
Oracle is designed to be a very portable database—it is available on every platform of relevance, from Windows to UNIX/Linux to cloud-based systems. However, the physical architecture of Oracle looks different on different operating systems. For example, on a UNIX/Linux operating system, you’ll see Oracle implemented as many different operating system processes, virtually a process per major function. On UNIX/Linux, this is the correct implementation, as it works on a multiprocess foundation. On Windows, however, this architecture would be inappropriate and would not work very well (it would be slow and nonscalable). On the Windows platform, Oracle is implemented as a single process with multiple threads. Even though the physical mechanisms used to implement Oracle from platform to platform vary, the architecture is sufficiently generalized that you can get a good understanding of how Oracle works on all platforms.
Chapter 3 covers files. Here, we’ll look at the five general categories of files that make up the database: parameter, data, temp, control, and redo log files. We’ll also cover other types of files, including trace, alert, dump (DMP), data pump, and simple flat files. We’ll look at the file area called the Fast Recovery Area (FRA), and we’ll also discuss the impact that Automatic Storage Management (ASM) has on file storage.
Chapter 4 covers the Oracle memory structures referred to as the System Global Area (SGA), Process Global Area (PGA), and User Global Area (UGA). We’ll examine the relationships between these structures, and we’ll also discuss the shared pool, large pool, Java pool, and various other SGA components.
Chapter 5 covers Oracle’s physical processes or threads. We’ll look at the three different types of processes that will be running on the database: server processes, background processes, and slave processes.
It was hard to decide which of these components to cover first. The processes use the SGA, so discussing the SGA before the processes might not make sense. On the other hand, when discussing the processes and what they do, I’ll need to make references to the SGA. These two components are closely tied: the files are acted on by the processes and won’t make sense without first understanding what the processes do.
What I’ll do, then, is define some terms and give a general overview of what Oracle looks like (if you were to draw it on a whiteboard). There will be two basic architectures to consider. One is the architecture the Oracle database employed exclusively from versions 6 through 11g (referred to now as single tenant in this book) and a new multitenant architecture (container database/pluggable database) available starting with Oracle 12c. Additionally, I’ll describe two variations of Oracle databases, namely, Oracle Real Application Clusters (RAC) and Oracle sharded databases. You’ll then be ready to get into some of the details.
Oracle Database Types
There are two terms that, when used in an Oracle context, seem to cause a great deal of confusion: database and instance . To be fair, part of the reason for this is that different database vendors use the same terms to mean different things. In Oracle terminology, a database is a collection of physical operating system files or disks. When using Oracle Automatic Storage Management (ASM), the database may not appear as individual, separate files in the operating system, but the definition remains the same.
In contrast, an instance is a set of Oracle background processes or threads and a shared memory area, which is memory that is shared across those threads or processes running on a single computer. This is the place for volatile, nonpersistent stuff, some of which gets flushed to disk. A database instance can exist without any disk storage whatsoever. It might not be the most useful thing in the world, but thinking about it that way definitely helps draw the line between the instance and the database.
The two terms, instance and database, are sometimes used interchangeably, but they embrace very different concepts, especially with the multitenant architecture and Oracle Real Application Clusters (RAC) architecture. In the earliest versions of Oracle, there was usually a one-to-one relationship between an instance and a database. This is probably why the confusion surrounding the terms arises. However, to be technically accurate, an instance refers to the processes and memory of Oracle. And a database refers to the physical files that hold data. A database may be accessible from many instances, but an instance will provide access to exactly one database (regardless of database type) at a time. This will become clearer in a moment. Let’s next look at the definition of a single-tenant database.
Single-Tenant (Non-container) Database
A single-tenant database or non-container database is a self-contained set of datafiles, control files, redo log files, parameter files, and so on that include all of the Oracle metadata (the definition of ALL_OBJECTS, for example), Oracle data, and Oracle code (such as the code for DBMS_OUTPUT), in addition to all of the application metadata, data, and code. This is the only type of database in Oracle releases prior to version 12c.
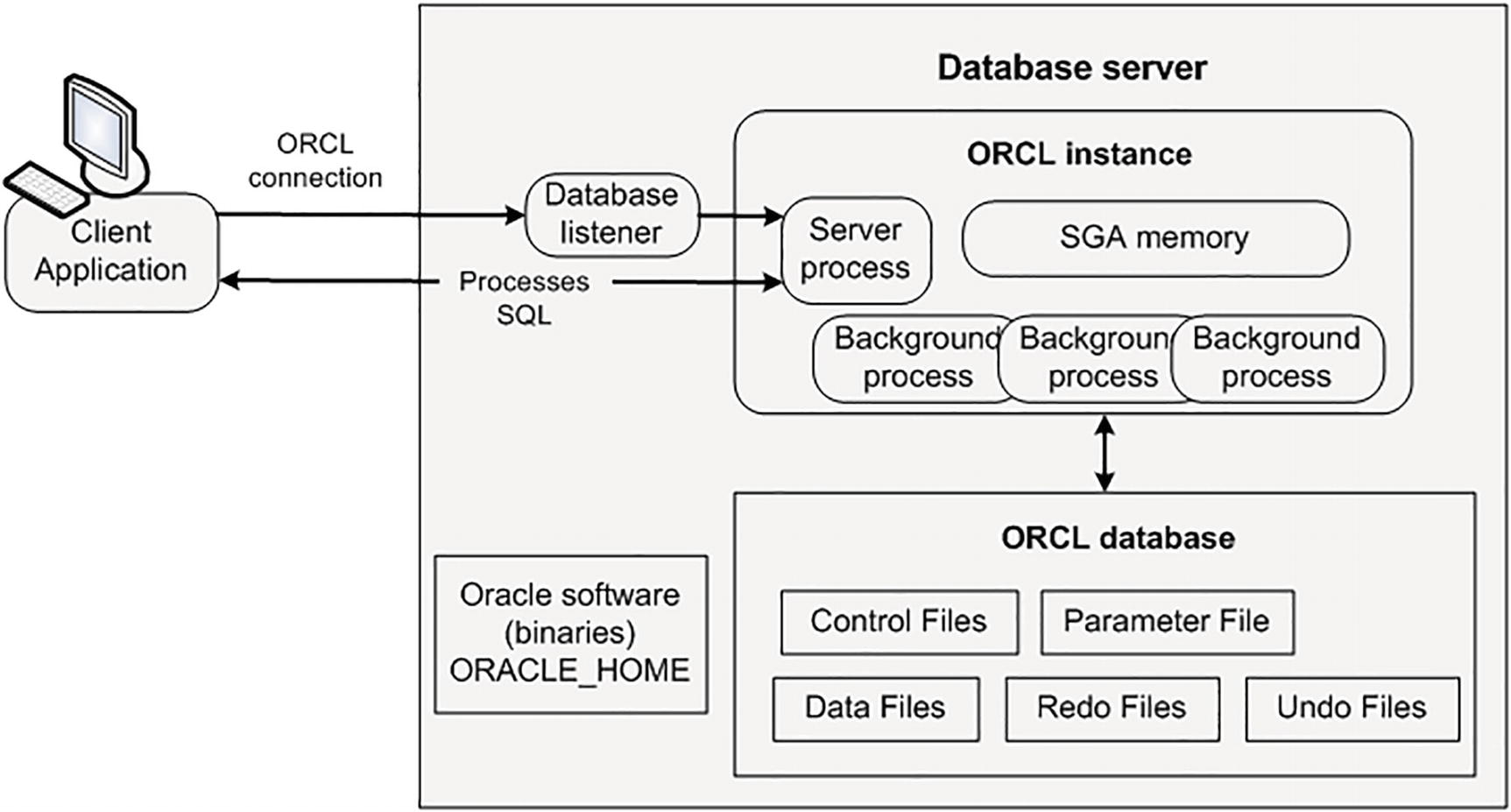
Oracle’s single-tenant (non-container database) architecture
Figure 2-1 shows that you have a single database server (sometimes referred to as host, machine, vm, node, and so on). On the database server, you have one instance (memory structures, background processes, and other processes) and one database (physical files on disk). The memory structures interact with client (user) processes accessing and manipulating the data (datafiles on disk). The client connects to the listener process running on the database server. The listener then hands off the connection to a server process that handles the SQL processing requests from the client.
Separate from the database files are the Oracle installation software files (sometimes referred to as binaries). These are typically installed in a location on disk named ORACLE_HOME (with various components stored in subdirectories). Some examples of binary files would be oracle, sqlplus, rman, dbca, expdp, impdp, lsnrctl, and so on.
To summarize, the prior example created a single-tenant (non-container) type database. This single-tenant type of database architecture has been deprecated by Oracle. Additionally, Oracle has stated that the single-tenant architecture is desupported starting with Oracle 21c. Having said that, this type of database is still widely used. Many legacy systems running on older versions of Oracle still use this architecture. Therefore, it’s important to be familiar with this type of database architecture.
Single-Tenant (Non-container) RAC Database
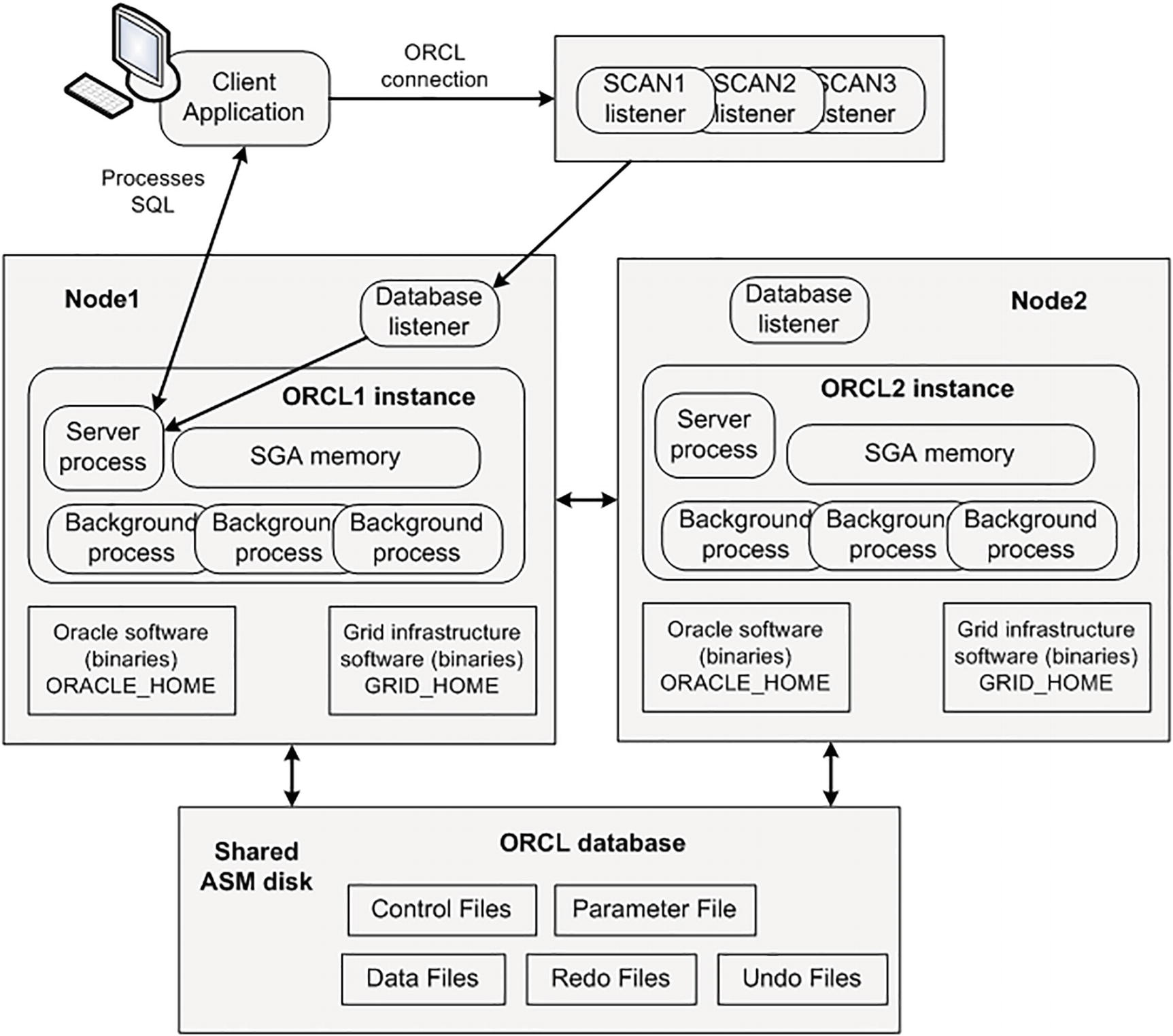
Oracle’s single-tenant (non-container database) architecture in a two-node RAC configuration
The client connects to a special Single Client Access Name (SCAN) RAC listener, which hands off the connection request to one of the database listeners (on node 1 in this example). The listener then connects the client request to a server process in the HR1 instance, which then handles any SQL processing initiated by the client. You can have one or more nodes in this configuration. Each instance uses the same physical ORCL database. The RAC software handles the complexity of multiple instances potentially simultaneously accessing the same blocks of data in the single set of database datafiles.
In addition to the Oracle home binaries, the RAC configuration requires the Grid Infrastructure software, which includes the Automatic Storage Management (ASM) software for managing the shared disks. The Grid software is typically installed in a location on disk named GRID_HOME (with various components stored in subdirectories). The Grid home software is separate from the Oracle home software.
To summarize, the database depicted in Figure 2-2 is a single-tenant, two-node RAC database. Again, the single-tenant type database has been deprecated by Oracle and will be desupported as of Oracle 21c.
Multitenant Container Database
Starting with Oracle 12c, Oracle introduced a new type of database, the multitenant container database and the associated pluggable databases. A multitenant container database (CDB) or root container database is a self-contained set of datafiles, control files, redo log files, parameter files, and so on that only include the Oracle metadata, Oracle data, and Oracle code. There are no application objects or code in these datafiles—only Oracle-supplied metadata and Oracle-supplied code objects. This database is self-contained in that it can be mounted and opened without any other supporting physical structures.
A pluggable database (PDB) is a set of datafiles only. It is not self-contained. A pluggable database needs a container database to be “plugged into” to be opened and accessible. These datafiles contain only metadata for application objects, application data, and code for those applications. There is no Oracle metadata or any Oracle code in these datafiles. There are no redo log files, control files, parameter files, and so on—only datafiles associated with a pluggable database. The pluggable database inherits these other types of files from the container database it is currently plugged into.
A pluggable database will be associated with a single container database at a time and is only indirectly associated with an instance; it will share the instance created to mount and open the container database. So, like a container database, a pluggable database can be associated with one or more instances at any point in time. The root container instance may be providing access to many (thousands) pluggable databases simultaneously. That is, a single instance may be providing services for many pluggable databases, but only one container database.
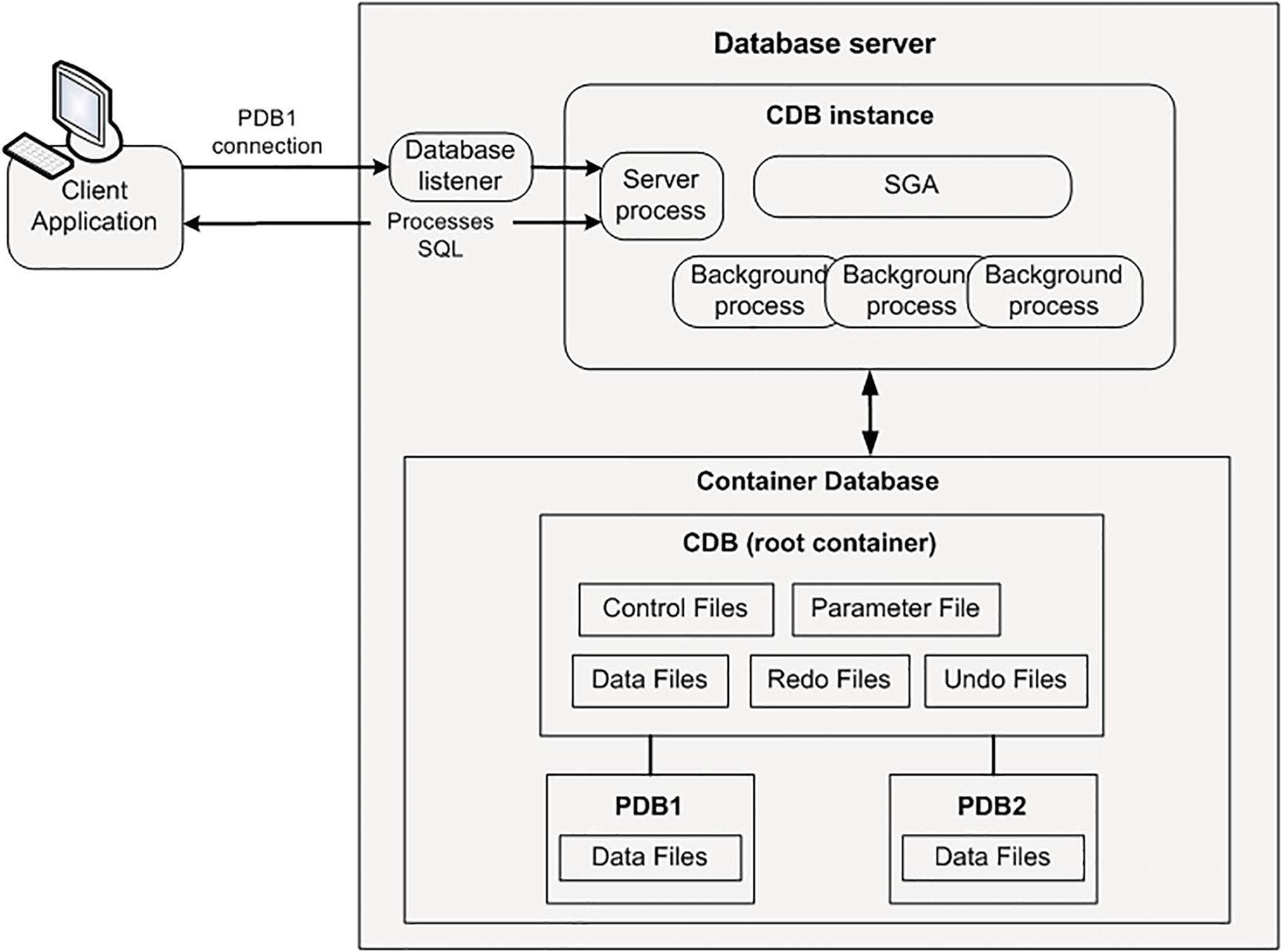
A container database with two pluggable databases
As depicted in Figure 2-3, the client initiates a connection to the PDB1 pluggable database. The listener connects the client to a server process which processes SQL requests. In this configuration, the client is connected to the CDB instance and accessing the PDB1 pluggable database. The client has no visibility to any other pluggable databases within the container. In other words, the client can only access data within the pluggable database that the client is currently connected to (PDB1 in this example).
This means you could have one application and all its users and objects in PDB1, and you could have a completely different application using PDB2. There are no collisions of users and objects between these two databases. They are physically implemented as two stand-alone pluggable databases (within a container database).
Multiple pluggable databases, subordinate to the container database, can be open and accessible simultaneously—but will all share the single instance created to open the container database. A pluggable database—in order to be used, to be queried—must be associated with a container database. That container database will only have Oracle data and metadata in it—just the information Oracle needs to “run.” The pluggable databases have the “rest” of the database metadata and data.
So, for example, the container database would have the definition of the “SYS” user (the metadata for the SYS user) and the compiled code and source code for objects like DBMS_OUTPUT and UTL_FILE. A pluggable database, on the other hand, would have the definition of an application schema like SCOTT, all of the metadata describing the tables in the SCOTT schema, all of the PL/SQL source code for the SCOTT schema, all of the GRANTS granted to the SCOTT schema, and so on. In short, a pluggable database has everything that describes a set of application schemas—the metadata for the accounts, the metadata for the tables in those accounts, and the actual data for those tables. A pluggable database is self-contained with respect to the application accounts it contains, but it needs a container database to be “opened” and queried. Therefore, you can say that a pluggable database is not “self-contained,” it needs something else in order to be opened and used.
A pluggable database is not directly opened by an instance, but rather an Oracle instance must be started and a container database mounted and opened by that instance. Once the container instance is up and running, and the container database is opened, that container database may open multiple pluggable databases. Each of these pluggable databases acts as if it were a “stand-alone” database. That is, they appear to be self-contained, stand-alone “single-tenant” databases. But they all share the same container database and container instance.
In Oracle 19c and above, you can have three customer-created pluggable databases in an Enterprise Edition database without any extra licensing required. With the multitenant license, you can have up to 4096 separate pluggable databases in a single container database.
When you start an Oracle instance, there are many processes associated with it (more on this in Chapter 5). Each instance is supported by about a hundred or so processes (varies by configuration). If you attempted to start up 50 single-tenant databases—where each database has an instance associated with it or its own instance—you would have upward of 5000 processes just to get the databases started! That is extremely taxing on the operating system, both to create that many processes and then to manage them.
Additionally, each instance would have its own SGA. Chapter 4 will cover what is in the SGA, but suffice it to say, there is a lot of duplication. Each SGA would have a cached copy of DBMS_OUTPUT in its shared pool, and each SGA would have a redo log buffer and many other duplicative data structures.
With pluggable databases, you can have the separation of application metadata, users, data, code, and so on, but avoid the redundant instances. That is, you can have a single instance with a single container database (the Oracle metadata, code, and data) that provides access to many pluggable databases, each hosting a separate application. That’s a massive reduction in server resource utilization. In general, the size of the single SGA you would allocate for these application pluggable databases will be smaller than the sum of the separate SGAs you would have to allocate otherwise.
From the perspective of a developer, a pluggable database is no different from a single-tenant database. The application connects to the database in exactly the same way it would connect to a single-tenant database in earlier releases. The differences lie in the underlying architecture—that of a single instance for many pluggable databases, and the resulting reduced resource utilization on the server and the ease of management for the DBA.
From a DBA perspective, there are many changes in the way a database is administered—positive changes. For example, if a DBA configured a container database for RAC, every pluggable database under that container would be RAC enabled. The same with Data Guard, RMAN backups, and so on. The DBA has one instance to configure and work with, instead of one instance per application as in the past.
Multitenant RAC Database

A two-node RAC container database with two pluggable databases
In this example, the client initiates a connection to the PDB1 pluggable database. This connects to the RAC SCAN listener, which hands off the connection request to one of the database listeners (node 1 in this example). The listener connects the client to a server process in the CDB1 instance. In this configuration, the client is connected to the CDB1 instance and accessing the PDB1 pluggable database. The client has no visibility to the other pluggable databases (PDB2) within the container. In other words, the client can only access data within the pluggable database that the client is currently connected to (PDB1 in this example).
Sharded Database
Starting with Oracle 12.2, the sharded database feature is a logical database that is horizontally partitioned across a pool of physical databases that don’t share any hardware infrastructure. In other words, each database in the shard is hosted on a dedicated server with its own CPU, memory, and disk. The sharded database logically looks like one database to the end-user application, but under the covers, it consists of one or more physical databases.
Each database in the sharded database is referred to as a shard. The database shards can be single instance or multi-instance RAC databases. When creating a table, a column needs to be specified as the distribution key. The distribution key can be defined as consistent, hash, or list. Each sharded database environment uses a sharded catalog database. The sharded catalog supports tasks such as automated shard deployment, centralized management of the sharded database, and multi-shard queries. There are also shard directors which are listeners that handle connection routing based on the sharding key.
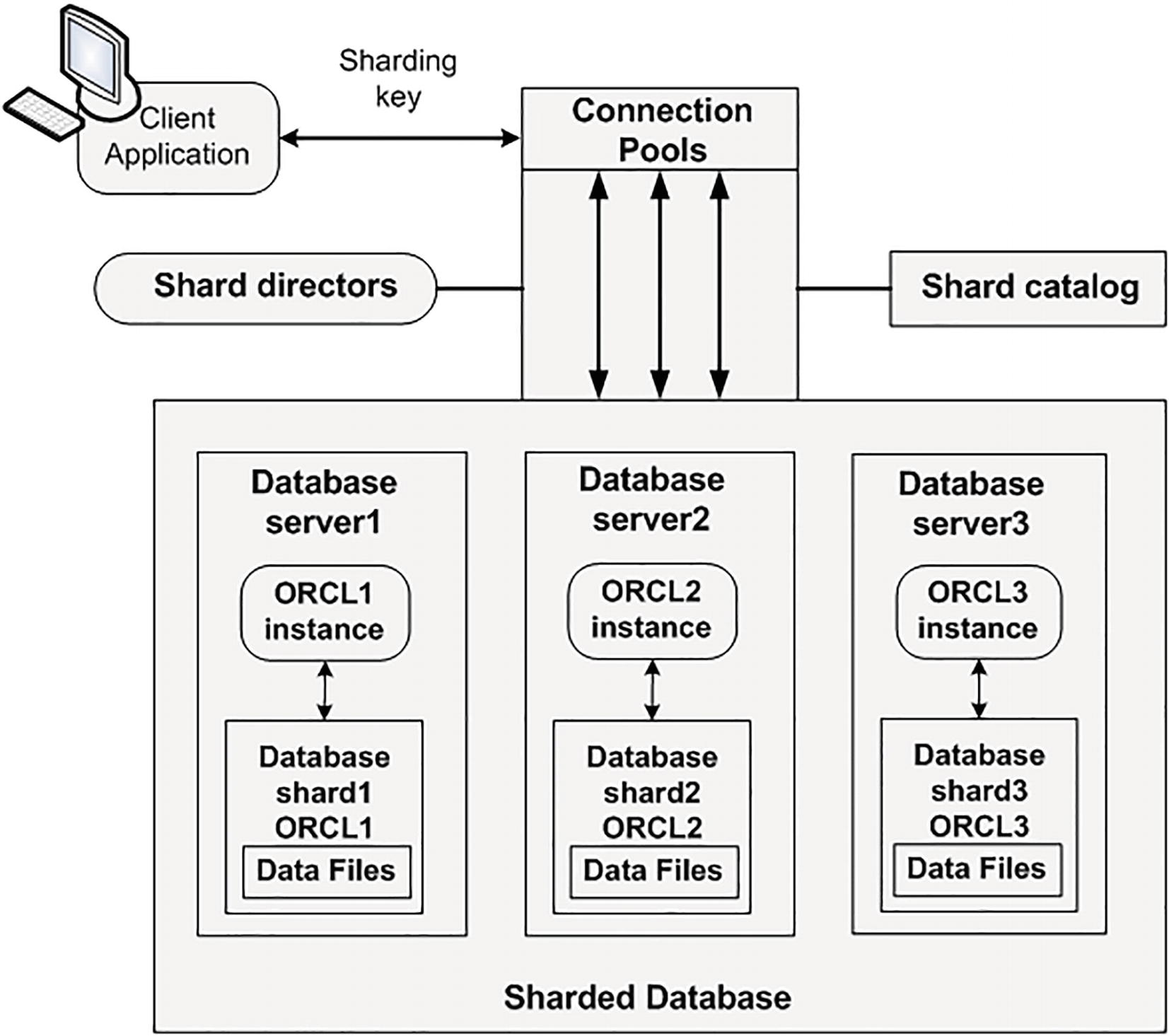
A sharded database that contains three database shards
Linear scalability: You can add or remove shards as your business requirements dictate.
Fault tolerance: The database shard exists on independent hardware; therefore, an outage on one database shard does not impact other shards.
Geographic distribution of data: You might want to do this for legal reasons or privacy regulation reasons.
Rolling upgrades: Each shard can be independently upgraded.
Regional performance: Each shard can exist in a specific geographic region with its own hardware and storage configuration.
Each database shard is self-contained, meaning each shard will have its own SGA and background processes. So unlike RAC, where multiple instances share the same set of physical database files, sharding is multiple databases (each with its own instance) presented to the end user as one logical database.
The SGA and Background Processes
Maintain many internal data structures that all processes need access to.
Cache data from disk; buffer redo data before writing it to disk.
Hold parsed SQL plans.
And so on.
Oracle has a set of processes that are “attached” to this SGA, and the mechanism by which they attach differs by operating system. In a UNIX/Linux environment, the processes will physically attach to a large shared memory segment, a chunk of memory allocated in the OS that may be accessed by many processes concurrently (generally using shmget() and shmat()). Under Windows, these processes simply use the C call, malloc(), to allocate the memory, since they are really threads in one big process and hence share the same virtual memory space.
Oracle also has a set of files that the database processes or threads read and write (and Oracle processes are the only ones allowed to read or write these files). In a single-tenant architecture, these files hold all of our table data, indexes, temporary space, redo logs, PL/SQL code, and so on. In a multitenant architecture, the container database will hold all of the Oracle-related metadata, data, and code; our application data will be separately contained in a pluggable database.
I cover these processes in Chapter 5, so just be aware for now that they are commonly referred to as the Oracle background processes. They are persistent processes that make up the instance, and you’ll see them from the time you start the instance until you shut it down.
It is interesting to note that these are processes, not individual programs. There is only one Oracle binary executable on UNIX/Linux; it has many “personalities,” depending on what it was told to do when it starts up. The same binary executable that was run to start the smon was also used to start the checkpoint background process. There is only one binary executable program, named simply oracle. It is just executed many times with different names.
Connecting to Oracle
In this section, we’ll take a look at the mechanics behind the two most common ways to have requests serviced by an Oracle server: dedicated server and shared server connections. We’ll see what happens on the client and the server in order to establish connections, so we can log in and actually do work in the database. Lastly, we’ll take a brief look at how to establish TCP/IP connections; TCP/IP is the primary networking protocol used to connect over the network to Oracle. And we’ll look at how the listener process on our server, which is responsible for establishing the physical connection to the server, works differently in the cases of dedicated and shared server connections.
Dedicated Server
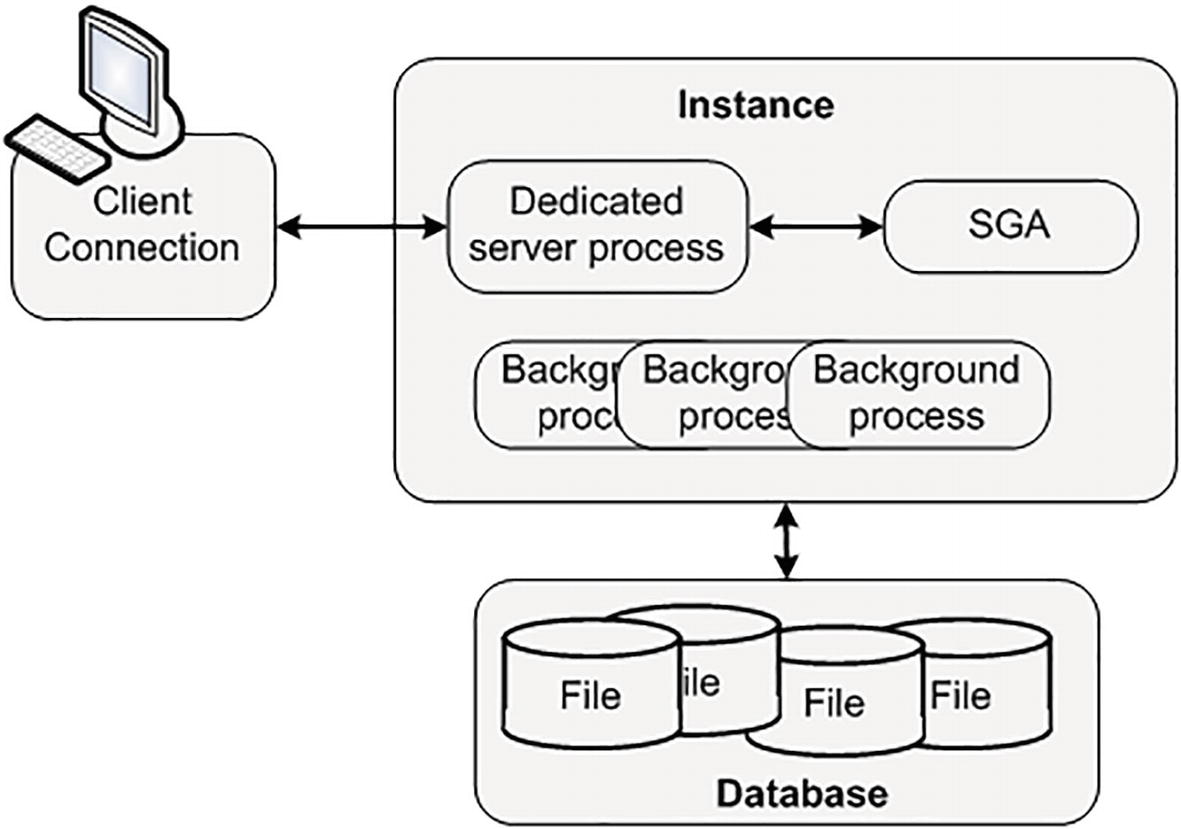
Typical dedicated server configuration
As noted, typically Oracle will create a new process for me when I log in. This is commonly referred to as the dedicated server configuration, since a server process will be dedicated to me for the life of my session. For each session, a new dedicated server will appear in a one-to-one mapping. My client process (whatever program is trying to connect to the database) will be in direct communication with this dedicated server over some networking conduit, such as a TCP/IP socket. It is this server process that will receive my SQL and execute it for me. It will read datafiles if necessary, and it will look in the database’s cache for my data. It will perform my update statements. It will run my PL/SQL code. Its only goal is to respond to the SQL calls I submit to it.
Shared Server
Oracle can also accept connections in a manner called a shared server, in which you wouldn’t see an additional thread created or a new UNIX/Linux process appear for each user connection.
In older versions of Oracle, a shared server was known as a multithreaded server or MTS. That legacy name is not in use anymore.
In a shared server, Oracle uses a pool of shared processes for a large community of users. Shared servers are simply a connection pooling mechanism. Instead of having 10,000 dedicated servers (that’s a lot of processes or threads) for 10,000 database sessions, a shared server lets us have a small percentage of these processes or threads, which are (as the name implies) shared by all sessions. This allows Oracle to connect many more users to the instance than would otherwise be possible. Our machine might crumble under the load of managing 10,000 processes, but managing 100 or 1000 processes is doable. In shared server mode, the shared processes are generally started up with the database and appear in the ps list.
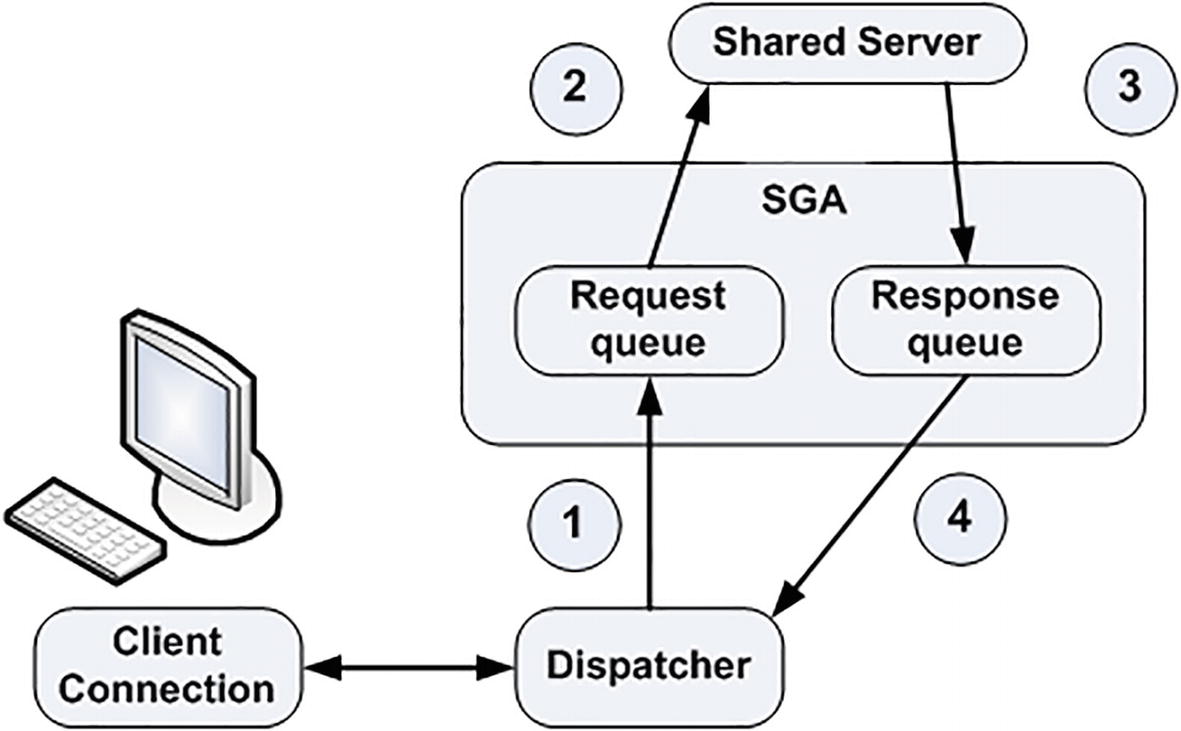
Steps in a shared server request
As shown in Figure 2-7, the client connection will send a request to the dispatcher. The dispatcher will first place this request onto the request queue in the SGA (1). The first available shared server will dequeue this request (2) and process it. When the shared server completes, the response (return codes, data, and so on) is placed into the response queue (3), subsequently picked up by the dispatcher (4), and transmitted back to the client.
As far as the developer is concerned, there is conceptually no difference between a shared server connection and a dedicated server connection. Architecturally, they are quite different, but that’s not apparent to an application.
How do I get connected in the first place?
What would start this dedicated server?
How might I get in touch with a dispatcher?
The answers depend on your specific platform, but the sections that follow outline the process in general terms.
Mechanics of Connecting over TCP/IP
We’ll investigate the most common networking case: a network-based connection request over TCP/IP. In this case, the client is situated on one machine and the server resides on another, with the two connected on a TCP/IP network. It all starts with the client. The client makes a request using the Oracle client software (a set of provided application program interfaces, or APIs) to connect to a database. The client could be a SQL*Plus on your laptop, an application using a JDBC connection, TOAD, SQL Developer, and so on.
Username: This is sometimes called the schema name or database user account.
Password: The password assigned to the username.
Hostname (or IP address): The host (server) that the database is running on.
Port: The port that the database listener is listening on. The default port is 1521.
Service name: You can conceptually think of a service name as a synonym for the database instance you want to connect to. The service name is oftentimes the instance name or the pluggable database name that you’re connecting to. More technically, a service name represents groups of applications with common attributes, service-level thresholds, and priorities. The number of instances offering the service is transparent to the application, and each database instance may register with the listener as willing to provide many services. So, services are mapped to physical database instances and allow the DBA to associate certain thresholds and priorities with them.
TNS stands for Transparent Network Substrate and is “foundation” software built into the Oracle client that handles remote connections, allowing for peer-to-peer communication.
The strings (ORCL or OCLD in these prior examples) could have been resolved in other ways. For example, it could have been resolved using a naming service provided by the Lightweight Directory Access Protocol (LDAP) server, similar in purpose to DNS for hostname resolution. However, the use of the tnsnames.ora file is common in most small to medium installations (as measured by the number of hosts that need to connect to the database) where the number of copies of such a configuration file is manageable.
Now that the client software knows where to connect to, it will open a TCP/IP socket connection to the server with the specified hostname and port. The connection to the instance on my laptop uses a hostname of localhost and a port of 1521 (the default port and can be configured on other ports). If the DBA (me) for our server has installed and configured Oracle Net, and has the listener listening on port 1521 for connection requests, this connection may be accepted. In a network environment, we will be running a process called the TNS listener on our server. This listener process is what will get us physically connected to our database. When it receives the inbound connection request, it inspects the request and, using its own configuration files, either rejects the request (because there is no such service, e.g., or perhaps our IP address has been disallowed connections to this host) or accepts it and goes about getting us connected.
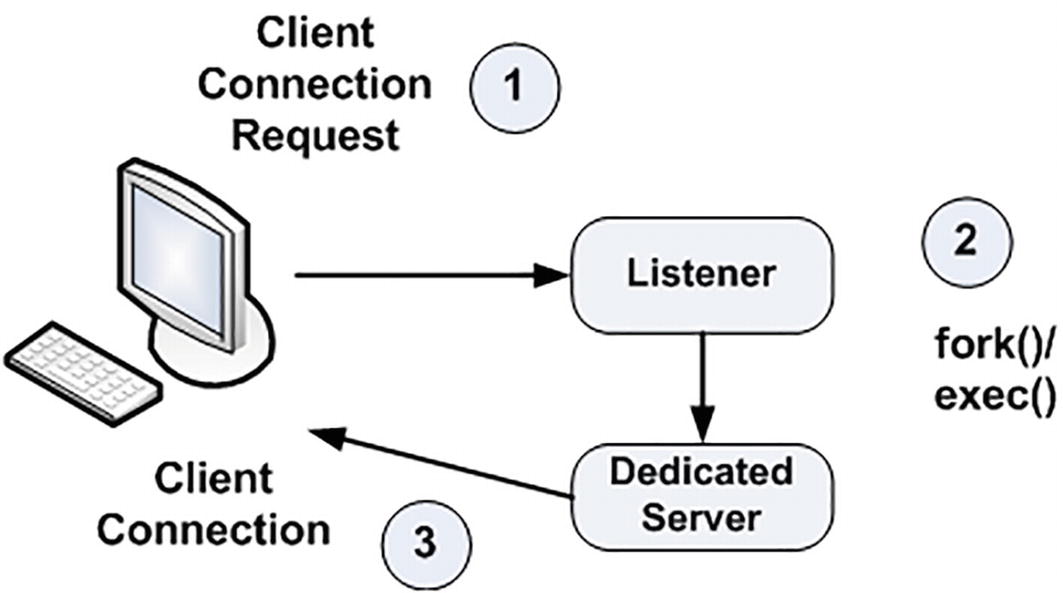
The listener process and dedicated server connections
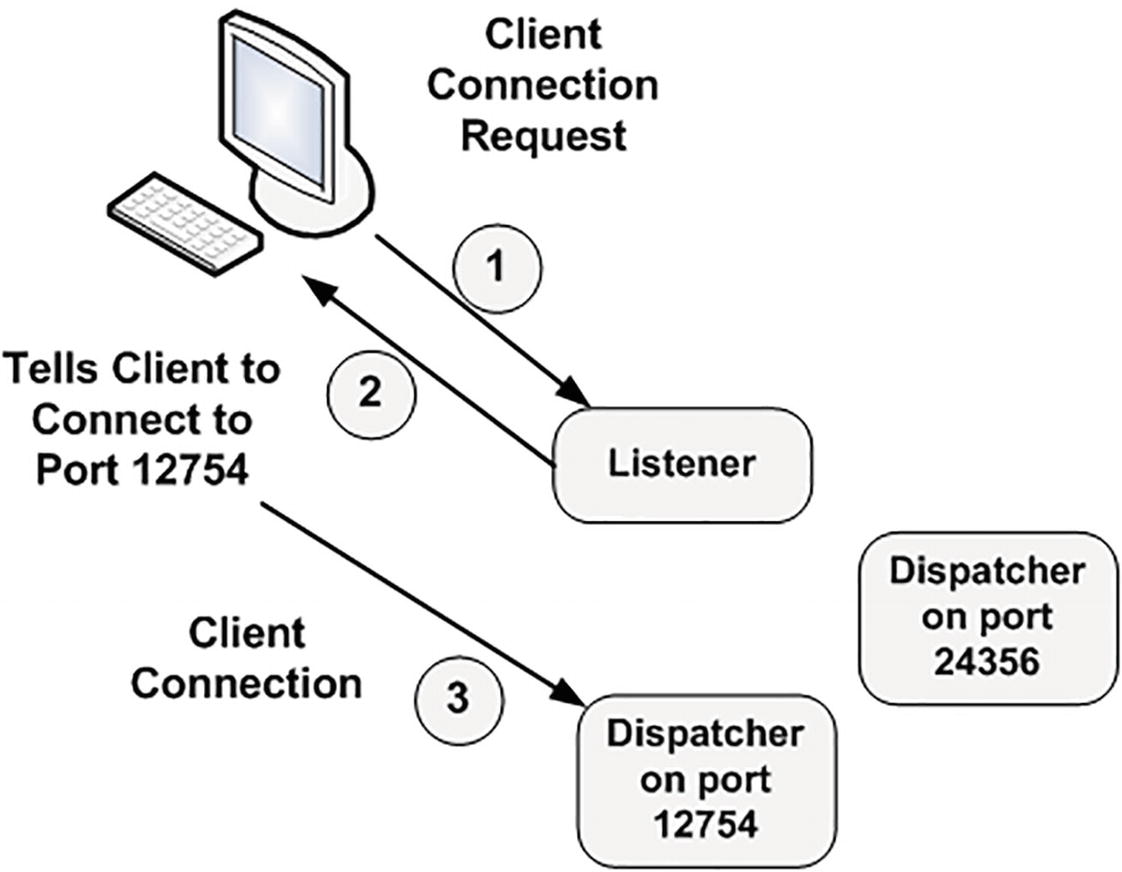
The listener process and shared server connections
From the client’s perspective, it doesn’t care or know if it’s making a dedicated server or shared server connection. The end result should be a successful connection to the database instance so that the client can interact with the database.
Summary
This completes our overview of the Oracle architecture. In this chapter, we defined the terms database, instance, container database, pluggable database, real application cluster (RAC) database, and sharded database. It’s especially important to understand Oracle’s multitenant architecture as this is the recommended Oracle architecture going forward. The use of non-CDB databases will be desupported by Oracle at some point in the future.
We also saw how to connect to the database through either a dedicated server connection or a shared server connection. It’s worth noting that an Oracle instance may use both connection types simultaneously. In fact, an Oracle database always supports dedicated server connections—even when configured for a shared server.
Now you’re ready to take a more in-depth look at the files that comprise the database and the processes behind the server—what they do and how they interact with each other. You’re also ready to look inside the SGA to see what it contains and what its purpose is. You’ll start in the next chapter by looking at the types of files Oracle uses to manage the data, and the role of each file type.