest way. However, in some cases, creating an object requires some more complex business logic that is not possible to implement in the constructor. For such cases, we can use a factory method on a domain service to create the object.
The Event class's primary constructor is internal, so the upper layers cannot directly create a new Event object. We should use the EventManager CreateAsync method to create a new Event object:
public class EventManager : DomainService
{
...
public async Task<Event> CreateAsync(
Organization organization,
string title,
DateTime startTime,
DateTime endTime,
string description)
{
return new Event(
GuidGenerator.Create(),
organization.Id,
await _eventUrlCodeGenerator.GenerateAsync(),
title,
startTime,
endTime,
description
);
}
}
We will return to domain services later, in the Implementing domain services section of this chapter. With this simple CreateAsync method, we are creating a valid Event object and returning the new object. We needed such a factory method because we used the eventUrlCodeGenerator service to generate URL code for the new event. The eventUrlCodeGenerator service internally creates a random, eight-character code for the new event and also checks whether that code was used by another event before (see its source code if you want to learn more). That's why it is async: it performs a database operation.
We've used a factory method of a domain service to create a new Event object because the Event class's constructor cannot use the eventUrlCodeGenerator service. So, you can create factory methods if you need external services/objects while creating a new entity.
Factory Service versus Domain Service
An alternative approach can be creating a dedicated class for the factory method. That means we could create an EventFactory class and move the CreateAsync method inside it. I prefer a domain service method for creating entities to keep the construction logic close to the other domain logic related to the entity.
Do not save the new entity to the database inside the Factory method and leave it to the client code (generally, an application service method). The Factory method's responsibility is to create the object and no more (think of it as an advanced constructor – an entity constructor cannot save the entity to the database, right?). The client code may need to perform additional operations on the entity before saving it. We will return to this topic in the next chapter.
Do not overuse factory methods and keep using simple public constructors wherever possible. Creating a valid entity is important, but it is just the beginning of an entity's lifecycle. In the next section, we will see how to change an entity's state in a controlled way.
Implementing business logic and constraints
An entity is responsible for keeping itself always valid. In addition to the constructor that ensures the entity is valid and consistent when it's first created, we can define methods on the entity class to change its properties in a controlled way.
As a simple rule, if changing a property's value has pre-conditions, we should make its setter private and provide a method to change its value by implementing the necessary business logic and validating the provided value.
See the Description property of the Event class:
public class Event : FullAuditedAggregateRoot<Guid>
{
...
public string Description { get; private set; }
public Event SetDescription(string description)
{
Description = Check.NotNullOrWhiteSpace(
description, nameof(description),
EventConsts.MaxDescriptionLength,
EventConsts.MinDescriptionLength);
return this;
}
}
The Description property's setter is private. We provide the SetDescription method as the only way to change its value. In this method, we validate the description value: it should be a string that has a length of more than 50 (MinDescriptionLength) and less than 2000 (MaxDescriptionLength). These constants are defined in the EventHub.Domain.Shared project, so we can reuse them in DTOs, as we will see in the next chapter.
Data Annotation Attributes on Entity Properties
You may ask whether we can use [Required] or [StringLength] attributes on the Description property instead of creating a SetDescription method and manually performing the validation. Such attributes require another system that performs the validation. For example, EF Core can validate the properties based on these data annotation attributes while saving the entity to the database. However, that's not enough because, in that way, the entity could be invalid until we try to save it to the database. The entity should always be valid!
Let's see a more complex example, again from the Event class:
public Event AddSession(Guid trackId, Guid sessionId,
string title, DateTime startTime, DateTime endTime,
string description, string language)
{
if (startTime < this.StartTime || this.EndTime <
endTime)
{
throw new BusinessException(EventHubErrorCodes
.SessionTimeShouldBeInTheEventTime);
}
var track = GetTrack(trackId);
track.AddSession(sessionId, title, startTime, endTime,
description, language);
return this;
}
private Track GetTrack(Guid trackId)
{
return Tracks.FirstOrDefault(t => t.Id == trackId) ??
throw new EntityNotFoundException(typeof(Track),
trackId);
}
The AddSession method accepts a trackId parameter since a session should belong to a track. It also accepts the sessionId of the new session (getting it as a parameter to let the client use the IGuidGenerator service to create the value). The remaining parameters are the required properties of the new session.
The AddSession method first checks whether the new session is within the event's time range, then finds the right track (throws an exception otherwise) and delegates the remaining work to the track object. Let's see the track.AddSession method:
internal Track AddSession(Guid sessionId, string title,
DateTime startTime, DateTime endTime,
string description, string language)
{
if (startTime > endTime)
{
throw new BusinessException(EventHubErrorCodes
.EndTimeCantBeEarlierThanStartTime);
}
foreach (var session in Sessions)
{
if (startTime.IsBetween(session.StartTime,
session.EndTime) ||
endTime.IsBetween(session.StartTime,
session.EndTime))
{
throw new BusinessException(EventHubErrorCodes
.SessionTimeConflictsWithAnExistingSession);
}
}
Sessions.Add(new Session(sessionId, Id, title,
startTime, endTime, description));
return this;
}
First of all, this method is internal to prevent using it out of the domain layer. It is always used by the Event.AddSession method shown earlier in this section.
The Track.AddSession method loops through all the current sessions to check whether any session time conflicts with the new session. If there's no problem, it adds the session to the track.
Returning this (the event object) from a setter method is a good practice since it allows us to chain the setters, for example, eventObject.SetTime(…).SetDescription(…).
Both of the example methods used the properties on the event object and did not depend on any external object. What if we need to use an external service or repository to implement the business rule?
Using external services in entity methods
Sometimes, the business rule you want to apply needs to use external services. Entities cannot inject service dependencies because of technical and design restrictions. If you need to use a service in an entity method, the proper way to do this is to get that service as a parameter.
Assume that we have a business rule for the event capacity: you cannot decrease the capacity to lower than the currently registered user count. A null capacity value means there is no registration limitation.
See the following implementation on the Event class:
public async Task SetCapacityAsync(
IRepository<EventRegistration, Guid>
registrationRepository, int? capacity)
{
if (capacity.HasValue)
{
var registeredUserCount = await
registrationRepository.CountAsync(x =>
x.EventId == @event.Id);
if (capacity.Value < registeredUserCount)
{
throw new BusinessException(
EventHubErrorCodes
.CapacityCanNotBeLowerThanRegisteredUserCount);
}
}
this.Capacity = capacity;
}
The SetCapacityAsync method uses a repository object to execute a database query to get the currently registered user count. If the count is higher than the new capacity value, then it throws an exception. The SetCapacityAsync method is async since it performs an async database call. The client (generally an application service method) is responsible for injecting and passing the repository service to this method.
The SetCapacityAsync method guarantees implementing the business rule because the Capacity property's setter is private, and this method is the only way to change it.
You can get external services into methods as parameters, as shown in this example. However, that approach makes the entity dependent on external services, making it complicated and harder to test. It also violates the single responsibility principle and mixes the business logic of different aggregates (EventRegistration is another aggregate root).
There is a better way to implement the business logic that depends on external services or works on multiple aggregates: domain services.
Implementing domain services
A domain service is another class in which we implement the domain rules and constraints. Domain services are typically needed when we need to work with multiple aggregates, and the business logic doesn't properly fit into any of these aggregates. Domain services are also used when we need to consume other services and repositories since they can use the dependency injection system.
Let's re-implement the SetCapacityAsync method (in the previous section) as a domain service method:
public class EventManager : DomainService
{
...
public async Task SetCapacityAsync(Event @event,
int? capacity)
{
if (capacity.HasValue)
{
var registeredUserCount = await
_eventRegistrationRepository.CountAsync(
x => x.EventId == @event.Id);
if (capacity.Value < registeredUserCount)
{
throw new BusinessException(
EventHubErrorCodes.CapacityCanNotBeLower
ThanRegisteredUserCount);
}
}
@event.Capacity = capacity;
}
}
In this case, we've injected IRepository<EventRegistration, Guid> into the EventManager domain service (see the source code for all the details) and got the Event object as a parameter. The setter of the Event.Capacity property is now internal so that it can be set only in the domain layer, in the EventManager class.
A domain service method should be fine-grained: it should make a small (yet meaningful and consistent) change to the aggregate. The application layer then combines these small changes to perform different use cases.
We will explore application services in the next chapter. However, I find it useful to show an example application service method here that updates multiple properties on an event in a single request:
public async Task UpdateAsync(Guid id,
UpdateEventDto input)
{
var @event = await _eventRepository.GetAsync(id);
O
@event.SetTitle(input.Title);
@event.SetTime(input.StartTime, input.EndTime);
await _eventManager.SetCapacityAsync(@event,
input.Capacity);
@event.Language = input.Language;
await _eventRepository.UpdateAsync(@event);
}
The UpdateAsync method takes a DTO that contains the properties to be updated. It first retrieves the Event object from the database as a single unit, then uses SetTitle and SetTime methods on the Event object. These methods internally validate the provided values and properly change the property values.
The UpdateAsync method then uses the domain service method, eventManager.SetCapacity, to change the capacity value.
We directly set the Language property since it has a public setter and no business rule (it even accepts the null value). Do not create setter methods if they have no business rules or constraints. Also, do not create domain service methods simply to change the entity properties without any business logic.
The UpdateAsync method finally uses the repository to update the Event entity in the database.
Domain Service Interfaces
You do not need to introduce interfaces (such as IEventManager) for domain services since they are essential parts of the domain and should not be abstracted. However, if you want to mock domain services in unit tests, you may still want to create interfaces.
A domain service method should not update the entity as a common principle. In this example, we set the Language property after calling the SetCapacityAsync method. If SetCapacityAsync updates the entity, we end up with two database update operations, which would be inefficient.
As another good practice, accept the entity object as the parameter (as we've done in the SetCapacityAsync method) rather than its id value. If you accept its id value, you need to retrieve the entity from the database inside the domain service. This approach makes the application code load the same entity multiple times in different places in the same request (use case), which is inefficient and leads to bugs. Leave that responsibility to the application layer.
A specific type of domain service method is the factory method to create aggregates, explained in the Using services to create aggregates section. Declare factory methods only if a public constructor on the aggregate root cannot implement the business constraints. This may be the case if checking the business constraint requires the use of external services.
We've used repositories in many places so far. The next section explains the implementation details of repositories.
Implementing repositories
To remember the definition, a repository is a collection-like interface used to access the domain objects stored in the data persistence system. It hides the complexity of data access logic behind a simple abstraction.
There are some main rules for implementing repositories:
- Repository interfaces are defined in the domain layer, so the domain and application layers can use them. They are implemented in the infrastructure (or database provider integration) layer.
- Repositories are created for aggregate root entities but not for sub-collection entities. That is because the sub-collection entities should be accessed over the aggregate root. Typically, you have a repository for each aggregate root.
- Repositories work with domain objects, not DTOs.
- In an ideal design, repository interfaces should be independent of the database provider. So, do not get or return EF Core objects, such as DbContext or DbSet.
- Do not implement business logic inside repository classes.
ABP provides an implementation of the repository pattern out of the box. We explored how to use generic repositories and implement custom repositories in Chapter 6, Working with the Data Access Infrastructure. Here, I will discuss a few best practices.
The last rule in the preceding list, "Do not implement business logic inside repository classes," is the most important rule because the others are clear to understand. Implementing business logic inside a repository is generally a result of incorrectly considering business logic.
See the following example repository interface:
public interface IEventRepository : IRepository<Event,
Guid>
{
Task UpdateSessionTimeAsync(
Guid sessionId, DateTime startTime, DateTime
endTime);
Task<List<Event>> GetNearbyEventsAsync();
}
At first sight, there is no problem; these methods are just performing some database operations. However, the devil is in the details.
The first method, UpdateSessionTimeAsync, changes the timing of a session in an event. If you remember, we had a business rule: a session's timing cannot overlap with another session on the same track. It also cannot overflow the event time range. If we implement that rule in the repository method, we duplicate that business validation because it was already implemented inside the Event aggregate. If we don't implement that validation, it is obviously a bug. In a true implementation, this logic should be done in the aggregate. The repository should only query and update the aggregate as a single unit.
The second method, GetNearbyEventsAsync, gets a list of events in the same city with the current user. The problem with this method is the current user is an application layer concept and requires an active user session. Repositories should not work with the current user. What if we want to reuse the same nearby logic in a background service where we don't have the current user in the current context? It is better to pass the city, date range, and other parameters to the method, so it simply brings the events. Entity properties are just values for the repositories. Repositories should not have any domain knowledge and should not use application layer features.
Repositories are fundamentally used to create, update, delete, and query entities. ABP's generic repository implementation provides most of the common operations out of the box. It also provides an IQueryable object that you can use to build and execute queries using LINQ. However, building complex queries at the application layer mixes your application logic with the data querying logic that should ideally be at the infrastructure layer.
See the following example method, which uses IRepository<Event, Guid> to get a list of events that a given user has spoken at:
public async Task<List<Event>> GetSpokenEventsAsync(Guid
userId)
{
var queryable =
await _eventRepository.GetQueryableAsync();
var query = queryable.Where(x => x.Tracks
.Any(track => track.Sessions
.Any(session => session.Speakers
.Any(speaker => speaker.UserId == userId))));
return await AsyncExecuter.ToListAsync(query);
}
In the first line, we are obtaining an IQueryable<Event> object. Then we are using the Where method to filter the events. Finally, we are executing the query to get the event list.
The problem with writing such queries into application services is leaking querying logic to the application layer and making it impossible to reuse the querying logic when we need it somewhere else. To overcome the problem, we generally create a custom repository method to query the events:
public interface IEventRepository : IRepository<Event,
Guid>
{
Task<List<Event>> GetSpokenEventsAsync(Guid userId);
}
Now, we can use this custom repository method anywhere we need to get the events at which a user was a speaker.
Creating custom repository methods is a good approach. But, with this approach, we have a lot of similar methods once the application grows. Assume that we wanted to get the event list in a specified date range, and we've added one more method:
public interface IEventRepository : IRepository<Event,
Guid>
{
Task<List<Event>> GetSpokenEventsAsync(Guid userId);
Task<List<Event>> GetEventsByDateRangeAsync(DateTime
minDate, DateTime maxDate);
}
What if we want to query the events with a date range and speaker filter? Create another method as shown in the following code block:
Task<List<Event>> GetSpokenEventsByDateRangeAsync(Guid userId, DateTime minDate, DateTime maxDate)
Actually, ABP provides the GetListAsync method, which takes an expression. So, we could remove all these methods and use the GetListAsync method with an arbitrary predicate.
The following example uses the GetListAsync method to get a list of events at which a user is a speaker in the next 30 days:
public async Task<List<Event>> GetSpokenEventsAsync(Guid
userId)
{
var startTime = Clock.Now;
var endTime = Clock.Now.AddDays(30);
return await _eventRepository.GetListAsync(x =>
x.Tracks
.Any(track => track.Sessions
.Any(session => session.Speakers
.Any(speaker => speaker.UserId == userId)))
&& x.StartTime > startTime && x.StartTime <=
endTime
);
}
However, we've returned to the previous problem: mixing the querying complexity with the application code. Also, isn't the query getting hard to understand? You know, in real life, we have queries with much more complexity.
Completely getting rid of complex queries may not be possible, but the next section offers an interesting solution to that problem: the specification pattern!
Building specifications
A specification is a named, reusable, combinable, and testable class to filter domain objects based on business rules. In practice, we can easily encapsulate filter expressions as reusable objects.
In this section, we will begin with the most simple, parameterless specifications. We will then see more complex, parameterized specifications. Finally, we will learn how to combine multiple specifications to create a more complex specification.
Parameterless specifications
Let's begin with a very simple specification class:
public class OnlineEventSpecification :
Specification<Event>
{
public override Expression<Func<Event, bool>>
ToExpression()
{
return x => x.IsOnline == true;
}
}
OnlineEventSpecification is used to filter online events, which means it selects an event if it is an online event. It is derived from the base Specification<T> class provided by ABP Framework to create specification classes easily. We override the ToExpression method to filter the event objects. This method should return a lambda expression that returns true if the given Event entity (here, the x object) satisfies the condition (we could simply write return x => x.IsOnline).
Now, if we want to get a list of online events, we can just use the repository's GetListAsync method with a specification object:
var events = _eventRepository
.GetListAsync(new OnlineEventSpecification());
Specifications are implicitly converted to expressions (remember, the GetListAsync method can get an expression). If you want to explicitly convert them, you can call the ToExpression method:
var events = _eventRepository
.GetListAsync(
new OnlineEventSpecification().ToExpression());
So, we can use a specification wherever we can use an expression. In this way, we can encapsulate expressions as named, reusable objects.
The Specification class provides another method, IsSatisfiedBy, to test a single object. If you have an Event object, you can easily check whether it is an online event or not:
Event evnt = GetEvent();
if (new OnlineEventSpecification().IsSatisfiedBy(evnt))
{
// ...
}
In this example, we have somehow obtained an Event object, and we want to check whether it is online. IsSatisfiedBy gets an Event object and returns true if that object satisfies the condition. I accept that this example seems absurd because we could simply write if(evnt.IsOnline). Such a simple specification was not necessary. However, in the next section, we will see more complex examples to make it much clearer.
Parameterized specifications
Specifications can have parameters to be used in filtering expressions. See the following example:
public class SpeakerSpecification : Specification<Event>
{
public Guid UserId { get; }
public SpeakerSpecification(Guid userId)
{
UserId = userId;
}
public override Expression<Func<Event, bool>>
ToExpression()
{
return x => x.Tracks
.Any(t => t.Sessions
.Any(s => s.Speakers
.Any(sp => sp.UserId == UserId)));
}
}
We've created a parameterized specification class that checks whether the given user is a speaker at an event. Once we have that specification class, we can filter the events as shown in the following code block:
public async Task<List<Event>> GetSpokenEventsAsync(Guid
userId)
{
return await _eventRepository.GetListAsync(
new SpeakerSpecification(userId));
}
Here, we've just reused the GetListAsync method of the repository by providing a new SpeakerSpecification object. From now on, we can reuse this specification class if we need the same expression later, in another place in our application, without needing to copy/paste the expression. If we need to change the condition later, all those places will use the updated expression.
If we need to check whether a user is a speaker at the given Event, we can reuse the SpeakerSpecification class by calling its IsSatisfiedBy method:
Event evnt = GetEvent();
if (new SpeakerSpecification(userId).IsSatisfiedBy(evnt))
{
// ...
}
Specifications are powerful to create named and reusable filters, but they have another power too: combining specifications to create a composite specification object.
Combining specifications
It is possible to combine multiple specifications using operator-like And, Or, and AndNot methods, or to reverse a specification with the Not method.
Assume that I want to find the events where a given user is a speaker, and the event is online:
var events = _eventRepository.GetListAsync(
new SpeakerSpecification(userId)
.And(new OnlineEventSpecification())
.ToExpression()
);
In this example, I combined SpeakerSpecification and OnlineEventSpecification objects to create a composite specification object. Explicitly calling the ToExpression class is necessary in this case because C# doesn't support implicitly converting from interfaces (the And method returns an ISpecification<T> reference).
The following example finds the in-person (offline) events in the next 30 days where the given user is a speaker:
var events = _eventRepository.GetListAsync(
new SpeakerSpecification(userId)
.And(new DateRangeSpecification(Clock.Now,
Clock.Now.AddDays(30)))
.AndNot(new OnlineEventSpecification())
.ToExpression()
);
In this example, we've reversed the OnlineEventSpecification object's filtering logic with the AndNot method. We've also used a DateRangeSpecification object that we haven't defined yet. It is a good exercise for you to implement yourself.
An interesting example could be extending the AndSpecification class to create a specification class that combines two specifications:
public class OnlineSpeakerSpecification :
AndSpecification<Event>
{
public OnlineSpeakerSpecification(Guid userId)
: base(new SpeakerSpecification(userId),
new OnlineEventSpecification())
{
}
}
The OnlineSpeakerSpecification class in this example combines the SpeakerSpecification class and the OnlineEventSpecification class, and can be used whenever you want to use a specification object.
When to Use Specifications
Specifications are especially useful if they filter objects based on domain rules that can be changed in the future, so you don't want to duplicate them everywhere. You do not need to define specifications for the expressions you are using just for reporting purposes.
The next section explains how to use domain events to publish notifications.
Publishing domain events
Domain events are used to inform other components and services about an important change to a domain object so that they can take action.
ABP Framework provides two types of event buses to publish domain events, each with a different purpose:
- The local event bus is used to notify the handlers in the same process.
- The distributed event bus is used to notify the handlers in the same or different processes.
Publishing and handling events are pretty easy with ABP Framework. The next section shows how to work with the local event bus, and then we will look at the distributed event bus.
Using the local event bus
A local event handler is executed in the same unit of work (in the same local database transaction). If you are building a monolith application or want to handle events in the same service, the local event bus is fast and safe to use because it works in the same process.
Assume that you want to publish a local event when an event's time changes, and you have an event handler that sends emails to the registered users about the change.
See the simplified implementation of the SetTime method of the Event class:
public void SetTime(DateTime startTime, DateTime endTime)
{
if (startTime > endTime)
{
throw new BusinessException(EventHubErrorCodes
.EndTimeCantBeEarlierThanStartTime);
}
StartTime = startTime;
EndTime = endTime;
if (!IsDraft)
{
AddLocalEvent(new EventTimeChangedEventData(this));
}
}
In this example, we are adding a local event, which will be published while updating the entity. ABP Framework overrides EF Core's SaveChangesAsync method to publish the events (for MongoDB, it is done in the repository's UpdateAsync method).
Here, EventTimeChangedEventData is a plain class that holds the event data:
public class EventTimeChangedEventData
{
public Event Event { get; }
public EventTimeChangedEventData(Event @event)
{
Event = @event;
}
}
Published events can be handled by creating a class that implements the ILocalEventHandler<TEventData> interface:
public class UserEmailingHandler :
ILocalEventHandler<EventTimeChangedEventData>,
ITransientDependency
{
public async Task HandleEventAsync(
EventTimeChangedEventData eventData)
{
var @event = eventData.Event;
// TODO: Send email to the registered users!
}
}
The UserEmailingHandler class can inject any service (or repository) to get a list of the registered users, and then send an email to inform them about the time change. You may have multiple handlers for the same event. If any handler throws an exception, the main database transaction is rolled back since the event handler is executed in the same database transaction.
Events can be published in entities, as shown in the previous examples. They can also be published using the ILocalEventBus service.
Let's assume that we don't publish the EventTimeChangedEventData event inside the Event class but want to publish it in an arbitrary class that can utilize the dependency injection system. See the following example application service:
public class EventAppService : EventHubAppService,
IEventAppService
{
private readonly IRepository<Event, Guid>
_eventRepository;
private readonly ILocalEventBus _localEventBus;
public EventAppService(
IRepository<Event, Guid> eventRepository,
ILocalEventBus localEventBus)
{
_eventRepository = eventRepository;
_localEventBus = localEventBus;
}
public async Task SetTimeAsync(
Guid eventId, DateTime startTime, DateTime endTime)
{
var @event =
await _eventRepository.GetAsync(eventId);
@event.SetTime(startTime, endTime);
await _eventRepository.UpdateAsync(@event);
await _localEventBus.PublishAsync(
new EventTimeChangedEventData(@event));
}
}
The EventAppService class injects the repository and ILocalEventBus service. In the SetTimeAsync method, we are using the local event bus to publish the same event.
The PublishAsync method of the ILocalEventBus service immediately executes the event handlers. If any event handler throws an exception, you directly get the exception since the PublishAsync method doesn't handle exceptions. So, if you don't catch the exception, the whole unit of work is rolled back.
It is better to publish the events in the entities or the domain services. If we publish the EventTimeChangedEventData event in the Event class's SetTime method, it is guaranteed to publish the event in any case. However, if we publish it in an application service, like in the last example, we may forget to publish the event in another place that changes the event times. Even if we don't forget, we will have duplicated code that is harder to maintain and open to potential bugs.
Local events are especially useful to implement side-effects such as taking extra action when the state of an object changes. It is perfect for de-coupling and integrating different aspects of the system. In this section, we have used it to send a notification email to the registered users when an event's time changes. However, it should not be misused by distributing business logic flow into event handlers and making the whole process hard to follow.
In the next section, we will see the second type of event bus.
Using the distributed event bus
In the distributed event bus, an event is published through a message broker service, such as RabbitMQ or Kafka. If you are building a microservice/distributed solution, the distributed event bus can asynchronously notify the handlers in other services.
Using the distributed event bus is pretty similar to the local event bus, but it is important to understand the differences and limitations.
Let's assume that we want to publish a distributed event in the Event class's SetTime method when the event's time changes:
public void SetTime(DateTime startTime, DateTime endTime)
{
if (startTime > endTime)
{
throw new BusinessException(EventHubErrorCodes
.EndTimeCantBeEarlierThanStartTime);
}
StartTime = startTime;
EndTime = endTime;
if (!IsDraft)
{
AddDistributedEvent(new EventTimeChangedEto
{
EventId = Id, Title = Title,
StartTime = StartTime, EndTime = EndTime
});
}
}
Here, we call the AddDistributedEvent method to publish the event (it is published when the entity is updated in the database). As an important difference from the local event, we are not passing the entity (this) object as the event data but copying some properties to a new object. That new object will be transferred between processes. It will be serialized in the current process and deserialized in the target process (ABP Framework handles the serialization and deserialization for you). So, creating a DTO-like object that carries only the required properties rather than the full object is better. The Eto (Event Transfer Object) suffix is the naming convention that we suggest but it is not necessary to use it.
The AddDistributedEvent (and AddLocalEvent) method is only available in the aggregate root entities, not for sub-collection entities. However, publishing a distributed event in an arbitrary service is still possible using the IDistributedEventBus service:
await _distributedEventBus.PublishAsync(
new EventTimeChangedEto
{
EventId = @event.Id,
Title = @event.Title,
StartTime = @event.StartTime,
EndTime = @event.EndTime
});
Inject the IDistributedEventBus service and use the PublishAsync method – that's all.
The application/service that wants to get notified can create a class that implements the IDistributedEventHandler<T> interface, as shown in the following code block:
public class UserEmailingHandler :
IDistributedEventHandler<EventTimeChangedEto>,
ITransientDependency
{
public Task HandleEventAsync(EventTimeChangedEto
eventData)
{
var eventId = eventData.EventId;
// TODO: Send email to the registered users!
}
}
The event handler can use all the properties of the EventTimeChangedEto class. If it needs more data, you can add it to the ETO class. Alternatively, you can query the details from the database or perform an API call to the corresponding service in a distributed scenario.
Summary
This chapter covered the first part of implementing DDD. We've explored the domain layer building blocks and understood their design and implementation practices using ABP Framework.
The aggregate is the most fundamental DDD building block, and the way we change an aggregate's state is very important and needs care. An aggregate should preserve its validity and consistency by implementing business rules. It is essential to draw aggregate boundaries correctly.
On the other hand, domain services are useful for implementing the domain logic that touches multiple aggregates or external services. They work with the domain objects, not DTOs.
The repository pattern abstracts the data access logic and provides an easy-to-use interface to other services in the domain and application layers. It is important not to leak your business logic into repositories. The specification pattern is a way to encapsulate data filtering logic. You can reuse and combine them when you want to select business objects.
Finally, we explored how we can publish and subscribe to domain events with ABP Framework. Domain events are used to react to changes to domain objects in a loosely coupled way.
The next chapter will continue with the building blocks, this time in the application layer. It will also discuss the differences between the domain and application layers with practical examples.