
10
The Production and Innovation Knowledge Repository
10.1. Introduction
A virtual enterprise is a networked organization where different autonomous entities collaborate toward a common goal. The business innovation in virtual enterprise environment (BIVEE) project introduces the notion of virtual innovation factory (VIF) as an innovation-oriented virtual enterprise whose goal is to support the production of innovation. Production of innovation takes place in the business innovation space (BIS), where active entities, such as the research and development (R&D) innovation teams, final users, partners or even competing companies and other actors, operate. Operational processes pertaining to the BIS define the core innovation value chain: sourcing raw ideas, transforming them into products (goods and services), and marketing and delivering new products. Finally, processes for the planning and monitoring of innovation projects conducted1 in the BIS characterize the managerial level of a VIF. All these kinds of activities require intensive collaboration, communication and interaction, and ultimately a high level of knowledge sharing among the involved autonomous actors. Indeed, knowledge is the main factor that enables continuous innovation in a world of rapidly changing markets, products, services and technologies (see, for example, [NON 00] for a thorough discussion of the notion of knowledge and its role in enterprise management). Efficient access to knowledge resources is, however, hindered by interoperability issues coming from fragmentation and heterogeneity of the involved players, their data, information and knowledge resources.
In order to address interoperability issues and enable sharing of knowledge, the BIVEE project proposes an approach based on semantic technologies. In particular, this chapter presents the design principles and the prototype definition of the Production and Innovation Knowledge Repository (PIKR), a semantics-based repository for knowledge resources related to the BIS where the VIF operates.
The PIKR is a virtual repository since actual resources (e.g. enterprise documents) physically reside locally, at the premises of the individual virtual enterprise (VE) partners, while the PIKR maintains and manages an ontology-based image of such resources, as the result of their semantic description. Leveraging on the semantic description of enterprise resources, the PIKR provides a set of services for supporting smart access to stored resources, facilitating the sharing of contents and supporting the information and knowledge interoperability with the ultimate goal of supporting innovation project management.
The design principles of the PIKR descend from the analysis of user requirements and the methodological framework elaborated within the BIVEE project. The analysis led to the recognition of core elements to be semantically described, namely documents, business processes (BPs) and key performance indicators (KPIs), and the relationships among them.
10.1.1. BIVEE innovation framework
The BIVEE project elaborated the business innovation reference framework (BIRF) [ROS 12] that works as the methodological framework to create and manage knowledge in the BIS. The BIRF is characterized by the notion of innovation waves, in which an innovation venture is articulated, and in which the activities carried out during the innovation lifecycle are organized. Four waves have been identified:
- – Creativity: all the activities related to the creation and first evaluation of new ideas.
- – Feasibility: the scope and the intended impact of new ideas are defined, including a first account of their technical and financial feasibility.
- – Prototyping: the first implementation of the evolving ideas, achieving a first full-scale working model. Such a model is tested and analyzed to verify the actual performance and features, also giving the possibility to rethink some design.
- – Engineering: activities aimed at producing the specification of the final version of the new product (essentially the bill of materials and manufacturing procedures), ready for the market, and the corresponding production process.
For each wave, a number of activities to be carried out in order for a wave to be completed have been identified. Examples are idea generation and idea analysis for the creativity wave, resource analysis and feasibility study for the feasibility wave, resource allocation for the prototyping wave, build and optimize for the engineering wave.
Each activity is further specified by providing the description of inputs and outputs in terms of knowledge chunks needed and produced by the activity, respectively, that will correspond to a document to be filled, in order for each activity to be completed. Finally, activities and documents are associated with a set of indicators expressing the quality of a document or the performance of an activity. An example of a document related to the (output of) idea generation activity is “Proposed Idea”, while the activity can be evaluated by indicators such as the cycle time and the investment in employee development. The systematic organization of indicators and documents includes the definition of indicators categories and objectives, documents prerequisites and constraints, and so forth.
10.1.2. Analysis of requirements
The starting point of the PIKR specification is the analysis of requirements that arise from the BIRF, discussed above, whose basic elements have to be semantically described, and the functional requirement provided by the BIVEE end-users. From the end-users’ point of view, the PIKR should enable managers to perform the following activities: (1) to evaluate ideas that are proposed within the VIF, to filter them, and hence to support the selection of promising ideas; (2) to monitor the status of an innovation project and its evolution; (3) to classify ideas; (4) to discover similarities among ideas at any stage (i.e. wave) of their development, for avoiding duplication, and improving the overall efficiency of the innovation process; (5) to reuse experience from past projects, by looking at results of both successful and dead projects and (6) to search for partners with specific competencies.
A selected list of the identified functional requirements follows: (1) to take into account different kinds of enterprise knowledge resources, such as documents, processes, products and KPIs; (2) to allow the management of VIF knowledge resources by means of classification and annotation mechanisms, taking into consideration application domain content of knowledge resources; (3) to support access and retrieval of resources by means of advanced search functions, based on exact and similarity matching; (4) to keep track of links and dependencies among knowledge resources for a smart access and manipulation of knowledge resources; (5) to support the evaluation of indicators for assessing the status of the activities in a VIF; (6) to provide reasoning capabilities over enterprise knowledge resources and (7) to provide collaborative mechanisms for facilitating the participation of the largest number of players in the process of continuous optimization and innovation.
The first two requirements are addressed by the internal organization of the PIKR, by means of an ontology-based framework that allows the semantic representation of different kinds of knowledge resources (see section 10.3). The rest of the requirements list is covered by semantics-based search functions and reasoning capabilities.
The remainder of the chapter is organized as follows. Section 10.2 introduces the key enabling technologies adopted by the PIKR. Section 10.3 describes the PIKR ontological framework that enables the semantics-based unified view given by the PIR in a virtual enterprise scenario. Section 10.4 presents the developed methodology for building the application domain ontologies. Sections 10.5 and 10.6 report on the techniques for the semantic annotation of the different kinds of knowledge resources. Section 10.7 outlines the implementation of the PIKR. Finally, section 10.8 concludes the chapter.
10.2. Key enabling semantic technologies
While the BIVEE platform, through its front-end, provides several tools (such as whiteboards, serious games and rewarding mechanisms) to foster social interactions and collaborative activities for supporting open innovation tasks, the PIKR offers to such tools services that enable the organization, interoperability, sharing and smart access to knowledge resources. The proposed infrastructure provides the following baseline services:
- – Ontology-based informative resource representation: the PIKR is organized as a federation of reference ontologies, which are primarily used to semantically enrich any kind of tangible and intangible artifact in the scope of a given VE. In particular, the ontologies are partitioned into knowledge resource ontologies (KROs), which are independent of any application domain and provide the means for the representation of the main knowledge resources (e.g. members’ profiles/competencies, BPs, reports and performance indicators), and domain specific ontologies (DSOs) which provide the semantics of a specific business scenario (e.g. automotive and cultural heritage).
- – Collaborative knowledge engineering: the PIKR supports the building of domain ontologies shared and agreed within the VE organizations. An iterative and incremental process, supported by a software platform built upon a semantic wiki, allows a community of practice, including knowledge engineers, domain experts and ontology stakeholders to cooperate for: (1) producing conceptual models and reaching a consensus on their suitability with respect to the application domain at hand, and (2) guaranteeing at the same time a sound formal encoding into a computational ontology. Depending on the particular requirements at hand, the output can be a full-fledged axiomatic theory, encoded as an OWL (Ontology Web Language) ontology, or a rich semantic network, implemented according to the simple knowledge organization system (SKOS) standard.
- – Semantic access and processing of knowledge: the PIKR exposes a set of services that exploit the ontology-based knowledge representation, in order to provide advanced semantic facilities for data harmonization, search and retrieval, and verification of business rules. Among them, a similarity engine, implementing the SemSim semantic similarity method [FOR 13], enables (1) concept-driven search service, (2) recommendation of contents to users, by matching users’ profiles with annotated resources and (3) correlation of knowledge fragments based on their semantic affinity.
10.3. Ontological framework
The objective of the PIKR is to create a semantics-based unified view of the information and knowledge created and transformed within the BIS where the VIF operates, by providing a semantics-based infrastructure for: (1) the representation of digital documental resources (DDRs) in terms of shared ontologies and (2) the enactment of reasoning and searching functionalities on the annotated DDRs.
We identified the following core elements to be semantically described. Documents, which are concrete footprints of all kinds of activities, both at production and innovation level; BPs, which describe all the activities related to the development of innovation projects and their implementation in production processes; KPIs for monitoring the progress of innovation projects and the related operational activities. Besides the aforementioned core elements identified in the BIVEE business innovation reference framework, knowledge related to the specific application domain is taken into account in terms of actors and their competencies (which refer to the capabilities of the VIF and its members) and business-related information, such as bill of materials and other production constraints, production techniques, patents and so forth.
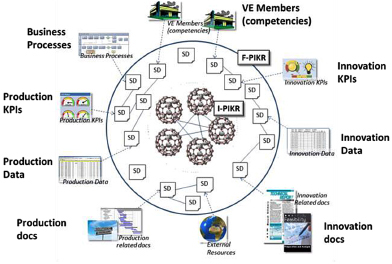
Figure 10.1. The PIKR structure
To this end, the structure of the PIKR is organized into two semantic layers (see Figure 10.1): (1) a federation of ontologies to deal with the aforementioned kinds of knowledge, collectively referred to as the intensional PIKR (I-PIKR), and (2) the semantic representation of the information relevant to VIF members in terms of the I-PIKR ontologies, through semantic descriptors (SDs), which constitute the factual PIKR (F-PIKR).
10.3.1. Knowledge resource ontologies
The enterprises that participate in a VE have different methods and tools to represent information and knowledge. The PIKR has the primary objective of acting as a common hub for the management of knowledge resources in a VE. In this perspective, an important role is played by the KROs, which are briefly introduced here.
10.3.1.1. DocOnto: document ontology
In virtual enterprises, document transfer is one of the commonly used ways to exchange business knowledge among parties. The document ontology (DocOnto) provides the means for the semantic categorization and annotation of “documents”. Running through the four innovation waves, many documents are produced, used, consumed and evaluated. For instance, in the creativity wave, given a problem or issue, many ideas can be proposed to address it. Some of them will pass the initial stage and will be further elaborated; some other will be discarded for different reasons. For instance, an idea could be discarded because it appears not to fit the current market conditions, or because the existing technologies are considered not mature or too expensive for gaining a valuable profit. Being able to record such information allows people to keep track of reasons that have guided decisions, and to represent a means for reusing acquired knowledge to save time and money in the future, if similar initiatives are proposed. For instance, in elaborating an idea, to dispose of documents produced in the previous project experiences that share the same or similar topics (e.g. the addressed research line, as well as the used technologies) of the current project results as relevant knowledge resources.
Starting from the analysis requirements from the BIVEE pilot users [SIN 12], and the BIRF, a set of Infosets (types of documents) for each innovation wave has been identified as shown below:
- – creativity: proposed idea, technical solution, preliminary market analysis, innovation report, prospective budget and creativity assessment;
- – feasibility: project proposal, alliance, market analysis, periodical subproject report and feasibility assessment;
- – prototyping: requirements, implementation roadmap, prototype technical report and prototype assessment;
- – engineering: protocols, bill of materials, budget, quality report, test, product data sheet and engineering assessment.
InfoSets are organized into three main sections grouping different kinds of InfoItems, which represent smaller pieces of information (i.e. properties):
- – header groups InfoItems such as the title of the document (or part of it), an abstract, the authors and contributors and the URI of the concrete document to be used for retrieving it;
- – content provides a definition of the content explicated by an informative resource in terms of the DSOs;
- – related knowledge resources allow InfoSets to be related between them (e.g. an AssessmentReport can be linked to the InfoSet where evaluated contents are described, e.g. a ProposedIdea).
10.3.1.2. ProcOnto: business process ontology
The business process ontology (ProcOnto) provides the means for representing and reasoning with process knowledge, by semantically describing BP models, and makes them available through reasoning facilities. SDs defined according to the ProcOnto allow us to achieve a machine-processable representation of a BP model, which can be: (1) enriched in terms of PIKR ontologies, to capture the knowledge regarding the entities involved in such a process, i.e. the business environment in which BPs are carried, and (2) related to other information resources through links among SDs.
For the definition of the ProcOnto, we propose to adopt the business process abstract language (BPAL) [MIS 11, SMI 13], a process ontology which provides constructs for capturing the structure and behavior of a BP represented according to a workflow perspective. BPAL supports the definition of a BP schema, by means of constructs to represent control flow dependencies, data flow, hierarchical decomposition of activities, preconditions and effects of activities. Thus, it is equipped with a formal behavioral semantics, which models the traces that are produced by the execution of BPs. The behavioral semantics of a BP schema captures the notions of state of the world and state updates, caused by the execution of activities, which reflect possible enactments of the BP (i.e. execution traces).
The ProcOnto thus encompasses modeling notions common to the most used and widely accepted BP modeling languages and, in particular, its core is based on BPMN 2.0 specification [OMG 11]. Being the constructs provided by the language a sufficient means for capturing structural and behavioral properties of a significant fragment of the BPMN standard, they allow us to deal with a large class of process models.
In the following, we introduce the main aspects of the ProcOnto by means of an exemplary SD (Table 10.1), resulting from the annotation of a production BP.
Table 10.1. Excerpt of semantic descriptor for the activity “Delivery by external agency”
| bpal: Activity | |
| Header | |
| Title | Delivery by external agency |
| Description | Arranging a goods delivering performed by an external retailer |
| Identifier | Delivering |
| Source | http://bivee.eng/ps/aidima/bp_mod_145.uml#Delivery_by_external_agency |
| Coverage | Production Space |
| ConformsTo | UML Activity Diagrams |
| Content | |
| TermRef | Shipment AND Outsourcing |
| Condition | ApprovedOrder(po) AND AllocatedInventory(po,in) AND DeliveryDeptUnavailable(po) |
| Effect | FulfilledOrder(po) AND IssuedInvoice(po,i) |
| Related Resources | |
| Participants | controller → SalesDept, performer → Retailer |
| Control Flow Dependencies | predecessor → analysis_order_size |
| Data Flow Dependencies | input → DeliveryOrder, output → Invoice, output → PackingSlip |
| Performance Indicator | reliability → Delivery Performance |
The descriptor reported in Table 10.1 is an instantiation of the ProcOnto class activity, representing a unit of work performed within a BP for the “Delivery by external agency”. In the header section, a number of meta-data are collected: Title (i.e. a label to refer to the activity), Description (i.e. a natural language definition of the activity), Identifier (i.e. the system unique reference), Source (i.e. the URL where the resource is published, which in this case is a fragment of a BP model made available by AIDIMA), Coverage (i.e. the scope of the activity, which in this case is the Production Space), Conforms To (i.e. the language the BP model is conformant to), which in this case is unified modeling language (UML).
The content section of a ProcOnto activity is specified in terms of: (1) a terminological annotation, which defines a correspondence between elements of a BP schema and concepts defined in the DSOs; in the example, the activity is described as a shipment which is given in outsourcing, (2) the condition under which it can be correctly executed, which in the example is represented by a situation where items in the inventory have been allocated to fulfill an approved order, if the delivery department is not available, and (3) the effects on the state of the world upon its execution, which in the example include the issuing of an invoice.
Other resources that can be related to an SD of an activity encompass: (1) the participants to the activity, e.g. the sales department assigned to the supervision or the retailer which actually performs the activity; (2) the control flow dependencies, e.g. the fact that the analysis of order size precedes the delivering; (3) the data flow dependencies, describing inputs (e.g. the delivery order) and outputs (e.g. packing slip) of the activity and (4) the KPIs associated with the activity for monitoring, e.g. the delivery performances to measure the activity reliability.
10.3.1.3. KPIOnto: key performance indicator ontology
Several definitions of performance indicators, different for goals, domain of interest, degree of precision and formalism, are provided, e.g. by international and national public bodies, in reference models such as the supply-chain reference model1 and value reference model (VRM). For the design of the KPIOnto and for the development of the BIRF, our approach aims to abstract the general features of such models, with a particular focus on VRM, which explicitly addresses networked enterprises. However, the KPIOnto allows us to describe indicators having different scope: “global” indicators, conceived to monitor the whole innovation project, and “local” indicators conceived to measure the performances of individual enterprises. It is worth noting that the latter are needed to derive, namely to compute, the former. For a more comprehensive description of the KPIOnto, please refer to Chapter 11.
10.4. Domain ontology building methodology
The conceptualization of domain-specific knowledge, shared and agreed by the VE organizations, and encoded in computational ontologies to be used for capturing in a formal and unambiguous way the knowledge resources of interest, is a crucial aspect. Here, the major challenge is to allow the participation of workers to elicit/codify their tacit knowledge, providing the means to convert it into something more explicit and processable. To this end, in the BIVEE project, a collaborative ontology building methodology has been developed. Such a methodology allows a community of practice [IRI 07], including knowledge engineers, domain experts and ontology stakeholders to cooperate for: (1) producing conceptual models and reaching a consensus on their suitability with respect to the application domain at hand, and (2) guaranteeing at the same time a sound formal encoding into a computational ontology.
Figure 10.2 presents an overview of the proposed approach, and its positioning within the socialization, externalization, combination, internalization (SECI) process [NON 00], a reference scheme that addresses knowledge production as a continuous enrichment process based on tacit and explicated knowledge transformations. Socialization is the mechanism of conveying new tacit knowledge in a community of practice through shared experiences (tacit to tacit). Knowledge acquisition and sharing can be facilitated through virtual environments, which are provided in our approach by a (semantic) wiki environment. The externalization that realizes the transformation of knowledge from a tacit to an explicated form is addressed by our approach through iterative phases aiming at an incremental construction of the ontology (i.e. from a lexicon to an axiomatic theory). The organization and integration of knowledge through collaboration and voting facilities ease the combination of different types of explicit knowledge, originating from different individuals. Finally, the reasoning capabilities enabled by a formal representation of knowledge support the ability of people to see connections, recognize patterns and the capacity to correlate fields, ideas and concepts. This contributes to the internalization, i.e. the process of embodying new knowledge in the human mind and social practices (explicit to tacit).
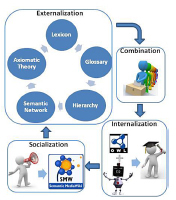
Figure 10.2. Ontology building methodology overview
The methodology introduced here provides a collaborative framework for defining, in a progressive way, a business ontology. A number of phases are iteratively conducted, each of which leads to a different outcome, namely lexicon, glossary, hierarchy, semantic network and axiomatic theory. According to this, an initial lexicon is enriched step-by-step with definitions, relations and finally with formal axioms with a level of rigor which depends on the requirements at hand:
- – Targeted knowledge: the proposed method has been conceived to support the representation of enterprise knowledge in terms of three main axes: (1) the involved players (VE members and potential clients), (2) production and innovation activities in the scope of the VE, associated with, for example, the available capabilities, skills and technologies, and (3) business objects pertinent to the VE reality, including, for example, business objects, documents and products (services and goods). To this end, we introduce some basic conceptual categories (referred to as kinds) following the object process actor language (OPAL) [DAN 07], to support the participants in the conceptualization process, identifying active entities (actors), transformations (processes) and passive entities (objects), with their properties (attributes). Therefore, upper level concepts are: (1) opal:Actor, representing active elements of a business domain, able to activate, perform or monitor a process, (2) opal:Process, representing any business activity or operation aimed at satisfying a business goal and operating on a set of business objects, (3) opal:Object, to represent entities a BP operates on, and (4) opal:Attribute, representing a measurable property associated with an individual (e.g. weight, name and color). We adopted OPAL as a “default” component of the proposed framework since it is a light-weight language, which has been validated in several international projects exhibiting a good trade-off between ontological rigor and acceptance in business realities.
- – Involved participants: communities of practice have been identified as the place where the conversion of tacit and human capital into explicit and structured social capital can occur [IRI 07]. We assume a community of practice involved in an ontology building process composed of a heterogeneous set of people, which we can roughly group as content providers and ontology stakeholders. Content providers can be distinguished as knowledge engineers (KEs), domain experts (DEs) and application experts (AEs). KEs are supposed to have skills in semantic technologies (e.g. conceptual modeling and formal languages), whereas DEs and AEs are experts, respectively, of the domain of interest and the particular application addressed. Among them, specific roles are entitled: the ontology master, who is the responsible coordinator of the whole building process; the mediators, who lead participants in collaborative activities. Ontology stakeholders can be users, i.e. the group of people who will operationally interact with ontology-based applications or, more in general, people who are interested in the success of the ontology building project.
- – Collaboration means: each phase of the ontology building process is delimited by deadlines, which are set by the ontology master. Within a phase, participants can express their contributions through three collaborative interactions means. Proposing content, which allows content providers to introduce new pieces of knowledge at each phase of the ontology building process (e.g. suggesting a new term, as well as proposing a natural language definition for a given term). Discussing relevant topics, such as: (1) validation issues related to the proposal, acceptance and removal of contents, and (2) strategic aspects related to, for example, the usage and consumption of the ontology, trends of the addressed domain and extensions in the direction of specific/emerging subdomains. Every member of the community can participate to discussions, coordinated by mediators who are in charge of monitoring discussion threads, highlighting the essence of the argumentations, and in case, proposing voting sessions for reaching a final agreement on discussed issues. Voting, which enables all the participants to express their preferences on proposed contents in a poll manner. Votes are expressed according to a graduated rate scale (e.g. 0=discard, 1=neutral and 2=accept) and can be supported with comments. We considered formal techniques [LIN 02] and [DEL 75]. In both, a mediator coordinates the activities without actively taking part to the vote. Furthermore, while in [LIN 02] voting is anonymous, in [DEL 75] it is organized in physical brainstorming sessions where all actors are involved. In our approach, we decided to adopt a non-anonymous voting system. This allows us to identify the most active people in the collaborative process, as well as their effective contribution to the ontology construction. Such an information is exploitable by the ontology master for selecting mediators on the basis of their quantitative, as well as qualitative participation. Voting activities determine an acceptance rate on contents to be validated. Customizable voting policies allow the ontology master to specify: (1) a quorum, which is the minimum number of needed votes to validate a proposed piece of content (e.g. 25% of the participants), as well as (2) a threshold on the sum of the collected votes (e.g. average rate above 60% of the highest allowed rate). Collaborative activities in our approach do not need the organization of physical meetings since they are supported by a web-based infrastructure, which allows remote interactions at any time and from any place.
10.5. Semantic annotation
10.5.1. Ontology-based lifting of value production space knowledge
The actors operating in the value production space (VPS) are supported in their work by the BIVEE platform, through the mission control room (MCR) [WOI 12], which provides its facilities through a hybrid meta-modeling platform, whose building blocks include: (1) the modeling language, which provides the means for building conceptual models, through a number of constructs predefined according to their semantics, syntax and graphical notation, (2) the modeling procedures, which define the stepwise usage of the modeling language, and (3) mechanisms and algorithms that enable the computer-based processing of models.
Conceptual models, such as BPs, value process chains and e3value models, are the key means for representing enterprise resources to allow stakeholders (e.g. designers, analysts, businessmen and engineers) to discuss requirements, validate design choices and support decision-making. Thus, conceptual models describing the VPS represent the main knowledge asset of the VE, reporting the “as is” situation and facilitating the improvement and the innovation ventures. Nevertheless, the management of such knowledge is limited due to the fact that graphical modeling languages and notations are mainly intended for human consumption, while they fail in making knowledge available in a machine-accessible form. Our objective is to develop a modeling platform that enables stakeholders to manage the knowledge through a human-oriented representation and enrich such representation with machine interpretable semantics for knowledge engineering. The final goal is a hybrid approach aimed at avoiding ambiguities and inconsistencies, providing a unified knowledge space to enable collaboration and knowledge sharing among humans and software applications, and ultimately supporting effective semantics-based production management. In particular, we propose a two-faceted semantics-based intervention. On the one hand, we propose the introduction of a semantically lifted enterprise model, which is represented in a formal, rigorous and machine-processable way, by using ontology-based languages; on the other hand, enterprise models enriched with semantic annotations. This approach enables the implementation of advanced reasoning facilities, for providing smart access and management of stored resources, reasoning over them, facilitating sharing of contents, increasing their quality and supporting knowledge interoperability.
10.5.1.1. Semantic enrichment of the VPS modeling framework
For each modeling perspective relevant to the VPS, a modeling language has been defined in the MCR, and ontological reference structures have been formalized in the PIKR, as reported in the following:
- – VE network model, describing the participating production units, including their organizational structure, capacities and capabilities; to support the annotation of such information, a production unit capability ontology (PUCO) is included in the DSOs, for the representation of actors and related capabilities, as shown in Figure 10.3. In the PUCO, we model production units as particular forms of organizational actors, which can be aggregated to realize a VE. For enriching and standardizing the representation of human actors and organizations, the friend of a friend (FOAF) vocabulary is also included, as shown in Figure 10.3. A production unit offers a number of capabilities, described in terms of: (1) a time interval, in which the capability can be offered for its implementation, (2) the KPIs that the capability is assumed to fulfill, in order to provide a quantitative and qualitative description of the commitment of the production unit (PU) in realizing a given outcome, (3) the task related to the capability, e.g. varnishing and delivering, (4) the business objects in the scope of the capability, e.g. chair and table, and (5) the tools/technologies that a production unit can exploit, e.g. metallic upholstery.
- – Products: the VPS is centered around the products the VE is able to realize, starting from the bill of materials and decomposing the product in components and finally in raw materials. As discussed in section 10.4, one of the targets of the DSO ontology building process is the object category, including a classification of final products, along with its tangible (physical) components (e.g. the monitor of a laptop) and intangible (non-physical) components (e.g. the warranty and assistance services associated with a laptop).
- – Business processes: the representation of BPs in the PIKR is realized through the ProcOnto, largely described in section 10.3.1.2.
- – Documents: the VPS documents in the scope of the BIVEE platform mainly regard documentation at the production unit level, such as guidelines, templates, description of services, service level agreements and the like.
- – KPIs: the support oriented to monitoring activities given by the PIKR involving the semantic representation and processing of performance indicators is the central subject of Chapter 11.
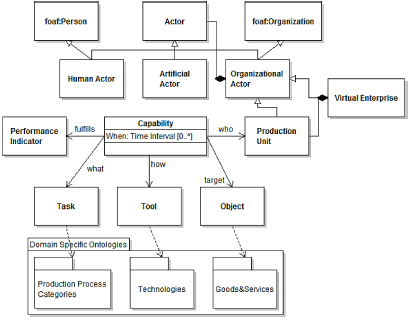
Figure 10.3. Overview of the production unit capability ontology
10.5.1.2. Technical integration of PIKR and MCR
In order to integrate the semantics-based representation framework realized in the PIKR with the VPS modeling framework realized in the MCR, we follow the semantic transit model proposed in [WOI 13]. This approach requires an extension of MCR meta-model, introducing a semantic model, which enables ontologies to be copied into the MCR using this “transit”, in order to be used for the annotation. In order to semantically enrich all the different kinds of modeling artifacts, the integration between PIKR and MCR is based on the following conceptual schema, as shown in Figure 10.4:
- – Meta-model annotation: the constructs which are defined in the meta-model of a particular modeling language are mapped to concepts defined in a meta-model ontology. Such a mapping can be considered as a predefined built-in of the framework. This kind of annotations relies on the KROs.
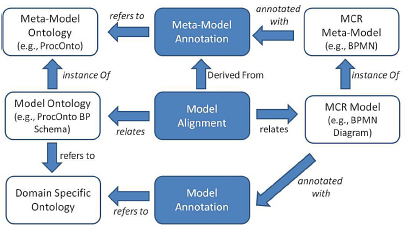
Figure 10.4. Conceptual integration between PIKR and MCR
- – Model alignment: a model alignment includes the correspondences among the entities of a given MCR model, instantiated according to the metamodel MM, and a model ontology MO instantiated according to a metamodel ontology MMO, provided that a meta-model annotation is available between MM and MMO. Basically, given an MCR model and its annotated meta-model, a model alignment can be automatically derived to generate a corresponding model ontology.
- – Model annotation: the elements occurring in a model are put in relation to concepts defined in some ontologies; in our framework, model-level annotations rely on DSOs.
The aforementioned integration impacts on the MCR modeling capabilities in two ways: (1) semantic models (ontologies) extend the modeling framework and enable the description of modeled entities, by referencing ontology fragments, and (2) automatic transformation of MCR models into interpretable ontologies.
As far as the mechanisms and algorithms implemented by the MCR are concerned, we have two main extensions: (1) ontology-based processing of models discussed in [TAG 12] that extends the SQL-based search and retrieval support given by the MCR to search and retrieve facilities discussed in [TAG 12], and (2) knowledge-based evaluation on models, providing semantic compliance checks on a model based on declarative constraints (both syntactically and semantically).
10.5.1.3. Application scenarios and main functionalities for the VPS
As far as the VPS is concerned, the BIVEE platform through the MCR provides two main categories of functionalities, related to (1) VPS design, where the business goals are defined, the VE is built, the business activities are structured into BP and KPIs for the VPS are identified, and (2) VPS monitoring and improvement, where KPIs are collected and measured to identify underperforming areas and drive the continuous improvement. Since point (2) is largely discussed in [TAG 13], in the following we focus on applicative facilities regarding VPS setup:
– VE setup
Once the goals of the VE to be constituted are defined, together with the requested competencies and production capabilities, the semantic profiling of VE members supports: (1) semantic search of partners for identifying who can take part to the VE, (2) allocation of production units to production activities according to their capabilities, and (3) definition of the bill of material and the identification of the associated production process, by navigating the product decomposition hierarchy.
– Reuse in modeling
During the setup of the VPS, the PIKR offers reuse facilities, based on the searching and querying baseline reasoning services. Especially in the VPS modeling phase, a pool of related resources can be suggested by the PIKR. Modeling does not start with a blank sheet, but by formulating a request and selecting the proposed results.
– Knowledge interoperability
The adoption of reference structures in the form of KROs and DSOs provides the means for the annotation of heterogeneous knowledge resources in terms of the same language via shared terminological definitions. This implies:
– Compliance of the designed VPS
The compliance of the designed VPS with respect to domain-specific constraints can be checked according to the consistency baseline PIKR service. Use cases include: (1) exploiting KPI reasoning facilities for verifying if the measurement data made available by VE members are sufficient or which KPI can be monitored with available data, or guaranteeing that no contradictory indicator will be computed at runtime, (2) verifying VE-specific business rules and regulation against the designed BPs, (3) checking semantic and syntactic correctness criteria formulated for a given modeling language supported by the MCR, and (4) assuring that the documented VE guidelines, description of services and service level agreements are properly reflected in the designed VPS.
10.5.2. Ontology-based lifting of business innovation space knowledge
10.5.2.1. Semantic enrichment of the BIS modeling framework
Each wave, namely creativity, feasibility, prototyping and engineering, is organized into a certain number of activities to be carried out in order for a wave to be completed. Each activity is characterized by a set of documents, which are the artifacts where innovation-related initiatives are accounted. As such, innovation-related documents represent valuable resources for sharing information about ongoing and past innovation initiatives. The main objective of the semantic enrichment of the BIRF is the semantic description of innovation-related documents by semantically abstracting and lifting their structure, and enriching their content in order to enable interoperability and openness, as well as reasoning services such as querying and retrieval of documents, reasoning over documents description, understanding similarities among documents, assessing status and quality of documents, and monitoring innovation activities. The semantic abstraction and lifting is performed in terms of the DocOnto, while the domain knowledge enrichment is performed in terms of the DSOs (see Figure 10.5).
Figure 10.5. Ontology-based support to document annotation
In section 10.3.1.1 we reported on the organization of the document ontology (DocOnto), in this section we will focus on the technical aspects concerning the interactions between the PIKR and VIF, as well as on the main application scenarios where the semantic enrichment of BIS resources can be exploited.
10.5.2.2. Technical integration of PIKR and VIF
The integration between the PIKR and VIF happens by means of a set of adaptors, which enable the VIF to interact with the PIKR for supporting the semantic lifting and the domain knowledge enrichment of documents in the BIS. The adaptors will allow the VIF to: (1) retrieve the structure of innovation-related documents as they are modeled in the DocOnto, (2) retrieve and query the DSOs, and (3) feed the F-PIKR with SDs of documents.
10.5.3. Application scenarios and main functionalities for the BIS
Once resources in the BIS (mainly, innovation-related documents) have been semantically described in terms of the DocOnto and DSOs, a number of functionalities can be enacted by the VIF through the interaction with the PIKR services.
10.5.3.1. Information flow management
Navigating through the document repository
Following the links defined in the DocOnto and connecting the different types of InfoSets, it will be possible to navigate the repository of documents.
Searching for documents
The most straightforward usage of ontology-based description of BIS resources is represented by the possibility of searching for innovation-related documents. As described in [TAG 12], the PIKR provides services for exact and similarity-based retrieval of annotated resources.
Suggesting related documents
While people are accessing a given document through the VIF, related documents could be proposed as additional resources to be inspected. Proposals can be identified on the basis of: (1) similar contents, for instance given a document annotated as a ProposedIdea, other idea documents referring to the same (or similar) objectives could be proposed, and (2) dependencies/associations between documents. For instance, given a document annotated as a ProposedIdea, the assessment report of the idea itself could be proposed.
Checking consistency and status of the documents in the BIS
The DocOnto defines dependencies between InfoSets. For instance, a ValidatedIdea report needs to refer to an existing ProposedIdea. If such information is not indicated, the system has to identify such an inconsistency and provide feedback to the VIF.
Proposing extensions to DSOs
Since innovation activities can go beyond existing frontiers or at least consider new application domains, it is possible that at the annotation time the DSOs lack the required knowledge. For this reason, the PIKR has to support the VIF in extending the DSOs by proposing a communication channel for proposing new concepts.
Supporting innovation observatory
A semantics-based crawler will support the monitoring of relevant initiatives happening outside the borders of a given virtual enterprise with respect to new innovative initiatives, innovation opportunities and existing initiatives that can be related to the VE’s activities.
Semantics-based social media for collaborative open innovation
Posts, comments and discussions of VIF users through the collaborative whiteboard will be semantically annotated/tagged as the other documental resources in the BIS, so that they can be positioned, grouped, localized one next to another and connected to one another forming knowledge clusters, with the intent to create an articulated picture of the hot issues at hand.
10.6. Semantic enrichment of semantic media contents
The analysis of semantic media contents (SMCs) aims at building a semantic representation of all the collective knowledge maintained in the overall VE. To this end, through the BIVEE front-end, SMCs are submitted to the PIKR to be semantically analyzed and annotated.
The annotation is represented by an ontology feature vector (OFV), i.e. an ordered set of references (URIs) to concepts defined in the reference ontology. The automatically suggested annotation can be validated and manually improved by users.
UC SE1: open collaboration – leveraging on crowd intelligence: when a new issue arises, an instance of the shared whiteboard (SW) is created, and the information related to the case is posted on it. The open sections of the SW are then accessed by contributors, which can provide comments and suggestions to find a solution. Each piece of content posted on the SW is automatically annotated by means of the semantic analysis provided by the PIKR. The annotation, expressed as an OFV, can be visualized and refined by each member invited to the SW.
10.6.1. Semantic search to foster idea creation
At each stage of the development of an idea, the BIVEE platform offers the possibility of performing a semantic search to automatically retrieve related resources (e.g. past innovation projects, ideas or solutions to problems). As the annotations, search criteria are expressed in the form of a feature vector as well. An autocompletion facility is provided by the frontend for easing the query formulation. As an alternative, focused search requests can be automatically formulated by selecting a given SMC (e.g. a post) and using the associated feature vector as the query to find related knowledge resources.
UC SS1: semantic search on past experience – once a user proposes a new idea through the BIVEE platform, he/she is interested in assessing if similar issues have been addressed in the past and collecting knowledge resources related to these previous initiatives as useful material for a further development of the proposed idea. To this end, the user formulates a search request (through an interactive search widget) by using the annotation associated with the proposed idea as the query, or by manually prompting a set of concept identifiers. The user further refines the target of the semantic search by selecting: (1) the target repository (i.e. the corporate memory of the enterprise, the business ecosystem repository or the outside world), and (2) the kind of resources (e.g. proposed ideas and open discussions) that should be retrieved.
10.6.2. Semantic correlation of SMCs
The semantic analysis performed by the PIKR on SMCs includes their indexing, aimed at computing and storing in advance, for each SMC, the clusters of semantically related items it belongs to. This functionality is then exploited to semantically correlate pieces of collective knowledge, as exemplified in the following use cases:
- – UC SC1: knowledge combination in the whiteboard – a group of users is working on an SW instance. One user triggers the PIKR to suggest automatically related knowledge items. New contents, e.g. open discussions and other SW instances, are added to the SW;
- – UC SC2: duplicated warning – better content advice: while a user (say U1) annotates an article (say a1), posted on an SW instance, another user (say U2) adds another article (say a2), on another SW instance, with the same subject of a1, but referring to a different source. U2 triggers a request to the PIKR for searching knowledge items semantically related to a2. During the process of suggesting similar contents, the PIKR understands that a1 and a2 contain very similar content. This is induced by the equivalence of the two annotations. The notification is raised to U2, who can: (1) avoid duplication and discard a2, if a1 and a2 represent the same article, and (2) maintain a2, since it has a high degree of similarity, but a better/richer informative content, with respect to a1.
10.6.3. User-driven content browsing
The following use cases focus on the exploitation of the semantic profile of a user (again given in terms of ontology concepts), and the semantic annotation of SMCs to enhance the navigation experience and the information consumption from a user perspective:
- – UC CB1: semantic routing – on a regular basis, the platform proactively suggests contents to users on the basis of their profile, through a notification on their personal page or email. Suggestions are computed by the PIKR by retrieving, for each topic in the user profile, the more relevant/recent/rated SMCs. Then, SMCs can be filtered/ranked on the basis of properties such as creation date, documental category, author, etc.;
- – UC CB2: profile-dependent content browsing – the user browses the contents maintained in the BIVEE platform through the BIVEE front-end, which invokes the PIKR to retrieve resources that are intended to be relevant to the user. To this end, a search request is automatically formulated on the basis of the user profile, and evaluated by the PIKR. Results are returned to the front-end for their visualization;
- – UC CB3: semantic storifying of posts – the user wants to understand the overall activities/trends regarding a particular issue at a VE level. A search request is formulated given a (set of) topic(s) and a time interval. All the related SMCs posted in the platform regardless authors and sources are arranged along a time line. The user can, for example, visualize such a time line, navigate the links to the original posts, identify groups of people dealing, at a given moment, with similar issues, analyze trends in the conversations and analyze the temporal distribution of participation.
10.7. Implementation
In this section, an updated and revised technical description of the PIKR software prototype is given. The architecture, as well as the technical implementation, has been conceived by following two main concepts: (1) service-oriented architecture, in order to have flexible and platform independent technological communication channels among the PIKR and the other software operating in the VE, and (2) linked data principles, for exposing, sharing and connecting pieces of data, information and knowledge by using semantic web technologies and standards. In particular, following the linked data approach, the PIKR provides, on the one hand a set of reference structures (i.e. ontologies) for the semantic description of enterprise knowledge resources, and on the other hand semantics-based services for accessing and reasoning about such descriptions. To enforce the openness of the platform from a technical perspective, every knowledge fragment is identified by a URI, accessible via HTTP, described by a resource description framework (RDF)/OWL and processable by reasoning services exposed as Web services.
Figure 10.6 shows the overall PIKR architecture, and its positioning within the BIVEE platform. The PIKR is intended to provide semantic facilities to the BIVEE front-end, which implements the functionalities to assist the innovation team in the management of an innovation project. Such functionalities, implemented by the components shown in the upper part of Figure 10.6, encompass: (1) the setup of the virtual enterprise, with the definition of its business goals, capabilities, production plans and so on, (2) definition of the business models needed for the enactment of the innovation and production projects (e.g. BPs, objects, goals, requirements and KPIs), (3) the support for the enactment of an innovation project along the four waves, for the coordination and planning of the activities conducted by the participant actors, and (4) the monitoring of both the VPS and BIS, in order to foster new improvements and further innovations. In doing this, the front-end interacts with the semantic layer, which offers a semantically enriched and machine-processable representation of the informative resources maintained by the back-end. The latter is in charge of (1) acquiring several kinds of resources from the information systems of the VE members through data adaptors and make them accessible by the platform through the raw data handler (see [TAG 13]), and (2) storing the different kinds of resources handled by the BIVEE platform (storage system), in particular the documental resources managed by the VIF, the models designed in the MCR and the activity logs relate to both VPS and BIS.
The PIKR connector is then responsible for handling the mapping between the data in the storage system and the corresponding semantic representation available in the semantic layer, while the semantic data handler (largely discussed in [TAG 13]) enriches the raw data handler to realize the reconciliation and manipulation of the local enterprise data.
10.7.1. PIKR architecture overview
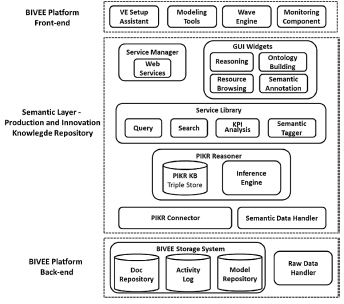
Figure 10.6. PIKR architecture and positioning within the BIVEE platform
The entry point for the PIKR reasoning functionalities is the service library. Several semantic services are implemented on top of the PIKR reasoner and the semantic resources (SDs and ontologies) constituting the PIKR knowledge base (KB). The latter is stored in the triple store, providing basic storage and retrieval facilities for OWL/RDF data. The various reasoning methods that operate on the PIKR KB are implemented by the (rule-based) inference engine, and are made available through a Web service interface, exposed by the service manager, and through the PIKR GUI, which enables user interaction through a wiki-like environment.
10.8. Conclusions
In this chapter, we have presented a semantics-based infrastructure, called PIKR, aimed at supporting innovation-related activities in a virtual enterprise context, by enabling knowledge classification and sharing, as well as interoperability among participating enterprises.
The PIKR has been designed by following the user requirements and the reference framework produced in the context of the BIVEE European project activities. From a technical point of view, the infrastructure is designed according to the linked data principles, describing knowledge resources and their semantic relations in terms of a federation of reference ontologies, and providing entry-points to process the maintained knowledge according to well-known standards (e.g. RDF/OWL and SPARQL) and technologies (e.g. Web services). While the actual knowledge resources (e.g. processes, documents and performance indicators) are stored at the premises of the respective owner companies in the virtual enterprise, the PIKR maintains resource images in the form of SDs that can be regarded as instances of the concepts defined in the ontologies. On top of these descriptions, a set of core semantic services is offered to ease the navigation and retrieval of resources, along with a set of facilities for reasoning about them, intended as a baseline for the development of additional services for populating and exploiting the PIKR.
10.9. Bibliography
[DAN 07] D’ANTONIO F., MISSIKOFF M., TAGLINO F., “Formalizing the OPAL eBusiness ontology design patterns with OWL”, Proceedings of the 3rd International Conference on Interoperability for Enterprise Software and Applications, Enterprise Interoperability II, Web Services, pp. 345–356, 2007.
[DEL 75] DELBECQ A.L., VAN DE VEN A.H., GUSTAFSON D.H., Group Techniques for Program Planners, Scott Foresman and Company, Glenview, IL, 1975.
[FOR 13] FORMICA F., MISSIKOFF M., POURABBAS E. et al., “Semantic search for matching user requests with profiled enterprises”, Computers in Industry, vol. 64, no. 3, pp. 191–202, April 2013.
[IRI 07] IRICK M.L., “Managing tacit knowledge in organizations”, Journal of Knowledge Management Practice, vol. 8, no. 3, 2007.
[LIN 02] LINSTONE H.A., TUROFF M. (eds), The Delphi Method: Techniques and Applications, Addison–Wesley Publications, Reading, MA, 2002.
[MIS 11] MISSIKOFF M., PROIETTI M., SMITH F., “Querying semantically enriched business processes”, in HAMEURLAIN A., LIDDLE S.W., SCHEWE K.D. et al. (eds), 22nd International Conference on Database and Expert Systems Applications, Toulouse, France, 29 August–2 September, LNCS, Springer, vol. 6861, pp. 294–302, 2011.
[NON 00] NONAKA I., TOYAMA R., KONNO N., “SECI, Ba and leadership: a unified model of dynamic knowledge creation”, Long Range Planning, vol. 33, no. 1, pp. 5–34, 2000.
[OMG 11] OMG, Business process model and notation, available at http://www.omg.org/spec/BPMN/2.0, 2011.
[ROS 12] ROSSI A., KNOKE B., EFENDIOGLU N. et al., Specification of business innovation reference framework (in the context of the VEMF), Deliverable D2.2, BIVEE European Project, 2012.
[SIN 12] SINACI A., PIERSANTELLI M., CRISTALLI C. et al., “A document centric approach for user requirements in BIVEE”, CEUR Workshop Proceedings, vol. 864, Article 5, 2012.
[SMI 13] SMITH F., PROIETTI M., “Rule-based behavioural reasoning on semantic business processes”, Proceedings of the 5th International Conference on Agents and Artificial Intelligence (ICAART), 2013.
[TAG 12] TAGLINO F., SMITH F., PROIETTI M. et al., Production and innovation knowledge repository, Deliverable D5.1, BIVEE European project, 2012.
[TAG 13] TAGLINO F., SMITH F., DIAMANTINI C. et al., Advanced interoperability services, Deliverable D5.3, BIVEE European project, 2013.
[WOI 12] WOITSCH R., EFENDIOGLU N., KNOKE B. et al., State of the art and mission control room specification, Deliverable D3.1, BIVEE European project, 2012.
[WOI 13] WOITSCH R., Hybrid Modeling with ADOxx: Virtual Enterprise Interoperability using Meta Models, NGEBIS13, Springer, 2013.