
11
Destructive Testing
Destructive testing is a great way to find defects. By deliberately triggering specific errors, subsequent problems often occur. Even more so than error testing, as covered in Chapter 7, Testing of Error Cases, destructive testing gives you the chance to take the system out of its usual modes of operation to check its subsequent behavior.
These tests cover disabling communication with remote systems to check on retries and recovery. Your system cannot guarantee it will ever receive a reply to a message, so these scenarios need to be checked. Some subsystems are designed to be redundant, so we also consider testing that resilience. Disabling other subsystems will cause functional failures, so this measures their extent and recovery. Unfortunately, failures in remote systems will happen one day, so checking their behavior is a vital source of real-world bugs.
This chapter also covers backing up and restoring. Until you have practiced restoring from your backups, they may be useless, so to have any faith, you need this form of testing. Your backups may rarely be used, but on the day that they are required, you’ll be glad you flushed the bugs from the system.
We’ll cover the following topics in this chapter:
- Advantages and disadvantages of destructive testing
- Failover testing
- System shutdowns
- Communication failure
- Chaos engineering
- Backup and restore testing
If you enjoy kicking sandcastles over at the beach just to watch how they crumble, these are the tests for you. After all the hard work of carefully building your system and getting it running perfectly, you can deliberately destroy it just to see what happens. The question for this chapter is, can your system run even in a degraded state? This is the time to take up your metaphorical dagger, and any other tools at your disposal, to break your system.
Advantages and disadvantages of destructive testing
Destructive tests cover a range of conditions that other areas of testing don’t touch. There is a class of bugs that you can only find with these tests, so make sure you include them in your test plan. The following table describes the advantages and disadvantages of destructive testing:
|
Advantages |
Disadvantages |
|
The only way to detect this class of issue |
Tests rare cases |
|
Verifies your resilience and recovery plans |
Requires specialist environments, tools, and tests |
|
Need to filter valid failures from invalid ones |
Table 11.1 – Advantages and disadvantages of destructive testing
After completing destructive testing, you will have much greater confidence in the resilience of your system to handle a wide range of adverse conditions.
On the downside, these tests can be de-prioritized compared to the core black- and white-box functional tests. This is particularly dangerous because system failures happen regularly and trigger issues. These cases may appear rare, but you will come across them before long.
These tests can be slower to run due to you needing to wait for timeouts or system recovery and require dedicated environments, tools, and configuration. Because they disrupt the system’s performance, they will delay other users if they are run on shared systems. Ideally, all these tests should be run on a separate installation if you have the resources and the time to set that up.
These tests also need dedicated tools to trigger specific failure modes and specialist configurations. This higher barrier of entry can cause delays, and, like all non-functional tests, they should be run after the functional tests. You can only test system recovery if it was running correctly in the first place.
The final challenge for destructive tests is identifying valid and invalid failures. When part of the system is down, some functions will be unavailable, so you need to be clear on exactly what the behavior should be in those circumstances. This detail might not be in the specification, so it will need to be added. Finding errors and diagnosing issues is also harder because the system will have many alarms due to the planned outage. Nevertheless, finding unnecessary dependencies and parts of your application that could keep working, despite a partial outage, is important information for your company.
Destructive testing is an extension of testing for error cases, as described in Chapter 7, Testing of Error Cases, but those tests involve sending invalid data to a working system. The difference here is that you deliberately disable your system in some way. This is also known as failover or disaster recovery testing, which tests a unique set of circumstances. First, we will look at disrupting parts of your system that shouldn’t cause outages, also known as failover testing.
Failover testing
Some parts of your system may be resilient to specific points of failure, so a great place to start destructive testing is to ensure those failovers happen successfully.
Designing destructive testing requires detailed knowledge of your system’s architecture. Which elements interact with each other, and what is the failure mode for each of them? What classes of redundancy are used by the various parts of your system? Ensure you understand these workings and how your system should behave in failure cases.
Classes of redundancy
Redundant systems could include a pair of switches both capable of routing all the traffic, multiple web servers to which traffic can be sent, and database systems such as Cassandra that are capable of continuing when one node is down, among many others. Redundancy may be at the hardware or software level, although the approach and items to check are equivalent in both cases.
The important distinction for your testing is the failover strategy used by your subsystems, as illustrated here:
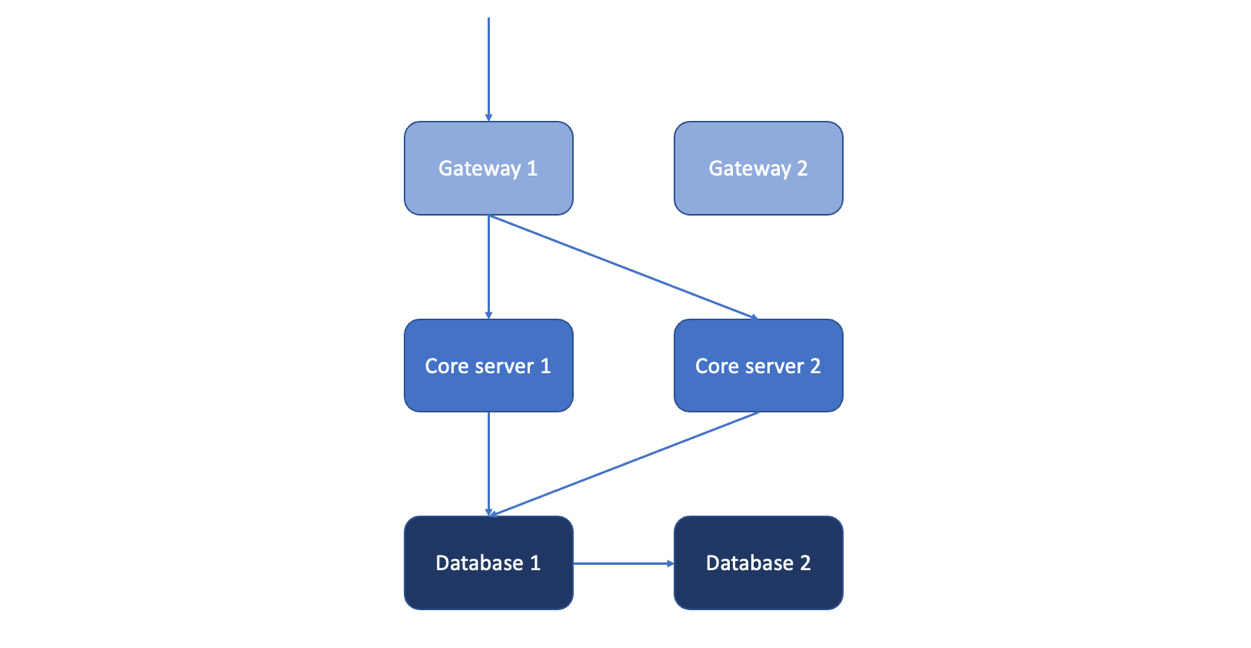
Figure 11.1 – Different failover strategies at different application layers
In this example, the pair of gateways work in a live-standby configuration. Only one accepts traffic at any time, but the system is capable of automatically detecting a problem with the live unit and using the backup instead. To test this, disable the live gateway and check that the automatic detection and rerouting properties send traffic to the second unit within the required timeout.
At the next stage, the core servers are configured in a live-live configuration, with both accepting live traffic simultaneously. Failover for this arrangement is faster since one server remains online and accepts traffic, so only transactions in flight during the failure should be affected. Once the gateways recognize the outage, they should reroute all traffic to the remaining server. Again, your task is to check that the outage is detected and that the system responds quickly and correctly.
At the lowest level, the databases work in a live-standby configuration, but unlike the other servers, they are stateful, with the master live-streaming its state to the backup. If you lose the master, you will lose any transactions it hadn’t had time to synchronize. Again, your system must detect the failure, reroute the traffic, and mark the backup database as the master. On recovery, the previous master database needs to resynchronize and become the backup, as described in the Failover recovery section.
Real-world example – Failing the failover server
I once worked for a company that hosted a private cloud running in a cold standby arrangement. Our core database ran in location A, with a backup ready to be brought live in location B. The control system to perform the failover was also hosted in location A.
This was a bad arrangement. Location A had an unreliable network and one day, we lost contact for several hours. Our main database went offline and, of course, we also lost the control system. Our backup database was reachable in location B, but we couldn’t tell the rest of the system to use it. Make sure you separate your core servers from the ones controlling any failovers.
If your system doesn’t have these automatic failover mechanisms in place, then implementing them is a priority. Testing non-redundant systems will be described in the System shutdowns section.
Performing failovers
Before performing a failover, ensure that your system is running correctly. You must start from a known good state before disrupting it. First, start a task to check a particular function – for instance, regular requests of a web page, running a ping command, or an ongoing action such as a video call. Then, shut down the subsystem under test. You need to check the behavior over two different periods – during the transition and after the failover when the system has recovered.
Throughout destructive testing, there are two failure modes to consider: graceful shutdown and hard shutdown. A graceful shutdown means invoking the software to stop itself, giving it time to finish any operations it was performing – for instance, closing external connections and completing I/O tasks – before stopping the software. The alternative is a hard shutdown, where you kill the process or otherwise completely stop the service without warning.
It can be helpful to ensure that graceful shutdowns are indeed graceful and cleanly finish their operations, but for destructive testing, hard shutdowns are the more interesting case. They test all the conditions graceful shutdowns do and more because they check that systems can recover from interruptions. Hard shutdowns also mimic crashes or hardware failures more realistically. In this case, systems will be interrupted rather than having time to finish their operations. While it can be useful to test both, hard shutdowns are the priority. If you only have time to try one type, use that one.
During the failover measure, ask yourself the following questions:
- What is the user experience?
- What monitoring alarms are raised?
- What errors are shown in the logging?
- Are there any unexpected side effects?
- What is the load performance?
To measure the user experience, you can set up a repeating check that runs throughout the failover event. You should see a pattern of successes, then failures, and then successes, with the failures lasting no longer than it takes for the system to recover. Those repeating checks can test multiple levels, such as client connections, web page loading, and system actions such as creating new entities. Likewise, your monitoring should report how long the system was unavailable, if it can detect issues as short as a failover. Error logs should definitely report the problem.
To measure load performance, run a load test while performing the failover. Instead of creating entities one at a time to measure the functionality, create them at the highest rate the system can sustain. This is likely to trigger failures, so you will need to decide what success rate is required. For a longer discussion on that class of tests, see Chapter 13, Stress Testing.
You can also add impairments to mimic real issues. There is the risk that your test environment is too perfect and controlled, which doesn’t represent the live system well. You can add all network impairments described in Chapter 7, Testing of Error Cases, such as latency and packet loss, to see how that affects the failover times, alarms, and user experience.
Remember to leave the failover in place. Problems may only become apparent after minutes or hours in the new state, such as memory leaks or performance degradation, so don’t be in a hurry to recover the service. Leave it disabled while performing another test to check that the system can function well while failing over.
Failover error reporting
Check that your application raises alarms while a subsystem is down. Generating a warning for a machine being offline is simple enough; hopefully, that is already in place. It’s harder to filter out alarms that are just effects of the main issue. If a web server is down, you shouldn’t have 10 errors from the edge servers telling you the same thing. As we saw in Chapter 10, Maintainability, alerts can be made dependent on each other so that it’s easier to find the source of the problem.
More importantly, are there any errors that shouldn’t be present? Are there any unexpected failures that could be avoided? Check your monitoring carefully to ensure the failure is as limited as possible.
In the logs, checks the errors that are raised in the same way. Many alerts will be related to your deliberate outage and, unlike monitoring, the knock-on effects cannot be filtered out. Again, you are looking for any extra errors beyond what you expect in that state.
Failover recovery
The main pass mark for failover testing is that the system should recover within the specified timeout. If it doesn’t, that’s a major bug to raise.
Given that the system does recover, carefully check that all key aspects are working now that you’re on the backup system. This will vary, depending on the part of the system you are testing. The primary functions, such as loading pages with one web server/database node offline, are easy to check. But can you add new users? This operation requires pages to load, and the database’s writes and reads, for instance. The details will depend on your system, but if possible, perform an entire regression test run while one part of the system has failed.
After the failover, you should measure the following aspects:
- How long does the system take to fully recover?
- Is all functionality restored?
- What monitoring alarms are still being raised?
- What errors are shown in the logging?
- Are transactions dropped, or does the system recover within its timeout?
- Measure server metrics for the remaining machines, such as the following:
- CPU usage
- Memory
- Disk usage
- Thread/process counts
The time taken for a failover to occur is one of the main differences between a graceful and hard shutdown. During a graceful shutdown of a redundant aspect of the system, the downtime should be minimal as it closes its current transactions and lets the other parts of the system know that it is going offline. In contrast, during a hard shutdown, there will be a delay waiting for a timeout while other parts of the system realize that the service is offline and initiate failovers. Measure the time carefully, from shutdown to full recovery. You’ll need to work with the development team to specify the expected time and how long would be too long to wait.
Compare the failover time to the transaction time for your system. If your web requests time out after 10 seconds, but failovers take 12, you will drop requests that began at the start of the failover. Those that started partway through the outage will succeed when the server recovers. Check your retry times and timeouts compared to your failover times; waiting a little longer for retries could make many more transactions succeed.
Measuring the system’s throughput once it has failed over should be part of that regression test plan, as described in Chapter 13, Stress Testing. The product specification should state the capacity when in failure mode. Should the system be capable of the same loading even when failed over? Or should the system be capable of more than twice the load you usually receive, so running at half capacity is still sufficient for your service? This is your chance to measure that degraded performance in practice.
System recovery
Finally, recover the disabled subsystem and ensure your application returns to its initial state. No monitoring alerts should persist, and all transactions should continue as normal as the system comes back online. Recovery is the most important step and shouldn’t require manual intervention. Any additional actions you have to take can be raised as bugs or feature requests for future improvement.
For stateless systems, coming back online is simple – they just need to be running. It’s more complex for stateful machines, which will need to resynchronize. For databases, this means copying the transactions they missed while offline. For processes that periodically read data, they must go back and catch up for the period they missed. In my experience, this area has rich pickings of bugs. Refer to the list of variables you can test for time fields from Chapter 5, Black-Box Functional Testing; you can reuse them here. What happens if the outage runs past midnight? Or the synchronization has to copy from another time zone or across a daylight savings change? This involves complex logic that you need to test.
After failover testing, you must move on to any parts of your system that aren’t covered by redundant systems and will affect the live service.
System shutdowns
Which parts of your system are single points of failure, and whose removal will disrupt the service? Like failover testing, for these services, you can mimic crashes, hardware failure, loss of power, or cloud computing services being down – anything that makes a subsystem unavailable for a prolonged period. Examine your system architecture again to identify all the possibilities so that you can work through them systematically.
Testing during a shutdown is often complicated due to the exact behavior not being specified. In some organizations, it is difficult to carefully define the behavior of a fully working system, let alone cover the different failure modes. Work with the developers and product owners to determine the performance in these situations.
In addition to single points of failure, you can trigger multiple outages or major outages – rather than simulating losing one switch, for instance, what happens if the entire site or cloud service has an outage? You may have no failure plan in place; if your cloud provider goes down, you might expect your service to be down until they recover. If so, make a note to plan for that contingency, at least in terms of communication. In operations, my motto was that everyone has a bad day. To control your service’s uptime, you must test backups for all your subsystems.
Shutdown test plan
Having identified the systems to disable and the behavior you should observe in that situation, you can now run through a test plan for shutdowns:
- Check the degraded functionality of the overall system
- Check the behavior of other services
- Check the loading of the degraded system
- Check the monitoring during the outage
- Check if the recovery is successful
- Check the behavior after recovery
First, test the system’s functionality to ensure the outage is limited to the subsystems you have shut down. Are there any further issues? If possible, run adapted regression testing, identifying which tests should still work. Are there any functions that should work but have been disabled by the outage?
Real-world example – Non-redundant VPNs
At one company I worked in, we had two offices and could connect to the VPN of either. If one site lost its connection, we could connect to the other. However, when one office went down for real, we lost access to its LDAP server. Users connecting to the other site couldn’t authenticate, so we couldn’t connect to either location.
Look out for any surprising losses in functionality when half of a redundant system is down, especially any that defeat the whole point of having redundancy. These may be hard to work out, so a practical test is the best way to be sure. Usually, these inefficiencies cause no problems other than imperceptible delays and loading, but during an outage, they can significantly degrade behavior. Removing unnecessary dependencies is vital for the day when you face such an outage for real.
Next, test for incorrect behavior in the remaining system. For example, check for repeated retries sending constant messages. These might be from applications back to the server or between servers within the system. There should be exponential backoffs to limit messaging, which rapidly increases the time between messages to reduce the load both on the sender and the receiver. Without those backoffs, it’s easy for you to DDoS yourself as your applications all spam your servers with messages when they fail to receive replies. It might look funny when a single application gets itself in a loop, but when a hundred thousand users can’t reach your service when it’s recovering from an outage, the humor wears off.
Shutdown error reporting
System errors should be reported back to the user. There will be expected errors, but they should be controlled and informative, saying that the system cannot complete their request temporarily. They shouldn’t give incorrect information, such as suggesting the user immediately retry, and they should be explicitly designed rather than silently timing out or presenting web server errors or backtraces. Those are bugs that need to be fixed.
Check the monitoring during the outage. Make sure there are accurate error reports that track exactly what has failed. Even better, add dependencies to your monitoring so that the system expects specific problems to follow from one core issue. For instance, if one server goes down, you don’t need 20 messages from your other servers telling you they can’t reach it. It’s much better to have a single, clear error rather than sifting through many consequences. For more on that, see Chapter 10, Maintainability.
Next, when you restart the server, does the system fully recover? Are there any manual steps you need to take before the service is restored? Those are improvements to make for the future. This may include VMs that have not been set to start on boot, services starting in the wrong order, or other common issues on a restart, but the system should be able to recover automatically. Anything else adds delays and risk to recovery from an actual outage.
Killing processes
As well as long-term outages simulated by failing over and shutting down the system, you can also mimic crashes by killing services. As mentioned previously, the critical test here is to ensure they recover without manual intervention. There should be errors and failures while the service restarts, but it should come back cleanly.
First, make a list of processes you can test. If you have an application communicating with central servers, this will start with the applications themselves, edge servers, core servers, and the database. Within each server, consider any web servers or other communications, then all processes and regularly scheduled jobs that run there.
As this is a quicker test, you can try this at many points within the state machine for your product. You can try this at several points in the signup cycle for a new user, for instance, or when receiving different API commands. Check what happens if a crash occurs during an upgrade, startup, or shutdown. The system should be left in a consistent state when it recovers – if a user needed to confirm their email address, for instance, is that still the case when the system comes back? As we saw in Chapter 6, White-Box Functional Testing, you need to identify all the different states and verify each.
While restarting services, look out for errors related to database entries. Database changes that should be performed as a group need to be committed in a single transaction, and this form of testing is one way to find those that aren’t. A crash interrupting an unprotected transaction can leave the database in an inconsistent state. Consider a Users table, where each user has related statistics in another table:

Figure 11.2 – Database tables before adding entries
The user ID in the Statistics table is a foreign key in the Users table. Whenever a new user is added, you need new entries in both places:
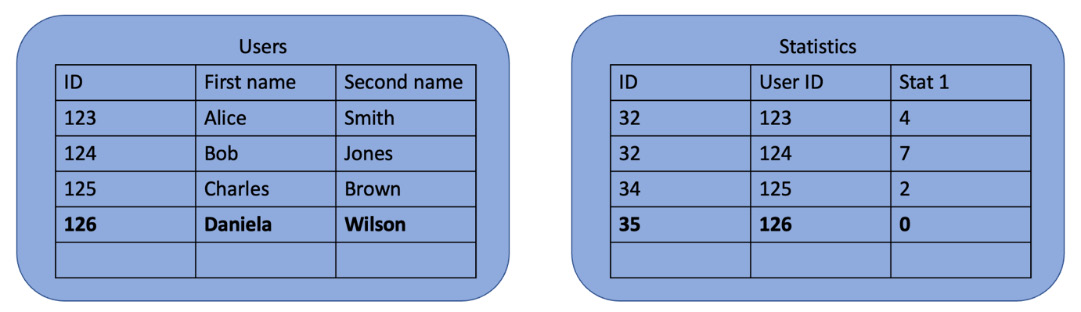
Figure 11.3 – Database tables after successfully adding an entry
One table has to be written first, however. If the Users table is updated, then the application suffers a crash, and it could be left in an inconsistent state:

Figure 11.4 – Database tables interrupted during writing
The transaction should be protected so that if you can’t write to both tables, the operation completely fails and writes to neither of them. However, if that’s not the case, then you may be left with a user partially created. They will appear in the application but fail as soon as they use their statistics and need to be manually fixed.
It is not easy to trigger a crash at precisely the right time, so killing processes isn’t a great way to find this class of errors, but it is most likely to encounter issues hit by real crashes. For example, the longer a database transaction takes, the more likely it is to be hit by both your testing and a real-life crash.
Code inspection is a better way to find these errors, which involves identifying the database operations that have to succeed or fail together. They are hard to find in testing, but deliberately slowing down database operations with debug commands or other I/O loads increases the chance of hitting errors.
Starting back up
Shutting down is easy; the trick is starting back up again. This also needs a careful test plan:
- Do all the machines automatically restart?
- Do all the necessary processes start?
- Are there any dependencies on startup?
- Do processes start in the correct order?
If you are adding a new machine or process to your system, check that it has been set to restart and in the correct order relative to its dependencies. Starting too early or late might cause delays or, in some cases, prevent it from booting at all.
If a startup is successful on its own, try shutting down combinations of services simultaneously to see if they can recover together. There can be many combinations, so prioritize those that rely on each other and interact in some way. For example, if both services require the other to be running, both being down would prevent either from starting.
Real-world example – After you. No, after you
In one company I worked at, we introduced a new protocol between our core servers. They had been mainly independent before, primarily communicating via a shared central database, but now, they could talk to each other directly.
This change introduced a host of problems, not least when we did the first upgrade after running the new system. The new protocol failed to start on our servers and the reason, it turned out, was that we’d upgraded them at the same time. So long as one side of the protocol lost connection, it would retry and eventually connect. However, if both sides went down simultaneously – for instance, due to an upgrade – it went into an error state, and neither side could recover. Restarts worked, but not simultaneously.
While restarting may generally work well, does it still succeed when your system is under a realistic load? Here, you will need load-testing tools to mimic your users: client connections, online players, data processing, or whatever service you provide. How well does your system cope while starting up while being hammered with connection requests or with a long processing queue waiting? That’s the situation you’ll face if there’s a crash during live operations, so that’s the one to test.
Next, we will consider a more subtle form of destructive test, where your system continues to run but different subsystems can’t communicate.
Communication failure
As well as shutting a service down, tests should introduce another common, realistic problem – communication failure. Like system outages, these are real scenarios: blocking communication simulates a network outage while all the services are still running.
Blocking communication allows for a more specific test – you can let most of the system continue as normal and just restrict access between two particular processes. This can test specific failure scenarios, although they may be less realistic. You should work through different options, varying between large realistic outages and small specific failures that are less realistic but test distinct failure modes within the system.
You can also alter when communication failures occur. During a message sequence, test what happens if you fail to receive a reply to each message. Like white-box testing state machines, this ensures there is correct error handling at every stage. This will need careful scripting so that you can coordinate sending messages with the network degradation on the destination machine.
When blocking traffic, always block the receiver rather than the sender of the message. While testing a service, it can be tempting to block its messages, as shown here:

Figure 11.5 – Blocking the service under test from sending messages
Since you are working with it already, this is often easy to do. However, blocking the sender lets the server know that the message failed, which will trigger a different error case compared to not receiving a reply. For a realistic outage, you need the receiver to fail to respond:

Figure 11.6 – Blocking the remote service from receiving messages
This might be harder to configure, as it needs to accept all other traffic, but setting up such filtering is necessary for a realistic test.
Communication failures are harder to emulate than shutdowns. It’s simple enough to turn off parts of your system! Communication failures, in contrast, will need dedicated tools to simulate a network failure in a controlled way, such as iptables and netem.
Whichever method you use, it’s helpful to run the same tests as for system shutdowns: check the system’s overall functionality for issues in other services, as well as loading, monitoring, and recovery.
Next, we will look at how to automatically perform destructive testing to look for possible issues using Chaos Monkey.
Chaos engineering
While it’s good to think through which combinations of systems and services you can disable and restart, there is always the possibility that you have missed something. For confidence in your application’s resilience, you can implement Chaos Monkey to automatically cause failures throughout your system.
This idea was made famous by Netflix, which introduced a program called Chaos Monkey to deliberately disable parts of their system. The best way to ensure you are resilient to any outage and can recover from it is by routinely doing it for real. Recall the options listed in the Classes of redundancy section:

Figure 11.7 – Different failover strategies at different application layers
The gateways represent systems that run in live-standby mode, with only a single server taking traffic, but a backup ready to come online. The core servers run live-live, with both taking traffic, and the database is also live-standby, but with replication to keep their state synchronized. Chaos Monkey will periodically disable different servers, testing each kind of resilience and recovery for your particular subsystems.
Its actions are limited, for instance, to disabling only a single subsystem at a time. To apply this to your architecture, you will need to list the relevant machines and identify which are supposed to have redundant systems in place. Then, Chaos Monkey will periodically select an item from that list at random and disable it, measure the key performance metrics (see the Failover testing section), and then re-enable the system and measure again.
An even better test of your resilience is to leave system-level regression testing running in parallel with Chaos Monkey to ensure that all functions are available while different subsystems are disabled. Where systems are independent, it should be possible to disable them simultaneously and see no effect – for instance, turning off one switch, one edge server, and one database to let the system run on the other half of those pairs.
Chaos Monkey provides resiliency load testing. While performing a single test might show that the system can recover successfully, can it recover every time? Are there timings or external scenarios that might cause it to fail? You can build confidence that the system can recover across various situations by repeatedly triggering different failures in the same area. We’ll see more benefits of load testing across multiple domains in Chapter 12, Load Testing.
Using Chaos Monkey is analogous to fuzz testing on interfaces (see Chapter 7, Testing of Error Cases). Rather than thinking through different problematic situations and combinations, you can add the possibilities and let the program work through them randomly, eventually covering all options. If you are truly confident, you can run this on your live instance, although I would recommend a dedicated test system first. When running successfully, you have far more confidence in your system, its performance when degraded, and its recovery.
Next, we will consider testing your backup and restore process.
Backup and restore testing
A crucial part of destructive testing is ensuring your backups can restore your system correctly. Your backups are worthless until they’ve been tried in practice. This is a significant operation and highly disruptive, so as with all destructive testing, you’ll need a dedicated test environment for it. The following is a checklist of tests to run around backup and restore:
- Is the system fully functional during backups?
- Are there different types of backups you can restore from?
- Partial or full backups
- Different database systems
- Streaming replication versus from one point in time
- How long do backup and restore operations take?
- Is there a warning if taking a backup is disrupted?
- Ensure you can restore from all backup types
- When restoring from a backup, is everything replaced?
- Are any manual steps required when restoring from a backup?
Taking a backup can be a disruptive operation in itself since it involves database tables being locked and operations being paused while copying. There are ways around these issues, but if related data is stored in separate locations, it may be necessary to lock different parts of the system while copies are taken to ensure consistency. Improving those issues can mean a major system re-architecture, so they are tough to fix. You can provide measurements on which functions are disrupted and for how long. Moving backups to the quietest periods of the week can mitigate their disruption, but data storage must be carefully designed to avoid issues.
Do you take different types of backups? If so, you will need to practice restoring each of them. For instance, if you have a streaming-replicated database, can you failover to the other unit? They contain up-to-date information, so if data is deleted, that deletion will be rapidly copied to the backup too. To recover lost data, you also need regular static backups. They will be outdated and won’t contain the latest changes, but they will let you go back to an earlier version if recent changes have been problematic. You need one test for each kind of backup you keep.
How long is it acceptable for backup and restore operations to take? Daily backups ideally take less than 24 hours, but you will have to judge how long is too long for your system. Since that depends on the quantity of data, you will need a large test installation to check it. Otherwise, you can measure the backup time from the live instance. More important, though, is the restoration time. In an emergency, how long would it take you to recover? You will need a large amount of test data to replicate this, but it is essential to know because it can be a long time for a large system, depending on your tools and architecture.
Your backup process should be resilient to failures. If you have a distributed system with data stored in different locations, a failure in one place needn’t mean the backup fails overall. If you have 10 data stores and one is unavailable, you can back up the other nine and raise a warning that the backup only partially succeeded. Even within one database, you can perform a partial backup to save only some of its data. If you have that in place, then you need to test that you can restore both full and partial backups and that those partial backups leave the system in a consistent state afterward.
Check that your monitoring system covers the status of your backups. If you deliberately disrupt it by stopping it completely or partially, do you get a warning to let you know? This should be as specific as possible; if the backup partially succeeded, does the monitoring process show you which part failed and why? The alarm should be clear about how out of date your backup is now and when the last backup succeeded.
Whether streaming from replicated or static files, partial backups or full, testing the restore process is the most crucial part of the process. You need to try all backup types, clearly recording the system’s state beforehand to ensure the changes are rolled back. Does the backup include all the configuration for the system, or is any missing? Look out for any recently added features, especially for supplementary data stores. Is anything stored outside your primary database, such as data files or logs? Check their state – how do the logs appear after they’ve been restored? Are there different steps to follow to restore other parts of the system?
Is your system left in a good state after performing a restore? If there are multiple data stores, do you have to restore all of them simultaneously? What happens if you don’t? Do your backups contain enough information to perform all those restorations and are they automatic run from a single command? Or are there multiple steps?
Keep careful track of all the manual steps required when restoring from a backup. If you have different data stores, do they each need separate steps and is the ordering important? Wherever possible, write a script to ensure that all the steps are taken in the correct order. In a distributed system, you may need to have access to many different subsystems, with enough permissions to read and write all the data there. Do specific steps have to be performed in a given order? Again, a script will guarantee that happens.
What checks can you add during this process to ensure that each step has succeeded before proceeding to the next? If there are several manual steps, then these checks need to be documented, but you should also raise an improvement to make them part of your script. If the script discovers any failures or surprises, it should stop in case continuing the restoration would leave the system in a bad state, but it should always be possible to override those checks. It might be less work to let the restoration continue and then fix the issues than it is to fix the problems and then restore. There are likely to be manual decisions during an operation as serious as restoring from a backup, so make sure any script gives you the option for that to happen.
Once you have restored your system as completely as possible, look out for subsequent bugs. For instance, are any sequence numbers repeated when you take the system back to an earlier state? Does that work successfully for both full and partial backups? Do connections still work to external systems, especially those that contain stored data? You can test this in both directions – if you delete data, is it restored correctly, and if you add data, is it removed correctly by the restore process? Is the state completely synchronized with those external systems, or is there a mechanism to detect inconsistencies and report them?
Real-world example – Only restoring half the configuration
In one company I worked at, our service stored some files in an external service. We maintained references and retrieved them from the service when our customers requested them. When we deleted a customer, we deleted their files on the service and our reference to them.
Problems arose when restoring from backup. The sequence was as follows:
1. Take a backup.
2. Delete a customer.
3. Restore from backup.
In that case, we deleted both the file and our reference to it in stage 2. In stage 3, we restored our reference, but we couldn’t recover the deleted file. We were left with a broken reference, and our system had no way to reconcile and fix the difference.
Restoring from backups rarely happens, but on that day, you need confidence that it will work. I’ve never personally been bitten by a restore operation failing. Still, there are tales in the industry of nightmare scenarios, lost weekends, and missing data as engineers struggle to recover systems affected by failures or attacks. It’s a vital part of testing, so check it regularly.
Summary
In this chapter, you learned about the importance of destructive testing and the main areas it covers. Deliberately degrading your system by stopping services or servers, blocking communications, triggering failovers, and restoring from backups are all vital areas to cover to ensure your system will perform well in live environments. None of these areas test features that customers use. They generally have far less development time devoted to them than features that provide users with more functionality or improve customer experience. However, without checking this behavior, how the entire system runs is at risk.
With areas of the system designed to be redundant, you need to ensure those failovers occur correctly. The monitoring process should report the error, but the overall functionality should not be changed. There may be a period of transition while the system detects the issue and reroutes traffic or processing, so you need to measure that time and ensure that full functionality is restored once it is complete.
For areas that are single points of failure, check the behavior when that service is down. There will be some service degradation, but it should be limited to the function provided by that service. Again, does the monitoring rapidly and correctly report the outage? Does the rest of the system keep functioning correctly? Are there any invalid behaviors in the rest of the system, such as constant retries? Does the service recover successfully once the service has been restored, without further manual steps? If the answer is no to any of those questions, then there is a defect in the system.
Communication failures are effectively similar to parts of the system being offline since they prevent particular messages from being sent. This is the realistic case of a temporary network outage, so you must ensure your service can survive. Are retries sent correctly, and does the system report the errors back to the user in a controlled and helpful way? Killing processes to simulate crashes requires similar considerations.
Once you have verified your system’s resilience, you can implement Chaos Monkey to constantly cause system issues. This provides much greater confidence that your system can fail over and recover from errors across many scenarios rather than just a single test.
We also considered backing up and restoring your system. This is a major operation that is rarely used, but you need to ensure it will work correctly. As a tester, it’s your job to provide that confidence. All backup types need to work, and you need to check the recovery of all the elements in your system.
In the next chapter, we’ll leave the system running happily but test your system’s maximum performance. Load testing checks that your application can handle peak activity and lets you plan for the future while proving test passes weren’t happy accidents and can be repeated many times across many different situations.