
7
Testing of Error Cases
In the last chapter, you saw how white-box testing techniques improve test coverage by examining how the code works. Understanding your application’s implementation lets you write more detailed tests covering more of the code behavior, in addition to the checks identified by black-box testing. This chapter examines how best to test the final aspect of core behavior: the code’s response to error conditions. There are still many other aspects, such as how usable, maintainable, and secure the application is, but this is the last section of testing focusing on the code’s active behavior, testing what it should do in different situations.
In this chapter, you will learn about the following topics:
- Expected versus unexpected failures
- Failing early
- Failing as little as possible, to avoid defect cascading
- Failing as specifically as possible to give user feedback
- Timeouts
- Network degradation
- Data failures
- Fuzzing
- User feedback
First, we will consider the advantages and disadvantages of error testing.
Advantages and disadvantages of error testing
Error case testing is unusual since it is separate from happy-path functionality, giving it a distinctive set of strengths and weaknesses:
|
Advantages |
Disadvantages |
|
May not have been considered by the product owners |
These are rarer conditions, so these tests are a lower priority |
|
May not have been considered by developers, so failures may be more serious |
Can be difficult to generate specific error cases |
|
Important to give user feedback if there is a problem |
Difficult to tell the ideal behavior in a failure mode |
|
Good error handling makes debugging easier | |
|
Can help to find linked issues |
Table 7.1 – Advantages and disadvantages of testing error cases
Testing error cases is important because the product owners may not have considered them. They are usually more interested in the main functionality than what happens when things go wrong. The developers, too, are likely to devote more time to the working cases than the failure modes, so performing this testing is a necessary check.
When your program is working well, your users are likely to be happy with it; the test comes when there is a problem. Does it provide clear, actionable feedback about what the customer should do? Is it worth the user trying again? Might their internet connection be to blame? You must inform your users if the problem is in the program itself and can’t be resolved by retrying.
Your program will inevitably hit errors during its usage; the challenge is how fast you can debug and resolve them. Good error handling allows you to rapidly see the cause of problems, rather than leaving you with a string of effects to pick through to find out what happened first.
By triggering one error, you can often uncover others. Does the application produce excessive logging when it fails? Does it have sensible retries and timeouts? You can only check these in practice by causing problems and observing the results.
On the downside, error testing is a lower priority. These cases are rarer than the happy-path tests in black- and white-box testing, and if they aren’t, your program is in serious trouble. Because they occur less frequently, they will have a lower priority, so factor that in when prioritizing testing and bug fixes. However, their importance is also a function of the severity of the failure. While your test case might be rare, it is still a critical bug if it results in a crash or data loss. When people questioned how much time I devoted to testing error cases, this was often my answer: probably I will only find minor issues, but there may be a major problem waiting to be discovered.
Error testing can be challenging to carry out in practice, and it can be difficult to identify all possible errors and trigger them. They may rely on unusual timing or a rare response from a third party. You may need to produce new test tools or add debug functions to your application to reproduce these cases reliably.
Finally, error cases need special attention in the specification. It may not be clear what the ideal behavior is during a failure or what is possible for your application. As noted previously, the product owner is likely to spend less time on these cases than the main functionality, so the desired outcome might not be documented thoroughly. I’ve seen a class of bugs we shipped because testers assumed a particular behavior was acceptable and expected during error handling when the application could have behaved better.
Don’t fall into that trap: spend time specifying the error conditions fully. With those strengths and weaknesses in mind, we will start by classifying errors your program might encounter as expected and unexpected.
Classifying expected versus unexpected problems
There are two classes of problems you might hit while testing. The first kind is an expected problem, for instance, an unusual or invalid condition coming in from an external system. Perhaps you send a message and never receive a reply, or the reply contains a blank required field. Maybe you only support 10 simultaneous sessions, but someone tries to connect an 11th. These cases will result in failures, but they are all expected. When your code is running in the real world, people may try to misuse it, and you have to be ready to handle that input. All the tests in this chapter are of this first kind – expected problems. Even if the external system you are talking to is another internal module, you have to be able to handle receiving any kind of rubbish back from it. Input validation is necessary on any interface.
The other class of problem is something invalid happening within code – attempting to use a null pointer, a calculation requires a division by zero, or a function should act on a list but the list is empty, for instance. Notice that the descriptions of these problems are different: they are all lower-level aspects of asking the code to do impossible things. With expected problems, I can list potential failure modes your code needs to handle, but I have no idea why a pointer ended up null or a list was empty – it should never happen. There’s no telling what external conditions might cause such problems since they should be impossible.
Expected problems should generate warnings that the behavior isn’t ideal, but your application should handle them gracefully with relevant feedback to the user. Unexpected problems should raise an error for the development team because they indicate that the code is at fault and needs to be fixed. We’ll revisit this important point in Chapter 10, Maintainability. There is an open question of whether the code should continue when it encounters such an error or not. If it is safety-critical, it should stop and fail-safe; if you are providing a less vital service, continuing to run despite errors can offer extra resilience.
The point of testing for error conditions is to handle expected errors so they don’t turn into unexpected ones. This chapter will consider many classes of possible failures that you can add to your test plans. They will fail, but that failure will be in a graceful, designed way, with no part of the application complaining that something impossible is happening. Your application should fail as early as possible when it detects an error to prevent failures from propagating through the system. That is one of the guiding philosophies for handling errors, as described next.
Error handling philosophies
In black- and white-box testing, the desired behavior is often obvious. The specification can help describe details, but you can often guess the intended behavior. That becomes much harder with error conditions. In these cases, your application will definitely fail; the only question is precisely how. The specification is now essential to describe the desired behavior as it will no longer be self-evident.
This chapter follows several principles for error handling that apply across a wide array of programming languages and environments. It will show you the importance of these principles and how to apply them to your testing:
- Fail as early as possible: Your application should raise an error as soon as it goes wrong to make debugging easier.
- Fail as little as possible: Failures should be graceful, with clear error messages to users indicating the problem. One failure shouldn’t lead to a cascade of other issues.
- Fail as specifically as possible: As we’ll see in the section on user feedback, the more precise you can be in your error handling, the better user experience you can provide.
We mentioned error conditions in Chapters 4 and 5 on black- and white-box testing, and there is a lot of overlap. In practice, you shouldn’t divide the test plan into success and error cases; instead, focus on one web page or API message and test all its scenarios together. However, the considerations for these tests are different, so I have devoted a specific chapter to them. I’ll let you combine the ideas from black-box, white-box, and error testing together when you write the test plan.
Your application should detect problems as early as possible. That helps prevent their effects from spreading, gives more accurate feedback to the user, and makes their diagnosis easier. Your task as a tester is to generate those problems to check that the error handling code is behaving correctly. Trying error cases means that all the tests described in this chapter will fail somehow. However, they are intended to fail, and the pass mark is that they should fail gracefully, with good feedback to the user about what went wrong with no additional side effects. Your application should never crash, for instance.
Next, we will consider these principles in more detail, starting with failing as early as possible.
Fail as early as possible
Your application should identify failures as soon as they happen. That means problems should become expected failures close to where that input was received, which brings a host of benefits in terms of user experience, debugging, and resilience. You’re aiming to avoid unexpected failures that propagate through the system.
Failing early in the release cycle
Failing early applies both to the project overall and within your application. In terms of the project, your goal is to catch bugs as soon after they are written as possible. In practice, that means writing unit tests alongside the code that constantly check the main functionality and error cases. Those will have limitations: being written by the developer, they don’t have a second pair of eyes, so any misreading of the specification will be written into both the code and the tests. And since they are unit tests, there is a class of integration and system problems they won’t be able to find. Still, contemporaneously written tests are an excellent way to start finding issues.
Failing early in the release cycle means that the test team has to be closely aligned with the developers to avoid delays between the code being available and being tested. Get a second opinion from the test team as soon as possible once the first version of the code is available. See Chapter 1, Exploratory Testing, for more on when exactly to initiate testing.
The focus of this chapter, however, is failing early within the application. By identifying errors and preventing further processing, you can accurately report the source of a problem in your program, rather than identifying its effects. That saves engineers time investigating how errors occurred. To demonstrate that, we will examine the case of a signup website and how well it handles errors in a user’s email address. The following sections consider best-case through to worst-case examples, where the code at different levels fails to reject the input to see the relative effects of bugs at different levels.
Catching errors in the frontend
When your application encounters invalid information, the best possible response is to fix it automatically. If a field is left blank, it could be populated with a default value, for instance. In the case of our signup email address, if the user includes capital letters, they can be automatically converted to lowercase before the address is saved. Since email addresses are case-insensitive, uppercase letters mean the same as lowercase letters so no information is lost. However, automatic fixing can only be applied in specific instances where alternative inputs have an agreed meaning.
Inputs that can’t be automatically corrected should be rejected as early as possible. There are strict rules governing the format of email addresses – they need to have precisely one @ symbol, for instance – and if a user doesn’t meet them, you should provide instant feedback. In terms of program architecture, the frontend can do that:

Figure 7.1 – Invalid inputs blocked by the frontend
The frontend of your application may be a web page, a physical screen or buttons, an app, an API, or some other interface with external systems. The frontend systems can then provide immediate feedback to the user telling them what went wrong and why, so they can fix it.
Identifying invalid entries early requires you to be completely clear on what is and isn’t valid. That should come from the specification, and those requirements need a test to check that your application rejects each illegal case.
Catching errors in the backend
If the unexpected input isn’t caught immediately, it can cause issues elsewhere. If the web interface happily accepts invalid email addresses and sends them off to the server, for instance, it might return an error or fail to respond at all:

Figure 7.2 – Invalid inputs blocked by the backend
The backend of your application might be a web server, cloud infrastructure, or any code modules that don’t deal with external interfaces. When receiving invalid information, it should raise a helpful error with details about what it received and why it is being rejected.
Remember, each part of your system should validate its inputs. Even if the frontend correctly rejects incorrect values, you can test that the remaining parts of the system also throw proper errors. These might only be theoretical, but deficiencies in the backend’s response could be exposed later if the frontend is changed or another interface is added. To do that testing, you might have to send fake messages rather than using the actual frontend so that you can send values it would otherwise reject. That shows some of the tools you need to test error cases beyond what you need for black- and white-box testing.
Real-world example - The Danish bug
I once worked on a hardware platform that could be localized into many different languages. For one release, we prepared our updated text strings as usual but instantly hit a problem for our Danish beta users. Their equipment became unusable and wouldn’t even boot. Unfortunately, there was a typo in the formatting of one of the Danish strings. A formatting check in the localization system had gone wrong, and the error propagated into our code.
Our hardware also failed to check and it read the strings so early during startup that the error prevented the application from starting. A change as minor as updating text strings had crippled the units, and we could only recover them by booting into the emergency recovery image. Because we didn’t catch the error early, it propagated through the system and caused a major problem.
If the backend doesn’t handle invalid information cleanly, then there may be no useful information about why it failed. The user will see a general error or a timeout without indicating what they should change to fix the problem.
Debugging is also tricky. Your backend will throw errors that you have to monitor somehow. If the error message is buried in a log you never look at, you may not notice this is failing at all, and if the logs don’t contain the values they received, you may not even see the invalid address that caused the problem. Fields that contain Personally Identifiable Information (PII), such as email addresses, have rules about how long that can be stored and who is allowed to access it, making debugging harder. See Chapter 9, Security Testing, for more details.
When you see the error, you need to analyze it to discover its source. You have to see the invalid value and understand its significance, and the further the error is from its cause, the more work you have to do as a tester or developer to understand it.
Catching errors written into the storage
Beyond the backend, your program storage can also reject invalid entries. That may be a database, a filesystem, or some other persistent store, and it can also validate its inputs:

Figure 7.3 – Invalid inputs blocked by the storage system
Checks by storage systems are generally less complex than is possible in the backend code but can still spot missing fields, excessive lengths, invalid data types, or other data format problems. Detailed checking for the syntax probably isn’t possible, however. You should validate the values your storage accepts, such as the type of each database field, making them as strict as possible. Again, to test those types, you may need a dedicated tool to let you avoid checks in the rest of the system. Catching errors as they are written to storage is your last chance to find them when they are generated because once invalid data is written to storage, it becomes much harder to debug and fix.
Catching stored errors
Invalid data could stay for years in storage before being retrieved and used for the first time. Again, the code should check for any invalid data coming from storage, and you can add checks for that. To test, you may need to deliberately write invalid entries to storage if other parts of the system correctly block them.
When faced with invalid data, the behavior could be anything from full functionality, with your program happily sending rubbish data to your users, to complete failure where your application can’t even start. As illustrated here, this is the case where the backend reads information out of storage:

Figure 7.4 – Invalid data detected when being read
Now you have three problems. In the short term, you have to find invalid data and fix or remove it to recover your app. Secondly, you also need to find out how the invalid data got into the database, which can be even more challenging. You have to check the history of the messages to see when this was written, and your logs may not go back far enough. Perhaps the user interface has since been fixed to block that error, so you cannot reproduce the problem. Maybe some interfaces, such as web and mobile apps, correctly reject the value, but the API lets them through. I’ve seen cases where we never worked out how bad data was written to storage.
Thirdly, depending on the failure mode, invalid data may have been building up for years, which means that as well as fixing the immediate issue and finding how the invalid data was written, you have to find and correct all the other invalid entries as well. The longer an error persists, the more work it creates for you.
The problems caused by invalid data grow over time. There is no hope of giving the user helpful feedback if the data sits in a database for a month before it triggers an error, so that is another benefit of testing error cases. If you discover your application accepts invalid data, you can improve performance to catch it earlier. That protects your application, makes debugging easier, and gives users an improved experience.
As well as catching errors quickly, your program needs to respond well, as described in the next section.
Fail as little as possible
What counts as a test passing when the functionality is failing? In the previous example, immediately identifying the problem and informing the customer exactly how to fix it is the best possible result. For external APIs, the criterion is similar – the best outcome is clearly stating in the logs or error messages which field caused the problem and why.
Sometimes, even the best failure mode is less than ideal. For instance, a failure to reach the infrastructure in a web application may result in a gateway timeout message. That is useless to end users – they are unlikely to understand it, and there is nothing they can do about it. The best thing you can do in that case is to show an unhappy robot or other symbol and let the user know they’ve done nothing wrong. They just need to wait, safe in the knowledge that somewhere on a distant console, a light has turned red, and an engineer is desperately trying to recover the service.
In each case, you will need to determine the best failure mode, by checking with the product owner. Often failure modes are not covered in feature specifications, but as they are user-facing, the product owner will want input on what to do. Ensure these are carefully documented during the feature specification review so you know what to expect during testing.
Even without a precise specification, some error responses are always wrong. Your application should never crash, for instance, or be left in a state that requires manual intervention to recover. The severity of a bug is roughly the chances of you hitting it multiplied by its effects when you do, minus any mitigations or workarounds you can put in place. While error conditions are unlikely to be encountered regularly, if they have severe outcomes then they are a top priority. That’s why it’s essential to test for them.
As described in the section Classifying expected versus unexpected errors, your application should be resilient to any possible inputs, checking and rejecting invalid ones as early as possible. Short of losing power, your program should keep running while ensuring errors don’t propagate through the system. Users should receive understandable and usable feedback for each fault, as described in the section Giving user feedback on errors. If that’s not the case, you can raise bugs for any examples of failures.
Aside from those extremes, there are many intermediate cases where you can choose whether to proceed with the processing or halt when encountering an error.
If your code controls a nuclear reactor or an airplane, then stopping completely at any unexpected conditions during startup is a safe way to operate. All inputs and data should be validated and understood before proceeding any further. For other applications, failing to provide service is the worst thing that can happen, for instance, on a website, a game, or a communications platform. In those cases, being resilient to errors, flagging them, but continuing to run may be the best outcome.
Real-world example – The fail-safe communication system
One communication system I worked on was designed to be fail-safe. While some minor errors didn’t interrupt processing, others prevented the system from starting. A typical sequence for this was the following:
1. The system started correctly with valid data.
2. Invalid data was written to the database, but the system kept running as it hadn’t detected it.
3. The system stopped, discovered the invalid data, and couldn’t restart.
The challenge was that this was a multi-homed system with many customers sharing one instance. A single error in a single part of a single customer configuration denied service for all the customers on that instance. Since this was a communication platform, there was little risk in starting up, even with errors. The worst that could happen was we would fail to provide service, and that was the result when the system failed to start. In that case, working around the error by disabling that configuration or that customer would lead to a more resilient system than preventing the instance from starting.
While continuing with processing may be a good outcome in lower-risk applications, an exception to that is when invalid data risks causing data loss through deletion or corruption. Failing to provide a service is not the worst thing that can happen if you risk losing customer data or configuration. You’ll have to weigh the chances of encountering those problems for each input in your system to choose whether continuing despite errors is the best course.
If failures aren’t caught early, you risk cascades of issues, as described next.
Understanding defect cascading
A single error can leave your system in an unknown state. Unless you have identified and replicated that problem as part of your testing, it also leaves your system in an untested state. Your application may work well, but there’s a higher risk of issues than during regular operation. Triggering one error state is a great way to look for other problems.
Example problems that arise during error handling include the following:
- Excessive logging – It’s vital to record information about errors, but if a failure is recurring many times a second, that adds load to the system, either in terms of disc usage or network bandwidth to report it. Using those resources can trigger further issues.
- Lack of detail in logging – A regular finding in post-mortem meetings after failures was that the logs were hard to use and didn’t have helpful information. Use the logs while you’re testing to discover weaknesses before the code goes live.
- Lack of context in logs – In a modern, distributed system, logs will be written by many different processes. You need an easy way to gather the relevant sections together to tell a coherent story about what happened.
- Infinite retry loops – Retries are useful when a module encounters an issue with an external system, but they need to be carefully handled. The application mustn’t send the same message again forever – there has to be a timeout. Systems getting locked by constantly attempting an action that will never work is a critical issue.
- Rapid retries with no backoff mechanism – A special case of infinite retry loops is when a module attempts the action without pausing, sending messages as fast as it can. This obviously drains resources on both the source and destination systems, which can cause other problems.
- Unnecessary dependencies between modules – A major cause of defects propagating through an application is dependencies between subsystems. Some are necessary, but others can be mitigated or avoided altogether. Having redundant routes rather than single points of failure, queues in front of databases, and removing unnecessary lookups, for instance, let your application continue despite problems.
- Modules failing due to the absence of others – Each module should stand alone and be able to run independently. If part of your system has failed then some functions will be unavailable, but the other modules should identify and mitigate the failure as far as possible rather than failing themselves.
- Modules failing to restart correctly – A special case of modules relying on others is if one cannot start without the presence of another. Again, some of these dependencies are unavoidable, but check where they are necessary. By systematically disabling systems and restarting others, you can flush those out.
- Lack of alarms indicating failures – Another regular finding in post-incident meetings I’ve attended is the lack of monitoring indicating failures. When you add new features with new failure modes, you need to add a check for them. See Chapter 10, Maintainability, for more on monitoring.
Many other possible knock-on effects will be unique to your application, so once you are in an error state, carefully check the system. Subsequent issues may be subtle and apparently unrelated to the initial problem, so keep your eyes open. See Chapter 11, Destructive Testing, for more information on testing while in an error state.
Real-world example – Self-inflicted DDoS
In one company where I worked, we started to experience crashes and slowdowns in our cloud infrastructure. The effects were hard to pin down – the crashes seemed unrelated to each other and were mainly due to watchdog timeouts, although it wasn’t clear what was triggering them. Eventually, we identified that disc usage was preventing the watchdog file from being written. Why was the disc so heavily loaded? Because large amounts of logs were being written, far more than in our previous release. Why was there so much logging? Because our clients were reconnecting at very high rates. Why were they reconnecting so often? Because there was no backoff mechanism to slow them down. Why were they reconnecting at all? Because a bug in our last release was causing regular disconnections.
One bug on the client side had caused a massive cascade of issues throughout our system. With better discs, we should have been able to handle that rate of disc access. There should have been rate limits on our logging, and there should have been warnings about the rates we were seeing. There shouldn’t have been so much written to the logs at all because the clients shouldn’t have reconnected so quickly. We should have had warnings when they dropped at that rate, and they shouldn’t have disconnected in the first place.
Putting strain on the system in one way can uncover a whole host of knock-on issues, so ensure testing these error cases is part of your test plans. Next, we consider the priority to place on error testing.
Prioritizing error case testing
For all the test cases described in this chapter, remember that the more obscure your failure mode, the lower priority the bug will be. Testing error cases is always less important than tests that cover the main functionality of a new feature since if they fail, that feature won’t work at all. Error cases shouldn’t usually happen, so their rarity lessens their impact. The more obscure the failure case, the rarer it is and is even less critical. Error case testing should be tempered with a knowledge of that priority. You can run this area of testing last, for instance, alongside the maintainability tests, which don’t affect customers directly, and destructive tests, which are another failure mode.
On the other hand, it is difficult to know in advance how bad any failures will be. For instance, if there is a bug when adding too many users, you will probably receive an unhelpful error message. That is a bug, but not a high-priority one. However, that failure could be far worse, crashing the application or locking up a thread that, if repeated, would eventually stop your application from working at all. Until you’ve done the test, you don’t know how bad the issue is, and the priority of the bug is a combination of how likely it is to happen and its severity when it does.
While there are only a few successful routes through code, there are many more possible failures, so it is possible to spend a very long time on these tests. Don’t get bogged down. Ensure that more critical testing is covered first, and only return to examining error cases once you are confident in the other behaviors.
With that priority in mind, here are common failure modes you should check for in your code.
Testing beyond the limits
What are your system’s limits, and what happens when you go beyond them? Part of the feature specification is to identify system limits and what values you are required to support. These can be difficult to judge, especially around loading. Having thousands of visitors a second to your website might be a problem you would love to have but, as a tester, it is your job to find out how well you can expect your site to perform.
System limits are of two types – policed and unpoliced. A policed limit is one in which the system actively blocks users from going beyond it. For instance, it might support 4 simultaneous players or a maximum group size of 20 users. You cannot configure the 5th player or the 21st user. That’s as opposed to unpoliced limits. System rates are typically of this kind: how many connections per second can you handle? Some configuration limits may also be unpoliced, such as the total number of users on the system, since nothing in the code will prevent the database from growing. You should test these different types of limits quite differently.
Policed limits should have a user interface that lets people know they are at the limit and cannot do anymore. That limit should be apparent before users try to use it – the Add user button should be grayed out with a note saying why, for instance, instead of letting users click the button. Chapter 8, User Experience Testing, describes user experience issues like this in more detail.
However, even if there is a user-interface limit, you still have to test the system behavior when users try to go beyond it. Sometimes limiting the interface isn’t possible, such as an API that could always accept more messages. On a web page, it’s possible for one user to load a page to add an item, a second user to add the final item, then the first user to submit their request. Stale web pages could still make invalid requests, making this a more obscure case, but still worth trying.
As described previously, the pass mark for these blocking tests is that your application should return a helpful message to users. For example, a red bar stating Error 652 is a failure; a pass is a message saying Maximum number of users reached or whatever text your user experience team has chosen.
As part of the feature specification, you need to carefully list all configurable entities to perform this testing on them. Where the limits are very large, you will need the scripts to drive the system to its maximum, as described further in Chapter 12, Load Testing.
For non-policed limits, the tests need to be different. There will be no user interface warning and nothing to prevent you from adding the 100,001st user; for instance, the system will just keep going. That means there is no user interface to test and no feedback to the user, so product managers and developers may argue that the limit can’t be tested. However, it is still important to pick a number to test up to – see Chapter 2, Writing Great Feature Specifications. That lets you know when you are approaching the limit and heading into an untested configuration.
For non-policed limits, the failure modes are different. When you have a large number of configured entities, lists can become unmanageably long, or the system might slow down – web pages may take so long that browsers show warnings about the page being broken, for instance. In this case, you will need to decide the acceptable performance with the product management team. While pages technically still load, the user experience of using them and searching for information is terrible. The fix for these issues might include pagination for tables with a limited number of entries per page, navigation buttons, and search options.
It is worth loading the system up to these limits before performing other regression tests so that you can look for interactions. The effects of having a large system load may not be apparent and may cause issues or slowness in unexpected areas. Only by having that in place before running other tests can you find those cases.
Other non-policed limits involve the rates that the system can run at, for instance, the number of transactions per second, simultaneous users or the rate of updates, and so on. Again, you will need to pick the acceptable limit you want the system to support and have the tools to drive that load. And again, it is best to perform other testing when this load is present – while the system might be able to support a high transaction rate in itself, that may prevent other operations from completing successfully. You will need to work out the dependent and independent variables to decide which combination of load and functionality might interact and should be tested together. For further tests when running the system at its limits and beyond, see Chapter 13, Stress Testing.
Driving the system can result in it being so slow that certain operations time out while waiting for responses. This is such a common and important failure mode that it should have dedicated testing, as described next.
Testing timeouts
One crucial failure when communicating with any remote system, whether internal or external to your application, is not receiving any response. That lack of response could be due to network issues, a problem with the destination system, or the message being invalid. Whatever the reason, there is a new set of failure modes to look for in this case related to timeouts and retries:
- The presence of timeouts on all messages
- Appropriate timeout lengths
- The use of heartbeat messages
- Retries for failed messages
At the most basic level, you have to check that a reasonable timeout is in place. If we pick a simple example with a client sending a message to a server, we need to make sure that the client notices the lack of response and reacts to it. There are cases where clients will enter the state of waiting for an answer forever. That is the first class of bugs you can raise.
Next, is inappropriate timeouts. You may need to discuss these with product owners; again, this is an area they may not have considered but will have an opinion on since changing the timeout might have customer-visible effects. In APIs, the specification might state how long different states should persist, or applications should wait for different responses. If that is the case, then check against that specification.
Suitable timeout lengths vary depending on context. Timeouts being too short mean valid responses could be missed, and you generate unnecessary errors. You need to check those relative to the loading at the time; a timeout may be sufficient during light system load but too short when the system has a lot of activity and operations take longer. You should test timeouts against the worst case that the system can handle.
It’s safer to allow timeouts to be too long, which is less likely to result in errors, although it may unnecessarily tie up system resources. An overly long timeout may look like an error to users, even if the system behaves as expected. Your users might give up rather than wait 10 seconds for a web page to load, for instance. That needs input from the user-experience team to determine the best reaction to a failed message.
Systems with continuous connections should send heartbeat messages to each other to check the other end is still running. You’ll need to check the timeout on those messages and prevent responses so you can test whether the disconnection is correctly detected and acted upon.
A more subtle timeout issue can occur in complex systems with at least three machines communicating with each other. That is when the timeout for an initial message is shorter than subsequent ones.
Consider a system in which module A sends a message to module B, and module B then forwards that message to module C. The timeout on the message from A to B is 30 seconds, but the timeout on the message from B to C is 60 seconds. In that case, the failure mode is shown as follows:
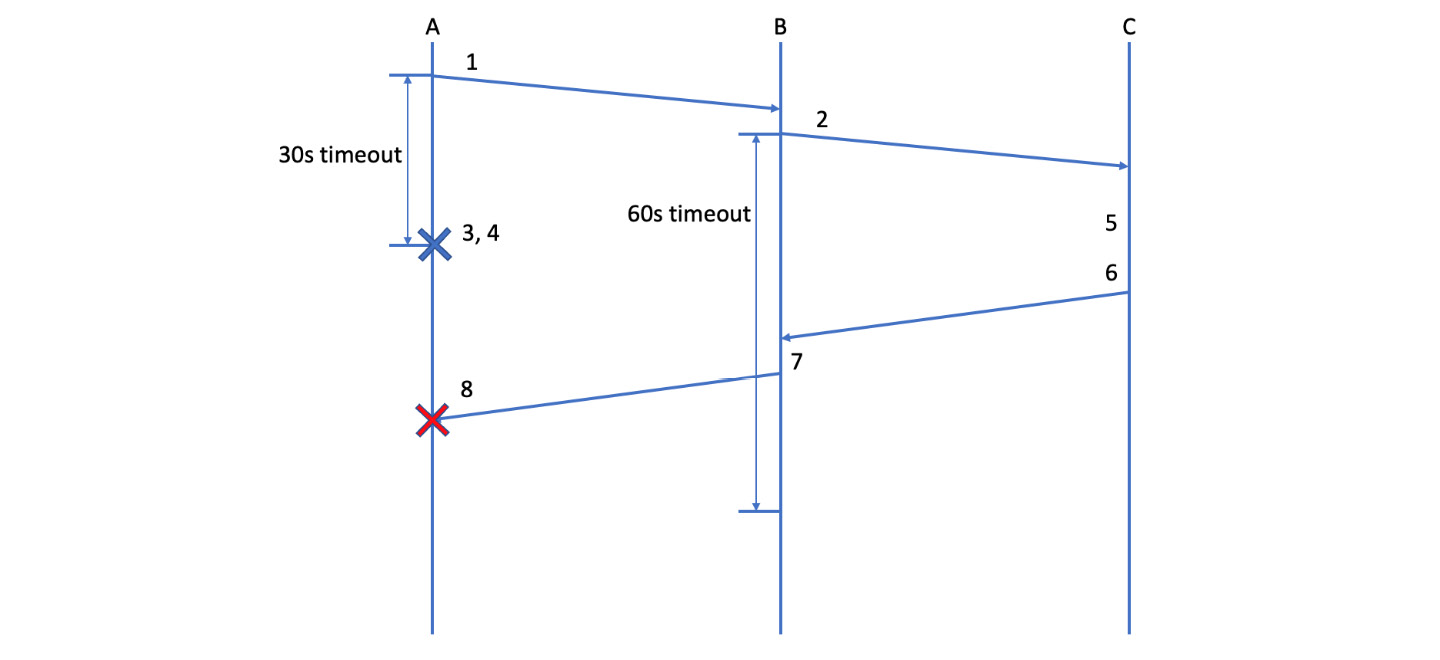
Figure 7.5 – Message failures with incorrectly figured timeouts
- A sends a message to B.
- B forwards it to C.
- 30 seconds pass
- A times out and fails after 30 seconds, returning an error.
- Another 15 seconds pass.
- C returns the answer to B within its 60-second timeout.
- B sends the answer back to A.
- A rejects the response because it has already timed out.
By the end of this sequence, A claims that B timed out, but B claims it responded successfully and has had its answer rejected. The logs can be challenging to read in this situation, but the underlying cause is simple enough – A’s timeout needs to be long enough to encompass all the subsequent timeouts downstream in the system. If those added together make for an unreasonable timeout at A, then the others need to be shortened. Alternatively, you need to give some feedback to the user that processing is continuing (see the Giving users feedback on errors section).
A final failure mode we will consider here is what the system should do after a timeout. Messages should generally be retried in case there was a transitory issue that was quickly resolved, but those retries need to be carefully implemented. Watch out for infinite retry loops. That critical bug will leave your system constantly sending out messages and spamming another system, waiting for a reply it will never receive. If the first 10,000 messages failed to generate a valid response, it’s unlikely the 10,001st will.
A special case of the infinite retry loop is when the client retries at maximum speed, with no time delay. That will max out the CPU on the client while sending messages at the fastest possible rate to the server. Have a serious word with the developer in that case; their lack of care has produced a significant risk to system stability.
That leaves the client application in an invalid state, but can also be highly damaging for the server. If the server is unable to respond to some requests, then clients with this bug can result in a system effectively performing a Distributed Denial of Service (DDoS) attack on itself, as in the previous example. A large array of clients will constantly send messages to the server, which is unable to process them, causing a DDoS attack. Over time, any other clients attempting this transaction will end up in the same state and worsen the situation. A system that starts off running only a little behind can end up crippled by the cumulative load that this produces.
In that case, the safe method of failing is to implement exponential backoffs. The client should retry, but not constantly. Instead, it should retry with exponentially increasing delays between each message, for instance, trying at 1 second, 2, 4, 8, 16, 32 seconds, and so on. That will prevent a buildup of load on the server, while also letting the client detect any recovery. That exponential backoff should stop at some maximum value, for example, 5 minutes, so it does not grow to ridiculous lengths of time. All that needs to be captured in the specification.
These timeout issues can affect any of the states and messages in the system, so you need to test them all. Anywhere a module sends a message and expects a response can suffer from these issues, so the specification needs to identify them all as part of your white-box testing to let you check their timeout handling. Some system messages are evident from the customer-facing behavior, but others may be subtle implementation details. You need to identify and test them all.
As well as failing to receive any response, intermittent responses can also pose significant problems for an application, as described in the next section.
Understanding network degradation
Many applications rely on the internet to transport data, but some are more sensitive to poor network conditions than others. Programs that send video, for instance, or online, real-time gaming, rely on high-quality, low-latency networks. Their behavior under suboptimal conditions is vital to users’ perception of their product since network problems occur with depressing frequency. Even for applications less sensitive to network performance, such as web pages, you can check how your application responds to problems.
Sources of network degradation
There are several types of network degradation for packet-switched networks such as the internet:
- Packet loss: The classic problem of networks, where sent packets aren’t received
- Latency: The scourge of gamers is a delay between sending the packets and receiving them at the far end
- Jitter: The variation in the latency of journey times
- Re-ordering: Packets sent in one order are received in a different order
- Duplication: One packet is received twice at the destination
These problems arise because packets sent as part of the same communication may take very different routes to reach their destination and pass through many switches and routers. If one of those switches is overloaded, it may drop your packets or add delays. However, only some of your packets might take that route.
Note that there is an alternative to packet-switched networks. Circuit-switched networks, such as standard telephones, create a direct connection between two machines. They offer lower latency and suffer from none of the issues listed previously. On the downside, they need to be centrally controlled and configured – there’s no option to simply share your Wi-Fi password and automatically let a new machine onto your network. Changing to a different Wi-Fi network takes a few seconds, but porting your mobile number to another provider requires a dedicated code and several days wait. In the end, the inflexibility of circuit-switched networks almost always makes them a second choice to packet-switched protocols such as TCP/IP, despite their potential problems.
Consider the following network, with a source sending packets to a destination. In TCP/IP, there will always also be a stream of acknowledgments flowing back from the destination to the source, but they can be ignored for this example, shown as follows:
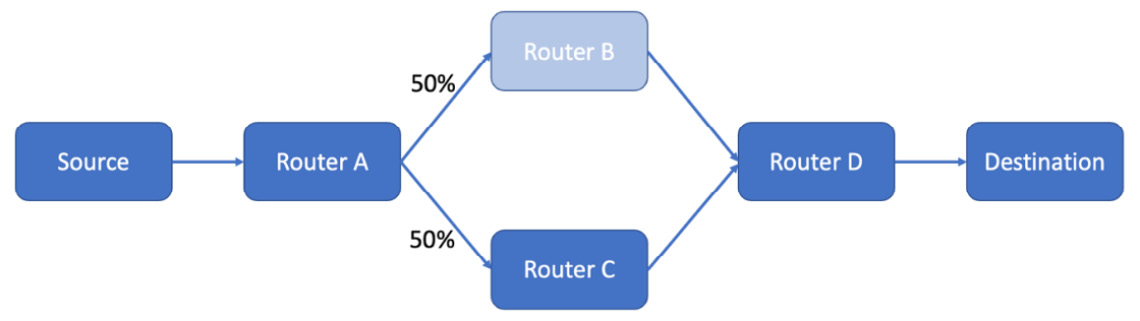
Figure 7.6 – An example network suffering degradation
Packets from Router A can take two routes to their destination. 50% go through Router B and 50% through Router C. Those routers are simultaneously taking lots of other traffic, and Router B is, unfortunately, failing to route packets.
If Router B drops all the packets sent to it, 50% of packets will be dropped overall. Note that if there are acknowledgments and retries, these could be sent again and may succeed with a delay. For simplicity, consider this a UDP stream where packets are sent without retries. If Router B only drops half the packets sent to it, then the overall packet loss on this connection is 50% x 50% = 25%.
Instead of packet loss, Router B might be working slowly, adding delays on that route. Then, half the packets are delayed but the other half avoid the issue, so you will see high jitter – significant variations in the time it takes packets to arrive. Some might take 20 ms while others take 200 ms, and your application has to handle both cases.
Because of a variation in delays, packets might arrive out of sequence, as shown in the following example:
|
Packet |
Time sent |
Transit time |
Time received |
|
1 |
0ms |
20ms |
20ms |
|
2 |
10ms |
200ms |
210ms |
|
3 |
20ms |
20ms |
40ms |
Table 7.2 – Varying transit times causing packet re-ordering
Packet 2 went through Router B and has a significant delay, so even though they are sent in the order 1, 2, and then 3, the destination receives them in the order 1, 3, and then 2.
Finally, many packet-switched protocols such as TCP/IP have retries built in. However, that can result in duplicate packets if timeouts are set incorrectly. See the example in the Testing timeouts section.
Let’s repeat the previous example, but after 100 ms, Router A detects that packet 2 has not been acknowledged and sends it again:
|
Packet |
Time sent |
Transit time |
Time received |
|
1 |
0ms |
20ms |
20ms |
|
2 |
10ms |
200ms |
210ms |
|
3 |
20ms |
20ms |
40ms |
|
2, retry |
110ms |
20ms |
130ms |
Table 7.3 – Varying transit times causing duplicate packets
The retried packet 2 goes via Router C and reaches its destination in 20 ms while Router B was still sending the initial attempt. This time, the destination receives the packets in the order 1, 3, 2, and 2. Your application needs to be able to detect and discard those duplicates.
Aside from degradations, there can also be problems if packets are larger than the maximum transmission unit for the network. That sets a limit, for instance, 1,400 bytes, on the maximum size of any one packet on the network. To send messages larger than that, you need to split the data across multiple packets, and the destination needs to reassemble them.
Real-world example – Too much debugging
In one place I worked, we used a third-party service for one of our features. Unfortunately, they were massively unreliable. We repeatedly pointed out issues and they finally devoted an engineer to investigate them. Immediately, there was a total outage. The system that seemed to have intermittent failures now didn’t work at all. We cursed their incompetence and demanded to know what had happened.
To investigate the problem, it turned out they had added debug information to each message. That had taken it beyond the MTU of the network, without the ability to split the information across packets. Instead of some failures, now every message was invalid until they turned the debugging off.
If your application implements packet handling rather than using third-party solutions, you will need to test each of those cases.
Testing degraded networks
Often, network problems will be handled lower in the stack, with your TCP/IP or VPN provider responsible for the logic to handle cases of network degradation. However, if your application deals with network packets, for instance, using UDP streams with retries as part of your application logic, these tests need to be part of your test plan. Even if your application doesn’t deal with packets directly, you can see how well it responds to poor network conditions.
The first point for network testing is that you need a solid network to test on. There’s no point adding in network degradations if your network is already performing poorly in random and unknown ways. Make sure you can rely on your network before starting this testing.
Network emulators allow you to introduce the specific impairments listed in the Sources of network degradation section for your testing. Chrome has a few network throttling options in the Network section of its Developer Tools. On Linux, you can use Netem, Windows has WinDriver or Traffic Shaper XP, Mac has Network Link Conditioner, and there are many others available. Even more realistic is to use a separate box, such as PacketStorm or Spirent. Then, the source machine is unchanged and the network issues are purely external, as they would be in reality.
Be aware that unless you buy expensive hardware, these have relatively low throughputs – they can only handle a few simultaneous connections. If you put significant traffic through the emulator, it will drop packets because it can’t handle the load. For those tests, use dedicated hardware solutions.
For testing, add specific impairments to check the response of your system. You can apply different levels of each type of impairment, testing the outcome at 1, 2, 5, or 10% packet loss, for instance, or different delays to introduce latency. In practice, however, impairments rarely happen independently; if some packets are dropped, others are likely to be delayed. Packet loss can also be random and evenly spread, or correlated and grouped in spikes of loss between periods of good connectivity.
The simplest setup is to physically place an emulator in line with the machine under test:

Figure 7.7 – A network emulator in line with a subsystem under test
That works for running tests locally, but a scalable solution requires you to be able to route packets to and from the network emulator to impair any connection. Be aware of the direction of the degradation – are you restricting packets to or from the system under test, or both?
With the impairments in place, measure the network conditions at both sides of the connection. This is vital to detect any unwanted impairments that may invalidate the testing and to check your desired impairments are applied correctly.
All those considerations lead to a massive space of possible combinations of network issues. You can choose those that are most relevant to your product and cause the most problems, and there are specifications and recommendations for patterns of impairments to consider.
During packet loss and high-jitter streams, the jitter buffer is a crucial part of the system test. The jitter buffer is a temporary store of packets as they arrive. During applications such as video streaming, packets are not played out immediately but stored for up to a few seconds. If the incoming stream is interrupted, the video can keep playing so long as the network recovers before the buffer is empty. A large buffer provides extra protection against network issues but delays the media stream. A short buffer plays media faster but offers little protection.
In practice, jitter buffer sizes will vary; during good network conditions, they will shrink since protection is not needed, reducing delays. On unreliable networks, the jitter buffer will increase, delaying the media but giving the best chance of continuous playback. If your application uses this technique, be sure to exercise both modes of working and the transition between them.
Even on a stable network, responses from remote systems may not contain the information you were expecting. That class of data failures is considered next.
Data failures
As well as failing to get any response, a much broader class of issues arises from receiving a message or input containing unexpected data. It may be surprising because your specification was wrong, or due to a gray area that was poorly specified. If the message’s sender is another part of your system, you can choose where to fix it – should the sender change the message, or should the receiver accept it correctly? If the sender is a third party, your application must handle that input, regardless of the specification.
The most basic failure is receiving an error in reply. Each message you send out needs to be tested for a variety of possible error responses. The pass mark here, as elsewhere, is that these errors are expected so they can be handled gracefully and as early as possible. Both the message and the error should be comprehensively logged, so you can replay each situation and check new code against it. By catching errors early, you can return as much information as possible to users, particularly letting them know whether it’s worth retrying that operation due to a temporary error or if the failures seem permanent.
Testing failures can be problematic with third-party systems because they may return an error once and then never again. To reproduce the issue, you may need a test harness that can mimic the external system but give you complete control over the responses it sends. There’s work to prepare that mock system, so unless an interface is particularly problematic, it may not be worth the investment in time. Then code reviews may be the only preparation possible, checking that the application is ready, in theory, to handle different error replies without running it for real.
Once you are past timeouts and error responses, you are down to the level of unexpected data within the individual fields of a message. Here, the possibilities are endless and will depend on the system you are testing, but again there are many common themes you can add to your test plans.
A simple first case is checking what happens when different fields are missing. The external system might respond without specific data, and your program needs to be able to handle that. Missing data might be mandatory, and its absence might mean the transaction fails, or there may be optional data, and the message can still be processed without it. The specification needs to clarify the requirements so that you can test each field.
If the data is present, it might still be invalid. Here the list of possible inputs for the different field types listed in the chapter on black-box testing is helpful again. For strings, check long values, Unicode values, special characters, and so on; for numeric fields, check negatives, decimals, and numbers out of range. See Chapter 5, Black-Box Functional Testing, for the complete list.
At a lower level, database queries might unexpectedly return no results. There may be one result when the application is expecting several, several when the application only wants one, or the query may return a vast number of results. Check that your application can handle each of those scenarios.
Once you have tested each field, you need to check for any interactions or dependencies between them. Perhaps your application handles one field being missing but not two related ones. Again, there is no easy way to see those dependencies, so it relies on your skill as a tester. To catch combinations you haven’t thought of, you can inject random data, in a testing technique known as fuzzing, described in the next section.
Fuzzing
Fuzzing involves generating randomized input to test the response of the system. You can use this technique to generate broken combinations and detect bugs when multiple seemingly independent fields are missing or corrupted in a message. Manually designing and implementing a search across all possible arrangements would be uneconomical, but an automated, randomized method can efficiently perform that testing.
To perform fuzz testing, pick an API interface in your system, one that is listening and accepting input. That might be a web server, a public API, or any other interface that could be inspected with a packet sniffer. That lets users see the format of the messages and shows where an attacker could to try to gain access.
Within that API, identify the individual messages to test, for example, /user/create. Then, list the variables within those messages, such as the name, email, and country location.
To be successful, fuzzed messages must be valid so they can be parsed and understood by the destination machine. Purely random messages will be rejected easily. Instead, the messages should be formatted correctly with valid field names, but invalid information should be placed in those fields. For an even wider test, you can also randomize the field names. The application under test will then attempt to parse the messages and have to handle the data it received.
It can be challenging to gauge the level of randomness required for fuzzing. A single invalid field may mean a message is rejected without checking the others, so limit the corruption of messages as far as possible. Instead of purely random inputs, you could randomly select from a prepared bank of invalid values. That increases the chance that the message will be processed properly, but limits the randomness of the list you prepared.
The OWASP Foundation has a great guide to fuzzing and available tools here: https://owasp.org/www-community/Fuzzing. Whichever tool you choose will require configuration to specify which aspects of a message should be fixed and which changed. Fuzzing is a significant investment of time and may only find obscure bugs unlikely to arise in practice, so it is only valuable on the most critical interfaces. It is also most useful on external interfaces, which may receive invalid data. Internal interfaces are even less likely to send each other the randomness described here, although it is still possible. Feedback from the system is valuable: if you have a protocol that hits errors that only fuzzing could realistically find, it is probably worthwhile for your system.
Finally in this section, we consider the feedback your application should provide to users during failures. These should be specified, and your testing should check them all.
Giving user feedback on errors
Every application will suffer failures at some point, either through internal faults or failures of third parties on which it relies. The measure of a great application is failing rarely, recovering quickly, and providing feedback while the problem persists. During error conditions, letting the users know what’s going on is the difference between a good user experience and a support case.
Real-world example – Deliberately stopping the video
On one video application I worked on, we implemented protection against packet loss on video streams. One important tactic was to reduce the bit rate – if the available bandwidth had dropped, we needed to fit our video stream to the available speed. That meant reducing the quality of the video, and sometimes even stopping the video entirely so that the audio could get through and users could still talk to each other.
Unfortunately, we didn’t give the user any indication of what the system was doing or why. They just saw the video quality degrade, and their video stopped working. The feature only made it as far as internal testing before we had many complaints. We were taking reasonable steps to mitigate a real problem, but we couldn’t ship the feature until we also gave the users feedback that their poor network connection was causing all the issues.
Alongside failing as early as possible, we can add the requirement to fail as precisely as possible. A poor application will just throw an error that a particular line of code encountered an issue. If you’re lucky enough to have a stack trace, you need to examine the variables to find one that might be causing the problem. Good code will validate its inputs, raising an error if any are invalid, indicating which one and why. Chapter 10, Maintainability, has more information on the importance of that internal feedback. All the error types discussed in this chapter should raise internal events to let the development team see what happened and why. In addition, they should give user feedback.
When you know why a failure occurred, you can let the user know. Whether on a hardware screen, an app interface, an API response, a web page, or any other interface, the requirement is to be as specific as possible. If an external connection fails, the user’s network may be down. That is a vital error to report since the user could fix it themselves.
Other errors are intermittent. If it is worth the user retrying the operation, let them know that. Again, give them as much information and power as possible. If they might be able to recover the system, tell them that. If performing the same operation is only likely to result in the same error, let the user know that. Don’t leave them fruitlessly trying the same requests until they eventually give up, which is the worst possible outcome.
If a transaction could legitimately take a long time, then let the user know that. They should have immediate feedback that their request has been received successfully and that your application is working on it. That might be in the form of a spinner or an intermediate screen. Without that, you risk users retrying operations that were already in progress, creating additional system load, and possibly delaying their response even further. For more on user feedback, see Chapter 8, User Experience Testing.
Most errors are, almost by definition, unexpected. If you knew that your application could fail that way, you would have protected against it. In that case, be honest with your users, too – let them know that something unexpected has happened and the application needs to be fixed. That fix, at least, involves identifying this error specifically so you can provide a better error report and fail more gracefully.
Summary
In this chapter, you have learned about testing error conditions within an application. These tests are designed to cause failures, but they should be caught early and be as limited as possible by expecting the issues and handling them gracefully. Unexpected errors, especially ones that persist over time, cause a poor user experience, are difficult to debug, and may cause other, much worse problems.
To test error cases, you should push the system beyond its specified limits, try the timeouts on messages, trigger communication failures with network errors, inject invalid fields, and fuzz messages with random data.
Carefully consider the priority of the error case testing. It is a lower priority than the rest of functional testing, which guarantees a new feature or application is working in usual cases. Public interfaces or mission-critical applications must be resilient to errors and perform well during expected operations. Even for less critical applications, if you don’t test for mistakes in advance, you will have to spend time debugging them when they appear in real-life situations. Whatever the error is, give the user as much information as possible to ensure the best experience.
In the next chapter, we will return to the customer-facing aspects of an application by considering testing for user interfaces.