
11
Code Development Expectations
In this chapter, we’ll cover code development expectations for a TPM. Though programming isn’t a core competency that you should expect to see come up in an interview, it is foundational to project and program success. If we don’t understand what our team is doing, and if we can’t relate, push back, and advise, then we will constantly be in the dark.
Trust is a very important part of being a leader. You need to be able to trust that your team knows what they are doing and are making the right decisions, but you also need to be able to verify progress and be there for your team when they need your input. Without understanding the basics of programming, it will be hard to achieve the right balance of trust and verification. With that in mind, we’ll go over some fundamental code concepts that are most relevant as a TPM. These concepts are not exhaustive but will provide a good foundation for additional knowledge related to programming. Along with system design and architectural landscape design in Chapter 12, these topics are important to any TPM position in the tech industry. Not every TPM has these foundational skills, but the best TPMs I know in the industry do.
We’ll explore these code development expectations through the following topics:
- Understanding code development expectations
- Exploring programming language basics
- Diving into data structures
- Learning design patterns
Let’s begin!
Understanding code development expectations
TPMs are surrounded by software development teams and interact with developers, support engineers, and development managers on a daily basis. They are involved in technical discussions around requirements, release management, and feature and system designs. So, in the midst of all of this software talk, let’s explore what level of code proficiency is expected in the TPM role.
No code writing required!
As a TPM, your focus will not be on writing code yourself, but on getting it written through others. Of all of the TPMs I know and have worked with, only two—including myself—have written code as part of their role. I’ve heard of TPMs writing code in start-ups, and this aligns with our need to wear many hats because the number of people involved in a start-up is comparatively small and the need to step up has a higher chance of occurring. In larger companies, roles are usually tightly defined, and the overlap and opportunity have a smaller chance of occurring.
The type of code I’ve written as part of my role was only to help me perform my job and was not related to project deliverables. In one case, I was doing some data analysis (wearing the hat of a data analyst as we did not have one on the team) and needed to take service logs and extract client information from each call to get a list of clients. I started by just using simple text manipulation in a text editor but saw an opportunity to write a script to get the job done much faster, so I wrote it. A fellow TPM wrote a script to pull and format data from a tool into a status report, reducing the time to draft the weekly status report. This wasn’t strictly needed to do the job, and no one saw the code, but it made our jobs easier.
Though not required, writing this fit my style of management, and I also anyway enjoy writing code. I say this to illustrate that though some TPMs may write code, it’s by no means a requirement of the job.
That being said, you will be working directly with software developers, and to be an effective leader and communicator, it’s best that you understand the basics of at least one programming language. We’ll start out by looking at basic concepts of programming.
Exploring programming language basics
Most companies lean heavily toward a specific language or set of languages, depending on what the code is used for. Server-side applications in enterprise settings tend to prefer Java, whereas machine learning (ML) applications perform fairly well in functional languages or hybrid languages such as Python. Whichever language you find yourself closest to, you should learn the basics of that language. If the team you work with is heavily using a functional language and you only know object-oriented (OO) languages, use this as an opportunity to bridge the gap and learn the fundamentals of functional programming. There are books on both language types referenced in the Further reading section of this chapter to get you started.
As a brief recap, OO programming (OOP) is a language paradigm where the application is defined by a series of objects that can interact with each other. An object consists of data fields and methods that act upon the data fields. Most OOP languages also support events, which are methods that are automatically invoked based on the state of the application. As an example, in a standard Windows dialog box, the OK and Cancel buttons on the dialog box are both objects. Both buttons have an event to handle when a user clicks on the button. The buttons also have data, such as the text on the button, pointers to the OnClick event, and even font settings for the text. By clicking on the Cancel button, the button’s OnClick event will interact with the dialog box—which is the parent object for the button—and have it close with a special state denoting that the dialog’s request was canceled. The application that invoked the dialog box will then act upon the canceled state. Not all actions are driven by the user, often referred to as being event-driven, but the concept of objects interacting with each other is the central concept of OOP. The interactions are through a series of written-out procedures to manipulate the state—this makes OOP a type of imperative programming.
In contrast, functional programming utilizes declarative programming. In a declarative language, the code does not describe how to perform an action, only what the outcome needs to be. In the popular declarative language SQL, you are stating which data you need in the SELECT clause, which filter to apply to the data in the WHERE clause, and which tables to retrieve the data in the FROM clause. You are not stating how to retrieve the data (such as running a loop over the data and for each object, retrieving specific fields, then sorting the resulting list). The language will determine how to best retrieve the data on its own.
The declarative nature of functional programming puts emphasis on the function, which is a method that returns a value, instead of objects and their interactions with one another. Therefore, the data remains local to the individual functions, which reduces side effects by not allowing non-local data manipulation. The data returned by the function is all that has been manipulated.
Regardless of the language type, you should know enough about the language to read through the code and have a basic grasp of what it is doing. This is especially useful in organizations where the code base is accessible to you (not all companies have an open code base nor allow non-developers access). Being able to read a method and see what it does instead of finding a developer to explain it can be a valuable time-saver and will give you the chance to understand your services at a deeper level.
A good start to understanding a language, and your own services, is understanding the method, function, and API signatures. To do this, you need to understand the components of the signature as well as what that API is doing. The following code snippet takes a look at an example method from the original source code (in C#) for the Windows Mercury messaging app. We’ll examine the method signature and discuss the basics of what the method is doing as an illustration of the level of depth that is useful in Figure 11.1:
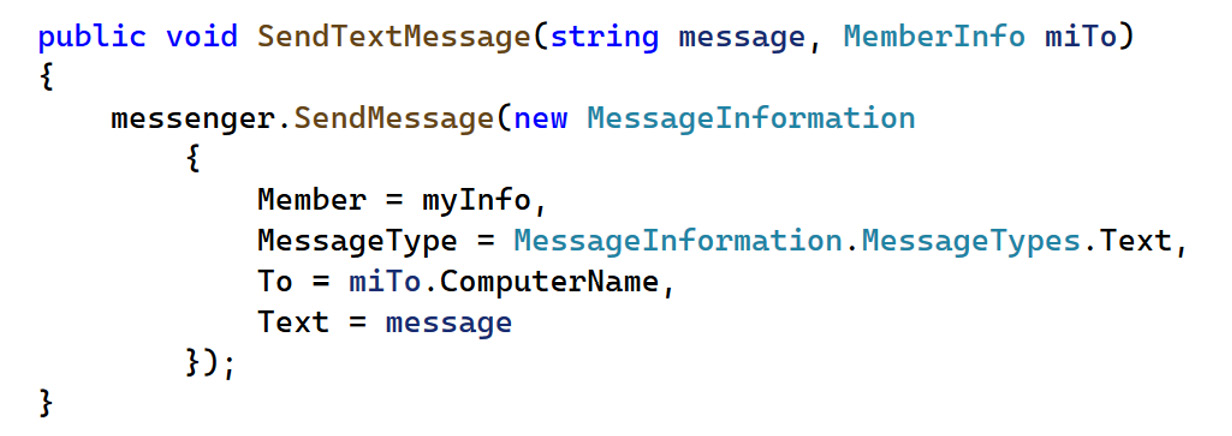
Figure 11.1 – Mercury code snippet
In this example, the method we are looking at is a method on the Member class that sends a text message to another client on the network. This is a method, as opposed to a function, as it is defined within a class and therefore has access to all information within the class. This tells us that the procedure does not return a value and is therefore a method. For a function, the keyword void would be an object or data type corresponding to the object or data type that the function returns. This method has two parameters: a string named message and an object of type MemberInfo called miTo.
Inside the method, the SendMessage method is invoked on an object named messenger. This method, in turn, is passed a single argument of a new object of type MessageInformation, which is instantiated inside the method.
There are several objects referenced within this method that are defined outside of this code snippet. However, some inferences can be made based on the names of these objects. For instance, we can guess the intent of the method is to send a text-based message from the current user to someone else on the network. Based on the method call to SendMessage on the messenger object, we can make an educated guess that the messenger object is responsible for sending the actual message. This is further backed up by the payload in the argument being information on the sender, client, and the actual message to be sent.
As you can see from this example, a full understanding of every construct in a language is not needed to build a good idea of what is going on. Following through from the method signature to what the method is doing can often build up enough context to understand what is going on. And if you have full access to the code, further investigation into these custom objects can solidify your confidence in what the method is doing and even where it is invoked from within the application. Though this is a method from within a class, this same exercise works for APIs of services and is extremely helpful in building an understanding of how the services and applications you work with interact with one another and the type of data they return.
Now that we have established a basic language literacy, we’ll move on to some fundamental programming constructs that will likely surround you in your day-to-day dealings with developers and SDMs.
Diving into data structures
Though a TPM is not held to the same level of proficiency as a software developer, we should understand the basic concepts of programming. We’ll cover the programming topics that come up the most in your day-to-day activities.
A Data structures and algorithms class was likely in your first or second year in college if you took a traditional route. As with most of the programming fundamentals, you won’t be using this yourself in your day-to-day work. However, you can think of them as a strong foundation for the language that your development team will be used in most conversations you have with them.
I’ll briefly go over a few of the more common data structures that I come across in design meetings, standups, and general work conversations. I encourage you to read through the books in the Further reading section on this topic for a more in-depth review. Even if you’ve taken the class and remember the concepts, it’s always good to refresh your memory.
Space and time complexities
Before discussing data structures, it is helpful to understand the key performance indicators (KPIs) that we measure them by. In a computer, random access memory (RAM) is where data is stored that is in active use, such as variables in an application. As RAM is limited, measuring the amount of space data takes up in RAM is an important consideration as it is a limited resource. The other consideration is the amount of time it takes to perform an action such as searching, inserting, deleting, or accessing data. This is especially true for OOP, where data is often accessed inside of loops that iterate over large datasets. The amount of time it takes to perform an action once is then compounded by the number of times the loop is run and can add up very quickly to a considerable time sink if the wrong data structure is utilized for the task.
Both of these measurements use what is referred to as big O (big “Oh”) notation. These measurements are essentially categories used for reference to understand the performance of a data structure or method. For this context, the big O notation is used assuming asymptotic growth and uses n to denote the input that impacts the growth. Essentially, these math functions represent the curve, or behavior, that the space or time performance will start to match as n gets large enough. As an example, if the amount of time it takes to access a specific element correlates linearly to where it is in the data structure—for instance, the fifth element in a collection—the big O would be O (n). As n increases, so does the time it takes, which is called linear time. However, if the amount of time it takes to access an element from a data structure is the same regardless of where in the data structure the element is, then the big O is O (1), or in other words, constant time. As a TPM, knowing where the complexity categories come from isn’t as important as knowing the relative costs associated with each big O. Figure 11.2 shows each big O category on a curve of operations versus elements:
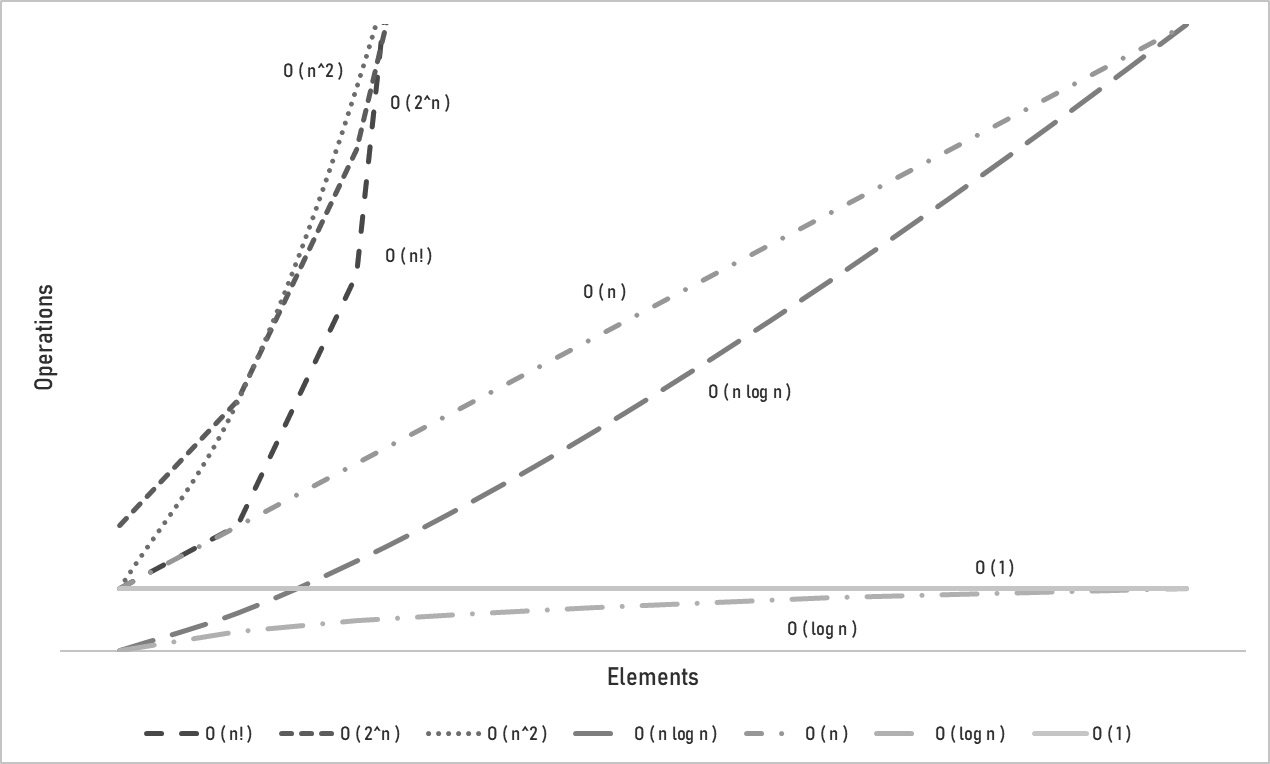
Figure 11.2 – Big O space and time complexity
As a TPM and not a software developer, this is one of the instances in which understanding the relative position of best to worst is more important than the how and why. In this diagram, we can see that a big O of O (n!) (n factorial) performs the worst once n gets large, and O (log n) and O (1) perform the best at near-flat curves. In the Data structures section, I’ll refer to the big O if it is of particular interest. It’s worth noting that these categories are models of the performance and won’t necessarily match real-world performance, especially as n becomes much larger than expected, as can happen in large-scale tech industry applications.
Data structures
There are a large number of data structures that you will come across in programming, so much so that there are entire books on this topic alone. I’ve added a good book that covers this extensively in the Further reading section at the end of this chapter. For now, I’ll summarize a few of the more common data structures that you’ll come across as a TPM listening and contributing to design reviews, standups, and various hallway conversations. The goal here isn’t to make you an expert, but to ensure you know enough to be comfortable in conversations and make informed decisions when appropriate.
Linear data structures
First up are linear data structures. These are a collection of objects that are accessed in a sequential fashion. In OOP, the most common way to act upon a large dataset is to loop through each piece of data and perform the same manipulation on each one. As such, linear data structures are some of the most common data structures you will encounter in OOP applications. We’ll discuss the three most common next.
Arrays are a sequentially allocated collection of values or objects accessed via one or more indices. The array can have multiple dimensions, the more common being a two-dimensional array, which can be visually thought of as a table with rows and columns. Arrays can be multi-dimensional as well and behave like a one-dimensional array where the value is an array itself. Since an array is sequentially allocated in memory, accessing a particular index is constant—a O (1) complexity—since the index represents the distance in memory from the starting point of the array, so to get to the 50th element, you add 50 to the starting point in memory.
Lists are a collection of objects that are accessed in a linear fashion where you can traverse forward and sometimes backward. Many modern lists also support accessing via an index, essentially making them a one-dimensional array of objects with built-in methods to manipulate the list. As such, they behave similarly to arrays in terms of complexity when an index is involved. Without an index, accessing a specific element has a O (n) complexity, and is constant with an index. In many languages, such as Java (ArrayList) and C# (List<T>), lists are internally structured as arrays but have built-in methods for manipulation. In this regard, lists are often preferred over arrays unless specific optimizations regarding size are required.
Dictionaries are a collection of key-value pairs where each key can only appear once in the collection, meaning that dictionaries are hash tables or hash maps—depending on the usage of the dictionary.
Figure 11.3 compares these three linear data structures:
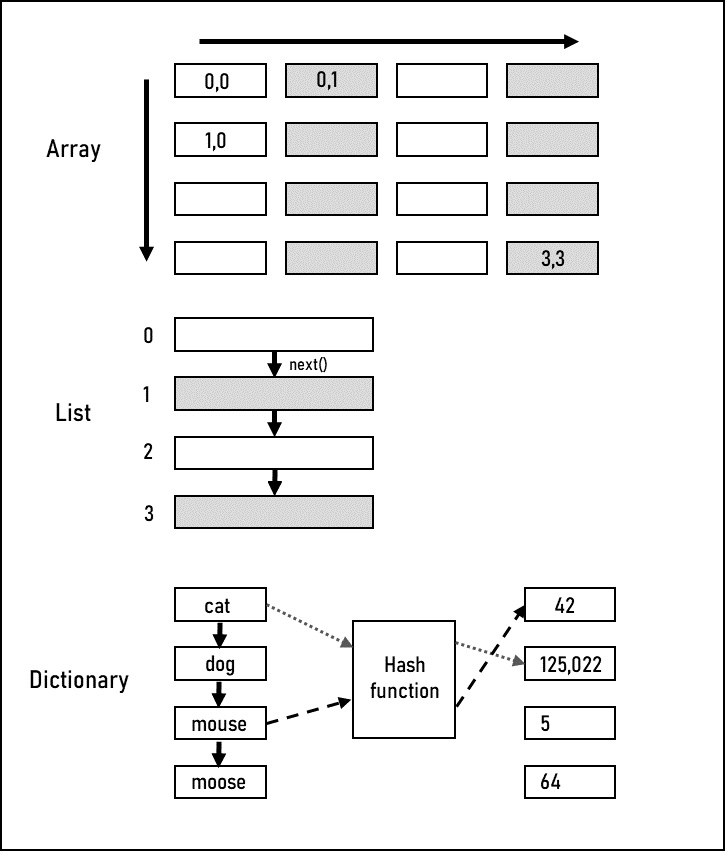
Figure 11.3 – Linear data structures
In this diagram, you can see that all of the data structures we’ve talked about so far are linear in that they have values that are accessed in a linear fashion, forward and backward, or directly via an index. Though a key is more abstract than a simple index, it is a direct accessor to a value, and many dictionaries allow you to enumerate through the collection using a next method. As these are all linear data structures, they have a constant O (1) complexity for accessing an element, but varying complexity for searching, adding, and deleting, depending on how each element is connected, or relates, to its neighbor. Arrays and generic Lists both have an O (n) cost for these actions as all items after the one you are adding or removing need to be reassigned to make room for the new element. If the list is sorted, this can be reduced to O log(n) by using a binary search. But if the list is a Linked List where there is no index, and every element is linked to the next element—and the previous element for Doubly Linked List—the operation is constant as only the references of the inserted item and previous and next elements need to be updated. The list doesn’t need to be traversed in any manner.
Now that we’ve discussed some of the common linear data structures, we’ll talk about non-linear data structures, including trees and maps.
Non-linear data structures
Trees are a collection of nodes, where each node can point to a collection of nodes called children where each child node can only be referenced once and the path between any two nodes is defined as an edge. This creates a hierarchical relationship to the data. There are many examples of trees in your day-to-day life, such as an organizational chart at work, or a phylogenetic tree that represents evolutionary relationships between organisms (this likely came up in a biology class!).
Graphs are similar to trees in that they are collections of nodes, and the path from one node to another is called an edge. Unlike a tree, however, a node can be referenced by more than one other node. Also, a node’s relationship to another node can be bi-directional. A graph is the computer science equivalent of a map graph in mathematics. The best real-world example of a graph is a road map. If the intersection of two or more roads is a node, then it’s easy to see where you can have a two-, three-, four-, and even five-way intersection. In this case, the roads are the edges that define the path between nodes, or intersections. In most types of trees and graphs, inserting, deleting, and searching all have the same complexity of O log(n), or logarithmic time, with a worst case of O (n).
Figure 11.4 illustrates a tree and a graph for comparison:
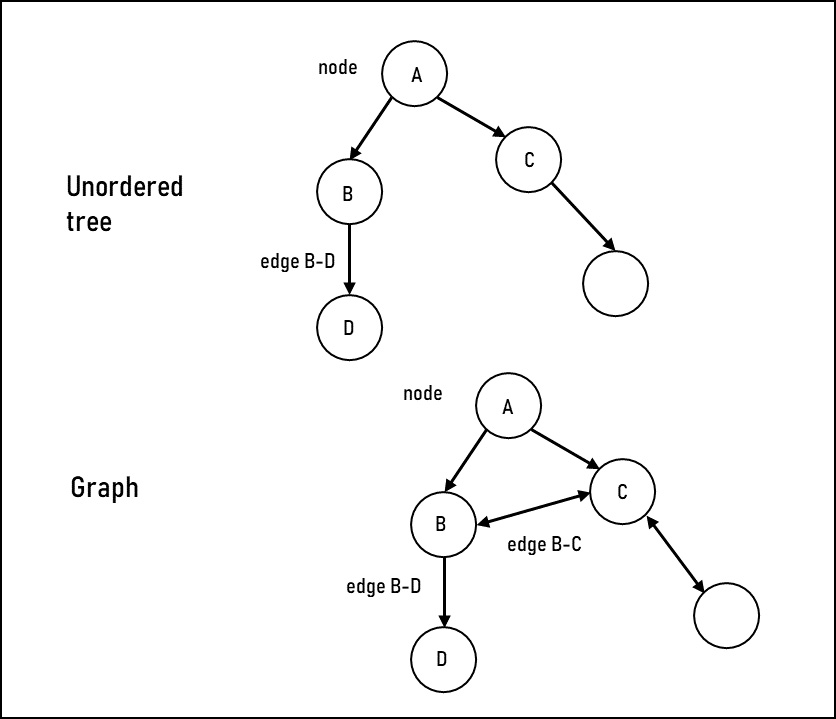
Figure 11.4 – Examples of non-linear tree and graph data structures
In this example, we have an unordered tree and a graph. The nodes are in the same locations to illustrate the similarities and differences. The nodes are represented as circles, with the path between nodes as the edges. Notice that in the unordered tree, the paths only go in a single direction and any one node is only referenced once. In the graph, the path between two nodes can be bi-directional, as seen on edge B-C. Also, nodes B and C are both referenced from two different nodes. In these ways, a graph allows for a more complex interrelationship between the nodes that a standard tree cannot provide.
These are all of the basic data structures that will be beneficial regardless of the discipline of the software teams that you will work alongside as a TPM in the tech industry. However, just as a TPM may be specialized, so can the development team, so additional data structures that are more closely related to the software being developed may be helpful. The Further reading section has an entry for data structures that goes over a larger list of useful structures. Use this as a starting point and dive deeper where needed.
Next, we’ll move on to design patterns to wrap up our basic expectations in code knowledge.
Learning design patterns
Design patterns is a class that I see developers take often while on-the-job, mainly as a refresher as it is taught in college. It ensures a common ground of understanding, which is why I encourage TPMs to take the class, if available, as well. Here, we’ll explore two groups of design patterns: creational and structural. There are more, but these are the two that I find the most useful for a TPM to have a good understanding of. To learn more, check out the Further reading section in this chapter.
Creational design patterns
Creational design patterns are related to the creation of objects. By creation, I’m referring to how to create an instance of an object. We’ll discuss three of the more common ones next.
Builder pattern
The builder pattern separates the construction of an object from the specific composition of that object. As an example, we’ll take the Mercury subsystem, where you might have two different styles of message you can send: rich text and simple text. A builder will allow you to specify a generic set of building methods that each object type will then provide its specific implementations of. The rich text builder would include additional steps in the method to handle rich text data such as text formatting, whereas the simple text builder would just need to deal with the text itself. In this way, the application can deal with a single builder object and, depending on which type is instantiated, the output can be specific to the needs of the object.
Figure 11.5 represents a simple builder pattern that is present in most OOP languages today:
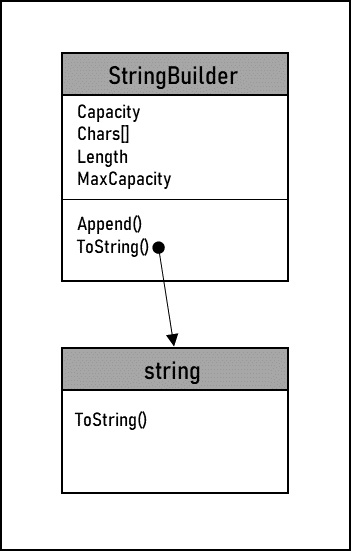
Figure 11.5 – Builder pattern
The StringBuilder class allows for the creation of a string from various complex data elements. The Append() method has several overrides that allow passing in every primitive data type to add to the end of the string. The creation method in this case is the ToString() method, which will take all elements appended to the builder and output a single string. Though seemingly simplistic, the StringBuilder class is significantly faster and takes less memory than simple string concatenation. This is because strings are immutable objects in most OOP languages, meaning that they cannot be modified. So, each addition of two strings creates an entirely new pointer and memory allocation. The StringBuilder class, on the other hand, stores all of the data in an array and only needs to update its memory allocation if the array runs out of space.
Simple factory pattern
A simple factory is where a class is used to create a specific type of object, usually through the use of an enum, or a group of constant values, to specify the type. Using the same message example as in the builder pattern, you can instead of a class that creates a message while passing in an enum to specify the type to create. Figure 11.6 demonstrates the flow of a simple factory:
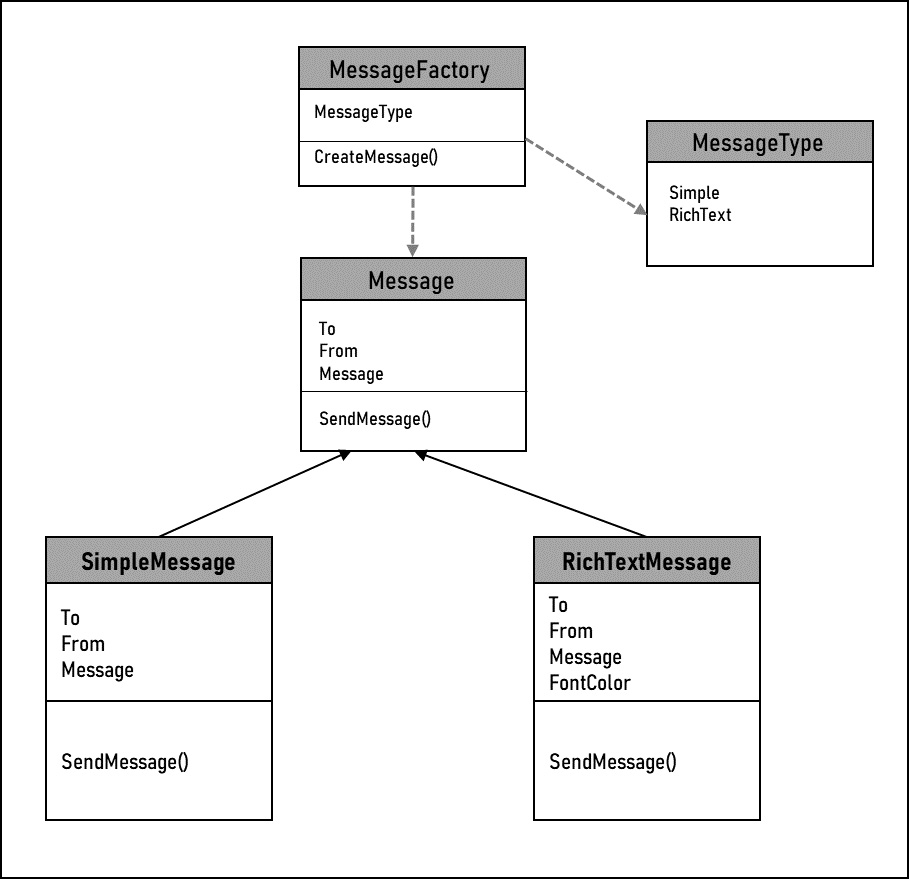
Figure 11.6 – Simple factory
The simple factory uses the Message class from the Mercury application as an example. The MessageFactory class takes in an enum to specify the type of message that you want to create and creates the correct instance. Notice how the RichTextMessage class has an additional property that neither the SimpleMessage class nor the Message class has that has data on the font color. The number of properties and methods can vary greatly between the objects created within a single simple factory.
Singleton pattern
A singleton is a pattern that ensures that only a single instance of a class can exist globally. This is done through the use of a static object within the class. A static object can’t be instantiated directly, and thus only one can exist. Figure 11.7 illustrates the behavior of a singleton class:
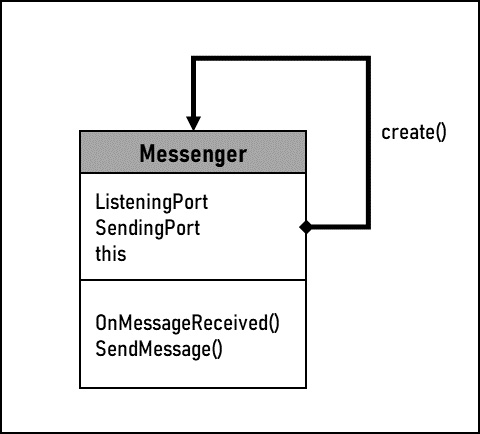
Figure 11.7 – Singleton
The Messenger class from the Mercury application is an example of a singleton class, as only a single instance of the Messenger class can exist. In this diagram, you can see that the class has a reference set to itself that is returned when asked for the object. If the object doesn’t exist yet, an instance is created as referenced.
As you can see, the creational design patterns will be a common occurrence as they relate to the creation of objects. Knowing the patterns and their names will help you interact more smoothly with your development team by having a common understanding of basic concepts so that you can focus on the problem you are trying to solve instead of trying to understand what the code or a design is actually doing.
Let’s now look at the other pattern that is often discussed in design reviews: structural design.
Structural design patterns
Whereas creational design patterns focus on object creation, structural design patterns take a step back and discuss how system components are related to one another. Though these do have in-code representations, and that is often what people look to for examples, I’ll be using the design approach as these patterns will come up in the system designs and architectural landscapes that we’ll cover in the next chapter.
Adapter pattern
The adapter pattern is used to convert between different object types, which often may serve similar purposes. From a code perspective, it’s similar to an abstract class and classes that extend them. From a system perspective, think of a currency conversion system. Each bank has its own currency conversion system, and you may need to interface with multiple banks depending on the currency you are converting. Instead of custom integrations for each bank, you can use an adapter to take your common data model used by your internal systems and convert it to the specific need of the bank you are calling. Figure 11.8 illustrates what this might look like:
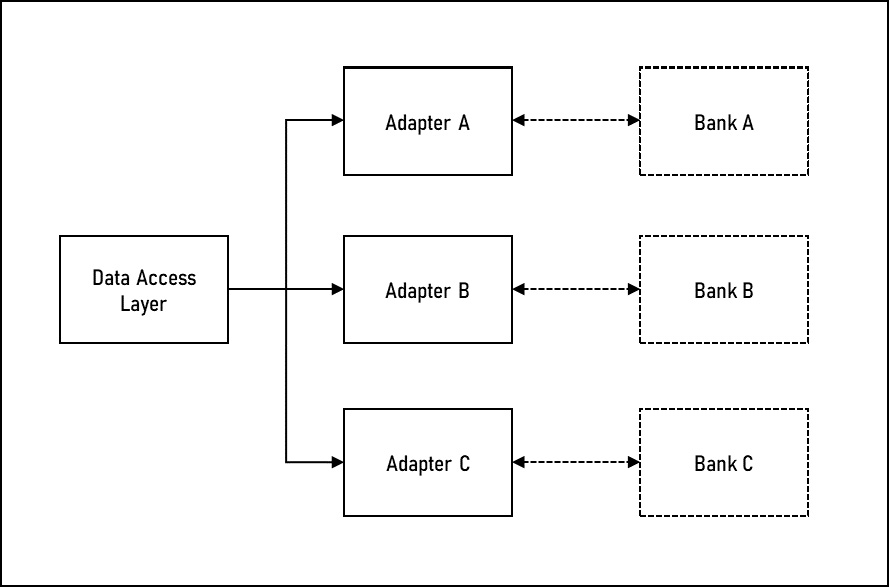
Figure 11.8 – Using adapters to connect with multiple currency converters
As you can see, the adapters act as a type of bridge between the internal systems and the needs of the external systems. Each adapter takes the internal data model and adapts it to a conversion request that is specific to the bank that it is calling. The data returned from each bank is then converted back into the internal data model. In this way, it encapsulates the details of those differences so that the rest of the system doesn’t need to know about them. So, if Bank A were to change its API, only Adapter A would need to be updated and the rest of the system would not need to be updated.
Decorator pattern
The decorator pattern allows the addition of new data to an existing object without changing the underlying object. Using the adapter example of multiple bank interfaces, each bank will have a different response that has different data in it. The adapter will fit that data into the internal data model, but you may need to append additional data to this that is not related to the bank call. This might include adding additional context to the data model that isn’t available at the time the conversion takes place or wasn’t relevant to that call—such as full customer information. Though it shouldn’t be sent to the bank, it may need to exist in the model so that a decorator can be invoked to add this information back in. Figure 11.9 shows how a decorator pattern would work:
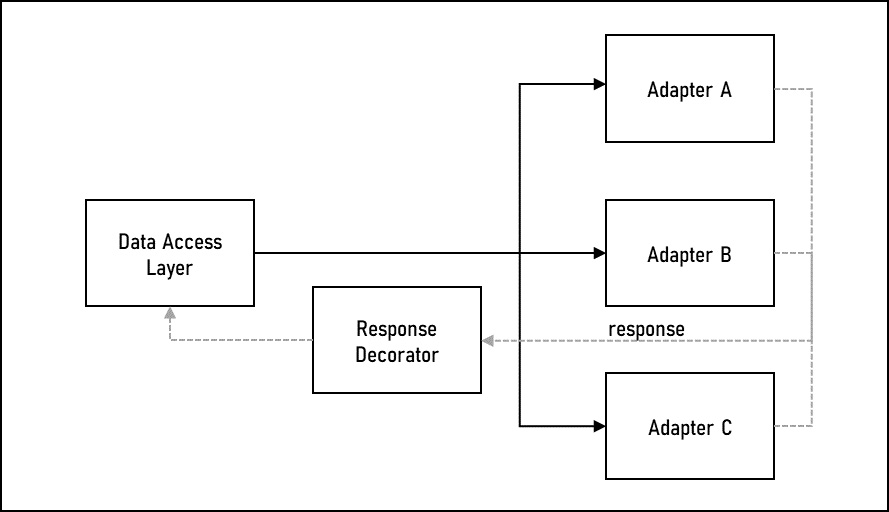
Figure 11.9 – Using a decorator to add data to a response
Using the adapter example from Figure 11.8, the response back to the data access layer takes a slightly different path through a response decorator. In practice, this may be multiple decorators or a single one that can add data, depending on the adapter that was invoked.
Façade pattern
Last but not least, the façade design pattern is used to simplify component interactions by reducing the number of systems that need to be interfaced with. Figure 11.10 illustrates a system map before and after a façade is introduced:
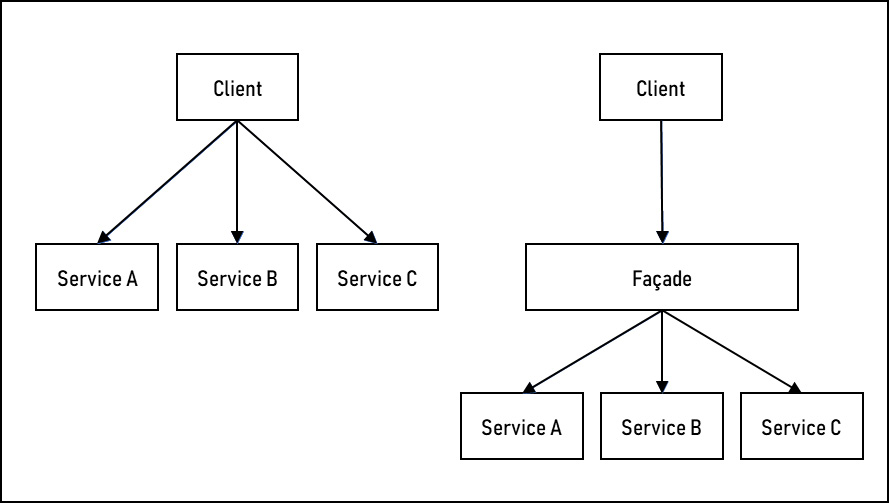
Figure 11.10 – Using a façade to simplify client interfaces
The façade on the right side of the figure reduces the number of connections between the components. It simplifies the landscape by reducing the amount of information each component (or service or client) needs to know about the landscape by delegating inter-system calls to a single component. This also has the added benefit of allowing underlying system changes and re-architecturing without impacting the calling clients.
Summary
Code development makes up a large portion of the deliverable work in a tech industry project or program. As a TPM, we are responsible for this work, though do not do this work ourselves. To ensure that we are successful in our role, we discussed the styles of programming that are most in use right now—OOP and functional programming. We learned that many languages allow for a mixture of the two styles in the same code base and that certain styles have benefits for particular tasks.
We learned about data structures that are commonly used and how their performance is measured using space and time complexities expressed through big O notation. We learned about simple list-based structures as well as more abstract structures, such as a graph that represents non-linear, unstructured, and complexly interrelated data.
Lastly, we discussed both creational and structural design patterns, which are foundational to feature and system designs. As such, these patterns will be useful for any design reviews you are a part of as a TPM.
In Chapter 12, we’ll dive into system design and architectural landscapes. Both of these are technical tools that you will be relying upon a lot as a TPM. We’ll explore both good and bad system design concepts using the Mercury application landscape to dive deeper.
Further reading
- Learning Object-Oriented Programming, by Gaston C. Hillar
This is a great introductory book OOP, starting with a basic real-world understanding of objects and methods. If you are unfamiliar with OOP or want an in-depth refresher, this is a good place to start.
https://www.packtpub.com/product/learning-object-oriented-programming/9781785289637
- Mastering Functional Programming, by Anatolii Kmetiuk
This book uses both a traditional functional language, Scala, as well as an OOP language staple, Java, to teach the foundations of functional programming. It then goes beyond the basics to get you comfortable using functional programming concepts and styles in your day-to-day programming.
https://www.packtpub.com/product/mastering-functional-programming/9781788620796
- Hands-On Design Patterns with Java, by Dr. Edward Lavieri
This book gives you a real hands-on approach to learning a large number of design patterns using Java. All design patterns I covered are also covered here at a greater depth, making it a good next step to dive deeper.
https://www.packtpub.com/product/hands-on-design-patterns-with-java/9781789809770
- Everyday Data Structures, by William Smith
This book discusses data structures as well as algorithms, a cornerstone of computer science, in great depth. It uses hands-on programming in various OOP languages to explore each data structure and algorithm. All the data structures I discussed are in this book, and I encourage you to dive deeper using this book.
https://www.packtpub.com/product/everyday-data-structures/9781787121041