
6
Trends in API Authentication
The previous chapter introduced you to the authentication and authorization flows available in the OAuth literature; we proposed a mapping between specific applications’ architectures and recommended an authentication and authorization flow. When you are looking for guidance on which OAuth flow to adopt, according to a specific need, the previous chapter provides a reference point, but it is important to outline that it is meant to provide guidance and answers bounded to specific needs. It does not help an organization to understand how to create governance and blueprints around authentication, as the concept is way more complicated than individual scenarios produced to address specific requirements.
The aim of this chapter is to report how authentication and authorization map to an API enterprise’s landscape and to discuss the implications of authentication and authorization at scale.
It is not possible to tackle this topic without introducing you to the challenges and complexity of API management, as authentication and authorization for APIs are part of this topic.
We will cover the following topics in this chapter:
- The complexity of defining standard guidance
- The vertical API approach
- API landscape complexity
- The application frontend API flow
- The application automation API
- The multiple IdP dilemma
- Defining enterprise standards for identity
- The service mesh and identity management
- Authentication implication in a service mesh
- Common antipatterns
Let’s discuss the complexity of defining common cross-organization standards nowadays.
The complexity of defining standard guidance
The complexity of defining guidance and blueprints for authentication is increasing year after year for various reasons:
- Increasing cloud adoption is leading big companies to take up a hybrid cloud model. The cloud is nothing more and nothing less than a data center, where the company can store cloud-native assets that need to co-exist with legacy applications. These cloud models are creating new authentication requirements for communication across data centers and cloud providers.
- The proliferation of APIs inside these big companies is creating new management needs and authentication requirements.
- The increase in software development speed, thanks to Agile practices and Platform as a Service (PaaS) cloud services, is creating more applications in less time, which is increasing the management footprint of a company much more quickly than before.
- The nature of cloud-native, serverless, and distributed applications requires authentication across different components. This is increasing the amount of management and governance required.
To summarize the preceding concepts, it is fair to say that in the IT world we left behind, there were fewer applications and APIs to manage, and they were developed slowly compared to today. This fact enables poor governance and poor control to be turned into technical debt in a very short timeframe, which in turn can get out of control quickly.
In the enterprise landscape of today, API development for heterogeneous needs proliferates at a scale that has never been reached in the past, and further attention is required to prevent too much complexity from arising within an organization due to multiple design choices. These choices in turn can include different authentication and authorization models.
Just to give an idea of the scale of the complexity we need to expect within a company, around 800 applications are developed and maintained on average at companies with more than 5,000 employees (each year, the number of applications developed is higher on average than the ones that are dismissed, and the trend is growing).
The vertical API approach
The code owned by the companies is usually developed by different teams. These teams can be either internal (employees of a company), external (contractors), or a combination of both. When is time to develop an API, the team assigned to doing so is commonly responsible, among the implementation itself, for the following aspects:
- Design decisions
- Security and authentication
- Documentation
- Change management
- Testing
- Monitoring
- Discoverability
All in all, we can state that different APIs are not just developed by different brains; they are also envisioned, implemented, and tested by different teams (we are going to refer to this process as a vertical API approach).
This kind of tight coupling between APIs and specific teams only works if the company needs to develop fewer APIs. Nowadays, organizations are facing disruption. The API landscape in a generic organization is clearly reaching a tipping point, and the vertical API approach described at the beginning of this section cannot be considered anymore for enterprises that need to scale. Let’s see in the upcoming sections the implication of identity here and how existing standards play a crucial role in enabling scaling.
You can understand at this point of the book that a company with different teams to perform each API development task independently would lead to an anarchic model, where every API would be defined, tested, and documented differently. If we apply this to thousands of APIs, it is clear that the vertical API approach is going to lead to maintainability issues within the organization. At many companies we have worked with, the situation is already out of control.
What we have described is exactly what is happening in most organizations — a proliferation of APIs, without any guidance or blueprints defined, and a lot of technical debt to face in the upcoming year.
API landscape complexity
To fully understand the complexity of API proliferation and the related OAuth implications, let’s start to enumerate what kind of API we can encounter today in an enterprise landscape.
The following table summarizes the most common use cases for APIs in an enterprise landscape:
|
API |
Description |
Example |
|
Application frontend API |
An HTTP endpoint that belongs to the application and is designed to be consumed by the application’s user |
Single-Page Application (SPA) |
|
Application automation API |
A publicly exposed HTTP endpoint that belongs to the application and is designed to be consumed by an automation service in a controlled way |
Automatic processes need to query the application |
|
Application backend API |
An internally exposed HTTP endpoint that belongs to the application and is designed to be consumed by other applications’ components |
Service Oriented Architecture (SOA), modular applications, microservice applications |
|
Internal reusable API |
An HTTP endpoint that does not belong to any specific application and provides a service that can be consumed |
A company’s CRM that needs to provide common information that can be consumed by different applications |
|
Partner API |
An HTTP endpoint that exposes internal services to external partners and companies |
A Visa credit card company that exposes services to be consumed by partners to manage transactions |
Table 6.1 – Types of API
The following diagram summarizes the types of API expressed in the table and will further outline the complexity that needs to be tackled:
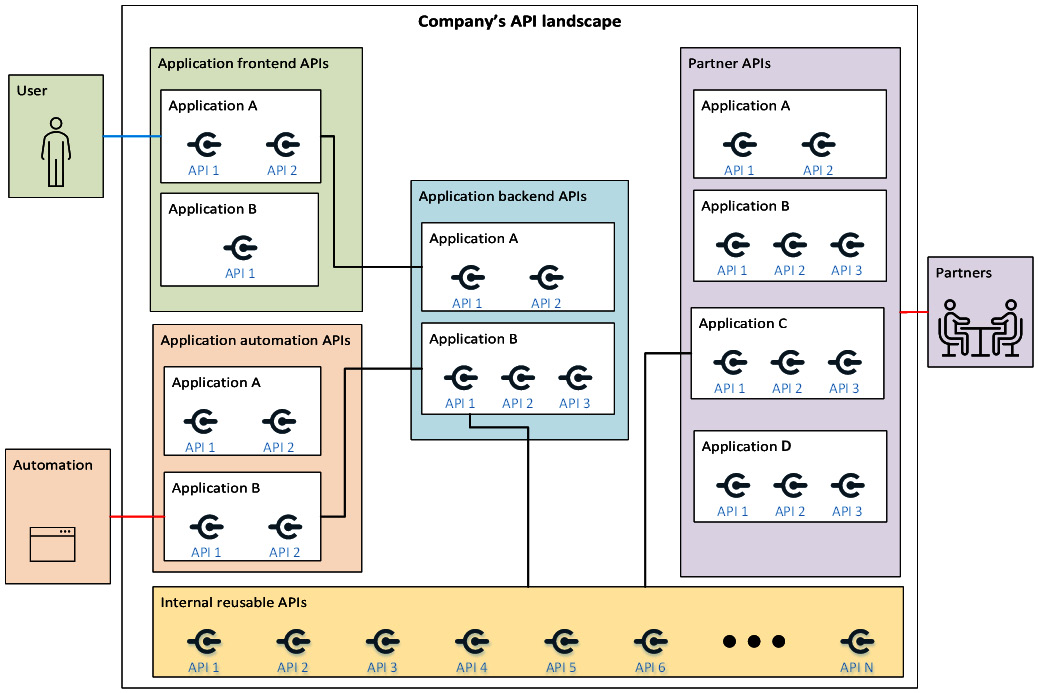
Figure 6.1 – A typical company’s API landscape
As per Table 6.1, the diagram contains five boxes, one for each API type that we expect to find within an organization. The diagram has been extremely simplified for ease of readability, and it may not exactly reflect how all organizations work today. It is, though, reflective of our heterogenous experience from the retail, finance, public governance, and telecoms industries.
In the diagram, three external actors are represented — users, automation processes, and partners. The diagram represents a typical company’s API landscape, which is the outer box with a white background. Within a company, different types of API are developed, as we mentioned in Table 6.1.
The three actors in the diagram (User, Automation, and Partners) interact with the related component (Application frontend APIs, Application automation APIs, and Partner APIs, respectively) that is supposed to publish assets to be served externally. The actors cannot interact with backend APIs or the internal reusable API layer, as they are not published and are only available for internal use. In the diagram, the lines represent the logical flow of communication that needs to be authenticated.
Before moving forward to explain the diagram in depth, it is important to note that the Automation actor and the Partners actor are usually represented by services and not humans. We mention this because it has authentication implications (systems cannot authenticate interactively among each other).
The User actor in the diagram, who ideally needs to interact with an API of a specific application (in the diagram, Application A, API 1), needs to perform interactive authentication. Interactive authentication with this application is represented by the line that connects the user actor with Application A.
The Automation actor represented in the diagram needs to interact with the application automation API of a specific application (in the diagram, Application B, API 1). The developers need to develop a service that can interact with the automation API and authenticate against it automatically in a server-to-server authentication flow (as explained in the previous chapters, this type of authentication can be done through the OAuth client credential flows). The authentication of the developer’s service is not interactive, and it is represented by the line that connects Automation to Application B.
The Partners actor represented in the diagram needs to interact with a specific partner API published by the company. This will then trigger server-to-server authentication in a similar fashion to the Automation actor because it can use a different Identity Provider (IdP). Like the Automation actor, this is an automatic authentication flow that can be achieved in OAuth by using the client credential flow and, as such, it is represented by the line that connects Automation with Application B.
The diagram proposes internal server-to-server communication with all the lines fully contained in the main central box (Company’s API landscape). This is because the internal authentication may differ from the external one, as different IdPs or even different protocols may be used. As an example, many internal communications systems rely on mutual TLS (mTLS) authentication rather than an OAuth flow (more details are provided in the The service mesh and identity management section).
It is important to note that the real world is usually more complex than Figure 6.1. As anticipated, multiple factors can complicate the design shown in the diagram even further.
The following is a list of complexities that are not captured in the diagram but that are common to find in enterprises. The following five items are exposed as points of reflection to help you envision the potential complexity of the diagram:
- The user actor can be internal to the company or external to the company. Accordingly, whether the user belongs to the organization or not, they can belong to a different IdP and, as such, the API authentication gets more complicated and an extra layer may be needed to hide this complexity. This degree of complexity and how to tackle it is better described in the The multiple IdP dilemma section of this chapter.
- The line that connects the Application frontend APIs box to the Application backend APIs box in the diagram represents server-to-server authentication (the API within the Application frontend API box needs to authenticate itself against the API in the Application backend API box). There may be use cases where the application backend API is designed to authenticate the user against the backend. Since the user cannot reach the backend directly, this is usually achieved by using a specific OAuth flow. This creates heterogeneous authentication flows in the backend, which goes beyond server-to-server authentication.
- We can also imagine that within the Internal reusable API box, the APIs are enabled to communicate with each other and can use a different authentication mechanism that is not represented in the diagram.
- Partner APIs may have their own backend layer, with another authentication round-trip, which is not part of the diagram.
- The automation frontend API may be consumed by an automatic service or by a human. The picture assumes that the API within the automation frontend API is consumed by an automatic service and not by a developer who interactively consumes the API. Both scenarios are valid; in our diagram anyway, the automatic service hits the authentication frontend API (with no human interaction involved). Moreover, it is important to note that the two assumptions (a developer or an automatic service) are not mutually exclusive. This means the diagram may have another box just for developers that will have access to extra features of the application through a dedicated portal. This isn’t in the diagram.
An important factor to reflect on is that in the real world, the landscape proposed in Figure 6.1 is the result of the development done by different teams at different points in time, across multiple business domains, developed across different platforms, and potentially with different technologies and methodologies.
Preventing the increase in complexity in API management is paramount to facilitating enterprise operations, keeping efficiency high, and reducing maintainability costs. By this point in this book, this concept must be clear.
What was just described has serious implications for authentication, and that’s why it is important to define standards. Before doing that, let’s analyze the public layer (by “public layer,” we mean the layer on the diagram that has authentication from an external actor) in the next section.
The application frontend API flow
The application frontend API is the logical layer that hosts the APIs that are supposed to be consumed by the application’s client. The flow is an extension of the single-page authentication pattern described in the previous chapter.
The following diagram outlines the subset of interactions reported in the previous diagram that involves this layer (the application frontend API).
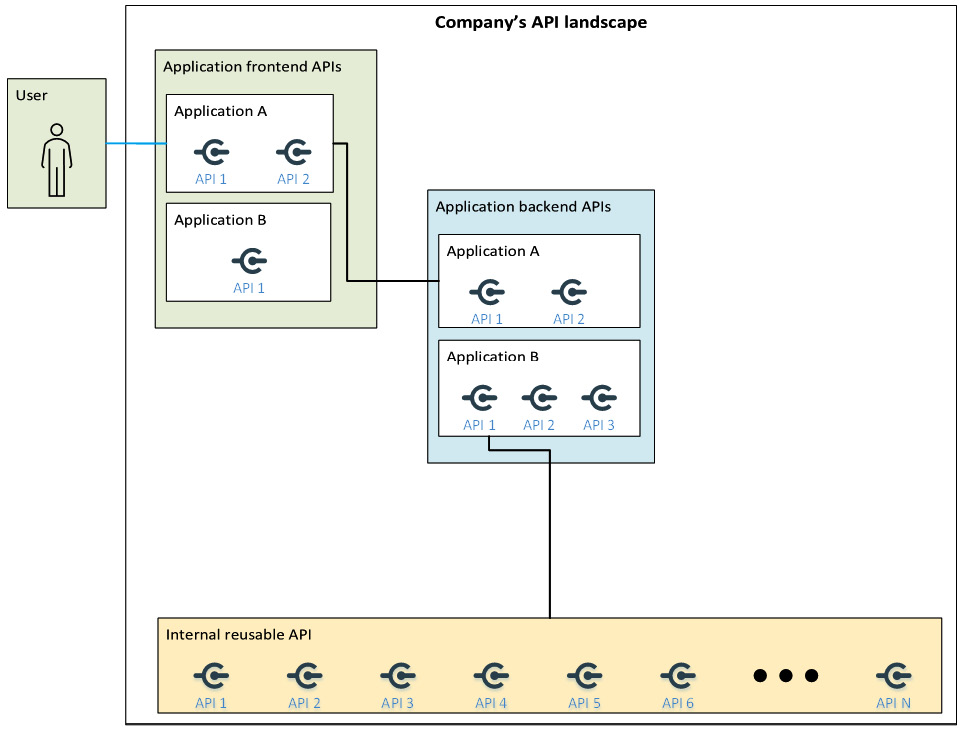
Figure 6.2 – Zooming in on the application frontend API
The frontend acts as a broker to send the request to a backend component synchronously or asynchronously, according to the application’s design and the architectural pattern chosen.
The flow considered in such a diagram is composed of the following steps:
- The user connects to the API, which we can assume is available on the internet. We can also assume that the user is using a SPA and the authentication flow represented by the line that connects the user to the application is the one discussed in Chapter 5, Exploring Identity Patterns, in the Single-page authentication pattern section.
- The API within the application frontend API box authenticates the user, understands its intent according to the request made by the SPA, and sends the request to another API that is deployed in the application backend API. Unlike the previous step, the authentication flow between these two components is internal and not interactive (with interactive, we refer to human interaction), as it is a system-to-system flow. In a context such as this, if OAuth is adopted, the recommended flow to use is the client credential grant flow.
- The application frontend API can take advantage of already developed logic by making a call to the internal reusable API layer. In the diagram, this flow starts from Application B only; taking advantage of the internal reusable API layer is an option for every application developed by the company regardless. This option has obviously been scoped out from the diagram, which is intended as a sample to outline a single round-trip. This is again a system-to-system authentication that, as outlined in the previous step can be achieved, in the case of OAuth, by adopting a client credential grant flow.
The flow described here is an example flow. We have worked with some customers that had the application frontend API connected directly to the internal reusable services for specific and exceptional requests that the API within the internal reusable services was able to serve without an intermediary. Although it is uncommon, in a portfolio of hundreds of applications, we are likely to find a use case like this, and this is another example of why it is important to define guidelines to have a uniform pattern across the company.
As a final note, it’s important to understand that the application frontend API can sometimes be developed with more than one logical layer. Think, for example, of a multi-device application that can share the same API across mobiles, browsers, and potentially other devices. The response to be provided needs to be tuned according to the specific device. This logic is sometimes abstracted from the application by adding an extra layer (known as a backend-for-frontend) that is responsible for translating the responses according to the target device. In this kind of architecture design, the application frontend API should be divided into two: one layer to receive, resend, and translate the request, and another layer to perform the API logic and act as a broker to send the requests to the application backend API.
The application automation API
The application automation API is designed to enable the automatic service to retrieve information from applications. One example could be an insurance portal, where customers (users) subscribe to a specific insurance policy by using the insurance website, developed as a SPA, and following the flow described in the previous chapter. At the end of the day, an automatic process calls the application automation API to retrieve all the insurance contracts finalized during the day by the customers for forecasting or reporting purposes. This specific example is also applicable to the partner automation API, where a partner of the insurance company needs to use an API to perform backend activities, retrieve data, or update contract clauses.
From a technical perspective, the partner automation API and application automation API usually use the same authentication flow due to a matching requirement: an automated service needs to be authenticated. What could change in the partner automation API is that the partner may belong to a different organization and as such use a different IdP. This may have implications for application registration. More information about this scenario can be found in the The multiple IDPs dilemma section later in the current chapter. For the sake of technical understanding of the authentication flow, we are going to describe the application automation API layer, but the concept is also relevant to the flows in the partner automation layer.
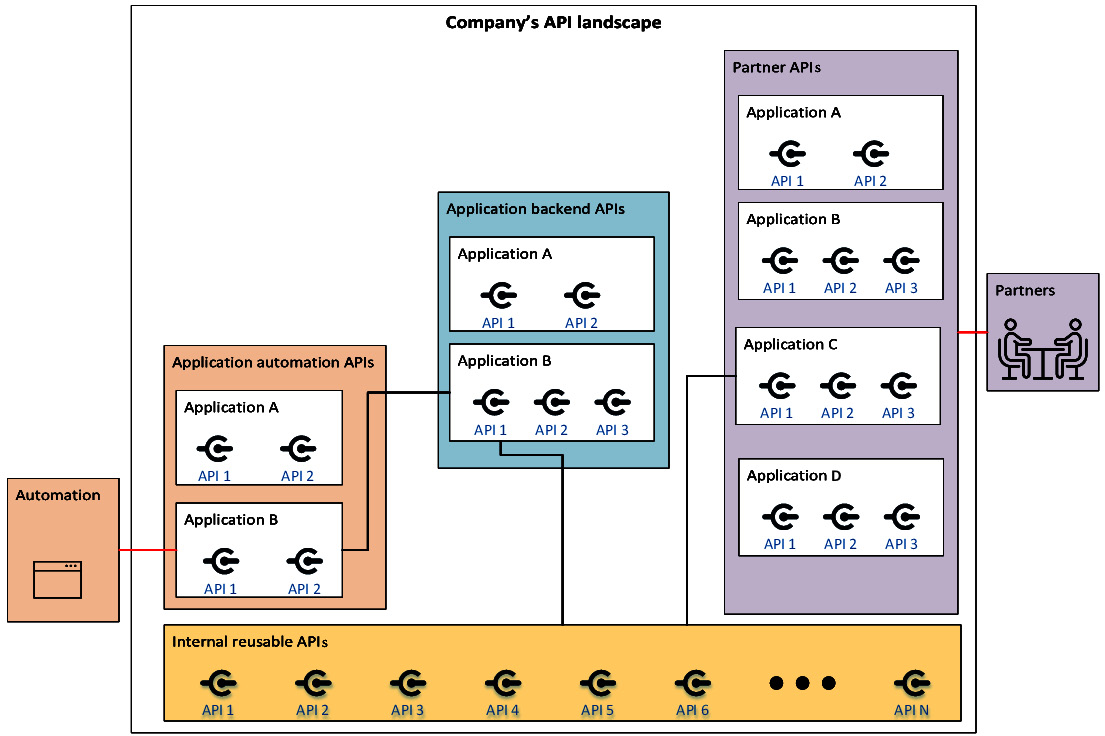
Figure 6.3 – Zooming in on the application automation APIs
In this flow, a service is authenticated in a non-interactive and unattended manner against the API. In OAuth, this is done by using the client credentials grant flow. Then, the server-side interactions (the lines fully included in the main box, Company’s API landscape), follow the same patterns already described in the previous section, The application frontend API flow. Here, a backend service is going to be triggered, as evident from the Application backend APIs box, which, in turn, can take advantage of an internal API. If the OAuth protocol is used for internal authentication, as before, the recommended flow to adopt is the client credential grant flow because it is a system-to-system authentication pattern.
As explained, in the real world, there may be circumstances where multiple IdPs are involved, which, of course, has implications for the authentication flow. Let’s look at this topic in more depth in the next section.
The multiple IdP dilemma
Having to deal with multiple IdPs is not as uncommon as one may think. Dealing with multiple IdPs can be the result of intended but also unintended design.
As mentioned previously in this chapter, the most notable side-effect of API proliferation is that different teams work in different ways, using different techniques and technologies, and sometimes this means using different IdPs. This is an example of unintended or unwanted IdPs, where a company needs to deal with multiple IdPs not because of a design choice but because of a lack of initial governance. There may be circumstances where multiple IdPs are the result of a design decision. It’s important to understand that collaboration extends beyond the enterprise.
Multiple IdPs are usually involved when an application’s scope spans multiple companies collaborating to achieve the application’s business logic, which needs to harness features provided by external APIs or applications outside the perimeter of an organization. However, this is not the only use case where multiple IdPs are brought into the picture. As a matter of fact, it is common to encounter them within the same organization for reasons that are summarized as follows:
- Typically, different user categories are stored and maintained within dedicated IdPs. Common examples include the following types of users:
- Employees
- Partners
- Customers
Each of such categories may have a dedicated IdP to serve authentication to the users it stores.
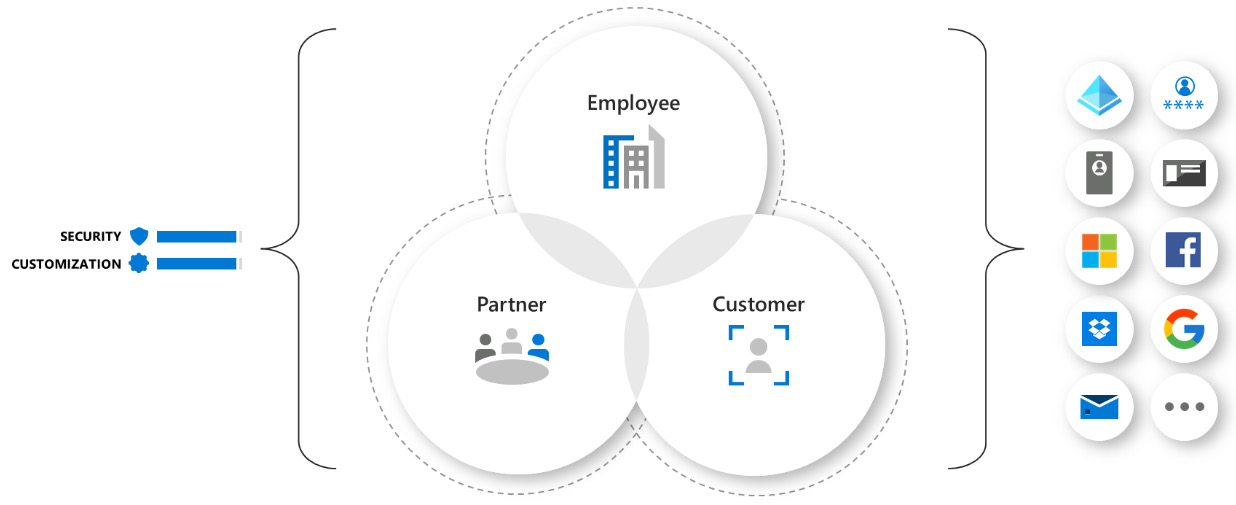
Figure 6.4 – Example of user categories
- The same user category (for instance, employees) can have multiple IdPs serving authentication, with each IdP storing a separate overlapping (duplicated) set of users or identities. This usually happens in large organizations that, over the years, have developed and deployed several authentication systems without having a centralized governance strategy to wisely and uniquely manage a specific user category. The net result is that clusters of applications rely on a single IdP and Single Sign-On (SSO) is only provided to clusters that share the same IdP, making it difficult to enhance productivity in scenarios where a user has to access applications that trust different IdPs.
There is no magic wand or formula that can easily fix the issue of having multiple IdPs. The main problem with having multiple authentication systems is that they are not easy to maintain and most of the time, they must be kept in sync so that the latest information about a user is always up to date. This process usually identifies one of the available IdPs as the source of authority for a specific identity, and this is often the seed from which the requirement to consolidate all existing identities into a single, authoritative authentication provider within an organization grows.
When we talk about IdPs, we refer to authentication systems that implement modern authentication protocols such as OAuth 2.0, OIDC, SAML, and WS-Federation, but we need to keep in mind that other authentication systems leveraging legacy protocols may still exist within a big enterprise – so, how do we get rid of this complexity?
The most recent approach to the problem is identifying the IdPs and, in general, the authentication systems that should provide the source of the information concerning the different user categories that the organization manages. The first iteration of this analysis may identify authentication systems that serve specific user categories and authentication protocols. The second, and the most time-consuming, iteration involves assessing all existing company applications together with the different types of users accessing them. At the end of these iterations, we will have a comprehensive map of the existing applications, the types of users accessing them, and the IdPs that provide authentication to each application and user. With all this valuable information, we can start planning to consolidate the existing applications, users, and IdPs by using the following guidelines:
- Identify the number of IdPs according to the different user categories: At first, it could make sense to have an IdP dedicated to each user category that is relevant to the organization. Common user categories are employees, business partners, and customers. This means that we may end up with three IdPs, but this is just a rule of thumb that does not account for the different applications an organization has, which may decrease or increase the number of IdPs needed.
- Consolidate IdPs according to common user categories accessing the same applications: In an enterprise, it is very common that an application has been designed just for internal users (for example, a pay slip web portal). That’s why it always makes sense to have an IdP that serves authentication to all the organization’s employees. It is, on the other hand, less common for an organization to have applications that are only accessed by external collaborators (for example, a web portal where a business partner can retrieve important documents published by the organization). In these cases, the involvement of multiple IdPs (internal employees and partners) could be an option.
In the latter scenario, since the application must logically serve two types of users, we could take advantage of having a single IdP storing and serving both user categories so that the application is not overloaded with the burden of orchestrating the authentication between two or more IdPs. The choice to have both employees and external collaborators stored in a single IdP must be considered carefully because it may introduce the risk of inadvertently allowing external users to access internal applications. IdPs such as Azure Active Directory provide additional tools and features (such as Conditional Access) that assist an administrator in separating the duties each user has between the objects defined within the IdP (mainly the applications). The identities of an organization’s customers are very often stored in a separate and dedicated IdP instead because of the different requirements of a customer’s identity. Usually, it requires different privacy and security settings, access to applications an employee usually does not need to use, login with social IdPs (such as Facebook and LinkedIn), and so on.
- Federate existing IdPs: The main goal of reducing the number of IdPs is to reduce the management effort of having identities spread across multiple authentication systems. Applications benefit from this approach too; with a reduced number of IdPs, applications only need to federate with a single IdP, which will authenticate the users so that they can be authorized by the application to access all its functionalities. Even if the previous guidelines have already been implemented, there may still be applications that need to be accessed by users belonging to different IdPs. In this scenario, the application can provide the means to be federated with these IdPs but, in most cases, the best solution would be to give the illusion that there is only one IdP (this concept will be further expanded in the Frontend authentication section in Chapter 9, Exploring Real-World Scenarios) and hide the complexity of retrieving and validating user credentials to the application. This will push the IdP complexity out of the business logic and enhance the application’s maintainability over time. This is possible thanks to the capabilities provided by the modern authentication protocol that we discussed in the previous chapters, such as the concept of delegating the authorization of the OAuth protocol.
An IdP can function both as an IdP and a service provider. This enables an IdP to be the service provider of another IdP.
How does this help when we have different users belonging to different IdPs? That’s straightforward: the application will federate with just one IdP – let’s name it IdP A (for example, the IdP containing customers’ identities) – and IdP A, on the other hand, will federate with another IdP; let’s name it IdP B (for example, the IdP containing the employees’ identities). In this scenario, once an unauthenticated user lands on the application, it will redirect the user to IdP A, where the user will be asked to either authenticate using an identity stored in IdP A or to use the identity of the federated IdP B (some vendors, such as Ping Identity, refer to this as a federation hub):
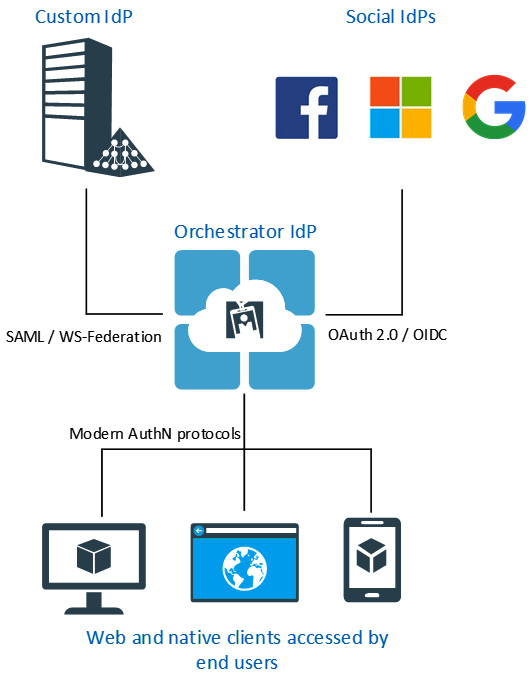
Figure 6.5 – Example of an IdP federating with multiple IdPs
We have talked about how to handle user credentials among different IdPs within the same organization, but what happens when different IdPs are managed by different companies?
When this kind of authentication involves user interaction, then a federation can be put in place so that the IdPs can trust each other and consequently allow the applications to accept credentials from users belonging to both companies.
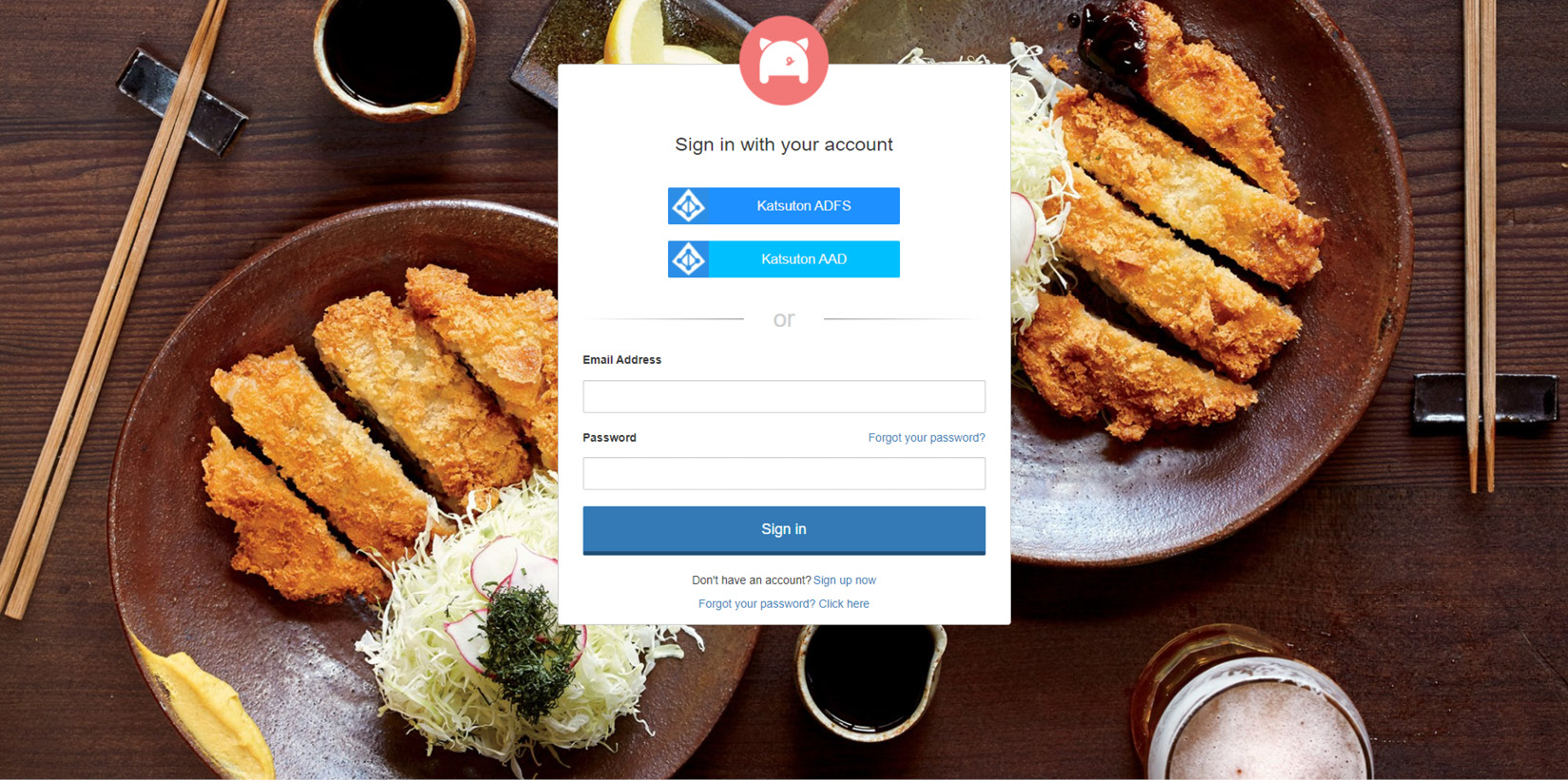
Figure 6.6 – Example of a login page of an IdP federated with other IdPs
When a user is not involved in the authentication process, then the answer becomes trickier — when does an application need to access an API that is registered in a different IdP? There is no straightforward answer. Either the application is also registered in the external IdP and starts using the credentials provided by the external administrator to retrieve an access token that the API trusts or a different type of authentication must be used. The most common alternative authentication method is using certificates in this case, typically mTLS, which is not covered by this book.
As discussed so far, having a way to design, develop, and maintain the services in a standardized fashion can help an organization reduce the overhead around the life cycle of a service or API. The next section will expand on this crucial topic.
Defining enterprise standards for identity
First and foremost, it is important to outline that defining standards or blueprints that are universally valid is not possible. This is because every company has different internal processes and different teams, and adopts different technologies. Most importantly, each company has a different business and, as such, they may have different priorities on how to manage internal APIs and services in general. Hence, this topic cannot be covered exhaustively with a single guideline. This section aims to expose the important principles and provide the items needed to define customized guidelines within a company to plan how to define services and APIs and, therefore, to dictate the authentication guidelines among these services.
The business impact of properly managing APIs and services depends on the strategy of the organization as well as the business context. Just to provide an example, there are companies that sell APIs to third-party developers as their main business. The standards to be defined in this context may be different from a company that mainly uses internal APIs in a service mesh for internal purposes to boost its internal business (there’s more about the service mesh in the next section).
Developing an API, in a structured way, requires standardizing multiple decisions. There are many pillars that can be seen as a minimum set of decisions an enterprise architect needs to address at a company level.
The following table contains some of the important concepts that a company needs to be aware of when creating a new service or API:
|
Pillar to structure the company’s APIs |
Description |
|
Discovery |
As reported previously, regardless of its physical location, for an API to be adopted, it is important to keep an internal registry within the company that can help the developers to find an API they may need to reuse to facilitate their development. As we’re going to see in upcoming chapters, certain technologies have this capability out of the box. |
|
Monitoring |
An API cannot be managed efficiently without live information that can report how it is being used and expose performance metrics. There are many tools that can help to define the monitoring pillar, and plenty of telemetry technology the API can take advantage of. As for the other pillars, it is extremely important to have a good level of consistency across the enterprise to simplify the maintenance and troubleshooting by the ops team, which should not switch from one tool to another according to the target API they need to monitor. It is important to understand that this pillar is usually connected with the development pillar because a technology choice can constrain what monitoring tools can be adopted. |
|
Security |
This is a hard topic to create a standard for. The reason is that each API can have different security requirements. For example, one API can expose sensitive internal information, while another API may be intended for public use to access information that isn’t sensitive. The advice here is to create different security tiers to enable the architect that is planning the API to choose the proper security tier according to the API target usage and requirements. |
|
Authentication |
This pillar needs to outline what an API consumer needs to do to authenticate against the API. The most important aspects this pillar needs to clarify are as follows:
Ideally, across the organization, it is recommended to adopt, if possible, a single IdP that needs to be defined by this pillar. This can help to simplify the processes and the overhead reported in the The multiple IdP dilemma section. |
|
Deployment |
This is usually connected to the DevOps practices adopted by the company, and it is recommended to be consistent with them. It is important that the whole deployment process is immutable and automatic to deploy and promote the API across different environments. If the API needs to be exposed externally, it is recommended the automation takes care of not only the deployment but also its exposure, and if OAuth is involved, the registration across the specific IdP. |
|
Testing |
This relates to what needs to be tested on an API and how it is supposed to be tested. Generally speaking, each API needs to be developed with unit testing. If the API is part of a microservices application or is in the general part of a serverless flow or an end-to-end flow, it is important to also define the integration tests needed to ensure it will work. Performance testing is an important aspect as well, and it is important to outline whether a distributed load test is needed and if so, what the benchmark is. Testing an API also has authentication implications because the test needs to mimic the caller and replicate the authentication flow of the caller, whether an OAuth client credential flow or a different protocol or flow. |
|
Development |
The development pillar is maybe the widest one in terms of what decisions need to be made. It defines, for example, which frameworks and technologies the company intends to support. It is important to note that these choices may have specific implications relating to monitoring, security, and testing, as they can, in turn, be based on technologies (such as libraries and SDKs) that need to be compatible with this pillar. Another important factor to decide how to define this pillar is the development cost. There are specific technologies that are easy to adopt for API development; other technologies where, for example, it is hard to find skilled developers; and others that are widely used but may require further overhead in API development. All of these aspects need to be carefully considered. It is important to outline that an API can be written in any technology without impacting the consumer, who just needs to access the HTTP endpoint. From a maintenance perspective, a company cannot have all the APIs developed differently because it would create issues in the future to find proper staff for maintenance purposes. |
|
Design |
The external design (the interface) should be well-defined. This can define the degree of re-usability and enable the client to properly consume the API. As part of this pillar, the team needs to define what message patterns and protocols the API will adopt (such as REST or GraphQL). |
|
Strategy |
This is the tactical goal of the API, as in, what value the API will bring to the organization and how much of a strategic impact is measured. It is paramount to define its life cycle and to be able to evaluate in the long term when it is time for the API to be removed or redeveloped. |
|
Documentation |
The developer should be able to start using the API easily with specific guidelines. (For example, how to reach the API on the network. Is it on the internet or the intranet? Is it hosted on a cloud service and if so, does it require any further security enablement, such as firewall exceptions?) |
Table 6.2 – Decision pillars
Describing the pillars of creating API guidelines within a company in detail is beyond the scope of this book. What is important is to understand the implications of authentication and, as stated, it is important to keep the number of IdPs adopted by the companies as low as possible and prevent teams from adopting IdPs that were not previously approved by the enterprise architect (or the team accountable for this approval). The proliferation of IdPs inside an organization is typical of many companies we have worked with, and it is usually the result of a lack of process and governance within the organization. Having multiple IdPs will lead to the consequences reported in the The multiple IdP dilemma section. If a single IdP is adopted, then authentication across services within a company becomes easy. As outlined, the typical design is to have one IdP to register the API/services and enable the OAuth client credential flow to happen in the following way:
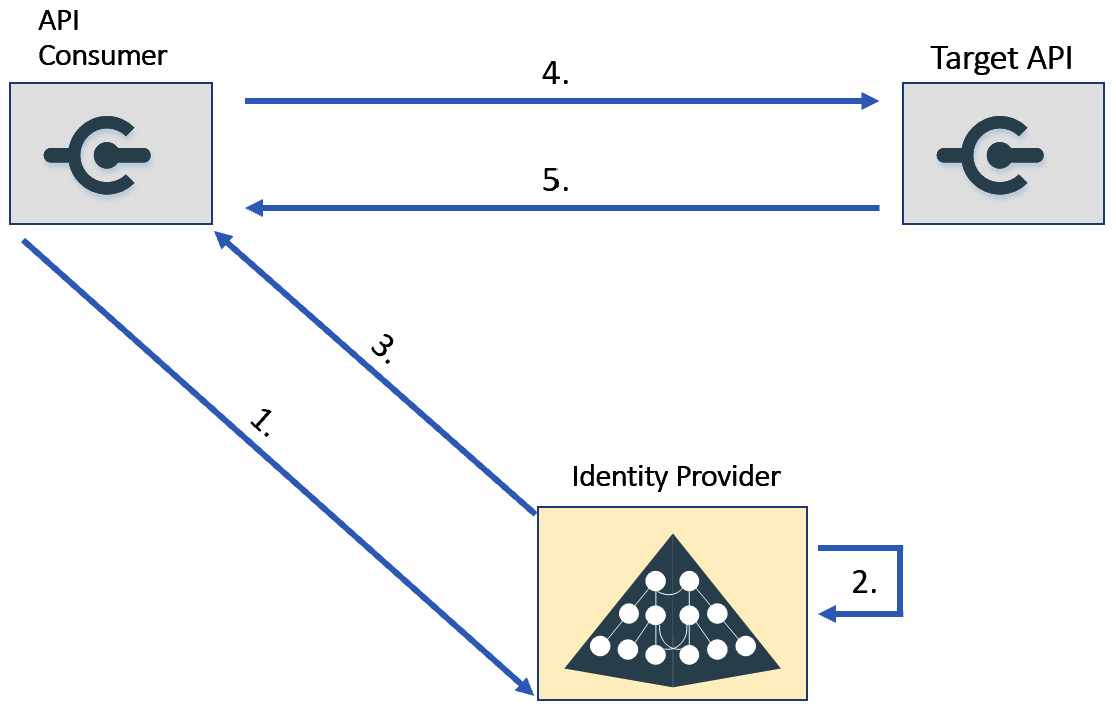
Figure 6.7 – API authentication with OAuth
For the sake of completeness, the following list will describe what happens in each iteration of the diagram:
- Authenticate with the client ID and the client secret to the token’s endpoint.
- Validate the client ID and the client secret and forge the access token.
- Deliver the access token.
- Request data from the target API by adding the access token in the HTTP request (the bearer authorization header).
- The target API provides a response to the caller.
It is implicit that it is mandatory to register the API consumer reported in Figure 6.7 because the application needs to have its own client ID and client secret to be able to request the access token from the IdP. It is not mandatory to register the target API (unless the API needs, in turn, to call another API) because the token can be validated without needing to contact the IdP.
In the next section, we are going to see how current technologies can facilitate and, in some circumstances, even remove the overhead required to define service-to-service authentication and authorization practices across the organization.
The service mesh and identity management
It is important to note that Figure 6.1 is the logical representation of how different types of APIs can be distributed within the organization for different purposes.
In the real world, the logical box represented in the diagram is usually distributed across different locations and data centers, and it is typically hosted on-premises or in the cloud, in a containerized platform, or more often a combination of all of them.
Nevertheless, what companies want to achieve is a simplified view that can hide complexity and enable the ops team of the company to manage the services easily, regardless of the physical distribution. We have recently encountered a trend of having the API deployed on the same hosting platform, which is typically a containerization platform (e.g Kubernetes). In the rest of the chapter, we are going to refer to a containerization platform as one cluster or a set of clusters that take advantage of the same technology stack (for example, Kubernetes or Istio).
Having a central view creates obvious benefits for management, as the ops team of a company can take advantage of a unified way to observe, manage, and deploy the APIs and services across the company.
Another important advantage is that, despite the fact that services can be distributed among multiple locations, this is transparent from the perspective of management and consumers (who consume the service or the API). Most of the complexity is hidden and handled by the containerization platform, which has the important duty of hiding low-level complexity and enabling the companies to focus on service deployment and management.
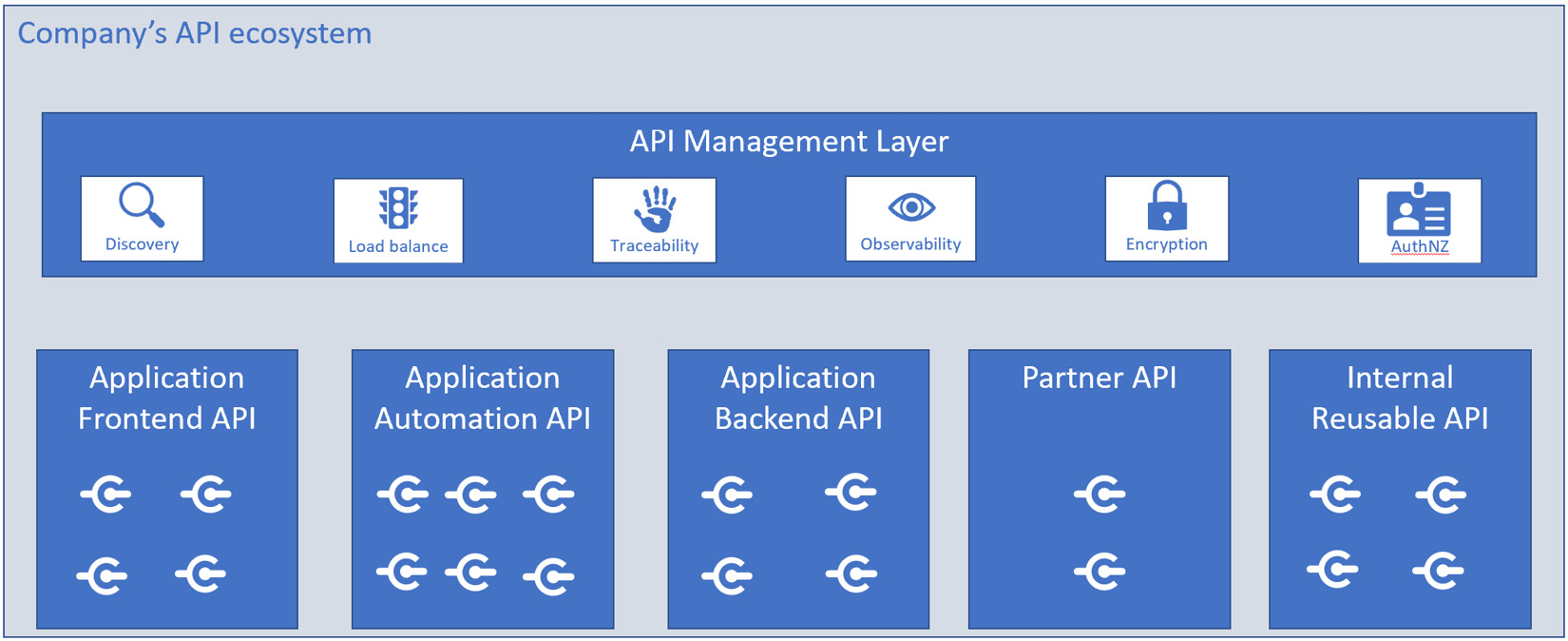
Figure 6.8 – Logical API grouping in a single-pane-of-glass fashion
As shown in the preceding diagram, all the APIs within the company can be reached through a single management layer. This management layer hides the network complexity of the API layers below. The layers below are typically hosted in a cluster on top of a software-defined network or, most typically, in multiple clusters. Using multiple clusters is usually done by adopting a combination of a physical network for cluster communication and a software-defined network to reach the internal services.
Technically speaking, it is important to outline that usually, containerization platforms such as Kubernetes, Mesos DC/OS, Docker Swarm, and Service Fabric do not have these capabilities out of the box. These capabilities are usually accomplished by including third-party products in the cluster, such as Istio, which is specifically designed to extend the capability of the Kubernetes containerization platform to include this management capability and, most importantly, enable multi-cluster management. From an infrastructural perspective, multi-cluster management is achieved by using techniques that are beyond the scope of this book, which is focused on authentication. If you are interested in going deeper into how to control multiple clusters, we recommend you learn about the sidecar pattern and understand how these kinds of patterns can be adopted to control the behavior of multiple distributed services (as tools such as Istio do).
The advantages of multi-cluster management do not stop with physical abstraction. If you think about it, you have a homogeneous way to expose, manage, and secure your company’s assets.
Figure 6.8 groups APIs in a unique view; this grouping is done regardless of the physical locations of each API. The view provides an abstraction that can enable the management to see all the clusters as one and focus on the API/services only. This is the most important purpose of a service mesh.
In our experience, the service mesh concept is interpreted differently across enterprises. For certain companies, the service mesh must only contain the API consumable internally. Other companies use the same logic definition to also include publicly exposed applications; this is done by taking advantage of the management layer capabilities to secure the service mesh. On another occasion, we observed companies that adopted two different types of containerization platforms — one that was strictly a service mesh focused on hosting the internal API managed centrally, and another that had a containerization platform for hosting public applications that are not supposed to be consumed by other services internally. The latter approach creates two different levels of management, which, in turn, adds some management overhead. The additional management overhead is sometimes justified to enhance security: having a single way to administer and manage APIs can expose a very sensitive attack surface (the administrator can edit services regardless of cluster locations and privileges). On the other hand, abstracting the services into a single management layer has the advantage of enabling an API, service, or application hosted in one cluster to interact with a service hosted in a different cluster out of the box.
For the sake of completeness, since we already stated that Figure 6.8 represents only a logical view of services that can be located in different places (and connected by a unified management layer), we are going to represent this concept in Figure 6.9 in a mixed view that is composed of both logical aspects (the API management layer) and the physical view. This will highlight that services can be hosted in different clusters, which can, in turn, be located in different data centers, or on top of cloud providers such as Microsoft Azure or Amazon Web Services:
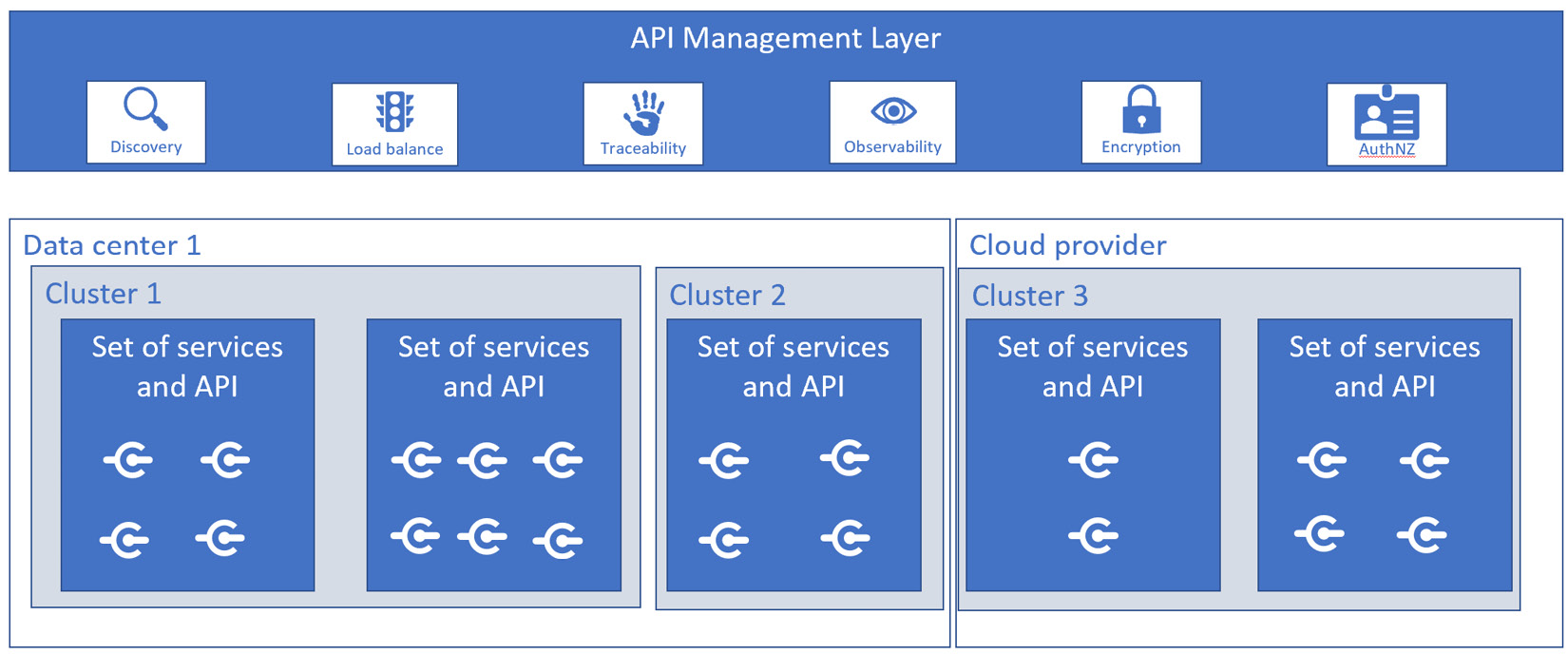
Figure 6.9 – Logical and physical view of a service mesh
Regardless of the service mesh definitions and configurations, it is important to review the management pillars offered by a service mesh. We are going to see that this adoption has implications for authentication and, often, adopting OAuth authentication for communication across services within a service mesh can be an unnecessary over-complication in this context. This concept will be better explained in the rest of the chapter.
The preceding diagram outlines the following pillars that represent the duties of the platform required to enable the management of the services in a unified view:
|
Pillar |
Description |
|
Discovery |
The discovery or service discovery has duties similar to the ones of the Domain Name Service (DNS). In other words, when a service or API needs to communicate with another service within the cluster, it needs to locate it. The orchestration platform provides the discovery service to enable each service to locate and reach the target API/service. This concept is even more important when there are multiple physical clusters in place. The goal of discovery is to abstract from the physical layer and let the API management layer route the traffic to the target service regardless of its physical location. In other words, the API management layer always knows how to route the traffic to reach a specific service in a specific cluster, and the service is located in the node of the cluster. |
|
Load balance |
It is important for a company, especially when the logical view represented in Figure 6.8 is made up of multiple physical clusters, to control the traffic among the API by implementing rules and performing advanced operations, such as blue-green deployment. |
|
Traceability |
The ability to trace requests, store them, and reproduce them enables companies to have an important asset that they can reproduce easily with the goal, and analyzing it, to either improve the quality, spot bugs, or boost their troubleshooting capabilities. |
|
Observability |
Having real-time telemetry for each deployment is paramount to enable a company to scale and introduce more APIs without losing its effectiveness to troubleshoot. Generally speaking, services, nodes, and clusters need to be consistently monitored at any point in time to enable the API to grow and keep the management overhead small at the same time. Unlike traceability, usually, observability is intended to be a high-level view of the service that is above the network stack. |
|
Encryption |
The messages exchanged between the services within the containerization platform should be encrypted and decrypted in a way that should not impact the logic of the services or APIs. Offloading the encryption to the containerization platform is a great benefit. |
|
AuthNZ |
Authentication and authorization, the ability to enable one service to communicate with another, can be centrally managed by the containerization platform. |
Table 6.3 – The service mesh pillars
Now that we have a clear understanding of the tendency of companies to keep increasing the number of APIs and services they have, it is time to focus on the authentication implications relating to the service mesh.
Authentication implications in a service mesh
Unlike the typical way of designing an OAuth flow, which needs to be designed according to the specific needs of the service or application, the service mesh has the advantage of having out-of-the-box capabilities to oversee authentication.
According to our experience, the killer use case to take advantage of the service mesh for authentication is service-to-service authentication, which, as outlined in the previous chapter, is typically achieved in OAuth by using the client credential flow. This is not how the service mesh typically handles authentication across services. If both services reside in the service mesh, authentication is usually performed by taking advantage of mTLS. The downside to using a certificate as a means to mutually authenticate services is the management of these certificates, which are supposed to expire eventually. A service mesh usually has the capability to automatically manage certificates, which eliminates the hassle of manually handling certificate renewal. This aspect enables a company to delegate the complexities of certificate management and mutual authentication to the service mesh product capabilities managed in a centralized manner.
Anyway, if the source API or service (the caller) that intends to consume the target API or service is hosted outside the service mesh, it may not be possible to completely delegate the authentication mechanism to the management layer of the service mesh. As such, we may lose the benefit of managing all the authentications homogeneously, and this is the reason why the trend right now is to host the APIs and services within the same service mesh.
Moreover, mTLS authentication, typically managed by the service mesh, is not always intended for interactive user authentication, which may need to take advantage of the OAuth flow reported in the previous part of the book. This often requires some ad hoc authentication. Authentication across components is a natural aspect of software design because each application, service, or API is designed for a different purpose, is supposed to be consumed by different stakeholders, and may need to be registered in an IdP.
For the out-of-the-box service-to-service communication provided by the service mesh, it is generally not necessary to register the service in an IdP. This is because the identity of the service is managed by the service mesh itself, and the service may not need to receive any OAuth-based authentication, as outlined in the following diagram, which is a sample taken from www.istio.io that describes how the Istio service mesh authenticates two services:
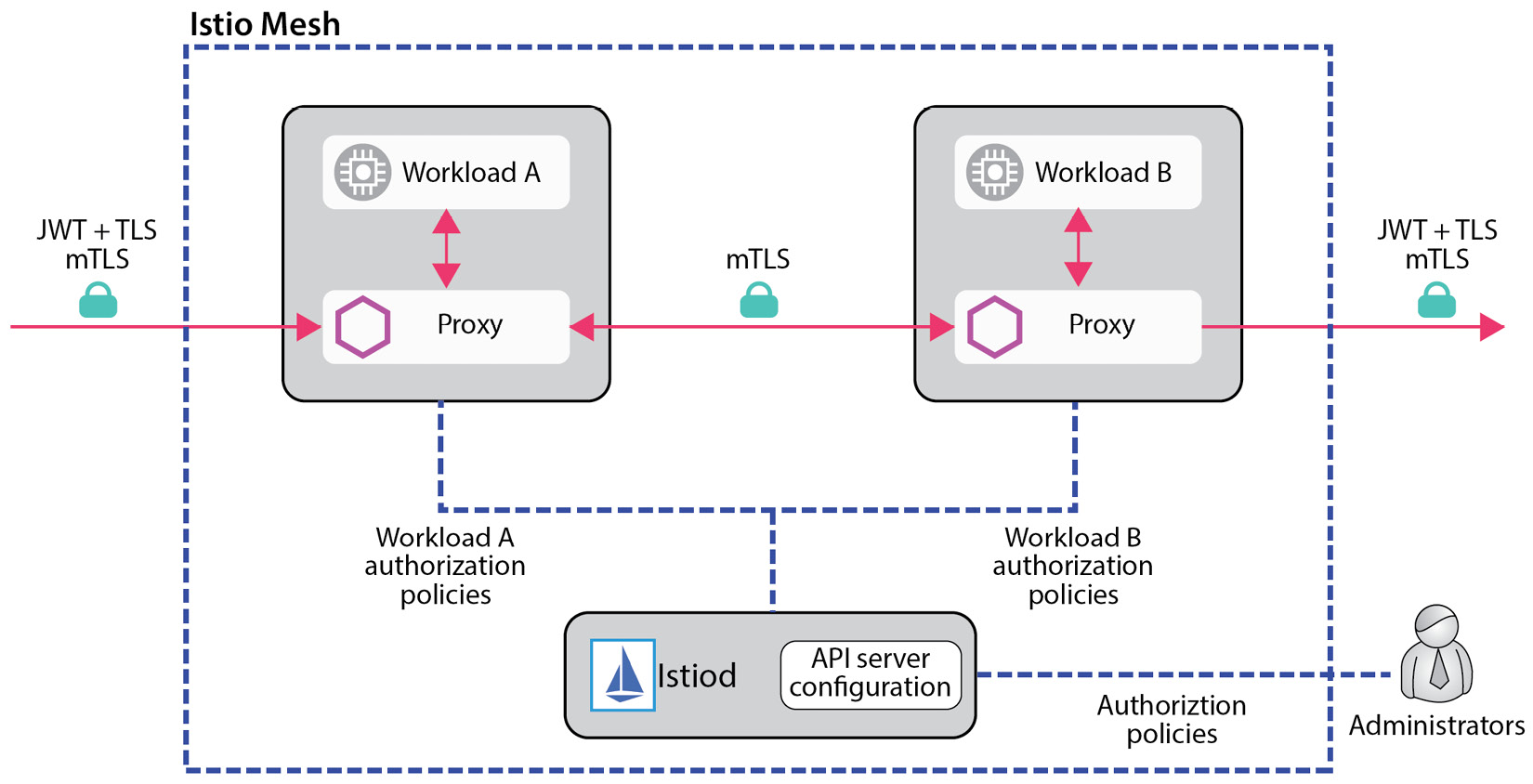
Figure 6.10 – Service-to-service authentication with Istio
In the preceding diagram, there are two services, Workload A and Workload B, which need to communicate with each other. It is not necessary to understand what the proxy is exactly; it is sufficient to see it as a component deployed by Istio in each service to control the services and implement the six pillars reported in Table 6.3. It is important to understand that in the diagram, the administrators (on the right side of the diagram) can centrally define authorization policies that will then be applied by Istio to authorize Workload A to communicate with Workload B and apply them without needing a dedicated IdP. The service mesh ideally takes care of all the related complexity.
We provided an example of Istio, as it is one of the most widely used service meshes across enterprises, but it is important to note that this is applicable, sometimes with subtle differences, to other technologies as well.
Now, we may wonder what happens if the service represented by Workload A in the figure is a web portal that users need to be authenticated against. In OAuth, this operation, as reported in the previous chapters, is usually achieved by using the auth code flow.
It is important to outline that the best implementation of a service mesh we were able to observe was focused on an internal service API. This means that in a service mesh, interactive authentication against a service may not even be needed. It is not uncommon to collapse multi-purpose APIs, applications, and services within the service mesh where interactive logon with OAuth is a relevant topic.
What the most widely used service mesh can do is validate the token before routing the request to the backend service or API within the service mesh. This means that if the client (for example, a browser) has the logic to authenticate the user against the IdP and gets the access token, then it is theoretically possible to enable the service mesh to validate the token and transparently route the request to the backend service without any authentication.
In many cases, this does not happen for the following reasons:
- From a security perspective, many companies do not want the access token to be released on the client side, and as such, it is not possible for the client to make requests with the access token against the API in the service mesh, which, in turn, cannot validate any tokens.
- From a portability perspective, if a client-facing application is developed by offloading the authentication or authorization logic to the service mesh, that application is not portable. This is because if the application is going to move to another containerization platform, a virtual machine, or a cloud PaaS service, it will lack the authentication and authorization logic that needs to be developed.
- The access token usually contains the claim audience, which reports the target service for which the token has been released; this would require some overhead to configure the service mesh to perform the checks.
- If the authentication and authorization logic is delegated to the service mesh, the target service would not be able to refresh the token.
These are some reasons why user authentication is usually still part of the application logic and is not delegated or offloaded to the service mesh. It should be clear that if a service within a service mesh needs to be part of the OAuth flow, it needs to obtain the user access token and it needs to be registered in an IdP. Regardless of where the user authentication is implemented, all the services/APIs must either have user authentication or server-to-server authentication implemented to prevent security issues. In other words, authentication needs to be implemented at every layer in any case.
As a final note in this section, it is important to outline that the service mesh is the hot topic of the moment. Features and functionality relating to this topic are evolving at a very fast pace. The service mesh is expected to gain some extra features and capabilities soon, and some of them may include evolution to facilitate user authentication.
Now that we have seen what the current trends are, in the final section, we are going to propose some practices to avoid pitfalls when it’s time to define standards in your organization.
Common antipatterns
Think about an organization where the proliferation of APIs has created many different islands with different APIs made using different technologies and standards. It is very common to see different teams attempting to create standards that are not widely applicable.
A typical case we want to mention is something that happened to one of our customers. The infrastructure team had been empowered by the management to resolve the problem of API and application proliferation and to bring order to the APIs and the applications in the company’s landscape. We are talking about a company that had more than 1,000 applications and APIs.
The infrastructure team defined a gateway to validate tokens and prevent any request from reaching the backend without the validation of a token, as follows:
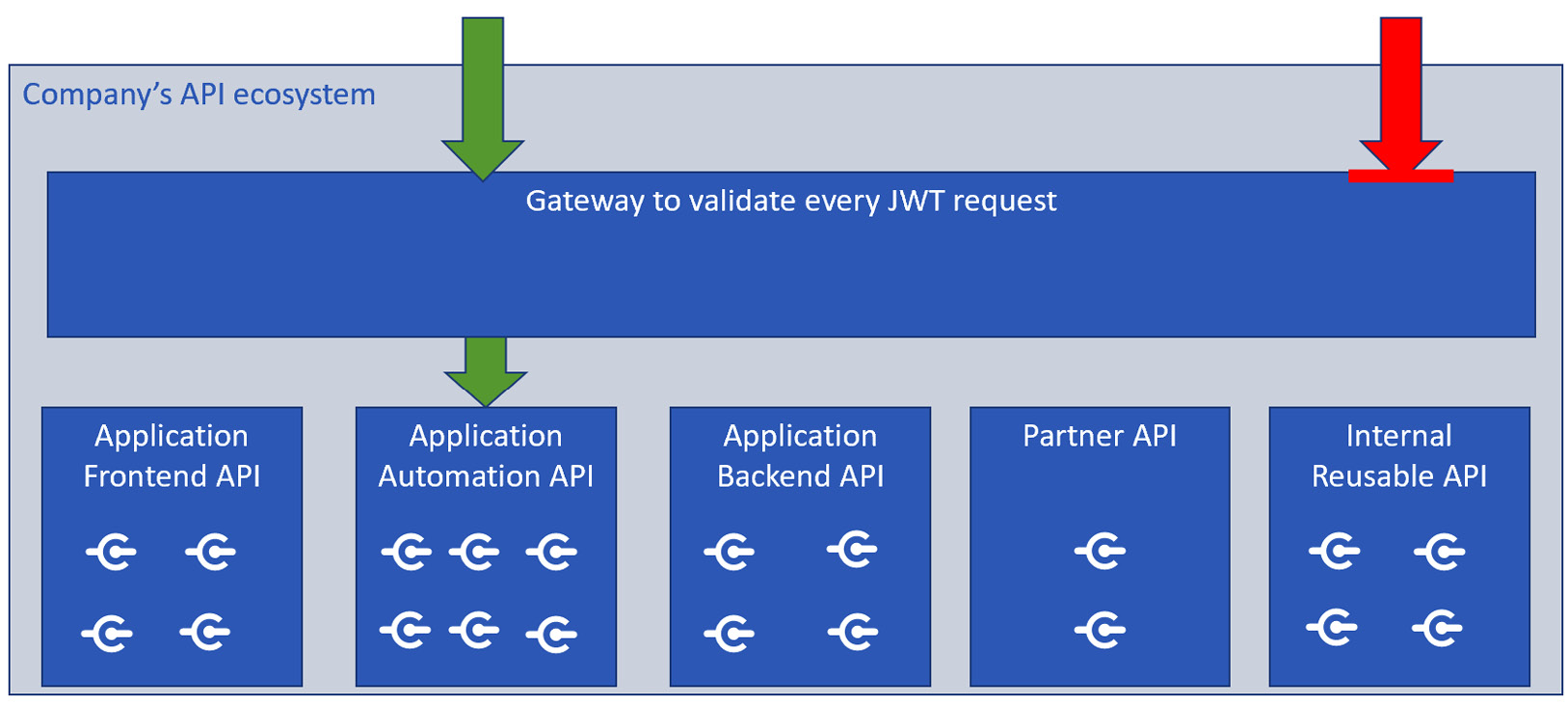
Figure 6.11 – Force check on every request
It is important to understand that this pattern has been applied to the entire application portfolio of the company in the development environment.
Despite the fact that, at first glance, it might look effective, it has created a lot of hassle and has never been promoted to the test or production environment.
The reason for this is that the problem has been trivialized too much by the infrastructure team. The application ecosystem of a company is extremely variable. Every application has different authentication requirements and a different OAuth flow. In general, it cannot be assumed all the clients are able to self-acquire an access token. This concept has implications for how the client is implemented, which protocol it is using, and if it’s OAuth, which OAuth flow is adopted. As a matter of fact, many applications stopped working and this pattern has been abandoned.
This is the typical mistake of the one-fits-all assumption, which is wrong, especially in the context of authentication.
These bad practices also taught us a couple of important lessons:
- In a large organization, it is paramount to have cooperation between teams and not work in silos. It is very likely that an infrastructure team that’s skilled in authentication may not be able to understand the complexity of the application’s software design; likewise, the software team responsible for the application software design may not understand infrastructural concepts managed by the infrastructure team. Establishing cooperation and DevOps practices in a company is paramount for success.
- Creating an authentication design for APIs and services when teams have already released many applications without proper standardization creates challenges that are hard to tackle.
Summary
In this chapter, we had the opportunity to understand how the current trends map to the topic of authentication, when OAuth is required, and when tools can help to facilitate authentication without OAuth.
We started the chapter by outlining the API proliferation phenomenon and the related implications. We then showed you a diagram to outline how APIs are typically organized within a company and how they are classified, as well as the authentication requirements for each classification. We also reported the modern way to manage services and APIs with a service mesh and the related authentication implications.
This chapter also outlined bad practices, such as multiple IdPs, and provided an example of a real-world antipattern that we encountered during our work. In the next chapter, we’re going to be a little more technical and focus on some of the most widely adopted cloud IdPs.