
PhantomJS is a browser, and the basic function of a browser is to access web pages. In this chapter, we will learn various techniques of loading web pages in PhantomJS, and we will explore beyond using it simply as a headless browser.
In a normal browser, opening a web page means typing a URL and letting the browser render the document fetched. It works almost the same way in PhantomJS, except that we don't actually wait for the page to be rendered before our eyes. Everything is done in a non-visual way. We don't see text, high-resolution images, or even animation on the page. We don't see anything that will show up on the screen.
We also do not type the URL in the address bar as we do in a normal browser. We create scripts to load the page. We learned in the previous chapter that to access a URL or a page in PhantomJS, we need to use the WebPage API.
var page = require('webpage').create();
page.open("http://www.packtpub.com", function(status) {
if ( status === "success" ) {
console.log("Page is loaded.");
phantom.exit(0);
}
});And that's how we open a page in PhantomJS. So what now? We don't use PhantomJS just to browse a page, but for more useful tasks such as filtering search results from the Google search engine, extracting Twitter messages and saving them to a file, or performing assertions on objects and text content of the web page for testing and site verification. These are some of the useful features of PhantomJS, and we can do a lot more with it.
Let's try a simple example first, then we will move to a more complex one. We will open a page and display the title of a URL passed as the first argument.
var system = require('system'),
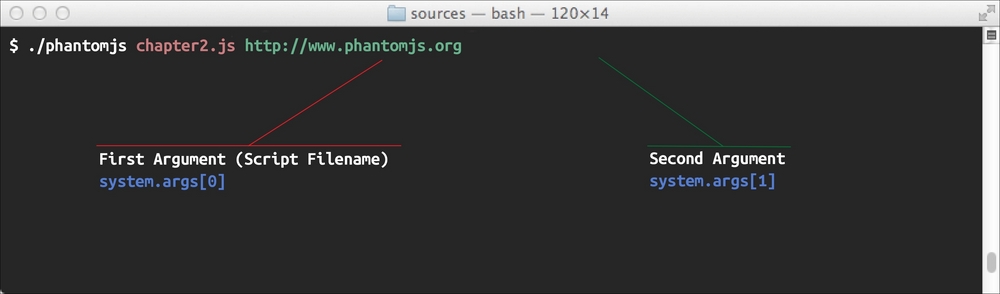
var url = system.args[1];We use the system module to retrieve the arguments. The first argument will always be your script filename, which will be at index 0 of the system arguments. The succeeding arguments are our script arguments, these can be of any use; for our example, we will assume that the second argument is a URL, as shown in the following screenshot:
We will now use that variable to open the page.
var system = require('system'),
var url = system.args[1];
var page = require('webpage').create();
page.open(url, function(status) {
if ( status === "success" ) {
console.log("Page is loaded.");
phantom.exit(0);
}
});In the preceding code, we passed the url variable as the first parameter of the open function of the WebPage API. Now, instead of the message that displays when the page is loaded, we are going to change that to display the title of the page.
page.open(url, function(status) {
if ( status === "success" ) {
var title = page.evaluate(function () {
return document.title;
});
console.log(title);
phantom.exit(0);
}The document or page title can be retrieved from the DOM objects, and to access that in PhantomJS we need to perform code evaluation since it is within the context of the web page. We wrapped our code reference into the web page evaluate() function. Within the context of the page, we can access the document object, and using the DOM API functions and attributes, we extract the title of the page.
Basically, we cannot access DOM objects outside the evaluate() function context. The web page evaluate() function will execute our code on a different context, think that we are having another sandbox within PhantomJS. All of the code evaluated will only exist on that certain block and won't affect or allow us to modify other code outside of it.
With this, we cannot even return the DOM nodes that we manipulate within evaluate() and perform further processing outside of it. We should do all necessary parsing, retrieval of data from DOM, and the manipulation and changing of node values within evaluate(). If we want to return anything outside of the context, it is either with a simple type of data (such as a String), or we should wrap it as JSON-serializable data.
var system = require('system'),
var url = system.args[1];
var page = require('webpage').create();
page.open(url, function(status) {
if ( status === 'success' ) {
var data = page.evaluate(function () {
return {
title: document.title,
numberOfNodes: document.getElementsByTagName('*').length,
documentUrl: document.URL
};
});
console.log('Page Stats'),
console.log('--------------------------------------------------'),
console.log('Title : ' + data.title);
console.log('URL : ' + data.documentUrl);
console.log('Number of Nodes: ' + data.numberOfNodes);
console.log('-----------------------------------------------------'),
}
phantom.exit(0);
});In the preceding code, within the evaluate() function, we created a return in JSON type. JSON syntax in the simplest form must be enclosed within curly braces. The data within the curly braces must have a name followed by a colon, and then the value. Each pair must be delimited with a comma. For example:
{
name: 'Tara',
age: 10
}To learn more about JSON, we can check out its main documentation site at http://json.org/.
The evaluate() function call returns the value of the title instead of a direct call to the console.log() function; the reason for this is that all calls for console message output will be suppressed. There is another technique available to do this, which will be discussed later on.
The data is returned and assigned to the receiving variable, which we then use to display on the web page. This completes our very simple example of retrieving a web page.