
CHAPTER 3
THE DATABASE MANAGEMENT SYSTEM CONCEPT
Data has always been the key component of information systems. In the beginning of the modern information systems era, data was stored in simple files. As companies became more and more dependent on their data for running their businesses, shortcomings in simple files became apparent. These shortcomings led to the development of the database management system concept, which provides a solid basis for the modern use of data in organizations of all descriptions.
OBJECTIVES
- Define data-related terms such as entity and attribute and storage-related terms such as field, record, and file.
- Identify the four basic operations performed on stored data.
- Compare sequential access of data with direct access of data.
- Discuss the problems encountered in a non-database information systems environment.
- List the five basic principles of the database concept.
- Describe how data can be considered to be a manageable resource.
- List the three problems created by data redundancy.
- Describe the nature of data redundancy among many files.
- Explain the relationship between data integration and data redundancy in one file.
- State the primary defining feature of a database management system.
- Explain why the ability to store multiple relationships is an important feature of the database approach.
- Explain why providing support for such control issues as data security, backup and recovery, and concurrency is an important feature of the database approach.
- Explain why providing support for data independence is an important feature of the database approach.
CHAPTER OUTLINE
Introduction
Data Before Database Management
Records and Files
Basic Concepts in Storing and Retrieving Data
The Database Concept
Data as a Manageable Resource
Data Integration and Data Redundancy
Multiple Relationships
Data Control Issues
Data Independence
DBMS Approaches
Summary
INTRODUCTION
Before the database concept was developed, all data in information systems (then generally referred to as “data processing systems”) was stored in simple linear files. Some applications and their programs required data from only one file. Some applications required data from several files. Some of the more complex applications used data extracted from one file as the search argument (the item to be found) for extracting data from another file. Generally, files were created for a single application and were used only for that application. There was no sharing of files or of data among applications and, as a result, the same data often appeared redundantly in multiple files. In addition to this data redundancy among multiple files, a lack of sophistication in the design of individual files often led to data redundancy within those individual files.
As information systems continued to grow in importance, a number of the ground rules began to change. Hardware became cheaper—much cheaper relative to the computing power that it provided. Software development took on a more standardized, “structured” form. Large backlogs of new applications to be implemented built up, making the huge amount of time spent on maintaining existing programs more and more unacceptable. It became increasingly clear that the lack of a focus on data was one of the major factors in this program maintenance dilemma. Furthermore, the redundant data across multiple files and even within individual files was causing data accuracy nightmares (to be explained further in this chapter), just as companies were relying more and more on their information systems to substantially manage their businesses. As we will begin to see in this chapter, the technology that came to the rescue was the database management system.
Summarizing, the problems included:
- Data was stored in different formats in different files.
- Data was often not shared among different programs that needed it, necessitating the duplication of data in redundant files.
- Little was understood about file design, resulting in redundant data within individual files.
- Files often could not be rebuilt after damage by a software error or a hardware failure.
- Data was not secure and was vulnerable to theft or malicious mischief by people inside or outside the company.
- Programs were usually written in such a manner that if the way that the data was stored changed, the program had to be modified to continue working.
- Changes in everything from access methods to tax tables required programming changes.
This chapter will begin by presenting some basic definitions and concepts about data. Then it will describe the type of file environment that existed before database management emerged. Then it will describe the problems inherent in the file environment and show how the database concept overcame them and set the stage for a vastly improved information systems environment.
DATA BEFORE DATABASE MANAGEMENT
As we said in Chapter 1, pieces of data are facts in our environment that are important to us. Usually we have many facts to describe something of interest to us. For example, let's consider the facts we might be interested in about an employee of ours named John Baker. Our company is a sales-oriented company and John Baker is one of our salespersons. We want to remember that his employee number (which we will now call his salesperson number) is 137. We are also interested in the facts that his commission percentage on the sales he makes is 10%, his home city is Detroit, his home state is Michigan, his office number is 1284, and he was hired in 1995. There are, of course, reasons that we need to keep track of these facts about John Baker, such as generating his paycheck every week. It certainly seems reasonable to collect together all of the facts about Baker that we need and to hold all of them together. Figure 3.1 shows all of these facts about John Baker presented in an organized way.
Records and Files
Since we have to generate a paycheck each week for every employee in our company, not just for Baker, we are obviously going to need a collection of facts like those in Figure 3.1 for every one of our employees. Figure 3.2 shows a portion of that collection.

FIGURE 3.1 Facts about salesperson Baker
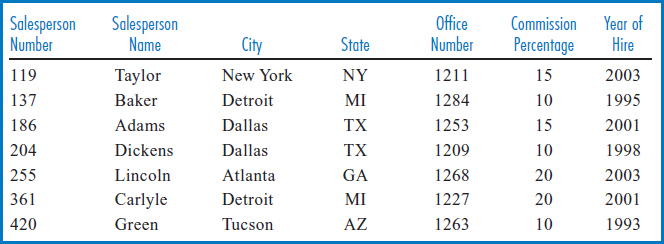
FIGURE 3.2 Salesperson file
3-A MEMPHIS LIGHT, GAS AND WATER
Memphis Light, Gas and Water (MLGW) is the largest “three-service” (electricity, natural gas and water) municipal utility system in the United States. It serves over 400,000 customers in Memphis and Shelby County, TN, and has 2,600 employees. MLGW is the largest of the 159 distributors of the federal Tennessee Valley Authority's electricity output. It brings in natural gas via commercial pipelines and it supplies water from a natural aquifer beneath the city of Memphis.
Like any supplier of electricity, MLGW is particularly sensitive to electrical outages. It has developed a two-stage application system to determine the causes of outages and to dispatch crews to fix them. The first stage is the Computer-Aided Restoration of Electric Service (CARES) system, which was introduced in 1996. Beginning with call-in patterns as customers report outages, CARES uses automated data from MLGW's electric grid, wiring patterns to substations, and other information, to function as an expert system to determine the location and nature of the problem. It then feeds its conclusion to the second-stage Mobile Dispatching System (MDS), which was introduced in 1999. MDS sends a repairperson to an individual customer's location if that is all that has been affected or sends a crew to a malfunctioning or damaged piece of equipment in the grid that is affecting an entire neighborhood. There is a feedback loop in which the repairperson or crew reports back to indicate whether the problem has been fixed or a higher-level crew is required to fix it.
The CARES and MDS systems are supported by an Oracle database running on Hewlett-Packard and Compaq Alpha Unix platforms. The database includes a wide range of tables: a Customer Call table has one record per customer reporting call; an Outage table has one record per outage; a Transformer table has one record for each transformer in the grid; a Device table has records for other devices in the grid. These can also interface to the Customer Information System, which has a Customer table with one record for each of the over 400,000 customers. In addition to its operational value, CARES and other systems feed a System Reliability Monitoring database that generates reports on outages and can be queried to gain further knowledge of outage patterns for improving the grid.

“Photo Courtesy of Memphis Light, Gas, and Water Division”
Let's proceed by revisiting some terminology from Chapter 2, and introducing some additional terminology along with some additional concepts. What we have been loosely referring to as a “thing” or “object” in our environment that we want to keep track of is called an entity. Remember that this is the real physical object or event, not the facts about it. John Baker, the real, living, breathing person whom you can go over to and touch, is an entity. A collection of entities of the same type (e.g., all the company's employees) is called an entity set. An attribute is a property of, a characteristic of, or a fact that we know about an entity. Each characteristic or property of John Baker, including his salesperson number 137, his name, city of Detroit, state of Michigan, office number 1284, commission percentage 10, and year of hire 1995, are all attributes of John Baker. Some attributes have unique values within an entity set. For example, the salesperson numbers are unique within the salesperson entity set, meaning each salesperson has a different salesperson number. We can use the fact that salesperson numbers are unique to distinguish among the different salespersons.
Using the structure in Figure 3.2, we can define some standard file-structure terms and relate them to the terms entity, entity set, and attribute. Each row in Figure 3.2 describes a single entity. Infact, each row contains all the facts that we know about a particular entity. The first row contains all the facts about salesperson 119, the second row contains all the facts about salesperson 137, and so on. Each row of a structure like this is called a record. The columns representing the facts are called fields. The entire structure is called a file. The file in Figure 3.2, which is about the most basic kind of file imaginable, is often called a simple file or a simple linear file (linear because it is a collection of records listed one after the other in a long line). Since the salesperson attribute is unique, the salesperson field values can be used to distinguish the individual records of the file. Speaking loosely at this point, the salesperson number field can be referred to as the key field or key of the file.
Tying together the two kinds of terminology that we have developed, a record of a file describes an entity, a whole file contains the descriptions of an entire entity set, and afield of a record contains an attribute of the entity described by that record. In Figure 3.2, each row is a record that describes an entity, specifically a single salesperson. The whole file, row by row or record by record, describes each salesperson in the collection of salespersons. Each column of the file represents a different attribute of salespersons. At the row or entity level, the salesperson name field for the third row of the file indicates that the third salesperson, salesperson 186, has Adams as his salesperson name attribute, i.e. he is named Adams.
One last terminology issue is the difference between the terms “type” and “occurrence.” Let's talk about it in the context of a record. If you look at a file, like that in Figure 3.2, there are two ways to describe “a record.” One, which is referred to as the record type, is a structural description of each and every record in the file. Thus, we would describe the salesperson record type as a record consisting of a salesperson number field, a salesperson name field, a city field, and so forth. This is a general description of what any of the salesperson records looks like. The other way of describing a record is referred to as a record occurrence or a record instance. A specific record of the salesperson file is a record occurrence or instance. Thus, we would say that, for example, the set of values {186, Adams, Dallas, TX, 1253, 15, 2001} is an occurrence of the salesperson record type.
3.1 ENTITIES AND ATTRIBUTES
Entities and their attributes are all around us in our everyday lives. Normally, we don't stop to think about the objects or events in our world formally as entities with their attributes, but they're there.
QUESTION:
Choose an object in your world that you interact with frequently. It might be a university, a person, an automobile, your home, etc. Make a list of some of the chosen entity's attributes. Then, generalize them to “type.” For example, you may have a backpack (an entity) that is green in color (an attribute of that entity). Generalize that to the entity set of all backpacks and to the attribute type color. Next, go through the same exercise for an event in your life, such as taking a particular exam, your last birthday party, eating dinner last night, etc.
Basic Concepts in Storing and Retrieving Data
Having established the idea of a file and its records, we can now, in simple terms at this point, envision a company's data as a large collection of files. The next step is to discuss how we might want to access data from these files and otherwise manipulate the data in them.
Retrieving and Manipulating Data There are four fundamental operations that can be performed on stored data, whether it is stored in the form of a simple linear file, such as that of Figure 3.2, or in any other form. They are:
- Retrieve or Read
- Insert
- Delete
- Update
It is convenient to think of each of these operations as basically involving one record at a time, although in practice they can involve several records at once, as we will see later in the book. Retrieving or reading a record means looking at a record's contents without changing them. For example, using the Salesperson file of Figure 3.2, we might read the record for salesperson 204 because we want to find out what year she was hired. Insertion means adding a new record to the file, as when a new salesperson is hired. Deletion means deleting a record from the file, as when a salesperson leaves the company. Updating means changing one or more of a record's field values, for example if we want to increase salesperson 420's commission percentage from 10 to 15. There is clearly a distinction between retrieving or reading data and the other three operations. Retrieving data allows a user to refer to the data for some business purpose without changing it. All of the other three operations involve changing the data. Different topics in this book will focus on one or another of these operations simply because a particular one of the four operations may be more important for a particular topic than the others.
One particularly important concept concerning data retrieval is that, while information systems applications come in a countless number of variations, there are fundamentally only two kinds of access to stored data that any of them require. These two ways of retrieving data are known as sequential access and direct access.
Sequential Access The term sequential access means the retrieval of all or a portion of the records of a file one after another, in some sequence, starting from the beginning, until all the required records have been retrieved. This could mean all the records of the file, if that is the goal, or all the records up to some point, such as up to the point that a record being searched for is found. The records will be retrieved in some order and there are two possibilities for this. In “physical” sequential access, the records are retrieved one after the other, just as they are stored on the disk device (more on these devices later). In “logical” sequential access the records are retrieved in order based on the values of one or a combination of the fields.
Assuming the records of the Salesperson file of Figure 3.2 are stored on the disk in the order shown in the figure, if they are retrieved in physical sequence they will be retrieved in the order shown in the figure. However, if, for example, they are to be retrieved in logical sequence based on the Salesperson Name field, then the record for Adams would be retrieved first, followed by the record for Baker, followed by the record for Carlyle, and so on in alphabetic order. An example of an application that would require the sequential retrieval of the records of this file would be the weekly payroll processing. If the company wants to generate a payroll check for each salesperson in the order of their salesperson numbers, it can very simply retrieve the records physically sequentially, since that's the order in which they are stored on the disk. If the company wants to produce the checks in the order of the salespersons' names, it will have to perform a logical sequential retrieval based on the Salesperson Name field. It can do this either by sorting the records on the Salesperson Name field or by using an index (see below) that is built on this field.
We said that sequential access could involve retrieving a portion of the records of a file. This sense of sequential retrieval usually means starting from the beginning of the file and searching every record, in sequence, until finding a particular record that is being sought. Obviously, this could take a long time for even a moderately large file and so is not a particularly desirable kind of operation, which leads to the concept of direct access.
Direct Access The other mode of access is direct access. Direct access is the retrieval of a single record of a file or a subset of the records of a file based on one or more values of a field or a combination of fields in the file. For example, in the Salesperson file of Figure 3.2, if we need to retrieve the record for salesperson 204 to find out her year of hire, we would perform a direct access operation on the file specifying that we want the record with a value of 204 in the Salesperson Number field. How do we know that we would retrieve only one record? Because the Salesperson Number field is the unique, key field of the file, there can only be one record (or none) with any one particular value. Another possibility is that we want to retrieve the records for all the salespersons with a commission percentage of 10. The subset of the records retrieved would consist of the records for salespersons 137, 204, and 420.
Direct access is a crucial concept in information systems today. If you telephone a bank with a question about your account, you would not be happy having to wait on the phone while the bank's information system performs a sequential access of its customer file until it finds your record. Clearly this example calls for direct access. In fact, the vast majority of information systems operations that all companies perform today require direct access.
Both sequential access and direct access can certainly be accomplished with data stored in simple files. But simple files leave a lot to be desired. What is the concept of database and what are its advantages?
THE DATABASE CONCEPT
The database concept is one of the most powerful, enduring technologies in the information systems environment. It encompasses a variety of technical and managerial issues and features that are at the heart of today's information systems scene. In order to get started and begin to develop the deep understanding of database that we seek, we will focus on five issues that establish a set of basic principles of the database concept:
- The creation of a data centric environment in which a company's data can truly be thought of as a significant corporate resource. A key feature of this environment is the ability to share data among those inside and outside of the company who require access to it.
- The ability to achieve data integration while at the same time storing data in a non-redundant fashion. This, alone, is the central, defining feature of the database approach.
- The ability to store data representing entities involved in multiple relationships without introducing data redundancy or other structural problems.
- The establishment of an environment that manages certain data control issues, such as data security, backup and recovery, and concurrency control.
- The establishment of an environment that permits a high degree of data independence.
Data as a Manageable Resource
Broadly speaking, the information systems environment consists of several components including hardware, networks, applications software, systems software, people, and data. The relative degree of focus placed on each of these has varied over time. In particular, the amount of attention paid to data has undergone a radical transformation. In the earlier days of “data processing,” most of the time and emphasis in application development was spent on the programs, as opposed to on the data and data structures. Hardware was expensive and the size of main memory was extremely limited by today's standards. Programming was a new discipline and there was much to be learned about it in order to achieve the goal of efficient processing. Standards for effective programming were unknown. In this environment, the treatment of the data was hardly the highest-priority concern.
At the same time, as more and more corporate functions at the operational, tactical, and strategic levels became dependent on information systems, data increasingly became recognized as an important corporate resource. Furthermore, the corporate community became increasingly convinced that a firm's data about its products, manufacturing processes, customers, suppliers, employees, and competitors could, with proper storage and use, give the firm a significant competitive advantage.
FIGURE 3.3 Corporate resources
Money, plant and equipment, inventories, and people are all important enterprise resources and, indeed, a great deal of effort has always been expended to manage them. As corporations began to realize that data is also an important enterprise resource, it became increasingly clear that data would have to be managed in an organized way, too, Figure 3.3. What was needed was a software utility that could manage and protect data while providing controlled shared access to it so that it could fulfill its destiny as a critical corporate resource. Out of this need was born the database management system.
As we look to the future and look back at the developments of the last few years, we see several phenomena that emphasize the importance of data and demand its careful management as a corporate resource. These include reengineering, electronic commerce, and enterprise resource planning (ERP) systems that have placed an even greater emphasis on data. In reengineering, data and information systems are aggressively used to redesign business processes for maximum efficiency. At the heart of every electronic commerce Web site is a database through which companies and their customers transact business. Another very important development was that of enterprise resource planning (ERP) systems, which are collections of application programs built around a central shared database. ERP systems very much embody the principles of shared data and of data as a corporate resource.
Data Integration and Data Redundancy
Data integration and data redundancy, each in their own right, are critical issues in the field of database management.
- Data integration refers to the ability to tie together pieces of related data within an information system. If a record in one file contains customer name, address, and telephone data and a record in another file contains sales data about an item that the customer has purchased, there may come a time when we want to contact the customer about the purchased item.
- Data redundancy refers to the same fact about the business environment being stored more than once within an information system. Data integration is clearly a positive feature of a database management system. Data redundancy is a negative feature (except for performance reasons under certain circumstances that will be discussed later in this book).
In terms of the data structures used in database management systems, data integration and data redundancy are tied together and will be discussed together in this section of the book.
Data stored in an information system describes the real-world business environment. Put another way, the data is a reflection of the environment. Over the years that information systems have become increasingly sophisticated, they and the data that they contain have revolutionized the ways that we conduct virtually all aspects of business. But, as valuable as the data is, if the data is duplicated and stored multiple times within a company's information systems facilities, it can result in a nightmare of poor performance, lack of trust in the accuracy of the data, and a reduced level of competitiveness in the marketplace. Data redundancy and the problems it causes can occur within a single file or across multiple files. The problems caused by data redundancy are threefold:
- First, the redundant data takes up a great deal of extra disk space. This alone can be quite significant.
- Second, if the redundant data has to be updated, additional time is needed to do so since, if done correctly, every copy of the redundant data must be updated. This can create a major performance issue.
- Third and potentially the most significant is the potential for data integrity problems. The term data integrity refers to the accuracy of the data. Obviously, if the data in an information system is inaccurate, it and the whole information system are of limited value. The problem with redundant data, whether in a single file or across multiple files, occurs when it has to be updated (or possibly when it is first stored). If data is held redundantly and all the copies of the data record being updated are not all correctly updated to the new values, there is clearly a problem in data integrity. There is an old saying that has some applicability here, “The person with one watch always knows what time it is. The person with several watches is never quite sure,” Figure 3.4.
Data Redundancy Among Many Files Beginning with data redundancy across multiple files, consider the following situation involving customer names and addresses. Frequently, different departments in an enterprise in the course of their normal everyday work need the same data. For example, the sales department, the accounts receivable department, and the credit department may need customer name and address data. Often, the solution to this multiple need is redundant data. The sales department has its own stored file that, among other things, contains the customer name and address, and likewise for the accounts receivable and credit departments, Figure 3.5.
FIGURE 3.4 With several watches the correct time might not be clear

FIGURE 3.5 Three files with redundant data
One day customer John Jones, who currently lives at 123 Elm Street, moves to 456 Oak Street. If his address is updated in two of the files but not the third, then the company's data is inconsistent, Figure 3.6. Two of the files indicate that John Jones lives at 456 Oak Street but one file still shows him living at 123 Elm Street. The company can no longer trust its information system. How could this happen? It could have been a software or a hardware error. But more likely it was because whoever received the new information and was responsible for updating one or two of the files simply did not know of the existence of the third. As mentioned earlier, at various times in information systems history it has not been unusual in large companies for the same data to be held redundantly in sixty or seventy files! Thus, the possibility of data integrity problems is great.

FIGURE 3.6 Three files with a data integrity problem
Multiple file redundancy begins as more a managerial issue than single file redundancy, but it also has technical components. The issue is managerial to the extent that a company's management does not encourage data sharing among departments and their applications. But it is technical when it comes to the reality of whether the company's software systems are capable of providing shared access to the data without compromising performance and data security.
Data Integration and Data Redundancy Within One File Data redundancy in a single file results in exactly the same three problems that resulted from data redundancy in multiple files: wasted storage space, extra time on data update, and the potential for data integrity problems. To begin developing this scenario, consider Figure 3.7, which shows two files from the General Hardware Co. information system. General Hardware is a wholesaler of hardware, tools, and related items. Its customers are hardware stores, home improvement stores, and department stores, or chains of such stores. Figure 3.7a shows the Salesperson file, which has one record for each of General Hardware's salespersons. Salesperson Number is the unique identifying “key” field and as such is underlined in the figure. Clearly, there is no data redundancy in this file. There is one record for each salesperson and each individual fact about a salesperson is listed once in the salesperson's record.
Figure 3.7b shows General Hardware's Customer file. Customer Number is the unique key field. Again, there is no data redundancy, but two questions have to be answered regarding the Salesperson Number field appearing in this file. First, why is it there? After all, it seems already to have a good home as the unique identifying field of the Salesperson file. The Salesperson Number field appears in the Customer file to record which salesperson is responsible for a given customer account. In fact, there is a one-to-many relationship between salespersons and customers. A salesperson can and generally does have several customer accounts, while each customer is serviced by only one General Hardware salesperson. The second question involves the data in the Salesperson Number field in the Customer file. For example, salesperson number 137 appears in four of the records (plus once in the first record of the Salesperson file!). Does this constitute data redundancy? The answer is no. For data to be redundant (and examples of data redundancy will be coming up shortly), the same fact about the business environment must be recorded more than once. The appearance of salesperson number 137 in the first record of the Salesperson file establishes 137 as the identifier of one of the salespersons. The appearance of salesperson number 137 in the first record of the Customer file indicates that salesperson number 137 is responsible for customer number 0121. This is a different fact about the business environment. The appearance of salesperson number 137 in the third record of the Customer file indicates that salesperson number 137 is responsible for customer number 0933. This is yet another distinct fact about the business environment. And so on through the other appearances of salesperson number 137 in the Customer file.
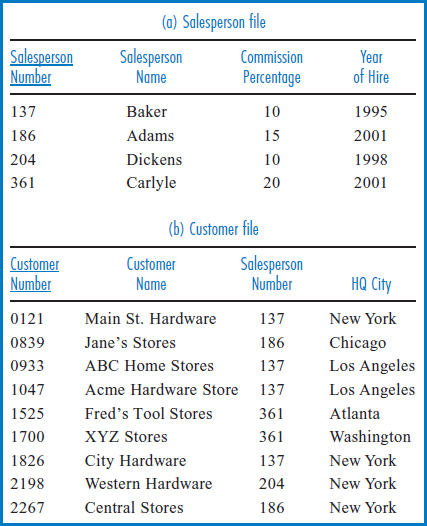
FIGURE 3.7 General Hardware Company files
Retrieving data from each of the files of Figure 3.7 individually is straightforward and can be done on a direct basis if the files are set-up for direct access. Thus, if there is a requirement to find the name or commission percentage or year of hire of salesperson number 204, it can be satisfied by retrieving the record for salesperson number 204 in the Salesperson file. Similarly, if there is a requirement to find the name or responsible salesperson (by salesperson number!) or headquarters city of customer number 1525, we simply retrieve the record for customer number 1525 in the Customer file.
But, what if there is a requirement to find the name of the salesperson responsible for a particular customer account, say for customer number 1525? Can this requirement be satisfied by retrieving data from only one of the two files of Figure 3.7? No, it cannot! The information about which salesperson is responsible for which customers is recorded only in the Customer file and the salesperson names are recorded only in the Salesperson file. Thus, finding the salesperson name will be an exercise in data integration. In order to find the name of the salesperson responsible for a particular customer, first the record for the customer in the Customer file would have to be retrieved. Then, using the salesperson number found in that record, the correct salesperson record can be retrieved from the Salesperson file to find the salesperson name. For example, if there is a need to find the name of the salesperson responsible for customer number 1525, the first operation would be to retrieve the record for customer number 1525 in the Customer file. As shown in Figure 3.7b, this would yield salesperson number 361 as the number of the responsible salesperson. Then, accessing the record for salesperson 361 in the Salesperson file in Figure 3.7a determines that the name of the salesperson responsible for customer 1525 is Carlyle. While it's true that the data in the record in the Salesperson file and the data in the record in the Customer file have been integrated, the data integration process has been awfully laborious.
This kind of custom-made, multicommand, multifile access (which, by the way, could easily require more than two files, depending on the query and the files involved) is clumsy, potentially error prone, and expensive in terms of performance. While the two files have the benefit of holding data non-redundantly, what is lacking is a good level of data integration. That is, it is overly difficult to find and retrieve pieces of data in the two files that are related to each other. For example, customer number 1525 and salesperson name Carlyle in the two files in Figure 3.7 are related to each other by virtue of the fact that the two records they are in both include a reference to salesperson number 361. Yet, as shown above, ultimately finding the salesperson name Carlyle by starting with the customer number 1525 is an unacceptably laborious process.
A fair question to ask is, if we knew that data integration was important in this application environment and if we knew that there would be a frequent need to find the name of the salesperson responsible for a particular customer, why were the files structured as in Figure 3.7 in the first place? An alternative arrangement is shown in Figure 3.8. The single file in Figure 3.8 combines the data in the two files of Figure 3.7. Also, the Customer Number field values of both are identical.
The file in Figure 3.8 was created by merging the salesperson data from Figure 3.7a into the records of Figure 3.7b, based on corresponding salesperson numbers. As a result, notice that the number of records in the file in Figure 3.8 is identical to the number of records in the Customer file of Figure 3.7b. This is actually a result of the “direction” of the one-to-many relationship in which each salesperson can be associated with several customers. The data was “integrated” in this merge operation. Notice, for example, that in Figure 3.7b, the record for customer number 1525 is associated with salesperson number 361. In turn, in Figure 3.7a, the record for salesperson number 361 is shown to have the name Carlyle. Those two records were merged, based on the common salesperson number, into the record for customer number 1525 in Figure 3.8. (Notice, by the way, that the Salesperson Number field appears twice in Figure 3.8 because it appeared in each of the files of Figure 3.7. The field values in each of those two fields are identical in each record in the file in Figure 3.8, which must be the case since it was on those identical values that the record merge that created the file in Figure 3.8 was based. That being the case, certainly one of the two Salesperson Number fields in the file in Figure3.8 could be deleted without any loss of information.)
The file in Figure 3.8 is certainly well integrated. Finding the name of the salesperson who is responsible for customer number 1525 now requires a single record access of the record for customer number 1525. The salesperson name, Carlyle, is right there in that record. This appears to be the solution to the earlier multifile access problem. Unfortunately, integrating the two files caused another problem: data redundancy. Notice in Figure 3.8 that, for example, the fact that salesperson number 137 is named Baker is repeated four times, as are his commission percentage and year of hire. This is, indeed, data redundancy, as it repeats the same facts about the business environment multiple times within the one file. If a given salesperson is responsible for several customer accounts, then the data about the salesperson must appear in several records in the merged or integrated file. It would make no sense from a logical or a retrieval standpoint to specify, for example, the salesperson name, commission percentage, and year of hire for one customer that the salesperson services and not for another. This would imply a special relationship between the salesperson and that one customer that does not exist and would remove the linkage between the salesperson and his other customers. To be complete, the salesperson data must be repeated for every one of his customers.
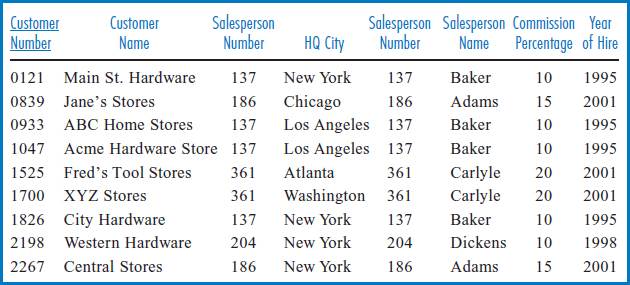
FIGURE 3.8 General Hardware Company combined file
The combined file in Figure 3.8 also illustrates what have come to be referred to as anomalies in poorly structured files. The problems arise when two different kinds of data, like salesperson and customer data in this example, are merged into one file. Look at the record in Figure 3.8 for customer number 2198, Western Hardware. The salesperson for this customer is Dickens, salesperson number 204. Look over the table and note that Western Hardware happens to be the only customer that Dickens currently has. If Western Hardware has gone out of business or General Hardware has stopped selling to it and they decide to delete the record for Western Hardware from the file, they also lose everything they know about Dickens: his commission percentage, his year of hire, even his name associated with his salesperson number, 204. This situation, which is called the deletion anomaly, occurs because salesperson data doesn't have its own file, as in Figure 3.7a. The only place in the combined file of Figure 3.8 that you can store salesperson data is in the records with the customers. If you delete a customer and that record was the only one for that salesperson, the salesperson's data is gone.
Conversely, in the insertion anomaly, General Hardware can't record data in the combined file of Figure 3.8 about a new salesperson the company just hired until she is assigned at least one customer. After all, the identifying field of the records of the combined file is Customer Number! Finally, the update anomaly notes that the redundant data of the combined file, such as Baker's commission percentage of 10 repeated four times, must be updated each place it exists when it changes (for example, if Baker is rewarded with an increase to a commission percentage of 15).
There appears to be a very significant tradeoff in the data structures between data integration and data redundancy. The two files of Figure 3.7 are non-redundant but have poor data integration. Finding the name of the salesperson responsible for a particular customer account requires a multicommand, multifile access that can be slow and error-prone. The merged file of Figure3.8, in which the data is very well integrated, eliminates the need for a multicommand, multifile access for this query, but is highly data redundant. Neither of these situations is acceptable. A poor level of data integration slows down the company's information systems and, perhaps, its business! Redundant data can cause data accuracy and other problems. Yet both the properties of data integration and of non-redundant data are highly desirable. And, while the above example appears to show that the two are hopelessly incompatible, over the years a few—very few—ways have been developed to achieve both goals in a single data management system. In fact, this concept is so important that it is the primary defining feature of database management systems:
A database management system is a software utility for storing and retrieving data that gives the end-user the impression that the data is well integrated even though the data can be stored with no redundancy at all.
Any data storage and retrieval system that does not have this property should not be called a database management system. Notice a couple of fine points in the above definition. It says, “data can be stored with no redundancy,” indicating that non-redundant storage is feasible but not required. In certain situations, particularly involving performance issues, the database designer may choose to compromise on the issue of data redundancy. Also, it says, “that gives the end-user the impression that the data is well integrated.” Depending on the approach to database management taken by the particular database management system, data can be physically integrated and stored that way on the disk or it can be integrated at the time that a data retrieval query is executed. In either case, the data will, “give the end-user the impression that the data is well integrated.” Both of these fine points will be explored further later in this book.
Multiple Relationships
Chapter 2 demonstrated how entities can relate to each other in unary, binary, and ternary one-to-one, one-to-many, and many-to-many relationships. Clearly, a database management system must be able to store data about the entities in a way that reflects and preserves these relationships. Furthermore, this must be accomplished in such a way that it does not compromise the fundamental properties of data integration and non-redundant data storage described above. Consider the following problems with attempting to handle multiple relationships in simple linear files, using the binary one-to-many relationship between General Hardware Company's salespersons and customers as an example.
First, the Customer file of Figure 3.7 does the job with its Salesperson Number field. The fact that, for example, salesperson number 137 is associated with four of the customers(it appears in four of the records) while, for example, customer number 1826 has only one salesperson associated with it demonstrates that the one-to-many relationship has been achieved. However, as has already been shown, the two files of this figure lack an efficient data integration mechanism; i.e., trying to link detailed salesperson data with associated customer data is laborious. (Actually, as will be seen later in this book, the structures of Figure 3.7 are quite viable in the relational DBMS environment. In that case, the relational DBMS software will handle the data integration requirement. But without that relational DBMS software, these structures are deficient in terms of data integration.) Also, the combined file of Figure 3.8 supports the one-to-many relationship but, of course, introduces data redundancy.
Figure 3.9 shows a “horizontal” solution to the problem. The Salesperson Number field has been removed from the Customer file. Instead, each record in the Salesperson file lists all the customers, by customer number, that the particular salesperson is responsible for. This could conceivably be implemented as one variable-length field of some sort containing all the associated customer numbers for each salesperson, or it could be implemented as a series of customer number fields. While this arrangement does represent the one-to-many relationship, it is unacceptable for two reasons. One is that the record length could be highly variable depending on how many customers a particular salesperson is responsible for. This can be tricky from a space management point of view. If a new customer is added to a salesperson's record, the new larger size of the record may preclude its being stored in the same place on the disk as it came from, but putting it somewhere else may cause performance problems in future retrievals. The other reason is that once a given salesperson record is retrieved, the person or program that retrieved it would have a difficult time going through all the associated customer numbers looking for the one desired. With simple files like these, the normal expectation is that there will be one value of each field type in each record (e.g. one salesperson number, one salesperson name, and so on). In the arrangement in Figure 3.9, the end-user or supporting software would have to deal with a list of values, i.e. of customer numbers, upon retrieving a salesperson record. This would be an unacceptably complex process.
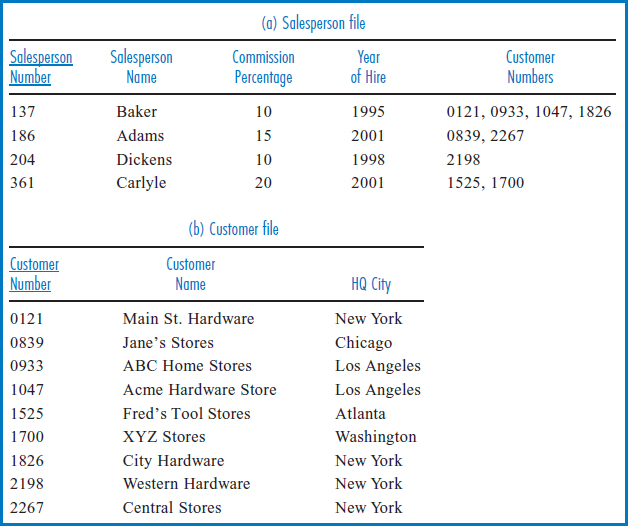
FIGURE 3.9 General Hardware Company combined files: One-to-many relationship horizontal variation
Figure 3.10 shows a “vertical” solution to the problem. In a single file, each salesperson record is immediately followed by the records for all of the customers for which the salesperson is responsible. While this does preserve the one-to-many relationship, the complexities involved in a system that has to manage multiple record types in a single file make this solution unacceptable, too.
A database management system must be able to handle all of the various unary, binary, and ternary relationships in a logical and efficient way that does not introduce data redundancy or interfere with data integration. The database management system approaches that are in use today all satisfy this requirement. In particular, the way that the relational approach to database management handles it will be explained in detail.
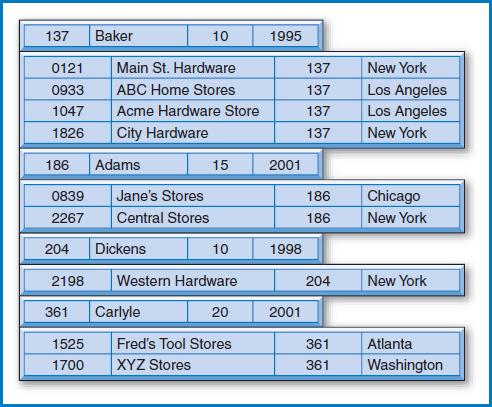
FIGURE 3.10 General Hardware Company combined files: One-to-many relationship vertical variation
Data Control Issues
The people responsible for managing the data in an information systems environment must be concerned with several data control issues. This is true regardless of which database management system approach is in use. It is even true if no database management system is in use, that is, if the data is merely stored in simple files. Most prominent among these data control issues are data security, backup and recovery, and concurrency control, Figure 3.11. These are introduced here and will be covered in more depth later in this book. The reason for considering these data control issues in this discussion of the essence of the database management system concept is that such systems should certainly be expected to handle these issues frequently for all the data stored in the system's databases.
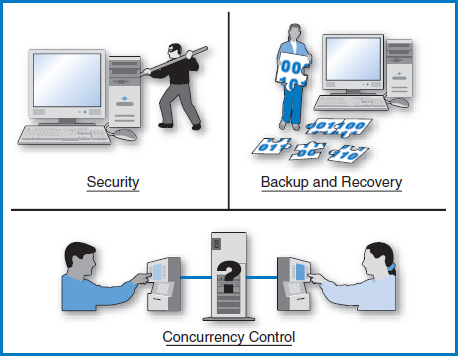
FIGURE 3.11 Three data control issues
Computer security has become a very broad topic with many facets and concerns. These include protecting the physical hardware environment, defending against hacker attacks, encrypting data transmitted over networks, educating employees on the importance of protecting the company's data, and many more. All computer security exposures potentially affect a company's data. Some exposures represent direct threats to data while others are more indirect. For example, the theft of transmitted data is a direct threat to data while a computer virus, depending on its nature, may corrupt programs and systems in such a way that the data is affected on an incidental or delayed basis. The types of direct threats to data include outright theft of the data, unauthorized exposure of the data, malicious corruption of the data, unauthorized updates of the data, and loss of the data. Protecting a company's data assets has become a responsibility that is shared by its operating systems, special security utility software, and its database management systems. All database management systems incorporate features that are designed to help protect the data in their databases.
Data can be lost or corrupted in any of a variety of ways, not just from the data security exposures just mentioned. Entire files, portions of databases, or entire databases can be lost when a disk drive suffers a massive accidental or deliberate failure. At the extreme, all of a company's data can be lost to a disaster such as a fire, a hurricane, or an earthquake. Hackers, computer viruses, or even poorly written application programs can corrupt from a few to all of the records of a file or database. Even an unintentional error in entering data into a single record can be propagated to other records that use its values as input into the creation of their values. Clearly, every company (and even every PC user!) must have more than one copy of every data file and database. Furthermore, some of the copies must be kept in different buildings, or even different cities, to prevent a catastrophe from destroying all copies of the data. The process of using this duplicate data, plus other data, special software, and even specially designed disk devices to recover lost or corrupted data is known as “backup and recovery.” As a key issue in data management, backup and recovery must be considered and incorporated within the database management system environment.
In today's multi-user environments, it is quite common for two or more users to attempt to access the same data record simultaneously. If they are merely trying to read the data without updating it, this does not cause a problem. However, if two or more users are trying to update a particular record simultaneously, say a bank account balance or the number of available seats on an airline flight, they run the risk of generating what is known as a “concurrencyproblem.” In this situation, the updates can interfere with each other in such a way that the resulting data values will be incorrect. This intolerable possibility must be guarded against and, once again, the database management system must be designed to protect its databases from such an eventuality.
A fundamental premise of the database concept is that these three data control issues—data security, backup and recovery, and concurrency—must be managed by or coordinated with the database management system. This means that when a new application program is written for the database environment, the programmers can concentrate on the details of the application and not have to worry about writing code to manage these data control issues. It means that there is a good comfort level that the potential problems caused by these issues are under control since they are being managed by long-tested components of the DBMS. It means that the functions are standard for all of the data in the environment, which leads to easier management and economies of scale in assigning and training personnel to be responsible for the data. This kind of commonality of control is a hallmark of the database approach.
Data Independence
In the earlier days of “data processing,” many decisions involving the way that application programs were written were made in concert with the specific file designs and the choice of file organization and access method used. The program logic itself was dependent upon the way in which the data is stored. In fact, the “data dependence” was often so strong that if for any reason the storage characteristics of the data had to be changed, the program itself had to be modified, often extensively. That was a very undesirable characteristic of the data storage and programming environments because of the time and expense involved in such efforts. In practice, storage structures sometimes have to change, to reflect improved storage techniques, application changes, attempts at sharing data, and performance tuning, to name a few reasons. Thus, it is highly desirable to have a data storage and programming environment in which as many types of changes in the data structure as possible would not require changes in the application programs that use them. This goal of “data independence” is an objective of today's database management systems.
DBMS APPROACHES
We have established a set of principles for the database concept and said that a database management system is a software utility that embodies those concepts. The next question concerns the nature of a DBMS in terms of how it organizes data and how it permits its retrieval. Considering that the database concept is such a crucial component of the information systems environment and that there must be a huge profit motive tied up with it, you might think that many people have worked on the problem over the years and come up with many different approaches to designing DBMSs. It's true that many very bright people have worked on this problem for a long time but, interestingly, you can count the number of different viable approaches that have emerged on the fingers of one hand. In particular, the central issue of providing a non-redundant data environment that also looks as though it is integrated is a very hard nut to crack. Let's just say that we're fortunate that even a small number of practical ways to solve this problem have been discovered.
Basically, there are four major DBMS approaches:
- Hierarchical
- Network
- Relational
- Object-Oriented
The hierarchical and network approaches to database are both called “navigational” approaches because of the way that programs have to “navigate” through hierarchies and networks of data to find the data they need. Both of these technologies were developed in the 1960s and, relative to the other approaches, are somewhat similar in structure. IBM's Information Management System (IMS), a DBMS based on the hierarchical approach, was released in 1969. It was followed in the early 1970s by several network-based DBMSs developed by such computer manufacturers of the time as UNIVAC, Honeywell, Burroughs, and Control Data. There was also a network-based DBMS called Integrated Data Management Store (IDMS) produced by an independent software vendor originally called Cullinane Systems, which was eventually absorbed into Computer Associates. These navigational DBMSs, which were suitable only for mainframe computers, were an elegant solution to the redundancy/integration problem at the time that they were developed. But they were complex, difficult to work with in many respects, and, as we said, required a mainframe computer. Now often called “legacy systems,” some of them interestingly have survived to this very day for certain applications that require a lot of data and fast data response times.
CONCEPTS IN ACTION
3-B LANDAU UNIFORMS
Landau Uniforms is a premier supplier of professional apparel to the healthcare community, offering a comprehensive line of healthcare uniforms and related apparel. Headquartered in Olive Branch, MS, the company, which dates back to 1938, has continuously expanded its operations both domestically and internationally and today includes corporate apparel among its products. Landau sells its apparel though authorized dealers throughout the U.S. and abroad.
Controlling Landau's product flow in its warehouse is a sophisticated information system that is anchored in database management. Their order filling system, implemented in 2001, is called the Garment Sortation System It begins with taking orders that are then queued in preparation for “waves” of as many as 80 orders to be filled simultaneously. Each order is assigned a bin at the end of a highly automated conveyor line. The garments for the orders are picked from the shelves and placed onto the beginning of the conveyor line. Scanning devices then automatically direct the bar-coded garments into the correct bin. When an order is completed, it is boxed and sealed. The box then goes on another conveyor where it is automatically weighed, a shipping label is printed and attached to it, and it is routed to one of several shipping docks, depending on which shipper is being used. In addition, a bill is automatically generated and sent to the customer. In fact, Landau bills its more sophisticated customers electronically using an electronic data interchange (EDI) system.

“Photo Courtesy of Landau Uniforms”
There are two underlying relational databases. The initial order processing is handled using a DB2 database running on an IBM “i” series computer. The orders are passed on to the Garment Sortation System's Oracle database running on PCs. The shipping is once again under the control of the DB2/“i” series system. The relational tables include an order table, a customer table, a style master table, and, of course, a garment table with 2.4 million records.
The relational database approach became commercially viable in about 1980. After several years of user experimentation, it became the preferred DBMS approach and has remained so ever since. Chapters 4–8 of this book, as well as portions of later chapters, are devoted to the relational approach. The object-oriented approach has proven useful for a variety of niche applications and will be discussed in Chapter 9. It is interesting to note that some key object-oriented database concepts have found their way into some of the mainstream relational DBMSs and some are described as taking a hybrid “object/relational” approach to database.
YOUR TURN
3.2 INTEGRATING DATA
The need to integrate data is all around us, even in our personal lives. We integrate data many times each day without realizing that that's what we're doing. When we compare the ingredients needed for a recipe with the food “inventory” in our cupboards, we are integrating data. When we think about buying something and relate its price to the money we have in our wallets or in our bank accounts or to the credit remaining on our credit cards, we are integrating data. When we compare our schedules with our children's schedules and perhaps those of others with whom we carpool, we are integrating data. Can you think of other ways in which you integrate data on a daily basis?
QUESTION:
Consider a medical condition for which you or someone you know is being treated. Describe the different ways that you integrate data in taking care of that condition. Hints: Consider your schedule, your doctors' schedules, the amount of prescription medication you have on hand, the inventory of medication at the pharmacy you use, and so on.
SUMMARY
There are five major components in the database concept. One is the development of a datacentric environment that promotes the idea of data being a significant corporate resource and encourages the sharing of data. Another, which is really the central premise of database management, is the ability to achieve data integration while at the same time storing data in a non-redundant fashion. The third, which at the structural level is actually closely related to the integration/redundancy paradigm, is the ability to store data representing entities involved in multiple relationships without introducing redundancy. Another component is the presence of a set of data controls that address such issues as data security, backup and recovery, and concurrency control. The final component is that of data independence, the ability to modify data structures without having to modify programs that access them.
There are basically four approaches to database management: the early hierarchical and network approaches, the current standard relational approach, and the specialty object-oriented approach, many features of which are incorporated into today's expanded relational database management systems.
KEY TERMS
Attribute
Backup and recovery
Computer security
Concurrency control
Concurrency problem
Corporate resource
Data control issues
Data dependence
Data independence
Data integration
Data integrity problem
Data redundancy
Data retrieval
Data security
Datacentric environment
Direct access
Enterprise resource planning (ERP) system
Entity
Entity set
Fact
Field
File
Logical sequential access
Manageable resource
Multiple relationships
Physical sequential access
Record
Sequential access
Software utility
Well integrated
QUESTIONS
- What is data? Do you think the word “data” should be treated as a singular or plural word? Why?
- Name some entities and their attributes in a university environment.
- Name some entities and attributes in an insurance company environment.
- Name soe entities and attributes in a furniture store environment.
- What is the relationship between:
- An entity and a record?
- An attribute and a field?
- An entity set and a file?
- What is the difference between a record type and an occurrence of that record? Give some examples.
- Name the four basic operations on stored data. In what important way is one in particular different from the other three?
- What is sequential access? What is direct access? Which of the two is more important in today's business environment? Why?
- Give an example of and describe an application that would require sequential access in:
- The university environment.
- The insurance company environment.
- The furniture store environment.
- Give an example of and describe an application that would require direct access in:
- The university environment.
- The insurance company environment.
- The furniture store environment.
- Should data be considered a true corporate resource? Why or why not? Compare and contrast data to other corporate resources (capital, plant and equipment, personnel, etc.) in terms of importance, intrinsic value, and modes of use.
- Defend or refute the following statement: “Data is the most important corporate resource because it describes all of the others.”
- What are the two kinds of data redundancy, and what are the three types of problems that they cause in the information systems environment?
- What factors might lead to redundant data across multiple files? Is the problem managerial or technical in nature?
- Describe the apparent tradeoff between data redundancy and data integration in simple linear files.
- In your own words, describe the key quality of a DBMS that sets it apart from other data handling systems.
- Do you think that the single-file redundancy problem is more serious, less serious, or about the same as the multifile redundancy problem? Why?
- What are the two defining goals of a database management system?
- What expectation should there be for a database management system with regard to handling multiple relationships? Why?
- What are the problems with the “horizontal” and “vertical” solutions to the handling of multiple relationships as described in the chapter?
- What expectation should there be for a database management system with regard to handling data control issues such as data security, backup and recovery, and concurrency control? Why?
- What would the alternative be if database management systems were not designed to handle data control issues such as data security, backup and recovery, and concurrency control?
- What is data independence? Why is it desirable?
- What expectation should there be for a database management system with regard to data independence? Why?
- What are the four major DBMS approaches? Which approaches are used the most and least today?
EXERCISES
- Consider a hospital in which each doctor is responsible for many patients while each patient is cared for by just one doctor. Each doctor has a unique employee number, name, telephone number, and office number. Each patient has a unique patient number, name, home address, and home telephone number.
- What kind of relationship is there between doctors and patients?
- Develop sample doctor and patient data and construct two files in the style of Figure 3.5 in which to store your sample data.
- Do any fields have to be added to one or the other of the two files to record the relationship between doctors and patients? Explain.
- Merge these two files into one, in the style of Figure 3.6. Does this create any problems with the data? Explain.
- The Dynamic Chemicals Corp. keeps track of its customers and its orders. Customers typically have several outstanding orders while each order was generated by a single customer. Each customer has a unique customer number, a customer name, address, and telephone number. An order has a unique order number, a date, and a total cost.
- What kind of relationship is there between customers and orders?
- Develop sample customer and order data and construct two files in the style of Figure 3.5 in which to store your sample data.
- Do any fields have to be added to one or the other of the two files to record the relationship between customers and orders? Explain.
- Merge these two files into one, in the style of Figure 3.6. Does this create any problems with the data? Explain.
MINICASES
- Answer the following questions based on the following Happy Cruise Lines' data.
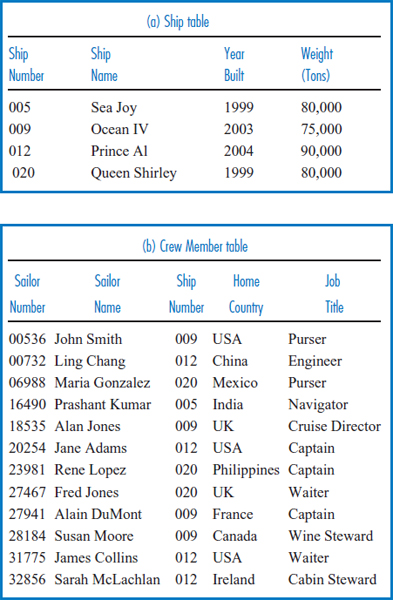
- Regarding the Happy Cruise Lines Crew Member file.
- Describe the file's record type.
- Show a record occurrence.
- Describe the set or range of values that the Ship Number field can take.
- Describe the set or range of values that the Home Country field can take.
- Assume that the records of the Crew Memberfile are physically stored in the order shown.
- Retrieve all of the records of the file physically sequentially.
- Retrieve all of the records of the file logically sequentially based on the Sailor Name field.
- Retrieve all of the records of the file logically sequentially based on the Sailor Number field.
- Retrieve all of the records of the file logically sequentially based on the Ship Number field.
- Perform a direct retrieval of the records with a Sailor Number field value of 27467.
- Perform a direct retrieval of the records with a Ship Number field value of 020.
- Perform a direct retrieval of the records with a Job Title field value of Captain.
- The value 009 appears as a ship number once in the Ship file and four times in the Crew Member file. Does this constitute data redundancy? Explain.
- Merge the Ship and Crew Member files based on the common ship number field (in a manner similar to Figure 3.8 for the General Hardware database). Is the merged file an improvement over the two separate files in terms of:
- Data redundancy? Explain.
- Data integration? Explain.
- Explain why the Ship Number field is in the Crew Member file.
- Explain why ship number 012 appears three times in the Crew Member file.
- How many files must be accessed to find:
- The year that ship number 012 was built?
- The home country of sailor number 27941?
- The name of the ship on which sailor number 18535 is employed?
- Describe the procedure for finding the weight of the ship on which sailor number 00536 is employed.
- What is the mechanism for recording the one-to-many relationship between crew members and ships in the Happy Cruise Lines database above?
- Regarding the Happy Cruise Lines Crew Member file.
- Answer the following questions based on the following Super Baseball League data.
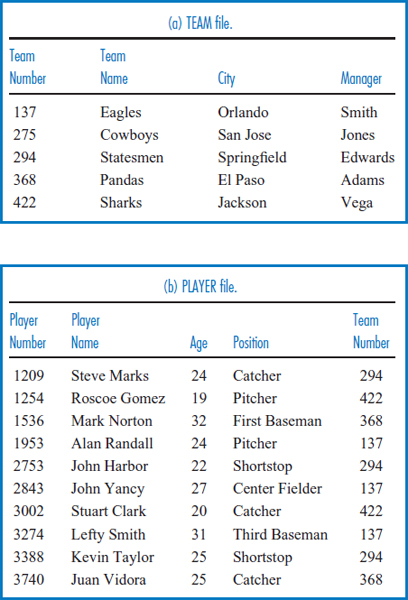
- Regarding the Super Baseball League Player file shown below.
- Describe the file's record type.
- Show a record occurrence.
- Describe the set or range of values that the Player Number field can take.
- Assume that the records of the Player file are physically stored in the order shown.
- Retrieve all of the records of the file physically sequentially.
- Retrieve all of the records of the file logically sequentially based on the Player Name field.
- Retrieve all of the records of the file logically sequentially based on the Player Number field.
- Retrieve all of the records of the file logically sequentially based on the Team Number field.
- Perform a direct retrieval of the records with a Player Number field value of 3834.
- Perform a direct retrieval of the records with a Team Number field value of 20.
- Perform a direct retrieval of the records with an Age field value of 24.
- The value 294 appears as a team number once in the Team file and three times in the Player file. Does this constitute data redundancy? Explain.
- Merge the Team and Player files based on the common Team Number field (in a manner similar to Figure 3.8 for the General Hardware database). Is the merged file an improvement over the two separate tables in terms of:
- Data redundancy? Explain.
- Data integration? Explain.
- Explain why the Team Number field is in the Player file.
- Explain why team number 422 appears twice in the Player file.
- How many files must be accessed to find:
- The age of player number 1953?
- The name of the team on which player number 2288 plays?
- The number of the team on which player number 2288 plays?
- Describe the procedure for finding the name of the city in which player number 3002 is based.
- What is the mechanism for recording the one-to-many relationship between players and teams in the Super Baseball League database, above?
- Regarding the Super Baseball League Player file shown below.