
Chapter 12
Protecting Yourself from Google Hackers
Abstract
Protecting yourself from Google Hackers involves building a good, solid security policy, deploying Web server safeguards, hacking your own site, and getting help from Google to safeguard your data.
Keywords
security policy
hacking your own site
links to sites
Google hacking defense
Introduction
The purpose of this book is to help you understand the tactics a Google hacker might employ so that you can properly protect yourself and your customers from this seemingly innocuous threat. The best way to do this, in my opinion, is to show you exactly what an attacker armed with a search engine like Google is capable of. There is a point at which we must discuss in no uncertain terms exactly how to prevent this type of information exposure or how to remedy an existing exposure. This chapter is all about protecting your site (or your customer’s site) from this type of attack.
We’ll look at this topic from several perspectives. First, it’s important that you understand the value of strong policy with regard to posting data on the Internet. This is not a technical topic and could very easily put the techie in you fast asleep, but a sound security policy is absolutely necessary when it comes to properly securing any site. Second, we’ll look at slightly more technical topics that describe how to secure your Web site from Google’s (and other search engine’s) crawlers. We’ll then look at some tools that can be used to help check a Web site’s Google exposure, and we’ll spend some time talking about ways Google can help you shore up your defenses.
There are too many types of servers and configurations to show how to lock them all down. A discussion on Web server security could easily span an entire book series. We’ll look at server security at a high level here, focusing on strategies you can employ to specifically protect you from the Google hacker threat. For more details, please check the references in the Section “Links to Sites.”
A Good Solid Security Policy
The best hardware and software configuration that money can buy can’t protect your resources if you don’t have an effective security policy. Before implementing any software assurances, take the time to review your security policy. A good security policy, properly enforced, outlines the assets you’re trying to protect, how the protection mechanisms are installed, the acceptable level of operational risk, and what to do in the event of a compromise or disaster. Without a solid, enforced security policy, you’re fighting a losing battle.
Web server safeguards
There are several ways to keep the prying eyes of a Web crawler from digging too deeply into your site. However, bear in mind that a Web server is designed to store data that is meant for public consumption. Despite all the best protections, information leaks happen. If you’re really concerned about keeping your sensitive information private, keep it away from your public Web server. Move that data to an intranet or onto a specialized server that is dedicated to serving that information in a safe, responsible, policy-enforced manner.
Don’t get in the habit of splitting a public Web server into distinct roles based on access levels. It’s too easy for a user to copy data from one file to another, which could render some directory-based protection mechanisms useless. Likewise, consider the implications of a public Web server system compromise. In a well-thoughtout, properly constructed environment, the compromise of a public Web server only results in the compromise of public information. Proper access restrictions would prevent the attacker from bouncing from the Web server to any other machine, making further infiltration of more sensitive information all the more difficult for the attacker. If sensitive information were stored alongside public information on a public Web server, the compromise of that server could potentially compromise the more sensitive information as well.
We’ll begin by taking a look at some fairly simple measures that can be taken to lock down a Web server from within. These are general principles; they’re not meant to provide a complete solution but rather to highlight some of the common key areas of defense. We will not focus on any specific type of server but will look at suggestions that should be universal to any Web server. We will not delve into the specifics of protecting a Web application, but rather we’ll explore more common methods that have proven especially and specifically effective against Web crawlers.
Directory Listings and Missing Index Files
We’ve already seen the risks associated with directory listings. Although minor information leaks, directory listings allow the Web user to see most (if not all) of the files in a directory, as well as any lower-level subdirectories. As opposed to the “guided” experience of surfing through a series of prepared pages, directory listings provide much more unfettered access. Depending on many factors, such as the permissions of the files and directories as well as the server’s settings for allowed files, even a casual Web browser could get access to files that should not be public.
Normally, this file (which should be called .htaccess, not htaccess) serves to protect the directory contents from unauthorized viewing. However, a server misconfiguration allows this file to be seen in a directory listing and even read.
Directory listings should be disabled unless you intend to allow visitors to peruse files in an FTP-style. On some servers, a directory listing will appear if an index file (as defined by your server configuration) is missing. These files, such as index.html, index.htm, or default.asp, should appear in each and every directory that should present a page to the user. On an Apache Web server, you can disable directory listings by placing a dash or minus sign before the word Indexes in the httpd.conf file. The line might look something like this if directory listings (or “indexes,” as Apache calls them) are disabled:

Robots.txt: Preventing Caching
The robots.txt file provides a list of instructions for automated Web crawlers, also called robots or bots. Standardized at www.robotstxt.org/wc/norobots.html, this file allows you to define, with a great deal of precision, which files and directories are off-limits to Web robots. The robots.txt file must be placed in the root of the Web server with permissions that allow the Web server to read the file. Lines in the file beginning with a # sign are considered comments and are ignored. Each line not beginning with a # should begin with either a User-agent or a disallow statement, followed by a colon and an optional space. These lines are written to disallow certain crawlers from accessing certain directories or files. Each Web crawler should send a user-agent field, which lists the name or type of the crawler. The value of Google’s user-agent field is Googlebot. To address a disallow to Google, the user-agent line should read:

According to the original specification, the wildcard character * can be used in the user-agent field to indicate all crawlers. The disallow line describes what, exactly; the crawler should not look at. The original specifications for this file were fairly inflexible, stating that a disallow line could only address a full or partial URL. According to that original specification, the crawler would ignore any URL starting with the specified string. For example, a line like Disallow: /foo would instruct the crawler to ignore not only /foo but /foo/index.html, whereas a line like Disallow: /foo/ would instruct the crawler to ignore /foo/index.html but not /foo, since the slash trailing foo must exist. For example, a valid robots.txt file is shown here:

This file indicates that no crawler is allowed on any part of the site – the ultimate exclude for Web crawlers. The robots.txt file is read from top to bottom as ordered rules. There is no allow line in a robots.txt file. To include a particular crawler, disallow its access to nothing. This might seem like backward logic, but the following robots.txt file indicates that all crawlers are to be sent away except for the crawler named Palookaville:
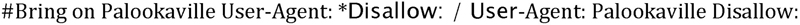
Notice that there is no slash after Palookaville’s disallow. (Norman Cook fans will be delighted to notice the absence of both slashes and dots from anywhere near Palookaville.) Saying that there’s no disallow is like saying that user agent is allowed – sloppy and confusing, but that’s the way it is.
Google allows for extensions to the robots.txt standard. A disallow pattern may include * to match any number of characters. In addition, a $ indicates the end of a name. For example, to prevent the Googlebot from crawling all your PDF documents, you can use the following robots.txt file:

Once you’ve gotten a robots.txt file in place, you can check its validity by visiting the Robots.txt Validator at www.sxw.org.uk/computing/robots/check.html.
Hackers don’t have to obey your robots.txt file. In fact, Web crawlers really don’t have to either, although most of the big-name Web crawlers will, if only for the “CYA” factor. One fairly common hacker trick is to view a site’s robots.txt file first to get an idea of how files and directories are mapped on the server. In fact a quick Google query can reveal lots of sites that have had their robots.txt files crawled. This, of course, is a misconfiguration, because the robots.txt file is meant to stay behind the scenes.
NOARCHIVE: The Cache “Killer”
The robots.txt file keeps Google away from certain areas of your site. However, there could be cases where you want Google to crawl a page, but you don’t want Google to cache a copy of the page or present a “cached” link in its search results. This is accomplished with a META tag. To prevent all (cooperating) crawlers from archiving or caching a document, place the following META tag in the HEAD section of the document:

If you prefer to keep only Google from caching the document, use this META tag in the HEAD section of the document:

Any cooperating crawler can be addressed in this way by inserting its name as the META NAME. Understand that this rule only addresses crawlers. Web visitors (and hackers) can still access these pages.
NOSNIPPET: Getting Rid of Snippets
A snippet is the text listed below the title of a document on the Google results page. Providing insight into the returned document, snippets are convenient when you’re blowing through piles of results. However, in some cases, snippets should be removed. Consider the case of a subscription-based news service. Although this type of site would like to have the kind of exposure that Google can offer, it needs to protect its content (including snippets of content) from nonpaying subscribers. Such a site can accomplish this goal by combining the NOSNIPPET META tag with IP-based filters that allow Google’s crawlers to browse content unmolested. To keep Google from displaying snippets, insert this code into the document:

An interesting side effect of the NOSNIPPET tag is that Google will not cache the document. NOSNIPPET removes both the snippet and the cached page.
Password-Protected Mechanisms
Google does not fill in user authentication forms. When presented with a typical password form, Google seems to simply back away from that page, keeping nothing but the page’s URL in its database. Although it was once rumored that Google bypasses or somehow magically side-steps security checks, those rumors have never been substantiated. These incidents are more likely an issue of timing.
If Google crawls a password-protected page either before the page is protected or while the password protection is down, Google will cache an image of the protected page. Clicking the original page will show the password dialog, but the cached page does not – providing the illusion that Google has bypassed that page’s security. In other cases, a Google news search will provide a snippet of a news story from a subscription site, but clicking the link to the story presents a registration screen. This also creates the illusion that Google somehow magically bypasses pesky password dialogs and registration screens.
If you’re really serious about keeping the general public (and crawlers like Google) away from your data, consider a password authentication mechanism. A basic password authentication mechanism, htaccess, exists for Apache. An htaccess file, combined with an htpasswd file, allows you to define a list of username/password combinations that can access specific directories. You’ll find an Apache htaccess tutorial at http://httpd.apache.org/docs/howto/ htac-cess.html, or try a Google search for htaccess howto.
Software default settings and programs
As we’ve seen throughout this book, even the most basic Google hacker can home in on default pages, phrases, page titles, programs, and documentation with very little effort. Keep this in mind and remove these items from any Web software you install. It’s also good security practice to ensure that default accounts and passwords are removed as well as any installation scripts or programs that were supplied with the software. Since the topic of Web server security is so vast, we’ll take a look at some of the highlights you should consider for a few common servers.
It certainly sounds like a cliché in today’s security circles, but it can’t be stressed enough: If you choose to do only one thing to secure any of your systems, it should be to keep up with and install all the latest software security patches. Misconfigurations make for a close second, but without a firm foundation, your server doesn’t stand a chance.
Hacking your own site
Hacking into your own site is a great way to get an idea of its potential security risks. Obviously, no single person can know everything there is to know about hacking, meaning that hacking your own site is no replacement for having a real penetration test performed by a professional. Even if you are a pen tester by trade, it never hurts to have another perspective on your security posture. In the realm of Google hacking, there are several automated tools and techniques you can use to give yourself another perspective on how Google sees your site. We’ll start by looking at some manual methods, and we’ll finish by discussing some automated alternatives.
As we’ll see in this chapter, there are several ways a Google search can be automated. Google frowns on any method that does not use its supplied Application Programming Interface (API) along with a Google license key. Assume that any program that does not ask you for your license key is running in violation of Google’s terms of service and could result in banishment from Google. Check out www.google.com/accounts/TOS for more information. Be nice to Google and Google will be nice to you!
Site Yourself
We’ve talked about the site operator throughout the book, but remember that site allows you to narrow a search to a particular domain or server. If you’re Sullo, the author of the (most impressive) NIKTO tool and administrator of cirt.net, a query like site:cirt.net will list all Google’s cached pages from your cirt.net server.
You could certainly click each and every one of these links or simply browse through the list of results to determine if those pages are indeed supposed to be public, but this exercise could be very time consuming, especially if the number of results is more than a few hundred.
Wikto
Wikto is an amazing Web scanning tool written by Roloef Temmingh while he was with Sensepost (www.sensepost.com). Wikto does many different things, but since this book focuses on Google hacking, we’ll take a look at the Google scanning portions of the tool. By default, Wikto launches a wizard interface. Wikto will first prompt for the target you wish to scan, as well as details about the target server. Clicking the Next button loads the Configuration panel. This panel prompts for proxy information and asks for your Google API key. The API issue is tricky, as Google is no longer giving out SOAP API keys. If you already have a SOAP API key, lucky you.
Notice that the output fields list files and directories that were located on the target site. All of this information was gathered through Google queries, meaning the transactions are transparent to the target. Wikto will use this directory and file information in later scanning stages.
Next, we’ll take a look at the GoogleHacks tab.
This scanning phase relies on the Google Hacking Database. Clicking the Load Google Hacks Database will load the most current version of the GHDB, providing Wikto with thousands of potentially malicious Google queries. Once the GHDB is loaded, pressing the Start button will begin the Google scan of the target site. What’s basically happening here is Wikto is firing off tons of Google queries, each with a site operator which points to the target Web site. The GHDB is shown in the upper panel, and any results are presented in the lower panel. Clicking on a result in the lower panel will show the detailed information about that query (from the GHDB) in the middle panel.
In addition to this automated scanning process, Wikto allows you to perform manual Google queries against the target through the use of the Manual Query button and the associated input field.
Wikto is an amazing tool with loads of features. Combined with GHDB compatibility, Wikto is definitely the best Google hacking tool currently available.
Advance dork
Advanced Dork is an extension for Firefox and Mozilla browsers, which provides Google Advanced Operators for use directly from the right-click context menu. Written by CP, the tool is available from https://addons.mozilla.org/en-US/firefox/addon/2144.
Like all Firefox extensions, installation is a snap: simply click the link to the .xpi file from within Firefox and the installation will launch.
Advanced Dork is context sensitive – right-clicking will invoke Advanced Dork based on where the right-click was performed. For example, right-clicking on a link will invoke link-specific options.
Right-clicking on a highlighted text will invoke the highlighted text search mode of Advanced Dork
This mode will allow you to use the highlighted word in an intitle, inurl, intext, site or ext search. Several awesome options are available to Advanced Dork.
Advanced Dork is an amazing tool for any serious Google user. You should definitely add it to your arsenal.
Getting help from Google
So far we’ve looked at various ways of checking your site for potential information leaks, but what can you do if you detect such leaks? First and foremost, you should remove the offending content from your site. This may be a fairly involved process, but to do it right, you should always figure out the source of the leak, to ensure that similar leaks don’t happen in the future. Information leaks don’t just happen; they are the result of some event that occurred. Figure out the event, resolve it, and you can begin to stem the source of the problem. Solving the local problem is only half the battle. In some cases, Google has a cached copy of your information leak just waiting to be picked up by a Google hacker.
Summary
The subject of Web server security is too big for any one book. There are so many varied requirements combined with so many different types of Web server software, application software, and operating system software that not a single book could do justice to the topic. However, a few general principles can at least help you prevent the devastating effects a malicious Google hacker could inflict on a site you’re charged with protecting.
First, understand how the Web server software operates in the event of an unexpected condition. Directory listings, missing index files, and specific error messages can all open up avenues for offensive information gathering. Robots.txt files, simple password authentication, and effective use of META tags can help steer Web crawlers away from specific areas of your site. Although Web data is generally considered public, remember that Google hackers might take interest in your site if it appears as a result of a malicious Google search. Default pages, directories and programs can serve as an indicator that there is a low level of technical know-how behind a site. Servers with this type of default information serve as targets for hackers. Get a handle on what, exactly; a search engine needs to know about your site to draw visitors without attracting undue attention as a result of too much exposure. Use any of the available tools, such as Gooscan, Wikto, Advanced Dork, to help you search Google for your site’s information leaks. If you locate a page that shouldn’t be public, use Google’s removal tools to flush the page from Google’s database.
Fast track solutions
A Good, Solid Security Policy
▪ An enforceable, solid security policy should serve as the foundation of any security effort.
▪ Without a policy, your safeguards could be inefficient or unenforceable.
Web Server Safeguards
▪ Directory listings, error messages, and misconfigurations can provide too much information.
▪ Robots.txt files and specialized META tags can help direct search engine crawlers away from specific pages or directories.
▪ Password mechanisms, even basic ones, keep crawlers away from protected content.
▪ Default pages and settings indicate that a server is not well maintained and can make that server a target.
Hacking Your Own Site
▪ Use the site operator to browse the servers you’re charged with protecting. Keep an eye out for any pages that don’t belong there.
▪ Use a tool like Gooscan, or Advanced Dork to assess your exposure. These tools do not use the Google API, so be aware that any blatant abuse or excessive activity could get your IP range cut off from Google.
▪ Use a tool like Wikto, which uses the Google API and should free you from fear of getting shut down.
▪ Use the Google Hacking Database to monitor the latest Google hacking queries. Use the GHDB exports with tools like Gooscan, or Wikto.
Getting Help from Google
▪ Use Google’s Webmaster page for information specifically geared toward Webmasters.
▪ Use Google’s URL removal tools to get sensitive data out of Google’s databases.
Links to sites
▪ http://www.exploit-db.com/google-dorks/ – The home of the Google Hacking Database (GHDB), the search engine hacking forums, the Gooscan tool, and the GHDB export files.
▪ http://www.seorank.com/robots-tutorial.htm – A good tutorial on using the robots.txt file.
▪ http://googleblog.blogspot.com/2007/02/robots-exclusion-protocol .html – Information about Google’s Robots policy.
▪ https://addons.mozilla.org/en-US/firefox/addon/2144 – Home of Cp’s Advanced Dork
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.