
CHAPTER 5
Stacks and Queues
Stacks and queues are relatively simple data structures that store objects in either first-in-first-out order or last-in-first-out order. They expand as needed to hold additional items, much as the linked lists described in Chapter 3 can. In fact, you can use linked lists to implement stacks and queues.
You can also use stacks and queues to model analogous real-world scenarios such as service lines at a bank or supermarket. But they are more often used to store objects for later processing by other algorithms such as shortest-path network algorithms.
This chapter explains stacks and queues. It explains what they are, stack and queue terminology, and methods you can use to implement them.
Stacks
A stack is a data structure where items are added and removed in last-in-first-out order. Because of this last-in-first-out (LIFO, usually pronounced “life-oh”) behavior, stacks are sometimes called LIFO lists or LIFOs.
A stack is similar to a pile of books on a desk. You can add a book to the top of the pile or remove the top book from the pile, but you can't pull a book out of the middle or bottom of the pile without making the whole thing topple over.
A stack is also similar to a spring-loaded stack of plates at a cafeteria. If you add plates to the stack, the spring compresses so that the top plate is even with the countertop. If you remove a plate, the spring expands so that the plate that is now on top is still even with the countertop. Figure 5-1 shows this kind of stack.

Figure 5-1: A stack is similar to a stack of plates at a cafeteria.
Because this kind of stack pushes plates down into the counter, this data structure is also sometimes called a pushdown stack. Adding an object to a stack is called pushing the object onto the stack, and removing an object from the stack is called popping the object off the stack. A stack class typically provides Push and Pop methods to add items to and remove items from the stack.
The following sections describe a few of the more common methods for implementing a stack.
Linked-List Stacks
Implementing a stack is easy using a linked list. The Push method simply adds a new cell to the top of the list, and the Pop method removes the top cell from the list.
The following pseudocode shows the algorithm for pushing an item onto a linked-list stack:
Push(Cell: sentinel, Data: new_value) // Make a cell to hold the new value. Cell: new_cell = New Cell new_cell.Value = new_value // Add the new cell to the linked list. new_cell.Next = sentinel.Next sentinel.Next = new_cell End Push
The following pseudocode shows the algorithm for popping an item off a linked list stack:
Data: Pop(Cell: sentinel) // Make sure there is an item to pop. If (sentinel.Next == null) Then <throw an exception> // Get the top cell's value. Data: result = sentinel.Next.Value // Remove the top cell from the linked list. sentinel.Next = sentinel.Next.Next // Return the result. Return result End Pop
Figure 5-2 shows the process. The top image shows the stack after the program has pushed the letters A, P, P, L, and E onto it. The middle image shows the stack after the new letter S has been pushed onto the stack. The bottom image shows the stack after the S has been popped off the stack.

Figure 5-2: It's easy to build a stack with a linked list.
NOTE See Chapter 3 for more details about using linked lists.
With a linked list, pushing and popping items both have O(1) run times, so both operations are quite fast. The list requires no extra storage aside from the links between cells, so linked lists are also space-efficient.
Array Stacks
Implementing a stack in an array is almost as easy as implementing one with a linked list. Allocate space for an array that is large enough to hold the number of items you expect to put in the stack. Use a variable to keep track of the next empty position in the stack.
The following pseudocode shows the algorithm for pushing an item onto an array-based stack:
Push(Data: stack_values [], Integer: next_index, Data: new_value) // Make sure there's room to add an item. If (next_index == <length of stack_values>) Then <throw an exception> // Add the new item. stack_values[next_index] = new_value // Increment next_index. next_index = next_index + 1 End Push
The following pseudocode shows the algorithm for popping an item off an array-based stack:
Data: Pop(Data: stack_values[], Integer: next_index) // Make sure there is an item to pop. If (next_index == 0) Then <throw an exception> // Decrement next_index. next_index = next_index - 1 // Return the top value. Return stack_values[next_index] End Pop
Figure 5-3 shows the process. The top image shows the stack after the program has pushed the letters A, P, P, L, and E onto it. The middle image shows the stack after the new letter S has been pushed onto the stack. The bottom image shows the stack after the S has been popped off the stack.
With an array-based stack, adding and removing an item both have O(1) run times, so both operations are quite fast. Setting and getting a value from an array generally is faster than creating a new cell in a linked list, so this method may be slightly faster than using a linked list. The array-based stack also doesn't need extra memory to store links between cells.
Unlike a linked-list stack, however, an array-based stack requires extra space to hold new items. How much extra space depends on your application and whether you know in advance how many items might need to fit into the stack. If you don't know how many items you might need to store in the array, you can resize the array if needed, although that will take extra time. If the array holds N items when you need to resize it, it will take O(N) steps to copy those items into the newly resized array.
Depending on how the stack is used, allowing room for extra items may be very inefficient. For example, suppose an algorithm occasionally needs to store 1,000 items in a stack, but most of the time it stores only a few. In that case, most of the time the array will take up much more space than necessary. If you know the stack will never need to hold more than a few items, however, an array-based stack can be fairly efficient.

Figure 5-3: It's easy to build a stack with an array.
Double Stacks
Suppose an algorithm needs to use two stacks whose combined size is bounded by some amount. In that case you can store both stacks in a single array, with one at each end and both growing toward the middle, as shown in Figure 5-4.

Figure 5-4: Two stacks can share an array if their combined size is limited.
The following pseudocode shows the algorithms for pushing and popping items with two stacks contained in a single array. To make the algorithm simpler, the Values array and the NextIndex1 and NextIndex2 variables are stored outside of the Push methods:
Data: StackValues[<max items>] Integer: NextIndex1, NextIndex2 // Initialize the array. Initialize() NextIndex1 = 0 NextIndex2 = <length of StackValues> - 1 End Initialize // Add an item to the top stack. Push1(Data: new_value) // Make sure there's room to add an item. If (NextIndex1 > NextIndex2) Then <throw an exception> // Add the new item. StackValues[NextIndex1] = new_value // Increment NextIndex1. NextIndex1 = NextIndex1 + 1 End Push1 // Add an item to the bottom stack. Push2(Data: new_value) // Make sure there's room to add an item. If (NextIndex1 > NextIndex2) Then <throw an exception> // Add the new item. StackValues[NextIndex2] = new_value // Decrement NextIndex2. NextIndex2 = NextIndex2 - 1 End Push2 // Remove an item from the top stack. Data: Pop1() // Make sure there is an item to pop. If (NextIndex1 == 0) Then <throw an exception> // Decrement NextIndex1. NextIndex1 = NextIndex1 - 1 // Return the top value. Return StackValues[NextIndex1] End Pop1 // Remove an item from the bottom stack. Data: Pop2() // Make sure there is an item to pop. If (NextIndex2 == <length of StackValues> - 1) Then <throw an exception> // Increment NextIndex2. NextIndex2 = NextIndex2 + 1 // Return the top value. Return StackValues[NextIndex2] End Pop2
Stack Algorithms
Many algorithms use stacks. For example, some of the shortest path algorithms described in Chapter 13 can use stacks. The following sections describe a few other algorithms that you can implement by using stacks.
Reversing an Array
Reversing an array is simple with a stack. Just push each item onto the stack and then pop it back off. Because of the stack's LIFO nature, the items come back out in reverse order.
The following pseudocode shows this algorithm:
ReverseArray(Data: values[]) // Push the values from the array onto the stack. Stack: stack = New Stack For i = 0 To <length of values> - 1 stack.Push(values[i]) Next i // Pop the items off the stack into the array. For i = 0 To <length of values> - 1 values[i] = stack.Pop() Next i End ReverseArray
If the array contains N items, this algorithm takes 2 × N steps, so it has run time O(N).
Train Sorting
Suppose a train contains cars bound for several different destinations, and it enters a train yard. Before the train leaves the yard, you need to use holding tracks to sort the cars so that the cars going to the same destination are grouped.
Figure 5-5 shows a train with cars bound for cities 3, 2, 1, 3, and 2 entering from the left on the input track. The train can move onto a holding track and move its rightmost car onto the left end of any cars on that holding track. Later the train can go back to the holding track and move a car from the holding track's left end back onto the train's right end. The goal is to sort the cars.

Figure 5-5: You can use stacks to model a train yard sorting a train's cars.
You can directly model this situation by using stacks. One stack represents the incoming train. Its Pop method removes a car from the right of the train, and its Push method moves a car back onto the right end of the train.
Other stacks represent the holding tracks and the output track. Their Push methods represent moving a car onto the left end of the track, and the Pop method represents moving a car off of the left end of the track.
The following pseudocode shows how a program could use stacks to model sorting the train shown in Figure 5-5. Here train is the train on the input track, track1 and track2 are the top and bottom holding tracks, and output is the output track on the right:
holding1.Push(train.Pop()) // Step 1: Car 2 to holding 1. holding2.Push(train.Pop()) // Step 2: Car 3 to holding 2. output.Push(train.Pop()) // Step 3: Car 1 to output. holding1.Push(train.Pop()) // Step 4: Car 2 to holding 1. train.Push(holding2.Pop()) // Step 5: Car 3 to train. train.Push(holding1.Pop()) // Step 6: Car 2 to train. train.Push(holding1.Pop()) // Step 7: Car 2 to train. train.Push(output.Pop()) // Step 8: Car 1 to train.
Figure 5-6 shows this process. The car being moved in each step has a bold outline. An arrow shows where each car moves.
NOTE A real train yard might need to sort several trains containing many more cars all at once using many more holding tracks that may connect in unique configurations. All of these considerations make the problem much harder than this simple example.
Of course, in a real train yard, each move requires shuffling train cars and can take several minutes. Therefore, finding a solution with the fewest possible moves is very important.
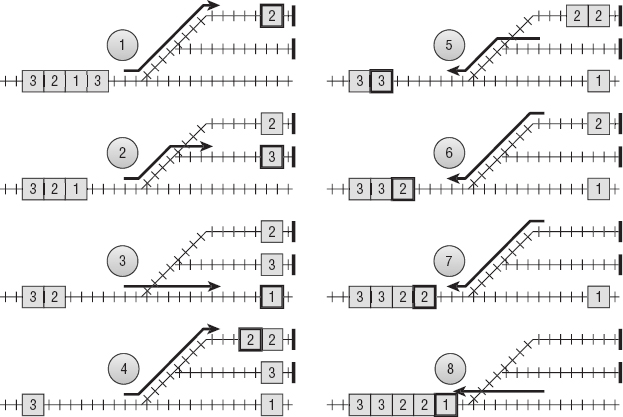
Figure 5-6: You can sort this train in eight moves by using two holding tracks and an output track.
Tower of Hanoi
The Tower of Hanoi puzzle, shown in Figure 5-7, has three pegs. One peg holds a stack of disks of different sizes, ordered from smallest to largest. You move the disks from one peg to another, one at a time, with the goal of restacking all the disks, ordered by size, on a different peg. You cannot place a disk on top of another disk that has a smaller radius.

Figure 5-7: The goal in the Tower of Hanoi puzzle is to restack disks from one peg to another without placing a disk on top of a smaller disk.
You can model this puzzle using three stacks in a fairly obvious way. Each stack represents a peg. You can use numbers giving the disks' radii for objects in the stacks.
The following pseudocode shows how a program could use stacks to model moving the disks from the left peg to the middle peg:
peg2.Push(peg1.Pop()) peg3.Push(peg1.Pop()) peg3.Push(peg2.Pop()) peg2.Push(peg1.Pop()) peg1.Push(peg3.Pop()) peg2.Push(peg3.Pop()) peg2.Push(peg1.Pop())
Figure 5-8 shows the process.

Figure 5-8: You can model the Tower of Hanoi puzzle with three stacks.
NOTE The example shown in Figure 5-8 uses only three disks so that the solution can fit easily into a figure. In general, the number of steps required to move N disks is 2N − 1, so the number of steps grows very quickly as N increases. If you had a stack of 35 disks and you moved them at a rate of one per second, it would take you more than 1,000 years to restack them on a different peg.
One solution to the Tower of Hanoi puzzle is a nice example of recursion, so it is discussed in greater detail in Chapter 9.
Stack Insertionsort
Chapter 6 focuses on sorting algorithms, but Chapter 3 briefly explains how to implement insertionsort with linked lists. The basic idea behind insertionsort is to take an item from the input list and insert it into the proper position in a sorted output list (which initially starts empty). Chapter 3 explains how to implement insertionsort with linked lists, but you also can implement it with stacks.
The original stack holds items in two sections. The items farthest down in the stack are sorted, and those near the top of the stack are not. Initially no items are sorted, and all the items are in the “not sorted” section of the stack.
The algorithm makes a second, temporary stack. For each item in the stack, the algorithm pulls the top item off the stack and stores it in a variable. It then moves all the other unsorted items onto the temporary stack.
Next the algorithm starts moving sorted items into the temporary stack until it finds the position where the new item belongs. At that point the algorithm inserts the new item into the original stack and moves all the items from the temporary stack back to the original stack.
The algorithm repeats this process until all the items have been added to the sorted section of the stack.
The following pseudocode shows the insertionsort algorithm at a fairly high level:
// Sort the items in the stack. StackInsertionsort(Stack: items) // Make a temporary stack. Stack: temp_stack = New Stack Integer: num_items = <number of items> For i = 0 To num_items - 1 // Position the next item. // Pull off the first item. Data: next_item = items.Pop() <Move the items that have not yet been sorted to temp_stack. At this point there are (num_items - i - 1) unsorted items.> <Move sorted items to the second stack until you find out where next_item belongs.> <Add next_item at this position.> <Move the items back from temp_stack to the original stack.> Next i End StackInsertionsort
For each item, this algorithm moves the unsorted items to the temporary stack. Then it moves some of the sorted items to the temporary stack, and then it moves all the items back to the original stack. At different steps the number of unsorted items that must be moved is N, N − 1, N − 2, ..., 2, 1, so the total number of items moved is N + (N − 1) + (N − 2) + ... + 2 + 1 = N × (N + 1) / 2 = O(N2). That means the algorithm has a run time of O(N2).
Stack Selectionsort
In addition to describing a linked-list insertionsort, Chapter 3 explains how to implement selectionsort with linked lists. The basic idea behind selectionsort is to search through the unsorted items to find the smallest item and then move it to the end of the sorted output list. Chapter 3 explains how to implement selectionsort with linked lists, but you can also implement it with stacks.
As in the insertionsort algorithm, the original stack holds items in two sections. The items farthest down in the stack are sorted, and those near the top of the stack are not. Initially, no items are sorted, and all the items are in the “not sorted” section of the stack.
The algorithm makes a second temporary stack. For each position in the stack, the algorithm moves all the unsorted items to the temporary stack, keeping track of the largest item.
After it has moved all the unsorted items to the temporary stack, the program pushes the largest item it found onto the original stack. It then moves all the unsorted items from the temporary stack back to the original stack.
The algorithm repeats this process until all the items have been added to the sorted section of the stack.
The following pseudocode shows the selectionsort algorithm at a fairly high level:
// Sort the items in the stack. StackSelectionsort(Stack: items) // Make the temporary stack. Stack: temp_stack = New Stack Integer: num_items = <number of items> For i = 0 To num_items - 1 // Position the next item. // Find the item that belongs in sorted position i. <Move the items that have not yet been sorted to temp_stack, keeping track of the largest. Store the largest item in variable largest_item. At this point there are (num_items - i - 1) unsorted items.> <Add largest_item to the original stack at the end of the previously sorted items.> <Move the unsorted items back from temp_stack to the original stack, skipping largest_item when you find it> Next i End StackSelectionsort
For each item, this algorithm moves the unsorted items to the temporary stack, adds the largest item to the sorted section of the original stack, and then moves the remaining unsorted items back from the temporary stack to the original stack. For each position in the array, it must move the unsorted items twice. At different steps there are N, N − 1, N − 2, ..., 1 unsorted items to move, so the total number of items moved is N + (N − 1) + (N − 2) + ... + 1 = N × (N + 1) / 2 = O(N2), and the algorithm has run time O(N2).
Queues
A queue is a data structure where items are added and removed in first-in-first-out order. Because of this first-in-first-out (FIFO, usually pronounced “fife-oh”) behavior, stacks are sometimes called FIFO lists or FIFOs.
A queue is similar to a store's checkout line. You join the end of the line and wait your turn. When you get to the front of the line, the cashier takes your money and gives you a receipt.
Usually the method that adds an item to a queue is called Enqueue, and the item that removes an item from a queue is called Dequeue.
The following sections describe a few of the more common methods for implementing a queue.
Linked-List Queues
Implementing a queue is easy using a linked list. To make removing the last item from the queue easy, the queue should use a doubly linked list.
The Enqueue method simply adds a new cell to the top of the list, and the Dequeue method removes the bottom cell from the list.
The following pseudocode shows the algorithm for enqueueing an item in a linked-list stack:
Enqueue(Cell: top_sentinel, Data: new_value) // Make a cell to hold the new value. Cell: new_cell = New Cell new_cell.Value = new_value // Add the new cell to the linked list. new_cell.Next = top_sentinel.Next top_sentinel.Next = new_cell new_cell.Prev = top_sentinel End Enqueue
The following pseudocode shows the algorithm for dequeueing an item from a linked-list stack:
Data: Dequeue(Cell: bottom_sentinel) // Make sure there is an item to dequeue. If (bottom_sentinel.Prev == top_sentinel) Then <throw an exception> // Get the bottom cell's value. Data: result = bottom_sentinel.Prev.Value // Remove the bottom cell from the linked list. bottom_sentinel.Prev = bottom_sentinel.Prev.Prev bottom_sentinel.Prev.Next = bottom_sentinel // Return the result. Return result End Dequeue
NOTE See Chapter 3 for more details about using linked lists.
With a linked list, enqueueing and dequeueing items have O(1) run times, so both operations are quite fast. The list requires no extra storage aside from the links between cells, so linked lists are also space-efficient.
Array Queues
Implementing a queue in an array is a bit trickier than implementing one with a linked list. To keep track of the array positions that are used, you can use two variables: Next, to mark the next open position, and Last, to mark the position that has been in use the longest. If you simply store items at one end of an array and remove them from the other, however, the occupied spaces move down through the array.
For example, suppose a queue is implemented in an array with eight entries. Consider the following series of enqueue and dequeue operations:
Enqueue(M) Enqueue(O) Enqueue(V) Dequeue() // Remove M. Dequeue() // Remove O. Enqueue(I) Enqueue(N) Enqueue(G) Dequeue() // Remove V. Dequeue() // Remove I.
Figure 5-9 shows this sequence of operations. Initially Next and Last refer to the same entry. This indicates that the queue is empty. After the series of Enqueue and Dequeue operations, only two empty spaces are available for adding new items. After that it will be impossible to add new items to the queue.
One approach to solving this problem is to enlarge the array when Next falls off the end of the array. Unfortunately, that would make the array grow bigger over time, and all the space before the Last entry would be unused.
Another approach would be to move the array's entries to the beginning of the array whenever Last falls off the array. That would work but would be relatively slow.

Figure 5-9: As you enqueue and dequeue items in an array-based queue, the occupied spaces move down through the array.
A more effective approach is to build a circular array , in which you treat the last item as if it were immediately before the first item. Now when Next falls off the end of the array, it wraps around to the first position, and the program can store new items there.
Figure 5-10 shows a circular queue holding the values M, O, V, I, N, and G.

Figure 5-10: In a circular queue you treat the array's last item as if it comes right before the first item.
A circular array does present a new challenge, however. When the queue is empty, Next is the same as Last. If you add enough items to the queue, Next goes all the way around the array and catches up to Last again, so there's no obvious way to tell whether the queue is empty or full.
You can handle this problem in a few ways. For example, you can keep track of the number of items in the queue, keep track of the number of unused spaces in the queue, or keep track of the number of items added to and removed from the queue. The CircularQueue sample program, which is available for download on the book's website, handles this problem by always keeping one of the array's spaces empty. If you added another value to the queue shown in Figure 5-10, the queue would be considered full when Next is just before Last, even though there was one empty array entry.
The following pseudocode shows the algorithm used by the example program for enqueueing an item:
// Variables to manage the queue. Data: Queue[<queue size>] Integer: Next = 0 Integer: Last = 0 // Enqueue an item. Enqueue(Data: value) // Make sure there's room to add an item. If ((Next + 1) Mod <queue size> == Last) Then <throw an exception> Queue[Next] = value Next = (Next + 1) Mod <queue size> End Enqueue
The following pseudocode shows the algorithm for dequeueing an item:
// Dequeue an item. Data: Dequeue() // Make sure there's an item to remove. if (Next == Last) Then <throw an exception> Data: value = Queue[Last] Last = (Last + 1) Mod <queue size> Return value End Dequeue
A circular queue still has a problem if it becomes completely full. If the queue is full and you need to add more items, you need to allocate a larger storage array, copy the data into the new array, and then use the new array instead of the old one. This can take some time, so you should try to make the array big enough in the first place.
Specialized Queues
Queues are fairly specialized, but some applications use even more specialized queues. Two of these kinds of queues are priority queues and deques.
Priority Queues
In a priority queue, each item has a priority, and the dequeue method removes the item that has the highest priority. Basically, high-priority items are handled first.
One way to implement a priority queue is to keep the items in the queue sorted by priority. For example, you can use the main concept behind insertionsort to keep the items sorted. When you add a new item to the queue, you search through the queue until you find the position where it belongs, and you place it there. To dequeue an item, you simply remove the top item from the queue. With this approach, enqueueing an item takes O(N) time, and dequeueing an item takes O(1) time.
Another approach is to store the items in whatever order they are added to the queue and then have the dequeue method search for the highest-priority item. With this approach, enqueueing an item takes O(1) time, and dequeueing an item takes O(N) time.
Both of these approaches are reasonably straightforward if you use linked lists.
The heap data structure described in the “Heapsort” section of Chapter 6 provides a more efficient way of implementing a priority queue. A heap-based priority queue can enqueue and dequeue items in O(log N) time.
Deques
Deque, which is usually pronounced “deck,” stands for “double-ended queue.” A deque is a queue that allows you to add items to and remove items from either end of the queue.
Deques are useful in algorithms where you have partial information about the priority of items. For example, you might know that some items are high priority and others are low priority, but you might not necessarily know the exact relative priorities of every item. In that case, you can add high-priority items to one end of the deque and low-priority items to the other end of the deque.
Deques are easy to build with doubly linked lists.
Summary
This chapter explained stacks and queues, two data structures that are often used by other algorithms to store items. In a stack, items are added to and then removed from the same “end” of the data structure in last-in-first-out order. In a queue, items are added at one end and removed from the other in first-in-first-out order.
You can use an array to build a stack fairly easily as long as it doesn't run out of space. If you build a stack with a linked list, you don't need to worry about the stack's running out of space.
You can also use an array to build a queue, although in that approach the items move through the array until they reach the end and you need to resize the array. You can solve that problem by using a circular array. You can also avoid the whole issue by using a doubly linked list to build a queue.
You can use stacks and queues to sort items in O(N2) time, although those algorithms are more exercises in using stacks and queues than in efficient sorting. The next chapter describes several sorting algorithms that give much better performance, with some running in O(N log N) time and others even running in O(N) time.
Exercises
Asterisks indicate particularly difficult problems.
- When you use a double stack, what is the relationship between the variables NextIndex1 and NextIndex2 when one of the stacks is full?
- Write an algorithm that takes as input a stack and returns a new stack containing the same items but in reverse order.
- Write a program that implements insertionsort with stacks.
- For each item, the stack insertionsort algorithm moves the unsorted items to the temporary stack. Then it moves some of the sorted items to the temporary stack, and then it moves all the items back to the original stack. Does it really need to move all the items back to the original stack? Can you improve the algorithm's performance by modifying that step? What does that do to the algorithm's Big O run time?
- What does the stack insertionsort algorithm mean in terms of train sorting?
- Write a program that implements selectionsort with stacks.
- What does the stack selectionsort algorithm mean in terms of train sorting?
- Write a program that implements a priority queue.
- Write a program that implements a deque.
- *Consider a bank where customers enter a single line that is served by several tellers. You enter the line at the end, and when you get to the front of the line, you are served by the next available teller. You can model this “multiheaded queue” with a normal queue that serves multiple tellers.
Make a program similar to the one shown in Figure 5-11 to simulate a multiheaded queue in a bank. Give the user controls to adjust the number of tellers, the amount of time between customer arrivals, the amount of time each customer stays, and the speed of the simulation. After the user specifies the parameters, run a simulation to see how the queue behaves. How does the number of tellers affect the average wait time?

Figure 5-11: In a bank queue, customers stand in a single line and then are helped by the next available teller.
- Write a program that implements insertionsort with queues.
- Write a program that implements selectionsort with queues.