
Voice Coding
Whether based on CDMA or TDMA, all digital systems need to encode the analog waveforms of speech into a bitstream. The program used for this is called a codec (coder/decoder), often embedded within a special chip called a DSP (Digital Signal Processor). Many different codecs are used in cellphones, and new ones are developed each year. The aim is to produce the lowest possible bit rate while maintaining acceptable sound quality. Because computing power is increasing continuously, newer phones and networks are capable of using more advanced compression technology. Some popular codecs are listed in Table 3.2, together with their main uses.
The standard by which voice codecs are judged is the G.711 system, used in the PSTN (Public Switched Telephone Network). Though most actual fixed phone lines are still analog, the fiber-optic networks at the carrier's core transport use this codec, as does ISDN (Integrated Services Digital Network), the digital phone standard. A system that sounds as good as G.711 is described astoll quality.
Though toll quality is a holy grail for speech codec designers, anyone who has ever used a telephone knows that it isn't perfect. Many operators are interested in streaming music over their networks, requiring much higher capacities. The unofficial standard for music on the Internet is MP3 (Motion Picture Experts Group Audio layer 3), which supports a variety of bit rates. At its lowest, it sounds like a badly tuned radio; at its highest, it is indistinguishable from a CD. For quality similar to broadcast FM radio, MP3 requires at least 96 kbps, a rate easily achievable by third-generation wireless systems.
| Codec | Bit Rate | Used for |
|---|---|---|
| Compact Disc | 1411 kbps | Stereo Music |
| MP3 | 16–192 kbps | Music over Internet |
| PSTN (G.711) | 64 kbps | Fixed Telephony |
| GSM 06.10 | 13 kbps | Mobile Telephony |
| G.729 | 8 kbps | Satellite Communications |
| IS-54 | 8 kbps | Mobile Telephony |
| G.723.1 | 5.3 kbps | Voice over Internet |
| Department of Defense | 2.4 kbps | Military Applications |
normal: Data CodingAll the codecs here can be used to reduce the bandwidth requirements for voice, but not for data. This is because they all use lossy compression, meaning it is impossible to recover the original sound wave. The human ear doesn't mind this because many sounds are inaudible to human listeners. Some lossy algorithms, such as MP3, employ a system called psychoacoustic coding, which tries to calculate which bits can safely be discarded based on models of human perception. This doesn't work with data because computers notice everything; even a single bit out of place in a program could prevent it from running. Data require lossless compression, which uses mathematical algorithms to search for repeated patterns. Web surfers might be familiar with the two types, thanks to the file formats commonly used on the Internet. GIF files use lossless compression and are ideal for line drawings or pictures containing text. JPG files use lossy and are more suited to photographs. But even without compression, the data rate that can be sent over a cellular system is often slightly more than that of the system's codec; for example, while the GSM codec needs 13 kbps, 14.4 kbps can be made available for data. The reason is that data is more tolerant than voice of jitter, the variation in the time that different packets of a message take to arrive at their destination. |
Waveform Coding
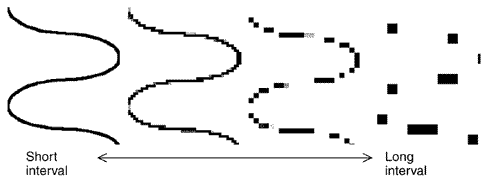
The simplest way to digitize a sound signal is to sample the waveform at regular intervals. This is called PCM (pulse code modulation) and is used by the CD and PSTN codecs. As shown in Figure 3.7, a shorter interval will result in more accurate sampling but a higher bit rate. The problem is that low bit rates require long intervals, which represent the waveform inaccurately and eventually make it unrecognizable.
ADPCM (adaptive differential PCM) codecs attempt to predict the value of the next sample from the previous samples. This increases the accuracy for a given bit rate and can compress a voice call down to about 16 kbps while maintaining acceptable quality. This alone is still too high for mobile systems, but prediction is used together with other techniques in most cellphone codecs.
Figure 3.7. Pulse code modulation
Vocoding
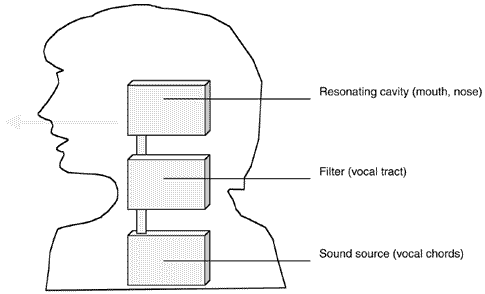
Although sound waves look random, the sounds produced in speech actually share many common characteristics, thanks to their common source: the human speech organs. Vocoders take advantage of this by approximating the human anatomy to simple mechanical devices, as in Figure 3.8. Sound is modulated by the vocal tract to produce a person's characteristic voice; it is then shaped by the nose, tongue, and lips to make individual words. This sound is either white noise direct from the lungs or a waveform produced by the vocal chords. Sounds made by the vocal chords are described as voiced and include all vowels as well as soft consonants such as d and b. The hard consonants like t and p are unvoiced.
Instead of sending an actual signal, a vocoder calculates how speech was produced and sends only the relevant pitch and tone information plus a description of the sender's mouth movements and vocal tract. A decoder then synthesizes a voice, using computerized equivalents of the sender's organs. This results in a very low data rate, but also poor quality—the precise characteristics of a vocal tract are very difficult to simulate, and so the voice sounds synthesized.
Vocoders are typically used only in very low data rate situations; for example, military and space communications. They can reach data rates as low as 1 kbps, at which it is hard to tell who is actually speaking. Another problem is that they fail to transmit any sounds other than the human voice, though this can be an advantage if the speaker is surrounded by undesirable background noise.
Figure 3.8. Model of human speech
Hybrid Codecs
Most codecs use a mixture of waveform and vocoding, usually based on synthesized speech with some PCM information. They also use characteristics of the human ear to strip out inaudible sounds; for example, a quiet musical instrument in the background of a louder one.
The precise bit rate depends on the quality of the sound and on how much processing power is available. For a mobile phone, the limiting factor is usually the need to compress and decompress in real-time, using a battery-operated device. The MP3 format is unusual in that it is very easy to decompress, but not to compress; converting sound files to the MP3 format requires a powerful computer, though players are much simpler.
Some newer speech codecs also include DSI (Digital Speech Interpolation), which can vary the bit rate, depending on the complexity of the speech. Almost no information at all is sent during periods of silence, enabling the channel to be used for something else, usually data. Because channels are allocated by the base station, this works more effectively on the downlink than the uplink.
normal: Web ResourcesThe OFDM Forum is an alliance of vendors set up to promote this new and complex technology. Its site tries to explain how the system works and the potential applications. The magazine Wireless Week carries on its site daily news stories about the cellular industry, plus a huge archive of information. Another magazine, Wireless System Design, has on its site detailed data about the various cellular technologies. http://www.arcx.com/sites/faq.htm This hobbyist site contains a detailed FAQ about cellular services in America and sections on how to locate and identify base stations. |