
Chapter 11
System Management
The function of a strong position is to make the forces holding it practically unassailable.
—On War, Carl Von Clausewitz
Learning Objectives
After studying this chapter, you should be able to:
Summarize the main threats to server security.
Distinguish between a type 1 hypervisor, a type 2 hypervisor, and containers.
Distinguish between network attached storage and storage area networks.
Summarize security considerations for network storage systems.
Understand the use of service level agreements.
Summarize the key concepts of performance and capacity management.
Provide an overview of a backup policy.
Understand the concepts involved in change management.
Present an overview of system management best practices.
System management, or systems management, generally applied in the realm of information technology, is the enterprisewide management of IT systems and is usually directed by an organization’s chief information officer (CIO). The Information Security Forum’s (ISF’s) Standard of Good Practice for Information Security (SGP) divides this discipline into two main areas: system configuration and system maintenance (see Figure 11.1). Each of these areas is further divided into four topics. The first, computer and network installations, is covered in Chapter 12, “Networks and Communications.” The remainder of the topics are discussed in this chapter.
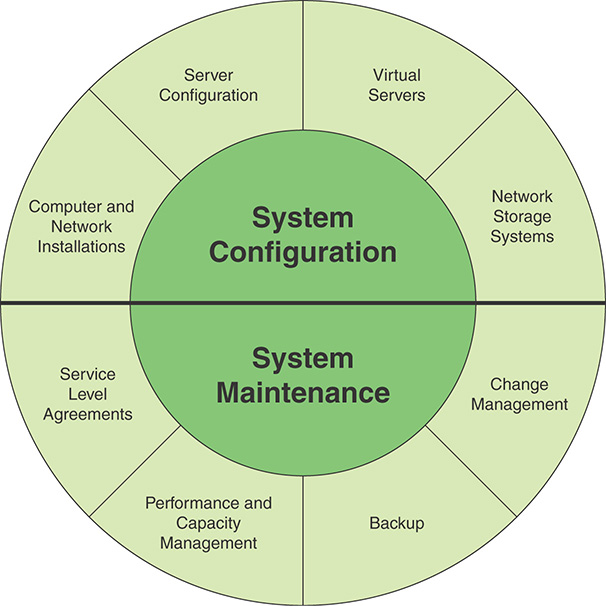
With respect to security, the objective of system configuration is to develop and enforce consistent system configuration policies that can cope with current and protected workloads and protect systems and the information they process and store against malfunction, cyber attack, unauthorized disclosure, and loss. Sections 11.1 through 11.3 address this area.
The objective of system maintenance is to provide guidelines for the management of the security of systems by performing backups of essential information and software, applying a rigorous change management process, and monitoring performance against agreed-upon service level agreements.
11.1 Server Configuration
Servers are the heart of any enterprise IT facility. Servers host shared applications, shared data, and other shared resources. Servers provide a wide variety of services to internal and external users, and many servers also store or process sensitive information for the organization. Some of the most common types of servers are application, web, email, database, infrastructure management, and file servers. This section addresses the general security issues of typical servers.
Threats to Servers
Server configuration needs to take into account the range of threats to server security that are possible or at least likely to exist. NIST SP 800-123, Guide to General Server Security, lists the following common security threats to servers:
Malicious entities can exploit software bugs in the server or its underlying operating system, hypervisor, or containers to gain unauthorized access to the server.
Denial-of-service (DoS) attacks can be directed to the server or its supporting network infrastructure, denying or hindering valid users from making use of its services.
Sensitive information on the server can be read by unauthorized individuals or changed in an unauthorized manner.
Sensitive information transmitted unencrypted or weakly encrypted between the server and the client can be intercepted. An example of weak encryption that is outdated but may still exist on legacy systems is single-stage Data Encryption Standard (DES).
Malicious entities can gain unauthorized access to resources elsewhere in the organization’s network via a successful attack on the server.
Malicious entities can attack other entities after compromising a server. These attacks can be launched directly (for example, from the compromised host against an external server) or indirectly (for example, placing malicious content on the compromised server that attempts to exploit vulnerabilities in the clients of users accessing the server). For many organizations, the majority of such attacks are internal (that is, from within the organization).
Requirements for Server Security
The following policy guidance is derived from a SANS Institute policy document template. The template defines some general requirements for server security as well as some specific configuration requirements.
An enterprise should impose the following general requirements for server security:
All internal servers deployed at the organization must be owned by an operational group that is responsible for system/server administration, including virtual servers.
Approved server configuration guides must be established and maintained by each operational group, based on business needs and approved by the chief information security officer (CISO).
Operational groups should monitor configuration compliance and implement an exception policy tailored to their environment. Each operational group must establish a process for changing the configuration guides, which includes review and approval by the CISO. The following items must be met:
Servers must be registered within the corporate enterprise management system. At a minimum, the following information is required to positively identify the point of contact:
Server contact(s) and location and a backup contact
Hardware and operating system/version
Main functions and applications, if applicable
Information in the corporate enterprise management system must be kept up-to-date.
Configuration changes for production servers must follow the appropriate change management procedures.
SANS Institute Information Security Policy Templates https://www.sans.org/securityresources/policies/
Specific configuration requirements include the following:
Operating system configuration should be in accordance with approved security guidelines.
Services and applications not used must be disabled where practical.
Access to services should be logged and/or protected through access control methods such as a web application firewall, if possible.
The most recent security patches must be installed on the system as soon as practical; the only exception is when an application immediately interferes with business requirements.
Trust relationships between systems are a security risk, and their use should be avoided. Do not use a trust relationship when some other method of communication is sufficient.
trust relationship
A relationship between two different domains or areas of authority that makes it possible for users in one domain to be authenticated by a domain controller in the other domain.
Always use the standard security principle of least required access to perform a function. Do not use root when a non-privileged account suffices.
If a methodology for secure channel connection is available (that is, technically feasible), perform privileged access over secure channels (for example, encrypted network connections using SSH or IPsec).
Servers should be physically located in an access-controlled environment.
Servers are specifically prohibited from operating from uncontrolled cubicle areas.
In addition, consider the following monitoring requirements:
All security-related events on critical or sensitive systems must be logged and audit trails saved as follows:
Keep all security-related logs online for a minimum of one week.
Retain daily incremental tape backups for at least one month.
Retain weekly full tape backups of logs for at least one month.
Retain monthly full backups for a minimum of two years.
Report security-related events to a security manager who reviews logs. Also report incidents to IT management. Prescribe corrective measures as needed. Security-related events include, but are not limited to:
Port-scan attacks
Evidence of unauthorized access to privileged accounts
Anomalous occurrences that are not related to specific applications on the host
11.2 Virtual Servers
Virtualization refers to a technology that provides an abstraction of the computing resources used by some software, which thus runs in a simulated environment called a virtual machine (VM). Benefits arising from using virtualization include better efficiency in the use of the physical system resources than is typically seen using a single operating system instance. This is particularly evident in the provision of virtualized server systems. Virtualization also provides support for multiple distinct operating systems and associated applications on the one physical system. This is more commonly seen on client systems.
Virtualization Alternatives
A hypervisor is software that sits between hardware and VMs and acts as a resource broker. It allows multiple VMs to safely coexist on a single physical server host and share that host’s resources. The virtualizing software provides abstraction of all physical resources (such as processor, memory, network, and storage resources) and thus enables multiple computing stacks, called VMs, to be run on a single physical host.
Each VM includes an operating system, called the guest operating system. This operating system can be the same as the host operating system or a different one. For example, a guest Windows operating system could be run in a VM on top of a Linux host operating system. The guest operating system, in turn, supports a set of standard library functions and other binary files and applications. From the point of view of the applications and the user, this stack appears as an actual machine, with hardware and an operating system; thus, the term virtual machine is appropriate. In other words, it is the hardware that is virtualized.
A hypervisor performs the following functions:
Execution management of VMs: This includes scheduling VMs for execution, virtual memory management to ensure VM isolation from other VMs, and context switching between various processor states. It also includes isolation of VMs to prevent conflicts in resource usage and emulation of timer and interrupt mechanisms.
Devices emulation and access control: A hypervisor emulates all network and storage (block) devices that different native drivers in VMs are expecting, mediating access to physical devices by different VMs.
Execution of privileged operations by hypervisor for guest VMs: Instead of being executed directly by the host hardware, certain operations invoked by guest operating systems, may have to be executed on its behalf by the hypervisor because of their privileged nature.
Management of VMs (also called VM life cycle management): A hypervisor configures guest VMs and controls VM states (for example Start, Pause, Stop).
Administration of hypervisor platform and hypervisor software: This involves setting parameters for user interactions with the hypervisor host as well as hypervisor software.
Type 1 and Type 2 Hypervisors
There are two types of hypervisors, distinguished by whether there is an operating system between the hypervisor and the host. A type 1 hypervisor (see Figure 11.2a) is loaded as a software layer directly onto a physical server, much as an operating system is loaded; this is referred to as native virtualization. The type 1 hypervisor directly controls the physical resources of the host. Once it is installed and configured, the server is then capable of supporting virtual machines as guests. In mature environments, where virtualization hosts are clustered together for increased availability and load balancing, a hypervisor can be staged on a new host. Then that new host is joined to an existing cluster, and VMs can be moved to the new host without any interruption of service.
Some examples of type 1 hypervisors are VMware ESXi, Microsoft Hyper-V, and Citrix XenServer.
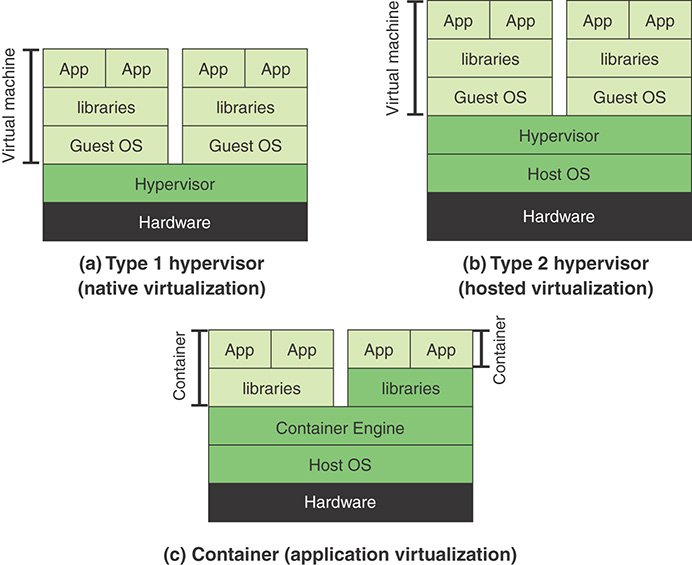
A type 2 hypervisor exploits the resources and functions of a host operating system and runs as a software module on top of the operating system (see Figure 11.2b); this is referred to as hosted virtualization, or nested virtualization. A type 2 hypervisor relies on the operating system to handle all the hardware interactions on the hypervisor’s behalf.
Key differences between the two hypervisor types are as follows:
Typically, type 1 hypervisors perform better than type 2 hypervisors. Because a type 1 hypervisor doesn’t compete for resources with an operating system, there are more resources available on the host, and, by extension, more virtual machines are hosted on a virtualization server using a type 1 hypervisor.
Type 1 hypervisors are considered to be more secure than type 2 hypervisors. Virtual machines on a type 1 hypervisor make resource requests that are handled externally to that guest, and they cannot affect other VMs or the hypervisor that supports them. This is not necessarily true for VMs on a type 2 hypervisor, and a malicious guest could potentially affect more than itself.
Type 2 hypervisors allow a user to take advantage of virtualization without needing to dedicate a server to only that function. Developers who need to run multiple environments as part of their process, in addition to taking advantage of the personal productive workspace that a PC operating system provides, can do both with a type 2 hypervisor installed as an application on their Linux or Windows desktop. The virtual machines that are created and used can be migrated or copied from one hypervisor environment to another, reducing deployment time and increasing the accuracy of what is deployed, reducing the time to market for a project.
Native virtualization systems, typically seen in servers, are used to improve the execution efficiency of the hardware. They are arguably also more secure, as they have fewer additional layers than the alternative hosted approach. Hosted virtualization systems are more common in clients, where they run at the same level as other applications on the host operating system, and are used to support applications for alternate operating system versions or types.
In virtualized systems, the available hardware resources—including include processor, memory, disk, network, and other attached devices—must be appropriately shared between the various guest operating systems. Processors and memory are generally partitioned between these operating systems and are scheduled as required. Disk storage can be partitioned, with each guest having exclusive use of some disk resources. Alternatively, a “virtual disk” can be created for each guest, which appears to the guest as a physical disk with a full file system but is viewed externally as a single “disk image” file on the underlying file-system. Attached devices such as optical disks or USB devices are generally allocated to a single guest operating system at a time. Several alternatives exist for providing network access. The guest operating system can have direct access to distinct network interface cards on the system; the hypervisor can mediate access to shared interfaces; or the hypervisor may implement virtual network interface cards for each guest, routing traffic between guests as required. This last approach is quite common and arguably the most efficient because traffic between guests does not need to be relayed via external network links. It does have security consequences in that this traffic is not subject to monitoring by probes attached to networks. Therefore, alternative, host-based probes are needed in such a system if such monitoring is required.
Some examples of type 2 hypervisors are VMware Workstation, Oracle VM Virtual Box, and Microsoft Windows Virtual PC.
Containers
A relatively recent approach to virtualization, known as container virtualization or application virtualization, is worth noting (refer to Figure 11.2c). In this approach, software known as a virtualization container runs on top of the host operating system kernel and provides an isolated execution environment for applications. Unlike hypervisor-based VMs, containers do not aim to emulate physical servers. Instead, all containerized applications on a host share a common operating system kernel. This eliminates the need for resources to run a separate operating system for each application and greatly reduces overhead.
For containers, only a small container engine is required as support for the containers. The container engine sets up each container as an isolated instance by requesting dedicated resources from the operating system for each container. Each container app then directly uses the resources of the host operating system. VM virtualization functions at the border of hardware and the operating system. It’s able to provide strong performance isolation and security guarantees with the narrowed interface between VMs and hypervisors. The use of containers, which sit in between the operating system and applications, incurs lower overhead but potentially introduces greater security vulnerabilities.
Container technology is built into Linux in the form of Linux Containers (LXC). Other container capabilities include Docker, FreeBSD Jails, AIX Workload Partitions, and Solaris Containers. There are also container management systems that provide mechanisms for deploying, maintaining, and scaling containerized applications. Kubernetes and Docker Enterprise Edition are two examples of such systems.
Virtualization Security Issues
van Cleeff et al.’s “Security Implications of Virtualization: A Literature Study” [CLEE09], SP 800-125, Guide to Security for Full Virtualization Technologies, and SP 800-125A, Security Recommendations for Hypervisor Deployment, detail a number of security concerns that result from the use of virtualized systems, including the following:
Guest operating system isolation: It is important to ensure that programs executing within a guest operating system can only access and use the resources allocated to it and cannot covertly interact with programs or data in either of the guest operating system’s or in the hypervisor.
Guest operating system monitoring by the hypervisor: The hypervisor has privileged access to the programs and data in each guest operating system and must be trusted as secure from subversion and compromised use of this access.
Virtualized environment security: It is important to ensure security of the environment, particularly in regard to image and snapshot management, which attackers can attempt to view or modify.
These security concerns are regarded as an extension of the concerns already discussed with securing operating systems and applications. If a particular operating system and application configuration is vulnerable when running directly on hardware in some context, it is most likely also vulnerable when running in a virtualized environment. And if that system is actually compromised, it is capable of attacking other nearby systems, whether they are also executing directly on hardware or running as other guests in a virtualized environment. The use of a virtualized environment improves security by further isolating network traffic between guests than is the case when such systems run natively and from the ability of the hypervisor to transparently monitor activity on all guest operating systems. However, the presence of the virtualized environment and the hypervisor can reduce security if there are vulnerabilities in it that attackers can exploit. Such vulnerabilities allow programs executing in a guest to covertly access the hypervisor and, hence, other guest operating system resources. This problem, known as VM escape, is of concern. Virtualized systems also often provide support for suspending an executing guest operating system in a snapshot, saving that image, and then restarting execution at a later time, possibly even on another system. If an attacker views or modifies this image, the attacker compromises the security of the data and programs contained within it.
It is clear that the use of virtualization adds additional layers of concern, as previously noted. Securing virtualized systems means extending the security process to secure and harden these additional layers. In addition to securing each guest operating system and applications, an organization must secure the virtualized environment and the hypervisor.
Securing Virtualization Systems
SP 800-125, which provides guidance for appropriate security in virtualized systems, states that organizations using virtualization should do the following:
Plan the security of the virtualized system carefully.
Secure all elements of a full virtualization solution, including the hypervisor, guest operating systems, and virtualized infrastructure—and also maintain their security
Ensure that the hypervisor is properly secured
Restrict and protect administrator access to the virtualization solution
Hypervisor Security
Secure the hypervisor by using a process similar to that with securing an operating system—that is, install it in an isolated environment, from known clean media, and update to the latest patch level in order to minimize the number of vulnerabilities present. The organization should then configure it so that it is updated automatically, disable or remove any unused services, disconnect unused hardware, use appropriate introspection capabilities with the guest operating systems, and monitor the hypervisor for any signs of compromise.
Limit access to the hypervisor to authorized administrators only, since these users are capable of accessing and monitoring activity in any of the guest operating systems. The hypervisor can support both local and remote administration. Configure appropriately, using suitable authentication and encryption mechanisms, particularly when using remote administration. Also consider remote administration access that is secured in the design of any network firewall and intrusion detection system (IDS) capability in use. Ideally such administration traffic should use a separate network, with very limited, if any, access provided from outside the organization.
Virtualized Infrastructure Security
Virtualized systems manage access to hardware resources such as disk storage and network interfaces. This access must be limited to just the appropriate guest operating systems that use any resource. As noted earlier, the configuration of network interfaces and use of an internal virtual network may present issues for organizations that wish to monitor all network traffic between systems. This should be designed and handled as needed.
Access to VM images and snapshots must be carefully controlled since these are another potential point of attack.
Hosted Virtualization Security
Hosted virtualized systems, as typically used on client systems, pose some additional security concerns. These result from the presence of the host operating system under, and other host applications beside, the hypervisor and its guest operating systems. Hence, there are yet more layers to secure. Further, the users of such systems often have full access to configure the hypervisor and to any VM images and snapshots. In this case, the use of virtualization is more to provide additional features and to support multiple operating systems and applications than to isolate these systems and data from each other and from the users of these systems.
It is possible to design a host system and virtualization solution that is more protected from access and modification by the users. This approach can be used to support well-secured guest operating system images that provide access to enterprise networks and data and to support central administration and update of these images. However, there remain security concerns due to possible compromise of the underlying host operating system unless it is adequately secured and managed.
11.3 Network Storage Systems
Organizations make use of two broad categories of computer storage for files, databases, and other data: local and networked. Local storage, commonly called direct access storage (DAS), is a dedicated digital storage device attached directly to a server or PC via a cable or residing as an internal drive. Most users’ computers and most servers have DAS. DAS creates data islands because data cannot be easily shared with other servers.
Networked storage is a term used to describe a storage device (usually many devices paired together) that is available over a network. This kind of storage maintains copies of data across high-speed local area network (LAN) connections and is designed to back up files, databases, and other data to a central location that can be easily accessed via standard network protocols and tools. Networked storage comes in the following topologies:
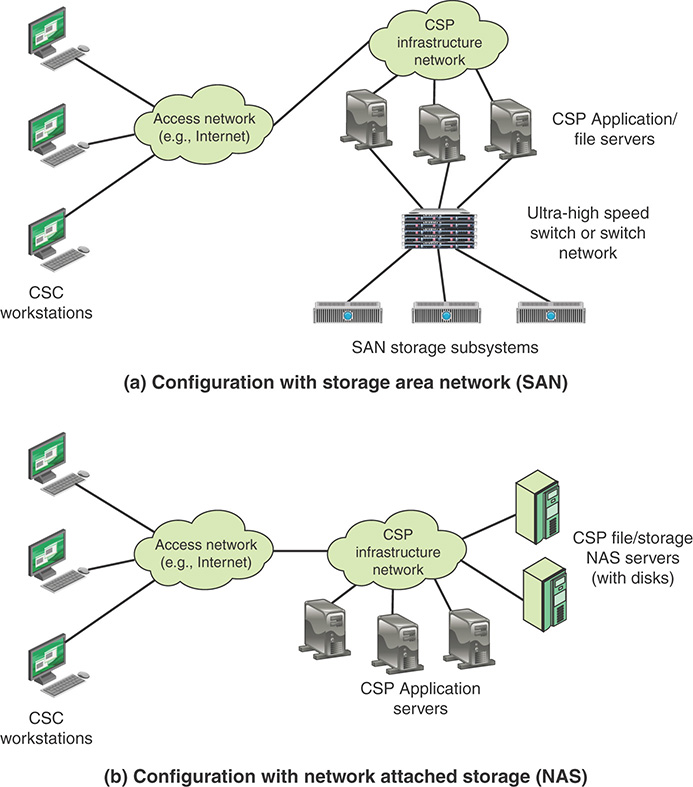
Storage area network (SAN): A SAN is a dedicated network that provides access to various types of storage devices, including tape libraries, optical jukeboxes, and disk arrays. To servers and other devices in the network, a SAN’s storage devices look like locally attached devices. A disk block–based storage technology, SAN is probably the most pervasive form of storage for very large data centers and is a de facto staple for database-intensive applications. These applications require shareable storage, large bandwidth, and support for the distances from rack to rack within the data center.
Network attached storage (NAS): NAS systems are networked appliances that contain one or more hard drives that are shared with multiple, heterogeneous computers. Their specialized role in networks is to store and serve files. NAS disk drives typically support built-in data protection mechanisms, including redundant storage containers or redundant arrays of independent disks (RAID). NAS enables file serving responsibilities to be separated from other servers on the network and typically provides faster data access than traditional file servers.
Figure 11.3 illustrates the distinction between SAN and NAS, using as an example cloud service customers (CSCs) connected to a cloud service provider (CSP).
The SGP recommends the following security measures:
Follow the system development and configuration security policies for design and configuration of network storage systems.
Be sure that SANs and NASs are subject to standard security practices (for example, configuration, malware protection, change management, patch management).
Ensure that the IT facility provides protection of network storage management consoles and administration interfaces.
Store encryption information on network storage systems.
Allow for additional security arrangements specific to NAS and SAN.
Security arrangements specific to NAS and SAN depend on the type of server configuration, whether virtualization is used, and network configuration.
11.4 Service Level Agreements
A service level agreement (SLA) is a contract between a service provider and its internal or external customers that documents what services the provider furnishes and defines the performance standards the provider is obligated to meet.
SLAs originated with network service providers but are now widely used in a range of IT-related fields. Companies that establish SLAs include IT service providers, managed service providers (MSPs), and cloud computing service providers. Corporate IT organizations, particularly those that have embraced IT service management (ITSM), enter SLAs with their in-house customers (users in other departments within the enterprise). An IT department creates an SLA so that its services can be measured, justified, and possibly even compared with those of outsourcing vendors.
managed service provider (MSP)
A company that remotely manages a customer’s IT infrastructure and/or end-user systems, typically on a proactive basis and under a subscription model.
IT service management (ITSM)
A general term that describes a strategic approach for designing, delivering, managing, and improving the way IT is used in an organization. The goal of every ITSM framework is to ensure that the right processes, people, and technology are in place so that the organization can meet its business goals.
A wide variety of SLAs are used in a number of contexts, each with its own typical metrics and service provisions. The following sections look at three important types of SLAs.
Network Providers
A network SLA is a contract between a network provider and a customer that defines specific aspects of the service to be provided. The definition is formal and typically defines quantitative thresholds that must be met. An SLA typically includes the following information:
A description of the nature of service to be provided: A basic service is an IP-based network connectivity of enterprise locations plus access to the Internet. The service can include additional functions, such as web hosting, maintenance of domain name servers, and operation and maintenance tasks.
The expected performance level of the service: The SLA defines a number of metrics, such as delay, reliability, and availability, with numeric thresholds.
The process for monitoring and reporting the service level: The SLA describes how performance levels are measured and reported.
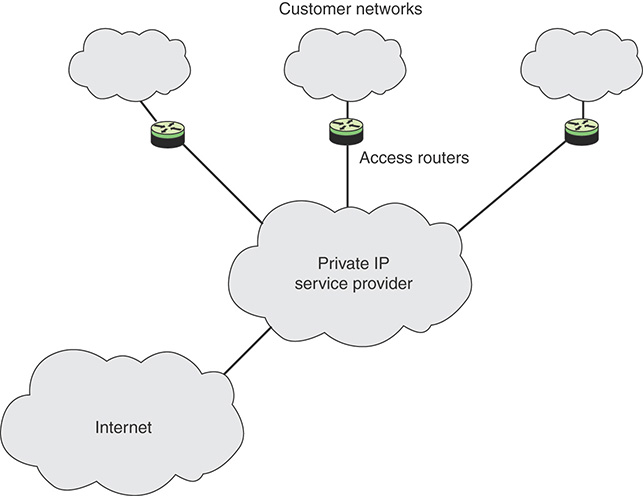
Figure 11.4 shows a typical configuration that lends itself to an SLA. In this case, a network service provider maintains an IP-based network. A customer has a number of private networks (for example, LANs) at various sites. Customer networks are connected to the provider via access routers at the access points. The SLA dictates service and performance levels for traffic between access routers across the provider network. In addition, the provider network links to the Internet and thus provides Internet access for the enterprise.
For example, the standard SLA provided by Cogent Communications for its backbone networks includes the following items [COGE16]:
Availability: 100% availability.
Latency (delay): Monthly average network latency for packets carried over the Cogent network between backbone hubs for the following regions is as specified:
Intra-North America: 45 milliseconds or less
Intra-Europe: 35 milliseconds or less
New York to London (transatlantic): 85 milliseconds or less
Los Angeles to Tokyo (transpacific): 125 milliseconds or less
Network latency (or round-trip time) is defined as the average time taken for an IP packet to make a round trip between backbone hubs within the regions specified above on the Cogent network. Cogent monitors aggregate latency within the Cogent network by monitoring round-trip times between a sample of backbone hubs on an ongoing basis.
Network packet delivery (reliability): Average monthly packet loss no greater than 0.1% (or successful delivery of 99.9% of packets). Packet loss is defined as the percentage of packets that are dropped between backbone hubs on the Cogent network.
An SLA can be defined for the overall network service. In addition, SLAs are defined for specific end-to-end services available across the carrier’s network, such as a virtual private network (VPN), or differentiated services.
Computer Security Incident Response Team
A computer security incident response team (CSIRT) is an organization that receives reports of security breaches, conducts analyses of the reports, and responds to the senders. An internal CSIRT is assembled as part of a parent organization, such as a government, a corporation, a university, or a research network. External CSIRTs provide paid services on either an ongoing or as-needed basis.
A computer security incident can involve a real or suspected breach or the act of willfully causing a vulnerability or breach. Typical incidents include the introduction of viruses or worms into a network, DoS attacks, unauthorized alteration of software or hardware, and identity theft of individuals or institutions. Hacking in general is considered a security incident unless the perpetrators were deliberately hired for the specific purpose of testing a computer or network for vulnerabilities; in that case, the hackers form part of the CSIRT, in a preventive role.
A CSIRT provides three main groups of services:
Reactive services (responses to incidents): These are the main sources of work of a CSIRT
Proactive services: Actions to prevent incidents from occurring in the future
Security quality management services: Services that do not involve incidents but rather include working with IT or other organization departments in which CSIRT members help solidify security systems
Response time is a critical consideration in assembling, maintaining, and deploying an effective CSIRT. A rapid, accurately targeted, and effective response minimizes the overall damage to finances, hardware, and software caused by a specific incident. Another important consideration involves the ability of the CSIRT to track down the perpetrators of an incident so that the guilty parties are shut down and effectively prosecuted. A third consideration involves hardening of the software and infrastructure to minimize the number of incidents that take place over time.
Table 11.1, from Carnegie Mellon University’s Handbook for Computer Security Incident Response Teams (CSIRTs) [CMU03], provides a representative list of service description attributes.
TABLE 11.1 CSIRT Service Description Attributes
Attribute |
Description |
|---|---|
Objective |
Purpose and nature of the service. |
Definition |
Description of scope and depth of service. |
Function descriptions |
Descriptions of individual functions within the service. |
Availability |
The conditions under which the service is available: to whom, when, and how. |
Quality assurance |
Quality assurance parameters applicable for the service. Includes both setting and limiting of constituency expectations. |
Interactions and information disclosure |
The interactions between the CSIRT and parties affected by the service, such as the constituency, other teams, and the media. Includes setting information requirements for parties accessing the service and defining the strategy with regard to the disclosure of information (both restricted and public). |
Interfaces with other services |
Definition and specification of the information flow exchange points between this service and other CSIRT services it interacts with. |
Priority |
The relative priorities of functions within the service and of the service compared to other CSIRT services. |
Cloud Service Providers
An SLA for a CSP includes security guarantees such as data confidentiality, integrity guarantees, and availability guarantees for cloud services and data. Roy et al.’s “Secure the Cloud: From the Perspective of a Service-Oriented Organization” [ROY15] lists the following considerations for a cloud provider SLA:
Cloud storage needs to adhere to regulatory compliance laws of the region of data residency. This complicates matters for data confidentiality. For instance, CSPs may resort to hosting their cloud servers in countries that do not enable the government to subpoena CSPs into sharing client data from their servers, citing a threat to the nation as the reason. The existence of such laws in some countries puts data confidentiality at risk.
Cloud storage SLAs should include strong proof of retrievability (PoR) guarantees; for instance, a cloud storage provider needs to provide strong metadata protection (that is, maintain freshness of data) as well as protection against loss (availability) or corruption (integrity) of data.
Service unavailability (due to VM crash, for example) or data unavailability (data being nonretrievable) is caused by both security and nonsecurity issues. For instance, Amazon EC2 offers service availability with a guaranteed monthly uptime of 99.95% to the Infrastructure as a Service (IaaS) customer (no matter the cause of the downtime).
Cloud network and front-end client applications must be secured against masquerading attackers (passive or active).
Provision must also be made in the SLA to allow the client to audit security controls.
There may be differences in detail between public and private cloud SLAs, but fundamentally an organization requires the same sort of services in both cases.
11.5 Performance and Capacity Management
Performance and capacity management ensures that the IT capacity matches current and future needs of the business and that throughput and runtime requirements defined by the business are fulfilled. The critical success factors are:
Understanding the current demands for IT resources and producing forecasts for future requirements
Being able to plan and implement the appropriate IT capacity to match business needs and to demonstrate cost-effective interaction with other processes during the application life cycle
The need to manage performance and capacity of IT resources requires a process to periodically review current performance and capacity of IT resources. This process includes forecasting future needs based on workload, storage, and contingency requirements. This process provides assurance that information resources supporting business requirements are continually available.
Most organizations already collect some capacity-related information and work consistently to solve problems, plan changes, and implement new capacity and performance functionality. However, organizations do not routinely perform trending and what-if analyses. What-if analysis is the process of determining the effect of a network change. Trending is the process of performing baselines of network capacity and performance issues and reviewing the baselines for network trends to understand future upgrade requirements. Capacity and performance management should also include exception management, where problems are identified and resolved before users call in, and Quality of Service (QoS) management, where network administrators plan, manage, and identify individual service performance issues.
11.6 Backup
Backup is the process of making a copy of files and programs, to facilitate recovery, if necessary. The objective is to ensure the integrity and availability of information processed and stored within information processing facilities.
The following is a useful set of policies to ensure effective backup:
Backups of all records and software must be retained such that computer operating systems and applications are fully recoverable. This is achieved using a combination of image copies, incremental backups, differential backups, transaction logs, or other techniques.
The frequency of backups is determined by the volatility of data; the retention period for backup copies is determined by the criticality of the data. At a minimum, backup copies must be retained for 30 days.
At least three versions of server data must be maintained.
At a minimum, one fully recoverable version of all data must be stored in a secure offsite location. An offsite location can be in a secure space in a separate building or with an approved offsite storage vendor.
Derived data should be backed up only if restoration is more efficient than creation in the event of failure.
An organization should store all data accessed from workstations, laptops, or other portable devices on networked file server drives to allow for backup. It should back up data located directly on workstations, laptops, or other portable devices to networked file server drives. Alternatively, data located directly on workstations, laptops, or other portable devices can be backed up using an approved third-party vendor. Convenience data and other information that does not constitute protected enterprise data do not carry this requirement.
Required backup documentation includes identification of all critical data, programs, documentation, and support items necessary to perform essential tasks during a recovery period. Documentation of the restoration process must include procedures for recovery from single-system or application failures, as well as for a total data center disaster scenario, if applicable.
Backup and recovery documentation must be reviewed and updated regularly to account for new technology, business changes, and migration of applications to alternative platforms.
Recovery procedures must be tested annually.
NIST SP 800-34, Contingency Planning Guide for Federal Information Systems, recommends a strategy for backup and recovery that takes into account a risk assessment of the information to be stored and recovered, if necessary. Table 11.2 summarizes the strategy based on the FIPS 199, Standards for Security Categorization of Federal Information and Information Systems, security categories (low, moderate, and high).
TABLE 11.2 Backup and Recovery Guidelines
FIPS 199 Availability Impact Level |
Information System Target Priority and Recovery |
|
|---|---|---|
Low |
Low priority: Any outage with little impact, damage, or disruption to the organization |
Backup: Tape backup Strategy: Relocate or cold site |
Moderate |
Important or moderate priority: Any system that, if disrupted, causes a moderate problem to the organization and possibly other networks or systems |
Backup: Optical backup, WAN/VLAN replication Strategy: Cold |
High |
Mission-critical or high priority: Damage to or disruption of these systems causes the most impact on the organization, mission, and other networks and systems |
Backup: Mirrored systems and disc replication |
Three types of sites for backup are defined as alternatives:
Cold site: A backup facility that has the necessary electrical and physical components of a computer facility but does not have the computer equipment in place. The site is ready to receive the necessary replacement computer equipment in the event that the user has to move from the main computing location to an alternate site.
Warm site: An environmentally conditioned workspace that is partially equipped with information systems and telecommunications equipment to support relocated operations in the event of a significant disruption.
Hot site: A fully operational offsite data processing facility equipped with hardware and software to be used in the event of an information system disruption.
The alternate site choice must be cost-effective and match the availability needs of the organization’s information systems. Thus, if a system requires near 100% availability, then a mirrored or hot site is the right choice. However, if the system allows for several days of downtime, then a cold site is a better option.
11.7 Change Management
COBIT 5 defines change management as a discipline which ensures that system software (operating systems and supporting applications), application software, and configuration files are introduced into production in an orderly and controlled manner. ISO 27002, Code of Practice for Information Security Controls, suggests the following items to be considered in implementing change management:
Identification and recording of significant changes
Planning and testing of changes
Assessment of potential impacts, including information security impacts, of such changes
Formal approval procedure for proposed changes
Verification that information security requirements have been met
Communication of change details to all relevant persons
Fallback procedures, including procedures and responsibilities for aborting and recovering from unsuccessful changes and unforeseen events
Provision of an emergency change process to enable quick and controlled implementation of changes needed to resolve an incident
Change management is critical for organizations and teams of various sizes and in various industries, including IT and manufacturing. It ensures that standardized methods, processes, and procedures are used for all changes, facilitate efficient and prompt handling of changes, and maintain the proper balance between the need for change and the potential detrimental impact it can cause.
The following guidelines are useful in developing a change management strategy:
Communication: Ensure that adequate advance notice of a change is given, especially if a response is expected. Provide clear guidance as to whom people should respond if they have comments or concerns.
Maintenance window: A maintenance window is a period of time when maintenance, such as patching software or upgrading hardware components, is performed. Users should be alerted well in advance of any service disruptions.
Change committee: This committee reviews change requests and determines whether they will be made. In addition, the committee may specify that certain changes to the proposed plan for implementing the change be made in order for it to be acceptable.
Critical changes: An unscheduled change may be necessary to respond to a critical event. Even though some steps may need to be bypassed, as much consideration as possible is given to the possible consequences of attempting the change. It is still important to obtain sufficient approval for the change. What constitutes sufficient approval varies and should be defined by the department or business unit.
Plan the change: The planning process is responsible for determining the following:
Who is responsible for the change
What effect the change will have
When the change should occur, based on the following factors:
When will the change have the least chance of interfering with operations?
Will appropriate support staff be available?
Can the change be made within the standard maintenance window?
Will there be enough time to review and test the proposed change?
Why making the change is important
How the change will be made
Whether the change results in any additional security issues or increases the risk to the system
Back-out procedures in case the change is not successful
What additional training and documentation are necessary for both support staff and end users
Document change requests: A change request form should be used to provide information about the change. A detailed form is appropriate for changes affecting data classified as confidential (highest, most sensitive), where protection is required by law, where the asset risk is high, and for information which provides access to physical or virtual resources. Table 11.3 describes the fields that comprise the change request form.
TABLE 11.3 Change Request Form Structure
Field
Description
Change Requested By
Enter the requester name and email address. If the request came from an external source, enter your name and the name of the external source.
Date of Change Request
Enter the date/time of the request.
Change Description
Enter a summary of the change required and a reason for the change.
Change Priority
Categorize the change request as urgent, high, medium, or low. If this change is time/date dependent, specify that here. Note that the change control committee may amend the priority/schedules depending on other activities.
Impact Assessment
Enter a summary of the business and technical functions that could be affected by these changes. Specify known risks and concerns in this section.
Pre-Deployment Test Plan
Describe how you will test the change before deployment. Note that testing changes greatly reduces the possibility of failures and unwanted surprises.
Back-Out Plan
Describe how a failed change can be backed out or how the resource can be restored to its previous state.
Post Deployment Test Plan
Describe how the change is tested to determine whether it was successful.
Change Approval
Specify whether the request was accepted or rejected. The change control committee should make this decision. If appropriate, a description of the decision should be included here.
Change Assignment
Specify the person responsible for implementing the change.
Test the change: If a test environment is available, test the change prior to implementation.
Execute the change: Include the following in the execution process:
Make sure support staff are available and prepared to assist in the change process.
If system availability is affected while the change is being made, notify affected individuals to let them know what to expect and when to expect it. They should also know who to contact if they experience difficulty as a result of the change.
Verify that the change was successful and that the system is stable.
Notify affected individuals that changes are complete.
Provide documentation and instruction to users who will be affected by the change.
Record that the change took place in the change log.
Keep a record of the change: Keep a log or other record of all changes to supplement the change request document.
11.8 System Management Best Practices
The SGP breaks down the best practices in the System Management category into two areas and eight topics and provides detailed checklists for each topic. The areas and topics are as follows:
System configuration: The objective of this area is to develop and enforce consistent system configuration policies that can cope with current and protected workloads and protect systems and the information they process and store against malfunction, cyber attack, unauthorized disclosure, and loss.
Computer and network installations: Outlines the basic principles and practices for assuring that computer and network installations meet capacity/performance requirements and security requirements. Items covered include use of single sign-on, firewalls, traffic isolation, and capacity management.
Server configuration: Addresses issues related to security to take into account in server configuration.
Virtual servers: Addresses security issues related to the use of virtual servers.
Network storage systems: Provides a checklist for security issues related to various types of network storage.
System maintenance: The objective of this area is to provide guidelines for the management of the security of systems by performing backups of essential information and software, applying a rigorous change management process, and monitoring performance against agreed service level agreements.
Service level agreements (SLA): Defines the business requirements for providers of any computer or network services, including those for information security, and to ensure that they are met.
Performance and capacity management: Provides guidelines for ensuring adequate performance, capacity, and availability of systems and networks.
Backup: Summarizes backup requirements and lists recommended measures for effective and secure backup.
Change management: Provides guidance to ensure that changes are applied correctly and that they do not compromise the security of business applications, computer systems, or networks.
11.9 Key Terms and Review Questions
Key Terms
After completing this chapter, you should be able to define the following terms:
computer security incident response team
managed service provider (MSP)
network attached storage (NAS)
security quality management service
system maintenance system management
Review Questions
Answers to the Review Questions can be found online in Appendix C, “Answers to Review Questions.” Go to informit.com/title/9780134772806.
1. Into how many areas does the SGP divide system management? Describe the areas.
2. According to NIST SP 800-123, what are some of the common security threats to servers?
3. According to policy guidance from the SANS Institute, what are some general requirements for server security?
4. What does virtualization mean? What benefits does it offer to an organization?
5. What is a hypervisor? What functions does it perform?
6. What are the two types of hypervisors, based on presence of the operating system between hypervisor and the host?
7. What does container virtualization mean?
8. What are the three categories of network storage systems?
9. What does SLA stand for, and what does it mean? What are some common SLAs encountered in an IT organization?
10. How can an organization ensure effective backup?
11. What are the three types of sites for backup, according to FIPS 199?
12. List some useful guidelines for developing a change management strategy.
11.10 References
CLEE09: van Cleeff, A., Pieters, W., and Wieringa, R., “Security Implications of Virtualization: A Literature Study.” International Conference on Computational Science and Engineering, IEEE, 2009.
CMU03: Carnegie Mellon University, Handbook for Computer Security Incident Response Teams (CSIRTs). CMU Handbook CMU/SEI-2004-HB-002, 2003.
COGE16: Cogent Communications, Inc., Network Services Service Level Agreement Global. September 2016. http://www.cogentco.com/files/docs/network/performance/global_sla.pdf
ROY15: Roy, A., et al., “Secure the Cloud: From the Perspective of a Service-Oriented Organization.” ACM Computing Surveys, February 2015.