
5.5 Characterization Set
Most methods for generating tests from FSMs make use of an important set known as the characterization set. This set is usually denoted by W and is sometimes referred to as the W-set. In this section, we explain how one can derive a W-set, given the description of an FSM. Let us examine the definition of the W-set.
The characterization set W for a minimal FSM Μ is a finite set of strings over the input alphabet of Μ such that for each pair of states (r, s) in Μ there exists at least one string in W that distinguishes state r from state s.
Let Μ = (X, Y, Q, q1, δ, O) be an FSM that is minimal and complete. A characterization set for M, denoted as W, is a finite set of input sequences that distinguish the behavior of any pair of states in M. Thus, if qi and qj are states in Q, then there exists a string s in W such that O(s, qi) ≠ O(s, qj), where s belongs to X+.
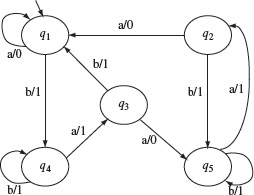
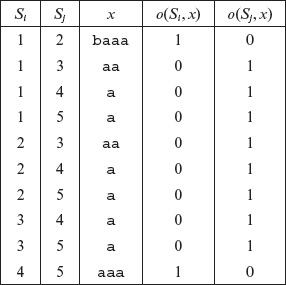
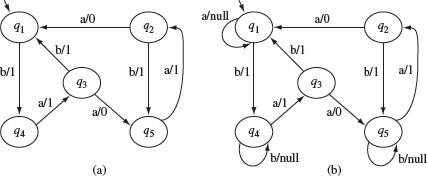
Example 5.7 Consider an FSM M = (X, Y, Q, q1, δ, O) where X = {a, b}, Y = {0, 1}, and Q = {q1, q2, q3, q4, q5}, q1 is the initial state. The state transition function δ and the output function Ο are shown in Figure 5.13. The set W for this FSM is given below.
W = {a, aa, aaa, baaa}
A distinguishing sequence x for two states r and s of an FSM Μ causes Μ to produce different outputs when excited by x starting in states r or in s.
Let us do a sample check to determine if indeed, W is the characterization set for M. Consider the string baaa. It is easy to verify from Figure 5.13 that when Μ is started in state q1 and excited with baaa, the output sequence generated is 1101. However, when Μ is started in state q2 and excited with input baaa, the output sequence generated is 1100. Thus, we see that O(baaa, q1) ≠ O(baaa, q2) implying that the sequence baaa is a distinguishing sequence for states q1 and q2. You may now go ahead and perform similar checks for the remaining pairs of states.
Figure 5.13 The transition and output functions of a simple FSM.
The algorithm to construct a characterization set for an FSM Μ consists of two main steps. The first step is to construct a sequence of k-equivalence partitions P1, P2, . . . , Pm where m > 0. This iterative step converges in at most n steps where n is the number of states in M. In the second step, these k-equivalence partitions are traversed, in reverse order, to obtain the distinguishing sequences for every pair of states. These two steps are explained in detail in the following two subsections.
5.5.1 Construction of the k-equivalence partitions
Recall that given Μ = (X, Y, Q, q1, δ, O), two states q1 ϵ Q and qj ϵ Q are considered k-equivalent, if there does not exist an s ϵ Xk such that O(s, qi) ≠ O(s, qj). The notion of k-equivalence leads to the notion of k-equivalence partitions.
A k-equivalence set consists of states that are k-equivalent, i.e., that cannot be distinguished by any string of length k or less over the input alphabet. A k-equivalent partition is a finite collection of k-equivalent sets such that each state in the FSM belongs to exactly one set. States that belong to different k-equivalent sets are considered k-distinguishable.
Given an FSM Μ = (X, Y, Q, q1, δ, O), a k-equivalence partition of Q, denoted by Pk, is a collection of n finite sets of states denoted as Σk 1, Σk 2, . . . , Σkn such that
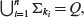
- States in Σkj , for 1 ≤ j ≤ n, are k-equivalent,
- If ql ϵ Σki and qm ϵ Σkj, for i ≠ j, then ql and qm must be k-distinguishable.
We now illustrate the computation of k-equivalence partitions by computing them for the FSM of Example 5.7 using a rather long example.
Example 5.8 We begin by computing the 1-equivalence partition, i.e. P1, for the FSM shown in Figure 5.13. To do so, write the transition and output functions for this FSM in a tabular form as shown below.
The next step in constructing P1 is to regroup the states so that all states that are identical in their output entries belong to the same group. Separation among two groups is indicated by a horizontal line as shown in the table below. Note from this table that states q1, q2, and q3 belong to one group as they share identical output entries. Similarly, states q4 and q5 belong to another group. Notice also that we have added a Σ column to indicate group names. You may decide on any naming scheme for groups. In this example, groups are labeled as 1 and 2.
The construction of P1 is now complete. The groups separated by the horizontal line constitute a 1-equivalence partition. We have labeled these groups as 1 and 2. Thus, we get the 1-equivalence partition as
P1 = {1, 2}
Group 1 = Σ11 = {q1, q2, q3}
Group 2 = Σ12 = {q4, q5}
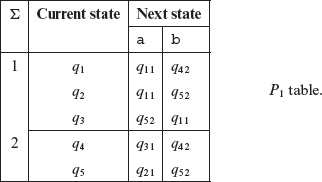
In preparation to begin the construction of the 2-equivalence partition, construct the P1 table as follows. First, we copy the “Next State” sub-table. Next, rename each Next State entry by appending a second subscript which indicates the group to which that state belongs. For example, the next state entry under column “a” in the first row is q1. As q1 belongs to group 1, we relabel this as q11. Other next state entries are relabeled in a similar way. This gives us the P1 table as shown below.
Each P-table contains two or more groups of states. Each group of states is k-equivalent for some k > 0.
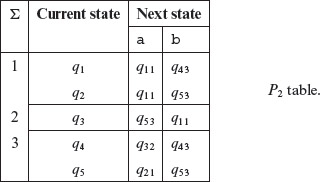
From the P1 table given above, construct the P2 table as follows. First, regroup all rows with identical second subscripts in its row entries under the Next State column. Note that the subscript we are referring to is the group label. Thus, for example, in q42 the subscript we refer to is 2 and not 4 2. This is because q4 is the name of the state in machine Μ and 2 is the group label under the Σ column. As an example of regrouping in the P1 table, the rows corresponding to the current states q1 and q2 have next states with identical subscripts and hence we group them together. This regrouping leads to additional groups. Next, relabel the groups and update the subscripts associated with the next state entries. Using this grouping scheme, we get the following P2 table.
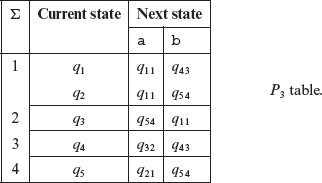
Notice that there are three groups in the P2 table. Regroup the entries in the P2 table using the scheme described earlier for generating the P2 table. This regrouping and relabeling gives us the following P3 table.
Further regrouping and relabeling of P3 table gives us the P4 table given below.
Note that no further partitioning is possible using the scheme described earlier. We have completed the construction of k-equivalence partitions, k = 1,2,3,4, for machine M.
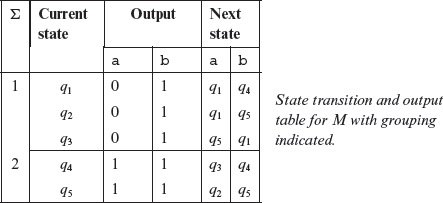
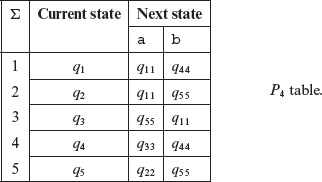
Notice that the process of deriving the Pk tables converged to P4 and no further partitions are possible. See Exercise 5.6 that asks you to show that indeed the process will always converge. It is also interesting to note that each group in the P4 table consists of exactly one state. This implies that all states in Μ are distinguishable. In other words, no two states in Μ are equivalent.
Let us now summarize the algorithm to construct a characterization set from the k-equivalence partitions and illustrate it using an example.
5.5.2 Deriving the characterization set
Having constructed the k-equivalence partitions, i.e. the Pk tables, we are now ready to derive the W-set for machine M. Recall that for each pair of states qi and qj in M, there exists at least one string in W that distinguishes qi from qj. Thus, the method to derive W proceeds by determining a distinguishing sequence for each pair of states in M. First, we sketch the method, referred to as the W procedure, and then illustrate it by a continuation of the previous example. In the procedure below, G(qi, x) denotes the label of the group to which an FSM moves when excited using input x in state qi. For example, in the table for P3, G(q2, b) = 4 and G(q5, a) = 1.
The characterization set is constructed from the P-tables by traversing the tables in the reverse order, i.e., the construction process begins with the last P-table and moves backwards.
The W-Procedure to derive W from a set of partition tables.
- Let M = (X, Y, Q, q1, δ, O) be the FSM for which P = {P1, P2, . . . , Pn} is the set of k-equivalence partition tables for k = 1,2, . . . , n. Initialize W = Ø.
- Repeat the steps (a) through (d) for each pair of states (qi, qj), i ≠ j, in M.
- Find an r, 1 ≤ r < n such that the states in pair (qi, qj) belong to the same group in Pr but not in Pr+1. In other words, Pr is the last of the P tables in which (qi, qj) belong to the same group. If such an r is found, then move to Step (b), otherwise find an η ϵ X such that O(qi, η) ≠ O(qj, η), set W = W ∪ {η}, and continue with the next available pair of states.
The length of the minimal distinguishing sequence for (qi, qj) is r + 1.
Denote this sequence as z = x0x1 . . . xr where xi ϵ X for 0 ≤ i ≤ r.
- Initialize z = ϵ. Let p1 = qi and p2 = qj be the current pair of states. Execute steps (i) through (iii) for m = r, r – 1, r – 2, . . . , 1.
- Find an input symbol η in Pm such that G(p1, η) ≠ G(p2, η). In case there is more than one symbol that satisfies the condition in this step, then select one arbitrarily.
- Set z = z.η.
- Set p1 = δ(p1, η) and p2 = δ(p2, η).
- Find an η ϵ X such that O(p1, η) ≠ O(p2, η). Set z = z.η.
- The distinguishing sequence for the pair (qi, qj) is the sequence z. Set W = W ∪ {z}.
- Find an r, 1 ≤ r < n such that the states in pair (qi, qj) belong to the same group in Pr but not in Pr+1. In other words, Pr is the last of the P tables in which (qi, qj) belong to the same group. If such an r is found, then move to Step (b), otherwise find an η ϵ X such that O(qi, η) ≠ O(qj, η), set W = W ∪ {η}, and continue with the next available pair of states.
Upon termination of the W procedure, we would have generated distinguishing sequences for all pairs of states in M. Note that the above algorithm is inefficient in that it derives a distinguishing sequence for each pair of states even though two pairs of states might share the same distinguishing sequence. (See Exercise 5.7.) The next example applies the W procedure to obtain W for the FSM in Example 5.8.
Example 5.9 As there are several pairs of states in M, we illustrate how to find the distinguishing input sequences for the pairs (q1, q2) and (q3, q4). Let us begin with the pair (q1, q2).
According to Step 2(a) of the W procedure, we first determine r. To do so, note from Example 5.8 that the last P-table in which q1 and q2 appear in the same group is P3. Thus r = 3.
Next, we move to Step 2(b) and set z = ϵ, p1 = q1, p2 = q2. From P3, we find that G(p1, b) ≠ G(p2, b) and update z to z = zb. Thus, b is the first symbol in the input string that distinguishes q1 from q2. In accordance with Step 2(b)(iii), reset p1 = δ(p1, b) and p2 = δ(p2, b). This gives us p1 =q4 and p2 = q5.
Going back to Step 2(b)(i), we find from the P2 table that G(p1, a) ≠ G(p2, a). Update z to z.a = ba and reset p1 and p2 to p1 = δ(p1, a) and p2 = δ(p2, a). We now have p1 = q3 and p2 = q2. Hence, a is the second symbol in the string that distinguishes states q1 and q2.
Once again return to Step 2(b)(i). We now focus our attention on the P1 table and find that states G(p1, a) ≠ G(p2, a) and also G(p1, b) ≠ G(p2, b). We arbitrarily select a as the third symbol of the string that will distinguish states q3 and q2. In accordance with Steps 2(b)(ii) and 2(b)(iii), z, p1, and p2 are updated as z = z.a = baa, P1 = δ(p1, a) and p2 = δ(p2, a). This update leads to p1 = q5 and P2 = q1.
Finally at Step 2(c), the focus is on the original state transition table for M. States q1 and q5 in the table are distinguished by the symbol a. This is the last symbol in the string to distinguish states q1 and q2. Next, set z = z.a = baaa. The string baaa is now discovered as the input sequence that distinguishes states q1 and q2. This sequence is added to W. Note from Example 5.7 that indeed baaa is a distinguishing sequence for states q1 and q2.
Next, the pair (q3, q4) is selected and the procedure resumes at Step 2(a). These two states are in a different group in table P1 but in the same group in M. Thus, r = 0. As O(q3, a) ≠ O(q4, a), the distinguishing sequence for the pair (q3, q4) is the input sequence a.
It is left to the reader to derive distinguishing sequences for the remaining pairs of states. A complete set of distinguishing sequences for FSM Μ is given in Table 5.2. The leftmost two columns labeled Si and Sj contain pairs of states to be distinguished. The column labeled x contains the distinguishing sequence for the pairs of states to its left. The rightmost two columns in this table show the last symbol output when input x is applied to state Si and Sj, respectively. For example, as we have seen earlier O(q1, baaa) = 1101. Thus, in Table 5.2, we only show the 1 in the corresponding output column. Notice that each pair in the last two columns is different, i.e. O(Si, x) ≠ O(Sj, x) in each row. From this table, we obtain W = {a, aa, aaa, baaa}. While the sequence aa can be used instead of using a, doing so would lead to a longer tests.
Table 5.2 Distinguishing sequences for all pairs of states in the FSM of Example 5.8.
5.5.3 Identification sets
Consider an FSM Μ = (X, Y, Q, q1, δ, O) with symbols having their usual meanings and |Q| = n. Assume that Μ is completely specified and minimal. We know that a characterization set W for Μ is a set of strings such that for any pair of states qi and qj in M, there exists a string s in W such that O(qi, s) ≠ (qj, s).
For state s in a minimal FSM there exists an identification set. This set contains strings over the input alphabet that distinguish s from all other states in the FSM.
Analogous to the characterization set for M, we associate an identification set with each state of M. An identification set for state qi ϵ Q is denoted by Wi and has the following properties: (a) Wi ⊆ W, 1 ≤ i ≤ n, (b) O(qi, s) ≠ O(qj, s), for any j, 1 ≤ j ≤ n, j ≠ i, s ϵ Wi, and (c) no subset of Wi satisfies property (b). The next example illustrates the derivation of the identification sets given W.
Example 5.10 Consider the machine given in Example 5.9 and its characterization set W shown in Table 5.2. From this table, we notice that state q1 is distinguished from the remaining states by the strings baaa, aa, and a. Thus, W1 = {baaa, aa, a}. Similarly, W2 = {baaa, aa, a}, W3 = {a, aa}, W4 = {a, aaa}, and W5 = {a, aaa}.
The W- and the Wp-methods are both used for generating test sets from a minimal and complete FSM. The Wp-method will likely generate a smaller test set.
While the characterization sets are used in the W-method, the Wi sets are used in the Wp-method. The W- and the Wp-methods are used for generating tests from an FSM. We are now well equipped to describe various methods for test generation given an FSM. We begin with a description of the W-method.
5.6 The W-method
The W-method is used for constructing a test set from a given FSM M. The test set so constructed is a finite set of sequences that can be input to a program whose control structure is modeled by M. Alternately, the tests can also be the input to a design to test its correctness with respect to some specification.
The implementation modeled by Μ is also known as the Implementation Under Test and abbreviated as IUT. Note that most software systems cannot be modeled accurately using an FSM. However, the global control structure of a software system can be modeled by an FSM. This also implies that the tests generated using the W-method, or any other method based exclusively on a finite state model of an implementation, will likely reveal only certain types of faults. Later in Section 5.9, we discuss what kinds of faults are revealed by the tests generated using the W-method.
Generation of a test set from an FSM using the W-method requires that the FSM be minimal, complete, connected and deterministic. For the generated test s to be directly applicable to the IUT it is necessary that the input alphabets of the FSM and the IUT be the same.
5.6.1 Assumptions
The W-method makes the following assumptions for it to work effectively.
- Μ is completely specified, minimal, connected, and deterministic.
- Μ starts in a fixed initial state.
- Μ can be reset accurately to the initial state. A nul1 output is generated during the reset operation.
- Μ and IUT have the same input alphabet.
Later in this section, we examine the impact of violating the above assumptions. Given an FSM M = (X, Y, Q, q0, δ, O), the W-method consists of the following sequence of steps.
Step A |
Estimate the maximum number of states in the correct design. |
Step B |
Construct the characterization set W for the given machine M. |
Step C |
Construct the testing tree for Μ and determine the transition cover set P. |
Step D |
Construct set Z. |
Step E |
Ρ · Ζ is the desired test set. |
We already know how to construct W for a given FSM. In the remainder of this section, we explain each of the remaining three steps mentioned above.
5.6.2 Maximum number of states
We do not have access to the correct design or the correct implementation of the given specification. Hence, there is a need to estimate the maximum number of states in the correct design. In the worst case, i.e. when no information about the correct design or implementation is available, one might assume that the maximum number of states is the same as the number of states in M. The impact of an incorrect estimate is discussed after we have examined the W-method.
The number of states in the IUT might be more or less as compared to the number of states in the corresponding FSM. When no information is available about the IUT, one may assume that the number of states in the IUT is the same as that in the corresponding FSM.
5.6.3 Computation of the transition cover set
A transition cover set, denoted as P, is defined as follows. Let qi and qj, i ≠ j, be two states in Μ. Ρ consists of sequences sx such that δ(q0, s) = qi and δ(qi, x) = qj. The empty sequence ϵ is also in P. We can construct Ρ using the “testing tree” of M. A testing tree for an FSM is constructed as follows.
A transition cover set contains strings that when used to excite an FSM Μ ensure the coverage of all transitions in M. The set is constructed using a testing tree. The testing tree itself is constructed using the FSM.
- State q0, the initial state, is the root of the testing tree.
- Suppose that the testing tree has been constructed until level k. The (k + 1)th level is built as follows.
- Select a node n at level k. If n appears at any level from 1 through k, then n is a leaf node and is not expanded any further. If n is not a leaf node then we expand it by adding a branch from node n to a new node m if δ(n, x) = m for x ϵ X. This branch is labeled as x. This step is repeated for all nodes at level k.
The following example illustrates construction of a testing tree for the machine in Example 5.8 whose transition and output functions are shown in Figure 5.13.
Example 5.11 The testing tree is initialized with the initial state q1 as the root node. This is level 1 of the tree. Next, we note that δ(q1, a) = q1 and δ(q1, b) = q4. Hence, we create two nodes at the next level and label them as q1 and q4. The branches from q1 to q1 and q4 are labeled, respectively, a and b. As q1 is the only node at level 1, we now proceed to expand the tree from level 2.
At level 2, we first consider the node labeled q1. However, another node labeled q1 already appears at level 1, hence this node becomes a leaf node and is not expanded any further. Next, we examine the node labeled q4. Note that δ(q4, a) = q3 and δ(q4, b) = q4. We therefore create two new nodes at level 3 and label these as q4 and q3 and label the corresponding branches as b and a, respectively.
We proceed in a similar manner down one level in each step. The method converges when at level 6 we have the nodes labeled q1 and q5 both of which appear at some level up the tree. We thus arrive at the testing tree for Μ as shown in Figure 5.14.
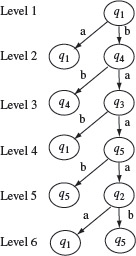
Figure 5.14 Testing tree for the machine with transition and output functions shown in Figure 5.13.
Once a testing tree has been constructed, the transition cover set Ρ is obtained Ρ by concatenating labels of all partial paths along the tree.
A partial path in a testing tree is a path obtained by traversing the tree starting at the root and terminating at an internal or a leaf node.
A partial path is a path starting from the root of the testing tree and terminating in any node of the tree. Traversing all partial paths in the tree shown in Figure 5.14, we obtain the following transition cover set.
It is important to understand the function of the elements of P. As the name transition cover set implies, exciting an FSM in q0, the initial state, with an element of P, forces the FSM into some state. After the FSM has been excited with all elements of P, each time starting in the initial state, the FSM has reached every state. Thus, exciting an FSM with elements of Ρ ensures that all states are reached, and all transitions have been traversed at least once. For example, when the FSM Μ of Example 5.8 is excited by the input sequence baab in state q1, it traverses the branches (q1, q4), (q4, q3), (q3, q5), and (q5, q5), in that order. The empty input sequence ϵ, does not traverse any branch but is useful in constructing the desired test sequence as is explained next.
Exciting an FSM once with each element of the transition cover set ensures coverage of all its states and transitions.
5.6.4 Constructing Ζ
Given the input alphabet X and the characterization set W, it is straightforward to construct Z. Suppose that the number of states estimated to be in the IUT is m and the number of states in the design specification is n, m ≥ n. Given this information, Ζ can be computed as follows.
Z = (X0 · W)∪(X · W)∪(X2 · W) . . .∪(Xm−1–n · W)∪(Xm−n · W)
It is easy to see that Z = X · W for m = n, i.e. when the number of states in the IUT is the same as that in the specification. For m < n, we use Z = X · W. Recall that X0 = {ϵ}, X1 = X, X2 = X · X, and so on, where the symbol "·" denotes the string concatenation operation. For convenience, we shall use the shorthand notation X[p] to denote the following set union
{ϵ} ∪ X1 ∪ X2 . . . ∪ Xp–1 ∪Xp.
We can now rewrite Ζ as Ζ = X[m–n]. W, for m≥n where m is the number of states in the IUT and n the number of states in the design specification.
5.6.5 Deriving a test set
Having constructed Ρ and Z, we can easily obtain a test set Τ as Ρ · Ζ. The next example shows how to construct a test set from the FSM of Example 5.8.
Example 5.12 For the sake of simplicity, let us assume that the number of states in the correct design or IUT is the same as in the given design shown in Figure 5.13. Thus, m = n = 5. This leads to the following Z:
Ζ = X° · W = {a, aa, aaa, baaa}
Catenating Ρ with Z, we obtain the desired test set.
Assuming that the IUT has one extra state, i.e. m = 6, we obtain Ζ and the test set P · Z as follows.

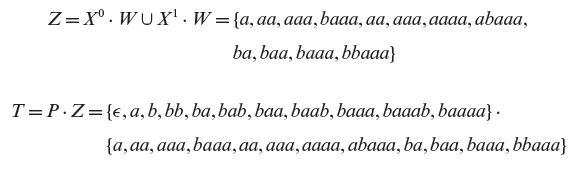
5.6.6 Testing using the W-method
To test a given IUT Μi against its specification M, we do the following for each test input.
- Find the expected response M(t) to a given test input t. This is done by examining the specification. Alternately, if a tool is available, and the specification is executable, one could determine the expected response automatically.
- Obtain the response Mi(t) of the IUT, when excited with t in the initial state.
- If M(t) = Mi(t), then no flaw has been detected so far in the IUT. M(t) ≠ Mi(i) implies the possibility of a flaw in the IUT under test, given a correct design.
Notice that a mismatch between the expected and the actual response does not necessarily imply an error in the IUT. However, if we assume that (a) M(t) and Mi(t) have been determined without any error, and (b) the comparison between M(t) and Mi(t) is correct, then indeed M(t) ≠ Mi(t) implies an error in the design or the IUT.
A mismatch between the expected output derived from an FSM and the actual output obtained from the IUT does not necessarily imply an error in the IUT.
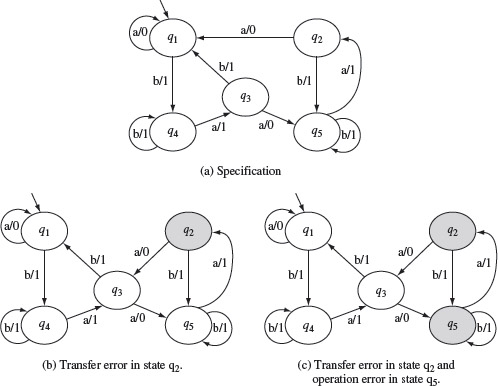
Example 5.13 Let us now apply the W-method to test the design shown in Figure 5.13. We assume that the specification is also given in terms of an FSM which we refer to as the “correct design.” Note that this might not happen in practice but we make this assumption for illustration.
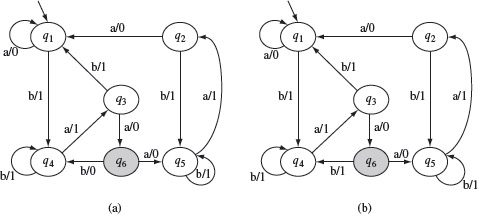
Consider two possible implementations under test. The correct design is shown in Figure 5.15(a) and is referred to as M. We denote the two erroneous designs, corresponding to two IUTs under test, as M1 and M2, respectively, shown in Figure 5.15(b) and (c).
Figure 5.15 The transition and output functions of FSMs of the design under test, denoted as Μ in the text and copied from Figure 5.13 and two incorrect designs in (b) and (c) denoted as M1, and M2 in the text.
Notice that M1 has one transfer error with respect to M. The error occurs in state q2 where the state transition on input a should be δ1(q2, a) = q1 and not δ1(q2, a) = q3. M2 has two errors with respect to M. There is a transfer error in state q2 as mentioned earlier. In addition, there is an operation error in state q5 where the output function on input b should be O2(q5, b) = 1 and not O2(q5, b) = 0.
To test M1 against M, we apply each input t from the set P · Z derived in Example 5.12 and compare M(t) with M1(t). However, for the purpose of this example, let us first select t = ba. Tracing gives us M(t)=11 and M1(t) = 11. Thus, IUT M1 behaves correctly when excited by the input sequence ba. Next, we select t = baaaaaa as a test input. Tracing the response of M(t) and M1(t) when excited by t, we obtain M(t) = 1101000 and M1(t) = 1101001. Thus, the input sequence baaaaaa has revealed the transfer error in M1.
Next, let us test M2 with respect to specification M. We select the input sequence t = baaba for this test. Tracing the two designs we obtain M(t) = 11011, whereas M2(t) = 11001. As the two traces are different, input sequence baaba reveals the operation error. We have already shown that x = baaaaaa reveals the transfer error. Thus, the two input sequences baaba and baaaaaa in P · Z reveal the errors in the two IUTs under test.
Tests generated from an FSM are assumed independent and need to be applied to the IUT in the start state. Thus, prior to applying a test input, the IUT needs to be brought to its start state.
Note that for the sake of brevity, we have used only two test inputs. However, in practice, one needs to apply test inputs to the IUT in some sequence until the IUT fails or the IUT has performed successfully on all tests.
Example 5.14 Suppose it is estimated that the IUT corresponding to the machine in Figure 5.13 has one extra state, i.e. m = 6. Let us also assume that the IUT, denoted as M1, is as shown in Figure 5.16(a) and indeed has six states. Testing M1 against t = baaba leads to M1(t) = 11001. The correct output obtained by tracing M against t is 11011. As M(t) ≠ M1(t), test input t has revealed the "extra state" error in S1.
Figure 5.16 Two implementations each of the design in Figure 5.13 each having an extra state. Note that the output functions of the extra state q6 are different in (a) and (b)
However, test t = baaba does not reveal the extra state error in machine M2 as M2(t) = 11011 = M(t). Consider now test t = baaa. We get M(t) = 1101 and M2(t) = 1100. Thus, the input baaa reveals the extra state error in machine M2.
5.6.7 The error detection process
Let us now carefully examine how the test sequences generated by the W-method detect operation and transfer errors. Recall that the test set generated in the W-method is the set Ρ · W, given that the number of states in the IUT is the same as that in the specification. Thus, each test case t is of the form r · s where r belongs to the transition cover set Ρ and s to the characterization set W. We consider the application of t to the IUT as a two-phase process. In the first phase, input r moves the IUT from its initial state q0 to some state qi. In the second phase, the remaining input s moves the IUT to its final state qj or qj′. These two phases are shown in Figure 5.17.
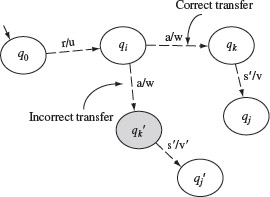
Figure 5.17 Detecting errors using tests generated by the W-method.
Each test derived using the W-method is of the kind rs where r is derived from the testing tree and s is an element of the characterization set.
When the IUT is started in its initial state, say q0, and excited with test t, it consumes the string r and arrives at some state qi as shown in Figure 5.17. The output generated so far by the IUT is u where u = O(q0, r). Continuing further in state qi, the IUT consumes symbols in string s and arrives at state qj. The output generated by the IUT while moving from state qi to qj is ν where v = O(qi, s). If there is any operation error along the transitions traversed between states q0 and qi, then the output string u would be different from the output generated by the specification machine Μ when excited with r in its initial state. If there is any operation error along the transitions while moving from qi to qj, then the output wv would be different from that generated by M.
The detection of a transfer error is more involved. Suppose there is a transfer error in state qi and s = as′. Thus, instead of moving to state qk, where qk = δ(qi, a), the IUT moves to state qk′ where qk′ = δ(qi, a). Eventually, the IUT ends up in state qj′ where qj′ = δ(qk′ , s′). Note that this step may take several transitions and hence is indicated by a dotted arrow in the figure. Our assumption is that s is a distinguishing sequence in W for states qi and qj′ . In this case, wv′ ≠ wv. If s is not a distinguishing sequence for qi and qj′ then there must exist some other input as″ in W such that wv″ ≠ wv where v″ = O(qk′ , s″).
5.7 The Partial W-method
The partial W-method, also known as the Wp-method, is similar to the W-method in that tests are generated from a minimal, complete, and connected FSM. However, the size of the test set generated using the Wp-method is often smaller than that generated using the W-method. This reduction is achieved by dividing the test generation process into two phases and making use of the state identification sets Wi, instead of the characterization set W, in the second phase. Furthermore, the fault detection effectiveness of the Wp-method remains the same as that of the W-method. The two-phases used in the Wp-method are described later in Section 5.7.1.
The partial W-method, referred to as the Wp-method, uses the state cover set and the state identification sets. Tests so generated are generally shorter than those generated by the W-method.
First, we define a state cover set S of an FSM Μ = (X, Y, Q, q0, δ, O). S is a finite non-empty set of sequences where each sequence belongs to X* and for each state qt ϵ Q, there exists an r ϵ S such that δ(q0, r) = qt. It is easy to see that the state cover set is a subset of the transition cover set and is not unique. Note that the empty string ϵ belongs to S which covers the initial state because, as per the definition of state transitions, δ(q0, ϵ) = q0.
For each state s in an FSM a state cover set contains at least one element that moves the FSM from its initial state to s. The empty string is a part of the state cover set.
Example 5.15 In Example 5.11 the following transition cover set was constructed for machine Μ of Figure 5.13.
P = {ϵ, a, b, bb, ba, bob, baa, baab, baaa, baaab, baaaa}
The following subset of Ρ forms a state cover set for M.
S = {ϵ, b, ba, baa, baaa}
We are now ready to show how tests are generated using the Wp-method. As before, let M denote the FSM representation of the specification against which we are to test an IUT. Suppose that M contains n > 0 states and the IUT contains m > 0 states. The test set T derived using the Wp-method is composed of subsets T1 and T2, i.e. T = T1 ∪ T2. Computation of subsets T1 and T2 is shown below assuming that M and the IUT have an equal number of states, i.e. m = n.
Procedure for test generation using the Wp-method.
|
Step 1 |
Compute the transition cover set P, the state cover set S, the characterization set W, and the state identification sets Wi for M. Recall that S can be derived from P and the state identification sets can be computed as explained in Example 5.10. |
|
Step 2 |
T1 = S ·W. |
|
Step 3 |
Let W be the set of all state identification sets of M, i.e. W = {W1, W2, . . . , Wn}. |
|
Step 4 |
Let R = {ri1 , ri2 , . . . rik} denote the set of all sequences that are in the transition cover set P but not in the state cover set S, i.e. R = P − S. Furthermore, let rij ϵ R be such that δ(q0, rij ) = qij. |
|
Step 5 |
|
End of Procedure for test generation using the Wp-method.
The ⊗ operator used in the derivation of T2 is known as the partial string concatenation operator. Having constructed the test set T, which consists of subsets Τ1 and T2, one proceeds to test the IUT as described in the next section.
The partial string concatenation operator is used in the construction of a subset of tests when using the Wp-method.
5.7.1 Testing using the Wp-method for m = n
Given a specification machine M and its implementation under test, the Wp-method consists of a two-phase test procedure. In the first phase, the IUT is tested using the elements of T1. In the second phase, the IUT is tested against the elements of T2. Details of the two phases follow.
Phase 1: Testing the IUT against each element of T1 tests each state for equivalence with the corresponding state in M. Note that a test sequence t in T1 is of the kind uv where u ϵ S and v ϵ W. Suppose that δ(q0, u) = qi for some state qi in M. Thus, the application of t first moves M to some state qi. Continuing with the application of t to M, now in state qi, generates an output different from that generated if v were applied to M in some other state qj , i.e. O(qi, v) ≠ O(qj, v), for i ≠ j. If the IUT behaves as M against each element of T1, then the two are equivalent with respect to S ·W. If not, then there is an error in the IUT.
Phase 2: While testing the IUT using elements of T1 checks all states in the implementation against those in M, it may miss checking all transitions in the IUT. This is because T1 is derived using the state cover set S and not the transition cover set P. Elements of T2 complete the checking of the remaining transitions in the IUT against M.
To understand how, we note that each element t of T2 is of the kind uv where u is in P but not in S. Thus, the application of t to M moves it to some state qi where δ(q0, u) = qi. However, the sequence of transitions that M goes through is different from the sequence it goes through while being tested against elements of T1 because u ∉ S. Next, M which is now in state qi, is excited with v. Now v belongs to Wi which is the state identification set of qi and hence this portion of the test will distinguish qi from all other states with respect to transitions not traversed while testing against T1. Thus, any transfer or operation errors in the transitions not tested using T1 will be discovered using T2.
Example 5.16 Let us reconsider the machine in Figure 5.13 to be the specification machine M. First, various sets needed to generate the test set Τ are reproduced below for convenience.
Next, we compute set T1 using Step 2.
Next, in accordance with Step 4 we obtain R as
R = P – S = {a , bb, bob, baab, baaab, baaaa}.
With reference to Step 4 and Figure 5.13, we obtain the following state transitions for the elements in R:
From the transitions given above, we note that when Μ is excited by elements a, bb, bab, baab, baaab, and baaaa, starting on each occasion in state q1, it moves to states, q1, q4, q1, q5, q5, and q1, respectively. Thus, while computing T2, we need to consider the state identification sets W1, W4, and W5. Using the formula in Step 5, we obtain T2 as follows.
The desired test set Τ = T1 ∪ T2. Note that Τ contains a total of 21 tests. This is in contrast to the 29 tests generated using the W-method in Example 5.12 when m = n.


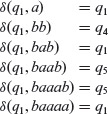

The next example illustrates the Wp-method.
Example 5.17 Let us assume we are given the specification Μ as shown in Figure 5.15(a) and are required to test IUTs that correspond to designs M1 and M2 in Figure 5.15(b) and (c), respectively. For each test, we proceed in two phases as required by the Wp-method.
Testing using the Wp-method proceeds in two phases. In the first phase, elements of test T1 are applied followed by those of test T2 where T1 and T2 are subsets of the tests generated using the Wp-method. Tests in Τ1 ensure that each state is reached and distinguished from the rest. However, doing so might miss the testing of all transitions which is done in phase 2 using tests from T2.
Test M1, phase 1: We apply each element t of T1 to the IUT corresponding to M1 and compare M1(t) with the expected response M(t). To keep this example short, let us consider test t = baaaaaa. We obtain M1(t) = 1101001. On the contrary, the expected response is M(t) = 1101000. Thus, test input t has revealed the transfer error in state q2.
Test M1, phase 2: This phase is not needed to test M1. In practice, however, one would test M1 against all elements of T2. You may verify that none of the elements of T2 reveal the transfer error in M1.
Test M2, phase 1: Test t = baabaaa that belongs to T1 reveals the error as M2(t) = 1100100 and Μ(t) = 1101000.
Test M2, phase 2: Once again this phase is not needed to reveal the error in M2.
Note that in both the cases in the example above, we do not need to apply phase 2 of the Wp-method to reveal the error. For an example that does require phase 2 to reveal an implementation error, refer to Exercise 5.15 that shows an FSM and its erroneous implementation and requires the application of phase 2 for the error to be revealed. However, in practice, one would not know whether or not phase 1 is sufficient. This would lead to the application of both phases and hence all tests. Note that tests in phase 2 ensure the coverage of all transitions. While tests in phase 1 might cover all transitions, they might not apply the state identification inputs. Hence, all errors corresponding to the fault model in Section 5.4 are not guaranteed to be revealed by tests in phase 1.
5.7.2 Testing using the Wp-method for m > n
The procedure for constructing tests using the Wp-method can be modified easily when the number of states in the IUT is estimated to be larger than that in the specification, i.e. when m > n. Steps 2 and 5 of the procedure described earlier need to be modified.
The Wp-method described earlier needs modification when the IUT has more states than the FSM from which the tests are generated.
For m = n, we compute T1 = S · W. For m > n we modify this formula so that T1 = S · Ζ where Ζ = X[m – n] · W as explained in Section 5.6.4. Recall that T1 is used in phase 1 of the test procedure. T1 is different from Τ derived from the W-method in that it uses the state cover set S and not the transition cover set P. Hence, T1 contains fewer tests than Τ except when P = S.
To compute T2, we first compute R as in Step 4. Recall that R contains only those elements of the transition cover set Ρ that are not in the state cover set S. Let R = Ρ – S = {ri1, ri2, . . . rik}. As before, rij ϵ R moves Μ from its initial state to state qij, i.e. δ(q0, rij) = qij. Given R, we derive T2 as follows.
where δ(q0, rij) = qij δ(qij, u) = ql, and Wl ϵ W is the identification set for state ql.
The basic idea underlying phase 2 is explained in the following. The IUT under test is exercised so that it reaches some state qi from the initial state q0. Let u denote the sequence of input symbols that move the IUT from state q0 to qi. As the IUT contains m > n states, it is now forced to take an additional (m – n) transitions. Of course, it requires (m – n) input symbols to force the IUT for that many transitions. Let ν denote the sequence of symbols that move the IUT from state qi to state qj in (m – n) steps. Finally, the IUT receives an input sequence of symbols, say w, that belong to the state identification set Wj. Thus, one test for the IUT in phase 2 is comprised of the input sequence uvw.
Notice that the expression to compute T2 consists of two parts. The first part is R and the second part is the partial string concatenation of X[m – n] and W. Thus, a test in T2 can be written as uvw where u ϵ R is the string that takes the IUT from its initial state to some state qi string ν ϵ X[m – n] takes the IUT further to state qj and string w ϵ Wj takes it to some state ql. If there is no error in the IUT, then the output string generated by the IUT upon receiving the input uvw must be the same as the one generated when the design specification Μ is exercised by the same string.
Example 5.18 Let us construct a test set using the Wp-method for machine Μ in Figure 5.13 given that the corresponding IUT contains an extra state. For this scenario, we have n = 5 and m = 6. Various sets needed to derive Τ are reproduced here for convenience.
First, Τ1 is derived as S · X[1] · W. Recall that X[1] denotes the set {ϵ}∪ X1.
T1 contains a total of 60 tests of which 20 are in S · W and 40 in S · X · W. To obtain T2, we note that R = Ρ – S = {a, bb, bab, baab, baaab, baaaa}. T2 can now be computed as follows.
T2 contains a total of 38 tests. In all the entire test set Τ = T1 ∪ T2 contains 81 tests. This is in contrast to a total of 44 tests that would be generated by the W-method. (See Exercises 5.16 and 5.17.)



5.8 The UIO-Sequence Method
The W-method uses the characterization set W of distinguishing sequences as the basis to generate a test set for an IUT. The tests so generated are effective in revealing operation and transfer faults. However, the number of tests generated using the W-method is usually large. Several alternative methods have been proposed that generate fewer test cases. In addition, these methods are either as effective or nearly as effective as the W-method in their fault detection capability. We now introduce two such methods. A method for test generation based on unique input/output sequences is presented in this section.
5.8.1 Assumptions
The UIO method generates tests from an FSM representation of the design. All the assumptions stated in Section 5.6.1 apply to the FSM that is input to the UIO test generation procedure. In addition, it is assumed that the IUT has the same number of states as the FSM that specifies the corresponding design. Thus, any errors in the IUT are transfer and operations errors only as shown in Figure 5.12.
5.8.2 UIO sequences
A unique input/output sequence, abbreviated as UIO sequence, is a sequence of input and output pairs that distinguishes a state of an FSM from the remaining states. Consider FSM Μ = (Χ, Y, Q, q0, δ, O). A UIO sequence of length k for some state s ϵ Q is denoted as UIO(s) and looks like the following sequence
A Unique Input/Output (UIO) sequence is a sequence of input/output pairs that are unique for each state in an FSM. Such a sequence might not exist.
UIO(s) = i1/o1 · i2/o2 · . . . i(k−1)/o(k−1) · ik/ok.
In the sequence given above, each pair a/b consists of an input symbol a that belongs to the input alphabet X and an output symbol b that belongs to the output alphabet Y. As before, the dot symbol (·) denotes string concatenation. We refer to the input portion of a UIO(s) as in(UIO(s)) and to its output portion as out(UIO(s)). Using this notation for the input and output portions of UIO(s), we can rewrite UIO(s) as
in(UIO(s)) = i1 · i2 · . . . i(k–1) · ik, and out(UIO(s)) = ο1 · ο2·… o(k–1) · ok.
When the sequence of input symbols that belong to in(UIO(s)) is applied to Μ in state s, the machine moves to some state t and generates the output sequence out(UIO(s)). This can be stated more precisely as follows,
δ(s, in(UIO(s)) = t, O(s, in(UIO(s))) = out(UIO(s)).
There is one UIO sequence for each state s in an FSM. The existence of such a sequence is not guaranteed.
A formal definition of unique input/output sequences follows. Given an FSM Μ = (X, Y, Q, q0, δ, O), the unique input/output sequence for state s ∈ Q, denoted as UIO(s), is a sequence of one or more edge labels such that the following condition holds.
O(s, in(UIO(s))) ≠ O(t, in(UIO(s))), for all t ∈ Q, t ≠ s.
The next example offers UIO sequences for a few FSMs. The example also shows that there may not exist any UIO sequence for one or more states in an FSM.
Example 5.19 Consider machine M1 shown in Figure 5.18. The UIO sequence for each of the six states in M1 is given below.
Using the definition of UIO sequences, it is easy to check whether or not a UIO(s) for some state s is indeed a unique input/output sequence. However, before we perform such a check, we assume that the machine generates an empty string as the output if there does not exist an outgoing edge from a state on some input. For example, in Machine M1 there is no outgoing edge from state q1 for input c. Thus, M1 generates an empty string when it encounters a c in state q1. This behavior is explained in Section 5.8.3.
Figure 5.18 Two FSMs used in Example 5.19. There is a UIO sequence for each state in Machine M1. There is no UIO sequence for state q1 in Machine M2.
State (s) UIO (s) q1
a/0 · c/1
q2
c/1· c/1
q3
b/1· b/1
q4
b/1· c/0
q5
c/0
q6
c/1· a/0
Let us now perform two sample checks. From the table above we have UIO(q1) = a/0 · c/1. Thus, in(UIO(q1) = ac, out(UIO(q1)) = 01. Applying the sequence a · c to state q2 produces the output sequence 0 which is different from 01 generated when a · c is applied to M1 in state q1. Similarly, applying ac to Machine M1 in state q5 generates the output pattern 0 which is, as before, different from that generated by q1. You may now perform all other checks to ensure that indeed the UIOs given above are correct.
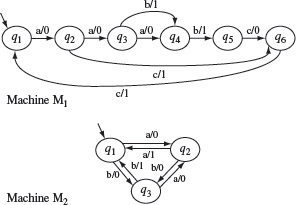
Example 5.20 Now consider Machine M2 in Figure 5.18. The UIO sequences for all states, except state q1, are listed below. Notice that there does not exist any UIO sequence for state q1.
State (s) UIO (s) q1
None
q2
a/1
q3
b/1
5.8.3 Core and non-core behavior
An FSM must satisfy certain constraints before it is used for constructing UIO sequences. First there is the “connected assumption” which implies that every state in the FSM is reachable from its initial state. The second assumption is that the machine can be applied a reset input in any state that brings it to its start state. As has been explained earlier, a null output is generated upon the application of a reset input.
An FSM must be connected for the UIO sequence method to be applicable.
The third assumption is known as the completeness assumption. According to this assumption, an FSM remains in its current state upon the receipt of any input for which the state transition function δ is not specified. Such an input is known as a non-core input. In this situation, the machine generates a null output. The completeness assumption implies that each state contains a self-loop that generates a null output upon the receipt of an unspecified input. The fourth assumption is that the FSM must be minimal. A machine that depicts only the core behavior of an FSM is referred to as its core-FSM. The following example illustrates the core behavior.
An FSM is assumed to remain in its current state and generate a null output when a transition on an input is not specified. Such an input is considered as non-core.
Example 5.21 Consider the FSM in Figure 5.19(a) that is similar to the one in Figure 5.13. Note that states q1, q4, and q5 have no transitions corresponding to inputs a, b, and b, respectively. Thus, this machine does not satisfy the completeness assumption.
As shown in Figure 5.19(b), additional edges are added to this machine in states q1, q4, and q5. These edges represent transitions that generate null output. Such transitions are also known as erroneous transitions. Figure 5.19(a) shows the core behavior corresponding to the machine in Figure 5.19(b).
While determining the UIO sequences for a machine, only the core behavior is considered. The UIO sequences for all states of the machine shown in Figure 5.19(a) are given below.
State (s) UIO (s) q1
b/1· a/1/· b/1· b/1
q2
a/0· b/1
q3
b/1· b/1
q4
a/1· b/1· b/1
q5
a/1· a/0· b/1
Note that the core behavior exhibited in Figure 5.19 is different from that in the original design in Figure 5.13. Self-loops that generate a null output, are generally not shown in a state diagram that depicts the core behavior. The impact of removing self-loops, that generate a non-null output, on the fault detection capability of the UIO method will be discussed in Section 5.8.9. In Figure 5.19, the set of core edges is {(q1, q4), (q2, q1), (q2, q5), (q3, q1), (q3, q5), (q4, q3), (q5, q2), (q1, q1), (q2, q2), (q3, q3), (q4, q4), (q5, q5)}.
Figure 5.19 (a) An incomplete FSM. (b) Addition of null transitions to satisfy the completeness assumption.
The core-behavior of an FSM does not include self loops that generate null outputs.
During a test, one wishes to determine if the IUT behaves in accordance with its specification. An IUT is said to conform strongly to its specification if it generates the same output as its specification for all inputs. An IUT is said to conform weakly to its specification if it generates the same output as that generated by the corresponding core-FSM.
Example 5.22 Consider an IUT that is to be tested against its specification Μ as in Figure 5.13. Suppose that the IUT is started in state q1 and the one symbol sequence a is input to it and the IUT outputs a null sequence, i.e. the IUT does not generate any output. In this case, the IUT does not conform strongly to M. However, on input a, this is exactly the behavior of the core-FSM. Thus, if the IUT behaves exactly as the core-FSM shown in Figure 5.19(a), then it conforms weakly to M.
5.8.4 Generation of UIO sequences
The UIO sequences are essential to the UIO-sequence method for generating tests from a given FSM. In this section, we present an algorithm for generating the UIO sequences. As mentioned earlier, a UIO sequence might not exist for one or more states in an FSM. In such a situation, a signature is used instead. An algorithm for generating UIO sequences for all states of a given FSM follows.
When a UIO sequence does not exist for some state s, another string known as its signature, is determined.
Procedure for generating UIO sequences
|
Input: |
(a) An FSM M = (X, Y, Q, q0, δ, O) where |Q| = n. (b) State s ∈ Q. |
|
Output: |
UIO(s) contains a unique input/output sequence for state s; UIO(s) is empty if no such sequence exists. |
|
Procedure: |
gen-UIO(S) |
|
/* |
Set(l) denotes the set of all edges with label l. |
|
|
label(e) denotes the label of edge e. |
|
|
A label is of the kind a/b where a ∈ X and b ∈ Y. |
|
|
head(e) and tail(e) denote, respectively, the head and tail states of edge e. */ |
|
Step 1 |
For each distinct edge label el in the FSM, compute Set(el). |
|
Step 2 |
Compute the set Oedges(s) of all outgoing edges for state s. Let NE = |Oedges|. |
|
Step 3 |
For 1 ≤ i ≤ NE and each edge ei ∈ Oedges, compute Oled[i], Opattern[i], and Oend[i] as follows: |
3.1 |
Oled[i] = Set(label(ei)) − {ei}. |
3.2 |
Opattern[i] = label(ei). |
3.3 |
Oend[i] = tail(ei). |
|
Step 4 |
Apply algorithm gen-1-uio(s) to determine if UIO(s) consists of only one label. |
|
Step 5 |
If simple UIO sequence found then return UIO(s) and terminate this algorithm, otherwise proceed to the next step. |
|
Step 6 |
Apply the gen-long-uio(s) procedure to generate longer UIO(s). |
|
Step 7 |
If longer UIO sequence found then return UIO(s) and terminate this algorithm, else return with an empty UIO(s) |
End of procedure gen-uio.
Procedure gen-1-uio
|
Input: |
State s ∈ Q. |
|
Output: |
UIO(s) of length 1 if it exists, an empty string otherwise. |
|
Procedure: |
gen-1-UIO (State S): |
|
Step 1 |
If Oled[i] = Ø for 1 ≤ i ≤ NE then return UIO(s) = label(ei) otherwise return UIO(s) = "". |
End of procedure gen-1-uio
Procedure for generating longer UIO sequences
|
Input: |
(a) Oedges, Opattern, Oend, and Oled as computed in gen-uio. |
|
|
(b) State s ∈ Q. |
|
Output: |
UIO(s) contains a unique input/output sequence for state s and is empty if no such sequence exists. |
|
Procedure: |
gen-long-uio (State s) |
|
Step 1 |
Let L denote the length of the UIO sequence being examined. Set L = 1. Let Oedges denote the set of outgoing edges from some state under consideration. |
|
Step 2 |
Repeat steps below while L < 2n2 or the procedure is terminated prematurely. |
2.1 |
Set L = L + 1 and k = 0. Counter k denotes the number of distinct patterns examined as candidates for UIO(s). The following steps attempt to find a UIO(s) of size L. |
2.2 |
Repeat steps below for i = 1 to NE. Index i is used to select an element of Oend to be examined next. Note that Oend[i] is the tail state of the pattern in Opattern[i]. |
|
2.2.1 |
Let Tedges(t) denote the set of incoming edges to state t. Compute Tedges(Oend[i]). |
|
2.2.2 |
For each edge te ∈ Tedges execute gen-L-UIO(te) until either all edges in Tedges have been considered or a UIO(s) is found. |
2.3 |
Prepare for the next iteration. Set k = NE. For 1 ≤ j ≤ k, set Opattern[j] = Pattern[j], Oend[j] = End[j], and Oled[j] = Led[j]. If the loop termination condition is not satisfied, then go back to Step 2.1 and search for UIO of the next higher length, else return to gen-uio indicating a failure to find any UIO for state s. |
End of procedure gen-long-uio
Procedure for generating UIO sequences of length L>1.
|
Input: |
Edge te from procedure gen-long-UIO . |
|
Output: |
UIO(s) contains a unique input/output sequence of length L for state s and is empty if no such sequence exists. |
|
Procedure: |
gen-L-uio ( edge te) |
|
Step 1 |
k = k + 1, Pattern[k] = Opattarn[k] · label(te). This could be a possible UIO. |
|
Step 2 |
End[k] = tail(te) and Led[k] = Ø. |
|
For each pair oe ∈ Oled[i], where h = head(oe) and t = tail(oe), repeat the next step. |
|
3.1 |
Execute the next step for each edge o ∈ Oedges(t). |
|
3.1.1 |
If label(o) = label(te) then Led[k] = Led[k]∪{(head(oe), tail(o))}. |
|
Step 4 |
If Led[k] = Ø, then UIO of length L has been found. Set UIO(s) = Pattern[k] and terminate this and all procedures up until the main procedure for finding UIO for a state. If Led[k] ≠ Ø, then no UIO of length L has been found corresponding to edge te. Return to the caller to make further attempts. |
End of Procedure gen-L-uio
5.8.5 Explanation of gen-uio
The idea underlying the generation of a UIO sequence for state s can be explained as follows. Let M be the FSM under consideration and s a state in M for which a UIO is to be found. Let E(s) = e1e2 . . . ek be a sequence of edges in M such that s = head(e1), tail(ei) = head(ei+1), and 1 ≤ i < k.
The gen-uio algorithm uses the gen-1-uio algorithm to generate a UIO of length 1. If such a UIO does not exist then it uses the gen-long-uio algorithm in an attempt to generate a longer UIO sequence. When a longer UIO sequence is not found, the algorithm terminates with an empty sequence.
For E(s), we define a string of edge labels as label(E(s)) = l1 · l2 · . . . lk−1 · lk, where li = label(ei), 1 ≤ i ≤ k, is the label of edge ei. For a given integer l > 0, we find if there is a sequence E(s) of edges starting from s such that label(E(s)) ≠ label(E(t)), s ≠ t for all states t in M. If there is such an E(s), then label(E(s)) is a UIO for state s. The uniqueness check is performed on E(s) starting with l = 1 and continuing for l = 2, 3, ... until a UIO is found or l = 2n2, where n is the number of states in M. Note that there can be multiple UIOs for a given state though the algorithm generates only one UIO, if it exists.
The gen-uio algorithm is explained with reference to Figure 5.20. Algorithm gen-uio for state s begins with the computation of some sets used in the subsequent steps. First, the algorithm computes Set(el) for all distinct labels el in the FSM. Set(el) is the set of all edges that have el as their label.
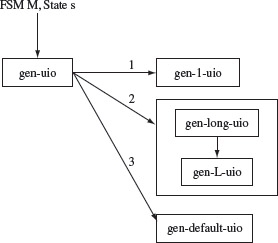
Figure 5.20 Flow of control across various procedures in gen-uio.
Next, the algorithm computes the set Oedges(s) which is the set of outgoing edges from state s. For each edge e in Oedges(s), the set Oled[e] is computed. Oled[e] contains all edges in Set(label(e)) except for the edge e. The tail state of reach edge in Oedges is saved in Oend[e]. The use of Oled will become clear later in Example 5.27.
Example 5.23 To find UIO(q1) for machine M1 in Figure 5.18, Set, Oedges and Oled are computed as follows.
Distinct labels in M1 = {a/0, b/1, c/0, c/1}
Set(a/0) = {(1, 2), (2, 3), (3, 4)a/0}
Set(b/1) = {(3, 4), (4, 5)}
Set(c/0) = {(5, 6)}
Set(c/1) = {(2, 6), (6, 1)}
Oedges(q) = {(1, 2)}, NE = 1
Oled[1] = {(2, 3), (3, 4)a/0}
Oend[1] = q2
Opattern[1] = a/0
Next, gen-1-uio is called in an attempt to generate a UIO of length 1. For each edge ei ∈ Oedges, gen-1-uio initializes Opattern[i] to label(ei) and Oend[i] to tail(ei). Opattern and Oend are used subsequently by gen-uio in case a UIO of length 1 is not found. gen-1-uio now checks if the label of any of the outgoing edges from s is unique. This is done by checking if Oled[i] is empty for any ei ∈ Oedges(s). Upon return from gen-1-uio, gen-uio terminates if a UIO of length 1 was found, otherwise it invokes gen-long-uio in an attempt to find a UIO of length greater than 1. gen-longer-uio attempts to find UIO of length L > 1 until it finds one, or L = 2n2.
Example 5.24 As an example of a UIO of length 1, consider state q5 in Machine M1 in Figure 5.18. The set of outgoing edges for state q5 is {(5, 6)}. The label of {(5, 6)} is c/0. Thus, from gen-uio and gen-1-uio, we get Oedges(q5) = {(5, 6)}, Oled[1] = Ø, Oen[1] = q6, and Opattern[1] = label(e1) = c/0. As Oled[1] = Ø, state q5 has a UIO of length 1 which is Opattern[1], i.e. c/0.
Example 5.25 As an example of a state for which a UIO of length 1 does not exist, consider state q3 in Machine M1 shown in Figure 5.18. For this state, we get the following sets:
Oedges(q3) = {(3, 4)a/0, (3, 4)b/1}, NE = 2
Oled[1] = {(1, 2), (2, 3)}, Oled[2] = {(4, 5)}
Opattern[1] = a/0, Opattern[2] = b/1
Oend[1] = q4, Oend[2] = q4
Opattern[1] = a/0, Opattern[2] = b/1
As no element of Oled is empty, gen-1-uio concludes that state q3 has no UIO of length 1 and returns to gen-uio.
In the event gen-1-uio fails, procedure gen-long-uio is invoked. The task of gen-long-uio is to check if a UIO(s) of length two or more exists. To do so, it collaborates with its descendent gen-L-uio. An incremental approach is used where UIOs of increasing length, starting at two, are examined until either a UIO is found or one is unlikely to be found, i.e. a maximum length pattern has been examined.
To check if there is UIO of length L, gen-long-uio computes the set Tedges(t) for each edge e ∈ Oedges(s), where t = tail(e). For L = 2, Tedges(t) will be a set of edges outgoing from the tail state t of one of the edges of state s. However, in general, Tedges(t) will be the set of edges going out of a tail state of some edge outgoing from state s′, where s′ is a successor of s. After initializing Tedges, gen-L-uio is invoked iteratively for each element of Tedges(t). The task of gen-L-uio is to find whether or not there exists a UIO of length L.
Example 5.26 There is no UIO(q1) of length one. Hence gen-long-uio is invoked. It begins by attempting to find a UIO of length two, i.e. L = 2. From gen-uio, we have Oedges(q1) = {(1, 2)}. For the lone edge in Oedges, we get t = tail((1, 2)) = q2. Hence Tedges(q2), which is the set of edges out of state q2, is computed as follows:
The gen-long-uio procedure is invoked when there is no UIO sequence of length 1.
gen-L-uio is now invoked first with edge (2, 3) as input to determine if there is a UIO of length two. If this attempt fails, then gen-L-uio is invoked with edge (2, 6) as input.
To determine if there exists a UIO of length L corresponding to an edge in Tedges, gen-L-uio initializes Pattern[k] by catenating the label of edge te to Opattern[k]. Recall that Opattern[k] is of length (L – 1) and has been rejected as a possible UIO(s). Pattern[k] is of length L and is a candidate for UIO(s). Next, the tail of te is saved in End[k]. Here, k serves as a running counter of the number of patterns of length L examined.
Next, for each element of Oled[i], gen-L-uio attempts to determine if indeed Pattern[k] is a UIO(s). To understand this procedure, suppose that oe is an edge in Oled[i]. Recall that edge oe has the same label as the edge ei and that ei is not in Oled[i]. Let t be the tail state of oe and Oedges(t) the set of all outgoing edges from state t. Then, Led[k] is the set of all pairs (head(oe), tail(oe)) such that label(te) = label(oe) for all ο ∈ Oedges(t).
Note that an element of Led[k] is not an edge in the FSM. If Led[k] is empty after having completed the nested loops in Step 3, then Pattern[k] is indeed a UIO(s). In this case, the gen-uio procedure is terminated and Pattern[te] is the desired UIO. If Led[k] is not empty, then gen-L-uio returns to the caller for further attempts at finding UIO(s).
Example 5.27 Continuing Example 5.26, suppose that gen-L-uio is invoked with i = 1 and te = (2, 3). The goal of gen-L-uio is to determine if there is a path of length L starting from state head(te) that has its label same as Opattern[i] · label(te).
Pattern[i] is set to a/0 · a/0 because Opattern[i] = a/0 and label((2, 3)) = a/0. End[i] is set to tail(2, 3) which is q3. The outer loop in Step 3 examines each element oe of Oled[1]. Let oe = (2, 3) for which we get h = q2 and t = q3. The set Oedges(q3) = {(3, 4)a/0, (3, 4)b/1)}. Step 3.1 now iterates over the two elements of OutEedges(q3) and updates Led[i]. At the end of this loop, we have Led[i] = {(2, 4)} because label((3, 4)a/0) = label((2, 3)).
Continuing with the iteration over Oled[1], oe is set to (3, 4)a/0 for which h = q2 and t = q4. The set Oedges(q4) = {(4, 5)}. Iterating over Oedges(q4) does not alter Led[i] because label((4, 5)) ≠ label((3, 4)a/0).
The outer loop in Step 3 is now terminated. In the next step, i.e. Step 4, Pattern[i] is rejected and gen-L-uio returns to gen-long-uio.
Upon return from gen-L-uio, gen-long-uio once again invokes it with i = 1 and te = (2, 6). Led[2] is determined during this call. To do so, Pattern[2] is initialized to a/0 · c/1 because Opattern[i] = a/0 and label(2, 6) = c/1, and End[2] to q6.
Once again, the procedure iterates over elements oe of Oled. For oe = (2, 3), we have as before, Oedges(q3) = {(3, 4)a/0, (3, 4)b/1}. Step 3.1 now iterates over the two elements of Oedges(q3). In Step 1, none of the checks is successful as label((2, 6)) is not equal to label((3, 4)a/0) or to label((4, 5)). The outer loop in Step 3 is now terminated. In the next step, i.e. Step 4, Pattern[2] is accepted as UIO(q1).
It important to note that Led[i] does not contain edges. Instead, it contains one or more pairs of states, (s1, s2) such that a path in the FSM from state s1 to state s2 has the same label as Pattern[i]. Thus, at the end of the loop in Step 3 of gen-L-uio, an empty Led[i] implies that there is no path of length L from head(te) to tail(te) with a label same as Pattern[i].
A call to gen-long-uio either terminates the gen-uio algorithm abruptly indicating that UIO(s) has been found, or returns normally indicating that UIO(s) is not found, and any remaining iterations should now be carried out. Upon a normal return from gen-L-uio, the execution of gen-long-uio resumes at Step 2.3. In this step, the existing Pattern, Led, and End data is transferred to Opattern, Oled, and Οend, respectively. This is done in preparation for the next iteration to determine if there exists a UIO of length (L + 1). In case a higher length sequence remains to be examined, the execution resumes from Step 2.2, else the gen-long-uio terminates without having determined a UIO(s).
Example 5.28 Consider M2 in Figure 5.18. We invoke gen-uio(q1) to find a UIO for state q1. As required in Steps 1 and 2, we compute Set for each distinct label and the set of outgoing edges Oedges(q1).
Distinct labels in M2 = {a/0, a/1, b/0, b/1}
Set(a/0) = {(1, 2), (3, 2)}
Set(a/1) = {(2, 1)}
Set(b/0) = {(1, 3), (2, 3)}
Set(b/1) = {(3, 1)}
NE = 2
Next, as directed in Step 3, we compute Oled and Οend for each edge in Oedges(q1). The edges in Oedges are numbered sequentially so that edge (1, 2) is numbered 1 and edge (1, 3) is numbered 2.
Oled[1] = {(3, 2)}
Oled[2] = {(2, 3)}
Oend[1] = q2
Oend[2] = q3
Opattern[1] = a/0
Opattern[2] = b/0
gen-1-uio(q1) is now invoked. As Oled[1] and Oled[2] are nonempty, gen-1-uio fails to find a UIO of length one and returns. We now move to Step 6 where procedure gen-long-uio is invoked. It begins by attempting to check if a UIO of length two exists. Towards this goal, the set Tedges is computed for each edge in Oedges at Step 2.2.1 of gen-long-uio. First, for i = 1, we have Oled[1] = (3, 2) whose tail is state q2. Thus, we obtain Tedges(q2) = {((2, 3), (2, 1)}.
The loop for iterating over the elements of Tedges begins at Step 2.2.2. Let te = (2, 3). gen-L-uio is invoked with te as input and the value of index i as 1. Inside gen-L-uio, k is incremented to 1 indicating that the first pattern of length two is to be examined. Pattern[1] is set to a/0 · b/0, End[1] to 3, and Led[1] initialized to the empty set.
The loop for iterating over the two elements of Oled begins at Step 3. Let oe = (3, 2) for which h = 3, t = 2, and Oedges(2) = {(2, 1), (2, 3)}. We now iterate over the elements of Oedges as indicated in Step 3.1. Let ο = (2, 1). As labels of (2, 1) and (2, 3) do not match, Led[1] remains unchanged. Next, ο = (2, 3). This time we compare labels of ο and te, which are the same edges. Hence, the two labels are the same. As directed in Step 3.1.1, we set Led[1] = (head(oe), tail(o)) = (3, 3). This terminates the iteration over Oedges. This also terminates the iteration over Oled as it contains only one element.
In Step 4, we find that Led[1] is not empty and therefore reject Pattern[1] as a UIO for state q1. Notice that Led[1] contains a pair (3, 3) which implies that there is a path from state q3 to q3 with the label identical to that in Pattern[1]. A quick look at the state diagram of M2 in Figure 5.18 reveals that indeed the path q3 → q2 → q3 has the label a/0 · b/0 which is the same as in Pattern[1].
Control now returns to Step 2.2.2 in gen-long-uio. The next iteration over Tedges(q2) is initiated with te = (2, 1). gen-L-uio is invoked once again but this time with index i = 1 and te = (2, 1). The next pattern of length two to be examined is Pattern[2] = a/0 · a/1. We now have End[2] = 1 and Led[2] = Ø. Iteration over elements of Oled[1] begins. Once again let oe = (3, 2) for which h = 3, t = 2, and Oedges(2) = {(2, 1), (2, 3)}. Iterating over the two elements of Oeges we find that the label of te matches that of edge (2, 1) and not of edge (2, 3). Hence, we get Led[2] = (head(oe), tail(2, 1)) = (3, 1) implying that Pattern[2] is the same as the label of the path from state q3 to state q1. The loop over Oled also terminates and control returns to gen-long-uio.
In gen-long-uio, the iteration over Tedges now terminates as we have examined both edges in Tedges. This also completes the iteration for i = 1 which corresponds to the first outgoing edge of state q1. We now repeat Step 2.2.2 for i = 2. In this iteration, the second outgoing edge of state q1, i.e. edge (1, 3), is considered. Without going into the fine details of each step, we leave it to you to verify that at the end of the iteration for i = 2, we get the following.
Pattern[3] = b/0 · a/0
Pattern[4] = b/0 · b/1
End[3] = 2
End[4] = 1
Led[3] = (2, 2)
Led[4] = (2, 1)
This completes the iteration set up in Step 2.2. We now move to Step 3. This step leads to the following values of Opattern, Oled, and Oend.
Opattern[1] = Pattern[1] = a/0 · b/0
Opattern[2] = Pattern[2] = a/0 · a/1
Opattern[3] = Pattern[3] = b/0 · a/0
Opattern[4] = Pattern[4] = b/0 · b/1
Oend[1] = End[1] = 3
Oend[2] = End[2] = 1
Oend[3] = End[3] = 2
Oend[4] = End[4] = 1
Oled[1] = Led[1] = (3, 3)
Oled[2] = Led[2] = (3, 1)
OIed[4] = Led[4] = (2, 1)
The while-loop continues with the new values of Opattern, Οend, and Oled. During this iteration L = 3 and hence patterns of length three will be examined as candidates for UIO(q1). The patterns to be examined next will have at least one pattern in Opattern as its prefix. For example, one of the patterns examined for i = 1 is a/0 · b/0 · a/0.
The gen-L-uio procedure is invoked first with e = (1, 2) and te = (2, 3) in Step 2.2.2. It begins with Pattern[1] = a/0 · b/0 and End[1] = 3.
Example 5.29 This example illustrates the workings of procedure gen-uio(s) by tracing through the algorithm for Machine M1 in Figure 5.18. The complete set of UIO sequences for this machine is given in Example 5.19. In this example, we sequence through gen-uio(s) for s = q1. The trace follows.
Input : State q1
Step 1
Find the set of edges for each distinct label in M1. There are four distinct labels in M1, namely a/0, b/1, c/0, and c/1. The set of edges for each of these four labels is given below.
Set(a/0) = {(1, 2), (2, 3), (3, 4)}
Set(b/1) = {(3, 4), (4, 5)}
Set(c/0) = {(5, 6)}
Set(c/1) = {(2, 6), (6, 1)}
Step 2
It is easily seen from the state transition function of M1 that the set of outgoing edges from state q1 is {(1,2)}. Thus, we obtain Oedges(q1) = {(1, 2)} and NE = 1.
Step 3
For each edge in Oedges, we compute Oled, Opattern, and Oend.
Oled[1] = {(1, 2), (2, 3), (3, 4)a/0} – {(1, 2)} = {(2, 3), (3, 4)a/0}.
Opattern[1] = label((1, 2)) = a/0, and
Oend[1] = tail((1, 2)) = 2.
Step 4
Procedure gen-1-UIO is invoked with state q1 as input. In this step, an attempt is made to determine if there exists a UIO sequence of length 1 for state q1.
gen-1-UIO
Input : State q1
Step 1
Now check if any element of Oled contains only one edge. From the computation done earlier, note that there is only one element in Oled, and that this element, Oled[1], contains two edges.
Hence, there is no UIO(q1) with only a single label. The gen-1-UIO procedure is now terminated and the control returns to gen-UIO.
gen-uio
Input : State q1
Step 5
Determine if a simple UIO sequence was found. As it has not been found, move to the next step.
Step 6
Procedure gen-long-UIO is invoked in an attempt to generate a longer UIO(q1).
gen-long-UIO
Input : State q1
Step 1
L = 1.
Step 2
Start a loop to determine if a UIO(q1) of length greater than 1 exists. This loop terminates when a UIO is found or when L = 2n2, which for a machine with n = 6 states translates to L = 72. Currently, L is less than 72 and hence continue with the next step in this procedure.
Step 2.1
L = 2 and k = 0.
Step 2.2
Start another loop to iterate over the edges in Oedges. Set i = 1 and ei = (1, 2).
Step 2.2.1
t = tail((1, 2)) = 2. Tedges(2) = {(2, 3), (2, 6)}.
Step 2.2.2
Yet another loop begins at this point. Loop over the elements of Tedges. First set te = (2, 3) and invoke gen-L-UIO.
gen-L-UIO
Input : te = (2, 3)
Step 1
k = 1, Pattern[1] = Opattern[1] · label((2, 3)) = a/0 · a/0.
Step 2
End[1] = 3, Led[1] = Ø.
Step 3
Now iterate over elements of Oled[1] = {(2, 3), (3, 4)a/0}. First select oe = (2, 3) for which h = 2 and t = 3.
Step 3.1
Another loop is set up to iterate over elements of Oedges(q3) = {(3, 4)a/0, (3, 4)b/1}. Select o = (3, 4)a/0.
Step 3.1.1
As label((3, 4)a/0) = label((2, 3)), set Led[1] = {(2, 4)}.
Next select o = (3, 4)b/1 and execute Step 3.1.1.
Step 3.1.1
As label((2, 3)) ≠ label((3, 4)b/1), no change is made to Led[1].
The iteration over Oedges terminates.
Next, continue from Step 3.1 with oe = (3, 4)a/0 for which h = 3 and t = 4.
Step 3.1
Another loop is set up to iterate over elements of Oedges(4) = {(4, 5)}, select o = (4, 5).
Step 3.1.1
As label((4, 5)) ≠ label((3, 4)a/0) no change is made to Led[1].
The iterations over Oedges and Oled[1] terminate.
Step 4
Led[1] is not empty which implies that this attempt to find a UIO(q1) has failed. Note that in this attempt the algorithm checked if a/0 · a/0 is a valid UIO(q1). Now return to the caller.
gen-long-UIO
Input : State q1
Step 2.2.2
Select another element of Tedges and invoke gen-L-UIO (e, te). For this iteration te = (2, 6).
gen-L-UIO
Input : te = (2, 6)
Step 1
k = 2, Pattern[2] = Opattern[1] · label((2, 6)) = a/0 · c/1.
Step 2
End[2] = 6, Led[2] = Ø.
Step 3
Iterate over elements of Oled[1] = {(2, 3), (3, 4)a/0}. First select oe = (2, 3) for which h = 2 and t = 3.
Step 3.1
Another loop is set up to iterate over elements of Oedges(3) = {(3, 4)a/0, (3, 4)b/1}, select o = (3, 4)a/0.
Step 3.1.1
As label((3, 4)a/0) ≠ label((2, 6)), do not change Led[2].
Next select o = (3, 4)b/1 and once again execute Step 3.1.1.
Step 3.1.1
As label((2, 6)) ≠ label((3, 4)b/1), do not change Led[2]. The iteration over Oedges terminates.
Next continue from Step 3.1 with oe = (3, 4)a/0 for which h = 3 and t = 4.
Step 3.1
Another loop is set up to iterate over elements of Oedges(4) = {(4, 5)}, select o = (4, 5).
Step 3.1.1
As label((4, 5) ≠ label((2, 6)) no change is made to Led[2].
The iterations over Oedges and Oled[2] terminate.
Step 4
Led[2] is empty. Hence UIO(q1) = Pattern[2] = a/0 · c/1. A UIO of length 2 for state q1 is found and hence the algorithm terminates.
5.8.6 Distinguishing signatures
As mentioned earlier, the gen-uio procedure might return an empty UIO(s) indicating that it failed to find a UIO for state s. In this case, we compute a signature that distinguishes s from other states one by one. We use Sig(s) to denote a signature of state s. Before we show the computation of such a signature, we need some definitions. Let W(qi, qj), i ≠ j be a sequence of edge labels that distinguishes states qi and qj. Note that W(qi, qj) is similar to the distinguishing sequence W for qi and qj except that we are now using edge labels of the kind a/b, where a is an input symbol and b an output symbol, instead of using only the input symbols.
A distinguishing sequence, or a signature, of state s is a sequence of input/output labels that are unique to s. In a sense this is a UIO sequence for s but computed using a different procedure than gen-uio.
Example 5.30 A quick inspection of M2 in Figure 5.18 reveals the following distinguishing sequences.
W(q1, q2) = a/0
W(q1, q3) = b/0
W(q2, q3) = b/0
To check if indeed the above are correct distinguishing sequences, consider states q1 and q2. From the state transition function of M2, we get O(q1, a) = 0 ≠ O(q2, a). Similarly, O(q1, b) = 0 ≠ O(q3, b), O(q2, a) ≠ O(q3, a) and O(q2, b) ≠ O(q3, b). For a machine more complex than M2, one can find W(qi, qj) for all pairs of states qi and qj using the algorithm in Section 5.5 and using edge labels in the sequence instead of the input symbols.
We use Pi(j) to denote a sequence of edge labels along the shortest path from state qj to qi. Pi(j) is known as a transfer sequence for state qj to move the machine to state qi. When the inputs along the edge labels of Pi(j) are applied to a machine in state qj, the machine moves to state qi. For i = j, the null sequence is the transfer sequence. As we see later, Pi(j) is used to derive a signature when the gen-uio algorithm fails.
A transfer sequence for a pair of states (r, s) is a sequence of edge labels that correspond to the shortest path from state s to state r.
Example 5.31 For M2, we have the following transfer sequences.
P1(q2) = a/1
P1(q3) = b/1
P2(q1) = a/0
P2(q3) = a/0
P3(q1) = b/0
P3(q2) = b/0
For M1 in Figure 5.18, we get the following subset of transfer sequences (you may derive the others by inspecting the transition function of M1).
P1(q5) = c/0 · c/1
P5(q2) = a/0 · a/0 · b/1 or P5(2) = a/0 · b/1 · b/1
P6(q1) = a/0 · c/1
A transfer sequence Pi(j) can be found by finding the shortest path from state qj to qi and catenating in order the labels of the edges along this path.
To understand how the signature is computed, suppose that gen-uio fails to find a UIO for some state qi ∈ Q where Q is the set of n states in machine Μ under consideration. The signature for s consists of two parts. The first part of the sequence is W(qi, q1) which distinguishes qi from q1.
Now suppose that the application of sequence W(qi, q1) to state qi takes the machine to some state t1. The second part of the signature for qi consists of pairs Pi(tk) · W(qi, qk+1) for 1 ≤ k < n. Notice that the second part can be further split into two sequences.
The first sequence, Pi(tk), transfers the machine from tk back to qi. The second sequence, W(qi, qk+1), applies a sequence that distinguishes qi from state qk+1. Thus, in essence, the signature makes use of the sequences that distinguish qi from all other states in the machine and the transfer sequences that move the machine back to state qi prior to applying another distinguishing sequence. Given that q1 ∈ Q is the starting state of M, a compact definition of the signature for state qi ∈ Q follows.
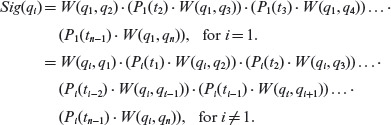
Example 5.32 We have seen earlier that gen-long-uio fails to generate a UIO sequence for state q1 in M2 shown in Figure 5.18. Let us therefore apply the method described above for the construction of a signature for state q1. The desired signature can be found by substituting the appropriate values in the following formula.
Sig(q1) = W(q1, q2) · (P1(t1) · W(q1, q3))
From Example 5.30, we have the following distinguishing sequences for state q1.
W(q1, q2) = a/0
W(q1, q3) = b/0
The application of W(q1, q2) to state q1 takes M2 to state q2. Hence we need the transfer sequence P1(q2) to bring M2 back to state q1. From Example 5.31 we get P1(q2) = a/1. Substituting these values in the formula for Sig(q1), we obtain the desired signature.
Sig(q1) = a/0 · a/1 · b/0
Later, while deriving test cases from UIO of different states, we will use signatures for states that do not possess a UIO.
5.8.7 Test generation
Let Μ = (X, Y, Q, q1, δ, O) be an FSM from which we need to generate tests to test an implementation for conformance. Let Ε denote the set of core edges in M. m is the total number of core edges in M. Recall that edges corresponding to a reset input in each state are included in E. The following procedure is used to construct a total of m tests, each corresponding to the tour of an edge.
An non-core edge in an FSM is any edge that is not a self loop that generates a null output.
- Find the UIO for each state in M.
- Find the shortest path from the initial state to each of the remaining states. As before, the shortest path from the initial state q1 to any other state qi ∈ Q is denoted by Pi(q1).
- Construct an edge tour for each edge in M. Let TE(e) denote a subsequence that generates a tour for edge e. TE(e) is constructed as follows
TE(e) = Phead(e)(1) · label(e) · UIO(tail(e)).
- This step is optional. It is used to combine the Μ test subsequences generated in the previous step into one test sequence that generates the tour of all edges. This sequence is denoted by ΤA. It is sometimes referred to as β-sequence. TA is obtained by catenating pairs of reset input and edge tour subsequences as follows
TA = Xe∈E((Re/null) · TE(e)).
TA is useful when the IUT can be brought automatically to its start state by applying an Re. In this case, the application of TA will likely shorten the time to test the IUT. While testing an IUT, the application of Re might be possible automatically through a script that sends a “kill process” signal to terminate the IUT and, upon the receipt of an acknowledgment that the process has terminated, may restart the IUT for the next test.
The next example illustrates the test generation procedure using the UIO sequences generated from M1 shown in Figure 5.18.
Example 5.33 The UIO sequences for each of the six states in M1 are reproduced below for convenience. Also included in the rightmost column are the shortest paths from state q1 to the state corresponding to the state in the leftmost column.
State(s) UIO (s) Pi(q1) q1
q2
q3
q4
q5
q6
a/0· c/1
c/1· c/1
b/1· b/1
b/1· c/0
c/0
c/1· a/0
null
a/0
a/0· a/0
a/0· a/0· a/0
a/0· a/0· a/0· b/1
a/0· c/1
We consider only the core edges while developing tests for each edge. For example, the self-loop in state q5 corresponding to inputs a and b, not shown in Figure 5.18, is ignored as it is not part of the core behavior of M1. Also note that edge (q6, q1) will be considered twice, one corresponding to the label c/0 and the other corresponding to label Re/null. Using the formula given above, we obtain the following tests for each of the 14 core edges.
Test count Edge (e) TE(e) 1
2
3
4
5
6
7
8
9
10
11
12
13
14
q1, q2
q1, q1
q2, q3
q2, q6
q2, q1
q3, q4
q3, q4
q3, q1
q4, q5
q4, q1
q5, q6
q5, q1
q6, q1
q6, q1
a/0· c/1· c/1
Re/null/· Re/null/· a/0· c/1
a/0· a/0· b/1· b/1
a/0· c/1· c/1· a/0
a/0· Re/null· a/0· c/1
a/0· a/0· a/0· b/1· c/0
a/0· a/0· b/1· b/1· c/0
a/0· a/0· Re/null· a/0· c/1
a/0· a/0· a/0· c/0
a/0· a/0· a/0· Re/null· a/0· c/1
a/0· a/0· b/1· c/0· c/1
a/0· a/0· a/0· b/1· Re/null· a/0· c/1
a/0· c/1· c/1· a/0· c/1
a/0· c/1· Re/null· a/0· c/1
The 14 tests derived above can be combined into a β-sequence and applied to the IUT. This sequence will exercise only the core edges. Thus, for example, the self-loops in state q5, corresponding to inputs a and b will not be exercised by the tests given above. It is also important to note that each TE(e) subsequence is applied with the IUT in its start state implying that a Re input is applied to the IUT prior to exercising it with the input portion of TE(e).
5.8.8 Test optimization
The set of test subsequences TE(e) can often be reduced by doing a simple optimization. For example, if TE(e1) is a subsequence of test TE(e2), then ΤΕ(e1) is redundant. This is because the edges toured by ΤΕ(e1) are also toured by TE(e2), and in the same order. Identification and elimination of subsequences that are fully contained in another subsequence generally leads to a reduction in the size of the test suite. In addition, if two tests are identical, then one of them can be removed from further consideration. (See Exercise 5.21.)
Tests generated using the UIO method can be reduced using a simple optimization Procedure.
Example 5.34 In an attempt to reduce the size of the test set derived in Example 5.33, we examine each test and check if it is contained in any of the remaining tests. We find that test 3 is fully contained in test 7, test 1 is contained in test 4, and test 4 is contained in test 13. Thus, the reduced set of tests consists of 11 tests: 2, 5, 6, 7, 8, 9, 10, 11, 12, 13, and 14 given in Example 5.33.
The tests derived in Example 5.33 are useful for a weak conformance test. To perform a strong conformance test of the IUT against the specification, we need to derive tests for non-core edges as well. The method for deriving such tests is the same as that given earlier for deriving TE(e) for the tour of edge e except that e now includes non-core edges.
Example 5.35 We continue Example 5.33for M1 and derive additional tests needed for strong conformance. To do so, we need to identify the non-core edges. There are 10 non-core edges corresponding to the six states. Figure 5.21 shows the state diagram of M1 with both core and non-core edges shown. Tests that tour the non-core edges can be generated easily using the formula for TE given earlier. The 10 tests follow.
Test count Edge (e) TE(e) 1
2
3
4
5
6
7
8
9
10
(q1, q1)b/null
(q1, q1)c/null
(q2, q2)b/null
(q3, q3)c/null
(q4, q4)a/null
(q4, q4)c/null
(q5, q5)a/null
(q5, q5)b/null
(q6, q6)a/null
(q6, q6)b/null
b/null· a/0· c/1
c/null· a/0· c/1
a/0· b/null· c/1· c/1
a/0· a/0· c/null· b/1· b/1
a/0· a/0· a/0· a/null· b/1· c/0
a/0· a/0· a/0· c/null· b/1· c/0
a/0· a/0· a/0· b/1· a/null· c/0
a/0· a/0· a/0· b/1· b/null· c/0
a/0· c/1· a/null· c/1· a/0
a/0· c/1· b/null· c/1· a/0
Figure 5.21 Machine Μ1, from Figure 5.18 with all non-core edges shown as dashed lines.
Note that a test for non-core edge e is similar to the tests for core edges in that the test first moves the machine to head(e). It then traverses the edge itself. Finally, it applies UIO(tail(e)) starting at state tail(e). Thus, in all, we have 21 tests to check for strong conformance of an IUT against M.
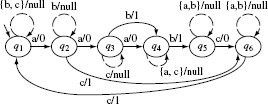
5.8.9 Fault detection
Tests generated using the UIO sequences are able to detect all operation and transfer errors. However, combination faults, such as an operation error and a transfer error might not be detectable. The next two examples illustrate the fault detection ability of the UIO method.
Tests generated using the UIO sequence method are able to detect all operation and transfer errors. However, errors that are a combination of operation and transfer errors might not be detected by such tests.
Example 5.36 Consider the transition diagram in Figure 5.22. Suppose that this diagram represents the state transitions in an IUT to be tested for strong conformance against machine M1 in Figure 5.21. The IUT has two errors. State q2 has a transfer error due to which δ(q2, c) = q5 instead of δ(q2, c) = q6. State q3 has an operation error due to which O(q3, b) is undefined.
Figure 5.22 State diagram of an IUT containing two faults. State q2 has a transfer error and q3 has an operation error. The behavior of this IUT is to be tested against that of the machine in Figure 5.21. Non-core edges are not shown.
To test the IUT against its specification as in Figure 5.21, one needs to apply the β sequence to the IUT and observe its behavior. The β sequence is obtained by combining all subsequences derived for weak and strong conformance in the earlier examples. However, as such a β sequence is too long to be presented here, we use an alternate method to show how the faults will be detected.
First, consider the transfer error in state q2. Let us apply the input portion of test 4, which is TE(q2, q6), to the IUT. We assume that the IUT is in its start state, i.e. q1, prior to the application of the test. From Example 5.33, we obtain the input portion as acca. The expected behavior of the IUT for this input is determined by tracing the behavior of the machine in Figure 5.21. Such a trace gives us O(q1, acca) = 0110. However, when the same input is applied to the IUT, we obtain O(q1, acca) = 010null.
As the IUT behaves differently than its specification, TE(q2, q6) has been able to discover the fault. Note that if test 4 has been excluded due to optimization, then test 13 can be used instead. In this case, the expected behavior is O(q1, accac) = 01101, whereas the IUT generates O(q1, accac) = 010null1 which also reveals a fault in the IUT.
Next, let us consider the operation error in state q3 along the edge (q3, q4)c/1. We use test 7. The input portion of this test is aabbc. For the specification, we have O(q1, aabbc) = 00110. Assuming that this test is applied to the IUT in its start state, we get O(q1, aabbc) = 00nullnull1 which is different from the expected output and thus test 7 has revealed the operation fault. (Also see Exercise 5.10.)
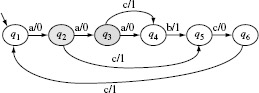
Example 5.37 Consider the specification shown in Figure 5.23(a). We want to check if tests generated using the UIO method will be able to reveal the transfer error in the IUT shown in Figure 5.23(b). UIO sequences and shortest paths from the start state to the remaining two states are given below.
State(s) UIO (s) Pi(q1) q1
q2
q3
a/1
a/0· a/1
b/1· a/1
(also a/0· a/0)
null
a/0
b/1
Figure 5.23 State diagram of an FSM for which a test sequence derived using the UIO approach does not reveal the error. (a) Specification FSM. (b) State diagram of a faulty IUT.
Given below are tests for touring each of the nine core edges including three edges that bring each state to state q1 upon reset. Notice that we have added the Re/null transition at the start of each test sequence to indicate explicitly that the machine starts in state q1 prior to the test being applied.
Edges (e) from each state to state q1, label(e) = Re/null
1
q1, q1
Re/null· Re/null· a/1
2
q2, q1
Re/null· a/1Re/null· a/1
3
q3, q1
Re/null· b/1· Re/null· a/1
Edges shown in Figure 5.23(a)
4
q1, q2
Re/null· a/1· a/0· a/1
5
q1, q3
Re/null· b/1· b/1· a/1
6
q2, q1
Re/null· a/1· a/0· a/1
7
q2, q3
Re/null· a/1· b/1· b/1· a/1
8
q3, q1
Re/null· b/1· b/1· a/1
9
q3, q2
Re/null· b/1· a/0· a/0· a/1
To test the IUT let us apply the input portion bba of test 5 that tours the edge (q1, q3). The expected output is 111. The output generated by the IUT is also 111. Hence, the tour of edge (q1, q3) fails to reveal the transfer error in state q1. However, test 9 that tours edge (q3, q2) does reveal the error because the IUT generates the output 1101, whereas the expected output is 1001, ignoring the null output. Note that tests 4 and 6 are identical and so are tests 5 and 8. Thus, an optimal test sequence for this example is the set containing tests 1, 2, 3, 4, 5, 7, and 9.
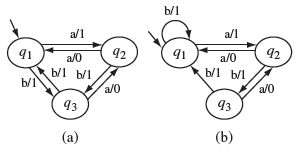
5.9 Automata Theoretic Versus Control-Flow Based Techniques
The test generation techniques described in this chapter fall under the automata theoretic category. There exist other techniques that fall under the control-flow based category. Here, we compare the fault detection effectiveness of some techniques in the two categories.
Several empirical studies have aimed at assessing the fault detection effectiveness of test sequences generated from FSMs by various test generation methods. Here we compare the fault detection effectiveness of the W and Wp-methods with four control-flow based criteria to assess the adequacy of tests. Some of the control theoretic can be applied to assess the adequacy of tests derived from FSMs against the FSM itself. In this section, we define four such criteria and show that tests derived from the W- and Wp-methods are superior in terms of their fault detection effectiveness than the four control-flow based methods considered.
Tests generated using the W- and Wp-methods guarantee the detection of all missing transitions, incorrect transitions, extra or missing states, and errors in the output associated with a transition given that the underlying assumptions listed in Section 5.6.1 hold. We show through an example that tests generated using these methods are more effective in detecting faults than the tests that are found adequate with respect to state cover, branch cover, switch cover, and the boundary interior cover test adequacy criteria. First, a few definitions before we illustrate this fact.
State cover:
A test set Τ is considered adequate with respect to the state cover criterion for an FSM Μ if the execution of Μ against each element of Τ causes each state in Μ to be visited at least once.
The state cover, transition cover, and the switch cover are control theoretic criteria for assessing the adequacy of tests generated from FSMs. The W, Wp, and the UIO methods are automata theoretic.
Transition cover:
A test set Τ is considered adequate with respect to the branch, or transition, cover criterion for an FSM Μ if the execution of Μ against each element of Τ causes each transition in Μ to be taken at least once.
Switch cover:
A test set Τ is considered adequate with respect to the 1-switch cover criterion for an FSM Μ if the execution of Μ against each element of Τ causes each pair of transitions (tr1, tr2) in Μ to be taken at least once, where for some input substring ab ∈ X*, tr1 : qi = δ(qj, a) and tr2 : qk = δ(qi, b) and qi, qj, qk are states in M.
Boundary-interior cover:
A test set Τ is considered adequate with respect to the boundary-interior cover criterion for an FSM Μ if the execution of Μ against each element of Τ causes each loop body to be traversed zero times and at least once. Exiting the loop upon arrival covers the “boundary” condition and entering it and traversing the body at least once covers the “interior” condition.
The next example illustrates weaknesses of the state cover, branch cover, switch cover, and the boundary interior cover test adequacy criteria.
Example 5.38 This example is due to T.S. Chow. Machine M1 in Figure 5.24 represents the correct design while M′1 has an operation and a transfer error in state q2. Note that M1 has two states and four transitions.
Figure 5.24 Machine M′1 contains a transfer fault with respect to machine M1 in state q2.
Consider the input sequence t = aabb. t covers all states and transitions in M1 and hence is adequate with respect to the state coverage and transition coverage criteria. We obtain δM1(ql, t) = 0111 and δM1′(ql, t) = 0100. Thus, the operation error is detected but not the transfer error.
Next, consider machine M2 in Figure 5.25 that represents correct design while M′2 has a transfer error in state q3. In order for a test set to be adequate with respect to the switch cover criterion, it must cause the following set of branch pairs to be exercised.
Figure 5.25 Machine M′2 contains a transfer fault with respect to machine M2 in state q3.
The following table lists a set of test sequences adequate with respect to the switch cover criterion but do not reveal the transfer error in state q3. The second column in the table shows the output generated and the rightmost column lists the switches covered.
Test sequence (t) OM2(q1,t)(=OM′2(q1, t)) Switches covered abbaaab
aaba
aabb
baab
bb
0111001
0110
0110
0001
01
(tr1, tr2), (tr2, tr2), (tr2, tr3),
(tr3, tr4), (tr4, tr4), (tr4, tr5)
(tr1, tr3), (tr3, tr5), (tr5, tr1)
(tr1, tr3), (tr3, tr5), (tr5, tr6)
(tr6, tr4), (tr4, tr4), (tr4, tr5)
(tr6, tr5)
A simple inspection of machine M2 in Figure 5.25 reveals that all states are 1-distinguishable, i.e. for each pair of states (qi, qj), there exists a string of length 1 that distinguishes qi from qj, 1 ≤ (i, j) ≤ 3, i ≠ j. Later we define an n-switch cover and show how to construct one that reveals all transfer and operation errors for an FSM that is n-distinguishable.
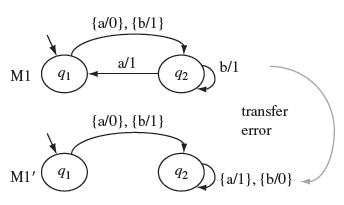
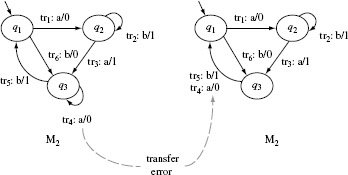
5.9.1 n-switch-cover
The switch-cover criterion can be generalized to an n-switch cover criterion as follows. An n-switch is a sequence of (n + 1) transitions. For example, for machine M3 in Figure 5.26, transition sequence tr1 is a 0-switch, tr1, tr2 is a 1-switch, tr1, tr2, tr3 is a 2-switch, and transition sequence tr6, tr5, tr1, tr3 is a 3-switch. For a given integer n > 0, we can define an n-switch set for a transition tr as the set of all n-switches with tr as the prefix. For example, for each of the six transitions in Figure 5.26, we have the following 1-switch sets.
tr1 : {(tr1, tr2), (tr1, tr3)}
tr2 : {(tr2, tr2), (tr2, tr3)}
tr3 : {(tr3, tr4), (tr3, tr5)}
tr4 : {(tr4, tr4), (tr4, tr5)}
tr5 : {(tr5, tr6), (tr5, tr1)}
tr6 : {(tr6, tr4), (tr6, tr5)}
An n-switch is a sequence of (n + 1) transitions. In test set derived for an FSM, Μ is considered to be adequate with respect to the n-switch cover criterion if it covers all n-switches in M.
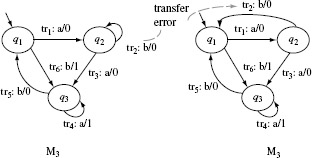
Figure 5.26 Machine M′3 contains a transfer fault with respect to machine M3 in state q2.
An n-switch set S for a transition tr in FSM Μ is considered covered by a set Τ of test sequences if exercising Μ against elements of Τ causes each transition sequence in S to be traversed. Τ is considered an n-switch set cover, if it covers all n-switch sets for FSM M. It can be shown that an n-switch set cover can detect all transfer, operation, extra, and missing state errors in a minimal FSM that is n-distinguishable (see Exercise 5.28). Given a minimal, 1-distinguishable FSM M, the next example demonstrates a procedure to obtain a 1-switch cover using the testing tree of M.
Example 5.39 Figure 5.27 shows a testing tree for machine M3 in Figure 5.26. To obtain the 1-switch cover, we traverse the testing tree from the root and enumerate all complete paths. Each path is represented by the sequence s of input symbols that label the corresponding links in the tree. The sequence s corresponding to each path is concatenated with the input alphabet of Μ as s.x where x ∈ Χ, X being the input alphabet. Traversing the testing tree in Figure 5.27 and concatenating as described gives us the following 1-switch cover.
Τ = {aba, abb, aaa, aab, baa, bab, bba, bbb}Figure 5.27 Testing tree of machine M3 in Figure 5.26.
We leave it to you to verify that T is a 1-switch cover for M3. Note that test aba ∈ Τ distinguishes M3 from M′3 as OM3(q1, abb) = 000 ≠ OM′3(q1, abb). Exercise 5.30 asks for the derivation of a test set from M2 in Figure 5.25 that is adequate with respect to 1-switch cover criterion.
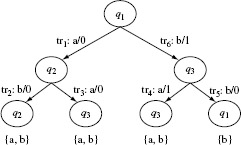
5.9.2 Comparing automata theoretic methods
Figure 5.28 shows the relative fault detection effectiveness of the transition tour (TT), Unique Input/Output (UIO), UIOv, Distinguishing Sequence (DS) Wp-, and W-methods. As is shown in the figure, the W-method, UIOv, Wp, and DS can detect all faults using the fault model described in Section 5.4.
Figure 5.28 Relative fault detection effectiveness and length of the test sets of various automata theoretic techniques.
The distinguishing sequence method constructs an input sequence x from an FSM Μ such that O(qi, x) is different for each qiin M. Sequences so constructed are able to detect all faults in our fault model. The UIO method is able to detect all output faults along transitions but not necessarily all transfer faults.
Note that the transition tour method has the lowest fault detection capability. In this method, test sequences are generated randomly until all transitions in the underlying FSM are covered. Redundant sequences are removed using a minimization procedure. One reason for the low fault detection ability of the TT method is that it checks only whether or not a transition has been covered and does not check the correctness of the start and tail states of the transition (see Exercise 5.25).
Tests generated using the transition tour method have the least fault detection effectiveness among those generated using other techniques considered in this chapter.
The relative lengths of test sequences is shown in Figure 5.28. Once again the W-method generates the longest, and the largest, set of test sequences while the TT method the shortest. From the relative lengths and fault detection relationships, we observe that larger tests tend to be more powerful than shorter tests. However, we also observe that smaller tests can be as powerful in their fault detection ability as the larger tests as indicated by comparing the fault detection effectiveness of the Wp- with that of the W-method.
In general the W-method generates larger test sequences than the Wp-method. However, the fault detection effectiveness of the tests generated are the same.
5.10 Tools
There are only a few freely available tools for generating tests from finite state models. However, a number of commercial tools are available that enable the tasks of model specification, exploration, and test generation. Some are mentioned below.
Spec Explorer: This tool from Microsoft is a giant in terms of what it offers to a tester. It allows the representation of a meta state model in Spec# and Asml languages that are based on C#. This model is an expression of the program’s intended behavior. What a program must do and what it must not do are specified in the Spec# model. The model need not express all of a program’s intended behavior. Instead, one may create several models from different points of views. From the model, the tool generates a number of FSMs that sample the program’s behavior. Tests are generated from each machine.
Documentation and link: http://research.microsoft.com/en-us/projects/specexplorer/
T-UPPAAL: This is a powerful tool for testing embedded real-time systems. The input to T-UPPAAL is a model of the system under test as a timed automata. Using this formal model, T-UPPAAL generates and executes timed test sequences.
Documentation and link: http://people.cs.aau.dk/~marius/tuppaal/
Spec-Explorer, T-UPPAAL, ModelJUnit are publicly available tools for generating tests from timed automata, FSMs, and EFSMs.
ModelJUnit: This is a Java library that extends JUnit. An FSM or EFSM model is specified as a set of Java classes. Tests are generated from these models.
Documentation and link: http://czt.sourceforge.net/modeljunit/index.html
WMethod: This is an easy-to-use tool to generate tests from an FSM. It takes an FSM as input and generates tests using the W-method described in this chapter.
Documentation and link: http://www.cs.purdue.edu/homes/apm/foundationsBook/
SUMMARY
The area of test generation from finite state models is wide. Research in this area can be categorized as follows:
- test generation techniques,
- empirical studies, and
- test methodology and architectures.
This chapter has focused primarily on test generation techniques from deterministic finite state models. Of the many available, three techniques, namely, the W-method, the UIO method, and the Wp-method, have been described. These methods are selected for inclusion due to their intrinsic importance in the field of FSM-based test generation and their high fault detection effectiveness. Each of these methods has also found its way into test generation from more complex models such as statecharts and timed automata. Thus, it is important for the reader to be familiar with these foundational test generation methods and prepare for more advanced and complex test generation methods.
Test generation from each of the techniques introduced in this chapter has been automated by several researchers. Nevertheless, students may find it challenging to write their own test generators and conduct empirical studies on practical FSM models.
Exercises
5.1 Modify the DIGDEC machine shown in Figure 5.3 so that it accepts a string over the alphabet X = {d, *}. For example, strings such as s = 324*41*9*199**230* are valid inputs. An asterisk causes the machine to execute the OUT(num) function where num denotes the decimal number corresponding to the digits received prior to the current asterisk but after any previous asterisk. Thus, the output of the machine for input string s will be
OUT(324) OUT(41) OUT(9) OUT(199) OUT(230)
Notice that the machine does not perform any action if it receives an asterisk following another asterisk.
5.2 Show that (a) V-equivalence and equivalence of states and machines as defined in Section 5.2.3 are equivalence relations, i.e. they obey the reflexive, symmetric, and transitive laws; (b) if two states are k-distinguishable for any k > 0, then they are also distinguishable for any n ≥ k.
5.3 Show that it is not necessary for equivalent machines to have an equal number of states.
5.4 Show that the set W of Example 5.7 is a characterization set for the machine in Figure 5.13.
5.5 Prove that the FSM Μ must be a minimal machine for the existence of a characterization set.
5.6 Prove that the method for the construction of k-equivalence partitions described in Example 5.8 will always converge, i.e. there will be a table Pn, n > 0, such that Pn = Pn+1.
5.7 The W-procedure for the construction of the W-set from a set of k-equivalence partitions is given on page 239. This is a brute force procedure that determines a distinguishing sequence for every pair of states. From Example 5.9, we know that two or more pairs of states might be distinguishable by the same input sequence. Rewrite the W-procedure by making use of this fact.
5.8 Prove that the k-equivalence partition of a machine is unique.
5.9 Prove that in an FSM with n states, at most n – 1 constructions of the equivalence classes are needed, i.e. one needs to construct only P1, P2, ...,Pn–1.
5.10 Given the FSM of Example 5.6, construct all mutants that can be obtained by adding a state to M.
5.11 Generate a set Τ of input sequences that distinguish all mutants in Figure 5.12 from machine M.
5.12 Show that any extra or missing state error in the implementation of design Μ will be detected by at least one test generated using the W-method.
5.13 Construct the characterization set W and the transition cover for the machine in Figure 5.23(a). Using the W-method, construct set Ζ assuming that m = 3 and derive a test set Τ. Does any element of Τ reveal the transfer error in the IUT of Figure 5.23(b)? Compare Τ with the test set in Example 5.37 with respect to the number of tests and the average size of test sequences.
5.14 Consider the design specification Μ as shown in Figure 5.15(a). Further, consider an implementation M3 of Μ as shown in Figure 5.29. Find all tests in T1 and T2 from Example 5.17 that reveal the error in M3.
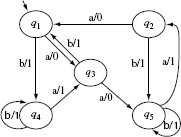
Figure 5.29 An implementation of Μ shown Figure 5.15(a) with a transfer error in state q1, on input a.
5.15 Consider the design specification in Figure 5.30(a). It contains three states q0, q1, and q2. The input alphabet X = {a, b, c}, and the output alphabet is Y = {0, 1}. (a) Derive a transition cover set P, the state cover set S, the characterization set W, and state identification sets for each of the three states. (b) From M, derive a test set Tw using the W-method and test set Twp using the Wp-method. Compare the sizes of the two sets, (c) Figure 5.30(b) shows the transition diagram of an implementation of Μ that contains a transfer error in state q2. Which tests in Tw and Twp reveal this error? (d) Figure 5.30(c) shows the transition diagram of an implementation of Μ that contains an extra state q3, and a transfer error in state q2. Which tests in Tw and Twp reveal this error ?
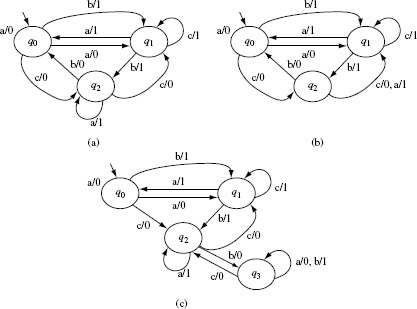
Figure 5.30 Three FSMs. (a) Design specification machine, (b) and (c) are machine indicating an erroneous implementation of the FSM in (a).
5.16 (a) Given an FSM Μ = (Χ, Y, Q, q0, δ, O) where |X| = nx, |Y| = ny, |Q| = nz, calculate the upper bound on the number of tests that will be generated using the W-method. (b) Under what condition(s) will the number of tests generated by the Wp-method be the same as those generated by the W-method?
5.17 Using the tests generated in Example 5.18, determine at least one test for each of the two machines in Figure 5.16 that will reveal the error. Is it necessary to apply phase 2 testing to reveal the error in each of the two machines ?
5.18 What is the difference between sequences in the W set and the UIO sequences ? Find UIO sequences for each state in the machine with transition diagram shown in Figure 5.13. Find the distinguishing signature for states for which a UIO sequence does not exist.
5.19 What will be the value of counter k when control arrives at Step 2.3 in procedure gen-long-uio?
5.20 For machine M2 used in Example 5.32, what output sequences are generated when the input portion of Sig(q1) is applied to states q2 and q3?
5.21 Suppose that tests ΤΕ(e1) and TE(e2) are derived using the method in Section 5.8.7 for a given FSM M. Is it possible that TE(el) = TE(e2)?
5.22 Generate UIO sequences for all states in the specification shown in Figure 5.13. Using the sequences so generated, develop tests for weak conformance testing of an IUT built that must behave as per the specification given.
5.23 Generate tests for weak conformance testing of machine M2 in Figure 5.18. Use the UIO sequences for M2 given on page 259.
5.24 Consider an implementation of the machine shown in Figure 5.21. The state diagram of the implementation is shown in Figure 5.31. Note that the IUT has two errors, a transfer error in state q2 and an operation error in state q6. In Example 5.36, the transfer error in q2 is revealed by test 4 (and 13). Are any of these tests successful in revealing the error in q2 ? Is there any test derived earlier that will reveal the error in q2 ? Which one of the tests derived in Example 5.33 and 5.35 will reveal the error in q6 ?
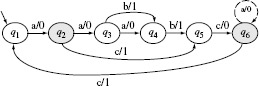
Figure 5.31 State diagram of an erroneous implementation of the machine in Figure 5.21.
5.25 Transition tours is a technique to generate tests from specification FSMs. A transition tour is an input sequence that when applied to an FSM in its start state traverses each edge at least once. (a) Find a transition tour for each of the two FSMs shown in Figure 5.18. (b) Show that a transition tour is able to detect all operation errors but may not be able to detect all transfer errors. Assume that the FSM specification satisfies the assumptions in Section 5.6.1. (c) Compare the size of tests generated using transition tours and the W-method.
5.26 In Example 5.38, we developed adequate tests to show that certain errors in the IUT are not detected. Derive tests using the W-method, and then using the Wp-method, and show that each test set derived detects all errors shown in Figure 5.32.
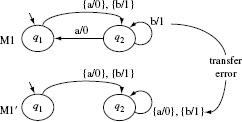
Figure 5.32 A transfer error.
5.27 FSM models considered in this chapter are pure in the sense that they capture only the control flow and ignore data definitions and uses. In this exercise, you will learn how to enhance a test set derived using any of the methods described in this chapter by accounting for data flows.
Figure 5.33 shows machine M, an augmented version of the FSM in Figure 5.13. We assume that the IUT corresponding to the FSM in Figure 5.33 uses a local variable Z. This variable is defined along transitions tr1 = (q1, q4) and tr3 = (q3, q5). Variable Ζ is used along transitions tr2 = (q2, q1) and tr4 = (q3, q1). Also, x and y are parameters of, respectively, inputs b and a. A data flow path for variable Ζ is a sequence Tr of transitions such that Ζ is defined on one transition along Tr and subsequently used along another transition also in Tr. For example, tr1, tr5, tr4 is a data flow path for Ζ in M, where Ζ is defined along tr1 and used along tr4. We consider only finite length paths and those with only one definition and one corresponding use along a path.
While testing the IUT against M, we must ensure that all data flow paths are tested. This is to detect faults in the defining or usage transitions. (a) Enumerate all data flow paths for variable Ζ in M. (b) Derive tests, i.e. input sequences, that will traverse all data flow paths derived in (a). (c) Consider a test set Τ derived for Μ using the W-method. Does exercising Μ against all elements of Τ exercise all data flow paths derived in (a) ? (Note: Chapter 7 provides details of data-flow based assessment of test adequacy and enhancement of tests.)
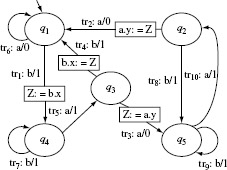
Figure 5.33 FSM of Figure 5.13 augmented with definition and use of local variable Z.
5.28 Let T be a set of test inputs that forms an n-switch set cover for a minimal n-distinguishable FSM M. Prove that Τ can detect all transfer, operation, extra, and missing state errors in M.
5.29 Show that a test set Τ that is adequate with respect to the boundary-interior coverage criterion may not be adequate with respect to the 1-switch cover criterion.
5.30 Derive a test set Τ from M2 shown in Figure 5.25 that is adequate with respect to the 1-switch cover criterion. Which test in Τ distinguishes M2 from M′2 and thereby reveals the error ? Compare Τ derived in this exercise with the test given in Example 5.38 and identify a property of the method used to construct Τ that allows Τ to distinguish M2 from M′2.