
2
Components of Cypher
Cypher is a declarative query language that makes it easy to write expressive and efficient queries to traverse, update, and administer a graph database. It provides a powerful way to express even complex graph traversals more simply so that you can concentrate on the domain aspects of your query instead of worrying about syntax.
Cypher expands upon a variety of established practices for querying. For example, the WHERE, ORDER BY, and CASE keywords are inspired by SQL syntax. Some of the list semantics are borrowed from Haskell and Python.
This chapter introduces the Cypher syntax with some examples. We will review the important aspects of the Cypher syntax and semantics in building graph traversal queries. We will discuss important keywords and the role they play in building the queries. We will take a look at the graph data model and how Cypher queries follow the data connections.
In this chapter, we will cover these aspects:
- Graph storage in Neo4j
- Using the Cypher syntax
- Using the nodes syntax
- Using the relationships syntax
- Working with Cypher keywords
Technical requirements
We should have Neo4j Desktop installed and have created a local instance. There are no special technical skills required to follow the concepts discussed in this chapter. Having knowledge of SQL can be useful in understanding Cypher, but is not required.
Graph storage in Neo4j
Before we look into the Cypher syntax to query the data, it is important to understand how the data is persisted as a graph. Data diagram representations give a good idea about how the Cypher queries can be written using the data model. We will take a look at a data diagram and see how it helps us with querying:
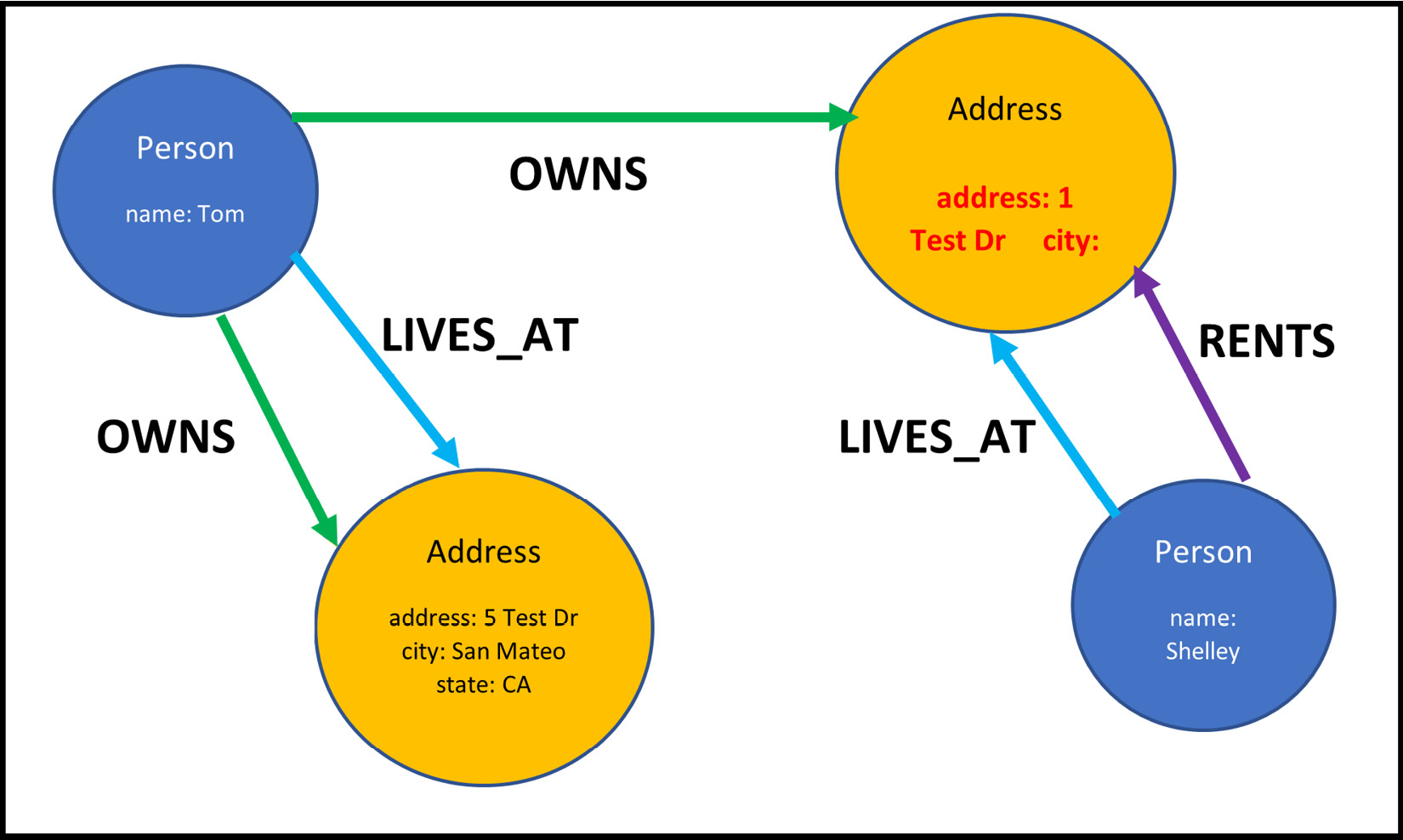
Figure 2.1 – Sample graph data diagram
This diagram shows how the data is stored in the database. Each node represents one entity that knows what relationship entities it is connected to and whether they are incoming or outgoing; each property is an entity that is associated with a node or relationship. Each relationship entity knows what nodes it is connected to and the direction of the relationship.
The preceding diagram tells us that a person named Tom owns two addresses. This person lives at one address and rents the other one. A person named Shelley lives at an address that is rented. If you read this diagram from the address perspective, it can be seen that the 1 Test Dr address is owned by Tom and is rented by Shelley, and the 5 Test Dr address is owned by Tom who also lives at that address.
If the preceding data diagram were represented as a graph data model, it would look like this:
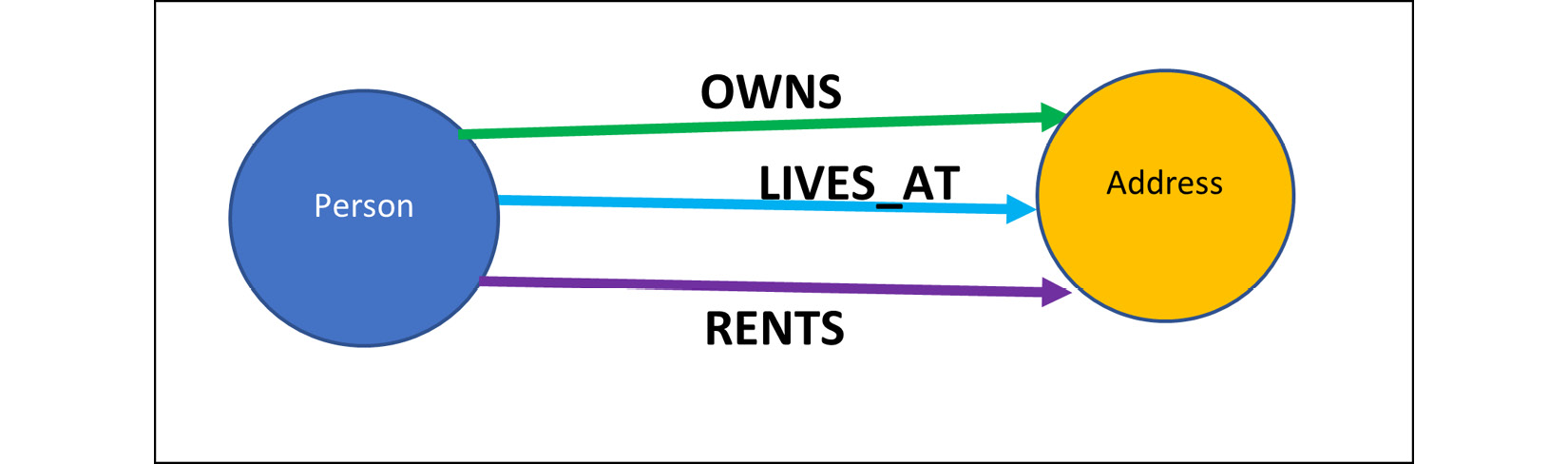
Figure 2.2 – Sample graph data model
This diagram shows what possible relationships can exist between given node types. In real data, these relationships need not exist for all nodes. A graph data model shows how the data can be connected and can provide a starting point for building graph traversals using Cypher queries.
Using the Cypher syntax
Cypher is like American Standard Code for Information Interchange (ASCII) art. A simple Cypher traversal query can look like this:
(A)-[:LIKES]->(B), (B)-[:LIKES]->(C), (A)-[:LIKES]->(C)
This also can be written as follows:
(A)-[:LIKES]->(B)-[:LIKES]->(C)<-[:LIKES]-(A)
If you notice the syntax, it reads more like a simple statement. A likes B, who likes C, who is also liked by A. Nouns represent nodes and verbs represent relationships.
Cypher supports various data types, which fall into three different categories.
Property types
The following are the different property types available in Cypher:
- Number:
- Integer
- Float
- String
- Boolean
- Spatial:
- Point
- Temporal:
- Date
- Time
- LocalTime
- DateTime
- LocalDateTime
- Duration
Property types can have the following characteristics.
- Can be a part of data returned by queries
- Can be used as input parameters
- Can be stored as properties on nodes or relationships
Let’s move on to the structural types available in Cypher.
Structural types
The following are the different structural types:
- Node
- Relationship
- Path
Let’s now move on to the composite types.
Composite types
The following are the different composite types:
- List
- Map
Now that we have reviewed the basic syntax of Cypher queries and property types, let’s look at the nodes syntax.
Using the nodes syntax
In Cypher, a node is surrounded by parentheses, (), making it resemble a circle in a diagram. Here are some example usages in Cypher:
- (p) – This represents a node identified with the p variable/alias. It can be of any type.
- () – This represents a node that is not assigned a variable or an alias. This is normally called an anonymous node, as it cannot be referenced later, except as part of a path.
- (:Person) – This represents a node with the Person label, but is not assigned to a variable or an alias.
- (p:Person) – This represents a node with a Person label, identified with the p variable/alias.
- (l:Location:Work) – This represents a node with multiple labels, Location and Work, identified with the l variable/alias.
Let’s move on to the relationships syntax.
Using the relationships syntax
In Cypher, a relationship can be represented using -->, which resembles an arrow on a diagram. Here are some example usages in Cypher:
- (p)-[:LIVES_AT]->(a) – This represents that the node identified by p is connected to another node, a, with a LIVES_AT relationship type. The direction of the relationship is from p to a.
- (p)-[r]->(a) – This represents that the node identified by p is connected to another node, a, with the direction of the relationship going from p to a. They can be connected via any relationship type. The relationship is assigned to the r variable/alias.
- (p)<-[r]-(a) – This represents that the node identified by p is connected to another node, a, with the direction of the relationship going from a to p. The nodes can be connected via any relationship type and the relationship is assigned to the r variable/alias.
- (p)-[r]-(a) – This represents that the node identified by p is connected to another node, a, with the direction of the relationship going either from p to a or from a to p. The nodes can be connected via any relationship type and the relationship is assigned to the r variable/alias.
- (p)-->(a) – This represents that the node identified by p is connected to another node, a, with the direction of the relationship going from p to a. The nodes can be connected via any relationship type. The relationship itself is not associated with any variable or alias. This is called an anonymous relationship.
Now that we have taken a look at the Cypher syntax and data types available, we will take a look at the keywords available in Cypher to build the queries.
Working with Cypher keywords
In this section, we will introduce the Cypher keywords and their syntax. Detailed usage of these keywords will be covered in upcoming sections of the book.
Let us start by using the MATCH and OPTIONAL MATCH keywords.
Using MATCH and OPTIONAL MATCH
The MATCH keyword allows you to specify the graph traversal patterns to find and return the data from Neo4j. It is most often coupled with a WHERE clause to filter out the results, and a RETURN clause to return the results.
- This shows a basic MATCH query that will find all nodes in the database and return them. It will also return all the node properties shown as follows:
MATCH (n)
RETURN n
- This query finds all the nodes that have the Movie label and returns the title property of that node. If there are no nodes with the Movie label, it does not return any results:
MATCH (n:Movie)
RETURN n.title
- This query finds any node that has the title property, checks whether its value is My Movie, and if so, returns a property named released. You can see here that there is no label mentioned in the query. This means we are looking at all the nodes that have the title property:
MATCH (n {title: 'My Movie' } )RETURN n.released
Caution
This is the most common mistake made in the early phases of learning Cypher. This query can cause a lot of issues to the DB server and should be avoided. We will discuss this more in the later sections.
- The following query will behave the same as the previous one. The only difference here is that the query is using an explicit WHERE condition, whereas the earlier query is using an implicit WHERE condition:
MATCH (n)
WHERE n.title = 'My Movie'
RETURN n.released
The OPTIONAL MATCH clause works similarly to MATCH with the exception that when there is no data matching the pattern specified, it will not stop the execution and returns null as result. In SQL terms, you can think of it like LEFT JOIN.
Let’s go through a few OPTIONAL MATCH clause examples below:
- This query returns data only if the database has nodes with the Movie label:
MATCH (n:Movie)
RETURN n.title
- This query will return at least a single value. If there are nodes with the Movie label, then the title property of those nodes is returned. If there are no Movie nodes, then a null value is returned:
OPTIONAL MATCH (n:Movie)
RETURN n.title
The MATCH clause will stop the query execution and returns no results if any of the MATCH segments do not return data. OPTIONAL MATCH will continue the next steps and return the data.
The following queries explain that behavior:
- If the database does not contain nodes with Movie or Person labels, then this query will not return any results. If nodes with these labels are present, then you will see a Cartesian product of those values:
MATCH (m:Movie)
MATCH (p:Person)
RETURN m.title, p.name
- In this query, if there are no nodes with the Movie label, then no results are returned. If the Movie nodes do exist but there are no nodes with the Person label, then the query would still return the results with p.name as null for each row:
MATCH (m:Movie)
OPTIONAL MATCH (p:Person)
RETURN m.title, p.name
- In this query, if no nodes with the Movie or Person labels exist, then a single row with null values is returned. If there are nodes with either a Movie or Person label, then the Cartesian product of those node values is returned:
OPTIONAL MATCH (m:Movie)
OPTIONAL MATCH (p:Person)
RETURN m.title, p.name
- This query shows the syntax of how you can traverse a path and return values of interest. If you notice here, we are accessing the Movie node as an anonymous node as we are not returning its values. We are starting from the Movie node and traversing the incoming ACTED_IN relationship and returning the names of the nodes it is connected to:
MATCH (:Movie {title:'Wall Street'})<-[:ACTED_IN]-(actor)RETURN actor.name
Let us continue with creating and deleting data from the graph using the CREATE and DELETE keywords.
Using CREATE and DELETE
The CREATE clause will let you create new nodes and relationships:
- This query creates a node with the Person label and a name property and returns the node:
CREATE (p:Person {name: 'Tom'})RETURN p
- This query creates a node without a label but with a property called name, and returns the node:
CREATE (p {name: 'Tom'})RETURN p
Caution
This is another common mistake. In Neo4j, labels are optional. By using this query, we create nodes without any labels, and querying for them would be very inefficient.
- This query creates a node with the Person label and a name property with the value of Tom. It has a node with the Address label, and properties of city with the value of New York and country with the value of USA, and a relationship named LIVES_AT between these nodes:
CREATE (p:Person {name:'Tom'})-[:LIVES_AT]->
(:Address {city:'New York', country:'USA'})
Note
This query does not have a RETURN clause. For CREATE statements, RETURN is optional.
We will look at the usage of DELETE next:
- The DELETE clause will let you delete nodes and relationships. This query finds a Person node named Tom and deletes it from the database. This can fail if this node has any relationships:
MATCH (p:Person {name: 'Tom'})DELETE p
This query finds a Person node with the name Tom and deletes the node and all the relationships this node is attached to from the database.
MATCH (p:Person {name:'Tom'})
DETACH DELETE pThis query deletes all the relationships with the LIVES_AT type for the Person node with the name Tom, keeping the node as it is.
MATCH (:Person {name:'Tom'})-[r:LIVES_AT]->()
DELETE rCaution
If the node is connected to many relationships, this can have a negative impact on the database. We will discuss options to do this safely in the upcoming sections.
This query deletes all the nodes and relationships in the database.
MATCH (n) DETACH DELETE n
Caution
Depending on how much data is in the database, this query can cause Out of Memory exceptions. We will discuss options for safe bulk deletion in the upcoming sections.
Let us continue with manipulating properties on nodes and relationships using the SET and REMOVE keywords.
SET and REMOVE
The SET clause allows us to set the properties or labels on a node or set the properties on relationships. It can be used in conjunction with the MATCH or CREATE clauses:
- This query finds the Person node named Tom and sets the age to 20:
MATCH (n:Person {name:'Tom'})SET n.age = 20
- This query finds the Person node named Tom and adds the additional label, Actor, to it:
MATCH (n:Person {name:'Tom'})SET n:Actor
- This query finds the Person nodes named Tom and Joe and copies the properties from Tom to Joe:
MATCH (n:Person {name:'Tom'})MATCH (o:Person {name:'Joe'})SET o=n
The REMOVE clause is used to remove or delete properties from nodes or relationships. It can also remove labels from nodes:
- This query finds a Person node that has the Actor label and is named Tom and removes the Actor label from the node:
MATCH (n:Person:Actor {name:'Tom'})REMOVE n:Actor
- This query finds the Person node named Tom and removes the age property from the node:
MATCH (n:Person {name:'Tom'})REMOVE n.age
Let us continue with filtering data using WHERE and other keywords.
Using WHERE, SKIP, LIMIT, and ORDER BY
The WHERE clause is how we can use filter the data in Cypher. Cypher provides options for both an implicit WHERE qualifier and an explicit WHERE clause:
- This is an implicit WHERE usage in Cypher. This makes our query read more like an English statement. One limitation of this usage is that it can only be used for exact property matches. It cannot be used with range checking or Boolean expressions:
MATCH (n:Person {name:'Tom'})RETURN n.age
In explicit WHERE usage, you get a lot more control over the expressions:
- We can see in this query how a complex Boolean expression can be used in the WHERE clause. All the Boolean operators, such as OR, AND, NOT, and XOR, are supported. Also, this query uses alias names for the returned values using the AS keyword:
MATCH (n:Person)
WHERE
n.name = 'Peter'
XOR (n.age < 30 AND n.name = 'Timothy')
OR NOT (n.name = 'Timothy' OR n.name = 'Peter')
RETURN
n.name AS name,
n.age AS age
- This query shows how to filter nodes using a label. It is returning all nodes that are labeled Swedish. The second one shows another way to write the same query:
// Explicit WHERE label check
MATCH (n)
WHERE n:Swedish
RETURN n.name, n.age
// Implicit WHERE label check. Most common usage
MATCH (n:Swedish)
RETURN n.name, n.age
- The following queries show how to use range values in the WHERE clause. The first query is to find all the Person nodes whose age is less than 50. The second query is to find all the Person nodes whose age is between 30 and 60:
// Range query with less than a value
MATCH (n:Person)
WHERE n.age < 50
RETURN n.name, n.age
// Range query with in between values
MATCH (n:Person)
WHERE 30 < n.age < 60
RETURN n.name, n.age
// This query shows how to check for property
// existence. This finds all Person nodes which have // title property.
MATCH (n:Person)
WHERE n.title IS NOT NULL
RETURN n.name, n.title
- This query shows all the Person nodes that do not have the title property and returns the names of those nodes:
MATCH (n:Person)
WHERE n.title IS NULL
RETURN n.name
- You can use a WHERE clause on relationships also. The first query shows the explicit usage of a WHERE clause. The second query shows the implicit usage of a WHERE clause. The usage is the same as with node properties:
// Explict WHERE condition
MATCH (n:Person)
-[k:KNOWS]->(f)
WHERE k.since < 2000
RETURN f.name
// Implicit WHERE condition
MATCH (n:Person)
-[k:KNOWS {since: 2000}]->(f)RETURN f.name
- This query shows how to use string operations in the WHERE clause. This query finds all Person nodes whose name starts with Tom. The other available string operators are ENDS WITH and CONTAINS:
MATCH (n:Person)
WHERE n.name STARTS WITH 'Tom'
RETURN n.name, n.age
- These queries show the usage of regular expressions in a WHERE clause. The second query shows how to escape the patterns in regular expressions:
MATCH (n:Person)
WHERE n.email =~ '.*\.com'
RETURN n.name, n.age, n.email
- If you want to have case-insensitive regular expressions, you can prepend the regular expression with (?i). This query can return a Person node named Andy, and so on:
MATCH (n:Person)
WHERE n.name =~ '(?i)ANDY.*'
RETURN n.name, n.age
- This query shows how you can use path expressions in the WHERE clause. This query finds the Person node Tom, and Andy and/or Bob who are connected to Tom; it returns the ages of Andy and/or Bob. This query also shows the usage of the IN operator with a list of possible values:
MATCH
(tom:Person {name: 'Tom'}),(other:Person)
WHERE
other.name IN ['Andy', 'Bob']
AND (other)(tom)
RETURN other.name, other.age
- This query uses a pattern with a NOT expression. This query returns the names and ages of all Person nodes who are not connected to Tom via an outgoing relationship:
MATCH
(person:Person),
(tom:Person {name: 'Tom'})WHERE NOT (person)-->(tom)
RETURN person.name, person.age
- This query shows how we can use the WHERE clause to find all outgoing relationships for Tom that start with C:
MATCH (n:Person)-[r]->()
WHERE n.name='Tom' AND type(r) =' 'C.*'
RETURN type( r ), r.since
Note
While this is valid syntax, its usage should be limited, as it may lead to non-performant queries. It should be limited to scenarios where you might not know all existing relationship names or relationship names can be dynamic.
In WHERE clauses, you can also use existential subqueries. The syntax of these queries looks like this:
EXISTS {
MATCH [Pattern]
WHERE [Expression]
}This allows you to specify a subquery as an expression. The WHERE clause in the subquery is optional, shown as follows.
- This query finds all Person nodes that have a HAS_DOG relationship connected to a Dog node:
MATCH (person:Person)
WHERE EXISTS {MATCH (person)-[:HAS_DOG]->(:Dog)
}
RETURN person.name AS name
- This query returns the names of every Person who has a HAS_DOG relationship connected to a Dog node, further specifying that the person and dog have the same name:
MATCH (person:Person)
WHERE EXISTS {MATCH (person)-[:HAS_DOG]->(dog:Dog)
WHERE person.name = dog.name
}
RETURN person.name AS name
Existential subqueries can also be nested.
Let us continue manipulating data using the MERGE keyword.
Using MERGE
A MERGE clause is an upsert operation. It will check for the existence of the node or path and if it doesn’t exist, it tries to create the node or path as applicable:
- This query creates a Person node if one does not already exist:
MERGE (p:Person)
RETURN p
Note
Remember this creates only one node. When you run this multiple times, it does not create multiple nodes.
The MERGE operation is not thread-safe. If you run the same query in parallel in multiple threads, it can create multiple nodes. To avoid this, you should use constraints.
MERGE is often used to make sure we do not create duplicate nodes and relationships in the database:
- This query makes sure there is only one Person node that exists in the database named Tom and aged 30. This is the most common usage of the MERGE clause. You should try to use the node primary key values only with the MERGE statement:
MERGE (p:Person {name: 'Tom', age: 30})RETURN p
At runtime, a MERGE statement lets us know whether a new node is being created or whether a handle to an existing node is returned. We can identify these scenarios using ON CREATE and ON MATCH clauses in conjunction with a MERGE clause. Both of those clauses are optional:
- If a Person node for Tom did not exist when the query was executed, a created property is set to the current timestamp. If the node did already exist (i.e., was created earlier), the updated property of the node is set to the current timestamp:
MERGE (p:Person {name: 'Tom', age: 30})ON CREATE
SET p.created = timestamp()
ON MATCH
SET p.updated = timestamp()
RETURN p
- This query does the following:
- Checks whether the person named Tom exists
- Checks whether the person named Andy exists
- Checks whether there is a KNOWS relationship between them
If any of these conditions is false, it will create a Person node named Tom, a Person node named Andy, and a KNOWS relationship between those nodes. The MERGE clause will try to create the whole path as it is provided. It is immaterial whether a Person node named Tom or Andy already exists. If you had a unique constraint on the name and if any of the nodes already existed, then this query would fail with a constraint error. If all the conditions are false or all of them true, then there won’t be any error:
MERGE (tom:Person {name: 'Tom'})
-[:KNOWS]->
(andy:Person {name: 'Andy'})- If you had a name unique constraint on the Person node, then this approach would not raise any errors.
This query follows these steps:
- If a person named Tom does not exist, it creates a Person node
- If a person named Andy does not exist, it creates a Person node
- If there is no KNOWS relationship between these Person nodes, then it creates one:
MERGE (tom:Person {name: 'Tom'})MERGE (andy:Person {name: 'Andy'})MERGE (tom)-[:KNOWS]->(andy)
For the MERGE clause, if you pass a variable as part of the path, it will not try to recreate that node.
Note
You should be very careful with MERGE to make sure you do not create multiple nodes and relationships. For that, you should understand PATH MERGE as explained previously to make sure you do not get errors with MERGE statements or create duplicated nodes. Also, note that the MERGE clause cannot be used with an explicit WHERE clause.
Let us continue with iterating the lists using the FOREACH keyword.
Using FOREACH
A FOREACH clause will let you iterate over a list of values and perform write operations using CREATE, MERGE, DELETE, SET, or REMOVE clauses. You cannot use a MATCH clause within a FOREACH clause:
- Assuming nodesList contains a list of nodes, this query will iterate over each node and set its marked property to true:
FOREACH(
n in nodesList |
SET n.marked = true
)
Let us continue with other means of iterating the lists using UNWIND.
Using UNWIND
An UNWIND clause converts a list into rows so that each entry can be processed:
- When you run this query, you will get four rows in the response, as shown here:
WITH [1,2,3,4] as list
UNWIND list as x
RETURN x
Let’s visualize the output:
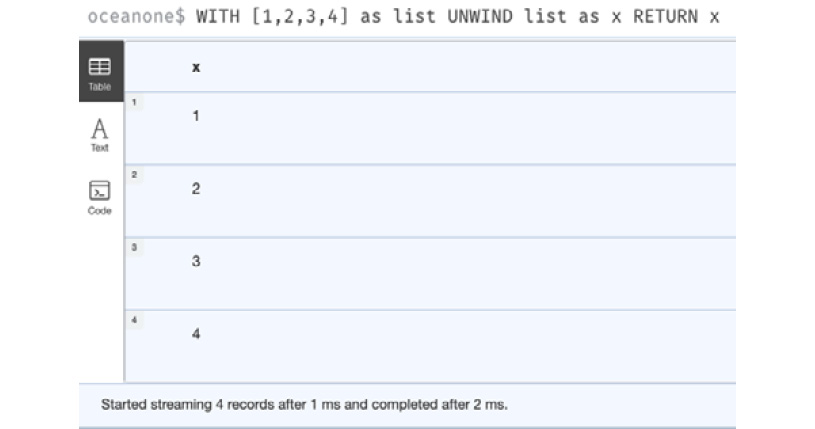
Figure 2.3 – UNWIND usage
Most of the time, an UNWIND clause is used to load batches of data into Neo4j. An example usage of this is shown next.
- This query takes a list of event maps and processes one map at a time to create year and event nodes based on the data in the map. If the list contains 100 records, then the highlighted section is executed once per record – a total of 100 times:
UNWIND $events AS event
MERGE (y:Year {year: event.year})MERGE (y)<-[:IN]-(e:Event {id: event.id})RETURN e.id AS x ORDER BY x
Note
As mentioned, this is the most common pattern used to load data in batches from a client. Also, you can notice here a PATH MERGE operation.
Next, let us take a look at returning data from queries using RETURN and other keywords, such as WITH, RETURN, ORDER BY, SKIP, and LIMIT.
A WITH clause allows queries to be chained together, making sure that the results from one query are piped to the next as starting data points for the next query.
A RETURN clause is the last part of the query.
ORDER BY, SKIP, and LIMIT clauses can be used with either WITH or RETURN clauses:
- In this query, we start with the Person node named Tom and all the Person nodes he knows, filter those nodes using a WITH clause to those whose name starts with An, and return the name and age of those persons ordered by age in descending order:
MATCH (tom:Person {name: 'Tom'})-[:KNOWS]->(other)
WITH other
WHERE other.name STARTS WITH 'An'
RETURN other.name as otherName, other.age as age
ORDER BY age DESC
- These two queries are the same in terms of results. We are finding all the Person nodes whose name starts with A , skipping the first three results and returning the next three results. You can see some similarities between the WITH and RETURN clauses. In a WITH clause, you have to use an alias when you are referring to properties and so on, but in a RETURN clause, it is not mandatory to use aliases:
// Using SKIP and LIMIT along WITH clause
MATCH (p:Person)
WHERE p.name STARTS WITH 'A'
WITH p.name as name
SKIP 3
LIMIT 3
RETURN name
// Using SKIP and LIMIT with RETURN clause
MATCH (p:Person)
RETURN p.name
SKIP 3
LIMIT 3
Next, let us take a look at the usage of the UNION keyword.
Using UNION and UNION ALL
A UNION clause is used to combine the results of two or more queries. Each query must return the same number of values with the same alias names:
- This query returns both Actor names and Movie names as the union of two individual queries. Notice that we use the same alias name in both query fragments. If the Actor name and Movie name are the same, that value is returned only once. UNION will only return distinct values across the query results:
MATCH (n:Actor)
RETURN n.name AS name
UNION
MATCH (n:Movie)
RETURN n.title AS name
- This query returns both Actor names and Movie names as the union of two individual queries. One difference here is that if the Actor name and Movie name are the same, then that value is repeated twice in the response. Unlike UNION, UNION ALL will return all values without filtering duplicate rows:
MATCH (n:Actor)
RETURN n.name AS name
UNION ALL
MATCH (n:Movie)
RETURN n.title AS name
Now, let us take a look at how to use indexes and constraints in Cypher.
Using indexes and constraints
Indexes and constraints play a critical role in obtaining optimal performance from the database, along with making sure data integrity is maintained.
The available index options are as follows:
- Single-property index
- Composite property index
- Text index
- Full-text index
The available constraints are as follows:
Now let us take a look at how to create an index on a single property.
Using a single-property index
Single-property indexes are indexed on a single property name of a node label or relationship.
This is how we can create a single property index on a node. This creates an index on the name property of nodes with the Person label. The highlighted sections are optional. If we don’t specify a name, then a generated name will be assigned to the index. The IF NOT EXISTS option will create the index only if an index for this name or combination does not yet exist:
CREATE INDEX person_name IF NOT EXISTS FOR (n:Person) ON (n.name)
Note
Remember the index is associated with a label, and only one label. When you query, you must specify this label in the MATCH query to be able to leverage the index.
This is how we can create a single-property index on a relationship:
CREATE INDEX knows_since IF NOT EXISTS FOR ()-[r:KNOWS]->() ON (r.since)
Now that we have seen how to create a single-property index on a node and relationship, let’s look at creating composite property indexes.
Using a composite property index
Composite indexes function similarly to single-property indexes but on combinations of two or more properties:
CREATE INDEX person_name_age IF NOT EXISTS FOR (n:Person) ON (n.name, n.age)
In most scenarios, a single-property index on each property might be more efficient.
The same approach can be used to create a composite property index on relationships also.
Text index
A text index is the same as a single-property index with the exception that it will only recognize and apply to string values. If there are other types of values assigned to that property, then they are not included in the index.
This creates a TEXT index on the Person name. If you create a TEXT index on a property that does not contain string values, then it is as good as not having an index on that property:
CREATE TEXT INDEX person_name_text IF NOT EXISTS FOR (n:Person) ON (n.name)
Note
The TEXT index can only be used as a single-property index.
It is possible to create a TEXT index on a relationship property also.
Now, let us take a look at creating full-text indexes.
Using a full-text index
Full-text indexes are Lucene native indexes. These can support multiple labels and properties to create a single index.
The query creates a full-text index for Movie and Book node labels for the title and description properties:
CREATE FULLTEXT INDEX full_text IF NOT EXISTS FOR (n:Movie|Book) ON EACH (n.title, n.description)
We can create a full-text index on relationship properties also.
Now, let us take a look at unique node property constraints.
Using unique node property constraints
We can create unique constraints on node or relationship properties.
This creates a unique constraint on the Person name property:
CREATE CONSTRAINT person_name_c IF NOT EXISTS FOR (n:Person) REQUIRE n.name IS UNIQUE
The unique constraint is backed by an index automatically.
Using existence constraints
Existence constraints can make sure a property exists on the node or relationship.
This query enforces that the name property exists when a Person node is created:
CREATE CONSTRAINT person_name_e IF NOT EXISTS FOR (n:Person) REQUIRE n.name IS NOT NULL
Existence constraints can be created on relationships as well.
Using node key constraints
Node key constraints are similar to primary keys in the RDBMS world.
Here, we are showing a node key with multiple properties. It can be with a single property also:
CREATE CONSTRAINT person_name_age IF NOT EXISTS FOR (n:Person) REQUIRE (n.name, n.age) IS NODE KEY
Let’s summarize our understanding of this chapter.
Summary
In this chapter, we have covered these aspects: basic Cypher syntax, nodes syntax, relationships syntax, data types available in Cypher, keywords available in Cypher, working with indexes, working with Constraints, and working with full-text indexes.
By now, you should be aware of the basic Cypher aspects and should be able to build basic Cypher queries.
Certain advanced aspects, such as subqueries and so on, are covered in later chapters, and built-in functions are introduced as we learn more about Cypher.
You can find the latest Cypher documentation in the Neo4j Cypher Manual (https://neo4j.com/docs/cypher-manual/current/).
You can also find a quick reference guide at https://neo4j.com/docs/cypher-refcard/current/.
In the next chapter, we will start building graph models and using Cypher to start loading data. We will be leveraging the concepts learned in this chapter to achieve that.