
Chapter 4. Traceback
This chapter covers the following topics:
• Traceback in the Service Provider Environment
For many years, enterprises, service providers, the government, and many other organizations have tried to develop tools and techniques to aid in the traceback of attacks. This chapter covers several lessons learned and techniques developed over the past to successfully trace back attacks or prepare the infrastructure to make this process easier. The techniques to track individual packets in a network must be done in an efficient, scalable fashion. The main goal of the traceback process is to find the source of attack or malignant traffic. By analyzing the packet contents of the attack traffic, you can determine information that may lead you to the source.
The traceback level of effort and methodologies may not be the same in all organizations. For instance, Internet service providers may use different techniques than those used in enterprises.
In the past, it was sometimes difficult to trace back attacks because of the use of spoofed packets. In addition, the packet stream may have been transmitted though many network devices that performed NAT, making it difficult for some enterprises and service providers to trace the original source IP address of the packet. Service providers and enterprises are now implementing antispoofing techniques that make it more difficult for spoofed attacks to succeed. For this reason, most attacks today are not sourced from spoofed IP addresses. Antispoofing techniques include the following:
• Source address validation described in RFC 2827/BCP38 and RFC 3704/BCP84
• Denial of your address space from external sources
• Denial of RFC 1918 private address space in your Internet edge routers
• Denial of multicast source addresses
• Filtering for RFC 3330 special use IPv4 addresses
• Use of Unicast Reverse Path Forwarding (uRPF)
• Cable source verification—Enhancements within Cisco cable modem termination system (CMTS) products that protect against spoofed attacks in Data-over-Cable Service Interface Specifications (DOCSIS) cable systems
Note
In Chapter 2, "Preparation Phase," you learned these techniques and how to protect your infrastructure against spoofed packets. See Chapter 2 to learn how to implement these types of infrastructure protection mechanisms.
Traceback in the Service Provider Environment
For the implementation of traceback techniques to be successful, they must meet the following requirements:
• Do not violate current protocol semantics and can be successful without changes in the core routing structure
• Are difficult for the attacker to detect and can function in a passive mode, without requiring much intervention
• Are useful in asymmetric environments
• Work through multiple hops, across jurisdictions
• Allow you to generate a good postmortem after an attack has mitigated
In some cases, it is difficult for the implementation of traceback techniques to meet all the requirements previously listed, and it is especially difficult for service providers. This is why it is extremely important for service providers to cooperate with each other to successfully trace back attacks. This is especially true because attackers are aware of many traceback schemes.
Tip
Major cooperative efforts exist between service providers and several organizations that promote these efforts. An example is the North American Network Operators Group (NANOG), which has excellent resources and information at http://www.nanog.org.
Another example is the Forum for Incident Response and Security Teams (FIRST), which has excellent resources and best practice guides at http://www.first.org/resources/guides.
When there are large numbers of sources or when sources are well distributed, traceback solutions often become extremely complex and expensive. Speed is a significant limitation of hop-by-hop traceback; therefore, hop-by-hop traceback can be difficult. It also requires substantial collaboration. For example, Figure 4-1 illustrates an old method being used by an individual who is attacking a victim who is numerous hops away from different service providers.
Figure 4-1. Hop-by-Hop Traceback

In this case, collaboration between service providers may be needed, and hop-by-hop traceback may take longer than expected. However, this is not what we typically see today. Figure 4-2 illustrates a more interesting scenario.
Figure 4-2. Hop-by-Hop Traceback with Botnets or Zombies

In Figure 4-2, the attacker controls three different botnets or groups of zombies. In this case, hop-by-hop traceback can be time consuming and ineffective. Botnets can consist of several hundred compromised machines. Even a relatively small botnet with only a couple of hundred bots can cause significant damage. The IP distribution of these bots makes the implementation of ingress filters (or filtering) difficult, especially because separate organizations are involved. In most cases, botnets are used to infect or spread malware to other machines. In numerous cases, botnets are controlled by the attacker who is using encrypted tunnels to protect his own communication channel.
Botnets come in hundreds of different types, some of which include:
• Agobot/Phatbot/Forbot/XtremBot
• SDBot/RBot/UrBot/UrXBot
• mIRC-based bots
• DSNX bots
• Q8 bots
• kaiten.cPerl-based bots
Tip
Shadowserver.com is an excellent website that reports botnet activity on the Internet on a daily basis. Many organizations use this information to become familiar with current trends. This site provides detailed graphics and metrics.
You can also obtain technical information about different types of bots at http://www.cert.org or at http://packetstormsecurity.nl.
Attackers who launch DDoS attacks can gain a major advantage by using reflectors to complicate the traceback process; this is known as attack obfuscation. Instead of the victim being able to trace back the attack traffic from himself directly to the slave, he must induce the operator of one of the reflector sites to do so on his behalf which can be administratively cumbersome or difficult.
Tracking botnets is a dilemma for many service providers and other organizations. To successfully perform traceback, you need to gather a significant amount of data about existing botnets, in many cases by analyzing captured malware. Many organizations are engaged in research to learn more about botnets and new techniques to combat them. An example of this is the Honeynet Project (http://honeynet.org). Honeynets are a collection of purposefully insecure machines (or honeypots) that are placed on the Internet for attackers to compromise. Researchers can then investigate and learn more about current threats. At the minimum, honeynets collect the following information to learn more about botnets:
• DNS name or IP address of the Internet relay chat (IRC) server and port number
• In some cases, passwords to connect to the IRC server (when applicable)
• Nickname of bot and ident (identification) structure
• IRC channel to join and channel password
Many researchers have observed that updates on the botnet malware are performed frequently. To understand this process more fully, consider an old worm whose propagation started in several botnets, Zotob.x. Zotob was created by Farid Essebar (known by his handle as Diabl0). He was a small-time adware/spyware installer, using Mytob (a mass mailing worm) to infect machines and install adware for money. On August 25, 2005, Essebar was arrested in Morocco. The FBI stated that it holds evidence that Essebar was paid by Atilla Ekici (known as coder), who used stolen credit card numbers to build Mytob variants, as well as Zotob. Many service providers and other organizations spent numerous hours investigating this incident. One of the methods used was the backscatter technique. Backscatter is a system that Chris Morrow and Brian Gemberling created while they were working at a major service provider in the United States. This method addresses the need of finding the entry point of a spoofed attack. It combines sinkhole routers and remotely triggered black hole (RTBH) filtering to create a traceback system that provides a result within minutes.
You can use Border Gateway Protocol (BGP)-enabled routers to set specific prefixes to a known and individually handled "next-hop" and see interesting effects when you set the "next-hop" in BGP for a host that is under attack to a single address that will be routed locally. Typically, you set a static route to Null0 so that the attack traffic is advertised with the new "next-hop." An Internet Control Message Protocol (ICMP) unreachable message is transmitted by a network device when it receives packets whose destination is unreachable (Null0). This "unreachable noise" is called a backscatter.
Note
Backscatter has been advocated by many people, but many also question its benefits. You can find more details about the backscatter technique at http://www.secsup.org/Tracking. Another good presentation on backscatter, which is by Barry Greene, a senior Cisco SP expert, is located at http://www.nanog.org/mtg-0110/ppt/greene.ppt.
Furthermore, if that traceback is then performed using a scheme that relies on observing a high volume of spoofed traffic, such as ITRACE or probabilistic packet marking, the attacker can undermine the traceback by spreading the trigger traffic of each slave across many reflectors. Doing this greatly increases the amount of time required by the traceback scheme to gather sufficient traffic to analyze. These methodologies have been suggested due to research initiatives by several organizations (mainly educational institutions). However, the initiatives, in most cases, are considered "science projects."
Many others have attempted IP traceback techniques such as probabilistic packet marking and deterministic packet markings; these attempts, however, have also been considered science projects.
Note
Wikipedia has a good, high-level description of probabilistic packet marking and deterministic packet markings at http://en.wikipedia.org/wiki/IP_Traceback.
Traceback in the Enterprise
The ability to track where attacks are coming from and the techniques that are used within an enterprise depend on the type of attack. If the attacks are coming from external sources, such as the Internet, the enterprises often depend on their providers to be able to track down sources of attack. Additionally, the network telemetry techniques and features discussed in Chapter 3, "Identifying and Classifying Security Threats," are extremely helpful for tracking where attack traffic is being generated.
One of the most powerful tools is NetFlow because it can give macroanalytical information on the traffic traversing your network. Traceback goes hand in hand with the identification and classification phases of incident response. NetFlow, SYSLOGs, DNS, and other telemetry mechanisms in conjunction with event correlation tools such as Cisco Secure Monitoring and Response System (CS-MARS) and Arbor Peakflow X are particularly helpful to trace back security incidents.
Just from a router command line (CLI), you can use NetFlow to collect valuable information. For example, if you notice a sudden increase in traffic over TCP port 445, you can use the show ip cache flow command with the include option to see the hosts that are sending this type of traffic, as shown in the following example:
myrouter>show ip cache flow | include 01BD
Fa1/0 10.36.1.66 Fa0/0 172.18.85.178 06 C5BC 01BD 93123135
Because NetFlow uses hexadecimal numbers for the protocol, source, and destination ports, 01BD is used in the include statement (01BD hexadecimal = 445 decimal). As you can see from the output, the router has received 93123135 TCP port 445 packets on its FastEthernet 1/0 interface from a host with the IP address 10.36.1.66, which is destined to a host with the IP address 172.18.85.178 residing on the FastEthernet0/0 interface.
In the following example, CS-MARS is used in combination with NetFlow and a Cisco IPS sensor. In Figure 4-3, the CS-MARS alerts the administrator about a host spreading the Nachi worm and doing a DoS via ICMP ping. The incident ID is I:155164925.
Figure 4-3. Worm Incident in CS-MARS
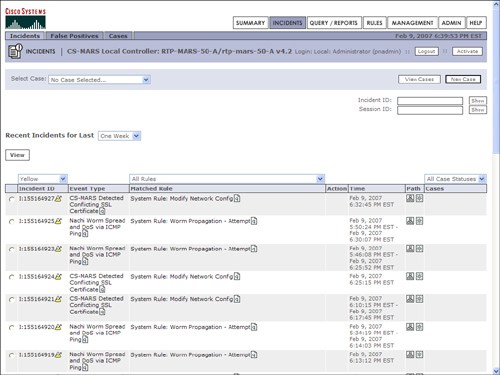
When the administrator clicks the Attack Path icon on the right, a new screen with the attack topology is displayed, as shown in Figure 4-4.
Figure 4-4. Attack Path
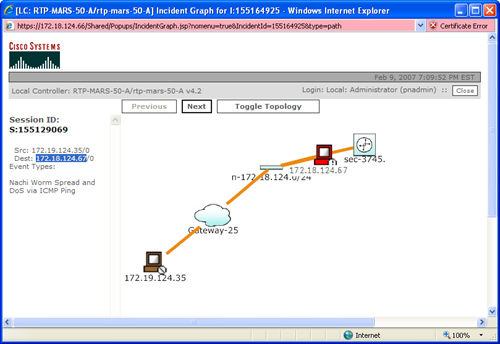
In Figure 4-4, you can see that the infected host is 172.19.124.35, and it is attacking a host with the IP address 172.18.124.67. This is a simple topology; however, CS-MARS is able to show you each hop based on the information imported and its configuration. Graphical representation like this one can save you many hours of investigation.
An additional example is shown in Figure 4-5.
Figure 4-5. Dot-Dot Attack

In Figure 4-5, a host with the IP address 10.10.1.10 (HQ-host1) is attempting to crash an IIS server (192.168.1.10 or HQ-web-1) by performing a dot-dot crash and running an attack. Notice that each hop in between is clearly represented, making the traceback process simple. CS-MARS correlated this information analyzing events from a Cisco IPS sensor and from firewall logs from a Cisco PIX security appliance.
Tracing botnet controllers and determining if you are a victim can be difficult. The following tips might help you or your organization if it has zombies:
• If you see a good deal of IRC traffic within your organization, it may be worth investigating further. IRC traffic is not common in most enterprises, and most of the botnets are organized and controlled over IRC.
• You can look for the most commonly used default IRC port (6667). In addition, you will want to expand to the full port range (from 6660 to 6669 or 7000). On the other hand, many botnet controllers can use nonstandard IRC ports. If you have a firewall within your organization, take a look at outbound connection attempts on any suspicious ports.
• IRC traffic usually manifests itself in cleartext, so sensors can be built to sniff particular IRC commands or other protocol keywords on a network gateway.
• If you notice that a large quantity of systems within your organization are trying to resolve the same DNS names or accessing the same server at once, you should immediately investigate further because those systems may be zombies. Also, periodically check your DNS caches. Many command and control tools will use a DNS domain that the herder (botnet administrator) can easily change as needed to relocate the botnet infrastructure.
• You can look for other obvious symptoms of being a victim. For example, if you see much port-scan traffic, it is a definite sign that machines are infected. You can use proper IDS/IPS signatures to find these and then investigate the source. In addition, if you see a lot of unexpected outbound SMTP traffic, you are likely to be hosting spam bots. You can use NetFlow to get statistics about these type of attacks.
Note
Chapter 12, "Case Studies," includes case studies with examples of how different types of organizations identify, classify, trace, and react to security incidents. Common traceback mechanisms are used in those examples.
Summary
Tracing back the source of attacks, infected hosts in worm outbreaks, or any other security incident can be overwhelming for many network administrators and security professionals. Attackers can use hundreds or thousands of botnets or zombies that can greatly complicate traceback and hinder mitigation after traceback succeeds. This chapter covered several techniques that can help you successfully trace back the sources of such threats; covering both service provider and enterprise techniques. Remember, traceback mainly involves the packet source. Using network telemetry tools like NetFlow, syslog, DNS, and others in conjunction with event correlation systems can save you hundreds of work hours and, consequently, save you money.